Dual-Tree Complex Wavelet Transform and Image Block Residual-Based Multi-Focus Image Fusion in Visual Sensor Networks

Abstract
: This paper presents a novel framework for the fusion of multi-focus images explicitly designed for visual sensor network (VSN) environments. Multi-scale based fusion methods can often obtain fused images with good visual effect. However, because of the defects of the fusion rules, it is almost impossible to completely avoid the loss of useful information in the thus obtained fused images. The proposed fusion scheme can be divided into two processes: initial fusion and final fusion. The initial fusion is based on a dual-tree complex wavelet transform (DTCWT). The Sum-Modified-Laplacian (SML)-based visual contrast and SML are employed to fuse the low- and high-frequency coefficients, respectively, and an initial composited image is obtained. In the final fusion process, the image block residuals technique and consistency verification are used to detect the focusing areas and then a decision map is obtained. The map is used to guide how to achieve the final fused image. The performance of the proposed method was extensively tested on a number of multi-focus images, including no-referenced images, referenced images, and images with different noise levels. The experimental results clearly indicate that the proposed method outperformed various state-of-the-art fusion methods, in terms of both subjective and objective evaluations, and is more suitable for VSNs.1. Introduction
Visual sensor networks (VSNs), wherein camera-equipped sensor nodes can capture, process, and transmit visual information, are an important research area which has attracted considerable attention in recent years [1,2]. Camera sensors collect a huge amount of visual data, which are rich in information and offer tremendous potential when used in VSNs [3,4]. Due to the resource and bandwidth requirements in VSNs, how to process such data using generally low-power sensor nodes is becoming a problem [5,6]. Image fusion can fuse these pictures into a single image. The fused image has a complete description of the scene, and is more accurate and suitable for both visual perception and further processing. This processing can reduce the randomness and redundancy and save storage space and bandwidth on the network, and hence improve the transmission efficiency in VSNs [7].
Because of the limited depth of focus in optical lenses [8], it is difficult to acquire an image that contains all relevant focused objects and hence some objects are in focus, but others will be out of focus and, thus, blurred. In VSNs, we have the opportunity to extend the depth of focus by using image fusion techniques.
Recently, image fusion techniques have been performed either in the spatial domain or frequency domain [9]. Spatial domain techniques are carried out directly on the source images. The main spatial domain techniques are weighted average, principal component analysis (PCA), intensity-hue-saturation (IHS), and Brovey transform [10]. The fused images obtained by these methods have high spatial quality, but they usually overlook the high quality of spectral information and hence suffer from spectral degradation [11]. In 2002, Li et al. [12] introduced the artificial neural network (ANN) for use in multi-focus image fusion. However, the performance of the ANN depends on the sample images and this is not an appealing characteristic. In 2011, Tian et al. [13] proposed a bilateral gradient to perform image fusion. However, there were some erroneous selections of some blocks in the focus region due to noise or undesired effects. Since the actual objects usually contain structures at many different scales or resolutions and multi-scale techniques are similar to the human visual system (HVS), the multi-scale techniques have attracted increasing interest in image fusion [14].
So far, frequency domain methods have been explored by using multi-scale transforms, including pyramid transforms [15,16], wavelet transforms [17,18], fast discrete curvelet transform (FDCT) [19], complex wavelet transform (CWT) [20] and non-subsampled contourlet transform (NSCT) [21]. Due to the outstanding localization capability in both the time and frequency domains, wavelet analysis has become one of the most commonly used methods in frequency domain fusion [18]. However, wavelet analysis cannot represent the directions of the image edges accurately, which results in a lack of shift-invariance and the appearance of pseudo-Gibbs phenomena in the fused image [22]. To overcome these shortcomings of the wavelet transform, Da Cunha et al. [23] proposed the NSCT. This method can not only give the asymptotic optimal representation of contours, but also possesses shift-invariance, and effectively suppresses pseudo-Gibbs phenomena [24]. In 2008, Qu et al. [25] proposed an image fusion method based on spatial frequency-motivated pulse coupled neural networks (SF_PCNN) in the NSCT domain, and proved that this method could extract more useful information and provide much better performance than typical fusion methods. However, the NSCT-based algorithm is time-consuming and of high complexity. The dual-tree complex wavelet transform (DTCWT) is also proposed for image fusion. This method deals with the shift variance phenomenon using parallel wavelet filtering with directionality support (six planes) [26]. Furthermore, this filtering provides a 1/2 sample delay in the wavelet branches of the dual trees allowing near-shift invariance and perfect reconstruction [27].
Multi-scale techniques can significantly enhance the visual effect, but in the focus area of the source image, the fused image clarity will have different degrees of information loss. This occurs because in the process of multi-scale decomposition and reconstruction, improper selection of fusion rules often causes the loss of useful information in the source image; this defect is almost impossible to completely avoid in the multi-scale based image fusion method [9].
In addition, it is noteworthy that there is a hypothesis whereby the source images are noise-free in most of the image fusion methods. These methods can always produce high-quality fused images with this assumption [28]. However, the images are often corrupted by noise that cannot be completely avoided during the image acquisition from VSNs [28].
Based on the above analysis, an image fusion method based on DTCWT with image block residual is proposed in this paper. The main differences and advantages of the proposed framework compared to other methods can be summarized as follows:
- (1)
For VSNs, a novel multi-focus image fusion framework which combines the DTCWT and image block residual techniques is proposed. The framework is divided into visual contrast based DTCWT based initial fusion and block residual based final fusion processes.
- (2)
In the visual contrast based DTCWT-based initial fusion process, the Sum-Modified-Laplacian (SML)-based visual contrast [29] and SML [30] are employed as the rules for low- and high-frequency coefficients in DTCWT domain, respectively. Using this model, the most important feature information is selected in the fused coefficients.
- (3)
In the block residual-based final fusion process, the image block residuals technique and consistency verification are proposed to detect the focus area and then a decision map is obtained. The decision map is used to guide which block should be selected from the source images or the initial fused image. Using this model, we can select pixels from the focus areas of source images to avoid loss of useful information to the greatest extent.
- (4)
Further, the proposed framework can provide a better performance than the various state-of-the-art fusion methods and is robust to noise. In addition, the proposed framework is efficient and more suitable for VSNs.
The rest of the paper is organized as follows: the related theories of the proposed framework are introduced in Section 2. The proposed fusion framework is described in Section 3. Experimental results and analysis are given in Section 4, and the concluding remarks are described in Section 5.
2. Preliminaries
This section covers two related concepts, including DTCWT and SML-based visual contrast, as described below.
