
Degradation Prediction Model Based on a Neural Network with Dynamic Windows

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Traditional Neural Network Based Prediction Model
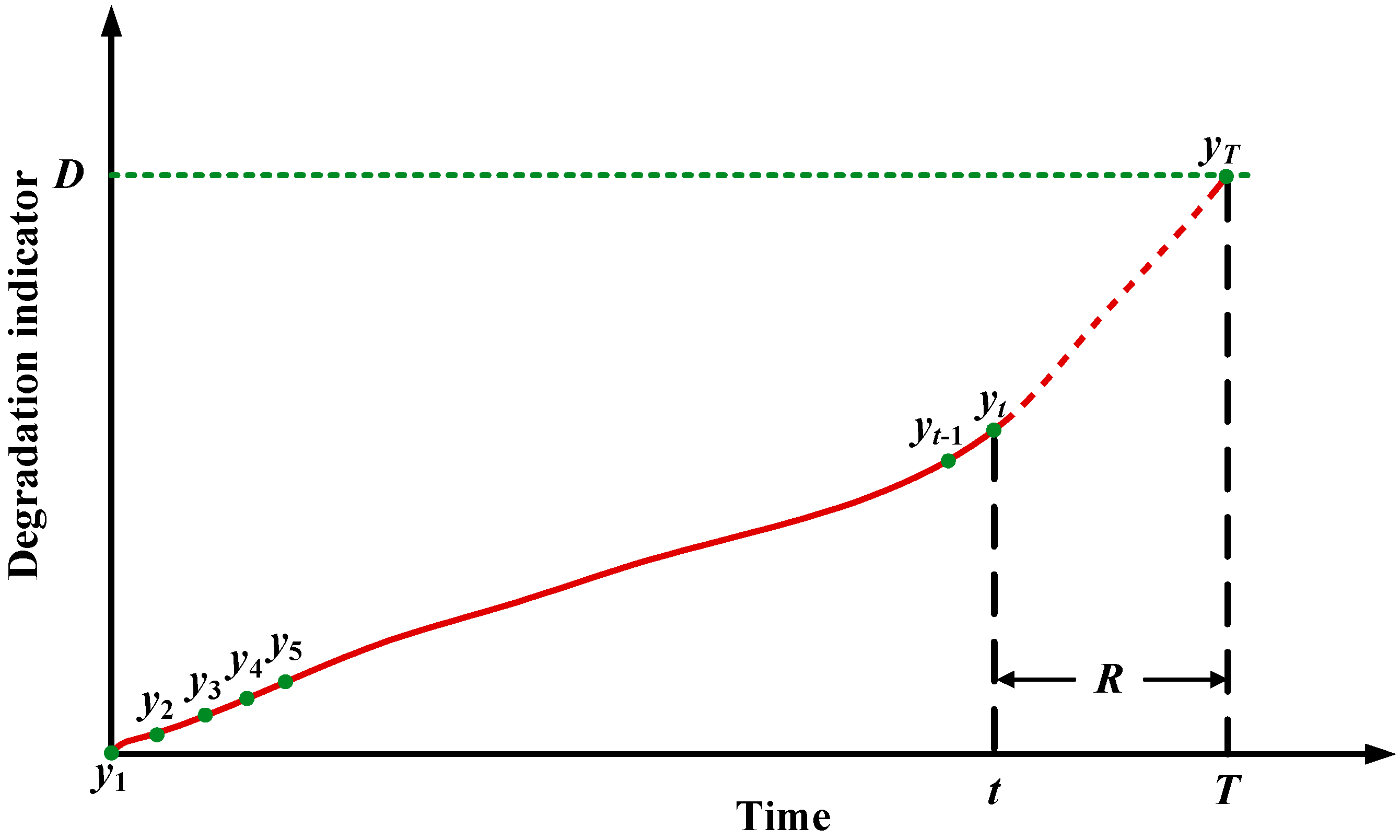
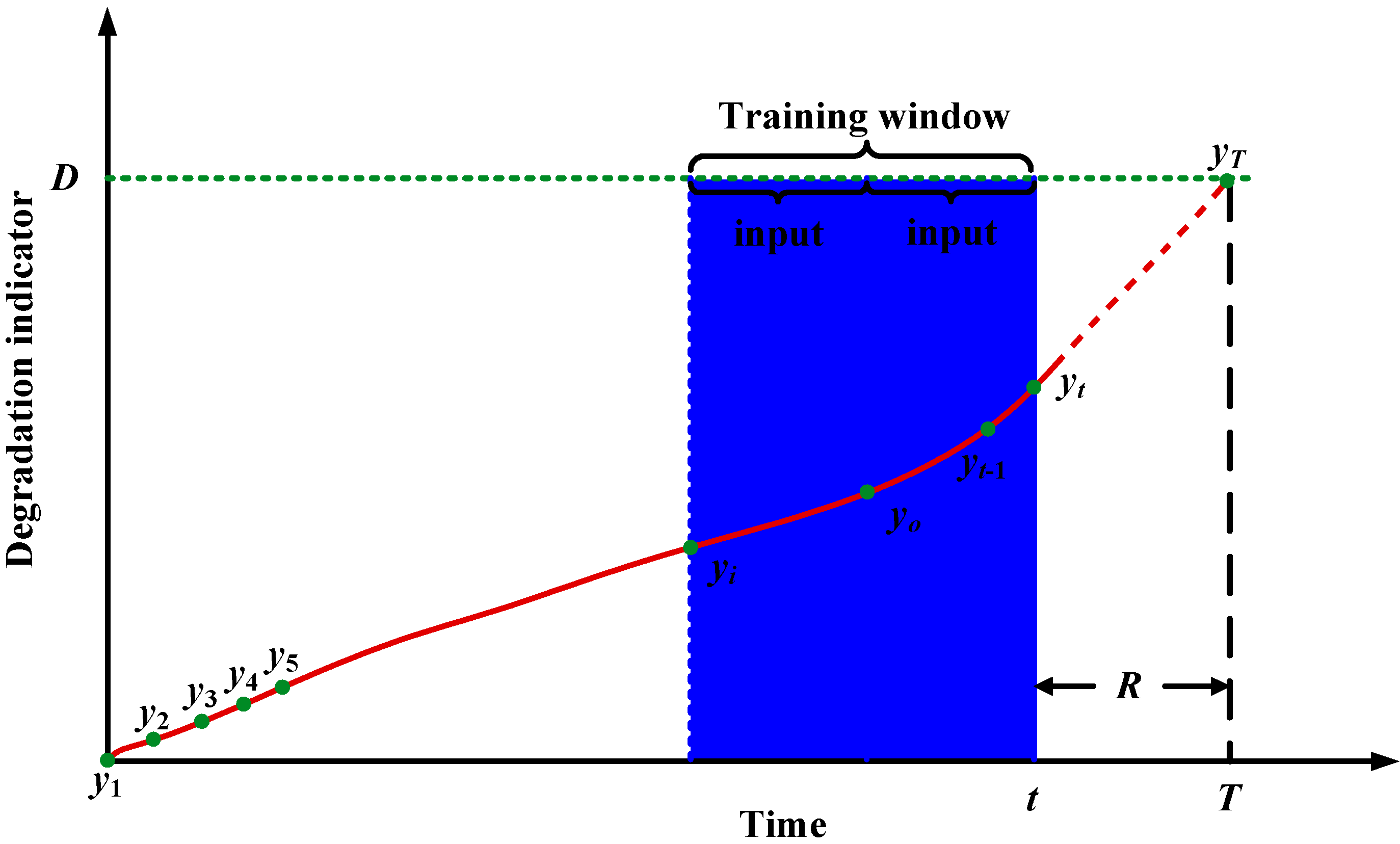
2.1. Problem Description
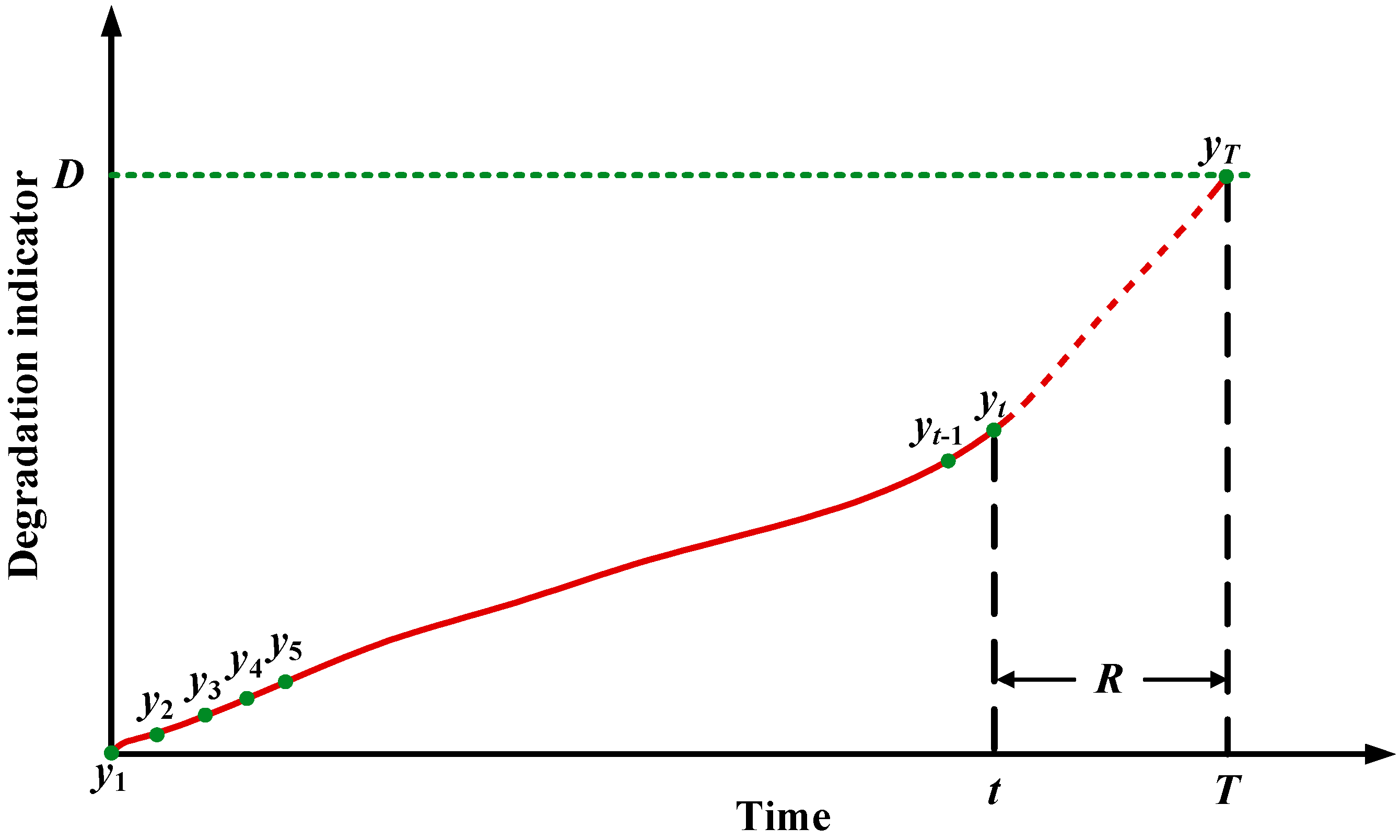
2.2. Rolling Prediction Based on a Neural Network

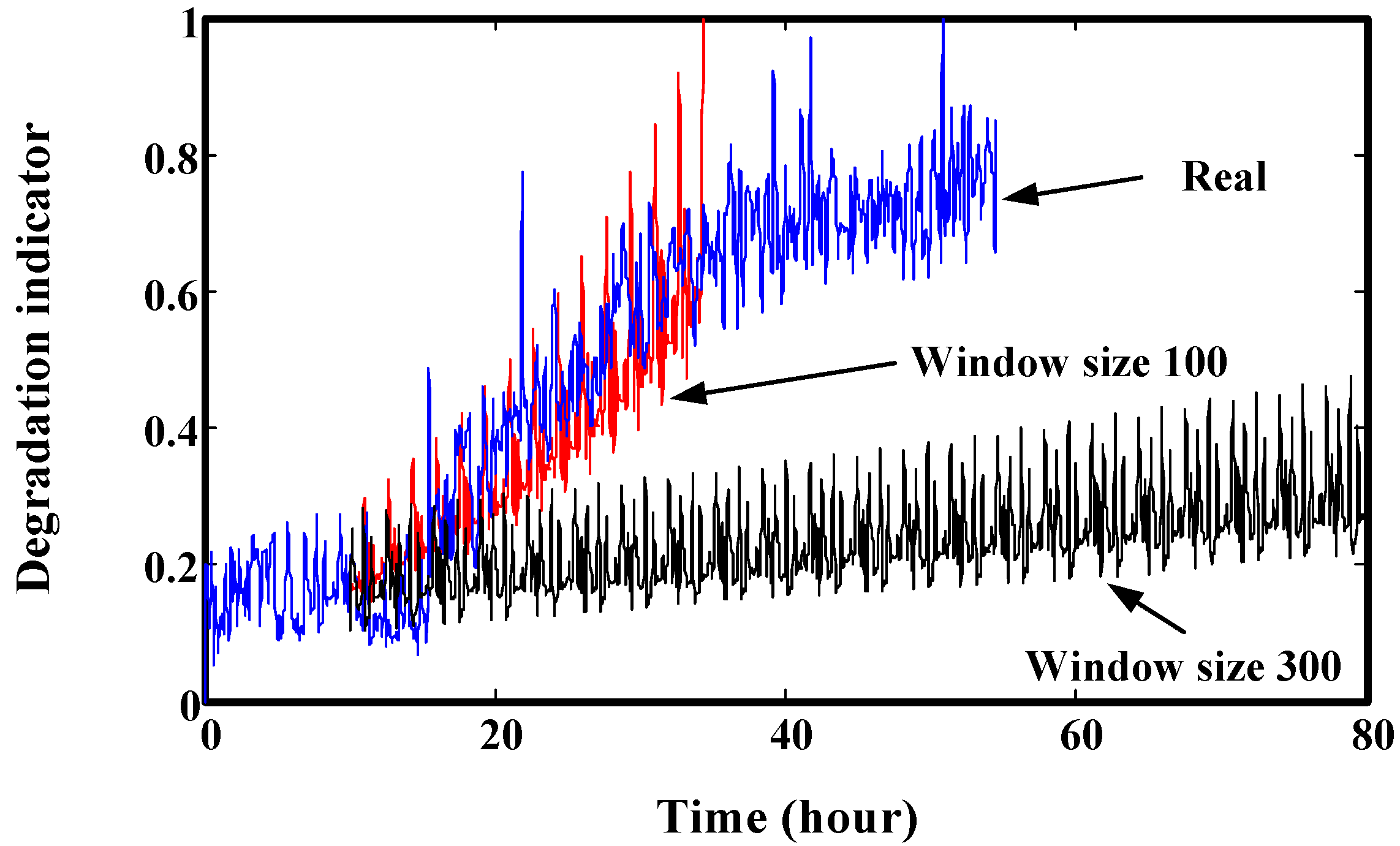
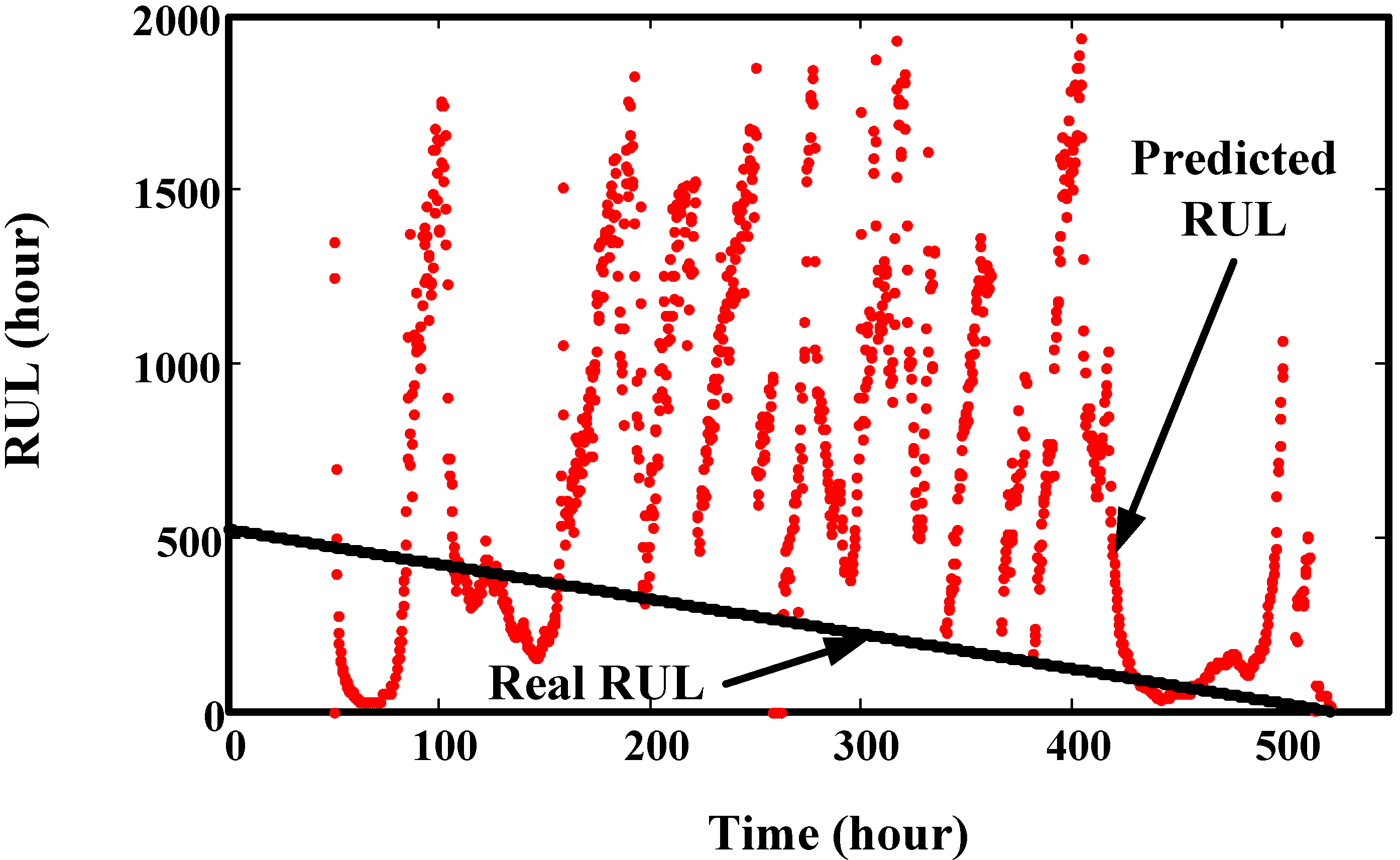
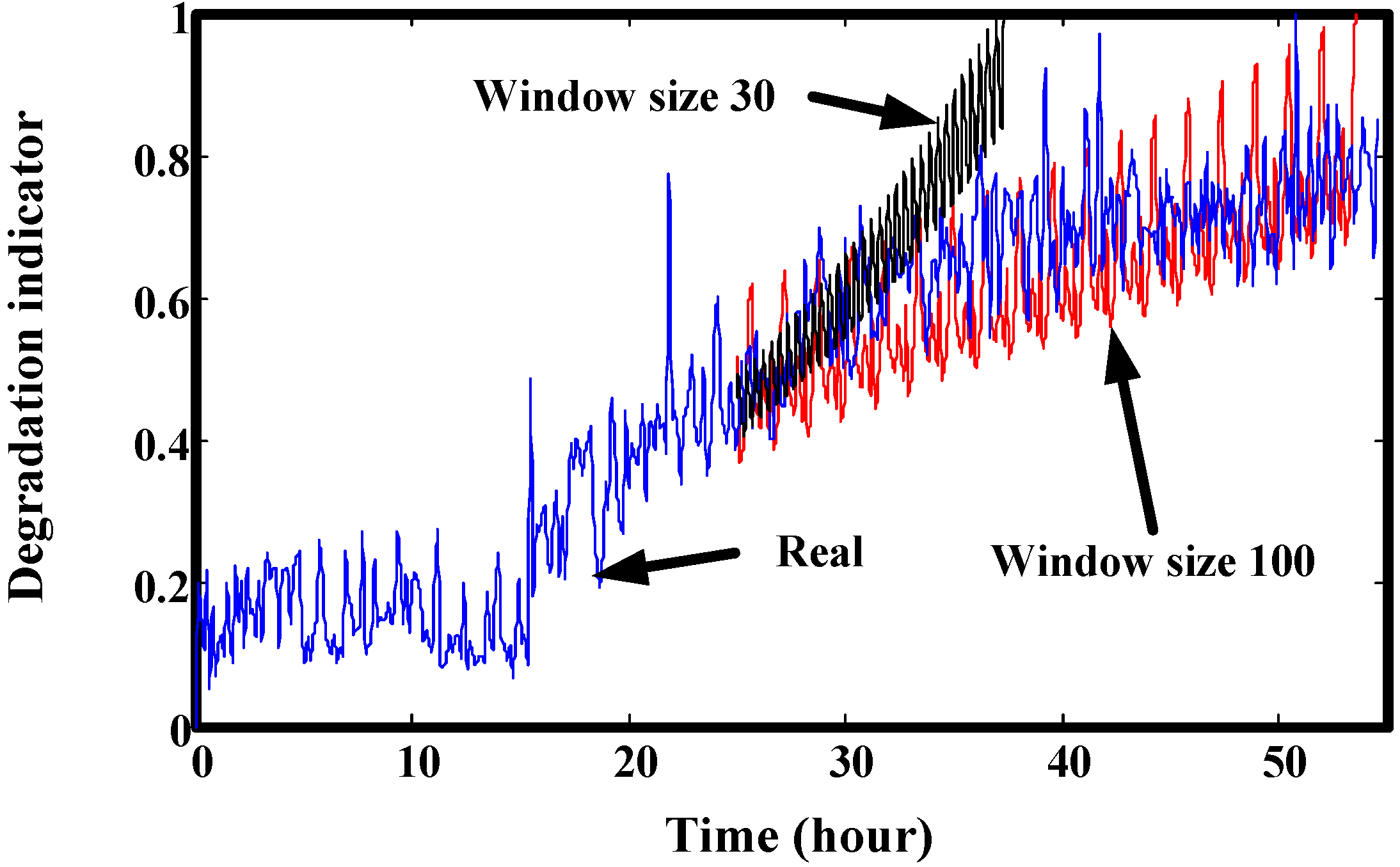
2.3. The Disadvantages of Neural Network-Based Prediction
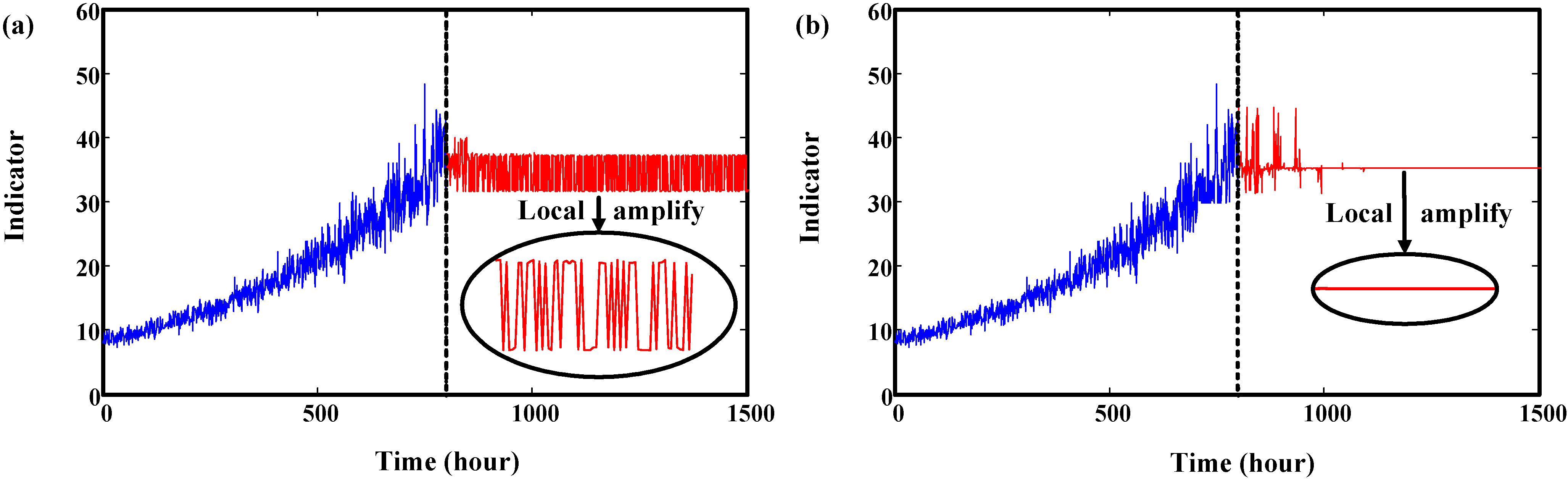
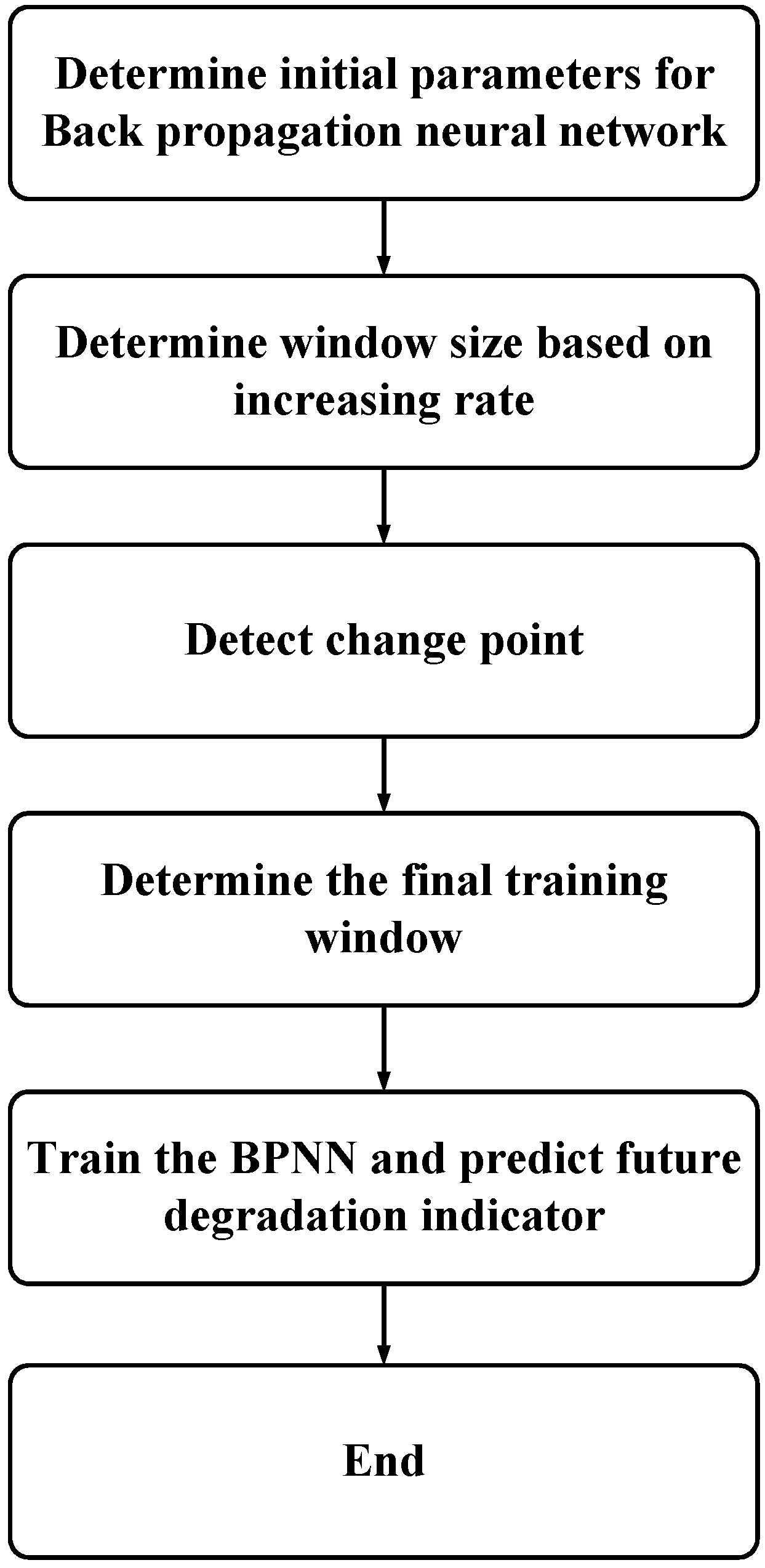
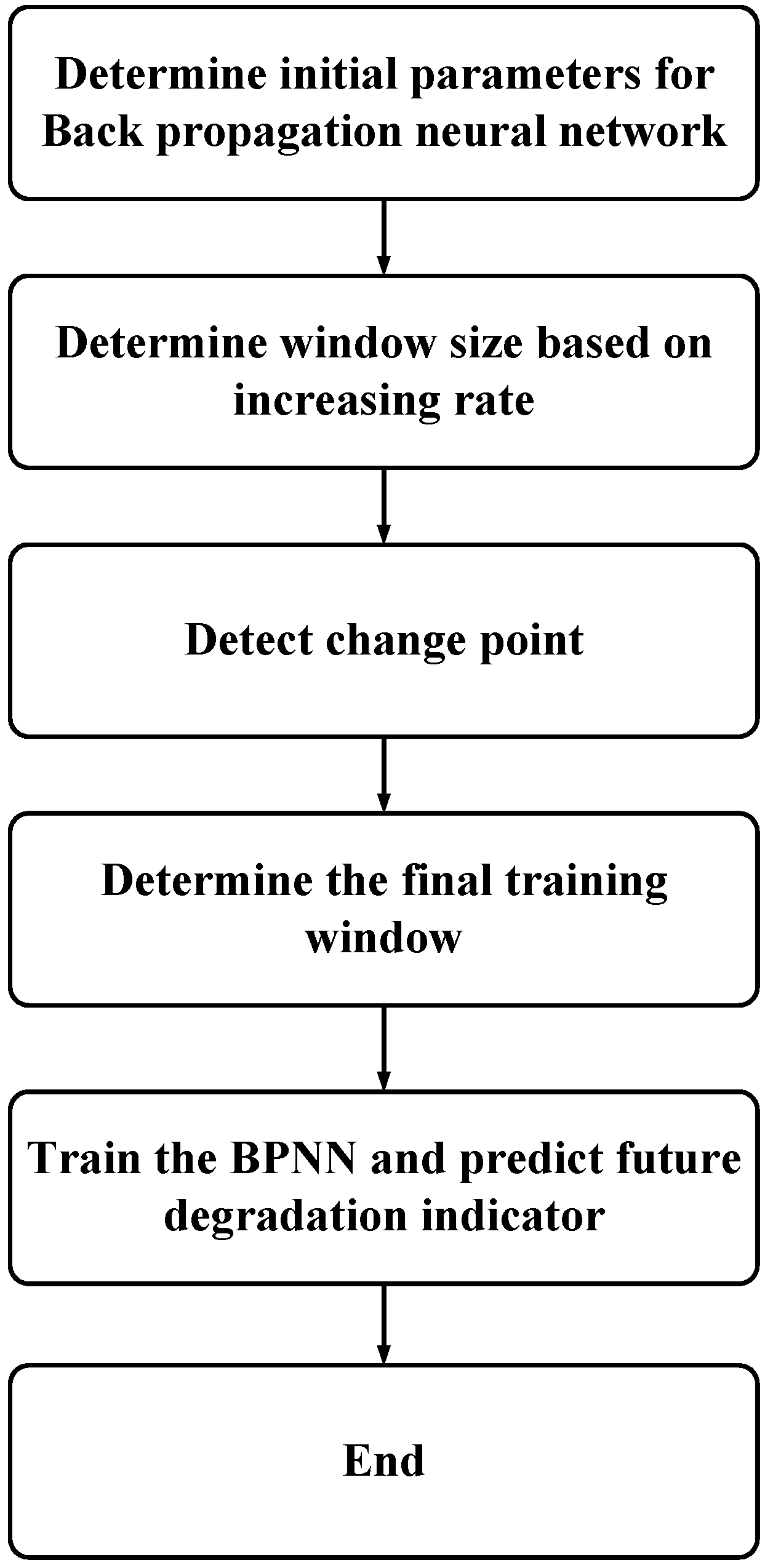
3. Proposed Neural Network-Based Prediction Model
3.1. Window Size Determination
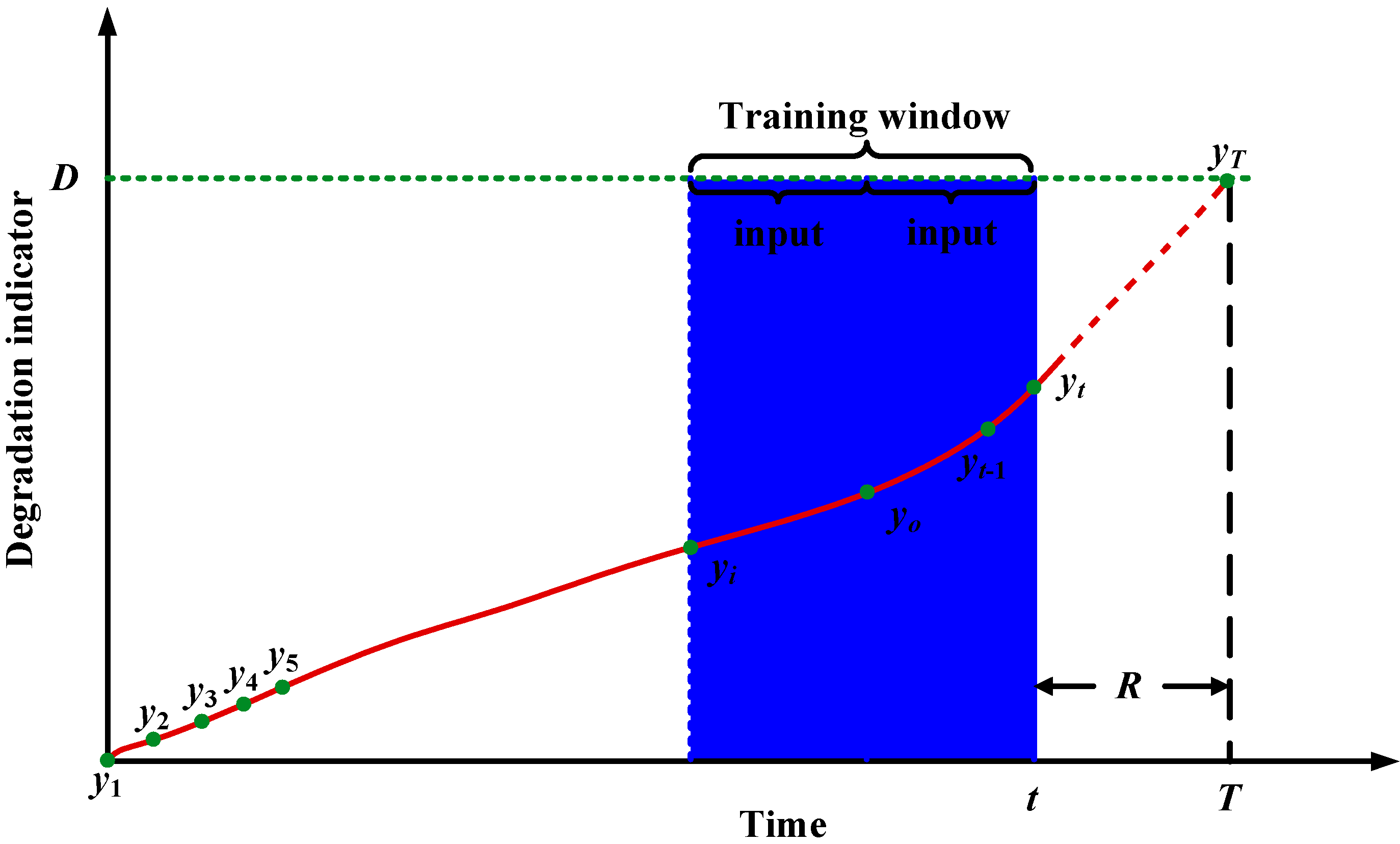
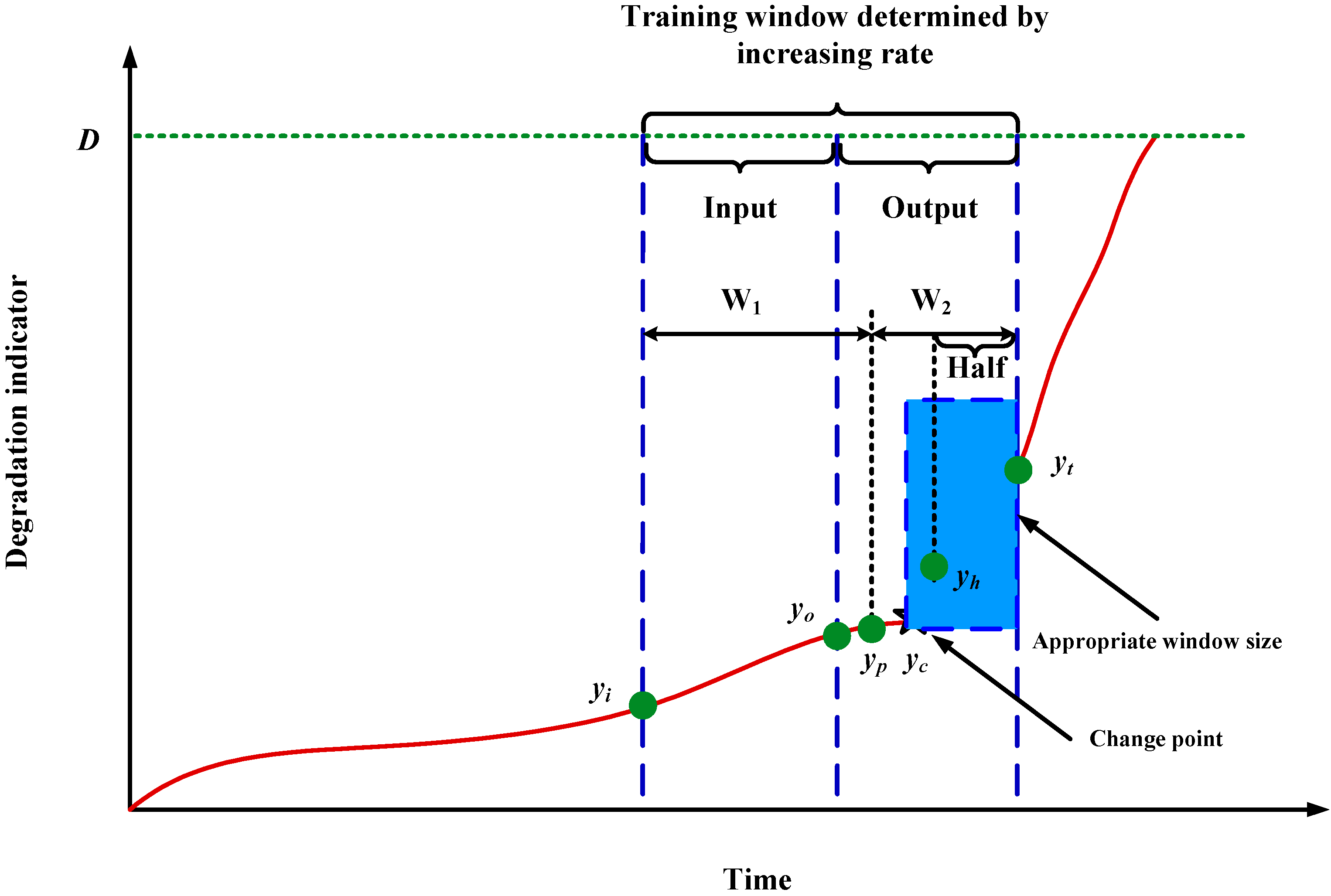
3.1.1. Window Size Determination Based on Increasing Rate
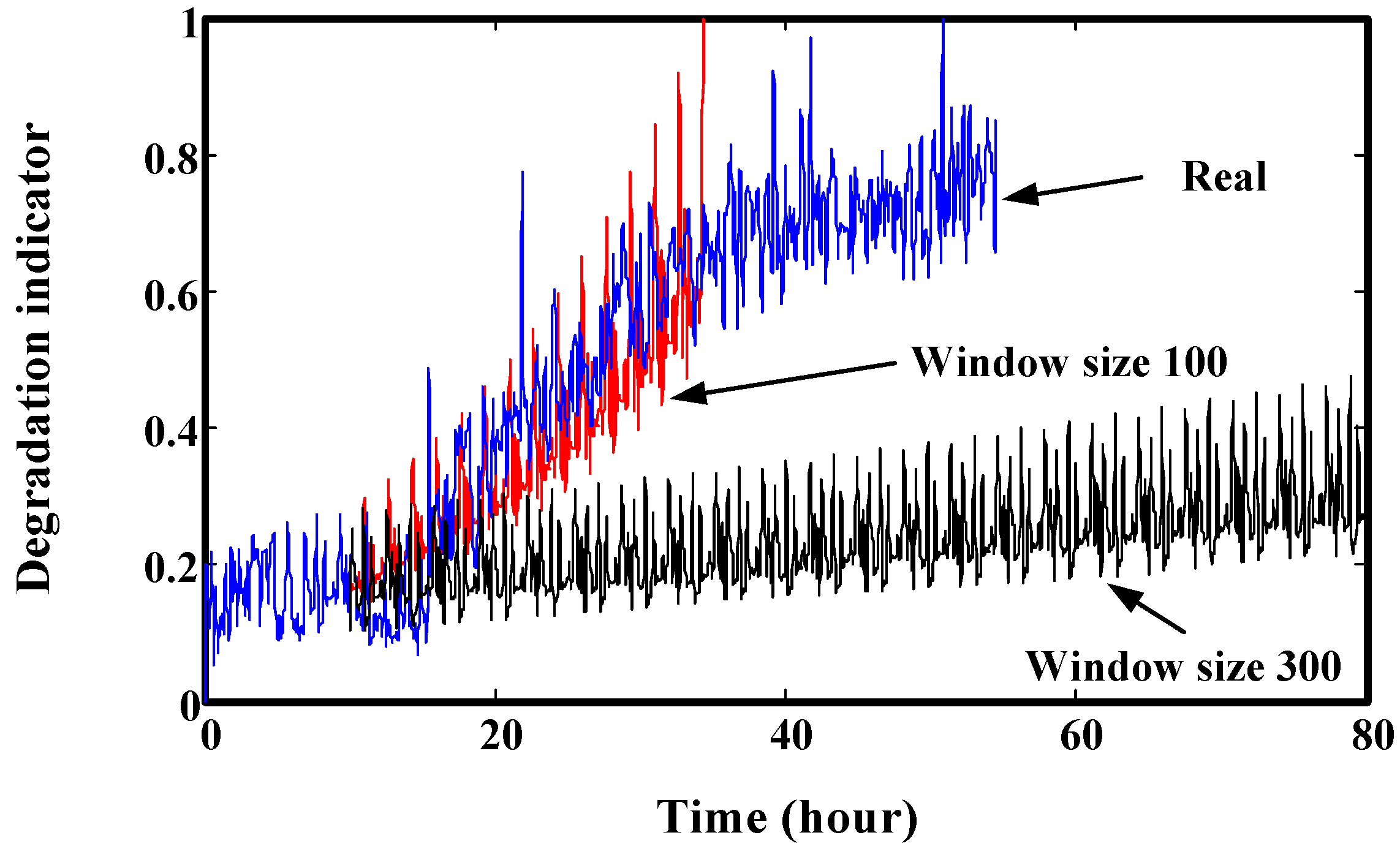
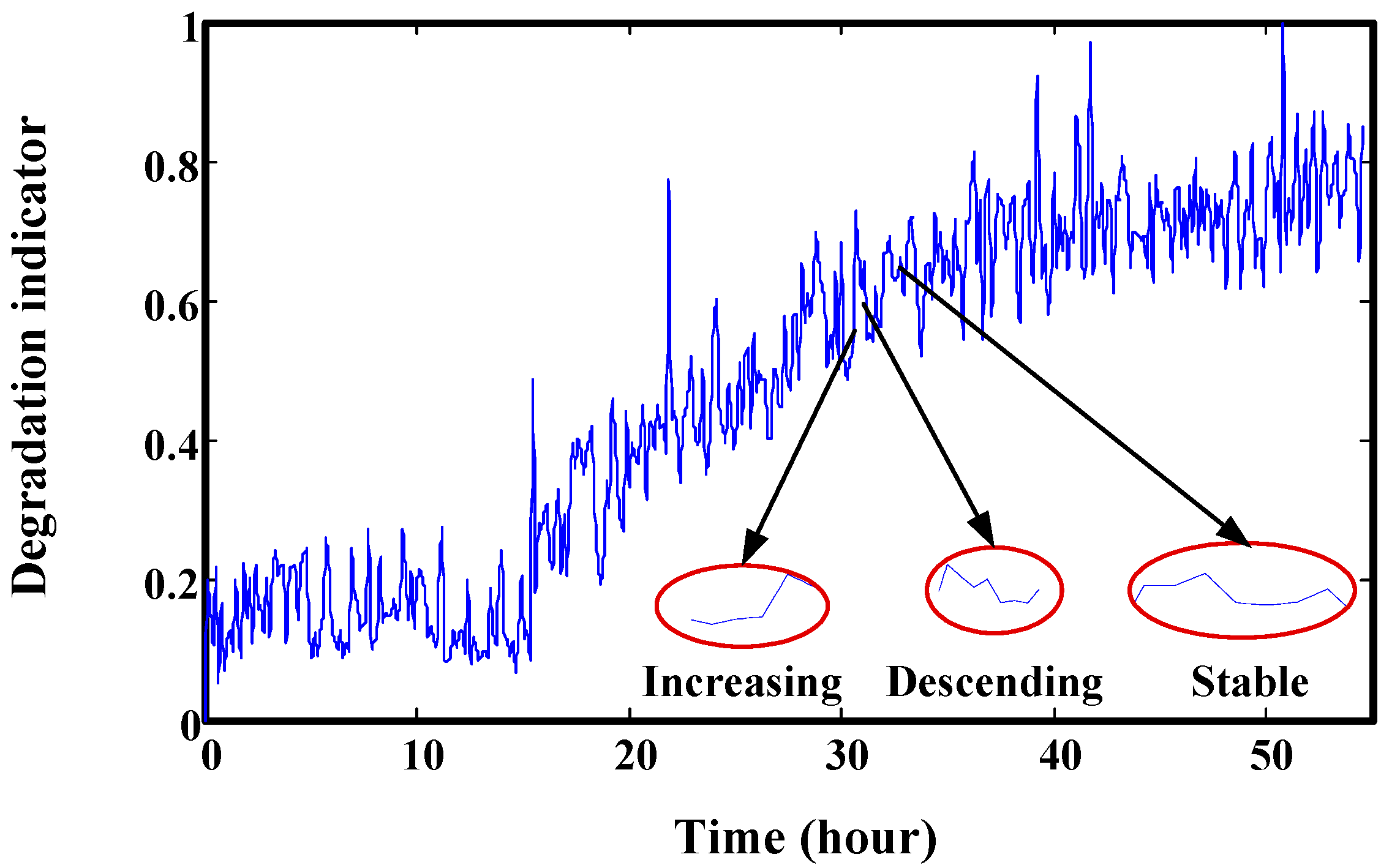
3.1.2. Window Size Adjusting When It Contains Change Point
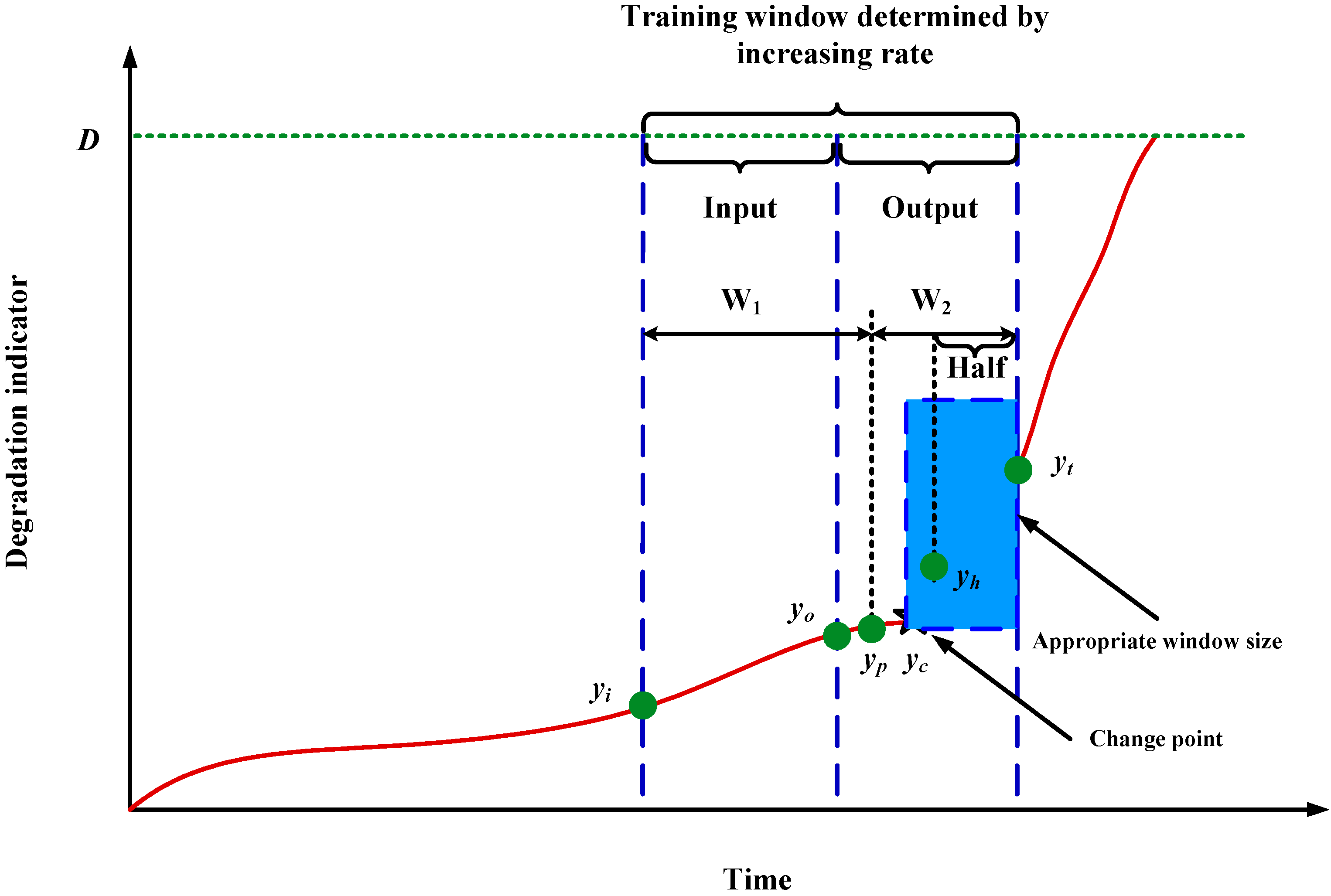
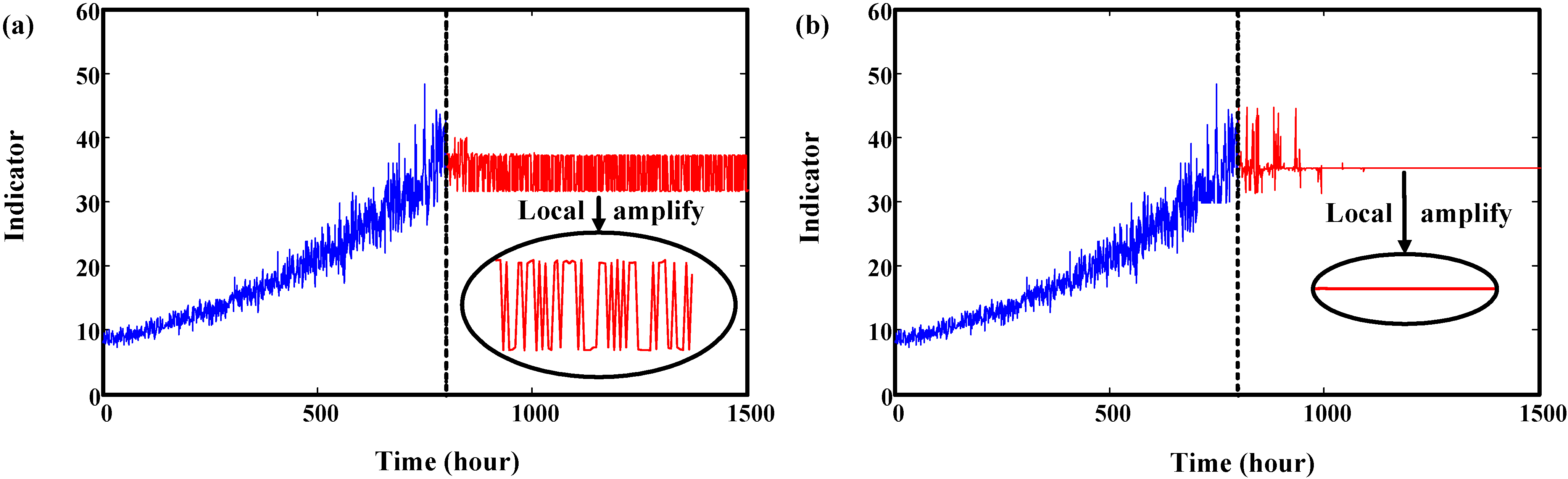
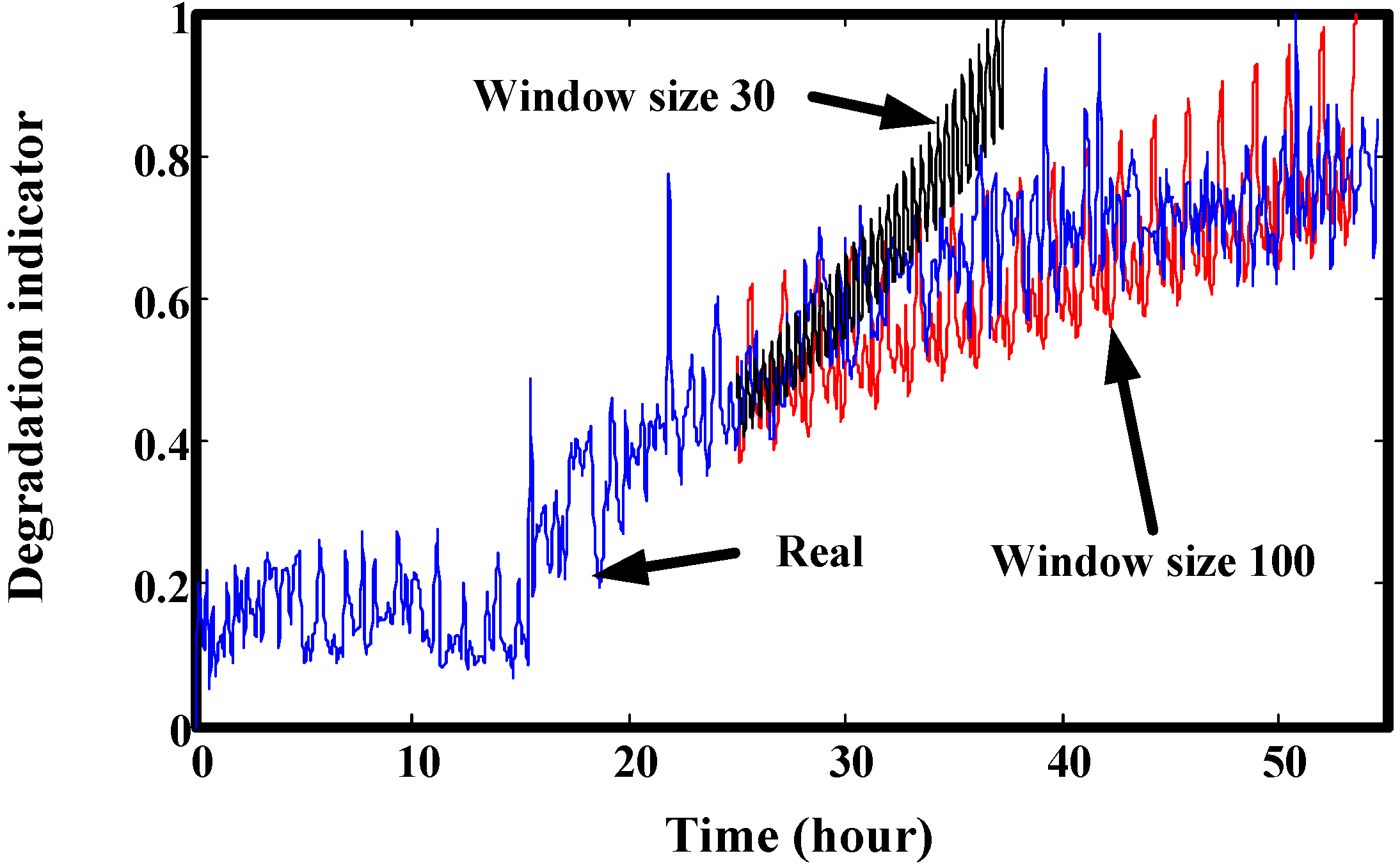
