
Gaussian Process Regression Plus Method for Localization Reliability Improvement

Abstract
:1. Introduction
2. Preliminaries
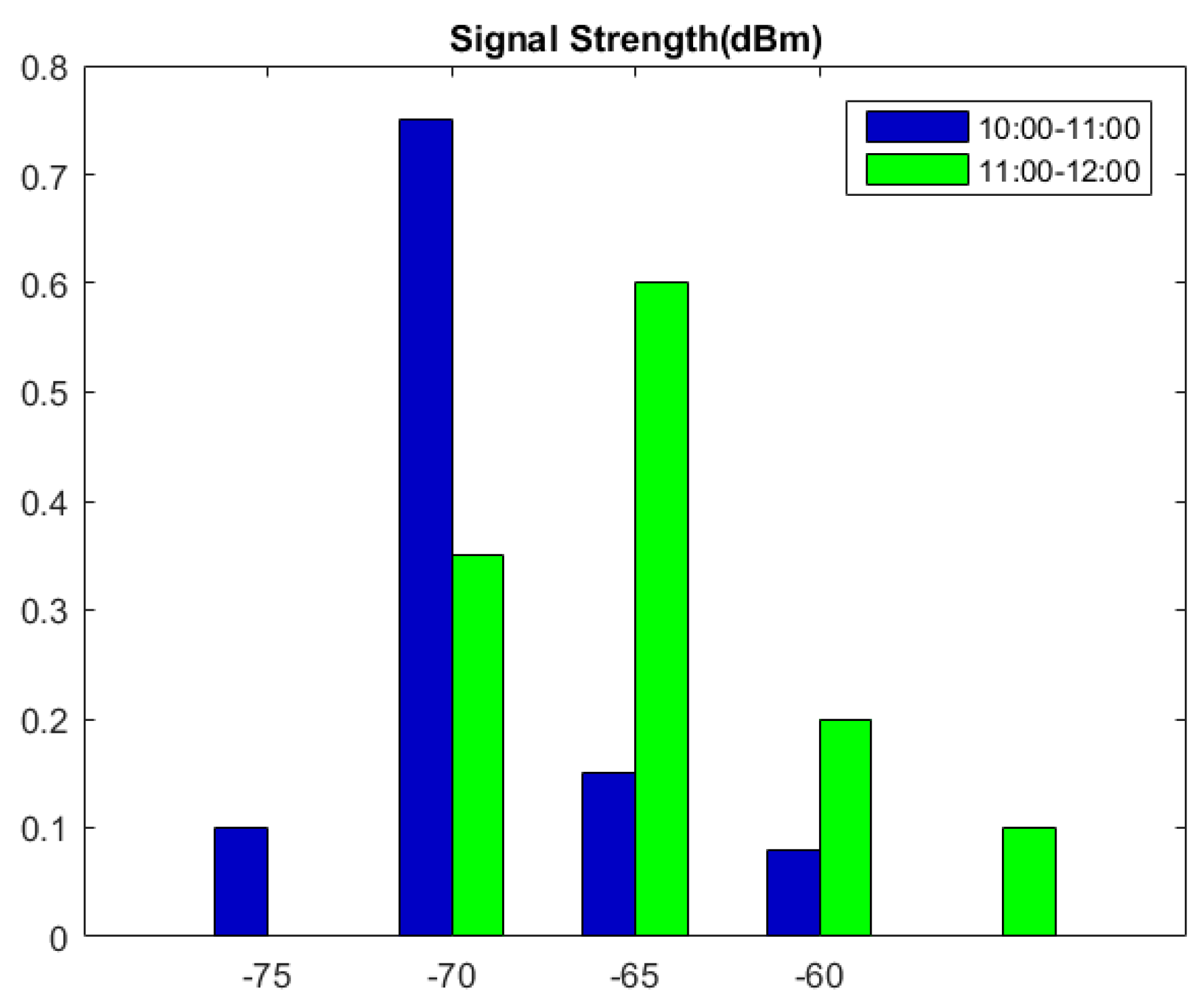
2.1. RSS Fingerprint
2.2. Gaussian Process
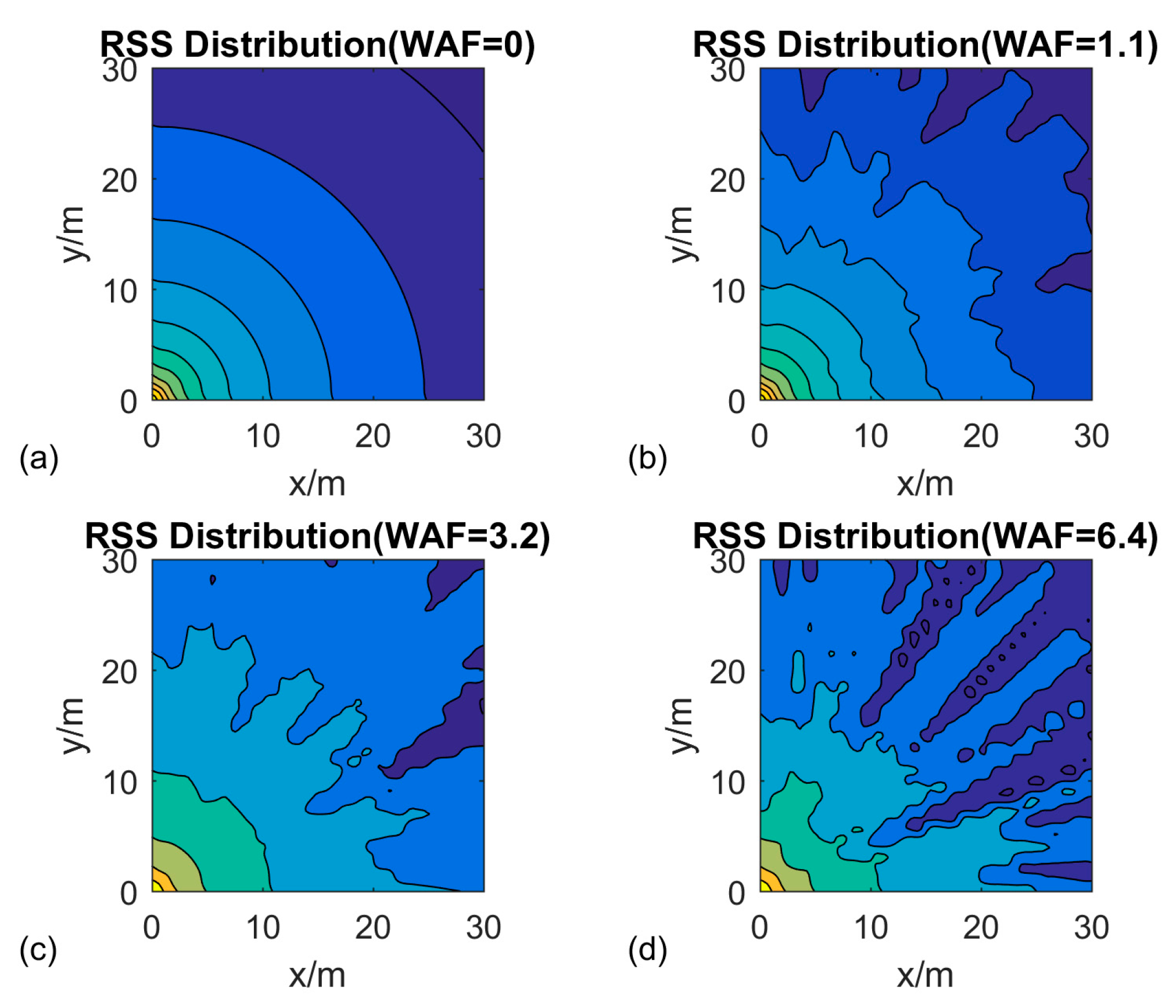
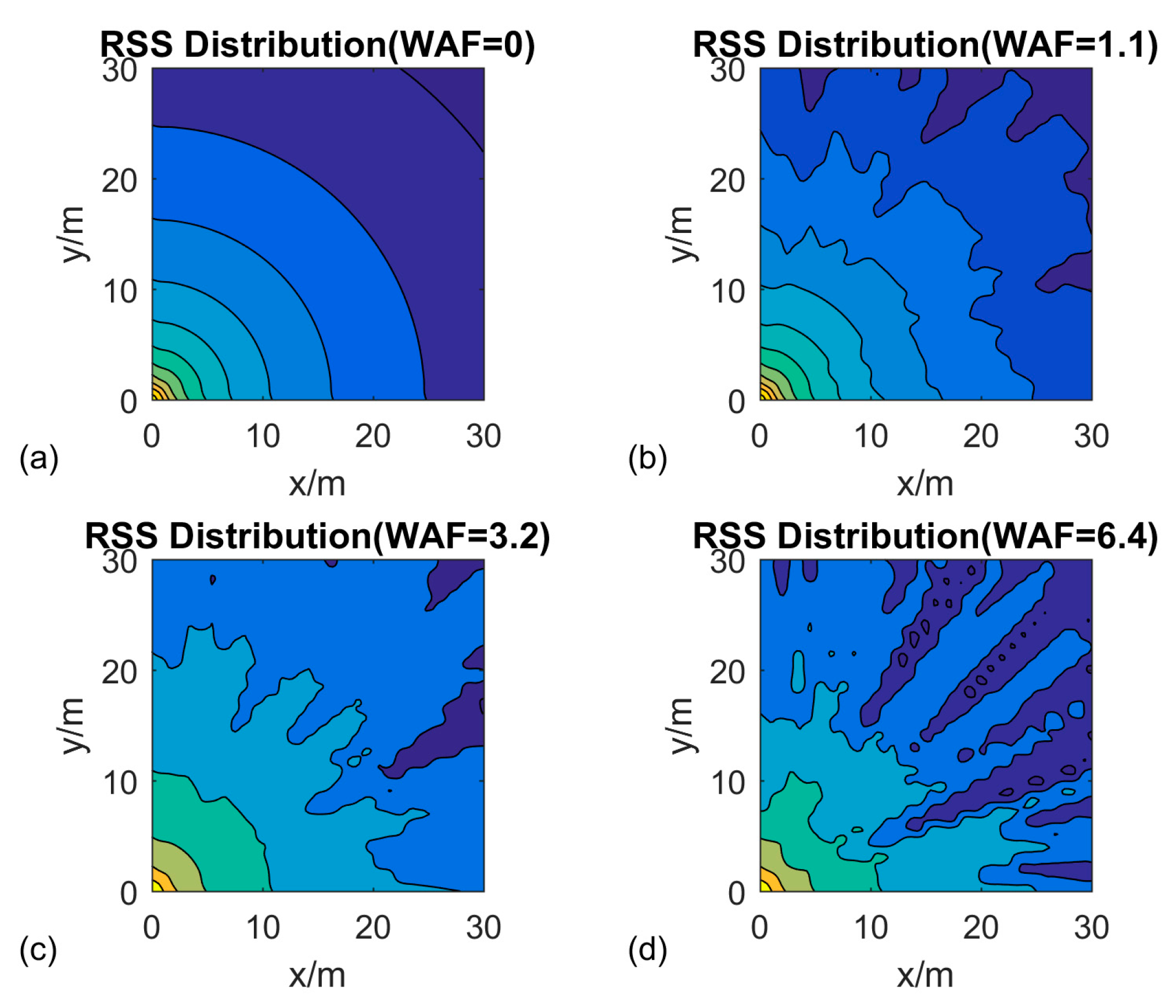
2.3. Weight-RSS Propagation Model
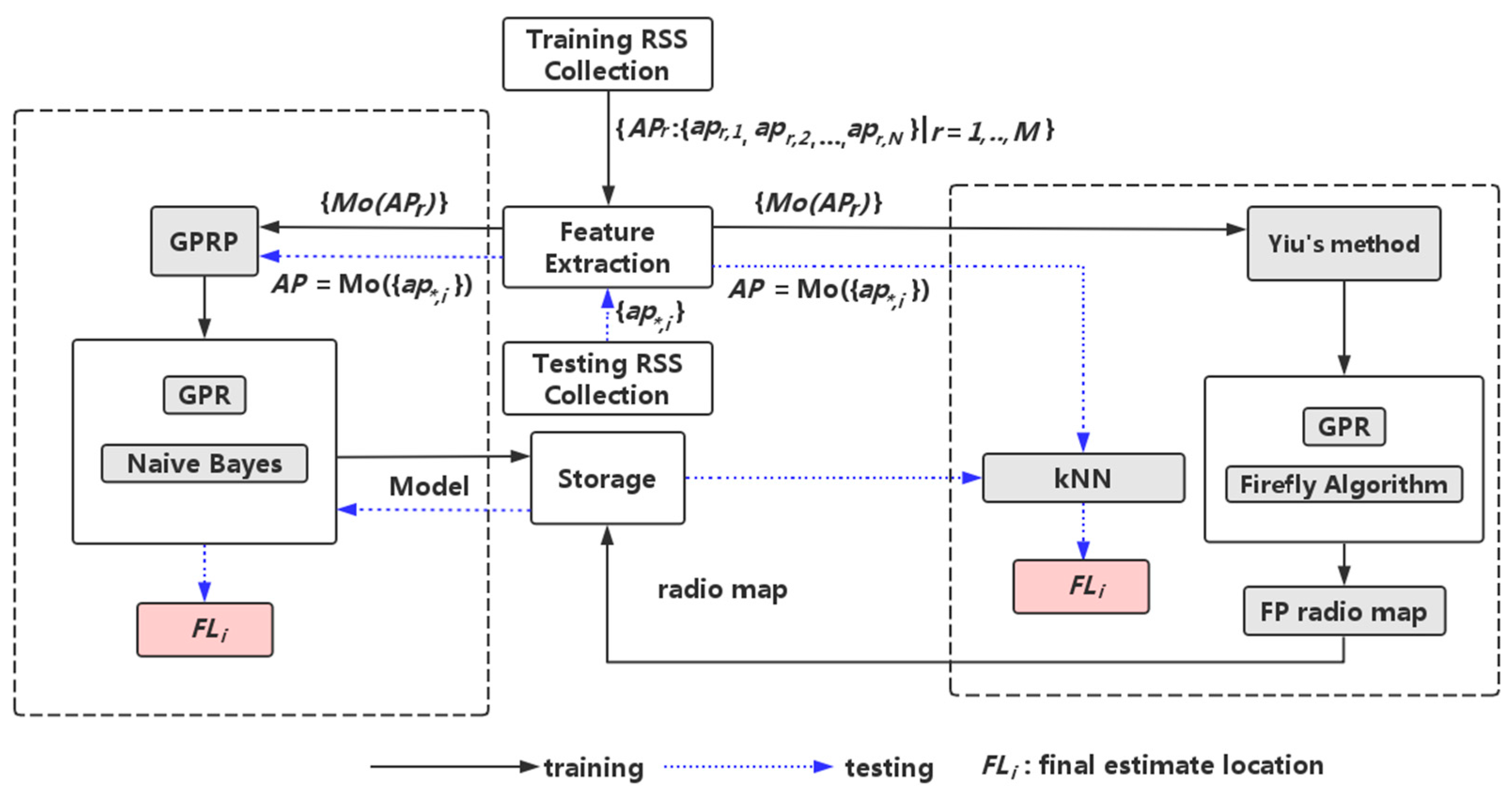
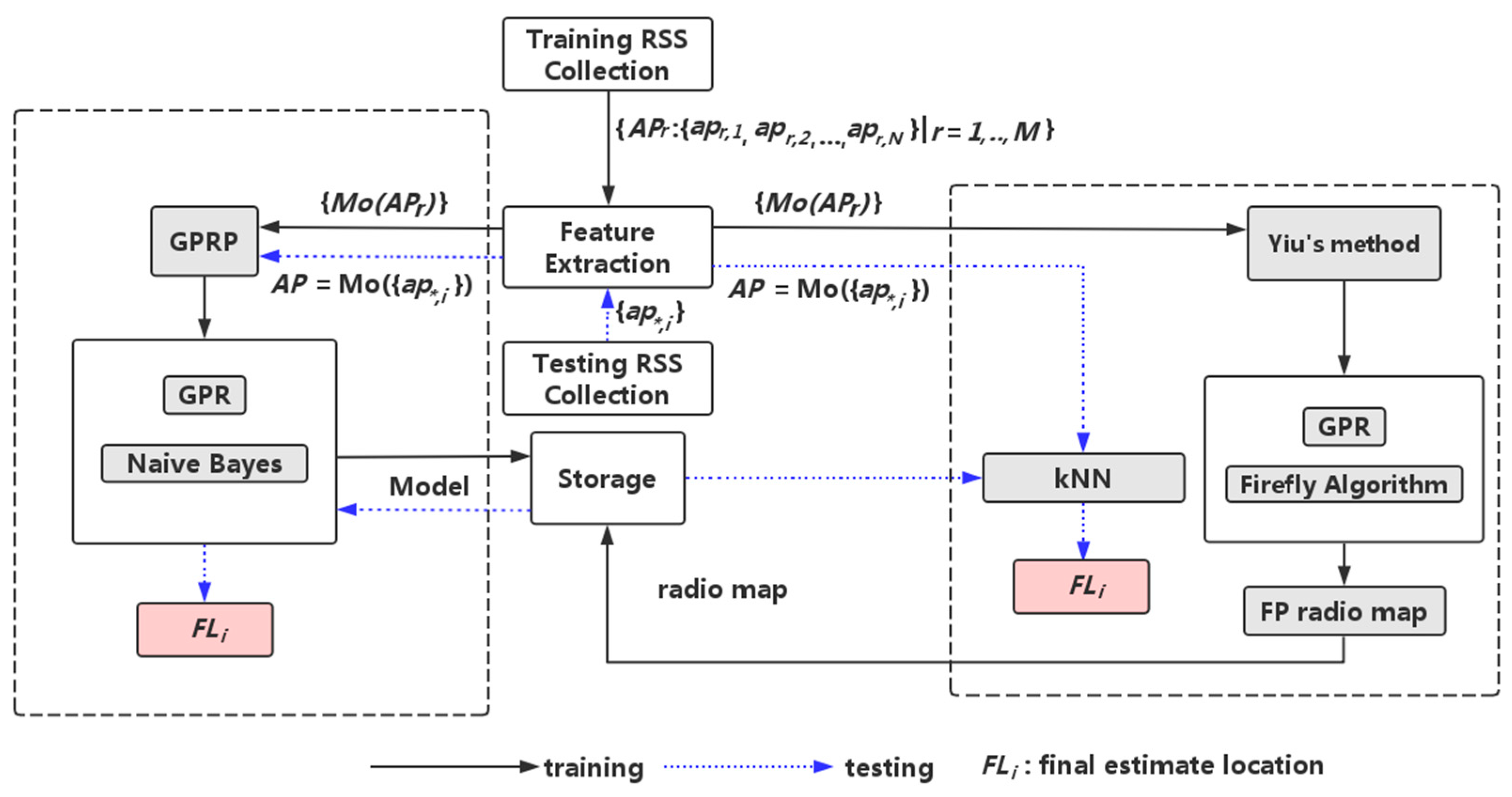
3. System Design
3.1. The Method of Gaussian Process Regression Plus
3.2. Naive Bayesian Location Model
- (1)
- ,
- (2)
- Events are partitioned by the sample space; their values are independent of each other,
- (3)
- .
- (1)
- The sample space is divided by and , and events in the sample spaces are represented as , which is the place derived from the proposed GPR method.
