
A Fault Tolerance Mechanism for On-Road Sensor Networks



Abstract
:1. Introduction
- A fault tolerant architecture for an on-road sensor network is proposed.
- Two optimization models of how to deploy the backup sensors and the redundant cluster heads are proposed.
- An algorithm to solve these deployment optimization models is proposed.
- A protocol of how to adaptively detect and recover the faults in the on-road sensor system is proposed.
2. Related Work
3. System Architecture
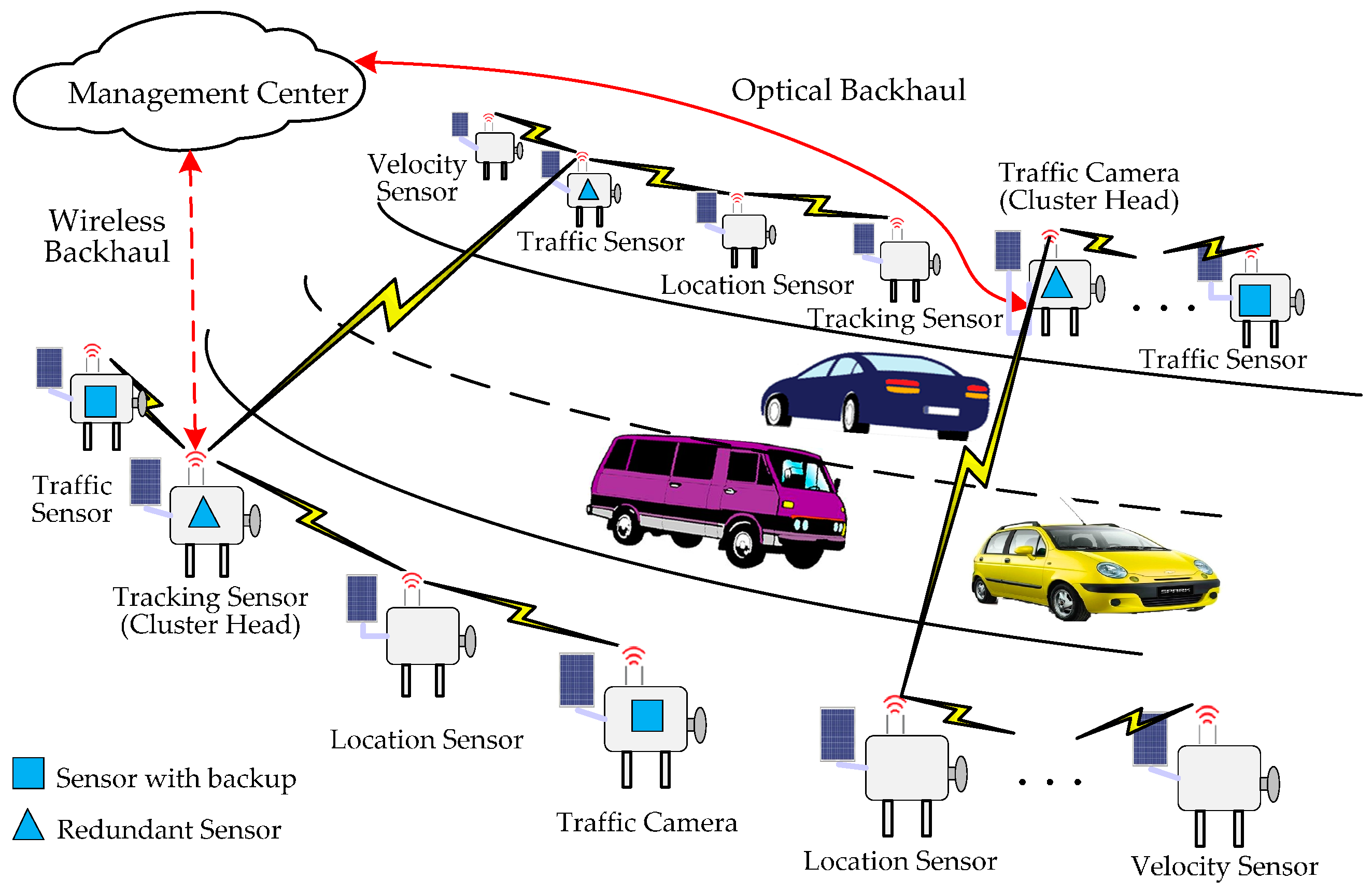
3.1. Architecture of the On-Road Sensor Network
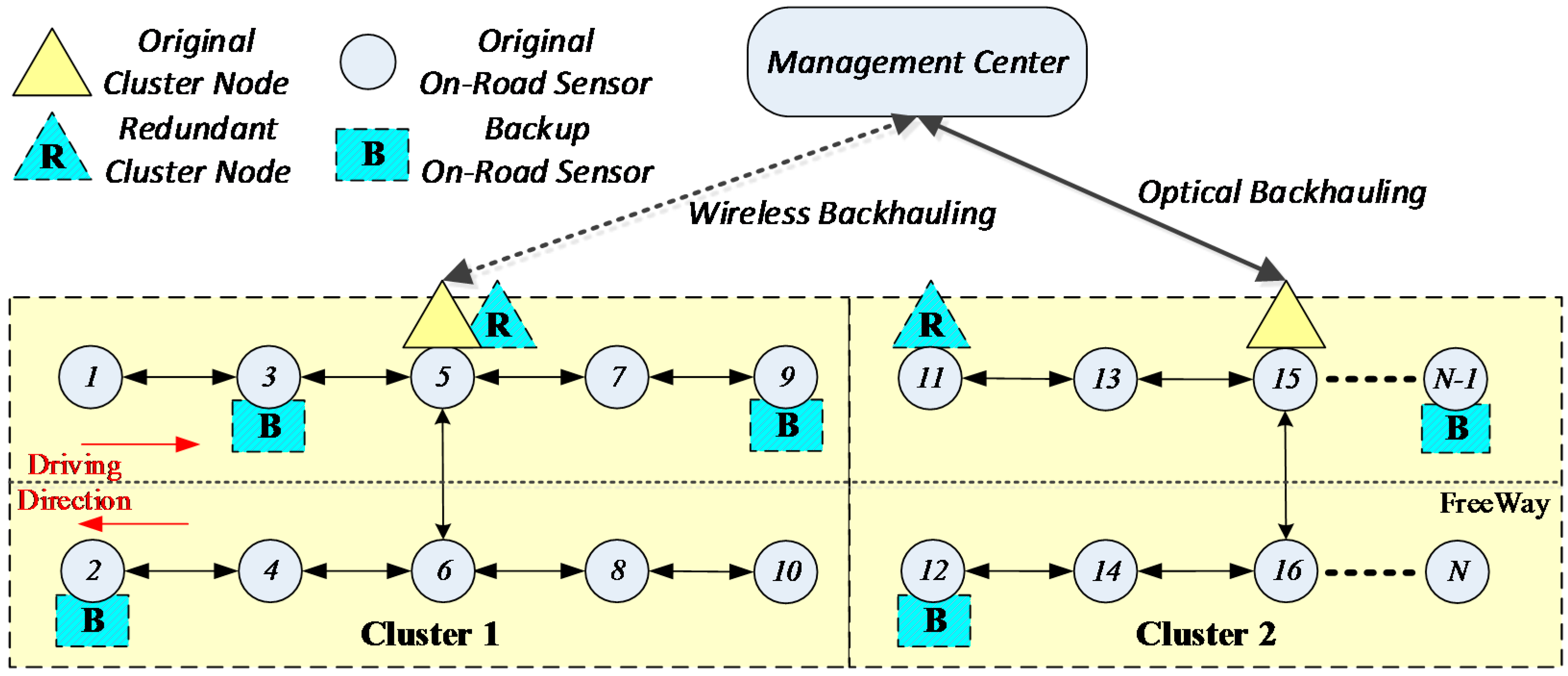
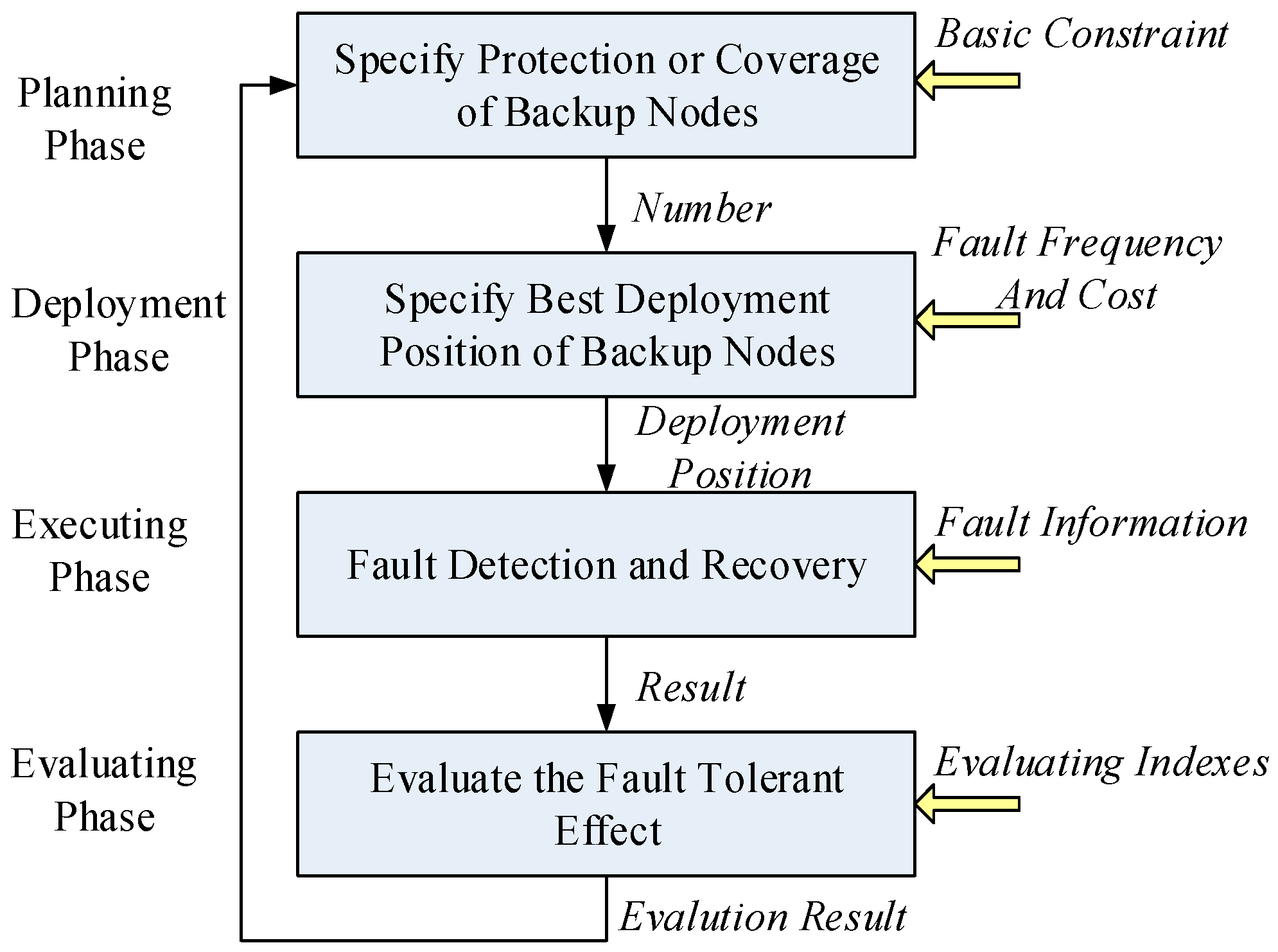
3.2. Tolerance Framework
4. Modeling and Problem Solving for Best Backup Sensor Deployment and Adaptive Fault Recovery
4.1. Best Backup Sensors Deployment Problem
4.1.1. Problem Model
4.1.2. Analysis
4.1.3. Solution on Backup On-Road Sensors Deployment
| Algorithm 1. SQP solving algorithm for the relaxed problem of (13). |
| 1: Initialization: the iteration , the initial point which makes and the convergence precision . 2: At the k-th iteration with solution , covert the original relaxed problem into QP form as (14). 3: Work out (14) by Lagrange multiplier method and lets . 