Creating Affording Situations: Coaching through Animate Objects


Abstract
1. Introduction
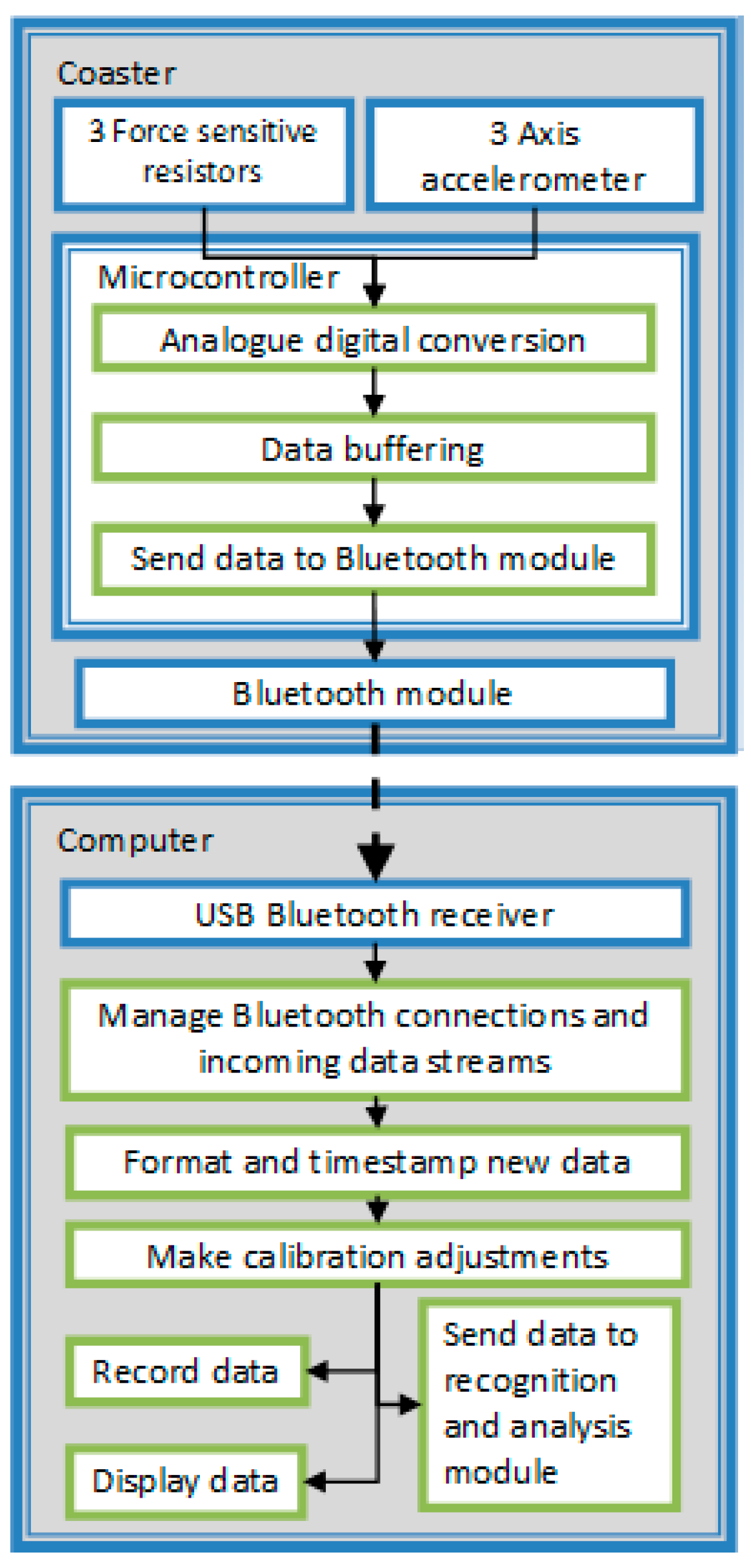
Designing Intelligent Objects
2. Evaluation and Initial User Trials
2.1. Participants and Trial Design
