
Tightly-Coupled Stereo Visual-Inertial Navigation Using Point and Line Features

Abstract
:1. Introduction
2. Mathematical Formulation
2.1. Notations and Convention
2.2. System Model
2.3. Measurement Model
2.3.1. Camera Model
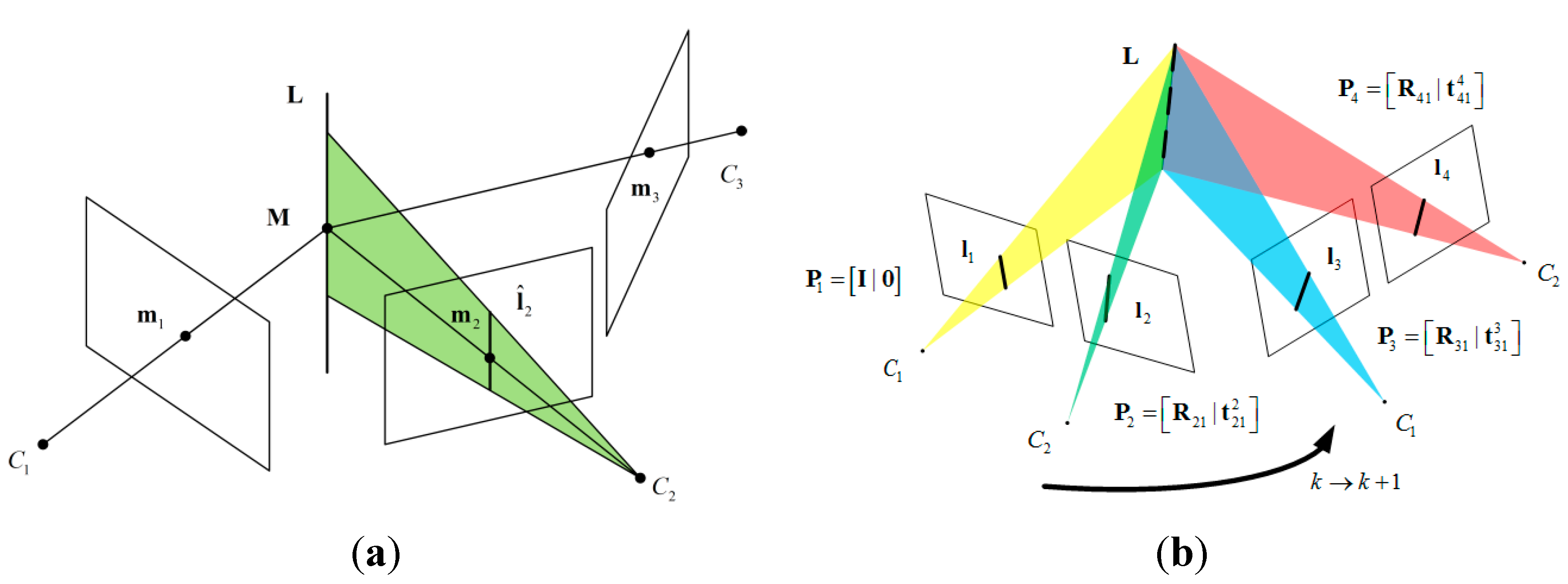
2.3.2. Review of the Trifocal Tensor
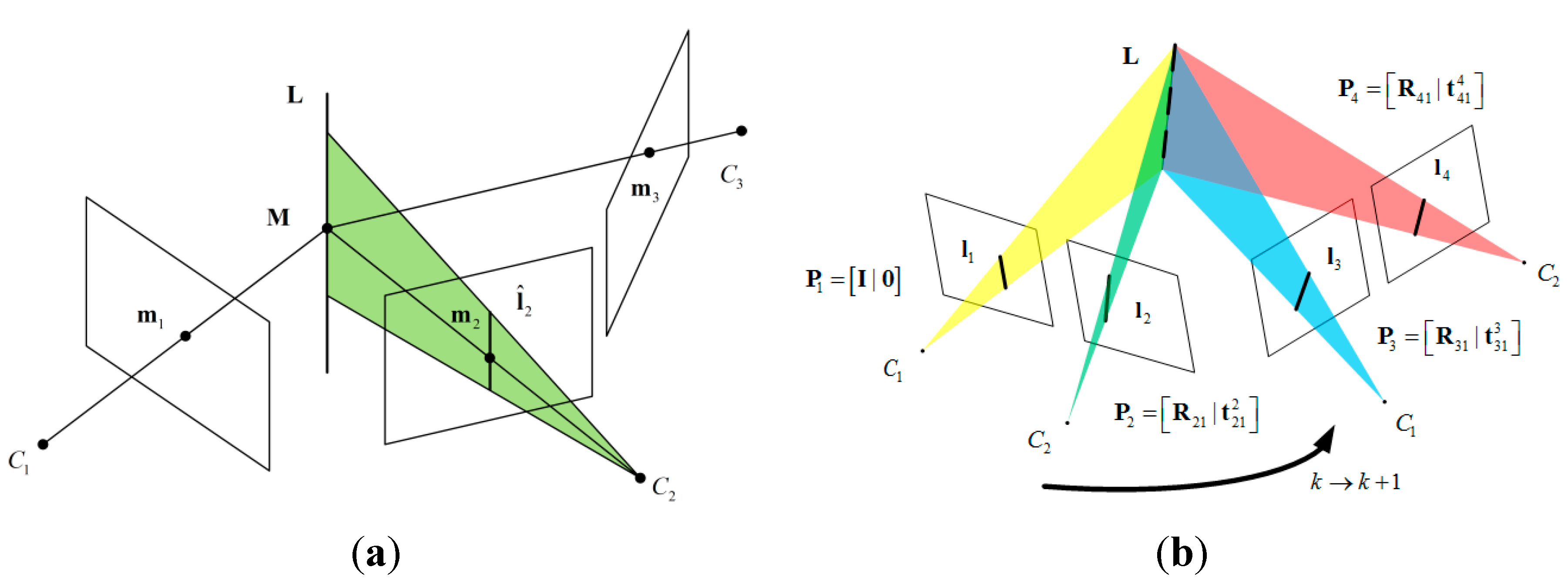
- (1)
- Compute the epipolar line , where is the fundamental matrix between the first and second views.
- (2)
- Compute the line which passes through and is perpendicular to . If and , then .
