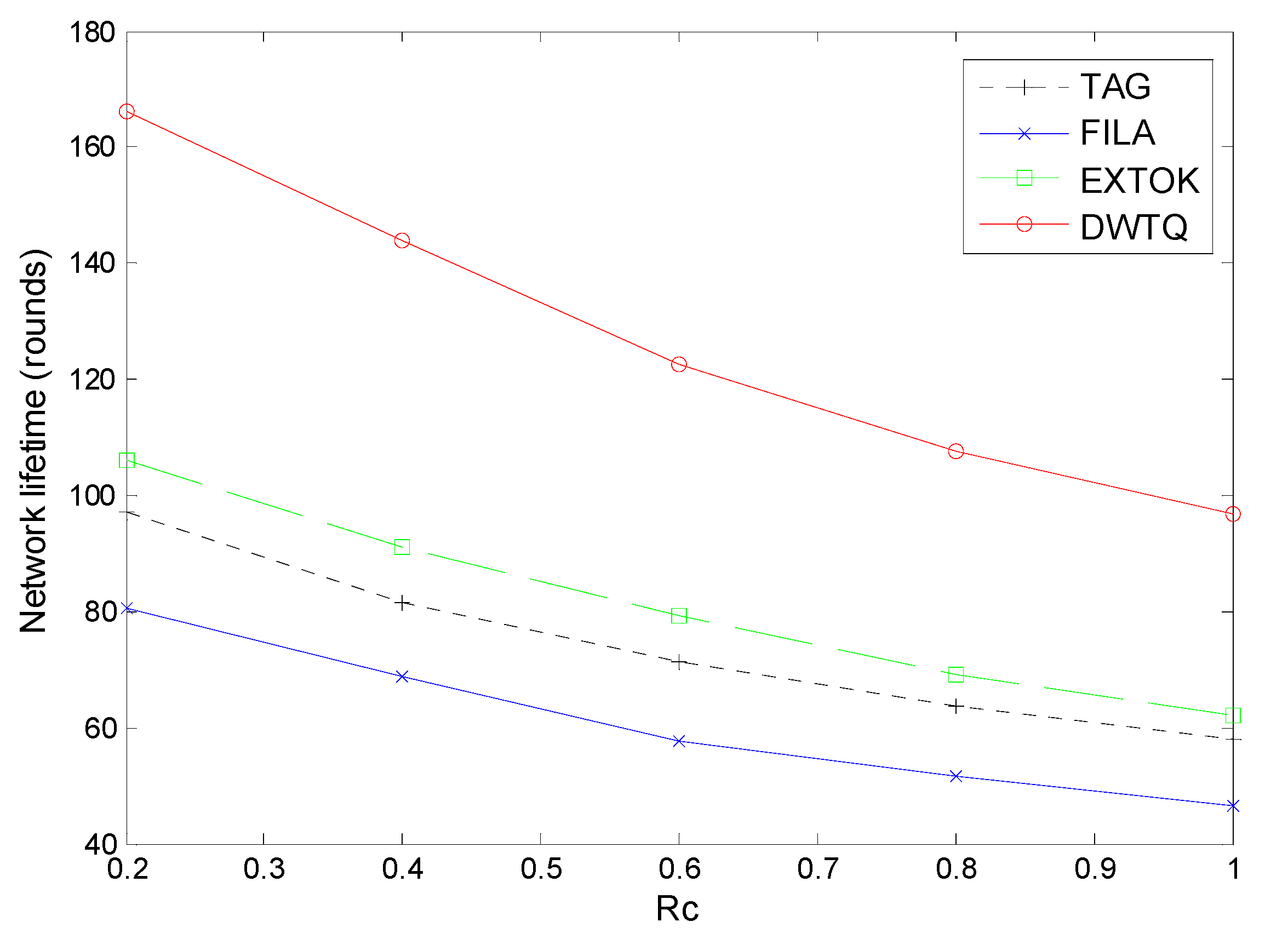
In this section, we evaluate the performance of RWTQ and DWTQ by both theoretical analysis and simulation. First, in
Section 5.1, we discuss how the performances of the filter-based approaches are affected by the size of the network, dynamics of sensors’ readings and decline of the whole readings’ range through a theoretical analysis based on a simple model. We first set up a simple wireless senor network with a square topology and then model the message, energy consumption, readings, physical phenomenon and the measurement error. The performance of filter-based approaches is compared with that of a representative aggregation-based approach TAG [
3]. The analysis results are presented in
Figure 8,
Figure 9,
Figure 10 and
Figure 11. Through theoretical analysis, we can find that the filter-based approaches are useless in certain situations and it is essential to develop a novel top-
query method. Then, in
Section 5.2,
Section 5.3,
Section 5.4 and
Section 5.5, we use the simulator ns-3 [
18] (version 3.21) to evaluate the performances of RWTQ and DWTQ. We compare them to TAG, FILA and EXTOK in terms of transmission cost, query accuracy, energy cost and network lifetime. Finally, in
Section 5.6, we give a concluding discussion of the simulations.
Table 2 is given for users to index the parameters.
5.1. The Failure of Filter-Based Top-k Query Approaches
Various metrics can be employed to evaluate the performance of a top- query approach and transmission cost is one of the most essential metrics. Therefore, our goal is to analyze the average transmission cost of filter-based approaches with different sizes of a network and the dynamics of the readings. The transmission cost is defined as the total amount of data transmitted in the whole network in a round of a top- query.
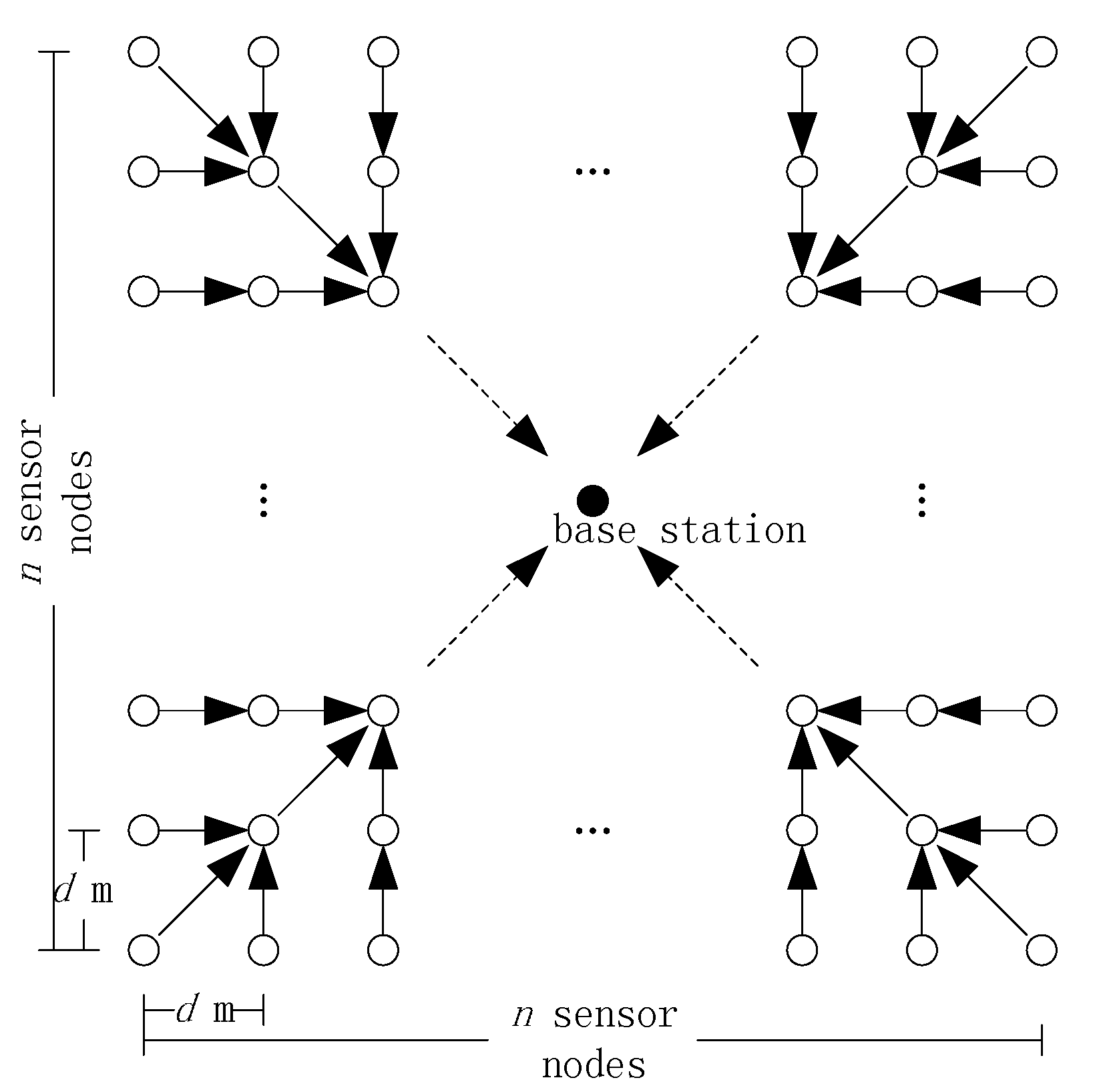
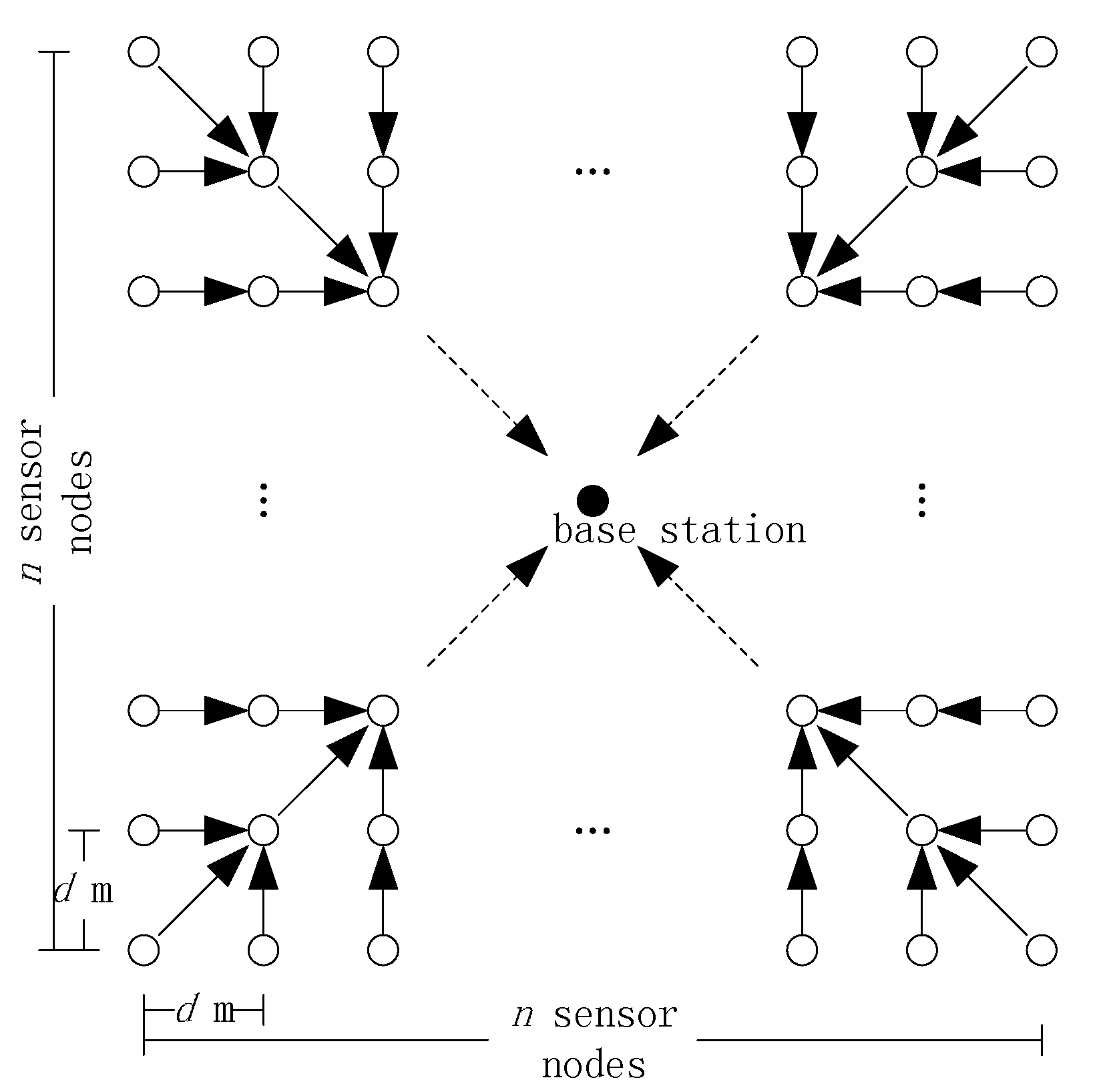
Figure 6.
Square-grid topology.
Figure 6.
Square-grid topology.
For analytic tractability, consider a square grid consisting of
nodes and the BS located at the center as shown in
Figure 6. For FILA and EXTOK, a TAG routing tree [
3] is employed by the nodes to communicate with the BS. In the initial phase of constructing the routing tree, the BS needs to broadcast a message asking the nodes to organize a routing tree. In addition, to improve the robust, the tree needs to be updated periodically. For the sake of convenience, the transmission cost of initializing and updating the routing tree is ignored. At the beginning, both FILA and EXTOK need to collect all the readings from the nodes to set filters and the corresponding transmission cost is also ignored.
Figure 7.
Initial distribution of the readings and filters.
Figure 7.
Initial distribution of the readings and filters.
In our analysis, the real value
of a physical phenomenon for
is modeled by a normal distribution with parameters
and
. The parameters
are assumed to be uniformly distributed on the interval [
,
], as shown in upper half of
Figure 7. We assume that the initial readings of the sensors equals to the mean values of physical phenomenon,
i.e.,
Based on these readings, the BS calculates the filters based on the method in [
1]. A unique filter [
,
] is designed for the
-th node in the top-
members and all the other nodes share a common filter
as shown in lower half of
Figure 7. In addition, each node has a normal distributed measurement error
. The reading of
