
A Dedicated Genetic Algorithm for Localization of Moving Magnetic Objects

Abstract
:1. Introduction
Genetic Algorithms
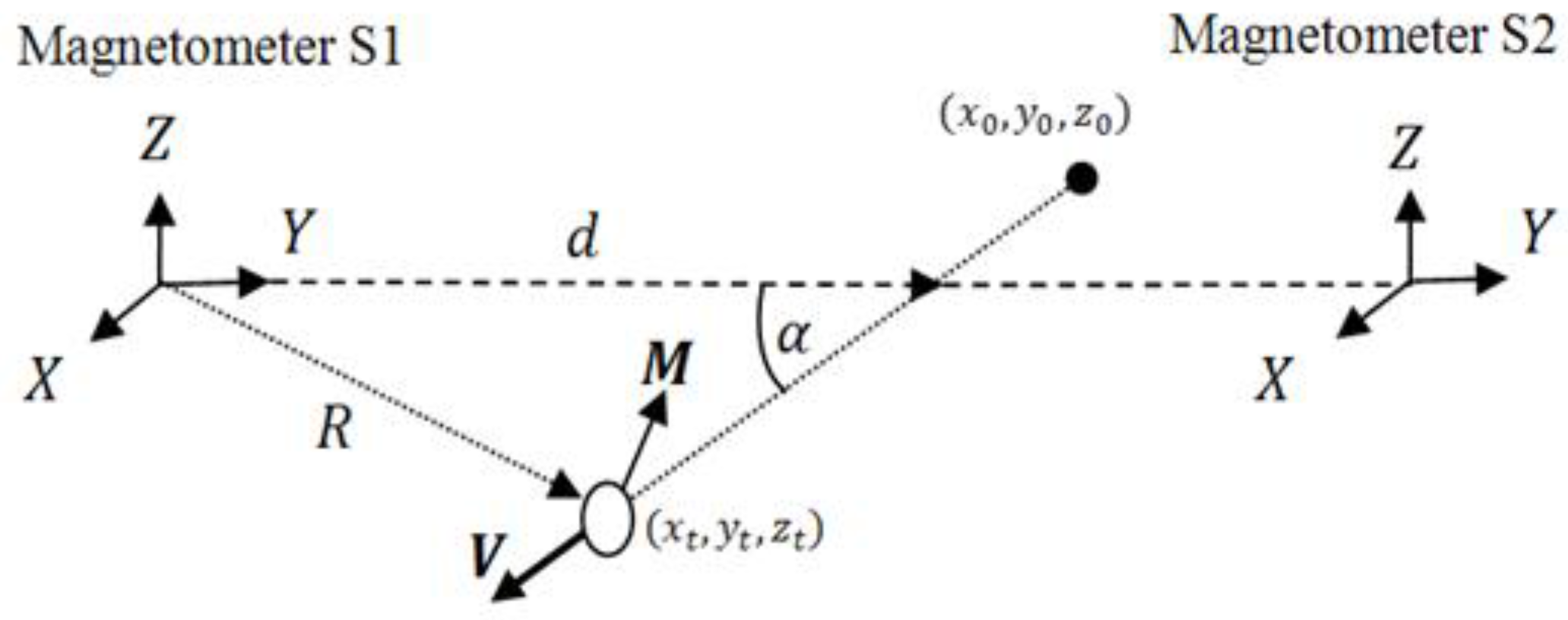
2. Experimental Section
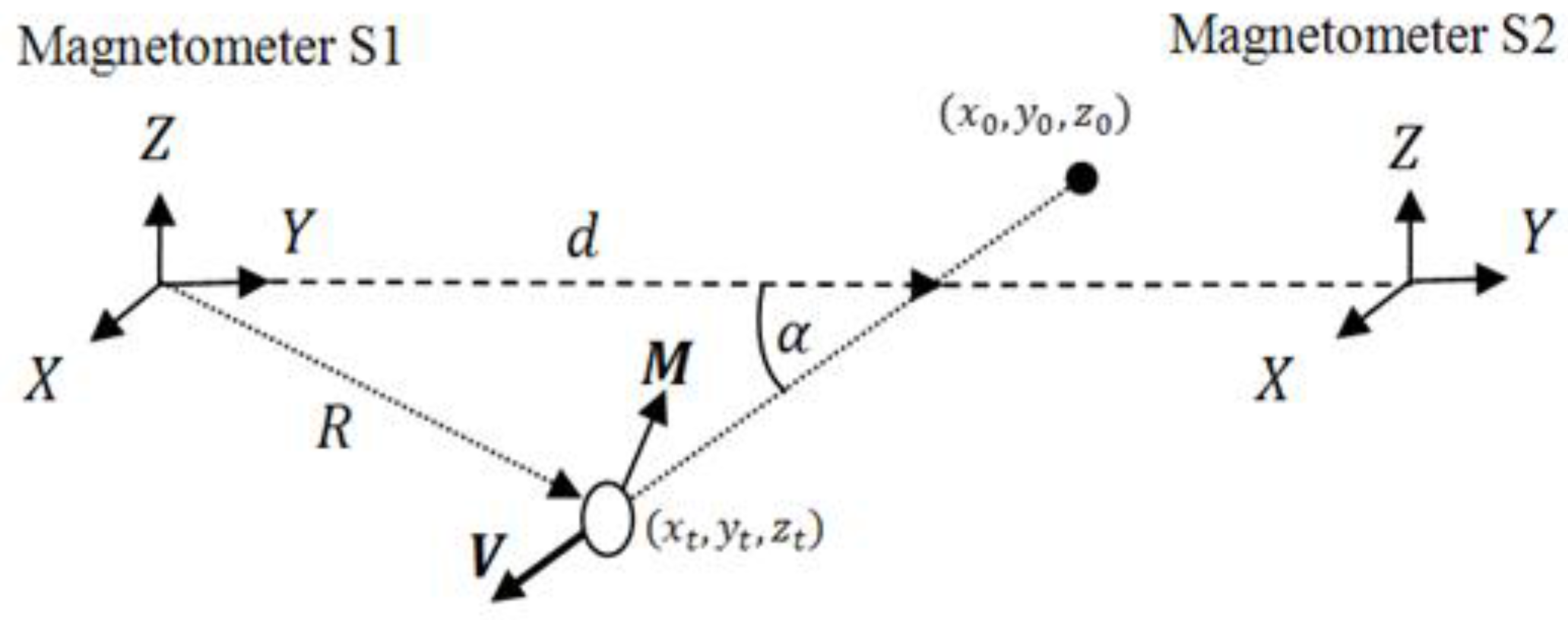
3. Genetic Algorithm Description
3.1. Data Preprocessing
3.2. Initial Population
3.3. Fitness Calculation
3.4. The Main GA Loop
- The generation index n exceeds the maximum allowed number Nmax.
