
A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks

Abstract
:1. Introduction
2. Related Works
2.1. Spectral Clustering Algorithm
| Algorithm 1: Spectral Clustering Algorithm | |
| Input: Dataset, number of clusters k, parameter σ and number of iterations Output: the set of k clusters /* Note the symbols of “” and “” represent comments in this algorithm. */ | |
| 1 | Calculate the affinity matrix and define /* In which and are the original data points i and j, repctively. */ |
| 2 | If then the |
| 3 | The D is the diagonal degree matrix and computed with elements: Given a graph G with n input vertices, the Laplacian matrix |
| 4 | Find the k largest eigenvectors of the matrix L and |
| 5 | Generate matrix y by renormalizing each x row, |
| 6 | Minimize the distortion of each row Y to regard as the point in clustering term using any clustering algorithm, such as a distance-based clustering approach. |
| 7 | Finally, the original point is assigned to cluster j when the row of belongs to the cluster j. |
| 8 | return the set of k clusters and cluster centre. |
2.2. DNN Algorithm
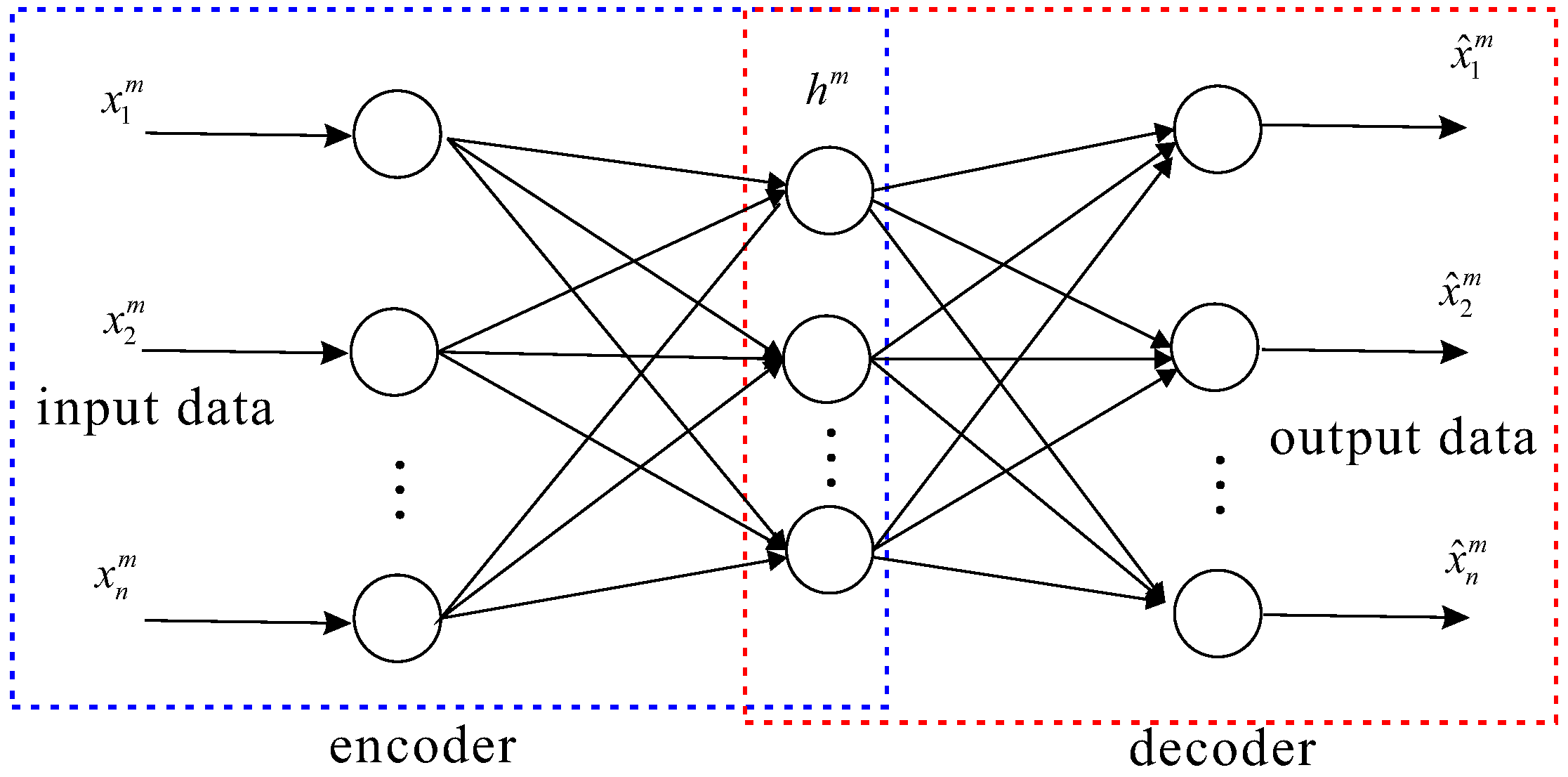
2.2.1. Auto-Encoders
2.2.2. Decoder
2.2.3. Sparse Auto-Encoder (SAE)
2.2.4. Denoising Auto-Encoders (DAEs)
2.2.5. Pre-Training
2.2.6. Fine-Tuning
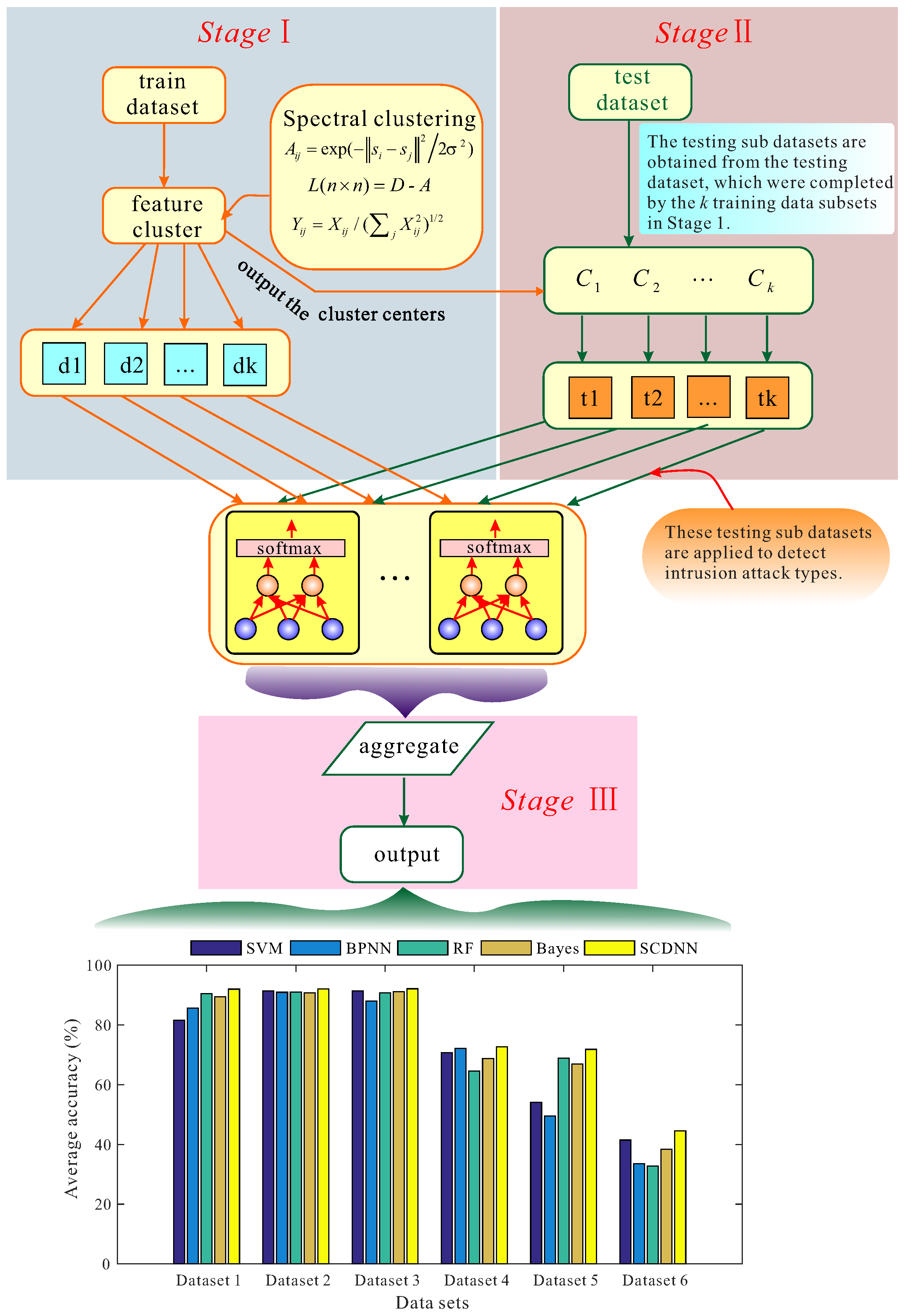
3. The Proposed Approach of SCDNN
3.1. SCDNN
3.2. The SCDNN Algorithm
| Algorithm 2: SCDNN | |
| Input: dataset, cluster number, number of hidden-layer nodes , number of hidden layers . Output: Final prediction results /*Note the symbols of “” and “” represent comments in this algorithm.*/ | |
| 1 | Divide the raw dataset into two components: a training dataset and a testing dataset. /*get the largest matrix eigenvectors and training data subsets*/ |
| 2 | Obtain the cluster centres and SC results using Algorithm 1. Here, the clustering results are regarded as training data subsets. /*Train each DNN with each training data subset*/ |
| 3 | The learning rate, denoising and sparsity parameters are set and the weight and bias are randomly initialised. |
