
User-Independent Motion State Recognition Using Smartphone Sensors




Abstract
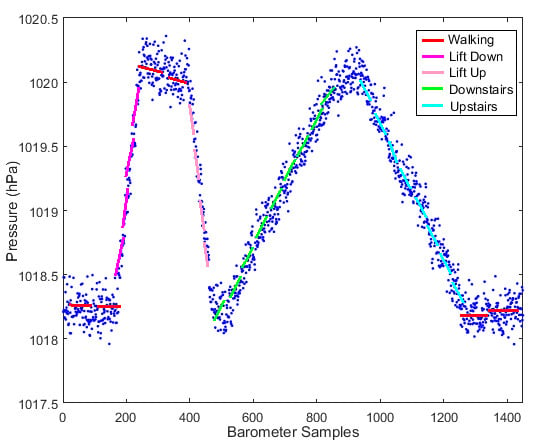
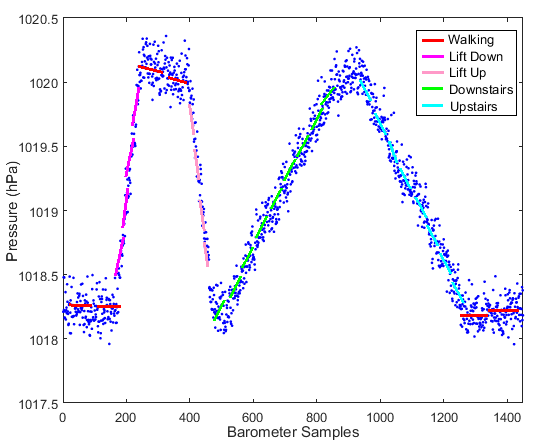
:
1. Introduction
2. Overview of Motion State Recognition
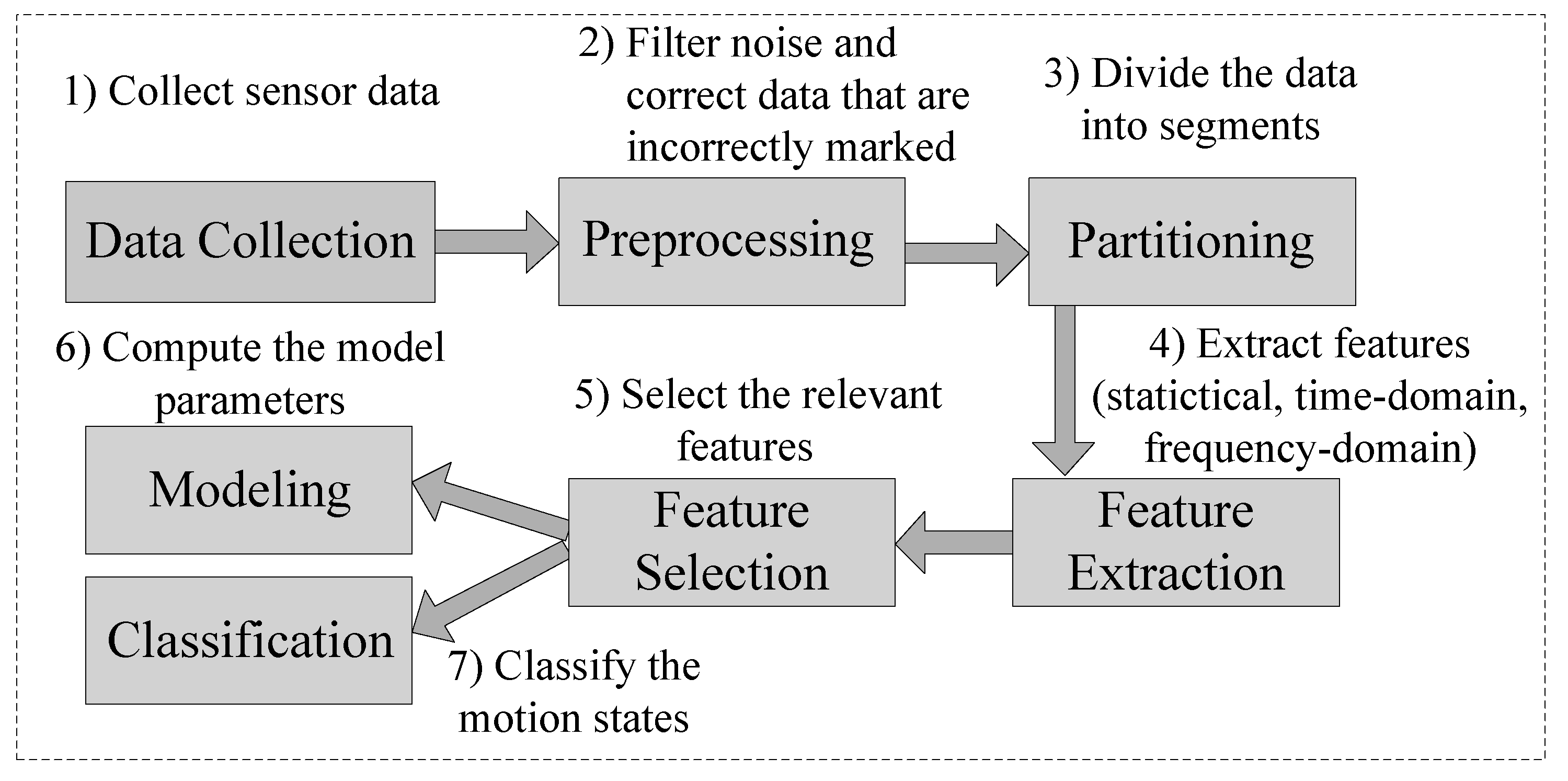

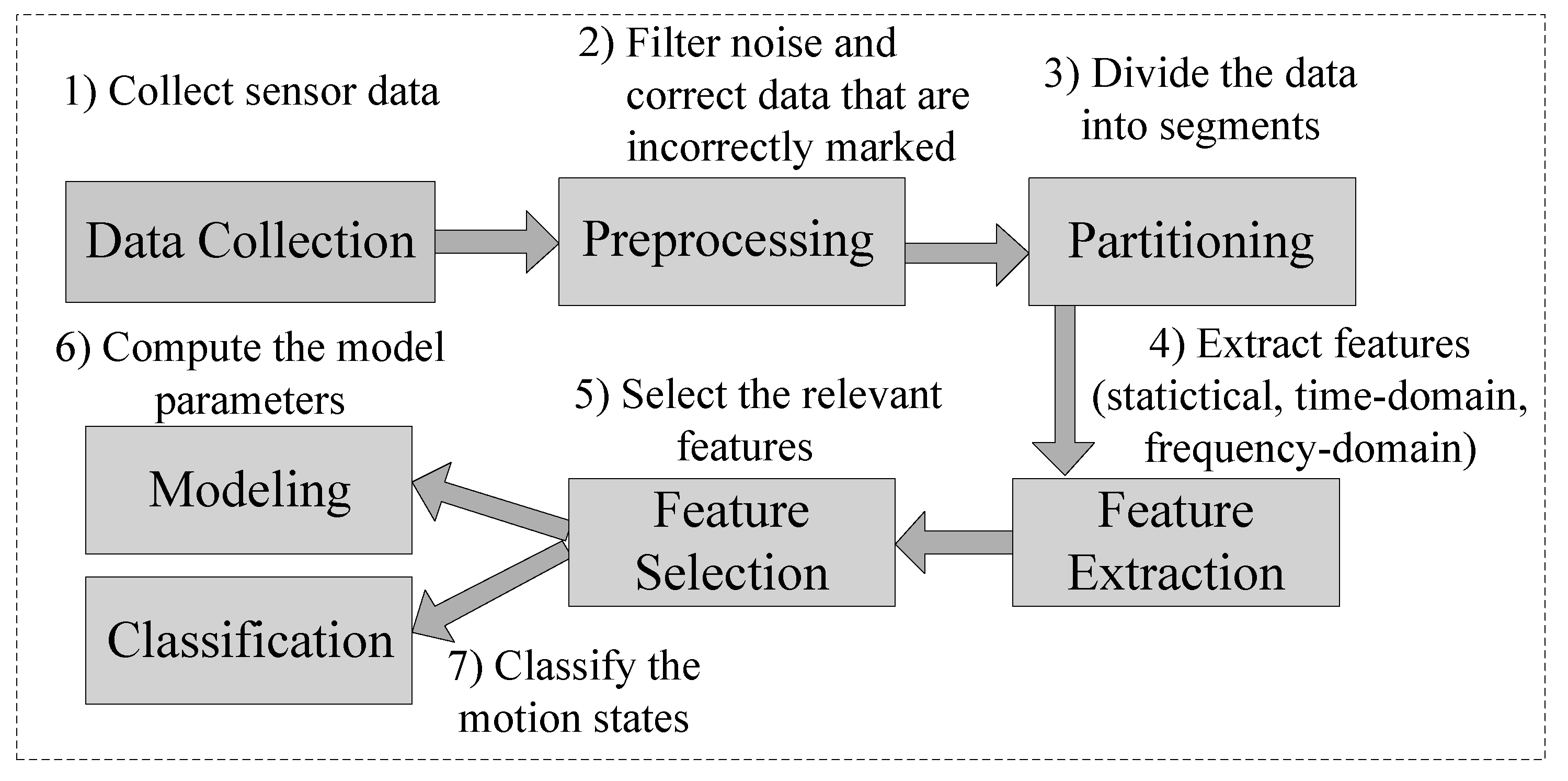
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Motion States | Definition |
|---|---|---|
| M1 | Still | The user carries a phone without any movement. |
| M2 | Walking | The user is walking with a phone. |
| M3 | Running | Horizontal running. |
| M4 | Downstairs | Going down stairs. |
| M5 | Upstairs | Going up stairs. |
| M6 | DownElevator | Taking an elevator downward. |
| M7 | UpElevator | Taking an elevator upward. |
| No. | Poses | Definition |
|---|---|---|
| P1 | The phone is put in the trouser pocket. | |
| P2 | Holding | The user keeps a phone in his or her hand without swinging. |
| P3 | Swinging | The user moves with a phone swinging in his or her hand. |
3. Feature Extraction and Selection
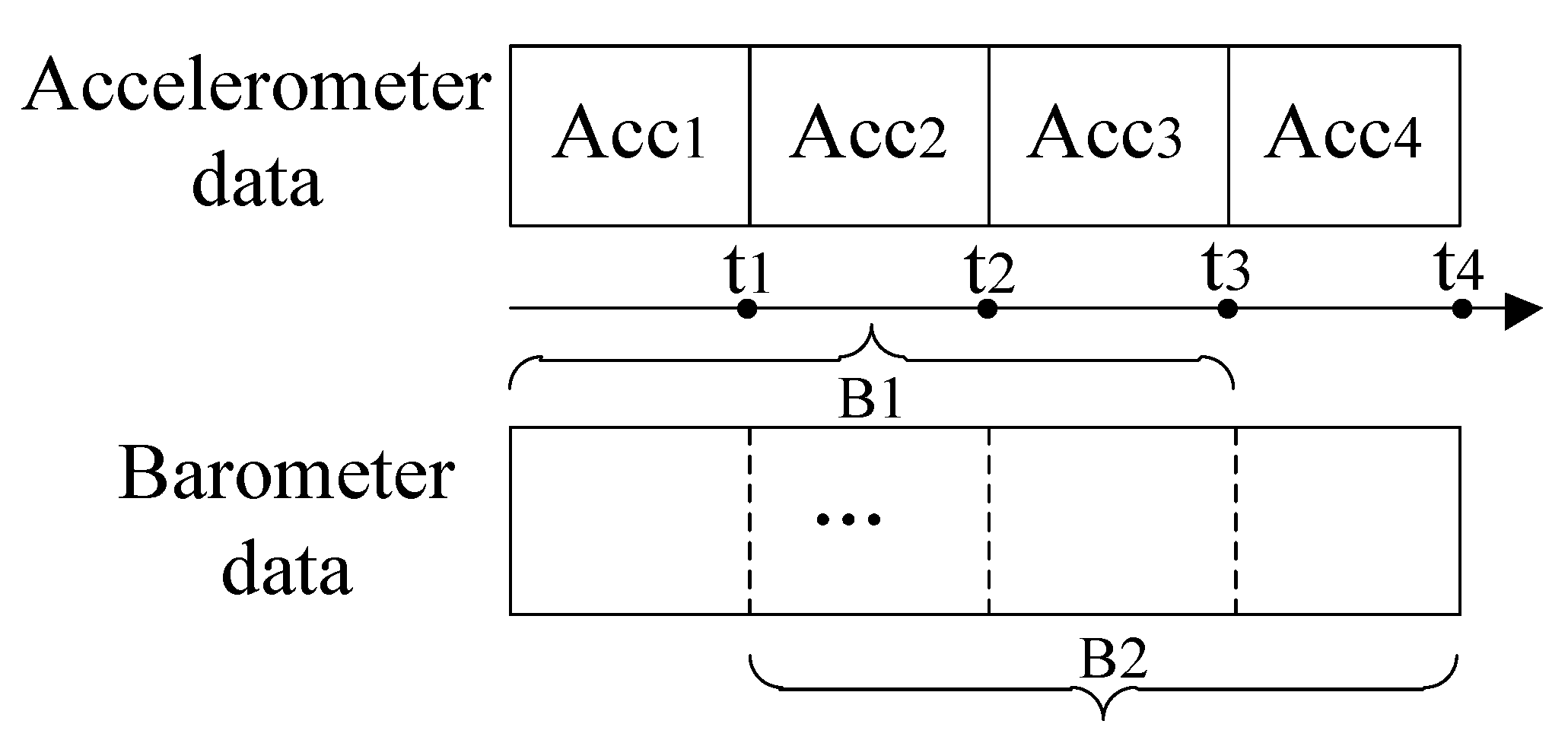
3.1. Partitioning
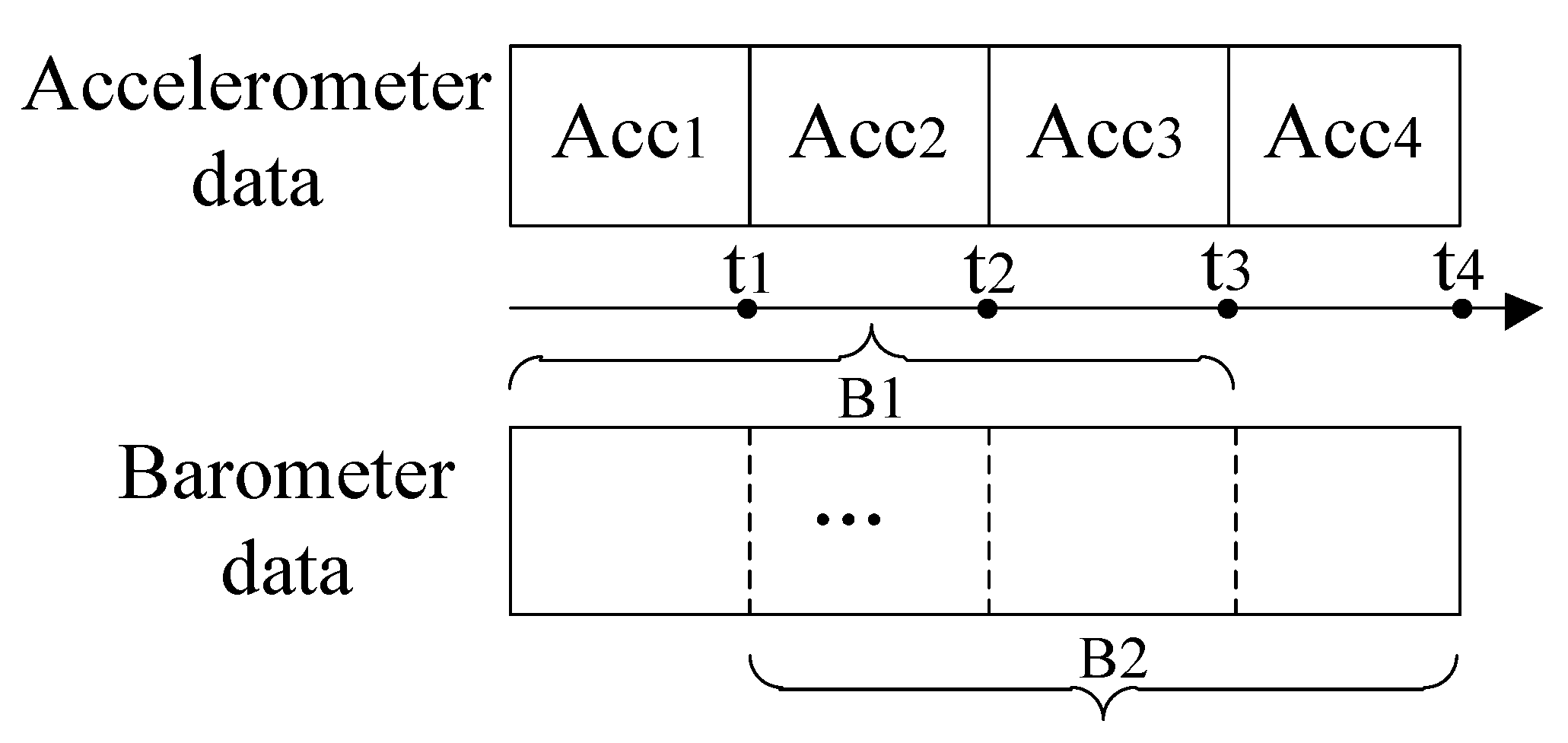
3.2. Feature Extraction

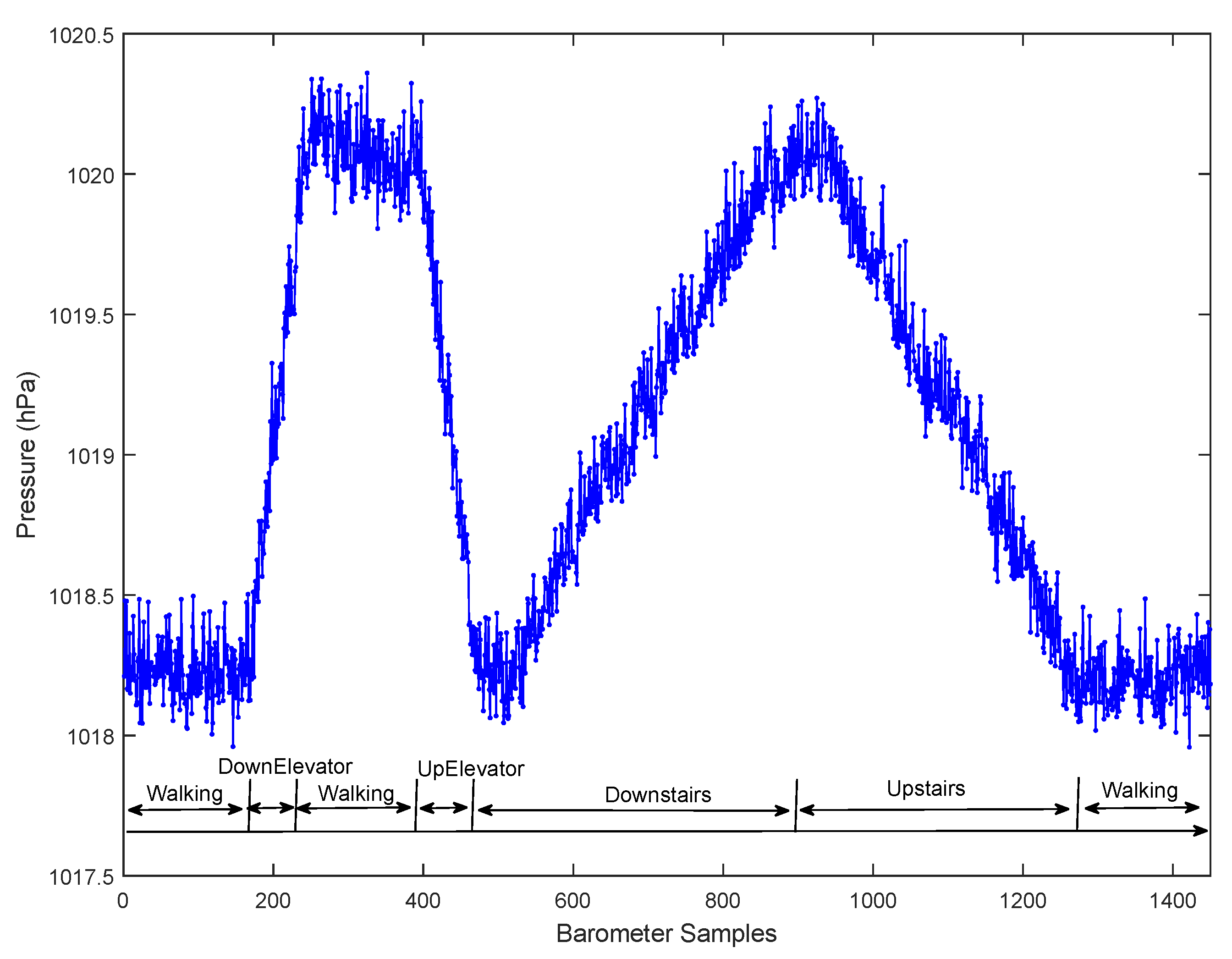

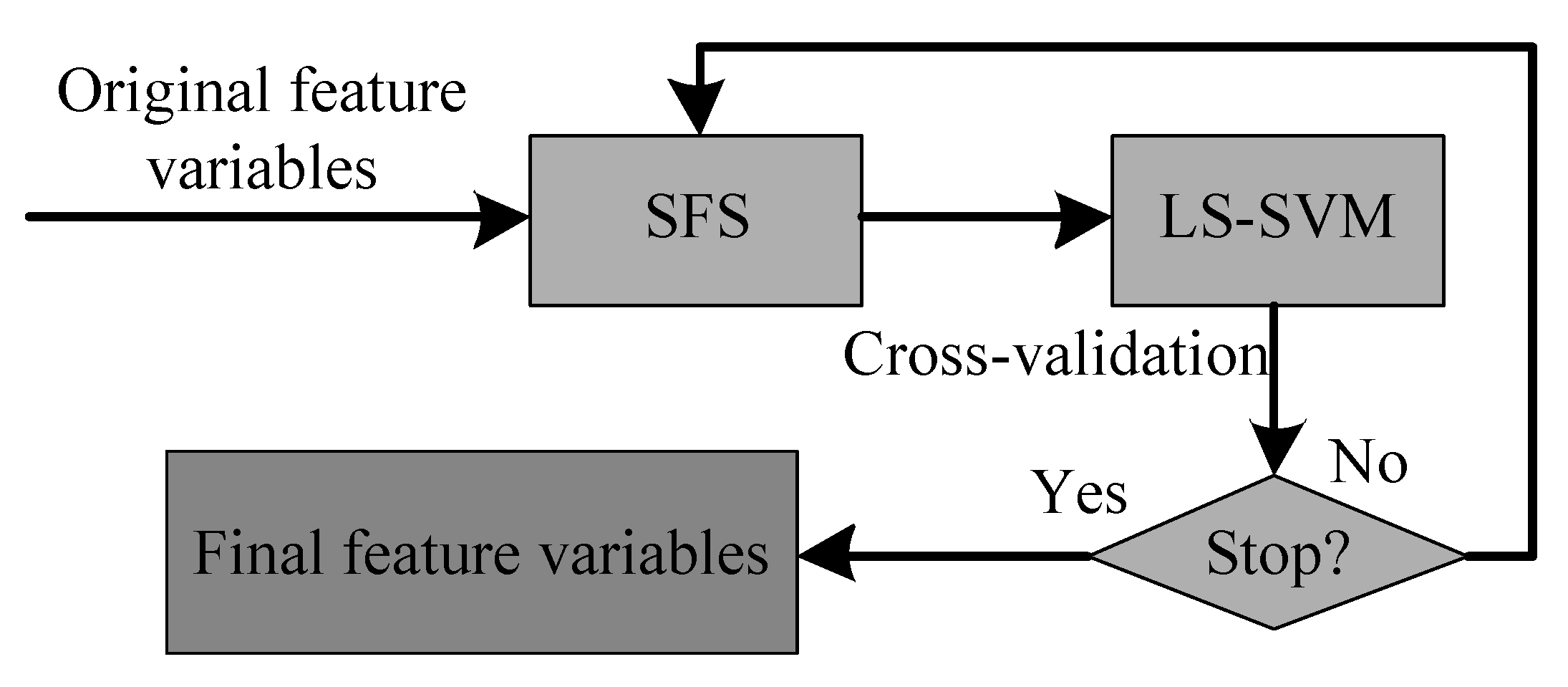
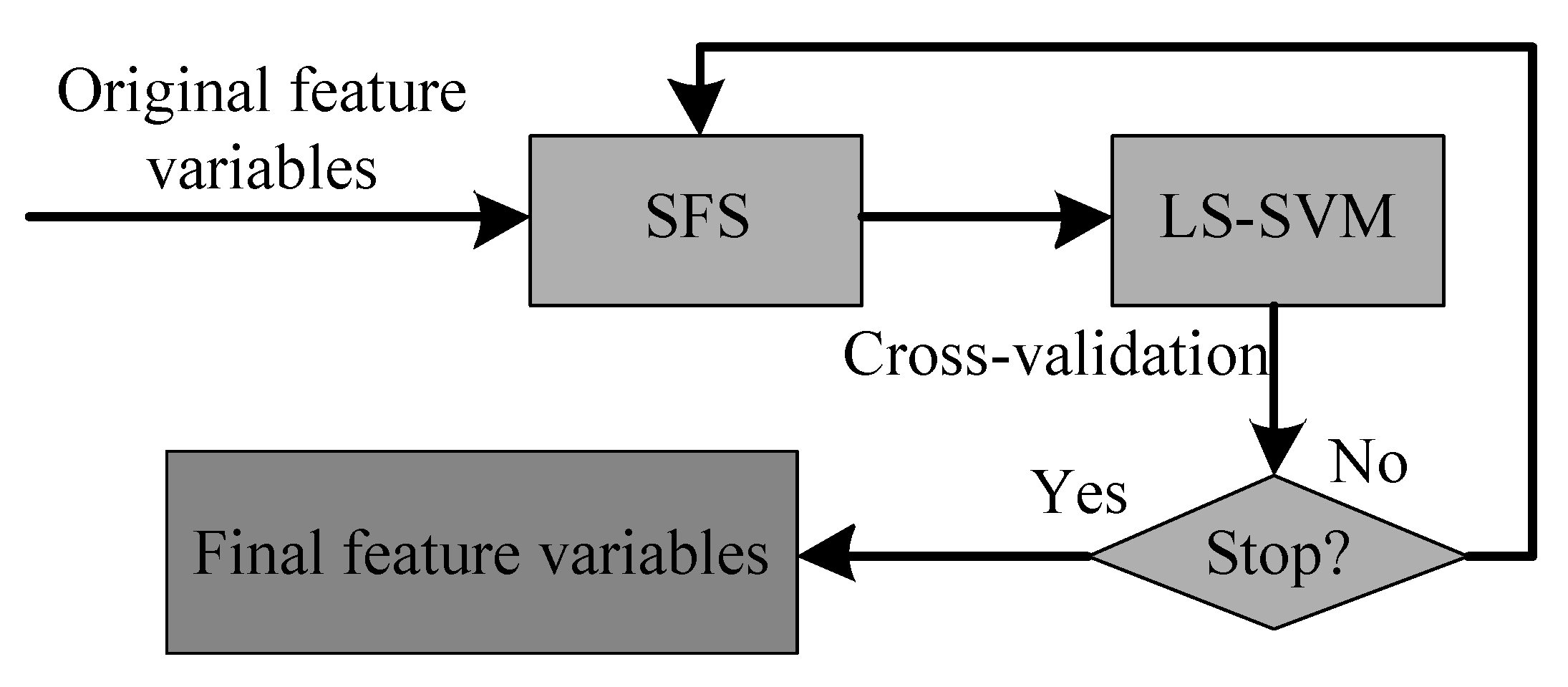
3.3. Feature Selection Method
4. Motion State Classification
4.1. Classifiers
