
RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems



Abstract
:1. Introduction
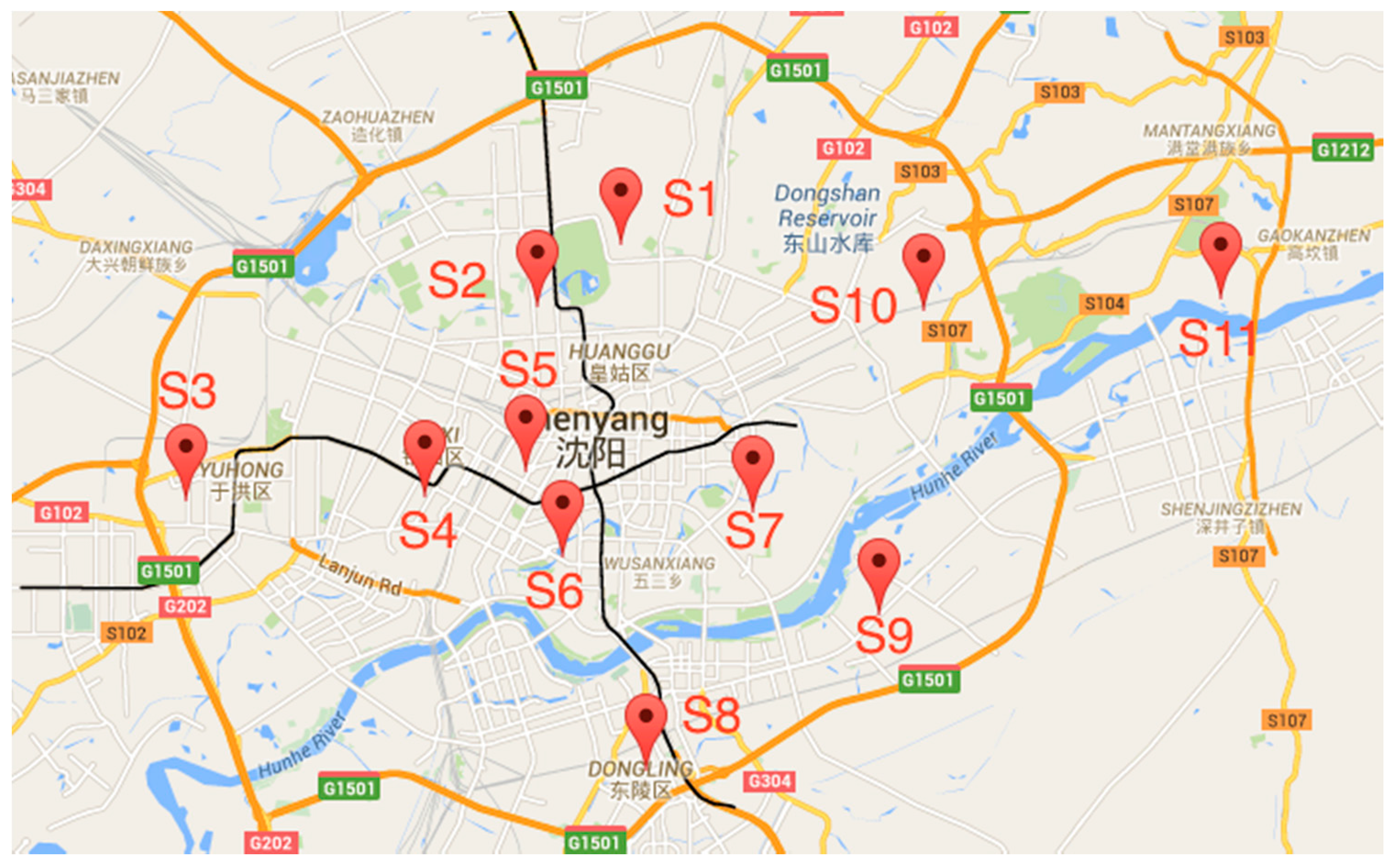
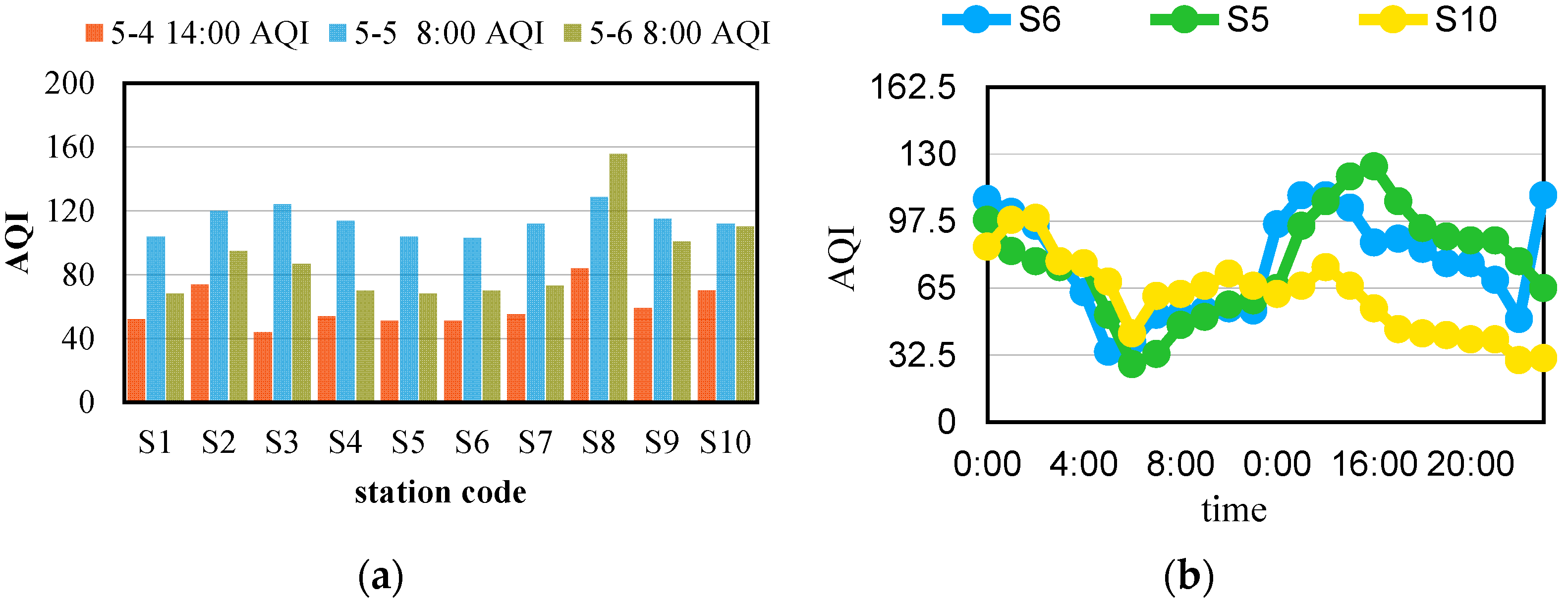
2. Related Work
3. Problem Description and Definition
3.1. Definition
3.1.1. Air Quality Index

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AQI | Air Pollution Level |
|---|---|
| 0–50 | Excellent |
| 51–100 | Good |
| 101–150 | Lightly Polluted |
| 151–200 | Moderately Polluted |
| 201–300 | Heavily Polluted |
| 300+ | Severely Polluted |
3.1.2. Traffic Congestion Status
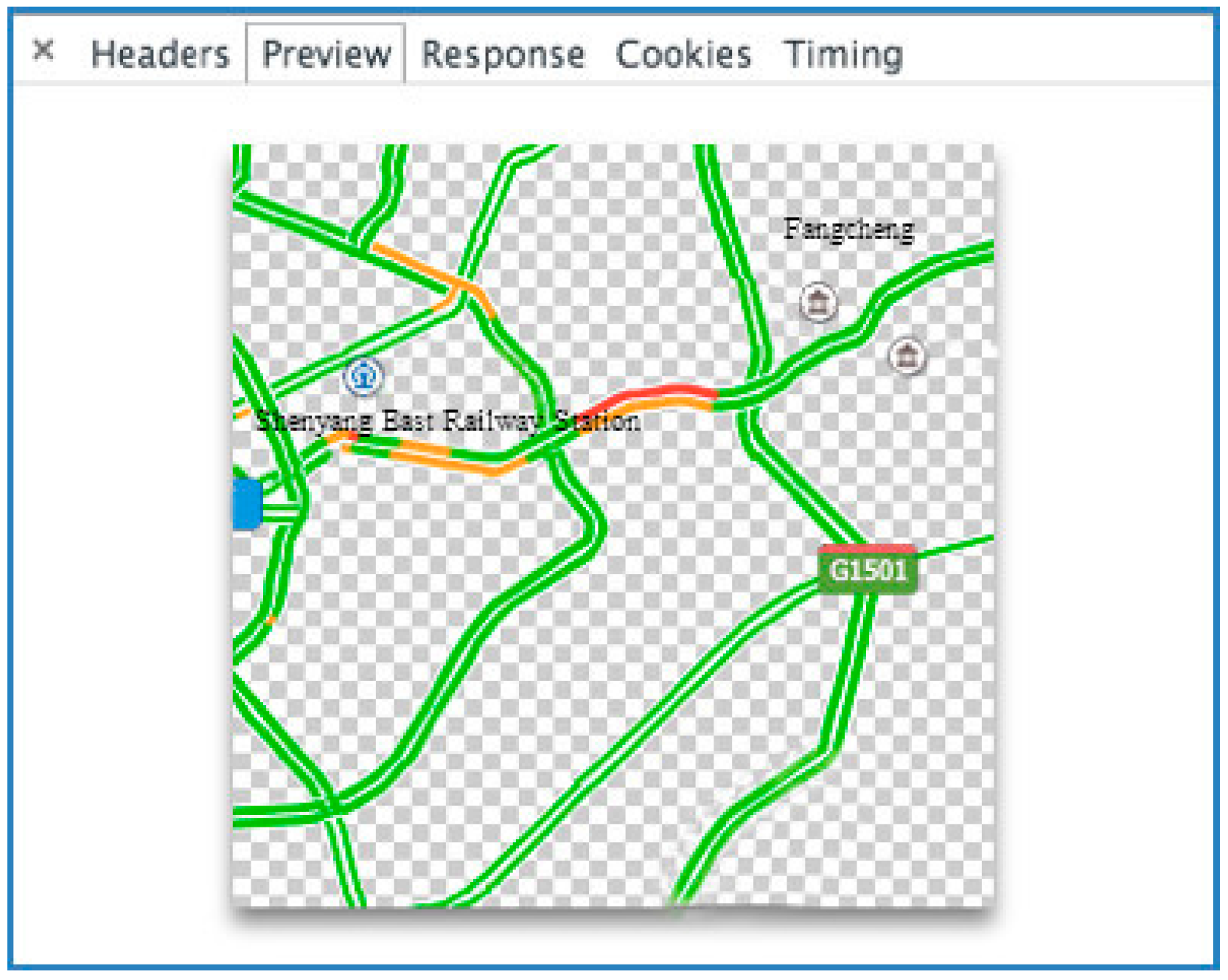
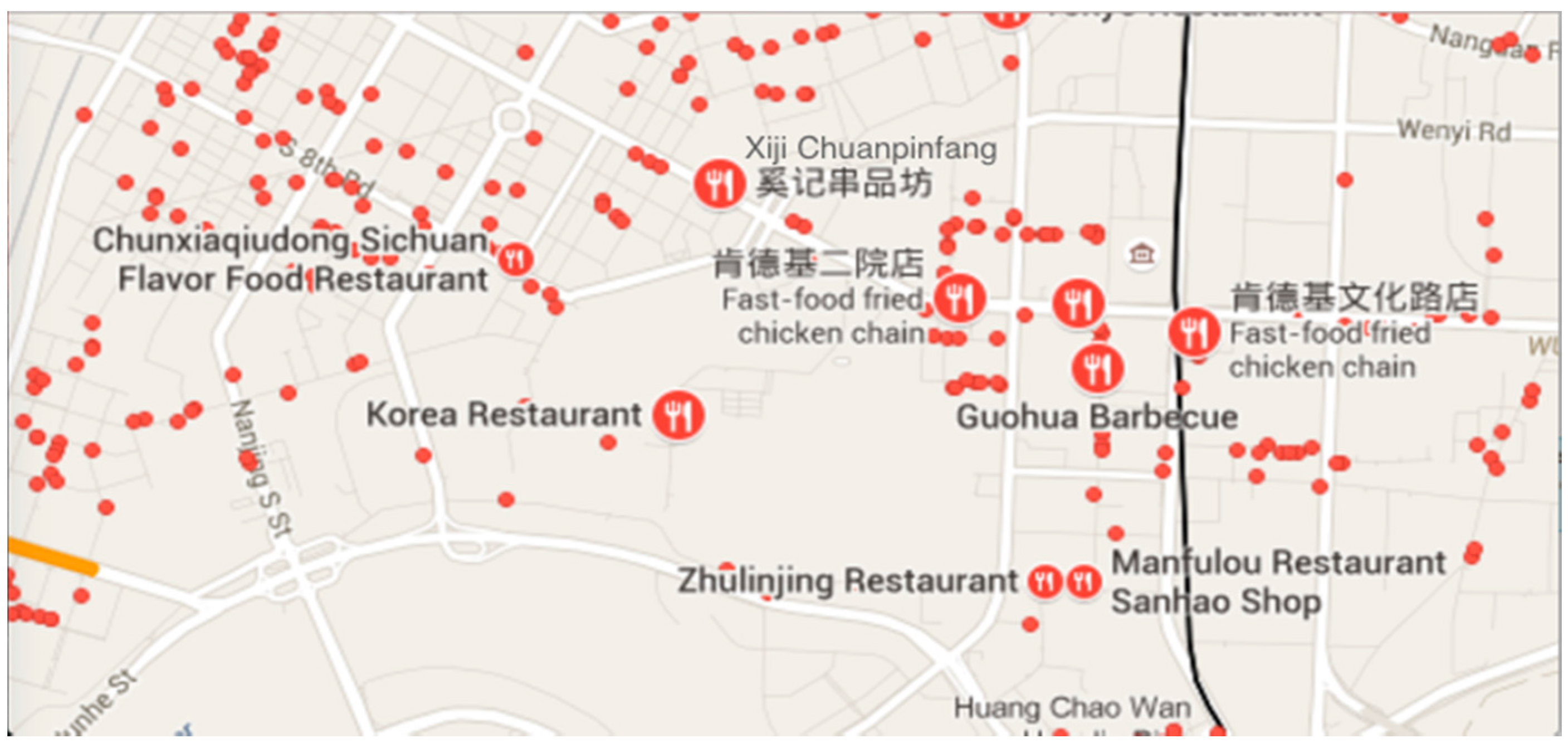
3.1.3. Point of Interest

3.2. Problem Formulation
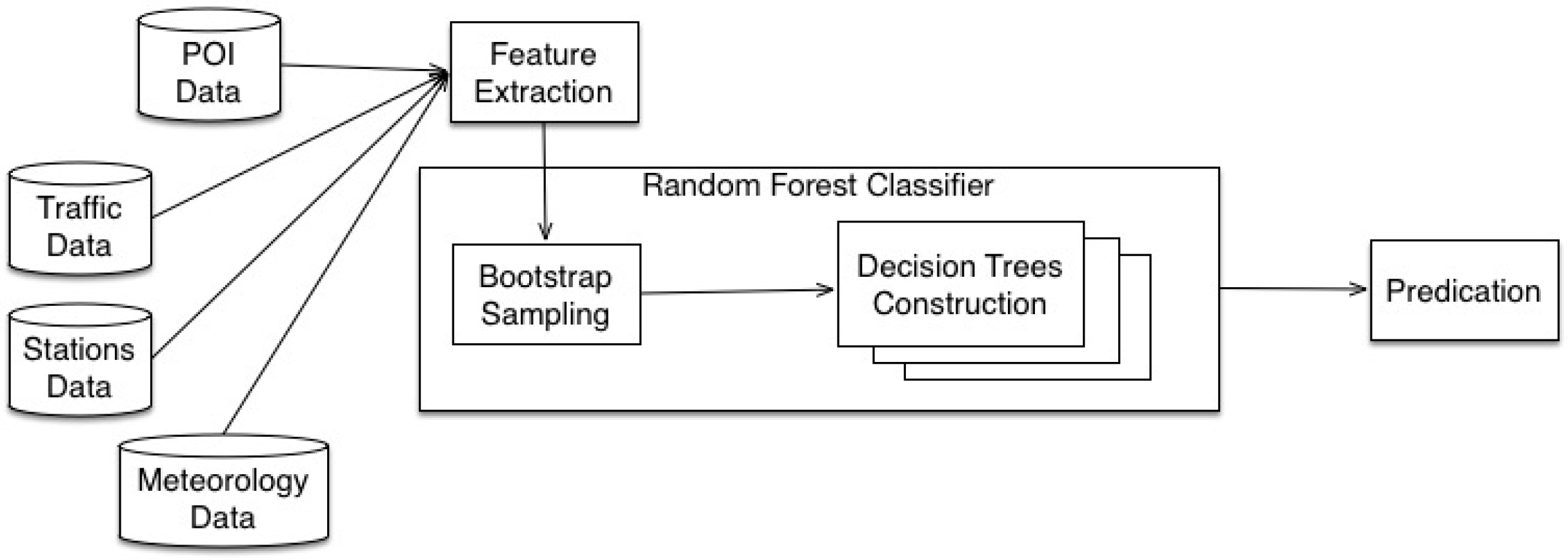
4. RAQ Algorithm


