A Steady-State Kalman Predictor-Based Filtering Strategy for Non-Overlapping Sub-Band Spectral Estimation

Abstract
: This paper focuses on suppressing spectral overlap for sub-band spectral estimation, with which we can greatly decrease the computational complexity of existing spectral estimation algorithms, such as nonlinear least squares spectral analysis and non-quadratic regularized sparse representation. Firstly, our study shows that the nominal ability of the high-order analysis filter to suppress spectral overlap is greatly weakened when filtering a finite-length sequence, because many meaningless zeros are used as samples in convolution operations. Next, an extrapolation-based filtering strategy is proposed to produce a series of estimates as the substitutions of the zeros and to recover the suppression ability. Meanwhile, a steady-state Kalman predictor is applied to perform a linearly-optimal extrapolation. Finally, several typical methods for spectral analysis are applied to demonstrate the effectiveness of the proposed strategy.1. Introduction
As one of the most important tools, spectral estimation [1] has been extensively applied in radar, sonar and control systems, in the economics, meteorology and astronomy fields, speech, audio, seismic and biomedical signal processing, and so on. In particular, sparse representation [2–4] opens an exciting new vision for spectral analysis. However, such methods are usually accompanied by high computational complexity, which makes their availability somewhat limited.
Sub-band decomposition-based spectral estimation (SDSE) [5] is an important research direction in spectral estimation, because it has several advantageous features, e.g., computational complexity decrease, model order reduction, spectral density whiteness, reduction of linear prediction error for autoregressive (AR) estimation and the increment of both frequency spacing and local signal-to-noise ratio (SNR) [6]. These features have been theoretically demonstrated under the hypothesis of the ideal infinitely-sharp bandpass filter bank [7]. Subsequent studies [8–10] indicate that these benefits aid complex frequency estimation in sub-bands, thereby enabling better estimation performance than that achieved in full-band. In addition, the computational complexity of most algorithms for spectral analysis has a superlinear relationship with the data size, and sub-band decomposition can considerably speed up these algorithms. Independently handling each sub-band enables parallel processing, which can further improve the computational efficiency. Both advantages are crucial for reducing the computational burden, especially when analyzing multi-dimensional big data, such as polarimetric and/or interferometric synthetic aperture radar images of large scenes.
Unfortunately, the ideal infinitely-sharp bandpass filter cannot be physically realized, and non-ideal (realizable) filters introduce energy leakage and/or frequency aliasing phenomena [11]. Due to these non-ideal frequency characteristics of analysis filters, spectral overlap between any two contiguous sub-bands occurs during the sub-band decomposition. Then, the performance of SDSE severely degrades.
In the relevant literature, several methods have been proposed to mitigate spectral overlap. We classify these methods into three categories. The first category is defined as ideal frequency domain filtering with a strict box-like spectrum, such as “ideal” Hilbert transform-based half-band filters [9] and harmonic wavelet transform-based filters [12,13]. Theoretically, sub-band decomposition with these filters is immune to spectral overlap. However, discrete Fourier transform will inevitably induce spectral energy leakage, which can likewise distort sub-band decomposition. The second category is known as convolution filtering with wavelet packet filters [8], Kaiser window-based prototype cosine modulated filters, discrete cosine transform (DCT) IV filters [10] and Comb filters [6,14]. It seems that increasing the filter order can improve the filtering performance and also the spectral overlap suppression capability. However, in the context of involving a finite-length sequence and performing convolution filtering, the nominal improvement of performance will lead to spectral energy leakage and inferior filtering accuracy [10]. Considering the compromise between suppressing spectral overlap and reducing spectral energy leakage, we have to restrict the filter order. The third category is frequency-selective filtering, and a representative method is SELF-SVD (singular value decomposition-based method in a selected frequency band) [15]. Essentially, SELF-SVD attempts to attenuate the interferences of the out-of-band components by the post-multiplication with an orthogonal projection matrix. Unfortunately, the attenuation is often insufficient when the out-of-band components are much stronger than the in-band components or the SNR is relatively low. In this case, the estimation of the in-band frequencies is seriously affected.
In this paper, a new filtering strategy is proposed to suppress spectral overlap for sub-band spectral estimation. First, we discuss the formation mechanism of spectral overlap. Nominally, a high-order finite impulse response (FIR) filter usually has a powerful ability in spectral overlap suppression. However, once we perform such a filter on a finite-length sequence with the convolution operation, the non-given samples at the forward and backward sampling periods of the sequence are assumed to be zeros. A certain filtering error therefore occurs and conversely disrupts the decomposed sub-bands. As a result, sub-band spectral analysis severely suffers from the mutual overlap of adjacent sub-band spectra. Second, we propose a filtering strategy to eliminate the filtering error and recover the suppression ability. This strategy intuitively takes the place of the artificial zeros with some extrapolated samples. Toward the problem of data extrapolation, many algorithms have been proposed based on various theories, such as linear prediction [16], Gerchberg–Papoulis [17], Slepian series [18], linear canonical transform [19] and sparse representation [20]. To establish an efficient method for the extrapolation in context and to evaluate the effectiveness of the proposed strategy, we preliminarily develop a linearly-optimal extrapolation based on the classical AR model identification and the Kalman prediction [21–23]. Third, we derive the formulas to estimate the residual filtering error and adapt two common information criteria with adaptive penalty terms for AR order determination. Moreover, equiripple FIR filters are applied as analysis filters in coordination with the proposed filtering, because of their advantageous features [11]. Finally, the entire algorithm and the computational complexity are summarized. Some details, such as the sub-band spectrum mosaicking procedure and parameter selection, are discussed in practice.
The remainder of the paper is organized as follows. In Section 2, the formation mechanism of spectral overlap is discussed. Based on this, a steady-state Kalman predictor-based filtering strategy is developed to suppress the overlapped spectra. In Section 3, the proposed filtering strategy is discussed for SDSE. In Section 4, experimental results with several typical algorithms for spectral analysis demonstrate the effectiveness of the proposed strategy. Finally, Section 5 concludes this paper.
2. Signal Filtering Based on AR Model Identification and Kalman Prediction
This section focuses on signal filtering. To reduce the filtering error induced by convolution filtering, we propose an extrapolation-based filtering strategy and apply a steady-state Kalman predictor for extrapolation. Two criteria with adaptive penalty terms for order determination are developed based on the estimation of the residual filtering error.
2.1. Problem Statement of Signal Filtering
FIR filters are typical linear time-invariant (LTI) systems. According to the linear system theory, the filter can be mathematically expressed as the convolution of its impulse response with the input. Suppose that {xn} is an input sequence and {hn} is the impulse response of a causal FIR filter; the filtered sequence {yn} can be derived as [11]:
In addition, the filtered sequence length L, the input sequence length N and the filter length Nf satisfy:
Theoretically, given a large enough stop-band attenuation, spectral overlap can be thoroughly suppressed. Moreover, the spectral estimation error in sub-bands can be neglected, as long as the width of the transition band and the ripple of the passband are sufficiently small. Nonetheless, the pursuit of excellent filtering performance substantially increases both the filter order and the length of the filtered sequence (refer to Equation (3)). Such a high order is more likely to create error in part or even all of the filtered samples. This result is contrary to our original objective, and the resultant filtering quality is undesirable.
From the perspective of a discrete-time system, the output sequence of the convolution operation is equivalent to the zero-state response of the filter system, because the initial state of every delay cell is zero prior to the excitation of the input sequence. We take the example of the direct-type FIR system [24]. The value of the output sample at any time depends on all or part of the input samples and the system state at that time. The first Nf − 1 output samples suffer from biases, because a part of the delay cells do not yet become input-driven states; analogously, the last Nf − 1 output samples are invalid, because a part of the delay cells restore the initial zero-states. Thus, the length of the valid part of the output sequence, defined as Lυ, satisfies:
Actually, if we rewrite Equation (1) in the following matrix form:
Referring to Equation (4), we note that, if the filter order is not less than the length of the input sequence, the output samples are all invalid. Thus, improving filtering performance by means of unlimited increasing filter order is meaningless.
In the next subsection, we will identify an efficient way to resolve this problem.
2.2. Filtering Procedure Based on Signal Extrapolation
The desired output of the filtering process should have two characteristics:
The original and filtered sequences should be of equal length;
During the filtering process, the states of the delay cells in the filter system should always maintain input-driven states, i.e., there are no artificial zeros, but authentic samples in X.