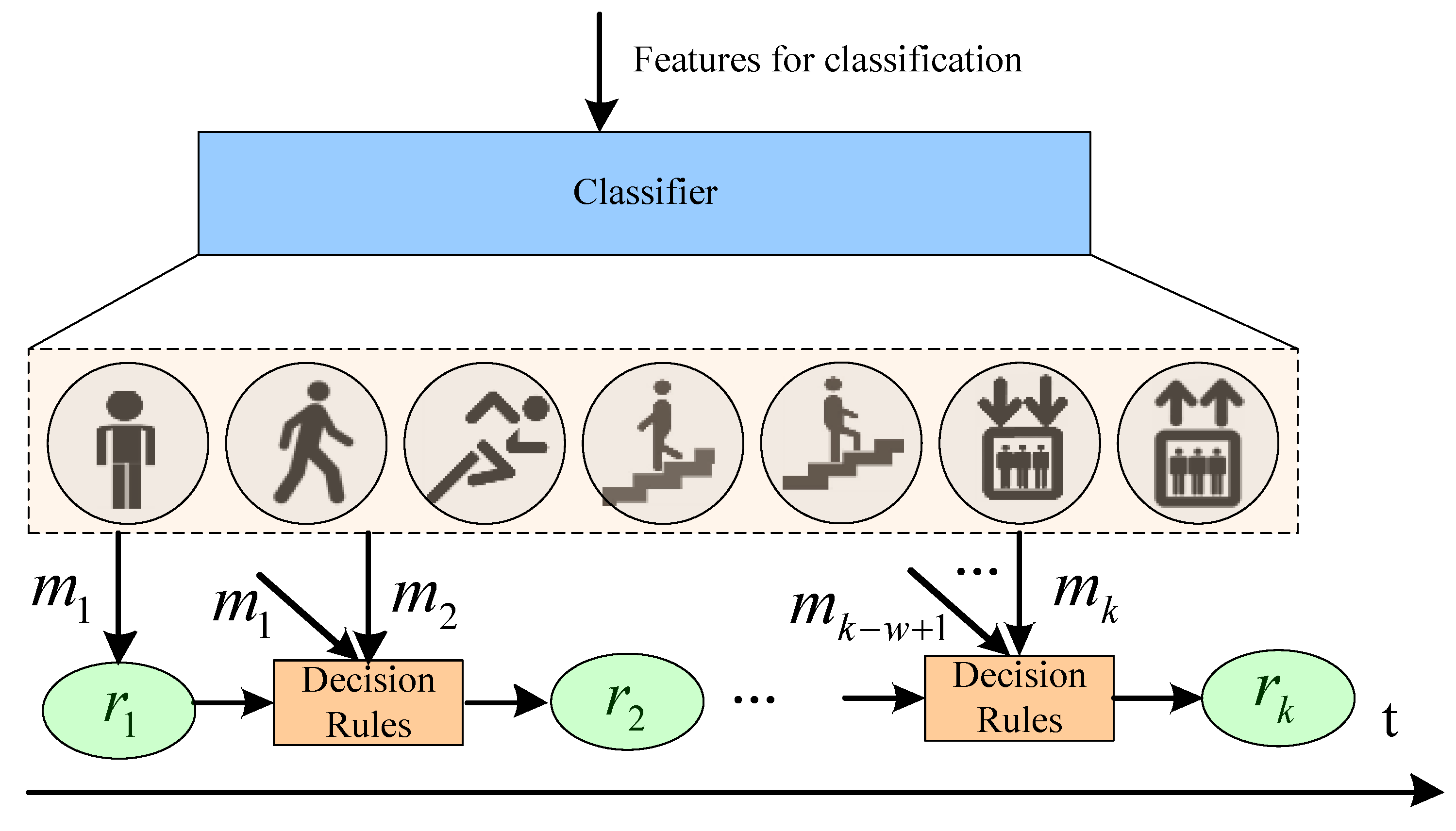
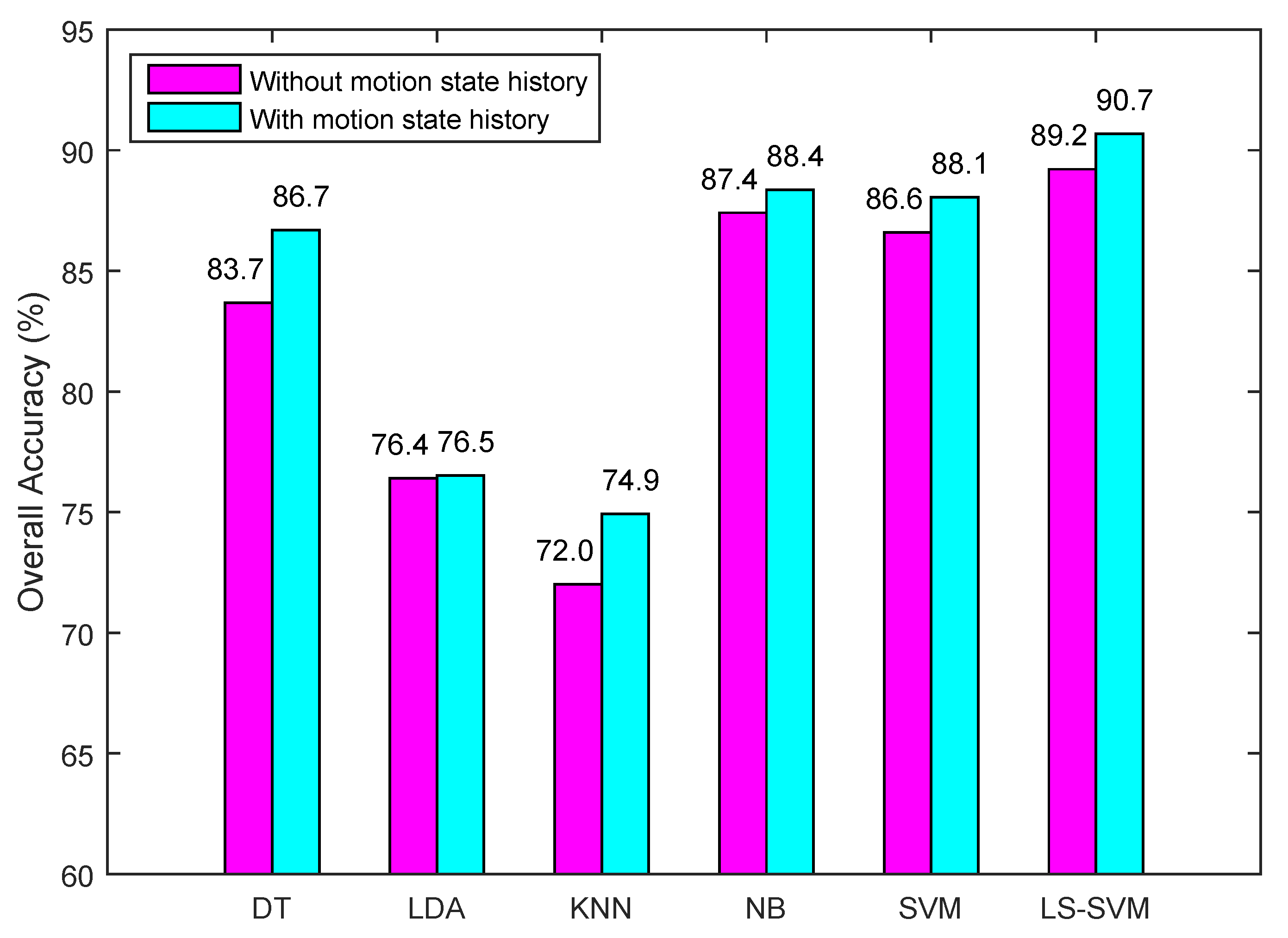
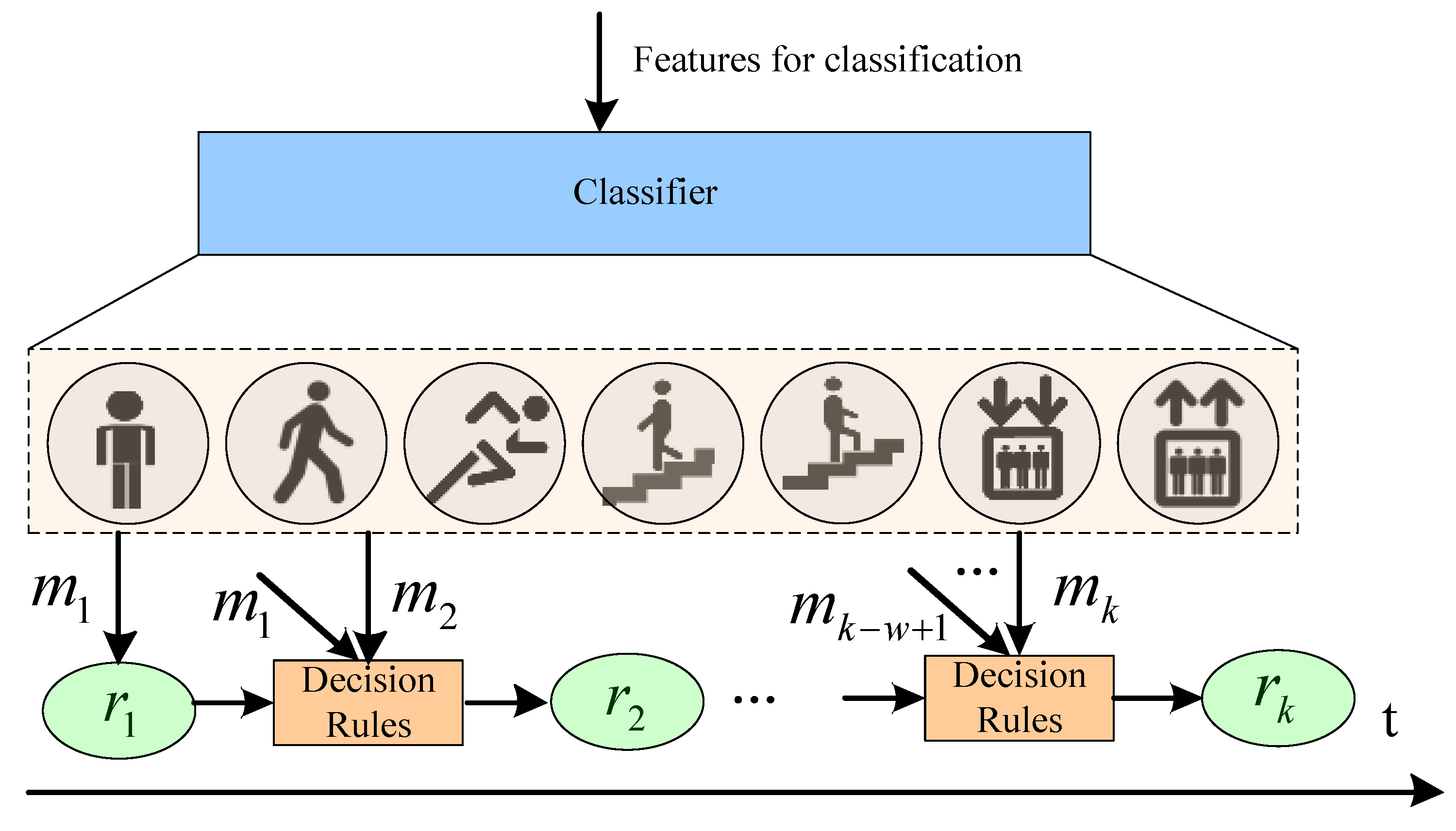
4.2. The Method for Incorporating Motion State History in Classification
5. Evaluation
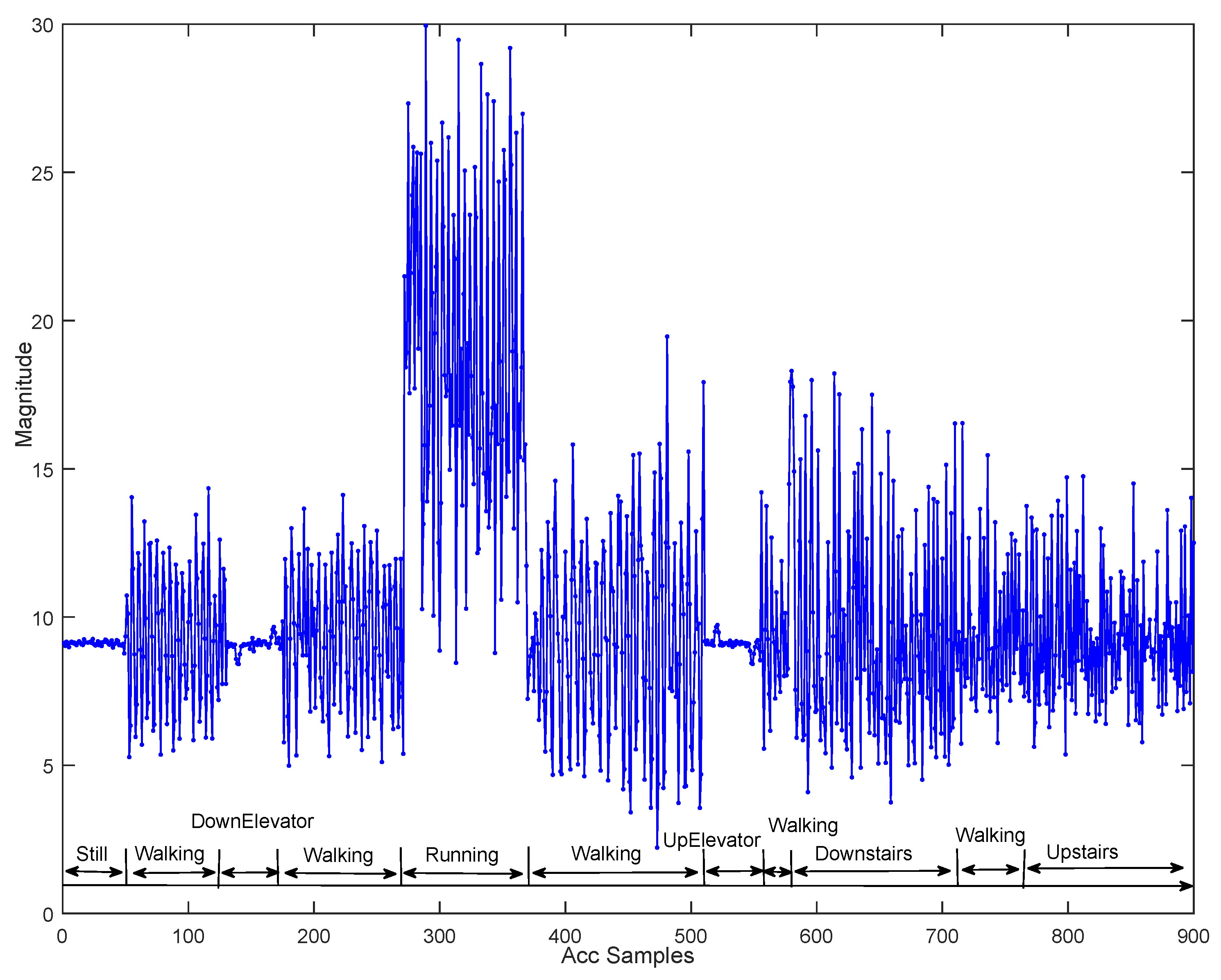
5.1. Data Collection
5.2. Performance Evaluation
| Motion States | Number of Segments |
|---|---|
| Still | 1471 |
| Walking | 5193 |
| Running | 801 |
| Downstairs | 1136 |
| Upstairs | 1079 |
| DownElevator | 275 |
| UpElevator | 284 |
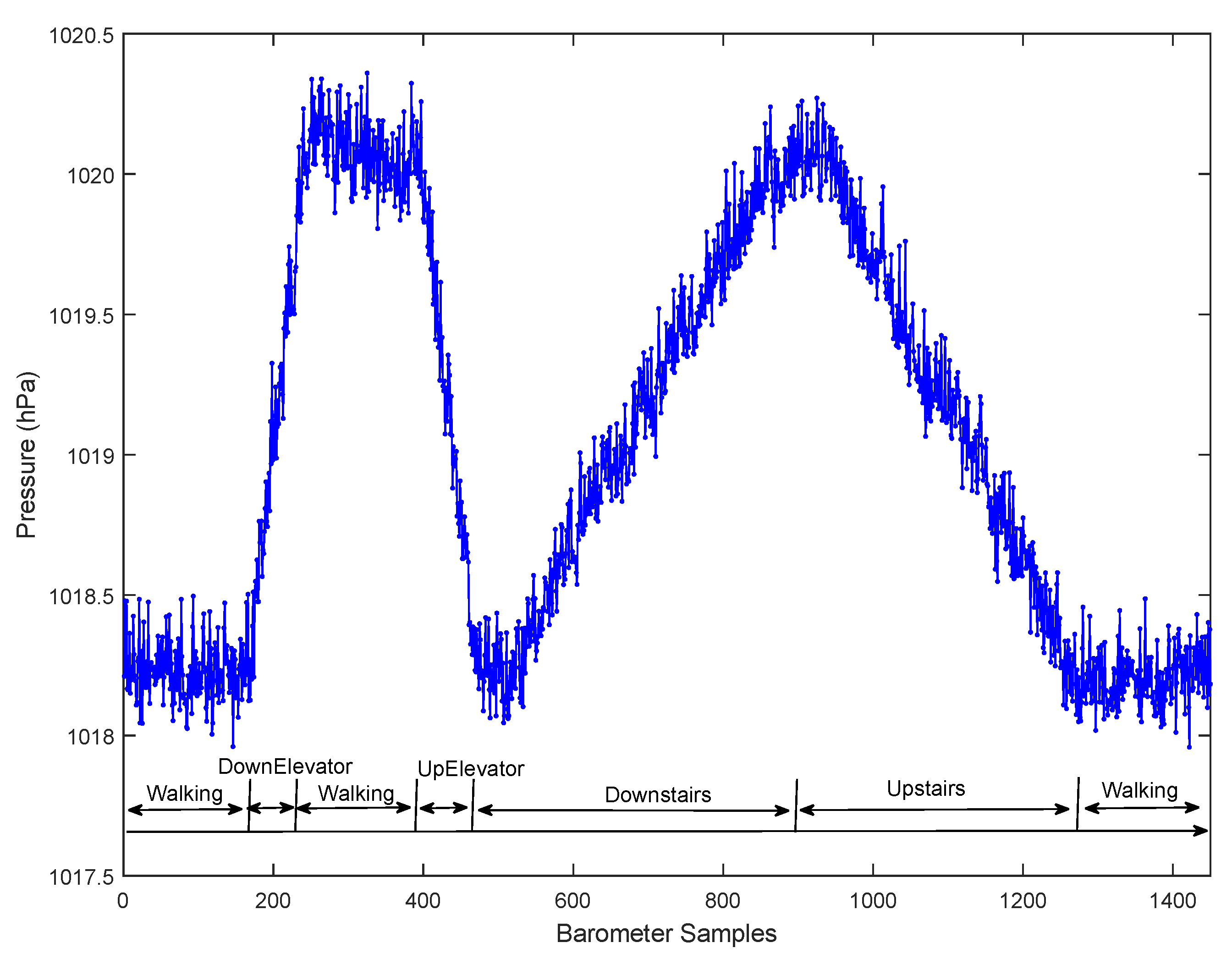
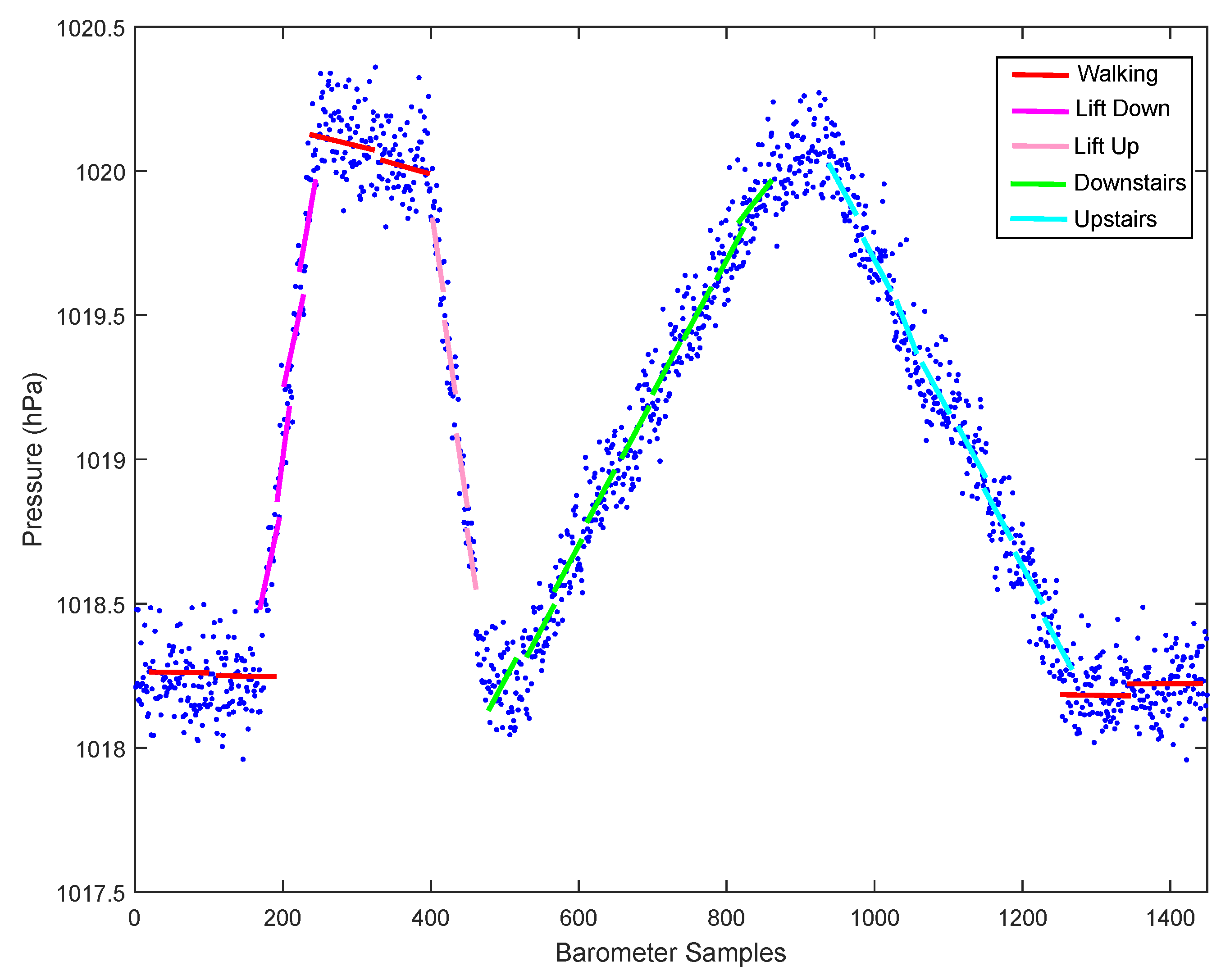
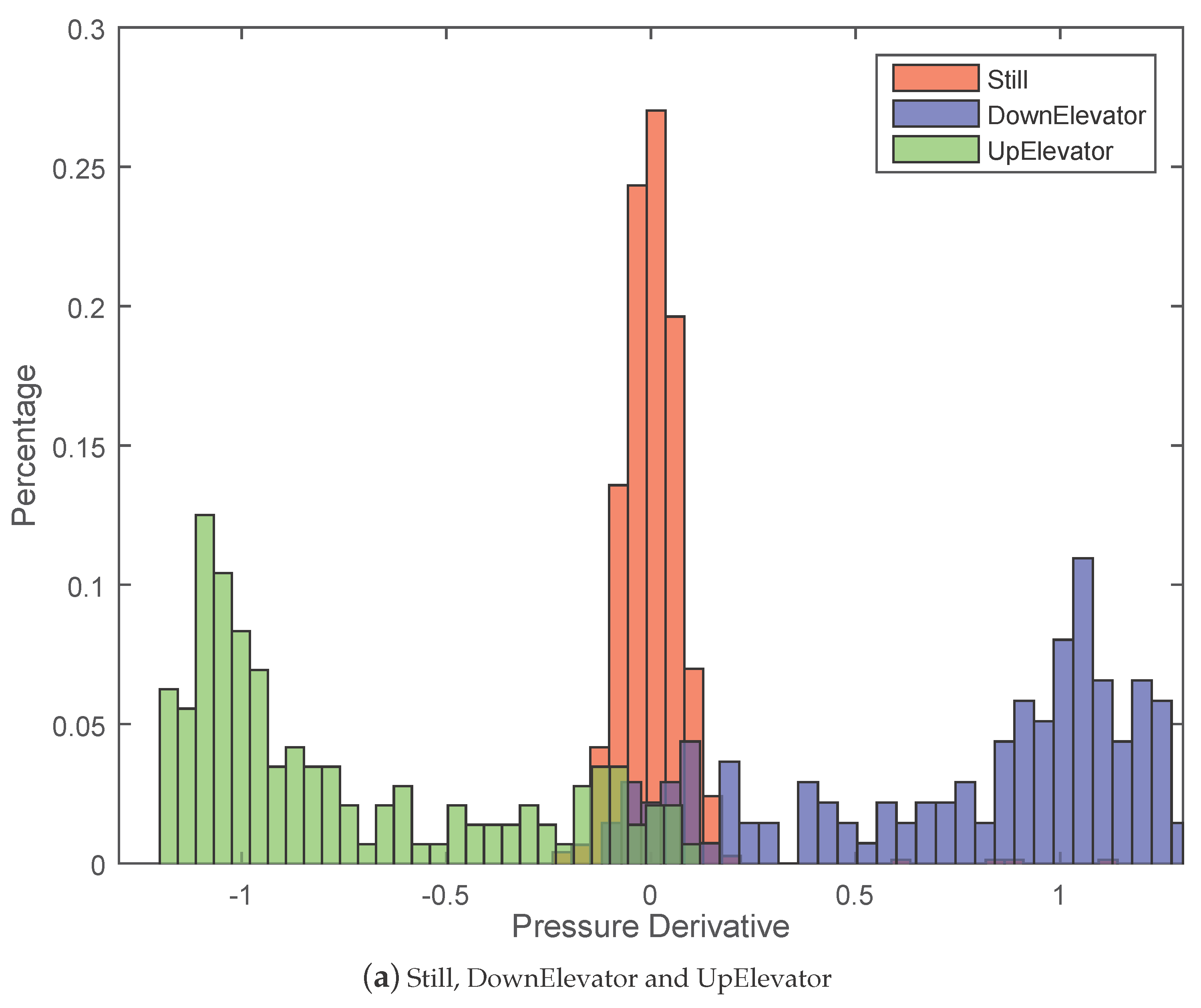
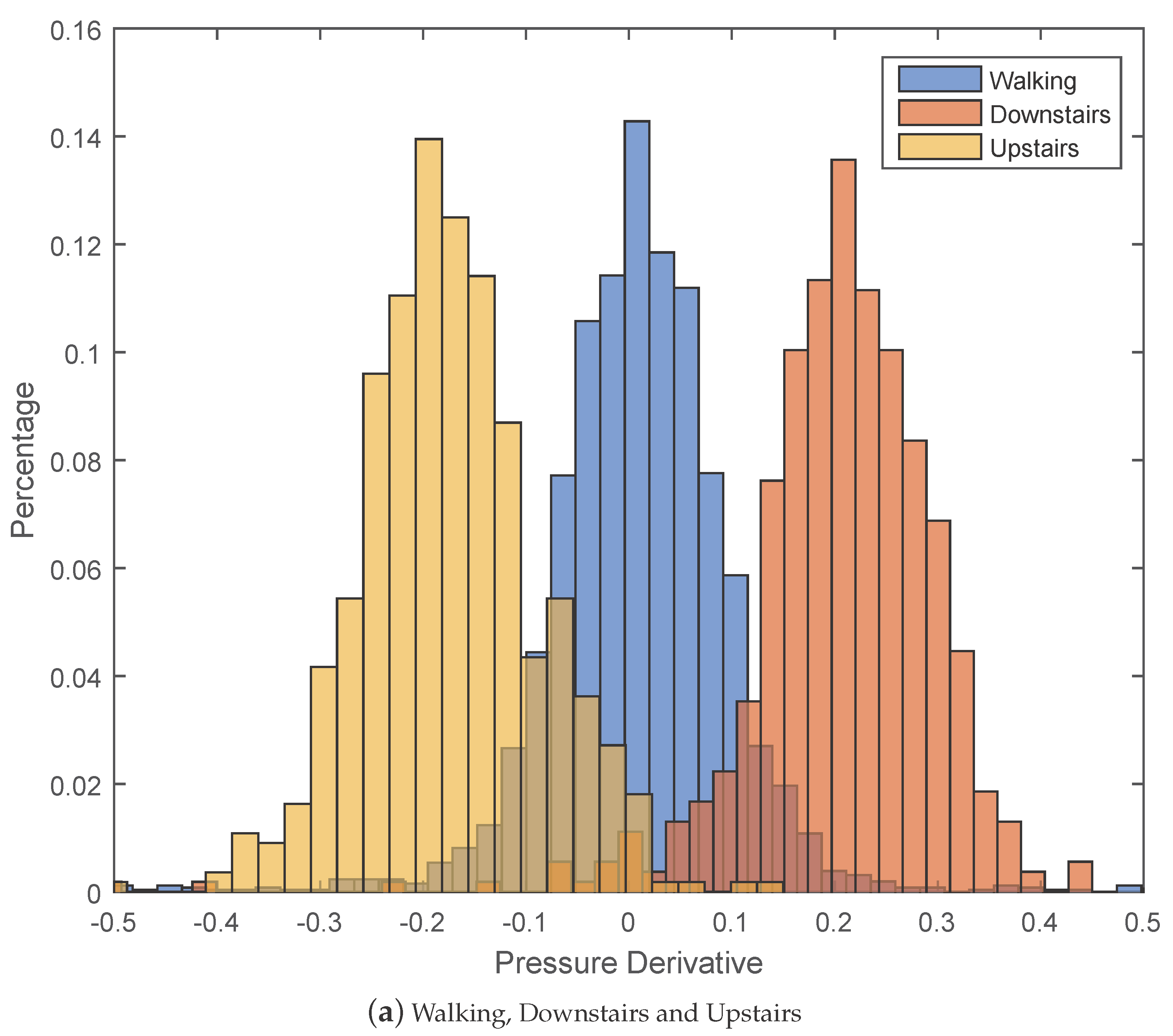
5.2.1. Effectiveness of Pressure Derivative Feature
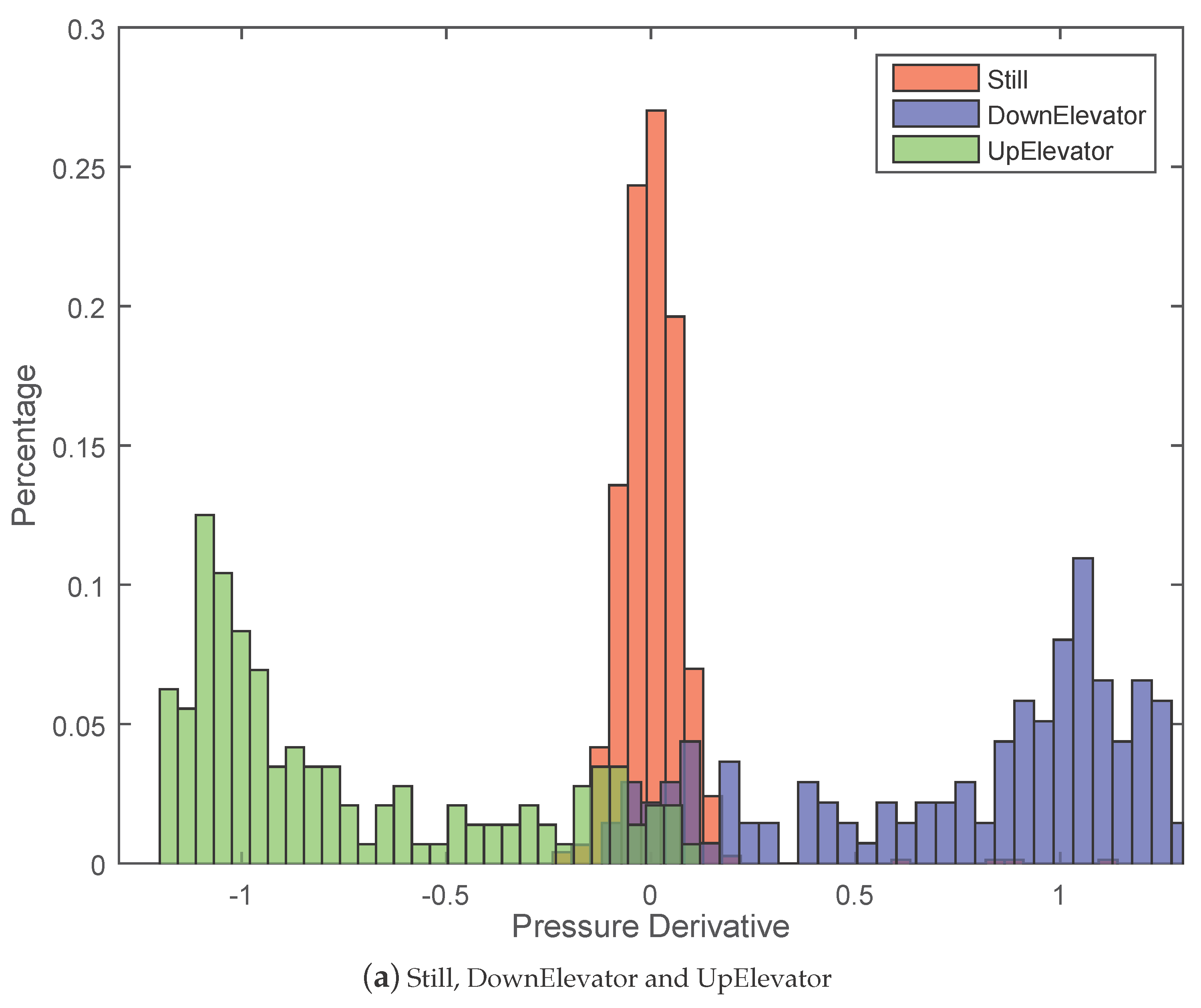
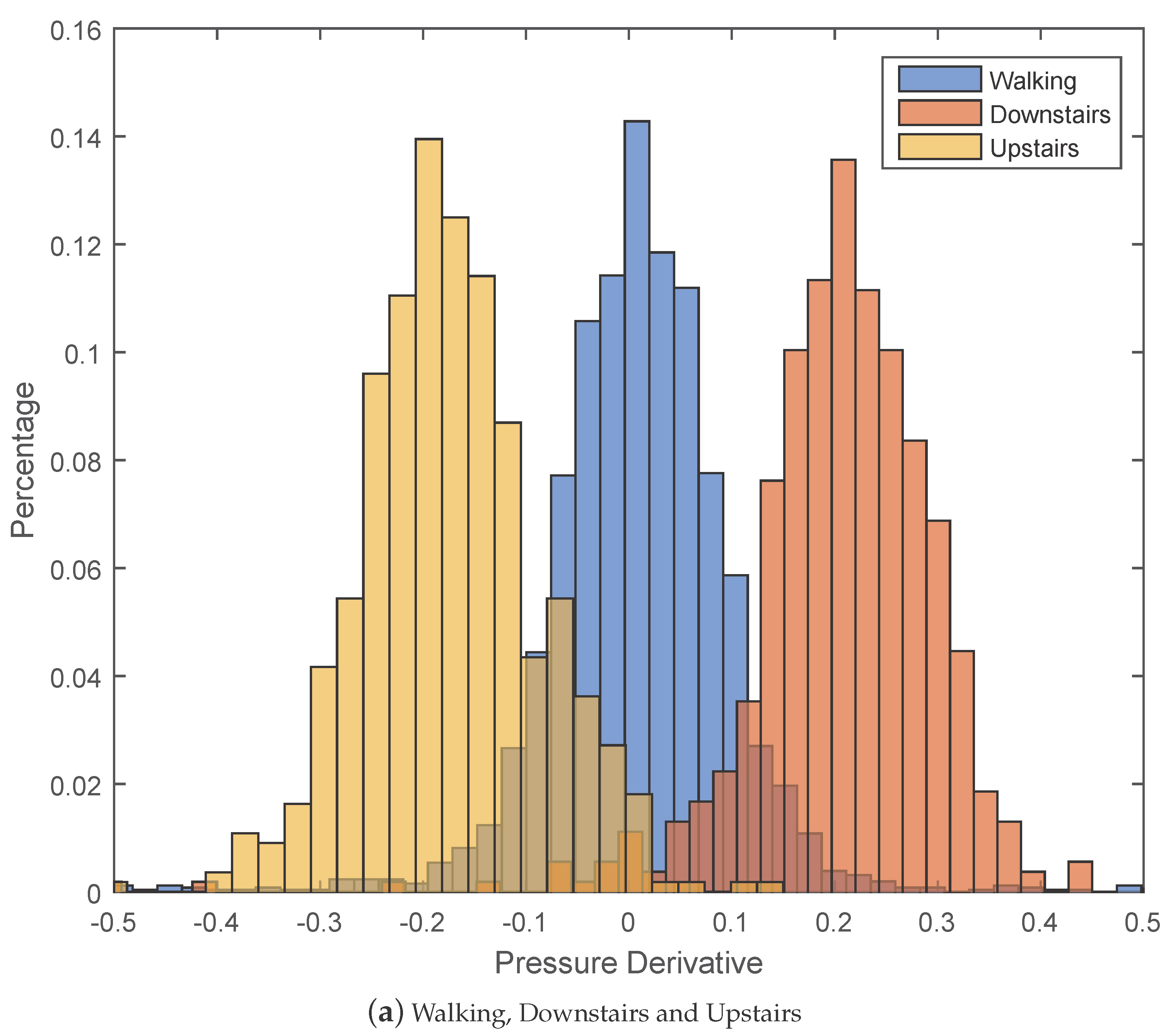
| Step No. | Feature Name |
|---|---|
| 1 | variance of the total acceleration |
| 2 | pressure derivative of barometer data |
| 3 | root mean square of the horizontal acceleration |
| 4 | skewness of the vertical acceleration |
| 5 | range of the vertical acceleration |
| 6 | pressure difference between two windows of barometer readings |
| 7 | maximum value of the vertical acceleration |
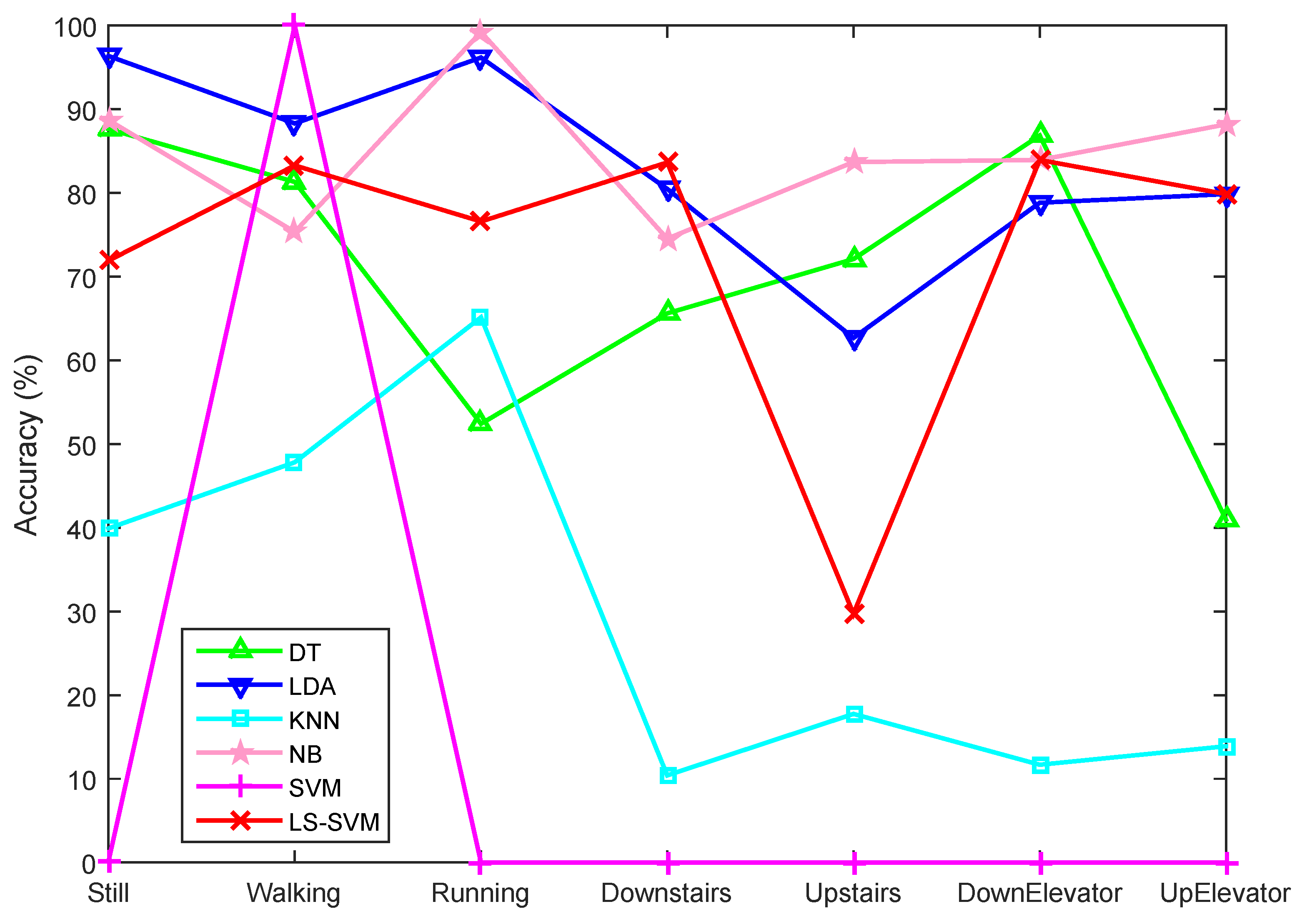
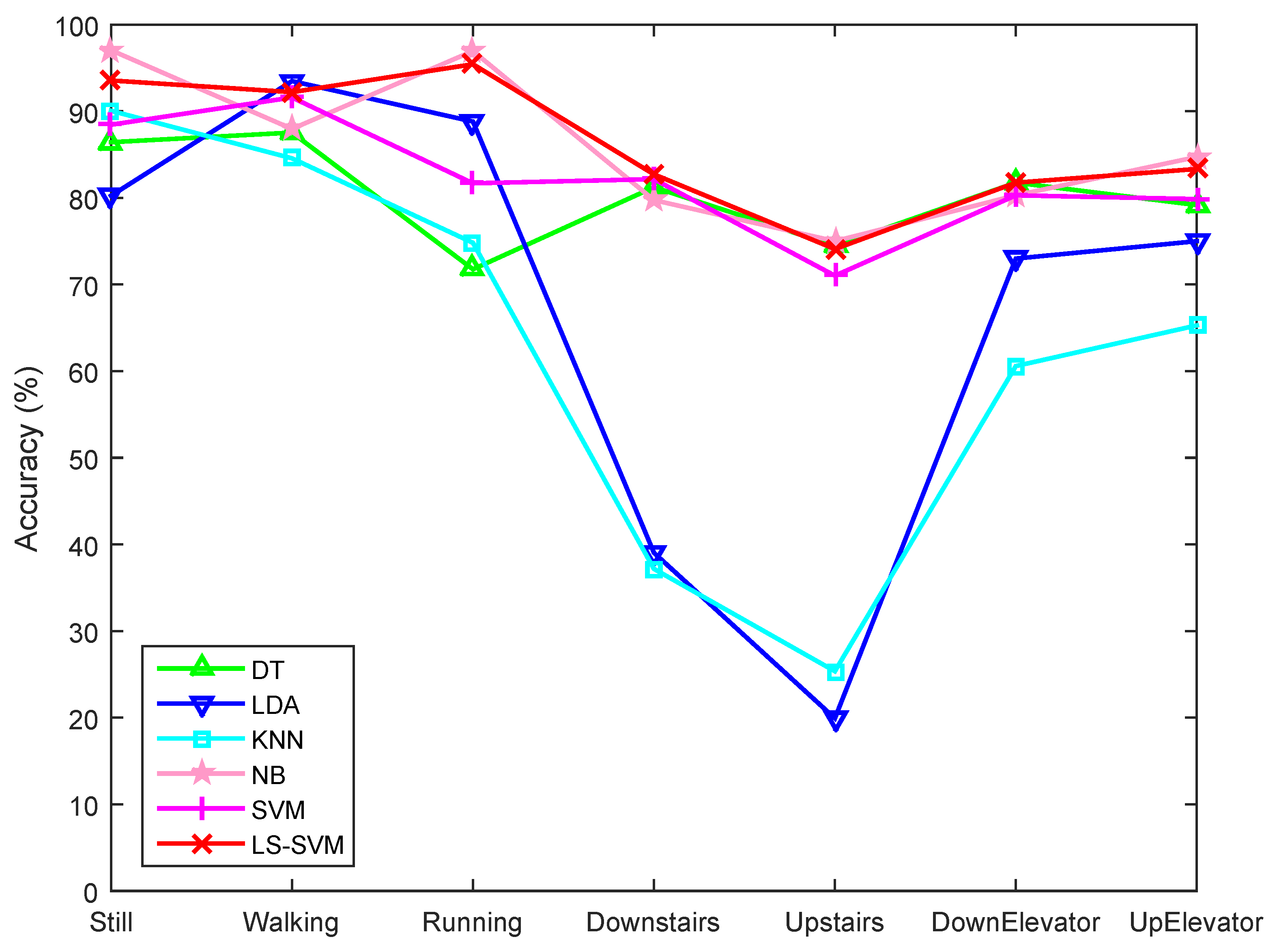
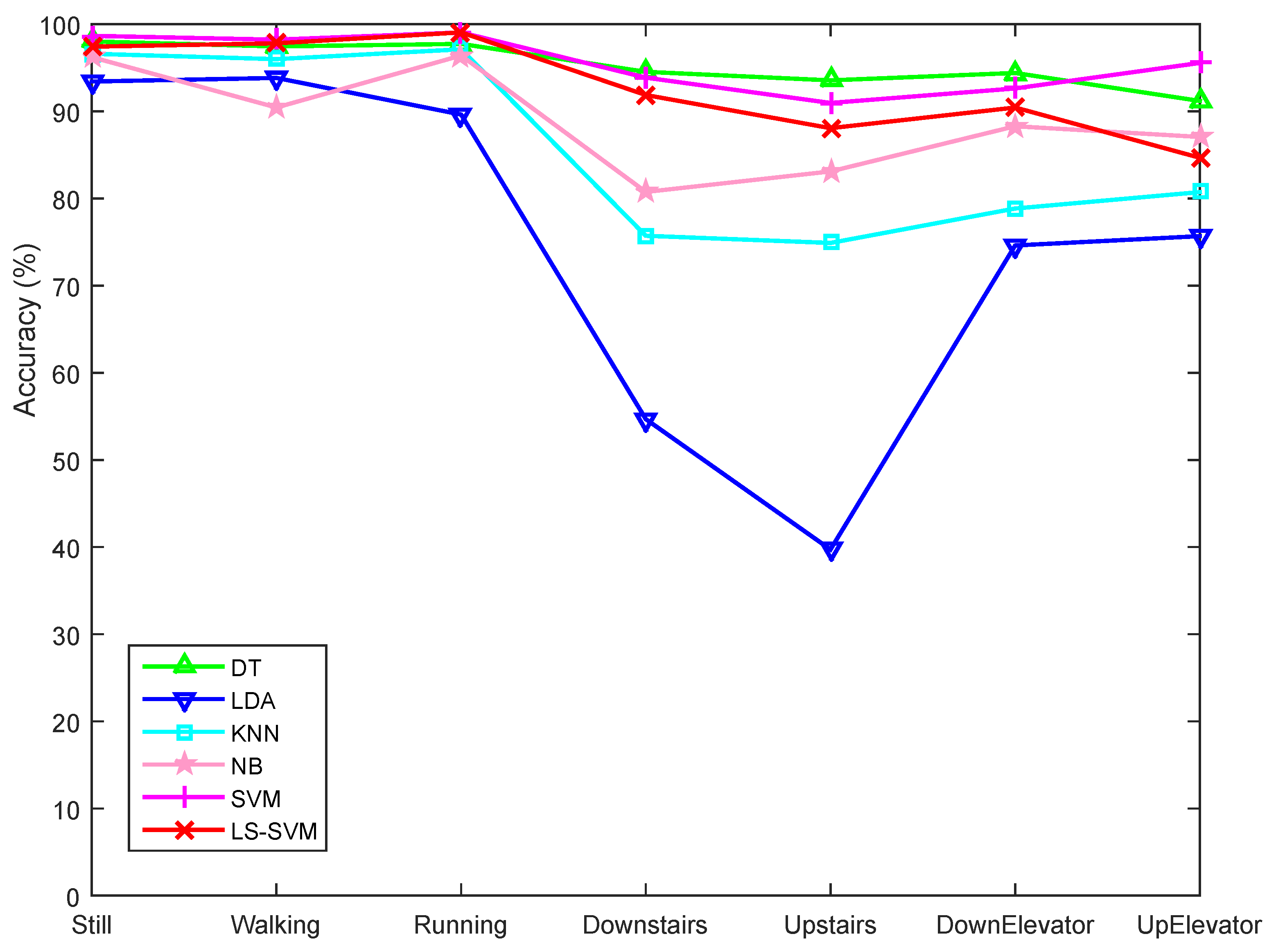
5.2.2. Motion State Recognition Accuracy
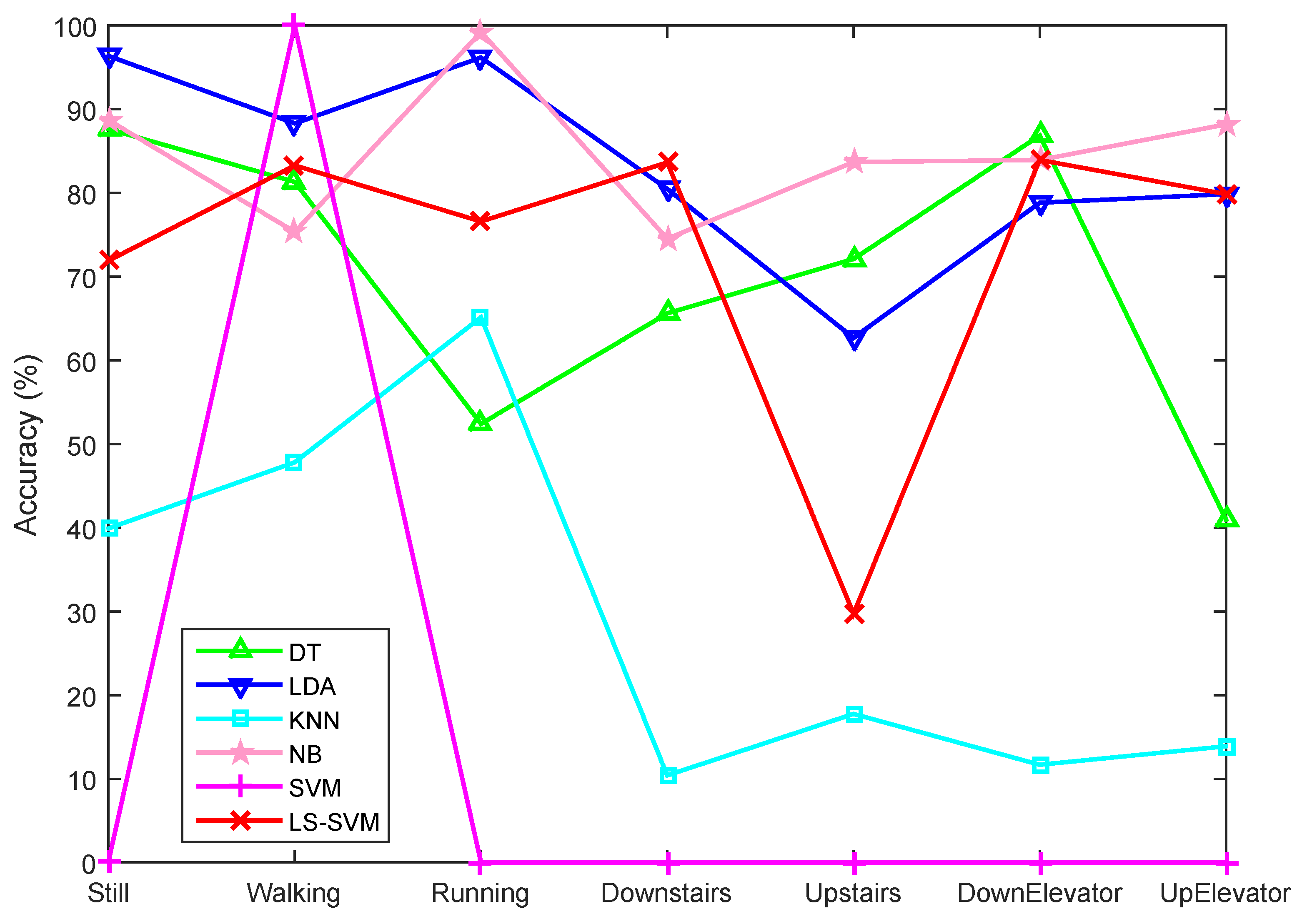