2.1. Dual-Tree Complex Wavelet Transform (DTCWT)
Wavelet transforms provide a framework in which an image is decomposed, with each level corresponding to a coarser resolution band [17]. Once the wavelet transform is implemented, every second wavelet coefficient at each decomposition level is discarded, resulting in components that are highly dependent on their location in the subsampling vector and with great uncertainty as to when they occurred in time [27]. This unfavorable property is referred to as shift variance (throwing away 1 of every 2 samples). Coupled with the limitations in the direction, wavelet analysis thus cannot accurately represent the directions of the edges of images [22]. To overcome these shortcomings of DWT, in 1998 Kingsbury [26] proposed the dual-tree complex wavelet transform (DTCWT), an over-complete wavelet transform which provides both good shift invariance and directional selectivity. The DTCWT idea is based on the use of two parallel trees, one for the odd samples and the other one for the even samples generated at the first level. These trees provide the signal delays necessary for every level and hence eliminate aliasing effects and achieve shift invariance [31]. The horizontal and vertical sub-bands are divided into six distinct sub-bands which are ±15, ±45, ±75. The advantages of DTCWT, i.e., shift invariance and directional sensitivity, give improved fusion results that outperform the discrete wavelet transform (DWT) [32]. Figure 1 shows the accumulated reconstructions from each level of DTCWT and DWT after four levels of decomposition. As shown the edge of the decomposed image (highlighted in the red rectangle), pseudo-Gibbs phenomena appear in DWT, while DTCWT shows smooth edges. That is because DTCWT can represent the line singularities and plane singularities more effectively than DWT. Detailed information about the design of DTCWT may be found in [31].
2.2. Sum-Modified-Laplacian Based Visual Contrast
For spatial domain based multi-focus image fusion, there are many typical focus measurements such as energy of image gradient (EOG), spatial frequency (SF), tenengrad, Laplacian energy and SML. In [33], the authors compared these measurements through extensive experiments, and the results proved that SML is the best measurement. In the transform domain, SML is also very efficient and can produce the best fused results [34]. The definition of SML is as follows:
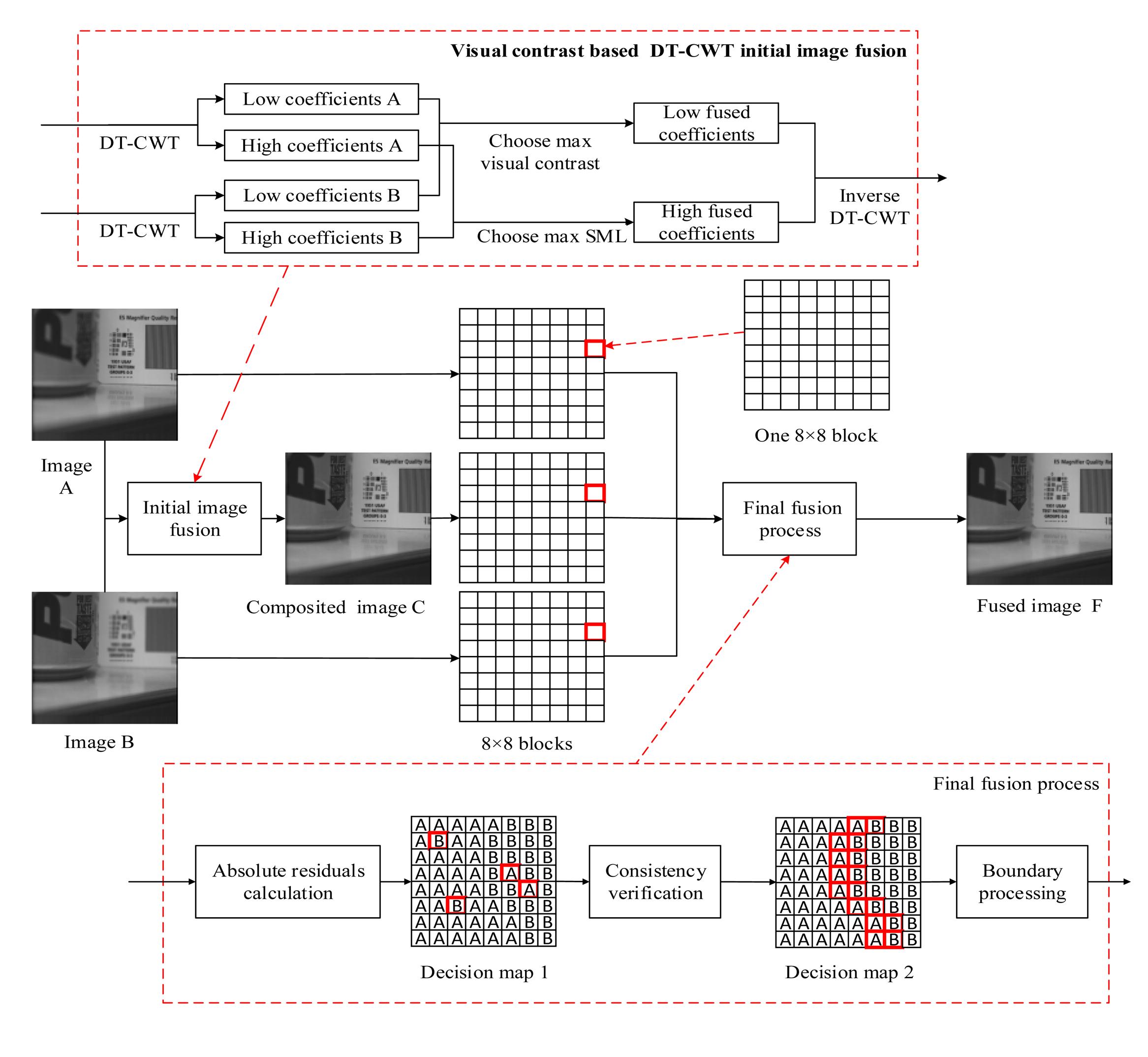
3. The Proposed Image Fusion Method
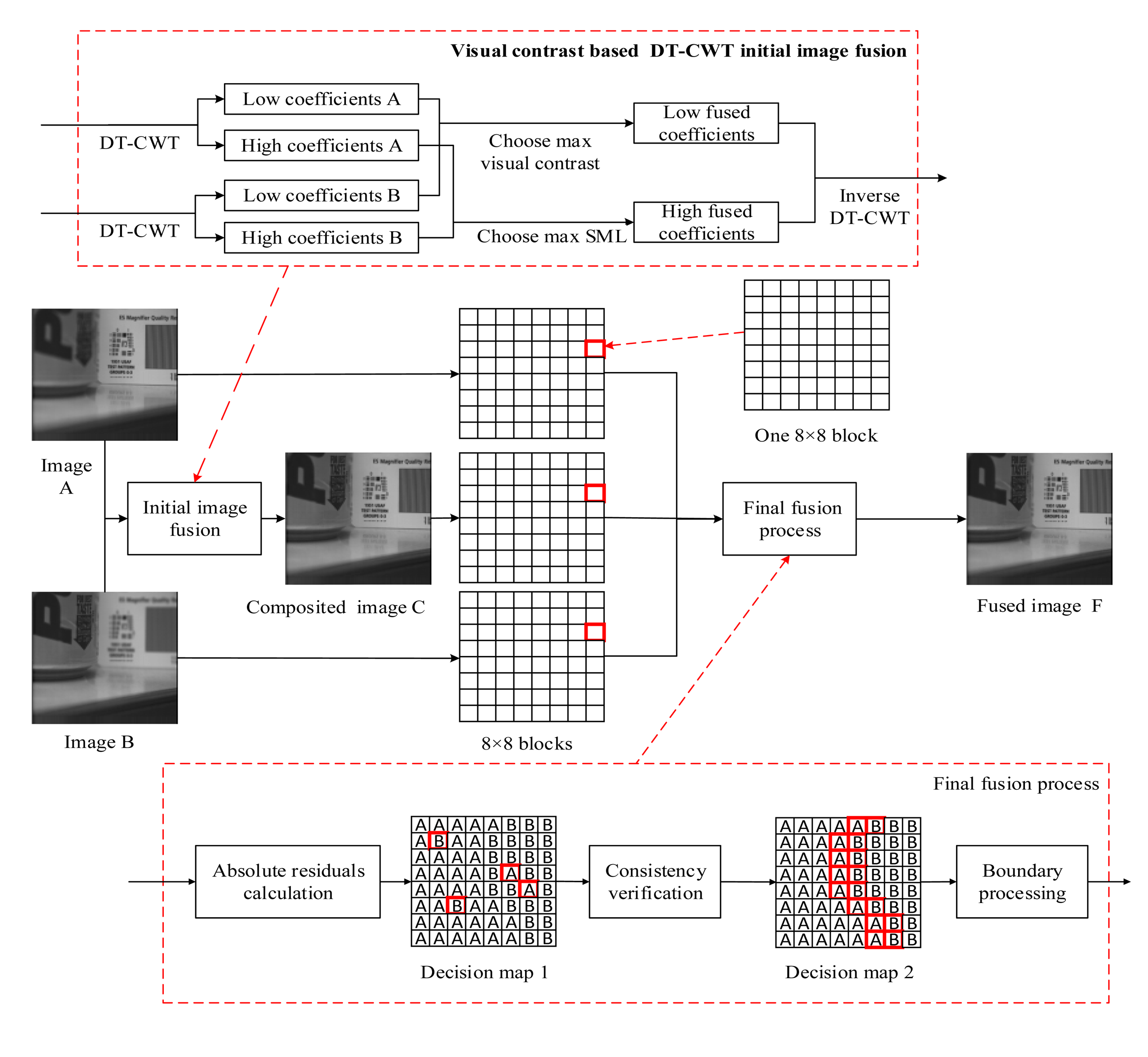
In this section, the proposed image fusion framework is depicted in Figure 2.
The framework includes two fusion procedures: the DTCWT based initial image fusion process and a hybrid final fusion process. The two processes are described as follows.
3.1. DTCWT Based Initial Image Fusion
In this subsection, the DTCWT based initial fusion, which applies new fusion rules for low- and high-frequency coefficients, respectively, is described in Algorithm 1.
| Algorithm 1. DTCWT based initial image fusion | |
| Input: Source images. | |
| Step 1: Load the source multi-focus images. | |
| Step 2: Perform three levels (how to set the level can be seen in literature [32]) DTCWT on source images to obtain two low frequency sub-bands and six high frequency sub-bands at each level. These sub-bands are denoted as:
| |
| Step 3: Fuse low- and high-frequency sub-bands via the following different rules to obtain composite low- and high-frequency sub-bands. The detail of low coefficients and high coefficients fusion are discussed as follows. | |
| Step 4: Perform three levels inverse DTCWT on the composited low- and high-frequency sub-bands to obtain the composited image. | |
| Output: The initial composited image. | |
The low frequency coefficients represent the approximate information and contain the most energy of the source images. The widely used rule is to apply averaging methods to produce the fused coefficients. However, this rule will reduce the contrast in the fused images. According to [30], the SML-based visual contrast is a criterion which considers the nonlinear relationship between the contrast sensitivity threshold of HVS and the background luminance. Therefore, we introduce SML-based visual contrast to fuse the low frequency sub-bands and the fusion process is given as follows:
