
A Dual-Field Sensing Scheme for a Guidance System for the Blind

Abstract
:1. Introduction
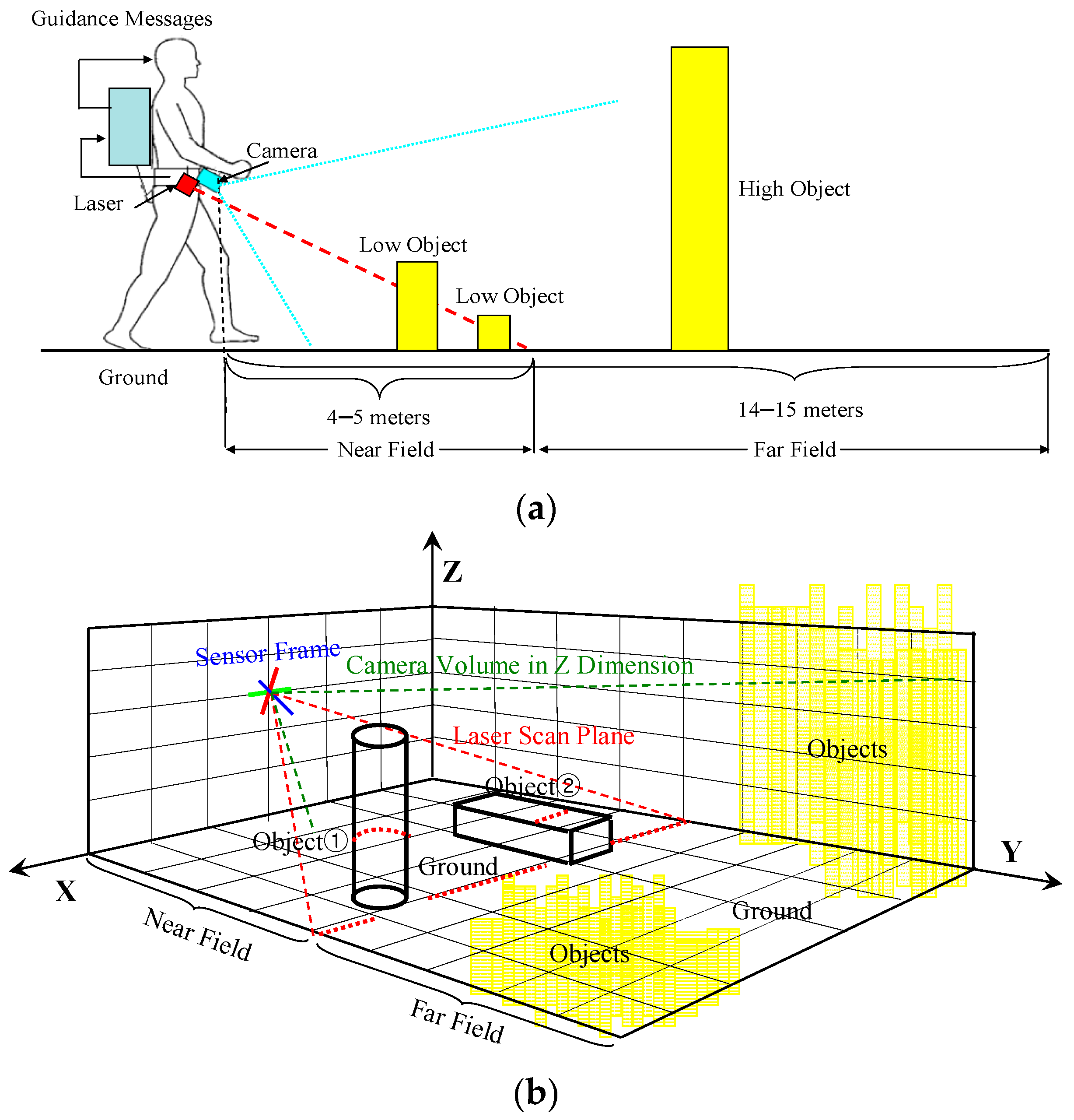
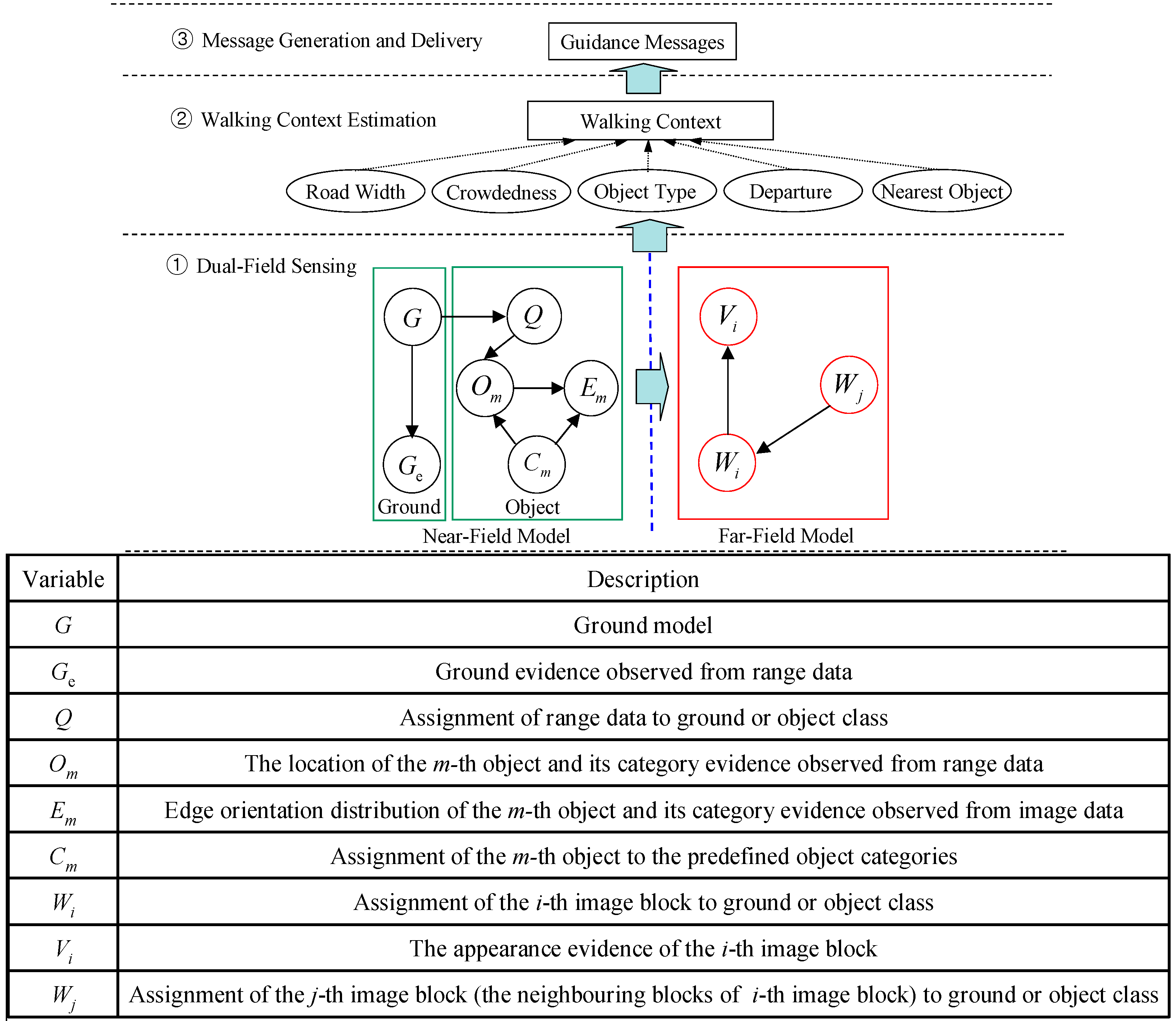
2. Dual-Field Sensing
2.1. Dual-Field Sensing Scheme
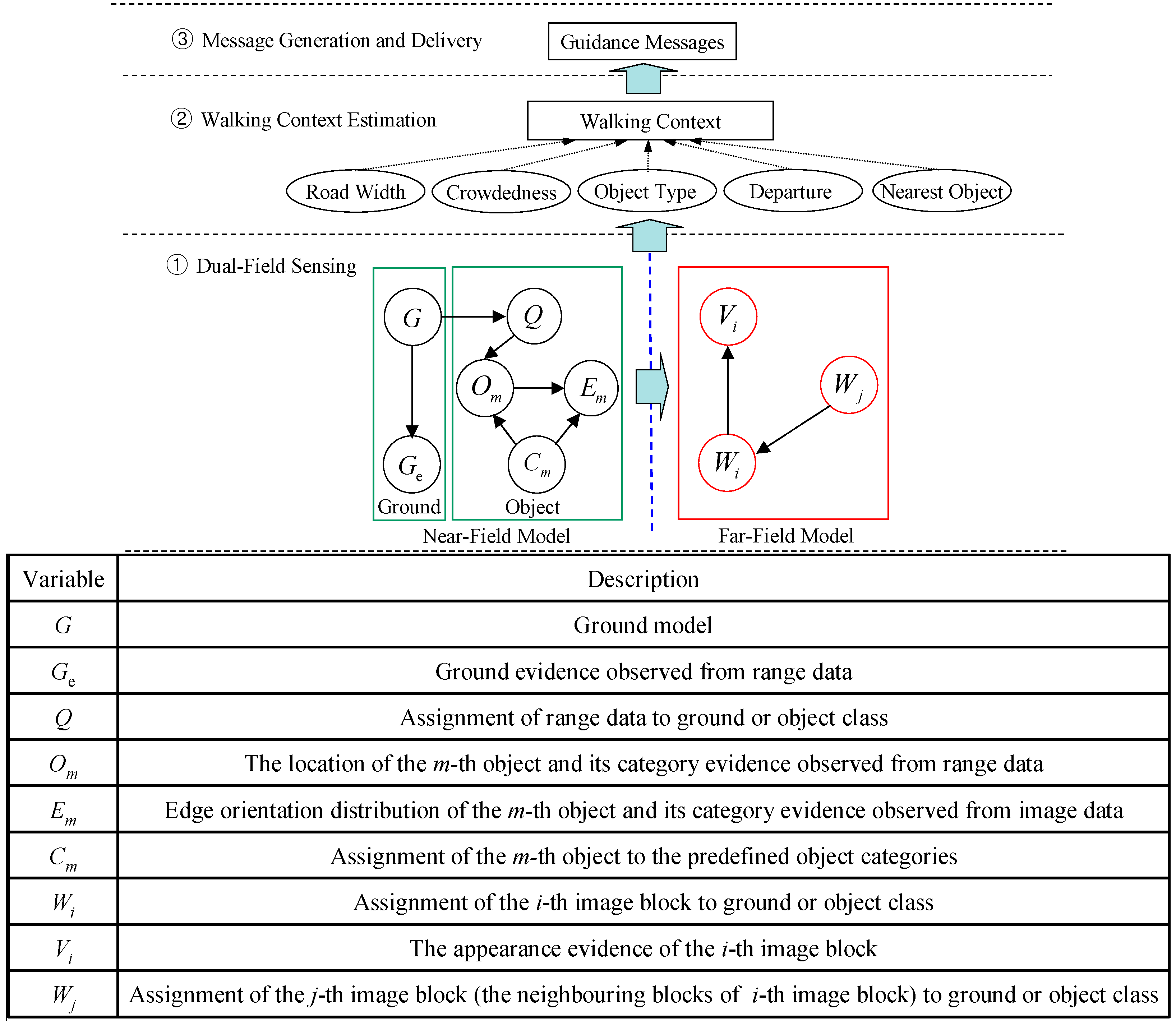
2.2. Dual-Field Sensing Model
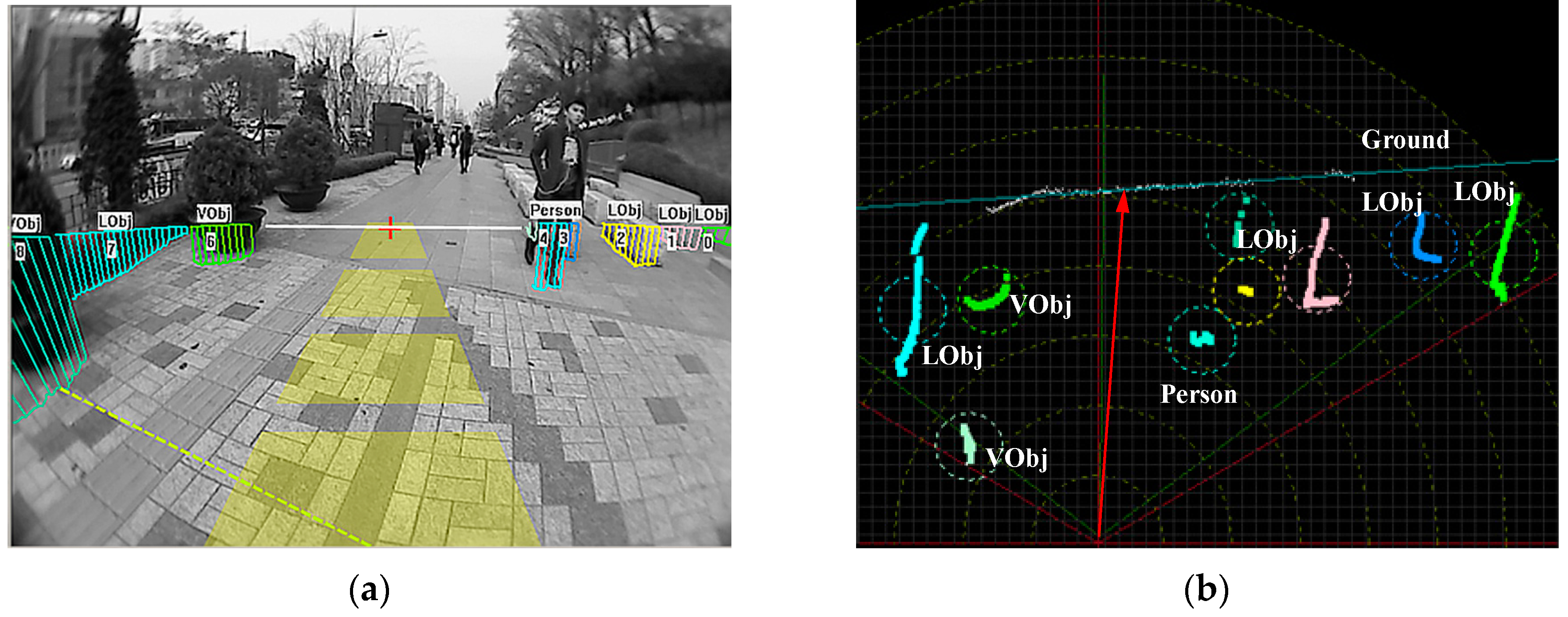
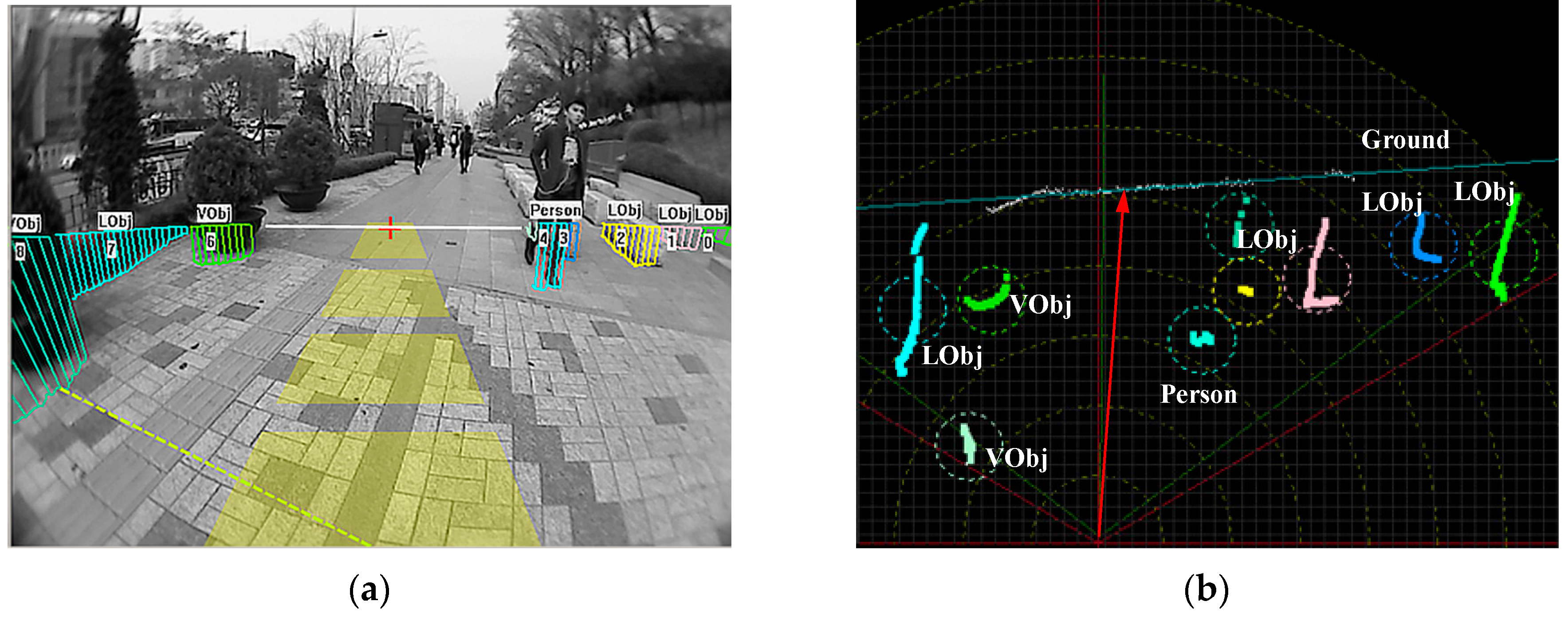
3. Far-Field Scene Interpretation
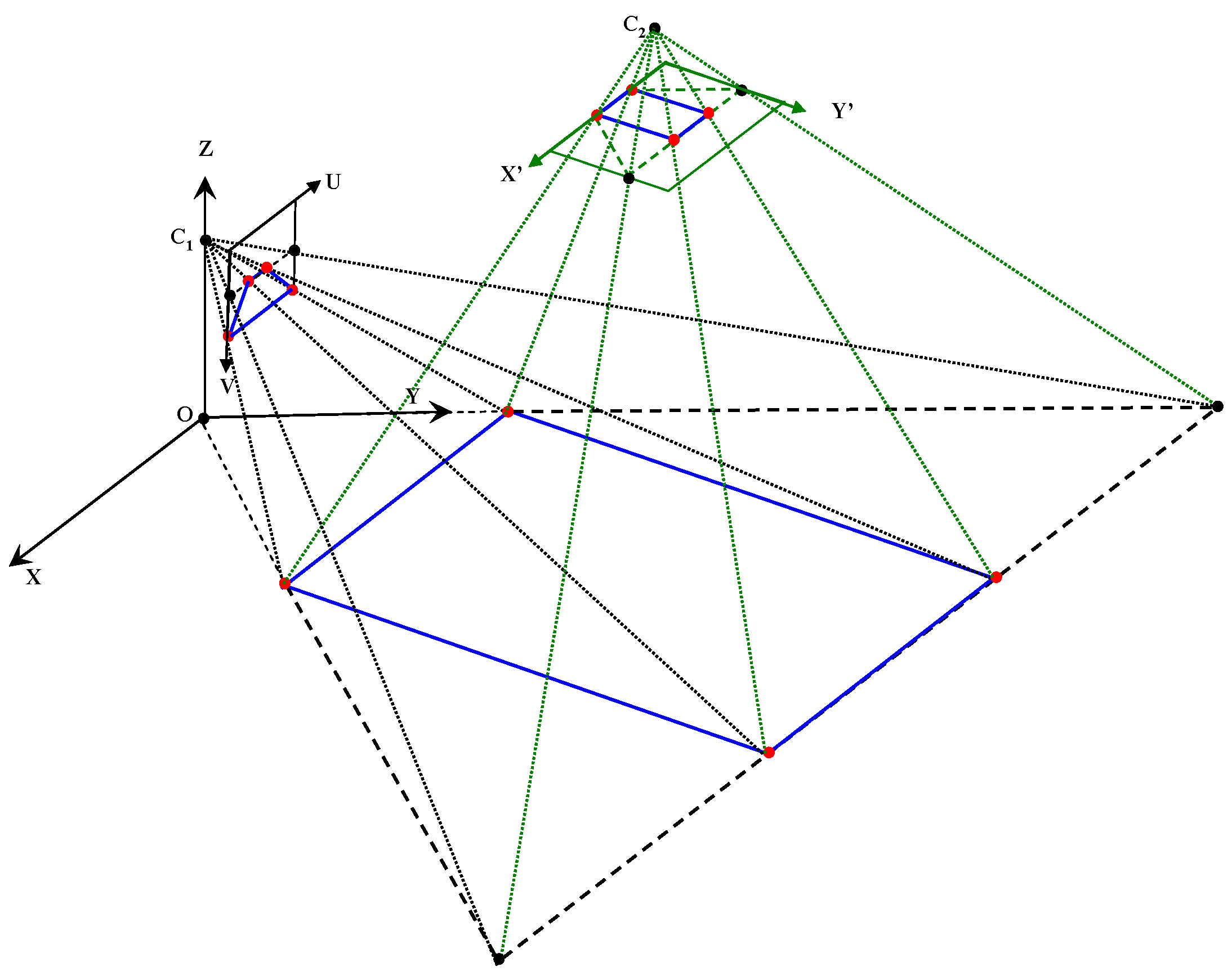
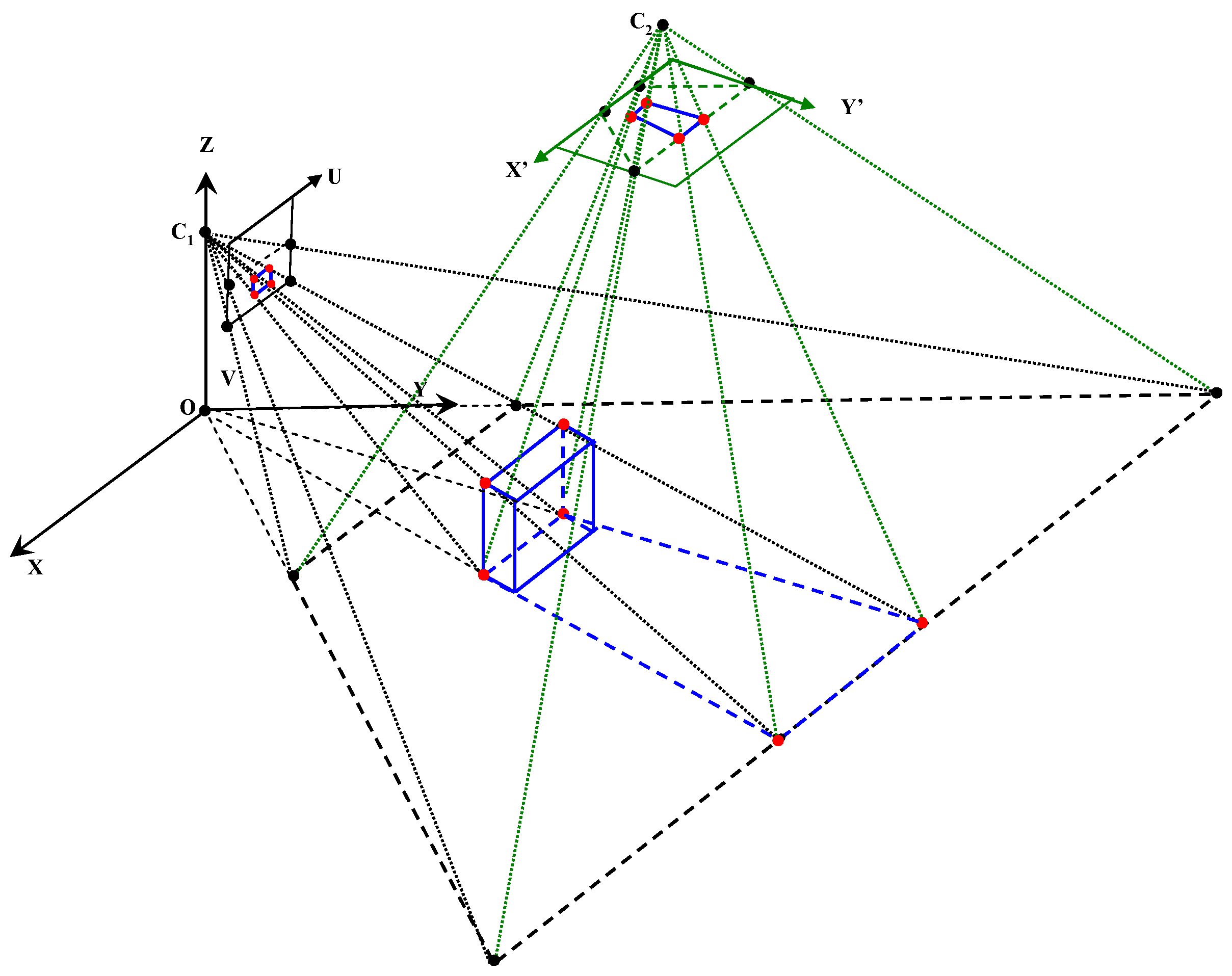
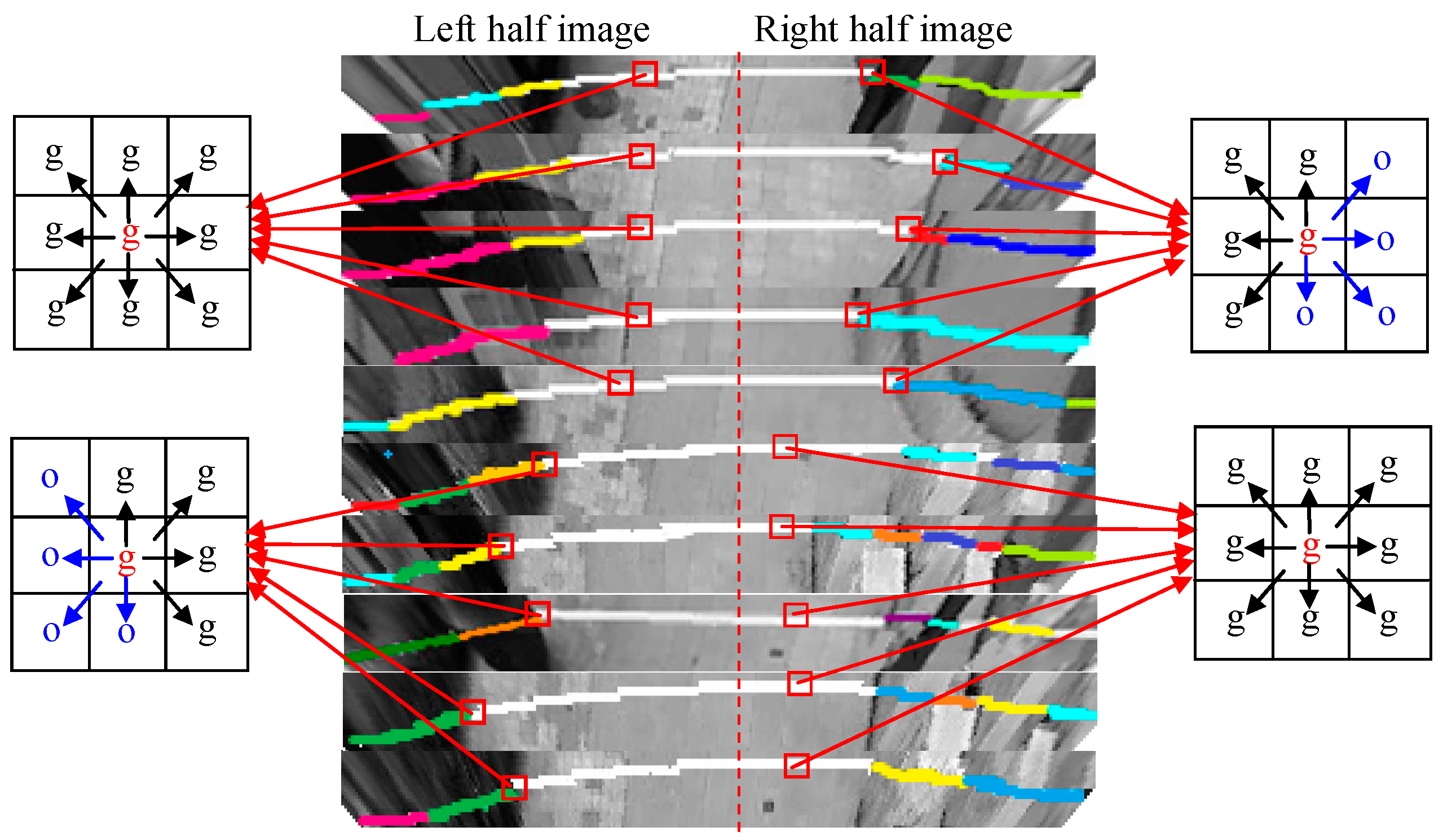
3.1. Far-Field Graphical Model
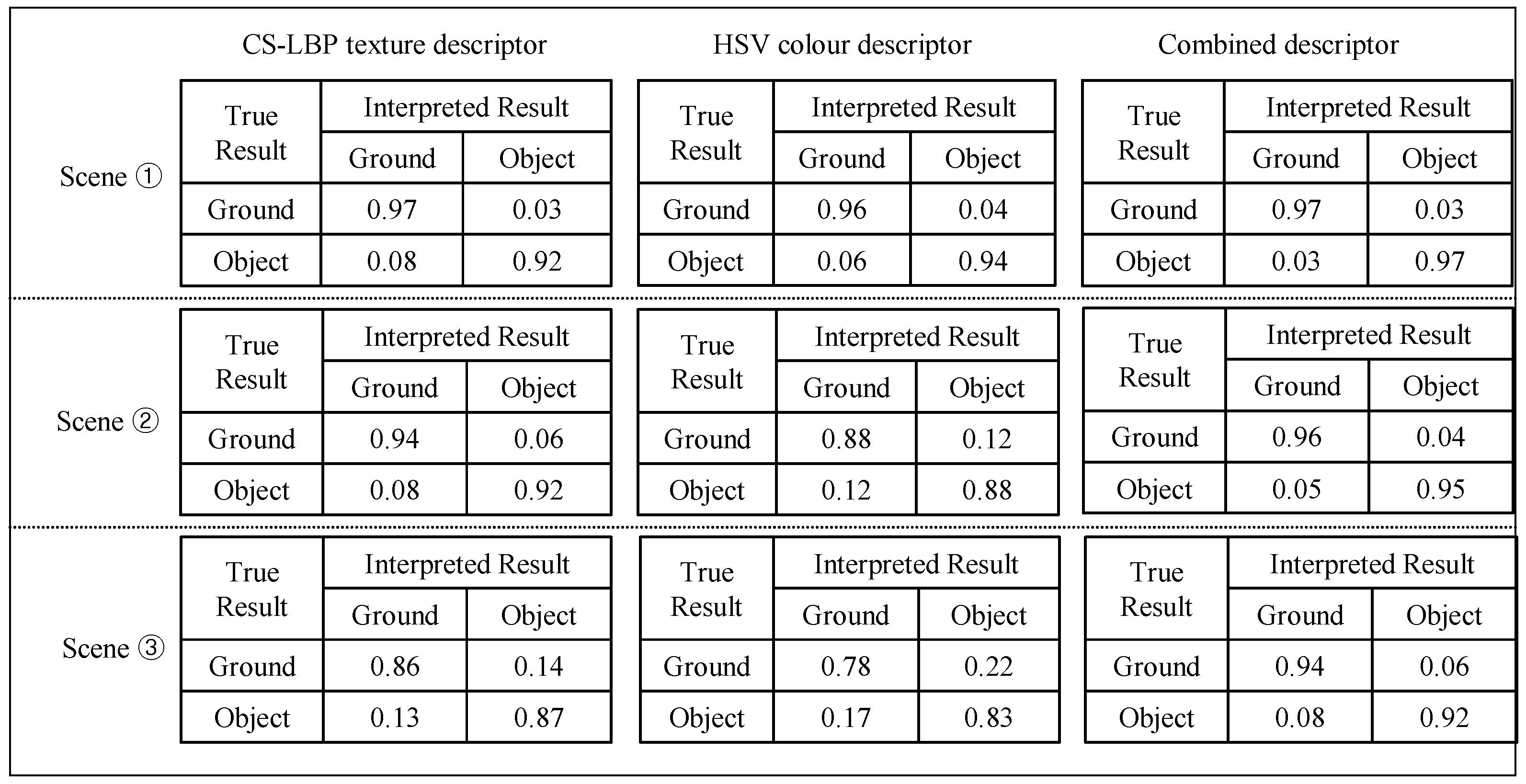
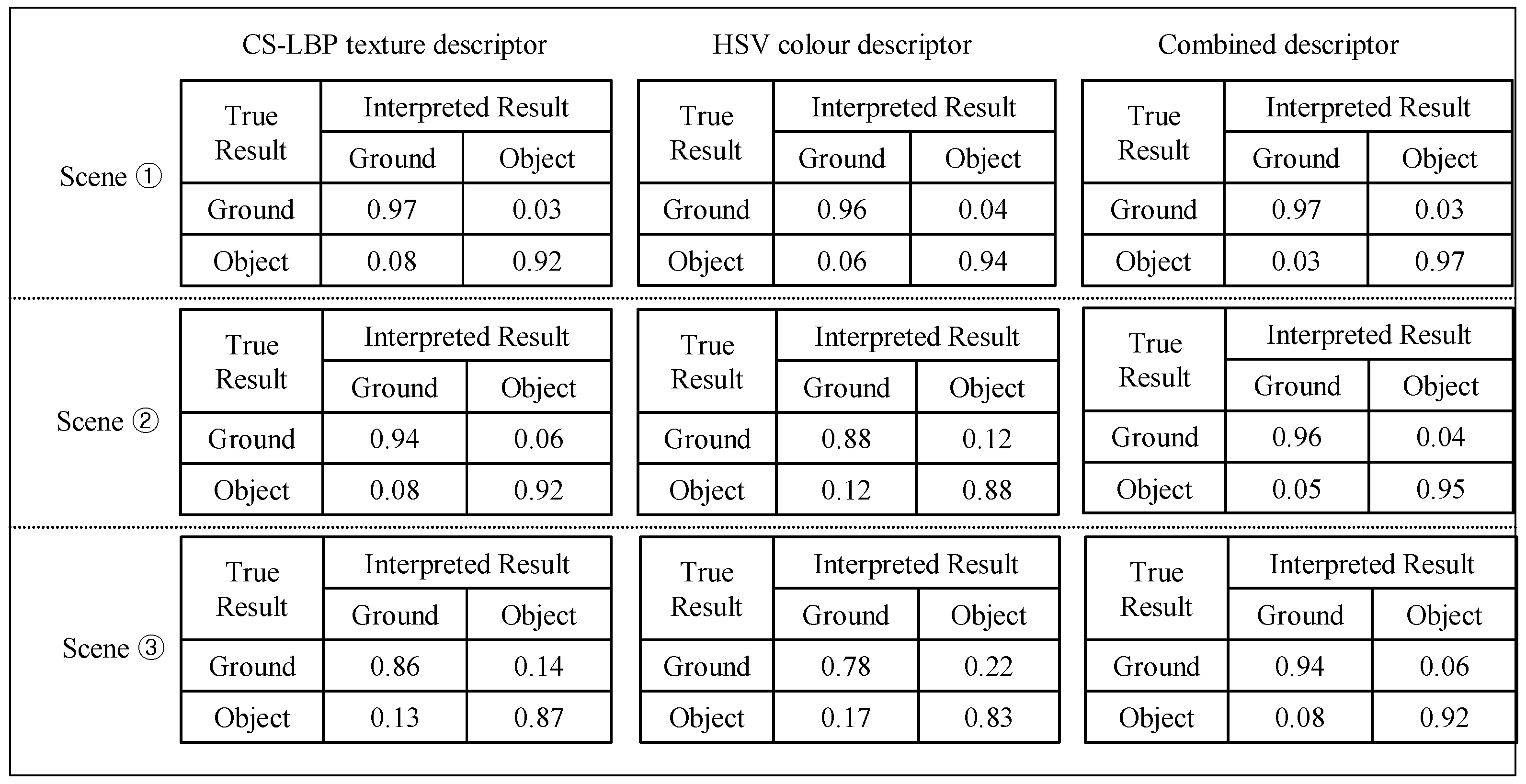
3.2. Cross-Field Appearance Interpretation
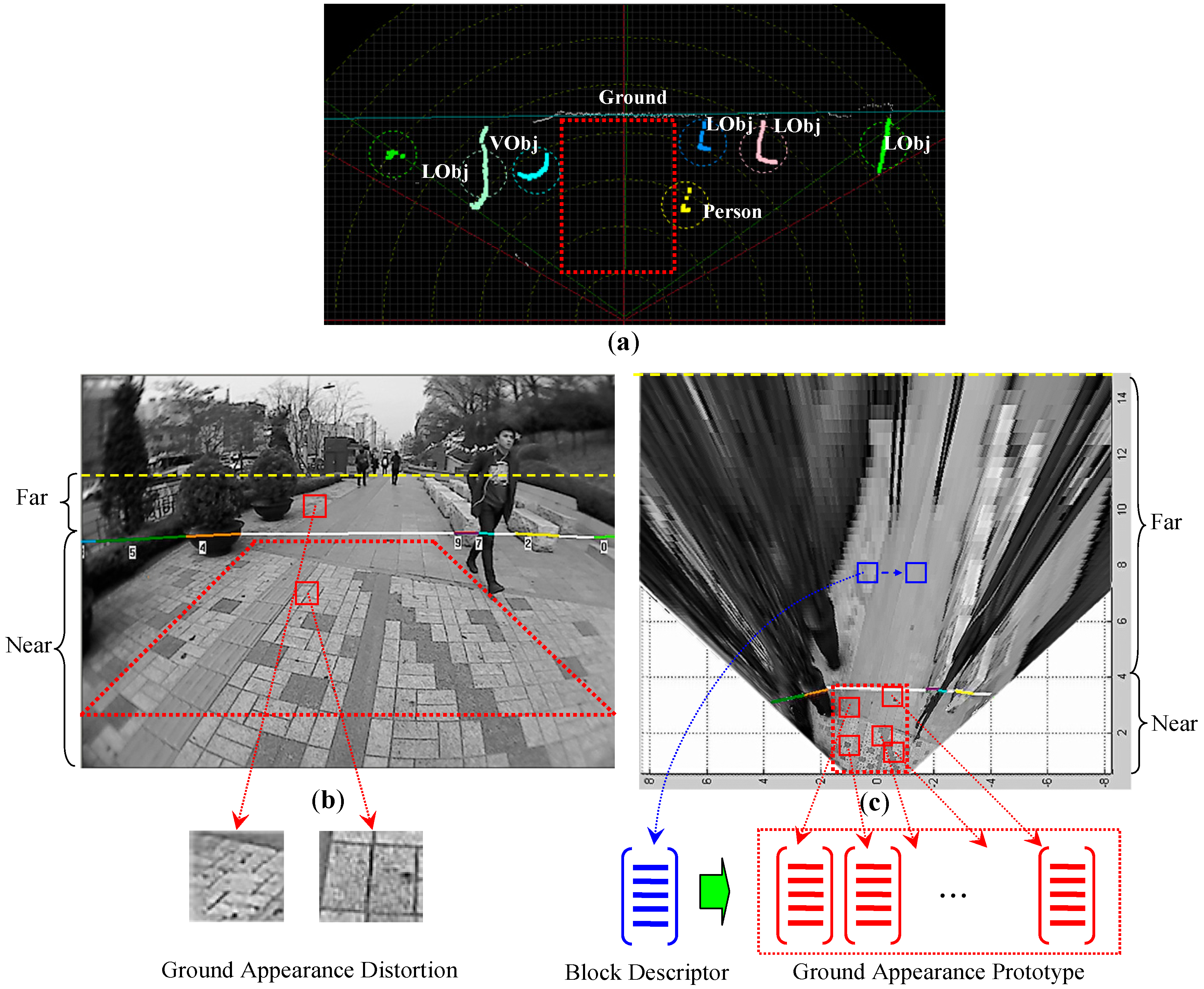
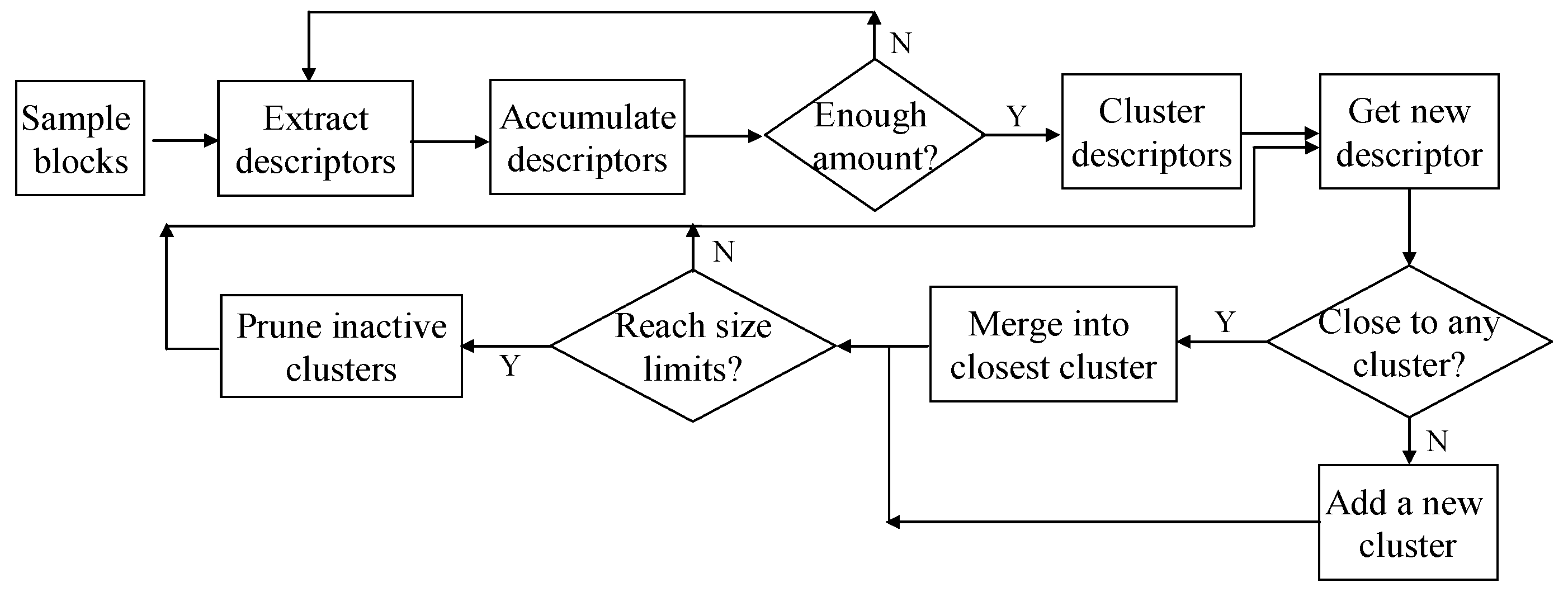
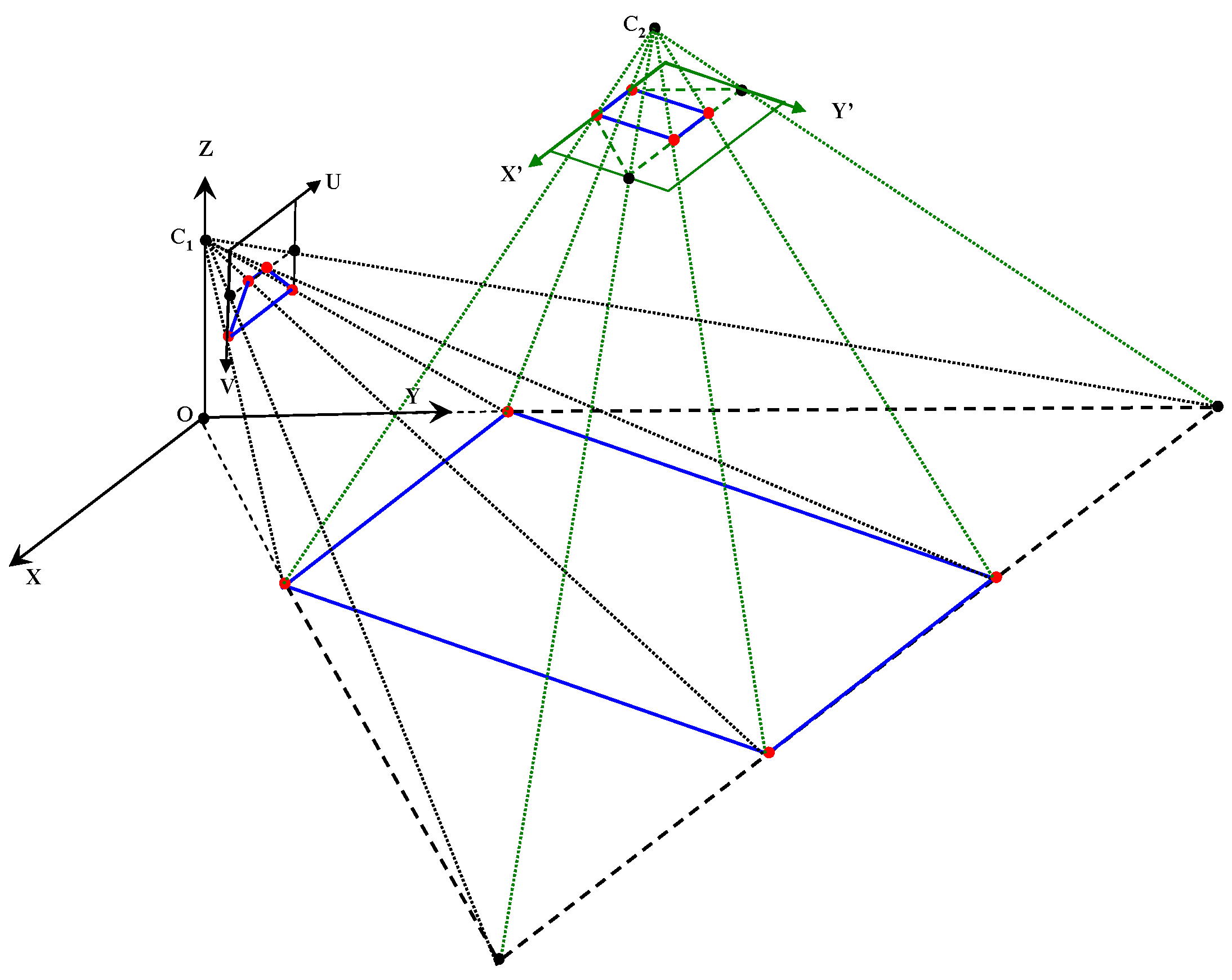
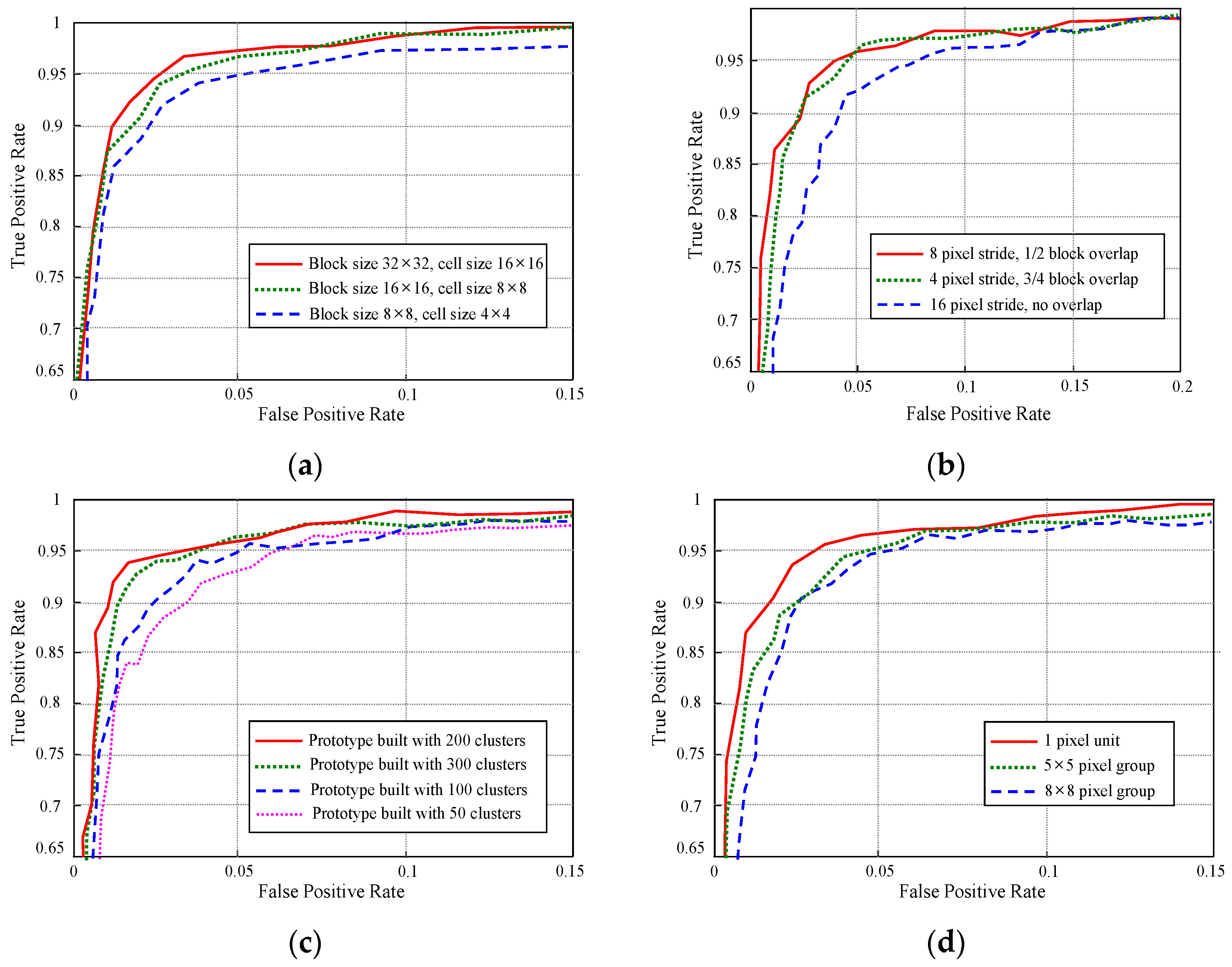
3.2.1. Appearance Prototype Building on Top-View Domain
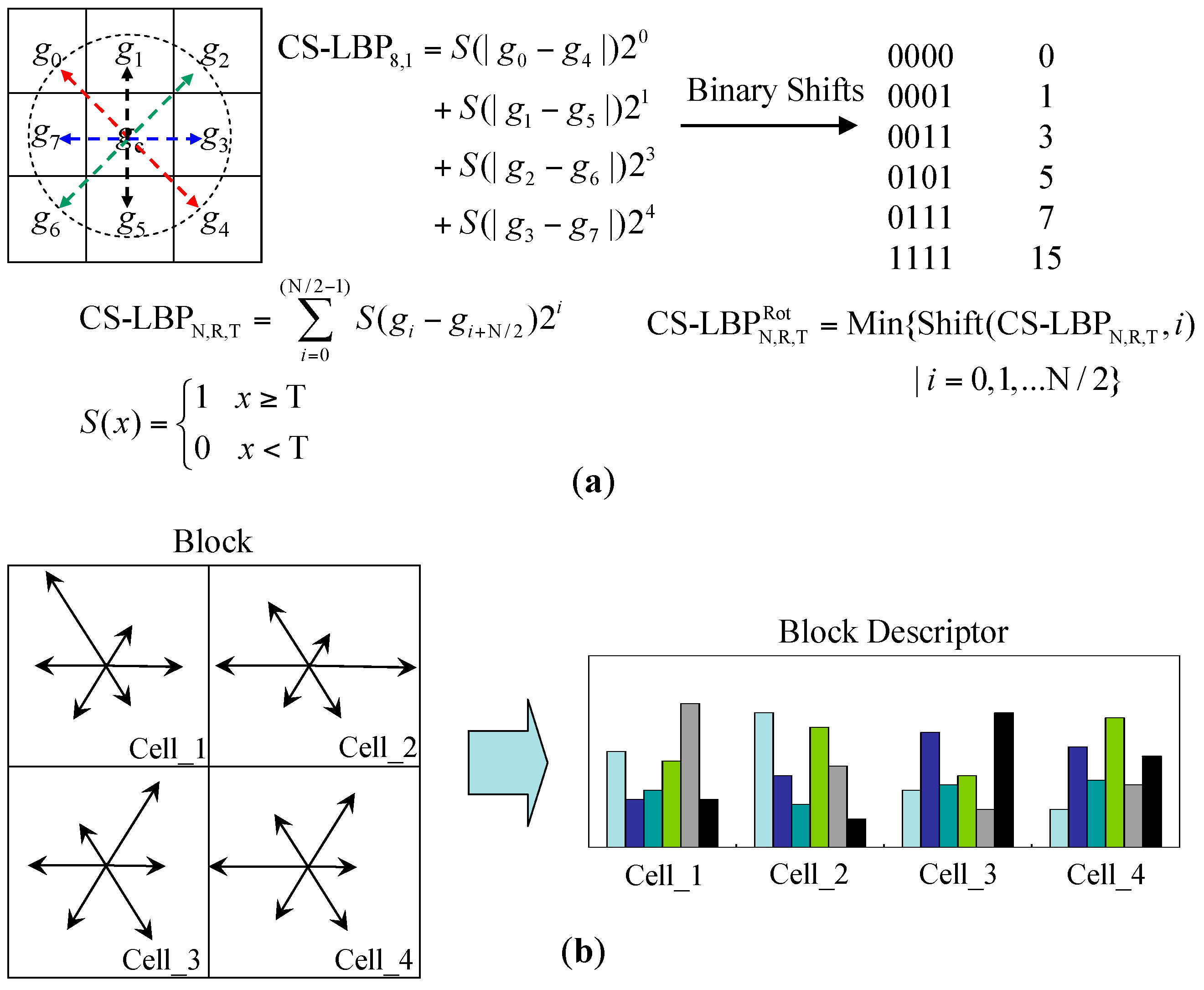
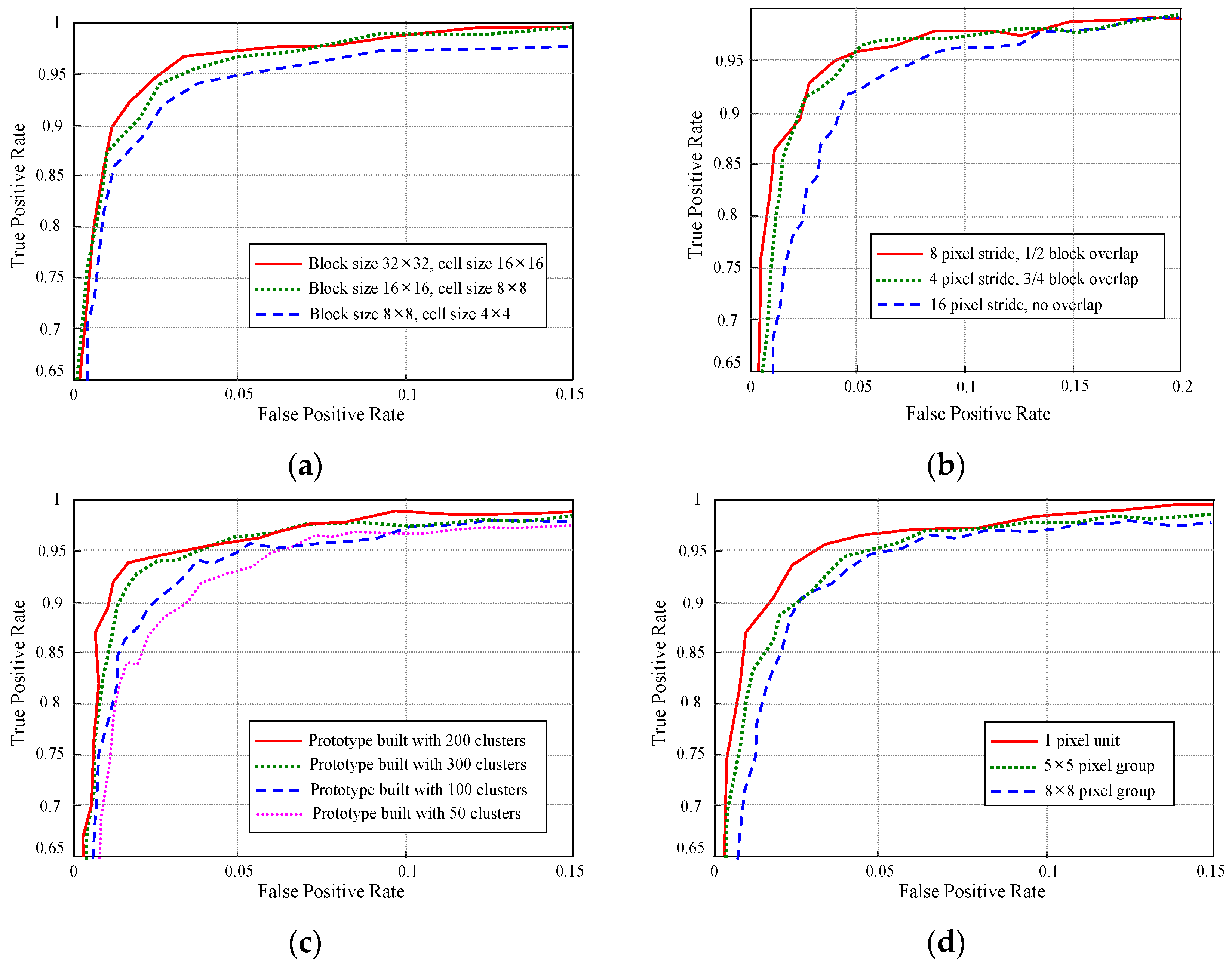
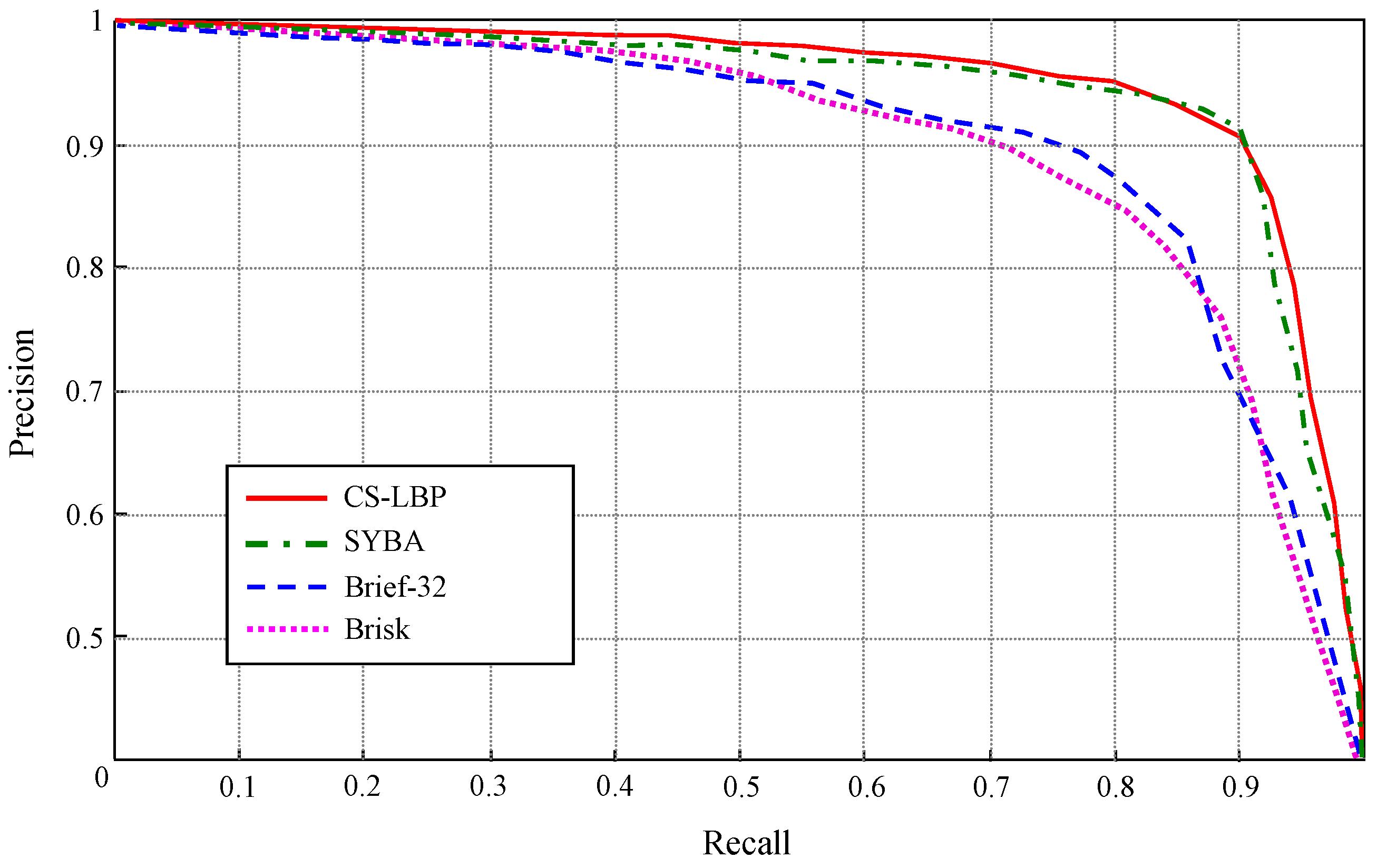
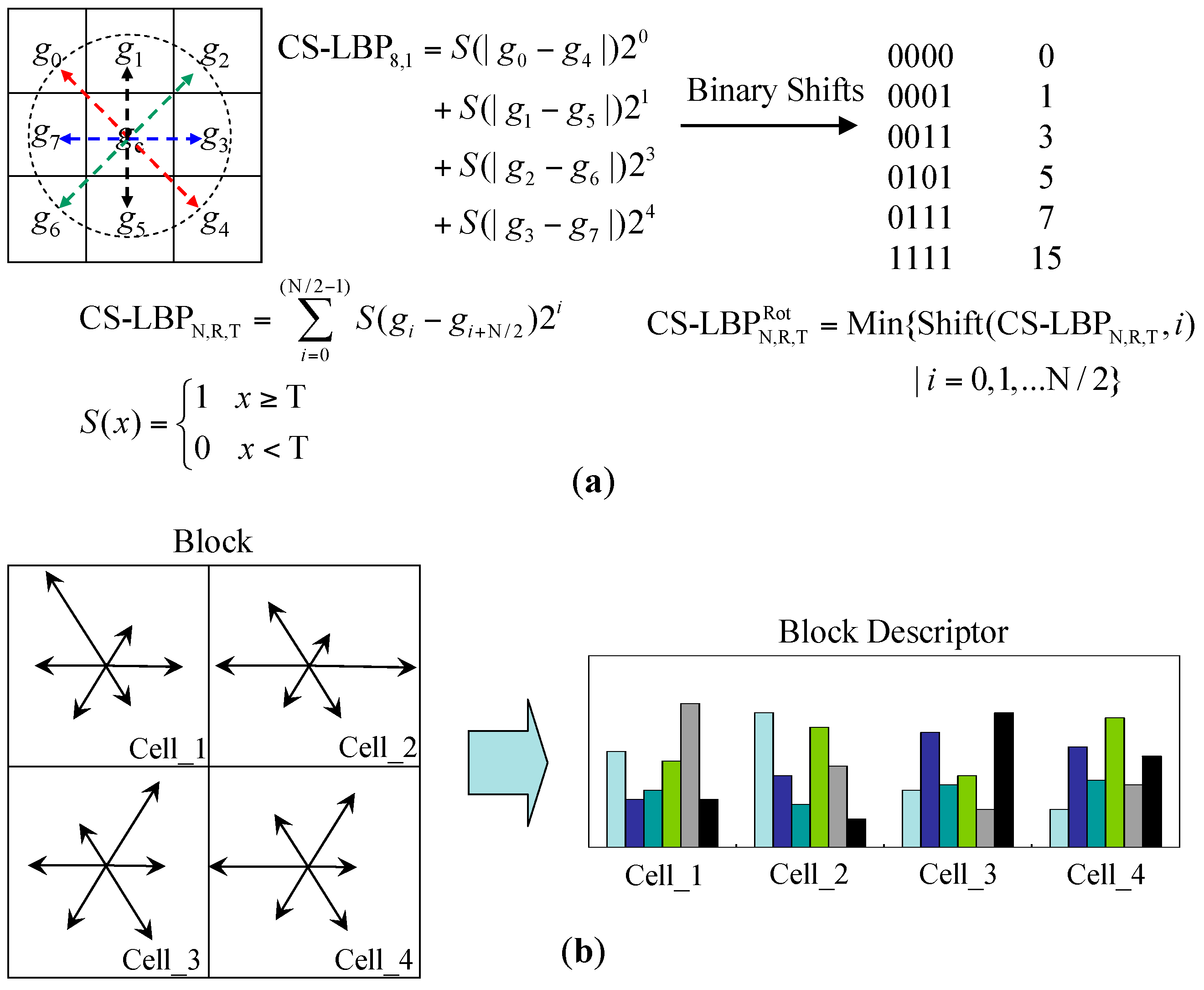
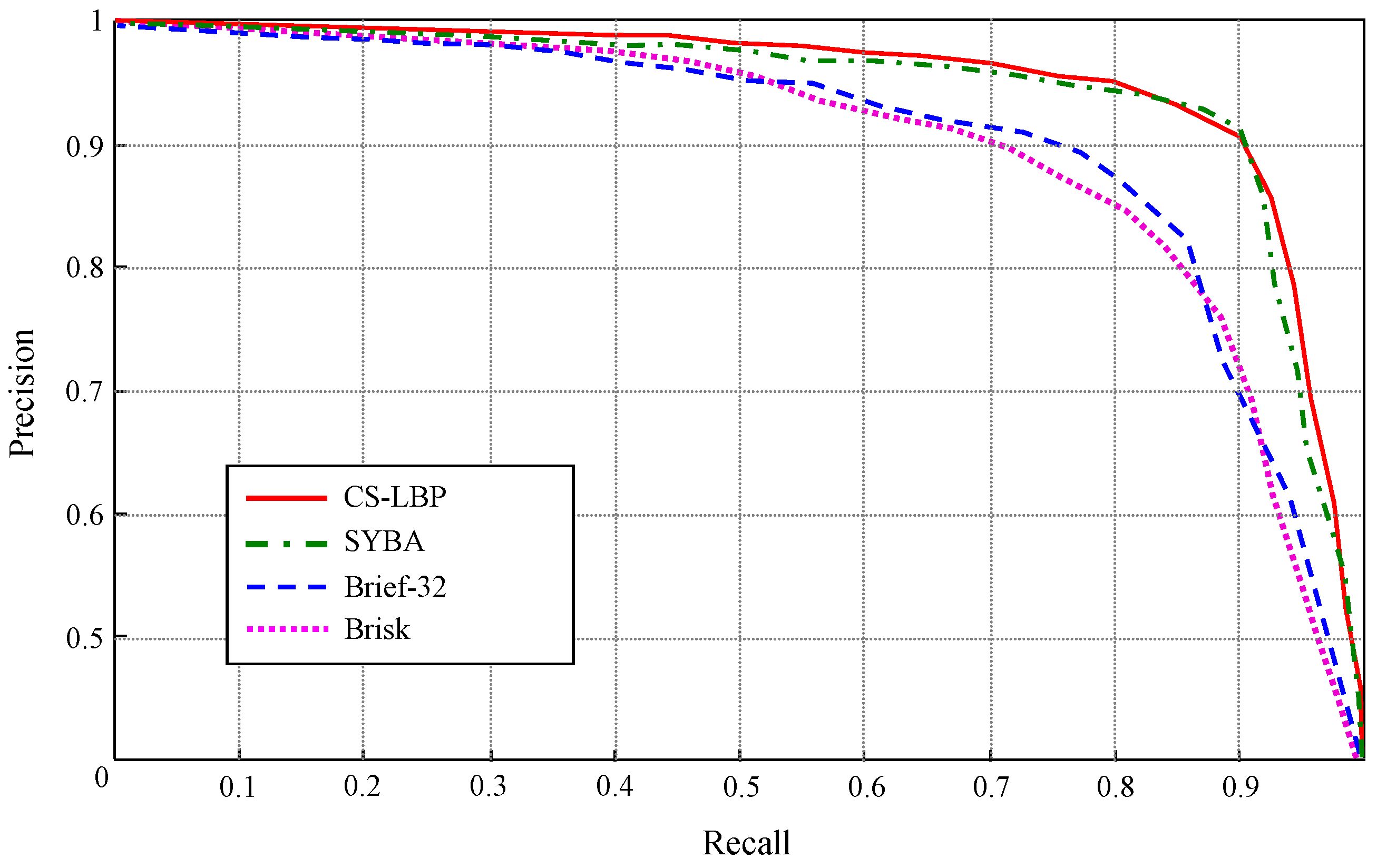
3.2.2. Appearance Descriptor Extraction
3.2.3. Cross-Field Appearance Prototype Matching
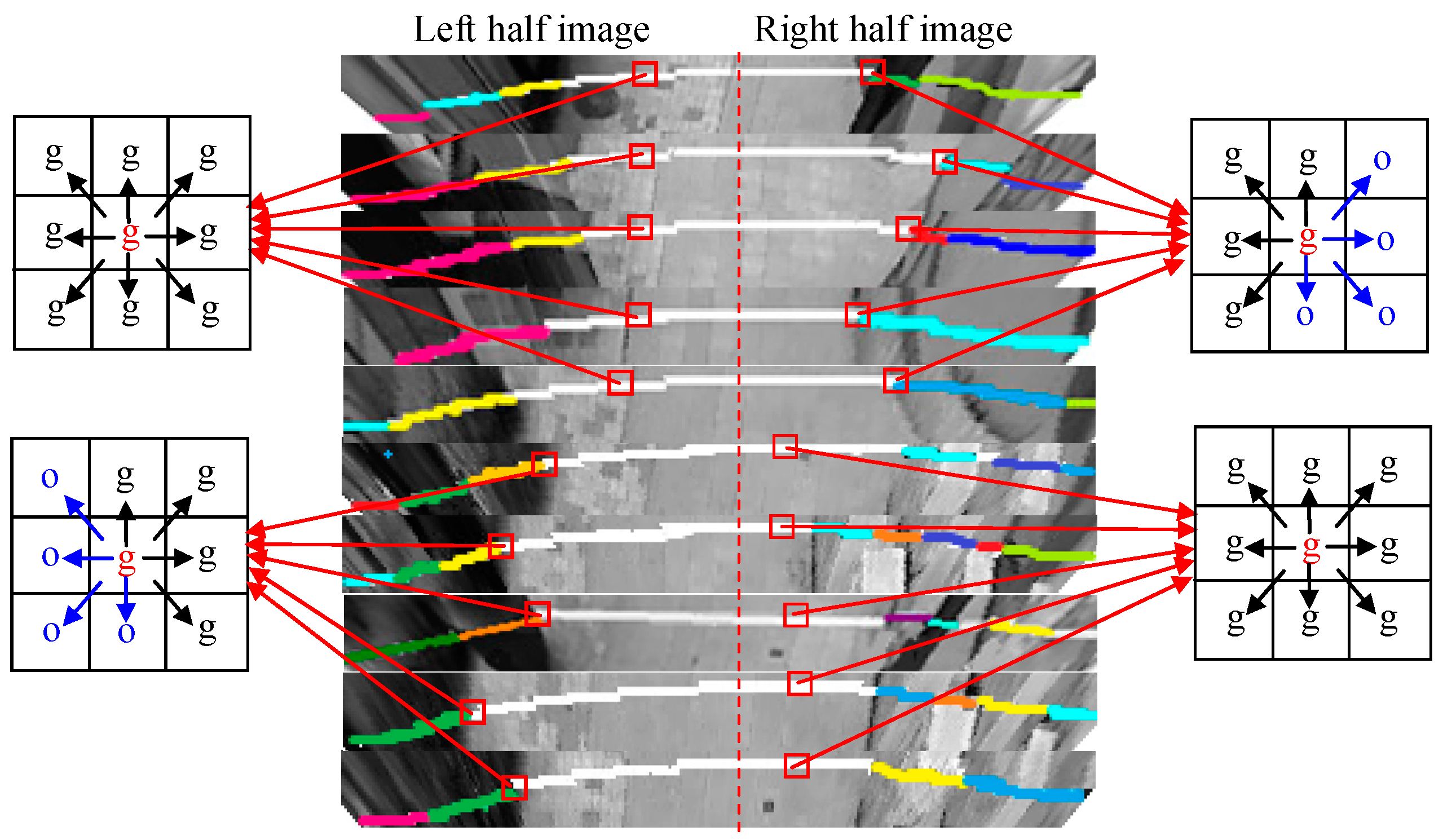
3.3. Cross-Field Spatial Context Propagation
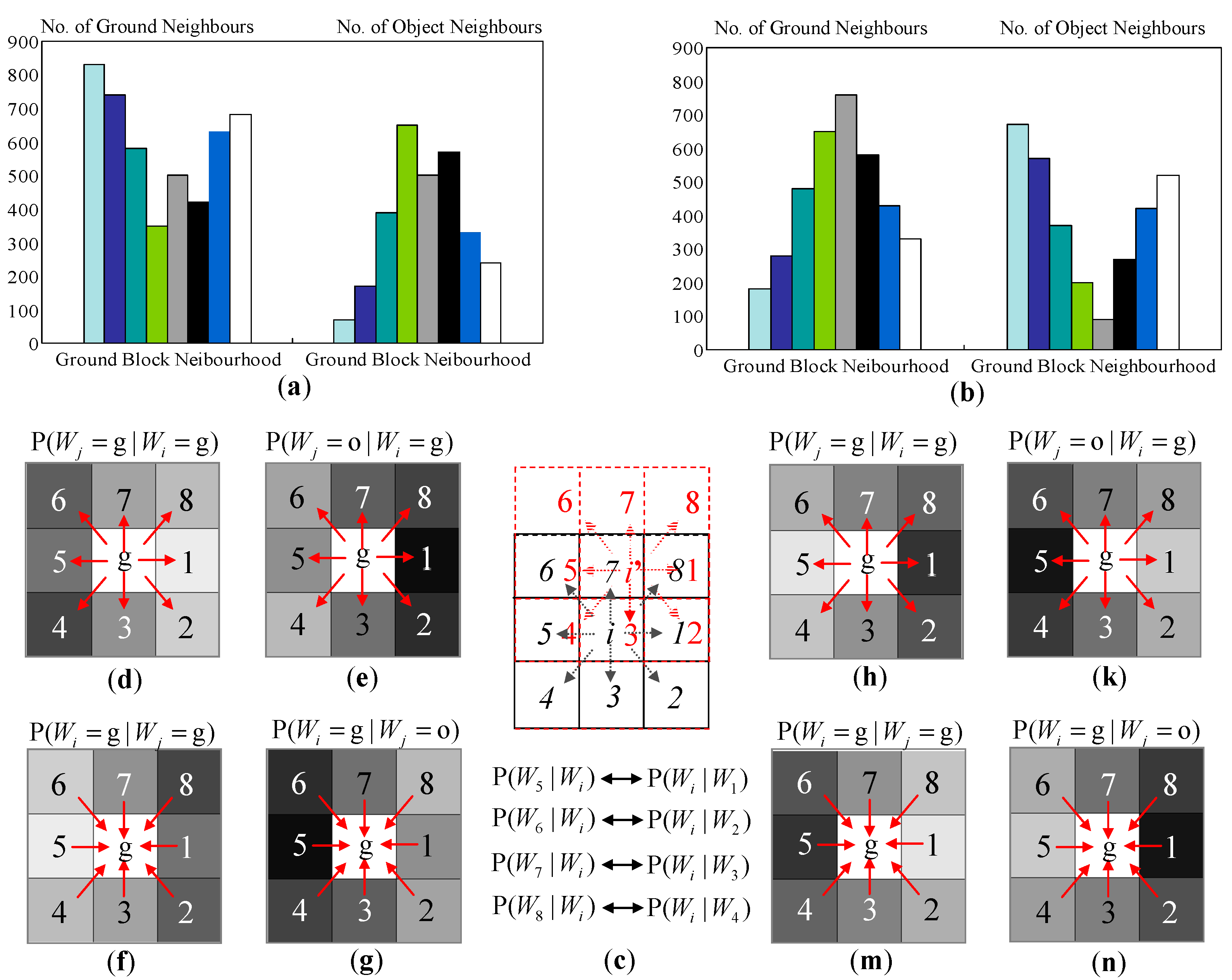
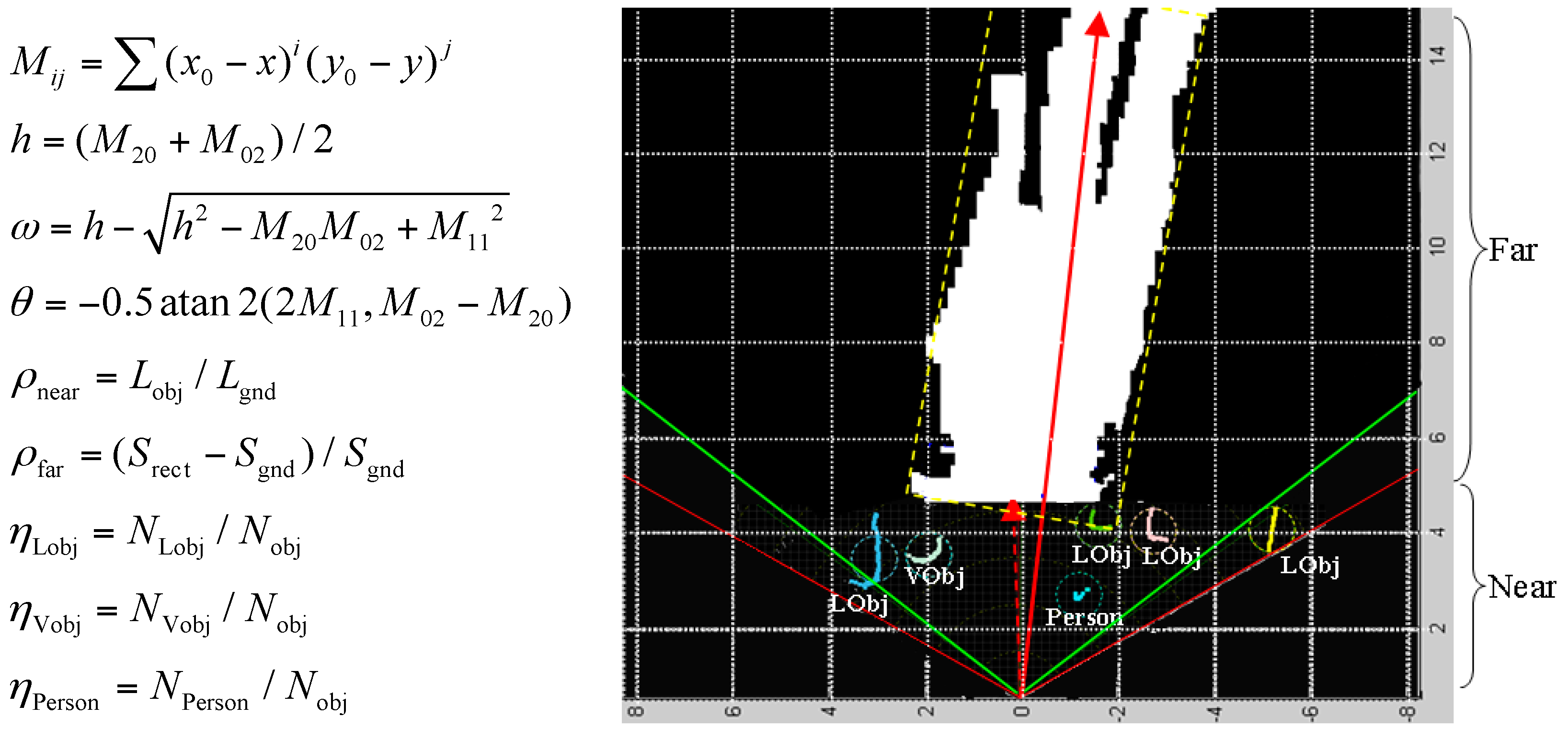
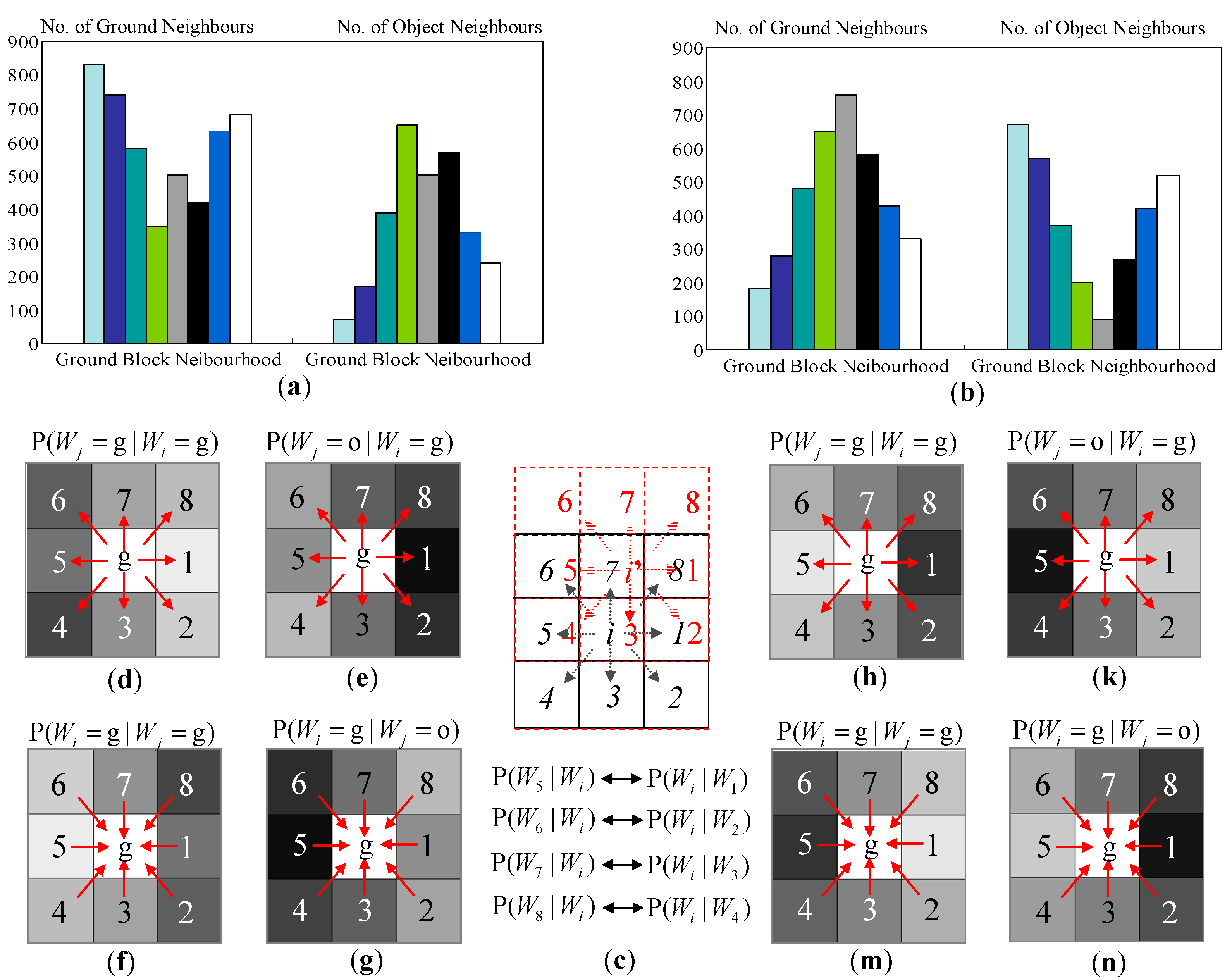
3.3.1. Spatial Distribution Properties in the Top-View Domain
3.3.2. Spatial Context Prototype Building
3.3.3. Spatial Context Propagation
4. Dual-Field Sensing Fusion
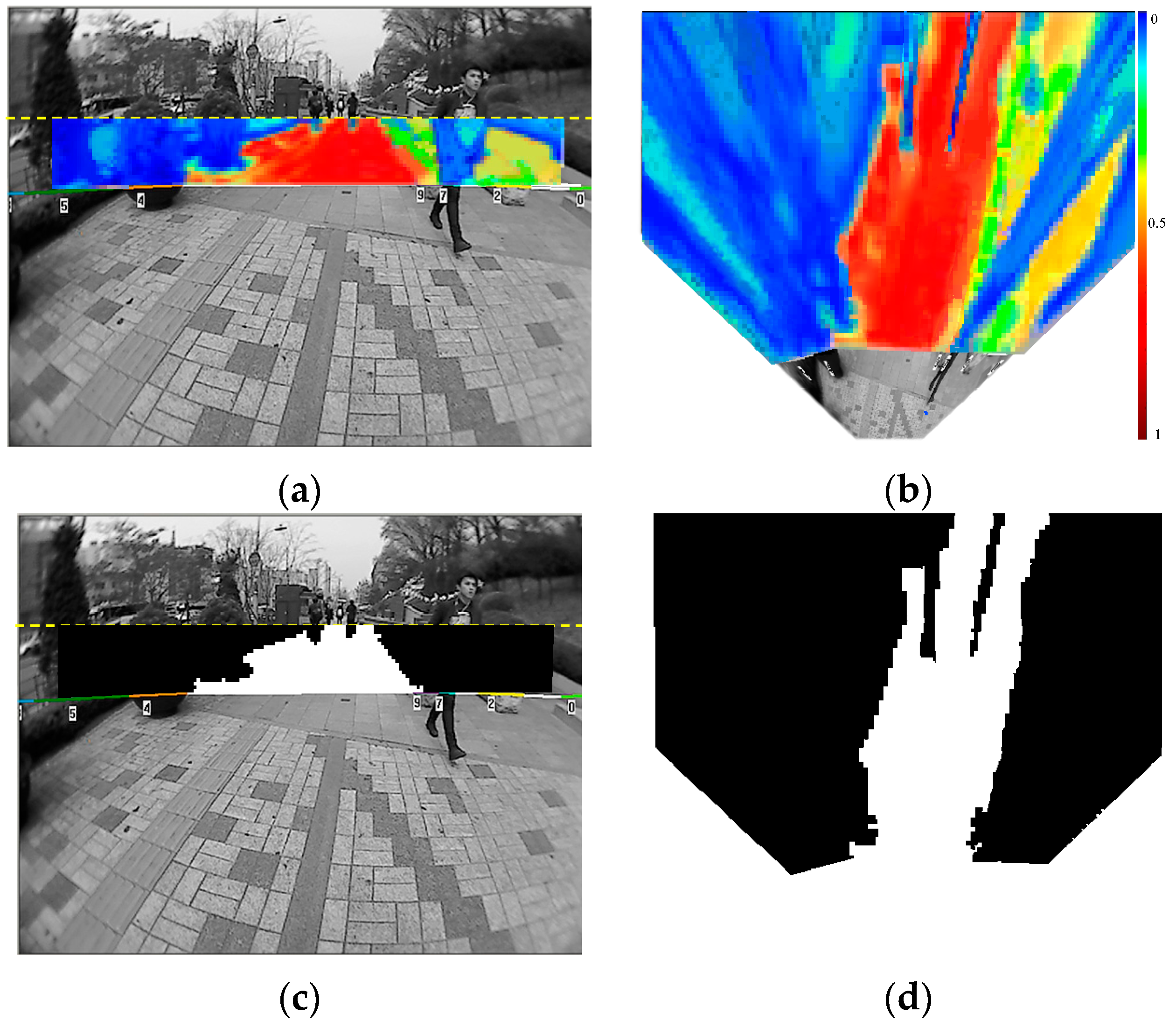