4.1. Data Collection and Feature Extraction
4.1.1. Meteorology Data
4.1.2. Traffic and Road Data

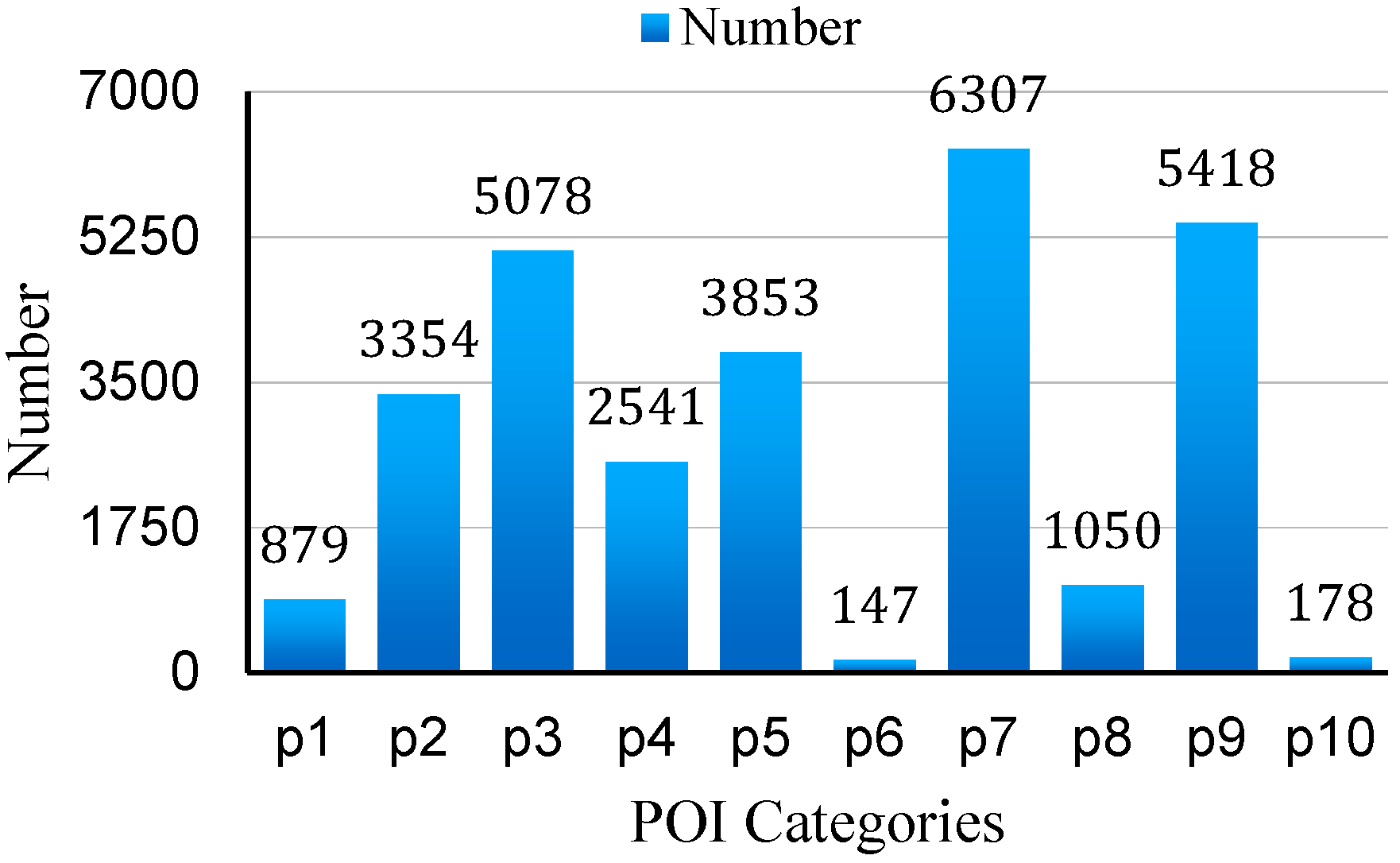
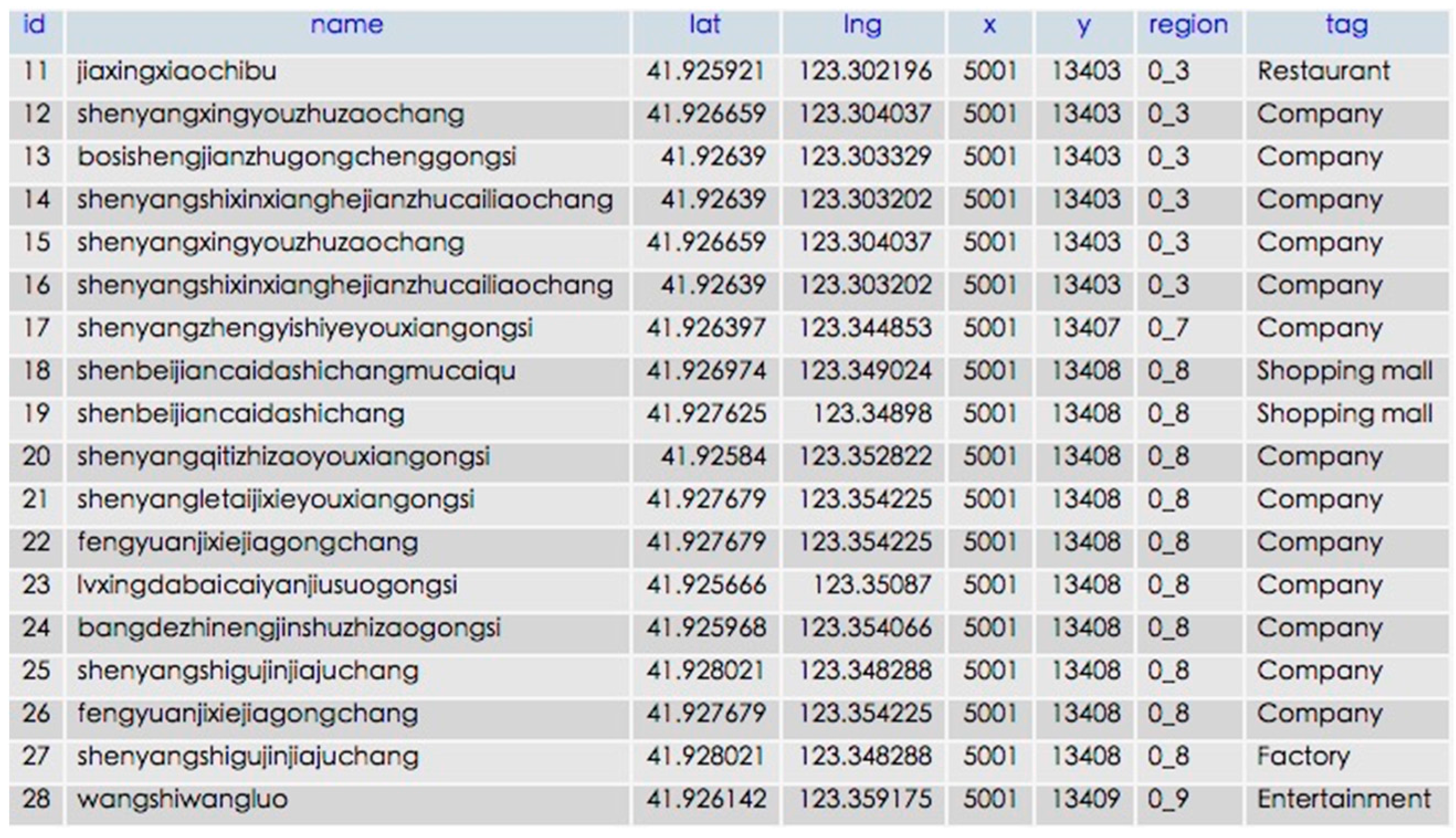
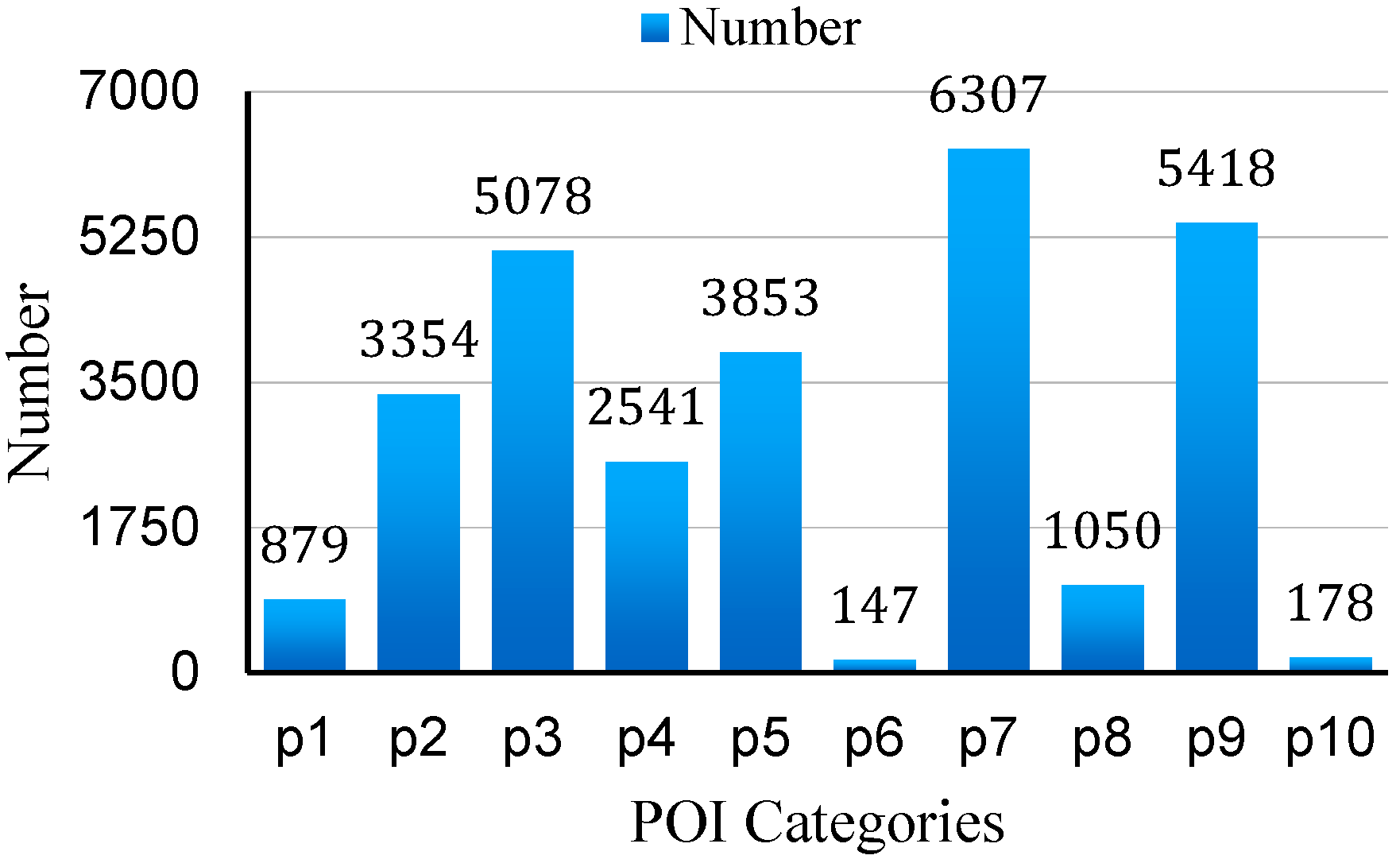
4.1.3. POI Data
| Code | POI Category |
|---|---|
| P1 | Transportation |
| P2 | Entertainment |
| P3 | Restaurant |
| P4 | Education |
| P5 | Residential District |
| P6 | Park |
| P7 | Company |
| P8 | Factory |
| P9 | Shopping mall |
| P10 | Gas station |
4.2. Random Forest Classification
4.2.1. Bootstrap Aggregating (Bagging)
4.2.2. Tree Growing and Splitting
4.3. Prediction
| Algorithm 1. RAQ | |
| Input: | A dataset S with features: Fmt, Fmh, Fmp, Fmw, Fmv, Fri, Ftcs, Fpn and labeled AQI level; unlabeled dataset U; trees quantity T; features quantity m; |