-th node consists of two parts,
i.e.,
where
and
both are random variable and normal distributed,
i.e.,
Based on the properties of the normal distribution, we can get that:
When a new query task comes, the reading
is very likely to change because of two reasons: the changes of
and affections of the measurement errors
. Therefore,
events,
i.e., the readings of non- top-
members beyond
, and
events,
i.e., the readings of top-
members become lower than
, possibly happen. The probability of
event and
event for the
-th reading is shown as follows:
where
is the cumulative distribution function of
and it is presented as follows:
As illustrated in [
1,
2], the number of
events and
events can significantly influence the transmission cost. If
, it is not necessary to probe any nodes that are not in the top-
members and the new filters are sent to the relevant nodes rather than all the nodes in the network. However, If
, to get the top-
readings, all the nodes that are not in the top-
members need to be probed and a new filter is reset for each of them. The probabilities of
and
are shown as follows:
In most practical applications, the parameter
is much less than
which is the size of the network. We can draw this conclusion from actual observations which are described in [
1,
2]. Therefore, the transmission cost in the condition of
is also much less than that in the condition of
. For the sake of convenience, we focus our attention on the transmission cost in the condition of
and ignore the transmission cost in the condition of
.
In a query, having found that
, the BS sends a probe message to all the nodes in the network asking them to upload the readings. The transmission cost in this phase is shown as follows:
where
is the length of a probe message. Having received the probe message, each node transfers its reading to the BS based on a routing tree (e.g., the TAG Tree). Assume that an aggregation technique is employed to reduce the transmission cost and the transmission cost is:
where
is the length of a node’s ID and
is the length of a reading. After the BS calculates the top-
readings, a unique filter is generated for each top-
member and a common filter is generated for all the non-top-
members. Then, the BS injects these filters into the network. First, the unique filters are installed by the top-
members. Then, the common filter is broadcasted in the whole network and all the non- top-
members need to install the new common filter. The transmission cost for the filters of top-
members depends on the locations of the members which is random. In average, the transmission cost is
in the network as shown in
Figure 6. Therefore, the transmission cost of updating the filters is:
So the expectation of the total transmission cost for a new query is:
As in Equation (19), is affected by two parts, i.e., and . However, is constant for a given network. As a result, is the most important parameter that affect significantly. Based on Equation (15), we can find that is mainly affected by the probabilities of a node join or leave the top- members which are affected by the variance of the readings and the distance between the filter and the mean of the reading (). As a result, when the range of the readings [, ] is constant, , and the variance of the readings can significantly affect the transmission cost. What’s more, the dynamics of [, ] can affect the performance of filter-based top- query even more significantly.