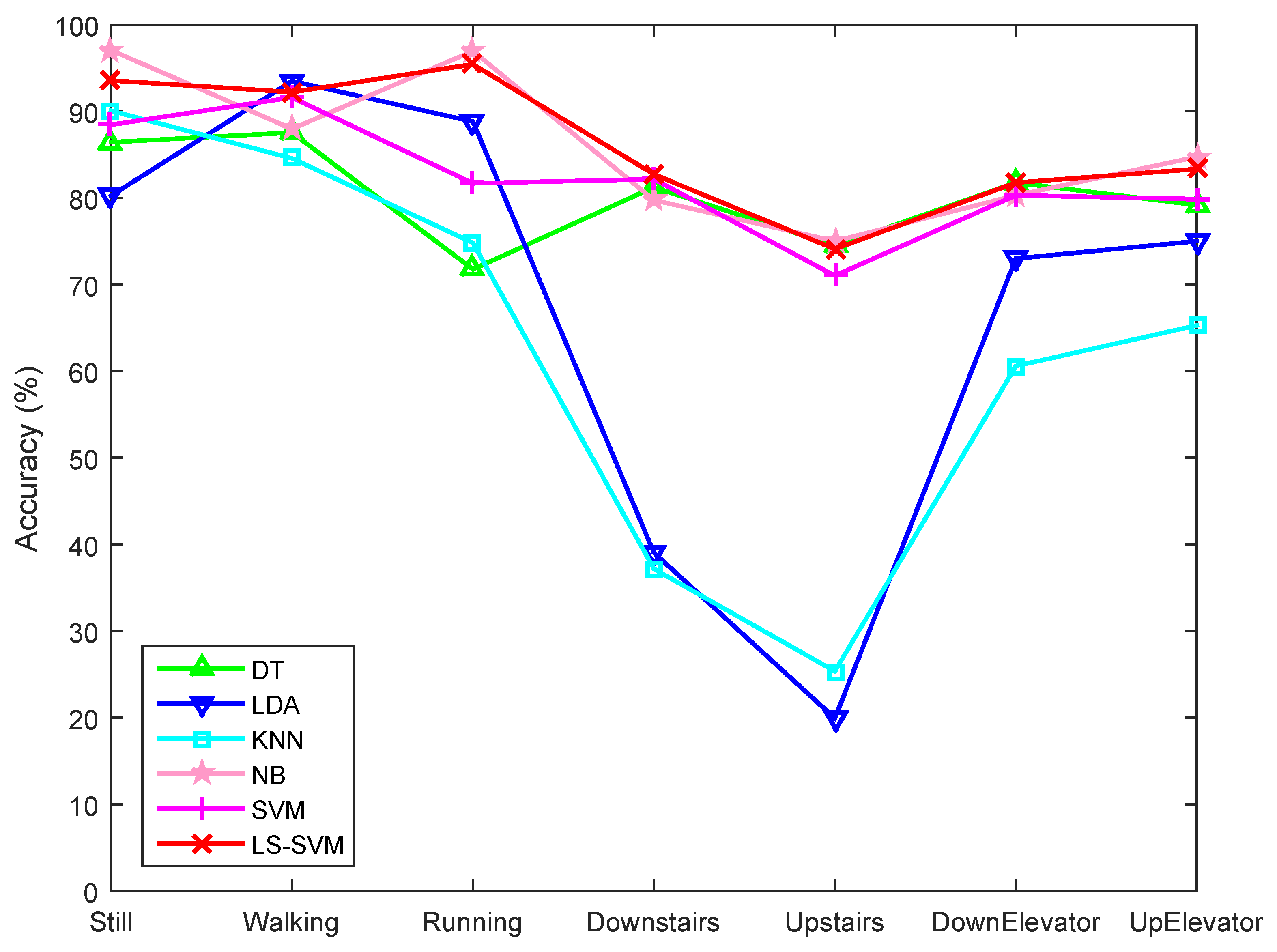
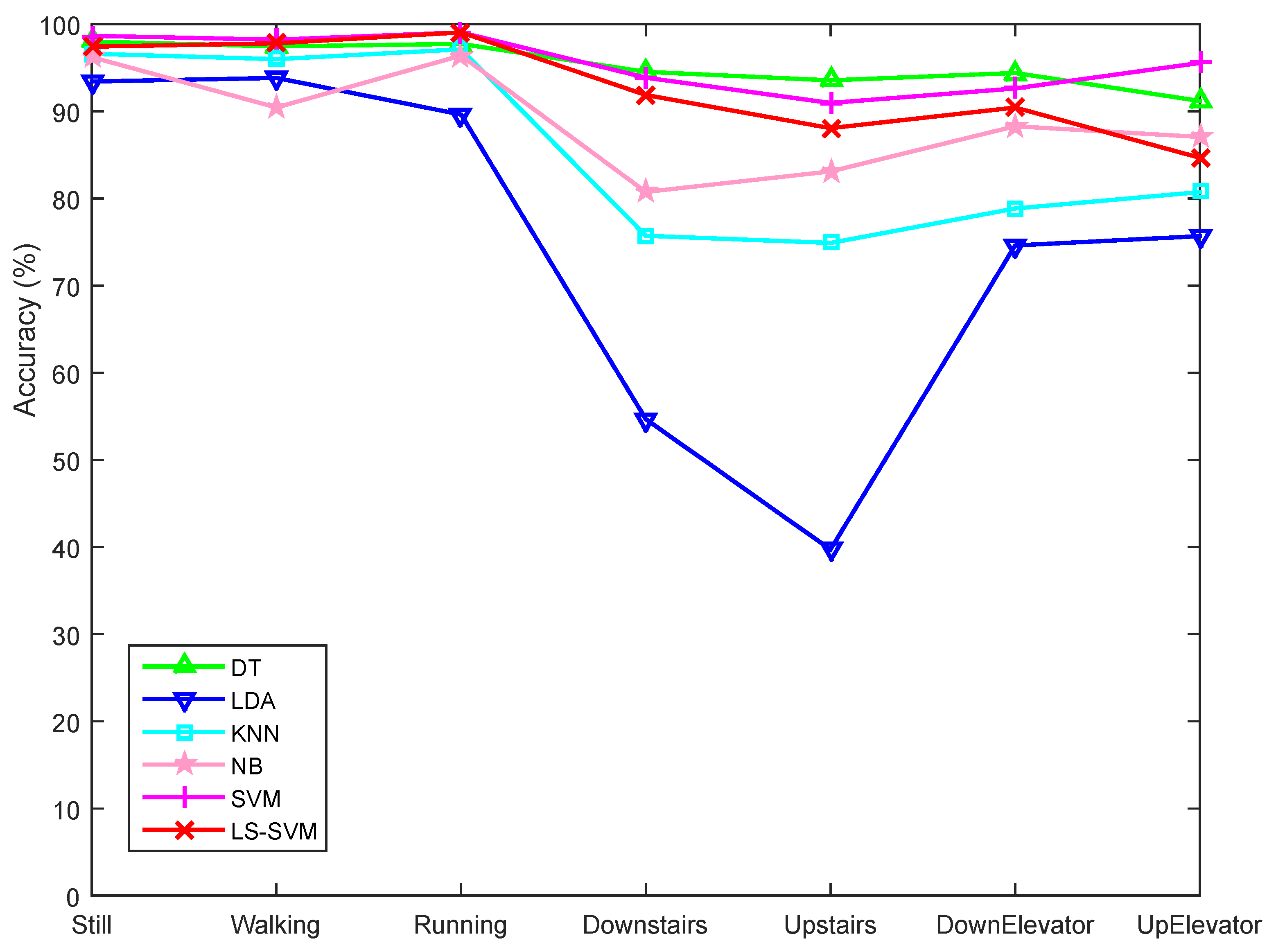
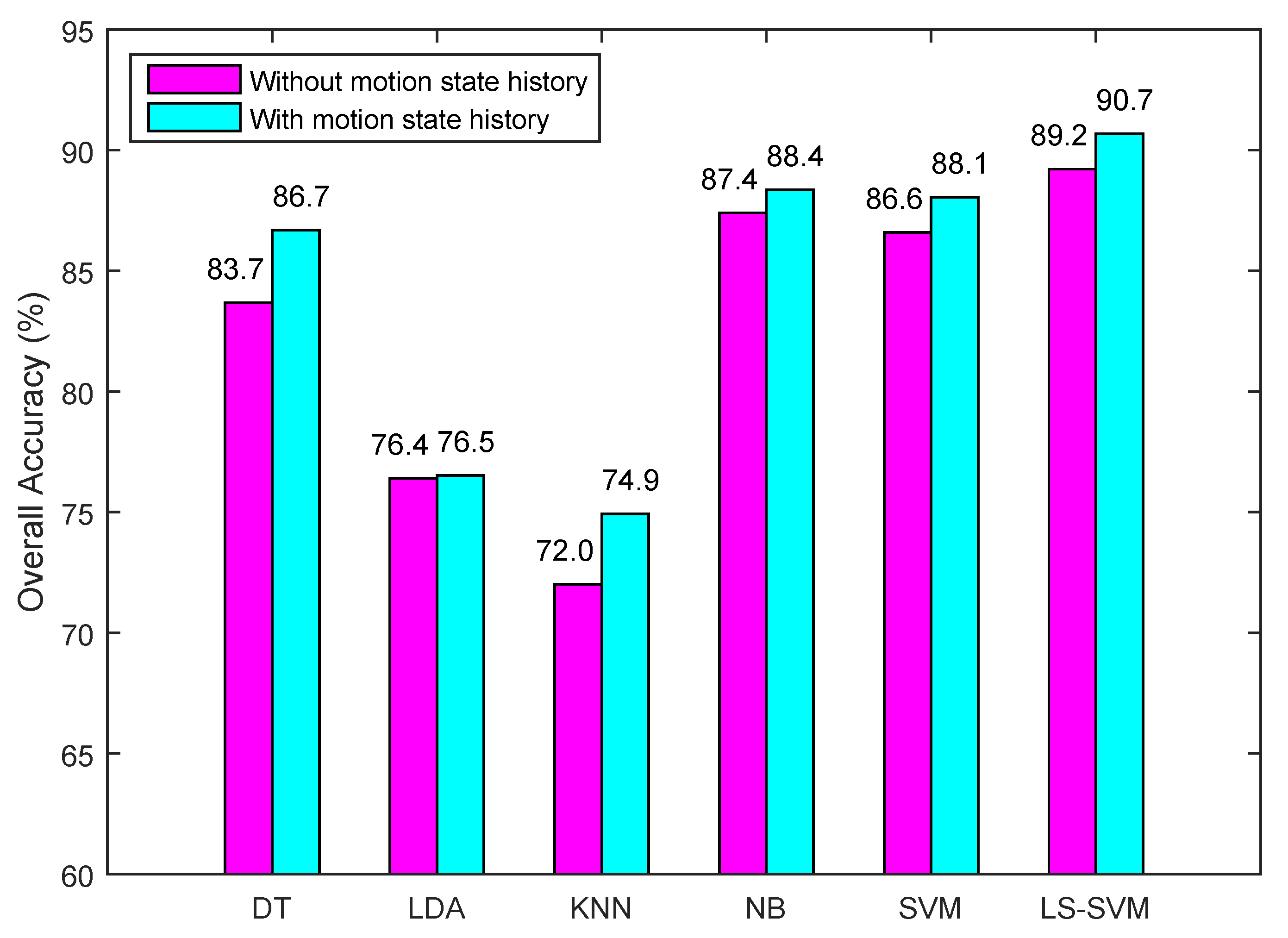
5.2.3. Influence of Window Size
| Window Size | Offset | Overall Accuracy | |||||
|---|---|---|---|---|---|---|---|
| DT | LDA | KNN | NB | SVM | LS-SVM | ||
| 0 | 72.64% | 75.18% | 69.28% | 77.28% | 79.18% | 79.66% | |
| 32 | 16 | 72.83% | 75.36% | 69.56% | 77.44% | 79.61% | 79.81% |
| 64 | 0 | 83.68% | 76.41% | 72.01% | 87.41% | 86.64% | 88.63% |
| 64 | 32 | 83.75% | 76.60% | 71.88% | 87.10% | 86.89% | 87.21% |
| 128 | 0 | 86.46% | 74.80% | 71.70% | 87.44% | 88.26% | 88.54% |
| 128 | 64 | 85.68% | 76.47% | 71.94% | 88.72% | 88.42% | 86.43% |
| 256 | 0 | 86.24 % | 75.55% | 70.68% | 86.79% | 87.66% | 88.29% |
| 256 | 128 | 83.89% | 77.98% | 70.83% | 88.21% | 87.69% | 88.10% |
5.2.4. Influence of Smartphone Poses
| Poses | Overall Accuracy of LS-SVM |
|---|---|
| 86.67% | |
| Holding | 89.09% |
| Swinging | 87.33% |
| Overall | 89.21% |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Incel, O.D.; Kose, M.; Ersoy, C. A review and taxonomy of activity recognition on mobile phones. BioNanoScience 2013, 3, 145–171. [Google Scholar] [CrossRef]
- Lockhart, J.W.; Pulickal, T.; Weiss, G.M. Applications of mobile activity recognition. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 1054–1058.