For the high frequency coefficients, the most popular fusion rule is to select the coefficients with larger absolute values, but this rule does not take any consideration of the surrounding pixels. The SML operator is developed to provide local measures of the quality of image focus [29]. In [33], it is proved that the SML is very efficient in the transform domain. Therefore, the composite rule for the high-frequency sub-bands is defined as:
3.2. The Final Fusion Process
After DTCWT-based initial image fusion, a novel hybrid method for obtaining the final fused image is proposed and the final fusion process is described in Algorithm 2. The detailed description of some key techniques and algorithms is as follows.
| Algorithm 2. The final fusion process | |
| Input: The source images and the initial composited image. | |
| Step 1: Load the source images and the initial composited image. | |
| Step 2: The source images and the initial fused image are partitioned into non-overlapping blocks. | |
| Step 3: Calculate the values of image block residual between the source images and initial composited image. | |
| Step 4: Compare the values of RVA(i0, j0) and RVB(i0, j0) (block residuals of A and B), and then obtain an initial decision map M1(i0, j0). | |
| Step 5: Consistency verification is employed to eliminate the defects of M1(i0, j0) that caused by noise or undesired effects, and then get a modified decision map CV(i0, j0) for next step. | |
| Step 6: Get a final decision map Z(i0, j0) by boundary processing. The final process can thus be illustrated as follows:
| |
| Output: The final fused image. | |
3.2.1. Image Block Residual
In multi-focus images, the focused region is more informative [28]. It is easy to find that blocks in the focus area have greater similarity to the blocks of the initial fused image. Therefore, the image block residual is proposed to test the similarity, which is defined as:
The block residual can be assumed as a similarity measure in image processing applications. Constructing an initial decision map by:
3.2.2. Consistency Verification
In a scene, we assume most blocks of a region are in the depth of focus of one source image. According to the theory of imaging, all the blocks in such region must be chosen from the image [5]. However, there can be some erroneous selection of some blocks due to noise or undesired effects. To remove these defects, consistency verification [37] is employed. If the center block comes from one image while the majority of the surrounding blocks come from the other one, the center sample is simply switched to the corresponding block in the other image. Here, consistency verification is applied in a 3 × 3 neighborhood window as in [7]. After consistency verification to M1(i0, j0), we get the modified decision map CV(i0, j0) for boundary processing.
3.2.3. Boundary Processing
Assume one block contains both clear areas and blurred areas, so it is meaningless to judge the block is in the focus area or not. According to the theory of imaging, these blocks are always on the boundary of focused region. Therefore, we could choose these blocks by the equations below:
If M2(i0, j0) = 1, the block at (i0, j0) from image A is from the focus area, and if M2(i0, j0) = −1, the block at (i0, j0) from image B is from the focus area. Equation (11) means if one of M2(i0, j0), M2(i0 + 1, j0), M2(i0, j0 + 1) and M2(i0 + 1, j0 + 1) equals to 1 and another one equals to −1, the block at (i0, j0) is on the boundary of focused region.
As we know, the initial fused image has extracted the most characteristics of the source images to some extent. On the boundary of the focused region, the blocks may contain both clear pixels and blurred pixels. To reduce the loss of useful information, we should choose the blocks of the initial fused image on the boundary of the focused region. Then, we can use the Equation (7) to get the fusion result.
