
A Hybrid PCA-CART-MARS-Based Prognostic Approach of the Remaining Useful Life for Aircraft Engines

 ,
,  ,
,
Abstract
:
1. Introduction
- Data-driven approach: The data-driven models for the prediction of the health or RUL of any system uses machine learning and pattern recognition techniques [3,4,5]. The main characteristic of this kind of models is that they do not require any previous knowledge about the device under analysis as the prediction is made according to the available information without taking into account the operating principles of the system.
- Model-based approach: in this approach the prognostic models are based on an understanding of the physical process and interrelationships among the different components and subsystems of the device [6]. The model-based-approach not only includes system modeling but would also apply physics of failure modeling [1] or any similar methodology.
- Hybrid approaches: These kinds of models try to make the most of both data-driven and model based approaches [1]. A hybrid model combines both data-driven methodologies with the knowledge of the device under study. Please do not confuse PHM hybrid approach with hybrid data-driven models, which are models that combine different pattern-recognition and machine learning models in order to predict either the RUL or the status of the system under study.
The Aircraft Engine Sensors
- Temperature sensors: These provide output readings proportional to temperature. The measurement of temperature can be accomplished using thermocouple or resistance temperature device (RTD) techniques depending upon system interface, temperature, or accuracy considerations.
- Pressure sensors: Currently the most common pressure sensors are those formed by two separate absolute pressure-sensing capsules. One senses system pressure and the other atmospheric pressure. In these devices, the output signal is the difference between the signals of both sensors.
- Sensors of speed (rpm): These kinds of sensors are usually installed directly on the low-pressure compressor rotor in order to determine the revolutions at the low-pressure section. They are also installed in the casing of driving mechanisms, as this is the most suitable place for the measurement of the speed of the high-pressure compressor section.