In order to give a visual presentation, we instantiate the parameters and then plot the transmission cost in figures. The parameters are set as in
Table 3. First, we fix the range [
,
] of the readings and present the probability of
and corresponding transmission cost with different parameters including
,
and
in
Figure 8,
Figure 9 and
Figure 10. Then, we assume that the reading of
decreases
times of
which is the width of
’s filter in a period of query and the simulation results are presented in
Figure 11.
Table 3.
Instantiation of parameters.
Table 3.
Instantiation of parameters.
| Symbol | Value |
|---|
| 1, 2, 5, 10 |
| N | 100, 200, 500, 1000, 2000 |
| , , , , | 4 bytes |
| 8 bytes |
| 30 (constant) |
| Decrease by m times of wi in each period of query, 0, 0.1, 0.2, 0.5, 1, 2 |
| 25 (constant) |
| Decrease by m times of wi in each period of query, m =0, 0.1, 0.2, 0.5, 1, 2 |
| |
| 0 |
| , , , , , , 1 |
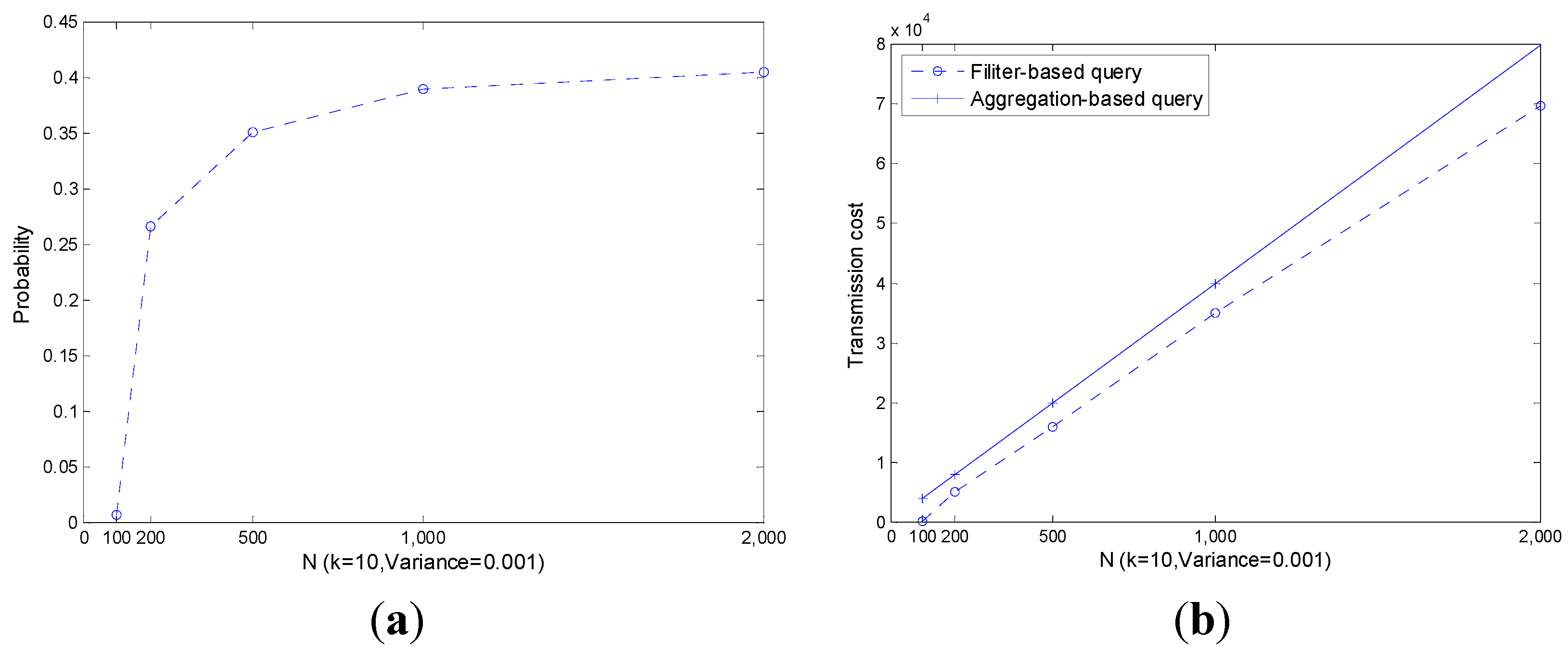
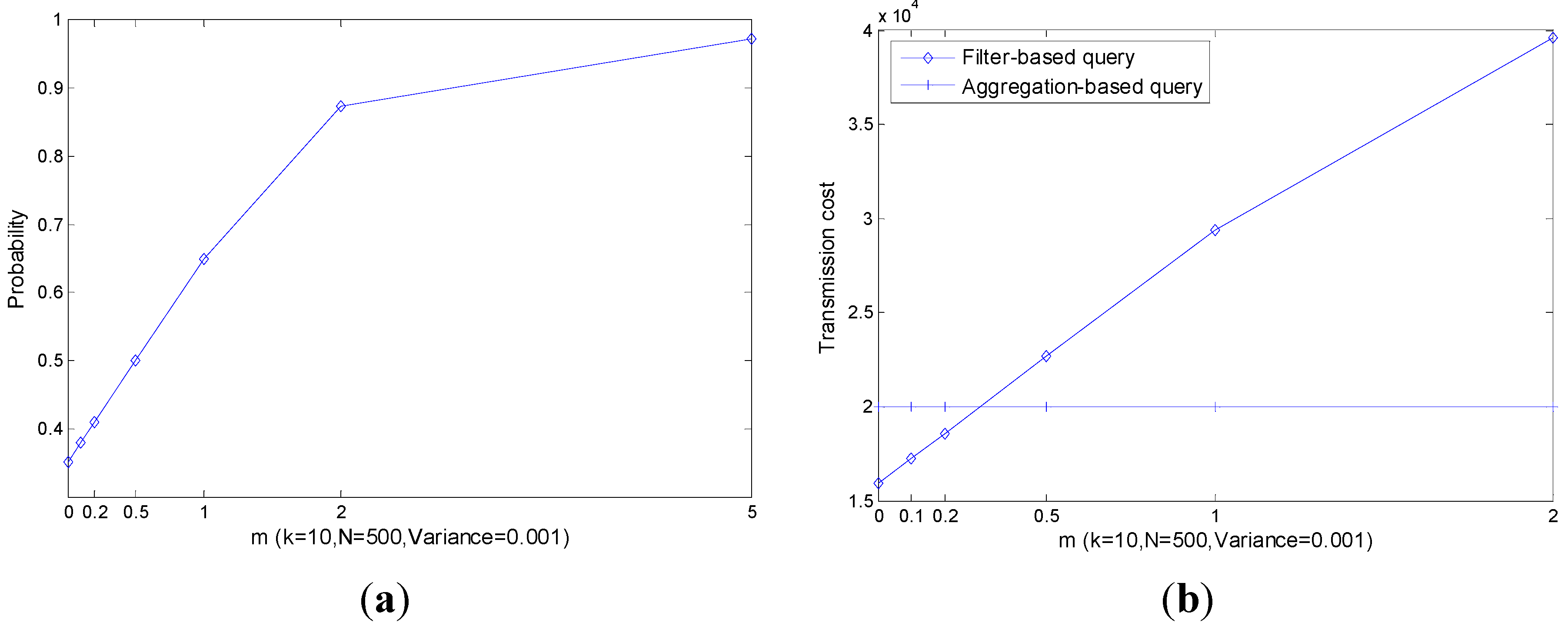
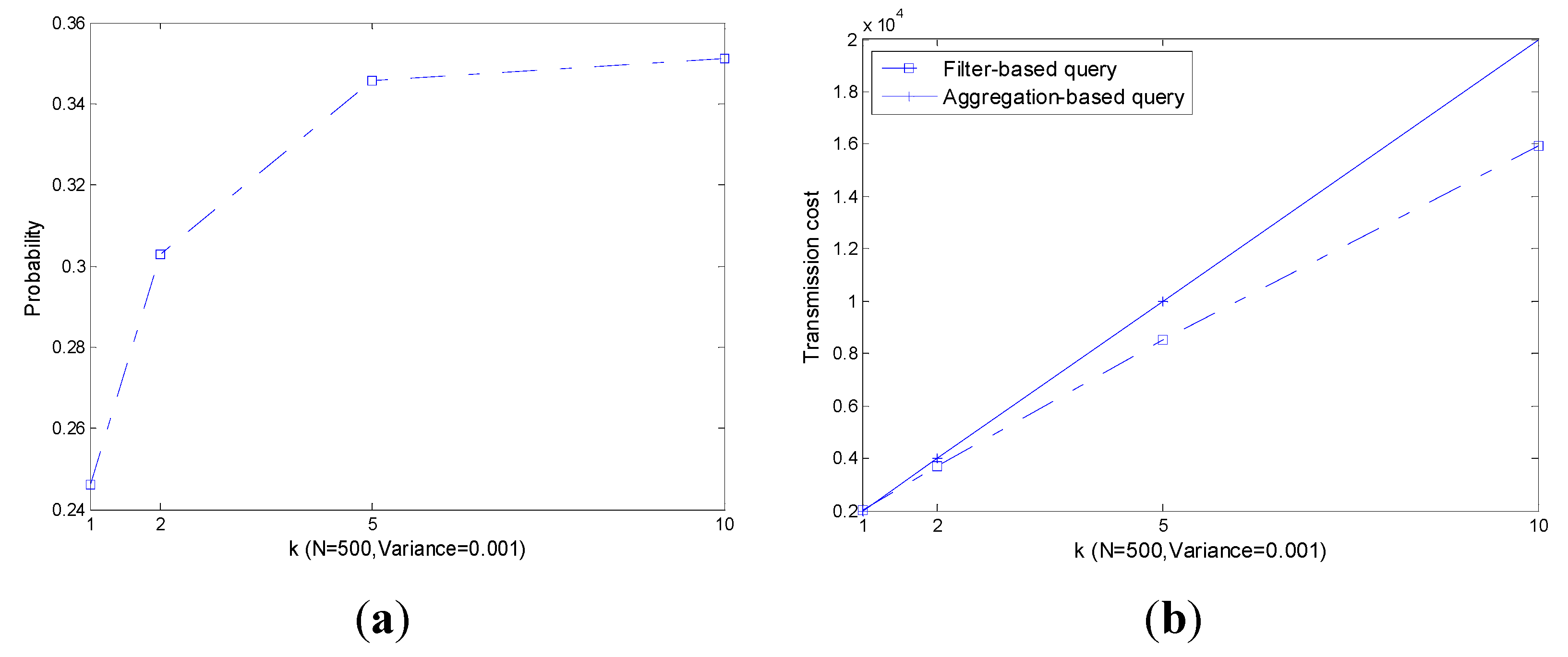
As shown in
Figure 8a, with the increase of
, the probability of
also increases especially when
is small. As a result, the transmission cost increases as plotted in
Figure 8b. However, the performance of the filter-based query is always slightly better than that of the aggregation-based query.
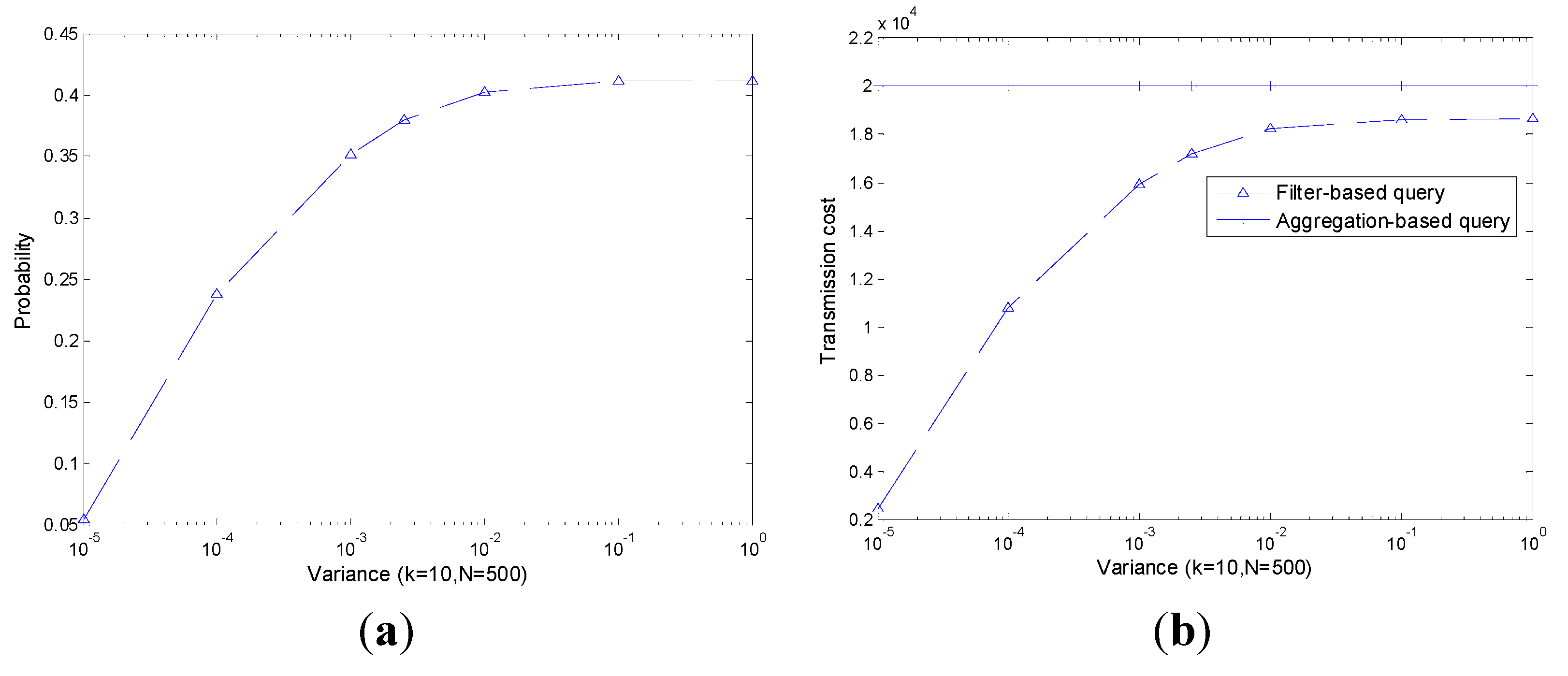
As shown in
Figure 9, like
, with the increase of
, both
and corresponding transmission cost increase significantly. The performance of the filter-based query is always slightly better than that of the aggregation-based query.