4. The Experimental Results and Analysis
In this section, the evaluation index system and the experimental results and analysis are described.
4.1. Evaluation Index System
Generally speaking, the measure of image fusion quality can be divided into two stages: subjective metrics and objective metrics [38]. Subjective evaluations always depend on the human visual characteristics and the professional knowledge of observers, thus the processes are time-consuming and have poor repeatability [39]. Objective evaluations can be easily performed by computers, completely automatically, and generally evaluate the similarity between the fused and the referenced image or source images [40]. Therefore, besides visual observation, six objective performance metrics are used to demonstrate the superior performance of the proposed algorithm. The quantitative evaluations can be divided into two classes: objective evaluation of results of referenced images and objective evaluation of results of non-referenced images.
4.1.1. Objective Evaluation of Results of Referenced Images
- (1)
Root Mean Square Error (RMSE): The RMSE is the cumulative squared error between the fused image and the referenced image and it is defined by:
where M × N is the size of fused image, F(i, j) and R(i, j) are the pixel value of the fused image and referenced image at the position (i, j), respectively. The lower the value of RMSE, the better the fusion effect.- (2)
Peak Signal to Noise Ratio (PSNR): The PSNR is a ratio between the maximum possible power of a signal and the power of noise that affects the fidelity [41]. The PSNR is formulated as:
where L is the dynamic range of the pixel values. Here, L = 255 is adopted. The greater the value of PSNR, the better the fusion effect.- (3)
Structural Similarity-based Metric (SSIM): The SSIM is designed by modeling any image distortion as the combination of the loss of correlation and radiometric and contrast distortion [42]. SSIM between the fused image and the referenced image is defined as follows:
in which uR, uF are mean intensity of the standard image and the fused image, respectively. σR, σF, σRF are the variances and covariance, respectively [43]. K1 and K2 are small constants, and L is the dynamic range of the pixel values. Here, the default parameters: K1 = 0.01, K2 = 0.03, L = 255 is adopted [44]. The greater the value of SSIM, the better the fusion effect.
4.1.2. Objective Evaluation of Results of Non-Referenced Images
- (1)
Standard deviation: The standard deviation can be used to estimate how widely spread the gray values in an image and defined as [45]:
where μ̂ is the mean value of the fused image. The larger the standard deviation, the better the result.- (2)
Mutual Information (MI): The MI can indicate how much information the fused image conveys about the source images [33]. MI between fusion image and the source images is defined as follows [46]:
in which:where MIAF and MIBF denote the normalized MI between the fused image and the source image A and B; a, b and f ε [0, L]. PA(a), pB(B) and pF(f) are the normalized gray level histograms of source images and fused image. pAF(a, f) and pBF(b, f) are the joint gray level histograms between the fused image and the source image A and B. The greater the value of MI, the better the fusion effect.- (3)
Edge Based Similarity Measure (QAB/F): QAB/F which proposed by Xydeas and Petrovic [47] gives the similarity between the edges transferred from the source images to the fused image. The definition is given as:
in which:where wA(i, j) and wB(i, j) are the corresponding gradient strengths for images A and B, respectively. and are the Sobel edge strength and orientation preservation values at location (i, j) for each source image [48]. The larger the value, the better the fusion effect result.
4.2. Experiments on Multi-Focus Image Fusion
The proposed fusion framework is tested on three sets of multi-focus image databases: non-referenced images, referenced images, and images with different noise. For all these image databases, the results of the proposed fusion scheme are compared with those of the state-of-the-art wavelet transform-, FDCT-, DTCWT-, and NSCT-based methods. The low- and high-frequency coefficients of the wavelet transform-, FDCT-, and DTCWT (DTCWT-1)-based methods are merged by the widely used fusion rule of averaging and selecting larger absolute values of the coefficient (average-maximum rule), respectively. The DTCWT-2 method is the DTCWT-based initial image fusion technique proposed in this paper. In addition, we introduce two NSCT-based methods (NSCT-1 and NSCT-2) for comparison. NSCT-1 involves merging the coefficients by an average-maximum rule; NSCT-2 merges the coefficients by SF_PCNN [25], which was proposed by Qu et al. in [25] and can make full use of the characteristics of PCNN and has been proven to outperform PCNN in the NSCT domain in fusing multi-focus images. In order to perform a fair comparison, the source images are all decomposed into three levels for those methods, except for the FDCT-based method (five is proven in [9] to be the best level in the FDCT-based image fusion method). For the wavelet-based method, the images are decomposed using the DBSS (2, 2) wavelet. For implementing NSCT, “9-7” filters and “pkva” filters (how to set the filters can be found in [49]) are used as the pyramidal and directional filters, respectively. It should be noted that since image registration is out of scope of this paper, like all the literatures, in all cases we assume the source images have been in perfect registration. A thorough survey of image registration techniques can be found in [50]. All the experiments are implemented in MATLAB R2012a on an Intel (R) Core (TM) i3-2330M CPU @2.2 GHz computer (ASUS, Taipei, Taiwan) with 4 GB RAM.