3.2. Rolling Prediction and Limitation
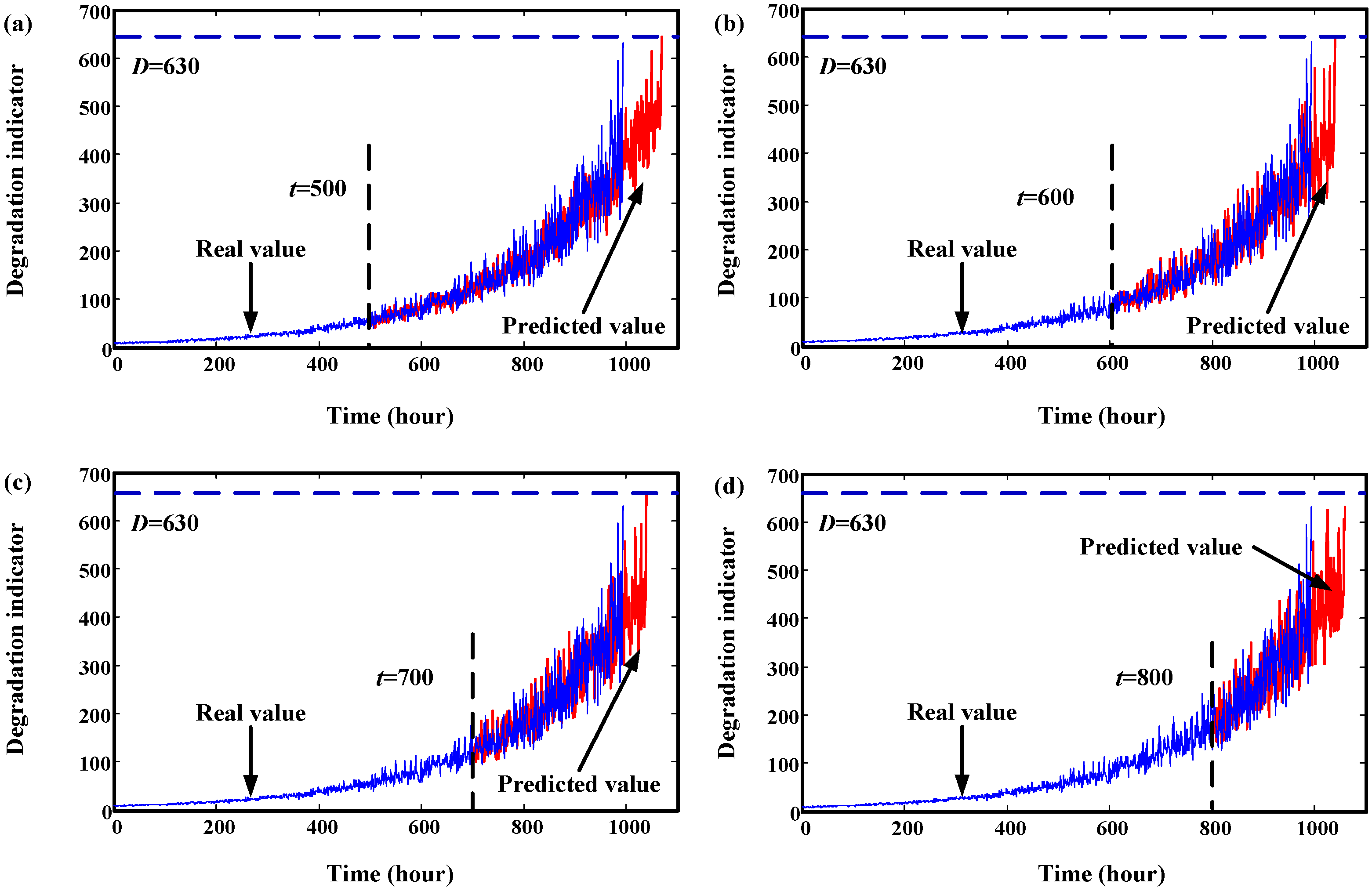
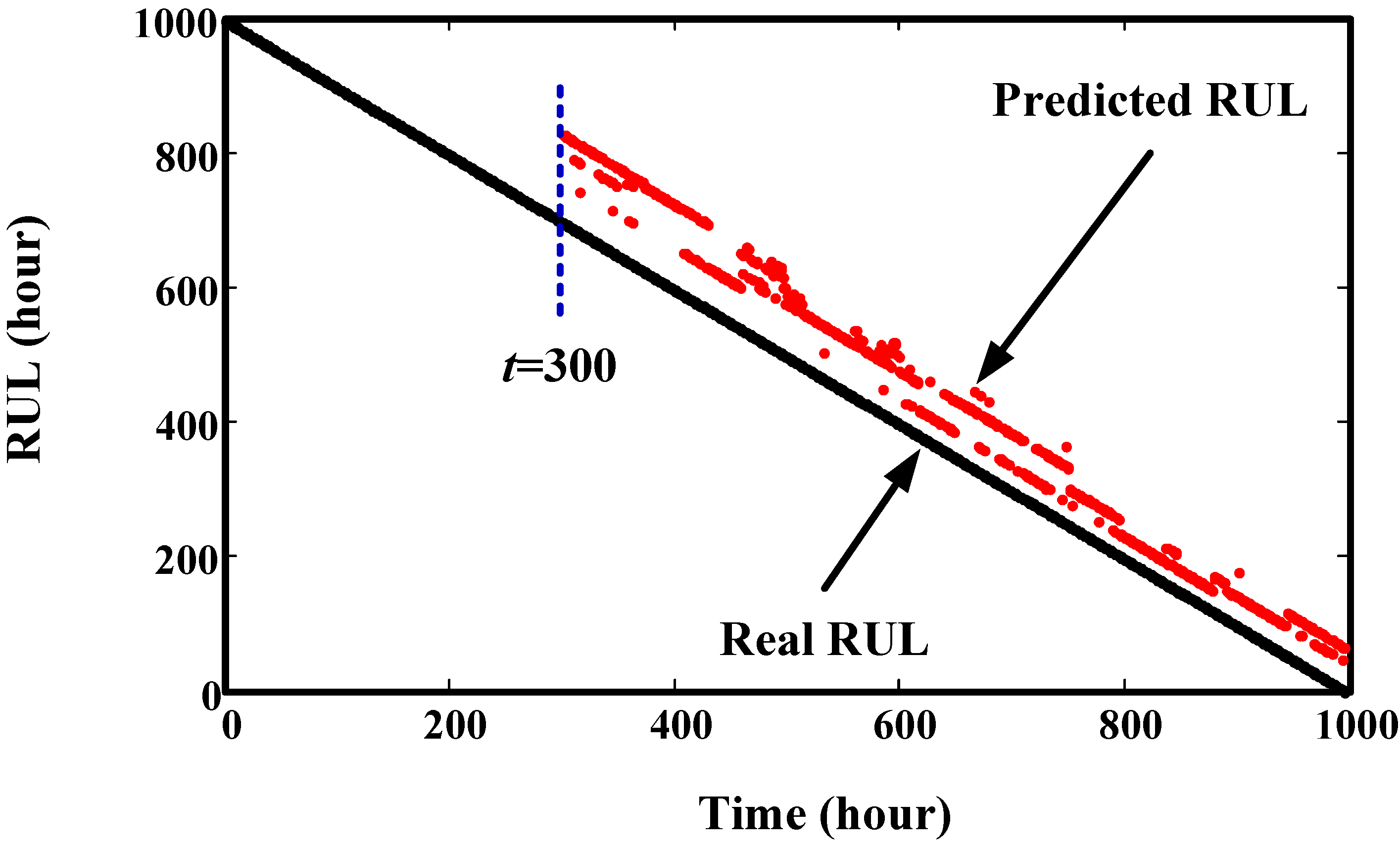
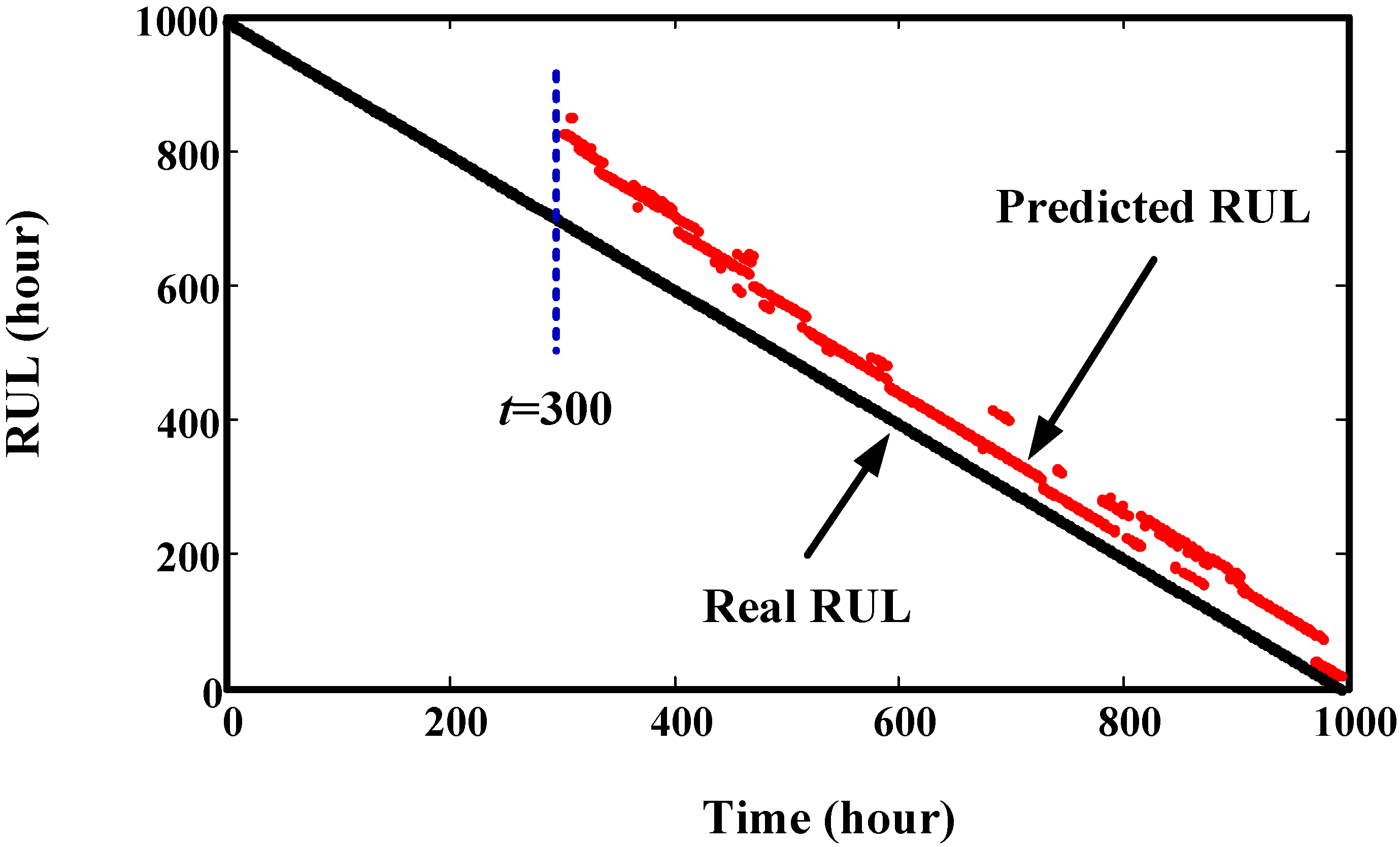
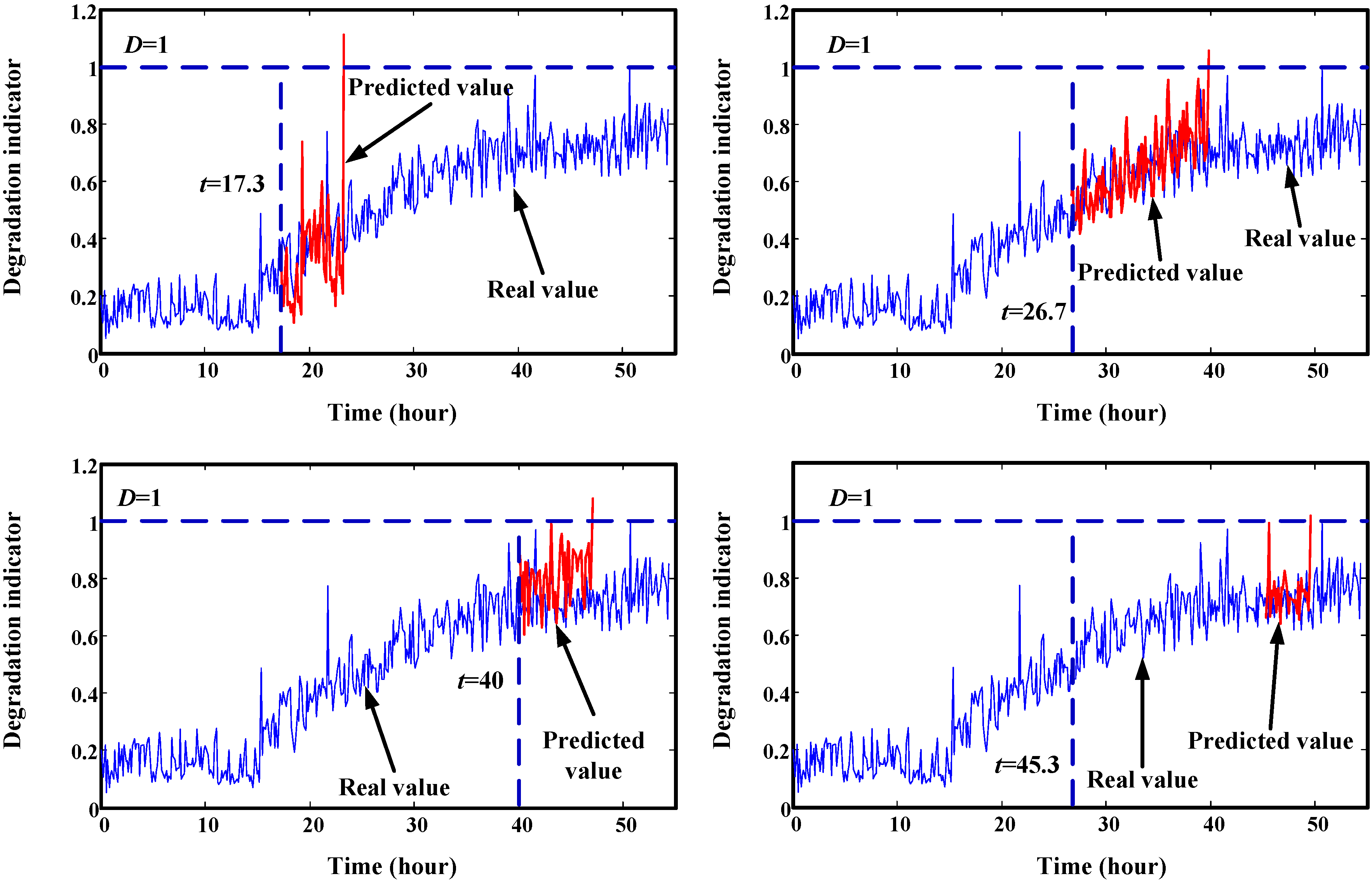
4. Validation by Simulated Degradation Data
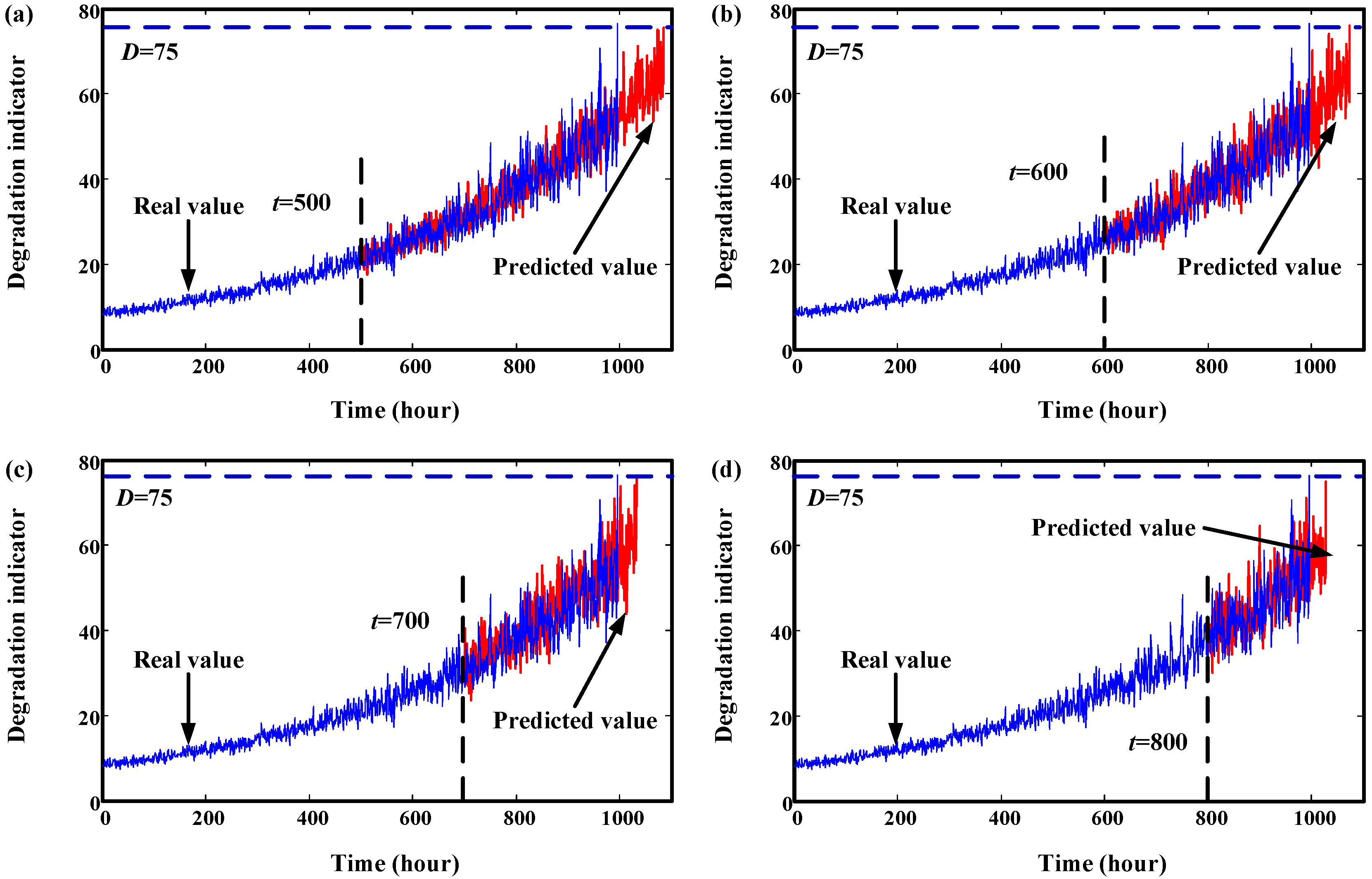
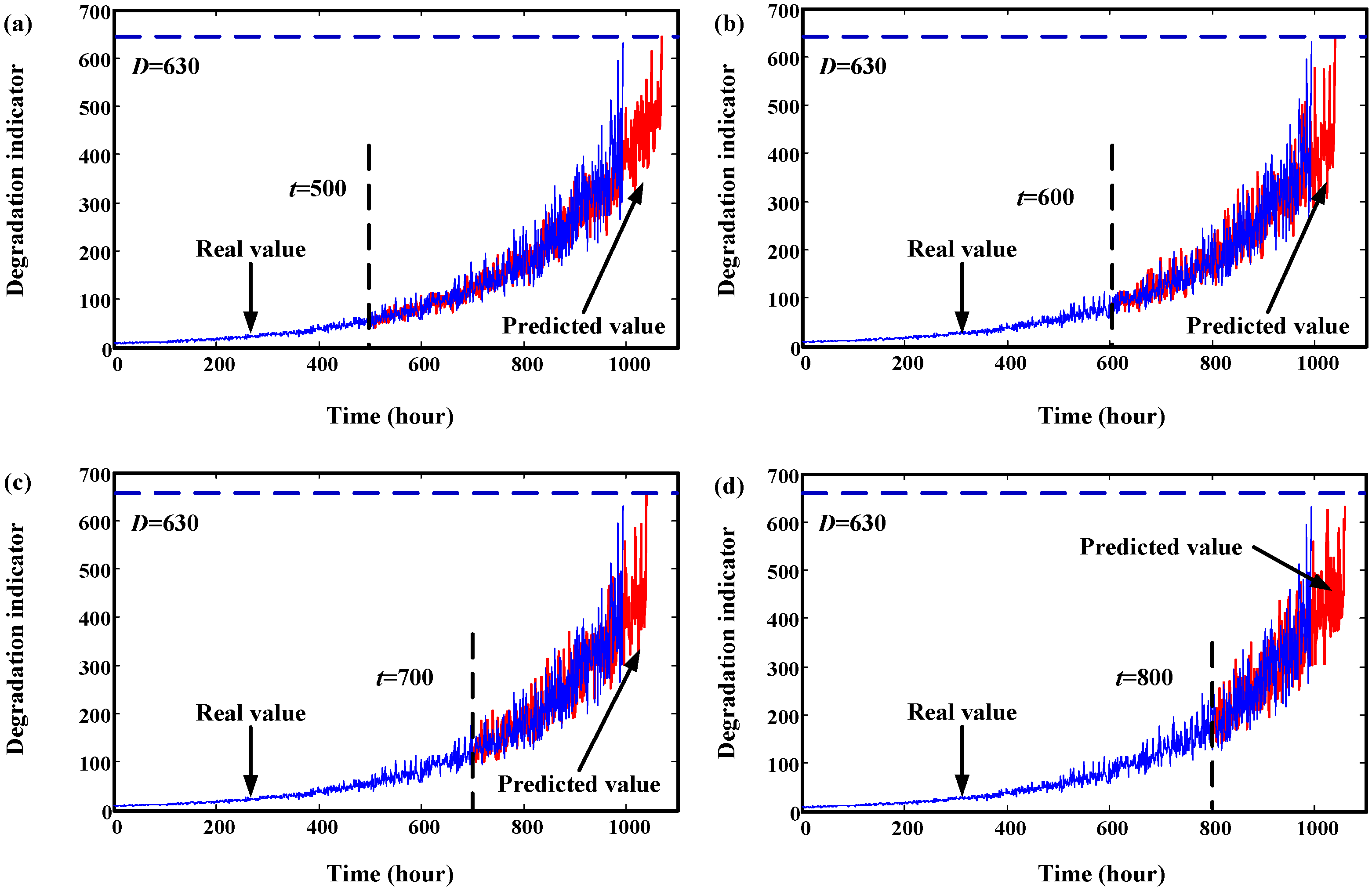

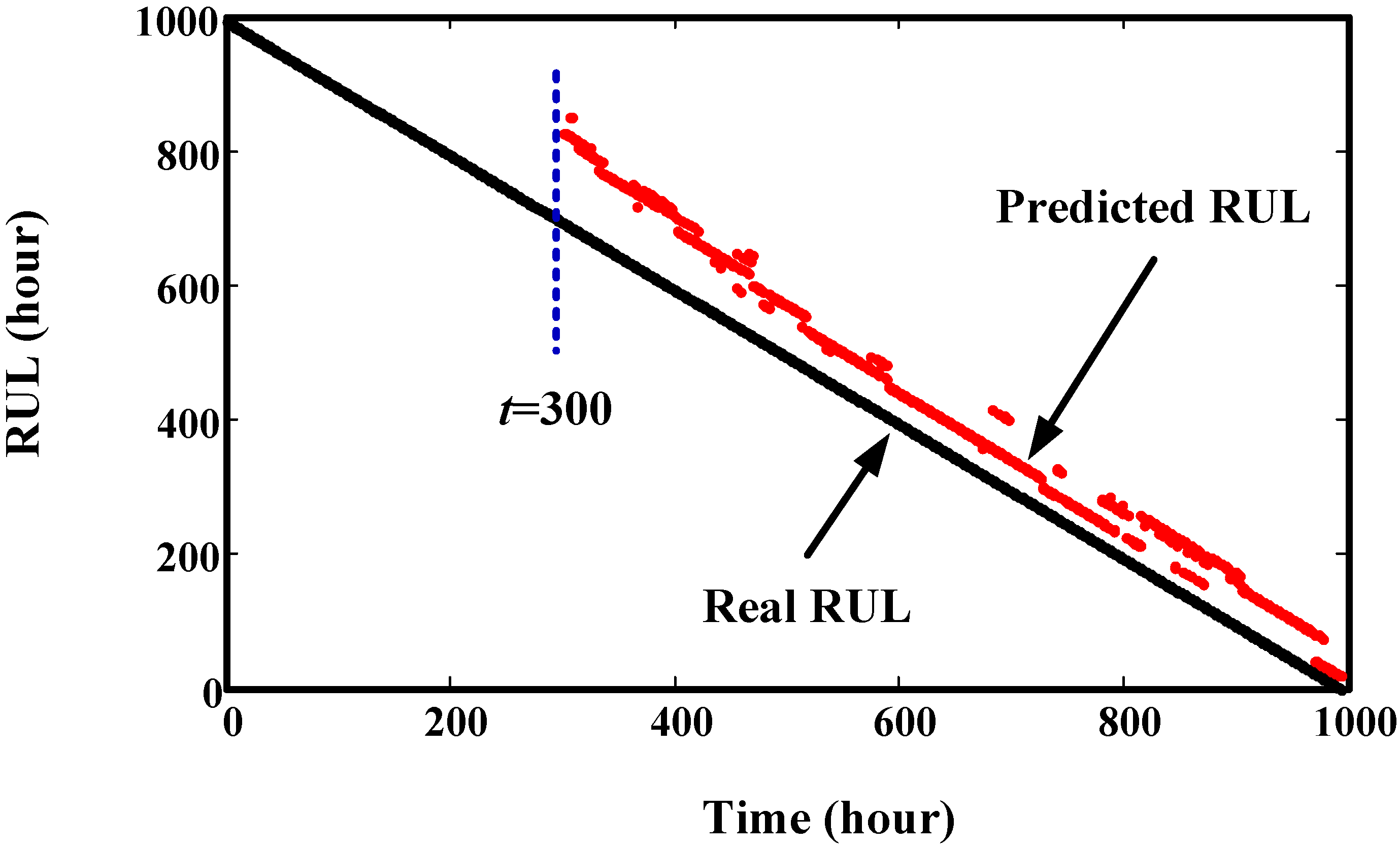
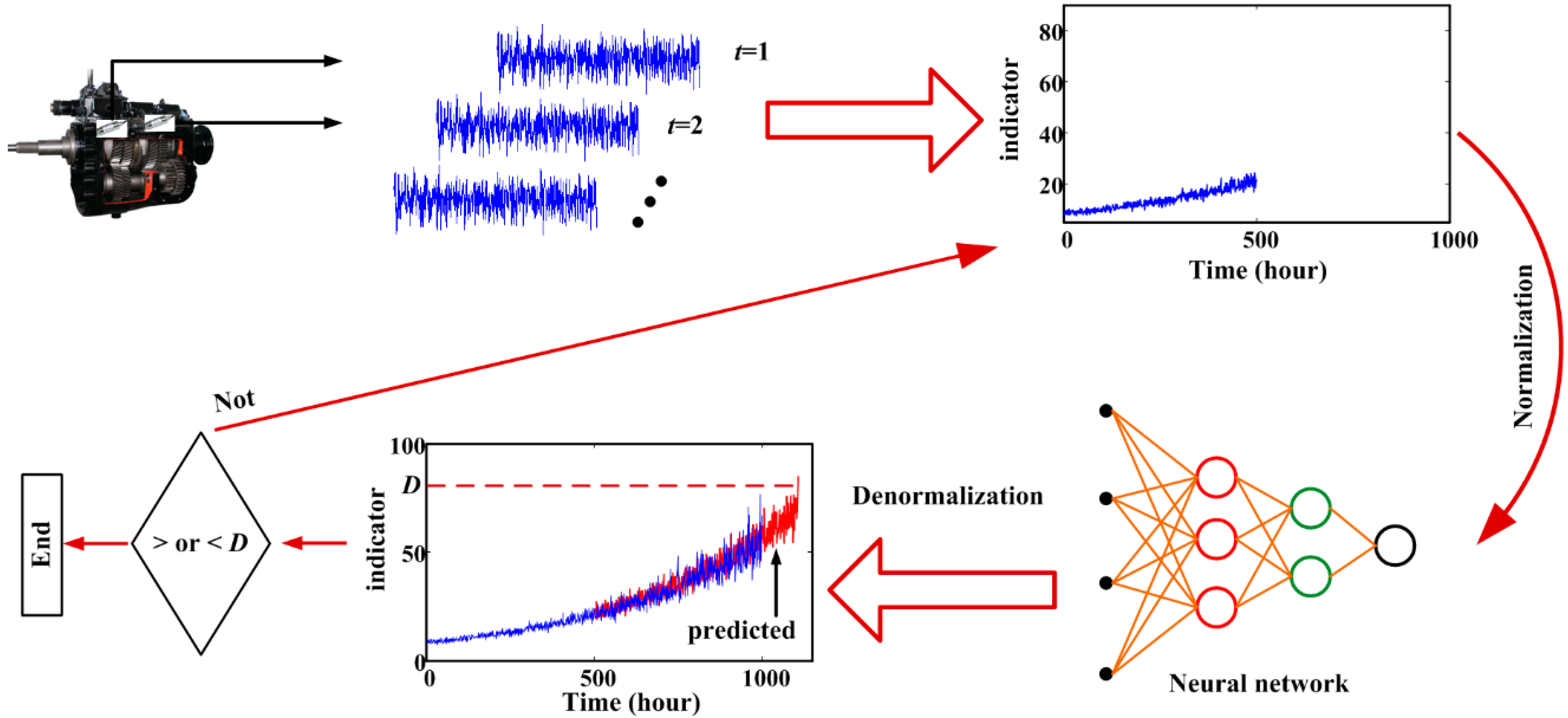
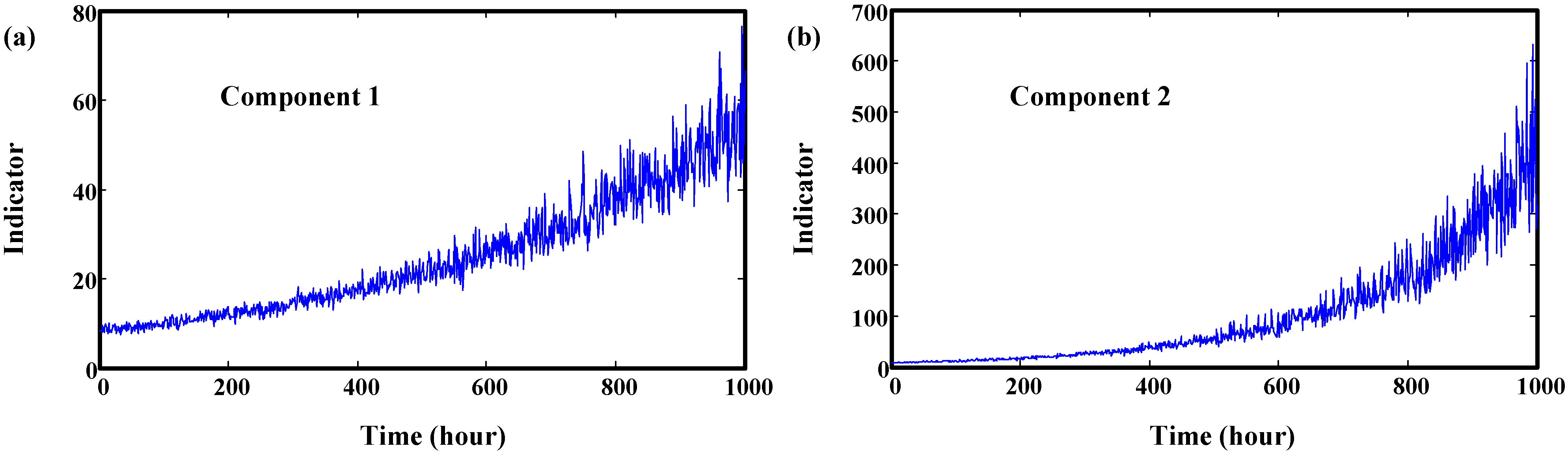
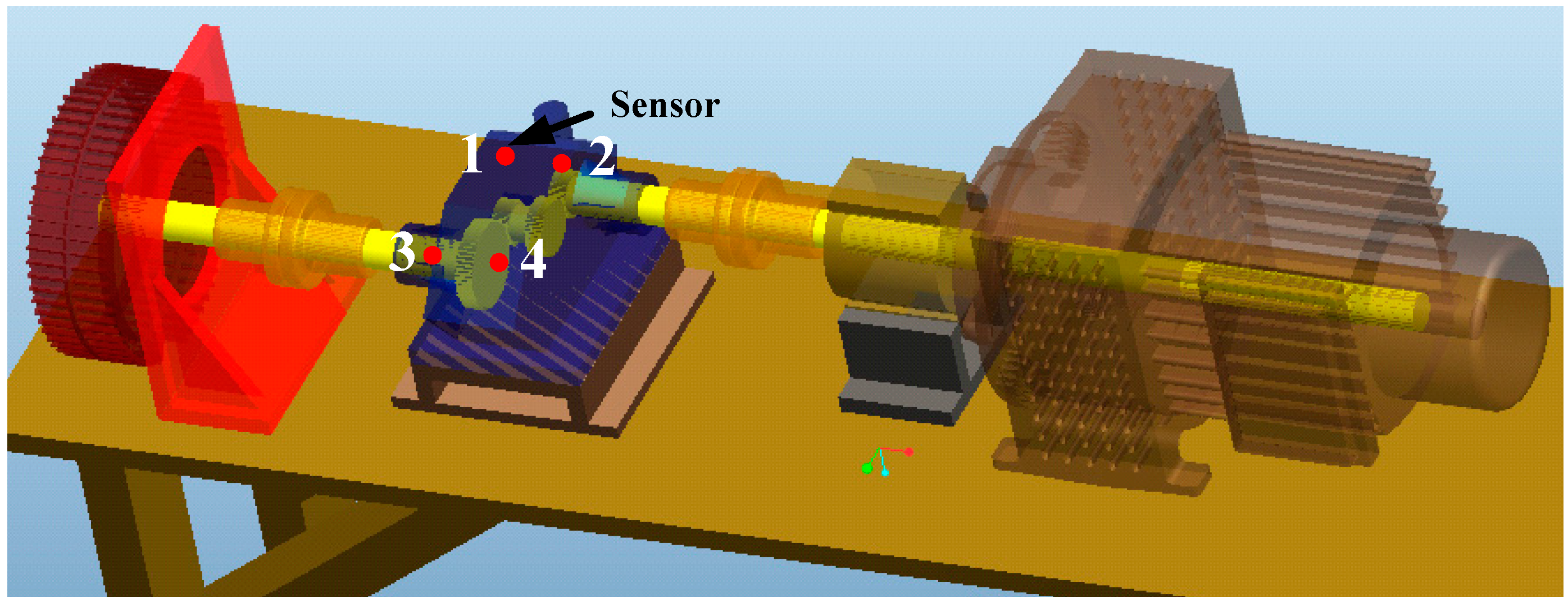
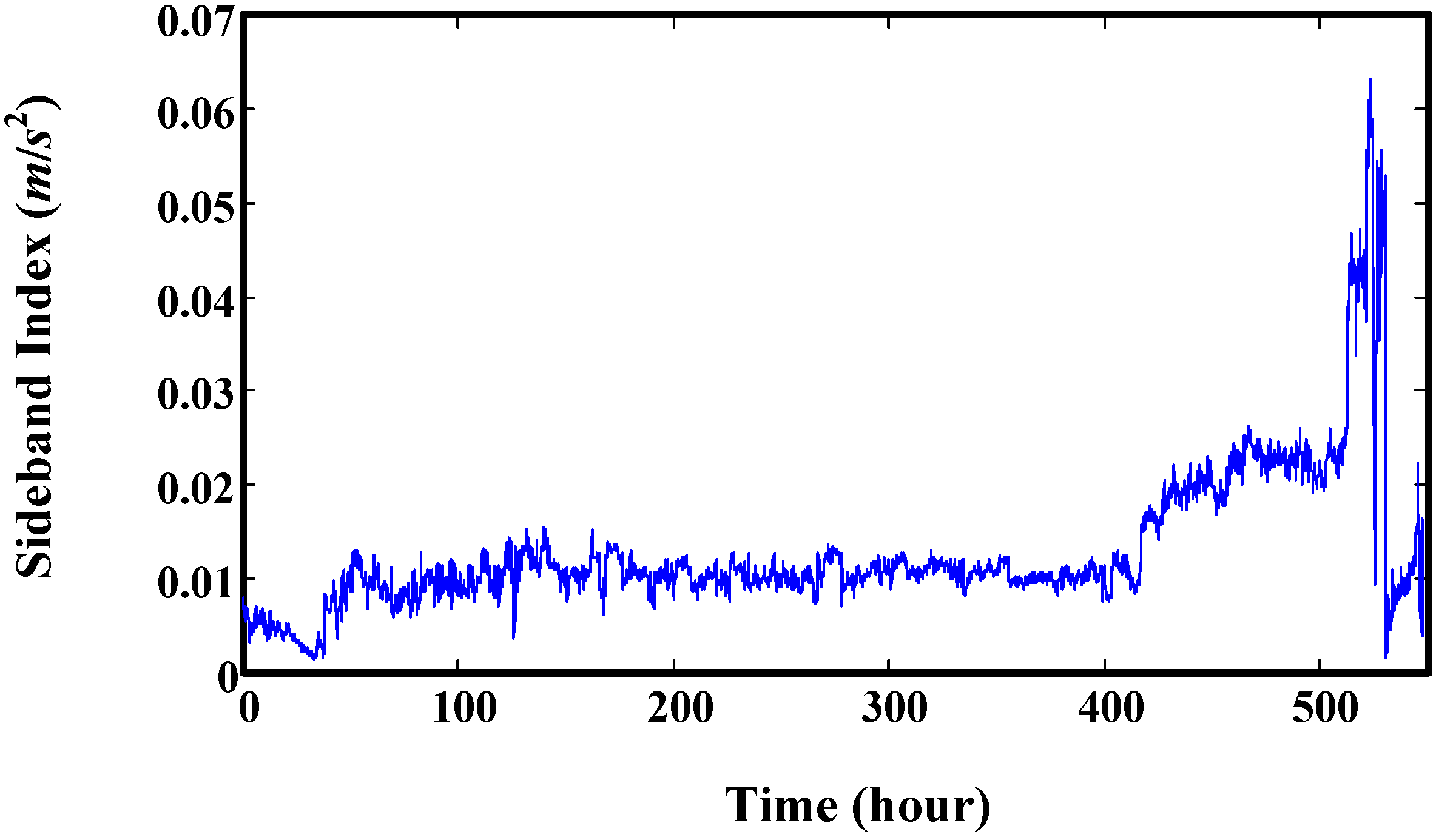
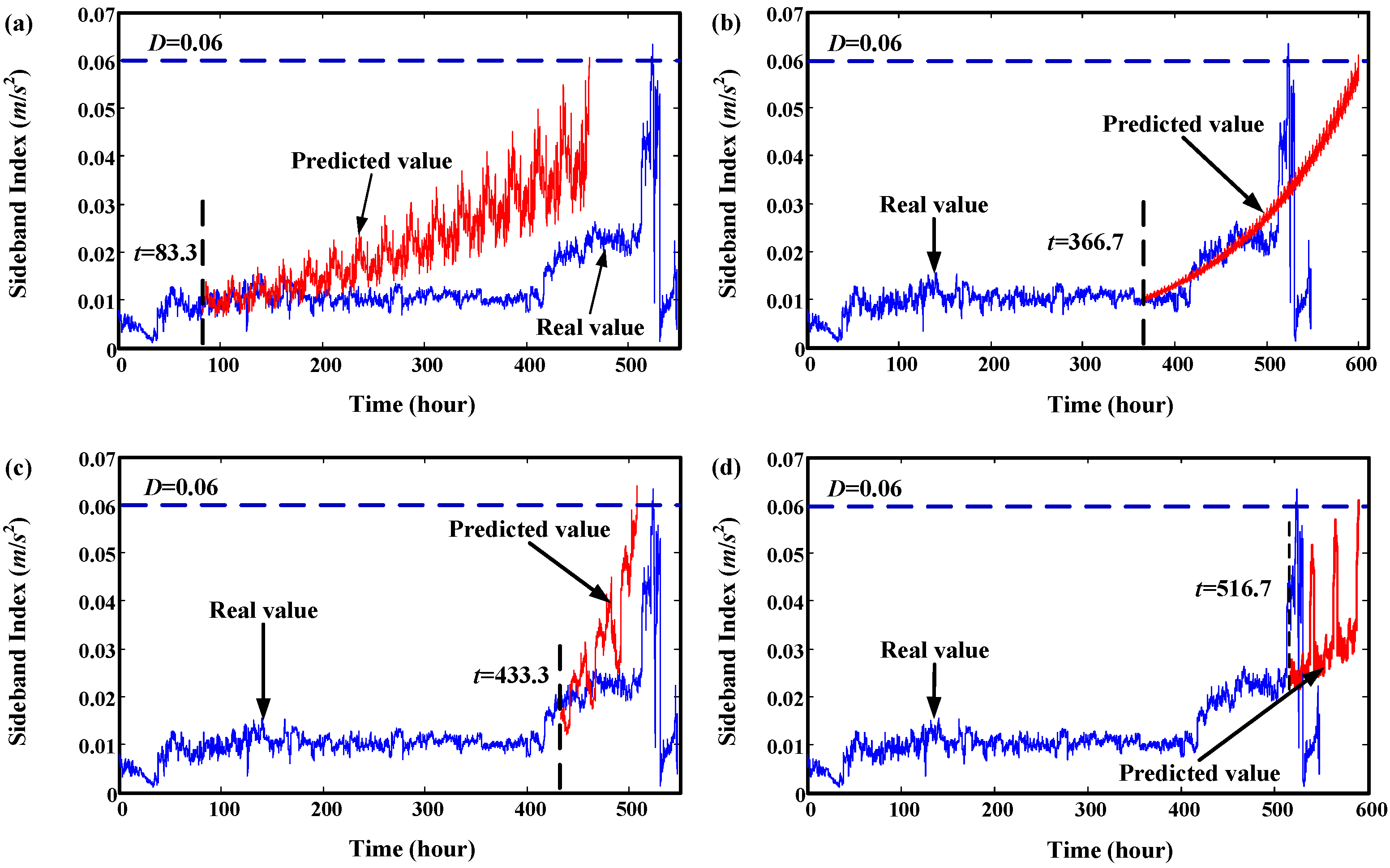
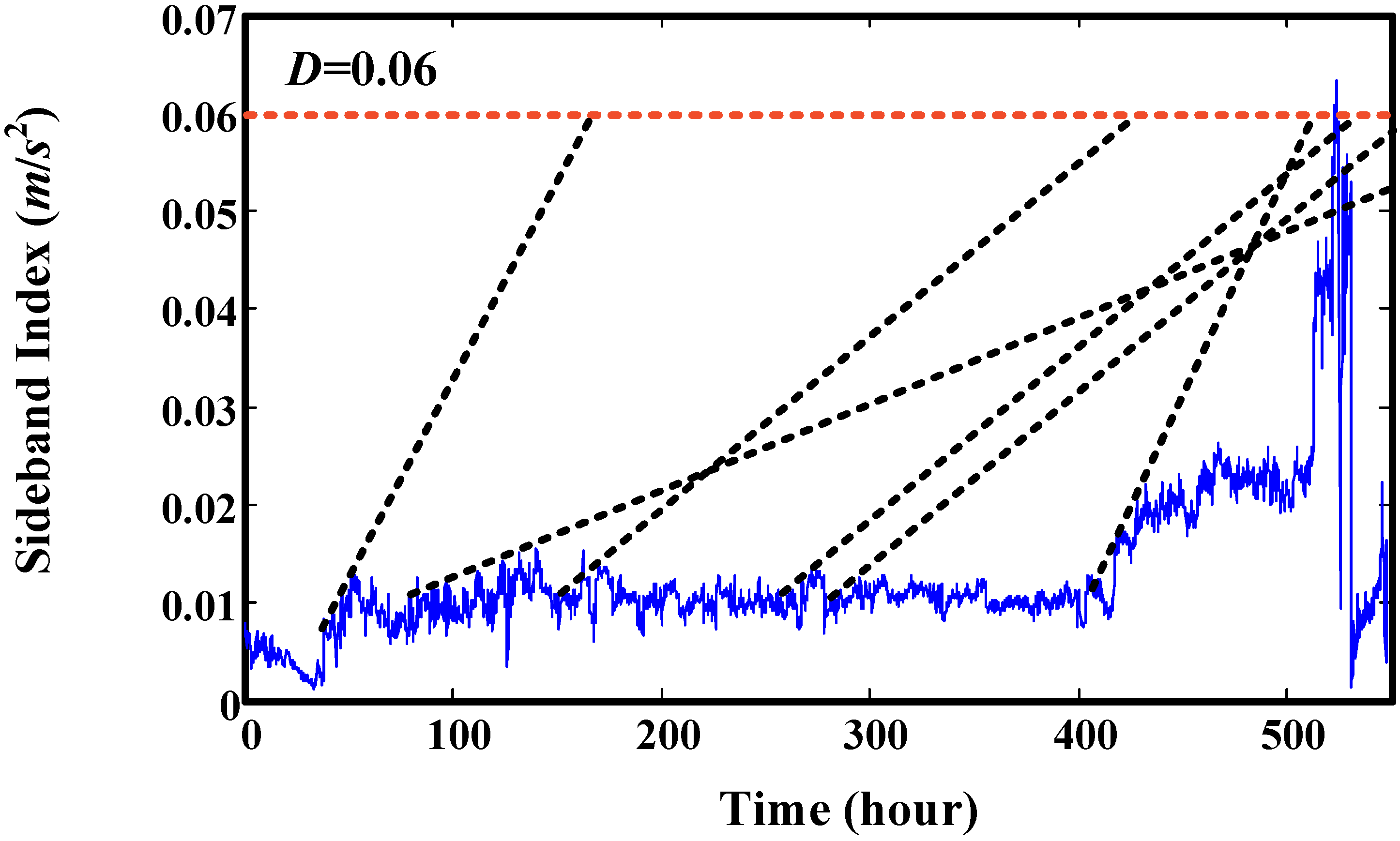
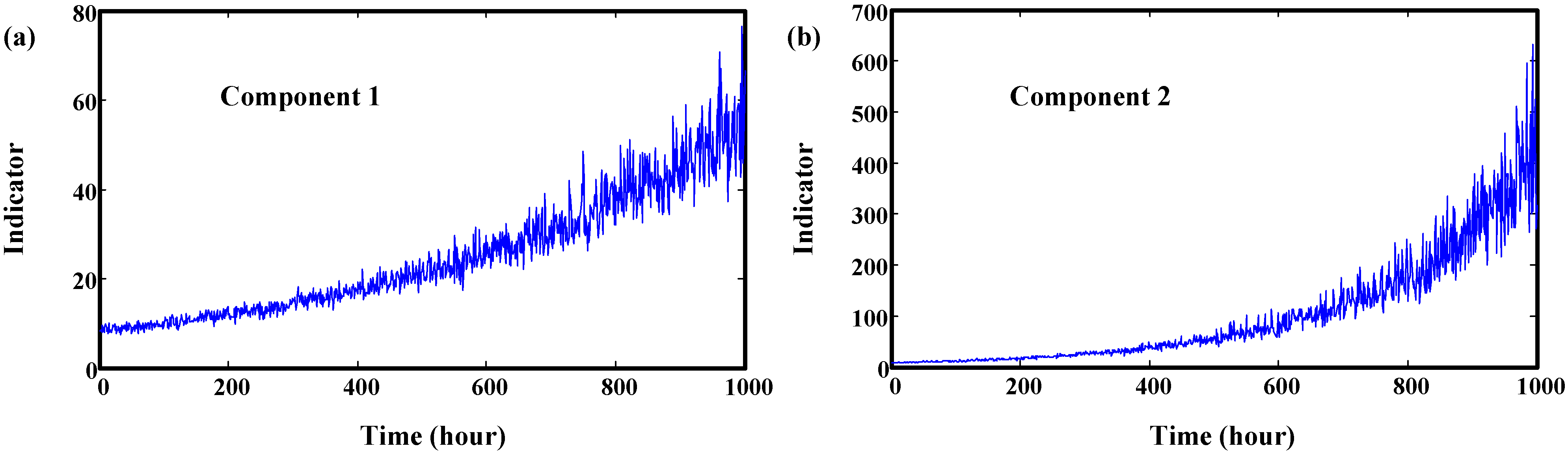
5. Validation by Gearbox Run-to-Failure Data
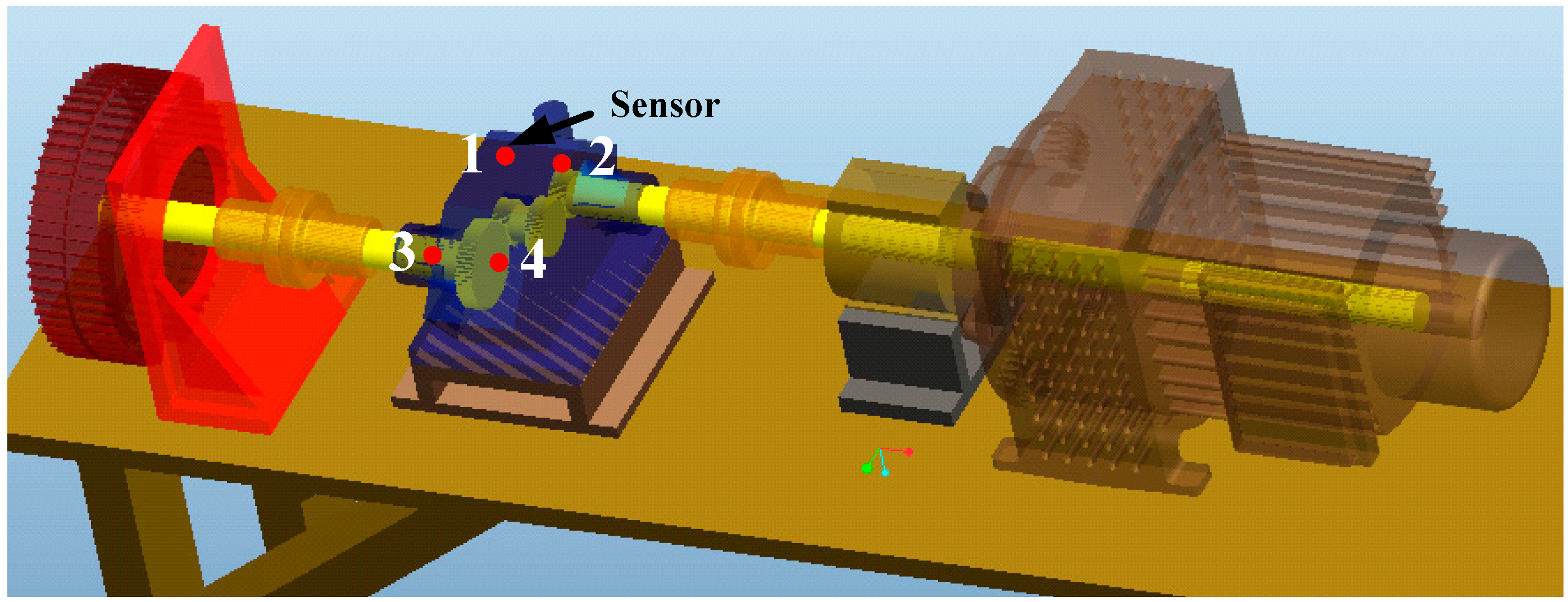
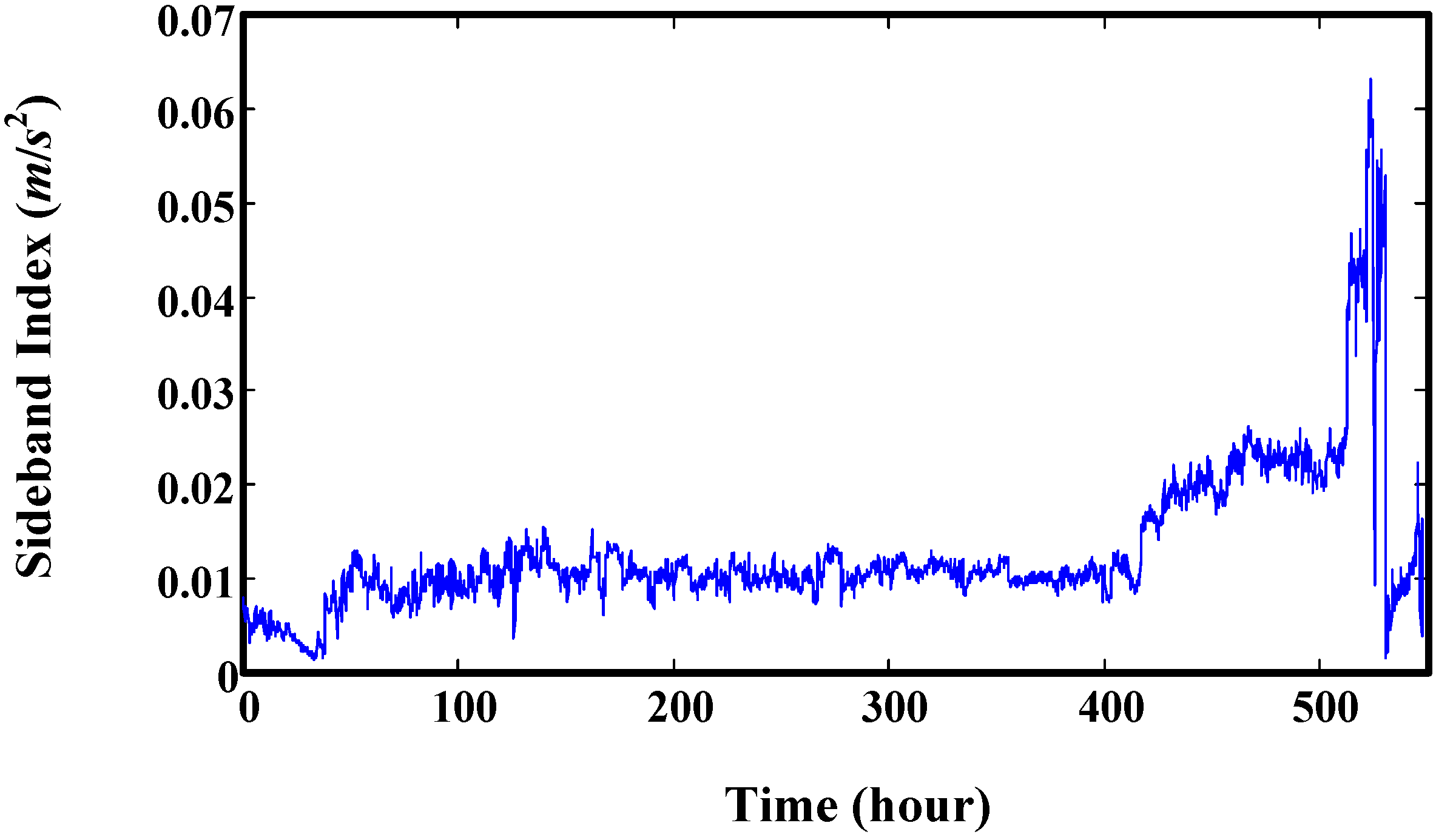

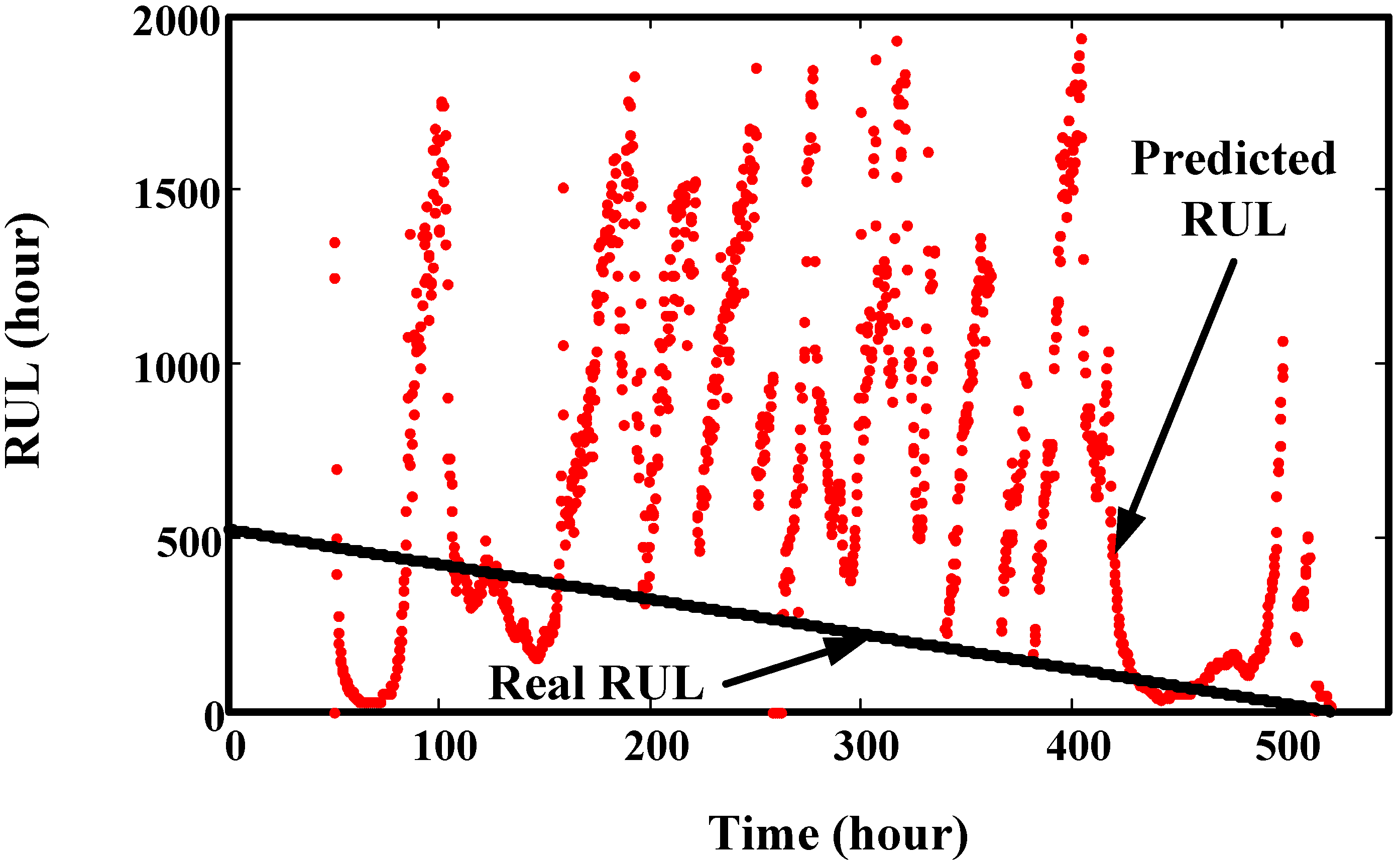
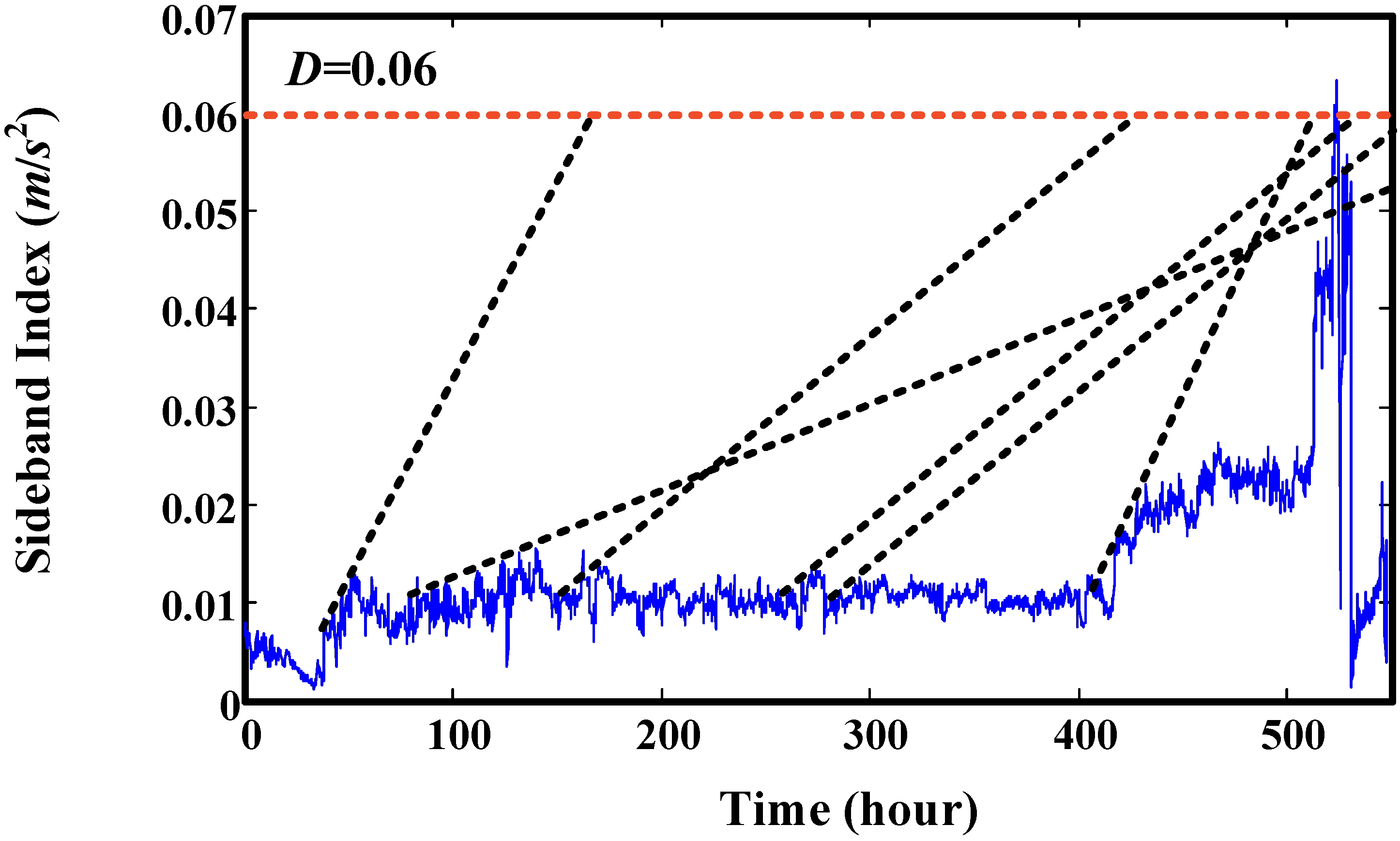
6. Validation by Helicopter Shaft Run-to-Failure Data
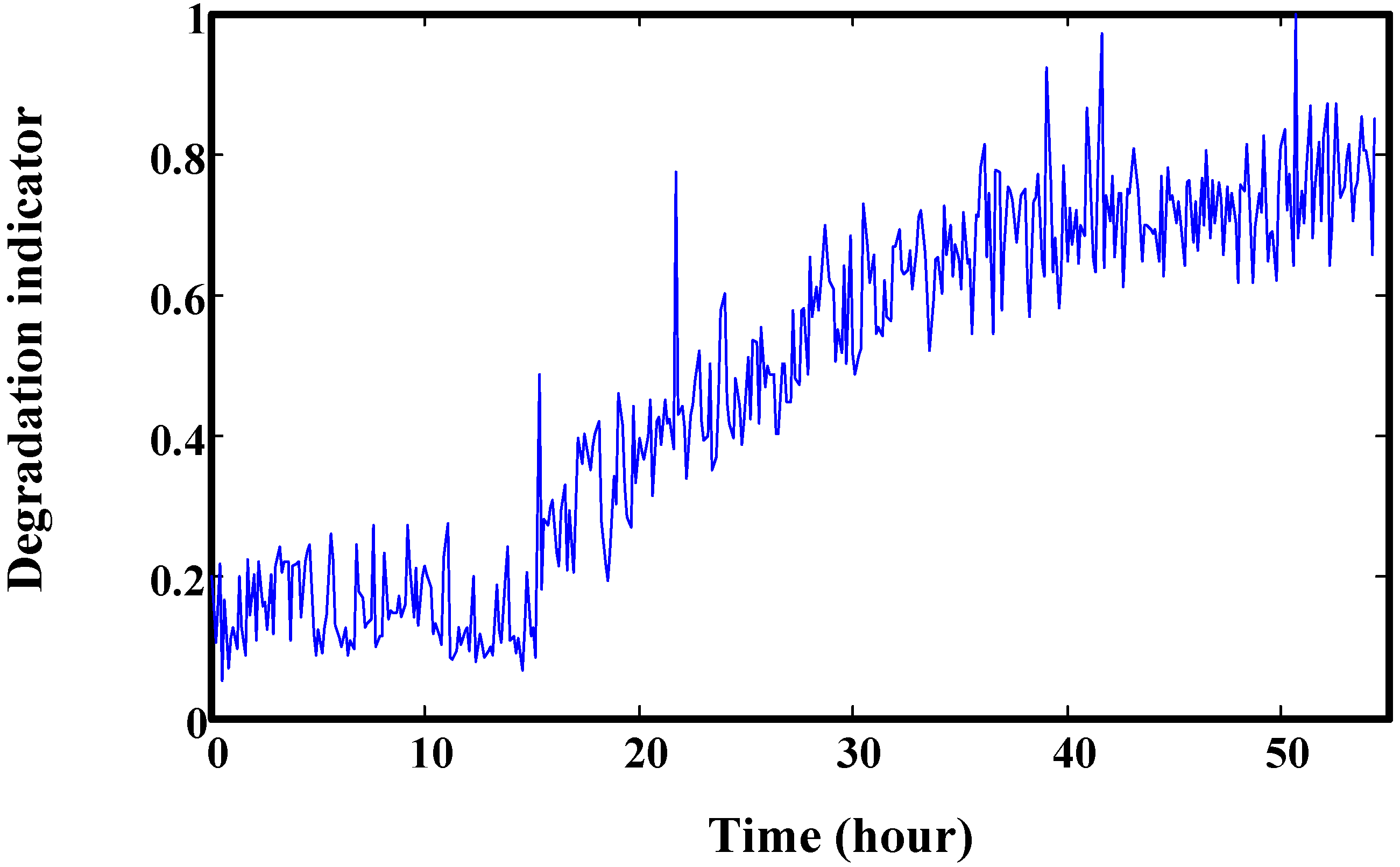
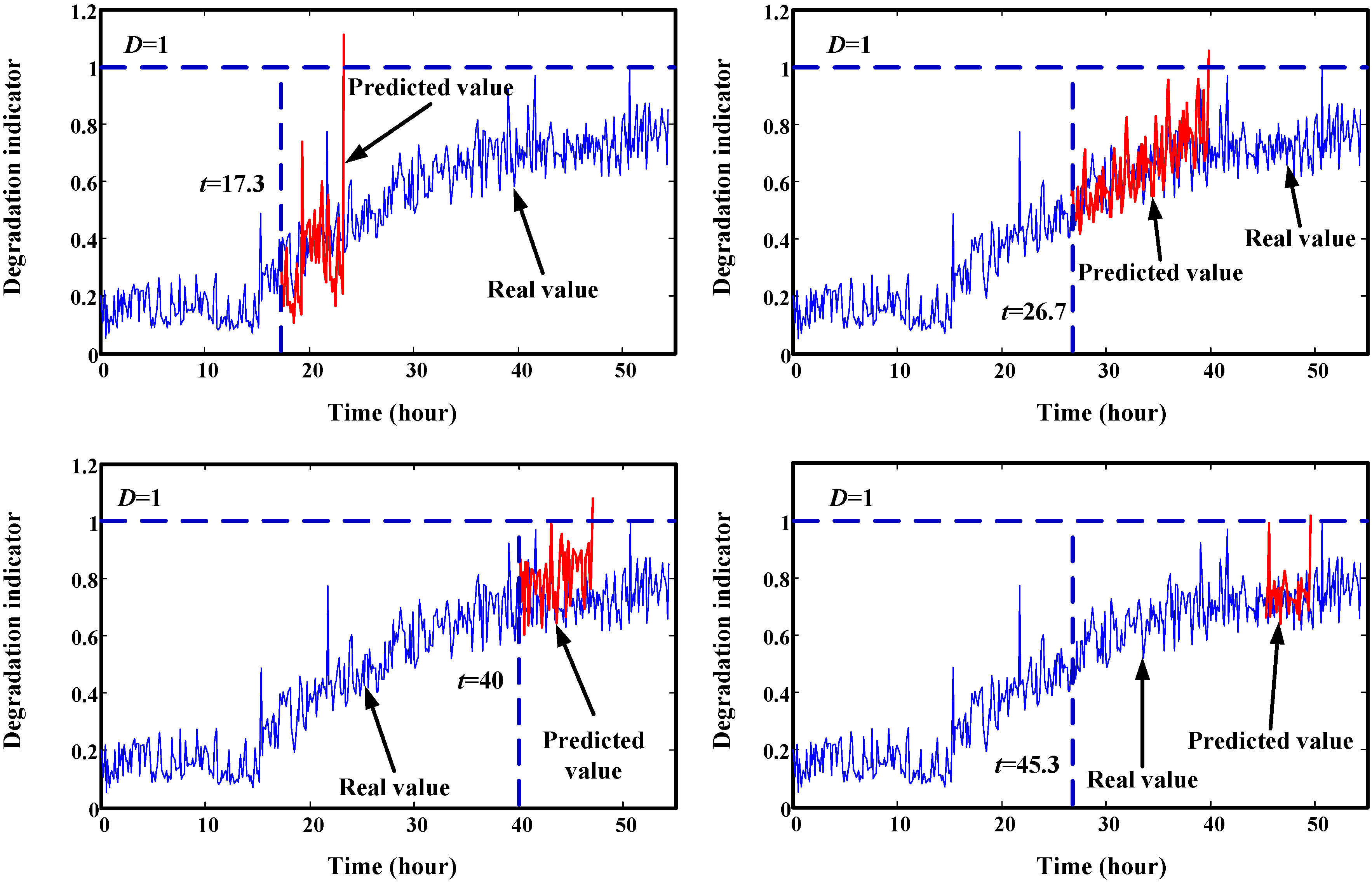
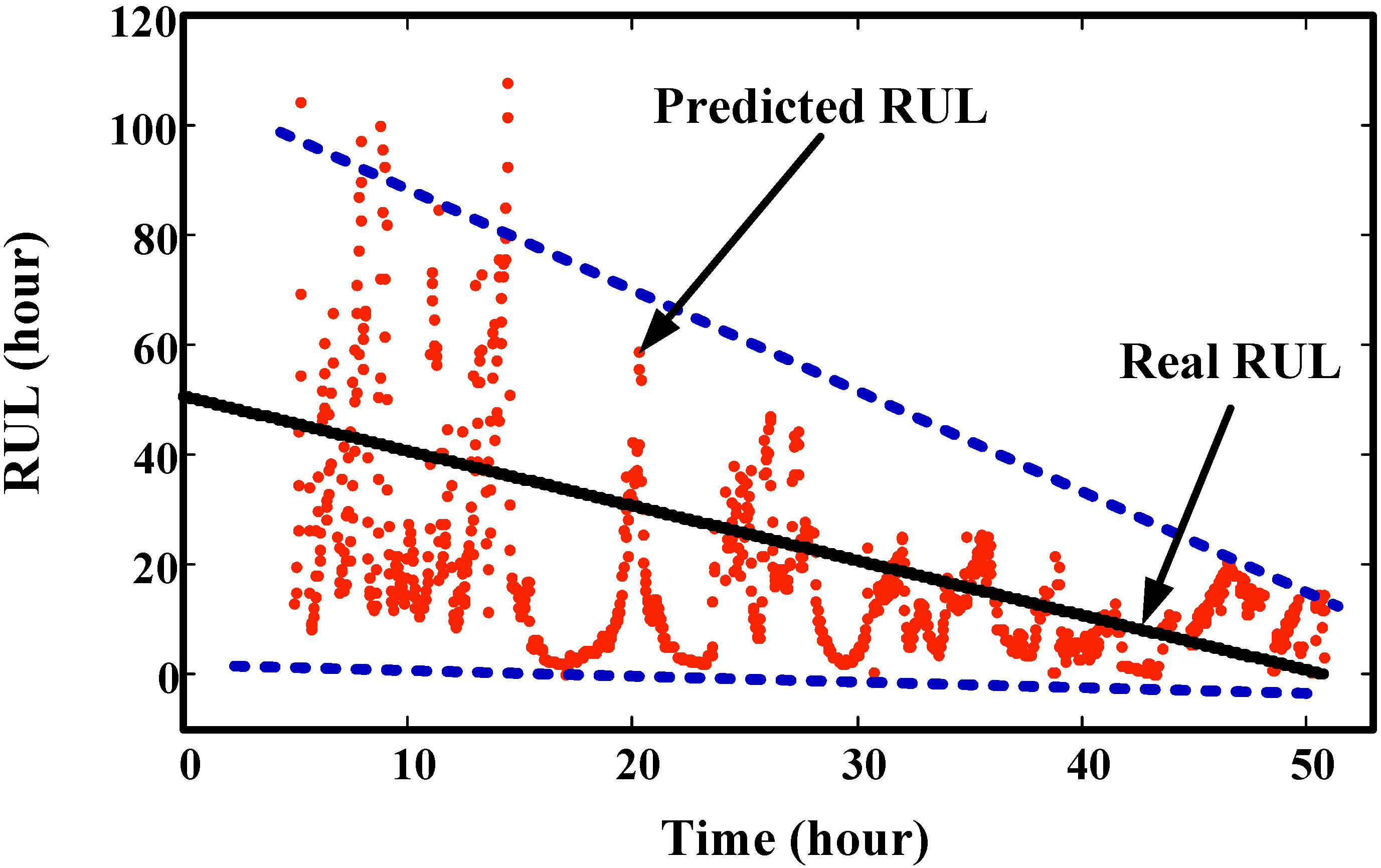
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tian, Z.G.; Jin, T.; Wu, B.R.; Ding, F.F. Condition based maintenance optimization for wind power generation systems under continuous monitoring. Renew. Energy 2011, 36, 1502–1509. [Google Scholar] [CrossRef]