- Sensors of fuel flow: These are usually vane sensors located downstream behind the fuel filter and the pump measuring the amount of fuel going to the engine. The importance of the fuel flow sensor is remarkable as it can immediately detect any engine abnormality involving an increase in fuel consumption.

2. Materials and Methods
2.1. The Database

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Variables | Symbol | Sensor |
|---|---|---|
| Total temperature at fan inlet (°R) | T2 | Sensor.Measurement1 |
| Total temperature at LPC outlet (°R) | T24 | Sensor.Measurement2 |
| Total temperature at HPC outlet (°R) | T30 | Sensor.Measurement3 |
| Total temperature at LPT outlet (°R) | T50 | Sensor.Measurement4 |
| Pressure at fan inlet (psia) | P2 | Sensor.Measurement5 |
| Total pressure in bypass-duct (psia) | P15 | Sensor.Measurement6 |
| Total pressure at HPC outlet (psia) | P30 | Sensor.Measurement7 |
| Physical fan speed (rpm) | Nf | Sensor.Measurement8 |
| Physical core speed (rpm) | Nc | Sensor.Measurement9 |
| Engine pressure ratio (P50/P2) | Epr | Sensor.Measurement10 |
| Static pressure at HPC outlet (psia) | Ps30 | Sensor.Measurement11 |
| Ratio of fuel flow to Ps30 (pps/psi) | phi | Sensor.Measurement12 |
| Corrected fan speed (rpm) | NRf | Sensor.Measurement13 |
| Corrected core speed (rpm) | NRc | Sensor.Measurement14 |
| Bypass ratio | BPR | Sensor.Measurement15 |
| Burner fuel-air ratio | farB | Sensor.Measurement16 |
| Bleed enthalpy | htBleed | Sensor.Measurement17 |
| Demanded fan speed (rpm) | Nf_dmd | Sensor.Measurement18 |
| Demanded corrected fan speed (rpm) | PCNfR_dmd | Sensor.Measurement19 |
| HPT coolant bleed (lbm/s) | W31 | Sensor.Measurement20 |
| LPT coolant bleed (lbm/s) | W32 | Sensor.Measurement21 |
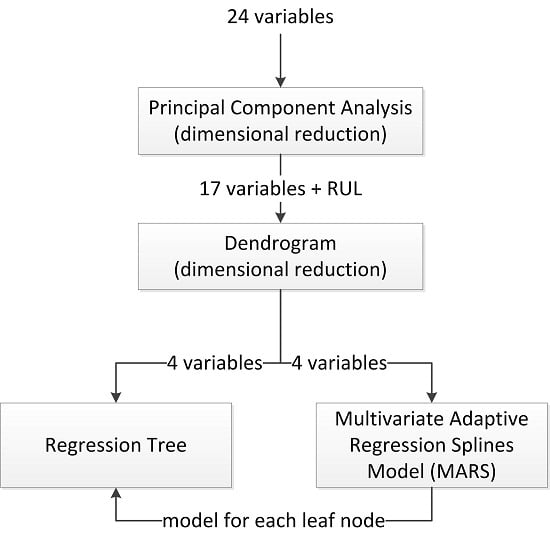
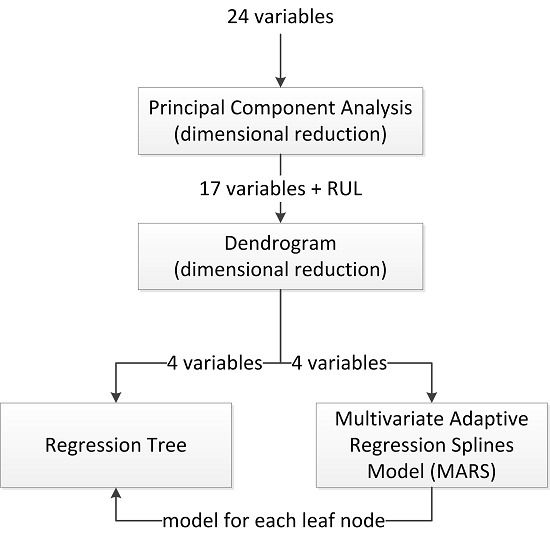
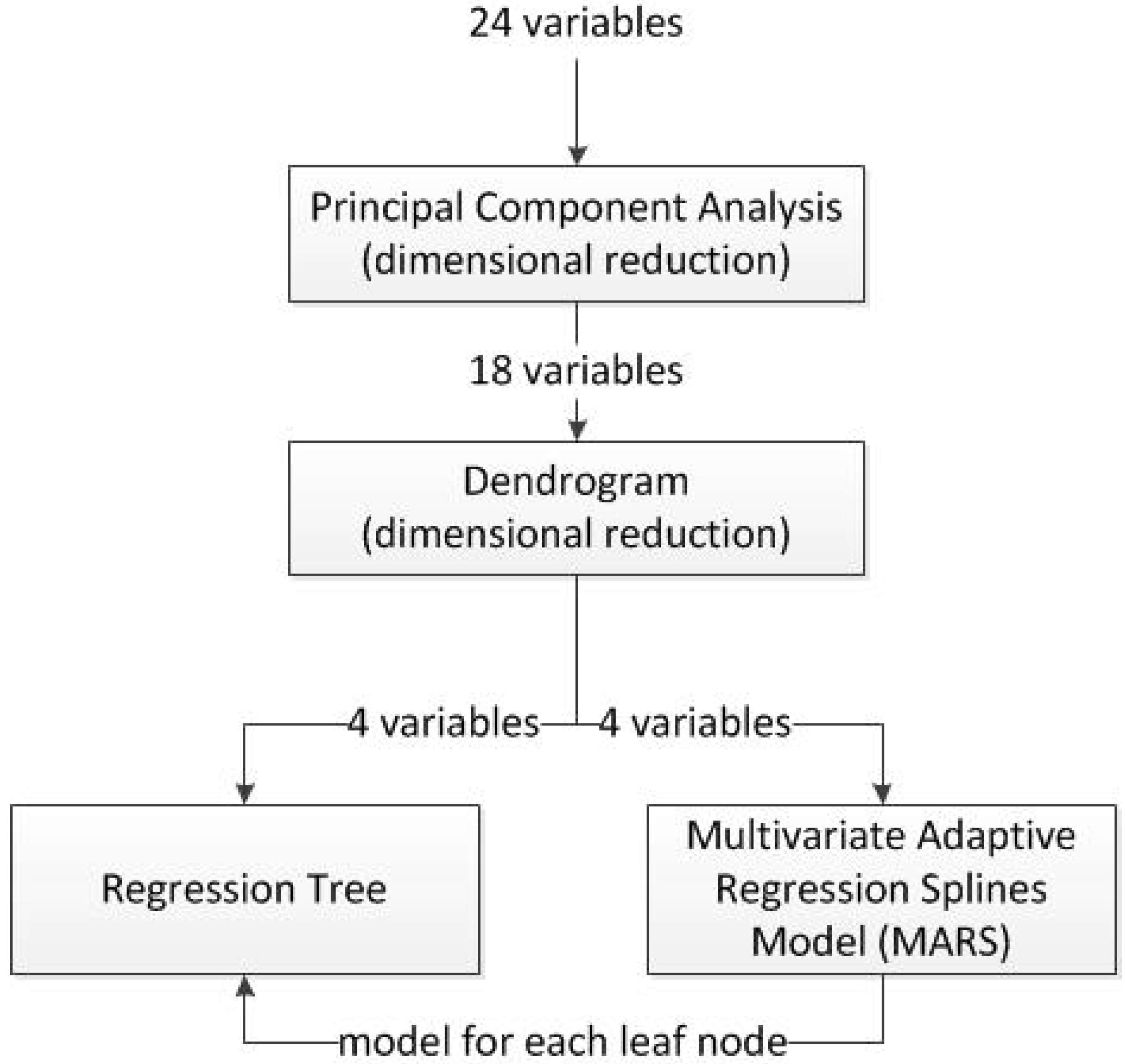
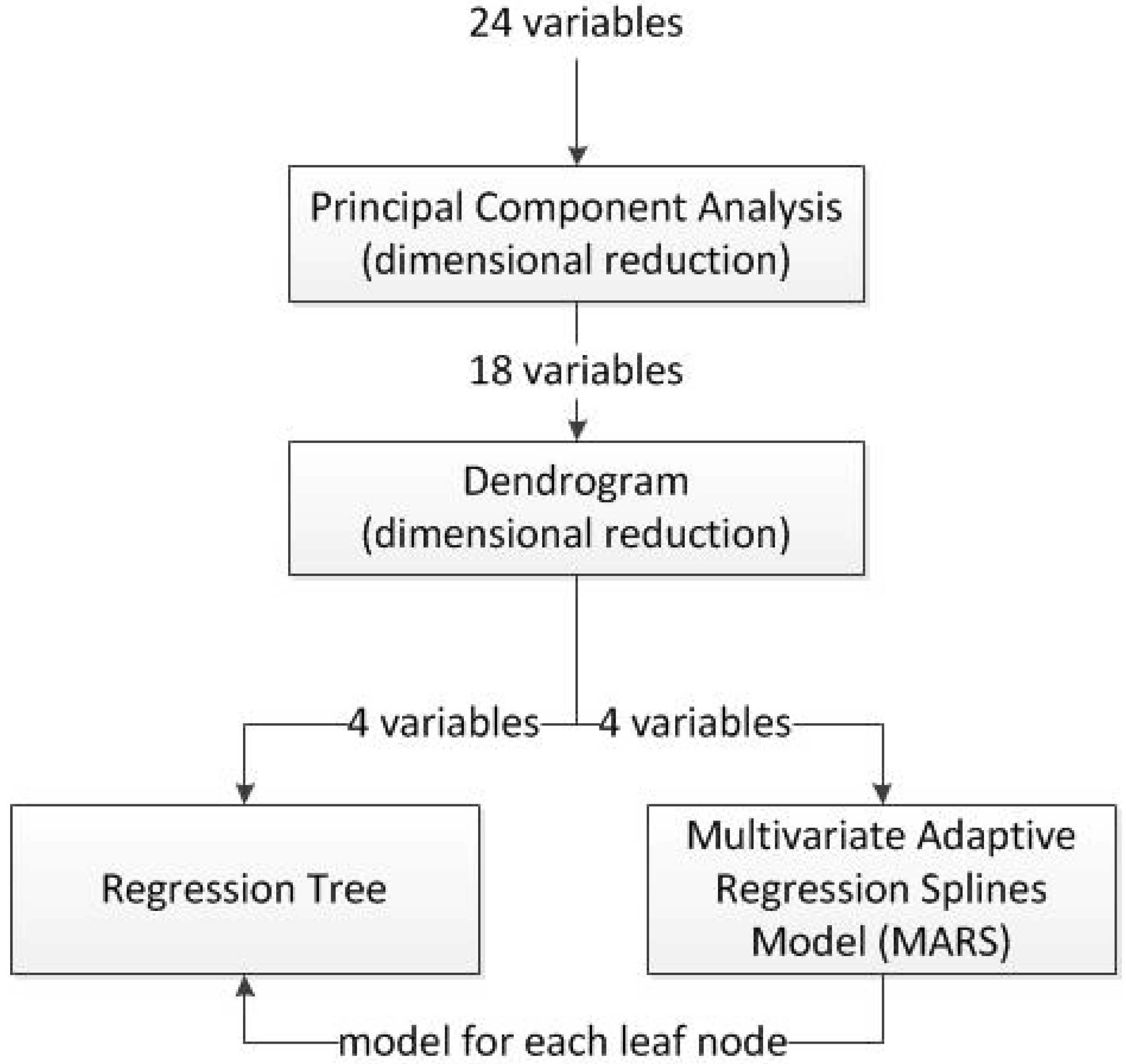
2.2. The Proposed Algorithm