As shown in
Figure 10, the transmission cost of an aggregation-based query is independent of the decrease of the readings’ range,
i.e., the transmission cost is always constant. The transmission cost of a filter-based query increases with the increase of
, however it outperforms the aggregation-based query all the time.
Though the performance of a filter-based query is affected by
,
and
, the filter-based query always outperforms an aggregation-based query. Note that, only part of the real transmission cost is presented and the others are ignored. In the following, we present the impact of readings’ range decline on the performance of transmission cost in
Figure 11.
Figure 8.
and co.rresponding transmission cost with different . (a) ; (b) Transmission cost.
Figure 8.
and co.rresponding transmission cost with different . (a) ; (b) Transmission cost.
Figure 9.
and corresponding transmission cost with different . (a) ; (b) Transmission cost.
Figure 9.
and corresponding transmission cost with different . (a) ; (b) Transmission cost.
Figure 10.
and corresponding transmission cost with different (a) ; (b) Transmission cost.
Figure 10.
and corresponding transmission cost with different (a) ; (b) Transmission cost.
Figure 11.
and corresponding transmission cost with the decreasing of readings’ range. (a) ; (b) Transmission cost.
Figure 11.
and corresponding transmission cost with the decreasing of readings’ range. (a) ; (b) Transmission cost.