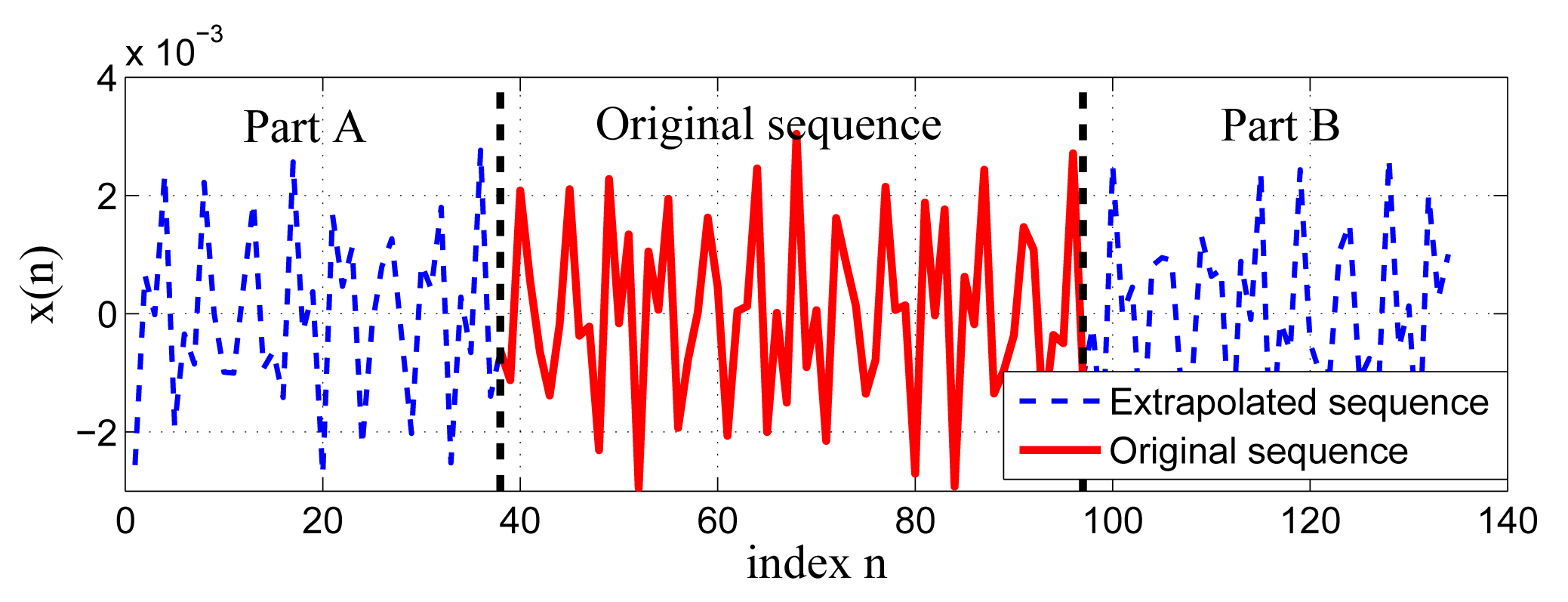
As shown in Equation (5), the convolution filtering assumes the unknown samples x−No, x−No+1, …, x−1; xN, xN+1, …, xN+No−1 to be zeros, which leads to the filtering error. Thus, an intuitive thought is to extrapolate the sequence along two sides to provide a series of estimates for the unknown samples. Taking place of the zeros in the matrix X with these estimates can mitigate the filtering error. The input sequence is extrapolated along both sides, yielding two extrapolated sequences, called Part A and Part B (see Figure 1). Suppose that LA and LB are the lengths of Part A and Part B, respectively; then, those LA + LB extrapolated samples are used to replace zeros in X. According to Equation (3), the length of the associated output sequence is LA + LB + N + No. From Equation (4), the effective length of the output can be given by LA + LB + N − No. To satisfy the requirement that the original and filtered sequence are of equal length, the extrapolated length can be derived as:
Now, we can conclude that the extrapolated length should be equal to the filter order. We define LG as the constant group delay of the filter. Between time No and time N + No, the output samples are valid. The output sample at time No + n (n = 1, 2, ⋯ , N) corresponds to the input sample at time No − LG + n (n = 1, 2, ⋯ , N), because of the group delay. Consequently, the input sample before time No − LG is merely used as a training sequence of the system state. Thus, we can obtain the relationships:
Let x̂n and ŷn be the extrapolated sequence and associated filtered result, respectively. Then, they satisfy:
The filtering process can be rewritten in matrix form as:
2.3. Signal Extrapolation Based on AR Identification and Kalman Prediction
According to the linear prediction theory [25], the AR model is an all-pole model, whose output variable only linearly depends on its own previous values, that is,
We choose the forward-backward approach [1] as the coefficient estimator for AR model, for its precision and robustness. Both criteria, including the Akaike information criterion (AIC) and Bayesian information criterion (BIC) [26] can be applied to determine the model order; whereas both criteria sometimes suffer from overfitting. An alternative method of order determination will be discussed in Section 2.4.
A linearly-optimal prediction for AR sequences is derived in [21–23] under the minimum mean square error (MMSE) criterion. However, the prediction formula involves a polynomial long division and a coefficient polynomial recursion [23], making the calculation of the prediction somewhat inconvenient. Alternatively, the following steady-state Kalman predictor [27] provides an equivalent prediction with the MMSE predictor, while offering a simpler formula to facilitate the computation.
The AR model is regarded as a dynamic system. A specific state-space representation for a univariate AR(p) process can be written as [25]:
The coefficient polynomials of xn and εn are Φ(q−1) and one, respectively. Since they are relative prime polynomials (or coprime), i.e., the transfer function is irreducible, the system of the AR model is a joint controllable and observable discrete linear stochastic system [28]. Thus, there exists a steady-state Kalman predictor:
Since both εn and en are the innovation processes of xn, they are equal [27]:
By comparing Equation (15) with Equation (19), we have:
Therefore, the one-step steady-state Kalman predictor can be derived as [28]:
Similarly, the k-step steady-state Kalman predictor can be presented as:
Here, define:
Then, we can obtain:
Analogously, the k-step backward extrapolation formula can be given by:
In order to evaluate the residual filtering error of the proposed filtering strategy, we derive the mean square error (MSE) in Appendix A1.
2.4. Adaptive Information Criteria for AR Order Determination
Given the impulse response of an analysis filter and AR coefficients, we can directly calculate MSE by Equations (A2) and (A10). The precision of AR coefficient estimation is concerned with AR order. Consequently, the filtering error at different AR orders can be evaluated with the preceding formulas; conversely, the calculation of MSE can be used for order determination.