4: To find on the ray where is the standard step size parameter 5: If satisfies convergence precision , then the optimal solution ; otherwise, next to step 6. 6. Modify by BFGS formula. 7. Let and repeat to step 2. |
| Algorithm 2. SQP-BB solving algorithm. |
| 1: Do continuous relaxation on problem (13) by replacing by . 2: Use SQP to find optimal solution for nonlinear programming problems (NLPs) on relaxed range. 3: If all variables in are integer, end. Otherwise, do next. 4: i-th point to the first non-integer . 5: Branch on and add and bounds respectively to the NLP relaxation. Solve two new NLP problems with SQP respectively and choose one solution with higher objective value. This will determine or . 6: Update the optimal objective value and solution vector , repeat to 3. |
4.2. Best Redundant Cluster Heads Deployment Problem
4.2.1. Problem Model
4.2.2. Analysis
4.2.3. Solution on Redundant Cluster Heads Deployment
4.3. Adaptive Fault Detection and Recovery Problem
4.3.1. Definition
4.3.2. Analysis
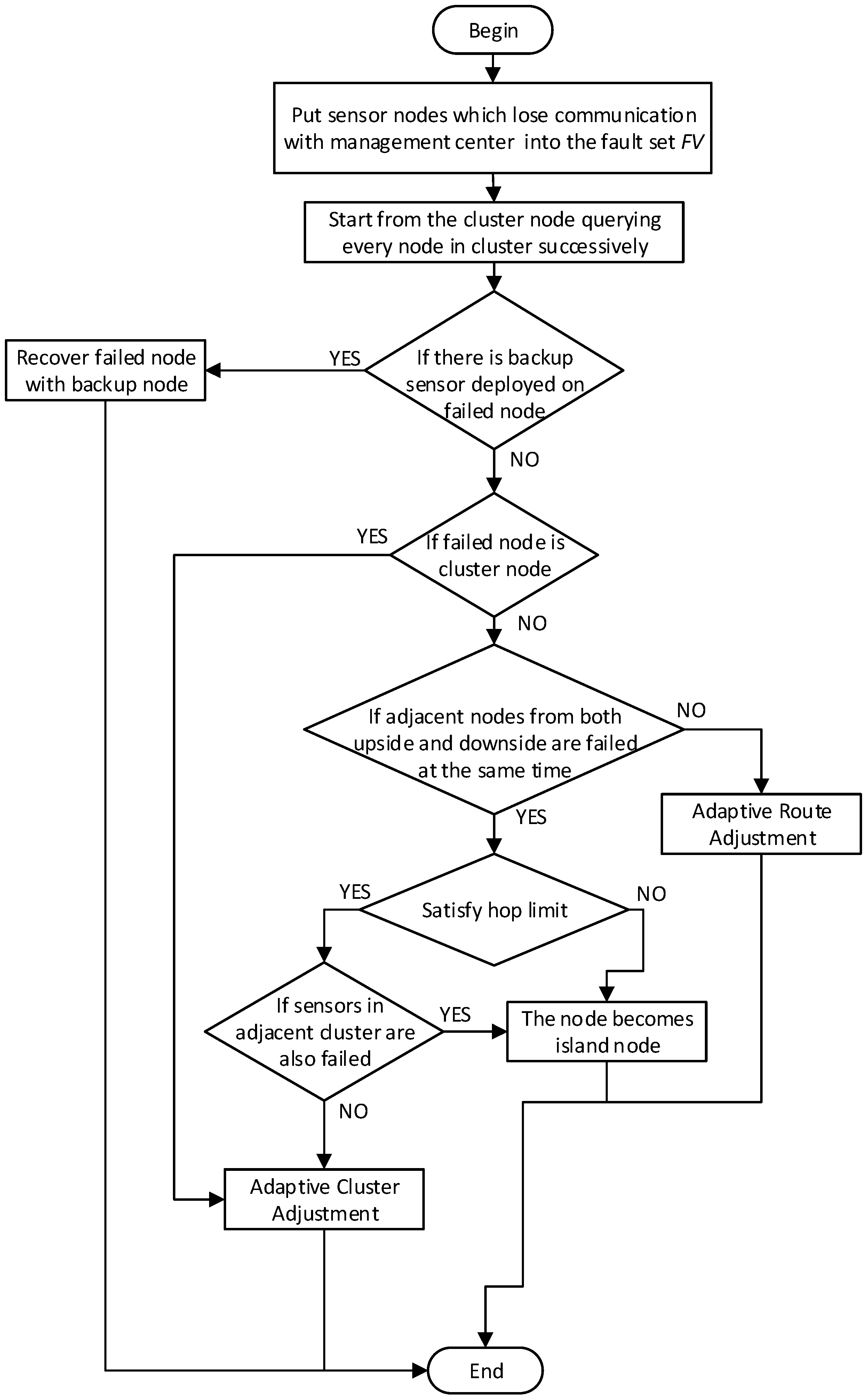
4.3.3. Procedures of Adaptive Detection and Resume Mechanism
- (1)
- If a cluster head has physically failed, there should be a cluster adjustment, which is shown in Figure 8.