- Dimensional reduction by means of Principal Components Analysis (PCA): In the first stage, a dimensional reduction by means of PCA was performed. These variables, which represented up to 90% of the total data variability, were held in order to be used in the next step of the process. Also, a rotated factor pattern of the variables retained was created using the varimax method [21,22].
- Study of selected variables similarity by means of a dendrogram: The remaining variables were classified by means of a dendrogram in order to find those which are most similar to the output variable, which in this case is the remaining useful life.
- Calculation of the regression tree: Using those variables that are most similar to the output variable, a regression tree was calculated.
- Calculation of a multivariate adaptive regression splines (MARS) model for each one of the leaf nodes of the regression tree: A MARS model, using as input variables all those considered of relevance by the dendrogram, was calculated for each of the leaf nodes of the regression tree.
2.3. Statistical Procedures Applied in the Algorithm
2.3.1. Dimensional Reduction: Principal Components Analysis
2.3.2. Dendrograms
2.3.3. Decision Trees
2.3.4. Multivariate Adaptive Regression Splines Models (MARS)
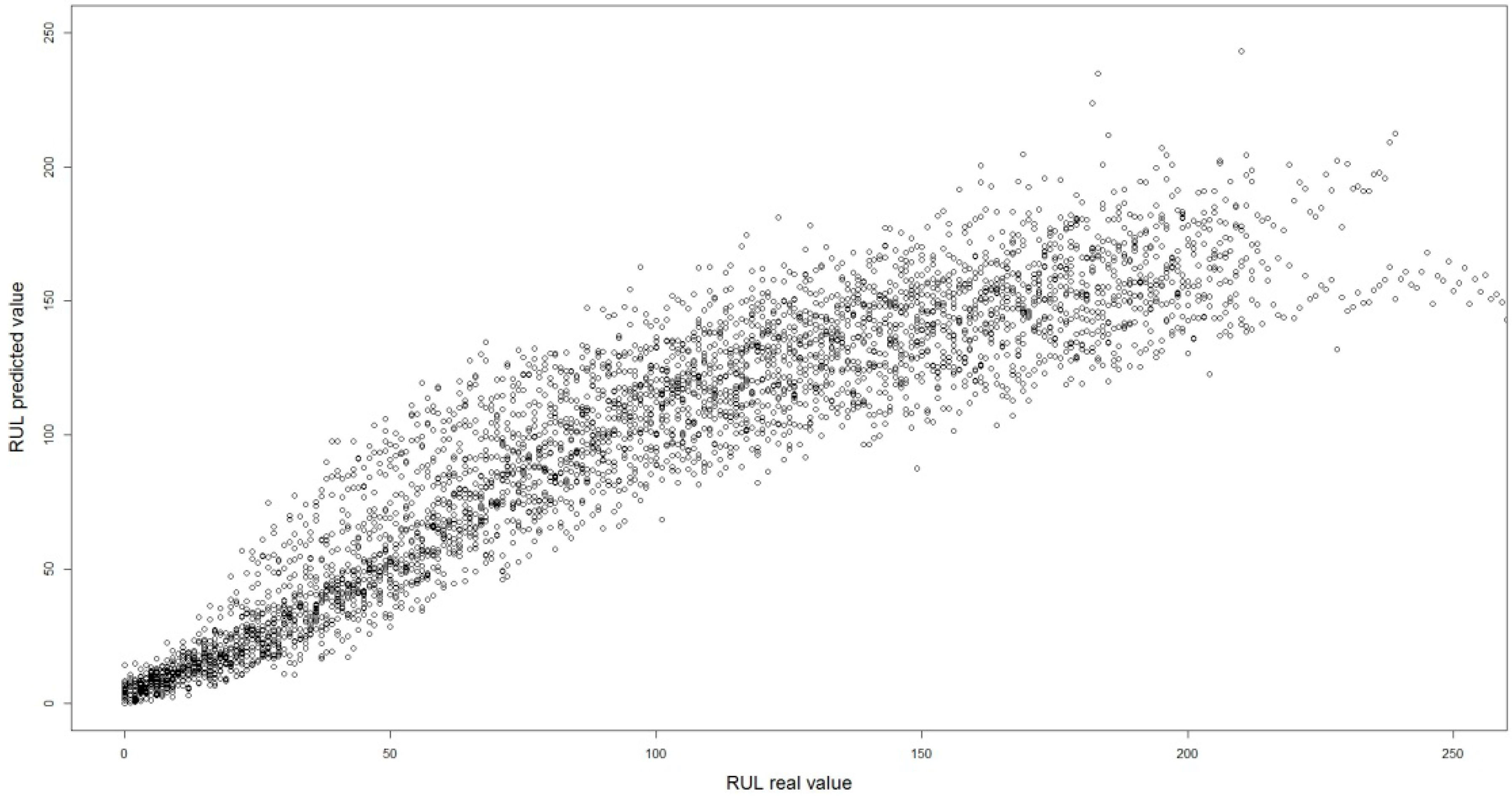
3. Results and Discussion
| Input Variables | Mean | Standard Deviation |
|---|---|---|
| Remaining useful life | 108.808 | 68.881 |
| Operational setting 1 | −8.870 × 10−6 | 0.003 |
| Operational setting 2 | 2.350 × 10−6 | 0.003 |
| Operational setting 3 | 100.000 | 10−6 |
| Total temperature at fan inlet (°R) | 518.670 | 10−6 |
| Total temperature at LPC outlet (°R) | 642.681 | 0.500 |
| Total temperature at HPC outlet (°R) | 1590.523 | 6.131 |
| Total temperature at LPT outlet (°R) | 1408.934 | 9.000 |
| Pressure at fan inlet (psia) | 14.620 | 10−6 |
| Total pressure in bypass-duct (psia) | 21.609 | 0.001 |
| Total pressure at HPC outlet (psia) | 553.368 | 0.885 |
| Physical fan speed (rpm) | 2388.097 | 0.070 |
| Physical core speed (rpm) | 9065.243 | 22.082 |
| Engine pressure ratio (P50/P2) | 1.300 | 10−6 |
| Static pressure at HPC outlet (psia) | 47.5412 | 0.267 |
| Ratio of fuel flow to Ps30 (pps/psi) | 521.414 | 0.738 |
| Corrected fan speed (rpm) | 2388.096 | 0.719 |
| Corrected core speed (rpm) | 8143.753 | 19.076 |