| 4 | The HL are set two hidden layers, HLN is set 40 nodes of the first hidden layer and 20 nodes of second hidden layer. |
| 5 | Compute the sparsity cost function . |
| 6 | Parameter weights and bias are updated as and . |
| 7 | Train k sub-DNNs corresponding to the training data subsets. |
| 8 | Fine-tune the sub-DNNs by using backpropagation to train them. |
| 9 | The final structure of the trained sub-DNNs is obtained and they are labelled with each training data subset. |
| 10 | Divide the testing dataset into subsets with SC. Cluster centre parameters from the training data clusters are used. |
| 11 | The testing data subsets are used to test corresponding sub-DNNs, based on each corresponding cluster centre between the testing and training data subsets. /*aggregate each prediction result*/ |
| 12 | Results are generated by each sub-DNN, are integrated and the final outputs are obtained. |
| 13 | return classification result = final output |
4. Experimental Results
4.1. Evaluation Methods
4.2. The Dataset
4.3. SCDNN Experiment I
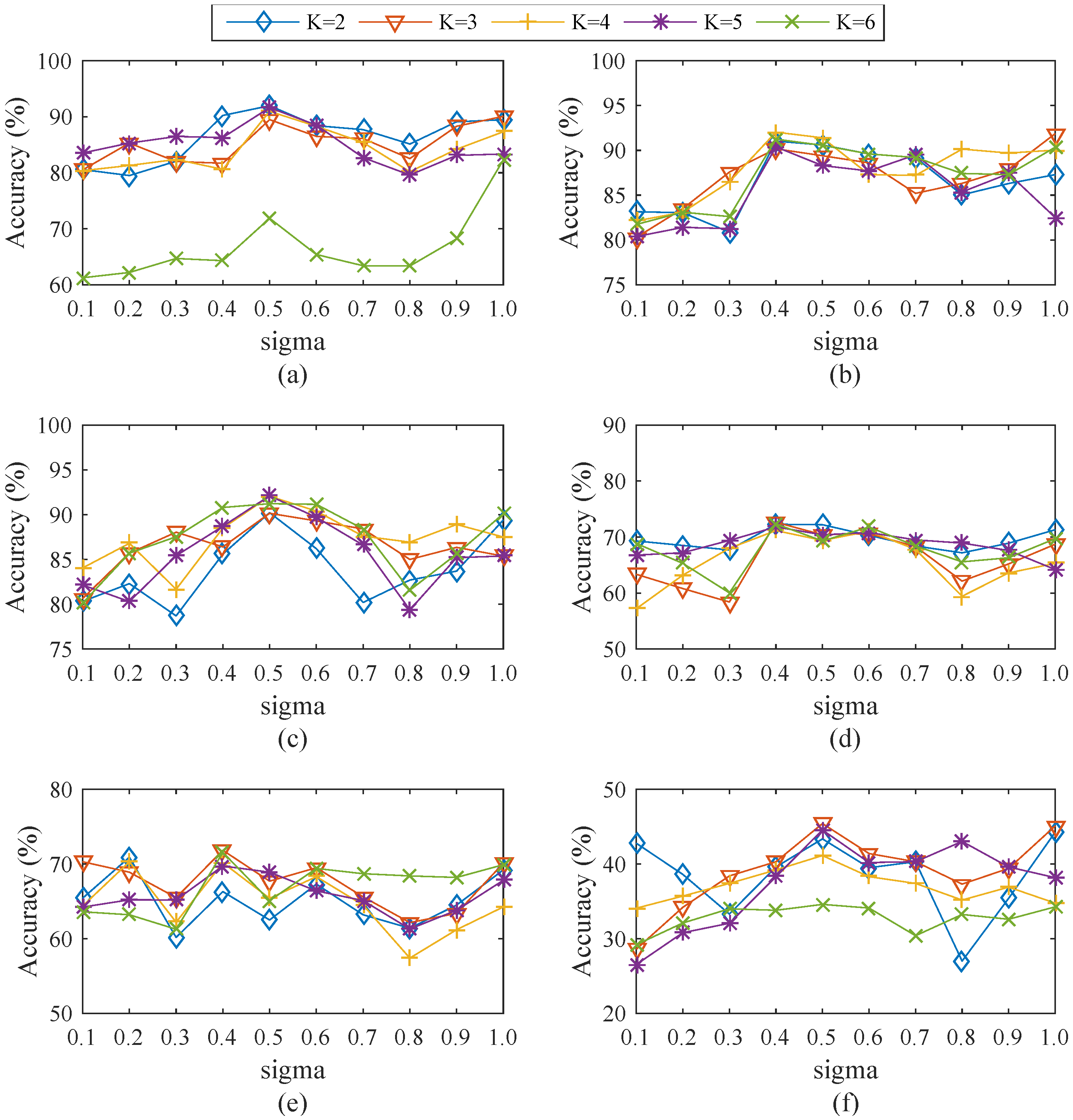
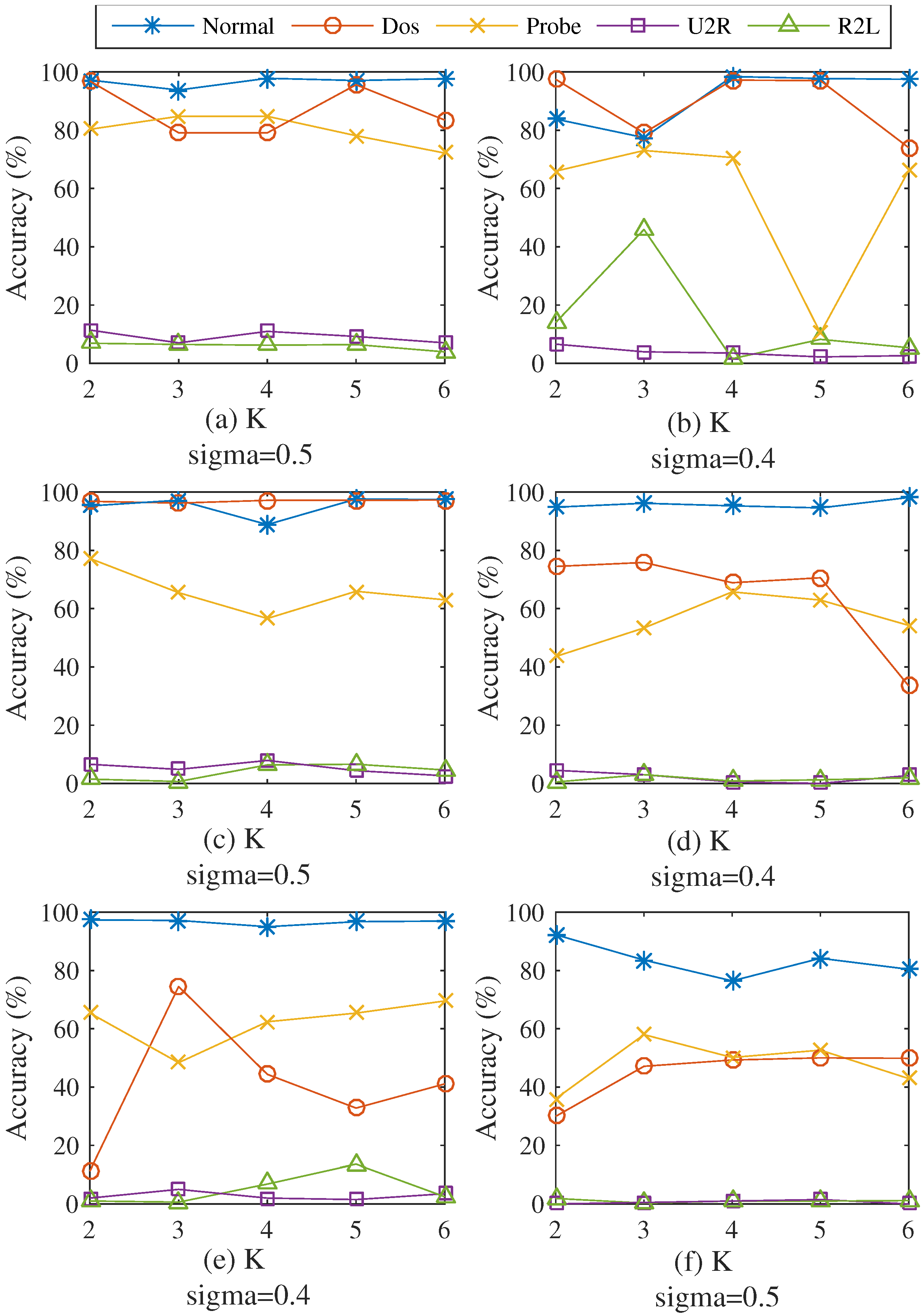
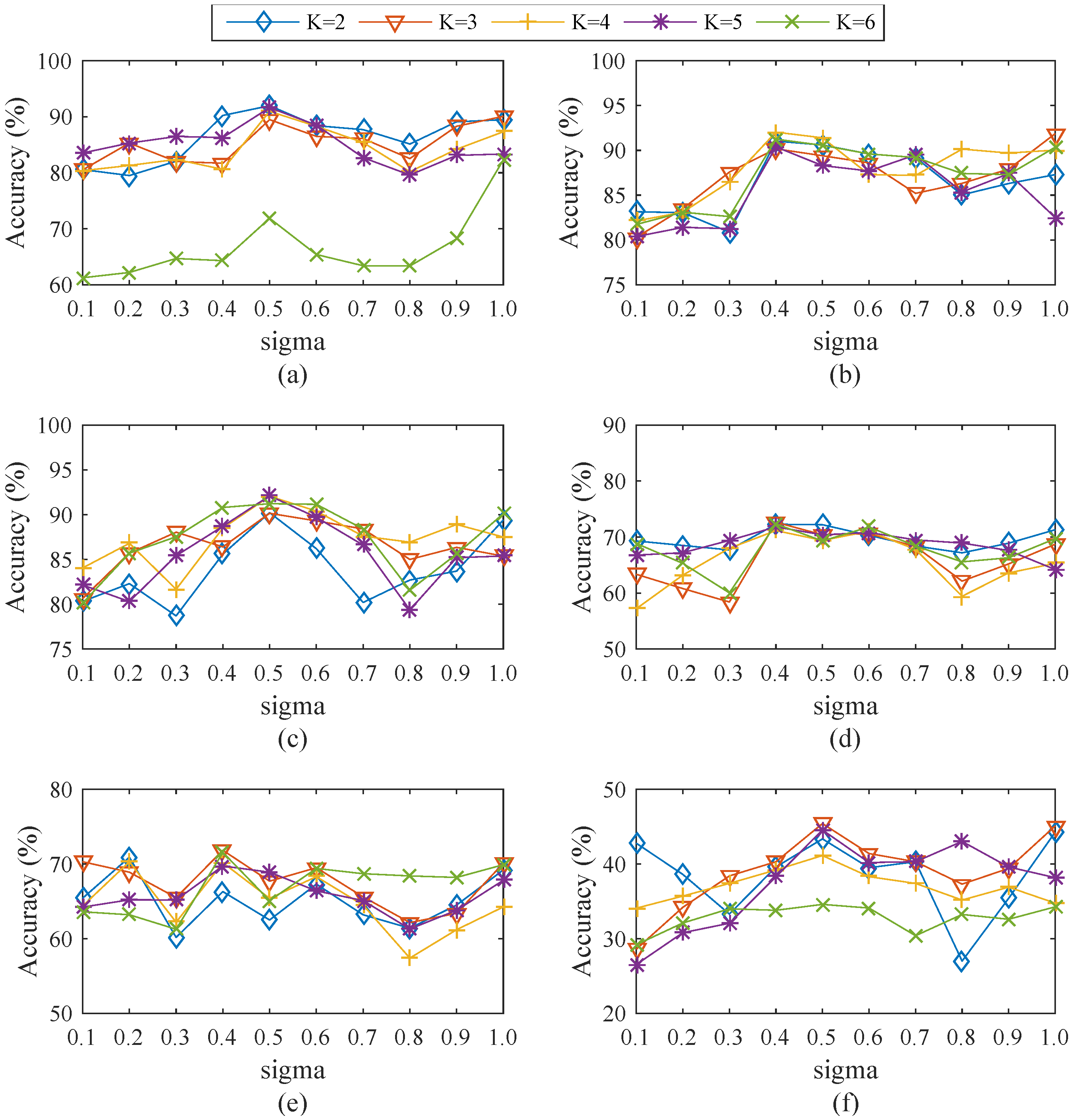
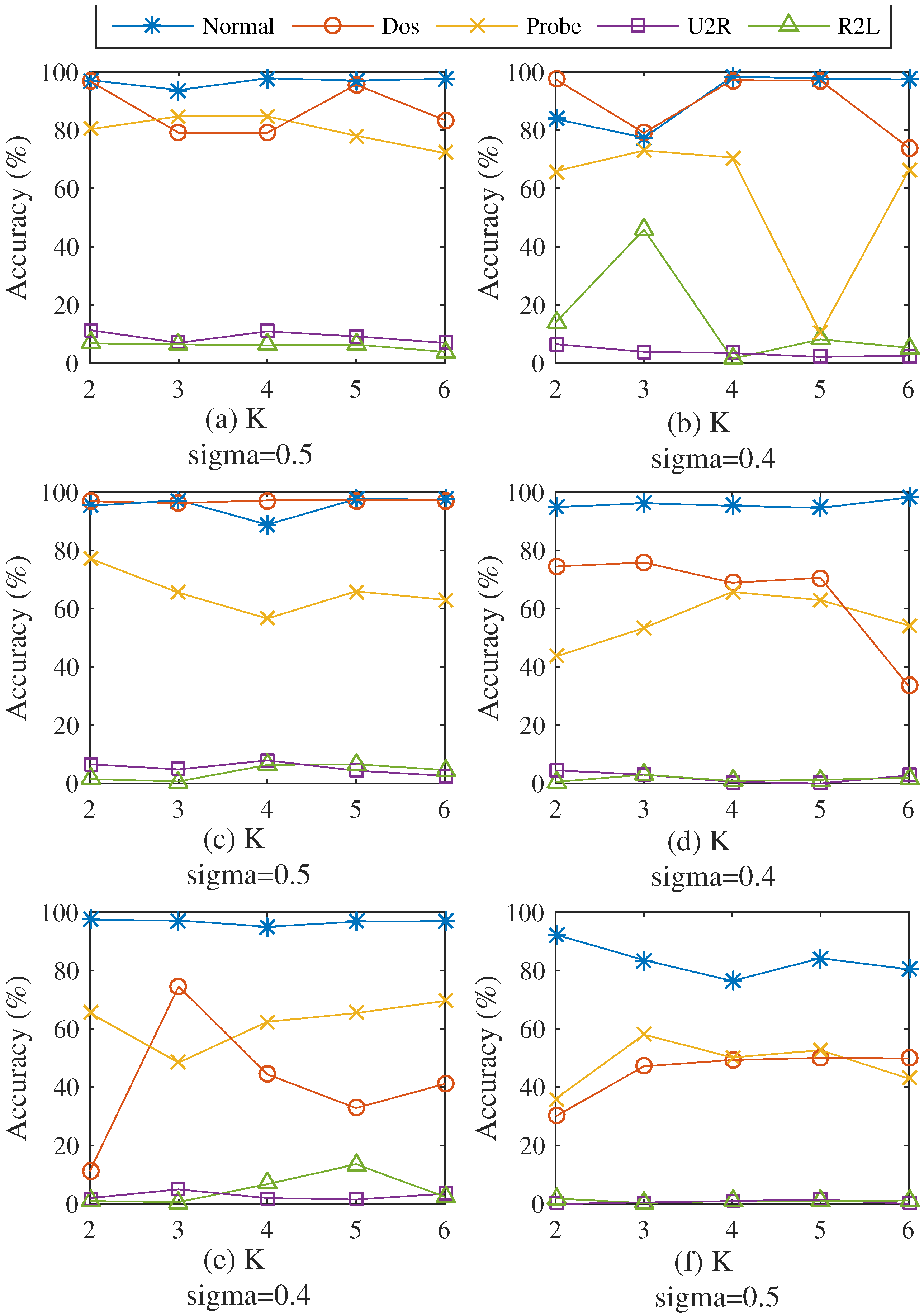
4.3.1. Efficiency of Varied Cluster Numbers and Values of σ
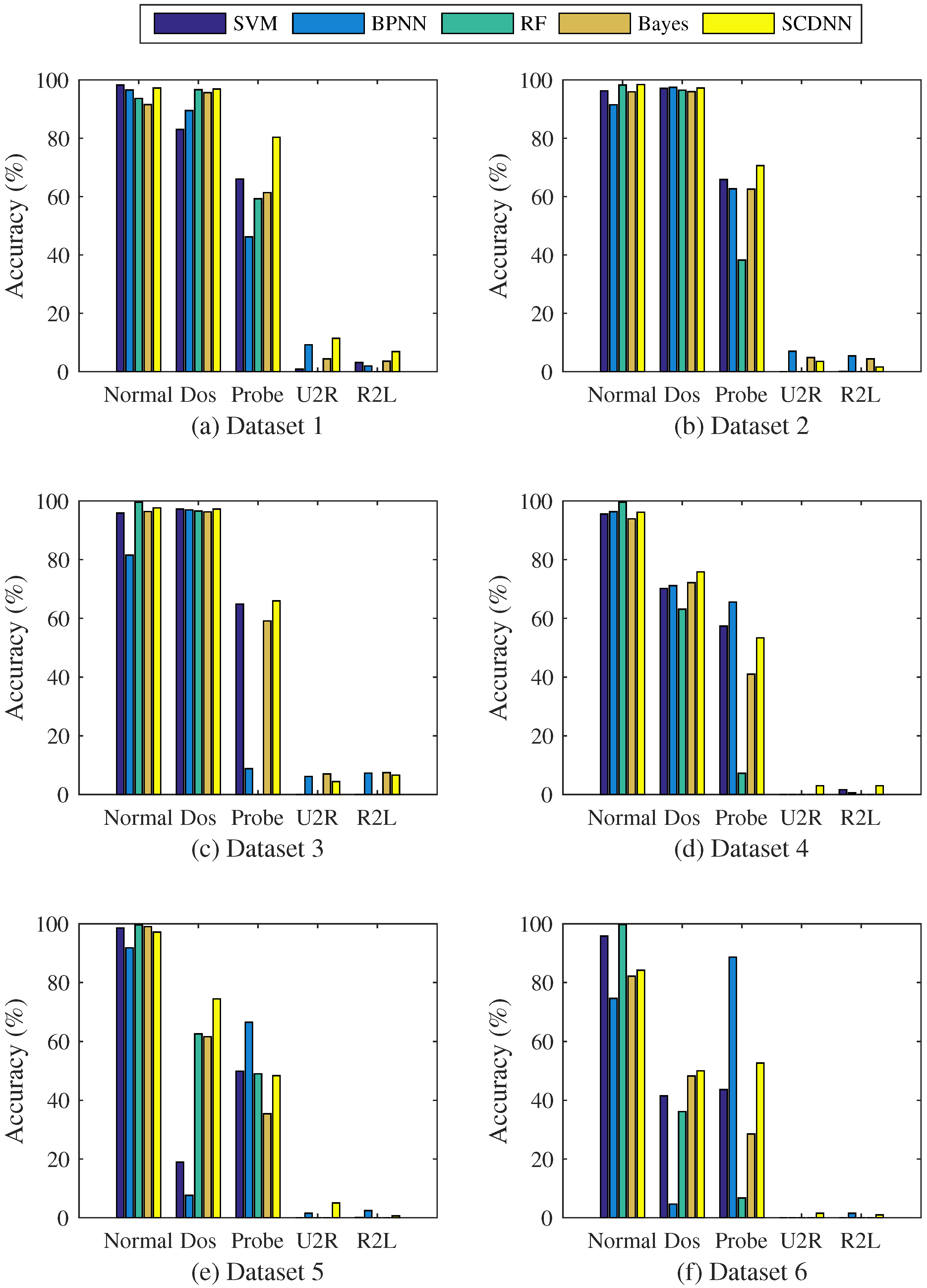
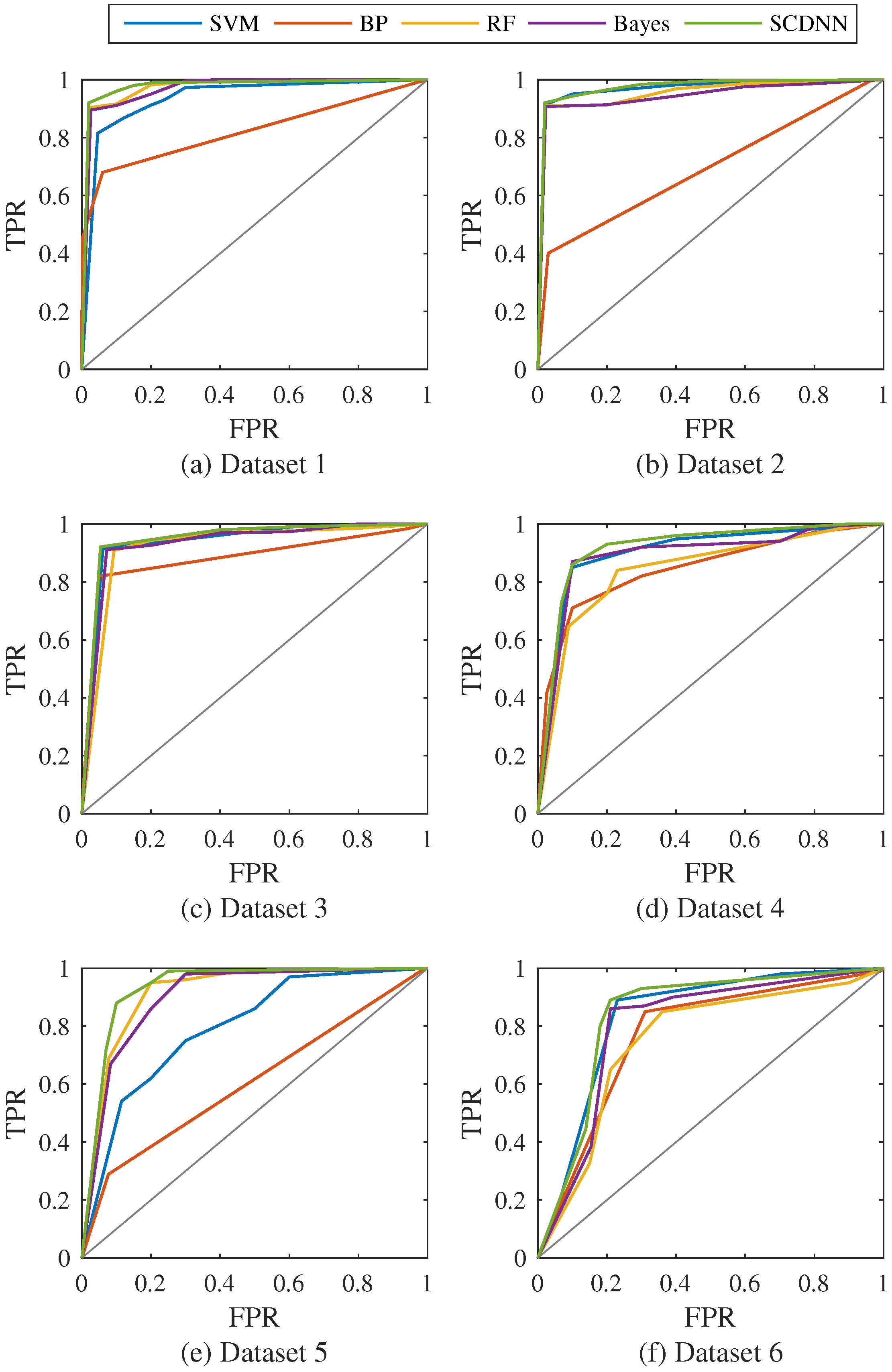
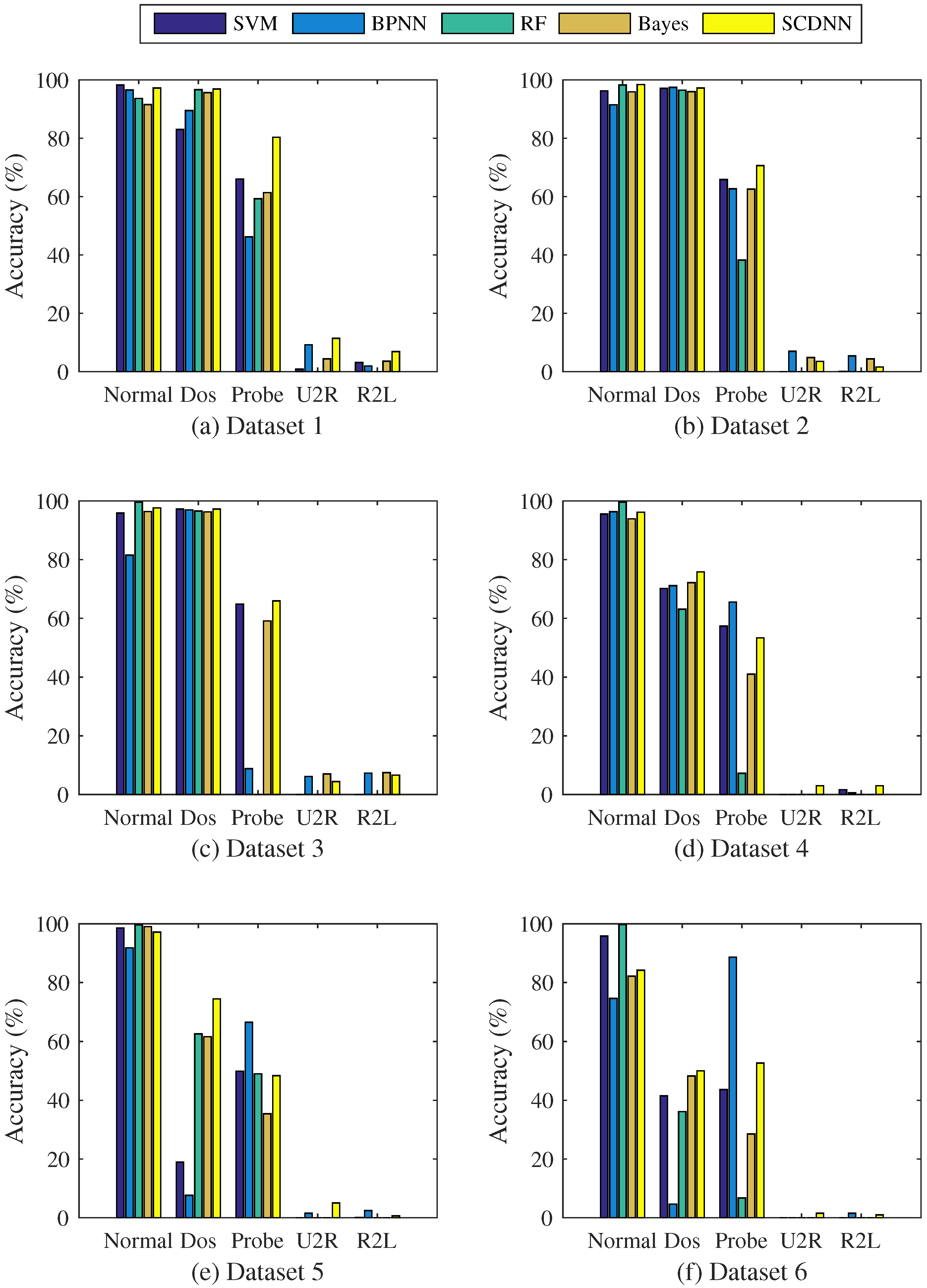
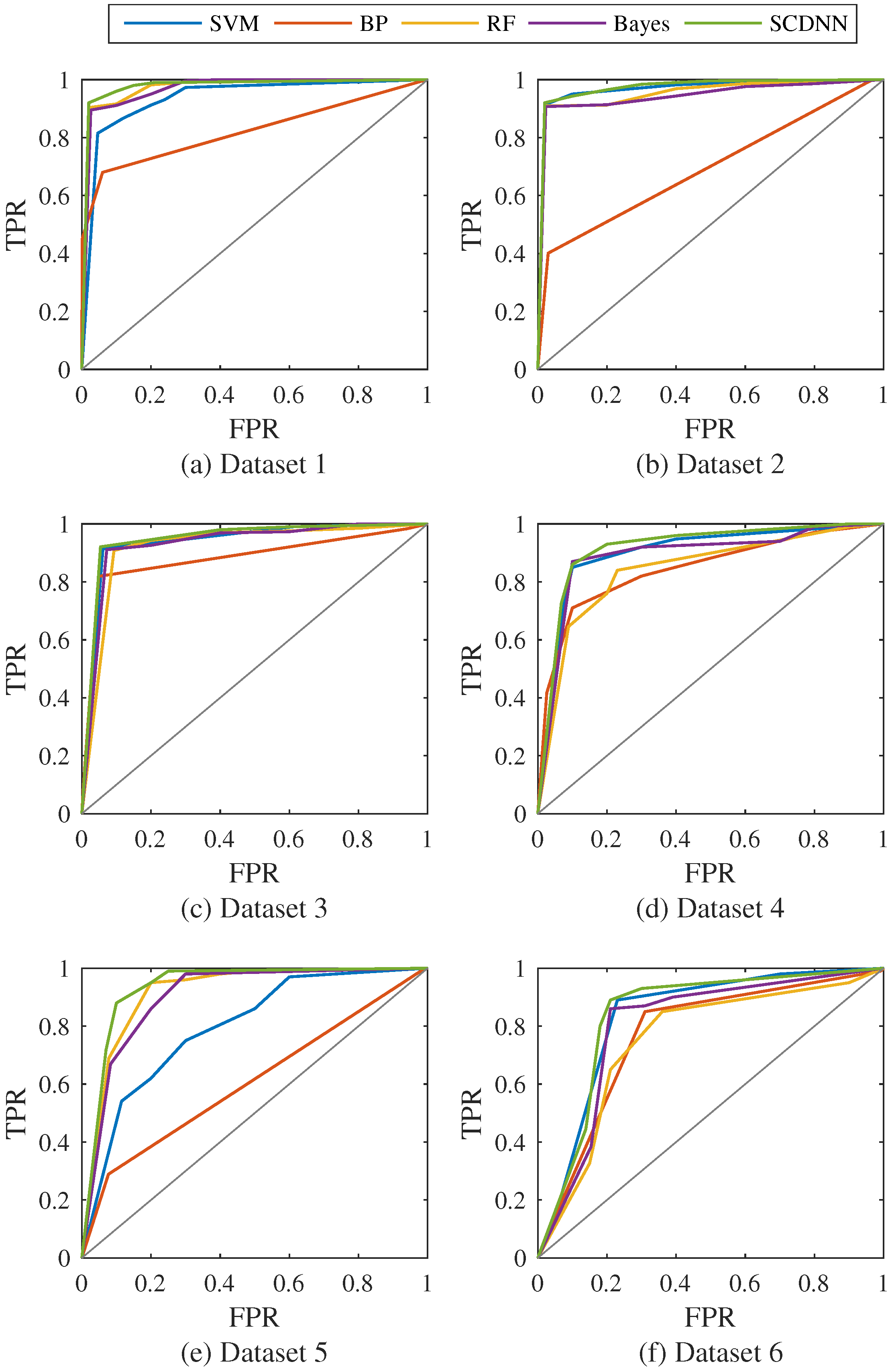
4.3.2. Results and Comparisons
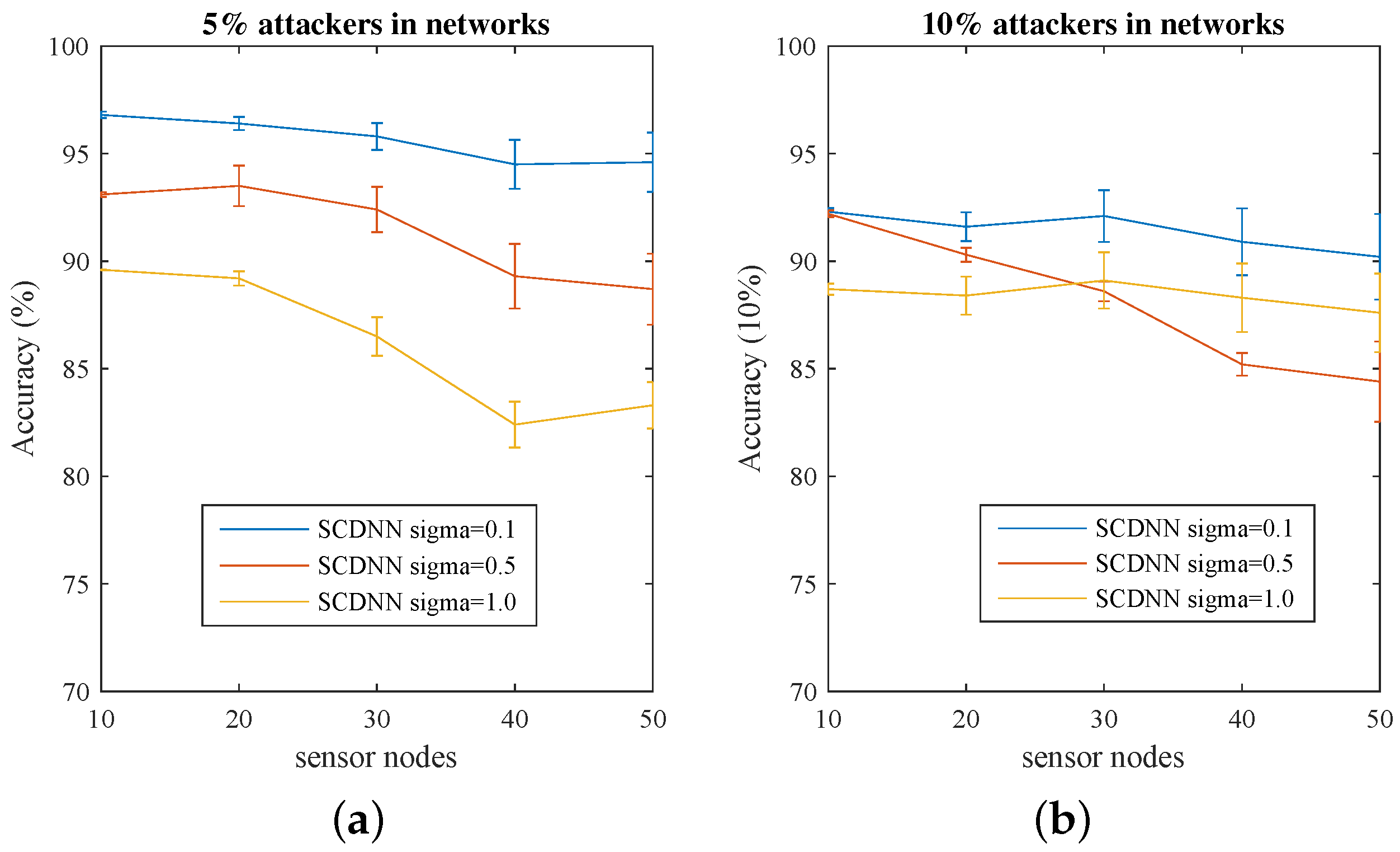
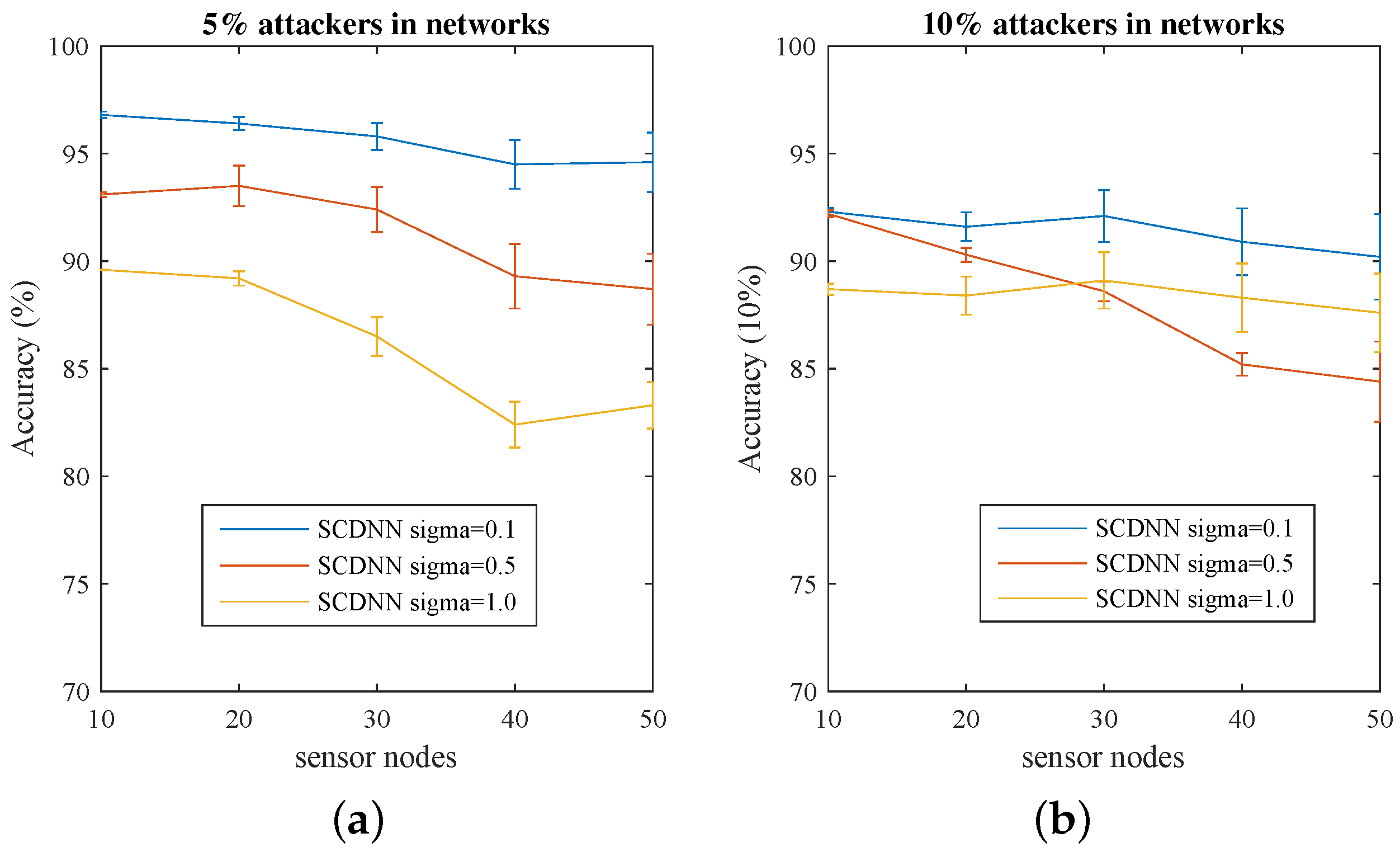
4.4. SCDNN Experiment II with a WSN Dataset
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machine |
| SOM | Self-Organizing Map |
| ANN | Artificial Neural Networks |
| RF | Random Forest |
| DNN | Deep Neural Network |
| PSO | Particle Swarm Optimization |
| KNN | K-Nearest Neighbour |
| IDS | Intrusion Detection System |
| SGD | Stochastic Gradient Descent |
| DoS | Denial of service |
| R2L | Remote to Local |
| U2R | User to Root |
| ER | Error Rate |
| TN | True Negative |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| BPNN | Backpropagation Neural Network |
