Abstract
To tackle robust object tracking for video sensor-based applications, an online discriminative algorithm based on incremental discriminative structured dictionary learning (IDSDL-VT) is presented. In our framework, a discriminative dictionary combining both positive, negative and trivial patches is designed to sparsely represent the overlapped target patches. Then, a local update (LU) strategy is proposed for sparse coefficient learning. To formulate the training and classification process, a multiple linear classifier group based on a K-combined voting (KCV) function is proposed. As the dictionary evolves, the models are also trained to timely adapt the target appearance variation. Qualitative and quantitative evaluations on challenging image sequences compared with state-of-the-art algorithms demonstrate that the proposed tracking algorithm achieves a more favorable performance. We also illustrate its relay application in visual sensor networks.1. Introduction
Object tracking via video sensors is an important subject and has long been investigated in the computer vision community. In common sense, an object, or a target, refers to a region in the video frame detected or labeled for specific purposes. Stable and accurate tracking of objects is fundamental to many real-world applications, such as motion-based recognition, automated surveillance, visual sensor network, video indexing, human-computer interaction, traffic monitoring, vehicle navigation, etc. [1].
Historically, visual trackers proposed in the early years typically kept the appearance model fixed throughout an image sequence. Recently, methods proposed to track targets while evolving the appearance model in an online manner, called online visual tracking, have been popular [2]. An online visual tracking method typically follows the Bayesian inference framework and mainly consists of three components: an object representation scheme, which considers the appearance formulation uniqueness of the target; a dynamical model (or state transition model), which aims to describe the states of the target and their inter-frame relationship over time; an observation model, which evaluates the likelihood of an observed image candidate (associated with a state) belonging to the object class. Although visual tracking has been intensively investigated, there are still many challenges, such as occlusions, appearance changes, significant motions, background clutter, etc. These challenges make the establishment of an efficient online visual tracker a difficult task.
1.1. Related Works
Appearance representation of the target is a basic, but important, task for visual tracking. Discrimination capability, computational efficiency and occlusion resistance are generally considered as the three main aspects in appearance modeling. For online visual tracking, the schemes can be classified into patch-based schemes (e.g., holistic gray-level image vector [3] and fragments [4–6]), feature-based schemes [7–10], statistics-based schemes [11–15] and their combinations.
Based on the differences in object observation modeling, online visual tracking can be generally classified into generative methods (e.g., [3,4,11–13,15–18]), discriminative methods (e.g., [7–10,15]) and hybrid methods (e.g., [19,20]). Generative methods focus on the exploration of a target observation with minimal predefined error based on separative evaluation criteria, while discriminative ones make attempts to maximize the margin or inter-class separability between the target and non-target regions using classification techniques. Typical techniques include boosting [8,9] and support vector machine (SVM) [7,21,22]. For the trackers using SVM, Avidan et al. [7] propose a tracking algorithm integrating SVM to discriminate the target from its background. Tian et al. [21] present a tracking system based on an ensemble of adaptively-weighted linear SVM classifiers based on their discriminative abilities. Bai and Tang et al. [22] propose an online Laplacian ranking support vector tracker (LRSVT), which incorporates the weakly labeled information to resist full occlusion and adapt to target appearance variation. Yet, there are still some limitations for these works. Firstly, most of them consider the classification problem on a single-patch level, which might lack flexibility and robustness when a drastic appearance occurs. Secondly, the features applied in these works are not unique enough. It could negatively influence the tracking performance when a similar object exists. In this paper, we continue to explore the application of SVM classifiers in online visual tracking, where the input features are coefficients of sparse representation on a patch level. Thus, the patch-based SVMs are grouped for classifier modeling.
As an elegant working model, sparse representation has recently been extensively studied and applied in pattern recognition and computer vision [23,24]. There are two basic problems [25]: the first one is to calculate the sparse solution of a linear system, while the second one refers to learning a suitable dictionary for approximation performance improvement. So far, the former one has been deeply exploring in visual tracking (e.g., [11–13,15,17,20]). Within the particle filtering framework, most of the works cast the tracking problem as searching the most likely sampling candidate of the target via l1 minimization. Mei and Ling [11] apply sparse representation to visual tracking and deal with occlusions via positive and negative trivial templates. Wang et al. [17] propose a novel online object tracking algorithm with sparse prototypes, which adopts principal component analysis (PCA) basis vectors and trivial templates to represent the tracked target sparsely, and solve the problem by using an iterative thresholding method. Zhong et al. [20] develop a hybrid tracking method, where a sparsity-based discriminative classifier (SDC) and a sparsity-based generative model (SGM) are cascaded for target location estimation. However, investigation of the second problem in visual tracking has just started. Liu et al. [12] develop a generative visual tracking algorithm with a static sparse dictionary of the target and dynamically online updated basis distribution model by K-selection, while a recent method proposed by Wang et al. [15] discriminates the target from the background based on the classification of the sparse coefficients with an over-complete dictionary without learning. Learning a dictionary for classification has recently been popular [26–28], which adds specific constraints in the dictionary learning (DL) model to gain discrimination ability. In these works, constraints have been considered on the class labels, learning process and sparse representation coefficients, and discriminability has been enforced in sparse codes during the dictionary learning process to improve classification accuracy. However, they fail to consider the dictionary design from a discriminative perspective. Moreover, the dictionary is often learned as a whole, and the learning process is very time consuming, which might not be suitable for a recognition application in continuous appearance variation circumstances.
1.2. Our Proposal
Inspired by the discussions above, this paper considers the dictionary learning problem for online visual tracking, as well as a visual tracking algorithm, incremental discriminative structured dictionary learning (IDSDL)-VT, including incremental discriminative structured dictionary learning and multiple linear classifiers. The workflow is shown in Figure 1. On a patch level, groups of positive and negative sparse coefficients of the target patches learned by the proposed incremental discriminative structured dictionary learning (IDSDL) algorithm are input to the support vector machines (SVMs) to train classifiers, which discriminate the target from the background. In the next frame, target candidates are sampled based on affine warping, and their corresponding coefficients are obtained. Then, given the learned model set, patch-based classifications are conducted to calculate the confidence set, and a K-combined voting (KCV) function is used to jointly locate the target. The dictionary set is incrementally adapted as time evolves.