4.1. Dual-Field Sensing Map
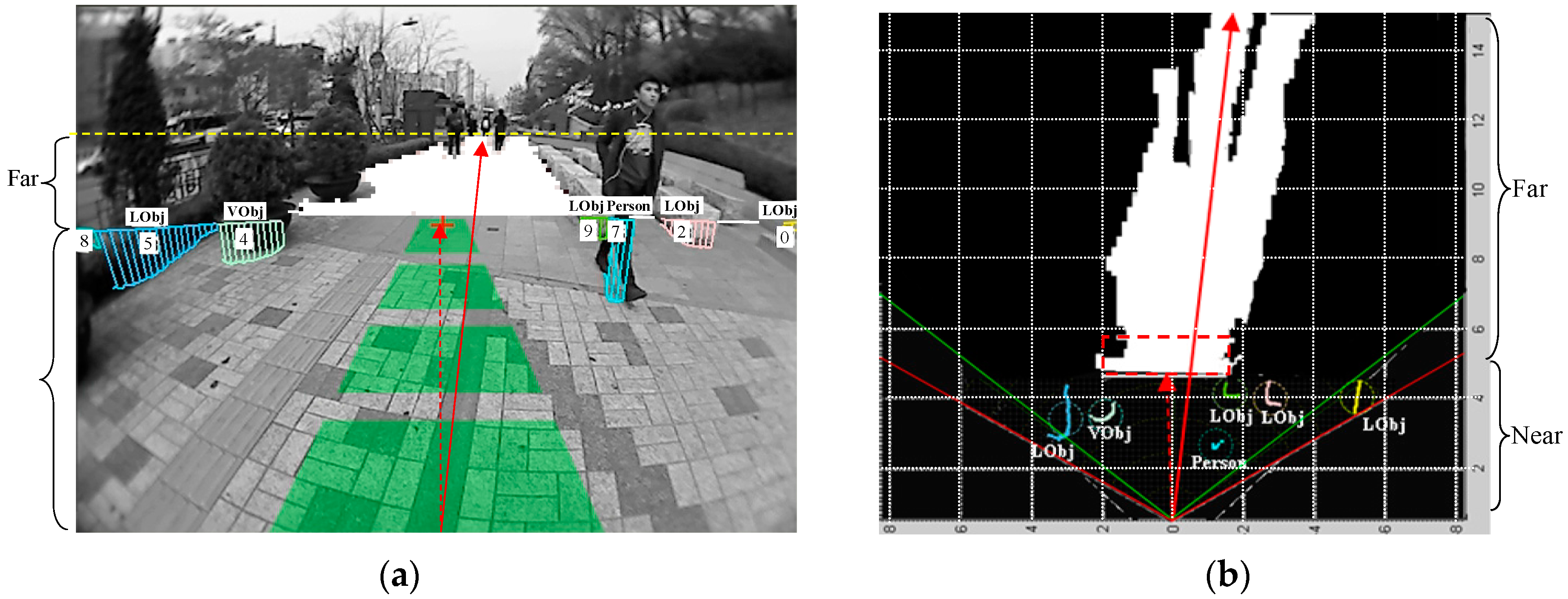
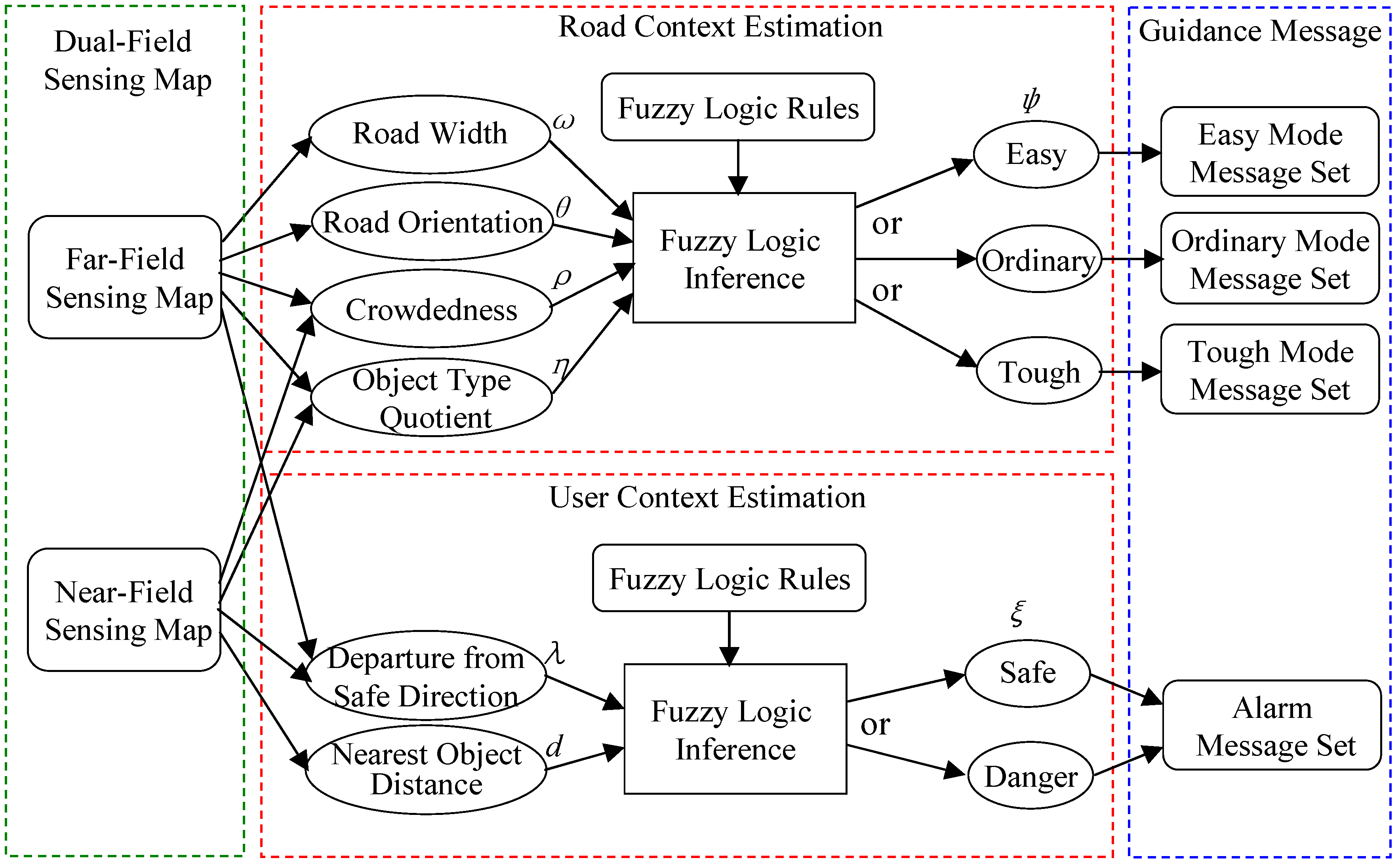
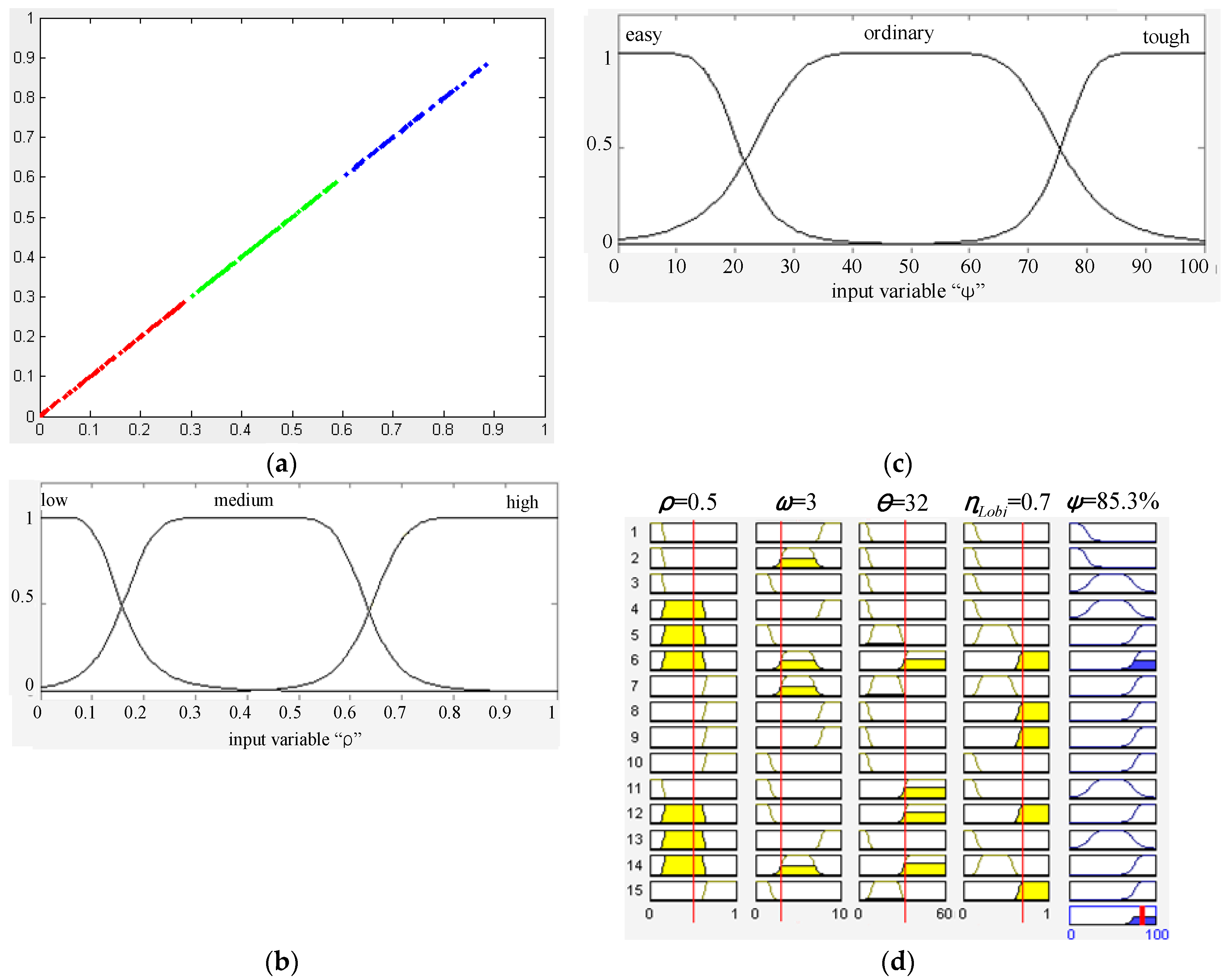
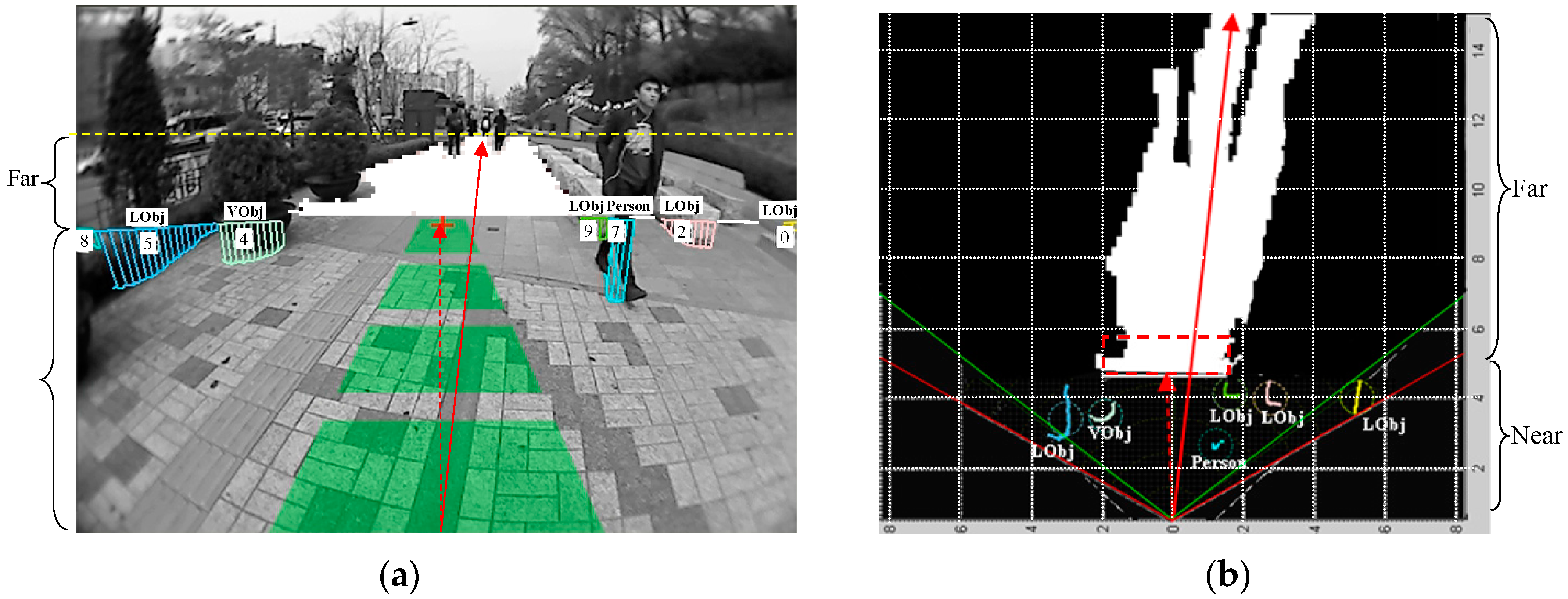
4.2. Walking Context Estimation Based on Dual-Field Sensing
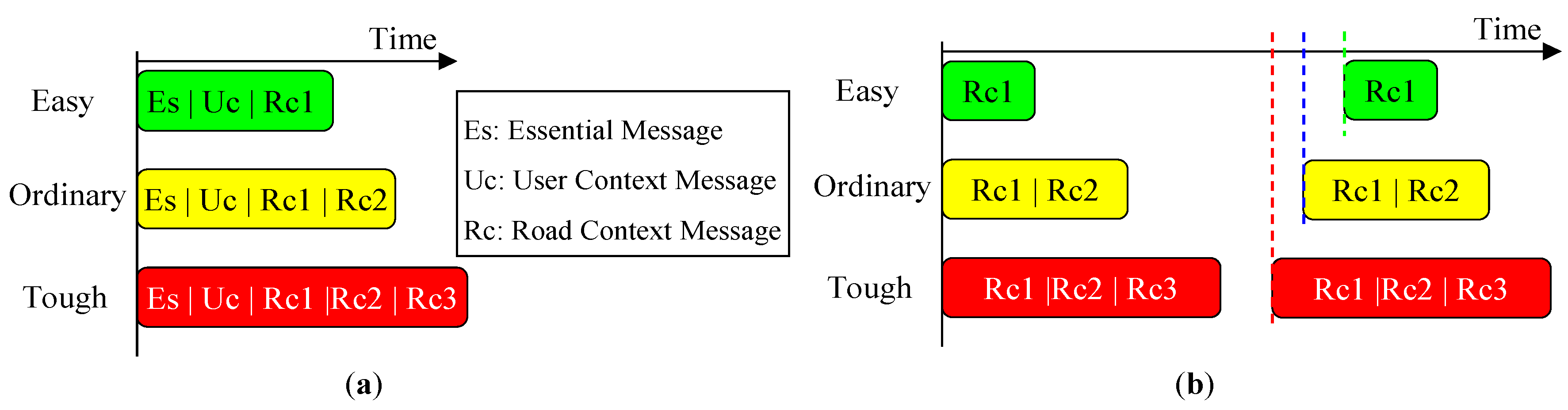
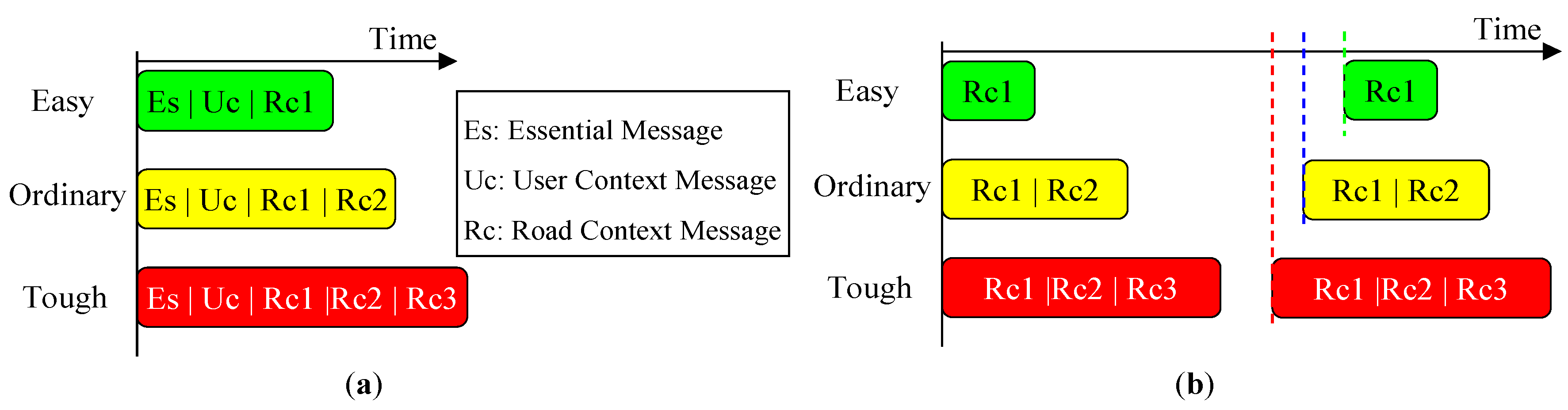
4.3. Context-Aware Guidance Based on Dual-Field Sensing
5. Experimental Results
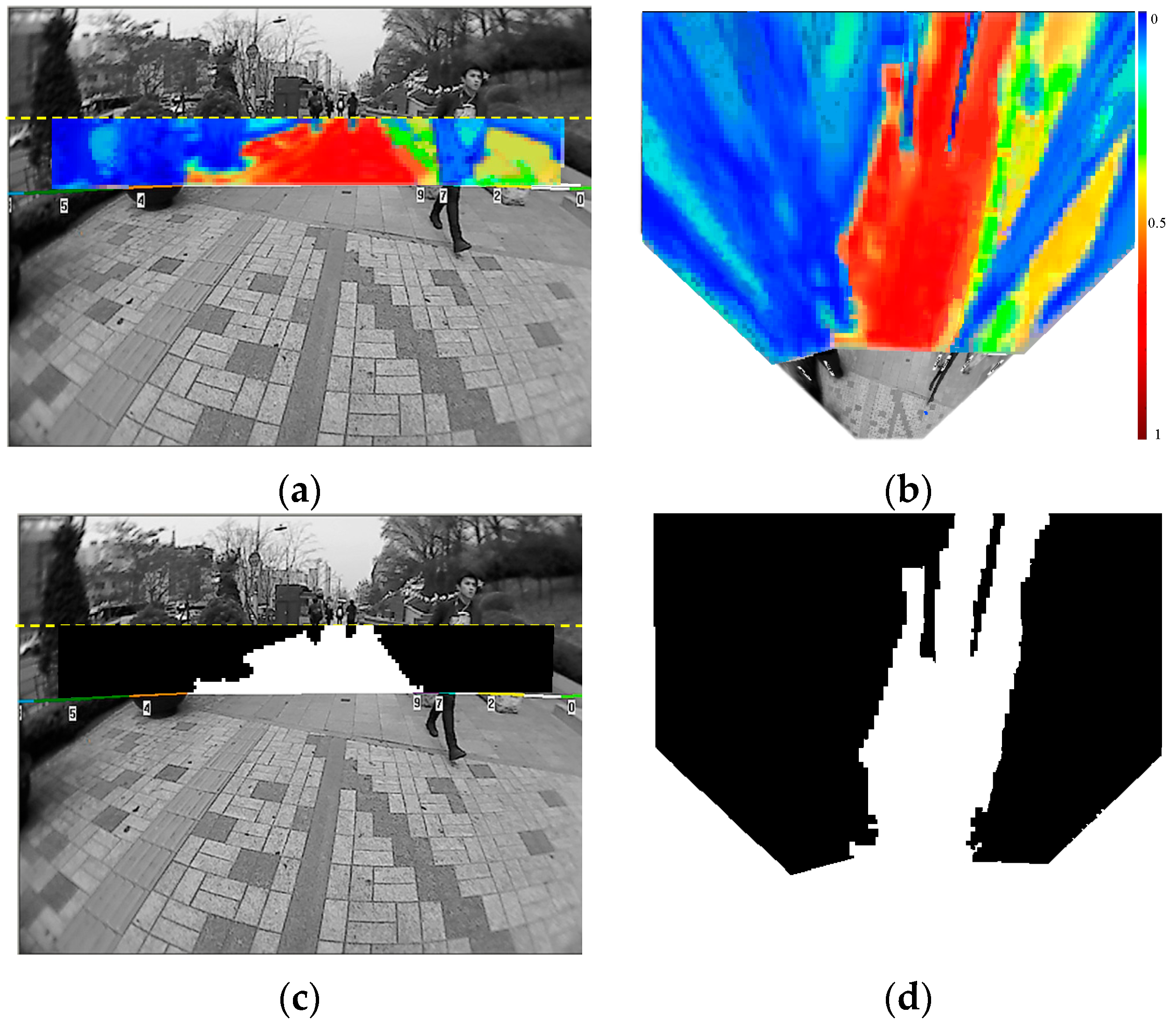
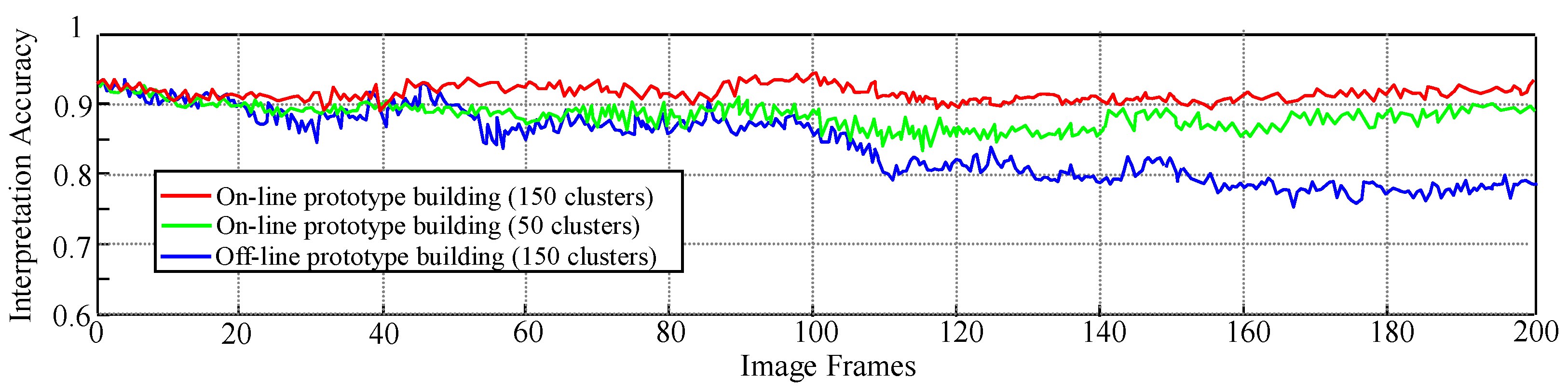
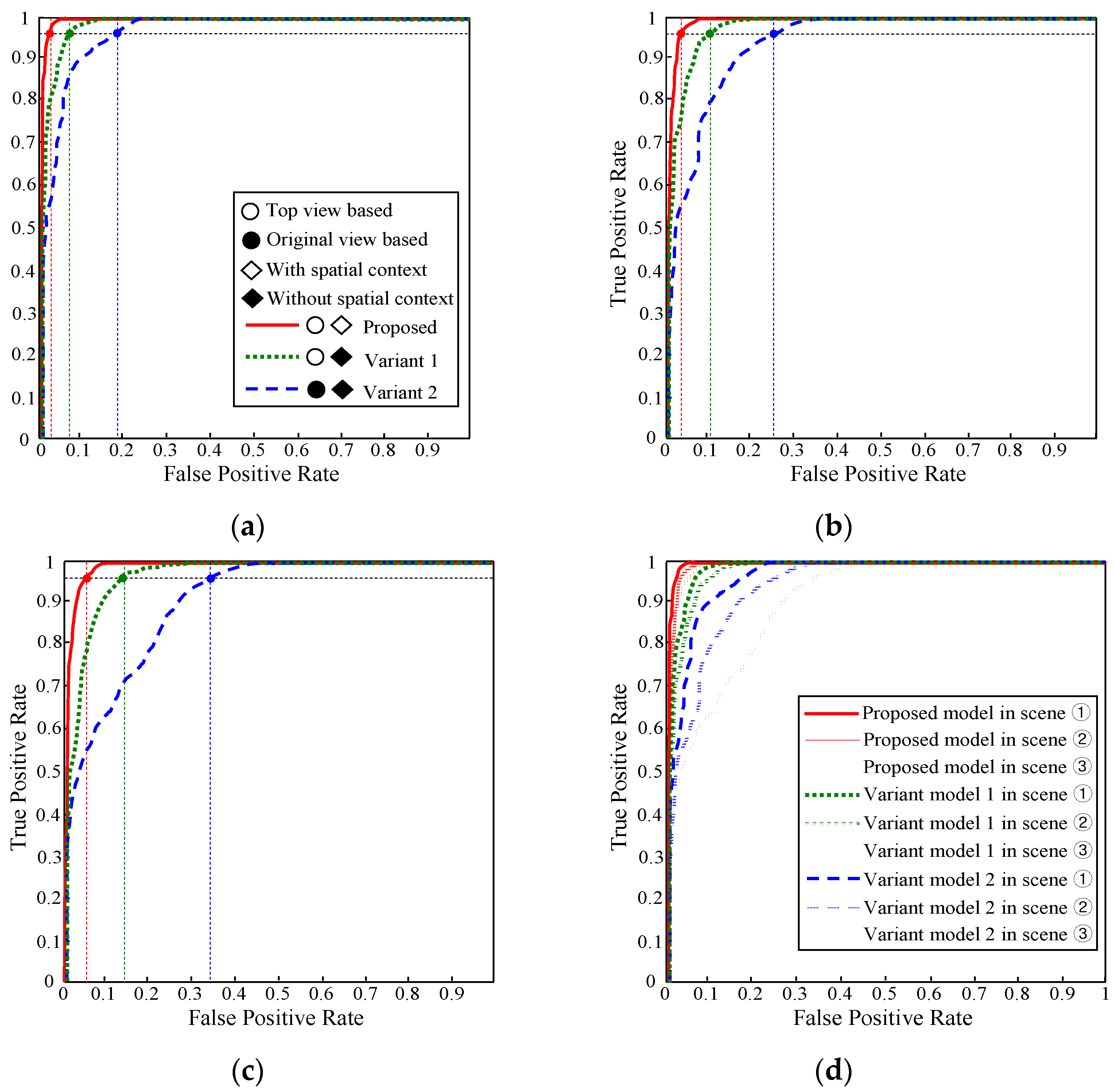
5.1. Interpretation Performance of the Far-Field Model
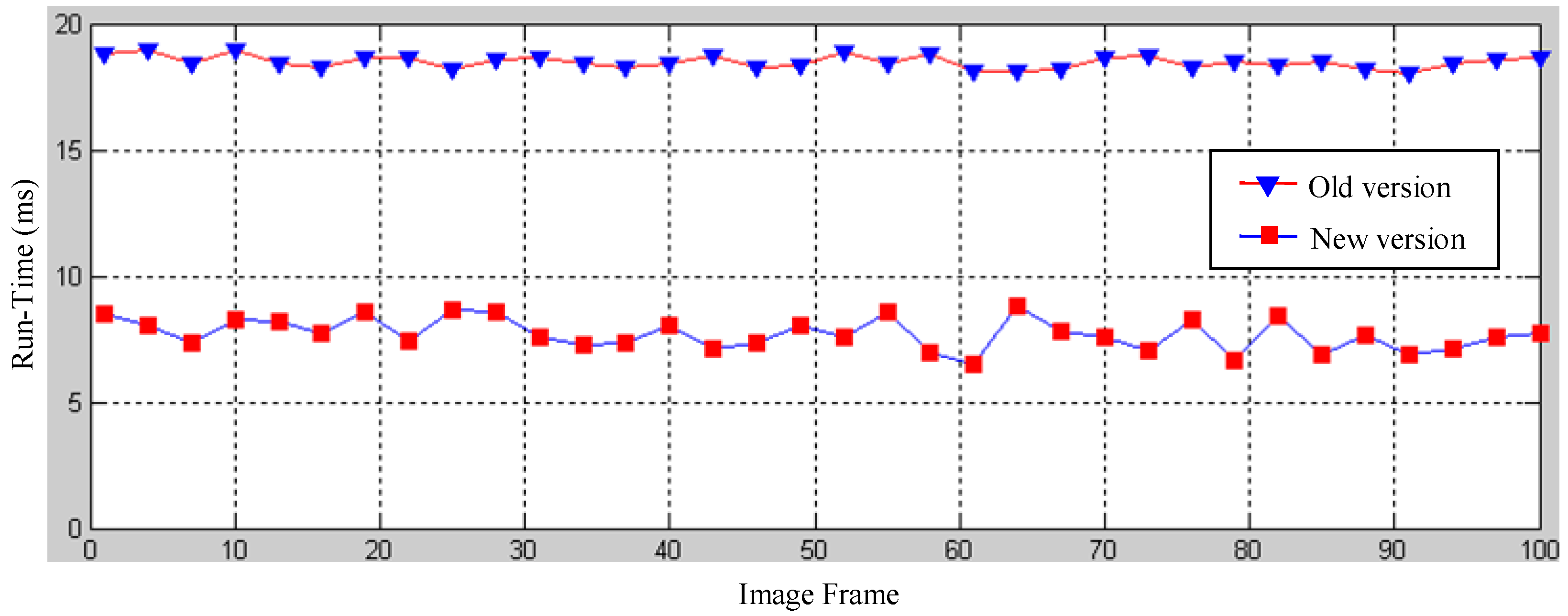
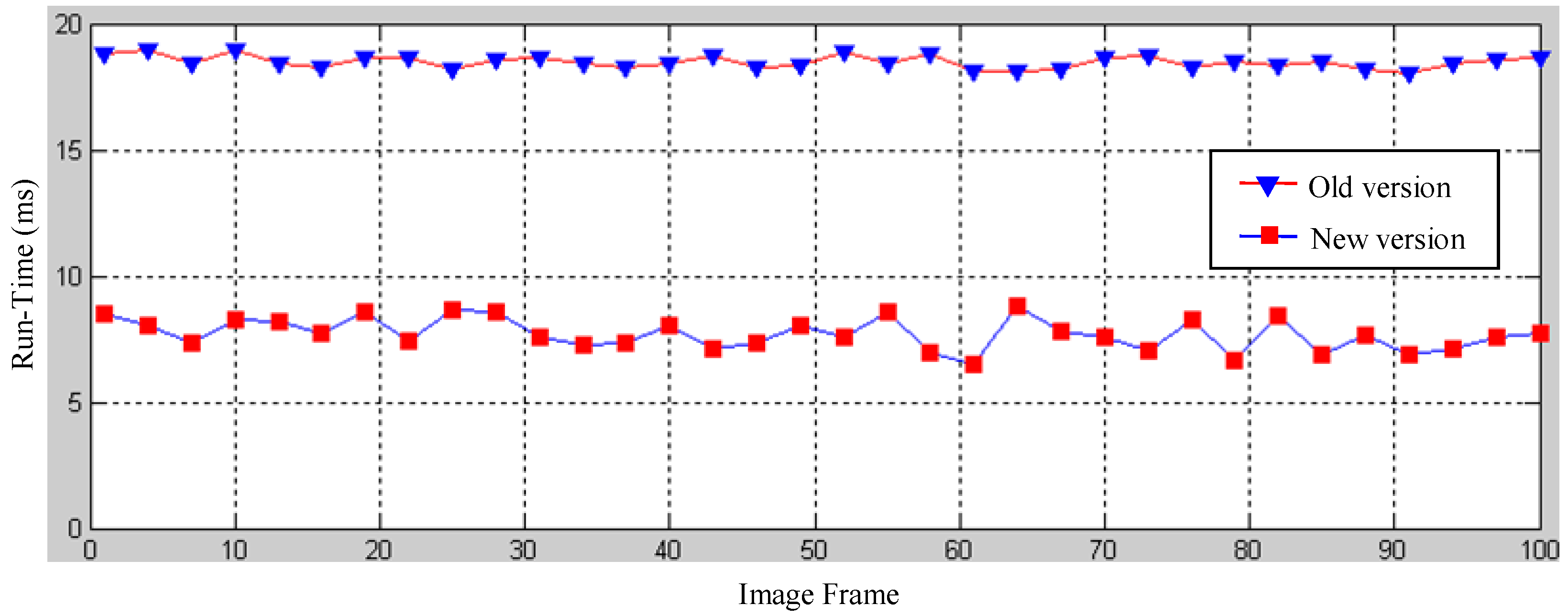
5.2. Run-Time Performance of the Dual-Field Sensing Model
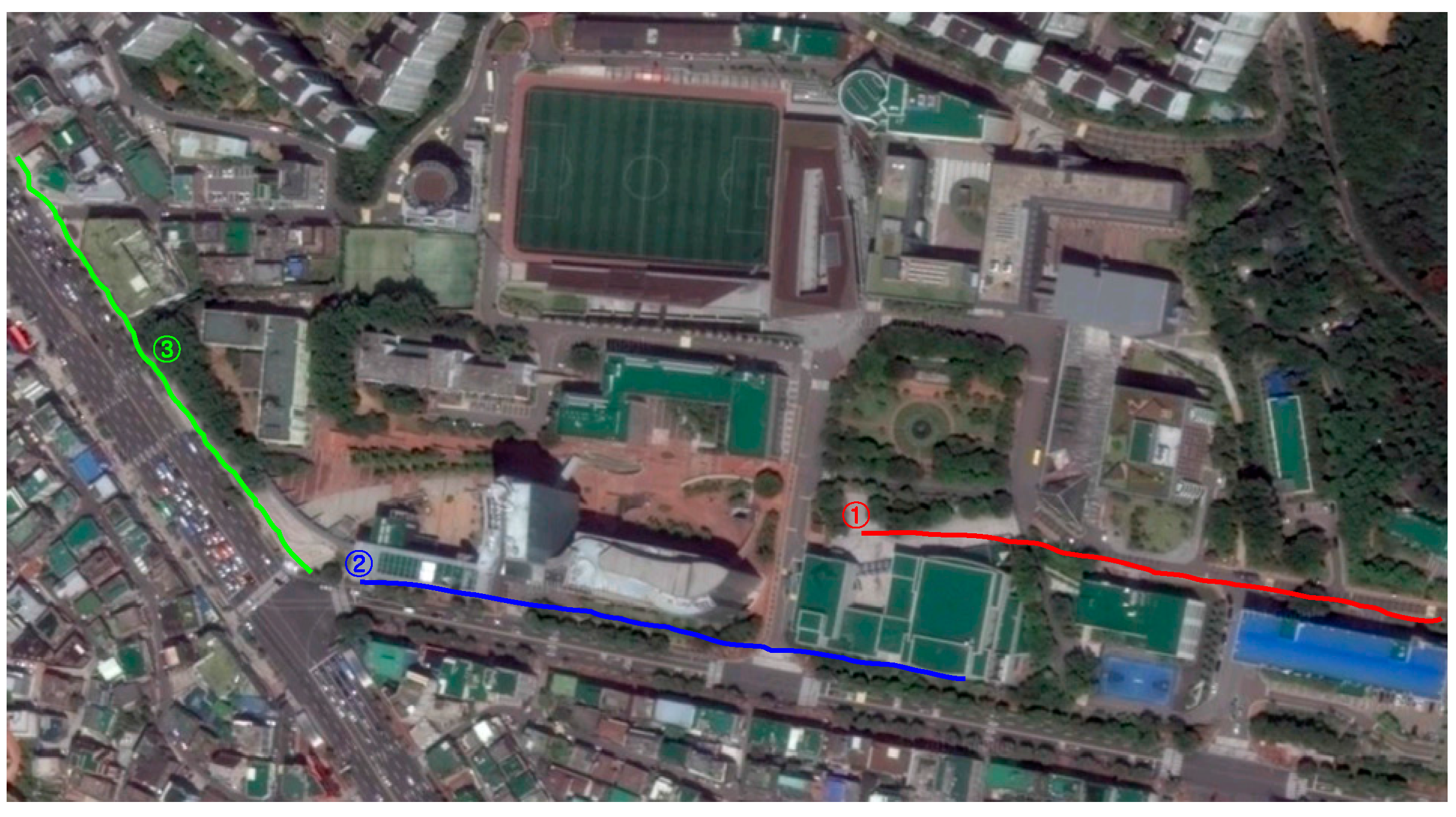
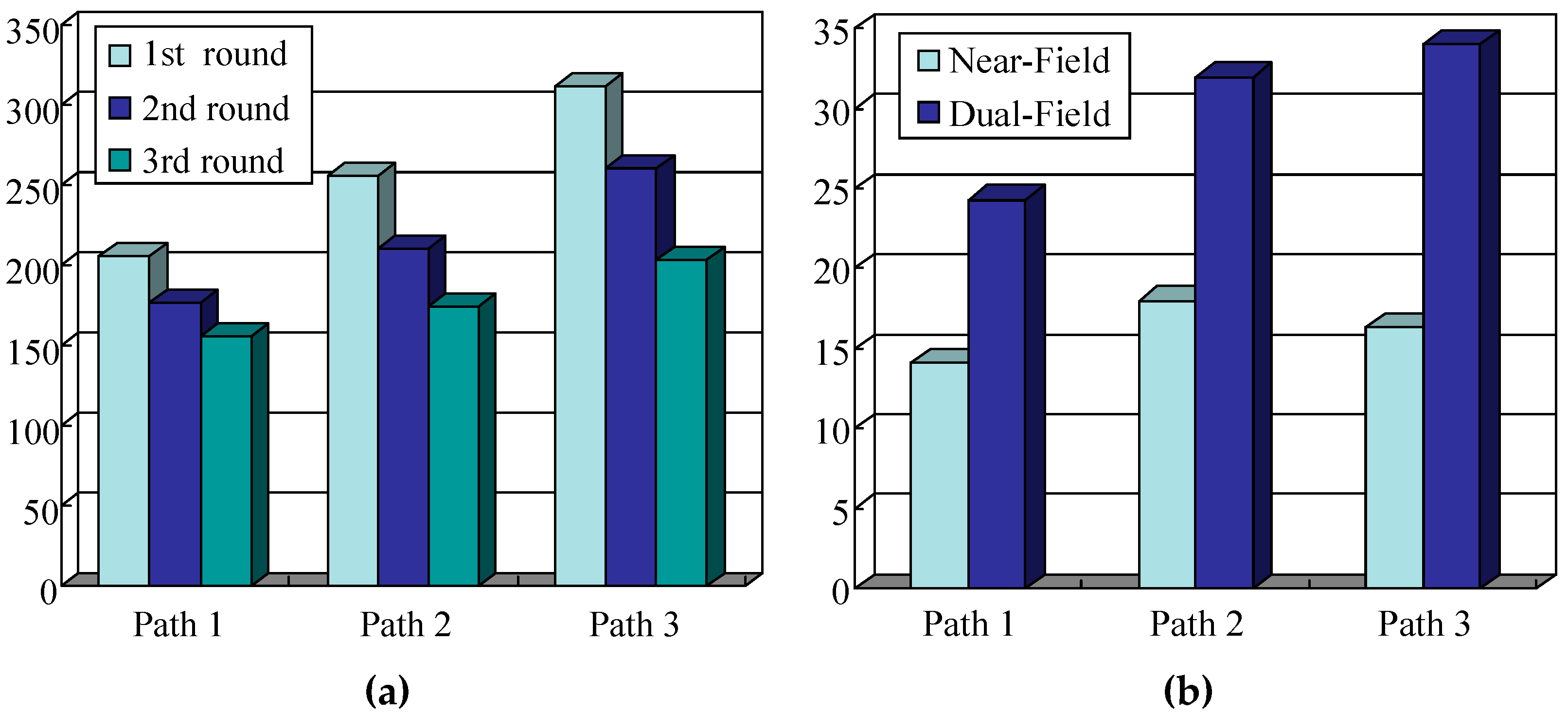
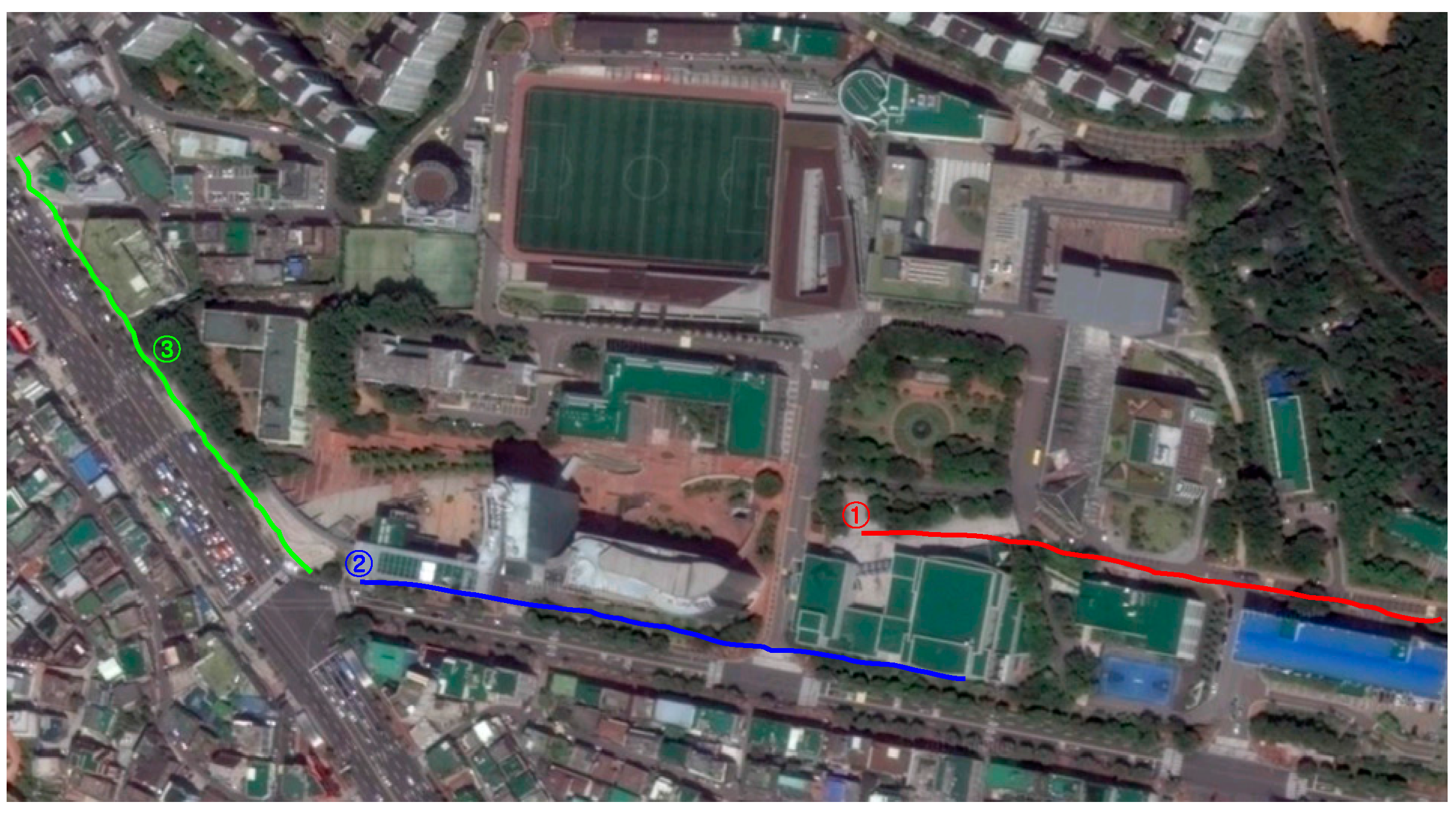
5.3. Guidance Performance of the Dual-Field Sensing Scheme
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lin, Q.; Han, Y. A Context-Aware-Based Audio Guidance System for Blind People Using a Multimodal Profile Model. Sensors 2014, 14, 18670–18700. [Google Scholar] [CrossRef] [PubMed]
- Dakopoulos, D.; Bourbakis, N.G. Wearable Obstacle Avoidance Electronic Travel Aids for Blind: A Survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 25–35. [Google Scholar] [CrossRef]
- Shoval, S.; Borenstein, J.; Koren, Y. Auditory Guidance with the Navbelt—A Computerized Travel Aid for the Blind. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 1998, 28, 459–467. [Google Scholar] [CrossRef]