- (2)
- The prior probability is computed as:
- (3)
- The posterior probability is computed as:
- (4)
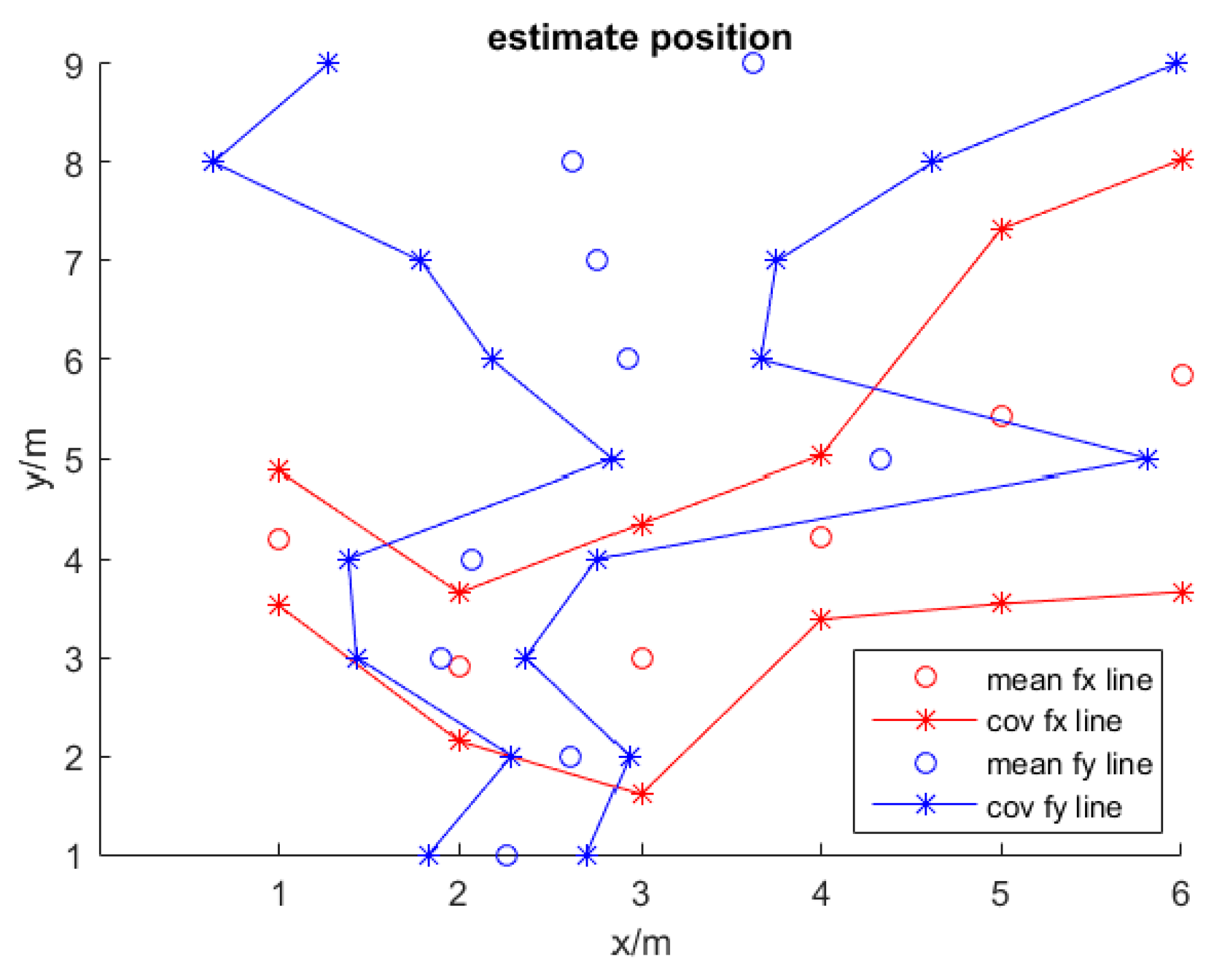
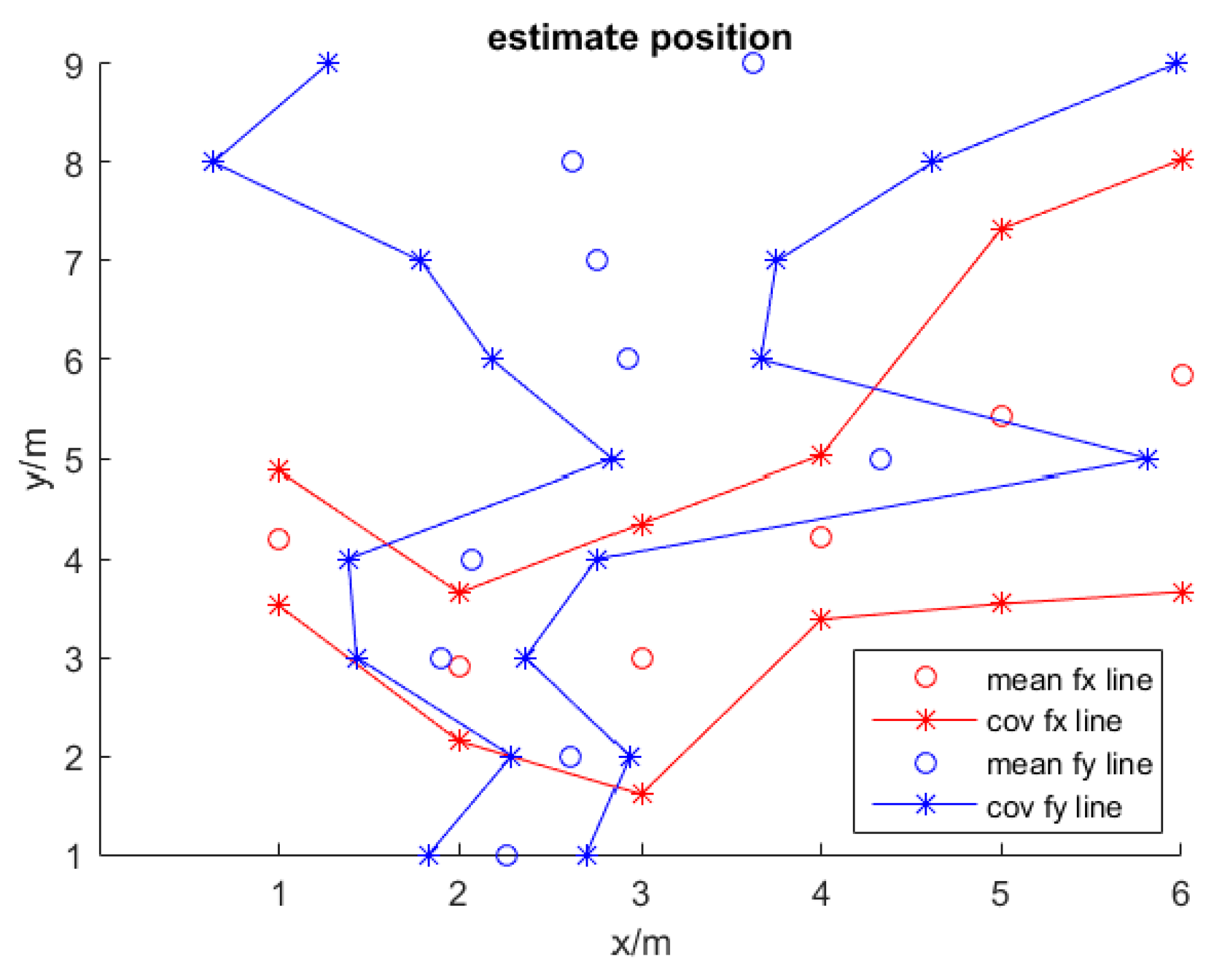
- The final location and error between the estimate positions are computed as follows:and:
4. Experiments and Discussion
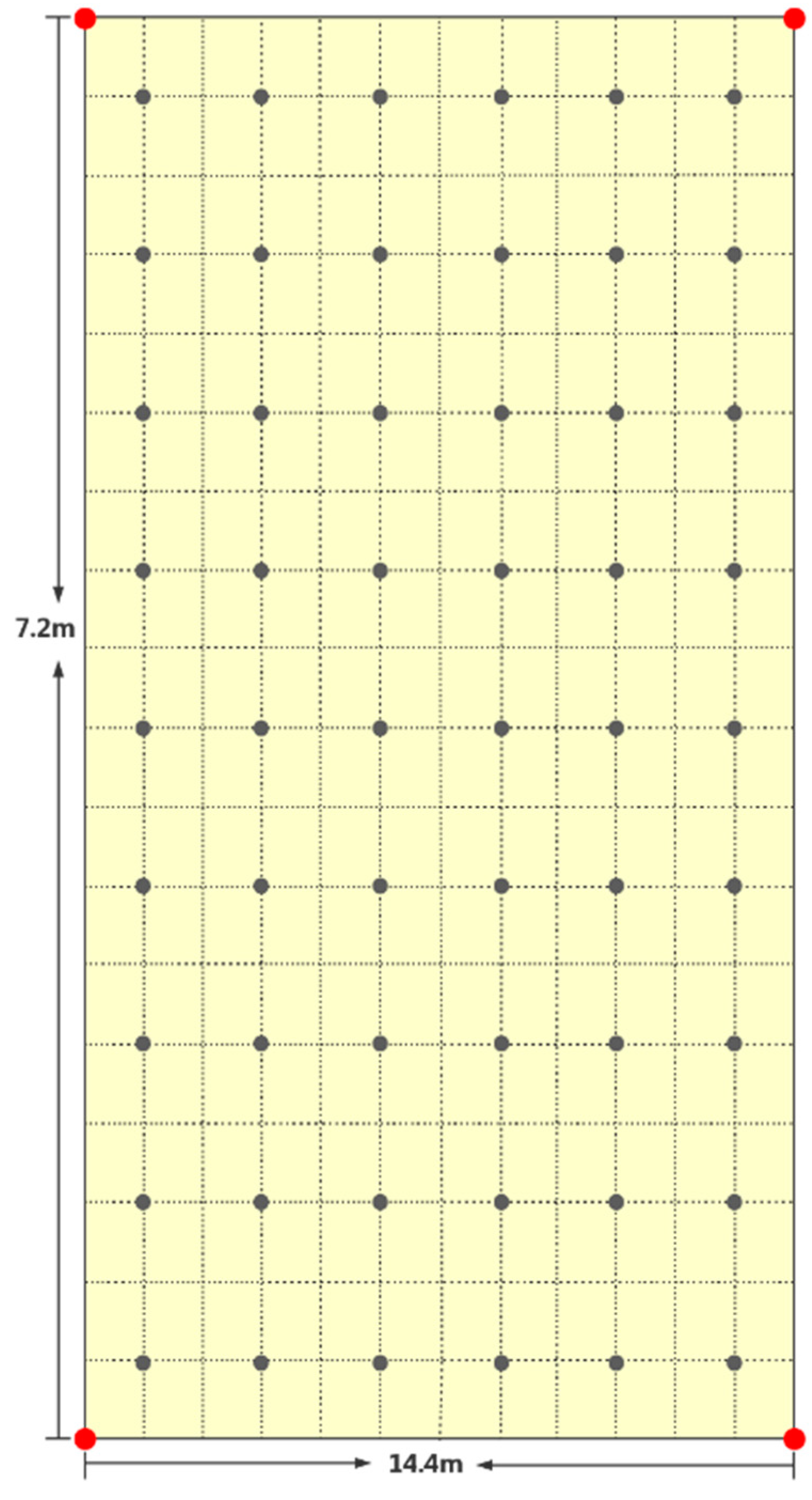
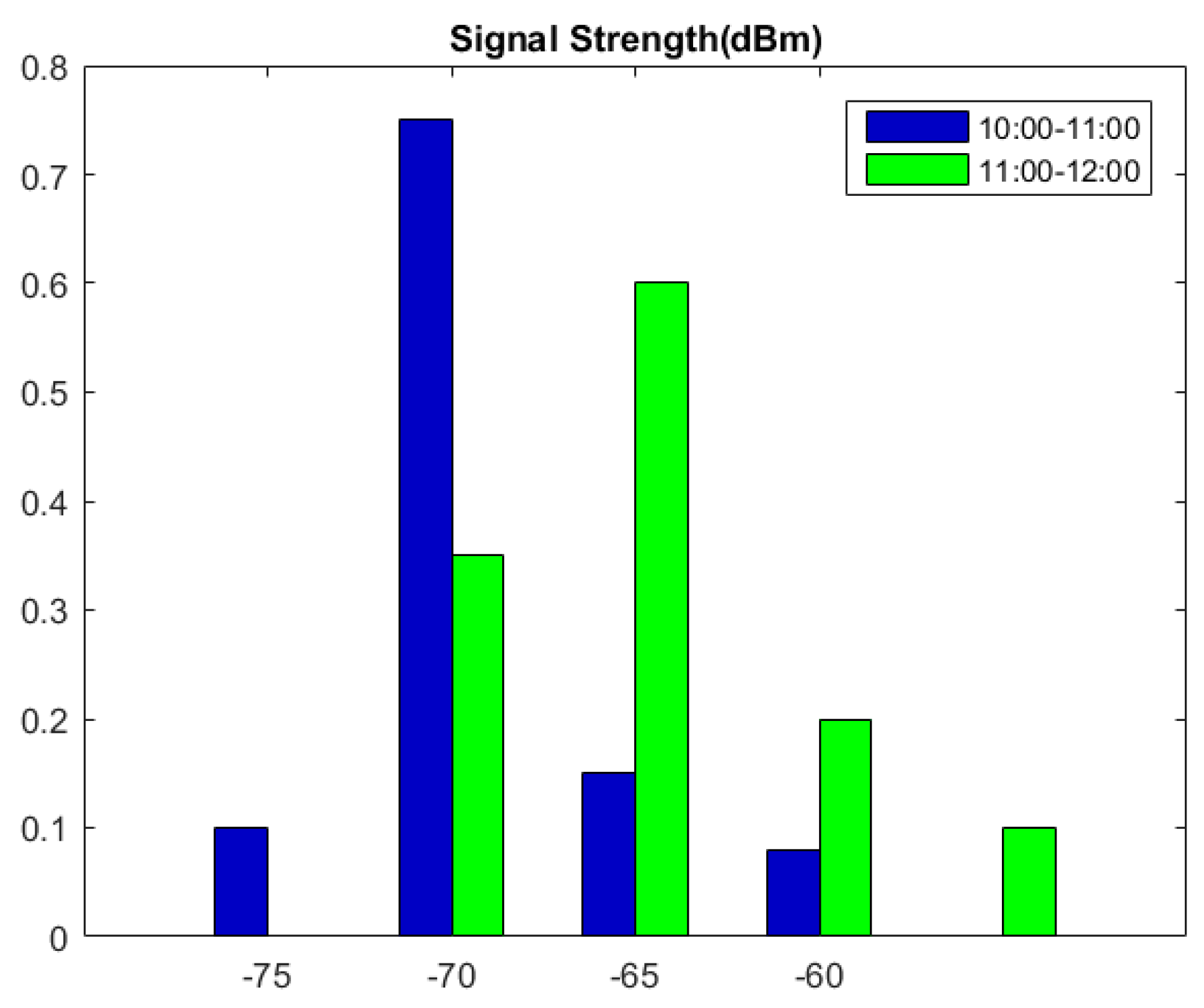
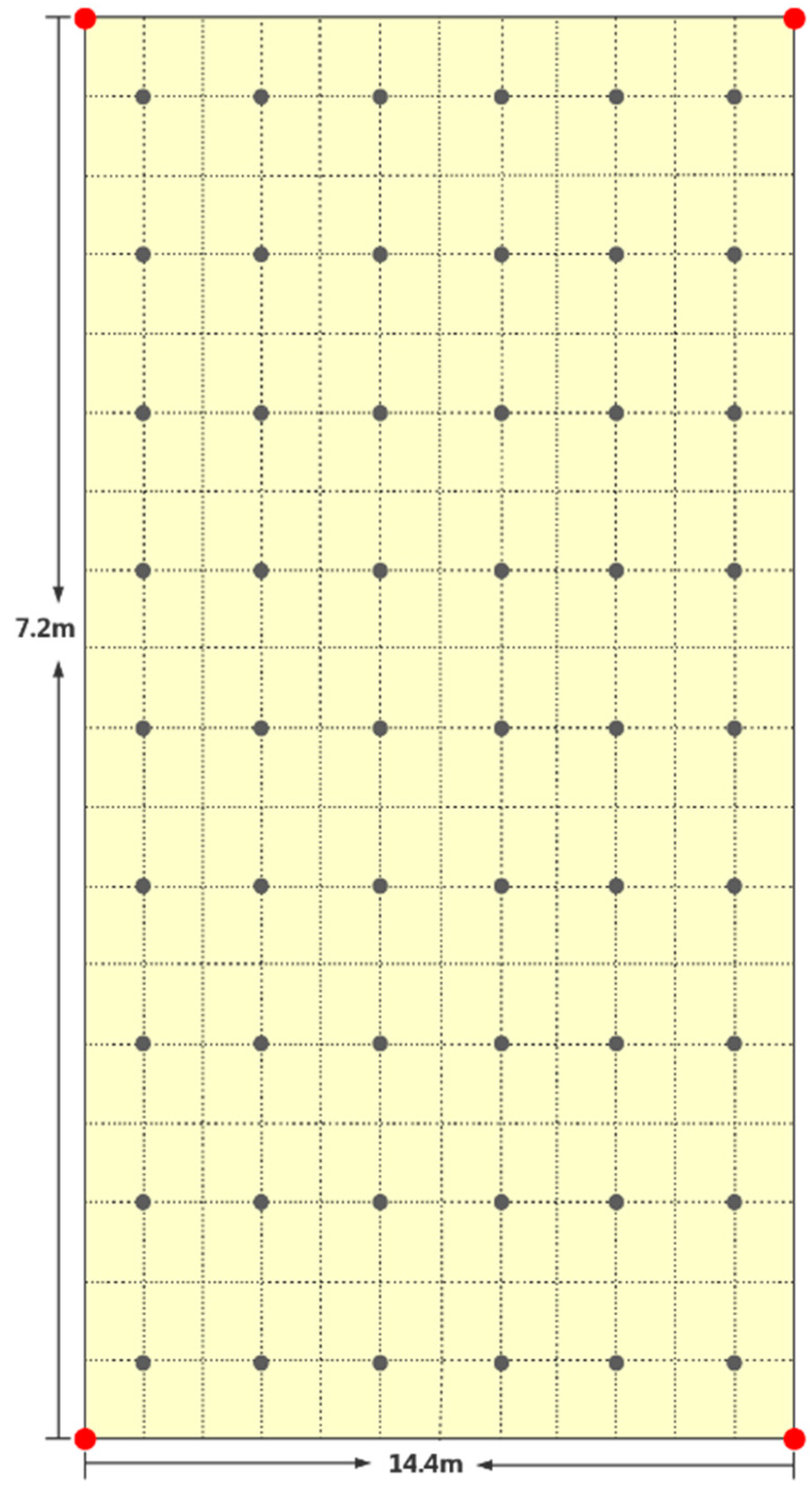
4.1. Experiment Environment Initialization
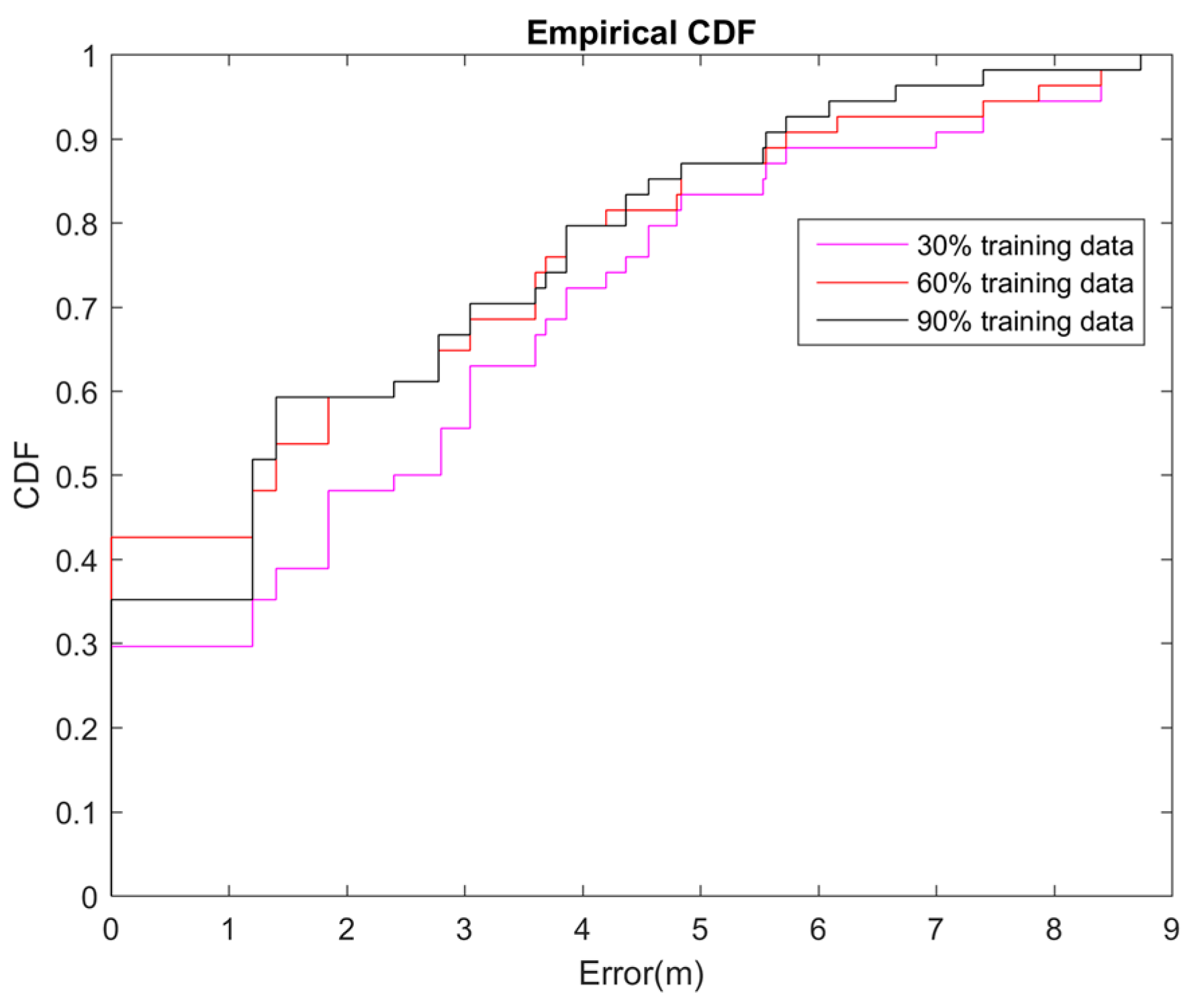
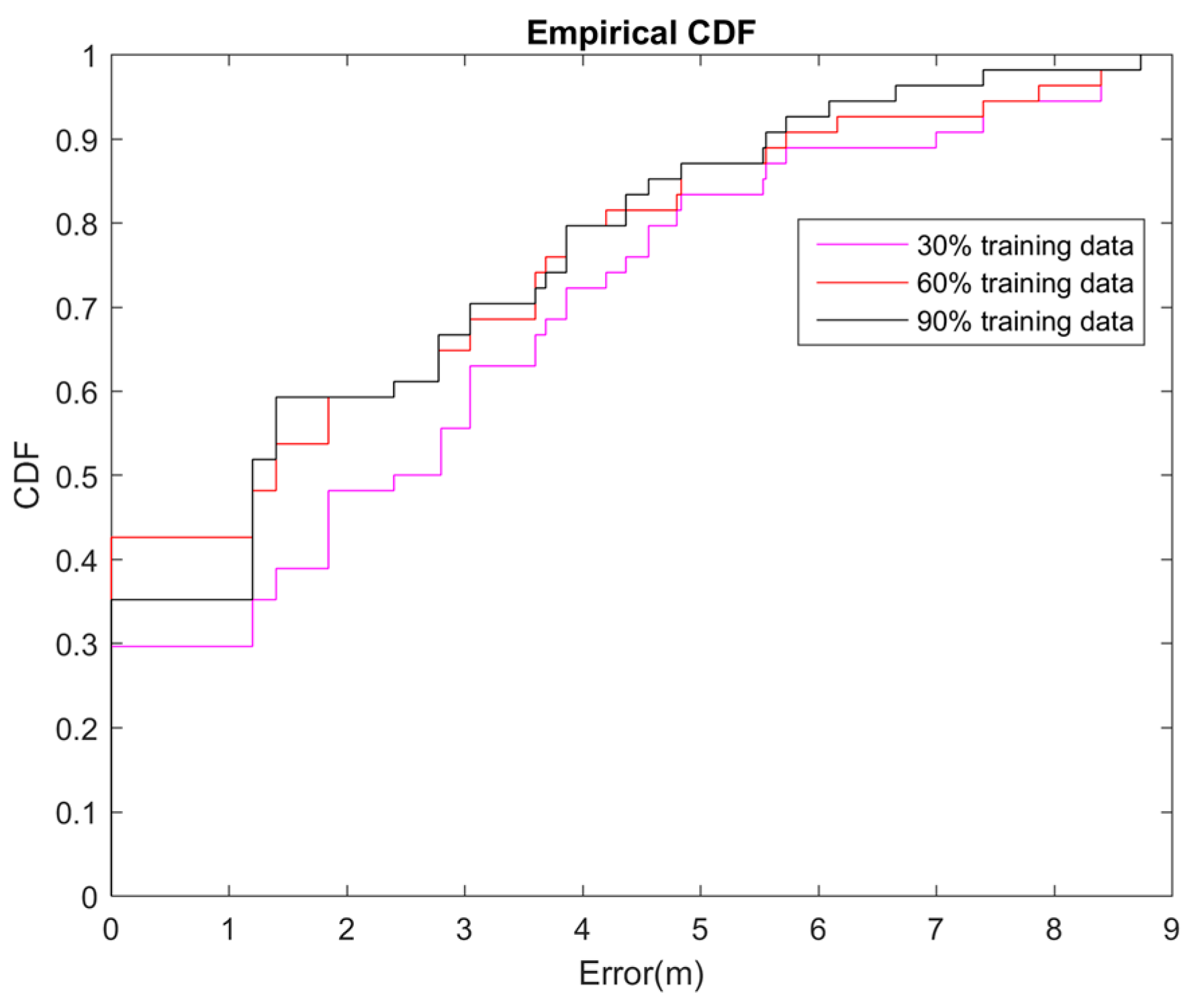
4.2. The Effect of the Different Training Data Size
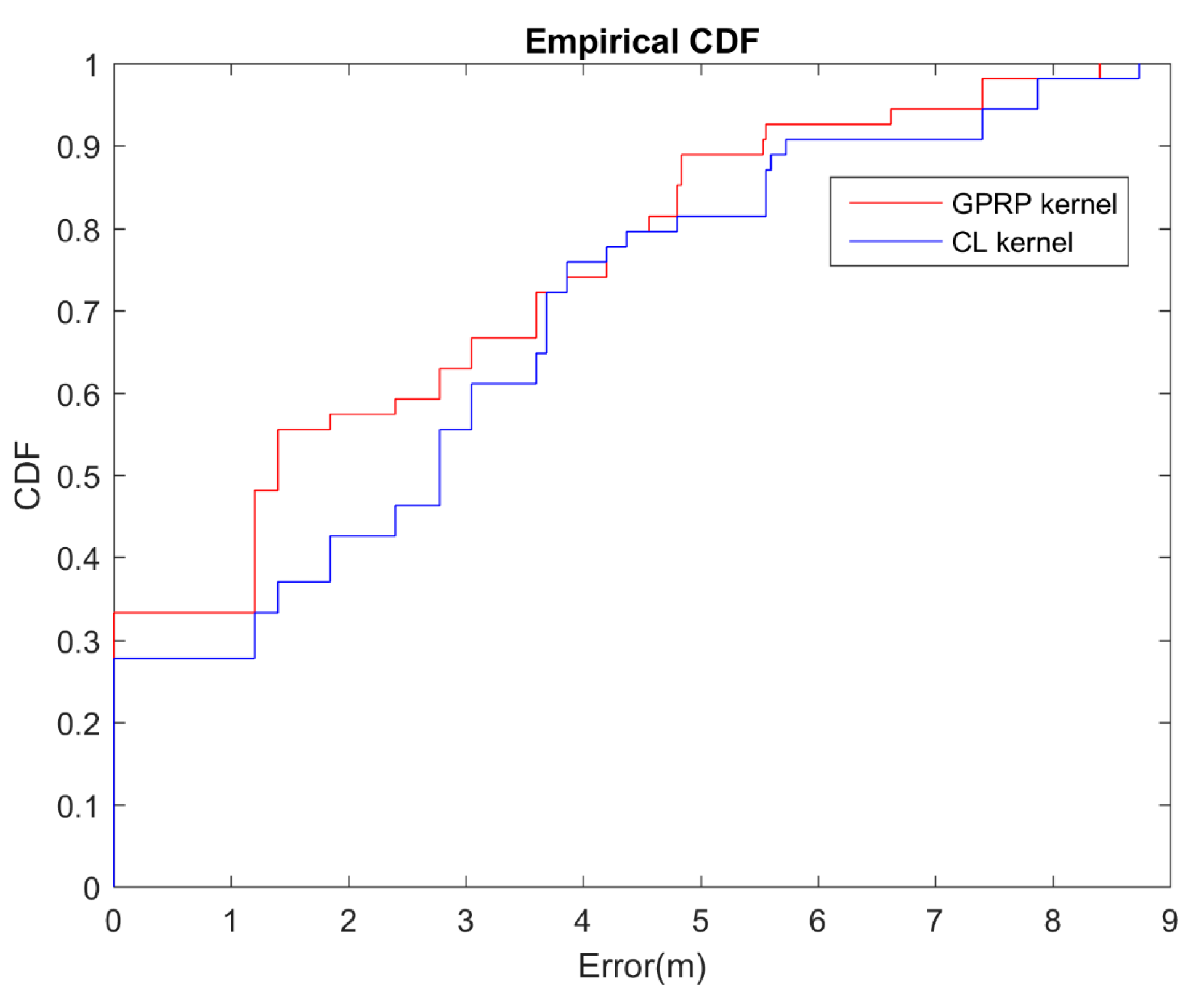
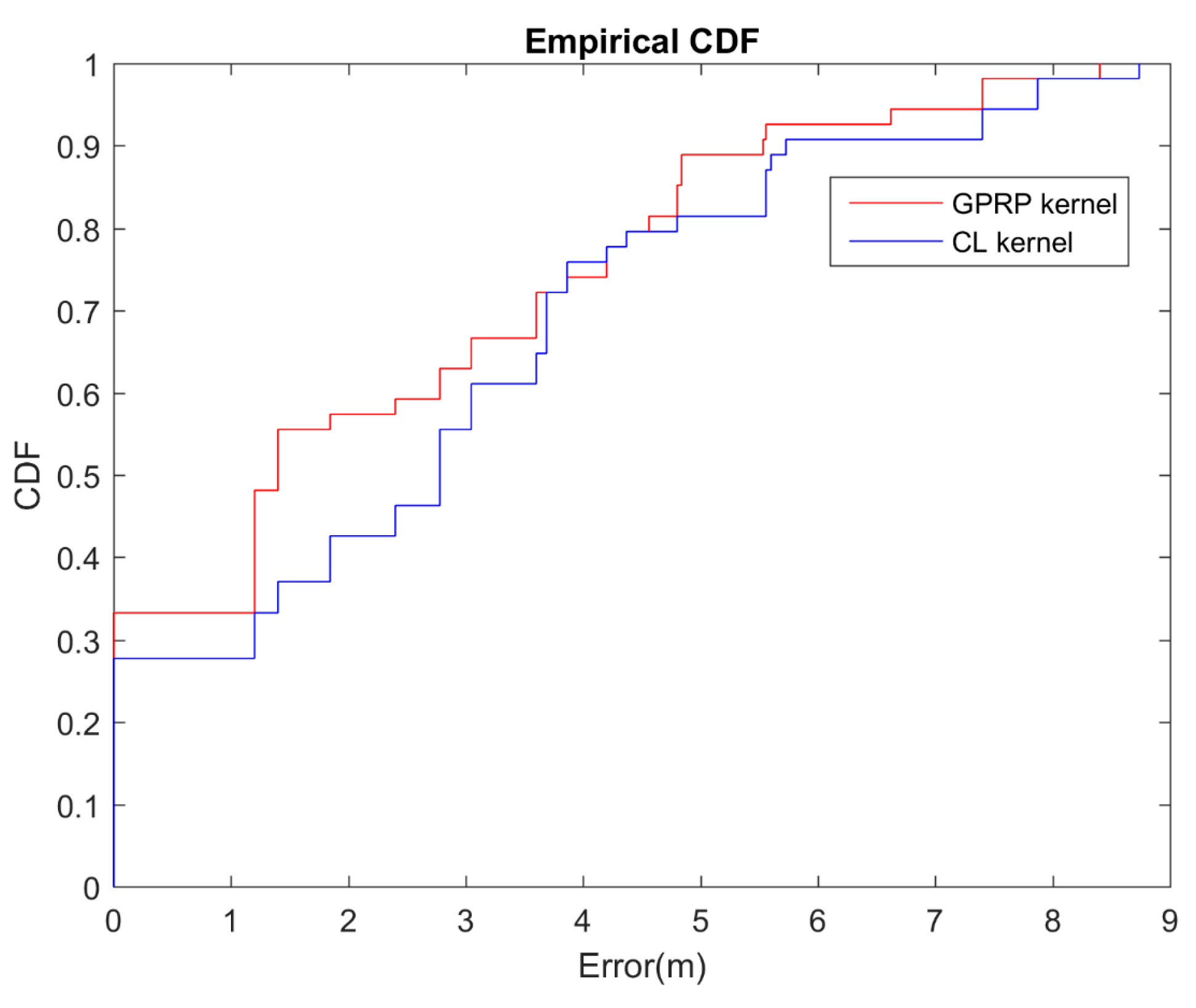
4.3. Effect on Different GPR Kernel
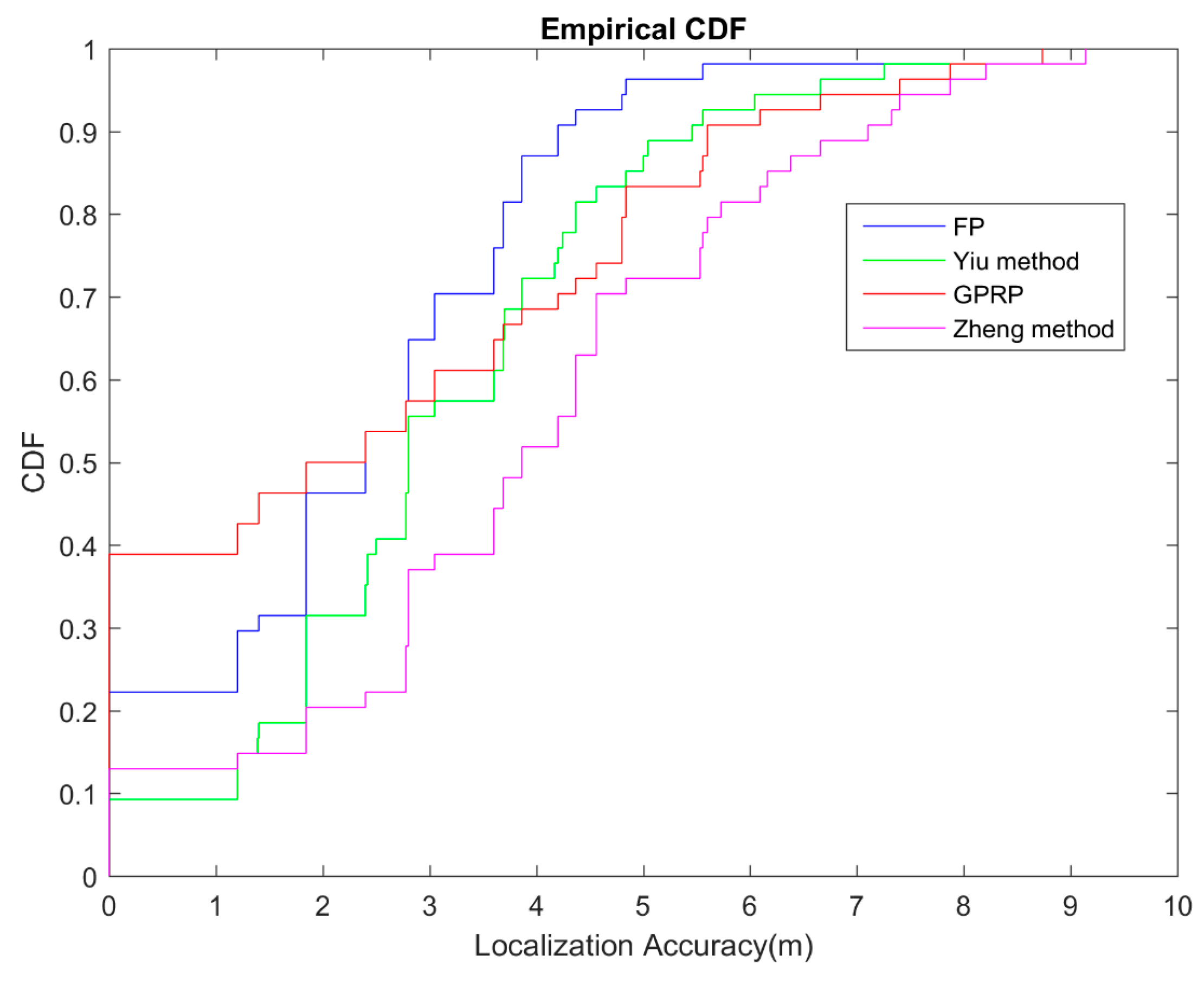
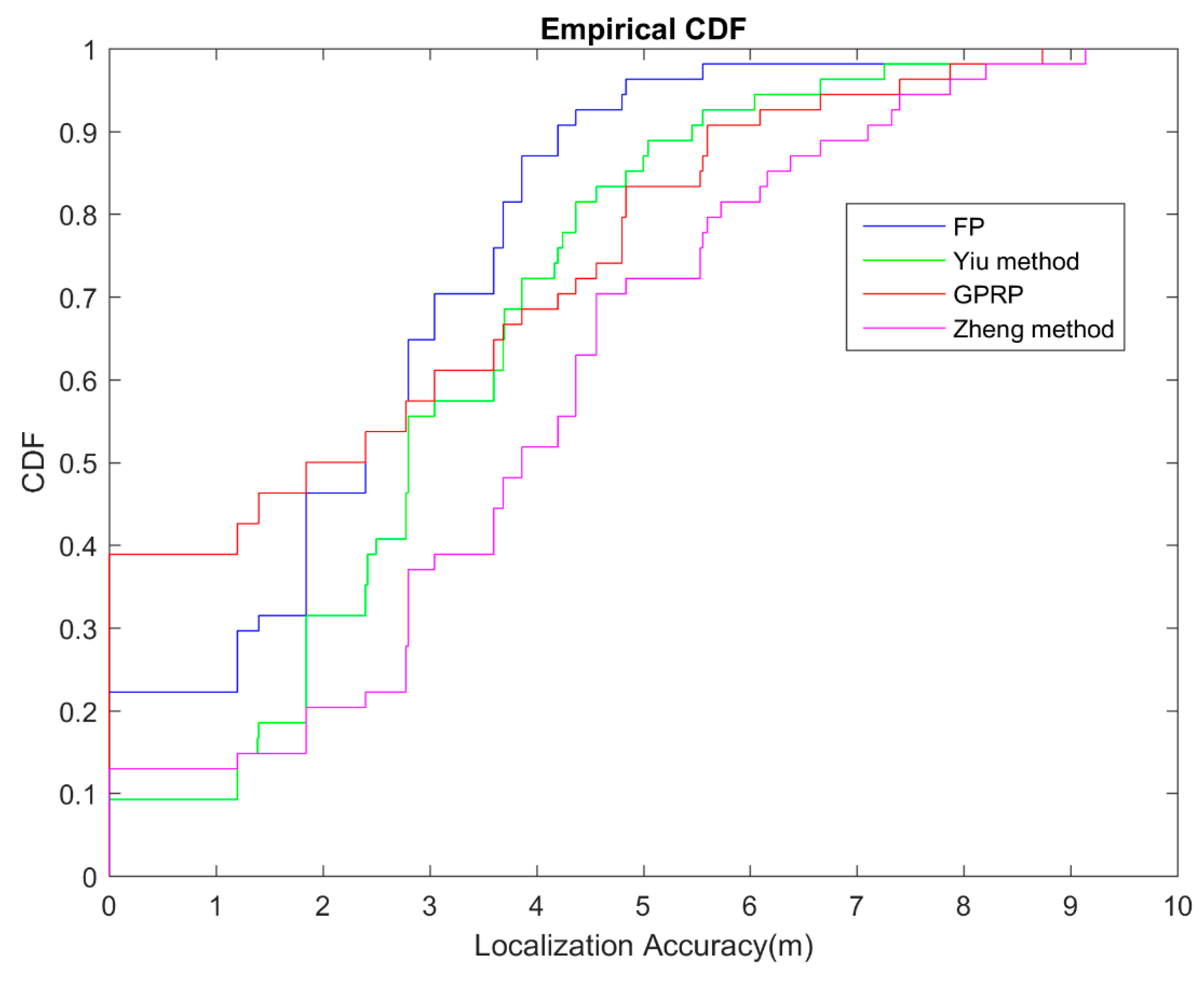
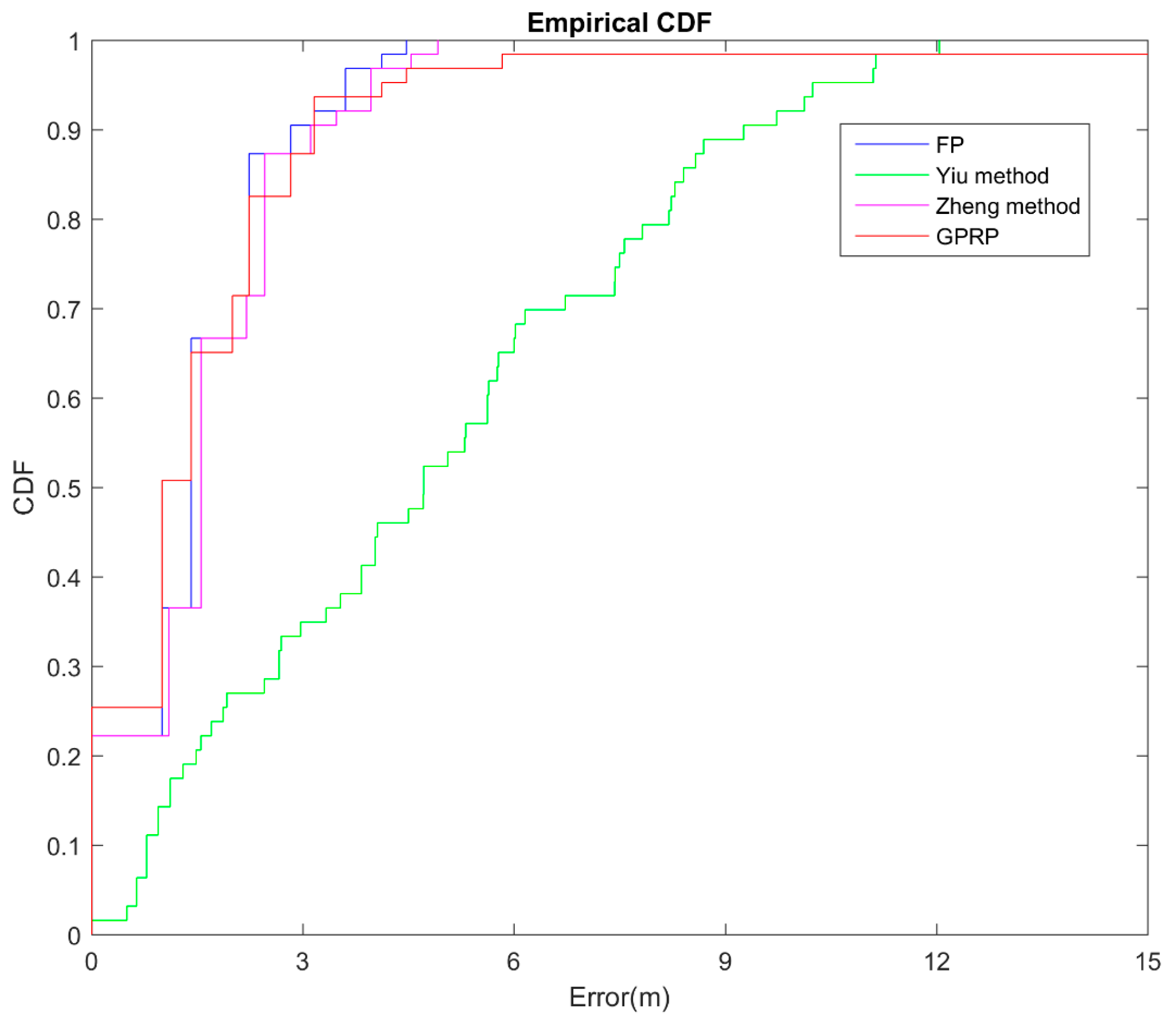
4.4. Performance Evaluation of GPRP
4.4.1. GPRP Robustness on Location Accuracy Testing
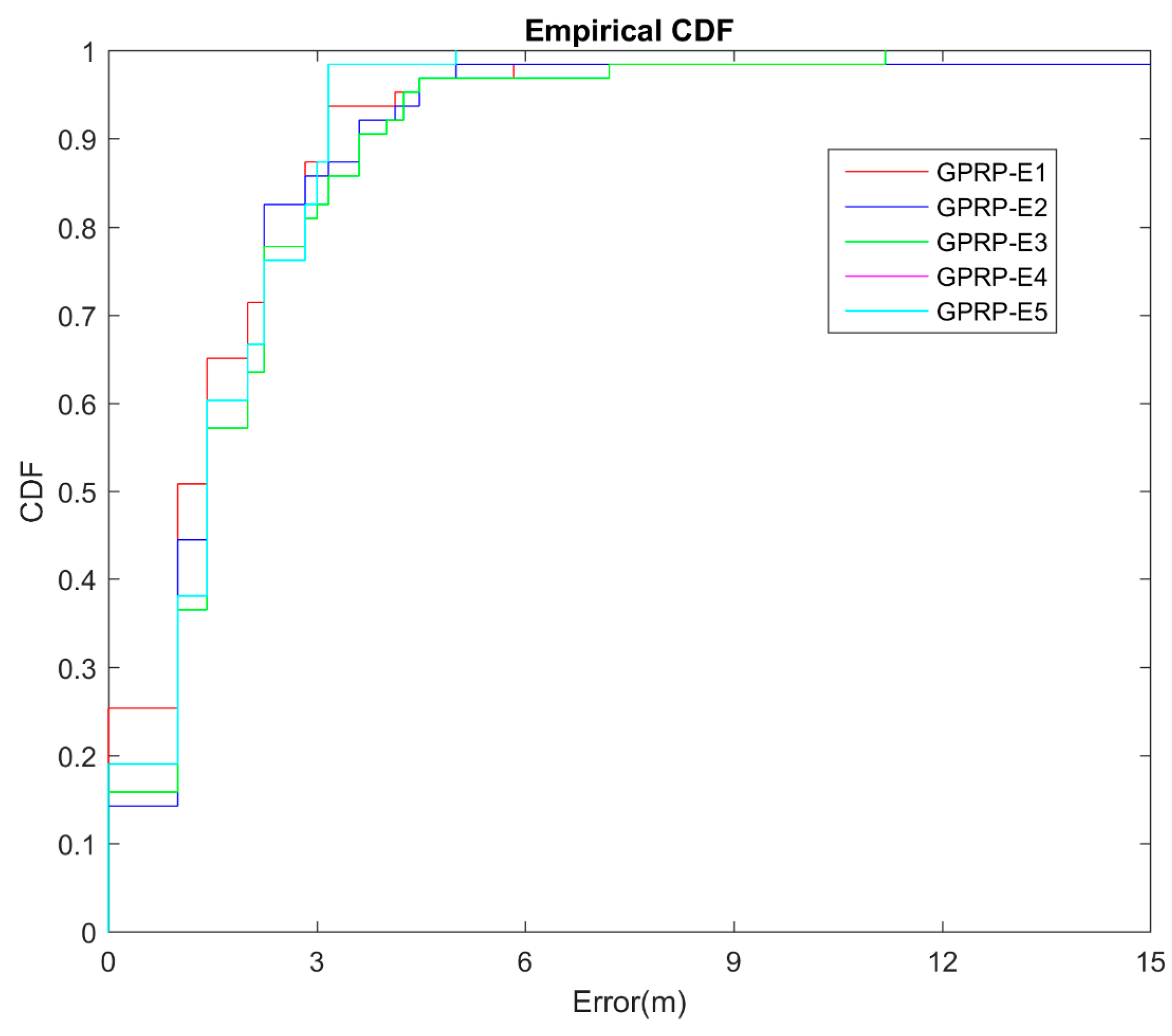
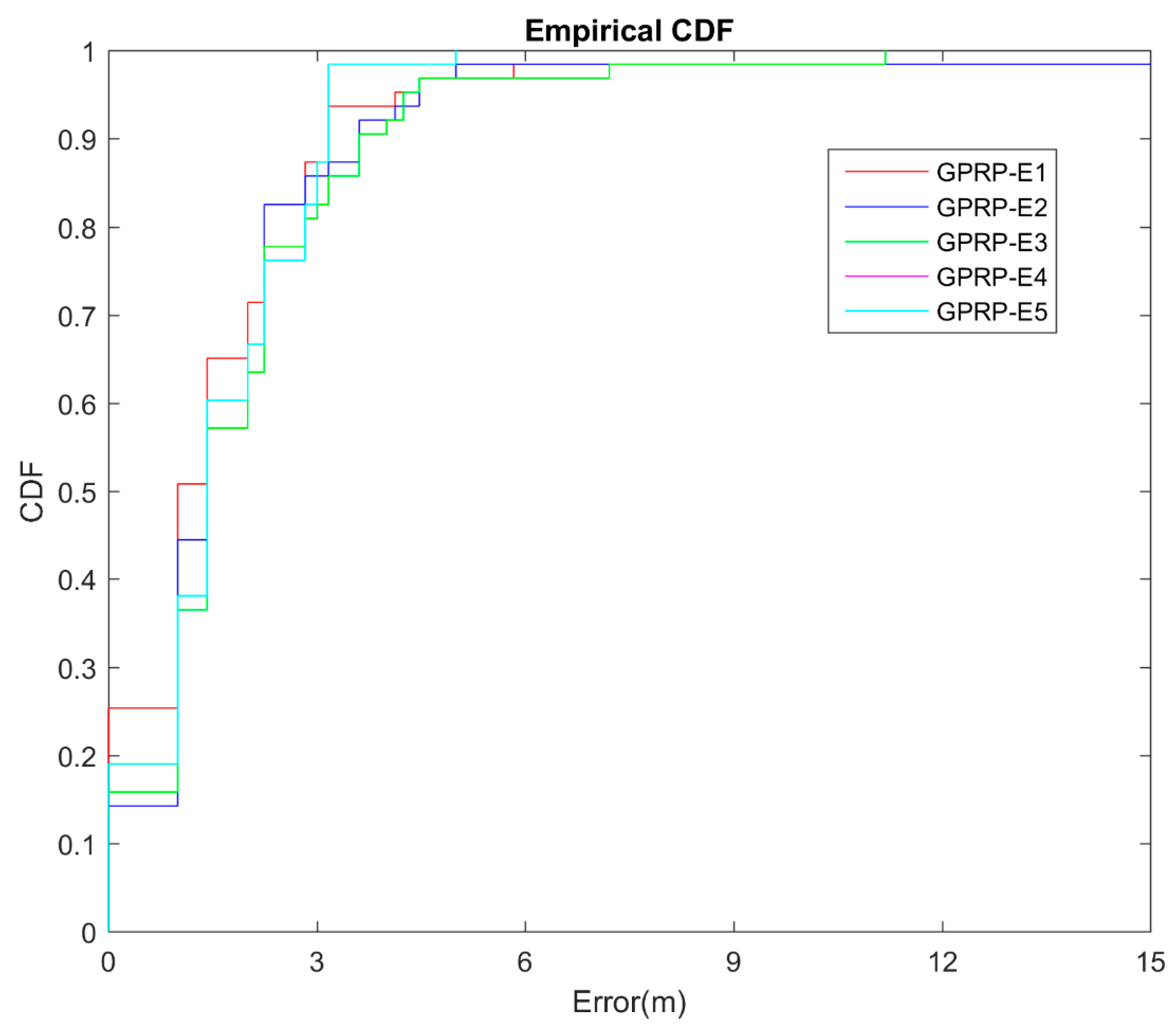
4.5. Localization Accuracy on Different Environments
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Own, C.-M.; Meng, Z.; Liu, K. Handling neighbor discovery and rendezvous consistency with weighted quorum-based approach. Sensors 2015, 15, 22364–22377. [Google Scholar] [CrossRef] [PubMed]
- Skalar, B. Rayleigh fading channels in mobile digital communication system part 1: Characterization. IEEE Commun. Mag. 1997, 35, 136–146. [Google Scholar] [CrossRef]
