
Node Self-Deployment Algorithm Based on an Uneven Cluster with Radius Adjusting for Underwater Sensor Networks

Abstract
:1. Introduction and Related Works
2. Models and Definitions
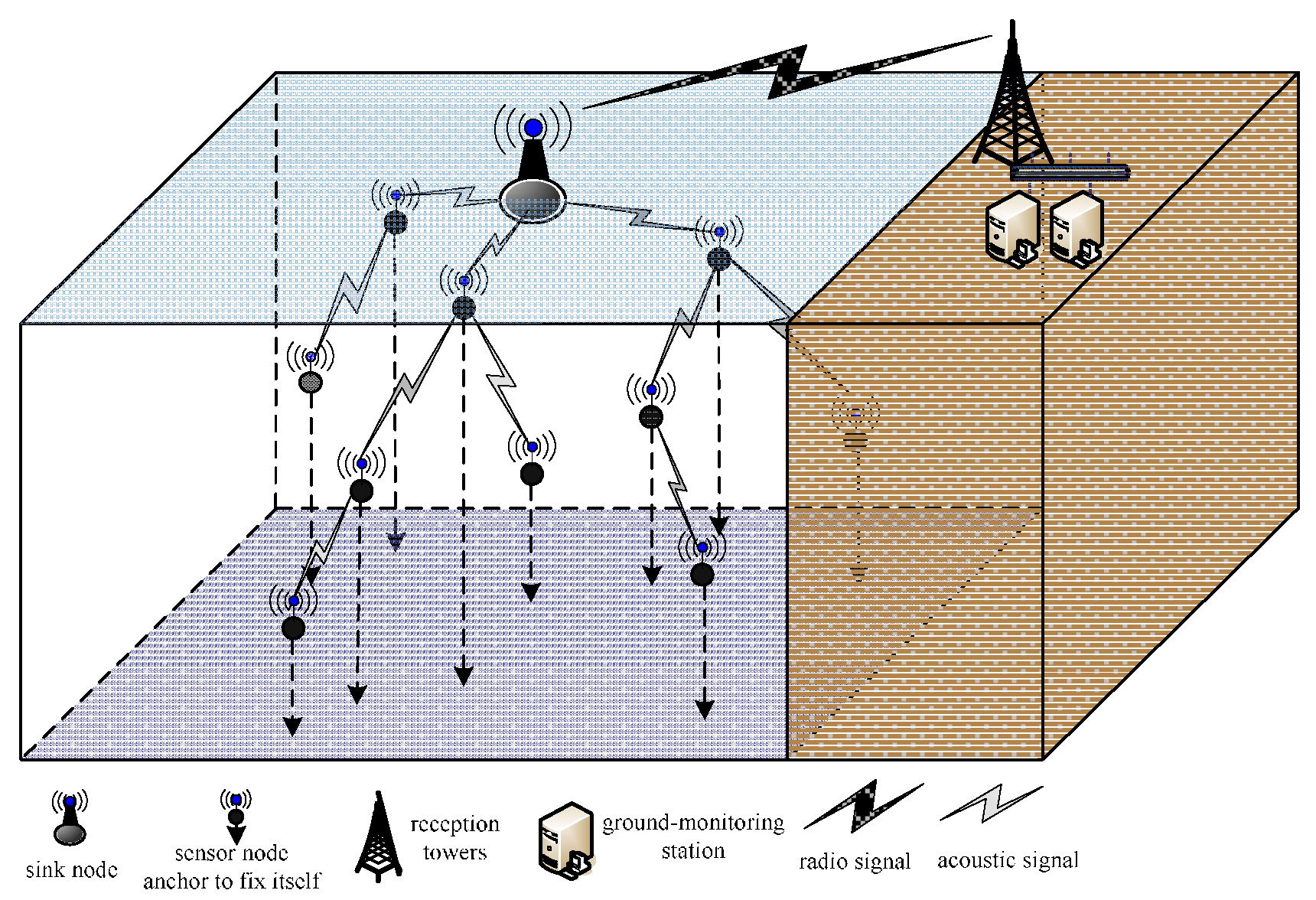
2.1. Network Model

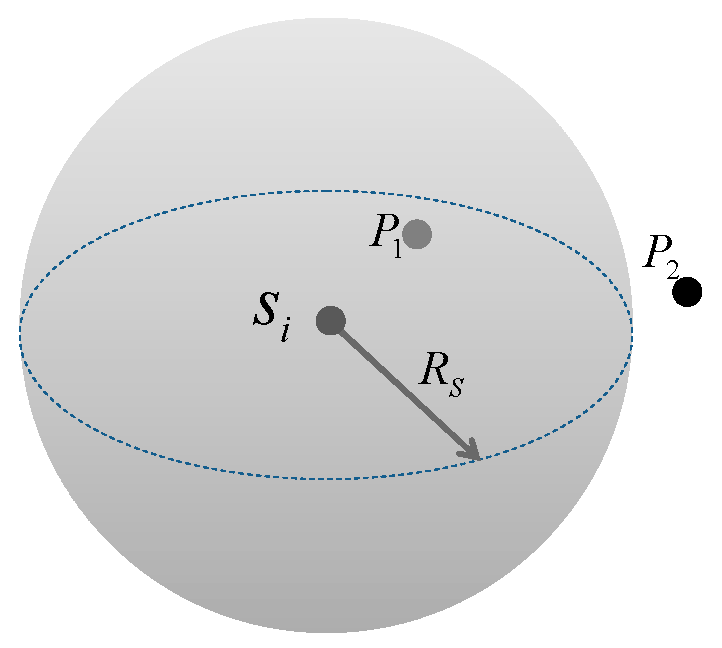
- The Boolean perception model is adopted to describe the node sensing. If the sensing radius of the node si is Rs, the space sensed by the node is a sphere whose center is the node location and Rs as the radius. An example is shown in Figure 2. The sphere with radius Rs is the sensed space of si. P1 is within the sphere and can be covered by si. On the contrary, P2 is beyond the sphere and cannot be covered by si.
- All nodes are isomorphic before deployment, but can adjust their transmission power by themselves, i.e., the communication radius Rc of the node can be adjusted with an adjusting precision of 1 m, but not more than the maximum communication radius Rc_Max determined by the physical device. The communication radius of a node will be changed by the distance to its next-hop node, i.e., the communication radius of a node is the rounded-down value of the distance between them when its next-hop node is determined.
- The network has only one sink node. Its position is fixed at the center of the water, and the transmission power and energy can be infinite.
- A node knows its own position and can determine the distance to the source according to the strength of the received signal.
2.2. Node Energy Consumption Model
2.3. Coverage Redundancy Rate
2.4. Network Coverage Rate
2.5. Network Connectivity Rate
2.6. Network Reliability
3. Algorithm Description and Process
3.1. Problem Description
3.2. Algorithm Description
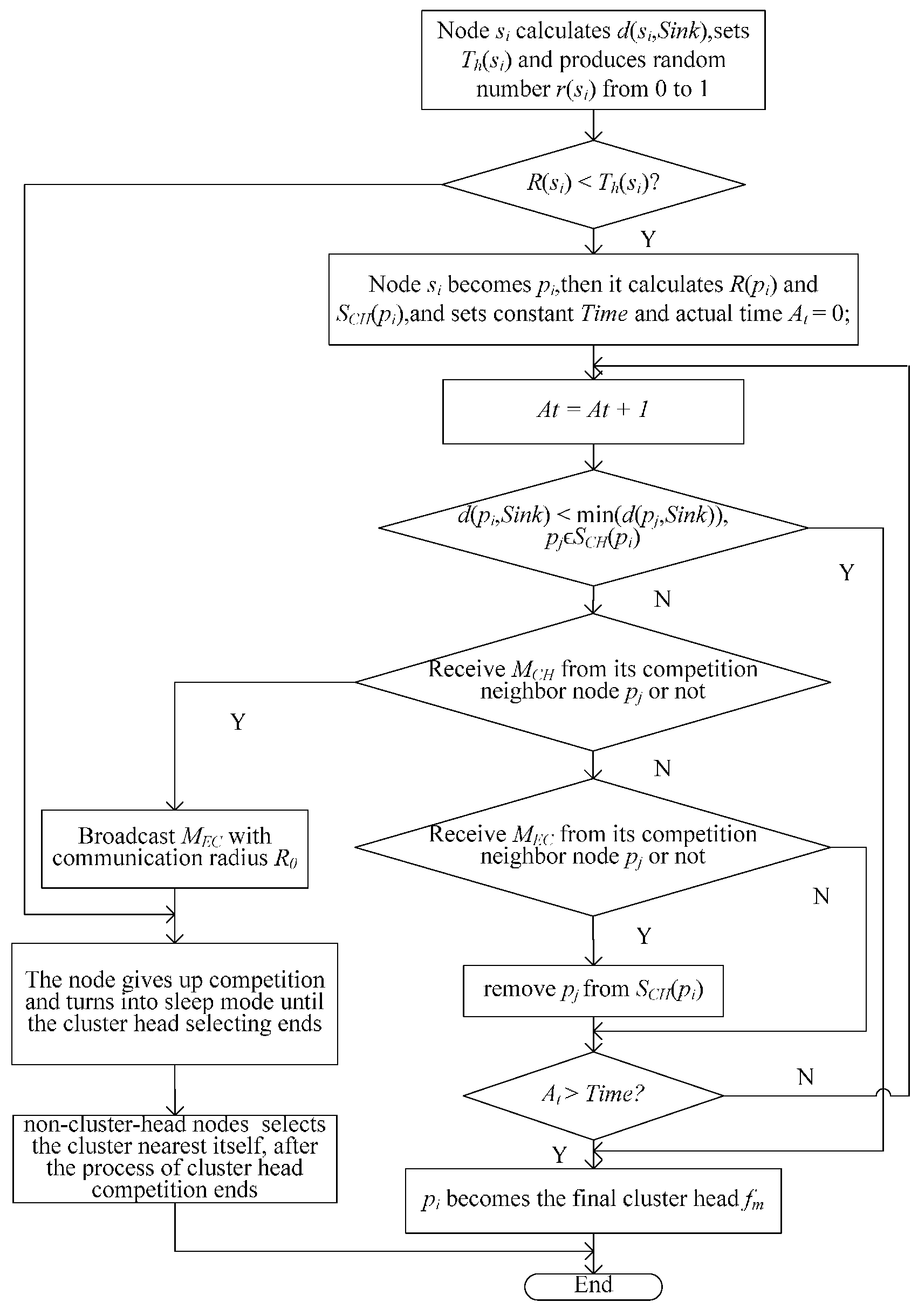
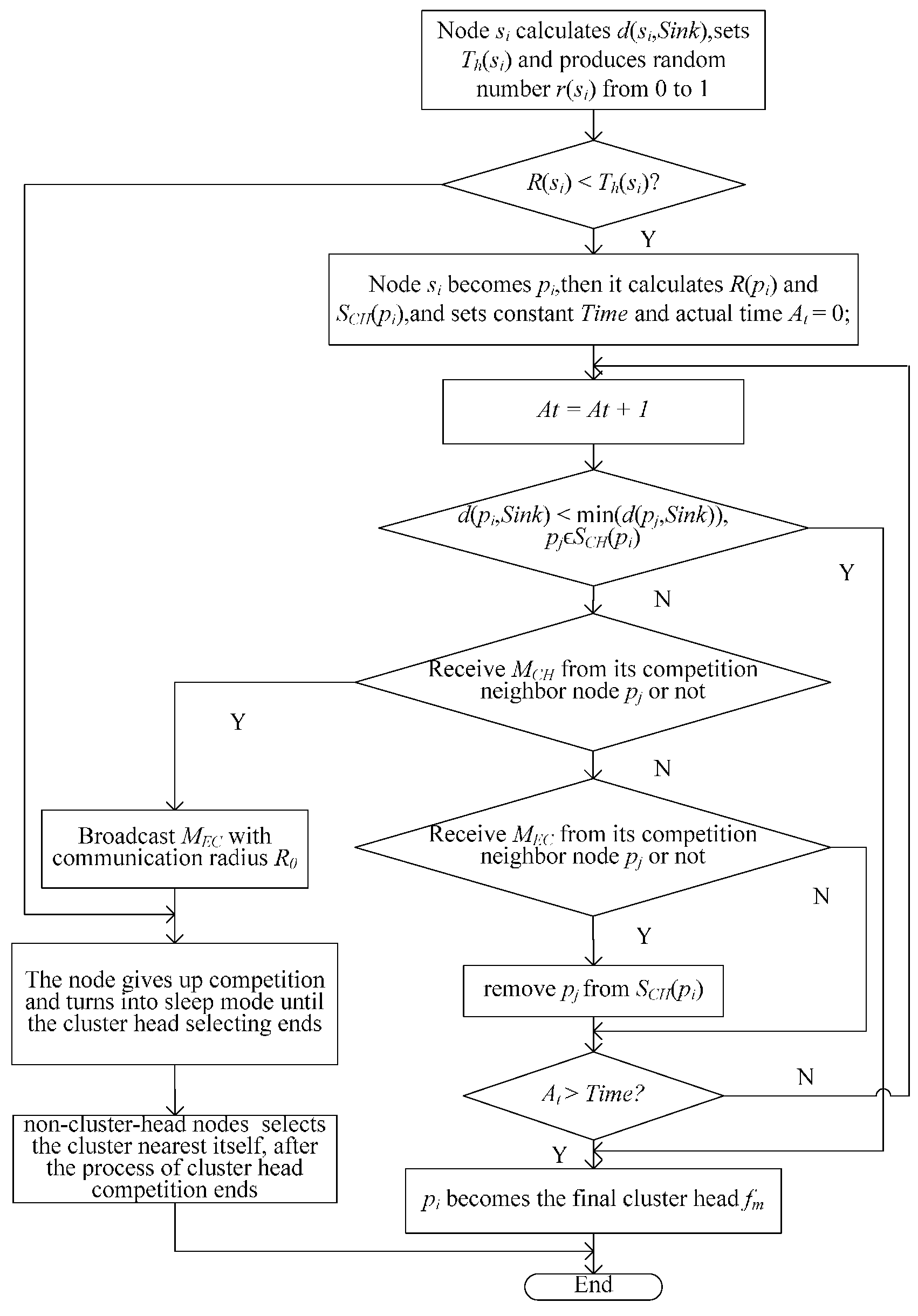
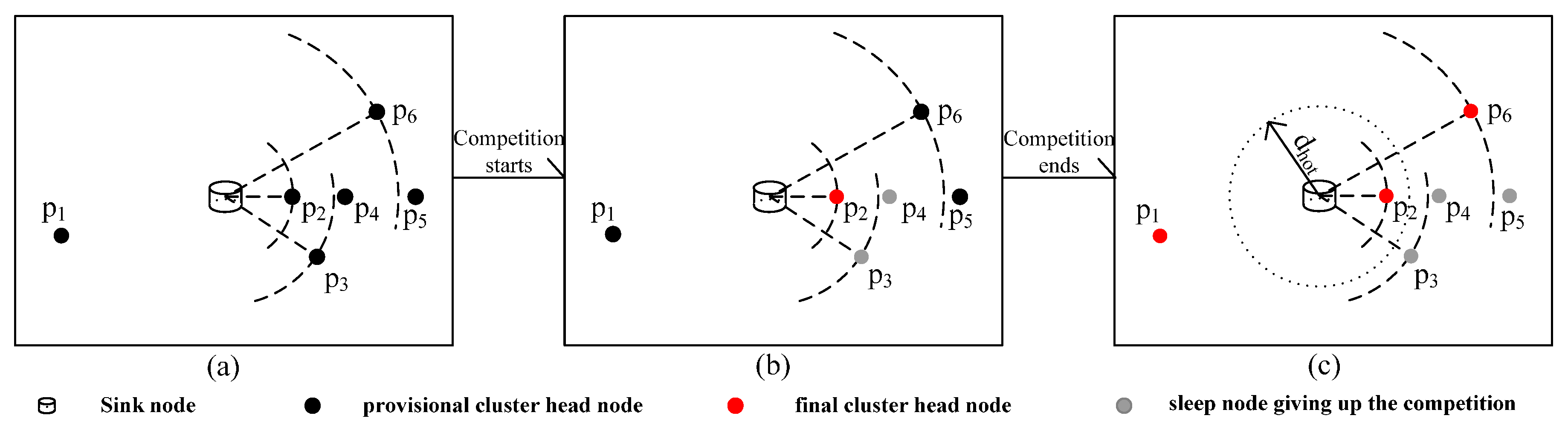
3.2.1. Uneven Clustering
- (1)
- d(pi,Sink) ≤ min(d(pj,Sink)), pj ϵ SCH(pi): pi becomes fm and broadcasts the “been cluster head” message MCH to notify its competition neighbor nodes with the communication radius of R0.
- (2)