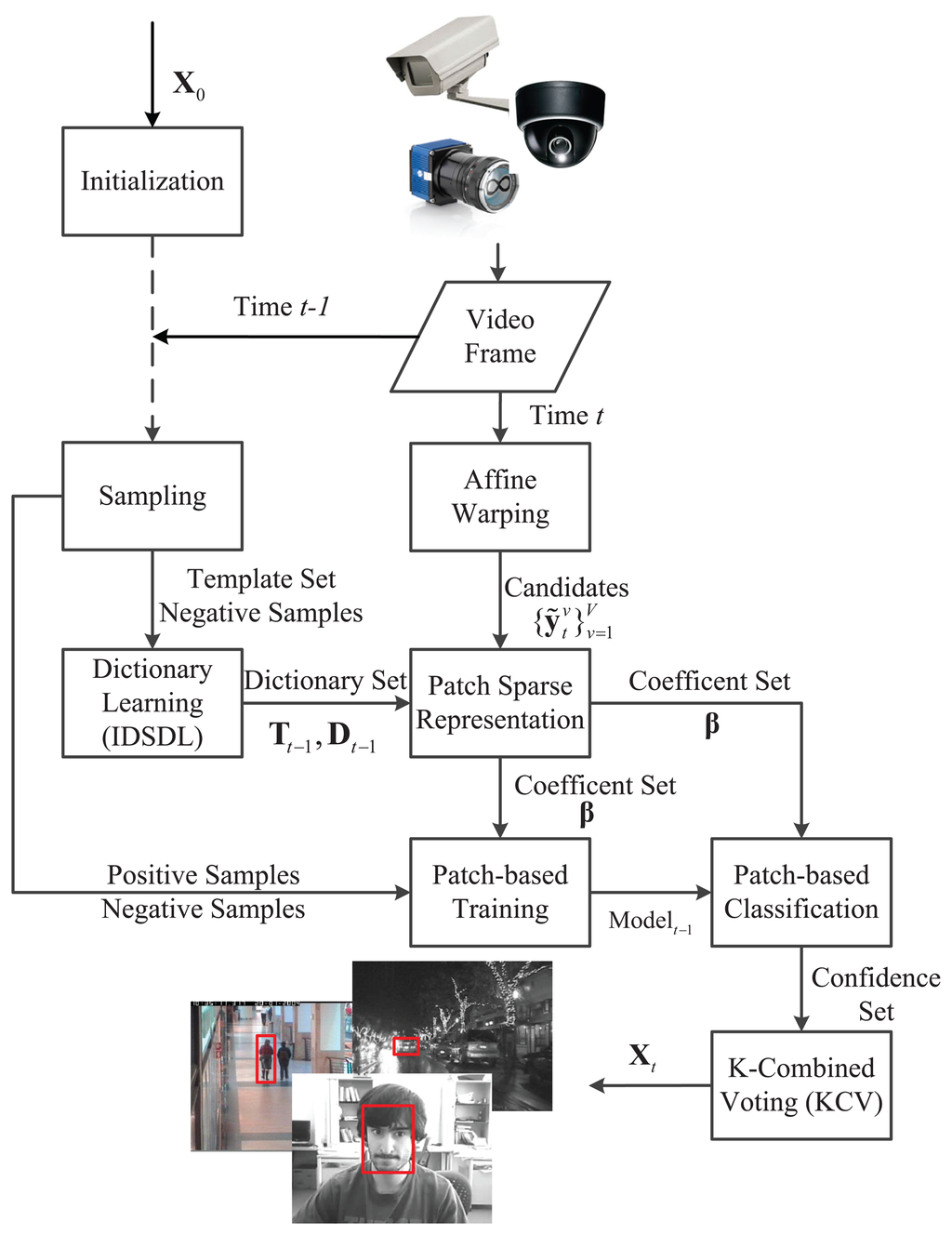
Compared with the dictionary learning papers referred to above, we do not solely rely on the optimization, but focus on the dictionary design with separate learning to improve the discriminative ability of the sparse coefficients for classification. Moreover, the dictionary is built on a patch level, and thus, a spatial multi-dictionary learning structure is established. Though numbers of papers have appeared based on sparse representation, few consider the dictionary learning aspect. There is a dictionary learning process in the algorithm proposed by Liu et al. [12], but it is a generative approach. Moreover, the algorithm proposed by Zhong et al. [20] is a hybrid one, and its discriminative ability is not based on the binary classifier, but the reconstruction error, which is used to generatively create weights for confidence modeling. The algorithm proposed by Wang et al. [15] is discriminative, yet constructed without learning. Differently, in this paper, we exploit dictionary learning within the discriminative tracking framework and establish a tracking process based on patch-based classifiers. The main contributions of the proposed algorithm can be described as follows: (1) compared with the previous sparse-representation-based tracking algorithms referred to above, a structured dictionary learning algorithm for discriminative classification is newly proposed; (2) compared with the generative tracking framework via the dictionary learning summarized above, the proposed approach integrates the learning process to formulate a discriminative visual tracking framework, which learns multiple classifiers on a structured level; (3) compared with a one-time peak-confidence calculation, a K-combined voting (KCV) function based on multiple classifier confidences is novelly proposed to locate the target. We focus on the dictionary design part rather than the optimization process. Experiments on both a single camera and visual sensor network are conducted to demonstrate the performance of the proposed method.
The rest of the paper is organized as follows. In Section 2, details of the proposed structured dictionary learning algorithm are described. Details of the proposed visual tracking algorithm within the Bayesian inference framework are proposed in Section 3. Experimental results and a discussion are given in Section 4. In Section 5, concluding remarks and a possible direction for future research are provided.
2. Discriminative Structured Dictionary Learning
We begin the description of the proposed dictionary learning algorithm, incremental discriminative structured dictionary learning (IDSDL), with the sparse appearance modeling as follows. Typically, the global appearance of an object under different illumination and viewpoint conditions is known to lie approximately in a low-dimensional subspace [11]. Basically, we assume that the target could be represented with a lower error by its overlapped patches in the form of the target templates' learning results in the previous frames. The template contains a set of images, each of which is cropped from the corresponding video frame based on the latest tracking results. Similar assumptions are also applied in other tracking algorithms based on sparse representation [11-13,15,17,20].
Suppose at time t, the target is sampled and vectorized into N separate overlapped patches with zero mean and unit variance, where the size of each patch is d2 × 1. Moreover, there exists a set of templates , where M refers to the number of the templates, and the corresponding patches , j = 1,2,…, M share the same patch sampling scheme with that of the target candidates and have been stacked, normalized and vectorized. Therefore, in the current frame, any patch of the target candidate , i = 1, 2, …, N could approximately lie in the linear span of the corresponding template patches:
In sparse representation, a dictionary refers to a matrix D = [d1, d2,…,dn] ∈ ℝ(d2×N)×M made up of a group of basis vectors, where the target signal is spanned. Given a training set of image patches, Y, classical dictionary learning methods learn an optimized dictionary, D, by solving the following objective function:
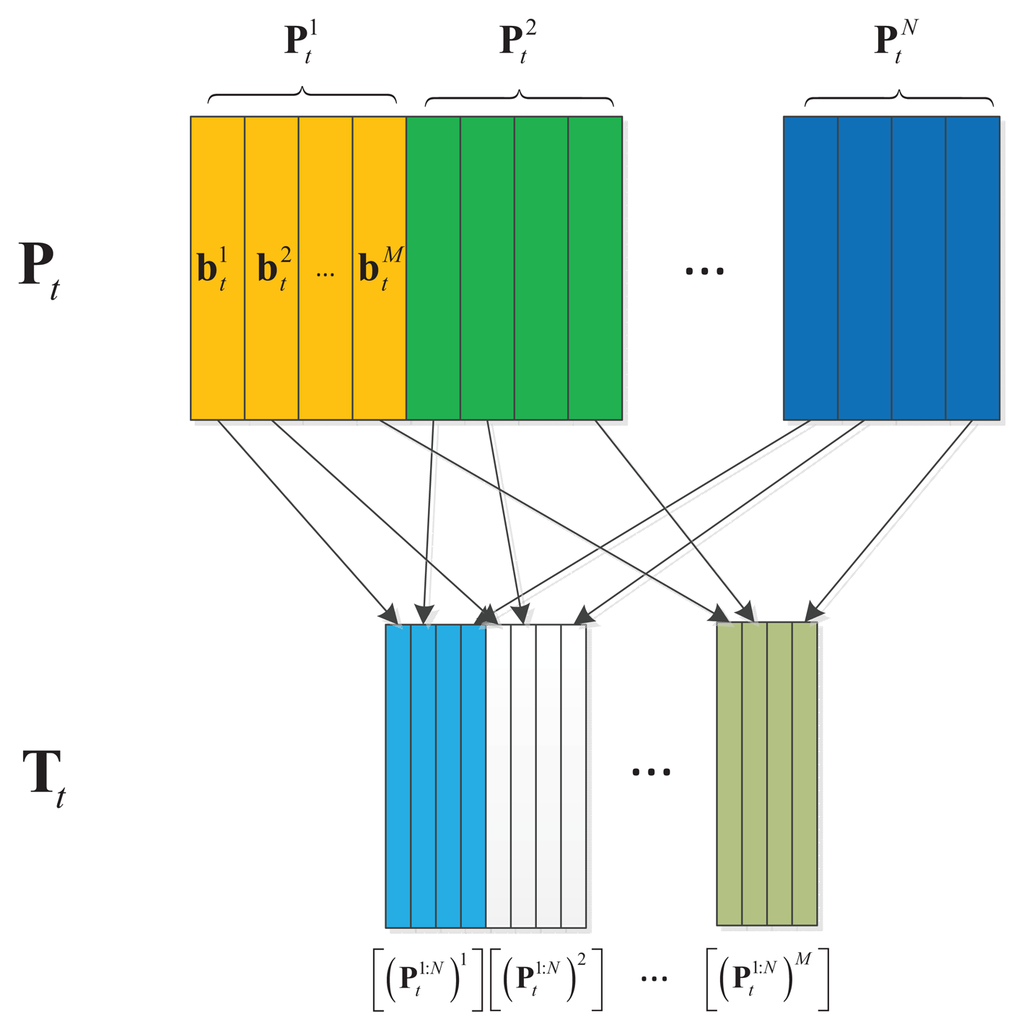
Based on the assumption and definition described above, we present an incremental discriminative structured dictionary learning method. A structured dictionary is defined as , as shown in Figure 2, where is its element corresponding to the i-th patch. Furthermore, is defined to be constructed as:
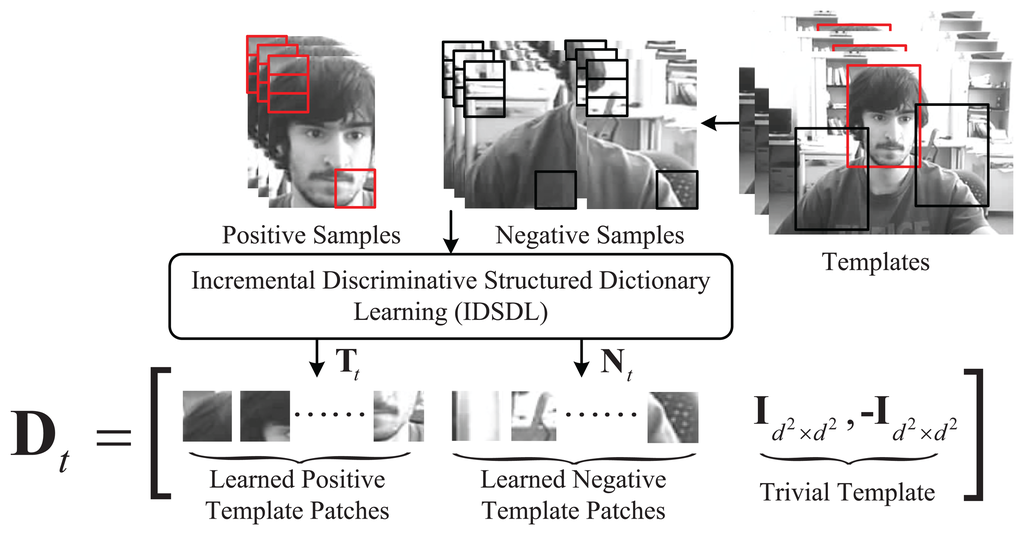