| SCDNN | Spectral Clustering and Deep Neural Network |
| SC | Spectral Clustering |
| SAE | Sparse Auto-Encoder |
| DAEs | Denoising Auto-Encoders |
| KL | Kullback-Leibler |
| NJW | Ng-Jordan-Weiss |
| WSN | Wireless Sensor Network |
| ROC | Receiver Operating Curves |
| AUC | Area under the ROC Curve |
| DBN | Deep Belief Networks |
| GA | Genetic Algorithms |
| STL | Self-Taught Learning |
| DRBM | Discriminative Restricted Boltzmann Machine |
| AODV | Ad hoc On-demand Distance Vector |
References
- Kabiri, P.; Ghorbani, A.A. Research on Intrusion Detection and Response: A Survey. Int. J. Netw. Secur. 2005, 1, 84–102. [Google Scholar]
- Barbara, D.; Wu, N.; Jajodia, S. Detecting Novel Network Intrusions Using Bayes Estimators. In Proceedings of the First SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001; pp. 1–17.
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, SE-13, 222–232. [Google Scholar] [CrossRef]
- Dokas, P.; Ertoz, L.; Kumar, V.; Lazarevic, A.; Srivastava, J.; Tan, P.N. Data mining for network intrusion detection. In Proceedings of the NSF Workshop on Next Generation Data Mining, Baltimore, MD, USA, 1–3 November 2002; pp. 21–30.
- Chen, W.H.; Hsu, S.H.; Shen, H.P. Application of SVM and ANN for intrusion detection. Comput. Oper. Res. 2005, 32, 2617–2634. [Google Scholar] [CrossRef]
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hsu, Y.F.; Lin, C.Y.; Lin, W.Y. Intrusion detection by machine learning: A review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- Marin, G. Network security basics. IEEE Secur. Priv. 2005, 3, 68–72. [Google Scholar] [CrossRef]
- Karami, A.; Guerrero-Zapata, M. A fuzzy anomaly detection system based on hybrid pso-kmeans algorithm in content-centric networks. Neurocomputing 2015, 149, 1253–1269. [Google Scholar] [CrossRef]
- Aburomman, A.A.; Reaz, M.B.I. A novel SVM-kNN-PSO ensemble method for intrusion detection system. Appl. Soft Comput. 2016, 38, 360–372. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), New York, NY, USA, 3–5 December 2015; pp. 21–26.