- d(pi,Sink) > min(d(pj,Sink)), pj ϵ SCH(pi): pi waits for messages from its competition neighbor nodes and takes the following corresponding operation according to the messages it receives:
- ➢
- pi receives MCH broadcasted by one of its competition neighbor node pj, gives up the cluster head competition and broadcasts the “exit competition” message MGC. It then converts to sleep mode.
- ➢
- pi receives MGC broadcasted by one of its competition neighbor node pj, removes node pj from SCH(pi), then compares the distance to the sink node with its updating competition neighbor nodes and continues the preceding operations.
- ➢
- pi cannot receive any message in Time and becomes fm.
3.2.2. Constructing a Connected Path by the Hybrid Radius Path-Selection Method
- (1)
- fm selects the cluster head nodes in the forward direction (i.e., the direction close to the sink node) from the nodes in NCH(fm) by Equation (11). These nodes are denoted by the cluster head nodes of the forward direction of fm BCH(fm):
- (2)
- fm selects the k nodes nearest to itself from the nodes in BCH(fm) as the set of alternative next-hop nodes FCH(fm). If the number of the nodes in BCH(fm) is smaller than k, FCH(fm) = BCH(fm). If the node number is zero, Step (3) is performed; otherwise, Step (4) is performed.
- (3)
- fm selects k non-cluster head nodes whose cluster head nodes are not fm in the forward direction within its Rc_Max as the set of alternative next-hop nodes FCH(fm). This process guarantees that the communication radius of fm is greater than the communication radius of its next-hop node.
- (4)
- fm selects a node sj from the nodes in FCH(fm) by minimizing the sum of the distance to fm and the distance to the sink node as its next-hop node next(fm):
- (5)
- If next(fm) is a non-cluster head node, the node becomes a cluster head node and finds its next-hop node according to the preceding process. Otherwise, the entire process ends.
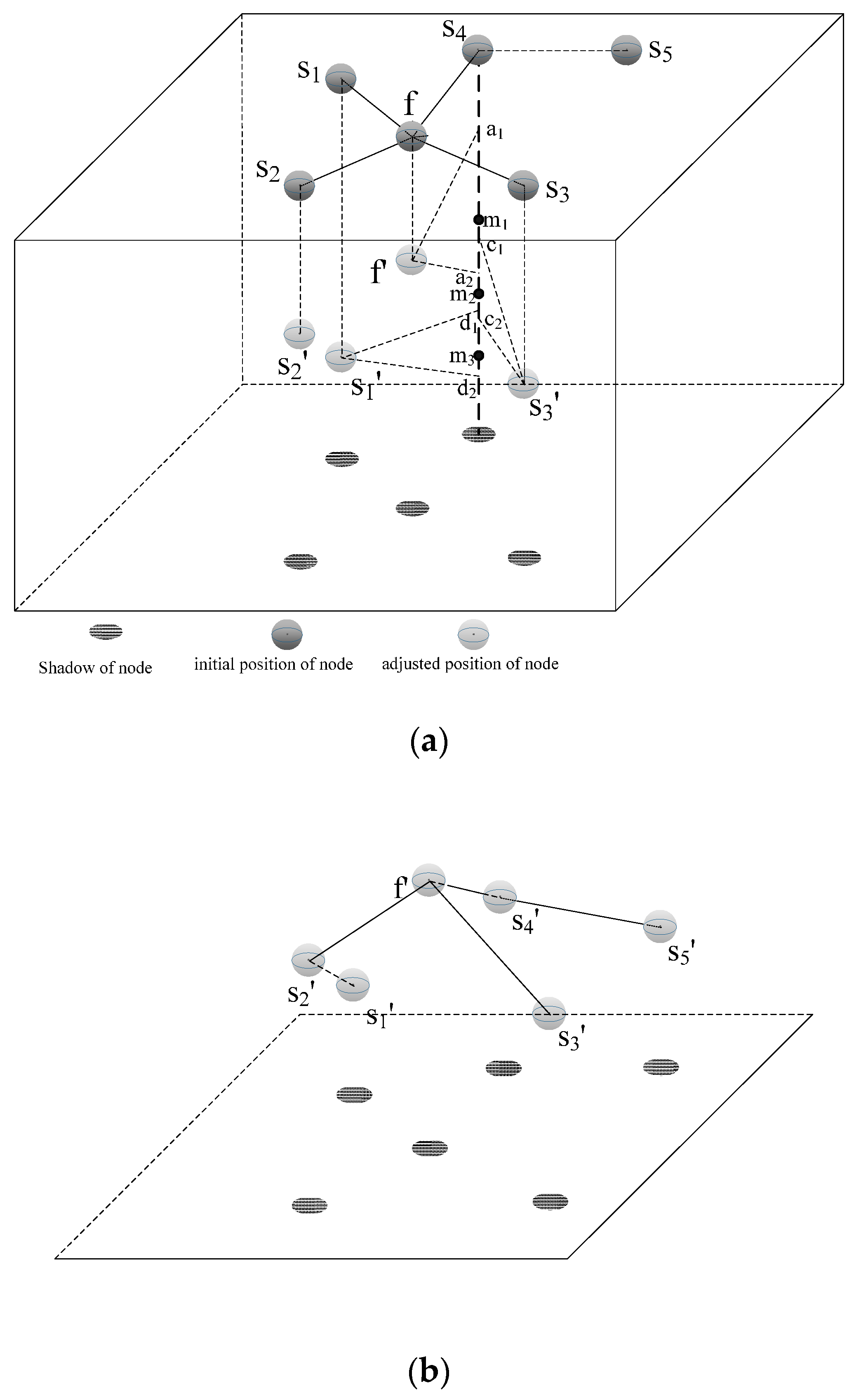
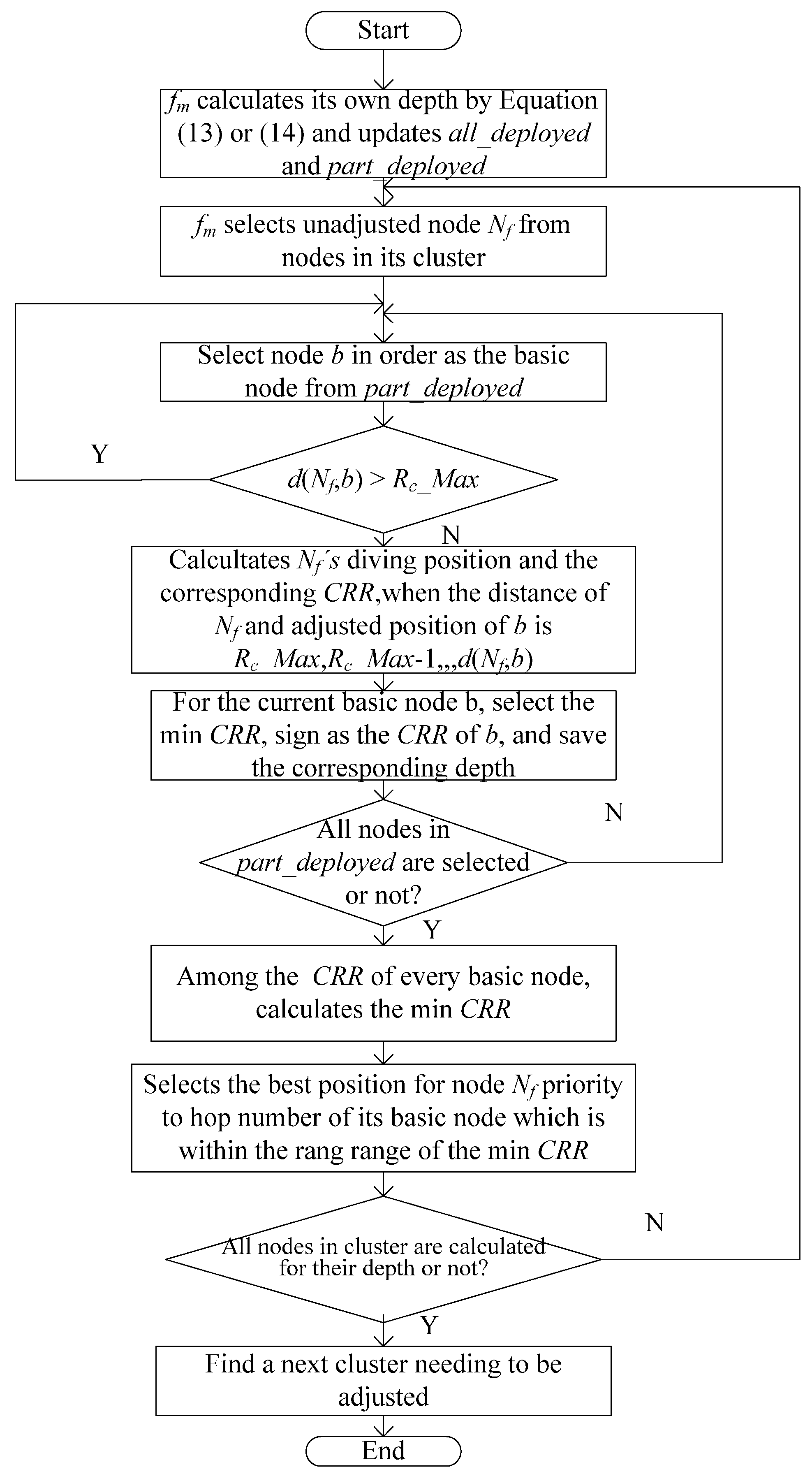
3.2.3. Cluster Head Node Calculating the Depth of Each Node in a Cluster
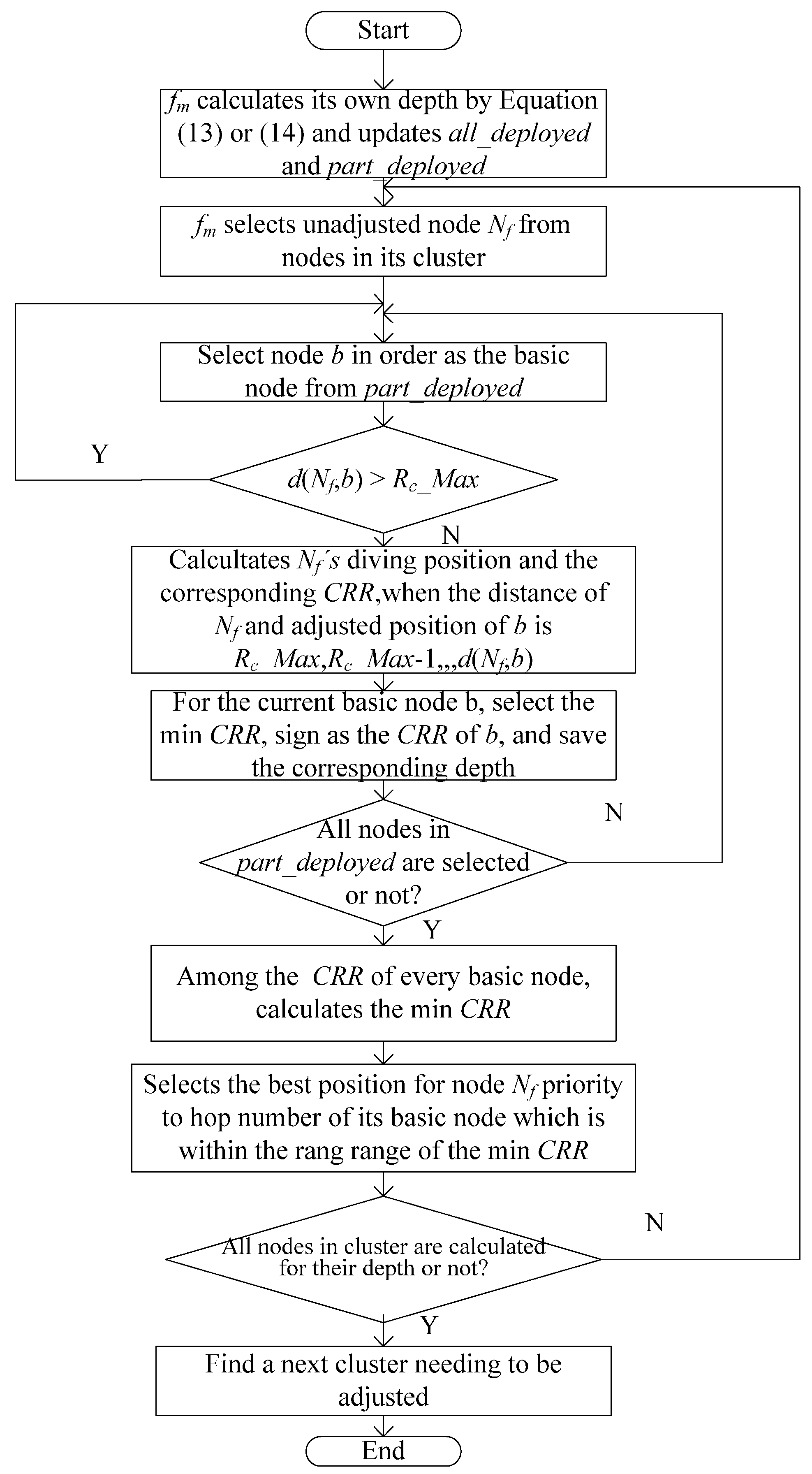
- (1)
