1. Introduction
Biometric systems are based on the subject’s characteristics to allow his/her identification [
1]. The main biometric systems use elements such as fingerprints, retina, face, voice,
etc. to characterize people and then classify them for subsequent identification and validation. Each of these systems requires the use of specific sensors to obtain the desired characteristics of the subject. Video cameras are often used as sensors to identify subjects or property although a radar could also be used to obtain the shape of a subject through reflection [
2,
3]. There are accurate and reliable classification systems based on acoustic radars:
Animal echolocation, developed by mammals such as bats, whales and dolphins through specific waveforms [
4,
5], or the identification of different types of flowers by other species [
6].
Acoustic signatures used in passive sonar systems [
7,
8], which analyze the signal received by a target in the time-frequency domain.
There is little literature on the use of an acoustic radar as a biometric system for human identification and an ultrasonic band rather than an audible frequency band is usually employed [
9,
10]. In previous works, the authors developed multisensor surveillance and tracking systems based on acoustic arrays and image sensors [
11,
12]. In another line of work, making the most of the adquired experience in acoustic arrays and image sensors, the authors developed a biometric identification system based on the acoustic images acquired with an electronically scanned array [
13]. The system tries to discriminate subjects in terms of their acoustic image, directly related to the subject’s shape, height and geometrical characteristics. These characteristics are considered “soft biometrics” and they used to be used along with other “hard biometics” (e.g., fingerprints) in order to uniquely identify a person.
The system obtained acoustic images by scanning the subjects in four frequencies of the acoustic band and in four different positions, defining an acoustic profile that comprises all of these images. Subsequently, the acoustic profile was compared to previously stored profiles to identify the subject. In this first system, Mean Square Error (MSE) between two images of the same frequency and position is used to compare the acoustic profiles, defining a global error as the sum of the errors associated with each image of the profile. Using the Equal Error Rate (EER) as a quality indicator, this system obtained an EER value of 6.22%, such as other emerging biometric identification systems [
14,
15,
16,
17].
In a later work [
18], the authors analyzed the contribution of each acoustic image—associated with a frequency and position—to the performance of the biometric system, finding that each image provides different degrees of information. Two main conclusions were obtained:
Each set of images associated to certain frequency provides different information, improving the system performance, thus, the number of frequencies used should be increased.
Information associated to certain subject positions only provides redundant information and does not improve the quality of the system, thus, the number of positions used should be decreased.
In a second stage of the analysis, a new global error function was proposed by weighting the MSE error of each image proportionately to the information that it provides. In this case, an EER value of 4% was obtained. The use of more efficient classification algorithms would provide an improvement in the classification error, which also represents an EER.
Since Support Vector Machines (SVMs) are algorithms that currently define Machine Learning [
19], it was decided to work with them in the classification tasks. Furthermore, SVMs are the unique algorithms used in the classification capable of working with high-dimensional data, such as the case of the acoustic profiles used.
This paper presents an improved biometric system that uses a SVM algorithm for classification and identification of subject. Since high dimensionality of acoustic profiles exponentially increases the computational burden of SVM classifiers, preprocessing and feature extraction techniques have been designed and implemented to improve the classifier performance. This new system is based on the results obtained in previous studies [
18].
In
Section 2, SVM classification algorithms and associated training techniques are explained.
Section 3 describes the biometric system, including acquisition, preprocessing and classification systems. In
Section 4, an analysis of the results is done and finally,