- Liao, L.; Fox, D.; Kautz, H. Extracting places and activities from gps traces using hierarchical conditional random fields. Int. J. Robot. Res. 2007, 26, 119–134. [Google Scholar] [CrossRef]
- Liao, L.; Patterson, D.J.; Fox, D.; Kautz, H. Learning and inferring transportation routines. Artif. Intell. 2007, 171, 311–331. [Google Scholar] [CrossRef]
- Sohn, T.; Varshavsky, A.; LaMarca, A.; Chen, M.Y.; Choudhury, T.; Smith, I.; Consolvo, S.; Hightower, J.; Griswold, W.G.; De Lara, E. Mobility detection using everyday gsm traces. In Proceedings of the 8th international conference of Ubiquitous Computing, Orange County, CA, USA, 17–21 September 2006; pp. 212–224.
- Eagle, N.; Pentland, A. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]
- Mun, M.; Estrin, D.; Burke, J.; Hansen, M. Parsimonious mobility classification using GSM and WiFi traces. In Proceedings of the Fifth Workshop on Embedded Networked Sensors, Charlottesville, VA, USA, 2–3 June 2008.
- Miluzzo, E.; Cornelius, C.T.; Ramaswamy, A.; Choudhury, T.; Liu, Z.; Campbell, A.T. Darwin phones: The evolution of sensing and inference on mobile phones. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010; pp. 5–20.
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Innovative Application of Artificial Intelligence Conference on Artificial Intelligence, Pisstsburgh, PA, USA, 9–13 July 2005; pp. 1541–1546.