AIC and BIC are two common information criteria, whose purpose is to find a model with sufficient goodness of fit and a minimum number of free parameters. In terms of the maximum likelihood estimate we can denote AIC and BIC as [26]:
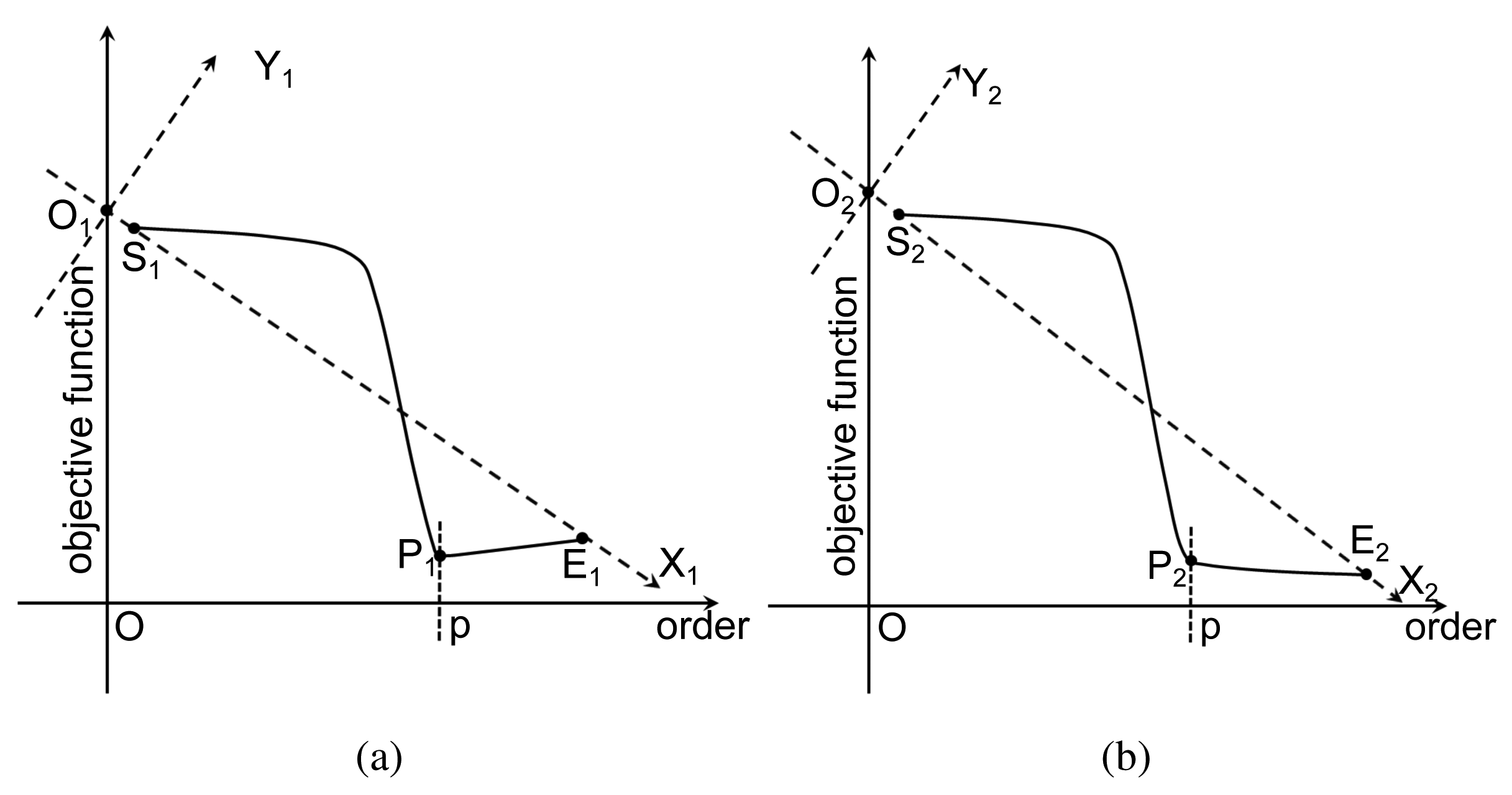
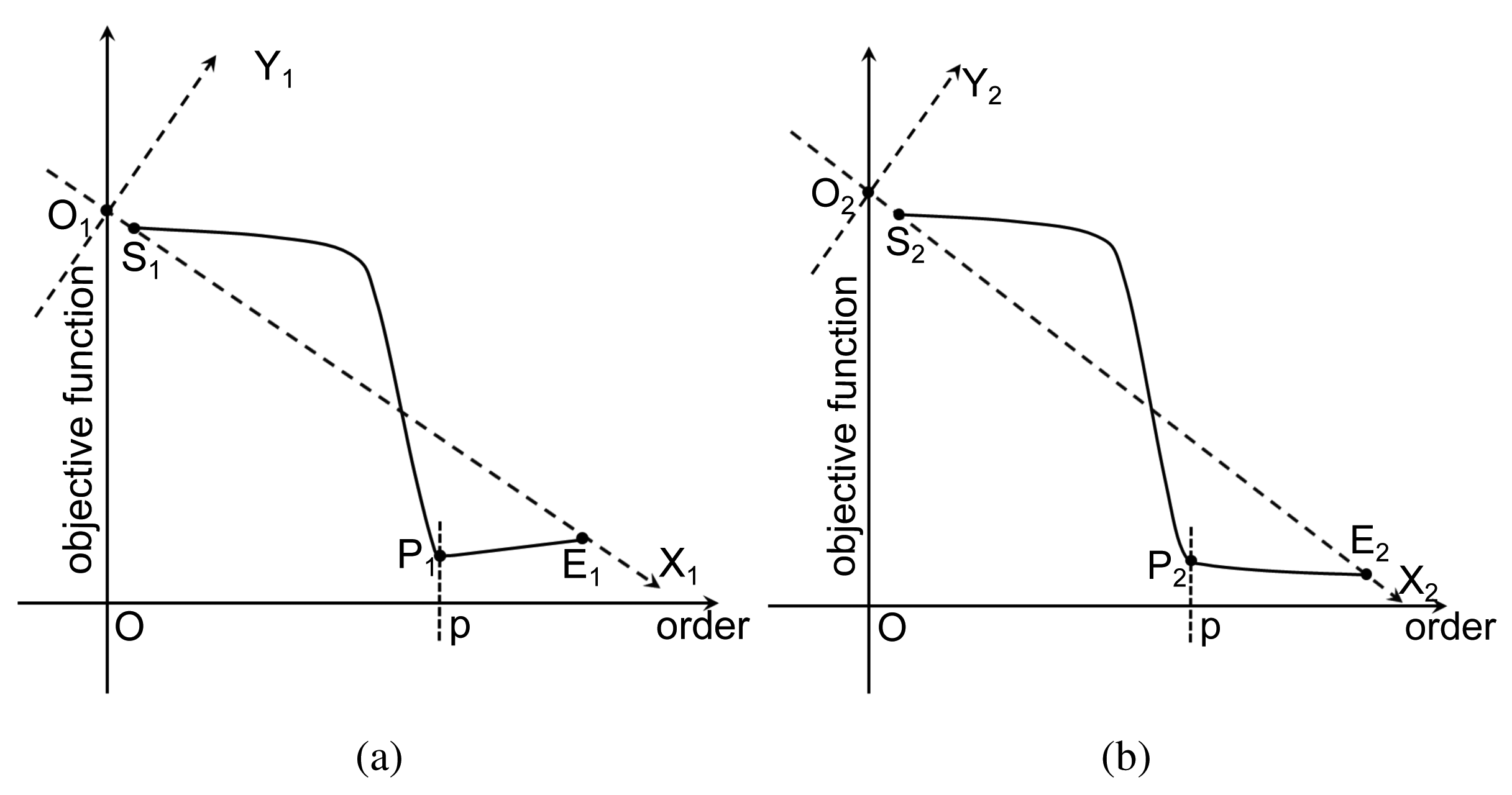
As explained in [29], due to the lack of samples, both criteria encounter the risk of overfitting, where the selected order will be larger than the truth order. In particular, AIC has the nonzero overfitting probability as the sample number tends to infinity. Theoretically, both criteria consist of two terms: the first term involves MSE, and it decreases with the increment of the order p; the other term is a penalty that is an increasing function of p. The preferred model order is the one with the lowest AIC or BIC value. As shown in Figure 2a, the objective function curve reaches its minimum value at the point P1, which gives the correct order p. However, sometimes, both criteria may fail to determine available orders, and those failures are often related to inadequate penalties. Figure 2b illustrates a representative case. Since the change of the objective function instantly slows down as the order exceeds p, the point P2 is the preferred point for order determination. However, the penalty strength is insufficient, so that the objective function is still falling after P2. To handle this situation, we propose an adaptive mechanism to adaptively adjust the penalty strength. A geometric interpretation is depicted in Figure 2b. We assume that the order interval for computation consists of the correct order. Then, the ray forms the X2 axis, while the ray forms the Y2 axis perpendicular to the ray throughout the intersection O2 of the ray and the objective function axis. Under the new coordination system X2O2Y2, the minimum point P2 of the curve can help to determine the correct order. Meanwhile, this modification has no impact on the case that the criterion works well (see Figure 2a).
Therefore the adaptive AIC (AAIC) based on MSE of the residual filtering error can be derived as:
Analogously, the adaptive BIC (ABIC) can be represented as:
3. Implementation of SDSE
In this section, we discuss the implementation details of SDSE based on the proposed filtering strategy. In particular, equiripple FIR filters are used as the analysis filters for their advantageous features. To suppress spectral overlap and improve spectral precision in practice, we introduce a mosaicking operation for sub-band spectra and discuss the compensation of the residual error of the composite spectrum. After that, we summarize the entire algorithm and analyze the computational complexity.