Section 5 presents the final conclusions.
2. Support Vector Machines
SVMs carry out binary classification by constructing a hyperplane defined by the weight vector
w and the bias term
b, as shown in
Figure 1, so samples of different classes will be divided by a separation, as wide as possible. Thereby, SVM algorithms are called maximum margin classifiers, being γ the margin of separation.
Figure 1.
Hyperplane for binary classification.
Figure 1.
Hyperplane for binary classification.
Based on a training set of
l known samples formed by data vectors
xi and the corresponding class labels
yi to which they belong:
Machine Learning algorithms obtain the hyperplane according to an optimization criterion, which must be validated subsequently.
In the validation phase, the class label of a new data vector
x can be predicted by projecting
x in the weight vector
w:
The sign of this projection will reveal the predicted class label. Thus, new samples are mapped into the n-dimensional space and a class will be associated to them, depending on which side of the hyperplane has been mapped.
There are different possible hyperplanes that divide the data space into two subsets. Typically, the maximum margin criterion is used as an appropriate optimization criterion to obtain the hyperplane with the greater margin of separation
γ (see
Figure 1). Only the vectors (or samples) positioned on the margin—which are called support vectors and that in
Figure 1 are surrounded by a circle—are necessary to describe this hyperplane.
For a canonical representation of the hyperplane, the constraints yi (w·xi+b) ≥ 1 must be met to find the margin γ = 2/||w||. The maximization of margin γ is equivalent to the minimization of (1/2) ||w||2, subject to the same restrictions.
Violation of restrictions involves the introduction of the variable ξ
i, giving rise to the so-called problem of soft-margin SVM optimization:
C is the regularization parameter, so that higher values of C correspond to stronger violations penalties.
In order to resolve the problem showed in Equation (3), it is rewritten in terms of positive Lagrange multipliers α
i. In this way, it is required to maximize the following expression:
subject to restrictions 0 ≤ α
i ≤ C and ∑
i α
iy
i = 0, given the relation:
where Ns denotes the number of resulting support vectors. The discriminant function on which the SVM optimization is based is obtained by substituting
w in Equation (2):
Essentially, a SVM is a two-class classifier but, in practice, it is very common to find problems associated with
K > 2 classes. In these cases, a multiclass classifier is needed. There are several methods that combine multiple two-class SVM to obtain a multiclass classifier. The most widespread methods are the one-
versus-all and the one-
versus-one [
19].
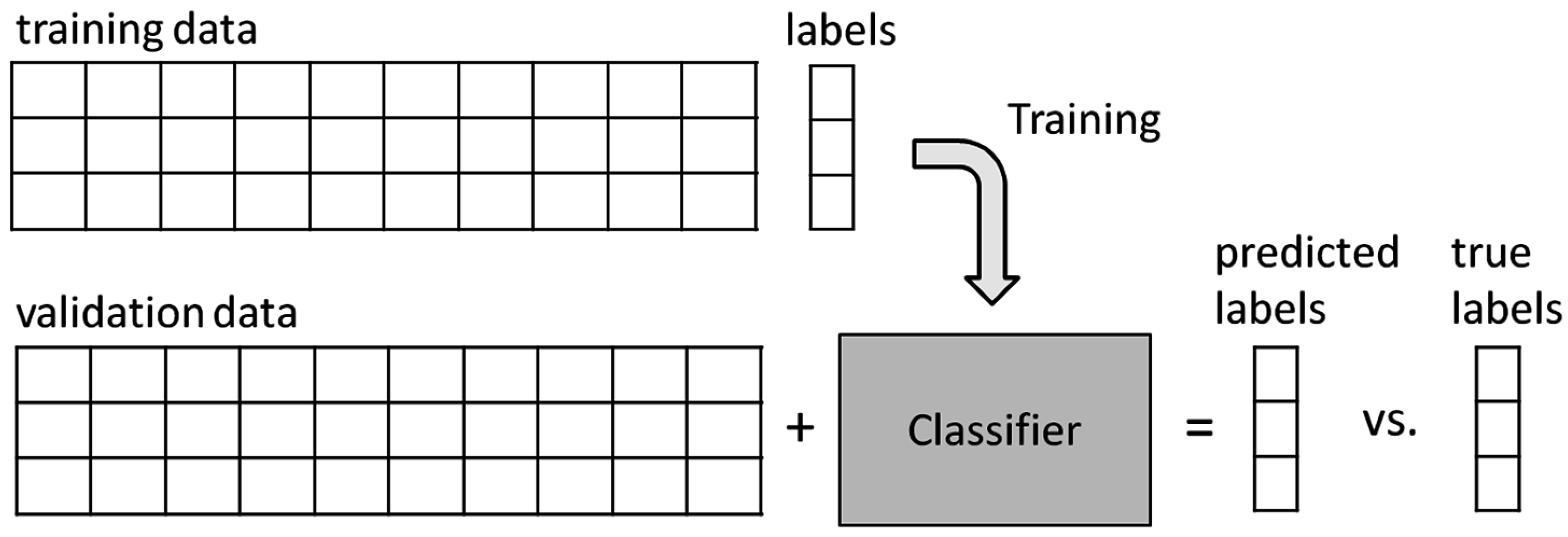
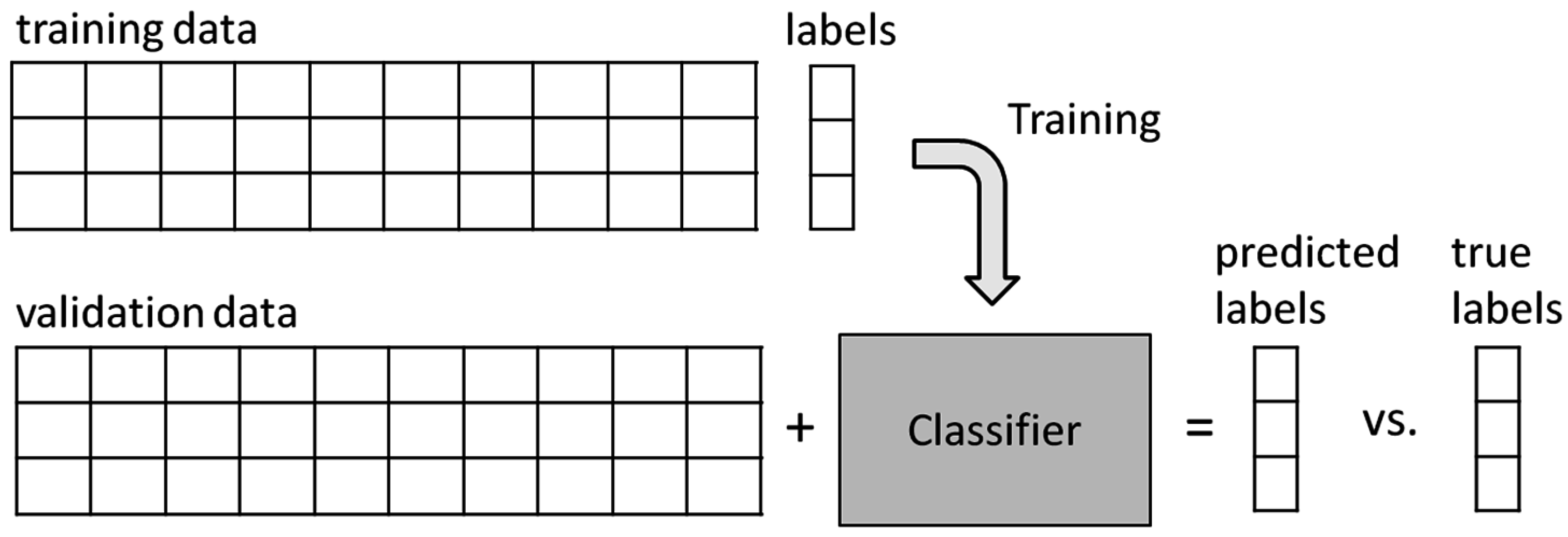
Training and Validation
The classifier learns from a training set—samples whose class labels are known—and defines a hyperplane. Then, this hyperplane is used to classify the samples from the validation set—whose classes are unknown. After that, the associated classes are compared with their corresponding classes and the error rate of the classifier is assessed, as shown in
Figure 2.
Figure 2.
Classifier training.
Figure 2.
Classifier training.
The number of available samples is finite (
N samples) and should be divided among the training set and the validation set. In this work, the classification algorithm is trained, using the two most common training methods:
Leave-One-Out (LOO)
Cross Validation (CV)
In LOO [
20], training is carried out using
N − 1 samples, and validation is performed using the sample which has been excluded. Errors are taken into account when the classification is wrong. This process is repeated
N times, each time excluding a different sample. The total number of errors gives an estimation of the classification error rate.
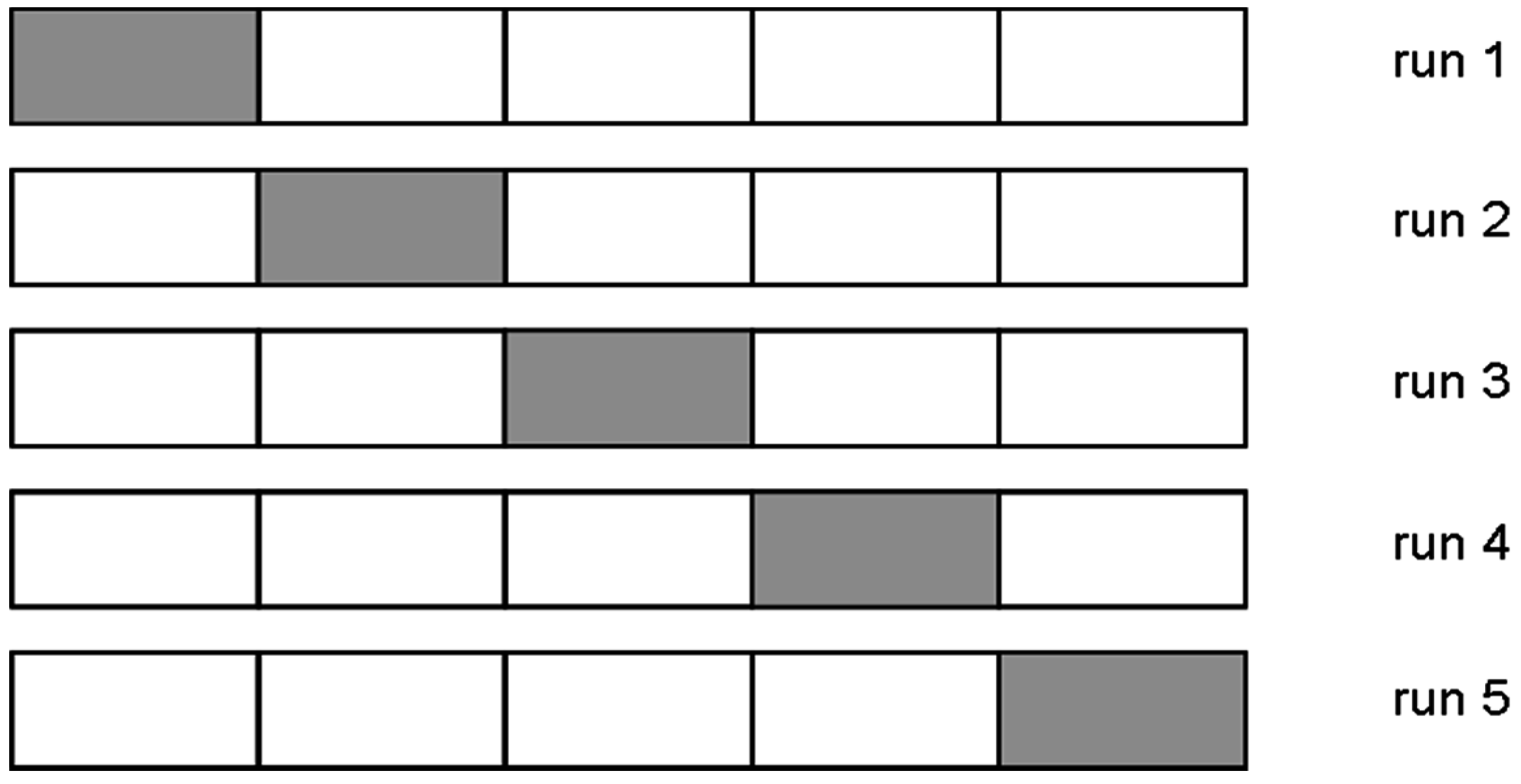
On the other hand, the CV method involves taking the available data samples and dividing them into
S groups (named folds) [
21].
S-1 folds are used to train the model, and the remaining fold is used to validate. This procedure is repeated
S times, taking a different fold each time to validate the model. Finally, the classification error rate is the average of the errors that have been obtained in each of the
S runs. An example of a 5-fold cross-validation (
S = 5) is shown in
Figure 3, where the fold used to validate is highlighted.
Figure 3.
5-fold Cross Validation.
Figure 3.
5-fold Cross Validation.