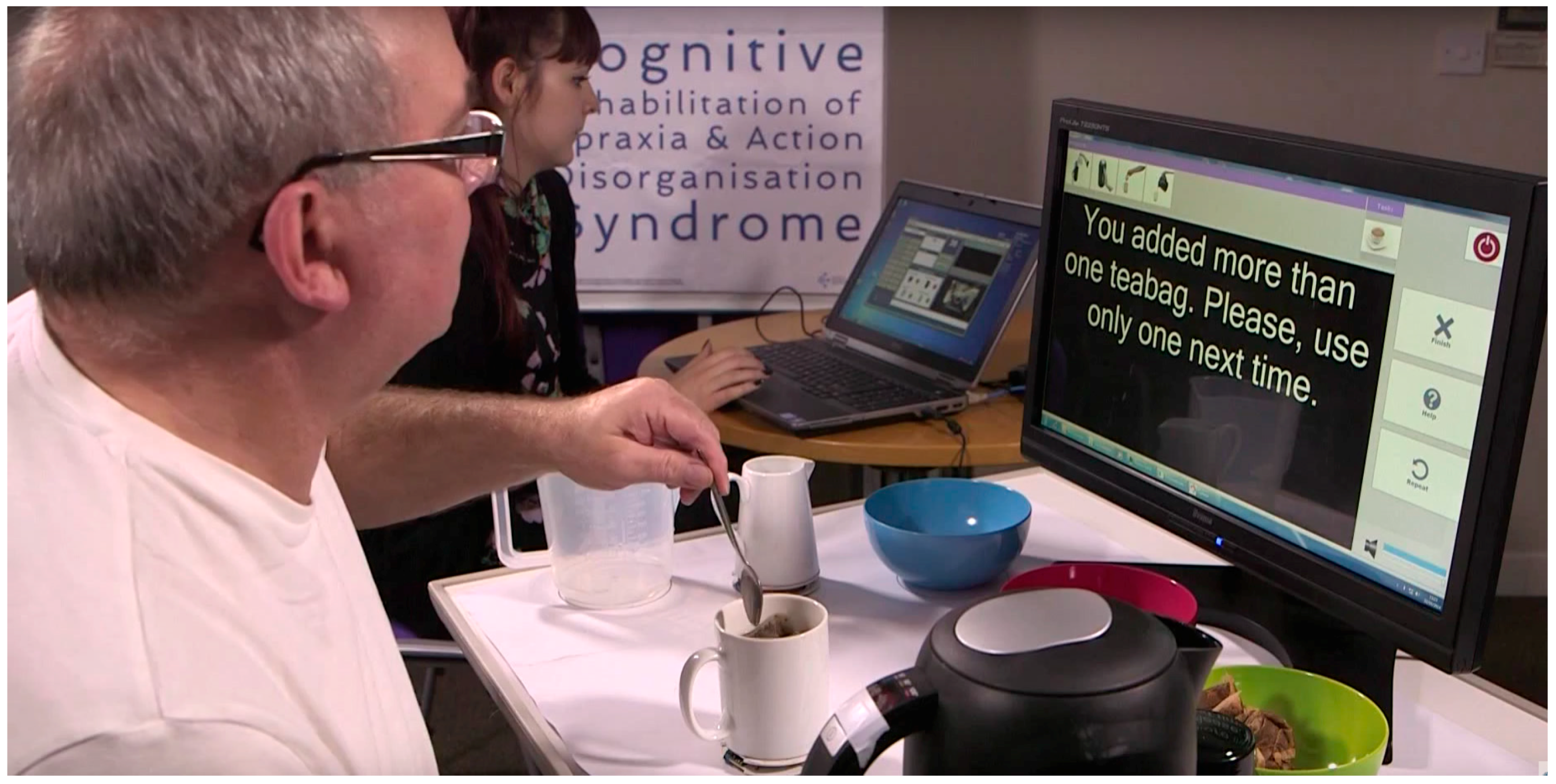
2.2. Trial One: Multimodal Cueing of Object State and Required Tasks
2.2.1. Procedure
2.2.2. Results
2.2.3. Conclusions
2.3. Trial Two: Hand and Handle Alignment in Picking up the Jug
2.3.1. Procedure