- Yilmaz, H.B.; Tugcu, T. Location estimation-based radio environment map construction in fading channels. Wirel. Commun. Mob. Comput. 2015, 15, 561–570. [Google Scholar] [CrossRef]
- Haeberlen, A.; Flannery, E.; Ladd, A.M.; Rudys, A.; Wallach, D.S.; Kavraki, L.E. Practical robust localization over large-scale 802.11 wireless networks. Int. Conf. Mob. Comput. Netw. 2016. [Google Scholar] [CrossRef]
- Bisio, I.; Cerruti, M.; Lavagetto, F.; Marchese, M.; Pastorino, M.; Randazzo, A. A trainingless wifi fingerprint positioning approach over mobile devices. IEEE Antennas Wirel. Propag. Lett. 2014, 13, 832–835. [Google Scholar] [CrossRef]
- Bisio, I.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Smart probabilistic fingerprinting for WiFi-based indoor positioning with mobile devices. Pervasive Mob. Comput. 2016, in press. [Google Scholar] [CrossRef]
- Hossain, A.K.M.; Soh, W.-S. A survey of calibration-free indoor positioning systems. Comput. Commun. 2015, 66, 1–13. [Google Scholar] [CrossRef]
- Zheng, Z.; Chen, Y.; He, T.; Sun, L.; Chen, D. Feature learning for fingerprint-based positioning in indoor environment. Int. J. Distrib. Sens. Netw. 2015, 2015, 1–11. [Google Scholar] [CrossRef]
- Xu, C.; Tao, W.; Feng, Z.; Meng, Z. Robust visual tracking via online multiple instance learning with fisher information. Pattern Recognit. 2015, 48, 3917–3926. [Google Scholar] [CrossRef]