- (2)
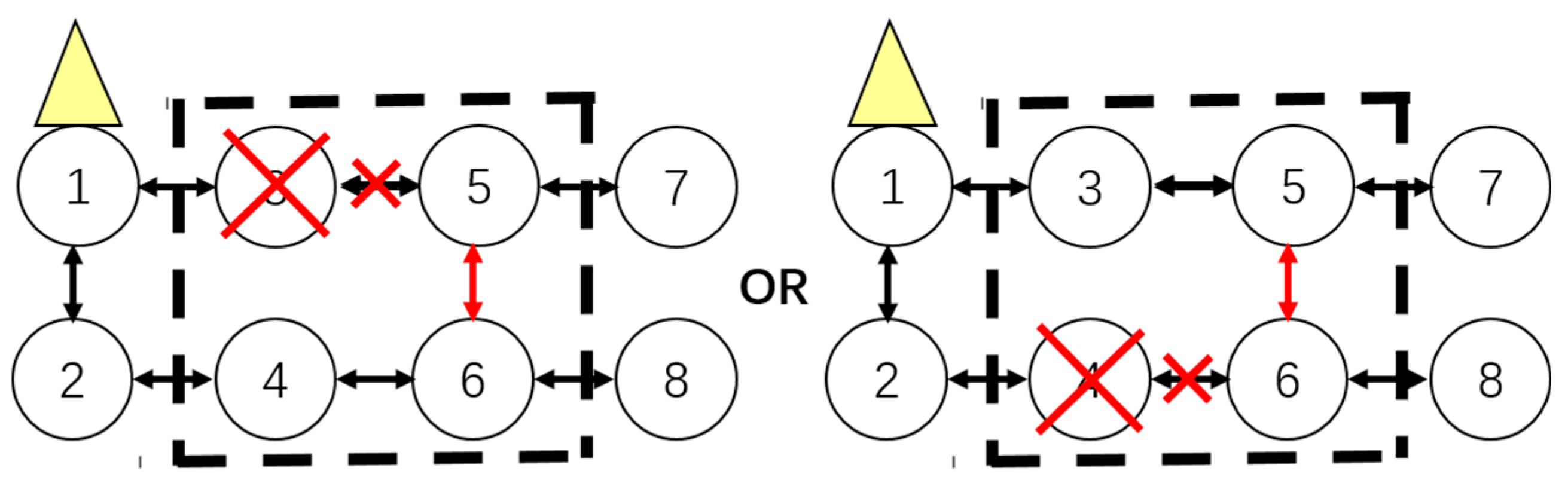
- If both sensor from upside and downside which are on the vertical or diagonal position in the window have failed at the same time, cluster adjustment should be executed as shown in Figure 9.
- (1)
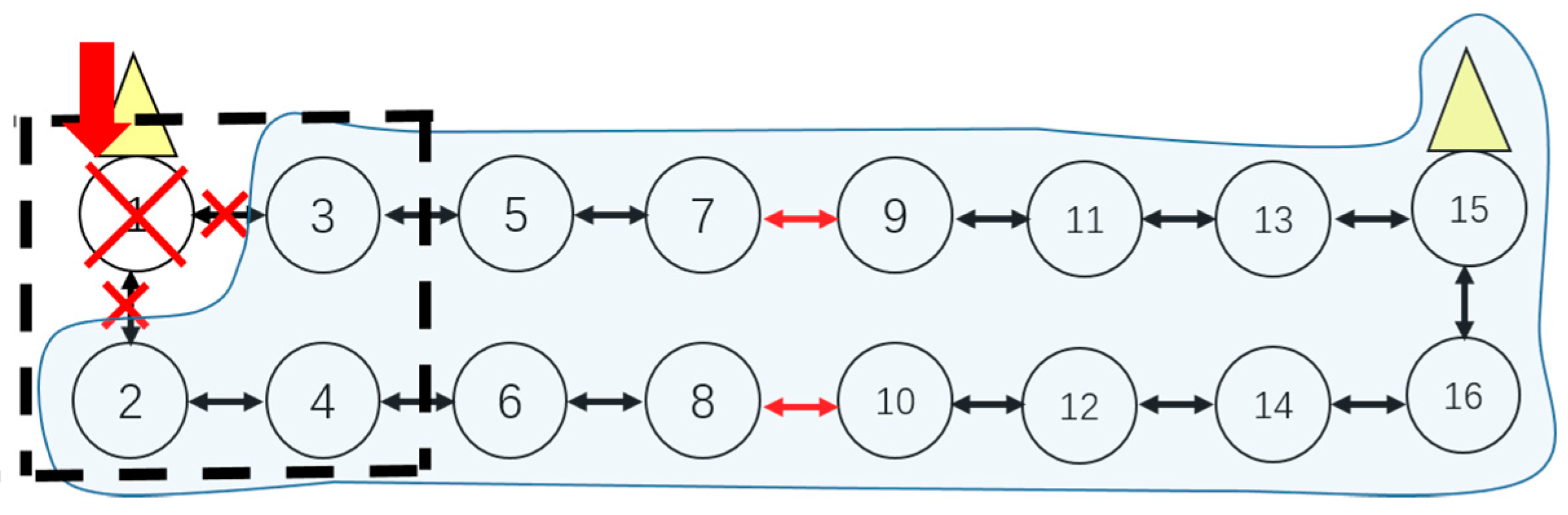
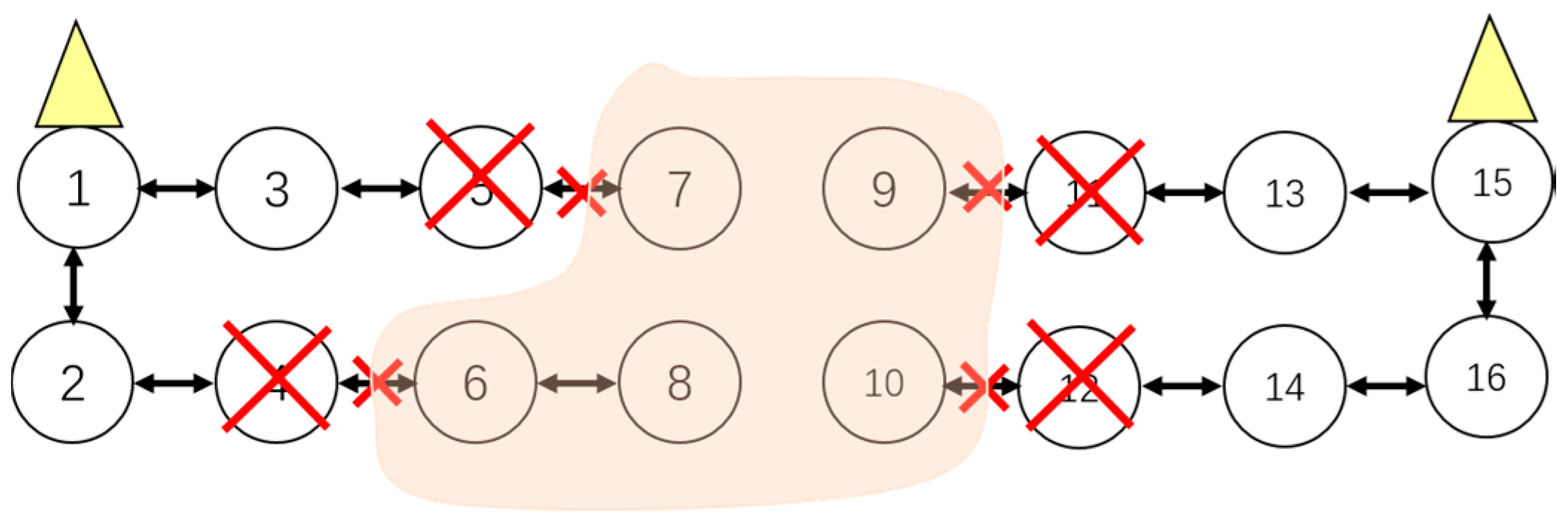
- Cluster adjustment should meet the hops constraint condition. The hops constraint limits the maximum number of sensors on one side of a cluster. Beyond the hops count limit, sensors will not be recovered resulting in a cluster of island sensors, which is shown in Figure 10.