2.3.2. Results
2.3.3. Conclusions
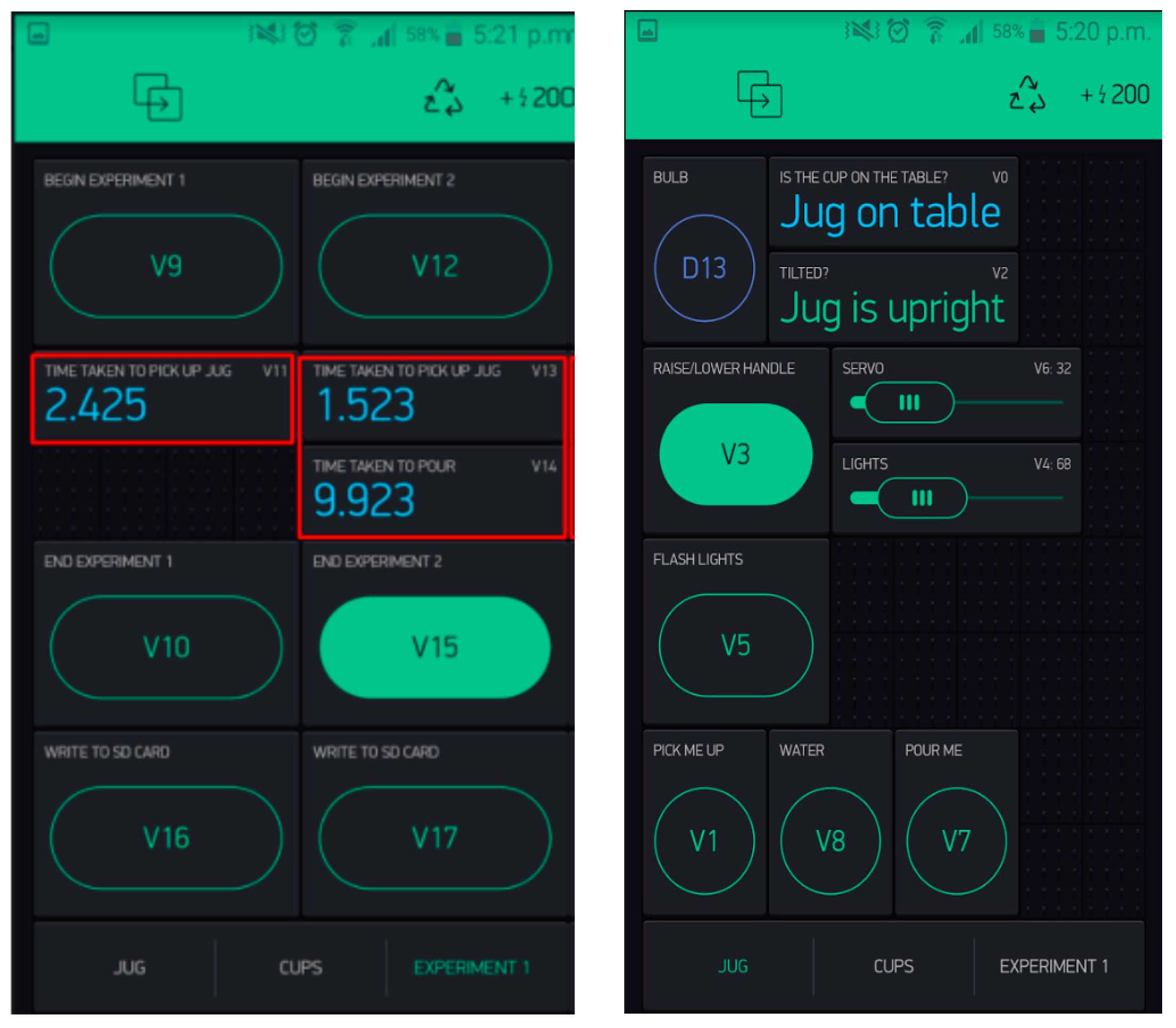
2.4. Cueing Action Sequences
2.4.1. Procedure
- Time taken to open drawer: Timer begins when light on the handle is on and timer ends when drawer is moved.