| Output: | AQI level |
| 1 | for T trees |
| 2 | randomly select m features from S; |
| 3 | for m features in each node |
| 4 | calculate information gain by Equation (3); |
| 5 | choose maximum gain to split the dataset in the node; |
| 6 | remove used feature from feature candidates; |
| 7 | input unlabeled data into trees; |
| 5 | get predicted AQI level according to Equations (5) and (6); |
5. Evaluation
5.1. Dataset
5.1.1. Monitoring Station Data
| Station_id | Aqi | CO (μg/m3) | NO2 (μg/m3) | SO2 (μg/m3) | O3 (μg/m3) | PM10 (μg/m3) | PM25 (μg/m3) | Time |
|---|---|---|---|---|---|---|---|---|
| 747 | 77 | 1.802 | 70 | 69 | 63 | 104 | 52 | 2015-05-24 03:00 |
| 750 | 139 | 2.233 | 62 | 70 | 57 | 125 | 106 | 2015-05-24 03:00 |
| 751 | 82 | 1.706 | 73 | 58 | 69 | 100 | 60 | 2015-05-24 03:00 |
| 741 | 85 | 1.942 | 80 | 64 | 43 | 94 | 63 | 2015-05-24 03:00 |
| 748 | 63 | 1.024 | 61 | 62 | 68 | 76 | 37 | 2015-05-24 04:00 |
| 749 | 67 | 1.358 | 60 | 29 | 62 | 81 | 48 | 2015-05-24 04:00 |
| 742 | 88 | 1.646 | 97 | 82 | 12 | 125 | 14 | 2015-05-24 04:00 |
| 743 | 84 | 0.808 | 68 | 167 | 45 | 117 | 52 | 2015-05-24 04:00 |
| 744 | 98 | 1.718 | 66 | 56 | 43 | 92 | 73 | 2015-05-24 04:00 |
| 745 | 86 | 1.333 | 78 | 72 | 9 | 121 | 37 | 2015-05-24 04:00 |
| 746 | 66 | 1.229 | 66 | 24 | 48 | 82 | 45 | 2015-05-24 04:00 |
| 747 | 63 | 1.175 | 58 | 48 | 70 | 75 | 36 | 2015-05-24 04:00 |
| Station_id | Latitude | Longitude |
|---|---|---|
| 741 | 41.841445 | 123.65436 |
| 742 | 41.758166 | 123.533761 |