- fm is a common node (having both the last-hop node and the next-hop node). If the communication radius of fm on the water surface RUA(fm) plus one is greater than the adjusted communication radius RA(fj) of its next-hop node fj, i.e., fm satisfies the feature of the uneven clustering after it adjusts its depth, fm regards its adjusted communication radius as RUA(fm) + 1 and calculates its diving depth; otherwise, fm regards the adjusted communication radius of its next-hop node RA(fj) plus one as its adjusted communication radius and calculates its diving depth. This process of calculating the diving depth of fm dep(fm) is formulated as follows:where RUA(fm) is the communication radius of fm before it adjusts its depth. In other words, RUA(fm) represents the distance between itself and its next-hop node on the water surface. RA(fm) is the communication radius of fm after it adjusts its depth. In other words, RA(fm) represents the distance between itself and its next-hop node after fm adjusts its depth.
- (2)
- If fm is a leaf node (having only next-hop nodes), it can reduce the CRR with its last-hop node by increasing its own depth. fm determines its depth dep(fm) by Equation (14) on the basis of whether it is the one-hop node of the sink node.

3.2.4. Finding a Next Cluster Needing to Adjust
4. Algorithm Analysis
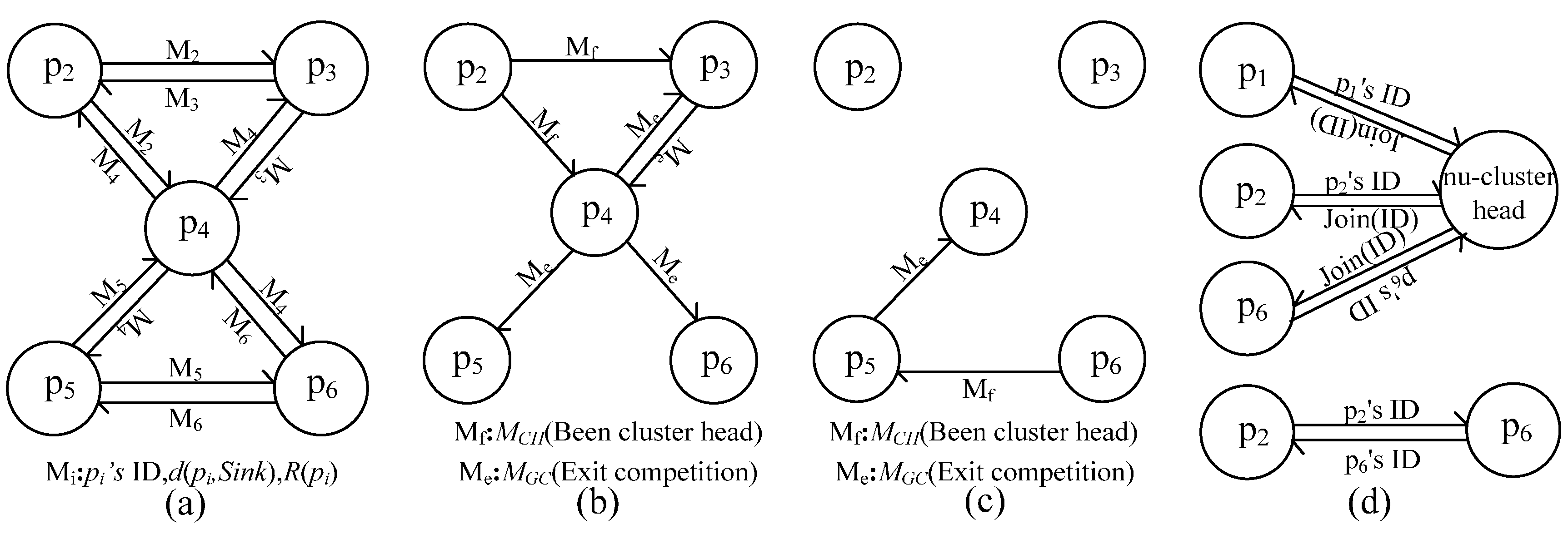
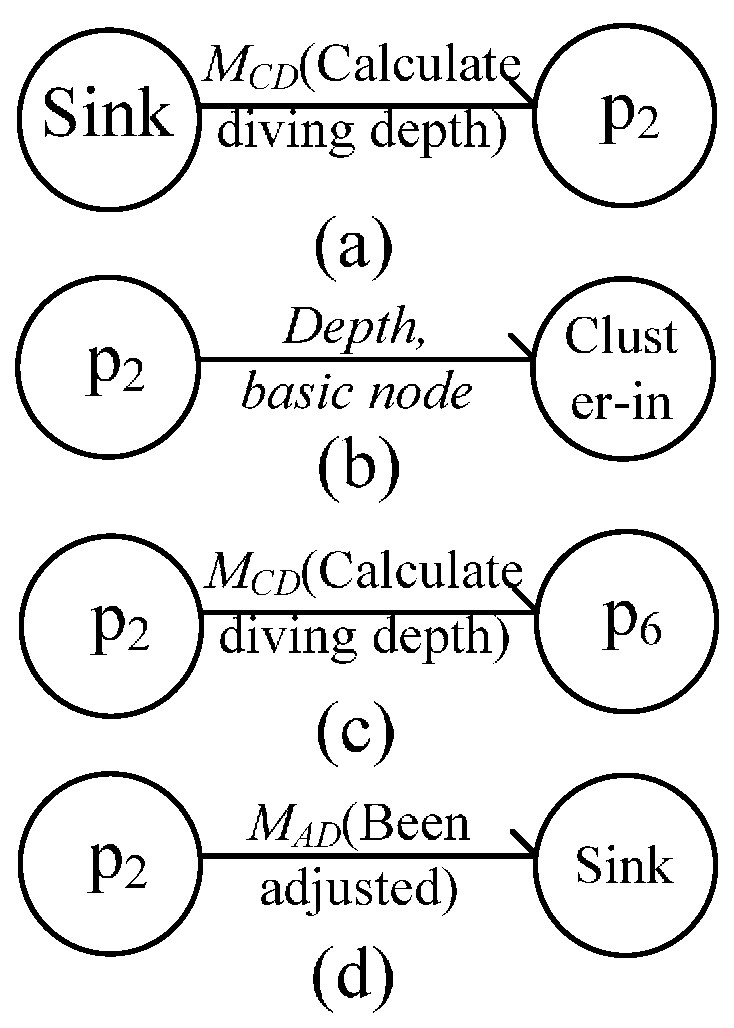
4.1. Message Flow between Nodes
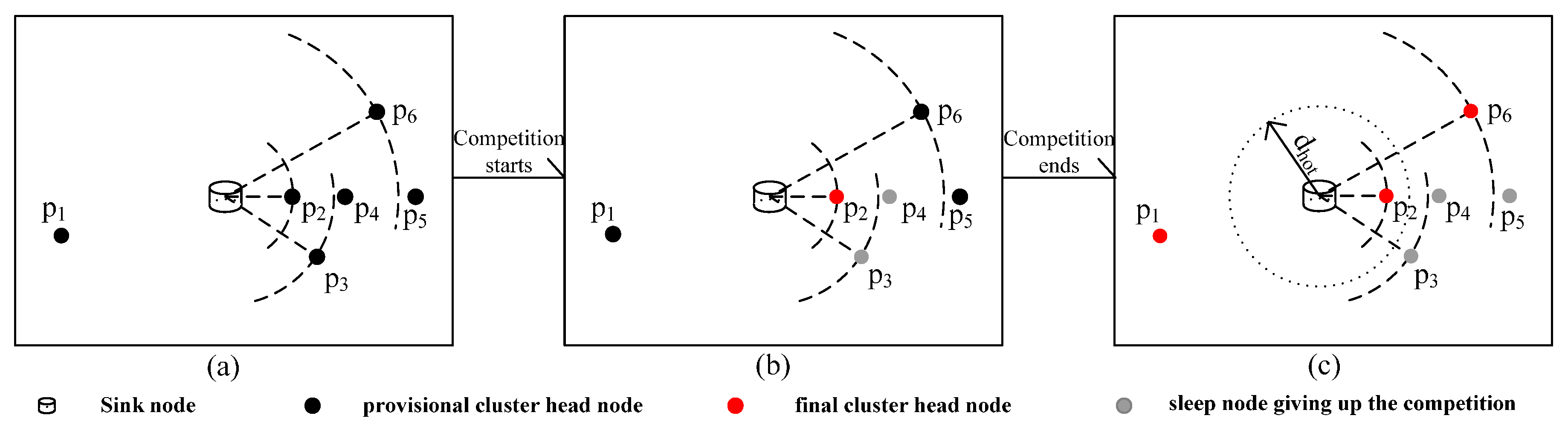
4.1.1. Message Flow during Uneven Clustering

4.1.2. Message Flow during Path Selection
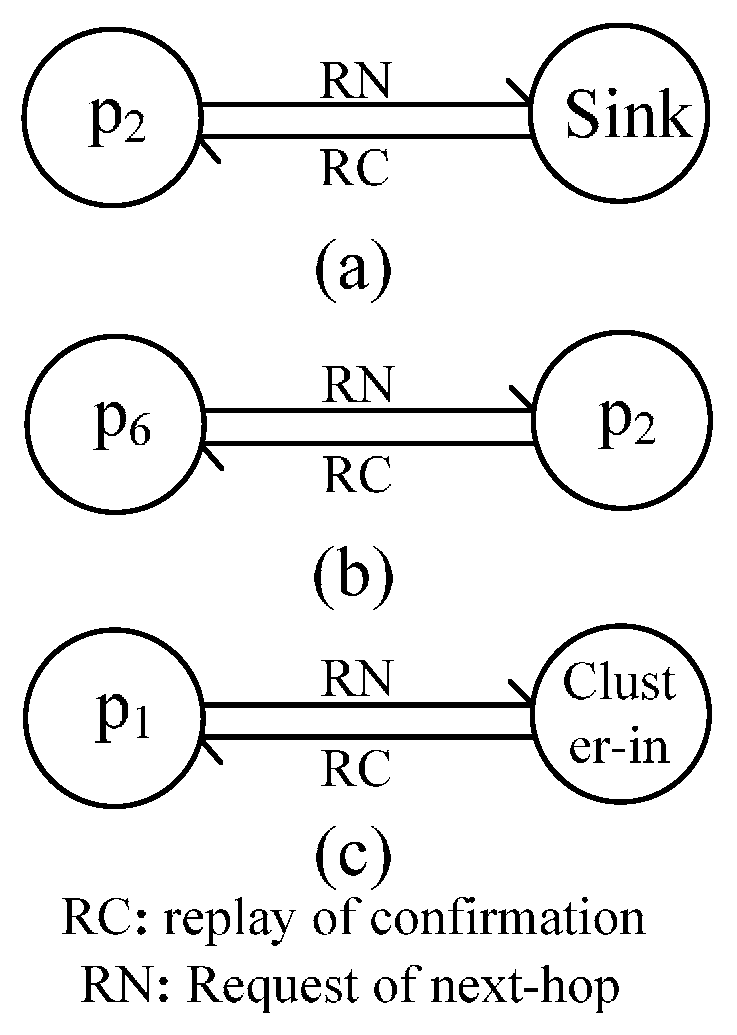
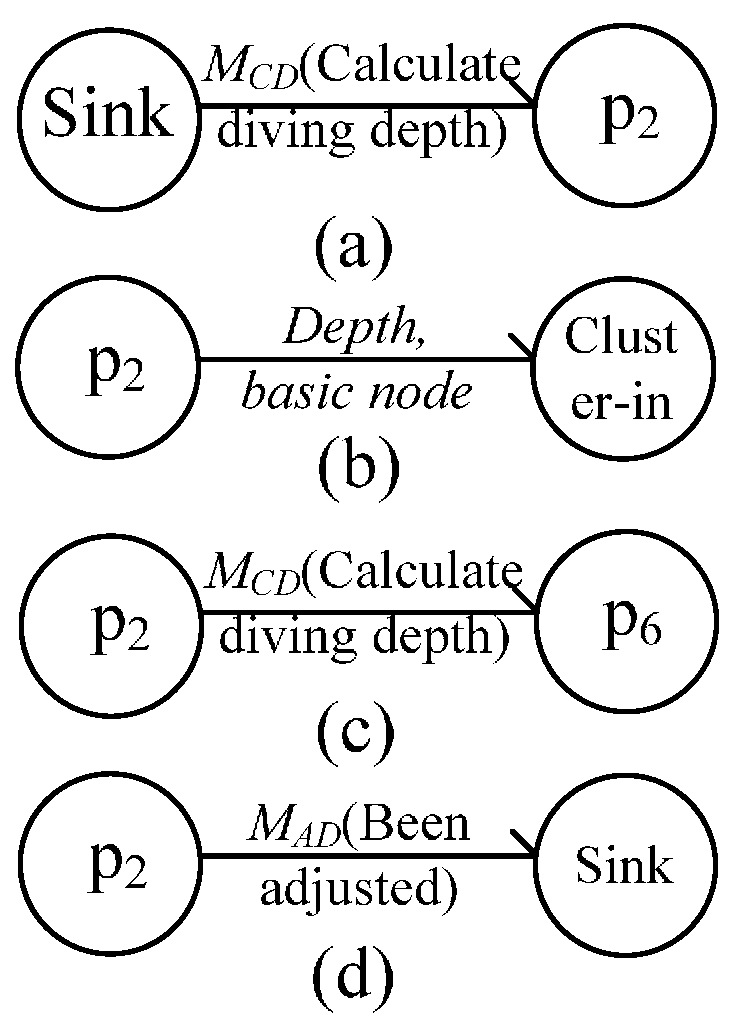
4.1.3. Message Flow during In-Cluster Node Position Adjustment
4.2. Complexity Analysis
4.2.1. Message Complexity
4.2.2. Time Complexity
5. Simulation and Performance Analysis
5.1. Simulation Scenario and Parameter Settings
- (1)
- The parameter settings are based on the CDA in [26], i.e., the sensing radius of nodes Rs is 40 m, and the communication radius of nodes Rc in CDA is 100 m. This study also considers the situation wherein the distance between two nodes is greater than 2Rs; thus, the maximum communication radius Rc_Max in URSA is also set to 100 m.