- (2)
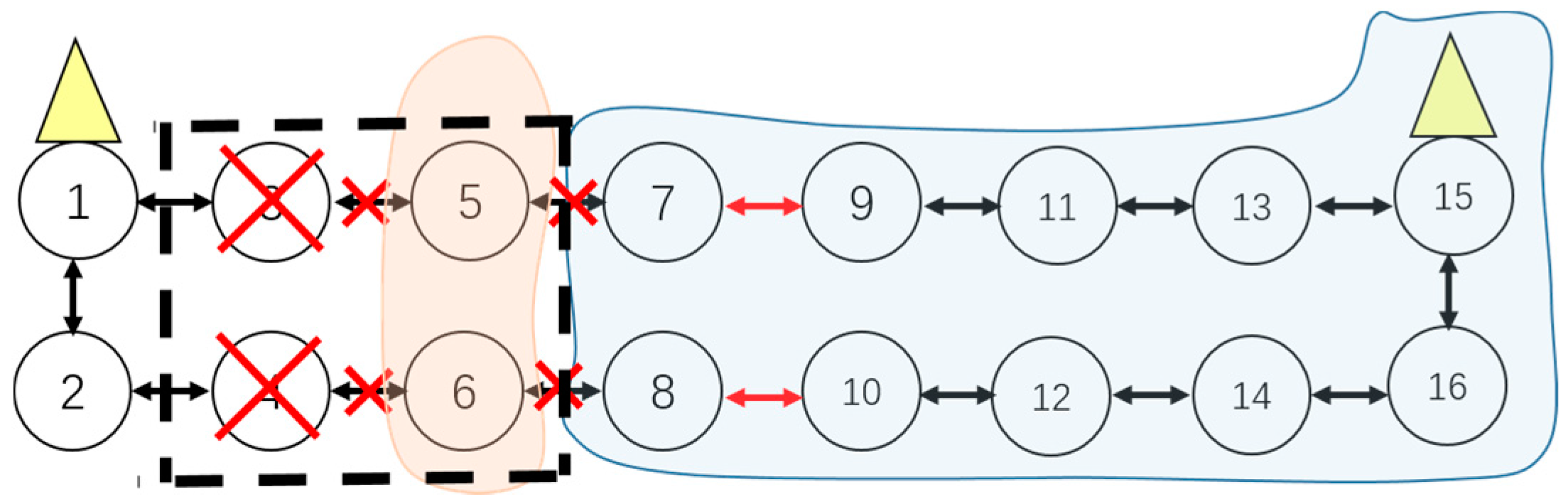
- Figure 11 shows that if sensors which belong to adjacent cluster respectively fail at the same time, cluster adjustment will be unsuccessful leaving lots of island sensors.
5. Simulation and Discussion
5.1. Evaluation Indexes
5.1.1. The Analysis for the Deployment of Backup On-Road Sensors
5.1.2. The Analysis of the Effectiveness of the ADR Protocol
5.1.3. The Analysis for the Redundant Cluster Head Deployment
5.2. Simulation Settings
5.3. Analytical Results and Discussions
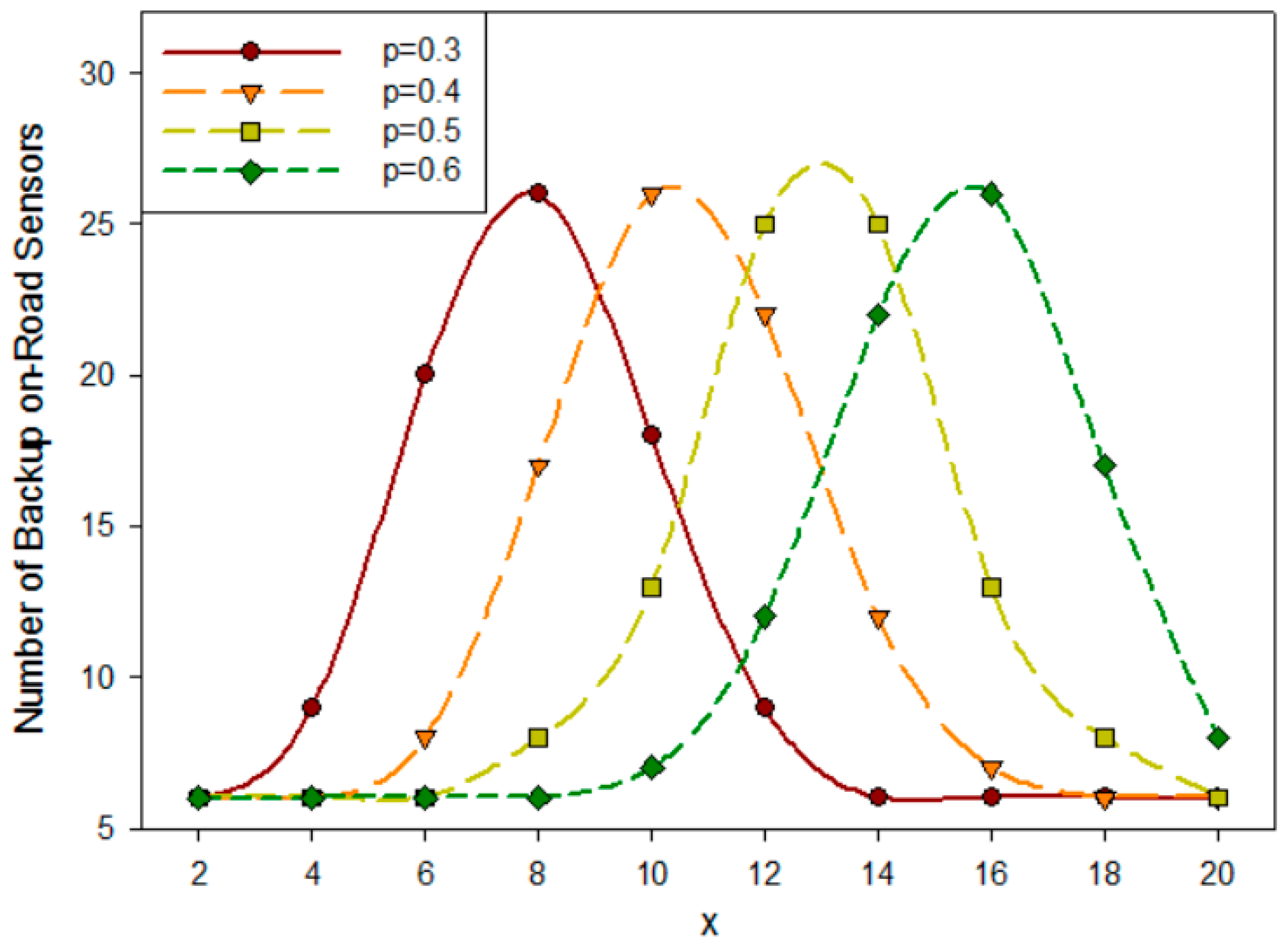
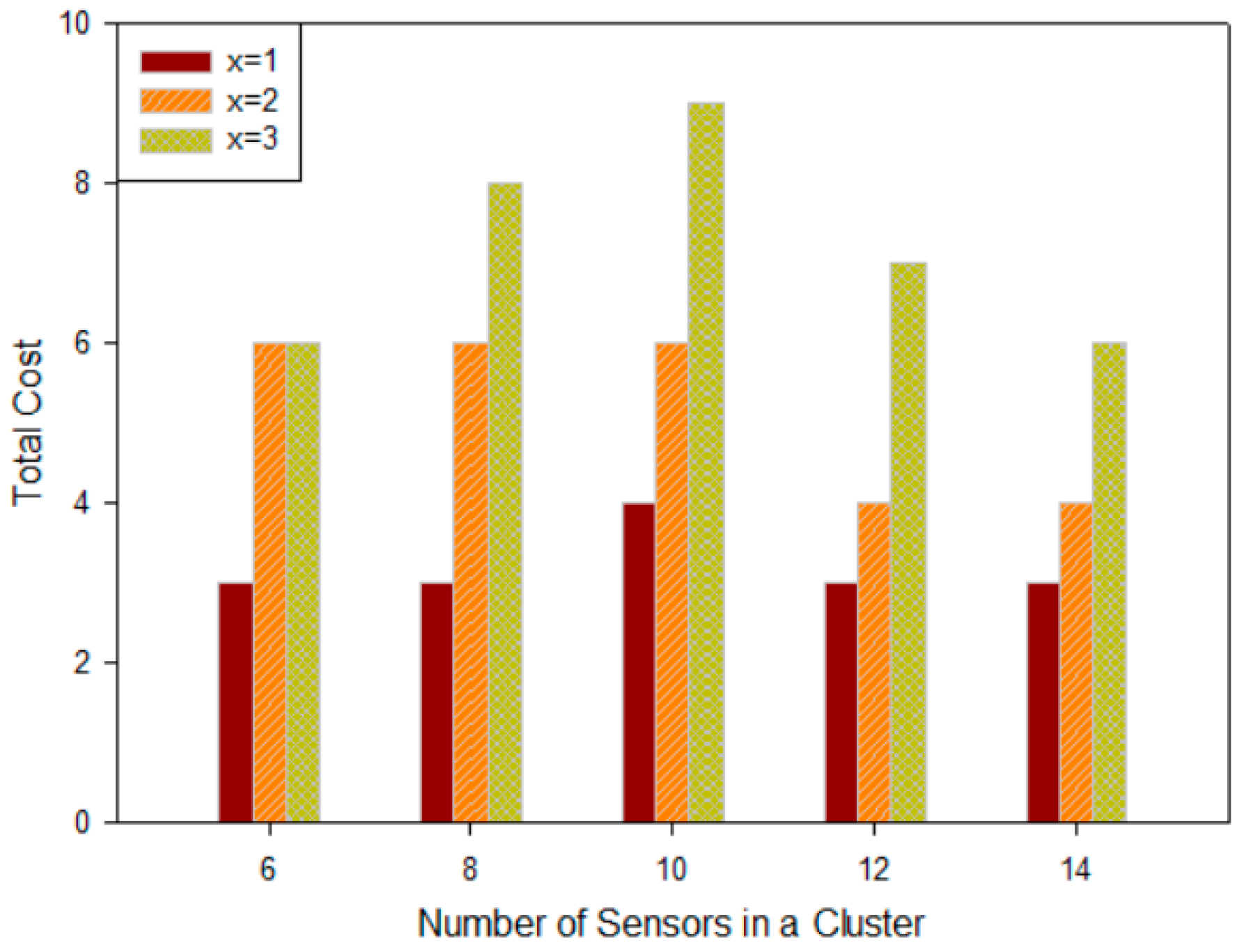
5.3.1. Quantitative Analysis for Backup On-Road Sensors
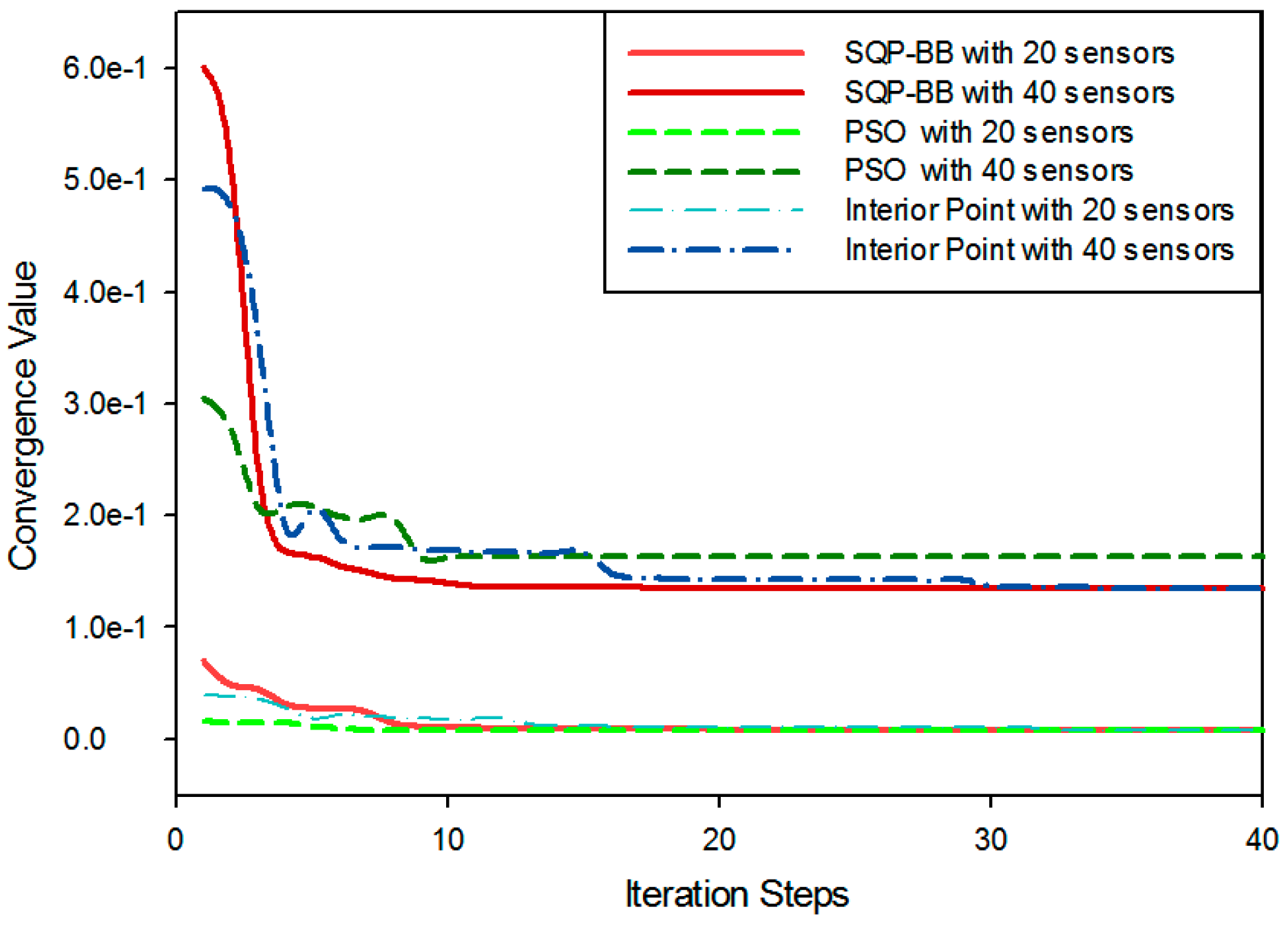
5.3.2. Performance Evaluation on the Proposed Algorithm
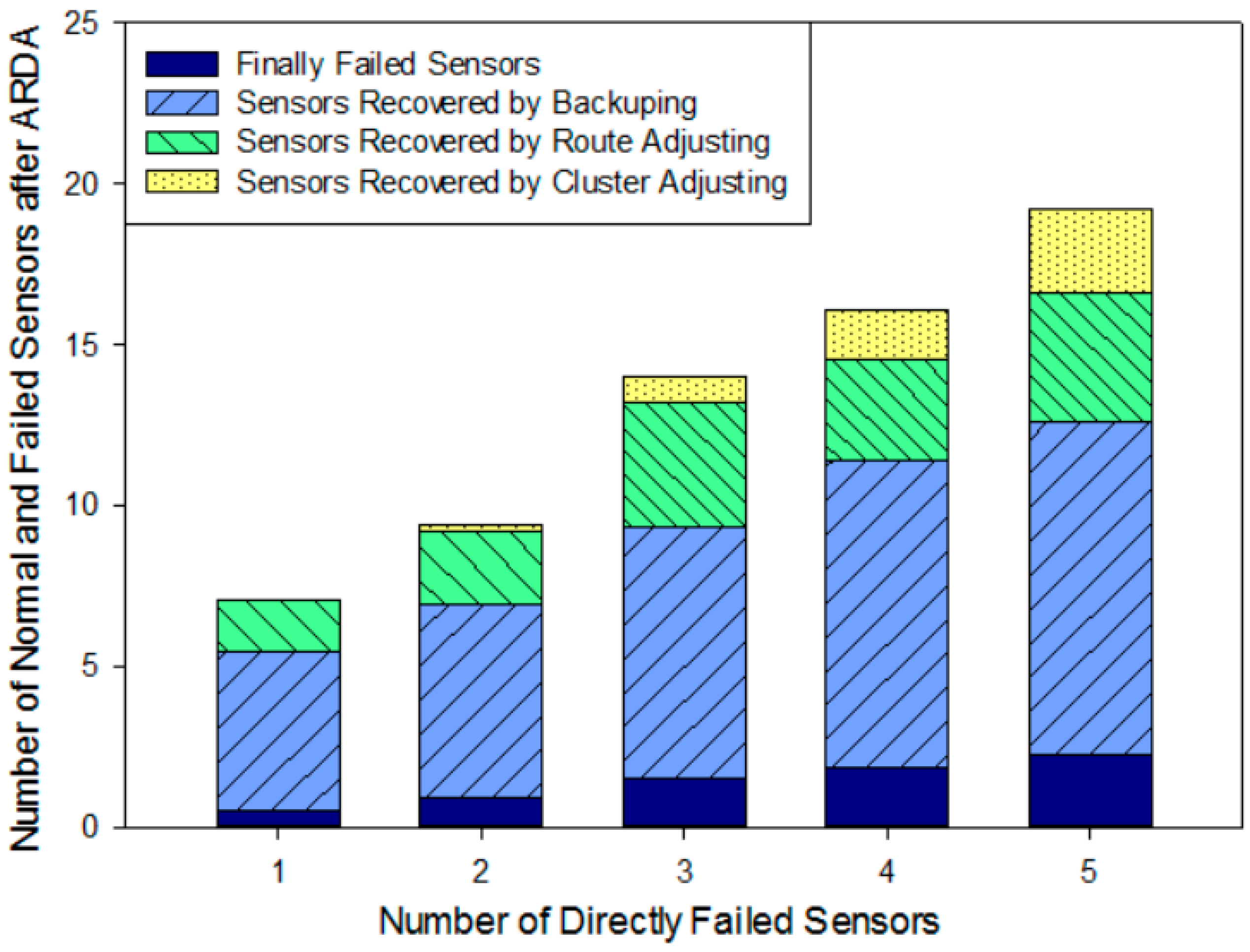
5.3.3. Deployment Accuracy Rate Analysis for Backup On-Road Sensors