3.1. Properties and Design of Equiripple FIR Filters
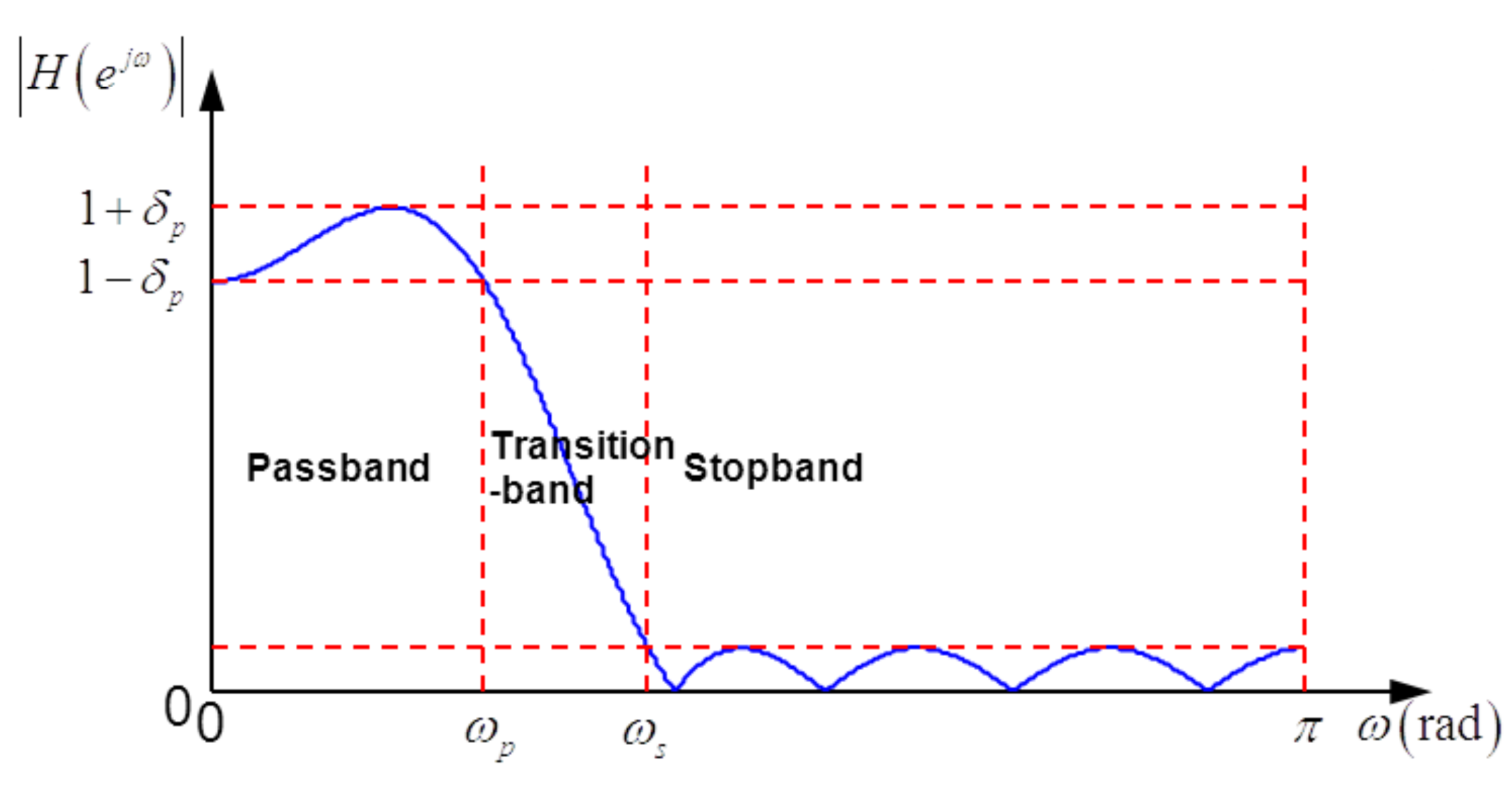
Besides the advantages of FIR filters, i.e., exact linear phase response and inherent stabilization, equiripple FIR filters have an explicitly specified transition width and passband/stop-band ripples (see Figure 3). As analysis filters, equiripple FIR filters can bring some important benefits, such as stop-band attenuation with a fixed maximum, the explicitly specified width of the invalid part of the sub-band spectrum (which corresponds to the transition-band spectrum) and a limited maximum deviation of the valid part of the sub-band spectrum (which corresponds to the passband spectrum). As shown in Figure 3, the specifications of a typical equiripple FIR filter consist of the passband edge ωp, stop-band edge ωs and maximum error in passband and stop-band δp, δs, respectively. The approximate relationship between the optimal filter length and other parameters developed by Kaiser [11] is:
The maximum passband variation and the minimum stop-band attenuation in decibels are defined as:
When the specification of a filter is explicitly specified, we can complete the design with the Parks–McClellan (PM) algorithm [30], since it is optimal with respect to the Chebyshev norm and results in about 5 dB more attenuation than the windowed design algorithm [11].
3.2. Practical Consideration of Equiripple FIR Filters
Firstly, the equiripple low-pass FIR filter is combined with a preprocessing step—complex frequency modulation—to form a passband filter for sub-band decomposition (see Figure 4).
The magnitude response of the analysis filter is shown in Figure 5, where ωH and ωL denote the high and the low edge of the stop-band, respectively. They satisfy:
As long as As is large enough and the downsample rate M meets the condition:
Secondly, due to the existence of the transition-band of each analysis filter, each sub-band spectrum contains two invalid parts. The spectral estimations of these invalid parts lead to errors. Consequently, according to [31], when mosaicking these sub-band spectral estimations into full-band, we should omit these invalid parts of spectral estimations. This procedure is illustrated in Figure 6. Thus, the composite full-band spectral estimation is practically immune to the spectral overlap.
Thirdly, due to the existence of passband ripples in equiripple FIR filters, there theoretically remains a small error in sub-band spectral estimations. Generally, by adjusting the maximum passband variation, we can limit the error to an allowable range. More precise spectral estimation necessitates compensation for the residual error. Since the ripple curve for any given equiripple FIR filter can be accurately measured, the compensation can be performed by weighting sub-band spectral estimations with the measured ripple curve.
Finally, we focus on selecting appropriate filter parameters in SDSE, which can improve the performance and reduce computational cost. The filter order should at least meet:
The maximum stop-band attenuation should exceed the dynamic range of the signal to be analyzed. Once the aforementioned conditions are satisfied, the shortest transition-width can be chosen by Equation (34). Moreover, specific requirement will help to set the maximum passband variation.
3.3. Computational Complexity of SDSE
| Algorithm 1 Non-overlapping sub-band spectral estimation with the steady-state Kalman predictor-based filtering strategy. |
| Input: The sequence . |
| Parameters: The maximum passband variation Ap and the minimum stop-band attenuation As in decibels; the sub-band number M. |
| Filter Design: |
| Set the stop-band edge ωs by Equation (39); |
| Set the passband edge ωp by Equations (34), (35), (36), (37) and (40); |
| Design the equiripple FIR filter by Parks–McClellan (PM) algorithm [30], and then, compute the impulse response and the group delay LG. |
| AR Identification and Order Selection: |
| for pi = ps to pe (usually set ps = 1, pe ⩽ N/2 − 1) do |
Estimate coefficients
of AR model by the forward and backward estimator, with
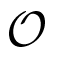 flops; flops; |
| Estimate the MSE
by (A10) and (A11), with
flops; |
| end for |
| Select an order p by Equation (31) or Equation (33), with
(N) flops. |
| Sequence Extrapolation: |
| Set the step-size k by Equation (28); |
| Calculate
by Equations (16), (17) and (24), with
((2p)k−1) flops; |
| Implement forward and backward extrapolations by Equations (26) and (27), and obtain
, with
(No p) flops. |
| Sub-Band Spectral Estimation: |
| Set a rational factor , where [[]] denotes a rational approximation; |
| for i = 1 to M do |
| Compute ωH and ωL by Equation (38) and ωH + ωL = (2i − 1) π/M; |
| Perform pre-modulation and filtering for
by Figure 4 and Equation (10), and the computational complexity is in
(2 (N + No) log (N + No)) flops; |
| Decimate the sequence , by a factor of M0, and obtain the sub-band sequence , where ⌈ ⌉ denotes the ceiling function; |
| Perform spectral analysis for the sub-band sequence , and denote the length of the sub-band spectrum as Ls; |
| Compute the length of overlapped spectrum by and omit the overlapped parts at both the left and the right side of the sub-band spectrum. |
| end for |
| Mosaic the residual sub-band spectrums into an entire spectrum. |
| Output: The entire spectrum. |
As shown in Algorithm 1, we summarize SDSE with the proposed filtering strategy and give the computational complexity of the major steps. First, the proposed strategy can greatly reduce the computational burden. We take the commonly-used amplitude and phase estimation (APES) [32] algorithm as an example. The full-band APES needs
(N2 log N) flops [33], while the computation requirement is decreased to
flops by SDSE with the proposed strategy. Second, except the sub-band spectral estimation, the main computation requirement is induced by the AR identification and the order selection. The computational complexity of this step is generally much lower than that of the sub-band spectral estimation. In particular, if a proper order or a small enough order interval is preselected before the AR identification, the computation of this step can be negligible.