4.2.1. Fusion of Referenced Multi-Focus Images
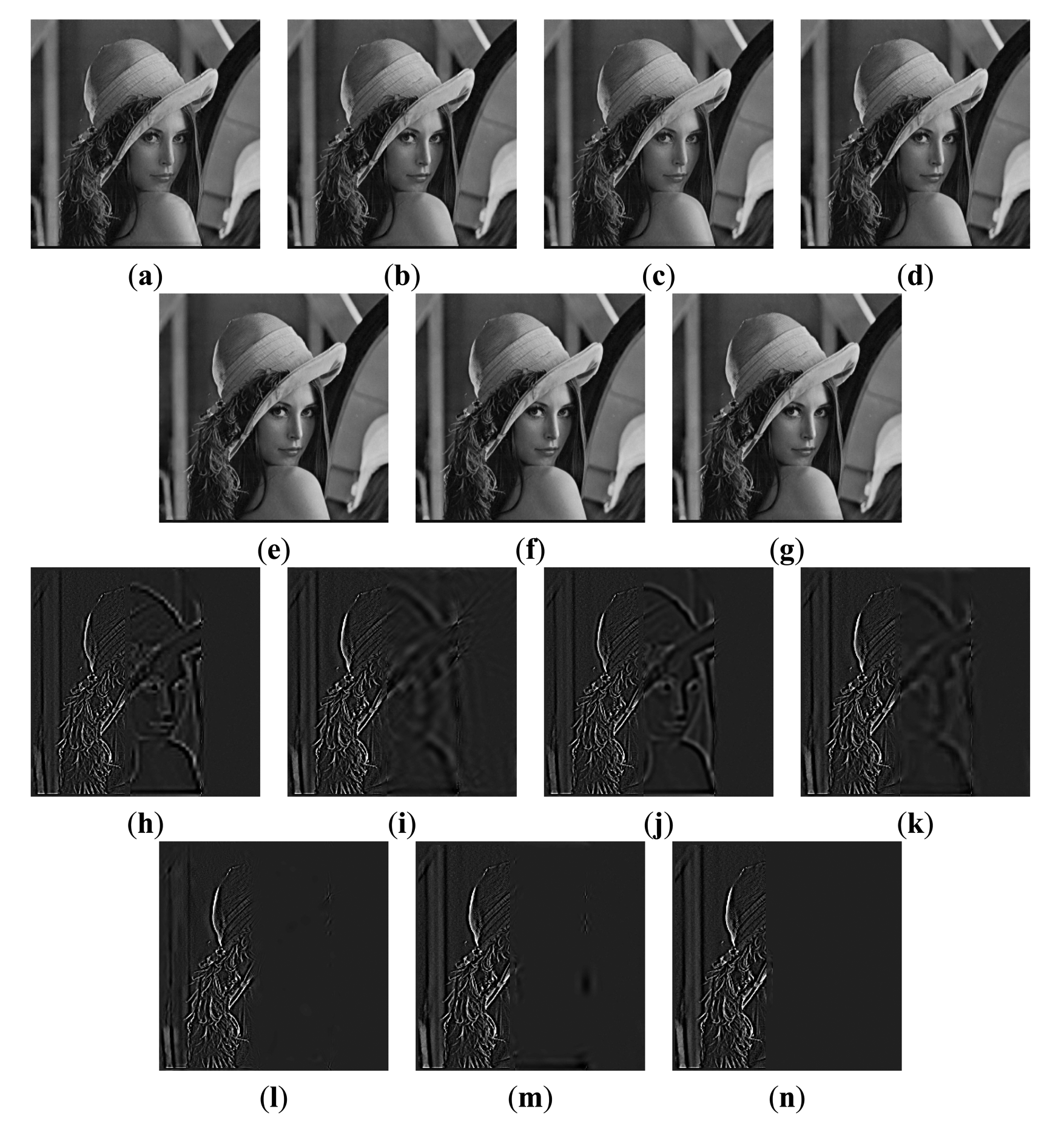
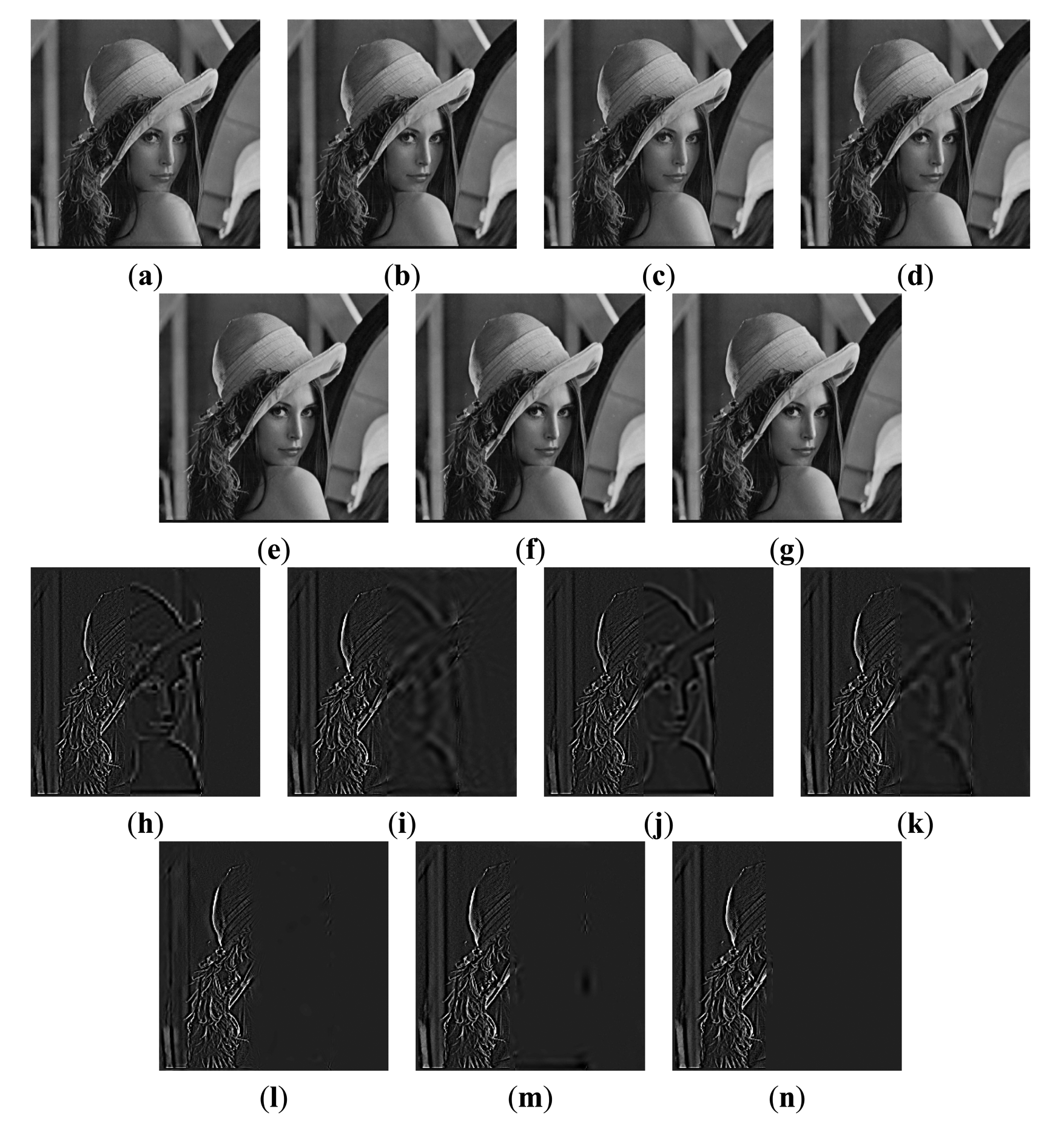
The first experiment is conducted using an extensive set of artificially generated images. Figure 3 shows the referenced Lena image, and two blurred artificial images that are generated by convolving the referenced image with an averaging filter centered on the left part and the middle part, respectively [51]. The fusion results of different images are shown in Figure 4a–g. For a clearer comparison, this paper has given the residual images [28] between the results and Figure 3b, and performed the following transform on each pixel of each residual image:
For the focused areas, the residual values between the fused images and the source image should be zero. According to the literature [9], in residual images, the lower residue the features, the more detail information in the focus region has been transferred to fused images and the better the corresponding method. From Figure 4, as mentioned above, the residual image between the result of the proposed method and Figure 3b is almost zero in the clear region. That is to say, the proposed method has extracted the most information from the clear region of Figure 3b.