- Hemminki, S.; Nurmi, P.; Tarkoma, S. Accelerometer-based transportation mode detection on smartphones. In Proceedings of the 11th ACM Conference on Embedded Networked Sensor Systems, Rome, Italy, 11–14 November 2013.
- Lee, M.W.; Khan, A.M.; Kim, T.S. A single tri-axial accelerometer-based real-time personal life log system capable of human activity recognition and exercise information generation. Pers. Ubiquitous Comput. 2011, 15, 887–898. [Google Scholar] [CrossRef]
- Pei, L.; Liu, J.; Guinness, R.; Chen, Y.; Kuusniemi, H.; Chen, R. Using LS-SVM Based Motion Recognition for Smartphone Indoor Wireless Positioning. Sensors 2012, 12, 6155–6175. [Google Scholar] [CrossRef] [PubMed]
- Martin, H.; Bernardos, A.M.; Iglesias, J.; Casar, J.R. Activity logging using lightweight classification techniques in mobile devices. Pers. Ubiquitous Comput. 2013, 17, 675–695. [Google Scholar] [CrossRef]
- Lara, O.D.; Perez, A.J.; Labrador, M.A. Centinela: A human activity recognition system based on acceleration and vital sign data. Pervasive Mob. Comput. 2012, 8, 717–729. [Google Scholar] [CrossRef]
- Zhu, C.; Sheng, W. Motion-and location-based online human daily activity recognition. Pervasive Mob. Comput. 2011, 7, 256–269. [Google Scholar] [CrossRef]