- Time taken to pick up spoon: Timer begins when drawer fully opened and timer ends when spoon picked up.
- Time taken to stir: Timer begins when spoon is picked up till head of the spoon is inside the cup.
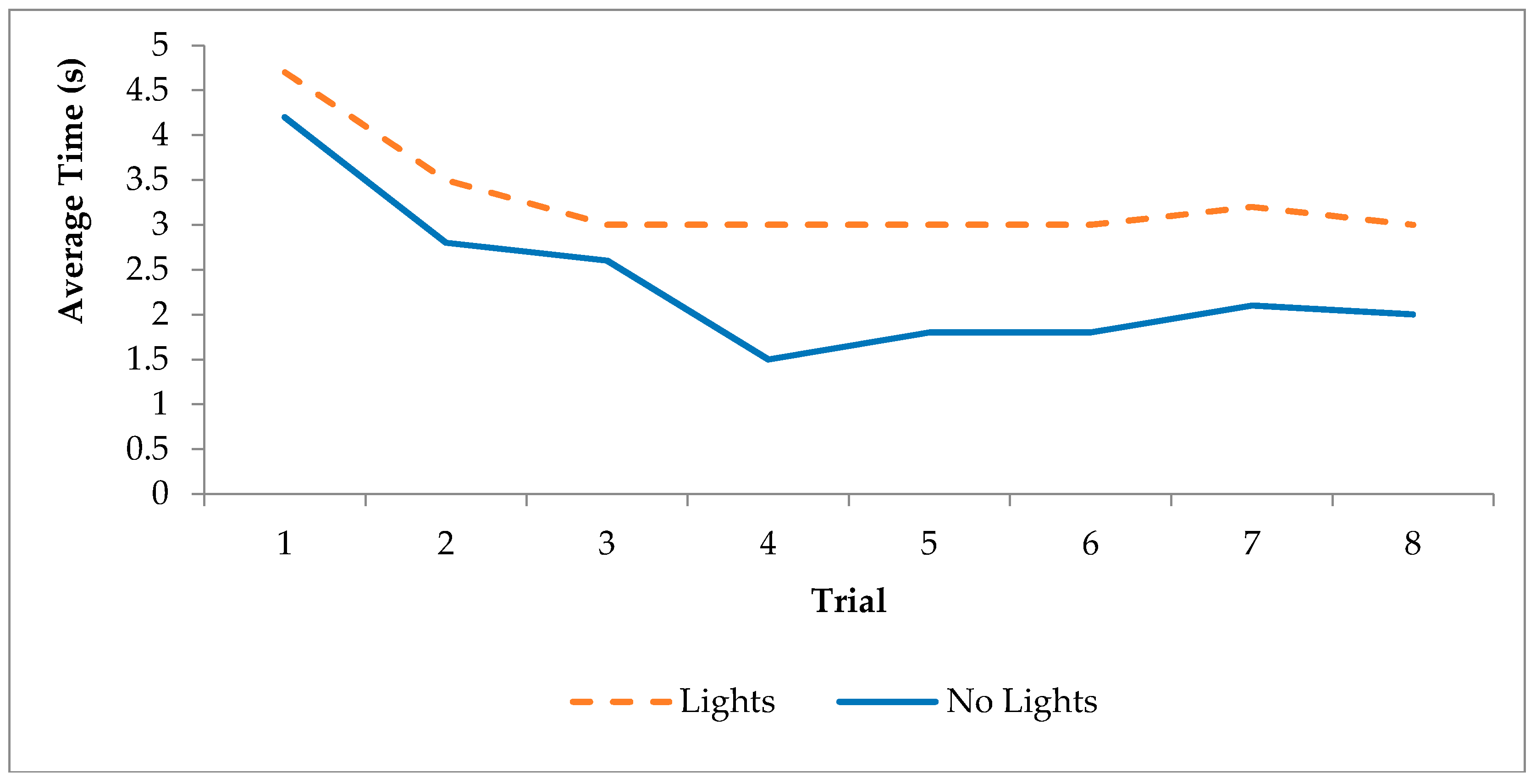
2.4.2. Results
2.4.3. Conclusions
3. Discussion
Creating Affording Situations
4. Conclusions
Author Contributions
Conflicts of Interest
References
- Op den Akker, H.; Jones, V.M.; Hermens, H.J. Tailoring Real-Time Physical Activity Coaching Systems: A Literature Survey and Model. User Model. User-Adapt. Int. 2014, 24, 351–392. [Google Scholar] [CrossRef]
- Hermsdörfer, J.; Bienkiewicz, M.; Cogollor, J.M.; Russel, M.; Jean-Baptiste, E.; Parekh, M.; Wing, A.M.; Ferre, M.; Hughes, C. CogWatch—Automated Assistance and Rehabilitation of Stroke-Induced Action Disorders in the Home Environment. In International Conference on Engineering Psychology and Cognitive Ergonomics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 343–350. [Google Scholar]
- Giachritsis, C.; Randall, G. CogWatch: Cognitive Rehabilitation for Apraxia and Action Disorganization Syndrome Patients. In Proceedings of the Seventh International Workshop on Haptic and Audio Interaction Design, Lund, Sweden, 23–24 August 2012. [Google Scholar]
- Jean-Baptiste, E.M.; Nabiei, R.; Parekh, M.; Fringi, E.; Drozdowska, B.; Baber, C.; Jancovic, P.; Rotshein, P.; Russell, M. Intelligent assistive system using real-time action recognition for stroke survivors. In Proceedings of the 2014 IEEE International Conference on Healthcare Informatics (ICHI), Verona, Italy, 5 March 2015; pp. 39–44. [Google Scholar]
- Jean-Baptiste, E.M.; Rotshtein, P.; Russell, M. POMDP based action planning and human error detection. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer International Publishing: Berlin, Germany, 2015; pp. 250–265. [Google Scholar]
- Jean-Baptiste, E.M.; Rotshtein, P.; Russell, M. CogWatch: Automatic prompting system for stroke survivors during activities of daily living. J. Innov. Digit. Ecosyst. 2016, 3, 48–56. [Google Scholar] [CrossRef]
- Kortuem, G.; Kawsar, F.; Fitton, D.; Sundramoorthy, V. Smart objects as building blocks for the Internet of Things. In IEEE Internet Computing; IEEE Computer Society: Washington, DC, USA, 2010; pp. 44–51. [Google Scholar]