4. Simulations and Analysis
In this section, both the feasibility and the effectiveness of the proposed strategy are evaluated by typical numerical simulations, including FIR filtering and line spectral analysis of 1D or 2D sequences.
4.1. Filtering Analysis Using the Proposed Strategy
Suppose that the input sequence {xn} is a mixed complex exponential sequence:
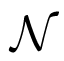 (0, σ2). Our purpose is to non-distortedly extract the weak component
from xn or completely eliminate the strong component
.
(0, σ2). Our purpose is to non-distortedly extract the weak component
from xn or completely eliminate the strong component
.The equiripple half-band low-pass FIR filter is chosen for the extraction. The specifications of the filter are:
The length of the designed filter based on the given specifications is 119.
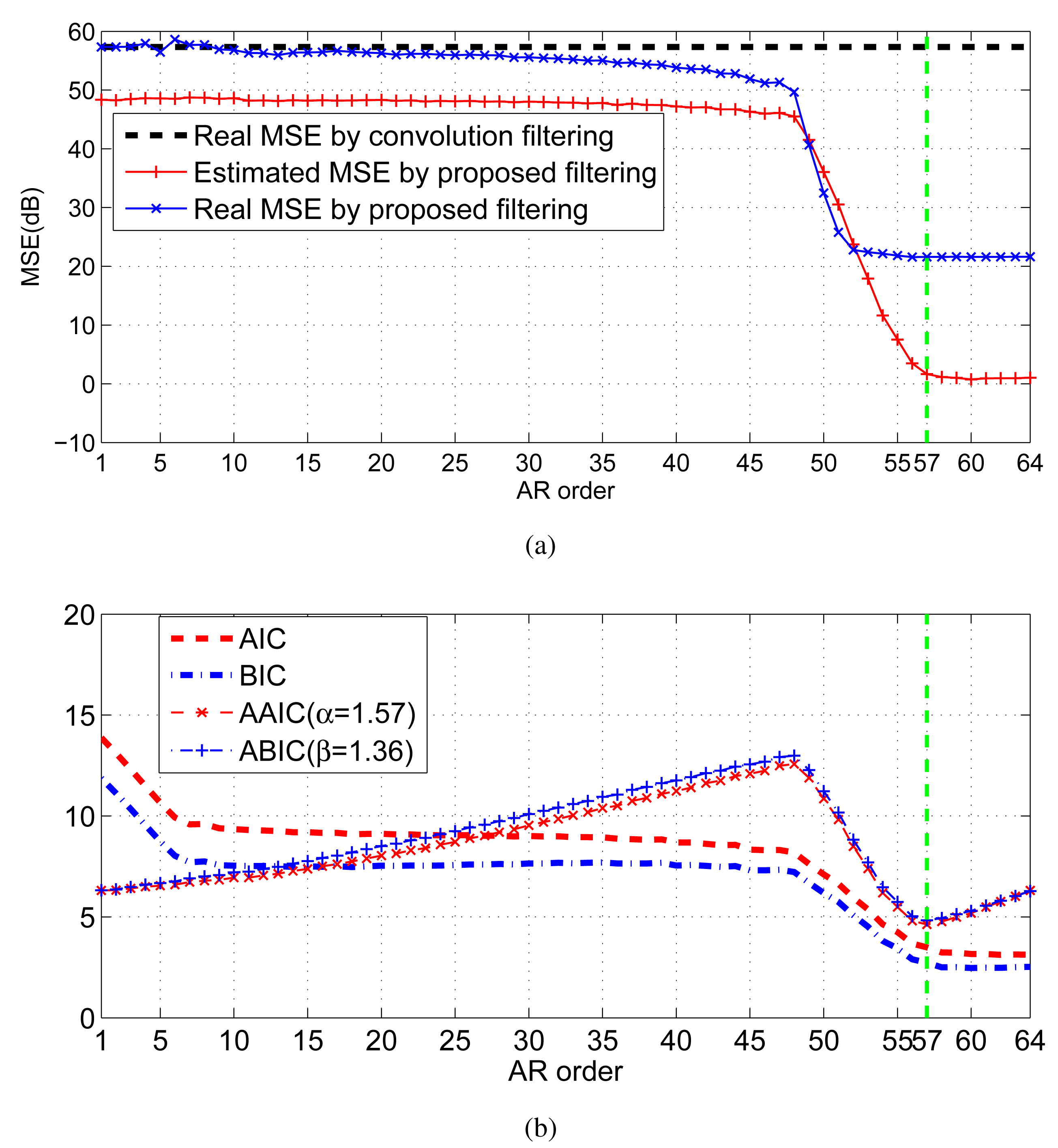
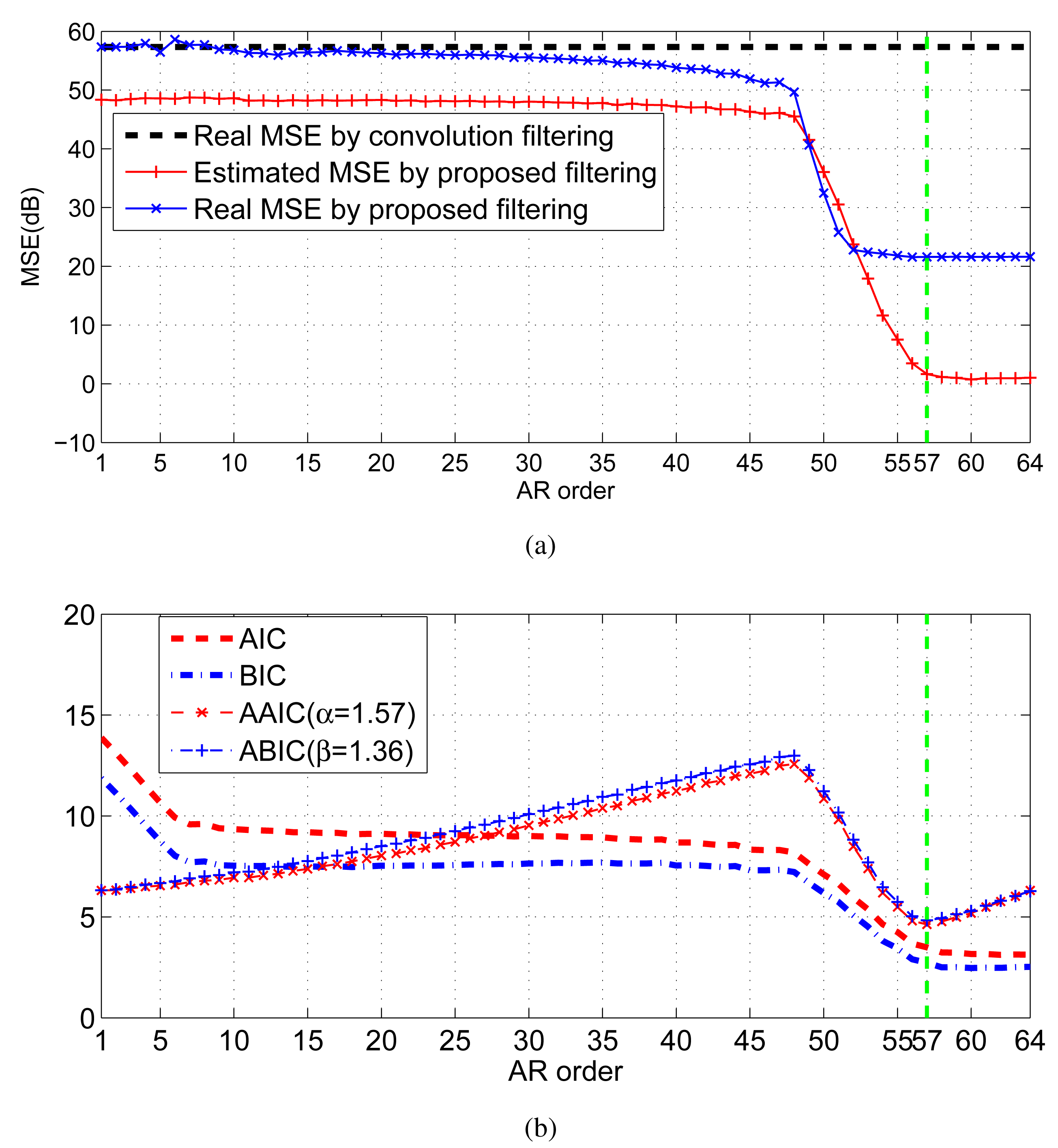
As shown in Figure 7a, the decreasing trend of the estimated residual error by the proposed strategy is consistent with the real error. When the order exceeds 57, the decrease of the estimated filtering error instantly slows down. Hence, the preferred order is 57. By comparison, due to the deficiency of the penalty strength, none of AIC and BIC can provide the right order; whereas, based on the adaptive penalty terms, both AAIC and ABIC get the right order 57 (see Figure 7b).