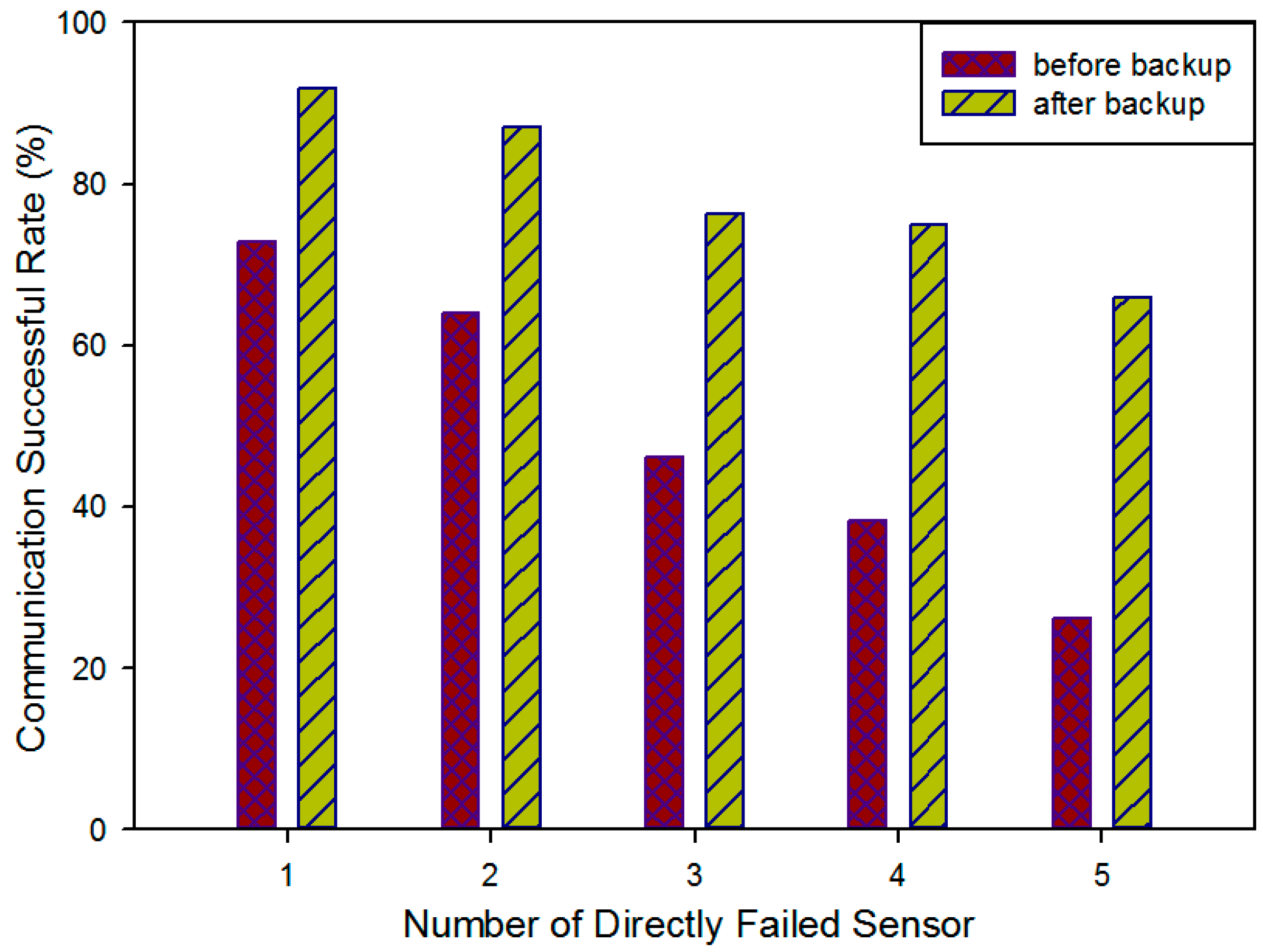
5.3.4. Communication Reliability Improved by Backup On-Road Sensors Deployment
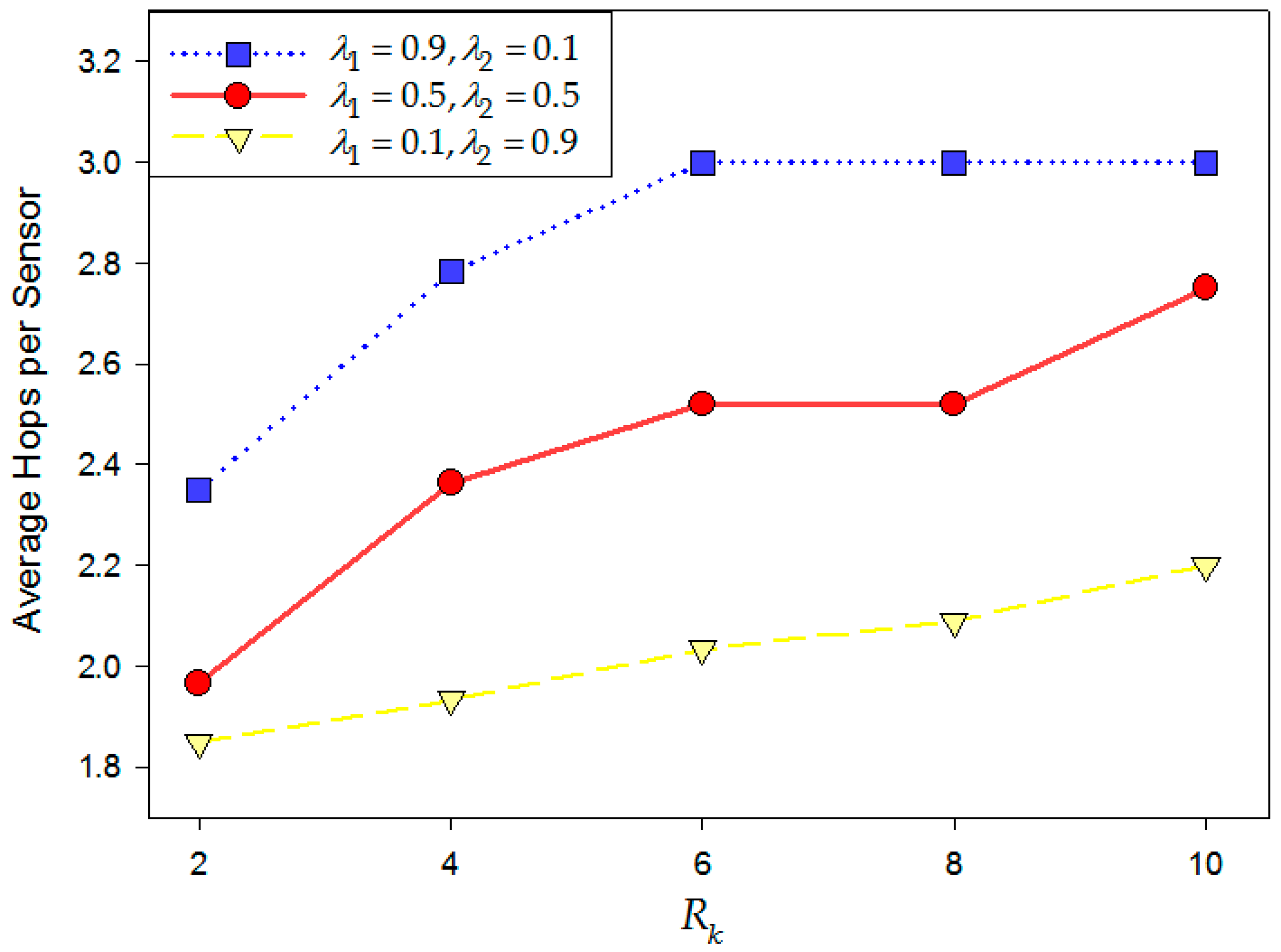
5.3.5. Resilience of Network Structure
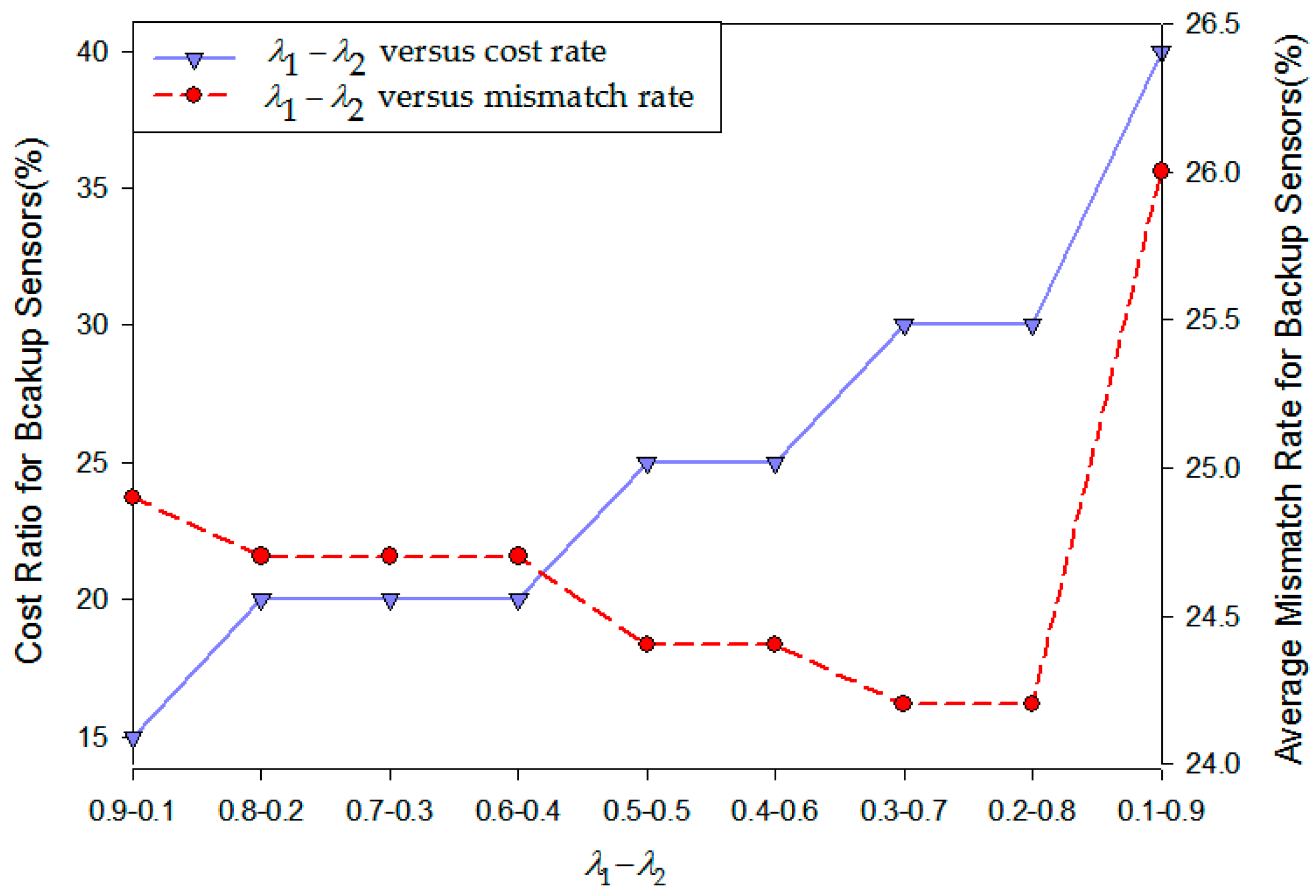
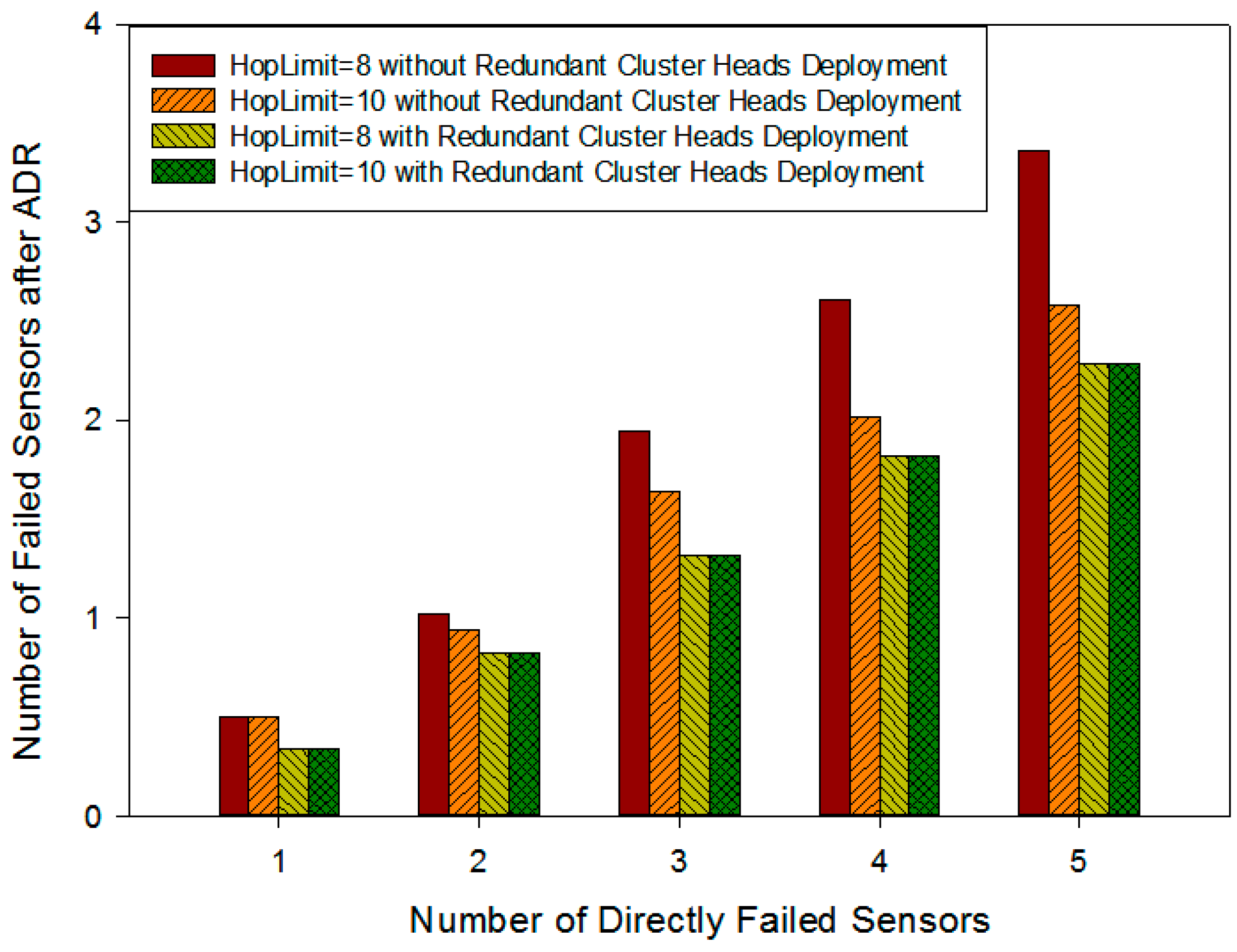
5.3.6. The Contribution of the Deployment with Redundant Cluster Heads to the Improvement in QoS
5.3.7. The Influence of Redundant Cluster Heads Deployment on the Network Resilience
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chan, K.Y.; Dillon, T.S.; Chang, E. An intelligent particle swarm optimization for short-term traffic flow forecasting using on-road sensor systems. IEEE Trans. Ind. Electron. 2013, 60, 4714–4725. [Google Scholar] [CrossRef]
- Chan, K.Y.; Khadem, S.; Dillon, T.S.; Palade, V.; Singh, J.; Chang, E. Selection of significant on-road sensor data for short-term traffic flow forecasting using the Taguchi method. IEEE Trans. Ind. Inform. 2012, 8, 255–266. [Google Scholar] [CrossRef]