- Xu, C.; Feng, Z.; Meng, Z. Affective experience modeling based on interactive synergetic dependence in big data. Future Gener. Comput. Syst. 2016, 54, 507–517. [Google Scholar] [CrossRef]
- Bekkali, A.; Masuo, T.; Tominaga, T. Gaussian processes for learning-based indoor localization. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing, Xi’an China, 14–16 September 2011; pp. 1–6.
- Yiu, S.; Yang, K. Gaussian process assisted fingerprinting localization. IEEE Internet Things J. 2015. [Google Scholar] [CrossRef]
- Youssef, M.; Agrawala, A. The Horus location determination system. Wirel. Netw. 2008, 14, 357–374. [Google Scholar] [CrossRef]
- Nurminen, H.; Talvitie, J.; Ali-Loytty, S.; Muller, P.; Lohan, E.S.; Piche, R.; Renfors, M. Statistical path loss parameter estimation and positioning using RSS measures in indoor wireless networks, positioning using RSS measurements in indoor wireless networks. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation, New South Wales Sydney, Australia, 13–15 November 2012; pp. 1–9.
- Small, J.; Smailagic, A.; Siewiorek, D.P. Determining User Location for Context Aware Computing through the Use of a Wireless Lan Infrastructure. Available online: http://www-2.cs.cmu.ed/~aura/docdir/small00.pdf (accessed on 26 March 2016).
- Zhou, J.; Chu, K.M.; Ng, J.K.-Y. Providing location services within a radio cellar network using ellipse propagation model. Int. Conf. Adv. Intell. Netw. Appl. 2005, 1, 559–564. [Google Scholar]