Suppose the target location has been estimated; the positive and negative training samples could be represented in the overlapped form by , li ∈ {+1, −1}. Corresponding patches are and s = s+ + s−, which separately refer to the number of positive samples, , and negative ones, . A local update (LU) strategy is introduced to both update the dictionary and improve the inter-patch independence and separability. For each patch in only the corresponding M columns of the dictionary with the same patch index are learned and temporarily stacked, while the rest columns stay fixed. Tt is not replaced until each column is updated. On the other hand, after is sparsely represented, is directly updated. The update process [30] is defined as:
| Algorithm 1 Incremental discriminative structured dictionary learning (IDSDL). | |
| Input: | |
| Nt0 −1i, , , i = 1, 2, …, N, Tt0 −1, λ1, λ2. | |
| 1: | , , , |
| 2: | for t = t0→T do |
| 3: | Obtain , by based on Equation (4). |
| 4: | for i = 1 → N do |
| 5: | Sparse representation of positive sample patches to obtain by Equation (2) based on Tt−1. |
| 6: | Sparse representation of negative sample patches to obtain by Equation (2) based on . |
| 7: | Update , |
| 8: | Update , . |
| 9: | for j = 1 → M do |
| 10: | Update by Equations (7) and (8) with . |
| 11: | Update by Equations (7) and (8) with . |
| 12: | end for |
| 13: | Update the learned dictionary part, , based on Equation (6). |
| 14: | Update the learned dictionary part, Dt, based on Equation (4). |
| 15: | end for |
| 16: | Update the template set, Tt, based on Equation (5). |
| 17: | end for |
| Output: | |
| Updated Tt, Dt. | |
3. A Tracking Framework Based on IDSDL and K-Combined Voting SVM Classification
3.1. The Principle of Online Visual Tracking Based on Bayesian Inference
An online visual tracking problem can be interpreted as a Bayesian recursive and sequential inference task in a Markov model with hidden state variables and is further divided into cascaded estimation of a dynamical model and observation model [3]. Suppose a set of target images Yt = {y1, y2,…, yt} have been given till time t; the hidden state vector of the target, represented as Xt, can be estimated as follows,
In the context of particle filtering, typically, a set of candidates , v = 1, 2, …,V is drawn from an importance distribution q(Xt|X1:t−1, y1:t) and the weights of the samples could be updated as:
3.2. Gaussian Affine Warping for Dynamical Modeling
Ideally, a dynamical model p(Xt|Xt−1) should be able to fully describe the variation of the target in detail, yet in most practical cases, this could be approximately parameterized. Typically, at time t, the geometric parametrization of the target region can be realized by an affine transformation as:
Based on the principle above, Ross et al. [3] propose a variant of the particle filter, called affine warping, where the state of the target can be described as a six-tuple set, Xt = {xt,yt, θt, st,αt, φt}, whose elements respectively denote x, y translations, rotation angle, scale, aspect ratio and skew direction. The elements of Xt are independently modeled by a Gaussian distribution around the previous state, as follows,
3.3. K-Combined Voting SVM Classification of Sparse Coefficients for Observation Modeling
The support vector machine (SVM) is one of the most widely used classifiers in machine learning and pattern recognition application. It makes attempts to find a separating hyperplane that maximizes the margin between two classes. The margin is defined as the distance of the closest point to the hyperplane. Given a set of instance-label pairs {βk, lk}, k = 1,2,…,s, βk ∈ ℝ n,lk ∈ {−1,+1}, it solves the following unconstrained optimization problem with a different loss function ξ(wk; βk, lk) as:
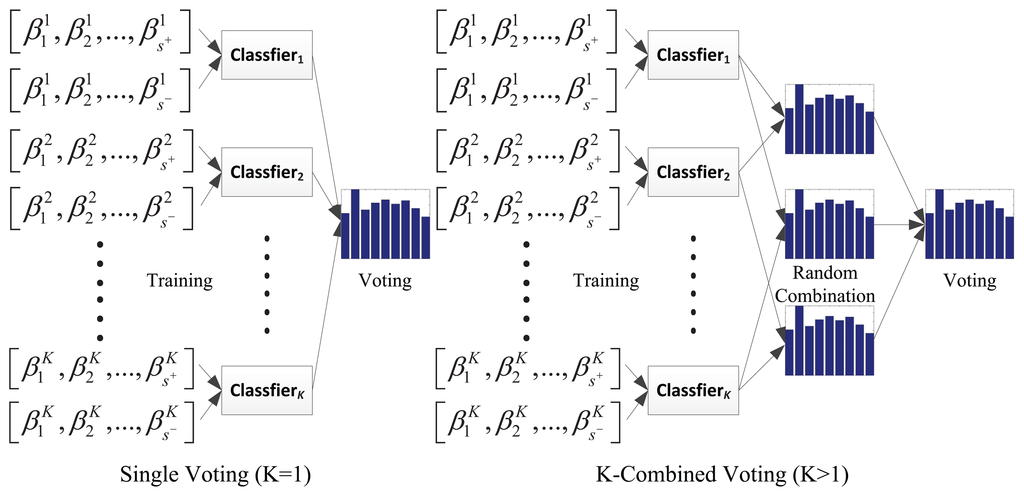
We consider the discriminative observation modeling on a patch level. Given the patch-based coefficients, β, of candidate Xt are obtained and P candidates have been sampled, for the p-th candidate, p = 1, 2,…, P, a function called K-combined voting (KCV) is proposed to compute the score, S(p*), recording the times that p* is selected as the result by:
To both timely adapt the variation of target appearance and maintain its original invariance, a progressive classification is applied. At time t0, the voting function is processed twice, when sequentially, wt−1 = wt0−1 and wt−1 = w0 are separately set. The former one is introduced to locate the target as an intermediate result based on its latest appearance model, while the latter one is used to locally refine the location with respect to its originality. Correspondingly, the dynamical modeling is also conducted twice to formulate a step-wise classification, similar to [15]. Thus, according to Equation (16), only the candidate most voted for is chosen as the estimation result.