- (2)
- According to [38], a proportionality constant c influences the uneven clustering results, namely if the value of c is small, the cluster size is small, and the number of clusters is large. The purpose of the current study is to appropriately increase the number of clusters near the sink node; hence, c is set to 0.7.
- (3)
- According to the method of calculating the optimum radius of hotspots dhot in [39] and the parameter of the simulation scene set in the current study, dhot is set to 50 m.
- (4)
- Other parameters are presented in Table 1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Length of data packet l | 1000 bits |
| Energy consumption of data reception Pr | 2 nJ/bit |
| Energy diffusion factor λ | 1.5 |
| Carrier frequency Fr | 24 kHz |
| Data transmission speed underwater | 300 bits/s |
| Initial competition radius R0 | 80 m |
| Probability threshold parameter Th1, Th2, Th3 | 0.8, 0.6, 0.5 |
| Parameter k | 3 |
5.2. Simulation Example
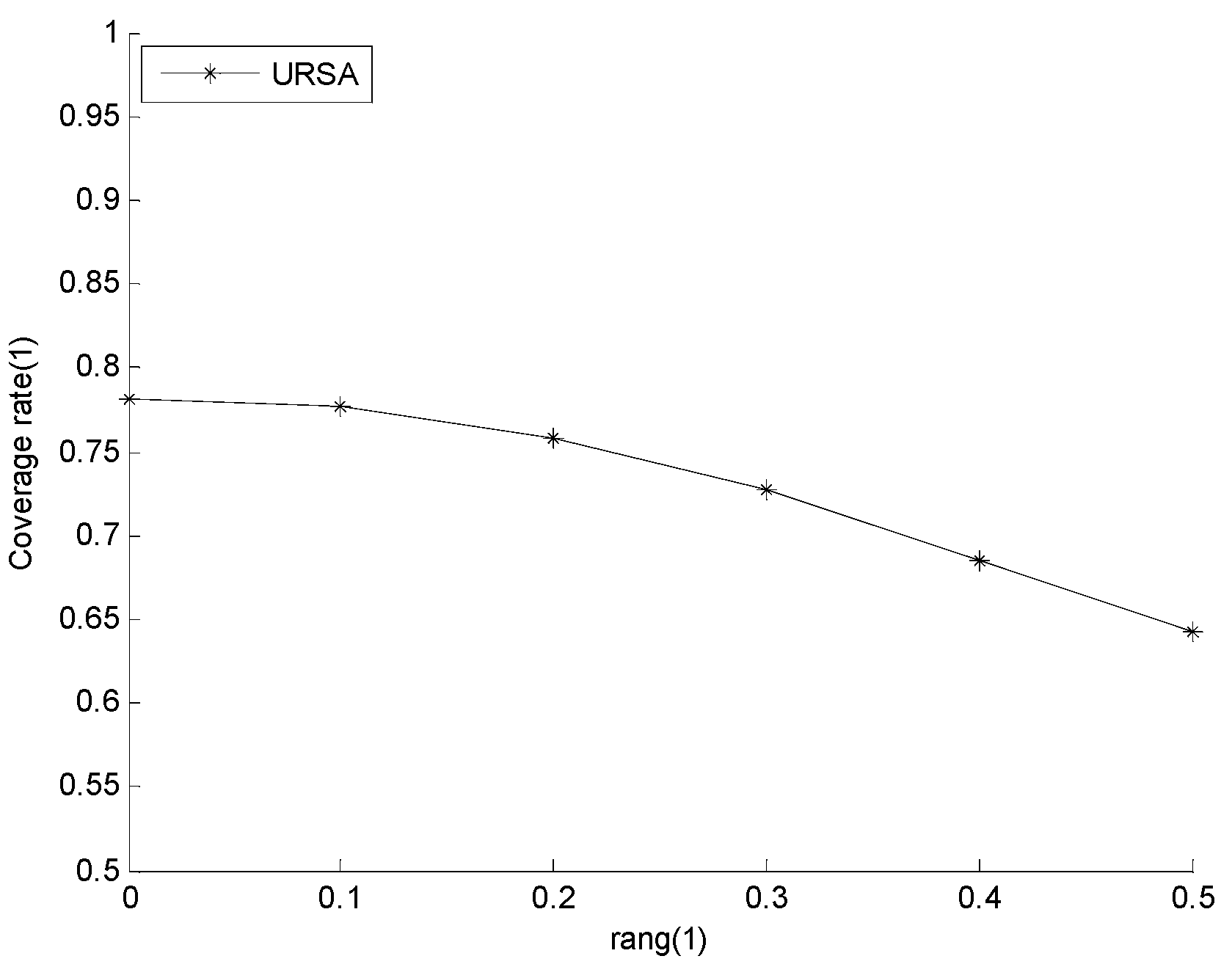
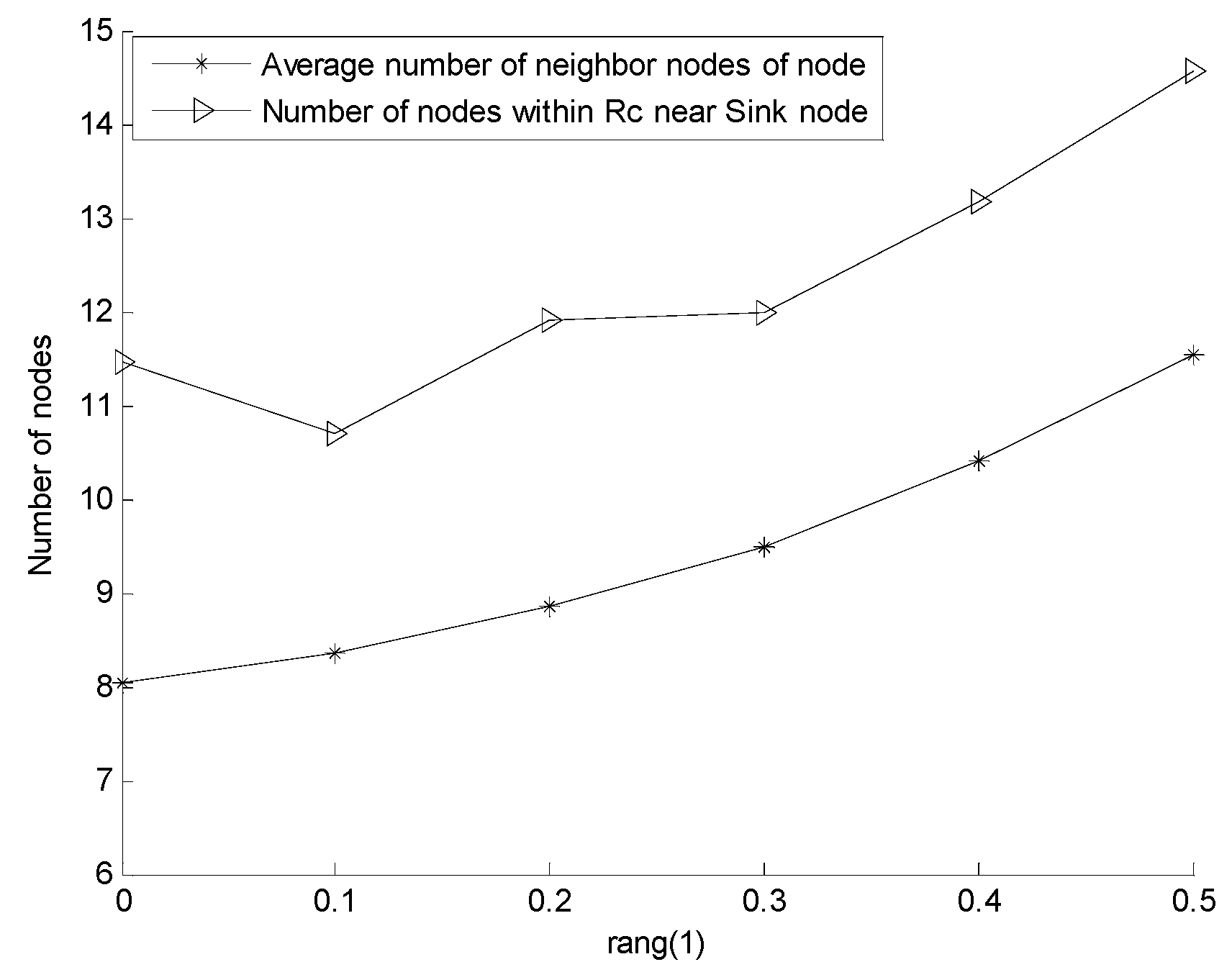
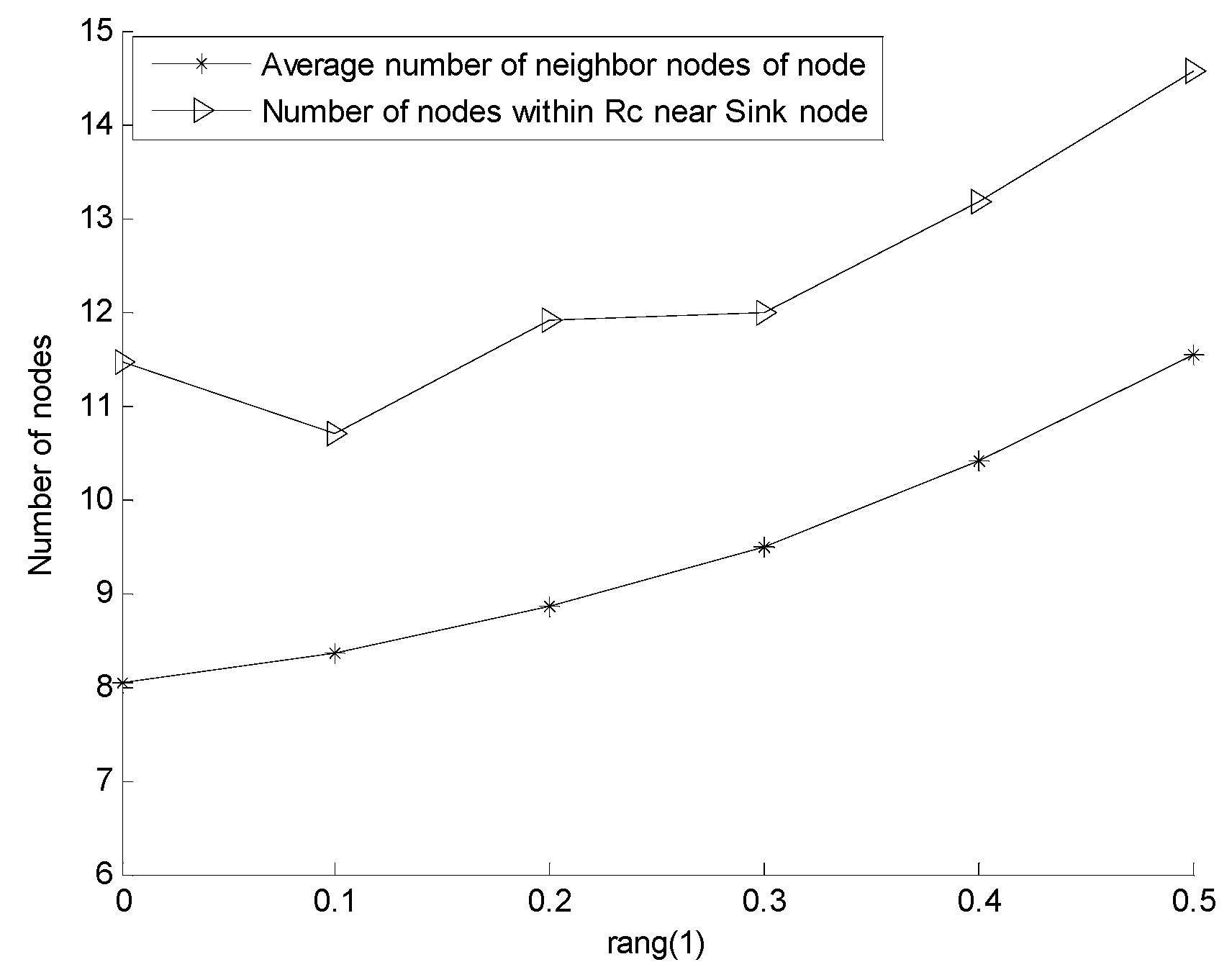
5.2.1. Effect of rang on Network Reliability and Network Coverage Rate

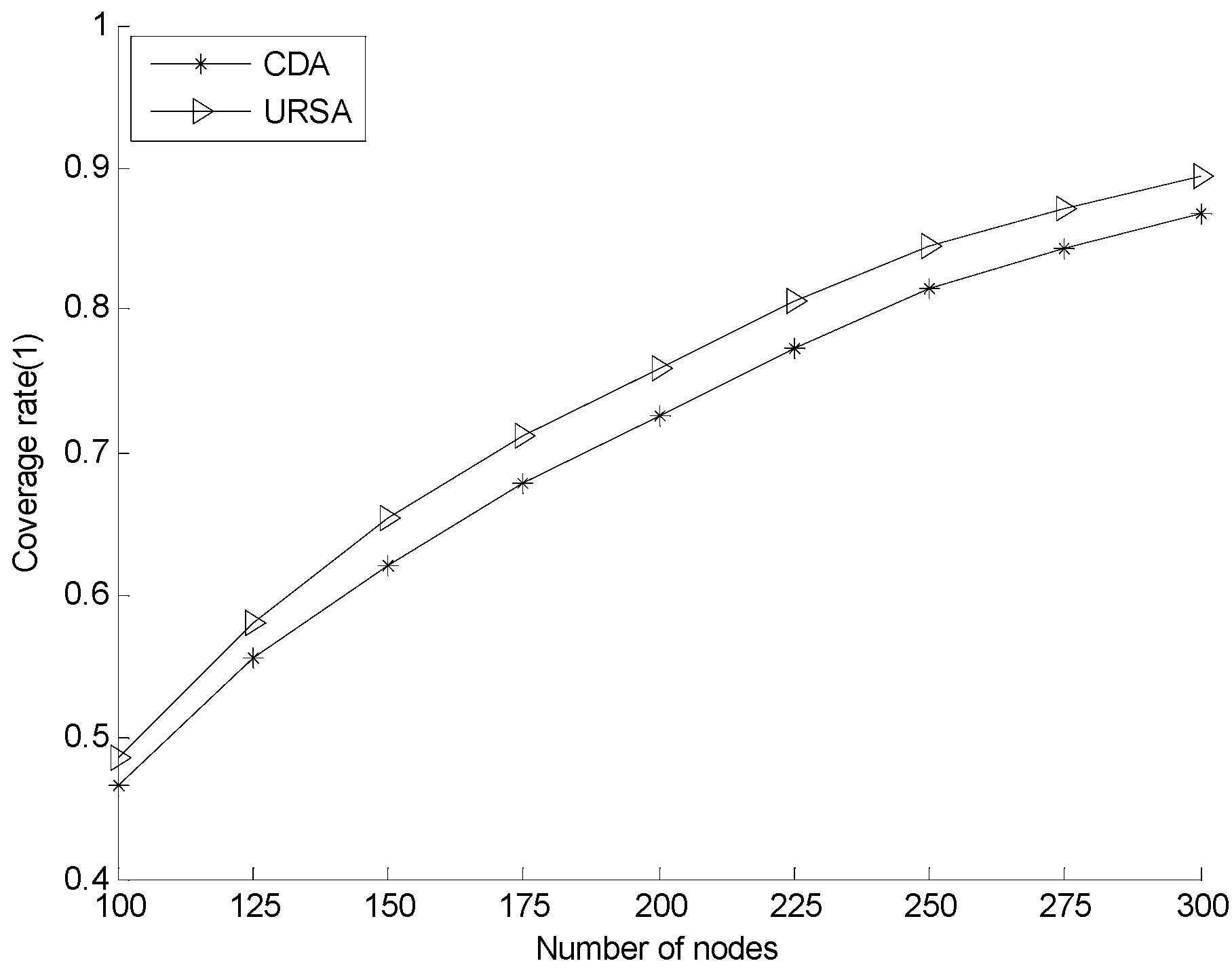
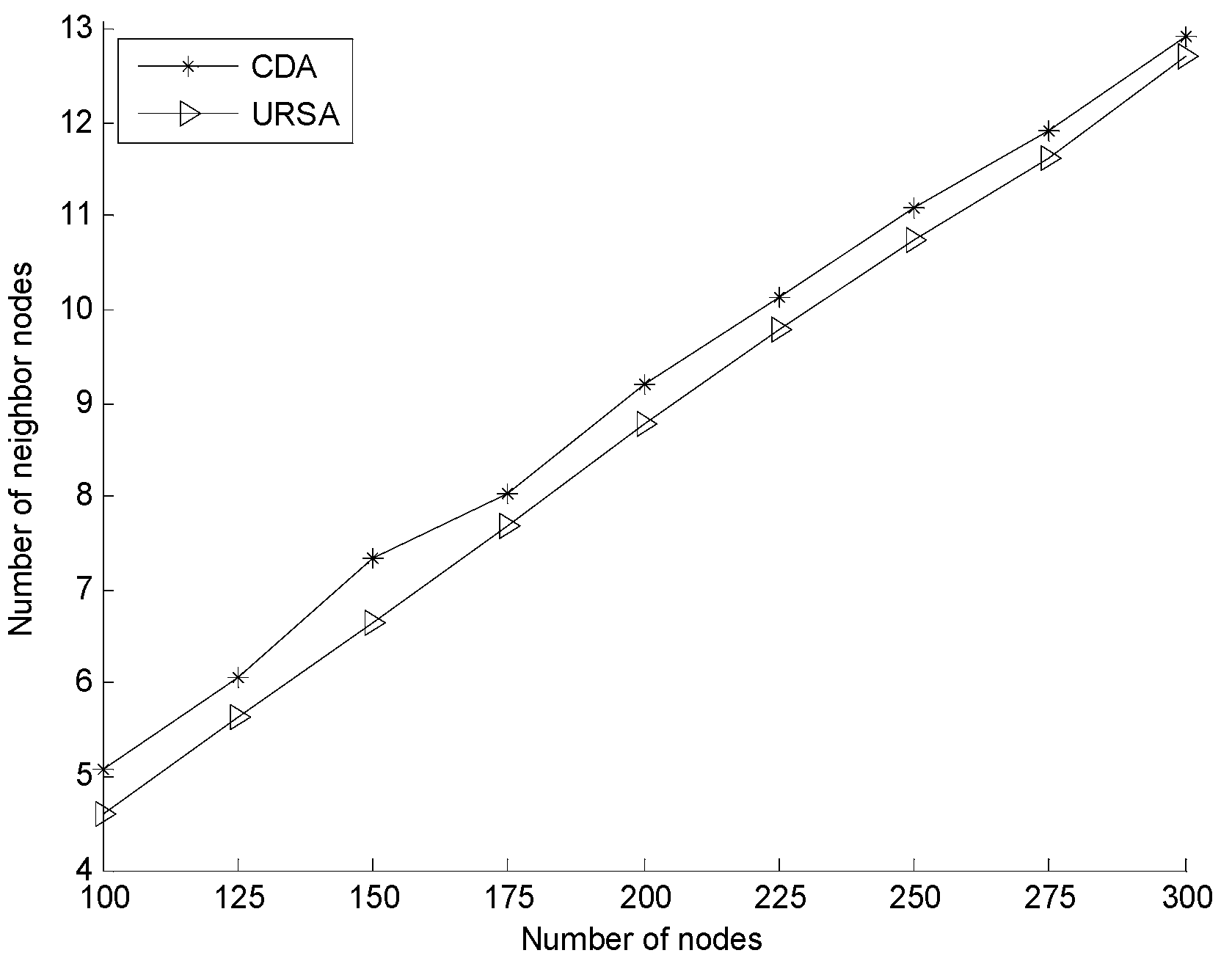
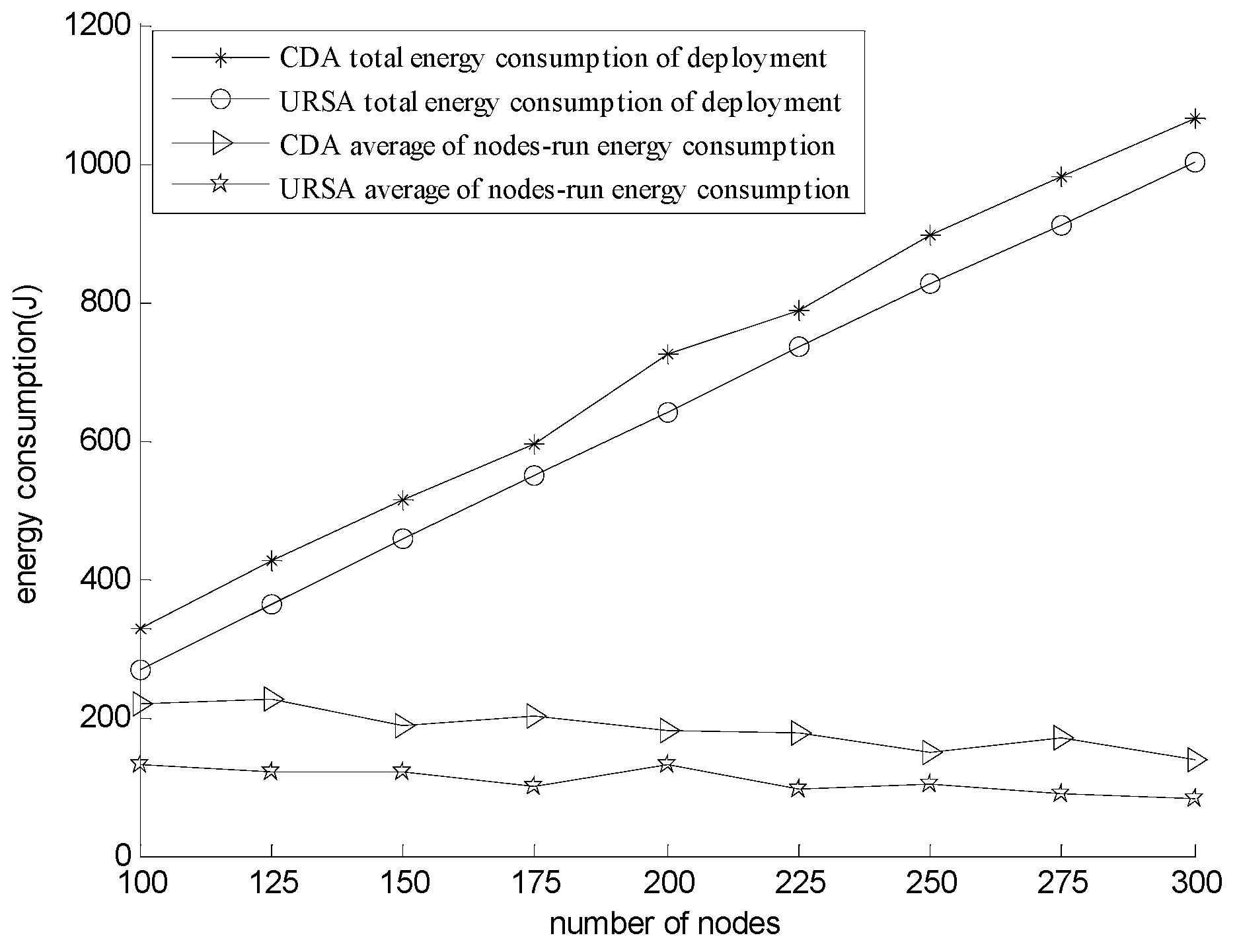
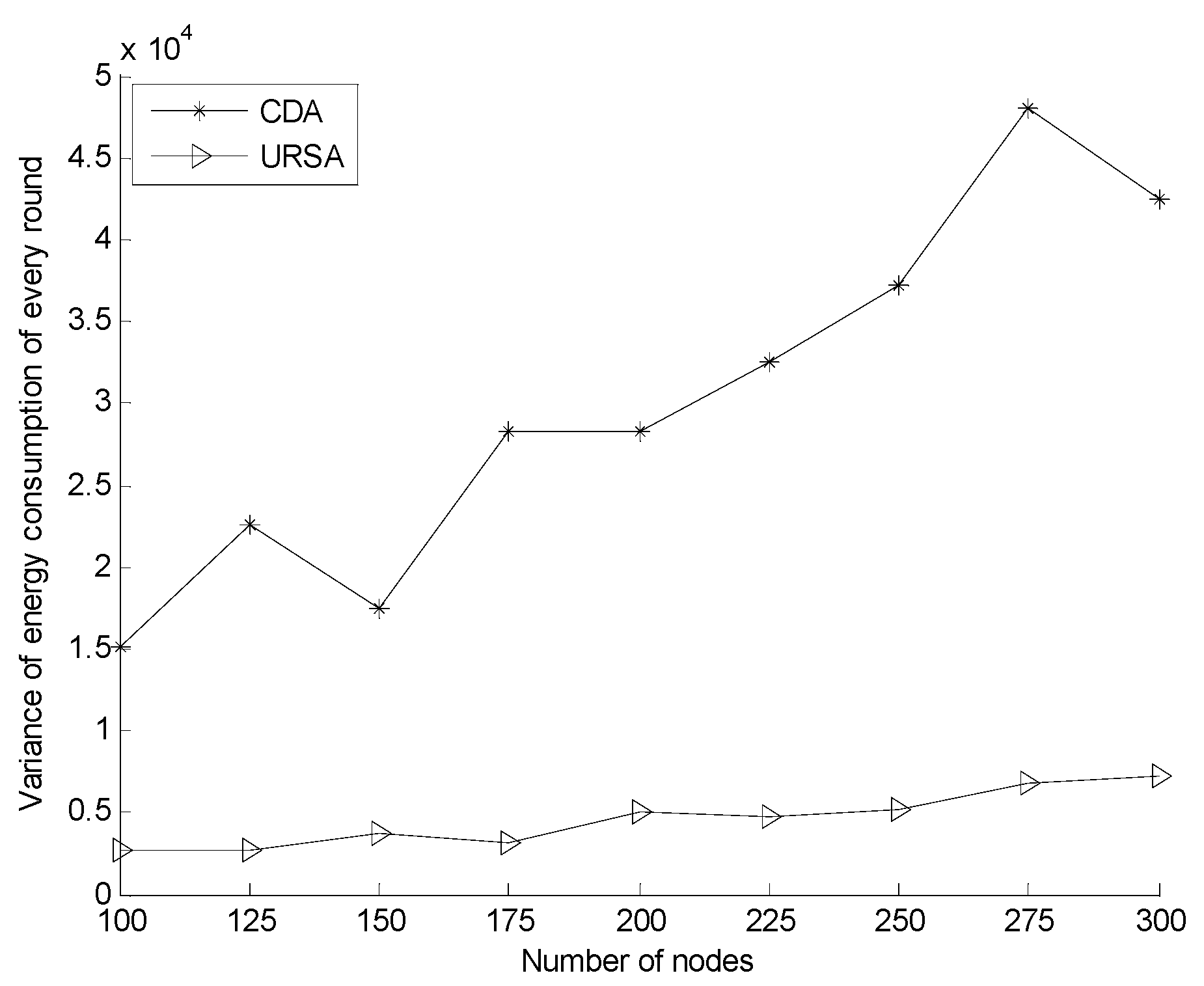
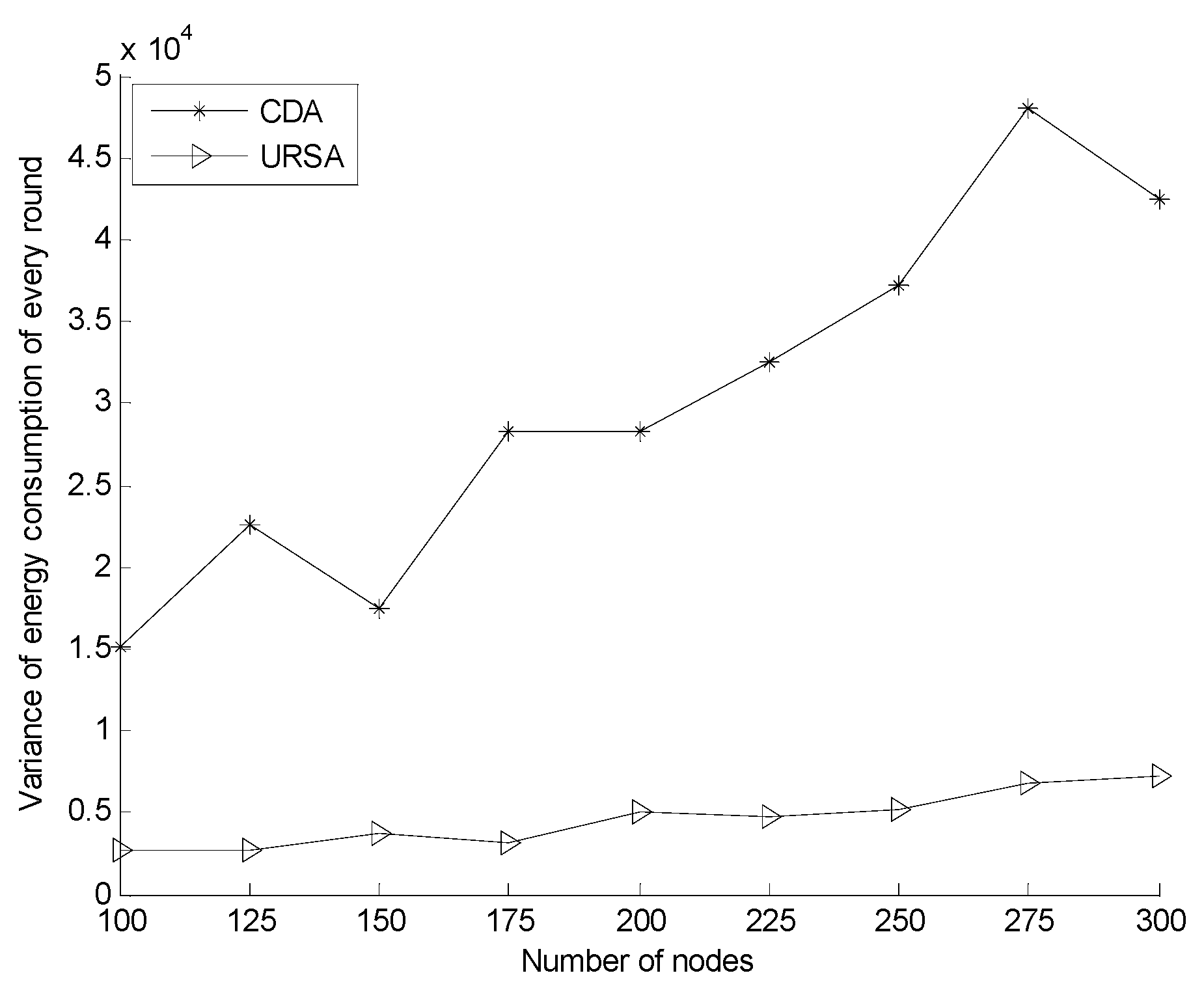
5.2.2. Effect of Varying N on Every Indicator
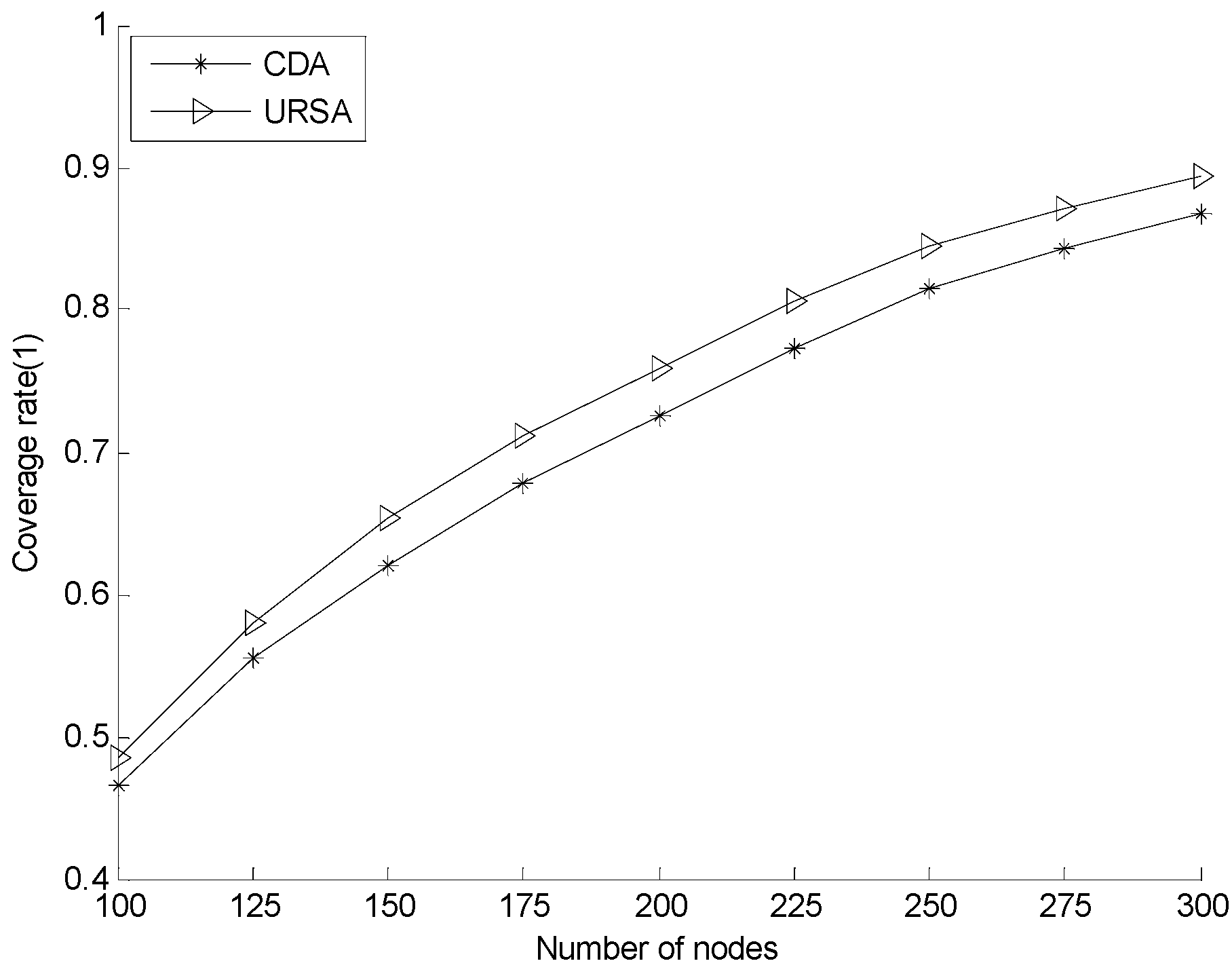
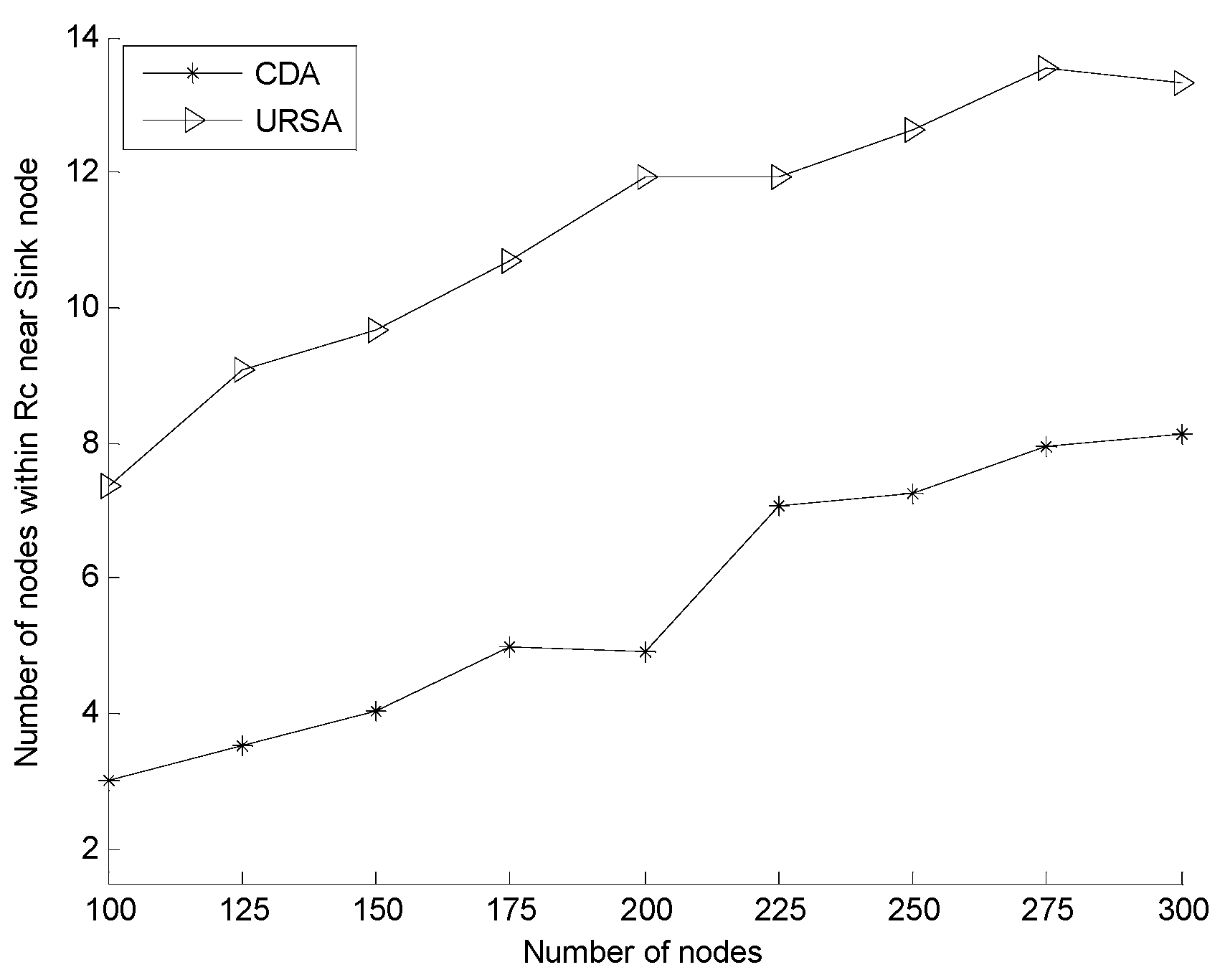
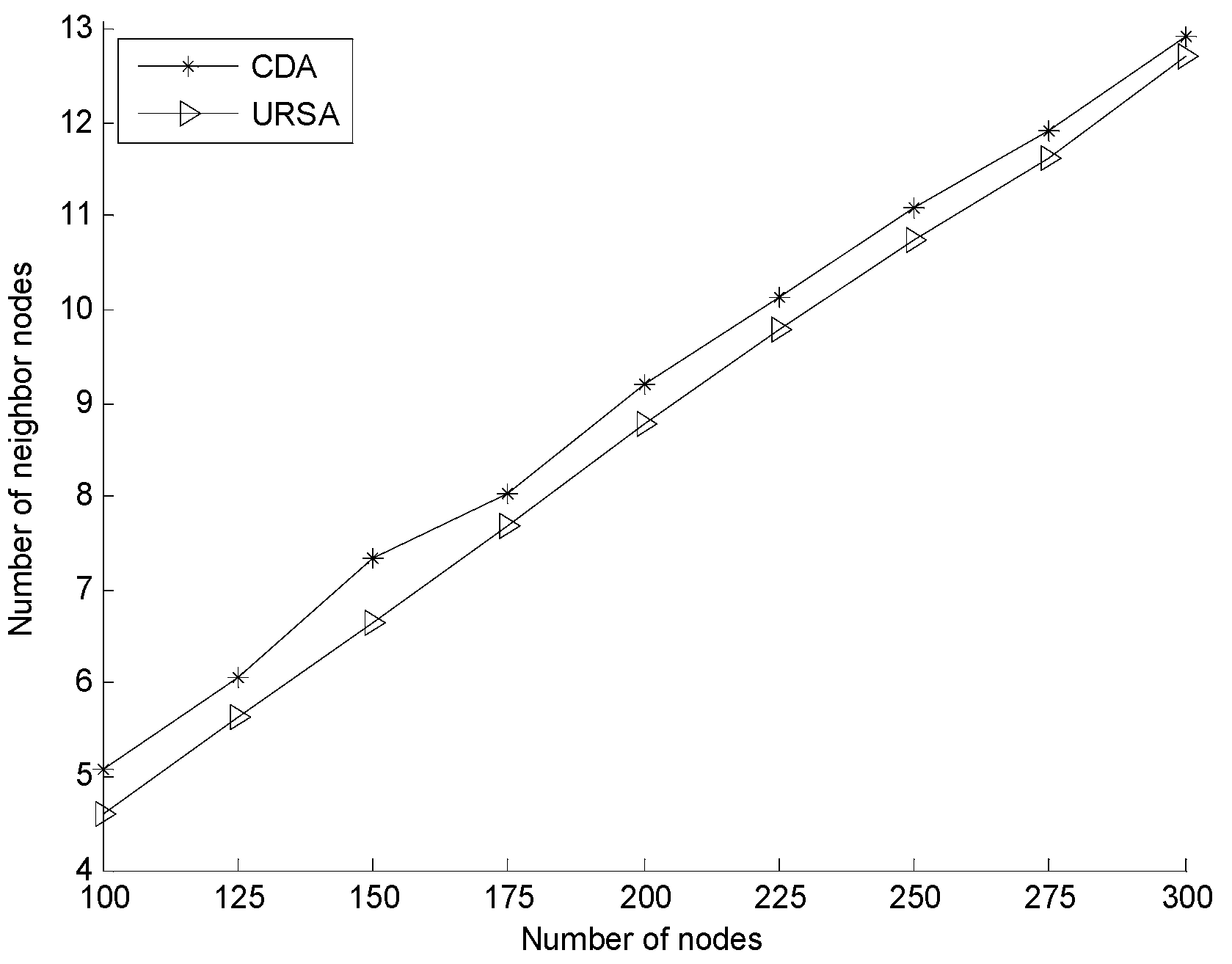
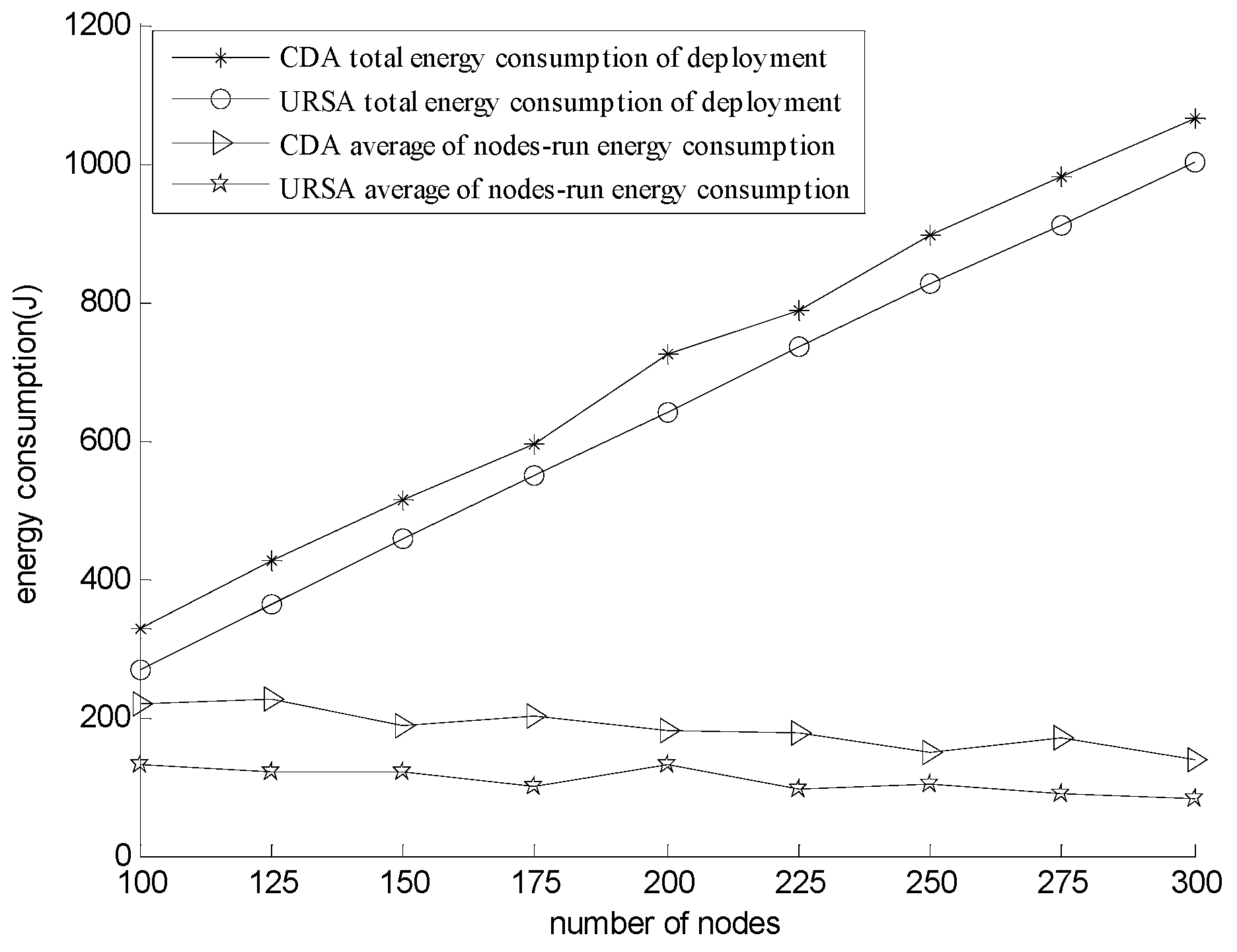
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Han, G.; Zhang, C.; Shu, L.; Sun, N.; Li, Q. A survey on deployment algorithms in underwater acoustic sensor networks. Int. J. Distrib. Sens. Netw. 2013, 1, 1–11. [Google Scholar] [CrossRef]
- Guo, Z.W.; Luo, H.J.; Hong, F.; Yang, M.; Lionel, M.N. Current Progress and Research Issues in Underwater Sensor Networks. J. Comput. Res. Dev. 2010, 47, 377–389. [Google Scholar]