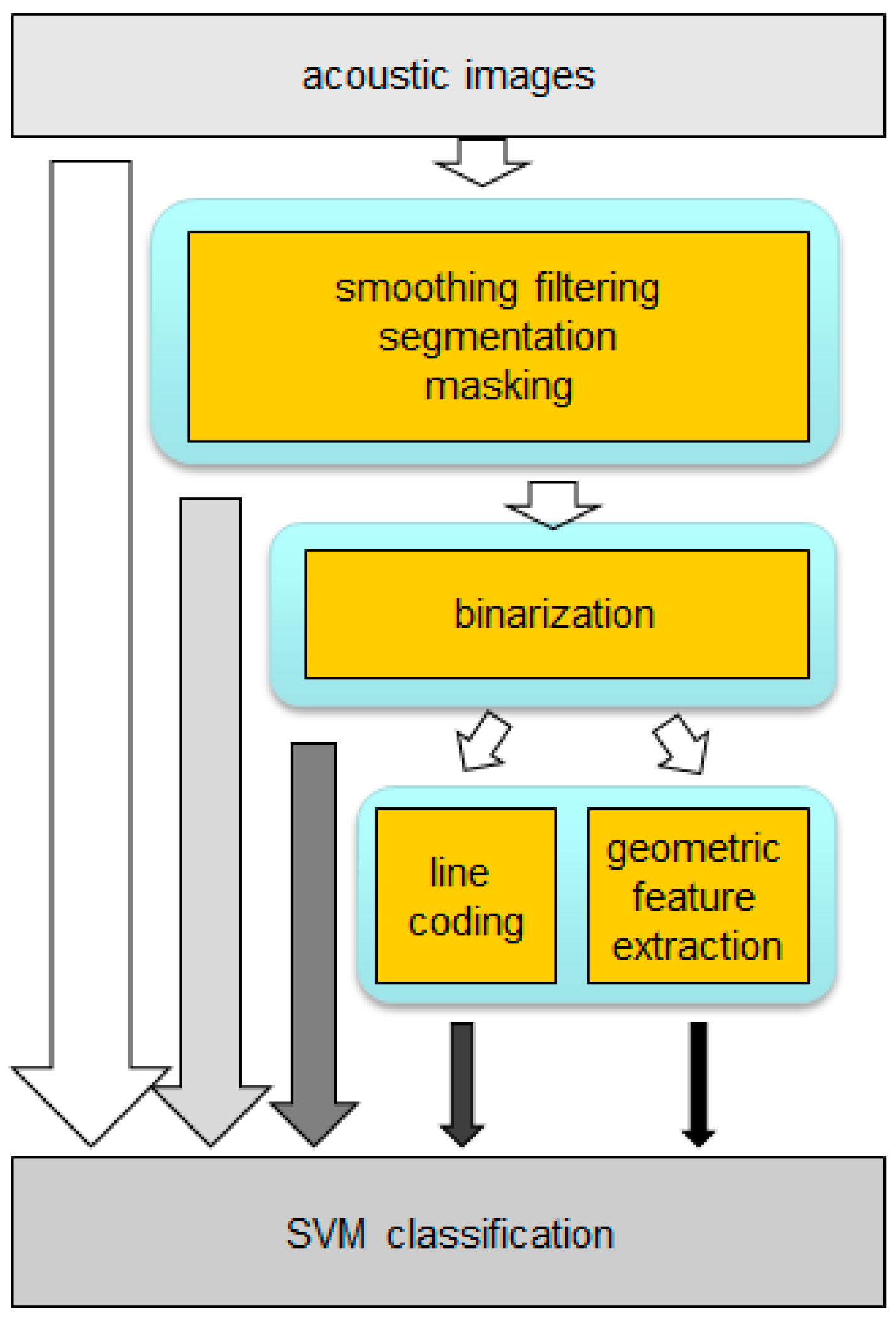
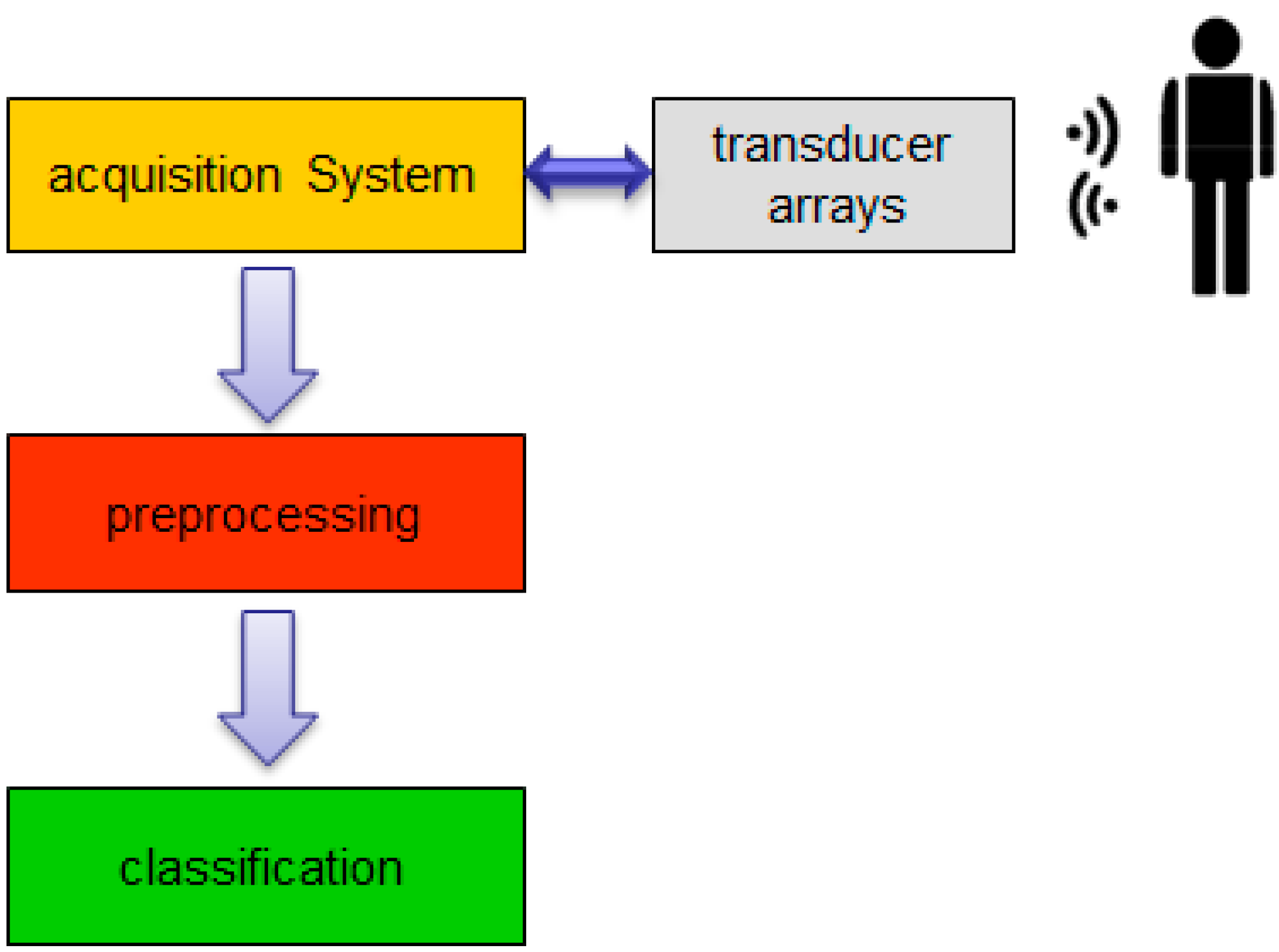
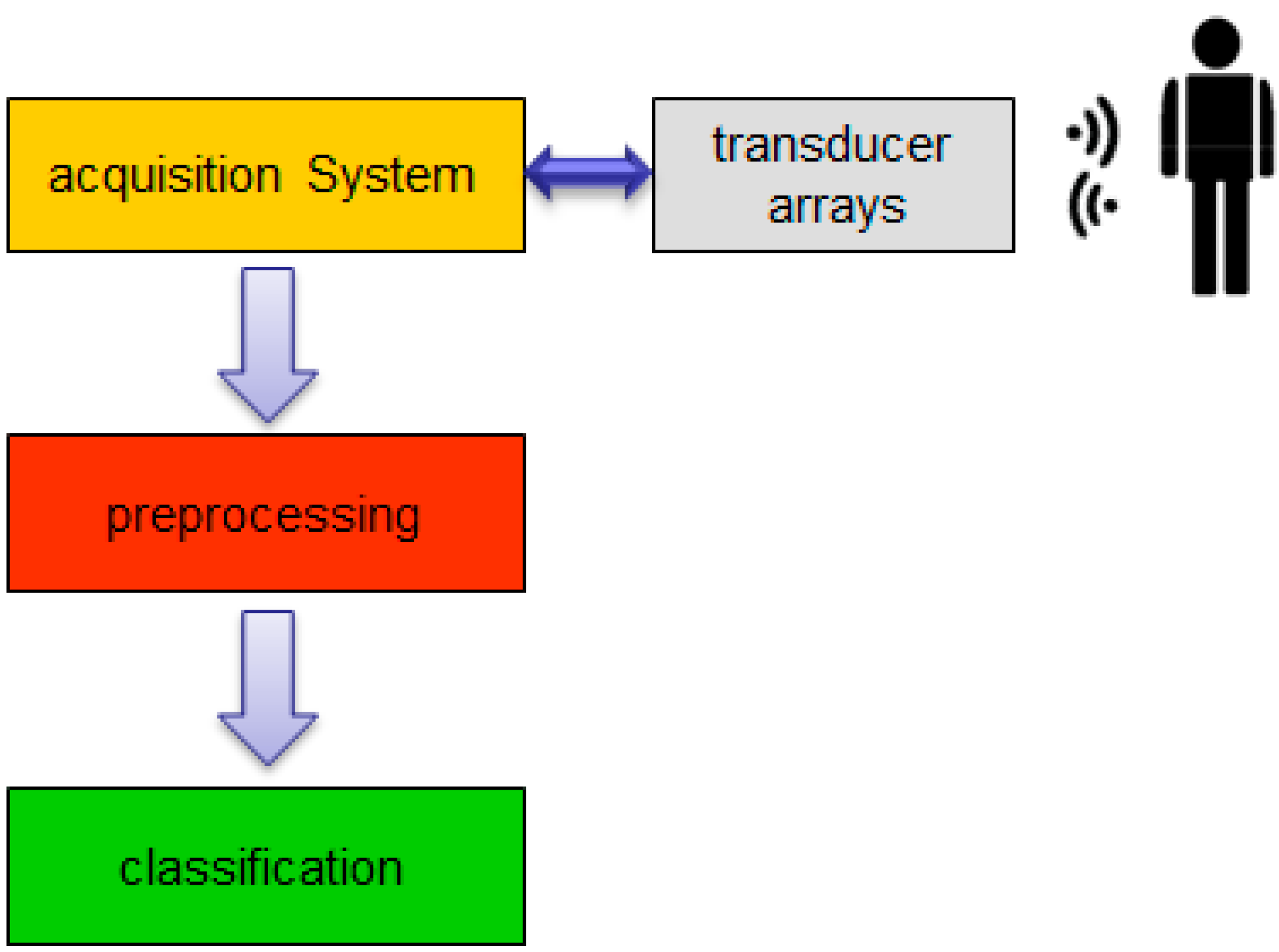
3. System Description
Based on basic radar/sonar principles [
22,
23], an acoustic detection and ranging system for biometric identification was proposed [
24], according to the block diagram in
Figure 4.