Figure 11 shows that the decrease of the readings’ range has a huge impact on
which is much bigger than the other parameters discussed previously. As shown in
Figure 8,
Figure 9 and
Figure 10, the limit value of
is about 0.5 with the increase of the parameters. However, in
Figure 11, the limit value of
is 1. As a result, when
, we can find in
Figure 11b that the transmission cost of a filter-based query is much larger than that of the aggregation-based query. In this situation, filters in the network are useless and a more efficient top-
query approach is needed.
In conclusion, filter-based top- query approaches are very sensitive to the size of the networks, dynamics of the sensors’ readings and decline of the whole range of the readings. In some situations, the filters can’t improve the performance of query approaches significantly. What’s more, in some certain situations, the filters are useless and even become the burden of approaches. Therefore, it is very meaningful to design a more efficient top- query approach.
5.2. Simulation Setup
In our simulation, 500 homogeneous sensor nodes are randomly scattered in a 200 m × 200 m region. For each simulation, to reduce the randomness of the simulation result, we do the same experiment for 10 times and present the average result. The temperatures contained in Intel Berkeley dataset [
19] is used to simulate the readings of the sensor nodes. Millions of pieces of recordings, including temperature, humidity, light and voltage, comprise the dataset generated by 54 sensor nodes deployed in the Intel Berkeley Research lab.
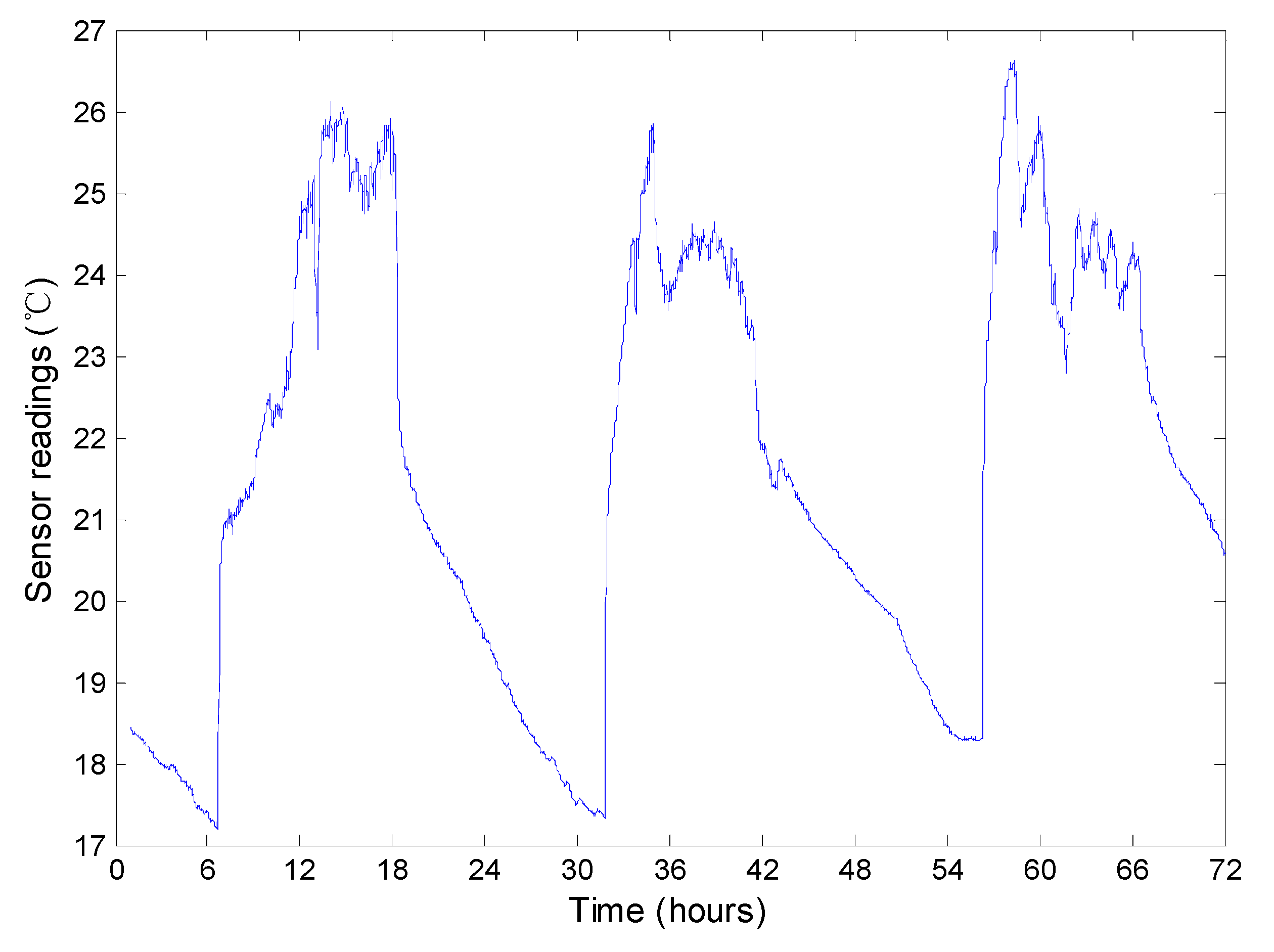
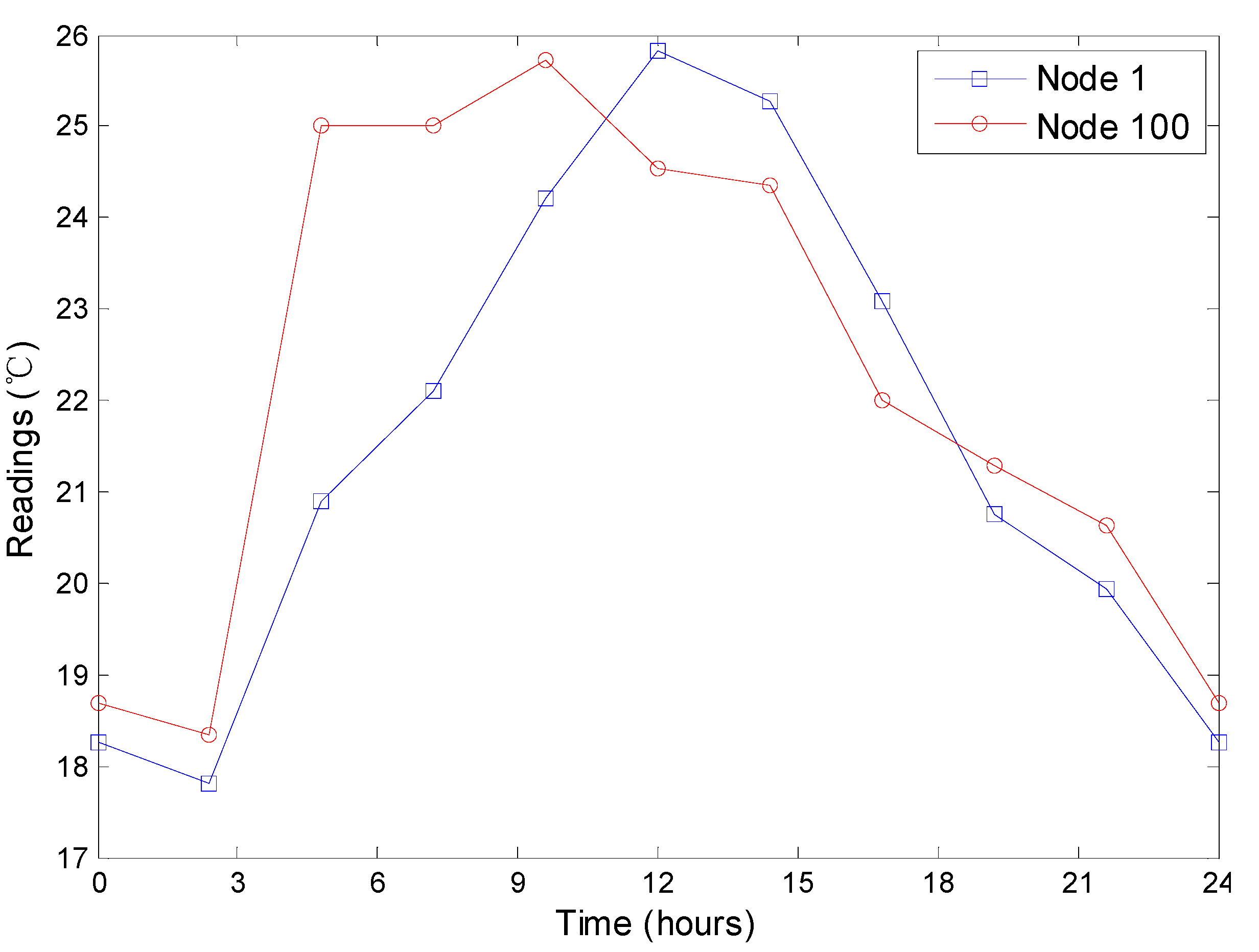
Figure 12 presents the temperature readings of the No. 1 node from March 1st to 3rd. For each day, we find that the temperatures increase from about 7 o’clock to 14 o’clock, fluctuate from about 14 o’clock to 18 o’clock and decrease from about 18 o’clock to 7 o’clock in the next day. As discussed previously in
Section 5.1, the decrease of the readings has a strong effect on the performance of the approaches. Therefore, we can perform an overall evaluation on the top-
query approaches using the dynamics of the readings.