- Tian, Z.G.; Wong, L.; Safaei, N. A neural network approach for remaining useful life prediction utilizing both failure and suspension histories. Mech. Syst. Signal Pr. 2010, 24, 1542–1555. [Google Scholar] [CrossRef]
- Tian, Z.G. An artificial neural network method for remaining useful life prediction of equipment subject to condition monitoring. J. Intell. Manuf. 2012, 23, 227–237. [Google Scholar] [CrossRef]
- Lu, C.; Tao, L.; Fan, H. An intelligent approach to machine component health prognostics by utilizing only truncated histories. Mech. Syst. Signal Pr. 2014, 42, 300–313. [Google Scholar] [CrossRef]
- Zhou, Y.F.; Sun, Y.; Mathew, J.; Wolff, R.; Ma, L. Latent degradation indicators estimation and prediction: A Monte Carlo approach. Mech. Syst. Signal Pr. 2011, 25, 222–236. [Google Scholar] [CrossRef]
- Zhang, X.H.; Kang, J.S.; Jin, T. Degradation modeling and maintenance decision based on Bayesian Belief Network. IEEE Trans. Reliab. 2014, 63, 620–633. [Google Scholar] [CrossRef]
- Dong, M.; He, D. A segmental hidden semi-Markov model (HSMM)-based diagnostics and prognostics framework and methodology. Mech. Syst. Signal Pr. 2007, 21, 2248–2266. [Google Scholar] [CrossRef]
- Dong, M.; He, D. Hidden semi-Markov model-based methodology for multi-sensor equipment health diagnosis and prognosis. Eur. J. Oper. Res. 2007, 178, 858–878. [Google Scholar] [CrossRef]
- Dong, M.; Yang, D.; Kuang, Y. PM2.5 concentration prediction using hidden semi-Markov model-based times series data. Expert Syst. Appl. 2009, 36, 9046–9055. [Google Scholar] [CrossRef]
- Liu, Q.M.; Dong, M.; Peng, Y. A novel method for online health prognosis of equipment based on hidden semi-Markov model using sequential Monte Carlo methods. Mech. Syst. Signal Pr. 2012, 32, 331–348. [Google Scholar] [CrossRef]
- Moghaddass, R.; Zuo, M.J. An integrated framework for online diagnostic and prognostic health monitoring using a multistate deterioration process. Reliab. Eng. Syst. Safe. 2014, 124, 92–104. [Google Scholar] [CrossRef]
- Si, X.S.; Wang, W.; Hu, C.H.; Chen, M.Y.; Zhou, D.H. A Wiener-process-based degradation model with a recursive filter algorithm for remaining useful life estimation. Mech. Syst. Signal Pr. 2013, 35, 219–237. [Google Scholar] [CrossRef]