- The best fitness exceeds a threshold value. Beyond this point no significant improvement of the results can be observed. Typical values range between 0.85 and 0.9.
- The best fitness has not changed significantly during the last past ten generations. The best fitness change is calculated according to the formula:
3.5. Implementation
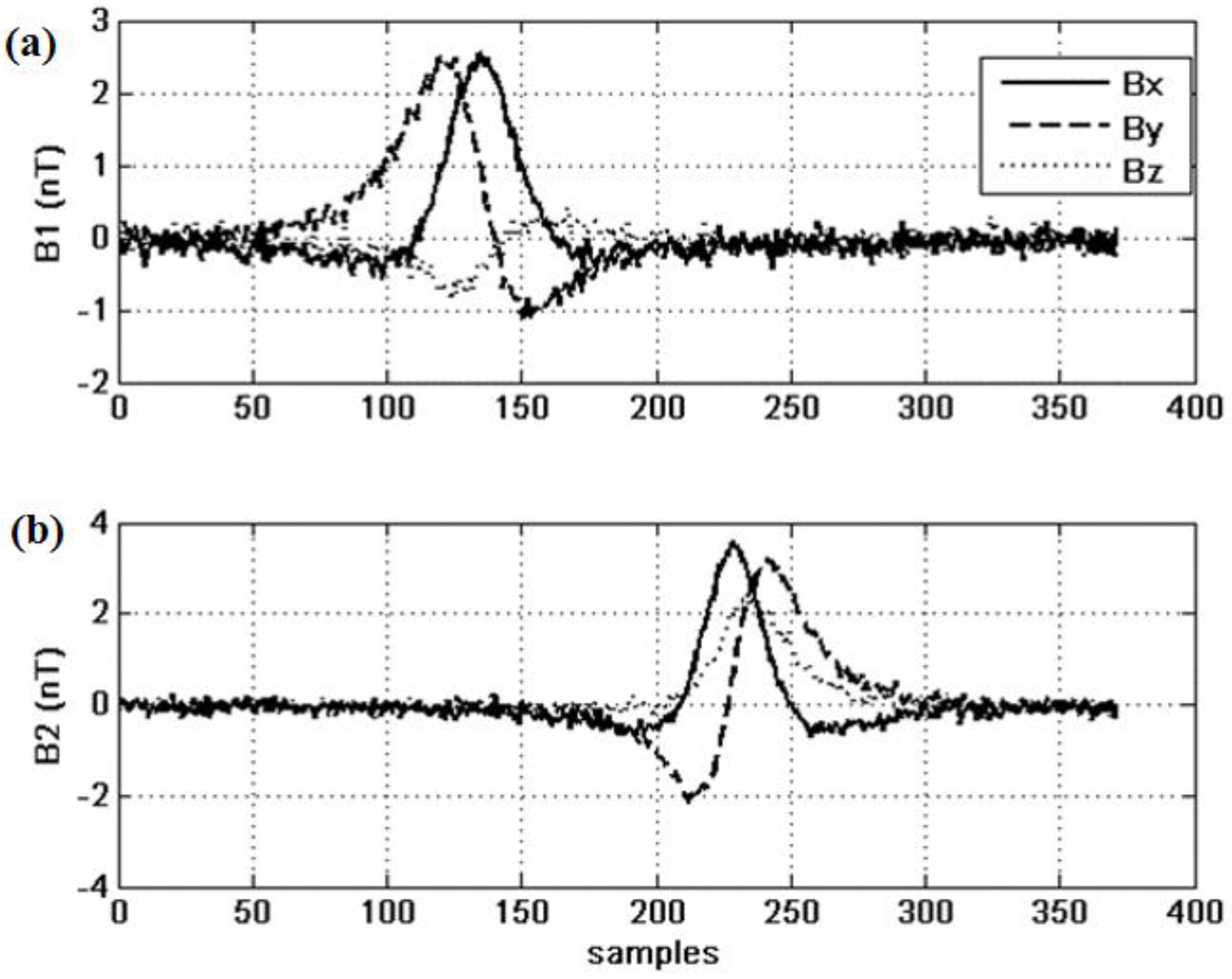
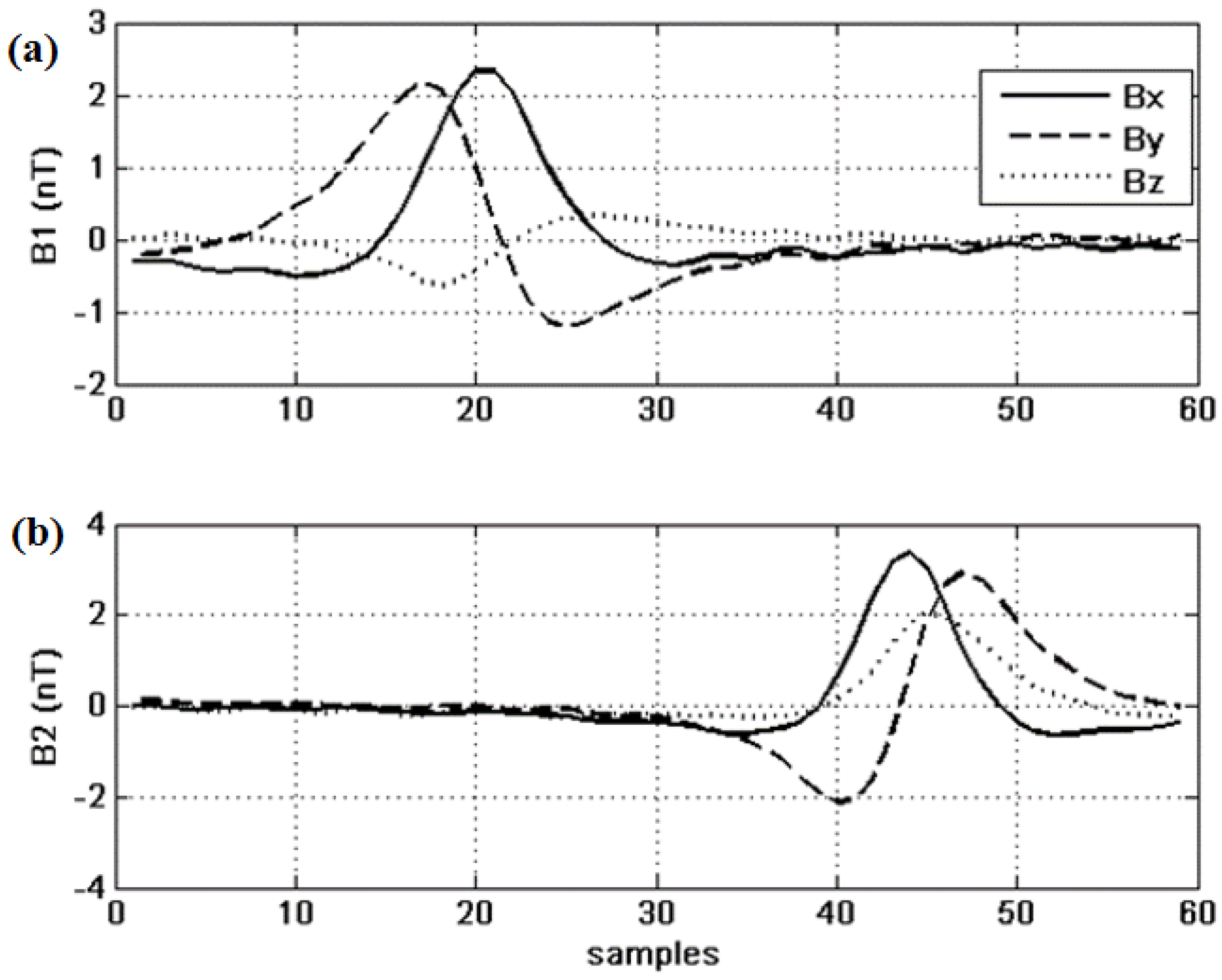
4. Results and Discussion
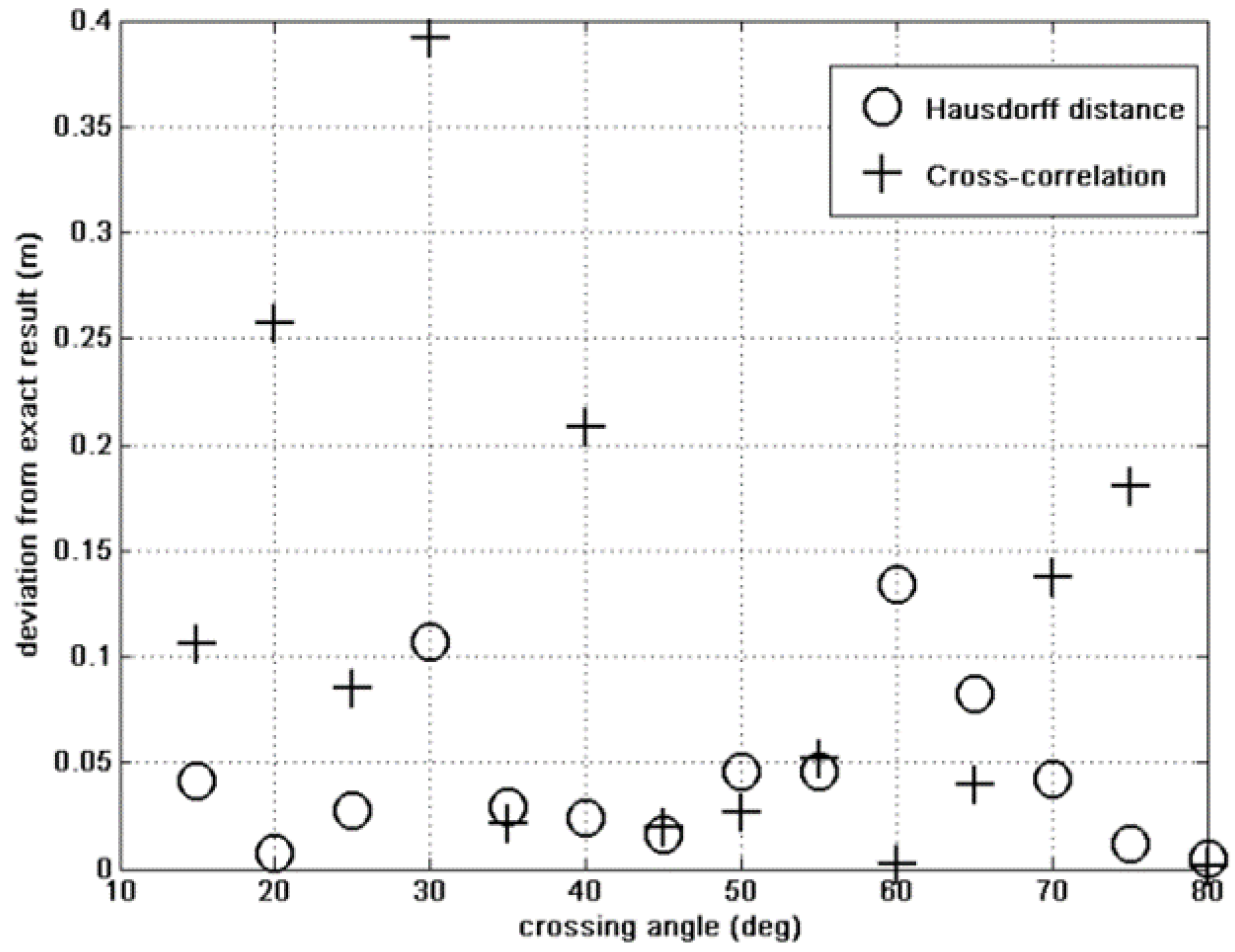
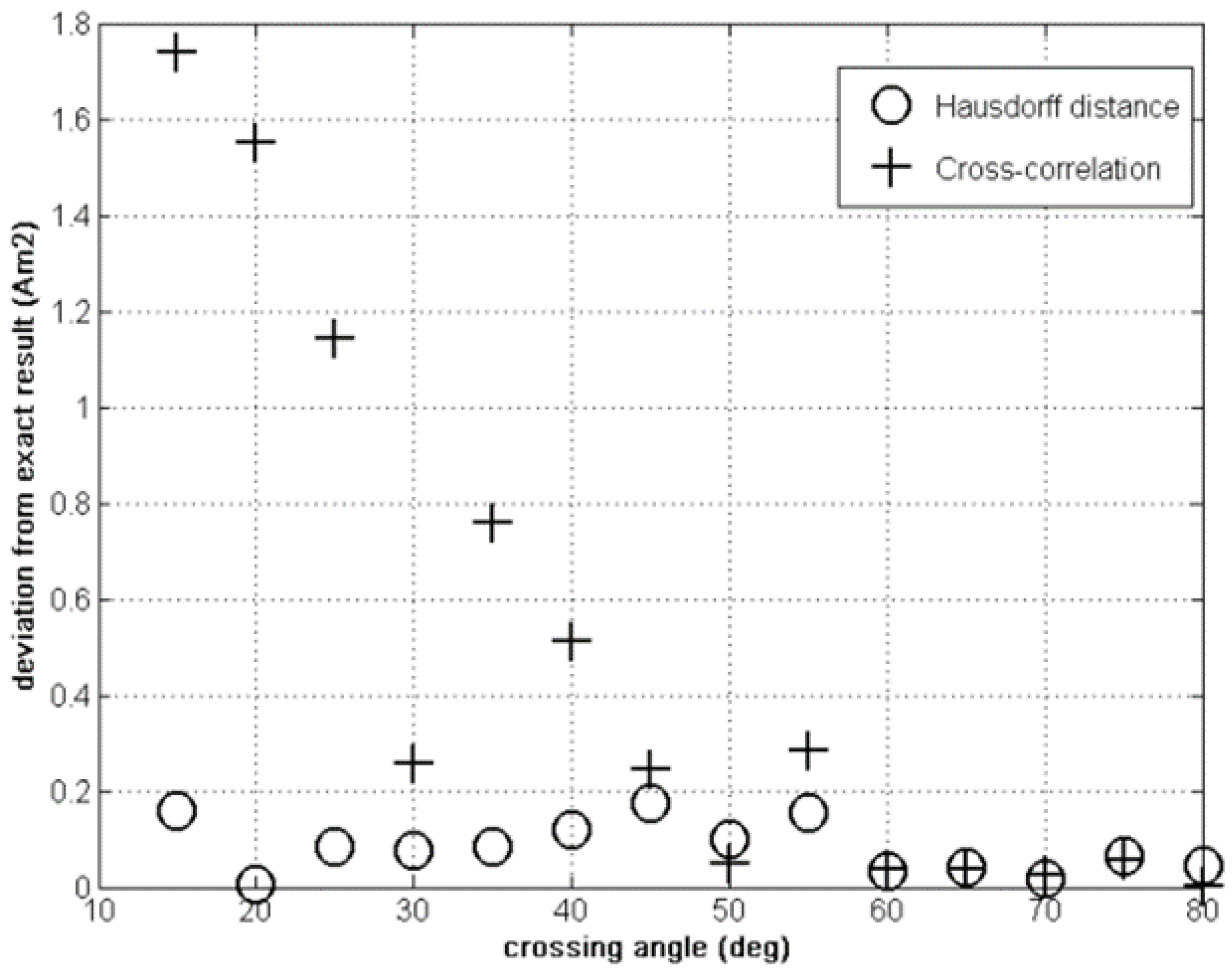
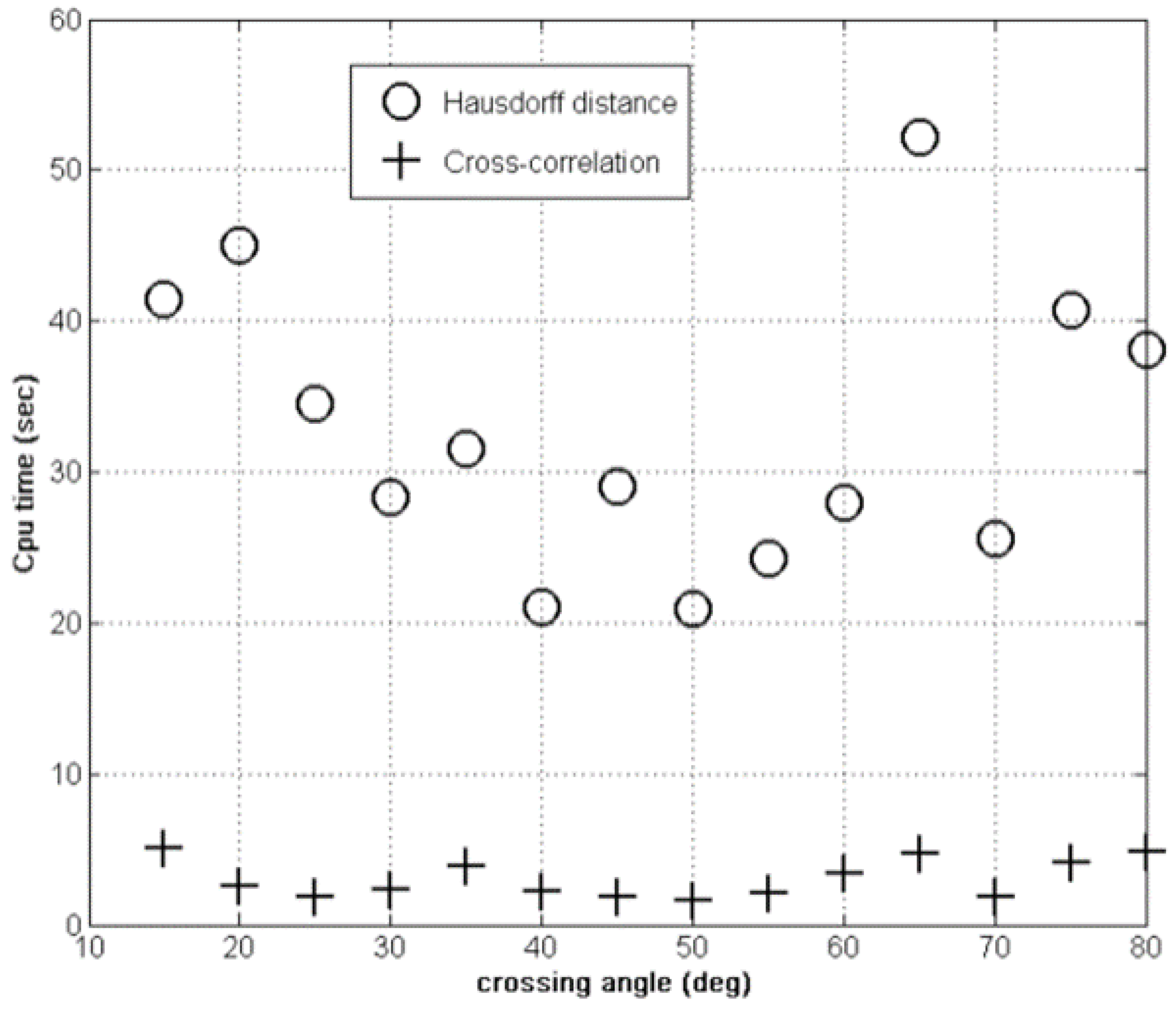