As the number of sensor nodes in the dataset is 54 and it is much smaller than that of our network, we need to design a dispatcher to dispatch the readings to 500 nodes considering the spatial correlation of sensor readings. First, we divide the 500 nodes into five clusters based on algorithm 1 and, for each cluster, select a representation located in the center.
Figure 12.
The temperature readings of the No.1 node from March 1st to 3rd.
Figure 12.
The temperature readings of the No.1 node from March 1st to 3rd.
Then, the readings of five nodes in the Intel Berkeley dataset are randomly selected and we extract the readings of each node in a random day. Then the readings of the five nodes are dispatched to the five clusters in our network respectively, i.e., every node’s readings in a day are dispatched to a cluster. In Intel Berkeley dataset, one node generates about 2000 readings in a day and the largest cluster in our network has about 150 nodes. As a result, it is enough that every node in our network can receive 10 readings and, therefore, each experiment can perform the query 10 rounds. Considering the temporal correlation, first, the readings for a node in Intel Berkeley dataset in a day are divided into 10 subsets based the time sequence. Then the number of the nodes in a cluster in our network is calculated and denoted by . In each subset, we randomly select readings. Intuitively, considering the spatial correlations between the readings, for each cluster, the representation has the highest reading and the other nodes’ readings decrease with the increase of the distance to the representation.
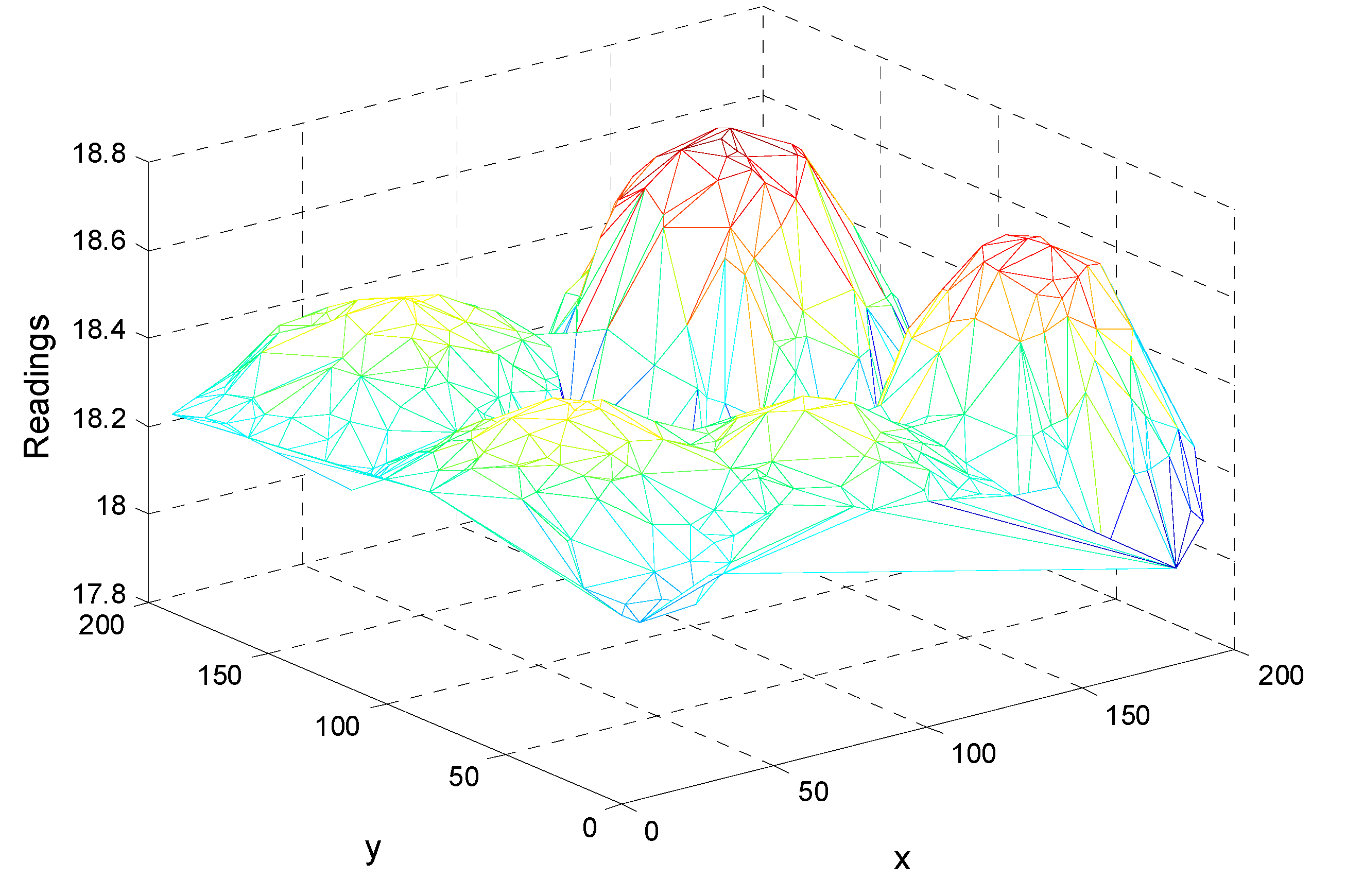
An example of the readings for a round of query is shown in
Figure 13. There are five extreme values in the overall network and the spatial correlation is also presented. In our simulation, each sensor node has ten readings in chronological order and each reading corresponding to one query round. The ten readings fluctuate as shown in
Figure 14, which is similar to a period of the readings shown in
Figure 12 to some extent. Note that the ten rounds rather than one round of top-
query comprise an experiment.
We compare our approaches with TAG, FILA and EXTOK in terms of transmission cost, query accuracy, energy cost and network lifetime. In our simulation, a sensor node identifier and reading both take 4 bytes.
Figure 13.
An example of the readings in a query round.
Figure 13.
An example of the readings in a query round.
Figure 14.
An example of the readings of a node in a simulation.
Figure 14.
An example of the readings of a node in a simulation.