- Noda, A.; Hirano, M.; Yamakawa, Y.; Ishikawa, M. A networked high-speed vision system for vehicle tracking. In Proceedings of the 2014 IEEE Sensors Applications Symposium (SAS), Queenstown, New Zealand, 18–20 February 2014; pp. 343–348.
- Nellore, K.; Hancke, G.P. A survey on urban traffic management system using wireless sensor networks. Sensors 2016, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- Wen, T.-H.; Jiang, J.-A.; Sun, C.-H.; Juang, J.-Y.; Lin, T.-S. Monitoring street-level spatial-temporal variations of carbon monoxide in urban settings using a wireless sensor network (WSN) framework. Int. J. Environ. Res. Public Health 2013, 10, 6380–6396. [Google Scholar] [CrossRef] [PubMed]
- Qin, H.; Li, Z.; Wang, Y.; Lu, X.; Zhang, W.; Wang, G. An integrated network of roadside sensors and vehicles for driving safety: Concept, design and experiments. In Proceedings of the 2010 IEEE International Conference on Pervasive Computing and Communications (PerCom), Mannheim, Germany, 29 March–2 April 2010; pp. 79–87.
- Kianfar, J.; Edara, P. Optimizing freeway traffic sensor locations by clustering global-positioning-system-derived speed patterns. IEEE Trans. Intell. Transp. Syst. 2010, 11, 738–747. [Google Scholar] [CrossRef]
- Chan, K.Y.; Dillon, T.S. On-road sensor configuration design for traffic flow prediction using fuzzy neural networks and Taguchi method. IEEE Trans. Instrum. Meas. 2013, 62, 50–59. [Google Scholar] [CrossRef]
- Komguem, R.D.; Stanica, R.; Tchuente, M.; Valois, F. WARIM: Wireless Sensor networks architecture for a reliable intersection monitoring. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1226–1231.
