
A Novel Multilayered RFID Tagged Cargo Integrity Assurance Scheme



Abstract
:1. Introduction
2. Cargo Inspection Management of Mobile Logistics
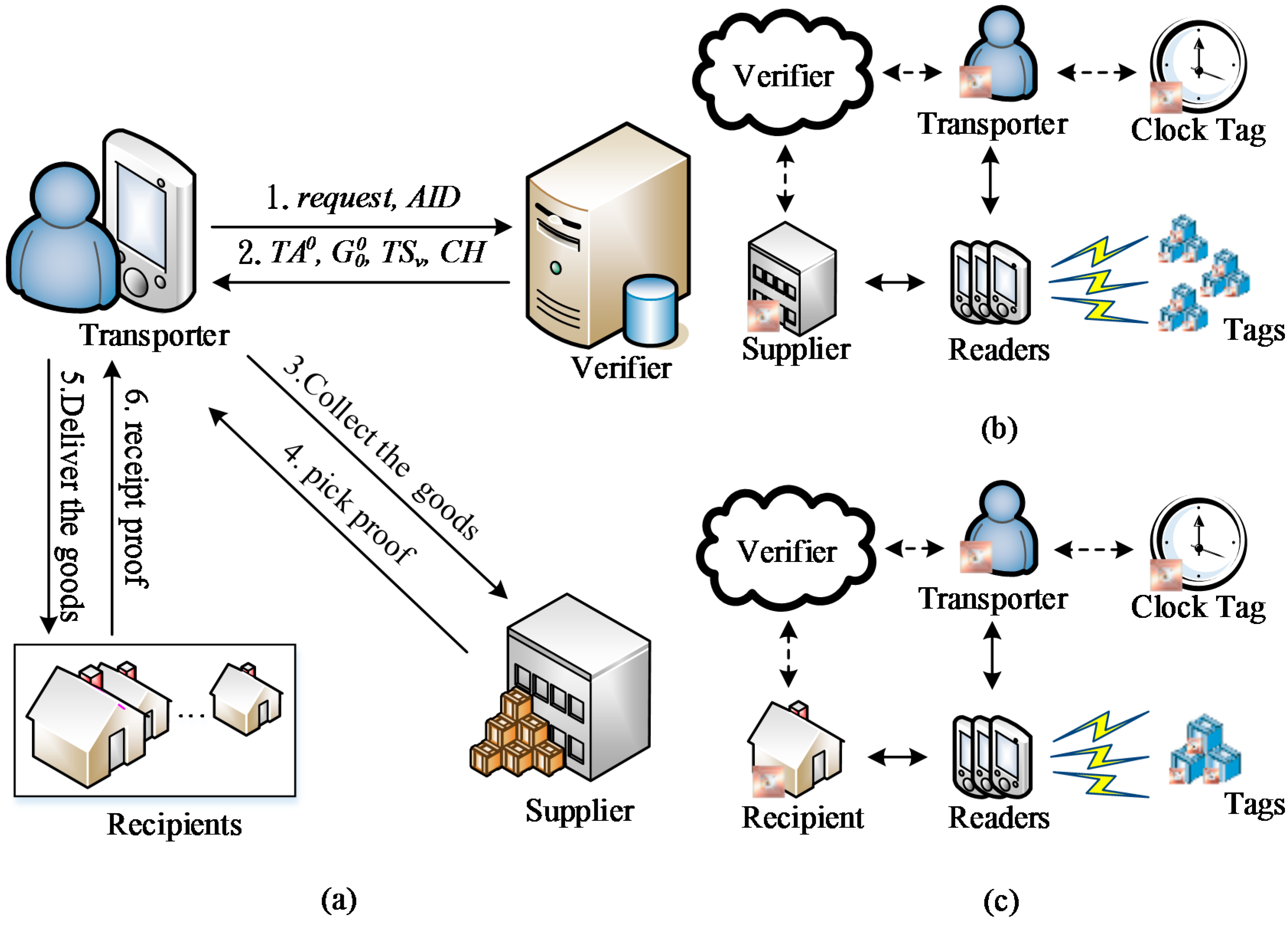
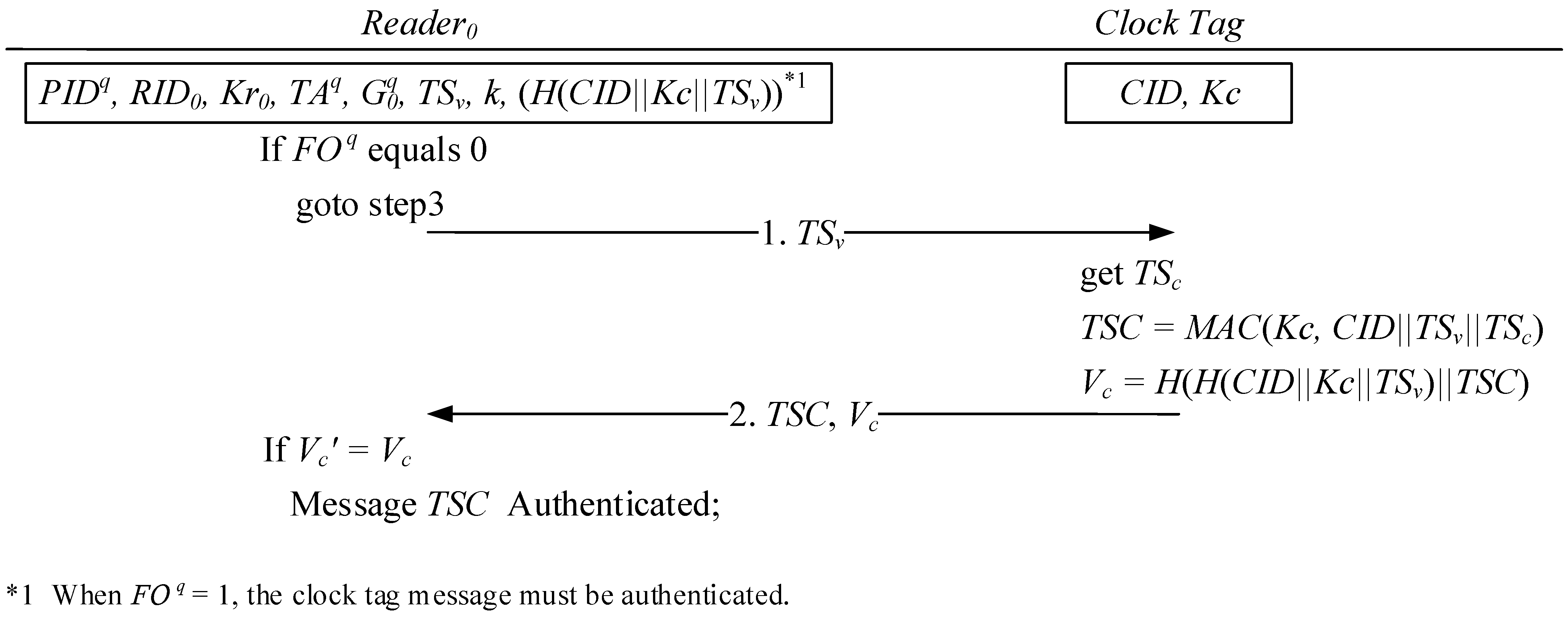
2.1. Initialization Phase

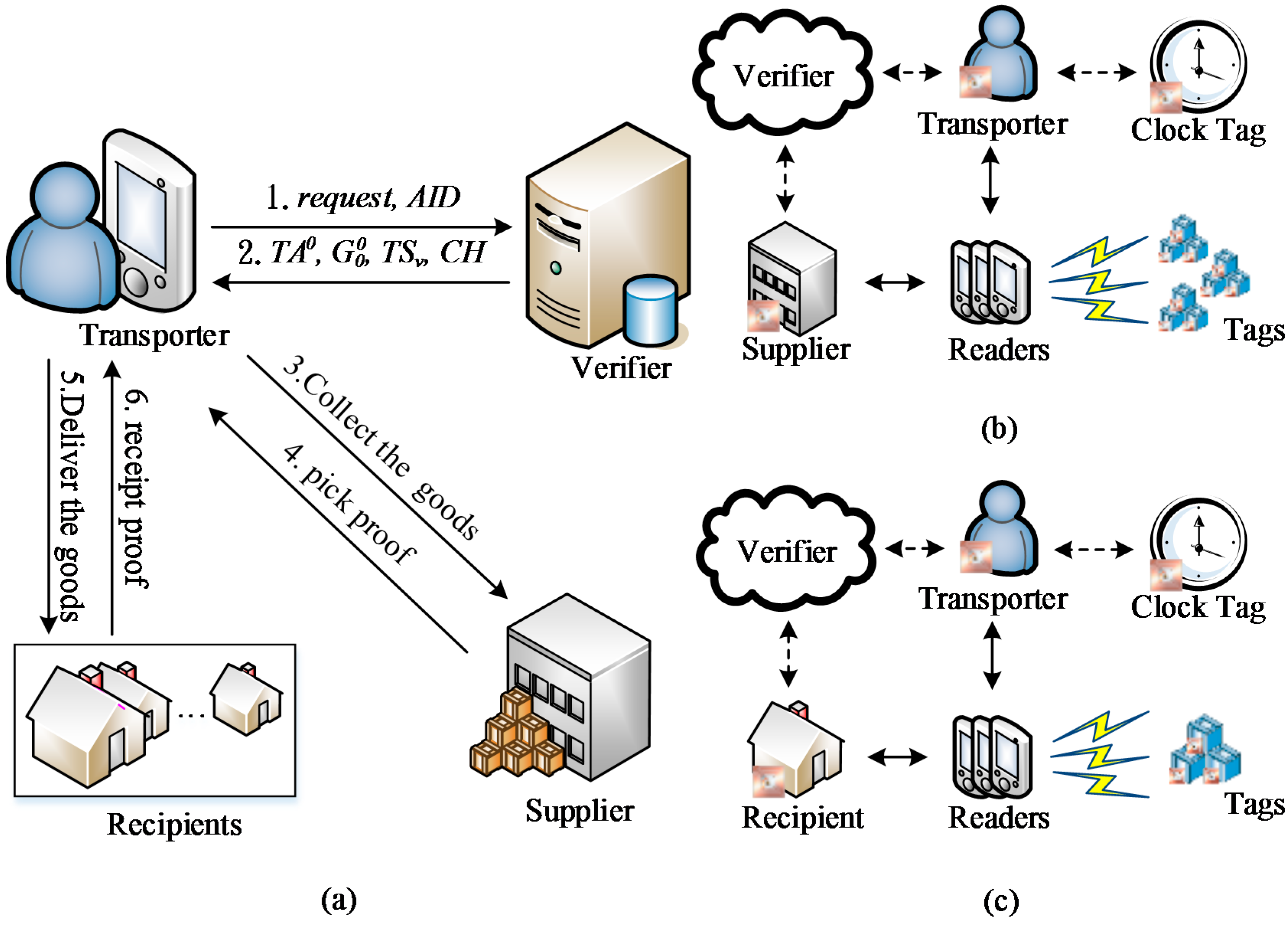{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| : a third-party verification server to reinspect grouping proofs | |
| : shipping supplier | |
| : transporter who delivers cargo | |
| : q-th recipient who receives the cargo | |
| : a third-party clock tag providing time for the system in offline phase | |
| Identification code for | |
| Identification code of a trusted and active third-party | |
| Identification code of the reader used by | |
| Identification code of | |
| Identification code of the -th reader used by | |
| Identification code of the -th tag for | |
| -th group code for | |