- Heidemann, J.; Stojanovic, M.; Zorzi, M. Underwater sensor networks: Applications, advances and challenges. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 2012, 370, 158–175. [Google Scholar] [CrossRef] [PubMed]
- Felemban, E.; Shaikh, F.K.; Qureshi, U.M. Underwater Sensor Network Applications: A Comprehensive Survey. Int. J. Distrib. Sens. Netw. 2015, 2015, 1–14. [Google Scholar] [CrossRef]
- Alam, S.M.N.; Haas, Z.J. Coverage and connectivity in three-dimensional networks with random node deployment. Ad Hoc Netw. 2014. [Google Scholar] [CrossRef]
- Han, G.; Zhang, C.; Shu, L. Impacts of Deployment Strategies on Localization Performance in Underwater Acoustic Sensor Networks. IEEE Trans. Ind. Electron. 2015, 62, 1725–1733. [Google Scholar] [CrossRef]
- Verma, D.; Tripathi, A.K. Time Synchronization in Wireless Sensor Network Based on Level Discovery Phase. Int. J. Comput. Appl. 2014, 104, 101–111. [Google Scholar]
- Liu, L.; Liu, L.; Zhang, N. A Complex Network Approach to Topology Control Problem in Underwater Acoustic Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3046–3055. [Google Scholar] [CrossRef]
- Aziz, A.A.; Sekercioglu, Y.A.; Fitzpatrick, P.; Ivanovich, M. A Survey on Distributed Topology Control Techniques for Extending the Lifetime of Battery Powered Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2013, 15, 121–144. [Google Scholar] [CrossRef]
- Felamban, M.; Shihada, B.; Jamshaid, K. Optimal node placement in underwater wireless sensor networks. In Proceedings of IEEE 27th International Conference on Advanced Information Networking and Applications (AINA), West Lafayette, IN, USA, 25–28 March 2013; pp. 492–499.
- Temel, S.; Unaldi, N.; Kaynak, O. On deployment of wireless sensors on 3-D terrains to maximize sensing coverage by utilizing cat swarm optimization with wavelet transform. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 111–120. [Google Scholar] [CrossRef]
- Xia, N.; Wang, C.S.; Zheng, R.; Jiang, J.G. Fish Swarm Inspired Underwater Sensor Deployment. Acta Autom. Sin. 2012, 38, 295–302. [Google Scholar] [CrossRef]