- Kang, M.J.; Kang, J.W. Intrusion Detection System Using Deep Neural Network for In-Vehicle Network Security. PLoS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Fiore, U.; Palmieri, F.; Castiglione, A.; De Santis, A. Network anomaly detection with the restricted Boltzmann machine. Neurocomputing 2013, 122, 13–23. [Google Scholar] [CrossRef]
- Salama, M.A.; Eid, H.F.; Ramadan, R.A.; Darwish, A.; Hassanien, A.E. Hybrid intelligent intrusion detection scheme. In Soft Computing in Industrial Applications; Springer: Berlin, Germany, 2011; pp. 293–303. [Google Scholar]
- Manikopoulos, C.; Papavassiliou, S. Network intrusion and fault detection: A statistical anomaly approach. IEEE Commun. Mag. 2002, 40, 76–82. [Google Scholar] [CrossRef]
- Qiu, M.; Gao, W.; Chen, M.; Niu, J.W.; Zhang, L. Energy efficient security algorithm for power grid wide area monitoring system. IEEE Trans. Smart Grid 2011, 2, 715–723. [Google Scholar] [CrossRef]
- Roman, R.; Zhou, J.; Lopez, J. Applying intrusion detection systems to wireless sensor networks. In Proceedings of the IEEE Consumer Communications & Networking Conference (CCNC 2006), Las Vegas, NV, USA, 8–10 January 2006.
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 31st IEEE Symposium on Security and Privacy, S&P 2010, Oakland, CA, USA, 16–19 May 2010; pp. 305–316.
- Zhang, Y.; Lee, W.; Huang, Y.A. Intrusion detection techniques for mobile wireless networks. Wirel. Netw. 2003, 9, 545–556. [Google Scholar] [CrossRef]
- Lin, W.C.; Ke, S.W.; Tsai, C.F. CANN: An intrusion detection system based on combining cluster centers and nearest neighbors. Knowl. Based Syst. 2015, 78, 13–21. [Google Scholar] [CrossRef]
- Grover, A.; Kapoor, A.; Horvitz, E. A Deep Hybrid Model for Weather Forecasting. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 379–386.
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the Second IEEE Symposium on Computational Intelligence for Security and Defence Applications, Ottawa, ON, Canada, 8–10 July 2009.
- Chilimbi, T.; Suzue, Y.; Apacible, J.; Kalyanaraman, K. Project adam: Building an efficient and scalable deep learning training system. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 571–582.
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338.
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 30–42. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2002, 2, 849–856. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. In Web-Age Information Management; Springer: Berlin, Germany, 2014; pp. 298–310. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS’10), Sardinia, Italy, 13–15 May 2010; pp. 249–256.
- Hinton, G.E.; Zemel, R.S. Autoencoders, minimum description length, and Helmholtz free energy. In Proceedings of the 6th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; pp. 3–10.
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Ng, A. Sparse Autoencoder; CS294A Lecture notes; Stanford University: Stanford, CA, USA, 2011; Volume 72, pp. 1–19. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Hinton, G.E. Connectionist learning procedures. Artif. Intell. 1989, 40, 185–234. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103.
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Palm, R.B. Prediction as a Candidate for Learning Deep Hierarchical Models of Data. Master’s Thesis, Technical University of Denmark, Lyngby, Denmark, 2012. [Google Scholar]
- Kayacik, H.G.; Zincir-Heywood, A.N.; Heywood, M.I. A hierarchical SOM-based intrusion detection system. Eng. Appl. Artif. Intell. 2007, 20, 439–451. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.X.; Ma, J.A.; Huang, L.H. A new approach to intrusion detection using Artificial Neural Networks and fuzzy clustering. Expert Syst. Appl. 2010, 37, 6225–6232. [Google Scholar] [CrossRef]
- Yi, Y.; Wu, J.; Xu, W. Incremental SVM based on reserved set for network intrusion detection. Expert Syst. Appl. 2011, 38, 7698–7707. [Google Scholar] [CrossRef]
- Koc, L.; Mazzuchi, T.A.; Sarkani, S. A network intrusion detection system based on a Hidden Naive Bayes multiclass classifier. Expert Syst. Appl. 2012, 39, 13492–13500. [Google Scholar] [CrossRef]
- Costa, K.A.; Pereira, L.A.; Nakamura, R.Y.; Pereira, C.R.; Papa, J.P.; Falcão, A.X. A nature-inspired approach to speed up optimum-path forest clustering and its application to intrusion detection in computer networks. Inf. Sci. 2015, 294, 95–108. [Google Scholar] [CrossRef]
- Japkowicz, N.; Shah, M. Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Kurosawa, S.; Nakayama, H.; Kato, N.; Jamalipour, A.; Nemoto, Y. Detecting Blackhole Attack on AODV-based Mobile Ad Hoc Networks by Dynamic Learning Method. Int. J. Netw. Sec. 2007, 5, 338–346. [Google Scholar]
- Huang, Y.A.; Lee, W. Attack analysis and detection for ad hoc routing protocols. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin, Germany, 2004; pp. 125–145. [Google Scholar]
- Maxion, R.A.; Roberts, R.R. Proper Use of ROC Curves in Intrusion/Anomaly Detection; University of Newcastle upon Tyne, Computing Science: Tyne, UK, 2004. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, R.J.; Zhou, Y.C. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Luxburg, U.V. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training Dataset | Testing Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Normal% | DoS% | Probe% | U2R% | R2L% | Normal% | DoS% | Probe% | U2R% | R2L% | |
| Dataset 1 | 17.96 | 72.28 | 7.583 | 0.096 | 2.079 | 19.48 | 73.90 | 1.339 | 0.073 | 5.205 |