Figure 4.
Functional description block diagram.
Figure 4.
Functional description block diagram.
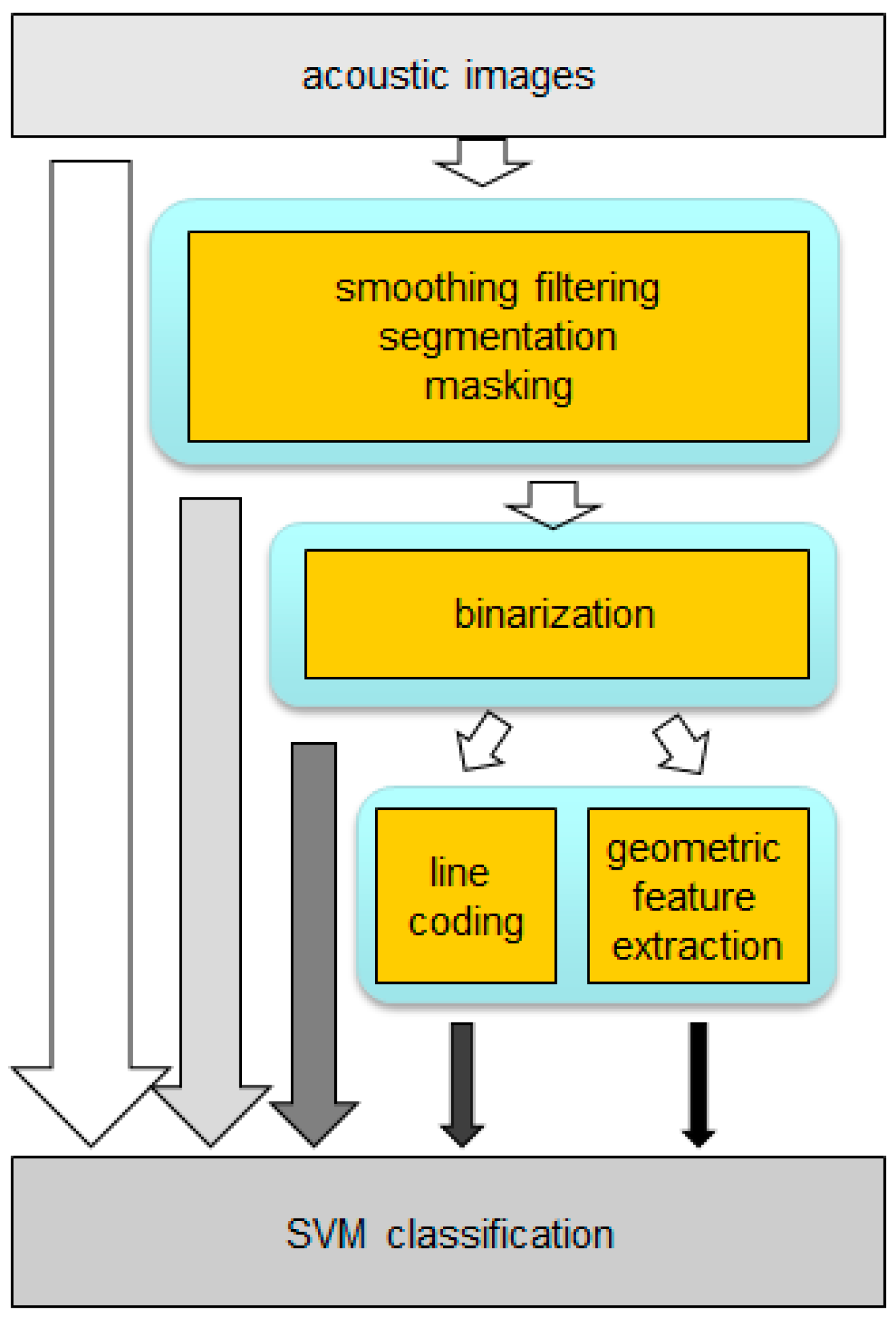
This system performs four main tasks: (i) subject scanning; (ii) acoustic images acquisition; (iii) images preprocessing and (iv) subject identification, based on classification algorithms.
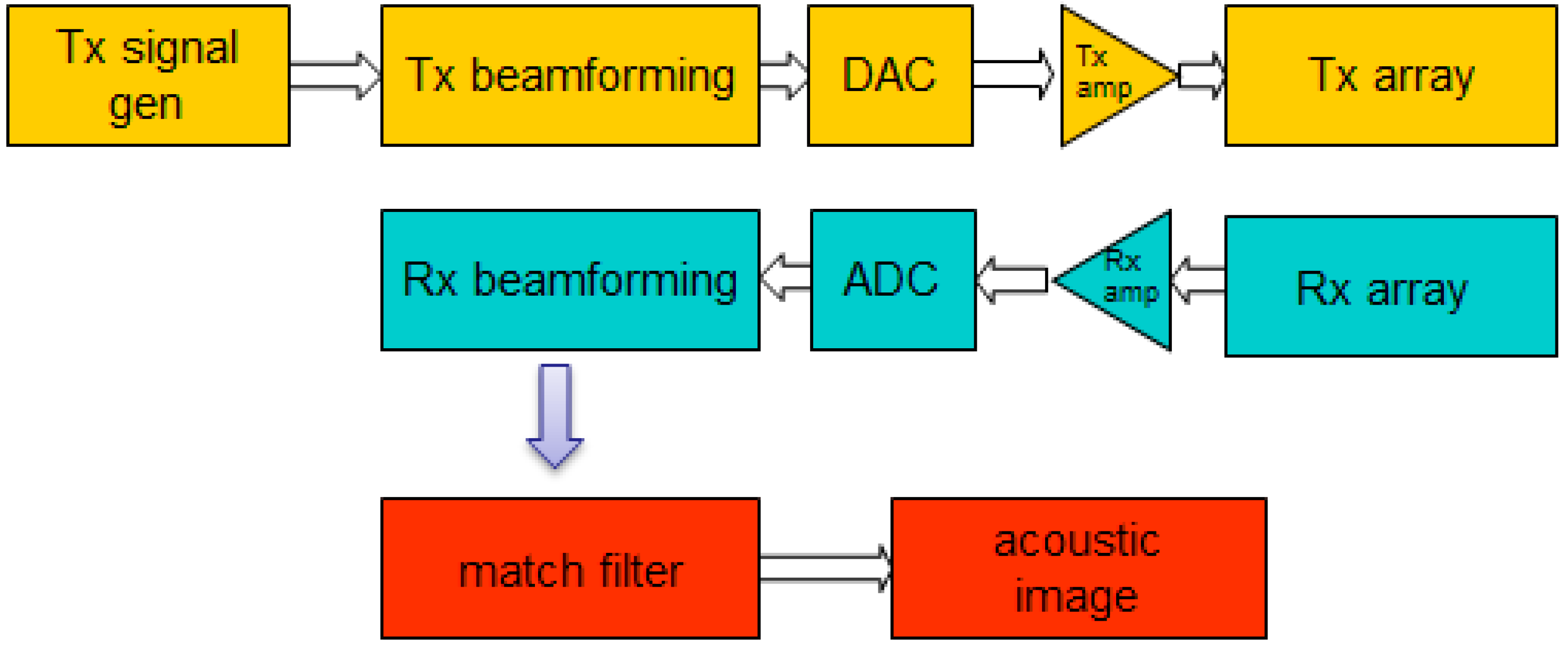
3.1. Acquisition System
The subject is electronically scanned in the azimuth coordinates using two linear arrays. For each steering angle the system performs: (i) transmission beamforming; (ii) reception beamforming and (iii) match filtering in the range coordinate. After processing all the steering angles, a two-dimensional matrix is formed and stored, representing the acoustic image.