| Bypass ratio | 8.442146 | 0.038 |
| Burner fuel-air ratio | 0.0300 | 10−6 |
| Bleed enthalpy | 393.212 | 1.549 |
| Demanded fan speed (rpm) | 2388.000 | 10−6 |
| Demanded corrected fan speed (rpm) | 100.000 | 10−6 |
| HPT coolant bleed (lbm/s) | 38.8163 | 0.181 |
| LPT coolant bleed (lbm/s) | 23.279 | 0.108 |
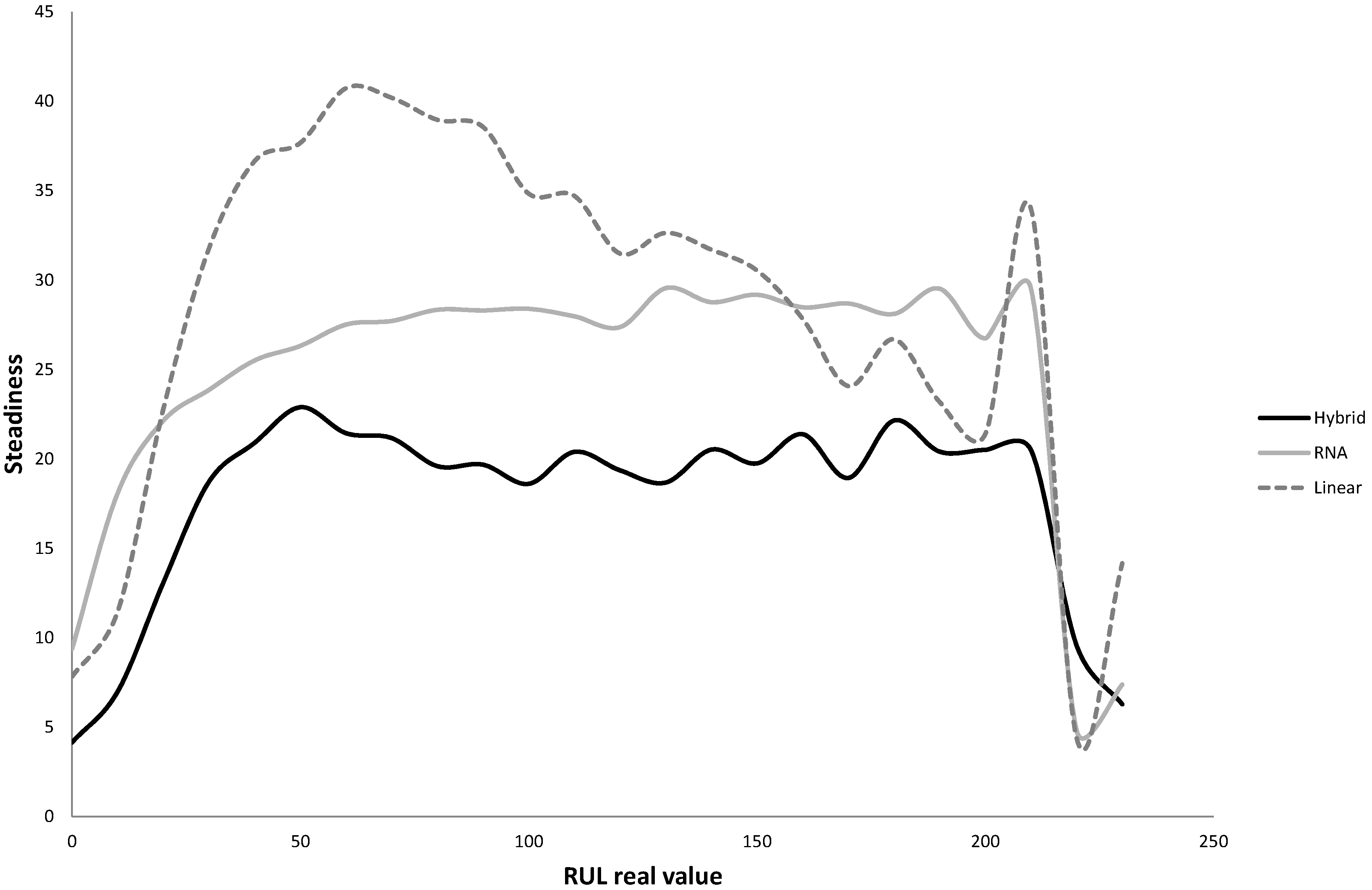
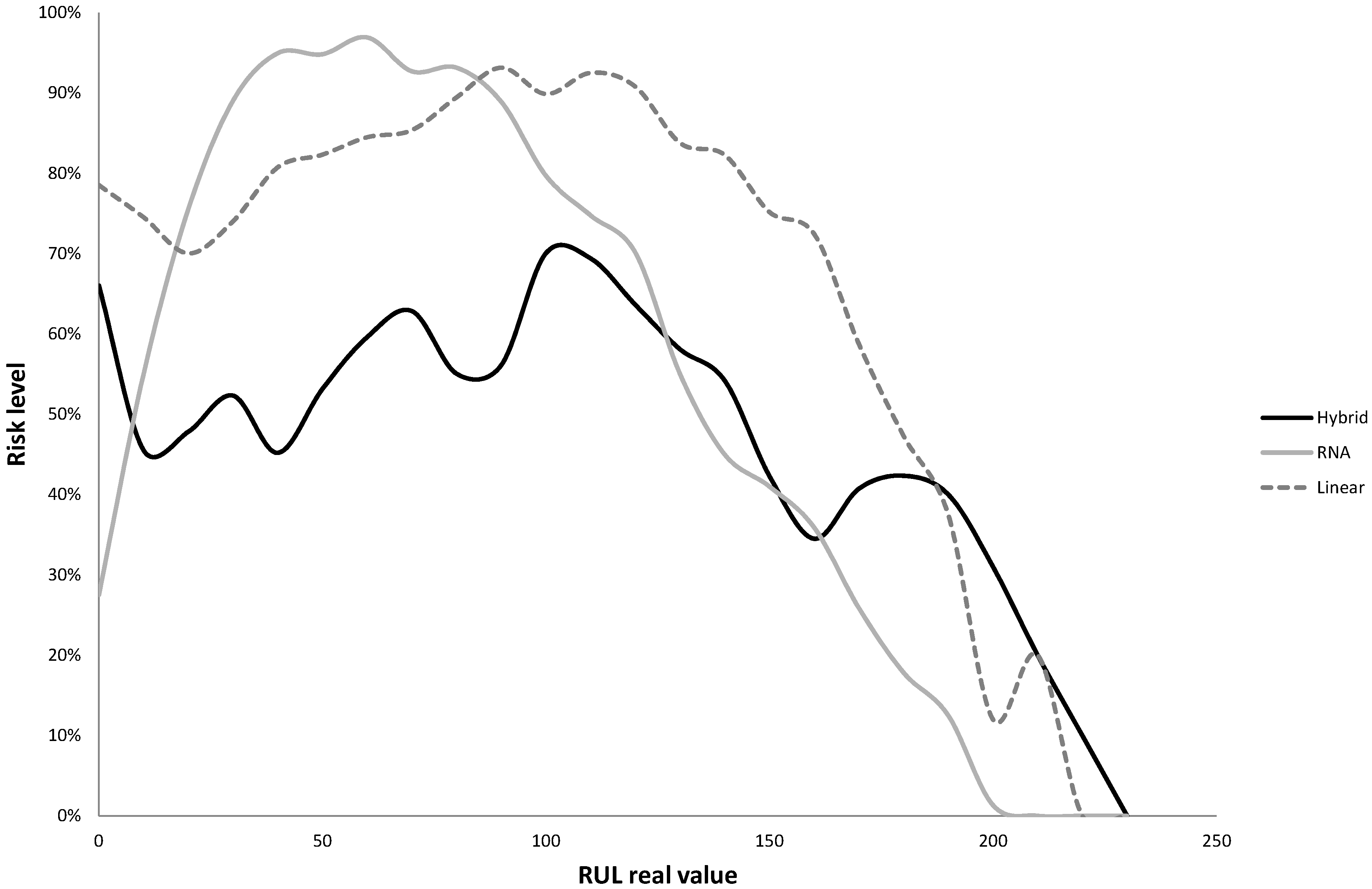
- Dimensional reduction by means of principal component analysis: The PCA algorithm was fed with 24 variables: the three operational settings and the 21 sensor measurements. A total of seven variables were discarded, and thus the total input variables subset was reduced from 24 to 17, containing a 91.2% of the variability of the data. This percentage of variability was explained by the seven principal components which were retained. A rotated pattern of variables was created using varimax method. Variables and factor loadings are shown in Table 3. Please note that represents the communality estimate and measures the ratio per unit of variance in an observed variable accounted for by the retained components. When the research was conducted, the use of a larger number of dimensions was checked. Using eight dimensions increased the variability contained to 92.1% and two variables more were added to the remaining variables subset, passing from 17 to 19. Nevertheless, the use of eight principal components was ruled out as in the next stage of the algorithm neither of the two new variables included were preserved when similarities were calculated by means of the dendrogram. The steps of the algorithm after the PCA are not performed in the space of the principal components as the next step of the algorithm is a dendrogram, in which similarities among variables and the RUL are analyzed; and although the model developed in this paper is data-driven, it is worthwhile to have the information corresponding to the original variables rather than the transformed ones, in order to be able to analyze the variables that take part in the model. Please also note that the variable subset obtained after this stage was also used for the training of both the linear regression and neural network models previously presented without any remarkable improvement in their results.