- Li, X.; Ci, L.; Yang, M. Deploying three-dimensional mobile sensor networks based on virtual forces algorithm. In Advances in Wireless Sensor Networks; Wang, R., Xiao, F., Eds.; Springer: Berlin, Germany; Heidelberg, Germany, 2013; pp. 204–216. [Google Scholar]
- Du, H.; Xia, N.; Zheng, R. Particle Swarm Inspired Underwater Sensor Self-Deployment. Sensors 2014, 14, 15262–15281. [Google Scholar] [CrossRef] [PubMed]
- Detweiler, C.; Doniec, M.; Vasilescu, I. Autonomous Depth Adjustment for Underwater Sensor Networks: Design and Applications. IEEE ASME Trans. Mechatron. 2012, 17, 16–24. [Google Scholar] [CrossRef]
- Younis, M.; Akkaya, K. Strategies and techniques for node placement in wireless sensor networks: A survey. Ad Hoc Netw. 2008, 6, 621–655. [Google Scholar] [CrossRef]
- Pompili, D.; Melodia, T.; Akyildiz, I.F. Deployment analysis in underwater acoustic wireless sensor networks. In Proceedings of the 1st ACM International Workshop on Underwater Networks, Los Angeles, CA, USA, 25 September 2006; pp. 48–55.
- Nazarzehi, V.; Savkin, A.V. Decentralized control of mobile three-dimensional sensor networks for complete coverage self-deployment and forming specific shapes. In Proceedings of the IEEE Conference on Control Applications (CCA), Sydney, Australia, 21–23 September 2015; pp. 127–132.
- Wang, Y.; Liu, Y.; Guo, Z. Three-dimensional ocean sensor networks: A survey. J. Ocean Univ. China 2012, 11, 436–450. [Google Scholar] [CrossRef]
- Detweiler, C.; Doniec, M.; Vasilescu, I.; Basha, E.; Rus, D. Autonomous depth adjustment for underwater sensor networks. In Proceedings of the Fifth ACM International Workshop on Underwater Networks, New York, NY, USA, 1 October 2010; pp. 12–16.
- Vasilescu, I.; Detweiler, C.; Rus, D. AquaNodes: An underwater sensor network. In Proceedings of the Second Workshop on Underwater Networks, New York, NY, USA, 14 September 2007; pp. 85–88.
- Wu, J.; Wang, Y.; Liu, L. A Voronoi-Based Depth-Adjustment Scheme for Underwater Wireless Sensor Networks. Int. J. Smart Sens. Intell. Syst. 2013, 6, 244–258. [Google Scholar]