3.4. Model Update
Once the current target location is estimated, the model is updated accordingly. In this paper, the update process is two fold. The first one is to adapt the dictionary using the proposed IDSDL algorithm proposed in the last section. Then, the positive and negative samples are sampled around the current estimated location of the target. Based on the learned results, sparse coefficients are obtained to train the SVM classifiers so that updated models are generated. Details of the IDSDL algorithm could refer to the last section, while the classifier training is described as follows.
To establish an efficient discriminative model at time t − 1, a local linear support vector classifier group corresponding to each patch, is separately trained [31]. contains the output support vectors, wt−1, for current patch. For each , an object function, J(w), is established. The training data is generated based on the samples drawn around the estimated target location and follow the same patch cropping pattern with that of target representation. For the i-th patch, the training data is made up of sparse coefficients by solving Equation (2) with as the dictionary. , , , separately correspond to the positive patches and negative ones of the candidates, and the i–th classifier for is learned to minimize the loss function:
3.5. Summary of the Proposed Algorithm
The proposed algorithm is summarized in Algorithm 2 based on the descriptions above.
| Algorithm 2 Visual tracking based on IDSDL and K-combined voting SVM classification. | |
| Input: | |
| Image sequence with T frames, initial target state X0, target region Y0, particle numbers v, overlapped percentage, cl, cs, K, M, λ1, λ2, Ψ0, C and N. | |
| Output: | |
| Current target state Xt | |
| 1: | (Initialization) Track the target during the first M frames to obtain the state, X1:M, and template set TM. |
| 2: | for t = M + 1 → T do |
| 3: | (Dynamical Modeling) Obtain V target candidates based on affine warping by Equation (14) with Ψ0. |
| 4: | (Observation Modeling) Obtain the sparse coefficients of the candidates based on Equation (2). |
| 5: | (Observation Modeling) Estimate the intermediate location of the target based on the multiple-linear-classifiers group by Equation (18) when wt = wto. |
| 6: | (Dynamical Modeling) Obtain V target candidates based on affine warping by Equation (14) with Ψ0. |
| 7: | (Observation Modeling) Obtain the sparse coefficients of the candidates based on Equation (2). |
| 8: | (Observation Modeling) Estimate the location of the target based on the multiple-linear-classifiers group by Equation (18) when wt = w0. |
| 9: | (Model update) Sample the positive and negative samples around the current estimated location of the target. |
| 10: | (Model update) Update Tt, Dt based on IDSDL by Algorithm 1. |
| 11: | (Model update) Update Modelt of multiple-linear-classifiers group based on Equation (19). |
| 12: | end for |
In Algorithm 2, the proposed dictionary learning algorithm is the most computational, while the online training and classification process does not take much running time, since the efficient linear SVM is applied. The dynamical modeling process takes the least running time according to the proposed straightforward process. To accelerate the process, we apply a C implementation of elastic net regulation proposed by Mairal et al. [30]. We also normalize the target patch to make it more efficient for data processing.
4. Experiment and Discussion
In this section, we present experiments on test videos to demonstrate the efficiency and effectiveness of the proposed algorithm.
4.1. Experiment Setup
The proposed tracking algorithm, IDSDL-VT, is implemented in MATLAB and C/C++ and runs at about 1.3 fps on a 3.4 GHz dual core PC with 8 GB of RAM. For parameter configuration, in each frame, each target region is normalized to 24 × 24, and the patch size is 12 × 12, d = 12, while the overlapped percentage of the neighbored patch is 0.5. Thus, N = 9. The number of particles is V = 600 for dynamical modeling. Moreover, the regularization constant, λ1 and λ2, in Equation (2) are set to 0.01, and the dictionary learning is processed once per frame. In Equation (18), K = 3, α = 0.5. During training, regions within two pixels around the target location are set as positive, while the ones in the outer four pixels are negative, and c = 10. Except Section 4.5, the target locations are manually labeled in the first five frames to generate the templates, M = 5.
To evaluate the efficiency of the proposed algorithms, nine benchmark video sequences, most of which are publicly available, are used under the challenges of lighting and scale changes, out-of-plane rotation and partial occlusion. Comparatively, the proposed tracker is evaluated against state-of-the-art algorithms, including Frag [4], IVT [3], VTD [16], L1T [11], TLD [10], MIL [9] and PLS [18]. The implementation is based on the source codes provided by the authors via their websites. Qualitative and quantitative evaluations are presented in the rest of this section.
It should be noted that the setting on a particle number and the regulation constant above is based on the setup of classical online visual tracking algorithms, for a better performance comparison [3,9–11,16]. Enlarging the normalized size of the target region and patch size would increase the computation time. Its current setting is established after the times of the experiments with reference to the related works. Moreover, the overlapped percentage of the neighbored patch is related to the appearance variation of the target region. Since a low percentage number would lead to lower efficiency and the benchmark video is of various kinds, a unbiased number, 0.5, is set. Values of K and α are empirically set based on the times of the experiments.
4.2. Qualitative Evaluation
Qualitative analysis and discussions are provided as follows. The visual challenges include heavy occlusion, illumination change, scale change, fast motion, cluttered background, pose variation, motion blur and low contrast.
The two test sequences, Occlusion 1 and Occlusion 2, in Figure 5 are separate from the work by Adam et al. [4] and the one by Ross et al. [9], both of which highlight partial occlusion, and set the region of high-resolution human faces as the targets for tracking, which is widely used in human-computer-interface application environments. The frame numbers of the sequences are 898 and 819 of a size of 320 × 240. Occlusion 2 is more challenging, because it also contains in-plane rotation and out-of-plane rotation. It is shown that for Occlusion 1, all the evaluation algorithms can follow the target approximately correctly, yet some of the algorithms deviate from the face when occlusion occurs (e.g., MIL [9] at #0307, #0539 and #0834, IVT [3], L1T [11], Frg [4], TLD [10] and VTD [16] at #0539). For Occlusion 2, the differences are more obvious. It can be found that L1T [11] drifts more from the target compared with other algorithms (e.g., MIL [9] at #0501 and #0732), and IVT [3] and TLD [10] cannot adapt the appearance when there are occlusion and head rotation (e.g., #0732). PLS [18] cannot continuously follow the target, while MIL [9] and Frag [4] estimate the target less accurately than the proposed algorithm.