| Variable | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | |
|---|---|---|---|---|---|---|---|---|
| Op.Set1 | 0.01 | −0.01 | 1 | 0.01 | 0 | 0 | 0 | 1 |
| Op.Set2 | 0.01 | −0.01 | 0.01 | 1 | 0 | 0 | 0 | 1 |
| Sensor.Measurement2 | 0.7 | 0.11 | 0.01 | 0 | 0.1 | 0.09 | 0.69 | 0.99 |
| Sensor.Measurement3 | 0.63 | 0.16 | 0 | 0 | 0.75 | 0.09 | 0.09 | 1 |
| Sensor.Measurement4 | 0.87 | 0.12 | 0.01 | 0.01 | 0.14 | 0.14 | 0.12 | 0.82 |
| Sensor.Measurement7 | −0.87 | −0.02 | 0 | −0.01 | −0.14 | −0.14 | −0.12 | 0.81 |
| Sensor.Measurement9 | 0.19 | 0.97 | 0 | 0 | 0.06 | 0.06 | 0.04 | 0.98 |
| Sensor.Measurement11 | 0.89 | 0.08 | 0.01 | 0 | 0.14 | 0.14 | 0.14 | 0.86 |
| Sensor.Measurement12 | −0.89 | −0.01 | 0 | 0 | −0.15 | −0.14 | −0.14 | 0.85 |
| Sensor.Measurement14 | 0.07 | 0.99 | 0 | 0 | 0.04 | 0.04 | 0.02 | 0.98 |
| Sensor.Measurement15 | 0.85 | 0.13 | 0 | 0.01 | 0.09 | 0.09 | 0.08 | 0.76 |
| Sensor.Measurement17 | 0.67 | 0.17 | 0 | 0 | 0.1 | 0.71 | 0.09 | 0.99 |
| Sensor.Measurement20 | −0.88 | −0.13 | 0 | 0 | −0.05 | −0.01 | 0 | 0.79 |
| Sensor.Measurement21 | −0.85 | −0.13 | −0.01 | 0 | −0.09 | −0.05 | −0.05 | 0.76 |
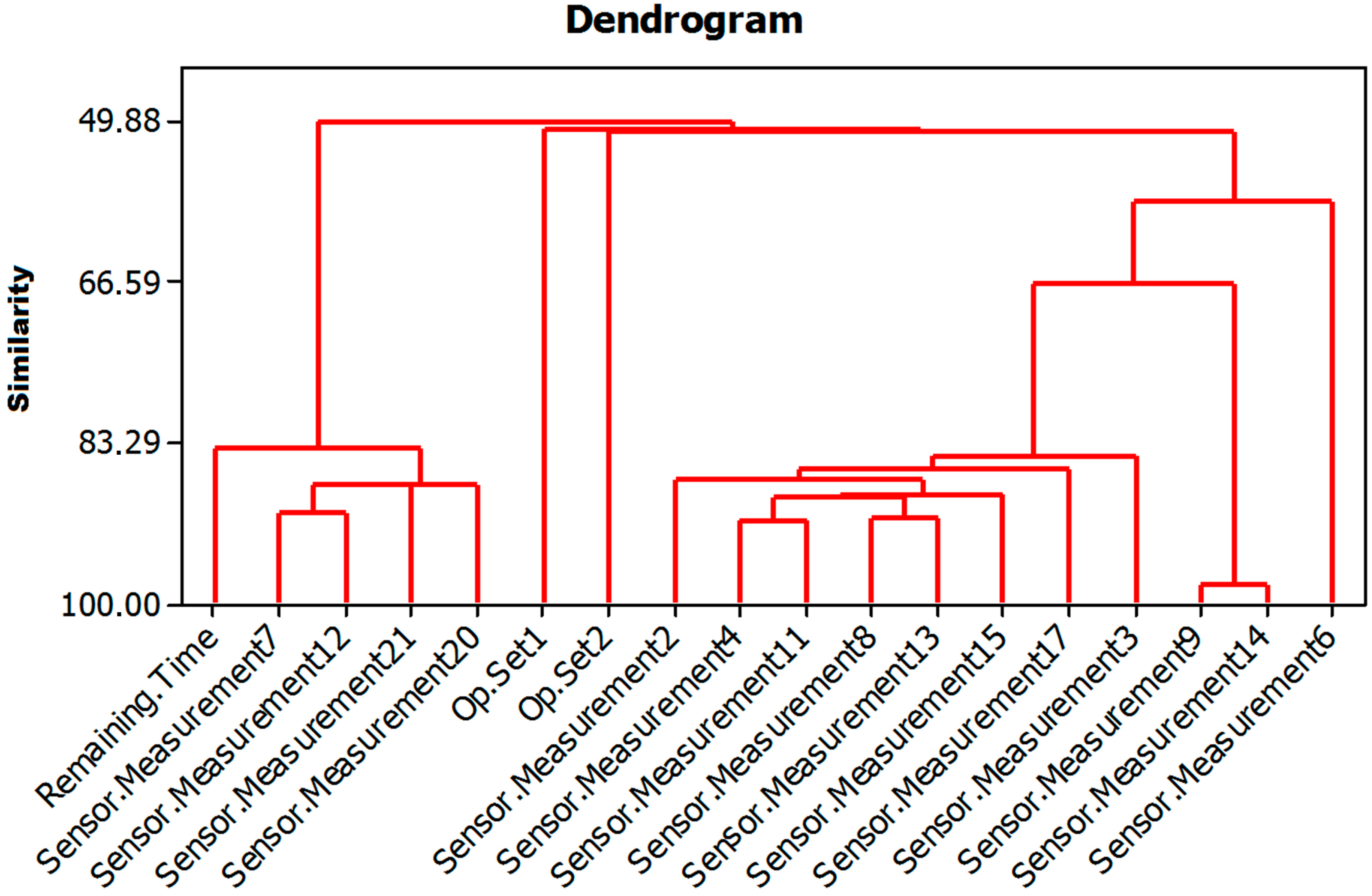
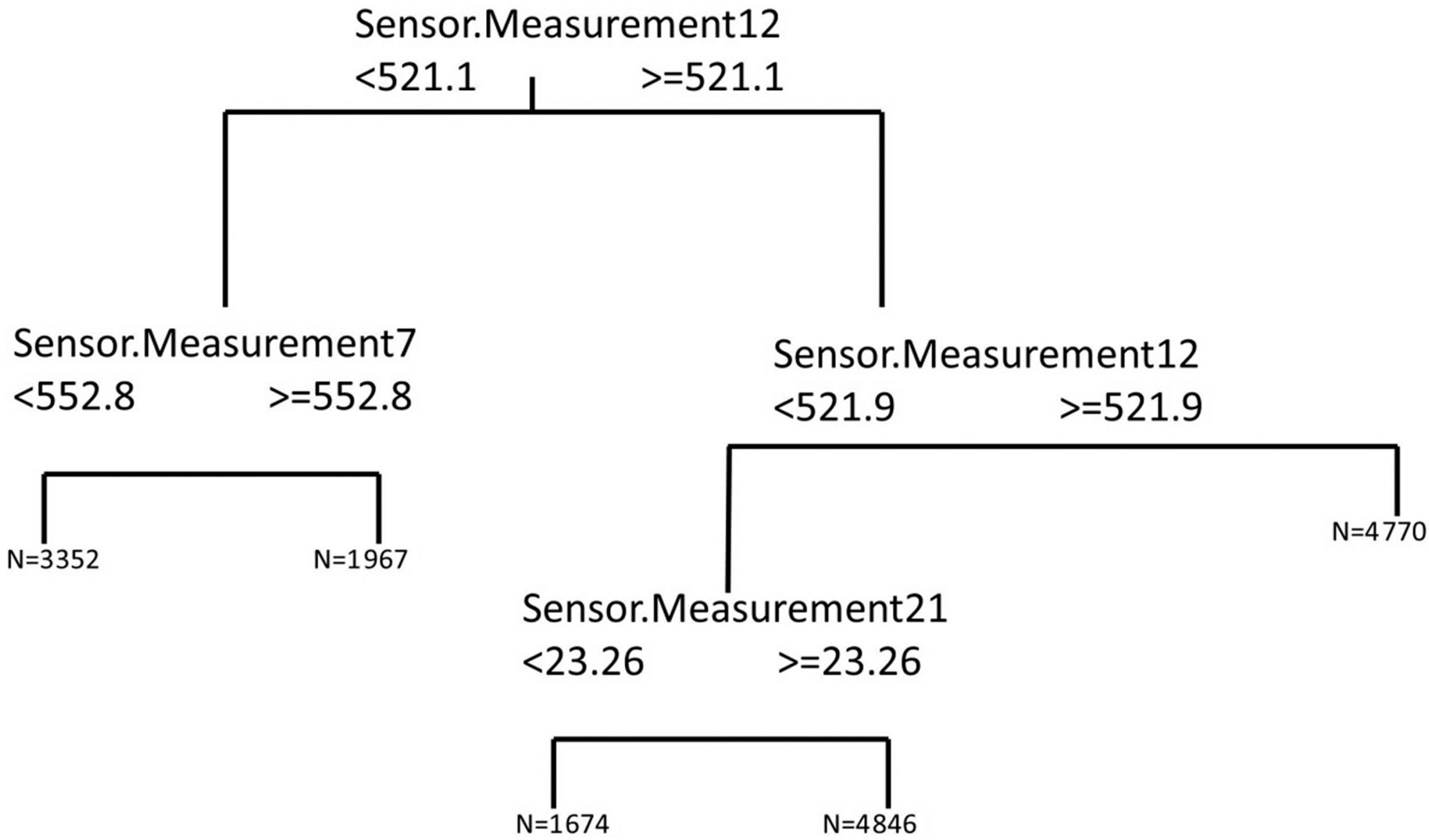
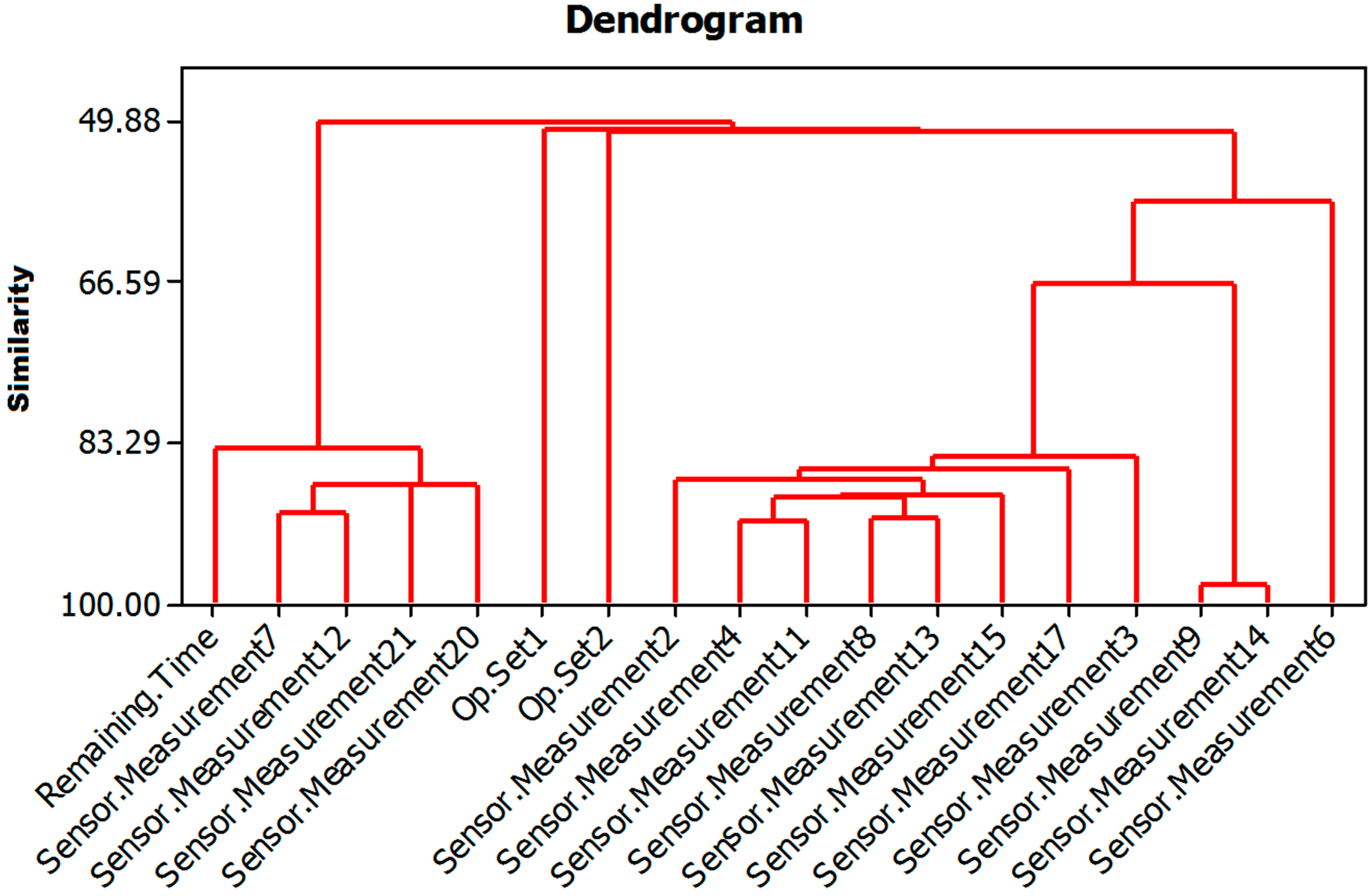
- Making a dendrogram with the selected variables: Figure 3 shows the dendrogram obtained with the 17 variables selected by the PCA plus the RUL. In this dendrogram, what can clearly be seen is the degree of similarity between variables, which will be decisive in choosing those variables that are related to the remaining useful lifetime (RUL) variable. The dendrogram shown in Figure 3 corresponds to one of the five repetitions. All the dendrograms obtained were very similar. The variables selected corresponded to four sensors: Sensor.Measurement7, Sensor.Measurement12, Sensor.Measurement20 and Sensor.Measurement21. As can be observed in Figure 3, these four variables have the largest degree of similarity to the remaining useful life variable. Therefore, in this step of the algorithm the number of input variables was reduced from 18 (17 plus the RUL) to 4.