- Ishii, H. The tangible user interface and its evolution. Commun. ACM 2008, 51, 32–36. [Google Scholar] [CrossRef]
- Ishii, H.; Leithinger, D.; Follmer, S.; Zoran, A.; Schoessler, P.; Counts, J. TRANSFORM: Embodiment of Radical Atoms at Milano Design Week. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 687–694. [Google Scholar]
- Kortuem, G.; Kawsar, F.; Sundramoorthy, V.; Fitton, D. Smart objects as building blocks for the internet of things. IEEE Internet Comput. 2010, 14, 44–51. [Google Scholar] [CrossRef]
- Zuckerman, O. Objects for change: A case study of a tangible user interface for behavior change. In Proceedings of the Ninth International Conference on Tangible, Embedded, and Embodied Interaction, Stanford, CA, USA, 15–19 January 2015; pp. 649–654. [Google Scholar]
- Sung, M.-H.; Chian, C.-W. The Research of Using Magnetic Pillbox as Smart Pillbox System’s Interactive Tangible User Interface. In International Conference on Human-Computer Interaction; Springer International Publishing: Berlin, Germany, 2016; pp. 451–456. [Google Scholar]
- Reeder, B.; Chung, J.; Le, T.; Thompson, H.J.; Demiris, G. Assessing older adults’ perceptions of sensor data and designing visual displays for ambient assisted living environments: An exploratory study. Methods Inf. Med. 2014, 53, 152. [Google Scholar] [CrossRef] [PubMed]
- Dobkin, B.H. A Rehabilitation-Internet-of-Things in the Home to Augment Motor Skills and Exercise Training. Neurorehabilit. Neural Repair 2016, 31, 217–227. [Google Scholar] [CrossRef] [PubMed]
- Gellersen, H.-W.; Beigl, M.; Krull, H. The MediaCup: Awareness technology embedded in an everyday object. In Handheld and Ubiquitous Computing 1st International Symposium HUC’99; Springer: Berlin, Germany, 1999; pp. 308–310. [Google Scholar]
- Poupyrev, I.; Nashida, T.; Okabe, M. Actuation and tangible user interfaces: The Vaucanson duck, robots, and shape displays. In Proceedings of the 1st International Conference on Tangible and Embedded Interaction, Baton Rouge, LA, USA, 15–17 February 2007. [Google Scholar]