- (3)
- The transferred point is
2.3.3. Stereo Vision Measurement Model via Trifocal Geometry
3. Estimator Description
3.1. Structure of the State Vector
3.2. Filter Propagation
3.3. Measurement Update
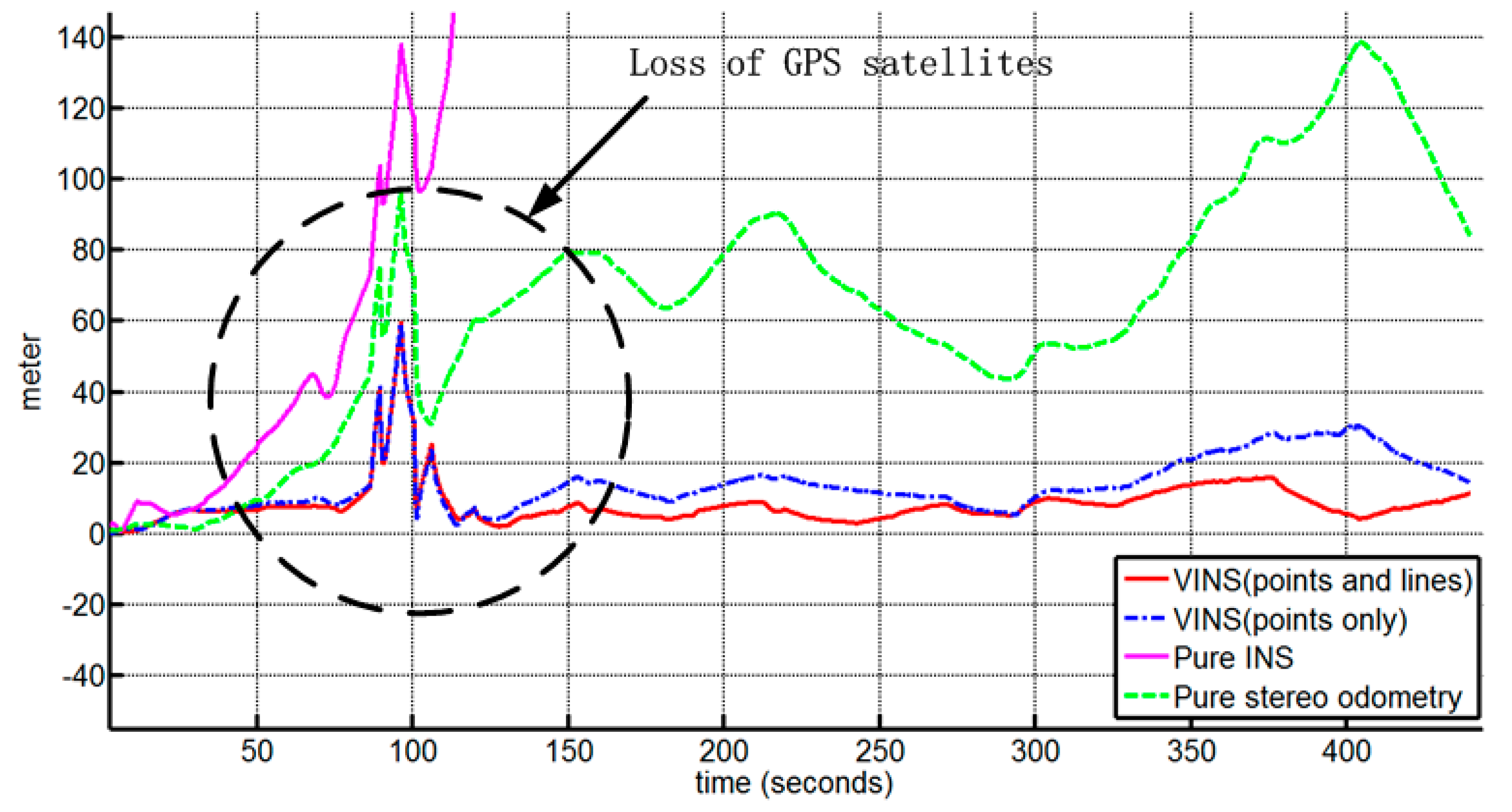
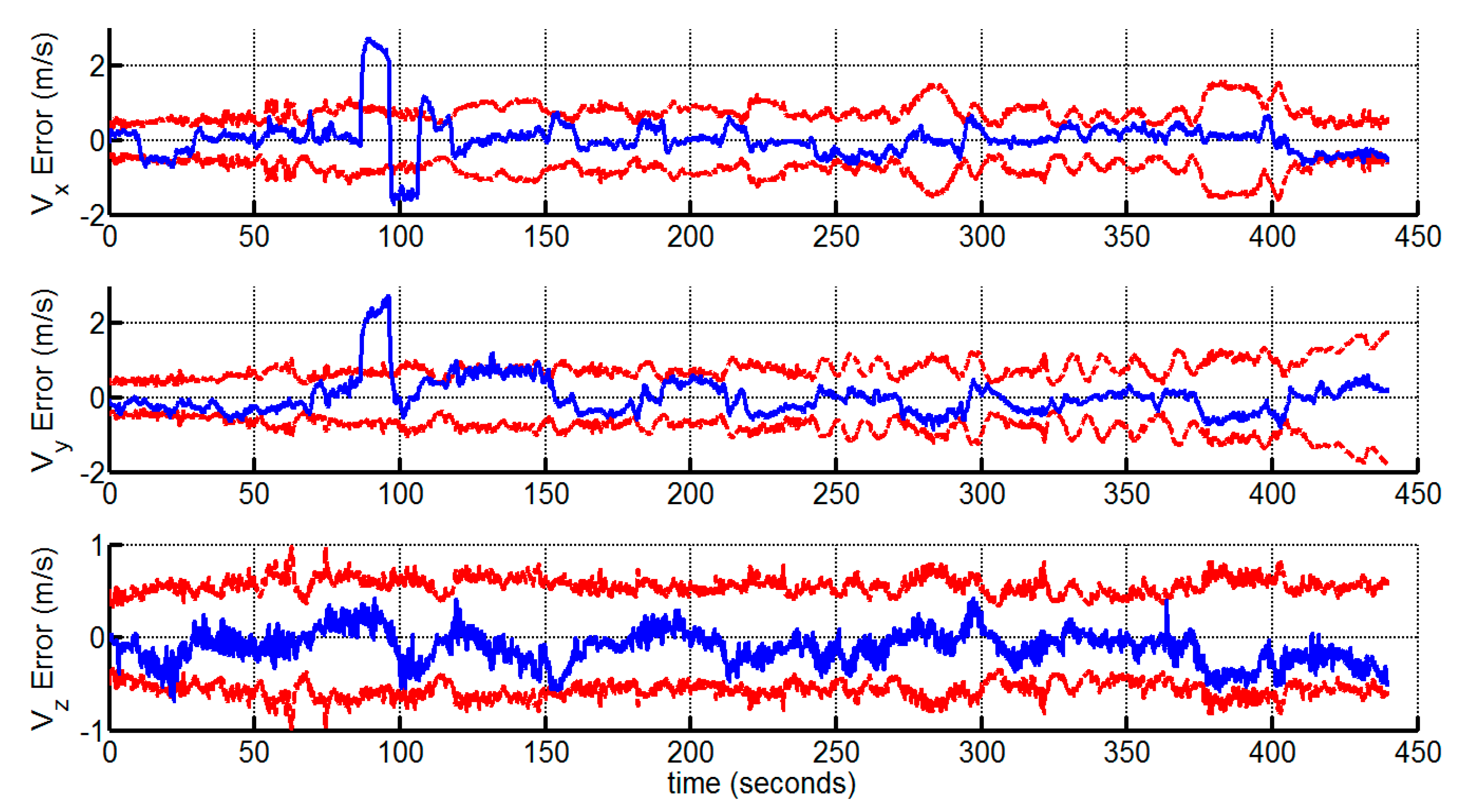
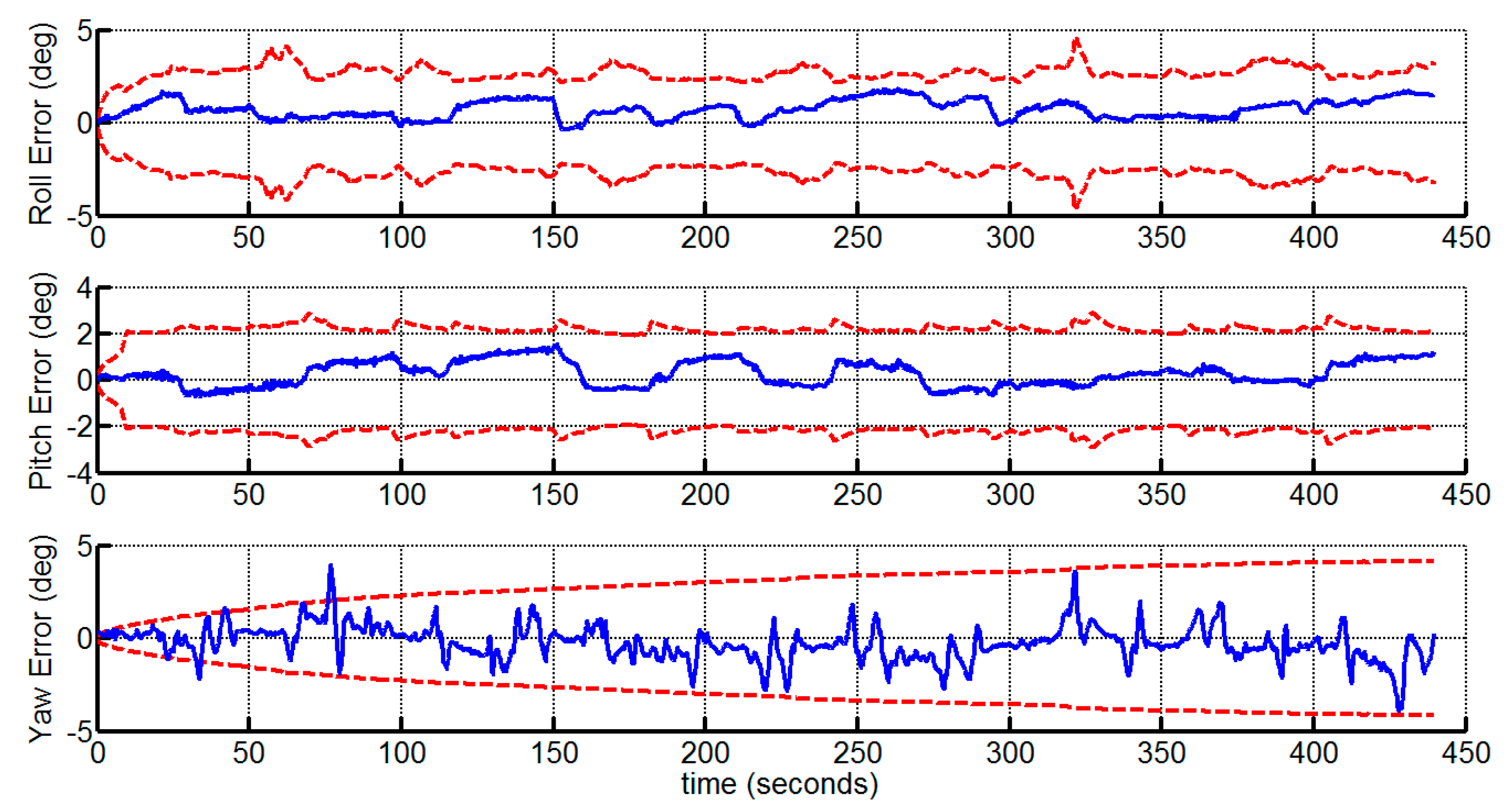
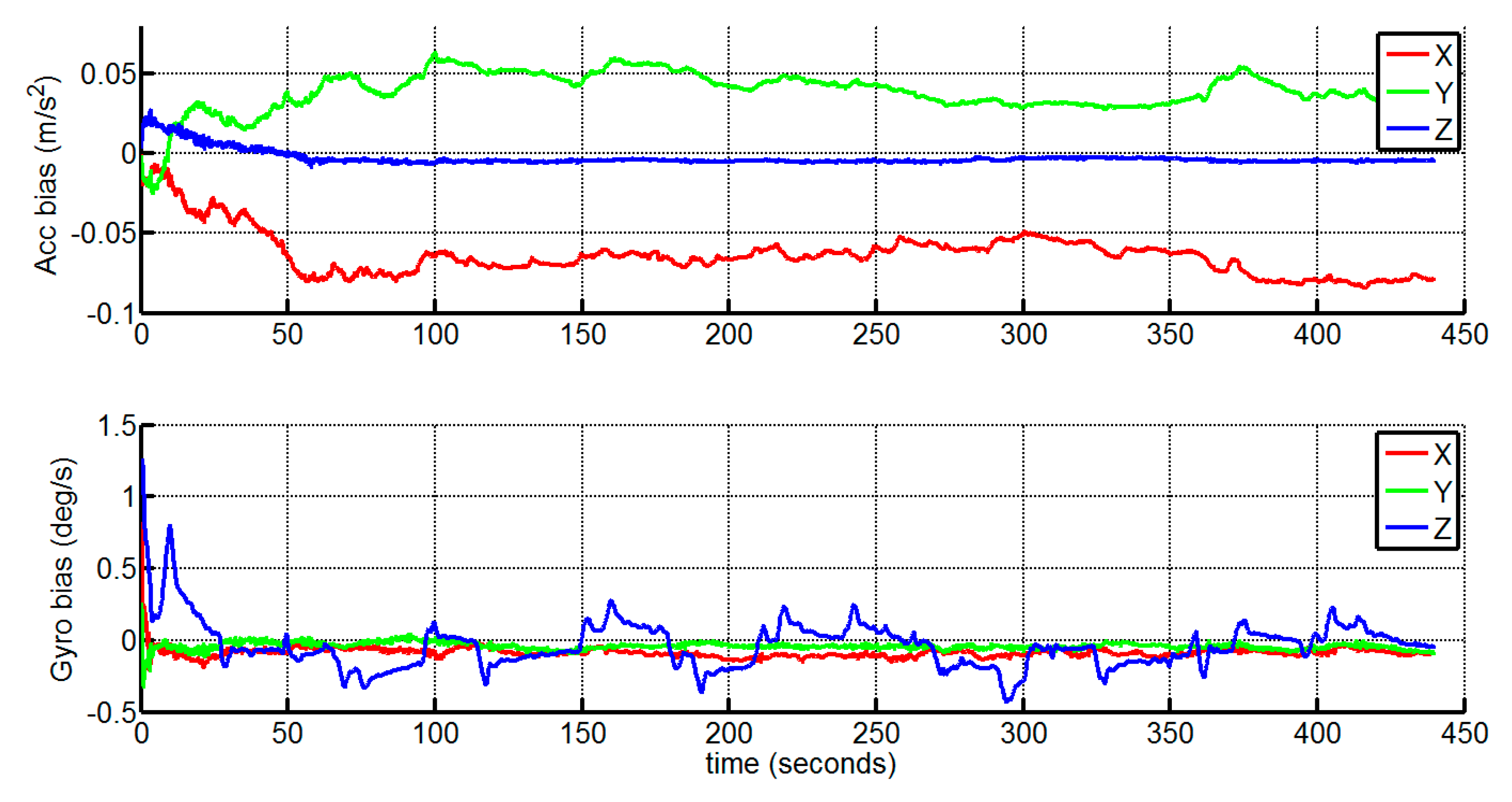
4. Experimental Results and Discussion