The sequences, Caviar 1 and Caviar 2, in Figure 6 come from the CAVIAR project ( http://groups.inf.ed.ac.uk/vision/CAVIAR/) with the frame numbers 382 and 500 of a size of 384×288. Both of them comprise severe partial occlusion and scale variation from far to near, which are typical scenes in surveillance applications. Moreover, there are similar objects near the target as the distractions. It is be shown that MIL [9], L1T [11] and PLS [18] do not perform well in Caviar 1. The first two methods fail to discover the target when the target is occluded by a similar object (e.g., #0130), while the latter one drifts away from the target (e.g., #0130 and #0218). Only the proposed tracker, VTD [16], Frag [4] and TLD [10], handle the heavy occlusion successfully. However, Frag [4] cannot smoothly adapt the scale changes of the person (e.g., #0278). In Caviar 2, almost all the trackers evaluated, except PLS [18] and MIL [9], can follow the target. However, many of them, including IVT [3], VTD [16] and TLD [10], cannot adapt the scale as the human moves near the camera (e.g., #0217 and #0496). In contrast, our algorithm performs well in terms of position estimation and scale adaptation.

The sequences, Car 11and David Indoor, in Figure 7 are from the work by Ross et al. [3] with the frame numbers 659 and 462 of a size of 720 × 480 and 320 × 240. Car 11are quite common in practical intelligent vehicle application environments and are very challenging, as this is a video at night. The target (the rear view of a car) is small and easily distracted by the surroundings, including similar vehicle appearance and glare. It is shown that only IVT [3], PLS [18] and the proposed algorithm successfully can track the target in the whole sequence, while the remaining drift away or take the surroundings as the target (e.g., MIL [9] at #0065, #0179 and #0300 and VTD [16] and L1T [11] at #0179 and #0300). David Indoorcontains out-of-plane rotation as the person turns his or her face and scale change, due to distance variation from the cameras. It also contains illumination changes, as the person walks from a dark room into areas with a spot light. For this sequence, some algorithms (e.g., Frag [4] and PLS [18]) drift away from the target during the tracking process, while some algorithms can not adapt the scale when out-of-plane rotation occurs (e.g., MIL [9] and L1T [11] at #0169 and #0398). Comprehensively and qualitatively speaking, the proposed algorithms perform the best.

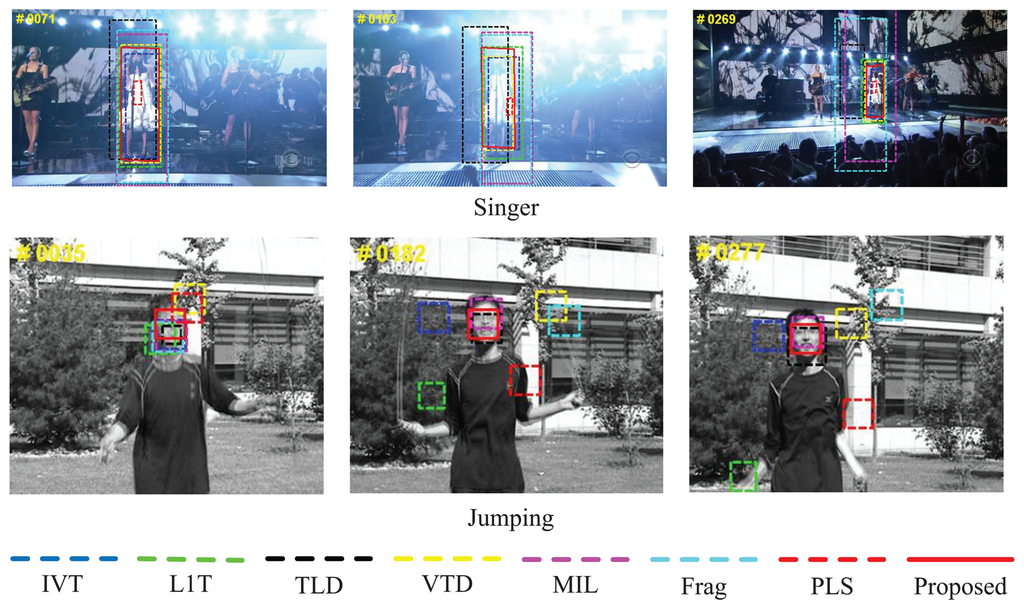
The two video sequences, Singerand Jumping, in Figure 8 are from the work by Kwon et al. [16] and TLD [10]. The frame numbers of the sequences are 321 of a size of 624 × 352 and 313 of a size of 352 × 288. Singeris challenging, as it contain illumination variation, and Deerhighlights abrupt motions. In the former one, only the results of partial trackers (e.g., the proposed algorithm and VTD [16]) are satisfactory, while the others cannot adjust the scale (e.g., Frag [4], L1T [11] and MIL [9]) or accurately locate the target (e.g., TLD [10] at #0071, #0103 and #0269; IVT [3] at #0126) a drastic scale and location deviation appears when lighting conditions change. Especially PLS [18] cannot capture the scale variation of the target through all the frames of Singer. In Jumping, the successful trackers only include the proposed algorithms, MIL [9] and TLD [10], while the others fail to capture the head of the person when he or she jumps up and down repeatedly. Comprehensively and qualitatively speaking, the proposed algorithms perform the best.
4.3. Quantitative Evaluation
Besides qualitative evaluation, quantitative evaluation of the tracking results is also an important issue for tracking performance evaluation. Similar to other classical works, two performance measurements are applied to compare the proposed tracker with the other reference trackers. Quantitative comparisons using average center errors (CE) based on Euclidean distance and the PASCAL [32] overlap rate (OR) criterion between the proposed method and the other ones are conducted.
Moreover, the average center error (ACE) and average overlap rate (AOR) are defined as:
To demonstrate the proposed improvement in the voting scheme, comparison between single voting and K-combined voting is also drawn on the benchmark sequences. The settings are the same with the ones above. It can be found that the proposed algorithm with K-combined voting is better in both center error evaluation and overlap rate evaluation. Even with single voting, the proposed tracker can perform better than other classical trackers on the overlap rate in most cases. It should be noted that, on the one hand, the performance with a low K would approach that in the single voting case. On the other hand, it could introduce the classification error when K is too high. In our experiments, we find that the trackers perform very well when K = 3.