4.1. Hausdorff versus Cross-Correlation Fitness
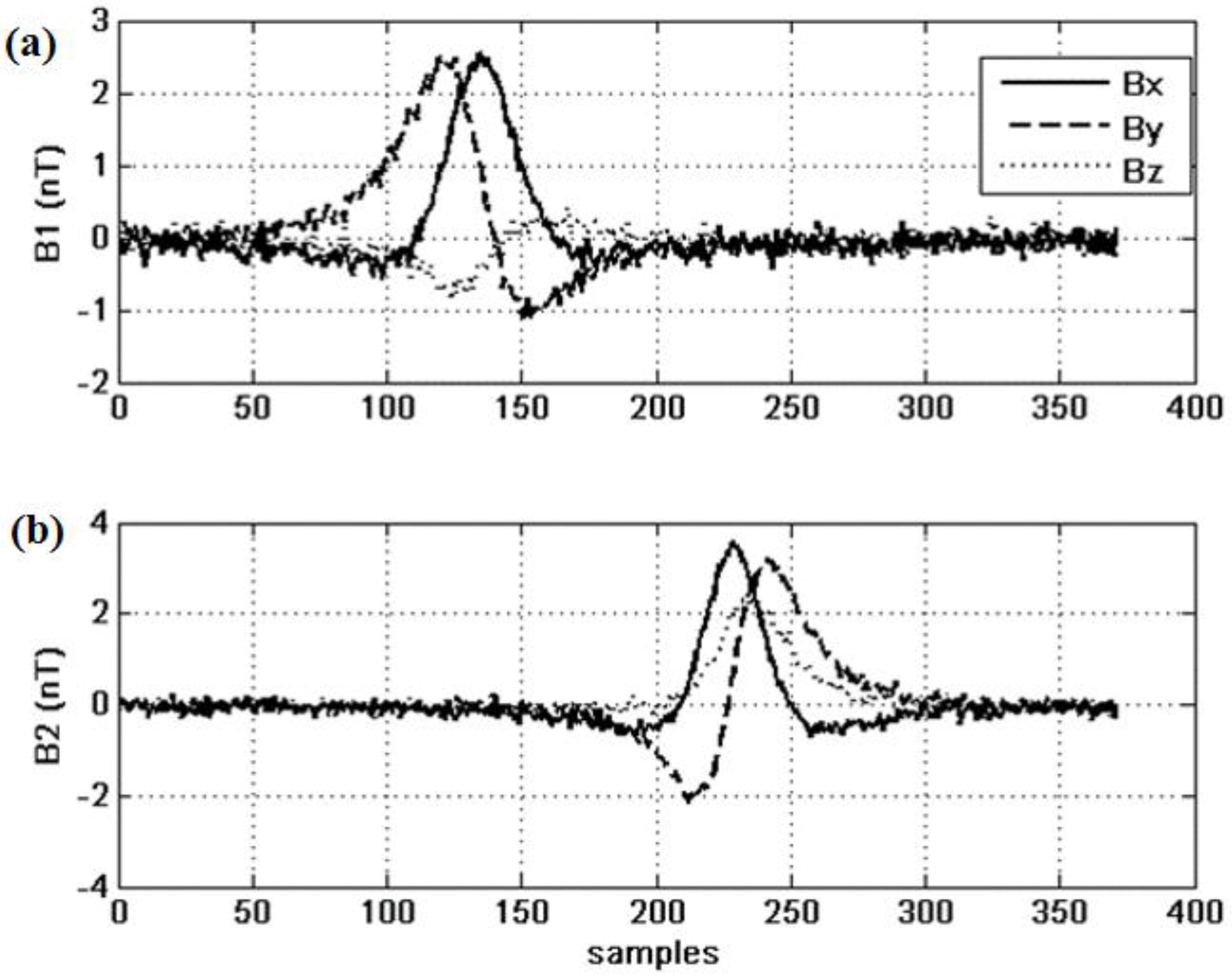
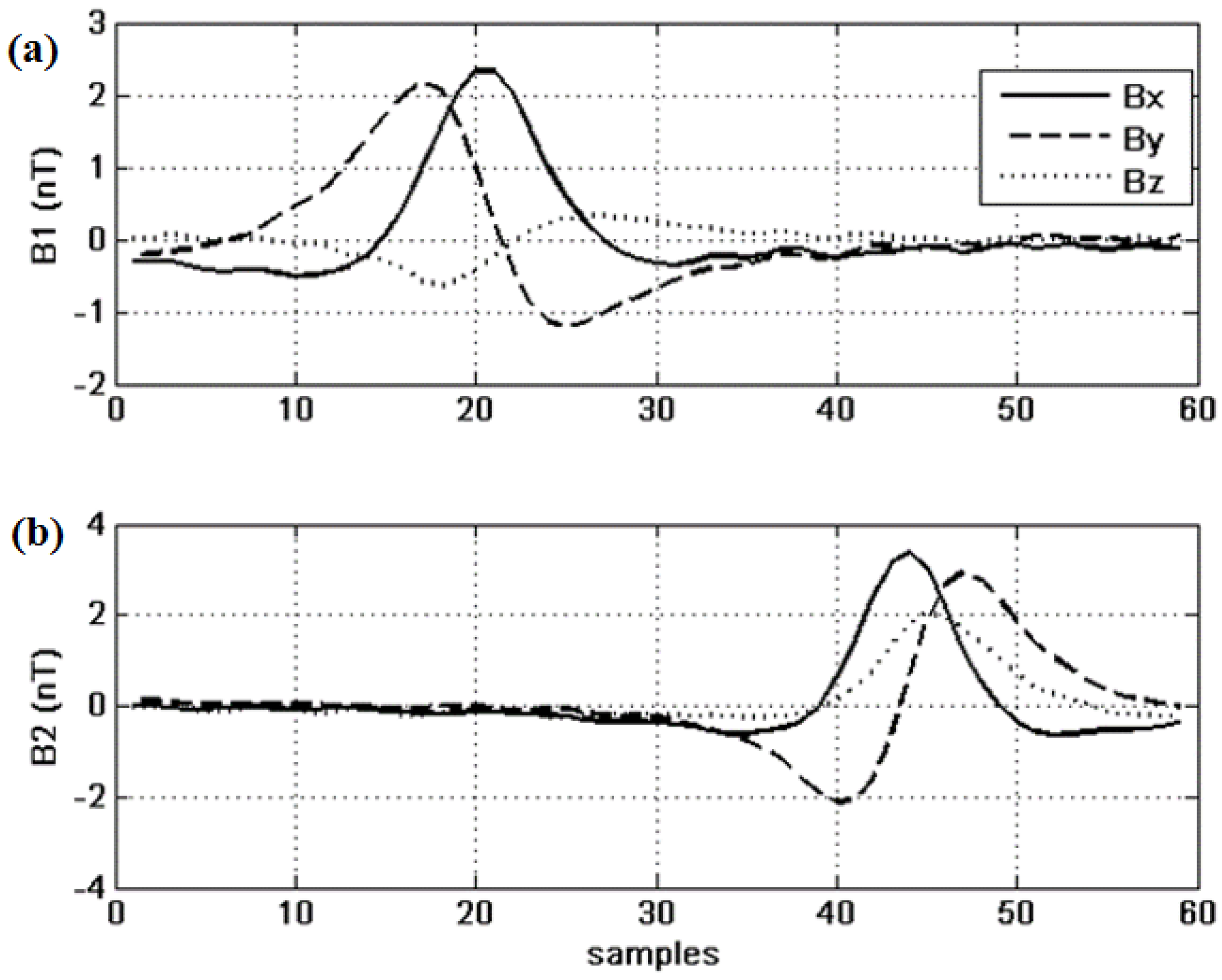
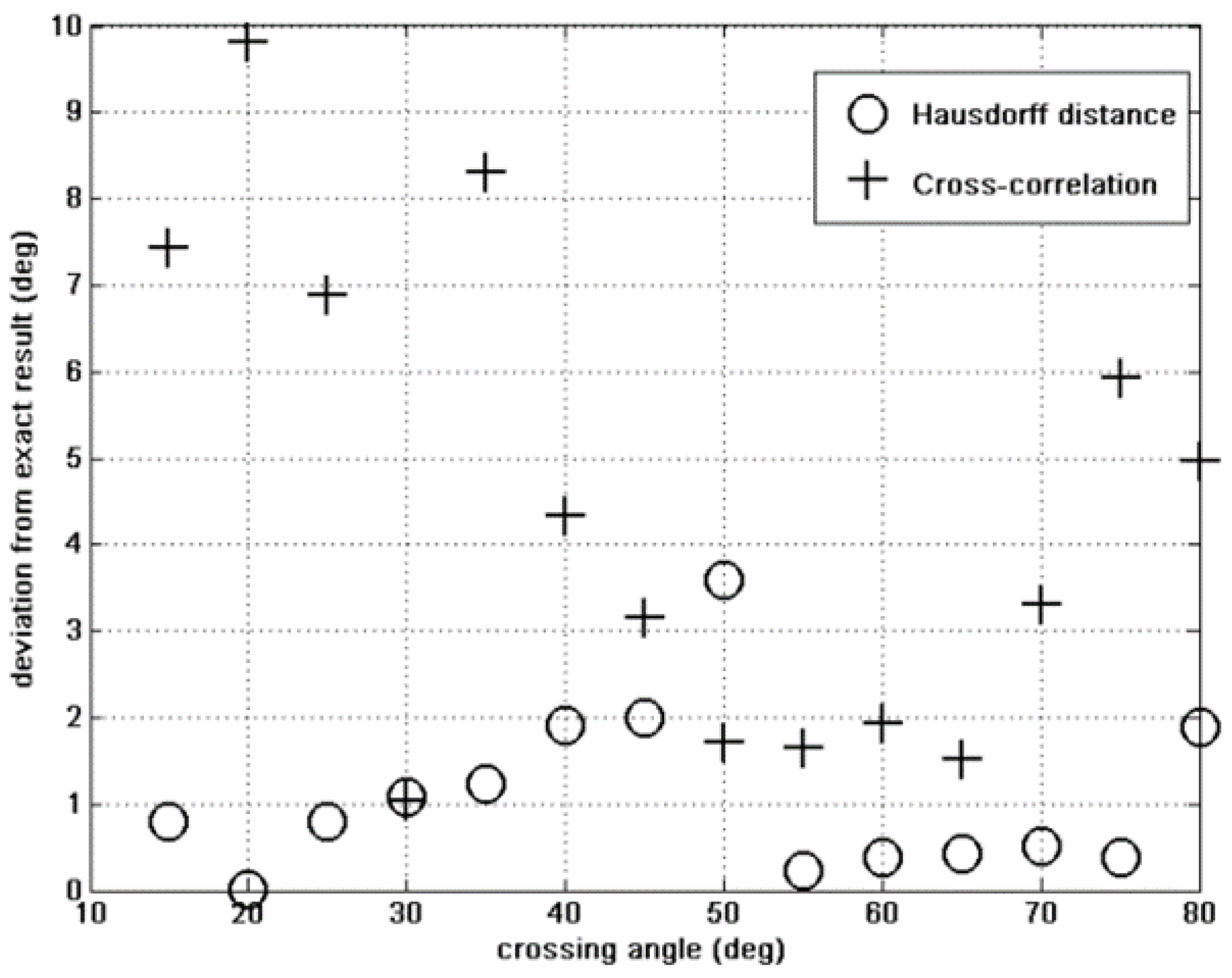
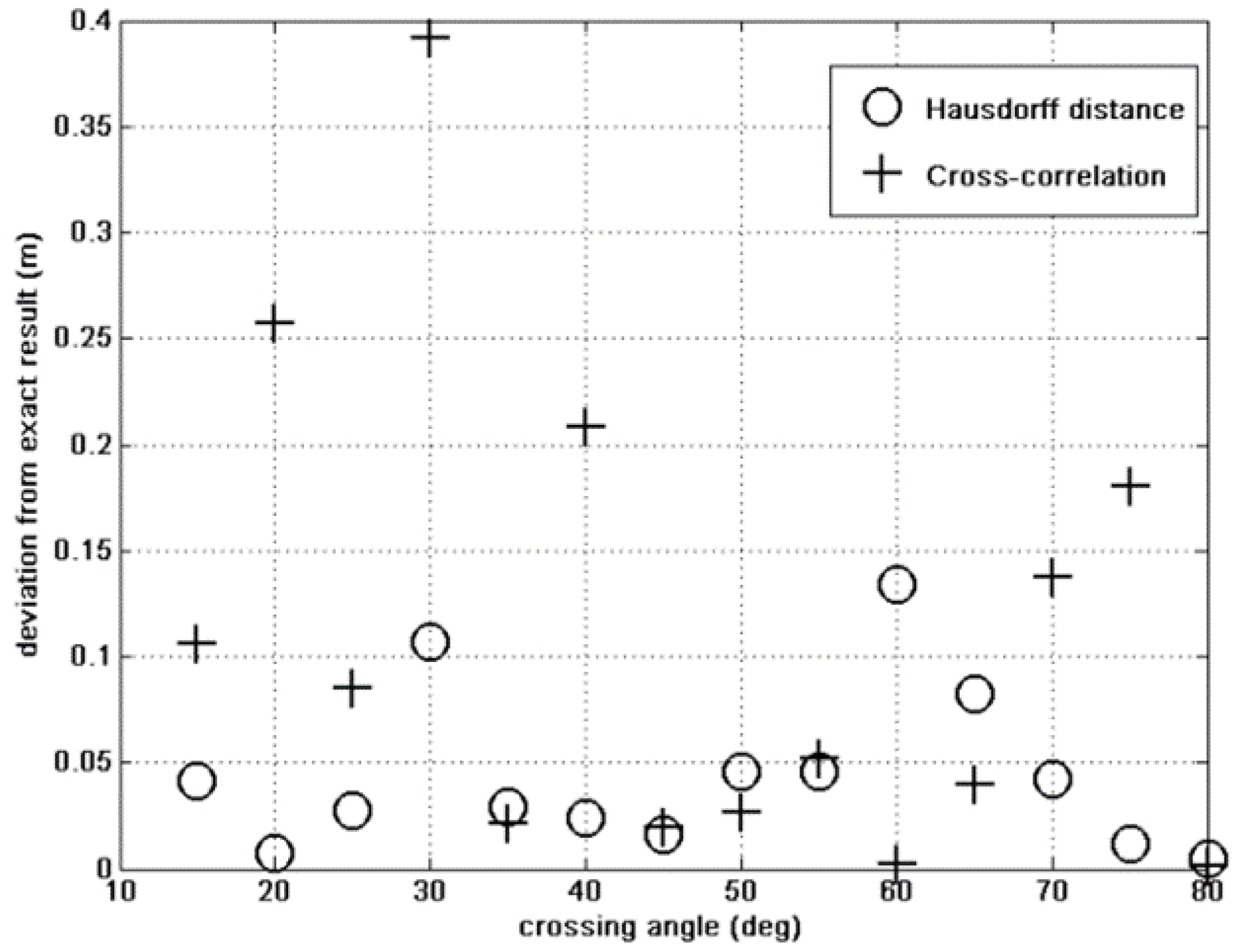

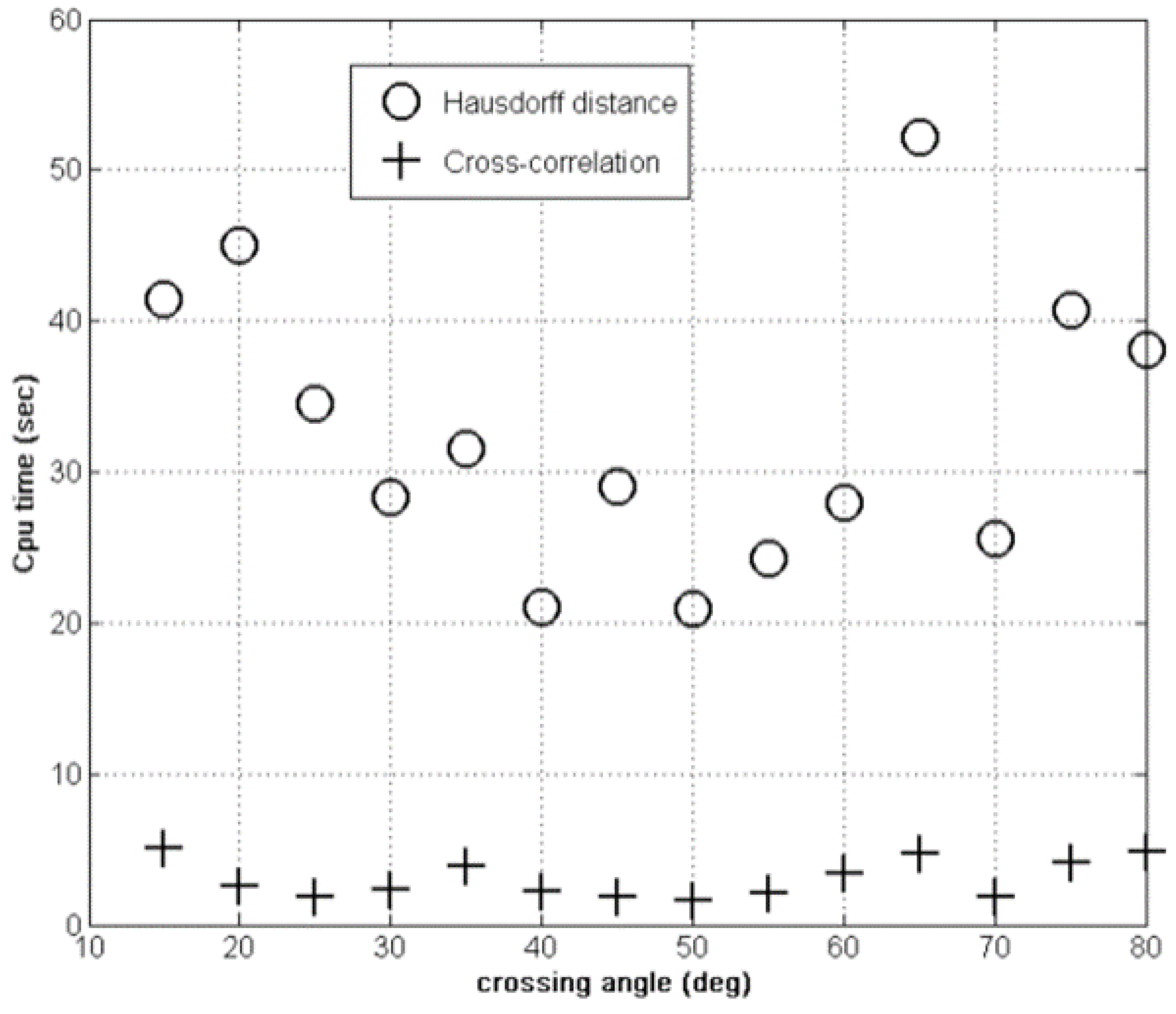
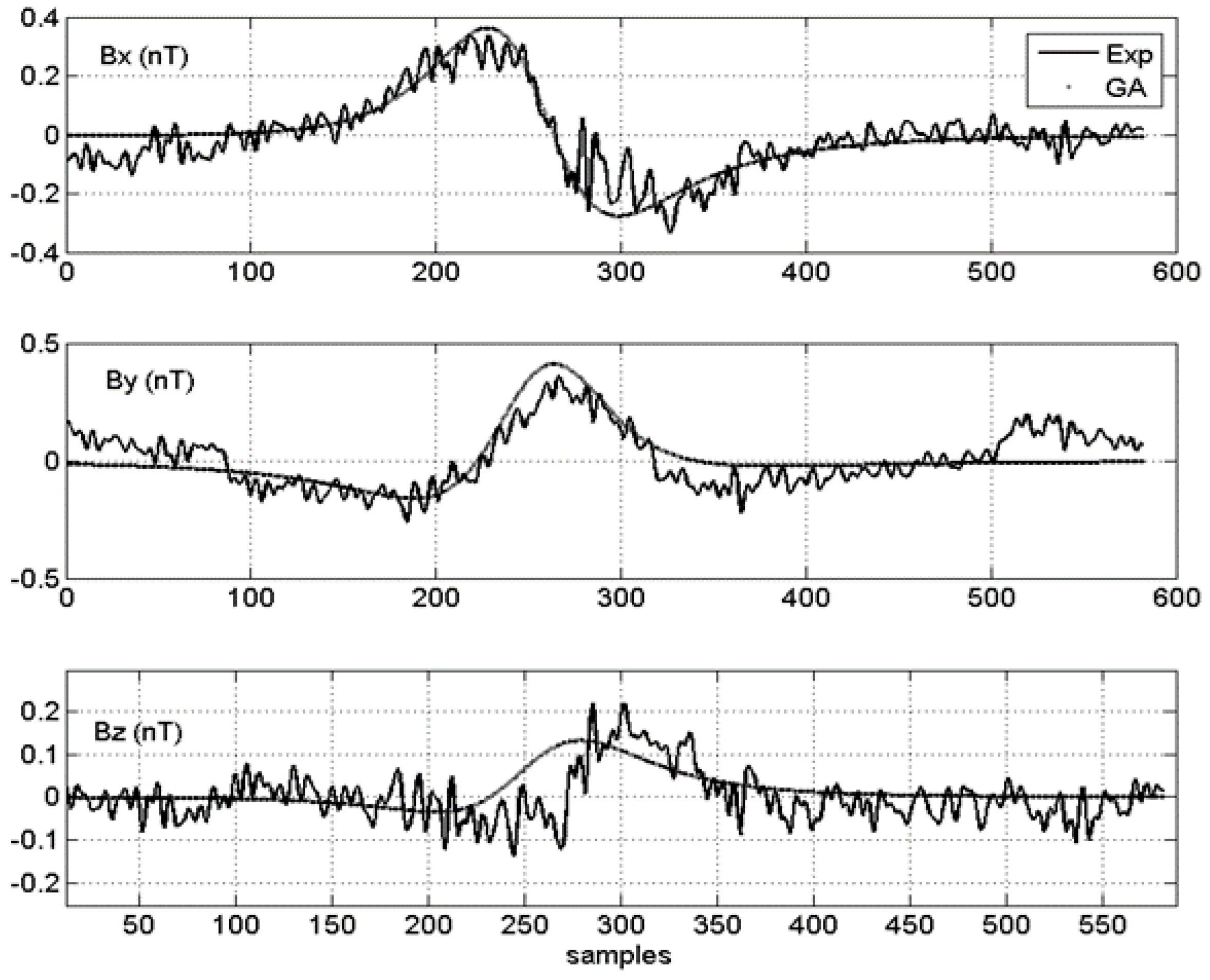
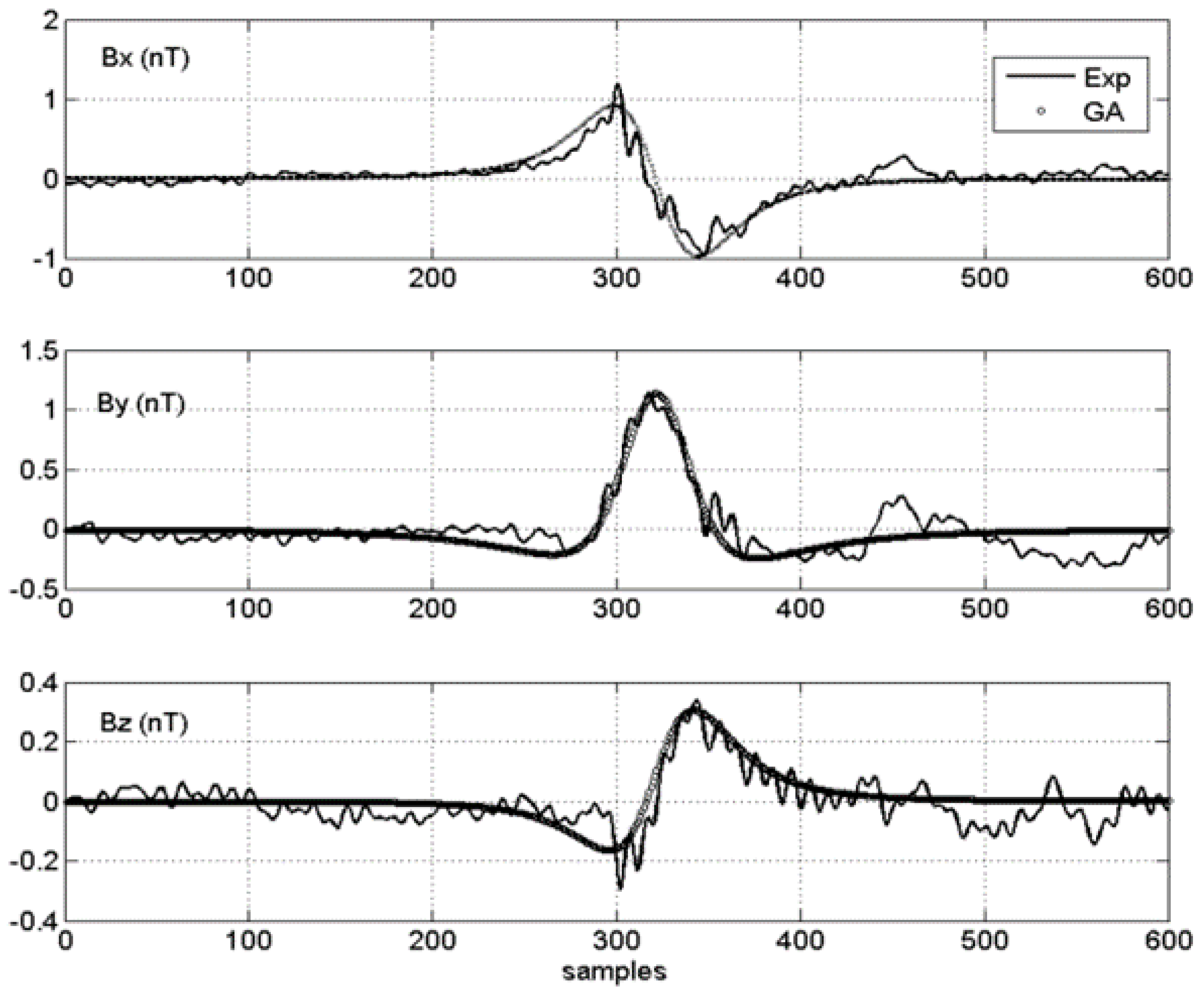
4.2. Results
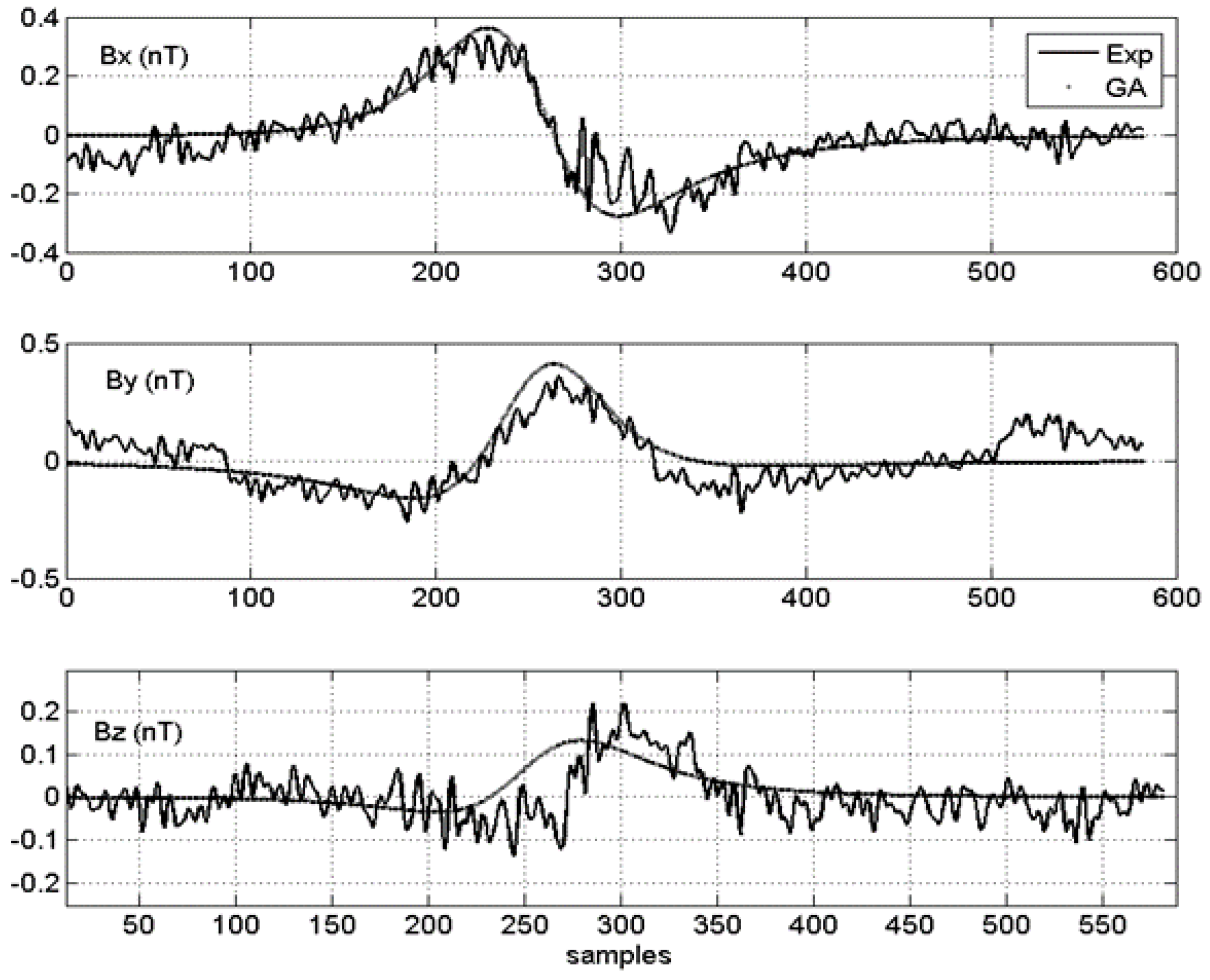
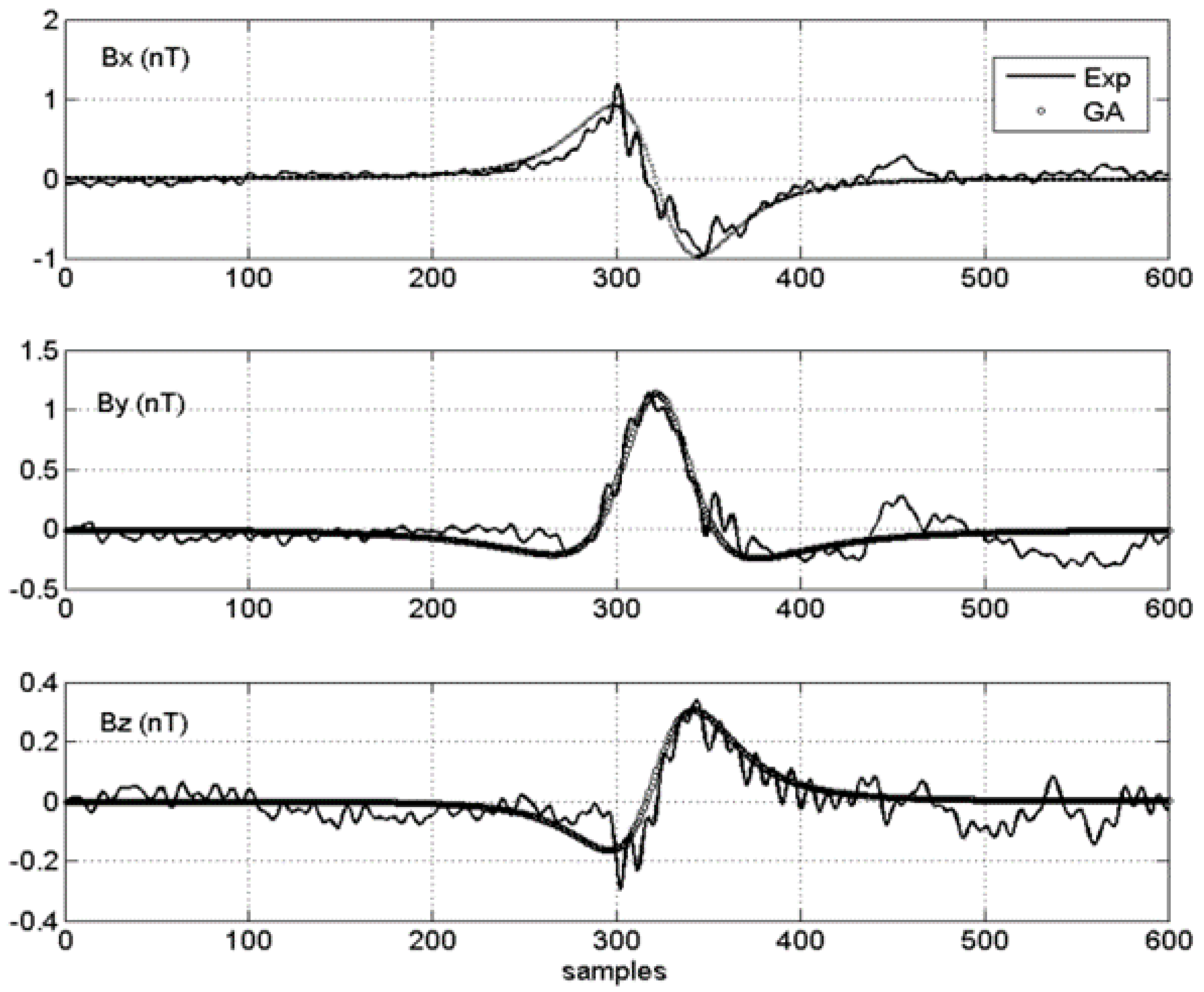