| Verification hash value for | |
| Shared key for and | |
| Shared key for and | |
| Shared key for and | |
| Shared key for and | |
| Session key among readers | |
| Public key for | |
| Private key for | |
| Public key for | |
| Private key for | |
| Random number generated by | |
| Random number generated by | |
| Random number generated by | |
| Random number generated by | |
| Random number generated by | |
| Timestamp generated by | |
| System time of | |
| Time threshold for generating grouping proofs | |
| Encryption function generated by message () through an employment of symmetric key () | |
| Signing function generated by through an employment of private | |
| Function for message authentication code generated by by an employment of | |
| Message authentication code generated from an employment of hash function by | |
| Judgement of whether the grouping proof for is generated in online or offline phase |
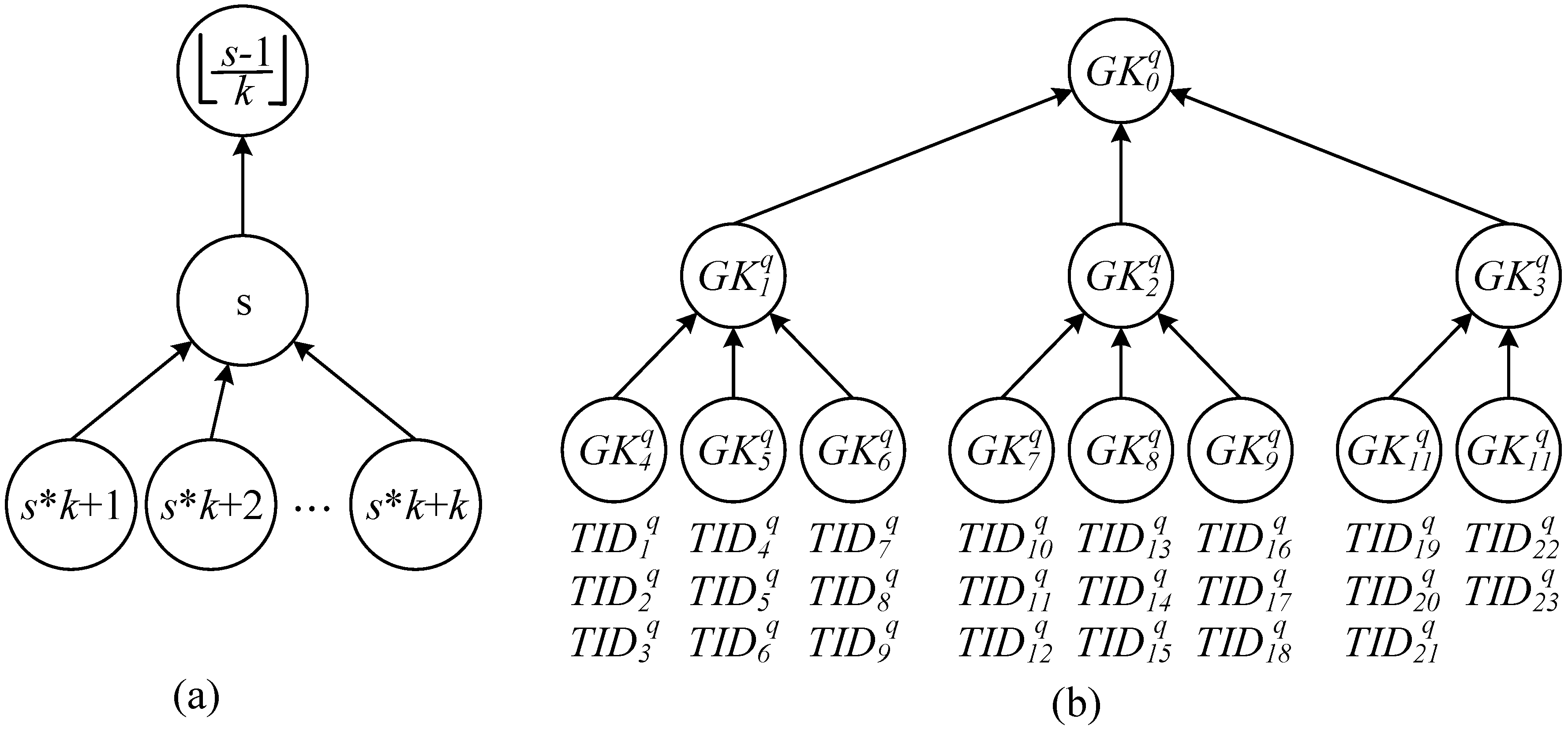
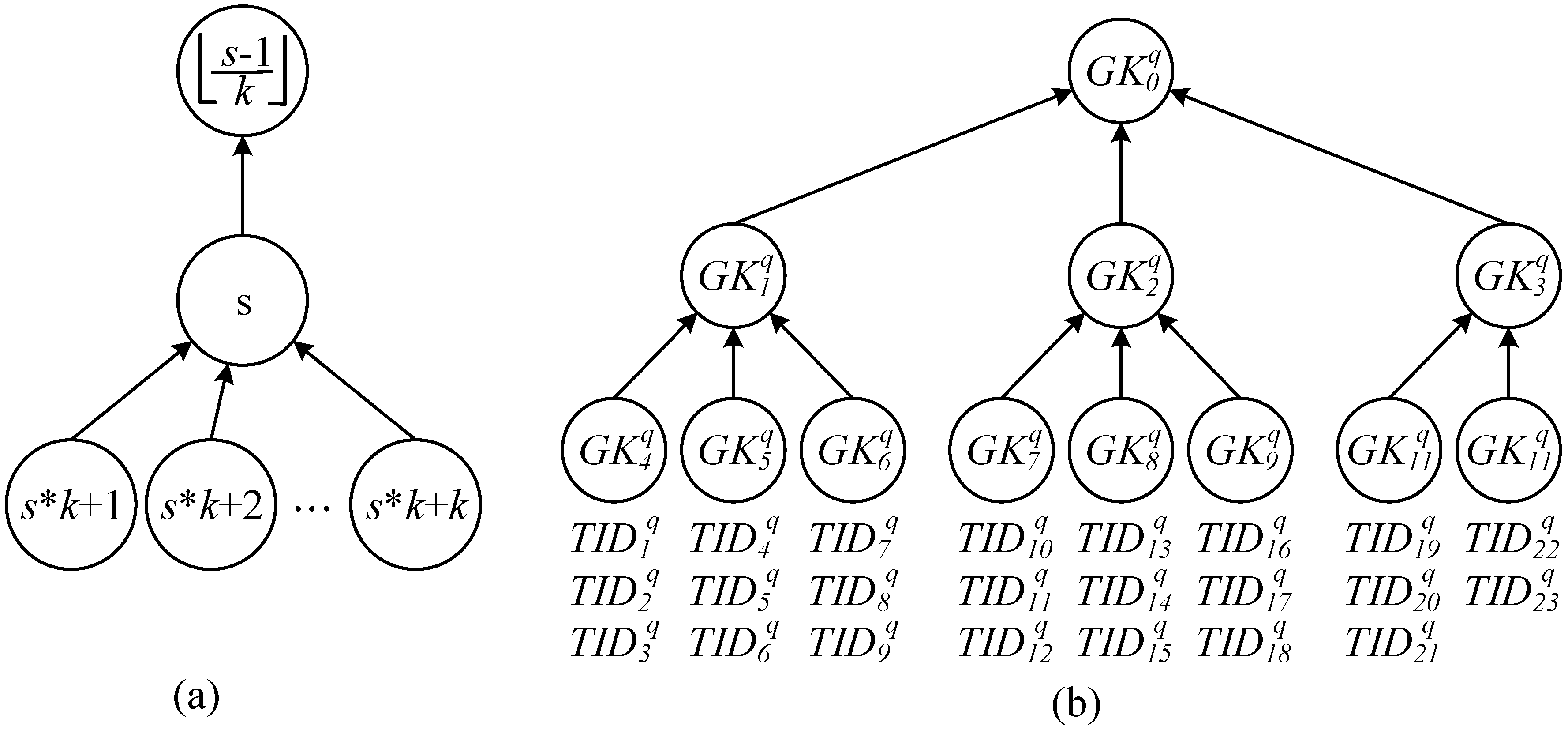
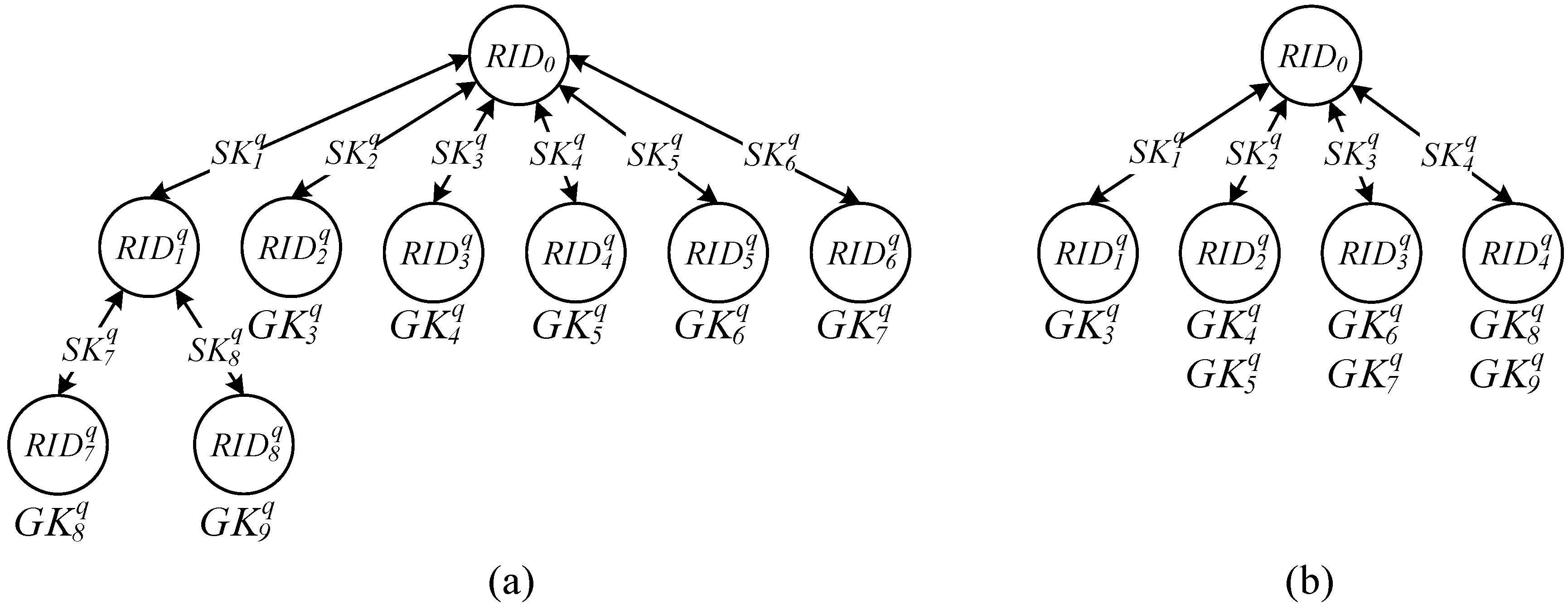
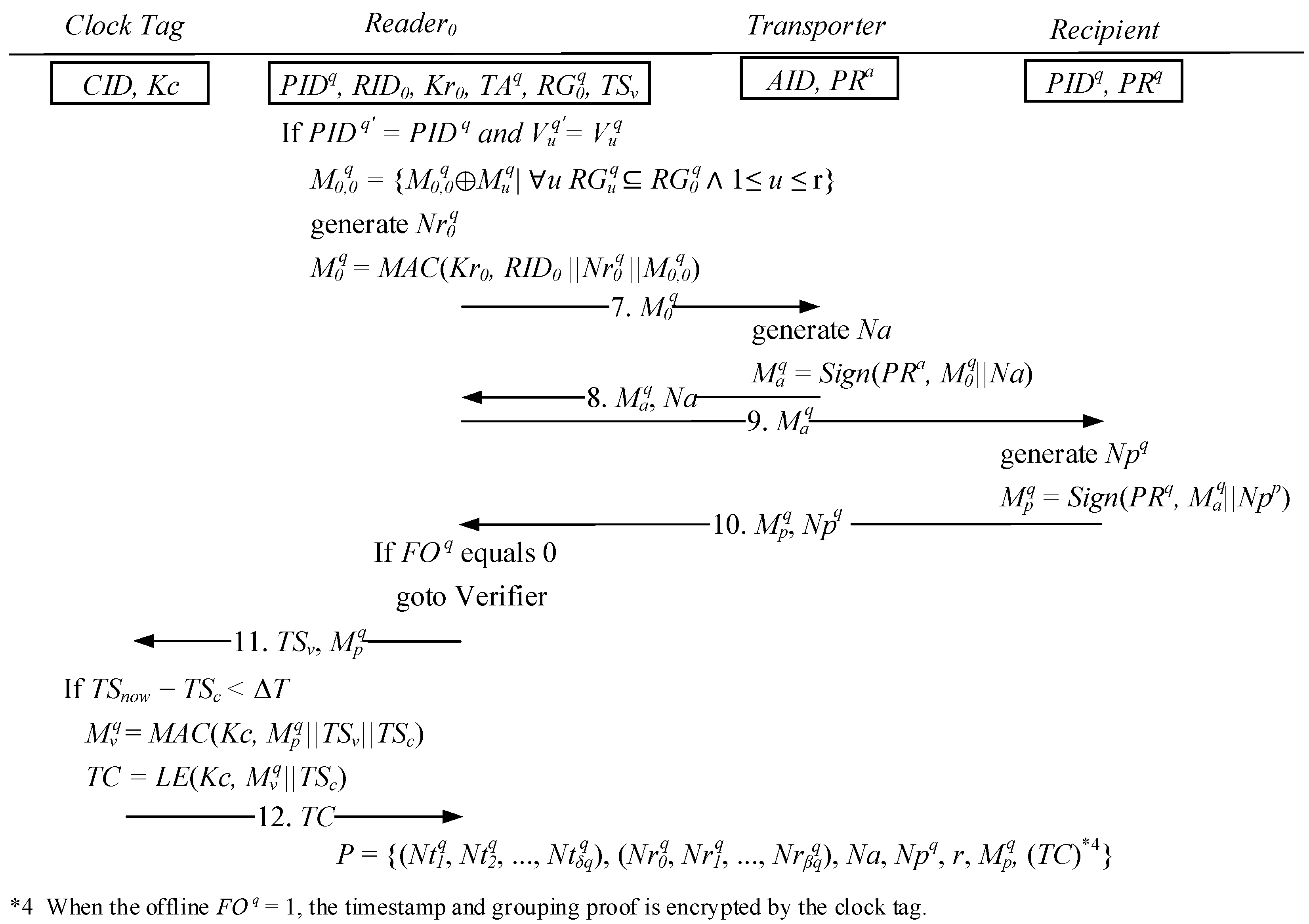
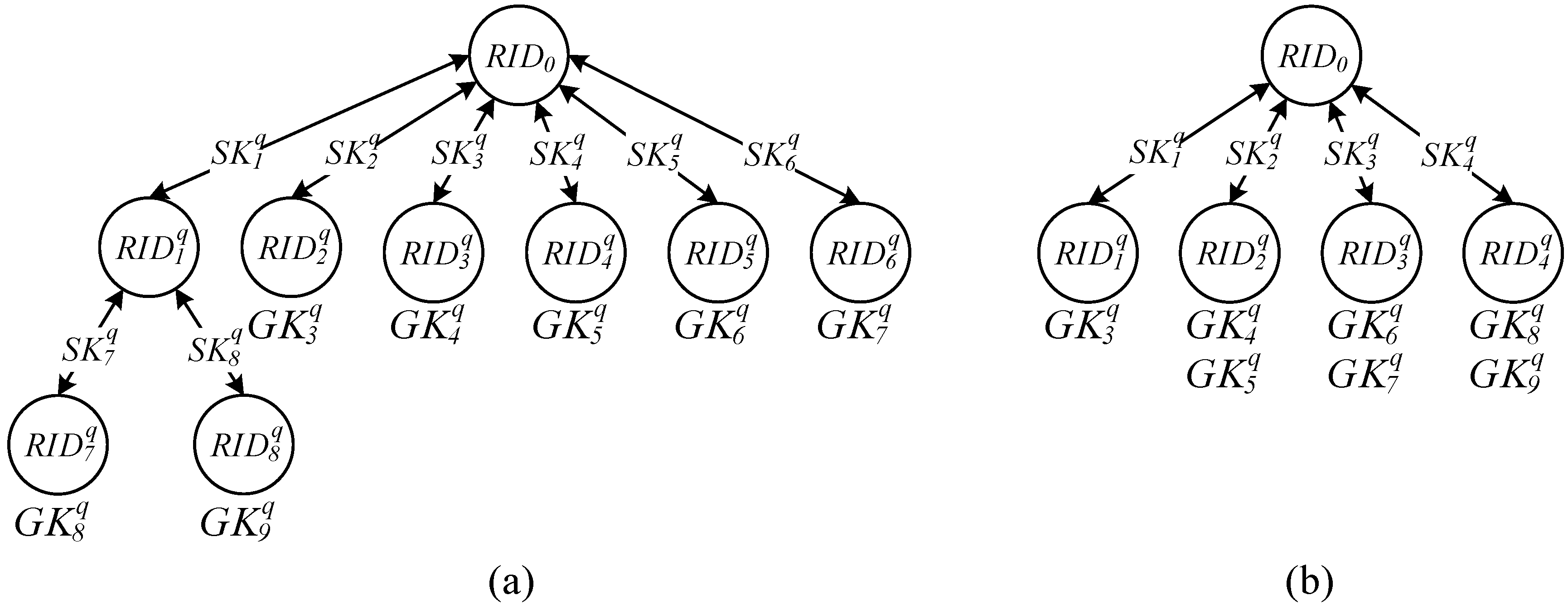
2.2. Integrity Verification Phase: Grouping Proof Protocol of a Multilayered Reader
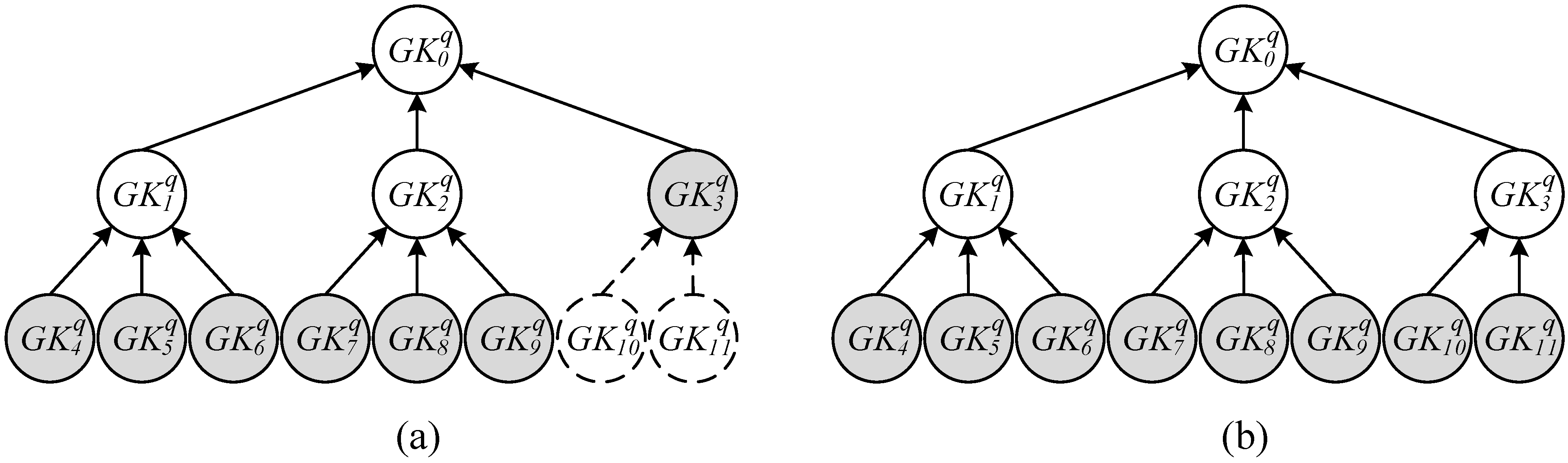
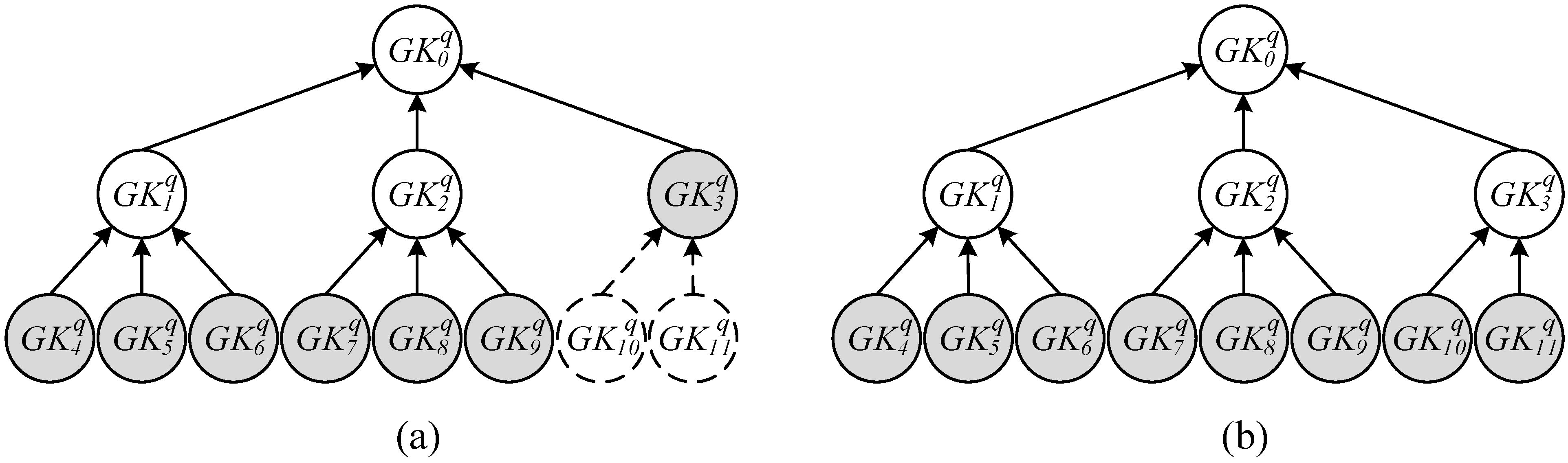
- Only one group key was distributed to each reader used by a recipient to maximize the benefit of concurrent reading; consequently, a total of readers was required to generate the grouping proofs.
- Distribute one or multiple group keys to the reader to satisfy the condition that within all the readers, the total number of tags that can be encrypted by the key was less than the number of r tags, and only a minimal number of readers for recipients was required [41,42,43]; therefore, grouping proofs were generated using the least resources.