- Akkaya, K.; Newell, A. Self-deployment of sensors for maximized coverage in underwater acoustic sensor networks. Comput. Commun. 2009, 32, 1233–1244. [Google Scholar] [CrossRef]
- Du, X.Y.; Li, H.; Zhou, L. Coverage Algorithm Based on Fixed-directional Movement for Underwater Sensor Network. Comput. Eng. 2015, 41, 76–80. [Google Scholar]
- Senel, F.; Akkaya, K.; Erol-Kantarci, M.; Yilmaz, T. Self-deployment of mobile underwater acoustic sensor networks for maximized coverage and guaranteed connectivity. Ad Hoc Netw. 2014. [Google Scholar] [CrossRef]
- Mehmood, A.; Lloret, J.; Noman, M.; Song, H. Improvement of the Wireless Sensor Network Lifetime using LEACH with Vice-Cluster Head. Ad Hoc Sens. Wirel. Netw. 2015, 28, 1–17. [Google Scholar]
- Ma, S.Q.; Guo, Y.C.; Lei, M.; Yang, Y.; Cheng, M.Z. A Cluster Head Selection Framework in Wireless Sensor Networks Considering Trust and Residual Energy. Ad Hoc Sens. Wirel. Netw. 2015, 25, 147–164. [Google Scholar]
- Heinzelman, W.B.; Chandrakasan, A.P.; Balakrishnan, H. An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 2002, 1, 660–670. [Google Scholar] [CrossRef]
- Ye, M.; Li, C.; Chen, G.; Wu, J. EECS: An energy efficient clustering scheme in wireless sensor networks. In Proceedings of the IEEE 24th Conference on Performance, Computing, and Communications, New York, NY, USA, 7–9 April 2005; pp. 535–540.
- Tsai, Y.R. Coverage-preserving routing protocols for randomly distributed wireless sensor networks. IEEE Trans. Wirel. Commun. 2007, 6, 1240–1245. [Google Scholar] [CrossRef]
- Abbasi, A.A.; Younis, M. A survey on clustering algorithms for wireless sensor networks. Comput. Commun. 2007, 30, 2826–2841. [Google Scholar] [CrossRef]
- Lloret, J.; Garcia, M.; Bri, D.; Diaz, J.R. A cluster-based architecture to structure the topology of parallel wireless sensor networks. Sensors 2009, 9, 10513–10544. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Liu, Y.; Yu, J. A new energy-efficient unequal clustering algorithm for wireless sensor networks. In Proceedings of the IEEE International Conference on Computer Science and Automation Engineering (CSAE), Shanghai, China, 10–12 June 2011; pp. 431–434.