Figure 5 shows the block diagram for the acquisition system.
Figure 5.
Acquisition system block diagram.
Figure 5.
Acquisition system block diagram.
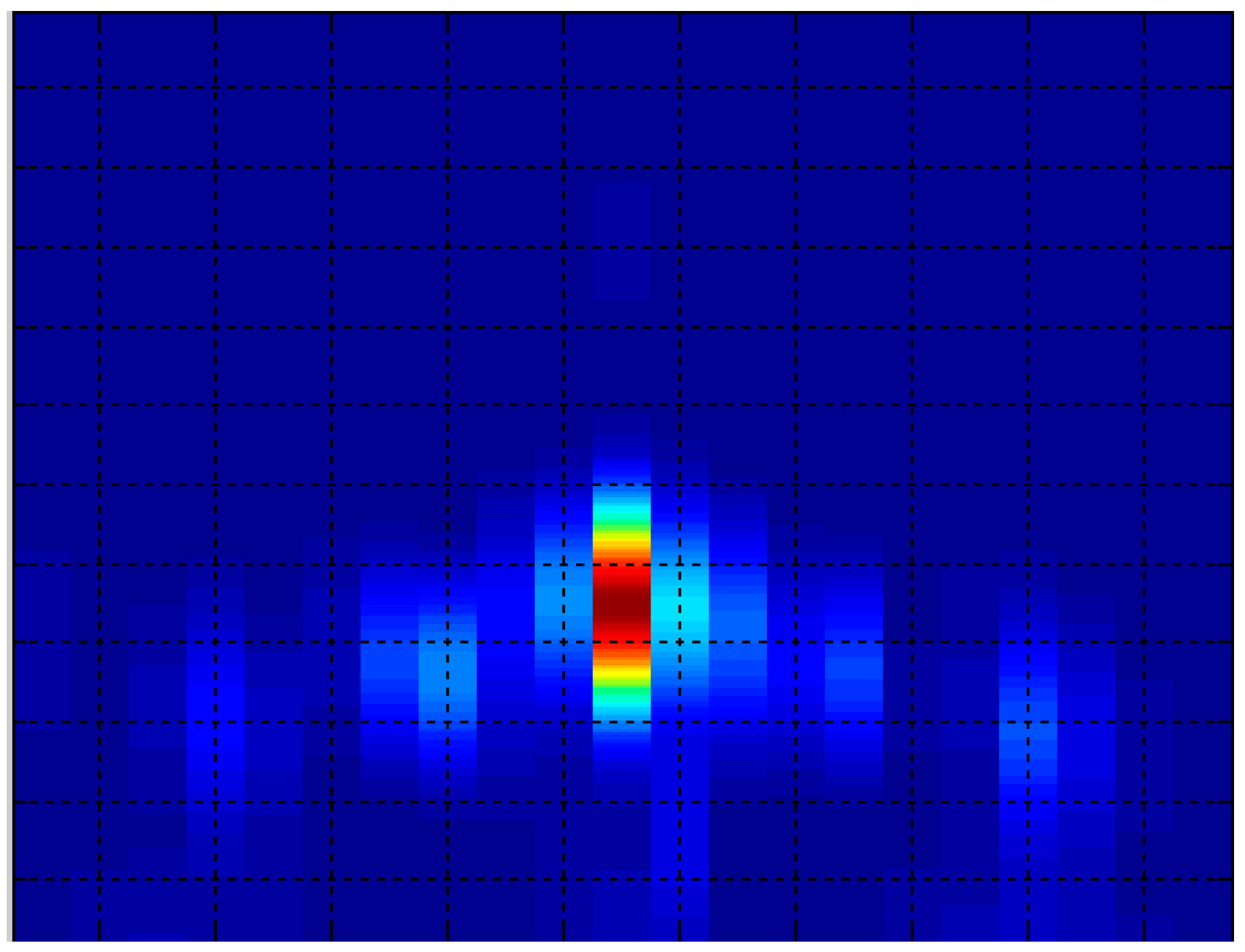
Figure 6 shows an example of an acoustic image, considering that the x axis represents the azimuth angle and the y axis, the range.
Figure 6.
Acoustic image example.
Figure 6.
Acoustic image example.
Based on the conclusions of previous works [
18], a new system that employs P = 3 spatial positions and F = 9 frequencies is defined. This system generates P
i acoustic profiles, associated to subject i and formed by P·F = 27 images.
The selected positions for the subject under analysis are: front view with arms outstretched (
p1), back view (
p2) and side view (
p3). The nine frequencies are 500 Hz-spaced, from 8 kHz (
f1) to 12 kHz (
f9). The number of beams used for each frequency is shown in
Table 1.
Table 1.
Number of beams vs. frequency.
Table 1.
Number of beams vs. frequency.