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR | # of Generations | Best Fitness (%) | Angle Offset (%) | Cross. Dist. Offset (m) | Moment Offset (mA2) |
|---|---|---|---|---|---|
| 1 | 164 | 65 | 18 | 2 | 0.2 |
| 5 | 85 | 80 | 3 | 0.8 | 0.1 |
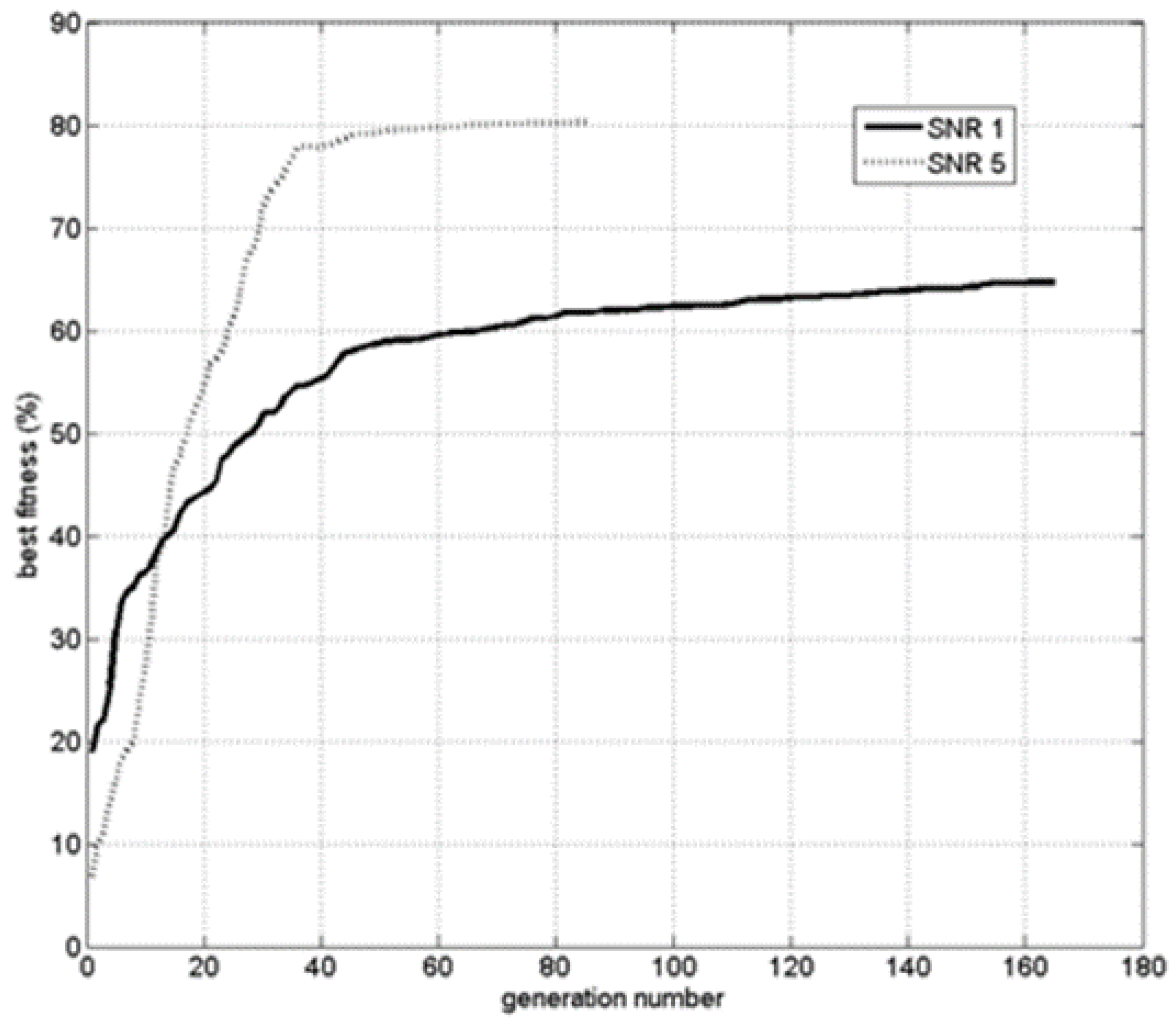
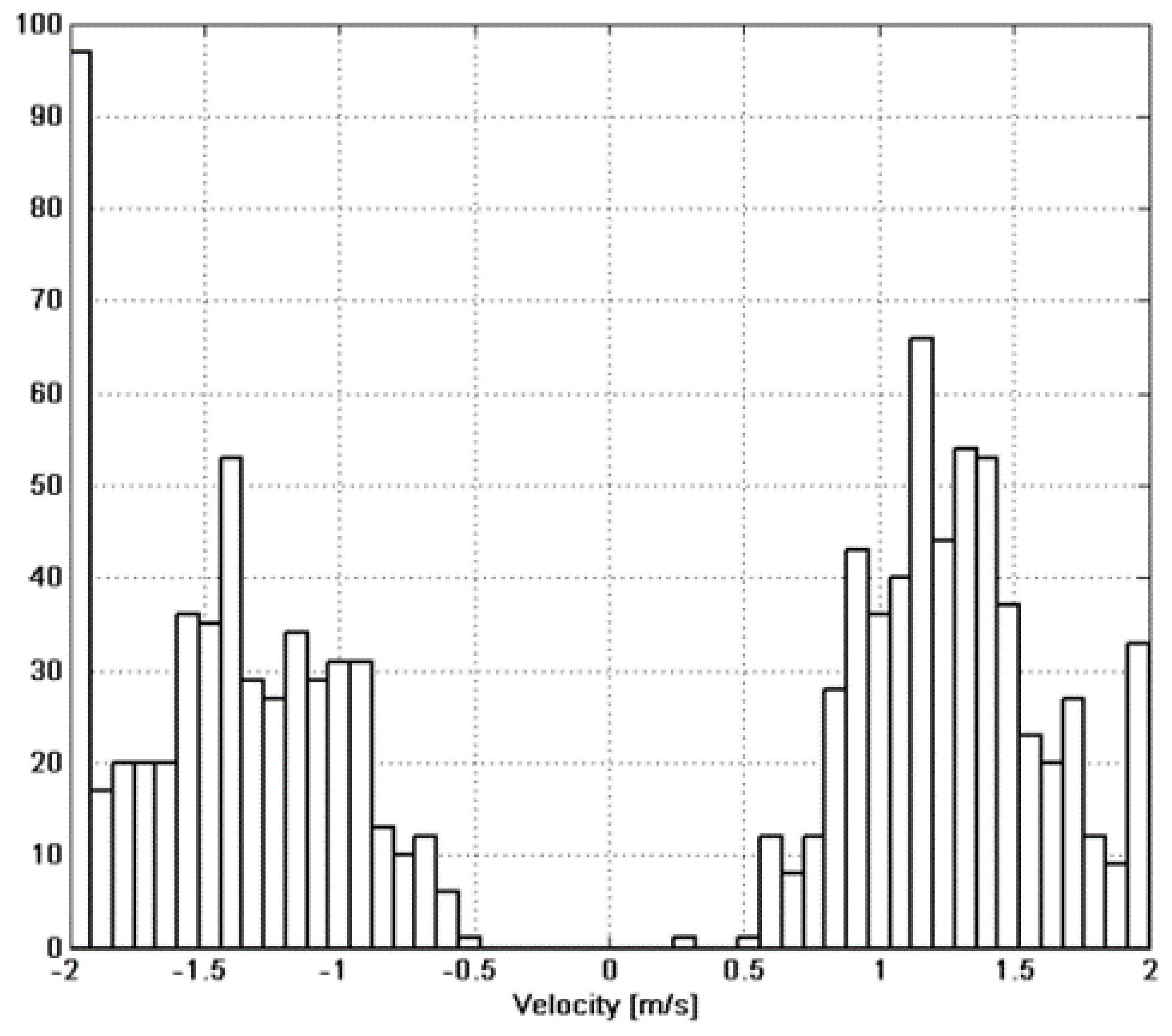
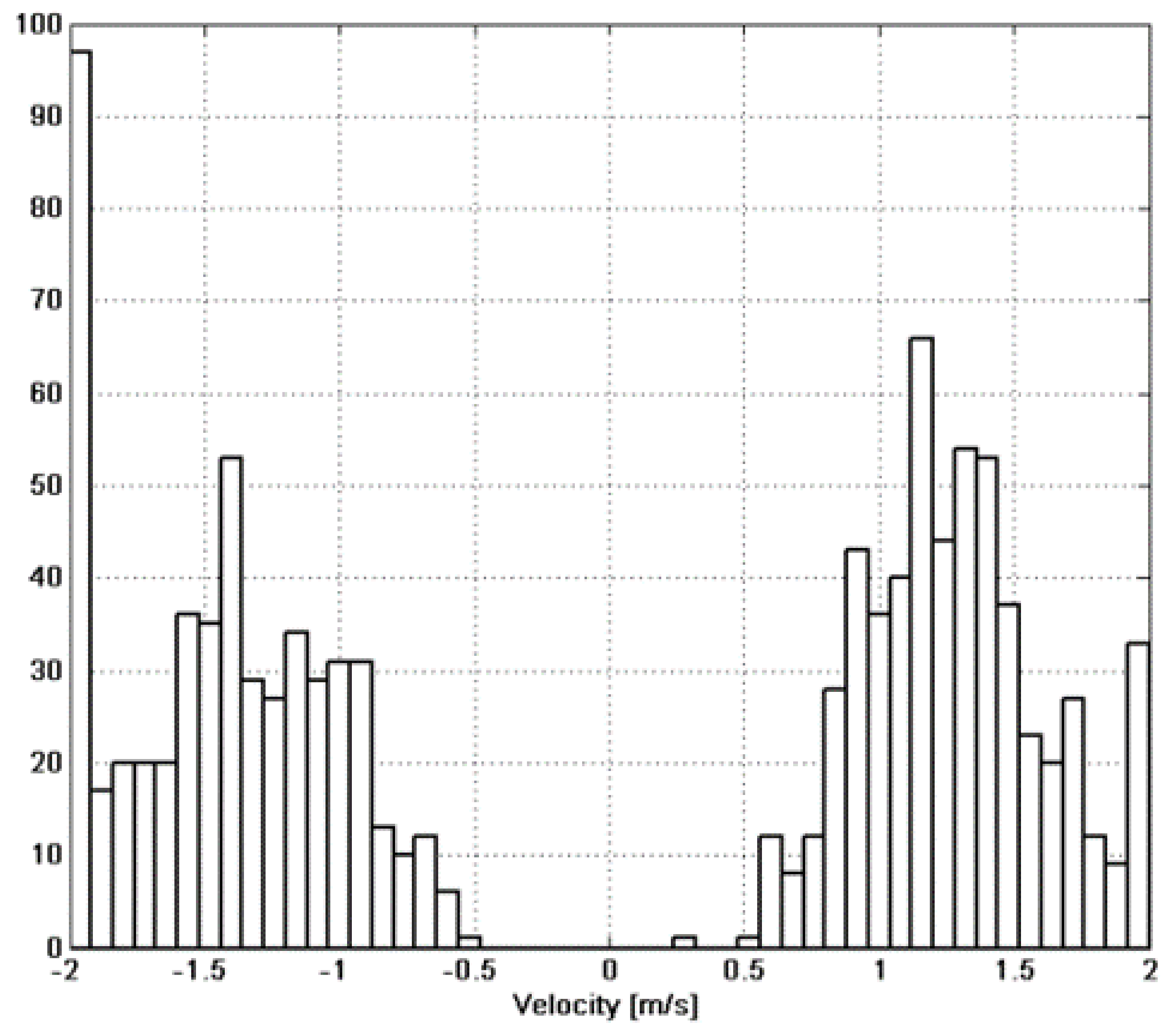
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Merlat, L.; Naz, P. Magnetic localization and identification of vehicles. Proc. SPIE 2003. [Google Scholar] [CrossRef]