- Kouris, I.; Koutsouris, D. A comparative study of pattern recognition classifiers to predict physical activities using smartphones and wearable body sensors. Technol. Health Care 2012, 20, 263–275. [Google Scholar] [PubMed]
- Lester, J.; Choudhury, T.; Kern, N.; Borriello, G.; Hannaford, B. A Hybrid Discriminative/Generative Approach for Modeling Human Activities. In Proceedings of the 2005 International Joint Conference on Artificial Intelligence, Edinburgh, UK, 31 July–5 August 2005; pp. 766–772.
- Hu, D.H.; Pan, S.J.; Zheng, V.W.; Liu, N.N.; Yang, Q. Real world activity recognition with multiple goals. In Proceedings of the 10th international conference on Ubiquitous computing, Seoul, Korea, 21–24 September 2008; pp. 30–39.
- Liao, L.; Fox, D.; Kautz, H. Location-based activity recognition. In Proceedings of the Nineteenth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 787–794.
- Chen, Z.; Zou, H.; Jiang, H.; Zhu, Q.; Soh, Y.C.; Xie, L. Fusion of WiFi, Smartphone Sensors and Landmarks Using the Kalman Filter for Indoor Localization. Sensors 2015, 15, 715–732. [Google Scholar] [CrossRef] [PubMed]
- Shang, J.; Gu, F.; Hu, X.; Kealy, A. APFiLoc: An Infrastructure-Free Indoor Localization Method Fusing Smartphone Inertial Sensors, Landmarks and Map Information. Sensors 2015, 15, 27251–27272. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S.; Mun, M.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Using mobile phones to determine transportation modes. ACM Trans. Sens. Netw. 2010, 6. [Google Scholar] [CrossRef]