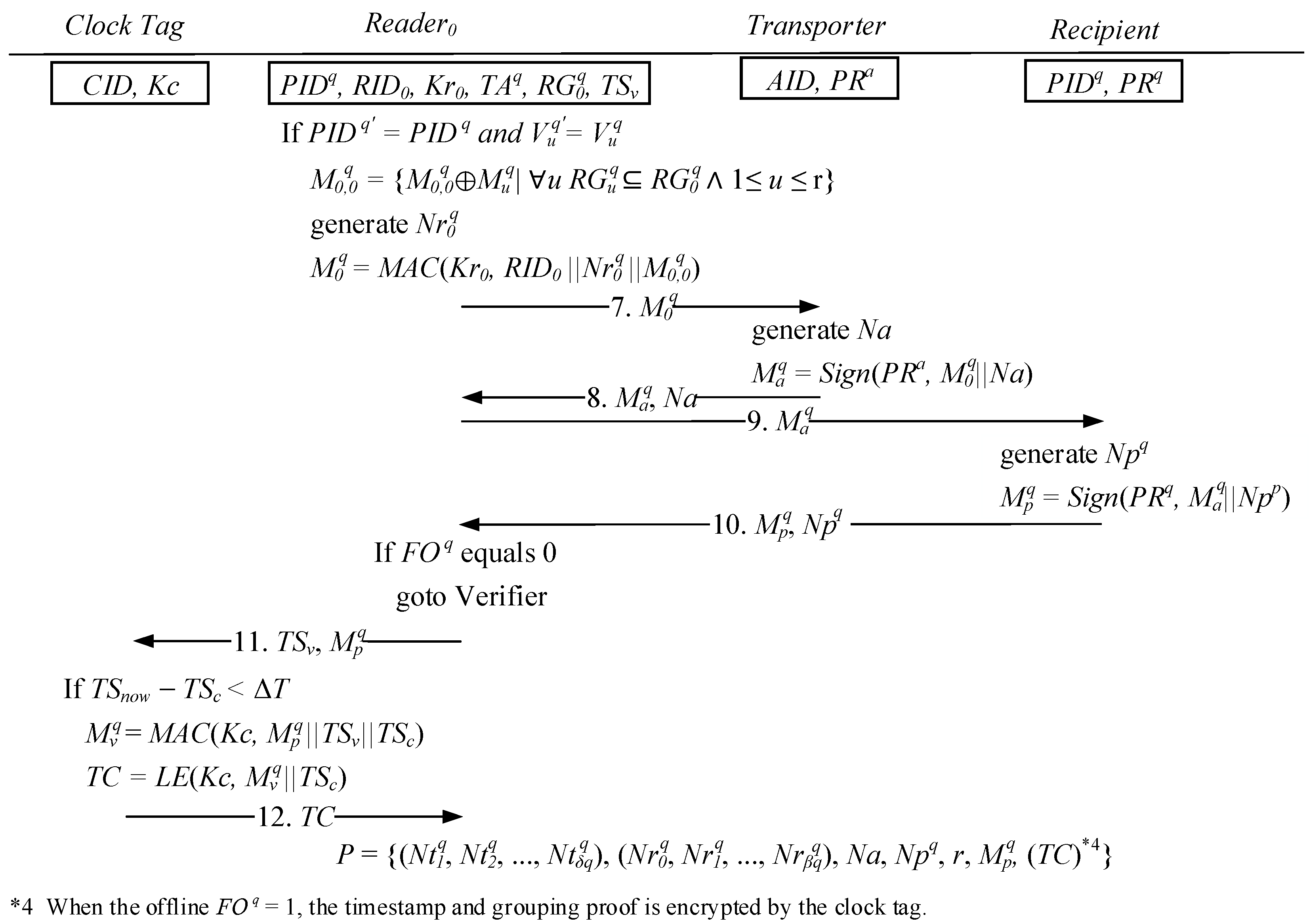
2.3. Dispute Resolution Phase
3. Security and Performance Analysis
| Protocol | Replay Attack | Tag Impersonation | Multi-Session Attack | Concurrency Attack | Denial of Proof |
|---|---|---|---|---|---|
| Burmester et al. [10] | O | O | O | X | ∆2 |
| Saito et al. [13] | X | X | O | X | X |
| Lin et al. [18] | O | O | O | O | X |
| Sun et al. [19] | O | O | O | ∆1 | X |
| Hermans et al. [20] | O | O | O | X | X |
| Lo et al. [21] | O | O | O | O | X |
| Ma et al. [22] | O | O | O | O | X |
| Chien et al. [24] | O | O | O | X | X |
| Peris-Lopez et al. [26] | O | O | O | O | X |
| Piramuthu [27] | O | O | X | X | X |
| Sundaresan et al. [28] | O | O | O | O | O |
| Yen et al. [32] | O | O | O | O | ∆2 |
| Leng et al. [37] | O | O | O | X | X |
| Huang et al. [44] | O | X | O | X | X |
| OMRGP | O | O | O | O | O |
| Protocol | Anonymity | Tracking Attack | Offline | Order Independent | Simultaneity |
|---|---|---|---|---|---|
| Burmester et al. [10] | O | O | O | X | ∆4 |
| Saito et al. [13] | O | ∆3 | X | X | X |
| Lin et al. [18] | X | X | O | X | X |