- Gupta, H.P.; Rao, S.V.; Tamarapalli, V. Analysis of stochastic k-coverage and connectivity in sensor networks with boundary deployment. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1861–1871. [Google Scholar] [CrossRef]
- Azpilicueta, L.; López-Iturri, P.; Aguirre, E.; Martínez, C.; Astrain, J.J.; Villadangos, J.; Falcone, F. Evaluation of deployment challenges of wireless sensor networks at signalized intersections. Sensors 2016, 16, 1140. [Google Scholar] [CrossRef] [PubMed]
- Fernández-Lozano, J.J.; Martín-Guzmán, M.; Martín-Ávila, J.; García-Cerezo, A. A wireless sensor network for urban traffic characterization and trend monitoring. Sensors 2015, 15, 26143–26169. [Google Scholar] [CrossRef] [PubMed]
- Masek, P.; Masek, J.; Frantik, P.; Fujdiak, R.; Ometov, A.; Hosek, J.; Andreev, S.; Mlynek, P.; Misurec, J. A Harmonized perspective on transportation management in smart cities: The novel IoT-driven environment for road traffic modeling. Sensors 2016, 16, 1872. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.A.; Kim, H.S.; Cho, H.B. Smart roadside system for driver assistance and safety warnings: Framework and applications. Sensors 2011, 11, 7420–7436. [Google Scholar] [CrossRef] [PubMed]
- Bhuiyan, M.Z.A.; Wang, G.; Cao, J.; Wu, J. Deploying wireless sensor networks with fault-tolerance for structural health monitoring. IEEE Trans. Comput. 2015, 64, 382–395. [Google Scholar] [CrossRef]
- Li, X.; Ouyang, Y. Reliable traffic sensor deployment under probabilistic disruptions and generalized surveillance effectiveness measures. Oper. Res. 2012, 60, 1183–1198. [Google Scholar] [CrossRef]
- Korkali, M.; Abur, A. Optimal sensor deployment for fault-tolerant smart grids. In Proceedings of the 2012 IEEE 13th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cesme, Turkey, 17–20 June 2012; pp. 520–524.
- Roumane, A.; Kechar, B.; Kouninef, B. Energy efficient fault tolerant routing mechanism for wireless sensor network. Comput. Inf. Sci. 2012, 5. [Google Scholar] [CrossRef]
- Rico, J.; Valiño, J.; Epifanio, E. Cluster head assignment in networks controlled by gateway entities (CHANGE): Simulation analysis of protocol performance. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Barcelona, Spain, 25–28 March 2013; pp. 1606–1611.
- Mammu, A.S.K.; Sharma, A.; Hernandez-Jayo, U.; Sainz, N. A novel cluster-based energy efficient routing in wireless sensor networks. In Proceedings of the 2013 IEEE 27th International Conference on Advanced Information Networking and Applications (AINA), Barcelona, Spain, 25–28 March 2013; pp. 41–47.
- Shortle, J.; Rebennack, S.; Glover, F.W. Transmission-capacity expansion for minimizing blackout probabilities. IEEE Trans. Power Syst. 2014, 29, 43–52. [Google Scholar] [CrossRef]
- Shi, Y.; Qiu, X.; Guo, S. Genetic algorithm-based redundancy optimization method for smart grid communication network. China Commun. 2015, 12, 73–84. [Google Scholar] [CrossRef]
- Wang, K.; Qiu, X.; Guo, S.; Qi, F. Fault Tolerance oriented sensors relay monitoring mechanism for overhead transmission line in smart grid. IEEE Sens. J. 2015, 15, 1982–1991. [Google Scholar] [CrossRef]
- Ramesh, M.V.; Rajan, P.; Divya, P. Augmenting packet delivery rate in outdoor wireless sensor networks through frequency optimization. In Proceedings of the 2014 International Conference on Computing, Communication and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–7.
- Khan, M.F.; Felemban, E.A.; Qaisar, S.; Ali, S. Performance analysis on packet delivery ratio and end-to-end delay of different network topologies in Wireless Sensor Networks (WSNs). In Proceedings of the 2013 IEEE Ninth International Conference on Mobile Ad-hoc and Sensor Networks (MSN), Dalian, China, 11–13 December 2013; pp. 324–329.
- Zhu, Y.H.; Qiu, S.; Chi, K.; Fang, Y. Latency aware IPv6 packet delivery scheme over IEEE 802.15.4 based battery-free wireless sensor networks. IEEE Trans. Mob. Comput. 2016, in press. [Google Scholar]
- Chaturvedi, P.; Daniel, A.K. Performance analysis of characteristic parameters for coverage model in wireless sensor networks. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 582–586.
- Yu, C.; Liu, Y.; Li, L. Research and application on the coverage range of the Zigbee protocol. In Proceedings of the IEEE Youth Conference on Information, Computing and Telecommunication, Beijing, China, 20–21 September 2009; pp. 1–4.
- Kumar Sahoo, P.; Chiang, M.-J.; Wu, S.-L. An efficient distributed coverage hole detection protocol for wireless sensor networks. Sensors 2016, 16, 386. [Google Scholar] [CrossRef] [PubMed]
- Felamban, M.; Shihada, B.; Jamshaid, K. Optimal node placement in underwater wireless sensor networks. In Proceedings of the 2013 IEEE 27th International Conference on Advanced Information Networking and Applications (AINA), Barcelona, Spain, 25–28 March 2013; pp. 492–499.
- Murdiyat, P.; Chung, K.S.; Chan, K.S. Predicting the network throughput of wide area WSN in rural areas. In Proceedings of the 20th Asia-Pacific Conference on Communication (APCC2014), Chon Buri, Thailand, 1–3 October 2014; pp. 106–111.
- Redwan, H.; Akele, G.; Kim, K.H. Cluster-based failure detection and recovery scheme in wireless sensor network. In Proceedings of the 2014 Sixth International Conference on Ubiquitous and Future Networks (ICUFN), Shanghai, China, 8–11 July 2014; pp. 407–412.
- Kumar, M.; Pattanaik, K.K.; Yadav, B.; Verma, R.K. Optimization of wireless sensor networks inspired by small world phenomenon. In Proceedings of the 2015 IEEE 10th International Conference on Industrial and Information Systems (ICIIS), Peradeniya, Sri Lanka, 18–20 Decmber 2015; pp. 66–70.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| N | Total number of the on-road sensors |
| Total number of the backup on-road sensors | |
| Total number of the redundant cluster heads | |
| SP | A binary vector of position for the on-road sensors |
| CP | A binary vector of position for the redundant cluster heads |
| Expense of purchase and installation per backup on-road sensor | |
| Expense of purchase and installation per cluster head | |
| RR | Reservation ratio for scalability |
| The k-th cluster of the system | |
| Coverage radius of the the k-th cluster | |
| M | Number of the fault types |
| Frequency of the j-th type fault of the i-th node |
| Parameter | Definition | Value |
|---|---|---|
| x Nodes fail in N nodes according to the N − x principle | {1,2,3} | |
| The initial number of the clusters | 6 | |
| The number of on-road sensors in a cluster | {20,26} | |
| The fault probability of the i-th on-road sensor | 0.5 | |
| Low threshold of fault frequency | 0.3 | |
| High threshold of fault frequency | 0.6 | |
| Coverage radius of the k-th cluster | {2,3,...,10} | |
| Procurement and deployment expanse for a single sensor | 1 unit | |
| RR | Reservation Ratio for scalability | 0.2 |
| Deployment cost of a reuse of the existed cluster head | 1 unit | |
| Deployment cost of a new cellular node’s machine | 7 units |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, L.; Guo, S.; Sun, J.; Yu, P.; Li, W. A Fault Tolerance Mechanism for On-Road Sensor Networks. Sensors 2016, 16, 2059. https://doi.org/10.3390/s16122059
Feng L, Guo S, Sun J, Yu P, Li W. A Fault Tolerance Mechanism for On-Road Sensor Networks. Sensors. 2016; 16(12):2059. https://doi.org/10.3390/s16122059
Chicago/Turabian StyleFeng, Lei, Shaoyong Guo, Jialu Sun, Peng Yu, and Wenjing Li. 2016. "A Fault Tolerance Mechanism for On-Road Sensor Networks" Sensors 16, no. 12: 2059. https://doi.org/10.3390/s16122059
APA StyleFeng, L., Guo, S., Sun, J., Yu, P., & Li, W. (2016). A Fault Tolerance Mechanism for On-Road Sensor Networks. Sensors, 16(12), 2059. https://doi.org/10.3390/s16122059