- Ulrich, I.; Borenstein, J. The Guidecane—Applying Mobile Robot Technologies to Assist the Visually Impaired People. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2001, 31, 131–136. [Google Scholar] [CrossRef]
- Shin, B.S.; Lim, C.S. Obstacle Detection and Avoidance System for Visually Impaired People. Lect. Notes Comput. Sci. 2007, 4813, 78–85. [Google Scholar]
- Cardin, S.; Thalmann, D.; Vexo, F. A Wearable System for Mobility Improvement of Visually Impaired People. Vis. Comput. J. 2007, 23, 109–118. [Google Scholar] [CrossRef]
- Yuan, D.; Manduchi, R. A Tool for Field Sensing and Environment Discovery for the Blind. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Washinton, DC, USA, 27 June–2 July 2004.
- Hesch, J.A.; Roumeliotis, S.I. Design and Analysis of a Portable Indoor Localization Aid for the Visually Impaired. Int. J. Robot. Res. 2010, 29, 1400–1415. [Google Scholar] [CrossRef]
- Baglietto, M.; Sgorbissa, A.; Verda, D.; Zaccaria, R. Human Navigation and Mapping with a 6DOF IMU and a Laser Scanner. Robot. Auton. Syst. 2011, 59, 1060–1069. [Google Scholar] [CrossRef]
- Fallon, M.F.; Johannsson, H.; Brookshire, J.; Teller, S.; Leonard, J.J. Sensor Fusion for Flexible Human-Portable Building-Scale Mapping. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012.
- Sainarayanan, G.; Nagarajan, R.; Yaacob, S. Fuzzy Image Processing Scheme for Autonomous Navigation of Human Blind. Appl. Soft Comput. 2007, 7, 257–264. [Google Scholar] [CrossRef]
- Peng, E.; Peursum, P.; Li, L.; Venkatesh, S. A Smartphone-Based Obstacle Sensor for the Visually Impaired. Lect. Notes Comput. Sci. 2010, 6406, 590–604. [Google Scholar]