- Chen, Y.-C.; Chiang, J.-R.; Chu, H.-H.; Huang, P.; Tsui, A. Sensor-assisted wifi indoor location system for adapting to environmental dynamics. In Proceedings of the 8th ACM International Symposium on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Montreal, QC, Canada, 10–13 October 2005; pp. 118–125.
- Xie, Y.; Wang, Y.; Nallanathan, A.; Wang, L. An improved K-nearest-neighbor indoor localization method based on spearman distance. IEEE Signal Process. Lett. 2016, 23, 351–355. [Google Scholar] [CrossRef]
- Chang, Q.; Li, Q.; Shi, Z.; Chen, W.; Wang, W. Scalable indoor localization via mobile crowdsourcing and gaussian process. Sensors 2016. [Google Scholar] [CrossRef] [PubMed]
- Larios, D.F.; Barbancho, J.; Molina, F.J. Locating sensors with fuzzy logic algorithms. In Proceedings of the IEEE Workshop on Computational Intelligence and Sensor Technology, Paris, France, 11–15 April 2011; pp. 57–64.
- Atia, M.M.; Noureldin, A.; Korenberg, M.J. Dynamic online-calibrated radio maps for indoor positioning in wireless local area networks. IEEE Trans. Mob. Comput. 2013, 12, 1774–1787. [Google Scholar] [CrossRef]
- Farid, Z.; Nordin, R.; Ismail, M. Recent advances in wireless indoor localization techniques and system. J. Comput. Netw. Commun. 2013. [Google Scholar] [CrossRef]