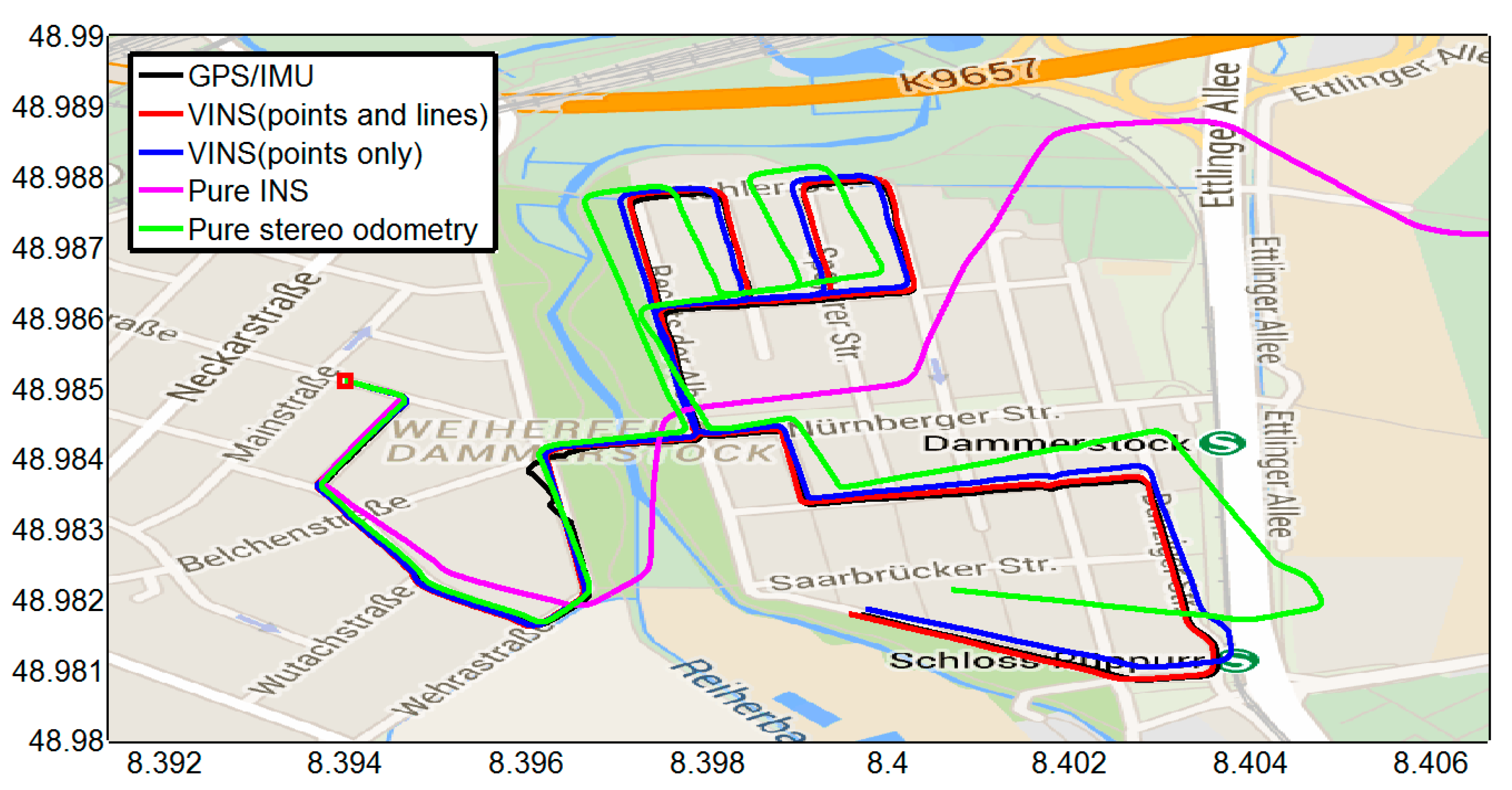
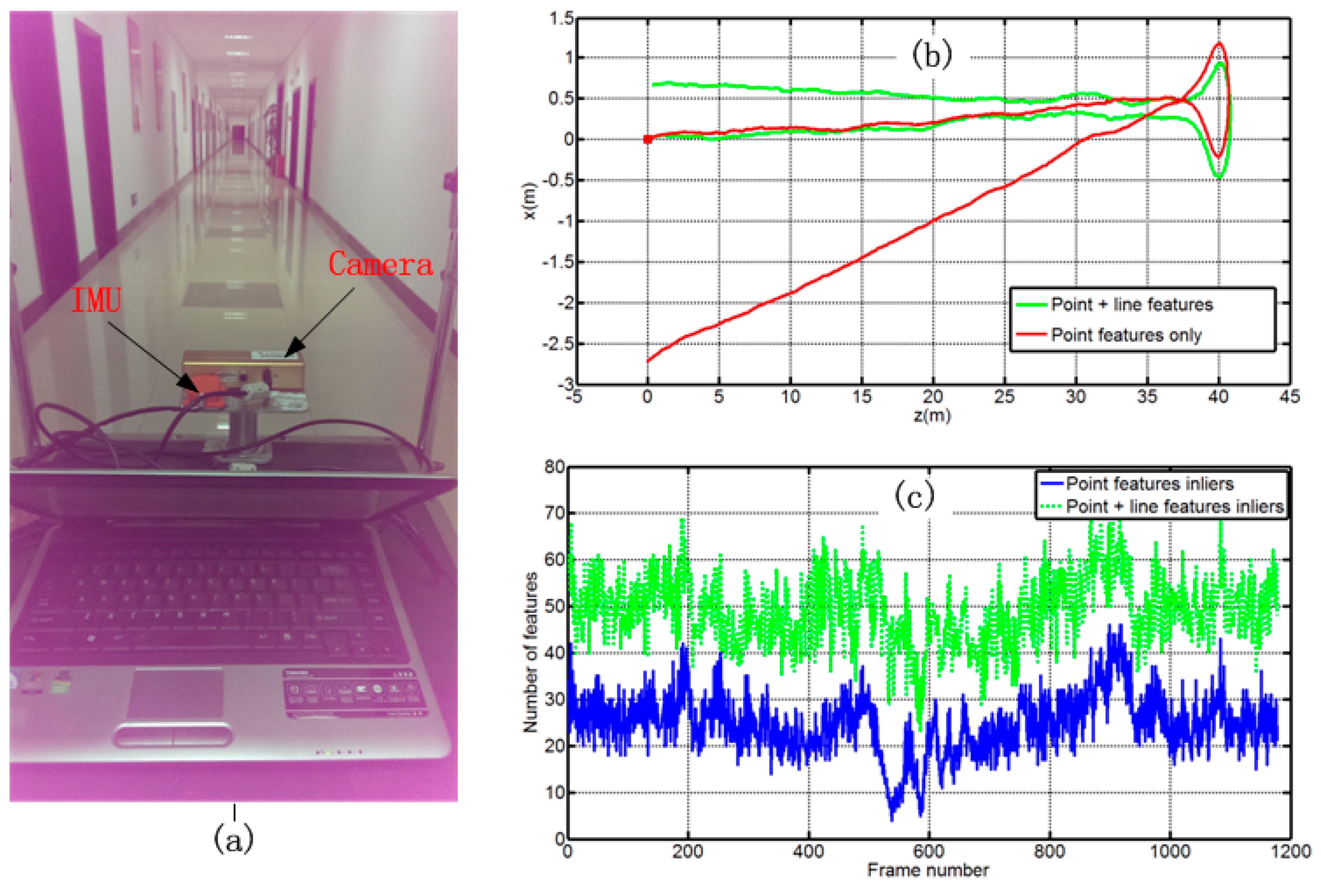
4.1. Outdoor Experiment
4.1.1. Feature Detection, Tracking, and Outlier Rejection

4.1.2. Experimental Results
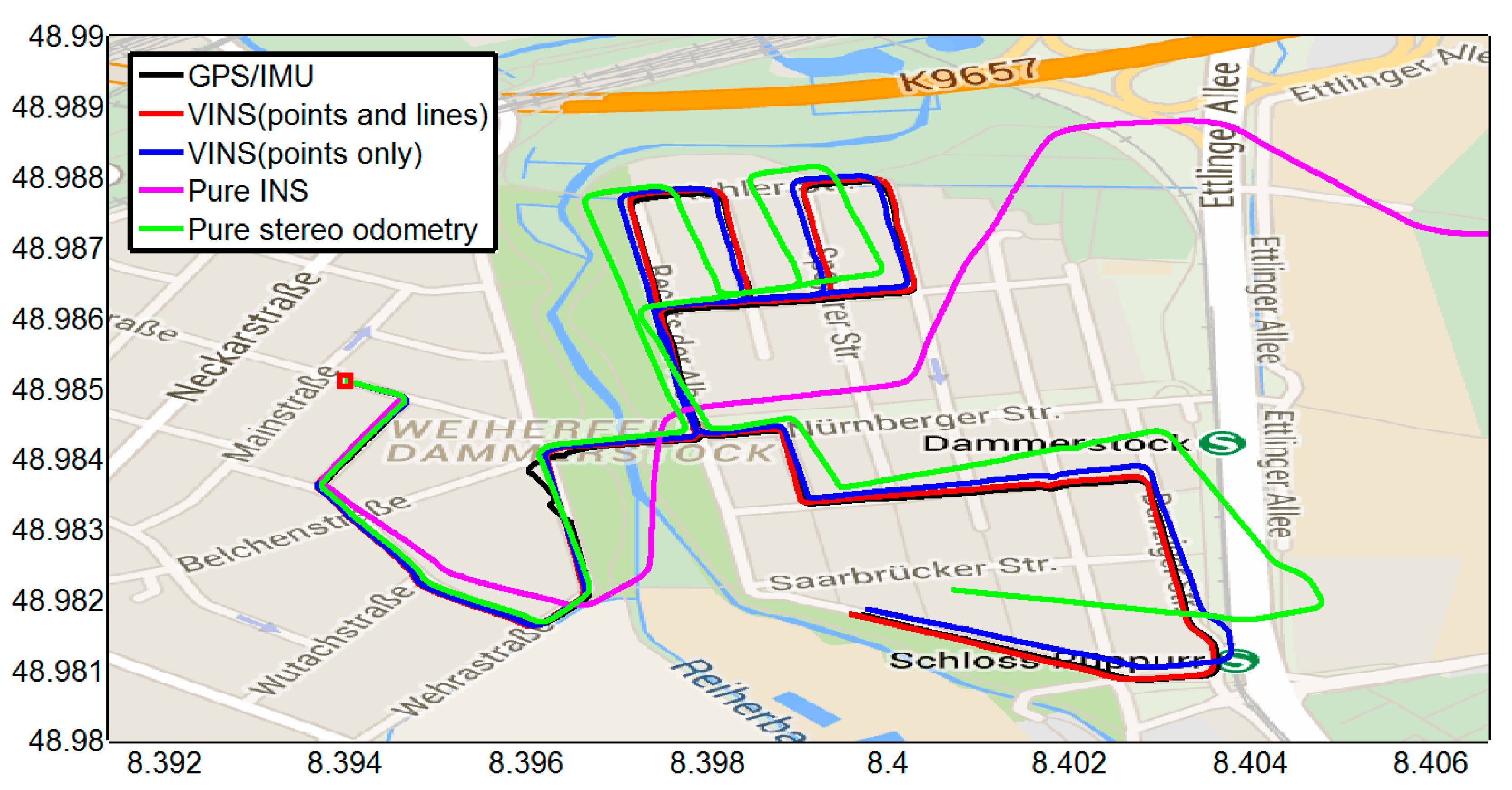


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Position RMSE (m) | Orientation RMSE (deg) |
|---|---|---|
| VINS (points and lines) | 10.6338 | 0.8313 |
| VINS (points only) | 16.4150 | 0.9126 |