- Lin, Q.; Hahn, H.; Han, Y. Top-View Based Guidance for Blind People Using Directional Ellipse Model. Int. J. Adv. Robot. Syst. 2013, 1, 1–10. [Google Scholar] [CrossRef]
- Bourbakis, N.G.; Keefer, R.; Dakopoulos, D.; Esposito, A. Towards a 2D Tactile Vocabulary for Navigation of Blind and Visually Impaired. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, San Antonio, CA, USA, 11–14 October 2009.
- Bourbakis, N. Sensing Surrounding 3-D Space for Navigation of the Blind—A Prototype System Featuring Vibration arrays and Data Fusion Provides a Near Real-time Feedback. IEEE Eng. Med. Biol. Maga. 2008, 27, 49–55. [Google Scholar] [CrossRef] [PubMed]
- Dunai, L.; Fajarnes, G.P.; Praderas, V.S.; Garcia, B.D.; Lengua, I.L. Real-time Assistance Prototype—A New Navigation Aid for Blind People. In Proceedings of the 36th Annual Conference on IEEE Industrial Electronics Society, Glendale, CA, USA, 7–10 November 2010.
- Rodríguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazán, J.; Cela, A. Assisting the Visually Impaired: Obstacle Detection and Warning System by Acoustic Feedback. Sensors 2012, 12, 17477–17496. [Google Scholar] [CrossRef] [PubMed]
- Pradeep, V.; Medioni, G.; Weiland, J. Robot Vision for the Visually Impaired. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010.
- Zöllner, M.; Huber, S.; Jetter, H.C.; Reiterer, H. NAVI—A Proof-of-Concept of a Mobile Navigational Aid for Visually Impaired based on the Microsoft Kinect. Lect. Notes Comput. Sci. 2011, 6949, 584–587. [Google Scholar]