| 743 | 41.71694 | 123.451378 |
| 744 | 41.788094 | 123.288852 |
| 745 | 41.838551 | 123.549754 |
| 746 | 41.855605 | 123.442396 |
| 747 | 41.773208 | 123.421573 |
| 748 | 41.785295 | 123.489395 |
| 749 | 41.79609169 | 123.4084114 |
| 750 | 41.789429 | 123.373275 |
| 751 | 41.83933982 | 123.4126515 |
5.1.2. Meteorological Data
| Temperature (Fmt, °C) | Barometric Pressure (Fmp, mmHg) | Humidity (Fmh, %) | Wind Speed (Fmw, m/s) | Visibility (Fmv, m) | Time |
|---|---|---|---|---|---|
| 18.8 | 748.6 | 56 | 2 | 16.0 | 2015-05-14 11:00:00 |
| 18.3 | 746.4 | 50 | 7 | 26.0 | 2015-05-14 08:00:00 |
| 17.0 | 744.6 | 63 | 3 | 12.0 | 2015-05-14 05:00:00 |
| 18.4 | 743.0 | 58 | 1 | 16.0 | 2015-05-14 02:00:00 |
| 19.7 | 743.9 | 63 | 1 | 18.0 | 2015-05-13 23:00:00 |
| 18.0 | 742.6 | 72 | 0 | 7.0 | 2015-05-13 21:00:00 |
5.1.3. Road and Traffic Data
5.1.4. POI

5.2. Evaluation Method
5.3. Results
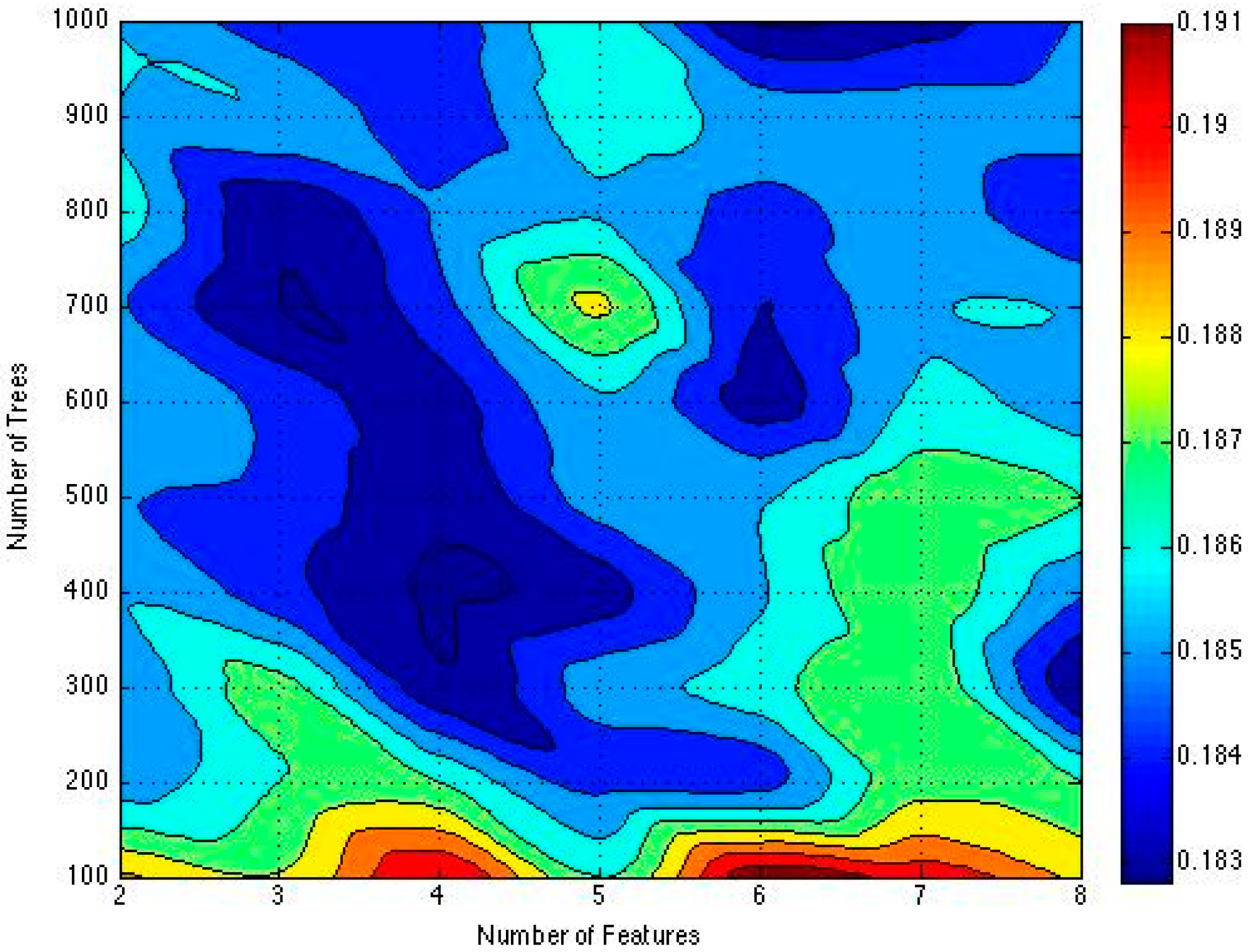
5.3.1. Effects of Parameters on Prediction Error Rate

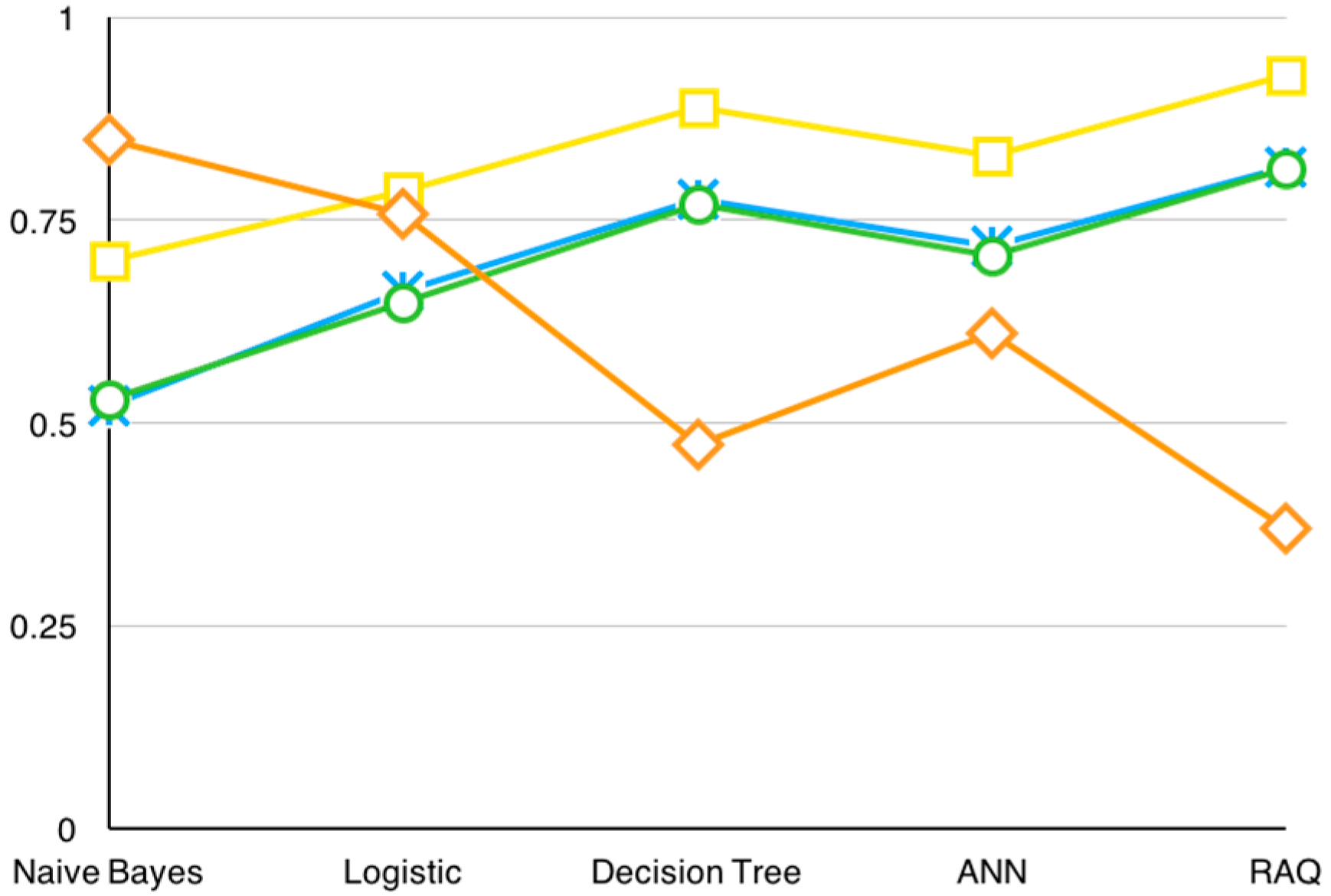
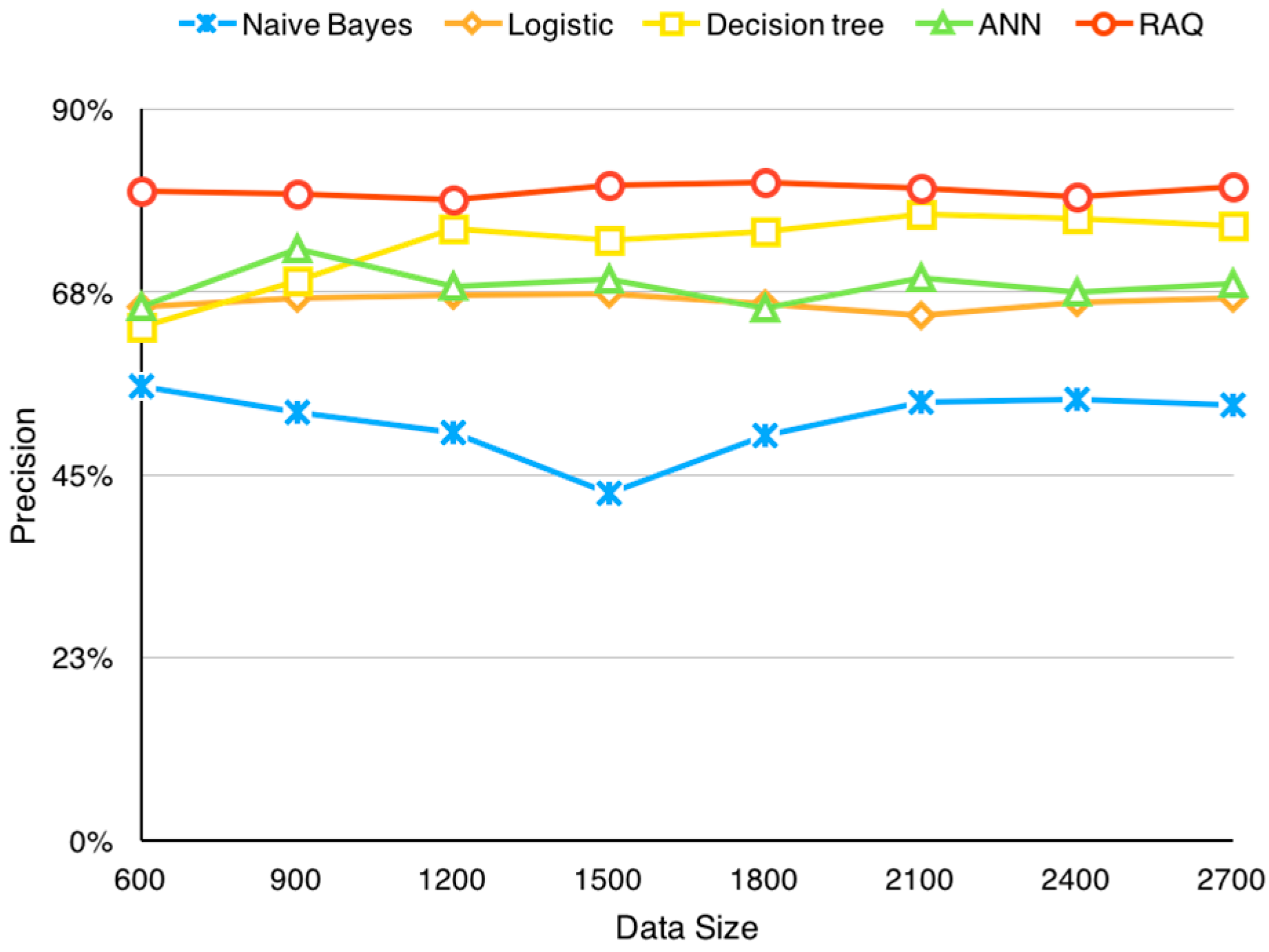
5.3.2. Comparison
| Algorithm | Precision | Y | N |
|---|---|---|---|
| NaïveBayes | 52.1% | 1408 | 1293 |
| Logistic | 66.2% | 1790 | 911 |
| Decision Tree | 77.4% | 2092 | 609 |
| ANN | 71.8% | 1940 | 761 |
| RAQ | 81.5% | 2203 | 498 |
| Algorithm | Recall | F-Score | ROC | RAE |
|---|---|---|---|---|
| Naive Bayes | 0.521 | 0.529 | 0.7 | 84.9% |
| Logistic | 0.663 | 0.649 | 0.785 | 75.8% |
| Decision Tree | 0.775 | 0.769 | 0.888 | 47.4% |
| ANN | 0.718 | 0.707 | 0.829 | 60.9% |
| RAQ | 0.816 | 0.814 | 0.928 | 36.9% |

6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Devarakonda, S.; Sevusu, P.; Liu, H.; Liu, R.; Iftode, L.; Nath, B. Real-time air quality monitoring through mobile sensing in metropolitan areas. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, New York, NY, USA, 11 August 2013.
- Mage, D.; Ozolins, G.; Peterson, P.; Webster, A.; Orthofer, R.; Vandeweerd, V.; Gwynne, M. Urban air pollution in megacities of the world. Atmos. Environ. 1996, 30, 681–686. [Google Scholar] [CrossRef]
- NASA. Available online: http://climate.nasa.gov/causes/ (accessed on 23 December 2015).
- South China Morning Post. Available online: http://www.scmp.com/topics/beijing-air-pollution (accessed on 5 May 2015).