| Pure INS | 2149.9 | 2.0034 |
| Pure stereo odometry | 72.6399 | 8.1809 |
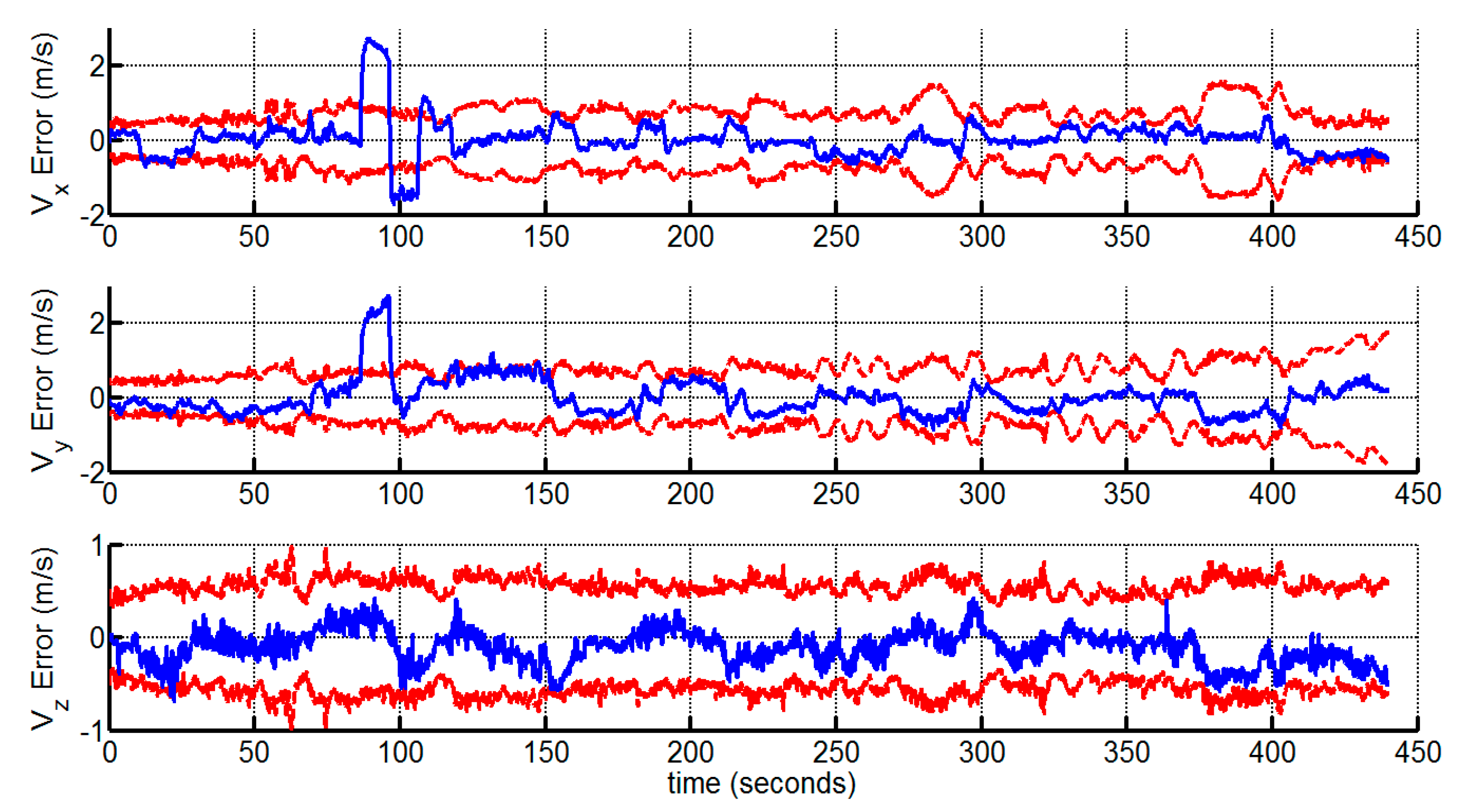
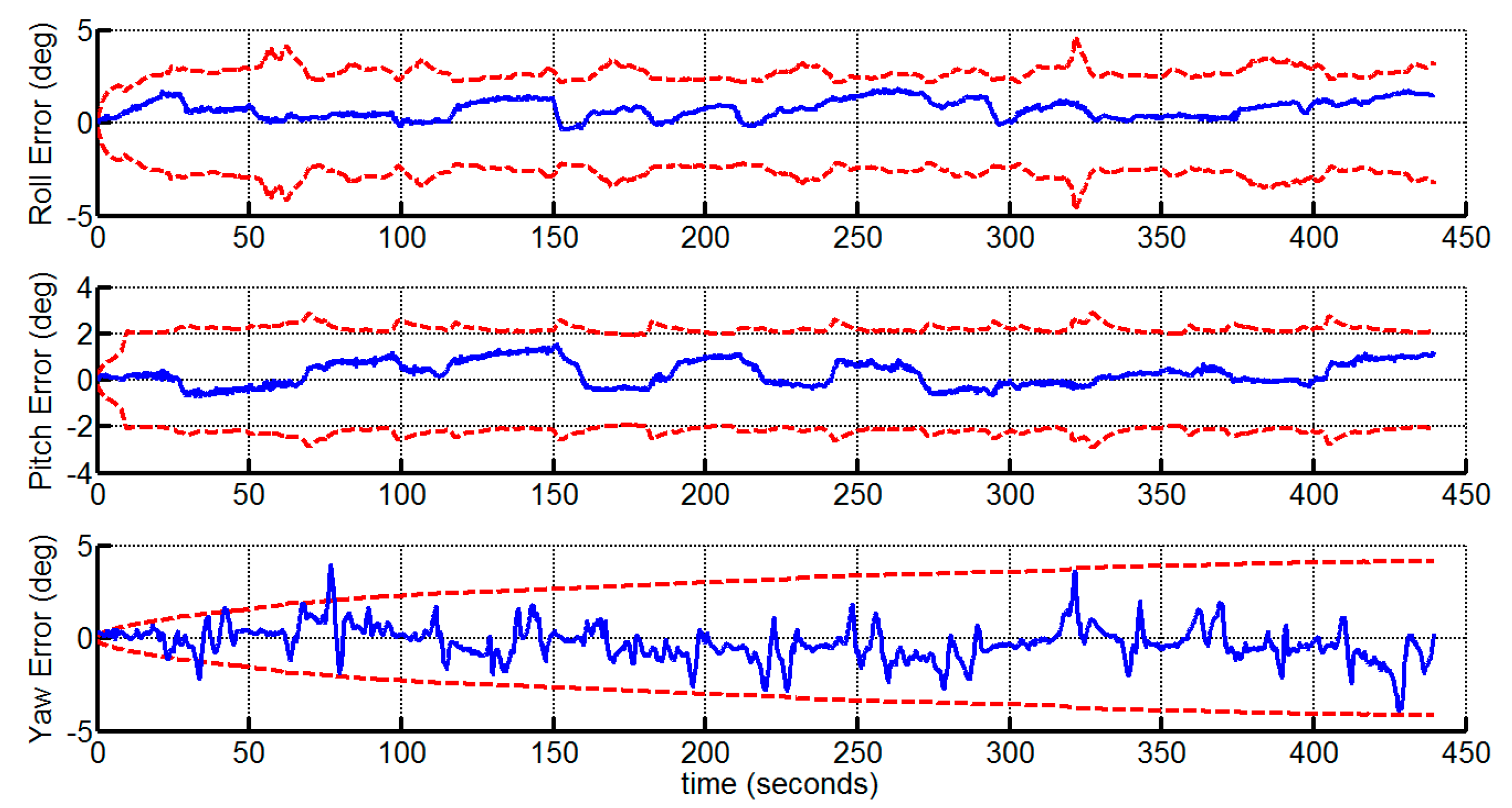
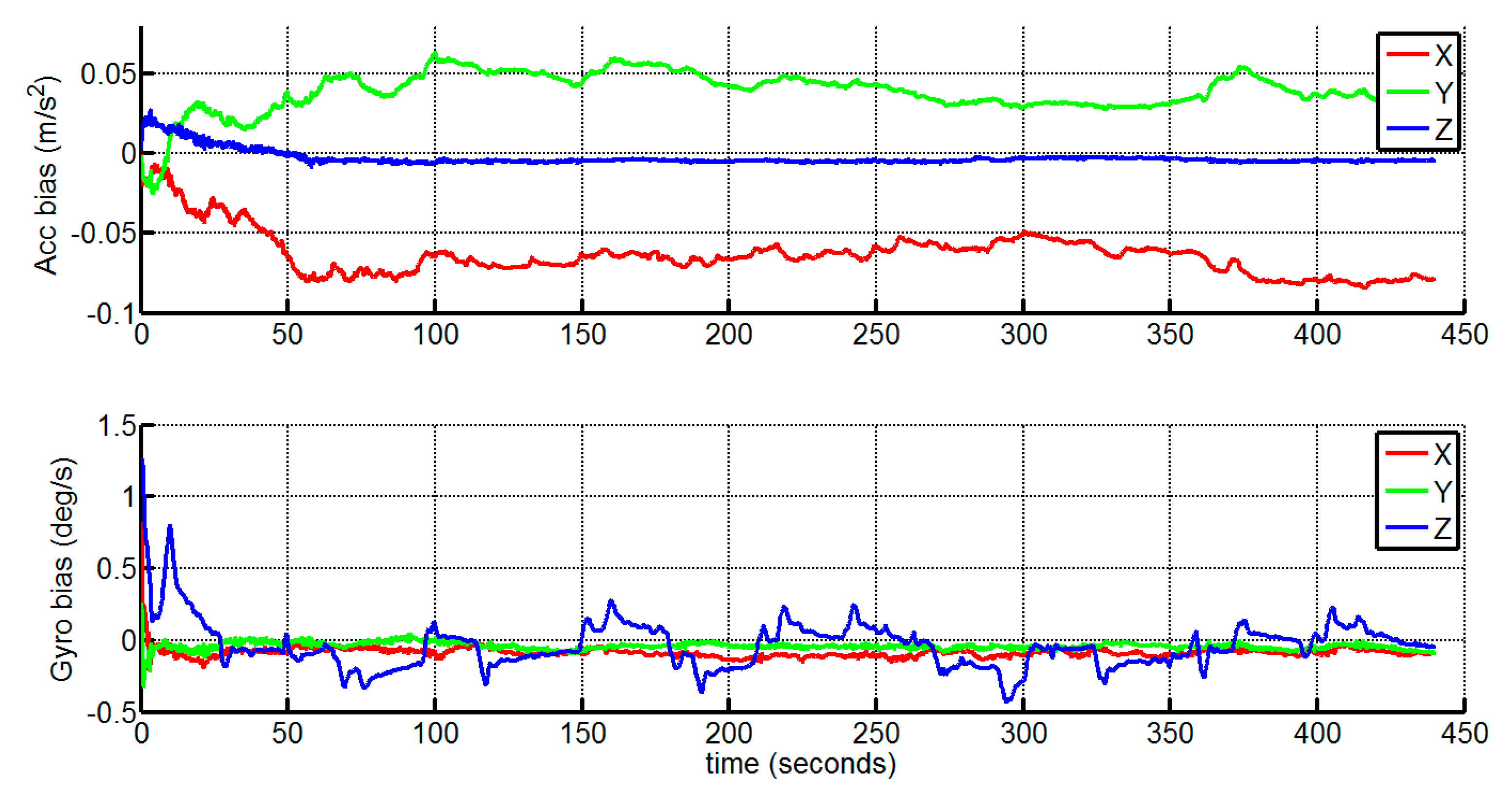
4.2. Indoor Experiment
| Sensors | Accuracies | Sampling Rates |
|---|---|---|
| IMU | Gyro bias stability (1 ): 1°/s Accelerometer bias stability: 0.02 m/s2 | 100 Hz |