- Ciurana, M.; Cugno, S.; Barceló-Arroyo, F. WLAN indoor positioning based on TOA with two reference points. In Proceedings of the 2007 4th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 22 March 2007; pp. 23–28.
- Krishnakumar, A.S.; Krishnan, P. The theory and practice of signal strength-based location estimation. In Proceedings of the IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, San Jose, CA, USA, 19–22 December 2005; pp. 1–10.
- Diono, M.; Rachmana, N. Indoor positioning system based on received signal strength (RSS) fingerprinting. In Proceedings of the 8th International Conference on IEEE Telecommunication Systems Services and Applications (TSSA), Kuta, Indonesia, 23–24 October 2014.
- Ounpraseuth, S.T. Gaussian Processes for Machine Learning. J. Am. Stat. Assoc. 2008, 103. [Google Scholar] [CrossRef]
- Stephen, M. Thomas Bayes’s bayesian inference. J. R. Stat. Soc. 1982, 145, 250–258. [Google Scholar]
- Alpaydin, E. Bayesian decision theory. Bayesian Anal. Uncertain. Econ. Theory 2014, 11, 47–59. [Google Scholar]
- Qiong, W.; Garrity, G.M.; Tiedje, J.M. Naive Bayesian classifier for rapid assignment of rRNA sequences into the new bacterial taxonomy. Appl. Environ. Microbiol. 2007, 73, 5261–5267. [Google Scholar]
- Lin, Y.P.; Chen, Z.P.; Yang, X.L. Mail filtering based on the risk minimization Bayesian algorithm. In Proceedings of the 6th World Multi-Conference on Systemics, Cybernetics and Informatics, Orlando, FL, USA, 14–18 July 2002; pp. 282–285.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Function | Equation Expression |