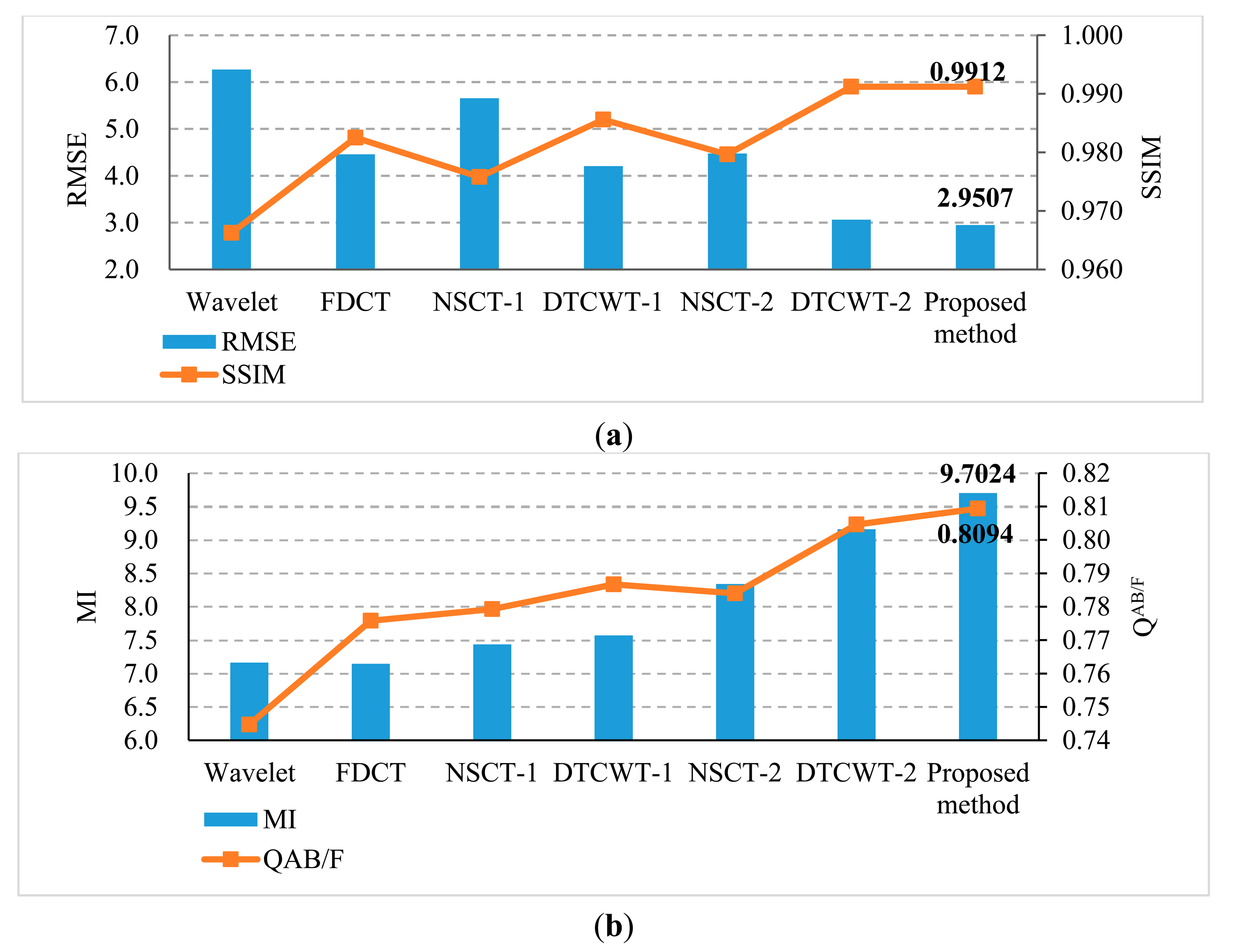
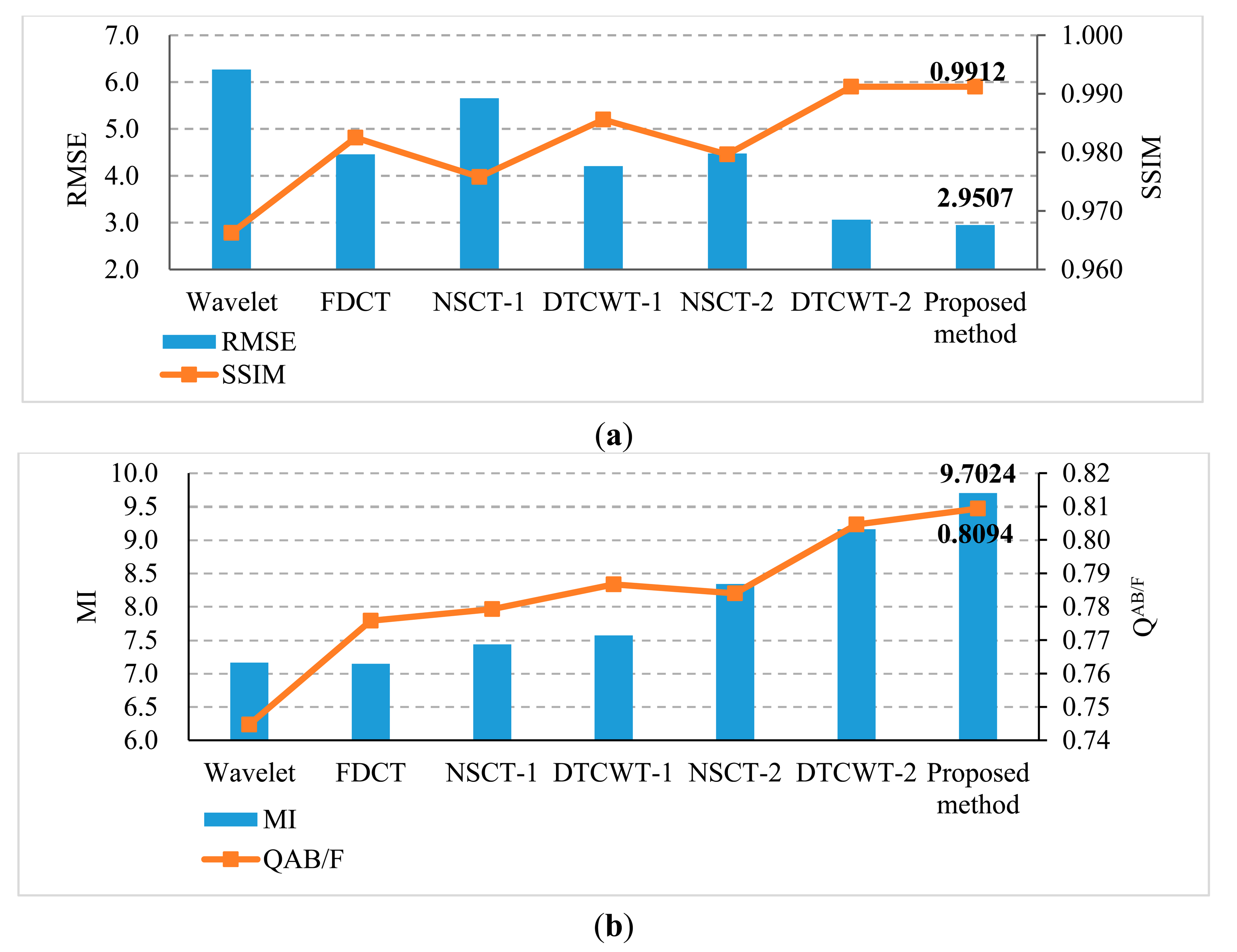
RMSE and SSIM are the metrics that measure the error or similarity between a referenced image and a fused image. Using these metrics the effect of the methods in the fusion of referenced multi-focus images can be measured well. In addition, MI and QAB/F are the state-of-the-art fusion performance metrics [25,40], which can be used to measure the fusion of no-reference multi-focus images. Figure 5 depicts the comparison on quantitative metrics of different methods; it is easy to find that the SSIM value of the proposed method is the largest (0.9912) and RMSE value is the smallest (2.9507). Both of them are the optimal values. That is to say, compared with other methods, the fused image of the proposed method is the closest to the referenced image. In addition, the MI and QAB/F values of the proposed method results also outperform the other methods.