| Stereo Camera | Resolution: 640 × 480 pixels Focus length: 3.8 mm Field of view: 70° Base line: 12 cm | 12 Hz |
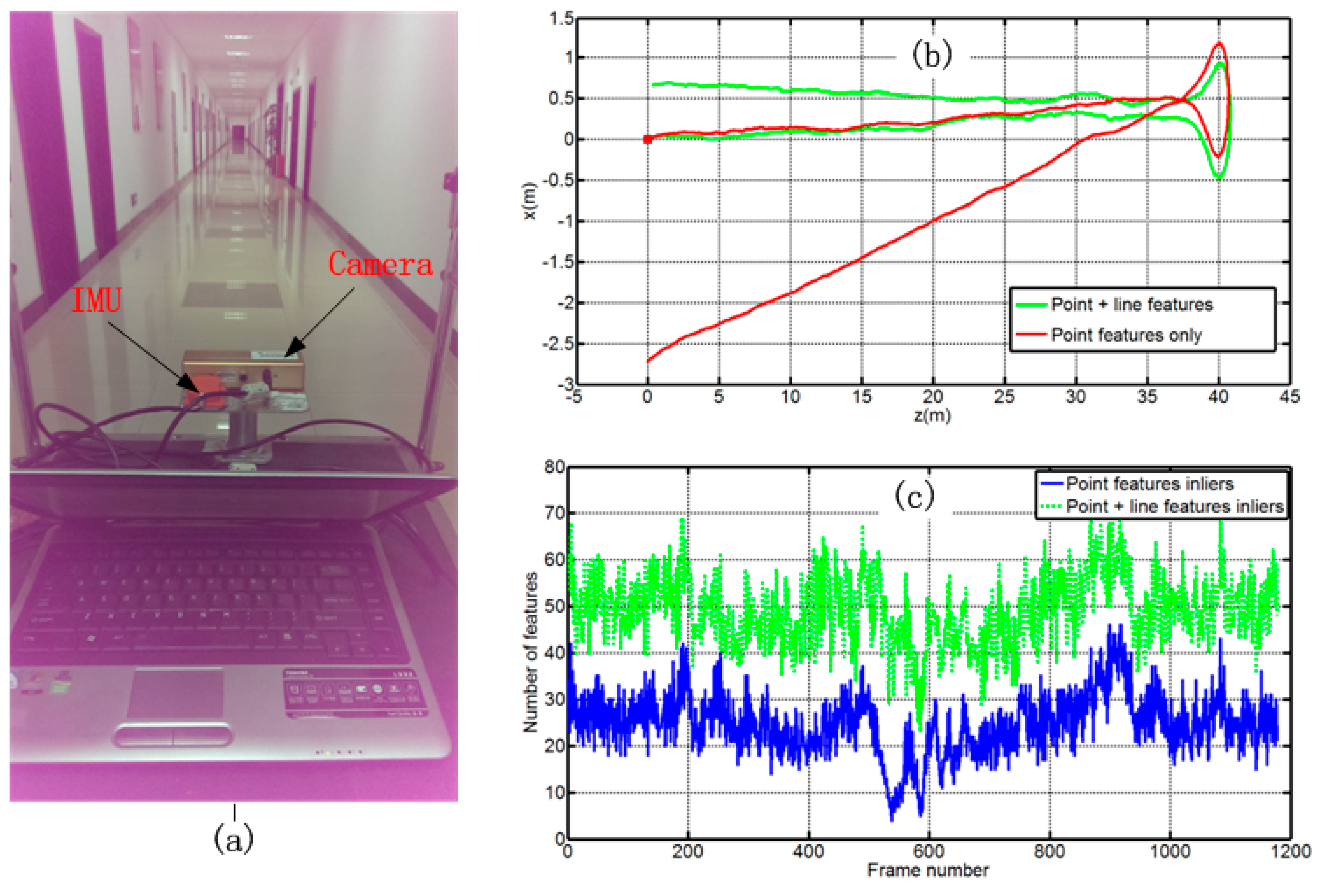
5. Conclusions/Outlook
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Titterton, D.H.; Weston, J.L. Srapdown Inertial Navigation Technology, 2nd ed.; The Institution of Electrical Engineers: London, UK, 2004. [Google Scholar]
- Kelly, J.; Sukhatme, G.S. Visual-inertial sensor fusion: Localization, mapping and sensor-to-sensor self-calibration. Int. J. Robot. Res. 2011, 30, 56–79. [Google Scholar] [CrossRef]
- Feng, G.H.; Wu, W.Q.; Wang, J.L. Observability analysis of a matrix kalman filter-based navigation system using visual/inertial/magnetic sensors. Sensors 2012, 12, 8877–8894. [Google Scholar] [CrossRef] [PubMed]
- Indelman, V.; Gurfil, P.; Rivlin, E.; Rotstein, H. Real-time vision-aided localization and navigation based on three-view geometry. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 2239–2259. [Google Scholar] [CrossRef]
- Weiss, S.; Achtelik, M.W.; Lynen, S.; Chli, M.; Siegwart, R. Real-time onboard visual-inertial state estimation and self-calibration of mavs in unknown environments. In Proceeding of the IEEE International Conference on Robotics and Automation, St. Paul MN, USA, 14–18 May 2012; pp. 957–964.