- Salem, A.; Hamada, T.; Asahina, J.K.; Ushijima, K. Detection of unexploded ordnance (UXO) using marine magnetic gradiometer data. Explor. Geophys. 2005, 36, 97–103. [Google Scholar] [CrossRef]
- McAulay, A. Computerized model demonstrating magnetic submarine localization. IEEE Trans. Aerosp. Electron. Syst. 1977, 3, 246–254. [Google Scholar] [CrossRef]
- Alimi, R.; Geron, N.; Weiss, E.; Ram-Cohen, T. Ferromagnetic mass localization in check point configuration using a Levenberg Marquardt algorithm. Sensors 2009, 9, 8852–8862. [Google Scholar] [CrossRef] [PubMed]
- Levenberg, K. A method for the solution of certain non–linear problems in least squares. Q. J. Appl. Math. 1944, 2, 164–168. [Google Scholar]
- Marquardt, D.W. An Algorithm for Least-Squares Estimation of Nonlinear Parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: a cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley Professional: Boston, MA, USA, 1989. [Google Scholar]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer: Berlin, Germany, 1996. [Google Scholar]
- Mahfoud, S.W.; Goldberg, D.E. Parallel recombinative simulated annealing: A genetic algorithm. Parallel Comput. 1995, 21, 1–28. [Google Scholar] [CrossRef]
- Min, H.; Smolinski, T.G.; Boratyn, G.M. A Genetic Algorithm-Based Data Mining Approach to Profiling the Adopters and Non-Adopters of E-Purchasing. Available online: ci.uofl.edu/rork/knowledge/publications/min_iri01.pdf (accessed on 17 September 2015).