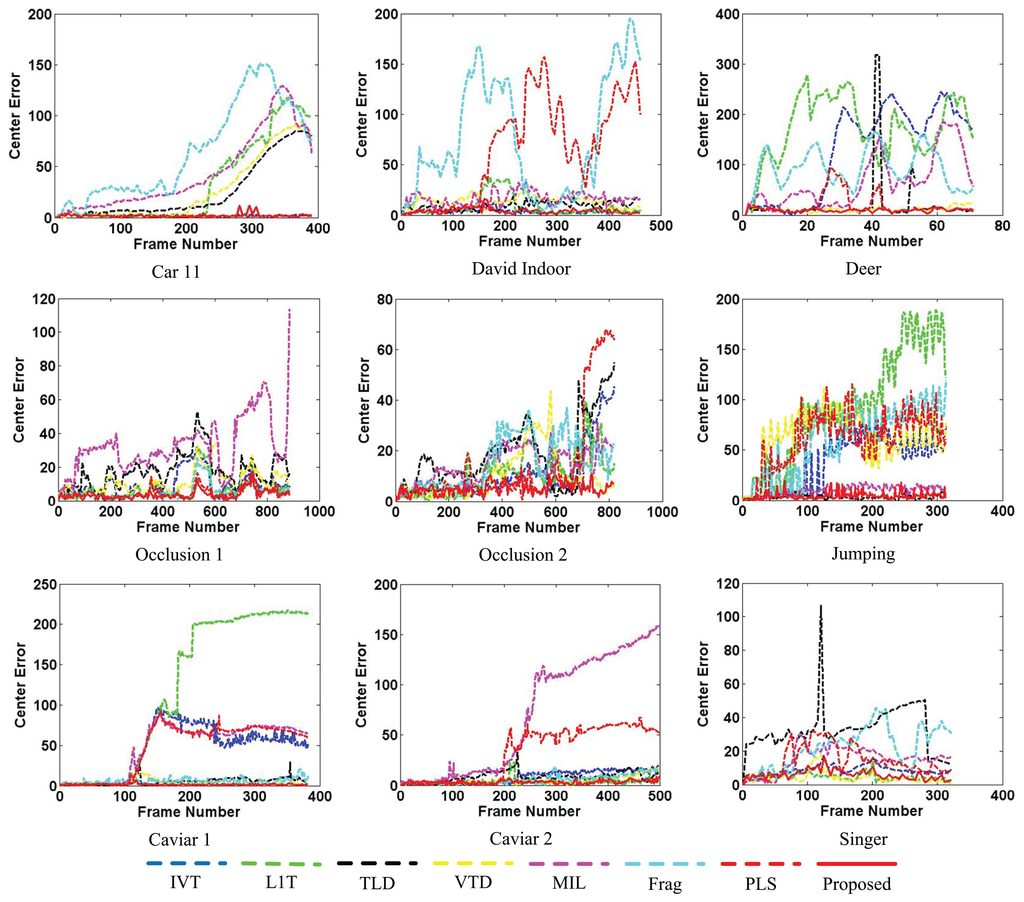
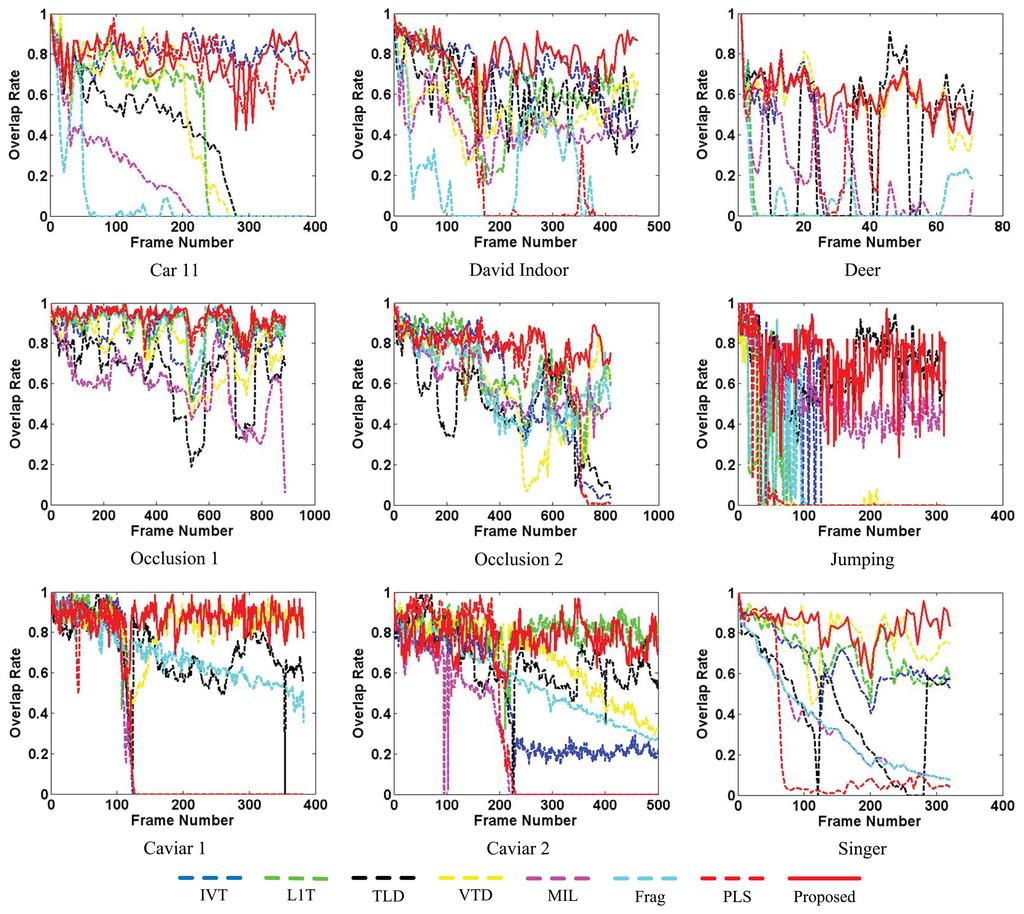
Figures 9 and 10 separately illustrate the center error and overlap rate figures for all the quantitatively evaluated sequences. Based on these figures, it can be seen that our proposed algorithm can obtain narrow ranges of fluctuations against the other algorithms (e.g., David Indoor and Jumping). Though the values of the proposed tracker are not the best all the time, they are lower in the center error and higher in the overlap rate than the other algorithms in most test frames. Thus, the proposed tracker provides comprehensively more favorable results in CEE and AOR averages than the other algorithms described in Table 1.
Overall, it can be concluded that the proposed tracker achieves better performance than the other state-of-the-art algorithms.

4.4. Dictionary Learning Results and Time
In this paper, a dictionary learning algorithm called incremental discriminative structured dictionary learning (IDSDL) is proposed to learn from positive and negative samples, joined to construct a structured dictionary with a newly established randomly permuted unit matrix for sparse representation. Each test sequence corresponds to a dictionary during the tracking process. Corresponding to the patch settings above, the selected learned dictionaries of sequence Occlusion 1 and David Indoor after 100 frames are shown in Figure 11 to demonstrate the proposed dictionary design and learning results. The values have been normalized before plotting for better illustration.

Moreover, the average computation time per frame of the proposed IDSDL algorithm based on different target normalized sizes are provided in Table 2. We take the challenging sequence, Car 11 as an example. The corresponding patch size is a quarter of the whole, and other parameter settings are the same as those described in the beginning of this section. The corresponding ACE and ORE are also provided. It can be shown that as the normalized size decreases, the running time gets shorter, yet the ACE and ORE get worse correspondingly. The proposed tracker fails to continuously track the target when the target patch is normalized to 8 × 8. This is because the details of the target are lost when the target region is interpolated on a more coarse-grained scale, and thus, the discrimination ability could not be satisfactorily maintained. In our experiments, the normalized size is established after the times of the experiments on all the test sequences with reference to the balance between accuracy and efficiency.