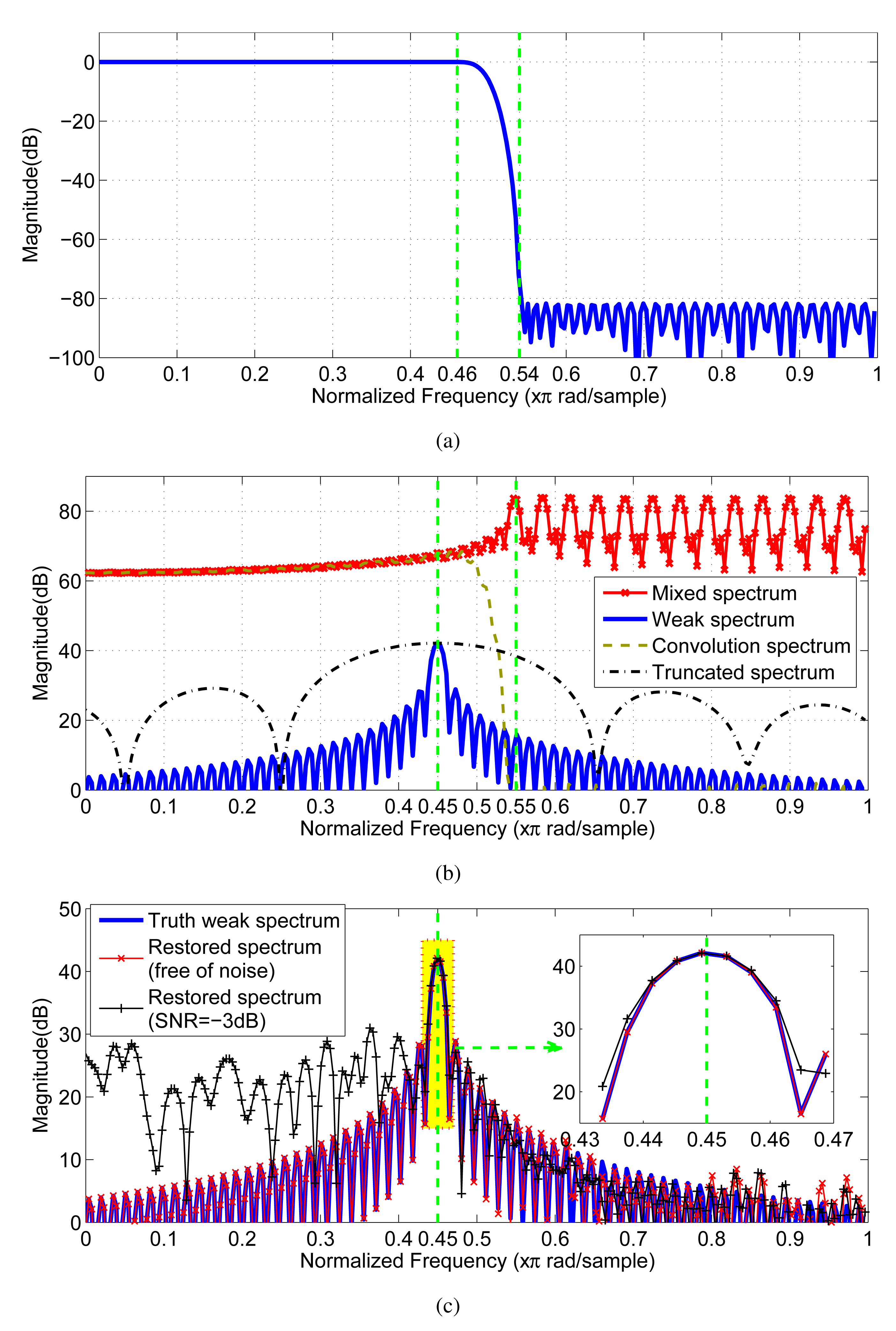
As shown in Figure 8b, the weak component is completely covered by the sidelobe of the out-of-band strong component thus, recognizing the existence of the weak component from the mixed spectrum is completely impossible. From the view of the magnitude response (see Figure 8a), the filter has the nominal ability of eliminating the interference of the out-of-band strong components for the in-band weak component. Due to the existence of the convolution filtering error, we still cannot find out the weak component from the convolution spectrum, as shown in Figure 8b. By contrast, once the samples contaminated by the filtering error are omitted by Equation (4) from the filtered sequence, the weak component reappears in the spectrum of the remaining samples (refer to the truncated spectrum in Figure 8b). However, the truncated spectrum has a much wider main lobe than the original spectrum, which means the spectral resolution suffers from a severe decrease. In order to simultaneously maintain the resolution and filter out the interference, we apply the proposed filtering strategy to handle the case. As shown in Figure 8c, based on the proposed strategy, the restored spectrum for the noiseless sequence closely coincides with the truth weak spectrum in shape, especially retaining the spectral resolution. In addition, even when the signal-to-noise (SNR) of is low to −3 dB (when σ2 = 1), the recovery is still effective (see the magnified details of Figure 8c).
4.2. Line Spectral Analysis Using 1-D Signals
A complex exponential model can be mathematically represented as:
(0, σ2). ϕk,
and
are i.i.d. uniform random variables on the interval from zero to 2π, i.e., ϕk,
,
∼
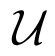 [0, 2π).
[0, 2π).In this case, we can get each component's SNR of :
We decompose the mixed-signal xn into four sub-bands using the proposed method with the filter parameter set as:
The sub-band, whose radian frequency is within [−0.125π, +0.125π), is used for frequency estimation. Furthermore, we estimate the frequencies of complex sinusoids of that are contained in both mixed-signal xn and the decomposed sub-band signal, via MUSIC, ESPRIT [34,35] and SELF-SVD [15] algorithms (see Table 1). As shown in Table 1, we analyze the performance based on the Monte Carlo method. Compared with ESPRIT, SELF-SVD in full-band spectral estimation suffers from obvious performance degradations or even failures. Although SELF-SVD can theoretically attenuate the out-of-band components for the in-band frequency estimations, the ability of attenuation is not always sufficient, especially when the power of the out-of-band components are much stronger than that of the in-band components or the SNR is relatively low. Instead of performing the SVD method in the entire frequency domain as ESPRIT, SELF-SVD just performs it in the frequency interval of interest. Obviously, the remaining out-of-band interferences will be treated as in-band components, so that the frequency estimation with SELF-SVD sometimes fails. In the experiment, the power ratio of the out-of-band components to the in-band components ω2 and ω4 is up to 10,000 times. As a result, the corresponding frequency estimation with SELF-SVD fails to work. When we eliminate the out-of-band interferences with our method, the estimation of SELF-SVD for the residual signal exhibits similar performance as ESPRIT. In addition, MSEs of MUSIC and ESPRIT indicate that the frequency estimation in the sub-band is much more accurate than that in the full-band.