| f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 |
|---|
| 13 | 15 | 15 | 17 | 17 | 17 | 19 | 19 | 21 |
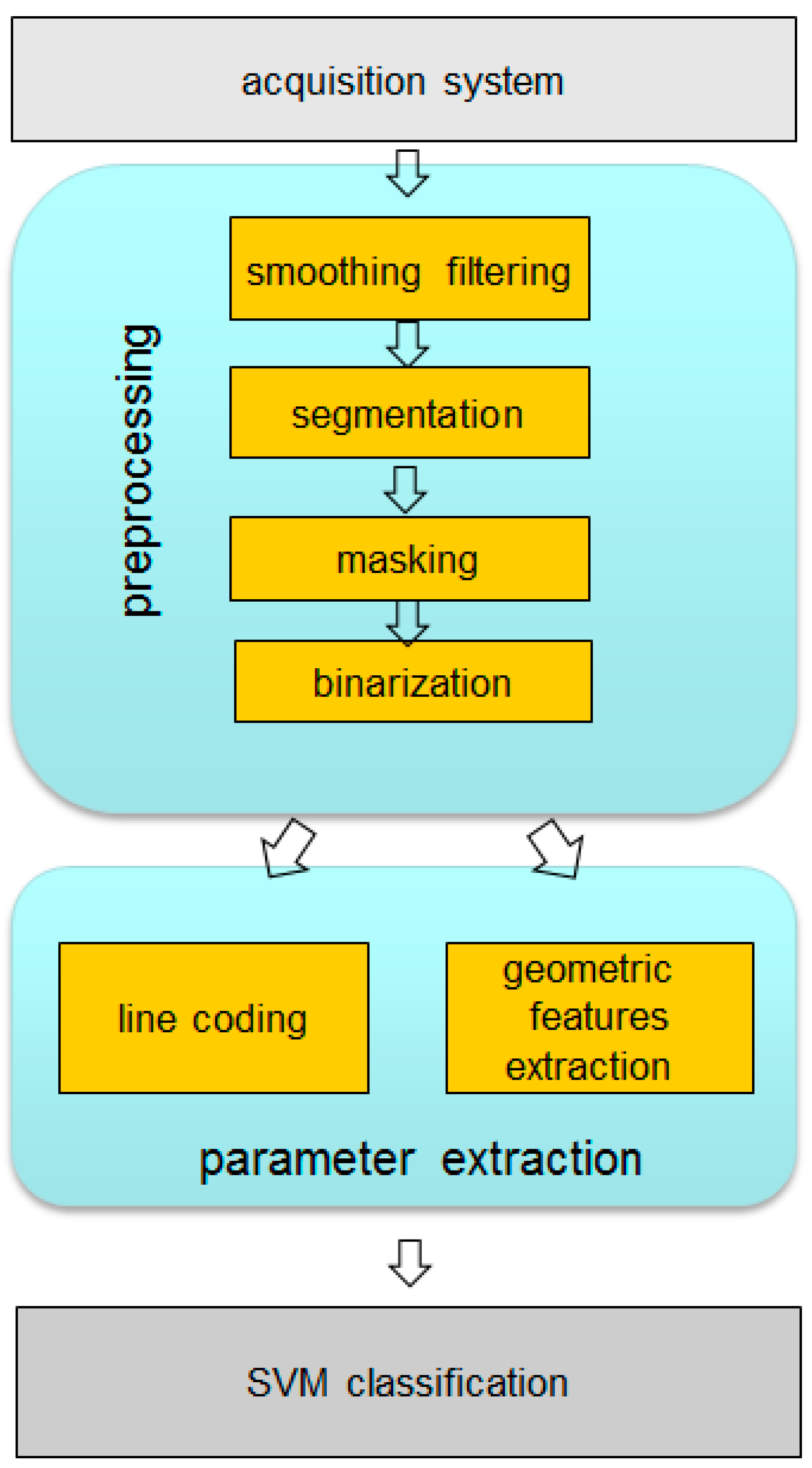
3.2. Preprocessing and Parametrization Techniques
With the purpose of reducing the dimension of the acoustic profiles, eliminating redundant or non-significant information and thus reducing the associated computational burden, several preprocessing and parametrization techniques on acoustic images have been evaluated. Among the preprocessing techniques, the following processes are implemented:
On the other hand, a reduced set of parameters was extracted from the acoustic images in order to characterize them. Two families of algorithms were analyzed:
Figure 7.
Preprocessing and parametrization techniques.
Figure 7.
Preprocessing and parametrization techniques.
First, a spatial filter was implemented to smooth images, in order to reduce multimodalities of torso echoes and improve the segmentation process [
10]. Then, a segmentation algorithm was used to differentiate pixels associated to the object from the pixels associated to the background.
The Expectation-Maximization (EM) algorithm is used to adjust a Gaussian Mixture Model (GMM) formed by two Gaussians, associated with foreground and background, respectively. The pixels associated with the background are zeroed.
The dimensions of the images N × M—where N is the number of rows (dimension in range) and M is the number of columns (dimension in azimuth)—are detailed for each frequency and position in
Table 2.
Table 2.
Image sizes.
| N × M | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 |
|---|
| p1, p2, p3 | 245 × 13 | 245 × 15 | 245 × 15 | 245 × 17 | 245 × 17 | 245 × 17 | 245 × 19 | 245 × 19 | 245 × 21 |
The profiles formed by the acoustic images are stored to be processed and that is why the size of each pixel of the images has to be defined. The final size of the profiles gives the required storage space, and is related with the computational burden associated to the system. In this case, the value of each pixel is stored in memory using B = 32 bits.
Using masking techniques, the size of the images is reduced by adjusting them to the area that the subjects take up on the image. A statistical analysis of the acquired images was performed to determine the common area for each position and frequency. The sizes of the images obtained by this technique for each frequency and position are detailed in
Table 3.
Table 3.
Masked image sizes.
Table 3.
Masked image sizes.
| N × M | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 |
|---|
| p1 | 145 × 13 | 145 × 15 | 145 × 15 | 145 × 17 | 145 × 17 | 145 × 17 | 145 × 19 | 145 × 19 | 145 × 21 |
| p2 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 | 155 × 11 |
| p3 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 | 171 × 9 |
Finally, the value of the pixels—encoded with 32 bits—is reduced to 1 bit by image binarization. This significantly reduces the storage space required. This operation is equivalent to associate a unit value to the foreground pixels.
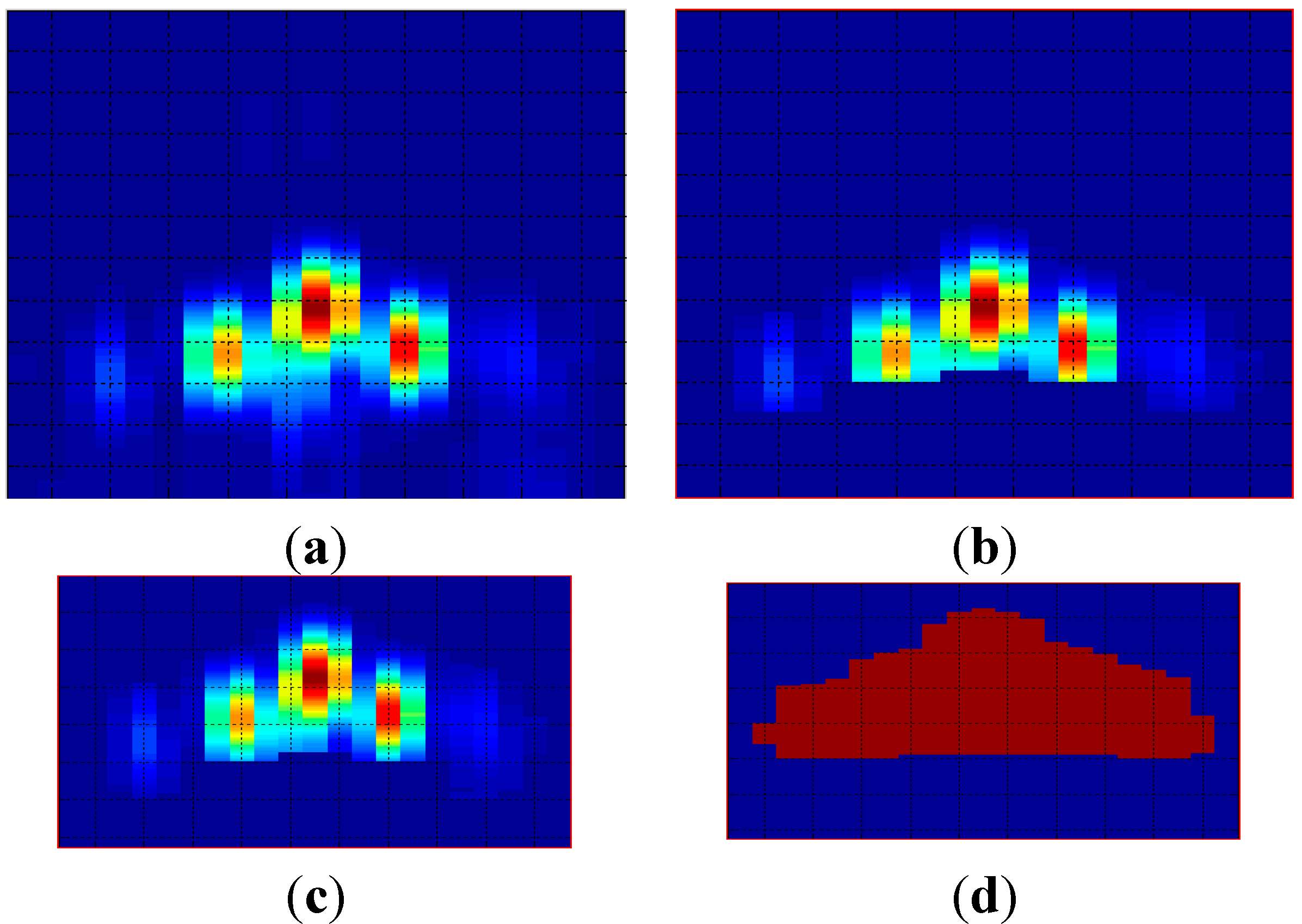
Figure 8 shows an example of the use of the preprocessing techniques, showing an original
Figure 8a, a segmented
Figure 8b, a masked
Figure 8c and a binarized
Figure 8d image.
Figure 8.
Pre-processed images: (a) original; (b) segmented; (c) masked; (d) binarized.
Figure 8.
Pre-processed images: (a) original; (b) segmented; (c) masked; (d) binarized.
Table 4.
Image sizes using Row-based Image Coding.
Table 4.