|---|---|
| Zero | 0 |
| Constant | ; |
| Linear | |
| Poly |
| Covariance Function | Equation Expression |
|---|---|
| Constant | |
| Linear | ; |
| Polynomial | |
| Exponential | |
| Rational quadratic |
| RMSE (m) | 1 m | 2 m | 3 m | 6 m | |
|---|---|---|---|---|---|
| GPRP method | 2.28 | 33.33% | 57.41% | 62.96% | 92.59% |
| CL method | 2.78 | 27.79% | 42.59% | 55.56% | 90.74% |
| ID for Testing Environment | WAF for Off-Line Training | WAF for On-Line Testing |
|---|---|---|
| E1 | 0.2 | 0.2 |
| E2 | 0.2 | 0.3 |
| E3 | 0.2 | 0.5 |
| E4 | 0.2 | 1 |
| E5 | 0.2 | 2 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; Meng, Z.; Own, C.-M. Gaussian Process Regression Plus Method for Localization Reliability Improvement. Sensors 2016, 16, 1193. https://doi.org/10.3390/s16081193
Liu K, Meng Z, Own C-M. Gaussian Process Regression Plus Method for Localization Reliability Improvement. Sensors. 2016; 16(8):1193. https://doi.org/10.3390/s16081193
Chicago/Turabian StyleLiu, Kehan, Zhaopeng Meng, and Chung-Ming Own. 2016. "Gaussian Process Regression Plus Method for Localization Reliability Improvement" Sensors 16, no. 8: 1193. https://doi.org/10.3390/s16081193
APA StyleLiu, K., Meng, Z., & Own, C.-M. (2016). Gaussian Process Regression Plus Method for Localization Reliability Improvement. Sensors, 16(8), 1193. https://doi.org/10.3390/s16081193