- Peterek, T.; Penhaker, M.; Gajdos, P.; Dohnalek, P. Comparison of Classification Algorithms for Physical Activity Recognition. In Proceedings of the 4th International Conference on Innovations in Bio-Inspired Computing and Applications, Ostrava, Czech, 22–24 August 2013; pp. 123–131.
- Park, J.G. Indoor Localization Using Place and Motion Signatures. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, June 2013. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing techniques for context recognition from accelerometer data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Rutkowski, L.; Jaworski, M.; Pietruczuk, L.; Duda, P. Decision trees for mining data streams based on the gaussian approximation. IEEE Trans. Knowl. Data Eng. 2014, 26, 108–119. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Rennie, J.D.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the poor assumptions of naive bayes text classifiers. In Proceedings of the Twentieth International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 616–623.
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 workshop on empirical methods in artificial intelligence, Washington, DC, USA, 4–10 August 2001; pp. 41–46.
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Krishnan, N.C.; Cook, D.J. Activity recognition on streaming sensor data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [PubMed]
- LS-SVMlab: A Matlab/C Toolbox for Least Squares Support Vector Machines. Available online: http://www.esat.kuleuven.ac.be/sista/lssvmlab/ (accessed on 20 July 2015).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Zhao, Z.; Morstatter, F.; Sharma, S.; Alelyani, S.; Anand, A.; Liu, H. Advancing Feature Selection Research—ASU Feature Selection Repository; Technical Report; Arizona State University: Tempe, AZ, USA, 2010. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, F.; Kealy, A.; Khoshelham, K.; Shang, J. User-Independent Motion State Recognition Using Smartphone Sensors. Sensors 2015, 15, 30636-30652. https://doi.org/10.3390/s151229821
Gu F, Kealy A, Khoshelham K, Shang J. User-Independent Motion State Recognition Using Smartphone Sensors. Sensors. 2015; 15(12):30636-30652. https://doi.org/10.3390/s151229821
Chicago/Turabian StyleGu, Fuqiang, Allison Kealy, Kourosh Khoshelham, and Jianga Shang. 2015. "User-Independent Motion State Recognition Using Smartphone Sensors" Sensors 15, no. 12: 30636-30652. https://doi.org/10.3390/s151229821
APA StyleGu, F., Kealy, A., Khoshelham, K., & Shang, J. (2015). User-Independent Motion State Recognition Using Smartphone Sensors. Sensors, 15(12), 30636-30652. https://doi.org/10.3390/s151229821