- Bonanni, L.; Lee, C.H.; Selker, T. CounterIntelligence: Augmented reality kitchen. In CHI’05; ACM: New York, NY, USA, 2005; p. 45. [Google Scholar]
- Howard, L.A.; Tipper, S.P. Hand deviations away from visual cues: Indirect evidence for inhibition. Exp. Brain Res. 1997, 113, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Pohl, P.S.; Filion, D.L.; Kim, S.H. Effects of practice and unpredictable distractors on planning and executing aiming after stroke. Neurorehabilit. Neural Repair 2003, 17, 93–100. [Google Scholar] [CrossRef] [PubMed]
- Bienkiewicz, M.N.; Gulde, P.; Schlegel, A.; Hermsdörfer, J. The Use of Ecological Sounds in Facilitation of Tool Use in Apraxia. In Replace, Repair, Restore, Relieve–Bridging Clinical and Engineering Solutions in Neurorehabilitation; Springer: New York, NY, USA, 2014. [Google Scholar]
- Young, W.R.; Shreve, L.; Quinn, E.J.; Craig, C.; Bronte-Stewart, H. Auditory cueing in Parkinson’s patients with freezing of gait. What matters most: Action-relevance or cue continuity? Neuropsychologia 2016, 87, 54–62. [Google Scholar] [CrossRef] [PubMed]
- Fitzmaurice, W.G.; Ishii, H.; Buxton, W. Bricks: Laying the foundations for graspable user interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; pp. 442–449. [Google Scholar]
- Hermsdörfer, J.; Li, Y.; Randerath, J.; Goldenberg, G.; Johannsen, L. Tool use without a tool: Kinematic characteristics of pantomiming as compared to actual use and the effect of brain damage. Exp. Brain Res. 2012, 218, 201–214. [Google Scholar] [CrossRef] [PubMed]
- Randerath, J.; Li, Y.; Goldenberg, G.; Hermsdörfer, J. Grasping tools: Effects of task and apraxia. Neuropsychologia 2009, 47, 497–505. [Google Scholar] [CrossRef] [PubMed]
- Graham, N.L.; Zeman, A.; Young, A.W.; Patterson, K.; Hodges, J.R. Dyspraxia in a patient with cortico-basal degeneration: The role of visual and tactile inputs to action. J. Neurol. Neurosurg. Psychiatry 1999, 67, 334–344. [Google Scholar] [CrossRef] [PubMed]
- Matheson, H.; Newman, A.J.; Satel, J.; McMullen, P. Handles of manipulable objects attract covert visual attention: ERP evidence. Brain Cogn. 2014, 86, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Tucker, M.; Ellis, R. On the relations between seen objects and components of potential actions. J. Exp. Psychol. Hum. Percept. Perform. 1998, 24, 830. [Google Scholar] [CrossRef] [PubMed]