- Lohn, J.D.; Colombano, S.P. A circuit representation technique for automated circuit design. IEEE Trans. Evol. Comput. 1999, 3, 205–218. [Google Scholar] [CrossRef]
- Alander, J.T. An Indexed Bibliography of Genetic Algorithms in Machine Learning; University of Vaasa: Vaasa, Finland, 2012. [Google Scholar]
- Levine, D. Application of a hybrid genetic algorithm to airline crew scheduling. Comput. Oper. Res. 1996, 23, 547–558. [Google Scholar] [CrossRef]
- Deaven, D.M.; Ho, K.M. Molecular geometry optimization with a genetic algorithm. Phys. Rev. Lett. 1995, 75, 288–291. [Google Scholar] [CrossRef] [PubMed]
- Cunha, A.G.; Covas, J.A.; Oliveira, P. Optimization of polymer extrusion with genetic algorithms. IMA J. Manag. Math. 1998, 9, 267–277. [Google Scholar] [CrossRef]
- Kundu, S.; Seto, K.; Sugino, S. Genetic algorithm application to vibration control of tall flexible structures. In Electronic Design, Test and Applications, 2002, Proceedings of the 1st IEEE International Workshop, Christchurch, New Zealand, 29–31 January 2002; pp. 333–337.
- Chen, K.C.; Hsieh, I.; Wang, C.A. A Genetic Algorithm for Minimum Tetrahedralization of a Convex Polyhedron. Ph.D. Thesis, Memorial University of Newfoundland, NL, Canada, 2003. [Google Scholar]
- Mahfoud, S.; Mani, G. Financial forecasting using genetic algorithms. Appl. Artif. Intell. 1996, 10, 543–566. [Google Scholar] [CrossRef]
- Yuret, D.; Maza, M. A genetic algorithm system for predicting the OEX. Tech. Anal. Stock. Commod. 1994, 6, 58–64. [Google Scholar]
- Smigrodzki, R.; Goertzel, B.; Pennachin, C.; Coelho, L.; Prosdocimi, F.; Parker, W.D. Genetic algorithm for analysis of mutations in Parkinson’s disease. Artif. Intell. Med. 2005, 35, 227–241. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Jiang, Y.; Zheng, J.; Peng, C.; Xiao, S. Discovering Critical Diagnostic Features for Heart Diseases with a Hybrid Genetic Algorithm. In Proceedings of the International Conference on Mathematics and Engineering Techniques in Medicine and Biological Sciences, METMBS 2003, Las Vegas, NV, USA, 23–26 June 2003; pp. 406–409.
- Vinterbo, S.; Ohno-Machado, L. A genetic algorithm approach to multi-disorder diagnosis. Artif. Intell. Med. 2000, 18, 117–132. [Google Scholar] [CrossRef]
- Sharples, N.P. Evolutionary Approaches to Adaptive Protocol Design. Ph.D. Thesis, University of Sussex, Brighton, UK, 2003. [Google Scholar]
- Kumar, A.; Pathak, R.M.; Gupta, M.C. Genetic algorithm based approach for designing computer network topology. In Proceedings of the 1993 ACM conference on Computer science, New York, NY, USA, 1 March 1993; pp. 358–365.
- Noshadi, A.; Shi, J.; Lee, W.S.; Shi, P.; Kalam, A. Genetic algorithm-based system identification of active magnetic bearing system: A frequency-domain approach. In Control & Automation (ICCA), Proceedings of the 11th IEEE International Conference, Taichung, Taiwan, 18–20 June 2014; pp. 1281–1286.
- Noshadi, A.; Shi, J.; Lee, W.S.; Shi, P.; Kalam, A. Optimal PID-type fuzzy logic controller for a multi-input multi-output active magnetic bearing system. Neural Comput. Appl. 2015. [Google Scholar] [CrossRef]
- Zolfagharian, A.; Noshadi, A.; Khosravani, M.R.; Zain, M.Z.M. Unwanted noise and vibration control using finite element analysis and artificial intelligence. Appl. Math. Model. 2014, 38, 2435–2453. [Google Scholar] [CrossRef]
- Wynn, W.M. Detection, localization, and characterization of static magnetic dipole sources. In Detection and Identification of Visually Obscured Targets; Taylor an Francis: Philadelphia, PA, USA, 1999; pp. 337–374. [Google Scholar]
- Costa, M.C.; Cauffet, G.; Coulomb, J.-L.; Bongiraud, J.-P.; le Thiec, P. Localization and Identification of a Magnetic Dipole by the Application of Genetic Algorithms. In Proceedings of Workshop on Optimization and Inverse Problems in Electromagnetism-OIPE 2000, Torino, Italy, 25–27 September 2000; pp. 25–26.
- Ginzburg, B.; Frumkis, L.; Kaplan, B.Z.; Sheinker, A.; Salomonski, N. Investigation of advanced data processing technique in magnetic anomaly detection systems. Int. J. Smart Sens. Intell. Ststems 2008, 1, 110–122. [Google Scholar]
- Rao, K.R.; Yip, P.; Rao, K.R. Discrete Cosine Transform: Algorithms, Advantages, Applications; Academic Press: Boston, MA, USA, 1990. [Google Scholar]
- Prescott, E.C.; Rodrick, R.J. Postwar U.S. Business Cycles: An Empirical Investigation. J. Money. Credit. Bank. 1997, 29, 1–16. [Google Scholar]
- Nelson, A.L.; Barlow, G.J.; Doitsidis, L. Fitness functions in evolutionary robotics: A survey and analysis. Rob. Auton. Syst. 2009, 57, 345–370. [Google Scholar] [CrossRef]
- Aronov, B.; Har-Peled, S.; Knauer, C.; Wang, Y.; Wenk, C. Fréchet distance for curves, revisited. In Algorithms–ESA 2006; Springer-Verlag: Berlin Heidelberg, Germany, 2006; pp. 52–63. [Google Scholar]
- Gómez, A.; Polo, C.; Vázquez, M.; Chen, D. Directionally alternating domain wall propagation in bistable amorphous wires. Appl. Phys. Lett. 1993, 62, 108–109. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alimi, R.; Weiss, E.; Ram-Cohen, T.; Geron, N.; Yogev, I. A Dedicated Genetic Algorithm for Localization of Moving Magnetic Objects. Sensors 2015, 15, 23788-23804. https://doi.org/10.3390/s150923788
Alimi R, Weiss E, Ram-Cohen T, Geron N, Yogev I. A Dedicated Genetic Algorithm for Localization of Moving Magnetic Objects. Sensors. 2015; 15(9):23788-23804. https://doi.org/10.3390/s150923788
Chicago/Turabian StyleAlimi, Roger, Eyal Weiss, Tsuriel Ram-Cohen, Nir Geron, and Idan Yogev. 2015. "A Dedicated Genetic Algorithm for Localization of Moving Magnetic Objects" Sensors 15, no. 9: 23788-23804. https://doi.org/10.3390/s150923788
APA StyleAlimi, R., Weiss, E., Ram-Cohen, T., Geron, N., & Yogev, I. (2015). A Dedicated Genetic Algorithm for Localization of Moving Magnetic Objects. Sensors, 15(9), 23788-23804. https://doi.org/10.3390/s150923788