- Takizawa, H.; Yamaguchi, S.; Aoyagi, M.; Ezaki, N.; Mizuno, S. Kinect Cane: An Assistive System for the Visually Impaired Based on Three-dimensional Object Recognition. In Proceedings of the IEEE International Symposium on System Integration, Fukuoka, Japan, 16–18 December 2012.
- Khan, A.; Moideen, F.; Lopez, J.; Khoo, W.L.; Zhu, Z. KinDectect: Kinect Detecting Objects. Lect. Notes Comput. Sci. 2012, 7383, 588–595. [Google Scholar]
- Filipea, V.; Fernandesb, F.; Fernandesc, H.; Sousad, A.; Paredese, H.; Barrosof, J. Blind Navigation Support System Based on Microsoft Kinect. In Proceedings of the 4th International Conference on Software Development for Enhancing Accessibility and Fighting Info-exclusion, Douro Region, Portugal, 19–22 July 2012.
- Brock, M.; Kristensson, P.O. Supporting Blind Navigation Using Depth Sensing and Sonification. In Proceedings of the ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013.
- Rosten, E.; Porter, R.; Drummond, T. FASTER and better: A Machine Learning Approach to Corner Detection. IEEE Tran. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef] [PubMed]
- Mallot, H.A.; Bülthoff, H.H.; Little, J.J.; Bohrer, S. Inverse Perspective Mapping Simplifies Optical Flow Computation and Obstacle Detection. Biol. Cybern. 1991, 64, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of Interest Regions with Local Binary Patterns. Pattern Recogn. 2009, 42, 425–436. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Scalable Nearest Neighbor Algorithms for High Dimensional Data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef] [PubMed]