Image sizes using Row-based Image Coding.
| L | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 |
|---|
| p1 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 |
| p2 | 155 | 155 | 155 | 155 | 155 | 155 | 155 | 155 | 155 |
| p3 | 171 | 171 | 171 | 171 | 171 | 171 | 171 | 171 | 171 |
Starting from the binarized images, two feature extraction techniques were applied, significantly reducing the size of the acoustic images. First, Line-based Image Coding algorithms were analyzed. The images are broken down into a set of lines that can be rows or columns. For each line, the number of pixels with unit value is encoded. In this way, the size of each image is significantly reduced, from a N·M size to a L size, where L is N or M, as encoding is performed by rows or columns, respectively. The value of each parameter is stored in the memory using B = 8 bits. In row coding, sizes of the images obtained at each position and frequency are shown in
Table 4.
In column coding, sizes of the images obtained for each frequency position are detailed in
Table 5.
Table 5.
Image sizes using Column-based Image Coding.
Table 5.
Image sizes using Column-based Image Coding.
| L | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 |
|---|
| p1 | 13 | 15 | 15 | 17 | 17 | 17 | 19 | 19 | 121 |
| p2 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| p3 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
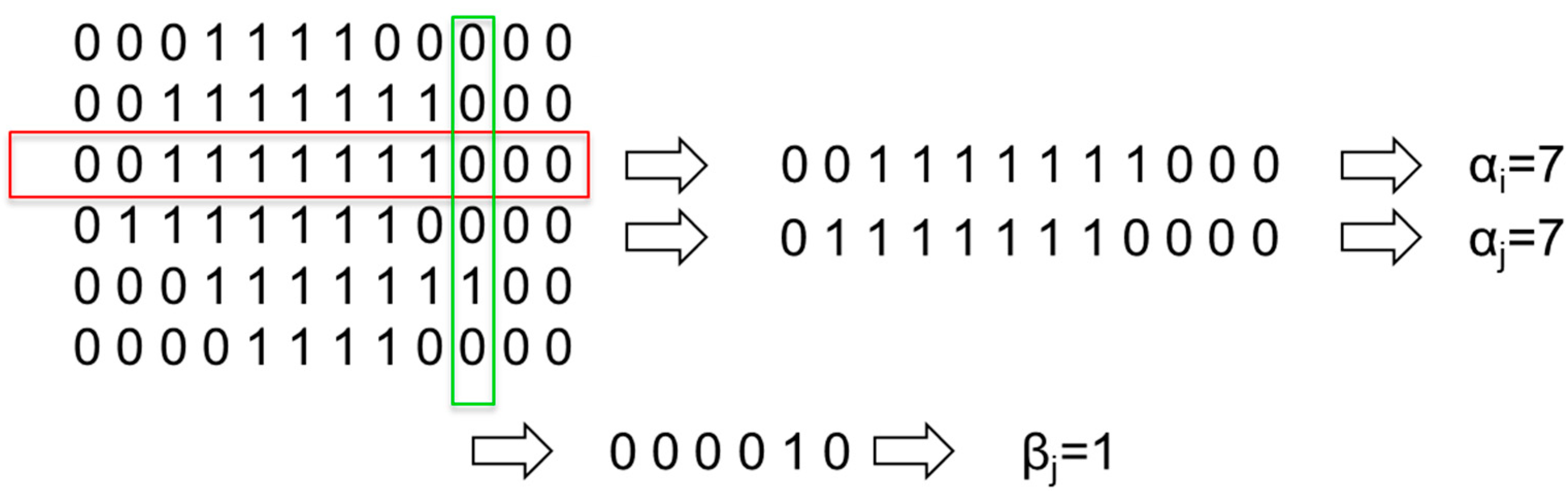
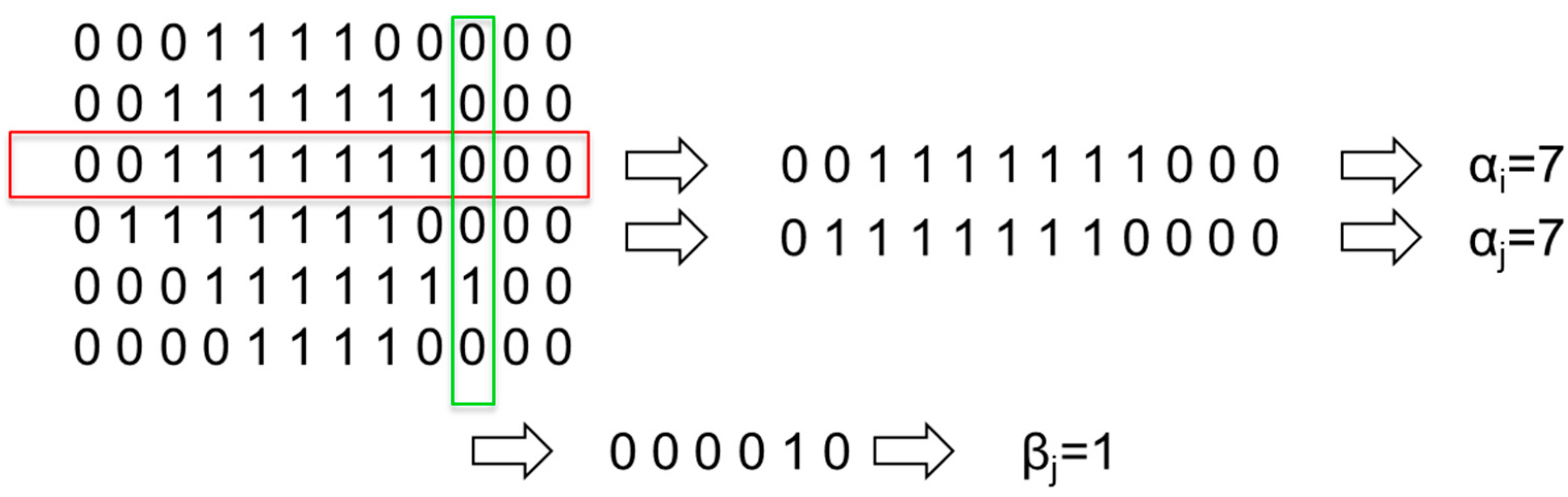
As an example,
Figure 9 represents Line-based Image Coding using rows and columns of an acoustic image of size 6 × 12.
Figure 9.
Line-based Image Coding.
Figure 9.
Line-based Image Coding.
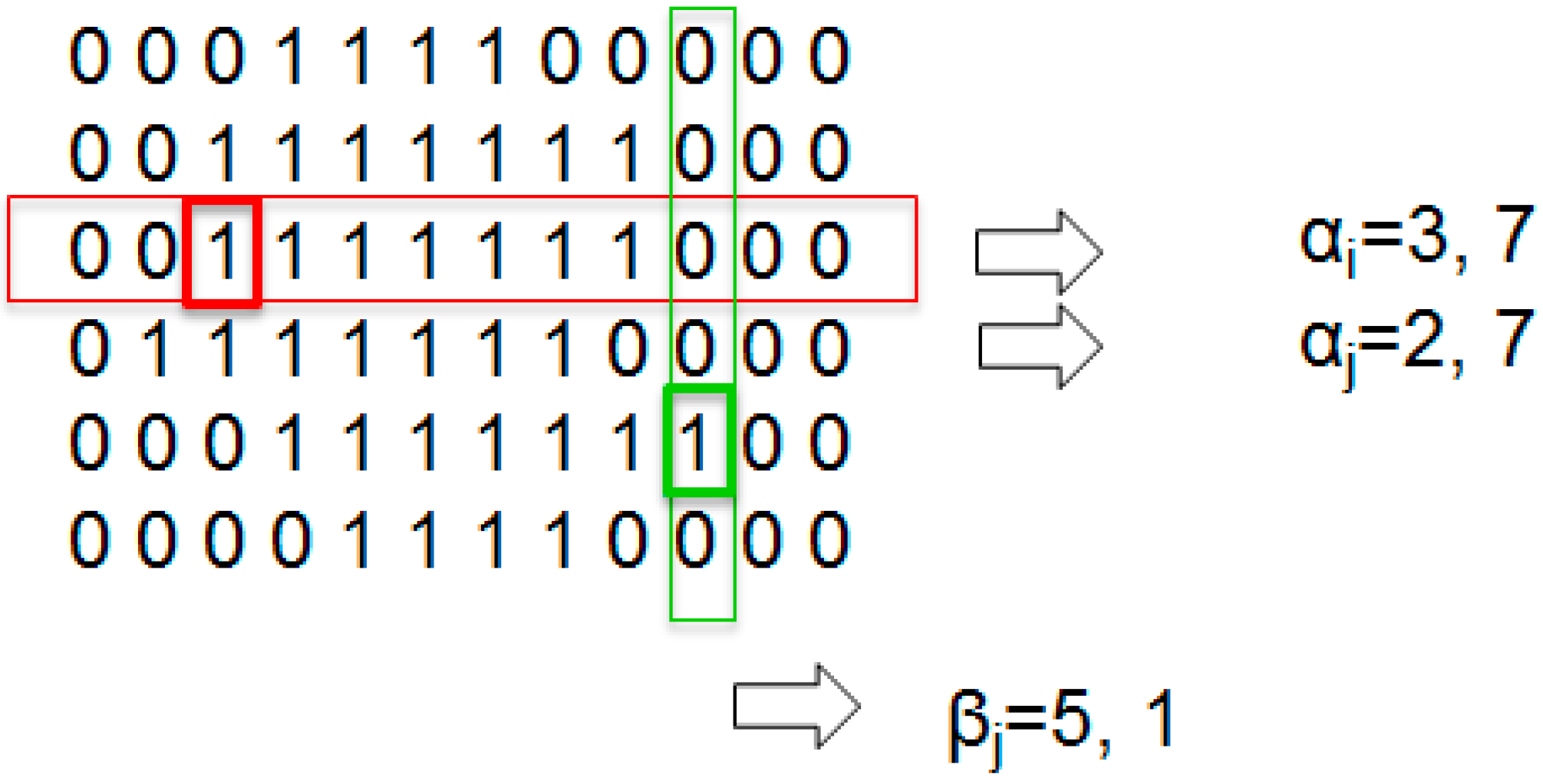
In
Figure 9, it can be observed that rows 3 and 4 gave an identical encoding, although they are different. To improve the information of each line and avoid ambiguous encodings, a second parameter that stores the starting position of the first nonzero pixel per line is added. With this improvement, the image dimension is doubled. As an example,
Figure 10 represents the new encoding methods for the previous image.