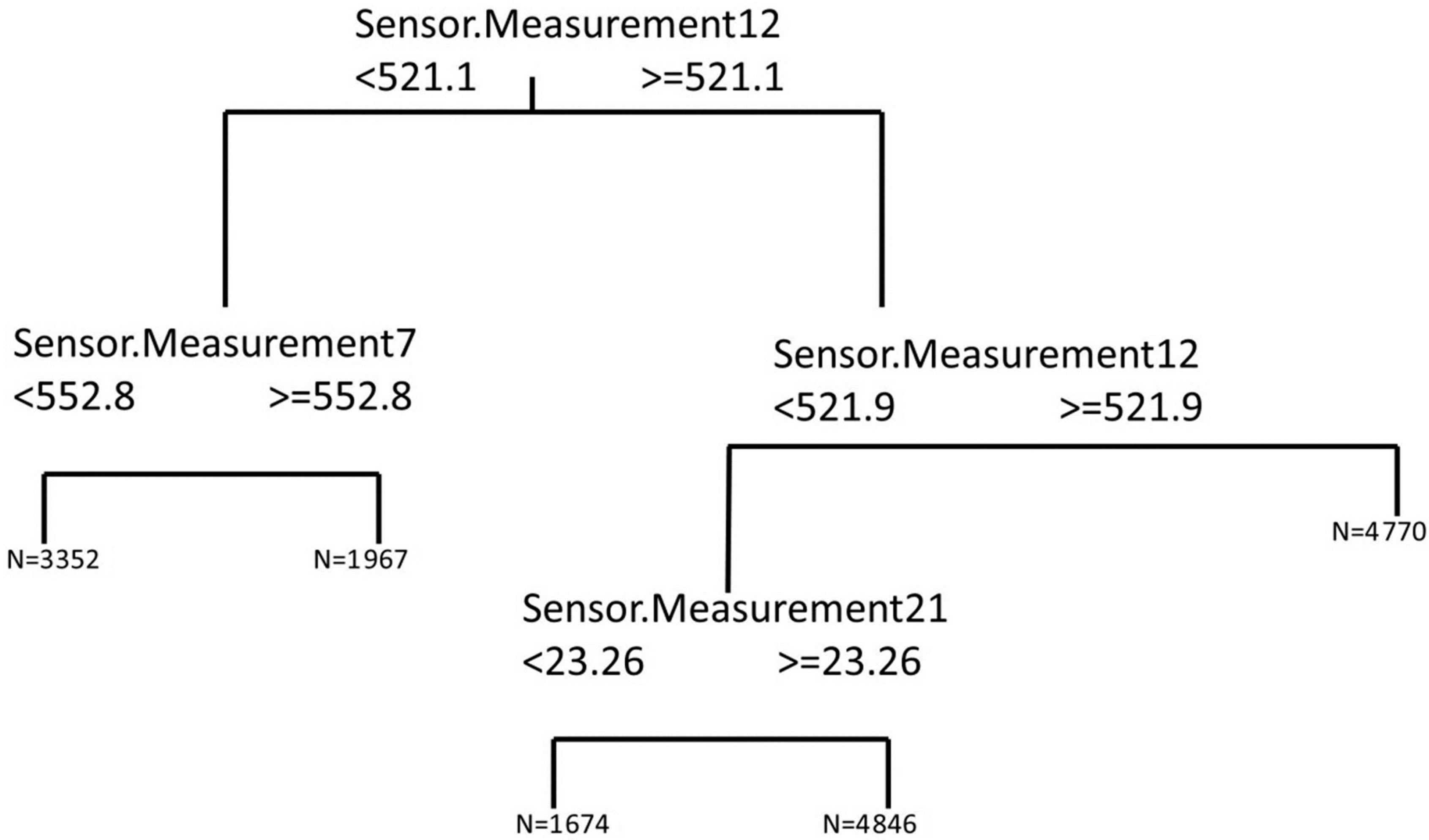
- Calculating a regression tree using variables that are more similar to the variable remaining useful life: For this problem, the four variables in the dendrogram that showed a level of similarity to the remaining useful life (called Remaining.Time in Figure 3) over 83.29% were used as input variables for a regression tree in which the remaining useful life is the output variable. The regression tree obtained is shown in Figure 3, and used to determine the cut-off points corresponding to the input variables. As can be observed in Figure 4, although four input variables were proposed for the regression tree model, only three are used for the cut-off points. The variables referred to are the following: Sensor.Measurement7, Sensor.Measurement12 and Sensor.Measurement21. The numbers named as N in the leaf nodes of the regression tree represent the number of cases that are in said node and that will therefore be used for the training of the corresponding MARS model.
- Training a MARS model: after the performance of the regression tree, a total of five different MARS models were trained. Each of these models corresponded to one of the end nodes of the regression tree. Each of the MARS models was trained with the part of the training subset that satisfied the conditions of their corresponding branches of the tree, using as dependent variables the four obtained as the outcome of the dendrogram (Sensor.Measurement7, Sensor.Measurement12, Sensor.Measurement12 and Sensor.Measurement21).
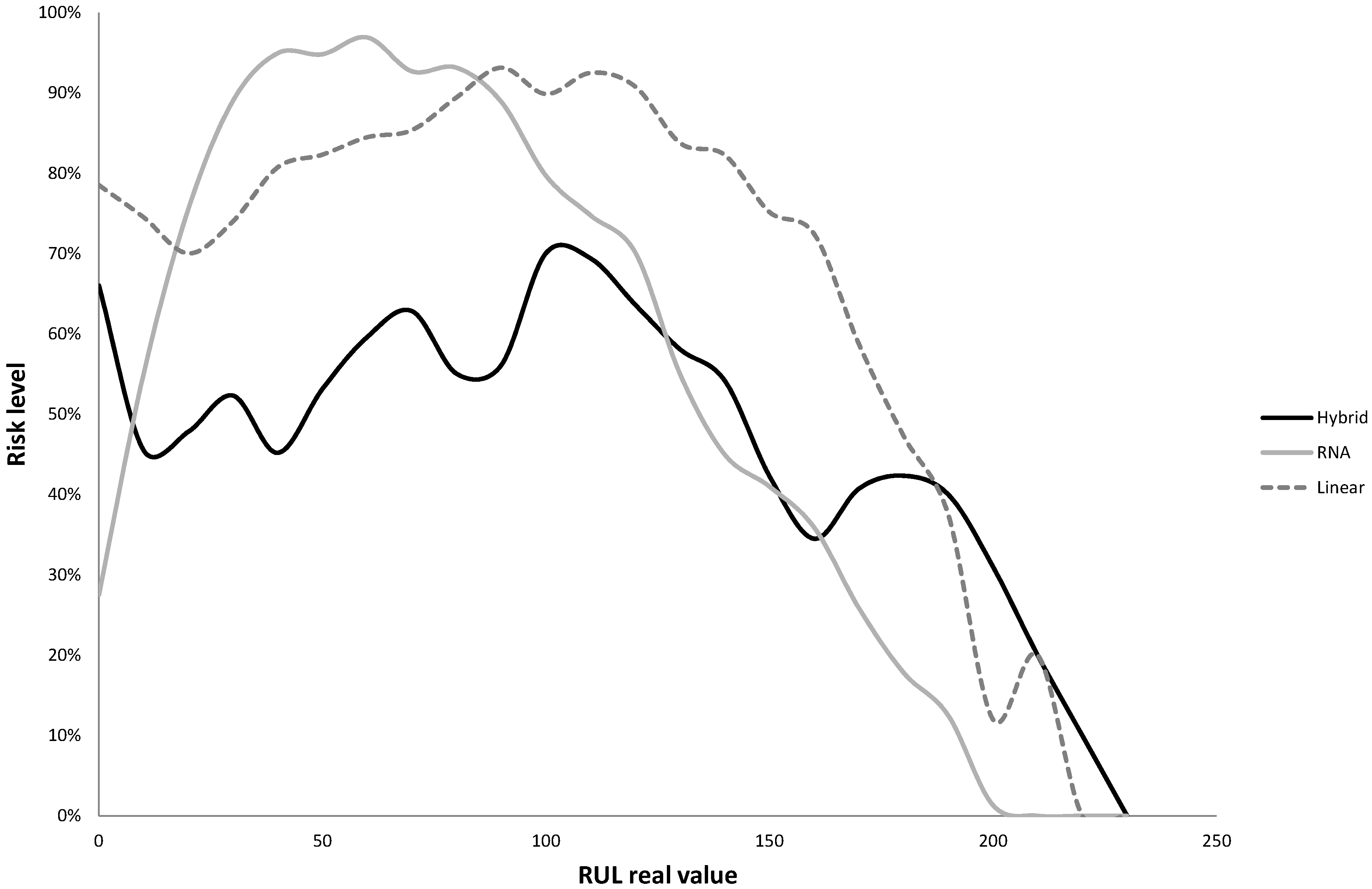
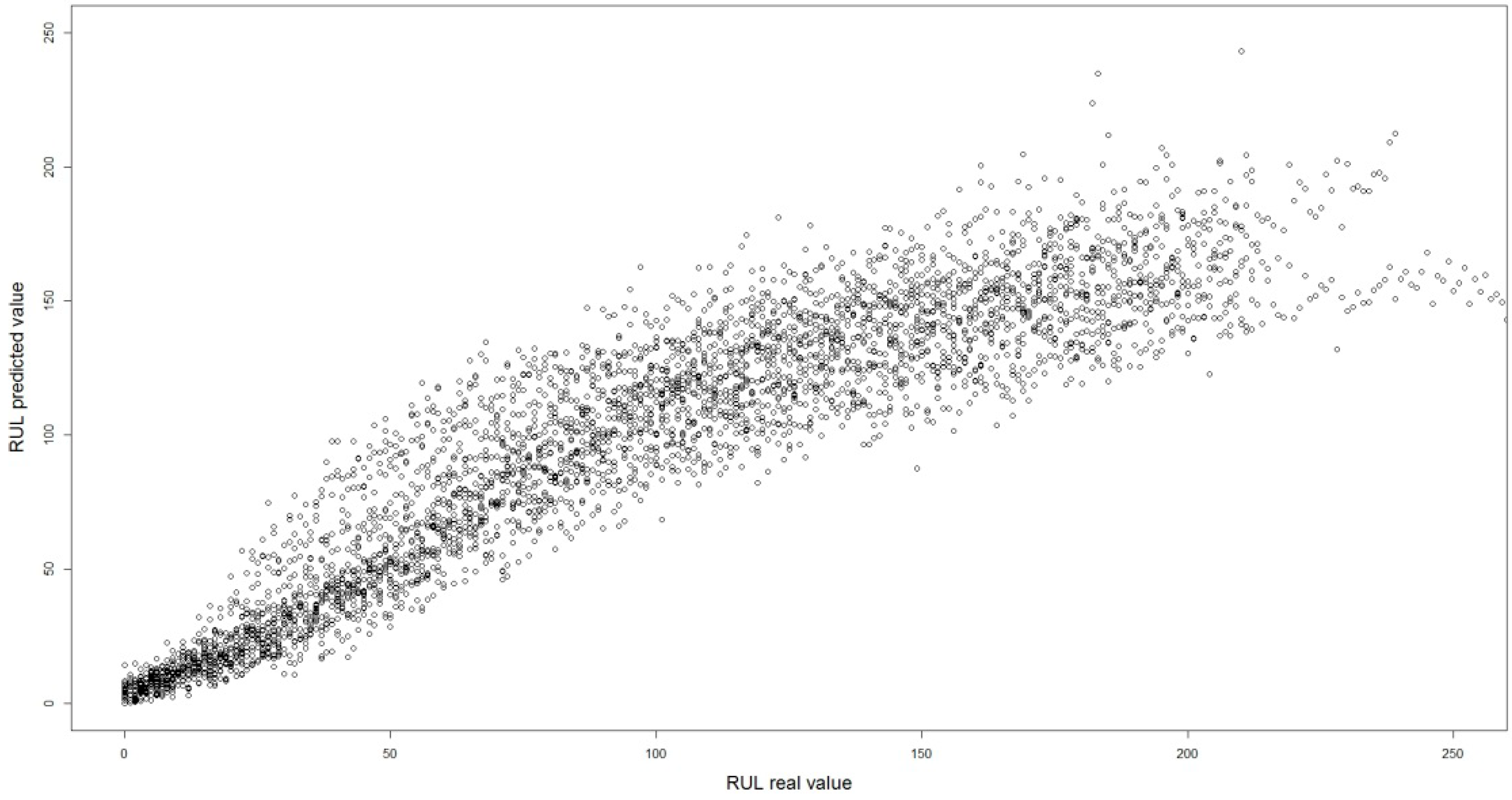
| Hybrid | Linear Regression | Neural Network | |||||
|---|---|---|---|---|---|---|---|
| Predicted | |||||||
| Negative | Positive | Negative | Positive | Negative | Positive | ||
| Actual | Negative | 2946 | 66 | 3002 | 10 | 2903 | 109 |
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cheng, S.; Azarian, M.H.; Pecht, M.G. Sensor systems for prognostics and health management. Sensors 2010, 10, 5774–5797. [Google Scholar] [CrossRef] [PubMed]
- Pecht, M.; Jaai, R. A prognostics and health management roadmap for information and electronics-rich systems. Microelectron. Reliab. 2010, 50, 317–323. [Google Scholar] [CrossRef]
- Pecht, M. Prognostics and Health Management of Electronics; Wiley-Interscience: New York, NY, USA, 2008. [Google Scholar]