- Tucker, M.; Ellis, R. The potentiation of grasp types during visual object categorization. Vis. Cogn. 2001, 8, 769–800. [Google Scholar] [CrossRef]
- Craighero, L.; Fadiga, L.; Rizzolatti, G.; Umiltà, C. Visuomotor priming. Vis. Cogn. 1998, 5, 109–126. [Google Scholar] [CrossRef]
- Craighero, L.; Fadiga, L.; Rizzolatti, G.; Umiltà, C. Action for perception: A motor- visual attentional effect. J. Exp. Psychol. Hum. Percept. Perform. 1999, 25, 1673–1692. [Google Scholar] [CrossRef] [PubMed]
- Bub, D.N.; Masson, M.E. Grasping beer mugs: On the dynamics of alignment effects induced by handled objects. J. Exp. Psychol. Hum. Percept. Perform. 2010, 36, 341. [Google Scholar] [CrossRef] [PubMed]
- Roest, S.A.; Pecher, D.; Naeije, L.; Zeelenberg, R. Alignment effects in beer mugs: Automatic action activation or response competition? Attent. Percept. Psychophys. 2016, 78, 1665–1680. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, K.; Goldenberg, G.; Daumüller, M.; Hermsdörfer, J. It takes the whole brain to make a cup of coffee: The neuropsychology of naturalistic actions involving technical devices. Neuropsychologia 2005, 43, 625–637. [Google Scholar] [CrossRef] [PubMed]
- Norman, D.A. The Design of Everyday Things; Doubleday: New York, NY, USA, 1990. [Google Scholar]
- Gaver, W. Technology affordances. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 27 April–2 May 1991; pp. 79–84. [Google Scholar]
- Gibson, J.J. The Ecological Approach to Visual Perception; Houghton Mifflin Company: Dublin, Republic of Ireland, 1986. [Google Scholar]
- Blevis, E.; Bødker, S.; Flach, J.; Forlizzi, J.; Jung, H.; Kaptelinin, V.; Nardi, B.; Rizzo, A. Ecological perspectives in HCI: Promise, problems, and potential. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 2401–2404. [Google Scholar]
- Cervantes-Solis, J.W.; Baber, C.; Khattab, A.; Mitch, R. Rule and theme discovery in human interactions with an ‘internet of things’. In Proceedings of the 2015 British HCI Conference, Lincolnshire, UK, 13–17 July 2015; pp. 222–227. [Google Scholar]