| Dataset 2 | 19.48 | 78.40 | 1.645 | 0.021 | 0.451 | 19.48 | 73.90 | 1.339 | 0.073 | 5.205 |
| Dataset 3 | 19.69 | 79.23 | 0.831 | 0.011 | 0.228 | 19.48 | 73.90 | 1.339 | 0.073 | 5.205 |
| Dataset 4 | 53.38 | 36.65 | 9.086 | 0.044 | 0.860 | 43.07 | 33.08 | 10.73 | 0.887 | 12.21 |
| Dataset 5 | 48.56 | 33.11 | 16.81 | 0.075 | 1.435 | 43.07 | 33.08 | 10.73 | 0.887 | 12.21 |
| Dataset 6 | 53.38 | 36.65 | 9.086 | 0.044 | 0.830 | 18.16 | 36.64 | 20.27 | 1.688 | 23.24 |
| Dataset | k | σ | Nor (%) | DoS (%) | Probe (%) | U2R (%) | R2L (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| Dataset 1 | k = 2 | 0.5 | 97.21 | 96.87 | 80.32 | 11.4 | 6.88 | 91.97 |
| Dataset 2 | k = 4 | 0.4 | 98.42 | 97.2 | 70.64 | 3.51 | 1.57 | 92.03 |
| Dataset 3 | k = 5 | 0.5 | 97.61 | 97.23 | 65.96 | 4.39 | 6.59 | 92.1 |
| Dataset 4 | k = 3 | 0.4 | 96.17 | 75.84 | 53.37 | 3.00 | 3.01 | 72.64 |
| Dataset 5 | k = 3 | 0.4 | 97.19 | 74.51 | 48.37 | 5.00 | 0.62 | 71.83 |
| Dataset 6 | k = 5 | 0.5 | 84.20 | 50.02 | 52.66 | 1.50 | 0.98 | 44.55 |
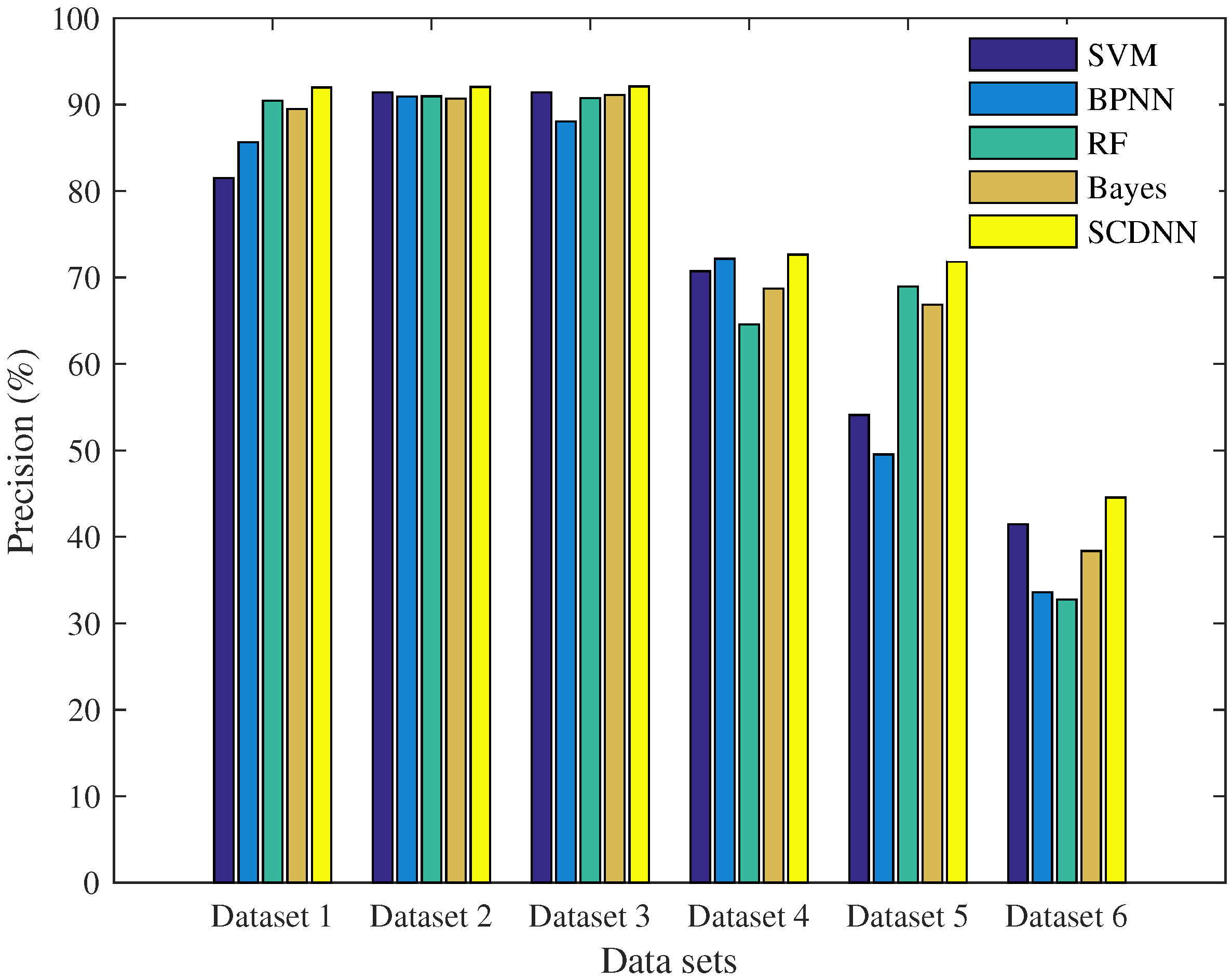
| Dataset | Model | Normal | DoS | Probe | U2R | R2L | Acc | Recall | ER |
|---|---|---|---|---|---|---|---|---|---|
| Dataset 1 | SVM | 98.21 | 83 | 66.01 | 0.88 | 3.14 | 81.52 | 77.72 | 18.48 |
| BP | 96.51 | 89.49 | 46.18 | 9.21 | 1.93 | 85.66 | 83.48 | 14.34 | |
| RF | 93.65 | 96.62 | 59.27 | 0 | 0 | 90.44 | 91.08 | 9.56 | |
| Bayes | 91.51 | 95.59 | 61.35 | 4.39 | 3.56 | 89.48 | 92.57 | 10.52 | |
| SCDNN | 97.21 | 96.87 | 80.32 | 11.4 | 6.88 | 91.97 | 91.68 | 8.03 | |
| Dataset 2 | SVM | 96.22 | 97.1 | 65.84 | 0 | 0.05 | 91.39 | 90.52 | 8.61 |
| BP | 91.44 | 97.42 | 62.69 | 7.02 | 5.41 | 90.93 | 92.88 | 9.07 | |
| RF | 98.23 | 96.48 | 38.26 | 0 | 0 | 90.95 | 89.51 | 9.05 | |
| Bayes | 95.92 | 95.98 | 62.55 | 4.82 | 4.38 | 90.69 | 91.07 | 9.31 | |
| SCDNN | 98.42 | 97.2 | 70.64 | 3.51 | 1.57 | 92.03 | 91.35 | 7.97 | |
| Dataset 3 | SVM | 95.87 | 97.23 | 64.86 | 0 | 0.06 | 91.41 | 90.59 | 8.59 |
| BP | 81.53 | 96.95 | 8.81 | 6.14 | 7.26 | 88.03 | 90.05 | 11.97 | |
| RF | 99.57 | 96.57 | 0 | 0 | 0 | 90.76 | 89.37 | 9.24 | |
| Bayes | 96.38 | 96.29 | 59.15 | 7.02 | 7.46 | 91.12 | 90.95 | 8.88 | |
| SCDNN | 97.61 | 97.23 | 65.96 | 4.39 | 6.59 | 92.1 | 92.23 | 7.9 | |
| Dataset 4 | SVM | 95.54 | 70.18 | 57.37 | 0 | 1.63 | 70.73 | 53.26 | 29.27 |
| BP | 96.35 | 71.17 | 65.55 | 0 | 0.58 | 72.16 | 57.79 | 27.84 | |
| RF | 99.63 | 63.11 | 7.23 | 0 | 0 | 64.57 | 40.45 | 35.43 | |
| Bayes | 93.9 | 72.18 | 41.02 | 0 | 0 | 68.73 | 52.78 | 31.27 | |
| SCDNN | 96.17 | 75.84 | 53.37 | 3 | 3.01 | 72.64 | 57.48 | 27.36 | |
| Dataset 5 | SVM | 98.57 | 18.93 | 49.89 | 0 | 0.11 | 54.1 | 20.45 | 45.9 |
| BP | 91.79 | 7.63 | 66.58 | 1.5 | 2.43 | 49.53 | 27.56 | 50.47 | |
| RF | 99.69 | 62.64 | 48.99 | 0 | 0 | 68.93 | 46.43 | 31.07 | |
| Bayes | 99.06 | 61.65 | 35.4 | 0 | 0 | 66.87 | 44.28 | 33.13 | |
| SCDNN | 97.19 | 74.51 | 48.37 | 5 | 0.62 | 71.83 | 55.08 | 28.17 | |
| Dataset 6 | SVM | 95.81 | 41.5 | 43.67 | 0 | 0 | 41.46 | 30.6 | 58.54 |
| BP | 74.72 | 4.61 | 88.67 | 0 | 1.53 | 33.59 | 30.6 | 66.41 | |
| RF | 99.72 | 36.15 | 6.74 | 0 | 0 | 32.73 | 18.9 | 67.27 | |
| Bayes | 82.16 | 48.25 | 28.52 | 0 | 0 | 38.37 | 30.08 | 61.63 | |
| SCDNN | 84.2 | 50.02 | 52.66 | 1.5 | 0.98 | 44.55 | 37.85 | 55.45 |
| Attack Name | Attack Description | Attack Type |
|---|---|---|
| Active Reply | The route reply is forged with abnormal support to reply. | 1 |
| Route drop | The routing packets are dropped with some specific address. | 2 |
| Modify Sequence | The number of target sequences increases with largest maximal values. | 3 |
| Rushing | Rushing of routing messages. | 4 |
| Data Interruption | A data packet is used to drop the route. | 5 |
| Route Modification | The route is modified in Routing Table Entries. | 6 |
| Change Hop | The route cost in routing tables entries is altered. | 7 |
| Dataset | Parameter | Sensor Nodes | ||||
|---|---|---|---|---|---|---|
| 10 Nodes | 20 Nodes | 30 Nodes | 40 Nodes | 50 Nodes | ||
| 5% Attacker in Networks | 96.8 | 96.4 | 95.8 | 94.5 | 94.6 | |
| 93.1 | 93.5 | 92.4 | 89.3 | 88.7 | ||
| 89.6 | 89.2 | 86.5 | 82.4 | 83.3 | ||
| 10% Attacker in Networks | 96.8 | 96.4 | 95.8 | 94.5 | 94.6 | |
| 93.1 | 93.5 | 92.4 | 89.3 | 88.7 | ||
| 89.6 | 89.2 | 86.5 | 82.4 | 83.3 | ||
| Dataset | SVM | BP | RF | Bayes | SCDNN |
|---|---|---|---|---|---|
| Dataset 1 | 0.88 | 0.82 | 0.94 | 0.93 | 0.95 |
| Dataset 2 | 0.95 | 0.78 | 0.94 | 0.94 | 0.95 |
| Dataset 3 | 0.95 | 0.88 | 0.94 | 0.94 | 0.95 |
| Dataset 4 | 0.82 | 0.72 | 0.78 | 0.80 | 0.83 |
| Dataset 5 | 0.71 | 0.61 | 0.80 | 0.79 | 0.82 |
| Dataset 6 | 0.61 | 0.56 | 0.58 | 0.61 | 0.65 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Wang, F.; Cheng, J.; Yu, Y.; Chen, X. A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks. Sensors 2016, 16, 1701. https://doi.org/10.3390/s16101701
Ma T, Wang F, Cheng J, Yu Y, Chen X. A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks. Sensors. 2016; 16(10):1701. https://doi.org/10.3390/s16101701
Chicago/Turabian StyleMa, Tao, Fen Wang, Jianjun Cheng, Yang Yu, and Xiaoyun Chen. 2016. "A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks" Sensors 16, no. 10: 1701. https://doi.org/10.3390/s16101701
APA StyleMa, T., Wang, F., Cheng, J., Yu, Y., & Chen, X. (2016). A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks. Sensors, 16(10), 1701. https://doi.org/10.3390/s16101701