- Desai, A.; Lee, D.J.; Ventura, D. An Efficient Feature Descriptor Based on Synthetic Basis Functions and Uniqueness Matching Strategy. Comput. Vis. Image Underst. 2016, 142, 37–49. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Ozuysal, M.; Trzcinski, T.; Strecha, C.; Fua, P. BRIEF: Computing a Local Binary Descriptor Very Fast. IEEE Tran. Pattern Anal. Mach. Intell. 2012, 34, 1281–1298. [Google Scholar] [CrossRef] [PubMed]
- Leutenegger, S.; Chli, M.; Siegwart, R. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Message Type | Message Content | Delivery Modality | Delivery Timing | Message Prototype | |
|---|---|---|---|---|---|
| Essential | Nearest Object Location | Tactile/Acoustic-Beeper | Continuous Real-Time | The frequency of the acoustic beeper/tactile units encodes distance, and the location of beeper signal in the acoustic space encodes orientation./The location of tactile units in the tactile array encodes orientation. | |
| Safe Direction | Verbal/Stereo Sound | Event-Triggered | ‘’Go (1 o’clock).’’/Stereo source location in the acoustic space generated between two earphones. | ||
| User Context | Alert Message | Verbal | Event-Triggered | “Large departure attention!”/“Collision attention!” | |
| Road Context | ψ | General Condition | Verbal | Periodic | “The road condition is (easy/ordinary/tough).” |
| d | Road Width | Verbal | Periodic | “The road ahead is (narrow/wide/very wide).” | |
| θ | Road Orientation | Verbal | Periodic | “The road ahead turns (11 o’clock).” | |
| ω | Crowdedness | Verbal | Periodic | “The road ahead is (spacious/crowded/highly crowded).” | |
| η | Dominant Object Type | Verbal | Periodic | “The road ahead is dominant by (vertical object/lateral object/person).” | |