Figure 10.
Line-based Image Coding with position.
Figure 10.
Line-based Image Coding with position.
Secondly, geometric feature extraction algorithms were analyzed. They show the following properties of images:
Area : A
Centroid: (cx, cy)
Perimeter: P
In this case, one parameter for area and perimeter, and two parameters for centroid are extracted from each image. The value of each parameter is stored in the memory using B = 32 bits.
Figure 11 shows the geometric features extracted from
Figure 8d.
Figure 11.
Geometric feature extraction.
Figure 11.
Geometric feature extraction.
3.3. Classification
In this work, tests based on linear SVM algorithms were performed. A linear SVM was used because, if the number of features is large, one may not need to map data of a higher dimensional space and using the linear kernel is good enough [
25]. Besides, although the dimension of the acoustic images is reduced with the preprocessing techniques, it is still too high in order to be used in SVMs based on a Gaussian kernel, involving an increment of the processing time and the computational burden, without an improvement in the classification error rate.
It was implemented with Matlab, specifically using the LIBSVM library, which allows multiclass SVM classification according to the
one-versus-one algorithm [
26]. The methods LOO and CV, with 10, 5 and 4 folds were used for algorithm training.
In the linear SVM, the regularization parameter C was set to 5000, since a usual practice is to assign C to the range of output values of the SVM algorithm [
27],
i.e., the maximum number of possible errors, which coincides with the total number of samples.
5. Conclusions
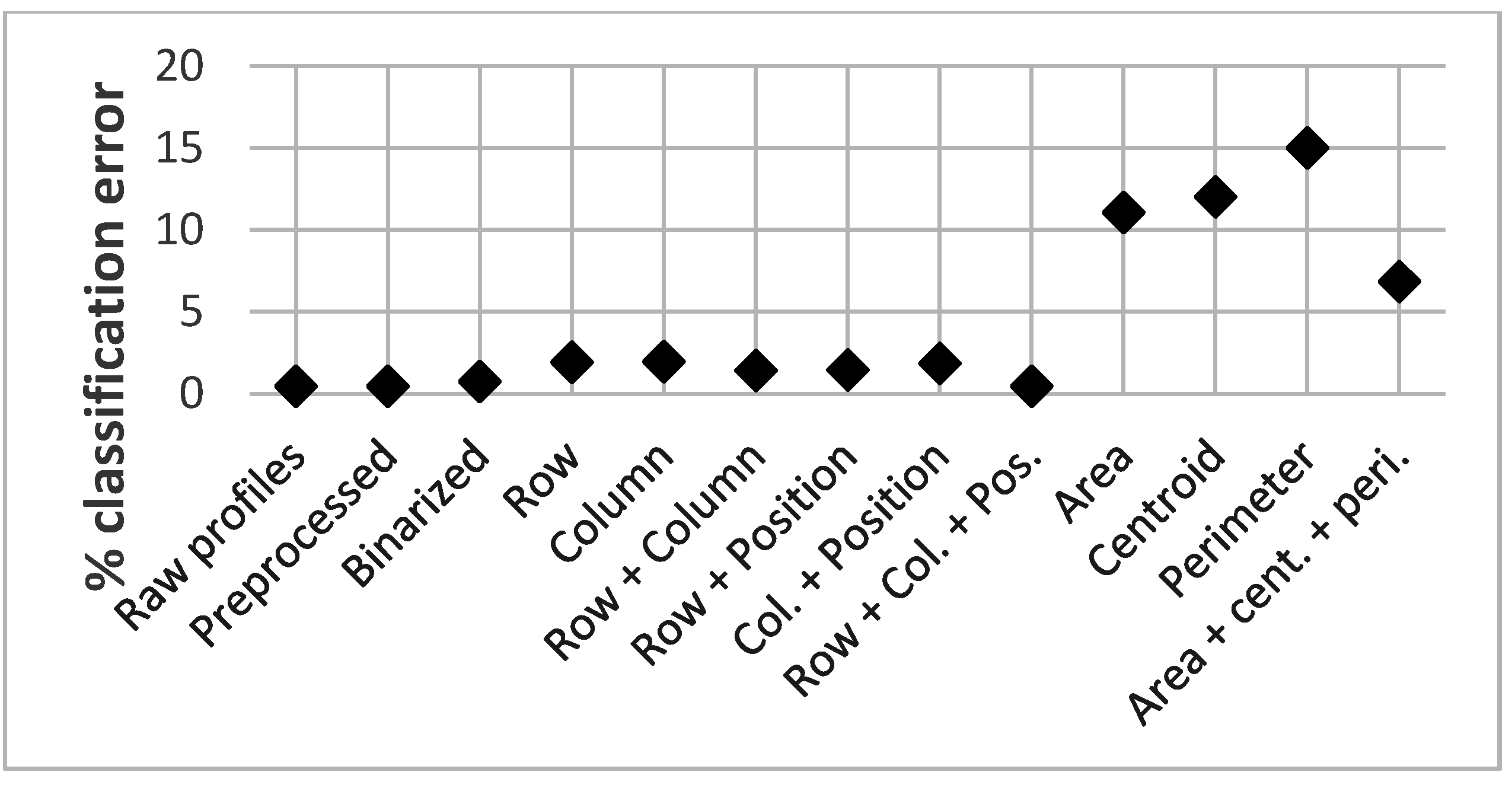
An innovative biometric system, which significantly improves the performance of previous systems developed by the research group, is presented in this paper. Its improvement has been achieved through an increment of the number of frequencies analyzed, a reduction of the number of scanning positions, the use of preprocessing techniques on acoustic images and the use of SVM algorithms for the classification task. Reliability and robustness of the system were improved by employing a large set of subjects called intruders, by increasing the number of acoustic profiles captured for each subject and by this regarding the clothes they were wearing during the test so as not to affect the classification.
It has been verified that, as the size of the acoustic profiles decreases by using the preprocessing techniques, the classification error increases, because relevant information is removed. However, the line coding algorithm based on length and position of rows and columns allows reducing computational burden in several orders of magnitude without increasing the classification error rate. In this case, the information of the profiles eliminated by the algorithm is not relevant to the classifier. Thus, this preprocessing algorithm has been selected to be used in the improved biometric system.
On the other hand, the fact that this line coding algorithm was based on binarized images shows that the relevant information for the classifier is associated to the contour of the image. Finally, it was observed that the geometric features extracted from the acoustic images do not provide enough information for the classifier.
Our research group is currently working on improving the biometric system by using bidimensional arrays, employing new algorithms based on Gaussian Mixture Models and creating a large database of acoustic profiles.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}