- Wang, Z.Q.; Hu, C.H.; Wang, W.; Si, X.S. An additive Wiener process-based prognostic model for hybrid deteriorating systems. IEEE Trans. Reliab. 2014, 63, 208–222. [Google Scholar] [CrossRef]
- Wang, X.L.; Balakrishnan, N.; Guo, B. Residual life estimation based on a generalized Wiener degradation process. Reliab. Eng. Syst. Safe. 2014, 124, 13–23. [Google Scholar] [CrossRef]
- Son, K.L.; Fouladirad, M.; Barros, A.; Levrat, E.; Iung, B. Remaining useful life estimation based on stochastic deterioration models: A comparative study. Reliab. Eng. Syst. Safe. 2013, 112, 165–175. [Google Scholar] [CrossRef]
- Si, X.S. An adaptive prognostic approach via nonlinear degradation modelling: Application to battery data. IEEE Trans. Ind. Electron. 2015. [Google Scholar] [CrossRef]
- Ye, Z.S.; Xie, M.; Tang, L.C.; Chen, N. Semiparametric estimation of Gamma processes for deteriorating products. Technometrics 2014, 56, 504–513. [Google Scholar] [CrossRef]
- Ye, Z.S.; Chen, N. The inverse Gaussian process as a degradation model. Technometrics 2014, 56, 302–311. [Google Scholar] [CrossRef]