5.3. Transmission Cost and Query Accuracy
For TAG and EXROK, the query results are the exact top-
readings in the networks, however, the query results of FILA have deviations which are affected by the properties of the network and the queries. The results of RWTQ and DWTQ also can’t be guaranteed to be the exact top-
readings. We define the query accuracy
as follows:
where
is the query results of the base station and
is the real top-
readings in the network. In this part, five tokens are injected into the network and we set
,
,
,
. For the different parameter
which controls the walk distance of a token, the transmission cost and query accuracy of RWTQ and DWTQ are significantly different. The simulation results are presented in
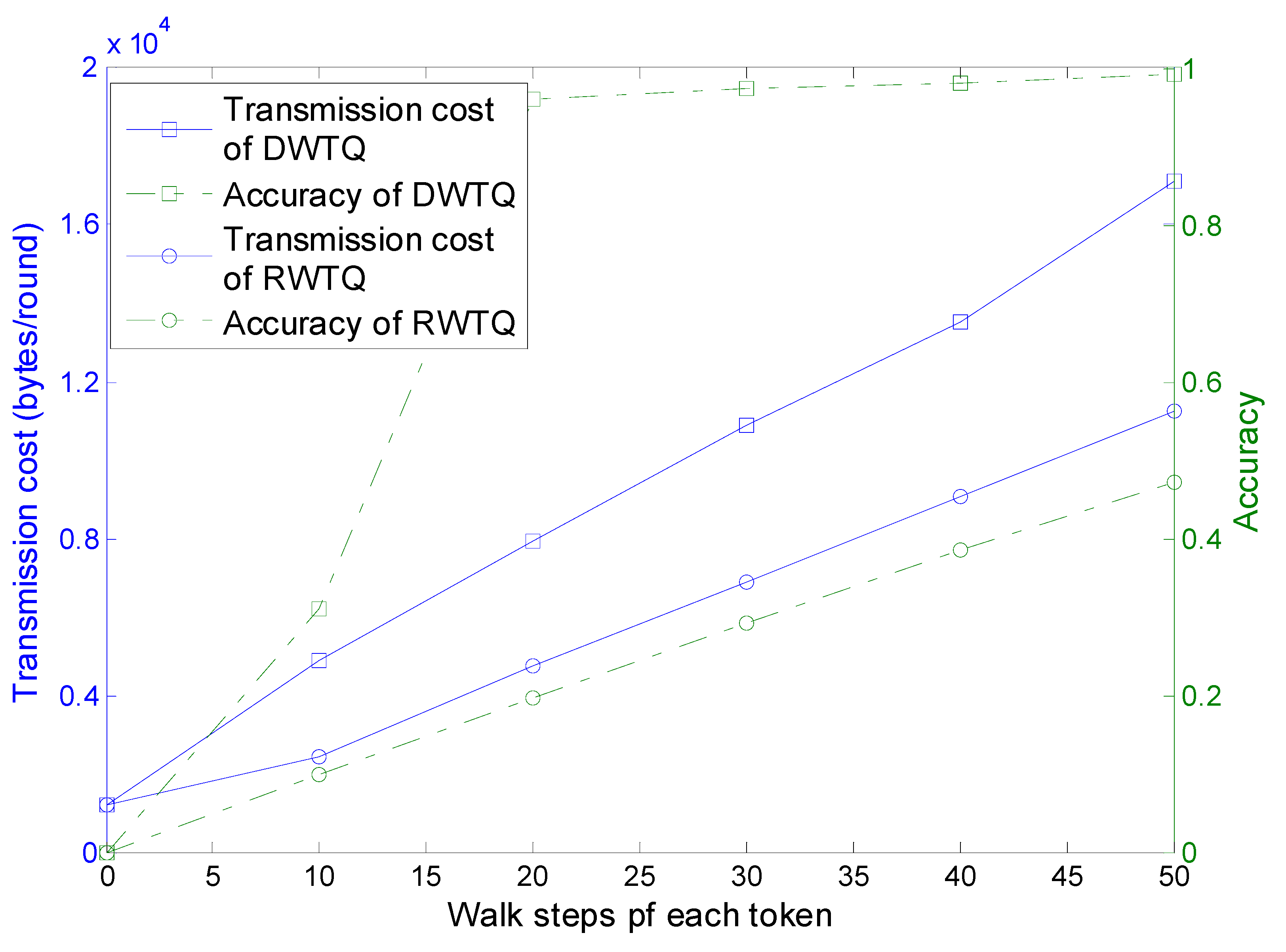
Figure 15.
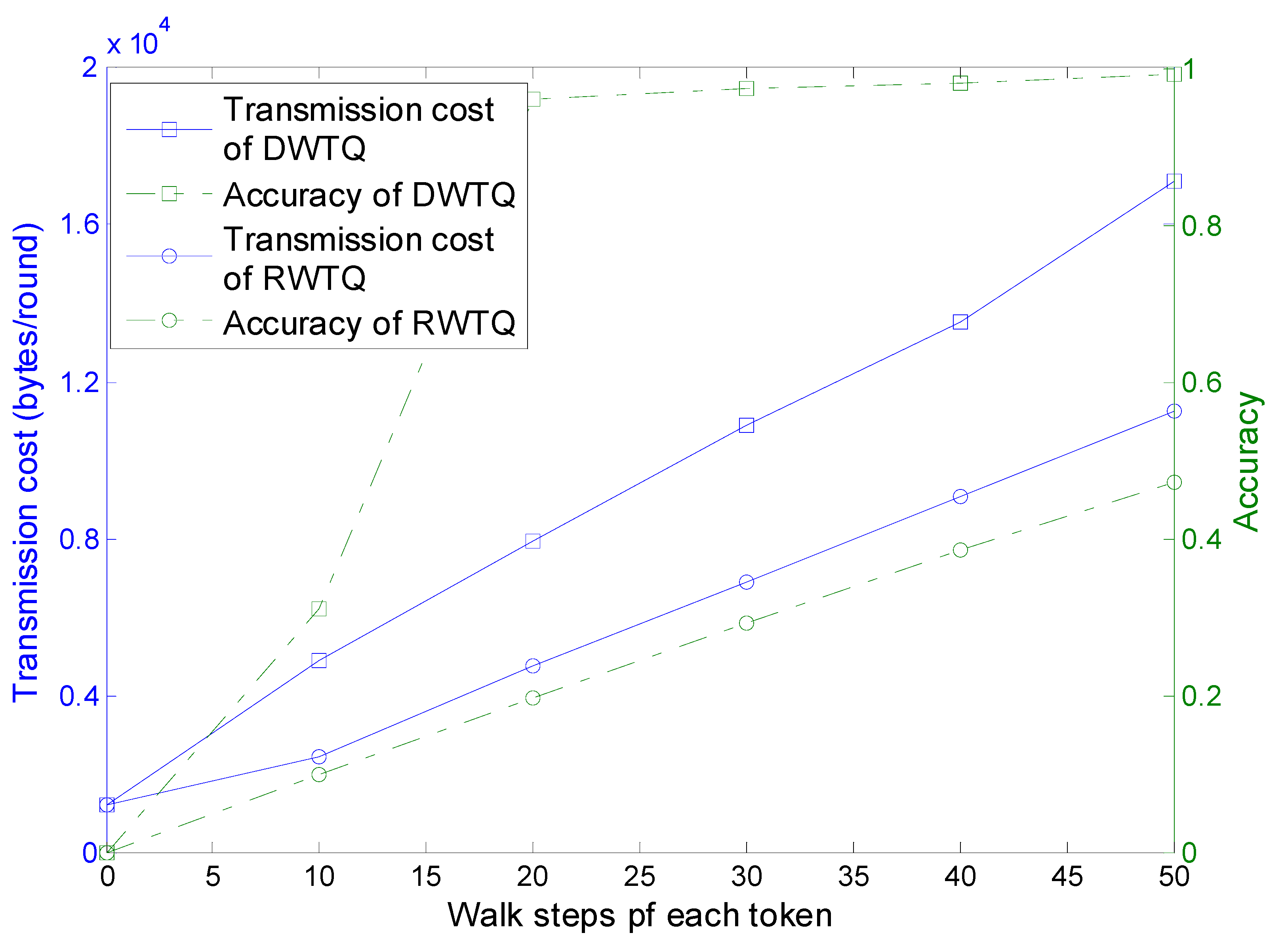
Figure 15.
Transmission cost and query accuracy.
Figure 15.
Transmission cost and query accuracy.
As the walk steps increase, the transmission cost and query accuracy of both DWTQ and RWTQ increase significantly. As shown in
Section 3 and
Section 4, the information contained in the tokens of DWTQ is larger than that of RWTQ, therefore, the transmission cost of DWTQ is always larger than that of RWTQ when their walk steps are equal. In addition, for the same walk steps, the query accuracy of DWTQ is much higher than that of RWTQ. However, we focus on the relationship between the transmission cost and the query accuracy. We can find in
Figure 15 that when the transmission cost is similar, then the accuracy of DWTQ is much higher than that of RWTQ. As an example, when DWTQ takes 1600 bytes in a round, the average accuracy is about 0.98 and the accuracy of RWTQ is smaller than 0.4. In conclusion, DWTQ outperforms RWTQ in transmission cost when the accuracy is set to be a constant in our simulation environment. In the following simulations, we use DWTQ to compare with the existing approaches.