4.3. Line Spectral Analysis Using 2D signals
Let Ck (k = 1, 2, …, K) be a series of random integers with unique values generated from a uniform discrete distribution on [1,1024 × 1024]. We define two sets of nonnegative integers as:
The 2D signal model can be expressed as:
(0, σ2) with σ2 = 0.005.
are uniform random variables on the interval from zero to 2π, i.e.,
.The spectrum of this 2D sequence is shown in Figure 9. Since the magnitude of is 60 dB greater than that of , the sidelobe of the former significantly affects the spectral estimation of the latter. This affect is especially more severe for the components around . The region inside the red pane is used to verify the performance of the proposed method.
The parameters of the analysis filter are selected as:
The comparison of Figure 10a and 10c indicates that the Fourier spectrum of is severely affected by . By contrast, the result shown in Figure 10b seems to be almost exactly the same as the desired result shown in Figure 10c. This decomposition result verifies the effectiveness of the proposed method.
To further testify the performance of our method, we select the APES [32] and the iterative adaptive approach (IAA) [36,37] for spectral estimation. Since the ideal frequency domain filters suffer from energy leakage and/or frequency aliasing problems, the APES result shown in Figure 10c is somewhat blurred. By contrast, the APES result of the decomposed sub-band based on the proposed strategy (see Figure 10d) is quite similar to the actual spectrum (see Figure 10e). Theoretically, the IAA is superior to the APES. However, as shown in Figure 10g, it is even more likely than the APES to suffer from out-of-band interferences. From the view of the sub-band IAA spectrum (see Figure 10h), most of the interferences are eliminated, while the remaining filtering error still has impacts on the spectrum. Thus, the spectral estimation experiment reveals that the sub-band decomposition based on the proposed method can provide relatively ideal performance; whereas the developed method for extrapolation is imperfect, so it can affect the performance of the IAA algorithm.
In addition, a simulated single-polarized SAR image of an airplane based on the physical and optical model is processed via the APES. The computation time of full-band APES (refer to Figure 11a) is 26.85 h, while the time of sub-band APES (refer to Figure 11b) is just 0.84 h. Obviously, the two imaging results only have tiny differences, which are hardly recognized.
5. Conclusion
This paper has investigated the problem of suppressing spectral overlap in sub-band spectral estimation. The spectral overlap phenomenon is originated from the non-ideal behavior of the analysis filtering, i.e., the filtering error. The error formation in convolution filtering was therefore discussed, based on which an extrapolation-based filtering strategy was proposed to greatly suppress spectral overlap. Several classical theories, including AR identification, Kalman prediction and the equiripple FIR filtering technique, are integrated into the strategy for linearly-optimal extrapolation. To resolve the “overfitting” in order determination with AIC and BIC, we modified the penalty terms for both criteria. The improved criteria adaptively adjust the penalty strength and avoid “overfitting” to some extent. Both 1D and 2D complex exponential signals are utilized to validate the performance of the proposed method. Moreover, we employed SAR image formation for a single-polarized SAR data, simulated based on electromagnetic theory, to testify the efficiency of our method. Future research will focus on developing more sophisticated methods for the problem of extrapolation, with which we can avoid model order determination and further improve the extrapolation precision.
Acknowledgments
The work was in part supported by the NSFC (No. 41171317), in part supported by the key project of the NSFC (No. 61132008), in part supported by the major research plan of the NSFC (No. 61490693), in part supported by the Aeronautical Science Foundation of China (No. 20132058003) and in part supported by the Research Foundation of Tsinghua University. The authors would also like to thank the reviewers for their helpful comments.
Author Contributions
Zenghui Li contributed to the original idea, algorithm design and paper writing. Bin Xu contributed in part to data processing. Jian Yang and Jianshe Song supervised the work and helped with editing the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix
A1. Residual Filtering Error Analysis
A stationary AR(p) process can be represented as:
Then k-step prediction formula in an alternative form is:
The prediction error is , and this mean that the variance and covariance are:
We define the desired output as ỹn and by analogy to Equation (11), we define its associated vector as:
All elements of X̃ are truth samples, which are assumed to be known for derivation. Then, according to (A6), we can derive the MSE as:
References
- Stoica, P.; Moses, R. Spectral Analysis of Signals; Robbins, T., Ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Çetin, M.; Stojanović, I.; Önhon, N.O.; Varshney, K.R; Samadi, S.; Karl, W.C.; Willsky, A.S. Sparsity-driven synthetic aperture radar imaging: Reconstruction, autofocusing, moving targets, and compressed sensing. IEEE Signal Process. Mag. 2014, 31, 27–40. [Google Scholar]
- Sun, K.; Liu, Y.; Meng, H.; Wang, X. Adaptive sparse representation for source localization with gain/phase errors. Sensors 2011, 11, 4780–4793. [Google Scholar]
- Stoica, P.; Babu, P.; Li, J. New method of sparse parameter estimation in separable models and its use for spectral analysis of irregularly sampled data. IEEE Trans. Signal Process. 2011, 59, 35–47. [Google Scholar]
- Rao, S.; Pearlman, W.A. Spectral estimation from sub-bands. Proceedings of IEEE-SP International Symposium on Time-Frequency and Time-Scale Analysis, Victoria, BC, Canada, 4–6 October 1992; pp. 69–72.
- Bonacci, D.; Mailhes, C.; Djuric, P.M. Improving frequency resolution for correlation-based spectral estimation methods using sub-band decomposition. Proceedings of 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; pp. 329–332.
- Rao, S.; Pearlman, W.A. Analysis of linear prediction, coding, and spectral estimation from sub-bands. IEEE Trans. Inf. Theory 1996, 42, 1160–1178. [Google Scholar]
- Lambrecht, C.B.; Karrakchou, M. Wavelet packets-based high-resolution spectral estimation. Signal Process. 1995, 47, 135–144. [Google Scholar]
- Rouquette, S.; Berthoumieu, Y.; Najim, M. An efficient sub-band decomposition based on the Hilbert transform for high-resolution spectral estimation. Proceedings of the IEEE-SP International Symposium on Time-Frequency and Time-Scale Analysis, Paris, France, 18–21 June 1996; pp. 409–412.
- Tkacenko, A.; Vaidyanathan, P.P. The role of filter banks in sinusoidal frequency estimation. J. Franklin Inst. 2001, 338, 517–547. [Google Scholar]
- Madisetti, V.K. The Digial Signal Processing Handbook, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Narasimhan, S.V.; Harish, M. Spectral estimation based on sub-band decomposition by harmonic wavelet transform and modified group delay. Proceedings of 2004 International Conference on Signal Processing and Communications, Bangalore, India, 11–14 December 2004; pp. 349–353.
- Narasimhan, S.V.; Harish, M.; Haripriya, A.R.; Basumallick, N. Discrete cosine harmonic wavelet transform and its application to signal compression and sub-band spectral estimation using modified group delay. Signal Image Video Process. 2009, 3, 85–99. [Google Scholar]
- Bonacci, D.; Michel, P.; Mailhes, C. Sub-band decomposition and frequency warping for spectral estimation. Proceedings of European Signal and Image Processing Conference (EUSIPCO), Toulouse, France, 3–6 September 2002; pp. 147–150.
- Stoica, P.; Sandgren, N.; Selén, Y.; Vanhamme, L.; Huffel, S.V. Frequency-domain method based on the singular value decompsition for frequency-selective NMR spectroscopy. J. Magn. Reson. 2003, 165, 80–88. [Google Scholar]
- Brito, A.E.; Chan, S.H.; Cabrera, S.D. SAR image superresolution via 2-D adaptive extrapolation. Multidimens. Syst. Signal Process. 2003, 14, 83–104. [Google Scholar]
- Papoulis, A. A new algorithm in spectral analysis and band-limited extrapolation. IEEE Trans. Circult Syst. 1975, CAS-22, 735–742. [Google Scholar]
- Devasia, A.; IAENG; Cada, M. Extrapolation of bandlimited signals using slepian functions. Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 23–25 October 2013; pp. 1–6.