- Peng, W.W.; Li, Y.F.; Yang, Y.J.; Huang, H.Z.; Zuo, M.J. Inverse Gaussian process models for degradation analysis: A Bayesian perspective. Reliab. Eng. Syst. Safe. 2014, 130, 175–189. [Google Scholar] [CrossRef]
- Ye, Z.S.; Xie, M. Stochastic modelling and analysis of degradation for highly reliable products. Appl. Stoch. Model Bus. Ind. 2014. [Google Scholar] [CrossRef]
- Tran, V.T.; Yang, B.; Oh, M.; Tan, A.C.C. Machine condition prognosis based on regression trees and one-step-ahead prediction. Mech. Syst. Signal Pr. 2008, 22, 1179–1193. [Google Scholar] [CrossRef]
- Tian, Z.G.; Zuo, M.J. Health condition prediction of gears using a recurrent neural network approach. IEEE Trans. Reliab. 2010, 59, 700–705. [Google Scholar] [CrossRef]
- Tran, V.T.; Yang, B.; Tan, A.C.C. Multi-step ahead direct prediction for the machine condition prognosis using regression trees and neuro-fuzzy systems. Expert. Syst. Appl. 2009, 36, 9378–9387. [Google Scholar] [CrossRef]
- Chen, C.; Vachtsevanos, G.; Orchard, M.E. Machine remaining useful life prediction: An integrated adaptive neuro-fuzzy and high-order particle filtering approach. Mech. Syst. Signal Pr. 2012, 28, 597–607. [Google Scholar] [CrossRef]