- People. Available online: http://politics.people.com.cn/GB/1026/17220033.html (accessed on 25 November 2015). (In Chinese)
- PM25.in. Available online: http://www.pm25.in/shenyang (accessed on 5 May 2015). (In Chinese)
- Ragland, K.W. Multiple Box Model for Dispersion of Air Pollutants from Area Sources. Atmos. Environ. 1973, 7, 1017–1032. [Google Scholar] [CrossRef]
- Bosanquet, C.H.; Pearson, J.L. The spread of smoke and gases from chimneys. Trans. Faraday Soc. 1936, 32, 1249–1263. [Google Scholar] [CrossRef]
- Zannetti, D.P. Lagrangian Dispersion Models. In Air Pollution Modeling; Springer U.S.: Boston, MA, USA, 1990; pp. 185–222. [Google Scholar]
- Pai, P.; Karamchandani, P.; Seifneur, C. Simulation of the regional atmospheric transport and fate of mercury using a comprehensive eulerian model. Atmos. Environ. 1997, 31, 2717–2732. [Google Scholar] [CrossRef]
- Ermak, D.L. User's Manual for SLAB: An Atmospheric Dispersion Model for Denser-Than-Air-Releases; Lawrence Livermore National Laboratory: Livermore, CA, USA, 1990. [Google Scholar]
- Liu, Y.; Sarnat, J.A.; Kilaru, V.; Jacob, D.J.; Koutrakis, P. Estimating Ground-Level PM2.5 in the Eastern United States Using Satellite Remote Sensing. Environ. Sci. Technol. 2005, 39, 3269–3278. [Google Scholar] [CrossRef] [PubMed]
- Martin, R.V. Satellite remote sensing of surface air quality. Atmos. Environ. 2008, 42, 7823–7843. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A.; Wang, J.; Gehrig, R.; Lee, Y.; Kumar, N. Satellite remote sensing of particulate matter and air quality assessment over global cities. Atmos. Environ. 2006, 40, 5880–5892. [Google Scholar] [CrossRef]
- Duncan, B.N.; Prados, A.I.; Lamsl, L.N.; Liu, Y.; Streets, D.G.; Gupta, P.; Hilsenrath, E.; Kahn, R.A.; Nielsen, J.E.; Beyersdorf, A.J.; et al. Satellite data of atmospheric pollution for US air quality applications: Examples of applications, summary of data end-user resources, answers to FAQs, and common mistakes to avoid. Atmos. Environ. 2014, 94, 647–662. [Google Scholar] [CrossRef]
- Khedo, K.K.; Perseedoss, R.; Mungur, A. A Wireless Sensor Network Air Pollution Monitoring System. Int. J. Wirel. Mob. Netw. 2010, 2, 31–45. [Google Scholar] [CrossRef]
- Ma, Y.; Richards, M.; Ghanem, M.; Guo, Y.; Hassard, J. Air Pollution Monitoring and Mining Based on Sensor Grid in London. Sensors 2008, 8, 3601–3623. [Google Scholar] [CrossRef]
- Rajasegarar, S.; Zhang, P.; Zhou, Y.; Karunasekera, S.; Leckie, C.; Palaniswami, M. High resolution spatio-temporal monitoring of air pollutants using wireless sensor networks. In Proceedings of the 2014 IEEE Ninth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 21–24 April 2014; pp. 1–6.
- Jiang, Y.; Li, K.; Tian, L.; Piedrahita, R.; Yun, X.; Mansata, O.; Lv, Q.; Dick, R.P.; Hannigan, M.; Shang, L. MAQS: A personalized mobile sensing system for indoor air quality monitoring. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; pp. 271–280.
- Hasenfratz, D.; Saukh, O.; Sturzenegger, S.; Thiele, L. Participatory air pollution monitoring using smartphones. In Proceedings of the 1st International Workshop on Mobile Sensing: From Smartphones and Wearables to Big Data, Beijing, China, 16 April 2012.
- Maisonneuve, N.; Stevens, M.; Ochab, B. Participatory noise pollution monitoring using mobile phones. Inf. Polit. 2010, 15, 51–71. [Google Scholar]
- Sivaraman, V.; Carrapetta, J.; Hu, K.; Luxan, B.G. HazeWatch: A participatory sensor system for monitoring air pollution in Sydney. In Proceedings of the 2013 IEEE 38th Conference on Local Computer Networks Workshops (LCN Workshops), Sydney, NSW, Australia, 21–24 October 2013; pp. 56–64.
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194.
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-Air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444.
- Hsieh, H.-P.; Lin, S.-D.; Zheng, Y. Inferring Air Quality for Station Location Recommendation Based on Urban Big Data. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 437–446.
- Chen, J.; Chen, H.; Pan, J.Z.; Wu, M.; Zhang, N.; Zheng, G. When big data meets big smog: A big spatio-temporal data framework for China severe smog analysis. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Orlando, FL, USA, 5–8 November 2013; pp. 13–22.
- Zhu, J.Y.; Sun, C.; Li, V.O.K. Granger-Causality-Based Air Quality Estimation with Spatio-Temporal (S-T) Heterogeneous Big Data. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 2015; pp. 612–617.
- Song, L.; Pang, S.; Longley, I.; Olivares, G.; Sarrafzadeh, A. Spatio-temporal PM2.5 prediction by spatial data aided incremental support vector regression. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 623–630.
- Hasenfratz, D.; Saukh, O.; Walser, C.; Hueglin, C.; Fierz, M.; Thiele, L. Pushing the spatio-temporal resolution limit of urban air pollution maps. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 69–77.
- United States Environmental Protection Agency. Available online: http://www3.epa.gov/airnow/aqi_brochure_02_14.pdf (accessed on 25 December 2015).
- China’s Ministry of Environmental Protection. Available online: http://kjs.mep.gov.cn/hjbhbz/bzwb/dqhjbh/jcgfffbz/201203/W020120410332725219541.pdf (accessed on 27 November 2015). (In Chinese)
- Wexler, H. The Role of Meteorology in Air Pollution, Monograph Series; World Health Organization: Geneva, Switzerland, 1961; pp. 46–49. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. In Breakthroughs in Statistics; Springer New York: New York, NY, USA, 1992; pp. 569–593. [Google Scholar]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- PM25.in: Air Quality Data Provider. Available online: http://pm25.in (accessed on 8 January 2016). (In Chinese)
- RP5.ru: Weather for 243 Countries of the World. Available online: http://rp5.ru (accessed on 8 January 2016).
- Baidu Map. Available online: http://map.baidu.com (accessed on 8 January 2016).
- Google Map. Available online: http://map.google.com (accessed on 8 January 2016).
- Breiman, L.; Cutler, A. Random Forests. Available online: https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm#ooberr (accessed on 25 November 2015).
- Weka 3: Data Mining Software in Java. Available online: http://www.cs.waikato.ac.nz/ml/weka/ (accessed on 25 November 2015).
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, Corvallis, OR, USA, 25–29 June 2006; pp. 233–240.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, R.; Yang, Y.; Yang, L.; Han, G.; Move, O.A. RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors 2016, 16, 86. https://doi.org/10.3390/s16010086
Yu R, Yang Y, Yang L, Han G, Move OA. RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors. 2016; 16(1):86. https://doi.org/10.3390/s16010086
Chicago/Turabian StyleYu, Ruiyun, Yu Yang, Leyou Yang, Guangjie Han, and Oguti Ann Move. 2016. "RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems" Sensors 16, no. 1: 86. https://doi.org/10.3390/s16010086
APA StyleYu, R., Yang, Y., Yang, L., Han, G., & Move, O. A. (2016). RAQ–A Random Forest Approach for Predicting Air Quality in Urban Sensing Systems. Sensors, 16(1), 86. https://doi.org/10.3390/s16010086