| Easy Context | Ordinary Context | Tough Context | ||||||
|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S1 | S2 | S3 | S1 | S2 | S3 |
| ω.wide | ω.normal | ω.narrow | ω.normal | ω.narrow | ω.wide | ω.narrow | ω.normal | ω.wide |
| ρ.low | ρ.medium | ρ.high | ρ.medium | ρ.high | ρ.low | ρ.high | ρ.medium | ρ.low |
| θ.small | θ.medium | θ.high | θ.medium | θ.high | θ.small | θ.high | θ.medium | θ.small |
| η.low | η.medium | η.high | η.medium | η.high | η.low | η.high | η.medium | η.low |
| Major Modules | Implementation Strategy |
|---|---|
| Top-view mapping | Pre-configured mapping table. |
| On-line prototype updating | On-line prototype update is triggered only at some key frames. |
| Appearance Prototype matching | Approximate nearest neighbor search based on the randomized k-d forest or k-means tree. |
| Spatial context propagation | Apply spatial propagation with 5 × 5 pixel group as a unit. |
| Platform Component | Specifications |
|---|---|
| CPU (Central Processing Unit) | Intel core i7@ 3.5GHZ |
| RAM (Random Access Memory) | 16GB DDR4 |
| GPU (Graphic Processing Unit) | Nividia Quadro M1000M |
| OS (Operating System) | Windows 7 64bit |
| C++ Compiler | Microsoft VC++ 2013 |
| Data Frame Component | Specifications |
|---|---|
| Laser range data | 480 range data points |
| Original-view image data | 640 × 480 HSV color space |
| Top-view image data | 370 × 210 HSV color space |
| Model Component | Module | Function | Runtime/Function | Runtime /Module |
|---|---|---|---|---|
| Near-field interpretation | Ground estimation | Ground model fitting | 8.74 ms | 8.74 ms |