- Vichare, N.; Pecht, M. Prognostics and Health Management of Electronics. IEEE Trans. Compon. Packag. Technol. 2006, 29, 222–229. [Google Scholar] [CrossRef]
- Schwabacher, M.; Goebel, K. A Survey of Artificial Intelligence for Prognostics. In Proceedings of the 2007 AAAI Fall Symposium: AI for Prognostics, Arlington, VA, USA, 8–11 November 2007; pp. 9–11.
- Liu, J.; Djurdjanovic, D.; Marko, K.; Ni, J.A. Divide and Conquer Approach to Anomaly Detection, Localization and Diagnosis. Mech. Syst. Signal Process. 2009, 23, 2488–2499. [Google Scholar] [CrossRef]
- Liu, J.; Wang, M.; Ma, F.; Yang, Y.B.; Yang, C.S. A data-model-fusion prognostic framework for dynamic system state forecasting. Eng. Appl. Artif. Int. 2012, 25, 814–823. [Google Scholar] [CrossRef]
- Bai, G.; Wang, P.; Hu, C.; Pecht, M. A generic model-free approach for lithium-ion battery health management. Appl. Energ. 2014, 135, 247–260. [Google Scholar] [CrossRef]
- Sánchez-Lasheras, F.; de Andrés, J.; Lorca, P.; de Cos Juez, F.J. A hybrid device for the solution of sampling bias problems in the forecasting of firms’ bankruptcy. Expert Syst. Appl. 2012, 8, 7512–7523. [Google Scholar] [CrossRef]
- García Nieto, P.J.; Alonso Fernández, J.R.; de Cos Juez, F.J.; Sánchez Lasheras, F.; Díaz Muñiz, C. Hybrid modelling based on support vector regression with genetic algorithms in forecasting the cyanotoxins presence in the Trasona reservoir (Northern Spain). Environ. Res. 2013, 122, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Xi, Z.; Jing, R.; Wang, P.; Hu, C. A copula-based sampling method for data-driven prognostics. Reliab. Eng. Syst. Safe 2014, 132, 72–82. [Google Scholar] [CrossRef]
- Si, X.-S.; Wang, W.; Hu, C.-H.; Zhou, D.-H. Remaining Useful Life Estimation—A Review on the Statistical Data Driven Approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Dean, F.; de Castro, J.; Litt, J. User’s Guide for the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS), NASA/ARL; Technical Manual TM2007-215026; NASA Center for AeroSpace Information: Cleveland, OH, USA, 2007.
- Wang, T.; Yu, J.; Siegel, D.; Lee, J. A similarity-based prognostics approach for remaining useful life estimation of engineered systems. In Proceedings of the IEEE International Conference on Prognostics and Health Management (PMH 2008), Denver, CO, USA, 6–9 October 2008; pp. 1–6.