4.5. Extending to Relay Tracking in Visual Sensor Networks
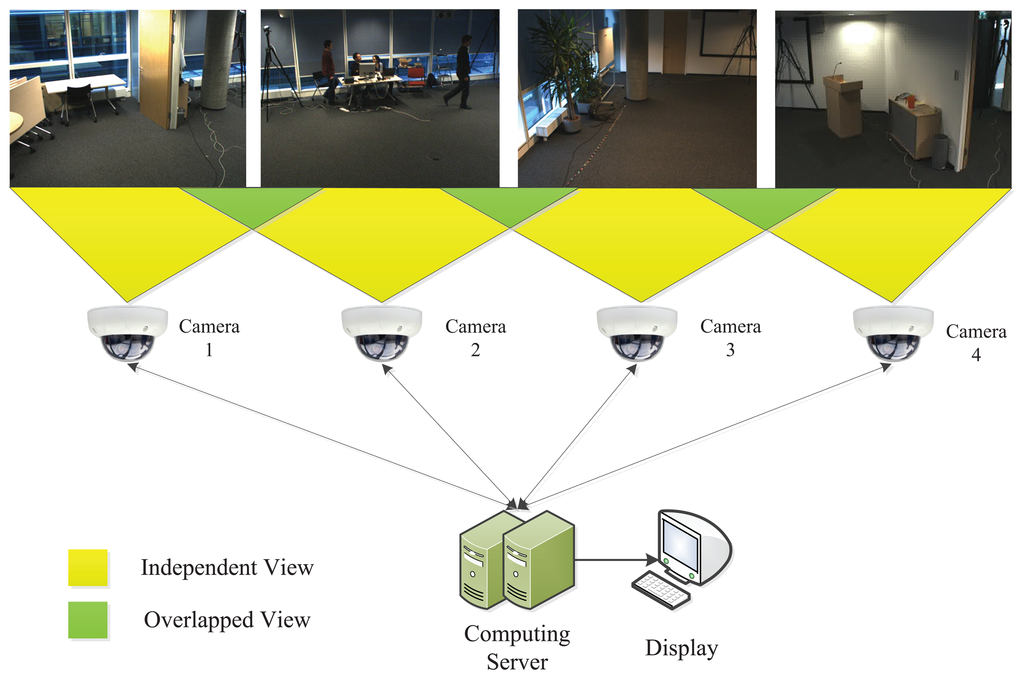
To demonstrate the potential application of the proposed algorithm, we evaluate its relay tracking performance in visual sensor networks. The test dataset is from the CATproject ( http://www. cat-project.at/). There are four cameras, and their fields of view are slightly overlapping. A person walks across the four cameras with different view points, which is regarded as the target. Our evaluation is established as shown in Figure 12. We assume that the cameras are connected by the local area network (LAN) with the computing server in the back-end. The videos acquired would be transmitted to the server without any time delay. Moreover, each camera corresponds to a tracker in the server.
In order to make use of the visual information acquired as much as possible, we establish the tracking process with a shared dictionary across all the cameras, shown in Figure 13. When the cameras are switched on, their trackers begin to work. Here, we assume that the person entering the scene is the one we are going to track. We apply foreground extraction based on Gaussian background modeling [33] to detect the newly appeared person in the boundary area (5% of the frame height and width in this paper). When the foreground area is larger than a predefined threshold, the person is considered to be detected. Once one camera detects the target, it records the corresponding location and starts to track the target. If there is no foreground detected, the process sends the dictionary learned during the tracking process in this camera. All the other trackers corresponding to different cameras would replace the old dictionary with a newly received one, so that the visual information on the dictionary level can be shared across the network. An empty dictionary is also sent in the no foreground detection and no tracking case. For a straight forward implementation, the person entering the boundary area for the second time is considered as a disappearance, so that the tracking process in the current camera stops.
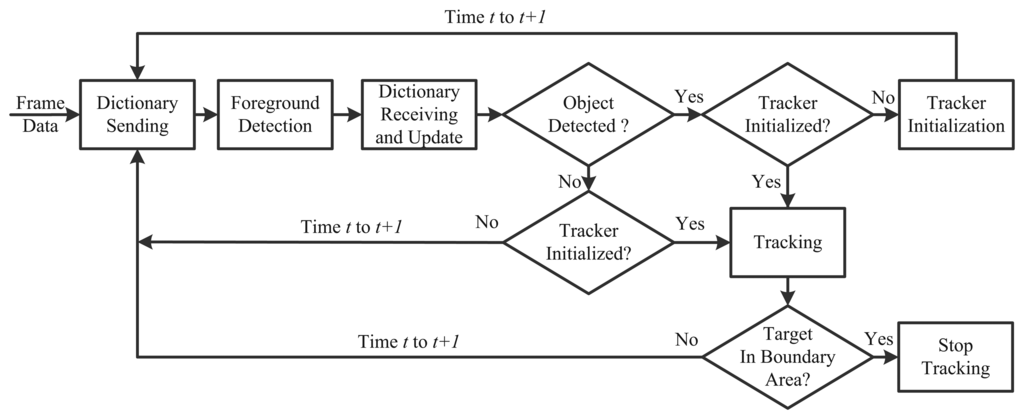
Quantitatively, we evaluate the lifecycle of the target once it is detected in one camera. In this paper, the lifecycle of a target is defined as:
Vertically, it can be found from the table that the proposed algorithm with dictionary sharing achieves higher values. This is mainly because of the satisfactory online tracking performance proposed above. Moreover, based on dictionary sharing, more visual information about the target could be obtained before the target enters the specific scene. Thus, the performance with the dictionary sharing is better than the one without sharing. Horizontally, all the values in Camera 2 and Camera 4 are lower than their counterparts in other columns. This is due to the background modeling in Camera 2 and Camera 4. In Camera 2, there are other moving objects as the target enters the scene, and in Camera 4, there is light variation. The foreground target could not be timely and correctly detected, which leads to a relatively poor lifecycle performance. Moreover, the value with the dictionary sharing in Camera 2 is not much higher than that without sharing, yet the opposite case occurs in Camera 3. This is because, due to the camera view point, the person's initial pose in Camera 2 is much different from those in other cameras. Thus, the corresponding dictionaries learned in other cameras could not provide much effective information about the target. It should be noted that the Kalman tracking method heavily and continuously relies on the background modeling performance. It could not track the target until its foreground is re-detected again, and due to the variation of foreground area, the target is not correctly labeled in some frames. Comparatively, our proposed tracker only relies on the foreground information once for location initialization, and with the dictionary sharing across the network, it achieves a better performance.
4.6. Discussion
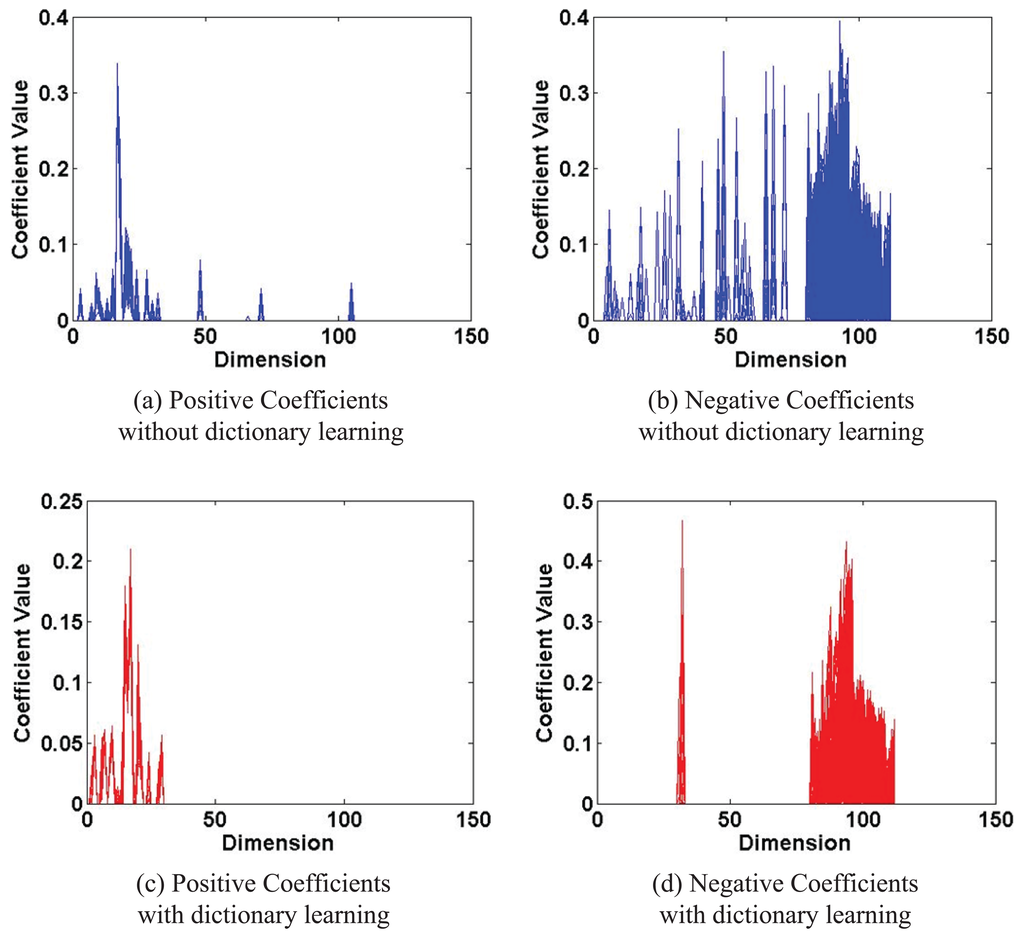
It can be found that our proposed tracker could perform more favorably than the other state-of-the-art trackers comprehensively in both qualitative and quantitative evaluation. We present some justifications here. For discriminative tracking algorithms, discrimination of the target from the background is critical. One of our contributions is the proposed IDSDL algorithm for dictionary learning. The proposed dictionary contains both a positive template set and negative samples, and during training, the LU strategy is proposed to only update its partial columns. Furthermore, the positive samples are used to update the positive part, and their negative counterparts are used to generate the learned negative part. Figure 14 shows the coefficients of positive and negative samples at #0016 in sequence Car 4with/without dictionary learning. These coefficients would be the input of the SVM classifiers for training. It can be found that, without dictionary learning, the coefficient values are more globally distributed across the dimension, while with dictionary learning, the data are more aggregated. Therefore, the proposed dictionary learning algorithm can improve the discrimination ability of the sparse coefficients, so that better classifiers and tracking performance could be obtained.