| Sun et al. [19] | O | O | O | O | O |
| Hermans et al. [20] | O | O | O | O | O |
| Lo et al. [21] | O | O | O | X | X |
| Ma et al. [22] | O | O | O | X | X |
| Chien et al. [24] | O | ∆3 | X | X | X |
| Peris-Lopez et al. [26] | O | O | X | X | X |
| Piramuthu [27] | X | X | X | X | X |
| Sundaresan et al. [28] | O | O | O | X | X |
| Yen et al. [32] | O | O | X | O | O |
| Leng et al. [37] | X | X | X | O | X |
| Huang et al. [44] | X | X | O | X | X |
| OMRGP | O | O | O | O | O |
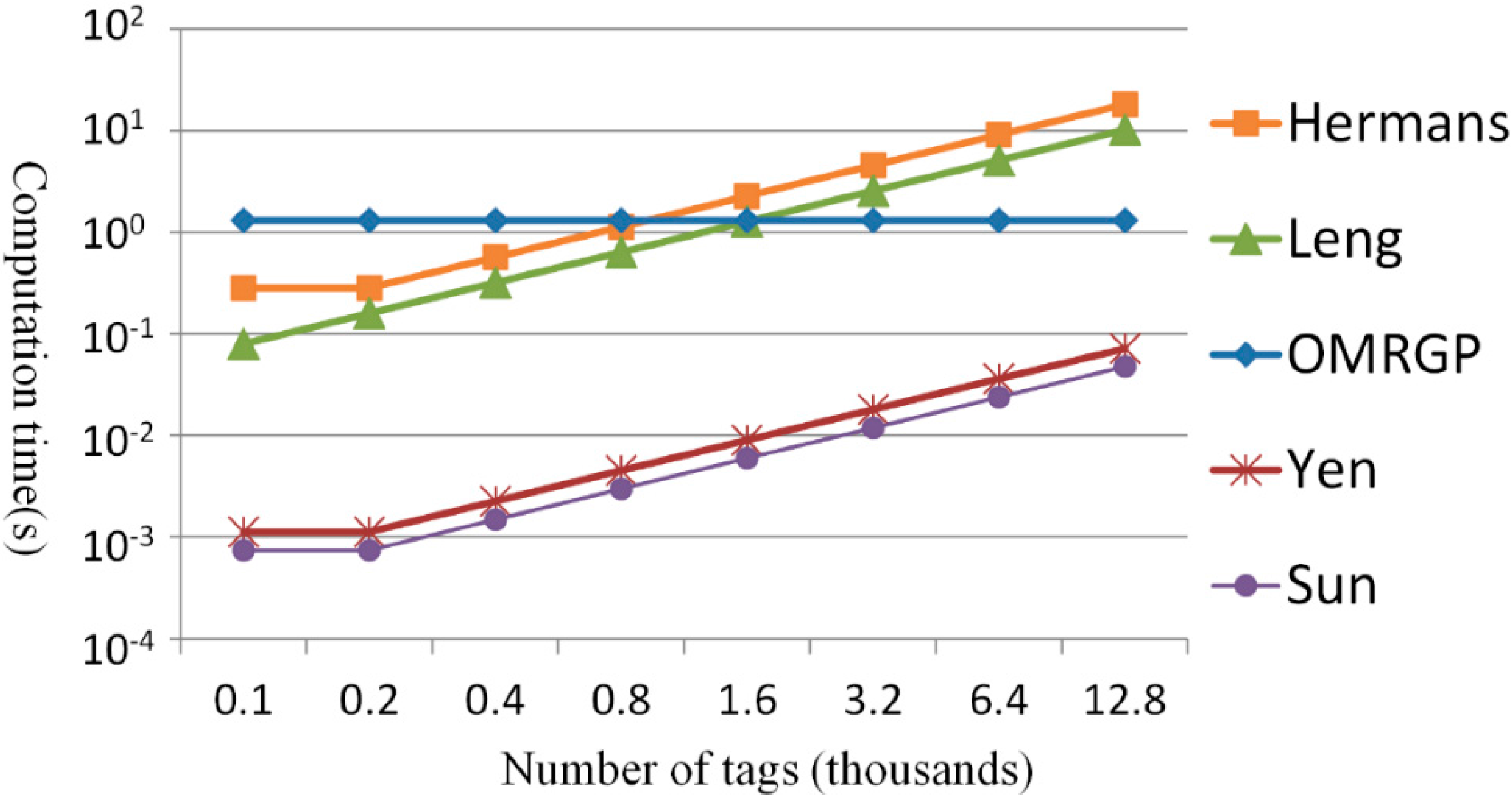
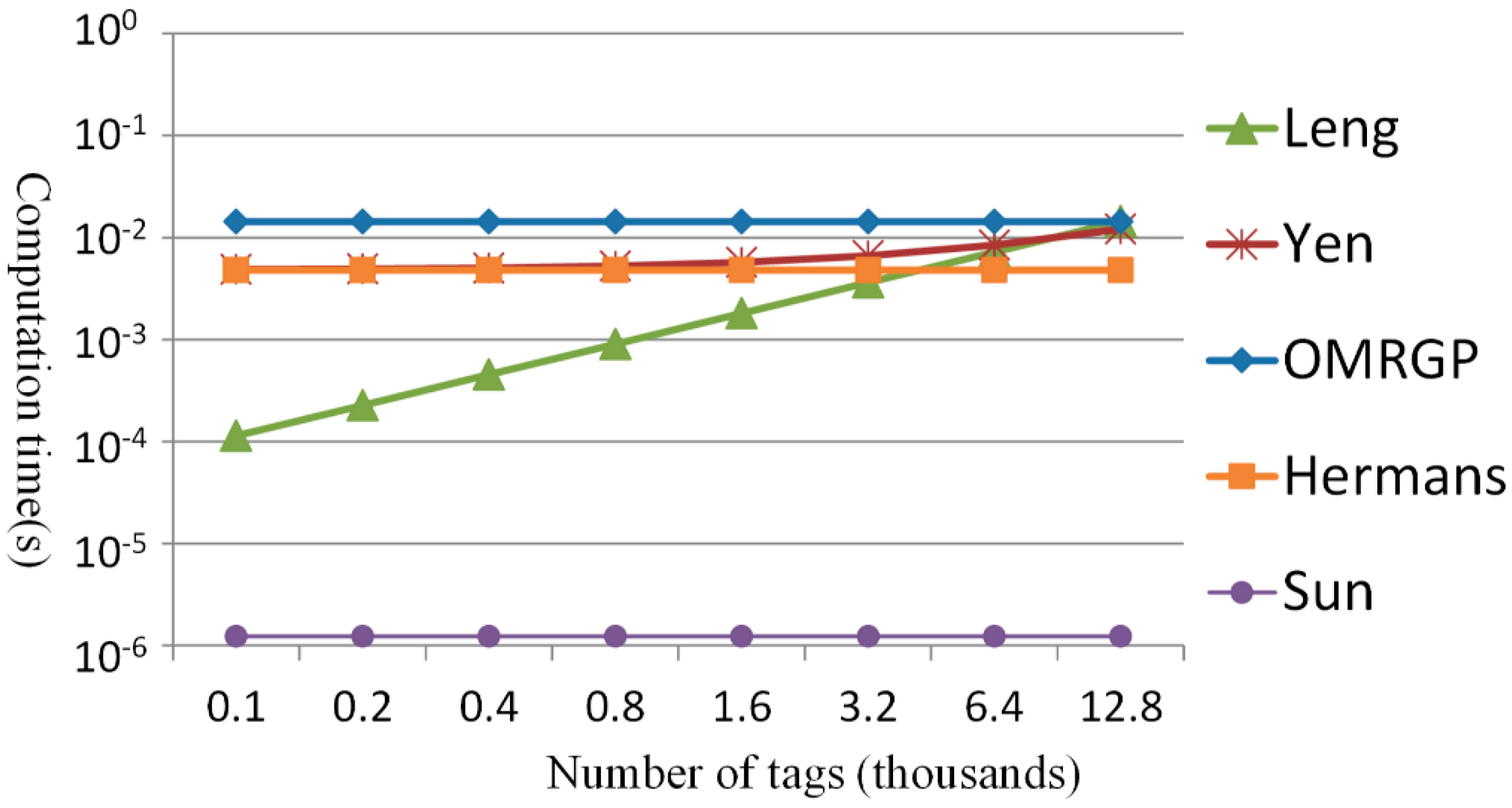
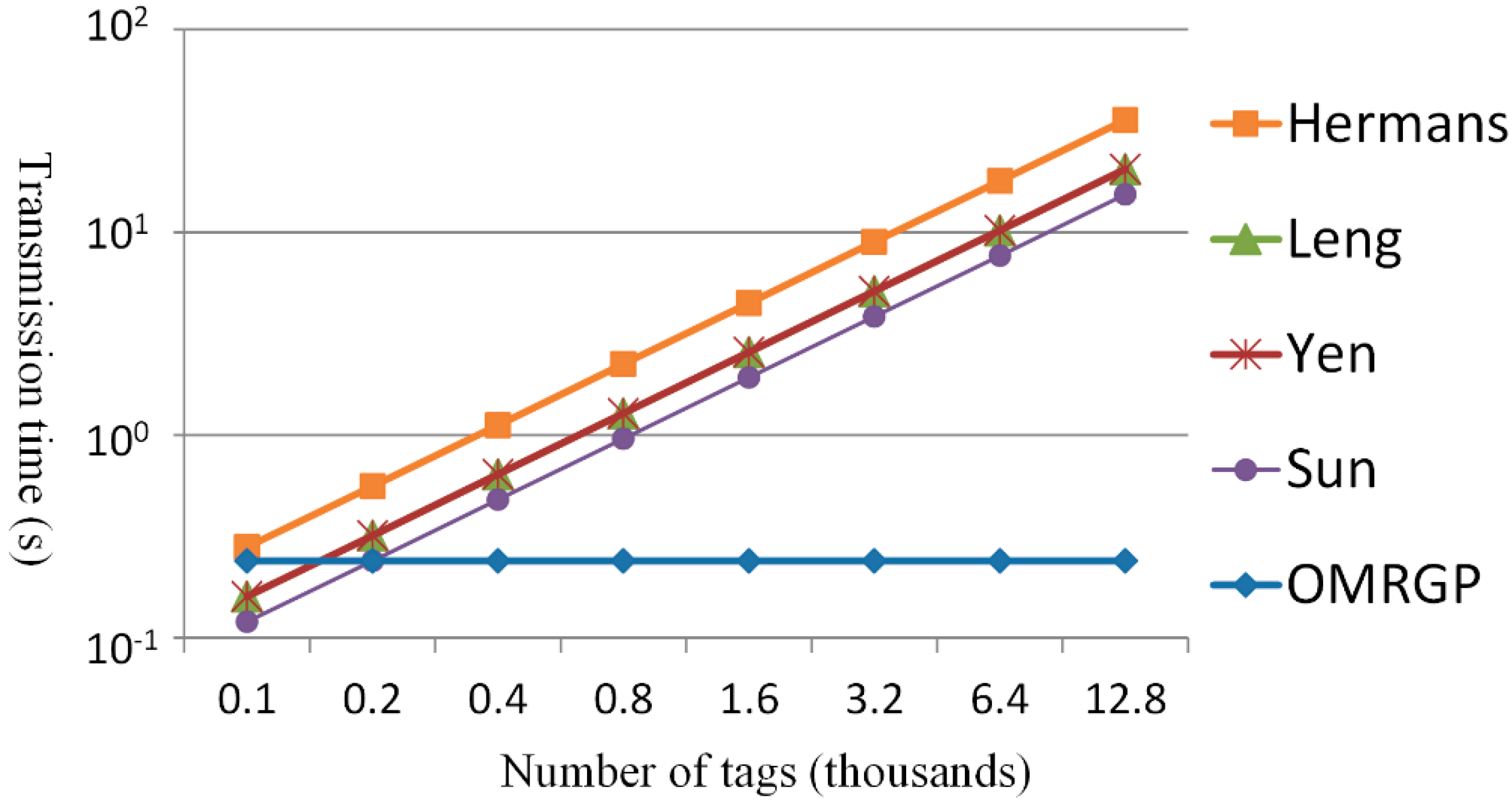
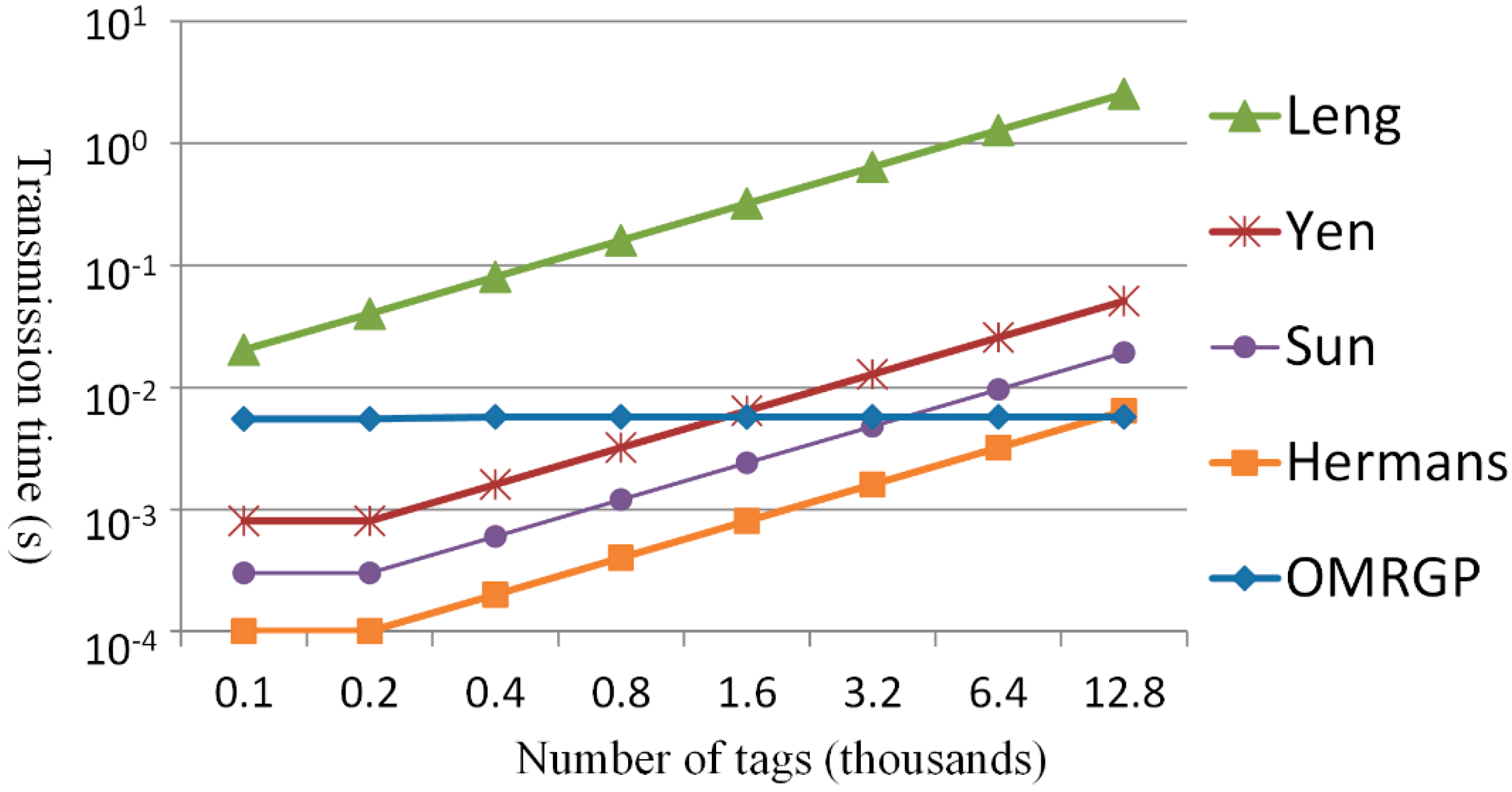
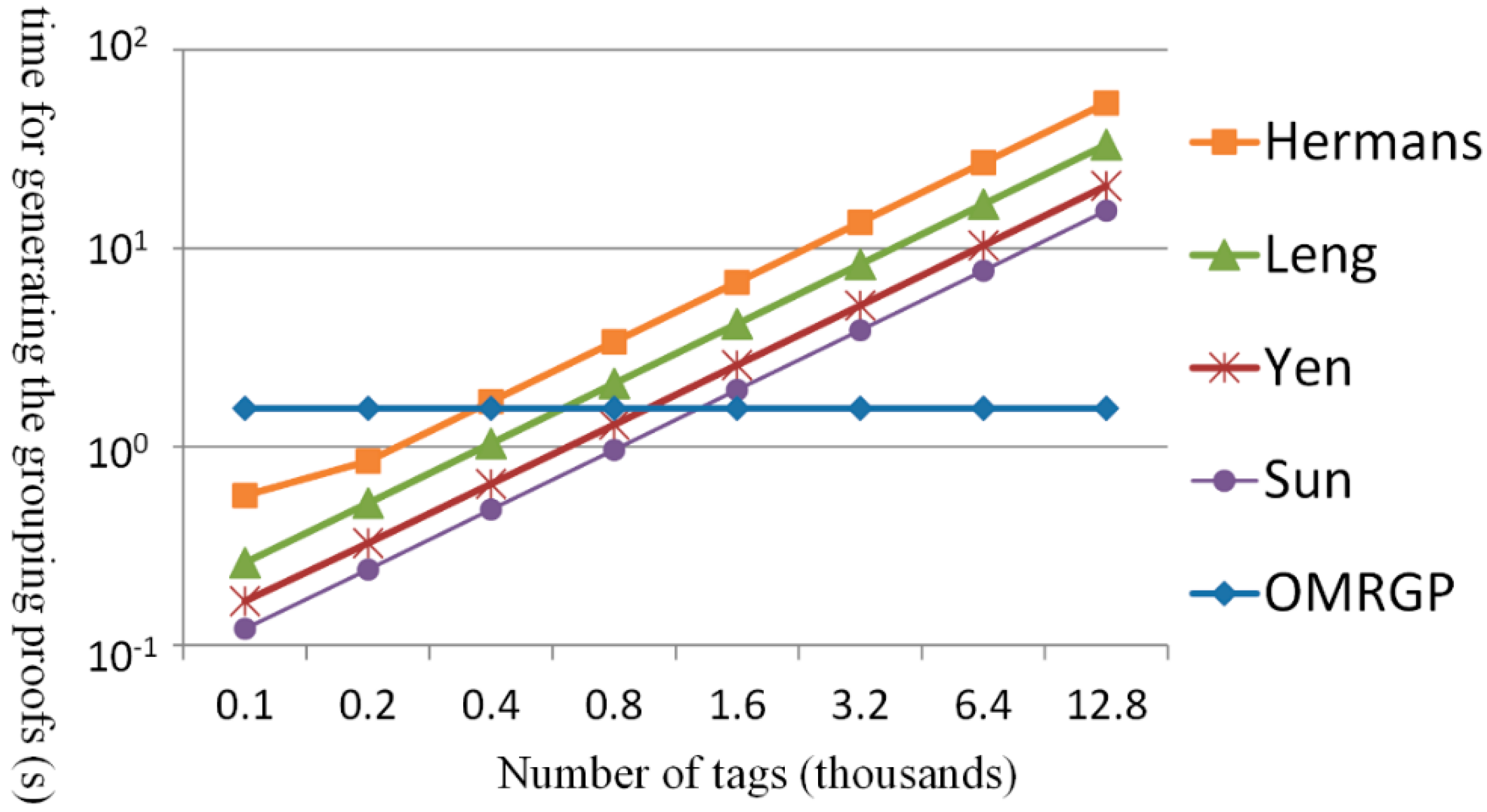
4. Effectiveness Analysis
| Name of the Method | Cargo Tag | Mobile Reader |
|---|---|---|
| Sun et al. [19] | ||
| Hermans et al. [20] | ||
| Yen et al. [32] | ||
| Leng et al. [37] | ||
| OMRGP |
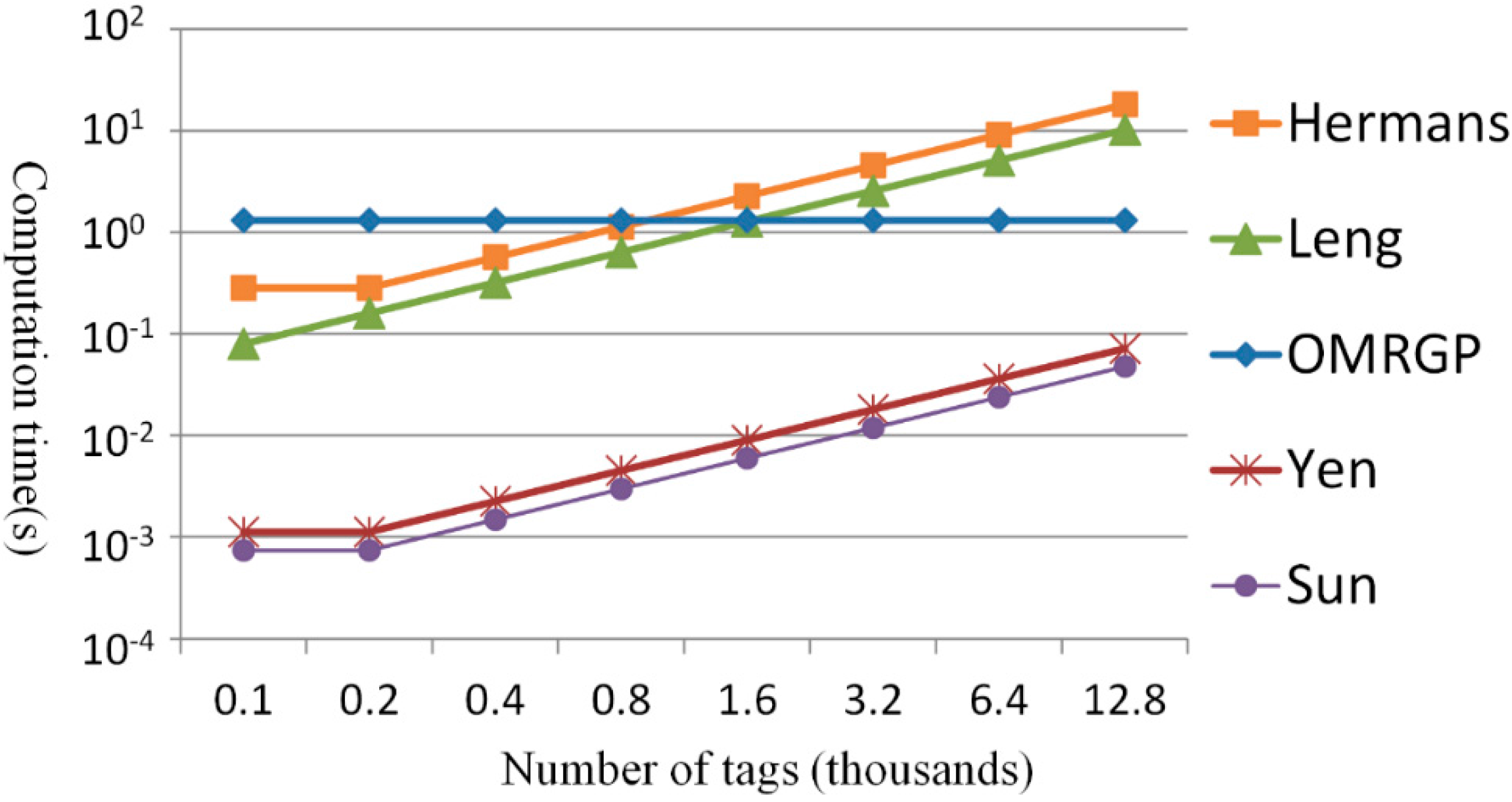
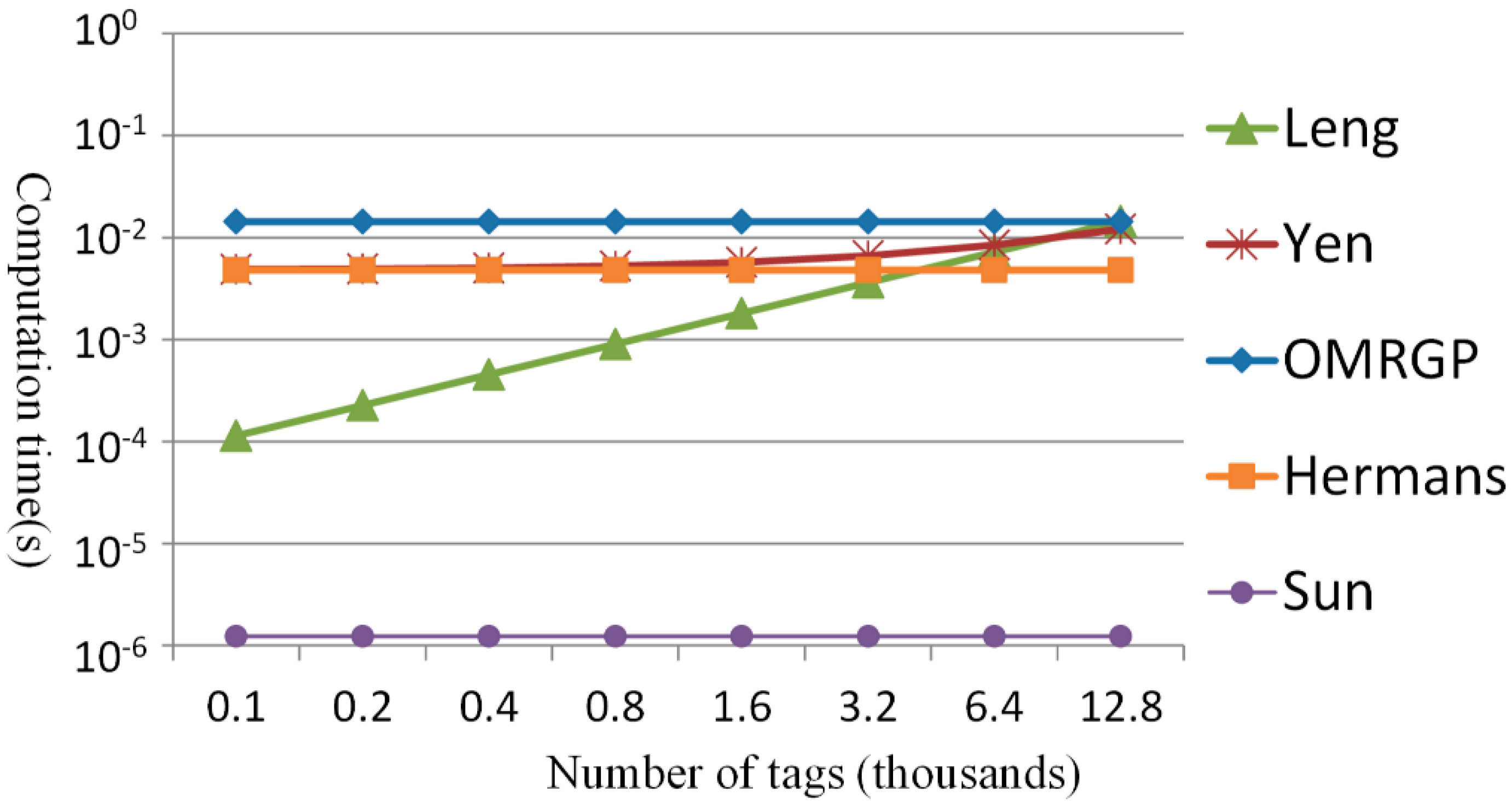
| Name of the Method | From Tag to Reader | From Reader to Tag (or Reader) |
|---|---|---|
| Sun et al. [19] | ||
| Hermans et al. [20] | ||