- Sikorska, J.Z.; Hodkiewicz, M.; Ma, L. Prognostic modelling options for remaining useful life estimation by industry. Mech. Sys. Signal Process. 2011, 25, 1803–1836. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Wu, C.H. Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks. Expert Syst. Appl. 2009, 36, 4321–4330. [Google Scholar] [CrossRef]
- Bi, Y.; Bell, D.; Wang, H.; Guo, G.; Greer, K. Combining Multiple Classifiers Using Dempster’s Rule of Combination for Text Categorization. Lect. Notes Artif. Int. 2004, 3131, 127–138. [Google Scholar]
- Cho, S.B.; Lee, J.H. Learning Neural Network Ensemble for Practical Text Classification. In Intelligent Data Engineering and Automated Learning; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2690, pp. 1032–1036. [Google Scholar]
- Wong, W.K.; Guo, Z.X. A hybrid intelligent model for medium-term sales forecasting in fashion retail supply chains using extreme learning machine and harmony search algorithm. Int. J. Prod. Econ. 2010, 128, 614–624. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2003. [Google Scholar]
- Grice, J.W. Computing and evaluating factor scores. Psychol. Methods 2001, 6, 430–450. [Google Scholar] [CrossRef] [PubMed]
- Orchard, M.; Tobar, F.; Vachtsevanos, G. Outer feedback correction loops in particle filtering-based prognostic algorithms: Statistical performance comparison. Stud. Inform. Control 2009, 18, 295–304. [Google Scholar]
- Hu, Y.; Baraldi, P.; di Maio, F.; Zio, E. A particle filtering and kernel smoothing-based approach for new design component prognostics. Rel. Eng. Syst. Safe 2015, 134, 19–31. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a Complex of Statistical Variables into Principal Components. J. Educ. Psychol. 1933, 24, 417–441, and 498–520. [Google Scholar] [CrossRef]
- Ismail, S.; Shabri, A. Stream Flow Forecasting using Principal Component Analysis and Least Square Support Vector Machine. J. Appl. Sci. Agric. 2014, 9, 170–180. [Google Scholar]
- Guhathakurta, P.; Rajeevan, M.; Thapliyal, V. Forecasting Indian summer monsoon rainfall by a Principal Component Neural Network model. Meteorol. Atmos. Phys. 1999, 71, 255–266. [Google Scholar] [CrossRef]
- Hu, T.; Wu, F.; Zhang, X. Rainfall-Runoff Modelling using Principal Component Analysis and Neural Network. Nord. Hydrol. 2007, 38, 235–248. [Google Scholar] [CrossRef]
- Therneau, T.M.; Atkinson, B.; Ripley, B. Rpart: Recursive Partitioning, R package Version 4.1-1; 2013.
- Friedman, J.H. Multivariate Adaptive Regression Splines (with discussion). Ann. Stat. 1991, 19, 1–141. [Google Scholar] [CrossRef]
- Sekulic, S.S.; Kowalski, B.R. MARS: A Tutorial. J. Chemometr. 1992, 6, 199–216. [Google Scholar] [CrossRef]
- Friedman, J.H.; Roosen, C.B. An Introduction to Multivariate Adaptive Regression Splines. Stat. Methods Med. Res. 1995, 4, 197–217. [Google Scholar] [CrossRef] [PubMed]
- García Nieto, P.J.; Alonso Fernández, J.R.; Sánchez Lasheras, F.; de Cos Juez, F.J.; Diaz Muñiz, C. A New improved study of cyanotoxins presence from experimental cyanobacteria concentrations in the Trasona reservoir (Northern Spain) using the MARS technique. Sci. Total Environ. 2012, 430, 88–92. [Google Scholar] [CrossRef] [PubMed]
- García Nieto, P.J.; Sánchez Lasheras, F.; de Cos Juez, F.J.; Alonso Fernández, J.R. Study of Cyanotoxins Presence from Experimental Cyanobacteria Concentrations Using a New Data Mining Methodology Based on Multivariate Adaptive Regression Splines in Trasona Reservoir (Northern Spain). J. Hazard. Mater. 2011, 195, 414–421. [Google Scholar] [CrossRef] [PubMed]
- Ramasso, E.; Saxena, A. Performance Benchmarking and Analysis of Prognostic Methods for CMAPSS Datasets. Int. J. Progn. Health Manag. 2014, 5, 1–15. [Google Scholar]
- Coble, J.; Hines, J. Prognostic algorithm categorization with PHM challenge application. In Proceedings of International Conference on prognostics and health management, Denver, CO, USA, 6–9 October 2008; IEEE: New York, NY, USA, 2008. [Google Scholar]
- Siegel, D. Evaluation of Health Assessment Techniques for Rotating Machinery. Master’s Thesis, Division of Research and Advanced Studies of the University of Cincinnati, Cincinnati, OH, USA, 2009. [Google Scholar]
- Ramasso, E. Contribution of belief functions to hidden Markov models with an application to fault diagnosis. In Proceedings of the International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; IEEE: New York, NY, USA, 2009. [Google Scholar]
- Wang, T. Trajectory Similarity Based Prediction for Remaining Useful Life Estimation. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2010. [Google Scholar]
- Riad, A.; Elminir, H.; Elattar, H. Evaluation of neural networks in the subject of prognostics as compared to linear regression model. Int. J. Eng. Technol. 2010, 10, 52–58. [Google Scholar]
- Abbas, M. System Level Health Assessment Of Complex Engineered Processes. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2010. [Google Scholar]
- Ramasso, E.; Gouriveau, R. Prognostics in switching systems: Evidential Markovian classification of real-time neuro-fuzzy predictions. In Proceedings of the International Conference on Prognostics and Health Management, Macao, China, 12–14 January 2010; IEEE: New York, NY, USA, 2010. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Heimes, F. Recurrent neural networks for remaining useful life estimation. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; IEEE: New York, NY, USA, 2008. [Google Scholar]
- Peel, L. Data driven prognostics using a Kalman filter ensemble of neural network models. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; IEEE: New York, NY, USA, 2008. [Google Scholar]
- Yidana, S.M.; Ophori, D.; Banoeng-Yakubo, B. A multivariate statistical analysis of surface water chemistry data—Tha Ankobra Basin, Ghana. J. Environ. Manag. 2008, 86, 80–87. [Google Scholar] [CrossRef]
- Lewis, P.D.; Parry, J.M. An exploratory analysis of multiple mutation spectra. Mutat. Res. 2002, 518, 163–180. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, S.; Mukherjee, K.; Sarkar, S.; Ray, A. Symbolic Transient Time-series Analysis for Fault Detection in Aircraft Gas Turbine Engines. In Proceedings of the 2012 American Control Conference, Montreal, QC, Canada, 27–29 June 2012; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2012; pp. 5132–5137. [Google Scholar]
- Liu, K.; Gebraeel, N.Z.; Shi, J. A Data-Level Fusion Model for Developing Composite health Indices for Degradation Modeling and Prognostic Analysis. IEEE Trans. Autom. Sci. Eng. 2013, 10, 652–664. [Google Scholar] [CrossRef]
- Zio, E.; di Maio, F. A Data-driven Fuzzy Approach for Predicting the Remaining Useful Life in Dynamic Failure Scenarios of a Nuclear System. Reliab. Eng. Syst. Safe 2010, 95, 49–57. [Google Scholar] [CrossRef]
- Ahmadzadeh, F.; Lundberg, J. Remaining Useful Life Prediction of Grinding Mill Liners Using an Artificial Neural Network. Miner. Eng. 2013, 53, 1–8. [Google Scholar] [CrossRef]
- Guzman, D.; de Cos Juez, F.J.; Myers, R.; Guesalaga, A.; Sánchez Lasheras, F. Modeling a MEMS deformable mirror using non-parametric estimation techniques. Opt. Express 2010, 18, 21356–21369. [Google Scholar] [CrossRef] [PubMed]
- García Nieto, P.J.; Martínez Torres, J.; de Cos Juez, F.J.; Sánchez Lasheras, F. Using multivariate adaptive regression splines and multilayer perceptron networks to evaluate paper manufactured using Eucalyptus globulus. Appl. Math. Comput. 2012, 219, 755–763. [Google Scholar] [CrossRef]
- Lee, J.; Ni, J.; Djurdjanovic, D.; Qiu, H.; Liao, H. Intelligent prognostics tools and e-maintenance. Comput. Ind. 2006, 57, 476–489. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lasheras, F.S.; Nieto, P.J.G.; De Cos Juez, F.J.; Bayón, R.M.; Suárez, V.M.G. A Hybrid PCA-CART-MARS-Based Prognostic Approach of the Remaining Useful Life for Aircraft Engines. Sensors 2015, 15, 7062-7083. https://doi.org/10.3390/s150307062
Lasheras FS, Nieto PJG, De Cos Juez FJ, Bayón RM, Suárez VMG. A Hybrid PCA-CART-MARS-Based Prognostic Approach of the Remaining Useful Life for Aircraft Engines. Sensors. 2015; 15(3):7062-7083. https://doi.org/10.3390/s150307062
Chicago/Turabian StyleLasheras, Fernando Sánchez, Paulino José García Nieto, Francisco Javier De Cos Juez, Ricardo Mayo Bayón, and Victor Manuel González Suárez. 2015. "A Hybrid PCA-CART-MARS-Based Prognostic Approach of the Remaining Useful Life for Aircraft Engines" Sensors 15, no. 3: 7062-7083. https://doi.org/10.3390/s150307062
APA StyleLasheras, F. S., Nieto, P. J. G., De Cos Juez, F. J., Bayón, R. M., & Suárez, V. M. G. (2015). A Hybrid PCA-CART-MARS-Based Prognostic Approach of the Remaining Useful Life for Aircraft Engines. Sensors, 15(3), 7062-7083. https://doi.org/10.3390/s150307062