- Kottas, D.G.; Roumeliotis, S.I. Efficient and consistent vision-aided inertial navigation using line observations. In Proceeding of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1540–1547.
- Li, M.Y.; Mourikis, A.I. High-precision, consistent EKF-based visual-inertial odometry. Int. J. Robot. Res. 2013, 32, 690–711. [Google Scholar] [CrossRef]
- Hesch, J.A.; Kottas, D.G.; Bowman, S.L.; Roumeliotis, S.I. Camera-imu-based localization: Observability analysis and consistency improvement. Int. J. Robot. Res. 2014, 33, 182–201. [Google Scholar] [CrossRef]
- Hu, J.-S.; Chen, M.-Y. A sliding-window visual-imu odometer based on tri-focal tensor geometry. In Proceeding of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 3963–3968.
- Corke, P.; Lobo, J.; Dias, J. An introduction to inertial and visual sensing. Int. J. Robot. Res. 2007, 26, 519–535. [Google Scholar] [CrossRef]
- Roumeliotis, S.I.; Johnson, A.E.; Montgomery, J.F. Augmenting inertial navigation with image-based motion estimation. In Proceeding of the IEEE International Conference on Robotics and Automation, Washington, DC, USA, 12–18 May 2002; pp. 4326–4333.
- Diel, D.D.; DeBitetto, P.; Teller, S. Epipolar constraints for vision-aided inertial navigation. In Proceeding of the Seventh IEEE Workshops on Application of Computer Vision, Breckenridge, CO, USA, 5–7 Janury 2005; pp. 221–228.
- Tardif, J.-P.; George, M.; Laverne, M. A new approach to vision-aided inertial navigation. In Proceeding of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 4146–4168.
- Sirtkaya, S.; Seymen, B.; Alatan, A.A. Loosely coupled kalman filtering for fusion of visual odometry and inertial navigation. In Proceeding of the 16th International Conference on Information Fusion (FUSION), Istanbul, Turkey, 9–12 July 2013; pp. 219–226.
- Mourikis, A.; Roumeliotis, S.I. A multi-state constraint kalman filter for vision-aided inertial navigation. In Proceeding of the IEEE Inernational Conference in Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3565–3572.
- Leutenegger, S.; Furgale, P.T.; Rabaud, V.; Chli, M.; Konolige, K.; Siegwart, R. Keyframe-based visual-inertial slam using nonlinear optimization. In Proceeding of the Robotics: Science and Systems, Berlin, Germany, 24–28 June 2013.
- Zhang, L. Line Primitives and Their Applications in Geometric Computer Vision. Ph.D. Thesis, Kiel University, Kiel, Germany, 15 August 2013. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Sola, J.; Vidal-Calleja, T.; Civera, J.; Montiel, J.M.M. Impact of landmark parametrization on monocular ekf-slam with points and lines. Int. J. Comput. Vision. 2012, 97, 339–368. [Google Scholar] [CrossRef]
- Weiss, S.; Siegwart, R. Real-time metric state estimation for modular vision-inertial systems. In Proceeding of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 4531–4537.
- Ford, T.J.; Hamilton, J. A new positioning filter: Phase smoothing in the position domain. Navigation 2003, 50, 65–78. [Google Scholar] [CrossRef]
- Van Der Merwe, R. Sigma-Point Kalman Filters for Probabilistic Inference in Dynamic State-Space Models. Ph.D. Thesis, Oregon Health & Science University, Portland, OR, USA, 9 April 2004. [Google Scholar]
- Julier, S.J. The scaled unscented transformation. In Proceeding of the American Control Conference, Anchorage, AK, USA, 8–10 May 2002; pp. 4555–4559.
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, Greece, 16–21 June 2012; pp. 3354–3361.
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Computer Vision–Eccv 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar]
- Zhang, Z.; Deriche, R.; Faugeras, O.; Luong, Q.-T. A robust technique for matching two uncalibrated images through the recovery of the unknown epipolar geometry. Artif. Intell. 1995, 78, 87–119. [Google Scholar] [CrossRef]
- Akinlar, C.; Topal, C. Edlines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. Line matching using appearance similarities and geometric constraints. In Pattern Recognition; Pinz, A., Pock, T., Bischof, H., Leberl, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7476, pp. 236–245. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory Algorithms and Software; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3D reconstruction in real-time. In Proceeding of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 Junuary 2011; pp. 963–968.
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceeding of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–8 November 2013; pp. 1280–1286.
- Coughlan, J.M.; Yuille, A.L. Manhattan world: Compass direction from a single image by bayesian inference. In Proceeding of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 941–947.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, X.; Wu, W.; Zhang, L.; Wang, Y. Tightly-Coupled Stereo Visual-Inertial Navigation Using Point and Line Features. Sensors 2015, 15, 12816-12833. https://doi.org/10.3390/s150612816
Kong X, Wu W, Zhang L, Wang Y. Tightly-Coupled Stereo Visual-Inertial Navigation Using Point and Line Features. Sensors. 2015; 15(6):12816-12833. https://doi.org/10.3390/s150612816
Chicago/Turabian StyleKong, Xianglong, Wenqi Wu, Lilian Zhang, and Yujie Wang. 2015. "Tightly-Coupled Stereo Visual-Inertial Navigation Using Point and Line Features" Sensors 15, no. 6: 12816-12833. https://doi.org/10.3390/s150612816
APA StyleKong, X., Wu, W., Zhang, L., & Wang, Y. (2015). Tightly-Coupled Stereo Visual-Inertial Navigation Using Point and Line Features. Sensors, 15(6), 12816-12833. https://doi.org/10.3390/s150612816