- Rosenbaum, D.A.; Vaughan, J.; Barnes, H.J.; Jorgensen, M.J. Time course of movement planning: Selection of handgrips for object manipulation. J. Exp. Psychol. Learn. Mem. Cogn. 1992, 18, 1058. [Google Scholar] [CrossRef] [PubMed]
- Schwarz, M.F.E.; Reed, E.S.; Montgomery, M.W.; Palmer, C.; Mayer, N.H. The quantitative description of action disorganization after brain damage—A case study. Cogn. Neuropsychol. 1991, 8, 381–414. [Google Scholar] [CrossRef]
- Hughes, C.M.L.; Baber, C.; Bienkiewicz, M.; Worthington, A.; Hazell, A.; Hermsdörfer, J. The application of SHERPA (Systematic Human Error Reduction and Prediction Approach) in the development of compensatory cognitive rehabilitation strategies for stroke patients with left and right brain damage. Ergonomics 2015, 58, 75–95. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
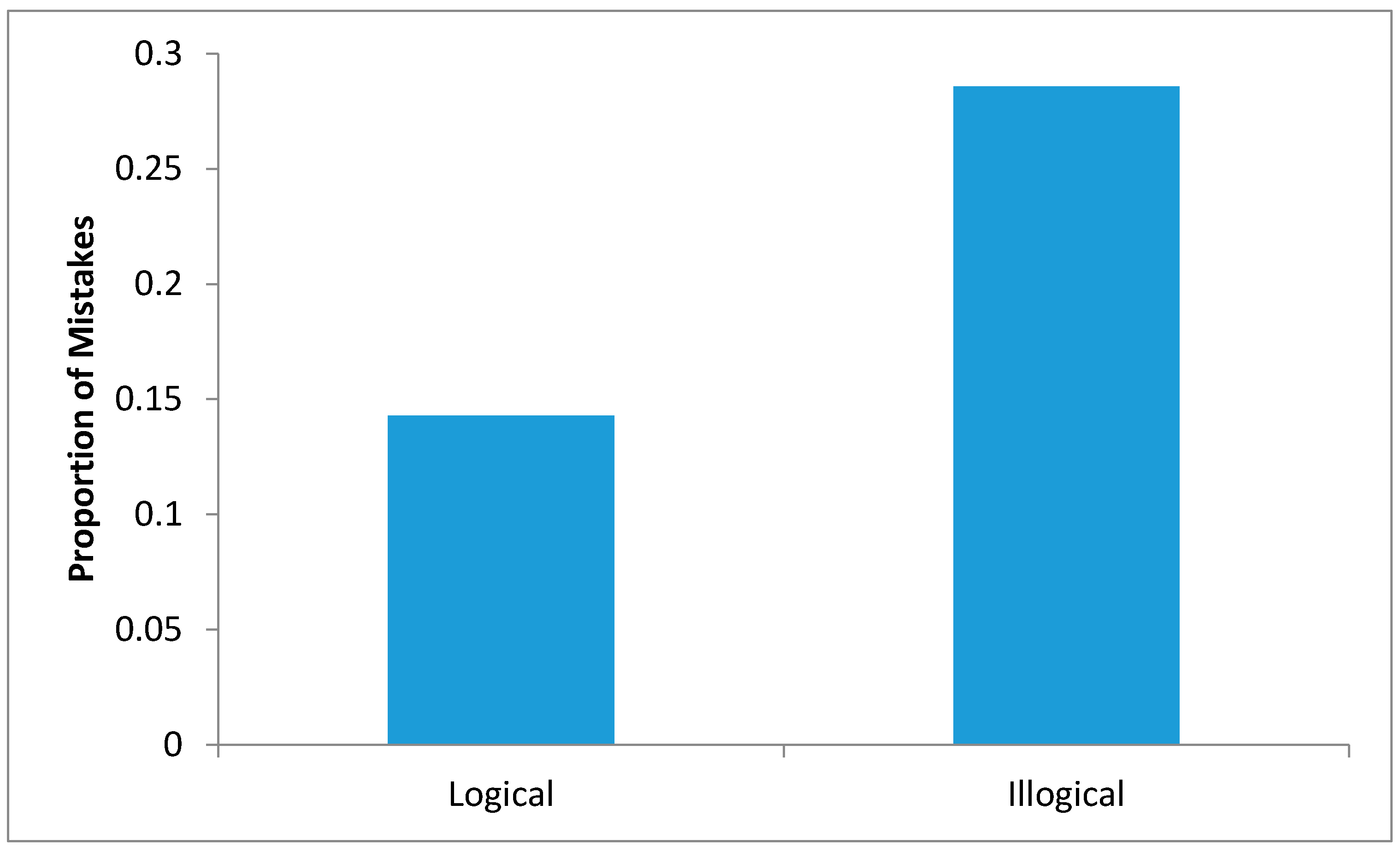{kind=link}
| Features of Coaching | Requirements for Support |
|---|---|
| Help improve, develop, learn skills | Define goal performance |
| Monitor and evaluate activity | Recognise actions and predict errors |
| Define targets for improvement | Define measures of effectiveness |
| Dialogue to discuss targets and plan programme of training | Determine route from current performance to goal |
| Tailoring programme to individual | Modify route to cater for individual capability |
| Evaluate progress | Recognise action against performance goal |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baber, C.; Khattab, A.; Russell, M.; Hermsdörfer, J.; Wing, A. Creating Affording Situations: Coaching through Animate Objects. Sensors 2017, 17, 2308. https://doi.org/10.3390/s17102308
Baber C, Khattab A, Russell M, Hermsdörfer J, Wing A. Creating Affording Situations: Coaching through Animate Objects. Sensors. 2017; 17(10):2308. https://doi.org/10.3390/s17102308
Chicago/Turabian StyleBaber, Chris, Ahmad Khattab, Martin Russell, Joachim Hermsdörfer, and Alan Wing. 2017. "Creating Affording Situations: Coaching through Animate Objects" Sensors 17, no. 10: 2308. https://doi.org/10.3390/s17102308
APA StyleBaber, C., Khattab, A., Russell, M., Hermsdörfer, J., & Wing, A. (2017). Creating Affording Situations: Coaching through Animate Objects. Sensors, 17(10), 2308. https://doi.org/10.3390/s17102308