| Object detection | Object range data labeling | 6.82 ms | 17.39 ms | |
| Object profile separation | 10.57 ms | |||
| Object classification | Multimodal profile histogram | 10.67 ms | 41.98 ms | |
| Generic object classification | 8.46 ms | |||
| Pedestrian classification | 22.85 ms | |||
| Near-field total | All near-field functions | 68.11 ms | 68.11 ms | |
| Far-field interpretation | Inverse Perspective Transform | Top-view mapping | 10.47 ms | 10.47 ms |
| Cross-field scene interpretation | Appearance prototype matching | 56.34 ms | 91.58 ms | |
| Spatial prototype propagation | 35.24 ms | |||
| On-line prototype updating | Appearance prototype updating | 21.42 ms | 38.24 ms | |
| Spatial prototype updating | 16.82 ms | |||
| Far-field total | All far-field functions | 129.82 ms | 129.82 ms | |
| Dual-field interpretation | All dual-field modules | All dual-field model functions | 197.93 ms | 197.93 ms |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Q.; Han, Y. A Dual-Field Sensing Scheme for a Guidance System for the Blind. Sensors 2016, 16, 667. https://doi.org/10.3390/s16050667
Lin Q, Han Y. A Dual-Field Sensing Scheme for a Guidance System for the Blind. Sensors. 2016; 16(5):667. https://doi.org/10.3390/s16050667
Chicago/Turabian StyleLin, Qing, and Youngjoon Han. 2016. "A Dual-Field Sensing Scheme for a Guidance System for the Blind" Sensors 16, no. 5: 667. https://doi.org/10.3390/s16050667
APA StyleLin, Q., & Han, Y. (2016). A Dual-Field Sensing Scheme for a Guidance System for the Blind. Sensors, 16(5), 667. https://doi.org/10.3390/s16050667