- Qiao, X.G.; Wang, H.Q.; Gao, S.B.; Wang, Z. A Chain Structure-Based Uneven Cluster Routing Algorithm for Wireless Sensor Networks (CSBUC). J. Appl. Sci. 2013, 13, 5220–5226. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.; Javaid, N.; Khan, F.A.; Durrani, M.Y. Co-UWSN: Cooperative Energy-Efficient Protocol for Underwater WSNs. Int. J. Distrib. Sens. Netw. 2015. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ruan, B.F. Cluster-Based Coverage-Preserving Routing Algorithm for Underwater Sensor Networks. Acta Electron. Sin. 2013, 10, 2067–2073. [Google Scholar]
- Chen, G.; Li, C.; Ye, M. An unequal cluster-based routing protocol in wireless sensor networks. Wirel. Netw. 2009, 15, 193–207. [Google Scholar] [CrossRef]
- Ye, M.; Chan, E.; Chen, G. On mitigating hot spots for clustering mechanisms in wireless sensor networks. In Proceedings of the IEEE International Conference on Mobile Adhoc and Sensor Systems (MASS), Vancouver, BC, Canada, 1 October 2006; pp. 558–561.
- Dantu, K.; Rahimi, M.; Shah, H. Robomote: Enabling mobility in sensor networks. In Proceedings of the 4th International Symposium on Information Processing in Sensor Networks, Los Angeles, CA, USA, 5–6 May 2005; pp. 404–409.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, P.; Xu, Y.; Wu, F. Node Self-Deployment Algorithm Based on an Uneven Cluster with Radius Adjusting for Underwater Sensor Networks. Sensors 2016, 16, 98. https://doi.org/10.3390/s16010098
Jiang P, Xu Y, Wu F. Node Self-Deployment Algorithm Based on an Uneven Cluster with Radius Adjusting for Underwater Sensor Networks. Sensors. 2016; 16(1):98. https://doi.org/10.3390/s16010098
Chicago/Turabian StyleJiang, Peng, Yiming Xu, and Feng Wu. 2016. "Node Self-Deployment Algorithm Based on an Uneven Cluster with Radius Adjusting for Underwater Sensor Networks" Sensors 16, no. 1: 98. https://doi.org/10.3390/s16010098
APA StyleJiang, P., Xu, Y., & Wu, F. (2016). Node Self-Deployment Algorithm Based on an Uneven Cluster with Radius Adjusting for Underwater Sensor Networks. Sensors, 16(1), 98. https://doi.org/10.3390/s16010098