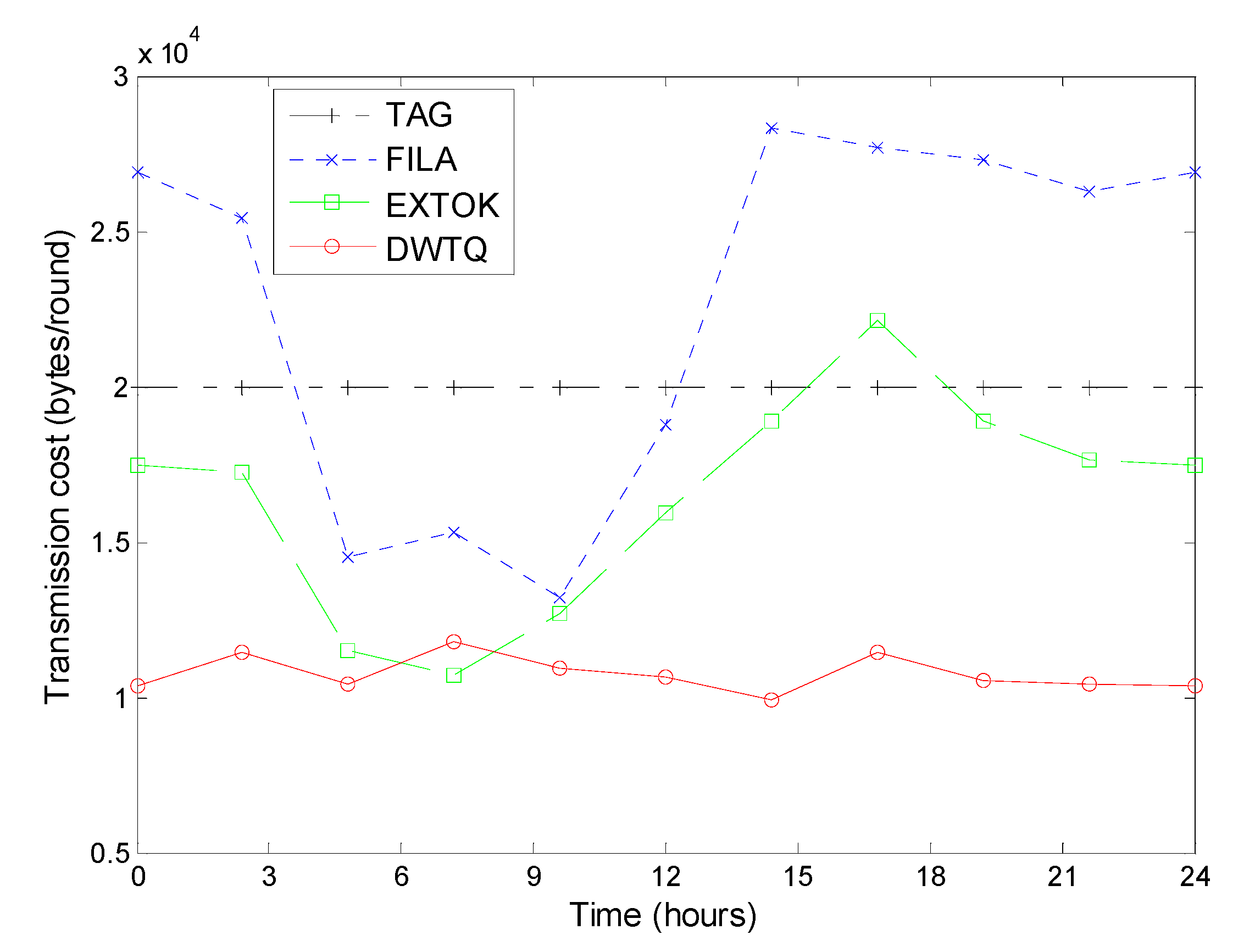
We now compare the transmission cost between DWTQ, TAG, FILA and EXTOK. In this simulation, each token walks 25 steps in the network. Different with traditional simulation, each experiment contains ten rounds of queries in a day in chronological order. The initial transmission cost for constructing routing trees and installing filters in TAG, FILA and EXTOK are ignored.
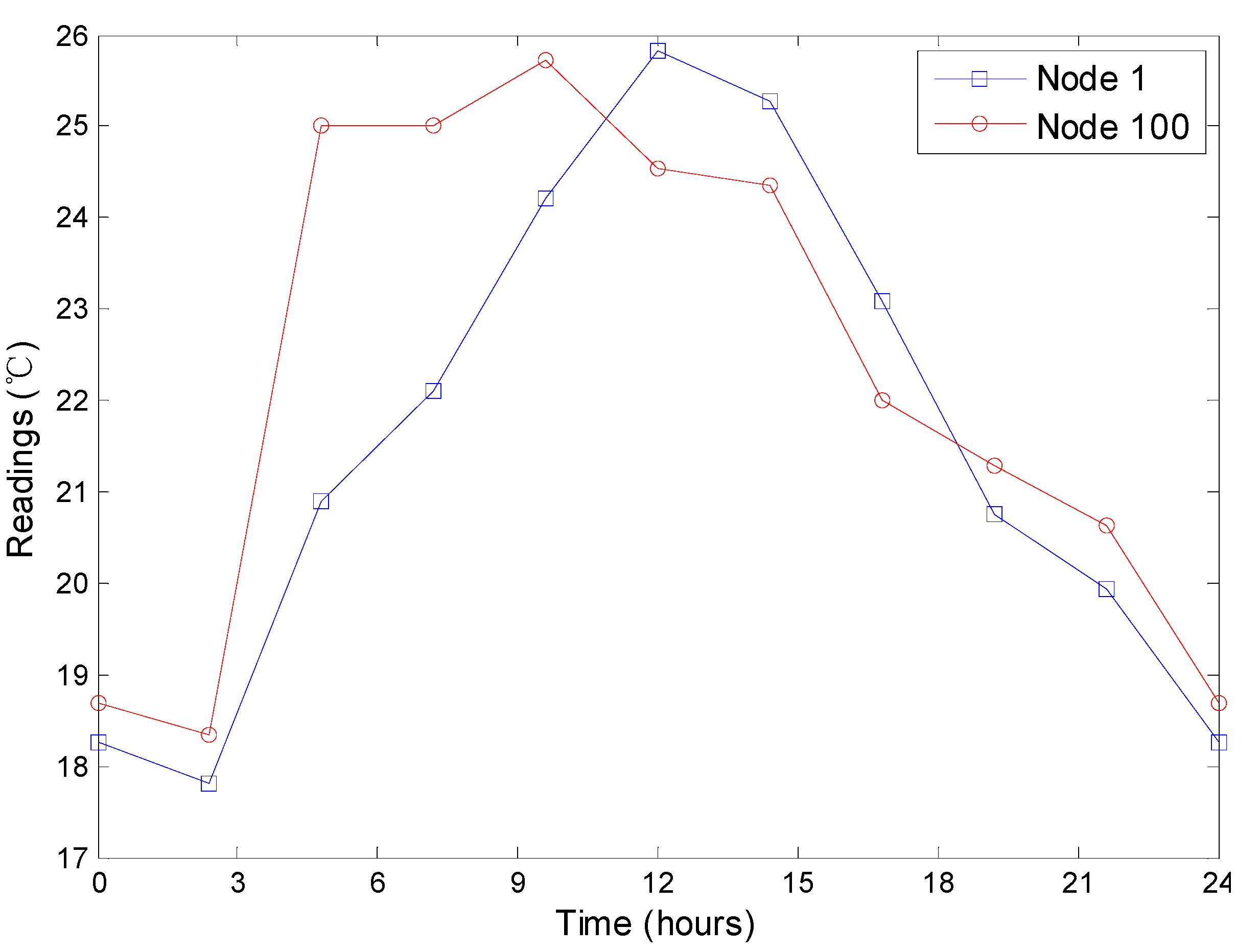
As shown in
Figure 16, at any time, the transmission cost of TAG and DWTQ is always relatively constant; on the contrary, the performances of FILA and EXTOK are very sensitive to the fluctuation of the temperature. When the temperature increases, the transmission costs of FILA and EXTOK are much smaller than that of TAG; when the temperature decreases, TAG outperforms FILA and EXTOK in transmission cost.
Figure 16.
Transmission cost versus different time.
Figure 16.
Transmission cost versus different time.
In most cases, the transmission cost of DWTQ is smaller than that of three other approaches. The reason is that the transmission cost of DWTQ is independent with the fluctuation of the readings and DWTQ makes full use of the spatial correlations between the readings. We should note that DWTQ trade query accuracy for communication overhead though the decreasing of the accuracy is very small in most cases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}