Confidence is also important for observation estimation. Our proposed KCV voting method combines the classifiers randomly and outputs their estimated result by a maximal scheme. Since the candidates are also generated randomly, the random combination could also be viewed as a supplementary re-sampling step from the particle filtering aspect. A limited combination of random sample points are still random, because the joint distribution of single Gaussian variables is still Gaussian. Thus, statistically speaking, it improves the estimation generalization during the tracking process. The maximal scheme is a nonlinear superposition process, and it creates more confidence points given limited candidates.
It has been shown from the experiments that our proposed tracker is currently not sufficient for real-time processing. Currently, it is mainly a MATLAB implementation with some C/C++ Mex functions. Most of the processing time is spent on the dictionary learning and classifier training part. It is certain that the processing could be several times faster in both single camera and visual sensor network cases when all the codes are re-written in C. The running speed could be higher if the processing could be paralleled or assisted with a graphic processing unit (GPU) coprocessor, since each patch could be independently processed before KCV without interleaving. Though the proposed tracker is slower, it achieves better performance in the accuracy evaluation.
5. Conclusions
This paper proposes an online discriminative visual tracking algorithm based on incremental discriminative structured dictionary learning and multiple linear classification based on randomly-combined voting. Not only qualitative, but also quantitative, evaluations are conducted, which demonstrate that, on challenging image sequences, the proposed tracking algorithm enjoys better performance than the state-of-the-art algorithms. It is also shown that our proposed algorithm could be applied to relay tracking with satisfactory performance in visual sensor networks. Our future work might focus on the application of the proposed dictionary learning method to other classification problems. The proposed algorithm could also be extended to multiple object tracking or the tracking of specific class (e.g., humans or their parts) given certain application environments.
Acknowledgments
This work is supported NSFC(no. 61171172 and no. 61102099), the National Key Technology R&D Program (no. 2011BAK14B02) and STCSM (Science and Technology Commission of Shanghai Municipality, China) under no. 10231204002, no. 11231203102 and no. 12DZ2272600. We also give our sincere thanks to the anonymous reviewers for their comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38. Article No. 13. [Google Scholar]
- Salti, S.; Cavallaro, A.; Di Stefano, L. Adaptive appearance modeling for video tracking: Survey and evaluation. IEEE Trans. Image Process. 2012, 21, 4334–4348. [Google Scholar]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I. Robust Fragments-Based Tracking Using the Integral Histogram. Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), New York, NY, USA, 17–22 June 2006; pp. 798–805.
- Zhou, Y.; Snoussi, H.; Zheng, S. Bayesian variational human tracking based on informative body parts. Opt. Eng. 2012, 51, 067203-1–067203-16. [Google Scholar]
- Zulkifley, M.A.; Rawlinson, D.; Moran, B. Robust observation detection for single object tracking: Deterministic and probabilistic patch-based approaches. Sensors 2012, 12, 15638–15670. [Google Scholar]
- Avidan, S. Support vector tracking. IEEE Trans. Pattern Anal. Mach. Intel. 2004, 26, 1064–1072. [Google Scholar]
- Grabner, H.; Bischof, H. On-line Boosting and Vision. Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 260–267.
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intel. 2011, 33, 1619–1632. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intel. 2011, 34, 1409–1422. [Google Scholar]
- Mei, X.; Ling, H. Robust visual tracking and vehicle classification via sparse representation. IEEE Trans. Pattern Anal. Mach. Intel. 2011, 33, 2259–2272. [Google Scholar]
- Liu, B.; Huang, J.; Yang, L.; Kulikowsk, C. Robust Tracking Using Local Sparse Appearance Model and K-Selection. Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1313–1320.
- Li, H.; Shen, C.; Shi, Q. Real-Time Visual Tracking Using Compressive Sensing. Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1305–1312.
- Sun, J. A fast MEANSHIFT algorithm-based target tracking system. Sensors 2012, 12, 8218–8235. [Google Scholar]
- Wang, Q.; Chen, F.; Xu, W.; Yang, M.H. Online Discriminative Object Tracking with Local Sparse Representation. Proceedinsg of 2012 IEEE Workshop on Applications of Computer Vision (WACV), Breckenridge, Colorado, USA, 9–11 January2012; pp. 425–432.
- Kwon, J.; Lee, K.M. Visual Tracking Decomposition. Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276.
- Wang, D.; Lu, H.; Yang, M.H. Online object tracking with sparse prototypes. IEEE Trans. Image Process. 2013, 22, 314–325. [Google Scholar]
- Wang, Q.; Chen, F.; Xu, W.; Yang, M.H. Object tracking via partial least squares analysis. IEEE Trans. Image Process. 2012, 21, 4454–4465. [Google Scholar]
- Dinh, T.B.; Medioni, G. Co-Training Framework of Generative and Discriminative Trackers with Partial Occlusion Handling. Proceedings of 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 642–649.
- Zhong, W.; Lu, H.; Yang, M.H. Robust Object Tracking via Sparsity-Based Collaborative Model. Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1838–1845.
- Tian, M.; Zhang, W.; Liu, F. On-line ensemble SVM for robust object tracking. Lect. Notes Comput. Sci. 2007, 4843, 355–364. [Google Scholar]
- Bai, Y.; Tang, M. Robust Tracking via Weakly Supervised Ranking SVM. Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1854–1861.
- Chen, J.; Wang, Y.; Wu, H. A coded aperture compressive imaging array and its visual detection and tracking algorithms for surveillance systems. Sensors 2012, 12, 14397–14415. [Google Scholar]
- Zhang, S.; Zhao, X.; Lei, B. Robust facial expression recognition via compressive sensing. Sensors 2012, 12, 3747–3761. [Google Scholar]
- Elad, M. Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing, 1st ed.; Springer: Heidelberg, Germany, 2010. [Google Scholar]
- Zhang, Q.; Li, B. Discriminative K-SVD for Dictionary Learning in Face Recognition. Proceedings of 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698.
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Fisher Discrimination Dictionary Learning for sparse representation. Proceedings of 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 543–550.
- Zhang, G.; Jiang, Z.; Davis, L.S. Online semi-supervised discriminative dictionary learning for sparse representation. Lect. Notes Comput. Sci. 2013, 7724, 259–273. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 2010, 11, 19–60. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive Background Mixture Models for Real-Time Tracking. Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Ft. Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 246–252.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).