- Shi, J.; Sha, X.; Zhang, Q.; Zhang, N. Extrapolation of bandlimited signals in linear canonical transform domain. IEEE Trans. Signal Process. 2012, 60, 1502–1508. [Google Scholar]
- Gosse, Laurent. Effective band-limited extrapolation relying on Selpian series and ℓ1 regularization. Comput. Math. Appl. 2010, 60, 1259–1279. [Google Scholar]
- Ljung, L. System Identification: Theory for the User, 2nd ed.; Prentice Hall: Upper Saddle River, NJ,USA, 1999; pp. 18–62. [Google Scholar]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994; pp. 72–116. [Google Scholar]
- Stoica, P. Multistep prediction of autoregressive signals. Electron. Lett. 1993, 29, 554–555. [Google Scholar]
- Oppenheim, A.V.; Schafer, R.W.; Buck, J.R. Discrete-Time Signal Processing, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1999; pp. 366–367. [Google Scholar]
- Peter, J.R.; Richard, A.D. Introduction to Time Series and Forecasting, 2nd ed.; Casella, G., Fienberg, S., Olkin, I., Eds.; Springer-Verlag: New York, NY, USA, 2002; pp. 137–174. [Google Scholar]
- McQuarrie, A.D.R.; Tsai, C.L. Regression and Time Series Model Selection; World Scientific Publishing: Singapore, Singapore, 1998; pp. 15–24. [Google Scholar]
- Deng, Z.L.; Gao, Y.; Mao, L. New approach to information fusion steady-state Kalman filtering. Automatica 2005, 41, 1695–1707. [Google Scholar]
- Deng, Z.L. Optimal Estimation Theory with Applications-Modeling, Filtering and Information Fusion Estimation; Harbin Institute of Technology Press: Harbin, China, 2005; pp. 47–102. [Google Scholar]
- Stoica, P.; Selen, Y. Model-order selection: A review of information criterion rules. IEEE Signal Process. Mag. 2004, 21, 36–37. [Google Scholar]
- Parks, T.W.; McClellan, J.H. Chebyshev approximation for nonrecursive digital filters with linear phase. IEEE Trans. Circuit Theory 1972, CT-19, 189–194. [Google Scholar]
- DeGraaf, S.R. SAR Imaging via Modern 2-D Spectral Estimation Methods. IEEE Trans. Image Process. 1998, 7, 729–761. [Google Scholar]
- Li, J.; Stoica, P. An adaptive filtering approach to spectral estimation and SAR imaging. IEEE Trans. Signal Process. 1996, 44, 1469–1484. [Google Scholar]
- Glentis, G.O. Efficient algorithms for adaptive Capon and APES spectral estimation. IEEE Trans. Signal Process. 2010, 58, 84–96. [Google Scholar]
- RAO, B.D.; HARI, K.V.S. Performance analysis of root-Music. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1939–1949. [Google Scholar]
- Roy, R.; Kailath, T. ESPRIT-Estimation of signal parameters via rotational invariance techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar]
- Yardibi, T.; Li, J.; Stoica, P.; Xue, M.; Braggeroer, A. B. Source localization and sensing: A nonparametric iterative adaptive approach based on weighted least squares. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 425–443. [Google Scholar]
- Xue, M; Xu, L.; Li, J. IAA spectral estimation: Fast implementation using the Gohberg-Semencul factorization. IEEE Trans. Signal Process. 2011, 59, 3251–3261. [Google Scholar]
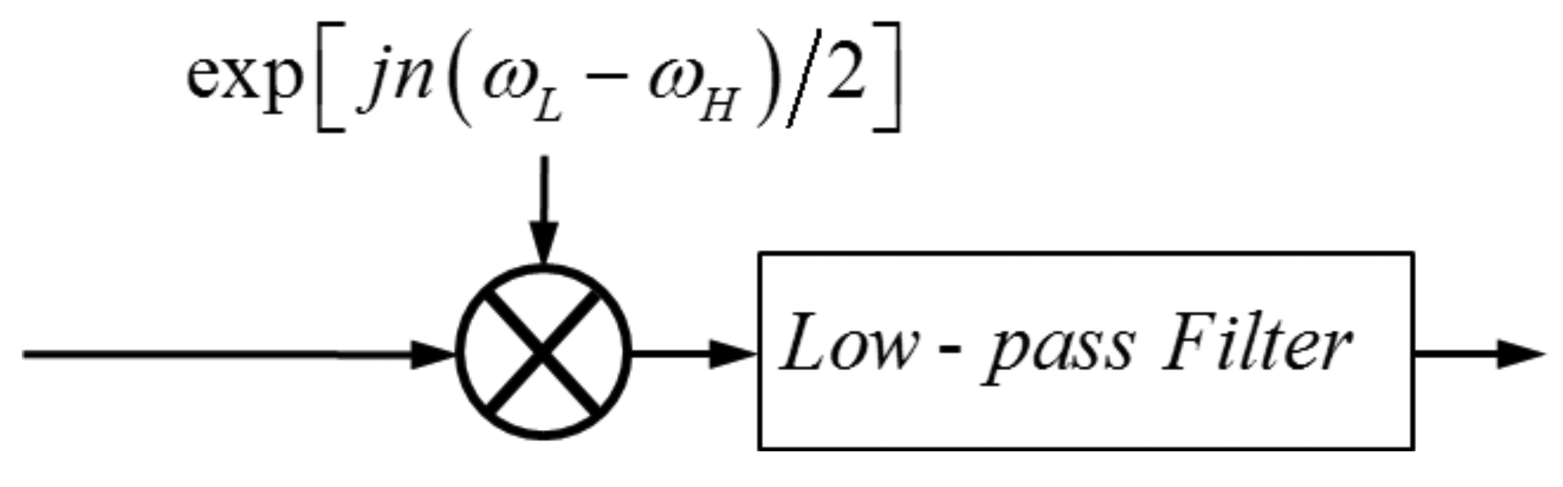



 corresponds to
: 60 dB; the red pane covers the region to be analyzed).
corresponds to
: 60 dB; the red pane covers the region to be analyzed).
corresponds to
: 60 dB; the red pane covers the region to be analyzed).
corresponds to
: 60 dB; the red pane covers the region to be analyzed).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Means and MSEs of Estimating Frequencies | Full-band | Sub-band | ||||
|---|---|---|---|---|---|---|
| MUSIC | ESPRIT | SELF-SVD | MUSIC | ESPRIT | SELF-SVD | |
| ω̄1 (ω1 = –0.07500π) | –0.0750π | –0.0750π | –0.0790π | –0.0749π | –0.0749π | –0.0750π |
| ω̄2 (ω2 = –0.03125π) | –0.0309π | –0.0309π | ∼ | –0.0308π | –0.0313π | –0.0308π |
| ω̄3 (ω3 = 0.01250π) | 0.0125π | 0.0125π | 0.0175π | 0.0123π | 0.0123π | 0.0126π |
| ω̄4 (ω4 = 0.05625π) | 0.0572π | 0.0572π | ∼ | 0.0555π | 0.0557π | 0.0555π |
| ω̄5 (ω5 = 0.10000π) | 0.1000π | 0.1000π | 0.1027π | 0.1000π | 0.1000π | 0.1000π |
| 0.0072 | 0.0072 | 1.8126 | 0.0057 | 0.0058 | 0.0044 | |
| 1.6462 | 1.6462 | ∼ | 0.1662 | 0.1259 | 0.1816 | |
| 0.0125 | 0.0125 | 2.8847 | 0.0081 | 0.0074 | 0.0060 | |
| 3.0443 | 3.0443 | ∼ | 0.1729 | 0.1199 | 0.1775 | |
| 0.0360 | 0.0360 | 0.7379 | 0.0049 | 0.0041 | 0.0046 | |
“∼” denotes meaningless estimates.(Monte Carlo analysis: 100 runs). SELF-SVD, singular value decomposition-based method in a selected frequency band.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Xu, B.; Yang, J.; Song, J. A Steady-State Kalman Predictor-Based Filtering Strategy for Non-Overlapping Sub-Band Spectral Estimation. Sensors 2015, 15, 110-134. https://doi.org/10.3390/s150100110
Li Z, Xu B, Yang J, Song J. A Steady-State Kalman Predictor-Based Filtering Strategy for Non-Overlapping Sub-Band Spectral Estimation. Sensors. 2015; 15(1):110-134. https://doi.org/10.3390/s150100110
Chicago/Turabian StyleLi, Zenghui, Bin Xu, Jian Yang, and Jianshe Song. 2015. "A Steady-State Kalman Predictor-Based Filtering Strategy for Non-Overlapping Sub-Band Spectral Estimation" Sensors 15, no. 1: 110-134. https://doi.org/10.3390/s150100110
APA StyleLi, Z., Xu, B., Yang, J., & Song, J. (2015). A Steady-State Kalman Predictor-Based Filtering Strategy for Non-Overlapping Sub-Band Spectral Estimation. Sensors, 15(1), 110-134. https://doi.org/10.3390/s150100110