- He, D.; Bechhoefer, E.; Ma, J.; Li, R. Particle filtering based gear prognostics using one-dimensional health index. In Proceedings of the 2011 Annual Conference of the Prognostics and Health Management Society, Montreal, QC, Canada, 25–29 September 2011.
- Ma, J.; He, D. An integrated approach for hybrid ceramic bearing life prognostics. In Proceedings of the 2011 Conference of the Society for Machinery Failure Prevention Technology, Virginia Beach, VA, USA, 10–13 May 2011.
- Yoon, J.; He, D. Development of an efficient prognostic estimator. J. Fail. Anal. Prev. 2015, 15, 129–138. [Google Scholar] [CrossRef]
- Maio, F.D.; Tsui, K.L.; Zio, E. Combining relevance vector machines and exponential regression for bearing residual life estimation. Mech. Syst. Signal Pr. 2012, 31, 405–427. [Google Scholar] [CrossRef]
- Wu, B.R.; Tian, Z.G.; Chen, M.Y. Condition-based maintenance optimization using neural network-based health condition prediction. Qual. Reliab. Eng. Int. 2013, 29, 1151–1163. [Google Scholar] [CrossRef]
- Gebraeel, N.G.; Lawley, M.A.; Li, R.; Ryan, J.K. Residual-life distribution from component degradation signals: A Bayesian approach. IIE. Trans. 2005, 37, 543–557. [Google Scholar] [CrossRef]