| Yen et al. [32] | ||
| Leng et al. [37] | ||
| OMRGP |
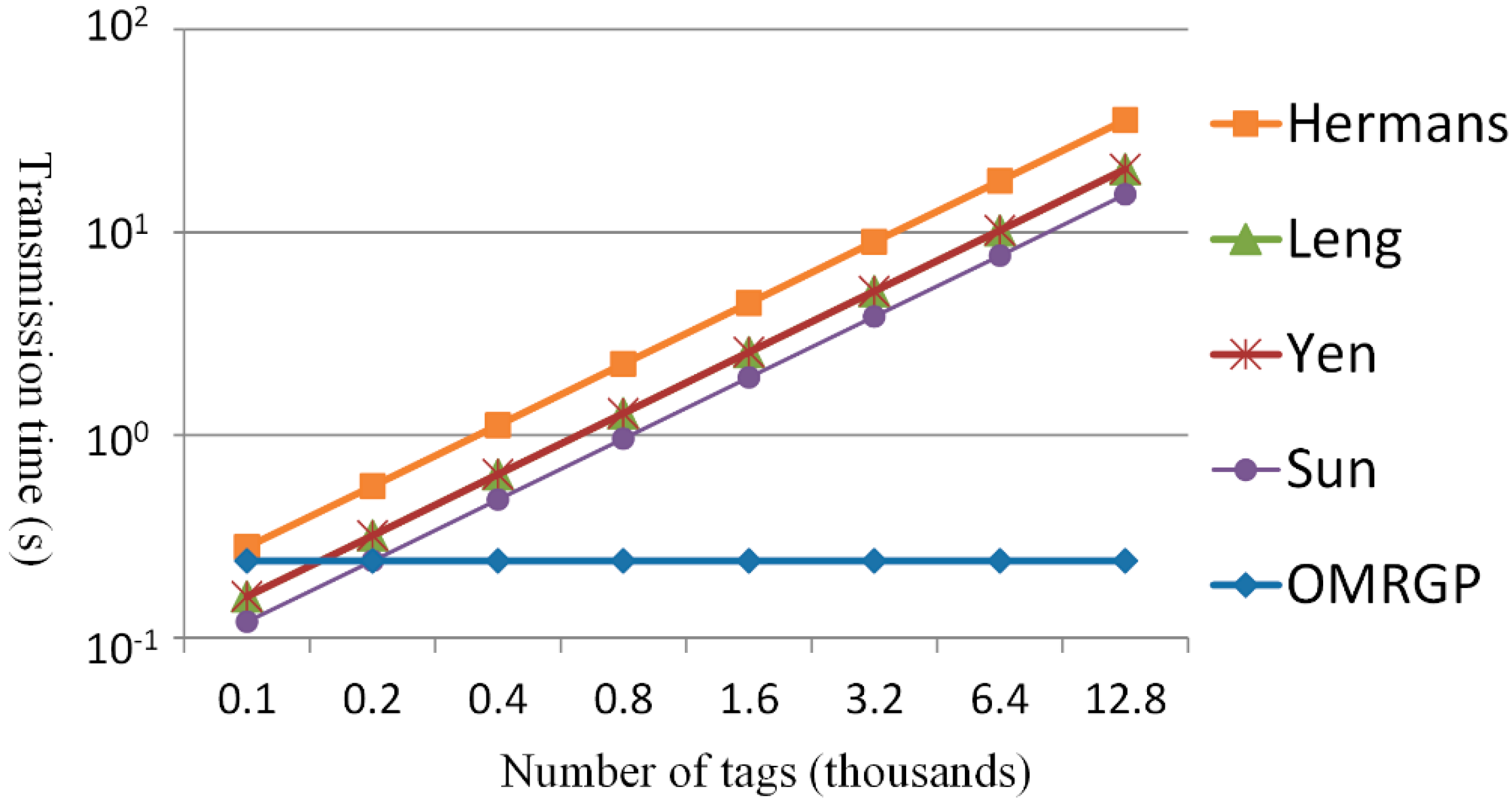
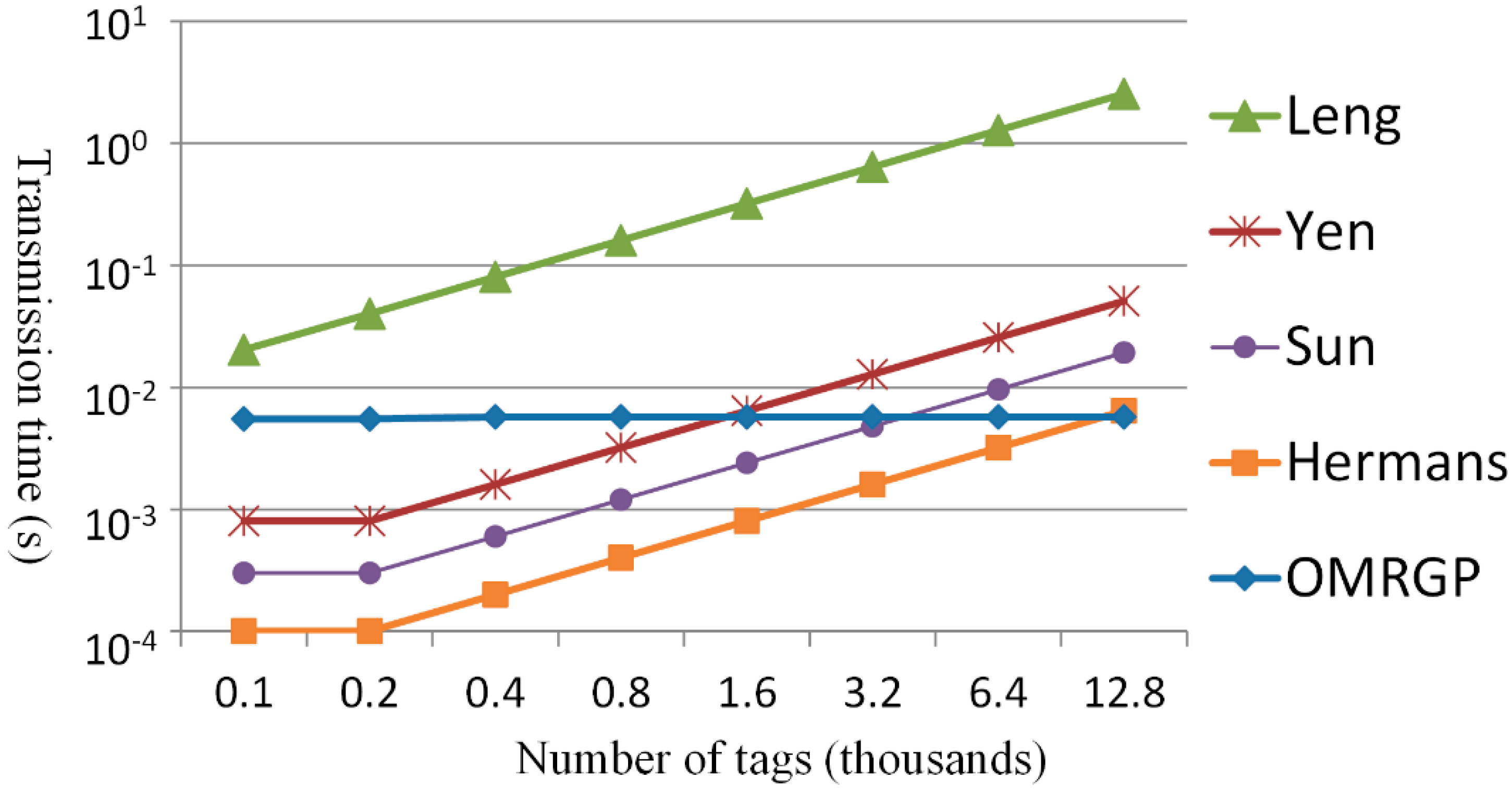
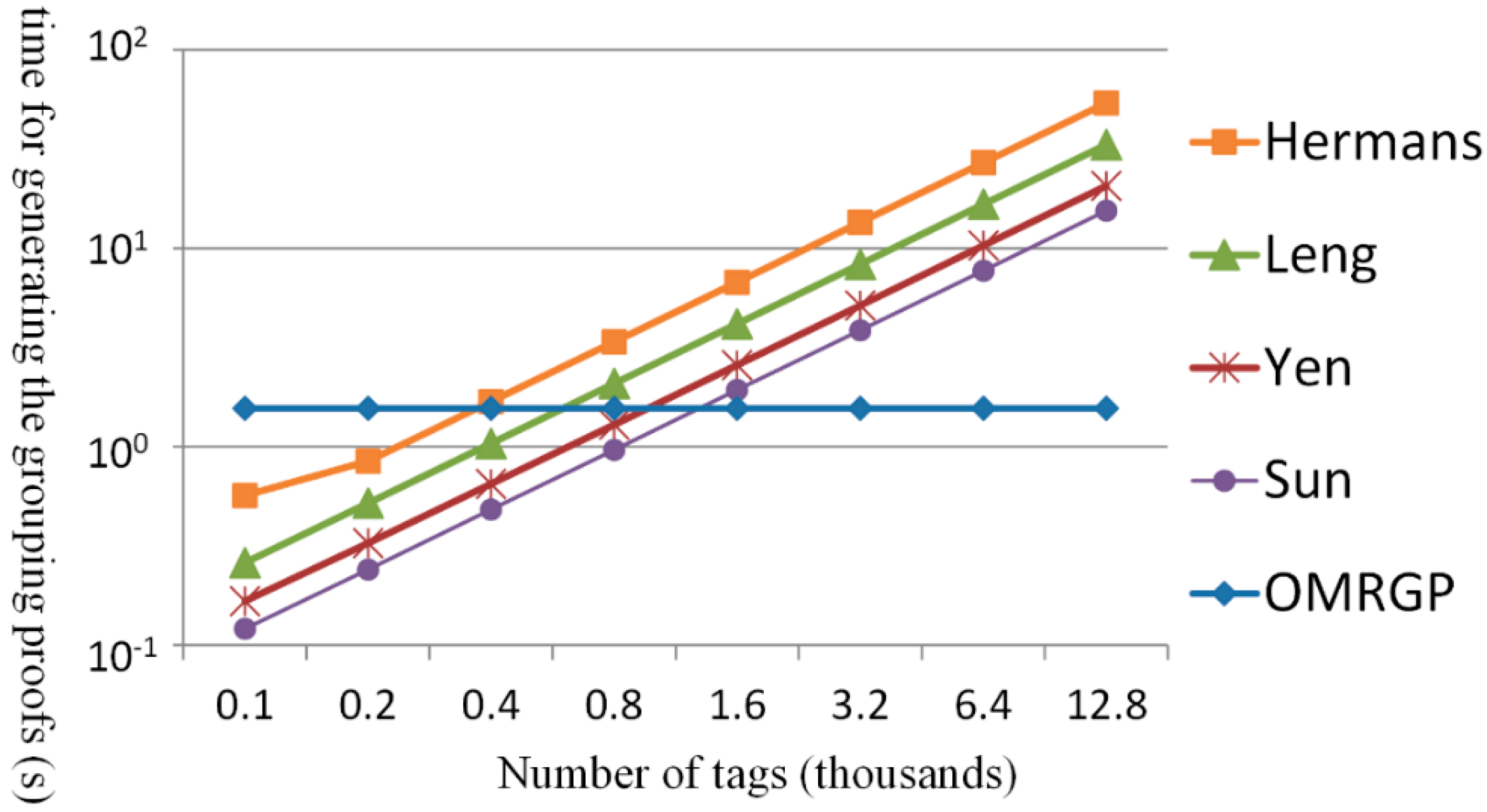
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Engberg, S.J.; Harning, M.B.; Jensen, C.D. Zero-knowledge Device Authentication: Privacy & Security Enhanced RFID preserving Business Value and Consumer Convenience. In Proceedings of the 2nd Annual Conference on Privacy, Security and Trust, Moncton, New Brunswick, Canada, 13–15 October 2004; pp. 89–101.
- Pisarsky, G.M. RFID Technology: An Analysis of Privacy and Security Issues. In Proceedings of the Computer Science Seminar SA3-T1–1, Hartford, CT, USA, 24 April 2004; pp. 1–5.
- Koh, C.E.; Kim, H.J.; Kim, E.Y. The impact of RFID in retail industry:Issues and critical success factors. Shopp. Cent. Res. 2006, 13, 101–117. [Google Scholar]
- Michael, K.; McCathie, L. The Pros and Cons of RFID in Supply Chain Management. In Proceedings of the International Conference on Mobile Business, Sydney, Australia, 11–13 July 2005; pp. 623–629.
- Ekwall, D.; Lantz, B. Seasonality of cargo theft at transport chain locations. Int. J. Phys. Distrib. Logist. Manag. 2013, 43, 728–746. [Google Scholar] [CrossRef]
- Ekwall, D.; Lantz, B. Cargo theft at non-secure parking locations. Int. J. Retail Distrib. Manag. 2015, 43, 204–220. [Google Scholar] [CrossRef]
- Ray, B.R.; Chowdhury, M.; Abawajy, J. Critical Analysis and Comparative Study of Security for Networked RFID Systems. In Proceedings of the 14th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Honolulu, HI, USA, 1–3 July 2013; pp. 197–202.
- Liang, Z.; Rodrigues, J.J.P.C. Service-oriented middleware for smart grid: principle, infrastructure, and application. IEEE Commun. Mag. 2013, 51, 84–89. [Google Scholar] [CrossRef]
- Lo, C.; Hsieh, W.; Huang, L. The Implementation of an Intelligent Logistics Tracking System Utilizing RFID. In Proceedings of the International Conference on Electronic Business, Beijing, China, 18–20 October 2004; pp. 199–204.
- Burmester, M.; Munilla, J. Group-Scanning for RFID Supply Management. In Proceedings of the IEEE RFID Technology and Applications Conference, Tampere, Finland, 8–9 September 2014; pp. 266–271.