- Zhang, X.H.; Kang, J.S.; Bechhoefer, E.; Zhao, J.M. A new feature extraction method for gear fault diagnosis and prognosis. Eksploat. Niezawodn. 2014, 16, 295–300. [Google Scholar]
- Bechhoefer, E.; Bernhard, A.; He, D.; Banerjee, P. Use of Semi Hidden Markov Models in the prognostics of shaft failure. In Proceedings of the American Helicopter Society 62nd Annual Forum, Phoenix, AZ, USA, 9–11 May 2006.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Xiao, L.; Kang, J. Degradation Prediction Model Based on a Neural Network with Dynamic Windows. Sensors 2015, 15, 6996-7015. https://doi.org/10.3390/s150306996
Zhang X, Xiao L, Kang J. Degradation Prediction Model Based on a Neural Network with Dynamic Windows. Sensors. 2015; 15(3):6996-7015. https://doi.org/10.3390/s150306996
Chicago/Turabian StyleZhang, Xinghui, Lei Xiao, and Jianshe Kang. 2015. "Degradation Prediction Model Based on a Neural Network with Dynamic Windows" Sensors 15, no. 3: 6996-7015. https://doi.org/10.3390/s150306996
APA StyleZhang, X., Xiao, L., & Kang, J. (2015). Degradation Prediction Model Based on a Neural Network with Dynamic Windows. Sensors, 15(3), 6996-7015. https://doi.org/10.3390/s150306996