- Lien, Y.H.; His, C.T.; Leng, X.; Chiu, J.H.; Chang, H.K. An RFID basedMulti-batch supply chain systems. Wirel. Pers. Commun. 2012, 63, 393–413. [Google Scholar] [CrossRef]
- Zhong, Z.; Qiu-Liang, X. Universal composable grouping-proof protocol for RFID tags in the internet of things. Chin. J. Comput. 2011, 34, 1188–1194. (In Chinese) [Google Scholar] [CrossRef]
- Saito, J.; Sakurai, K. Grouping Proof for RFID Tags. In Proceedings of the International Conference on Advanced Information Networking and Applications, Taipei, Taiwan, 28–30 March 2005; pp. 621–624.
- Juels, A. “Yoking-Proofs” for RFID Tags. In Proceedings of the 2nd Annual International Conference on Pervasive Computing and Communications, Orlando, FL, USA, 14–17 March 2004; pp. 138–143.
- Peris-Lopez, P.; Hernandez-Castro, J.C.; Estevez-Tapiador, J.M.; Ribagorda, A. Solving the Simultaneous Scanning Problem Anonymously: Clumping Proofs for RFID Tags. In Proceedings of the 3rd International Workshop on Security, Privacy and Trust in Pervasive and Ubiquitous Computing, Istanbul, Turkey, 19 July 2007; pp. 55–60.
- Peris-Lopez, P.; Safkhani, M.; Bagheri, N.; Naderi, M. RFID in eHealth: How to combat medication errors and strengthen patient safety. J. Med. Biol. Eng. 2013, 33, 363–372. [Google Scholar] [CrossRef]
- Yu, Y.C.; Hou, T.W.; Chiang, T.C. Low cost RFID real lightweight binding proof protocol for medication errors and patient safety. J. Med. Syst. 2012, 36, 823–828. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.C.; Lai, Y.C.; Tygar, J.D.; Yang, C.K.; Chiang, C.L. Coexistence Proof Using Chain of Timestamps for Multiple RFID Tags. In Proceedings of the Web and Network Technologies and Information Management, Huang Shan, China, 16–18 June 2007; pp. 634–643.
- Sun, H.M.; Ting, W.C.; Chang, S.Y. Offlined Simultaneous Grouping Proof for RFID Tags. In Proceedings of the 2nd International Conference on Computer Science and Its Applications, Jeju, Korean, 10–12 December 2009; pp. 1–6.
- Hermans, J.; Peeters, R. Private Yoking Proofs: Attacks, Models and New Provable Constructions. In Proceedings of the 8th International Conference on RFIDSec, Nijmegen, The Netherlands, 2–3 July 2012; pp. 96–108.
- Lo, N.W.; Yeh, K.H. Anonymous coexistence proofs for RFID tags. J. Inf. Sci. Eng. 2010, 26, 1213–1230. [Google Scholar]
- Ma, C.; Lin, J.; Wang, Y.; Shang, M. Offline RFID Grouping Proofs with Trusted Timestamps. In Proceedings of the International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 674–681.
- Bolotnyy, L.; Robins, G. Generalized “Yoking-Proofs” for a Group of RFID Tags. In Proceedings of the 3rd Annual International Conference on Mobile and Ubiquitous Systems: Networking & Services, San Jose, CA, USA, 17–21 July 2006; pp. 1–4.
- Chien, H.Y.; Liu, S.B. Tree-Based RFID Yoking Proof. In Proceedings of the International Conference on Networks Security, Wireless Communications and Trusted Computing, Wuhan, China, 25–26 April 2009; pp. 550–553.
- Ozcanhan, M.H.; Dalkilic, G.; Utku, S. Analysis of Two Protocols Using EPC Gen-2 Tags for Safe Inpatient Medication. In Proceedings of the Innovations in Intelligent Systems and Applications (INISTA), Albena, Bulgaria, 19–21 June 2013; pp. 1–6.
- Peris-Lopez, P.; Orfila, A.; Hernandez-Castro, J.C.; Lubbe, J. Flaws on RFID grouping-proofs. Guidelines for future sound protocols. J. Netw. Comput. Appl. 2011, 34, 833–845. [Google Scholar] [CrossRef]
- Piramuthu, S. On Existence Proofs for Multiple RFID Tags. In Proceedings of the ACS/IEEE International Conference on Pervasive Services, Lyon, France, 26–29 June 2006; pp. 317–320.
- Sundaresan, S.; Doss, R.; Piramuthu, S.; Zhou, W. A robust grouping proof protocol for RFID EPC C1G2 Tags. J. Inf. Forensics Secur. 2014, 9, 961–975. [Google Scholar] [CrossRef]
- Lien, Y.H.; Leng, X.; Mayes, K.; Chiu, J.H. Reading Order Independent Grouping Proof for RFID Tags. In Proceedings of the International Conference on Intelligence and Security Informatics, Taipei, Taiwan, 17–20 June 2008; pp. 128–136.
- Jantarapatin, S.; Mitrpant, C.; Tantibundhit, C.; Nuamcherm, T.; Kovintavewat, P. Performance Comparison of the Authentication Protocols in RFID System. In Proceedings of the Management of Emergent Digital EcoSystems, New York, NY, USA, 26–26 October 2010; pp. 131–136.
- Nuamcherm, T.; Kovintavewat, P.; Tantibundhit, C.; Ketprom, U.; Mitrpant, C. An Improved Proof for RFID Tags. In Proceedings of the International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Krabi, Thailand, 14–17 May 2008; pp. 737–740.
- Yen, Y.C.; Lo, N.W.; Wu, T.C. Two RFID-based solutions for secure inpatient medication administration. J. Med. Syst. 2012, 36, 2769–2778. [Google Scholar] [CrossRef] [PubMed]
- International Organization for Standardization. ISO/IEC 18000: Information Technology Automatic Identification and Data Capture Techniques—Radio Frequency Identification for Item Management Air Interface, 2003. Available online: http://www.iso.org/iso (accessed on 22 October 2015).
- Cha, J.R.; Kim, J.H. Novel Anti-Collision Algorithms for Fast Object Identification in RFID System. In Proceedings of the 11th International Conference on Parallel and Distributed Systems, Fukuoka, Japan, 22–22 July 2005; pp. 63–67.
- Zhai, J.; Wang, G. An Anti-Collision Algorithm Using Two-Functional Estimation for RFID Tags. In Proceedings of the International Conference on Computational Science and Its Applications, Singapore, 9–12 May 2005; pp. 702–711.
- Fuentes, J.M.; Peris-Lopez, P.; Tapiador, J.E.; Pastrana, S. Probabilistic yoking proofs for large scale IoT systems. Ad Hoc Netw. 2015, 32, 43–52. [Google Scholar] [CrossRef]
- Leng, X.; Lien, Y.; Mayes, K.; Markantonakis, K. An RFID grouping proof protocol exploiting anti-collision algorithm for subgroup dividing. Int. J. Secur. Netw. 2010, 5, 79–86. [Google Scholar] [CrossRef]
- EPCTM Radio-Frequency Identity Protocols Class-1 Generation-2 UHF RFID Protocol for Communications at 860 Mhz–960 Mhz, ver 2.0.0, EPCGlobal Inc., November 2013. Available online: http://www.gs1.org/sites/default/files/docs/epc/uhfc1g2_2_0_0_standard_20131101.pdf (accessed on 22 October 2015).
- Bockorick, R.C.; Cooper, S.; Diorio, C.; Dressler, D.; Gutnik, V.; Hagen, C.; Hara, D.; Hass, T.; Humes, T.; Hyde, J.; et al. Design of ultra-low-cost UHF RFID tags for supply chain applications. IEEE Comm. Mag. 2004, 42, 140–151. [Google Scholar]
- Xu, L.; Huang, C. Computation-efficient multicast key distribution. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 577–587. [Google Scholar]
- Balogh, J.; Békési, J.; Galambos, G. New lower bounds for certain classes of bin packing algorithms. J. Theor. Comput. Sci. 2012, 440, 1–13. [Google Scholar] [CrossRef]
- Fleszar, K.; Charalambous, C. Average-weight-controlled bin-oriented heuristics for the one-dimensional bin-packing problem. Eur. J. Oper. Res. 2011, 210, 176–184. [Google Scholar] [CrossRef]
- Gupta, J.N.D.; Ho, J.C. A new heuristic algorithm for the one-dimensional bin-packing problem. Prod. Plan. Control. 1999, 10, 598–603. [Google Scholar] [CrossRef]
- Huang, H.H.; Ku, C.Y. A RFID grouping proof protocol for medication safety of inpatient. J. Med. Syst. 2009, 33, 467–474. [Google Scholar] [CrossRef] [PubMed]
- Peris-Lopez, P.; Orfila, A.; Mitrokotsa, A.; Lubbe, J. A Comprehensive RFID solution to enhance inpatient medication safety. J. Med. Inf. 2001, 80, 13–24. [Google Scholar] [CrossRef] [PubMed]
- Man, A.S.W.; Zhang, E.S.; Lau, V.K.N.; Tsui, C.Y.; Luong, H.C. Low Power VLSI Design for a RFID Passive Tag baseband System Enhanced with an AES Cryptography Engine. In Proceedings of the 1st Annual RFID Eurasia, Istanbul, Turkey, 5–6 September 2007; pp. 1–6.
- Bogdanov, A.; Leander, G.; Paar, C.; Poschmann, A.; Robshaw, M.J.B.; Seurin, Y. Hash Functions and RFID Tags: Mind the Gap. Cryptographic Hardware and Embedded Systems; Springer Berlin Heidelberg: Heidelberg, Germany, 2008; pp. 283–299. [Google Scholar]
- Feldhofer, M.; Wolkerstorfer, J. Strong Crypto for RFID Tags—A Comparison of Low-Power Hardware Implementations. In Proceedings of the IEEE International Symposium on Circuits and Systems, New Orleans, LA, USA, 27–30 May 2007; pp. 1839–1842.
- Bo, S.; Ito, Y.; Nakano, K. CRT-Based DSP Decryption Using Montgomery Modular Multiplication on the FPGA. In Proceedings of the IEEE International Symposium on Parallel and Distributed Processing Workshops and Phd Forum, Shanghai, China, 16–20 May 2002; pp. 532–541.
- Tsoi, K.H.; Leung, K.H.; Leong, P.H.W. Compact FPGA-based true and pseudo random number generators. In Proceedings of the 11th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, Napa, CA, USA, 9–11 April 2003; pp. 51–61.
- Nakano, K.; Kawakami, K.; Shigemoto, K. RSA Encryption and Decryption Using the Redundant Number System on the FPGA. In Proceedings of the IEEE International Symposium on Parallel & Distributed Processing, Rome, Italia, 23–29 May 2009; pp. 1–8.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.H.; Luo, J.N.; Lu, S.Y. A Novel Multilayered RFID Tagged Cargo Integrity Assurance Scheme. Sensors 2015, 15, 27087-27115. https://doi.org/10.3390/s151027087
Yang MH, Luo JN, Lu SY. A Novel Multilayered RFID Tagged Cargo Integrity Assurance Scheme. Sensors. 2015; 15(10):27087-27115. https://doi.org/10.3390/s151027087
Chicago/Turabian StyleYang, Ming Hour, Jia Ning Luo, and Shao Yong Lu. 2015. "A Novel Multilayered RFID Tagged Cargo Integrity Assurance Scheme" Sensors 15, no. 10: 27087-27115. https://doi.org/10.3390/s151027087
APA StyleYang, M. H., Luo, J. N., & Lu, S. Y. (2015). A Novel Multilayered RFID Tagged Cargo Integrity Assurance Scheme. Sensors, 15(10), 27087-27115. https://doi.org/10.3390/s151027087