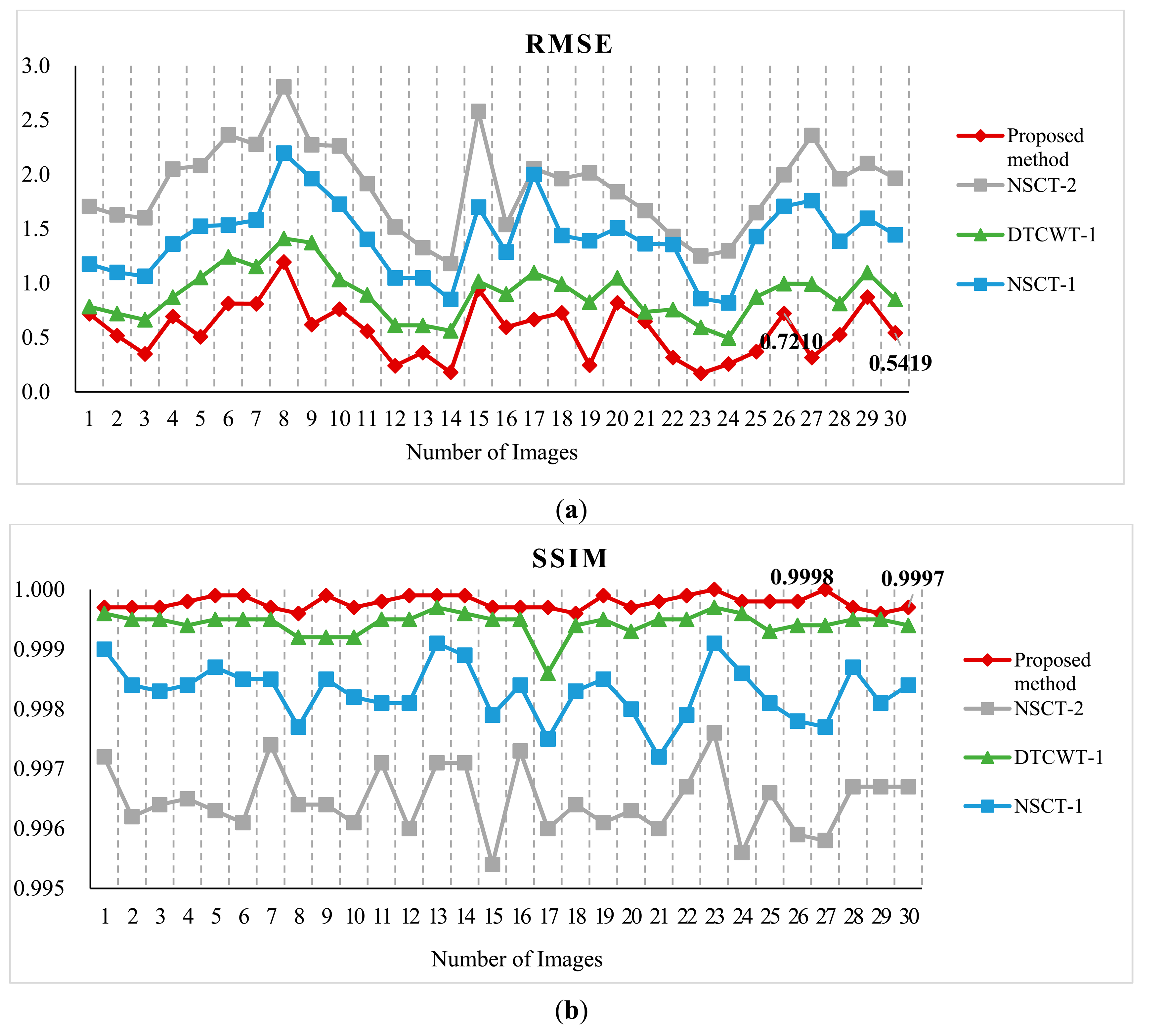
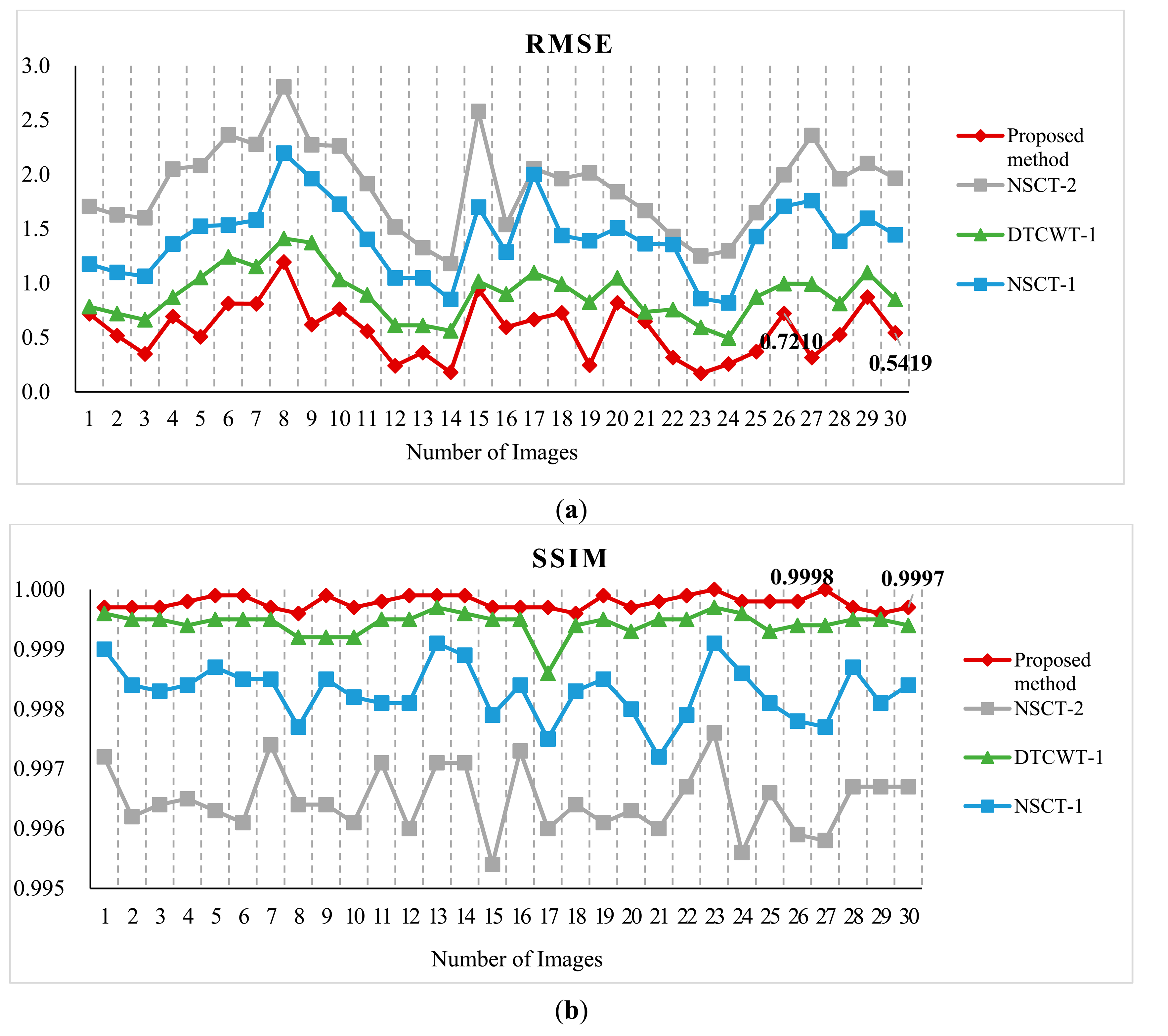
For further comparison, we experimented with more standard images. Figure 6 shows the standard test image database. The database is the standard grayscale test images that have been downloaded from [52]. The sizes of the test images are all 512 × 512. Each standard test image has been convolved with an averaging filter centered on the left part and right part, respectively. Figure 7 shows the typical examples of the fusion of artificial multi-focus images, the results of different methods and the corresponding residual images. From Figure 7, the residual images show that the proposed method results have extracted the most information from the focus region. Figure 8 shows the comparison on RMSE and SSIM of different methods for artificial multi-focus images. From Figure 8, it is seen that the results of the proposed method almost represent the referenced images with SSIM values approaching 1. From Figure 8, it is easy to find that in 30 sets of images, the SSIM and RMSE values of the proposed method results outperform other methods.
4.2.2. Fusion of Images in a Noisy Environment
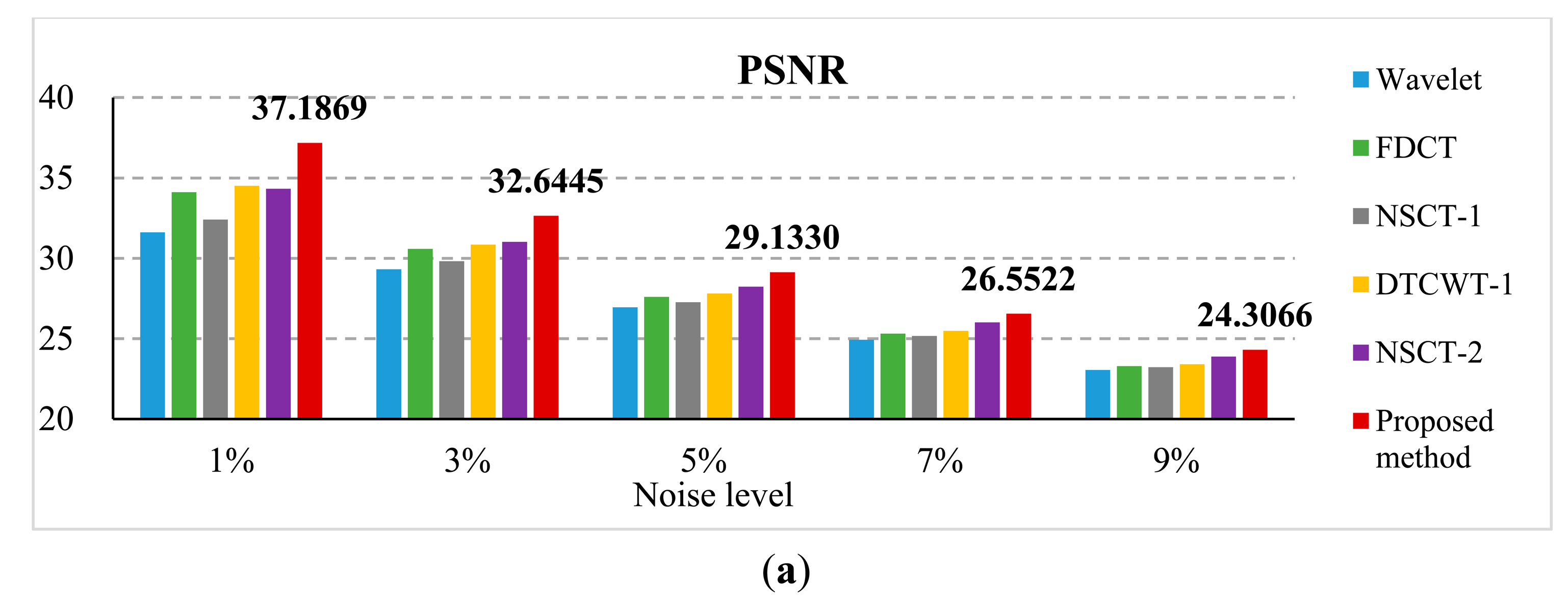
To evaluate the noise-robustness of the proposed framework, the second experiment is conducted on two blurred “Lena” images as shown in Figure 3b–c additionally corrupted with different Gaussian noise, with a standard deviation of 1%, 3%, 5%, 7% and 9%, respectively. Figure 9 shows the blurred images with 5% noise and the corresponding results of different methods. A quantitative evaluation comparison of the different methods for artificial images with different noise is shown in Figure 10. From Figure 10a, the PSNR values of the proposed method results are all the highest of the six methods. That is to say, in different noise environments, the results of the proposed method are closer to the referenced image than other methods. From Figure 10b,c, the MI and QAB/F values of the proposed method also outperform other methods. From the above analysis, we can observe that the proposed method provides the best performance and outperforms the other algorithms, even in noisy environments.
4.2.3. Fusion of Non-Referenced Multi-Focus Images
The third experiment is conducted on four sets of non-referenced multi-focus test images. These images are shown in Figure 11. The size of Figure 11a,b is 256 × 256, while the others are 480 × 640. The fusion results are shown in Figure 12a1–f1, a2–f2 and their sharpened residual images between the fused result and image focused on background are shown in Figure 12g1–l1,g2–l2. From the residual images, it is easy to find in the focused background areas that the proposed method has extracted more information than other methods and almost all of the useful information in the focus area of the source images has been transferred to the fused image.
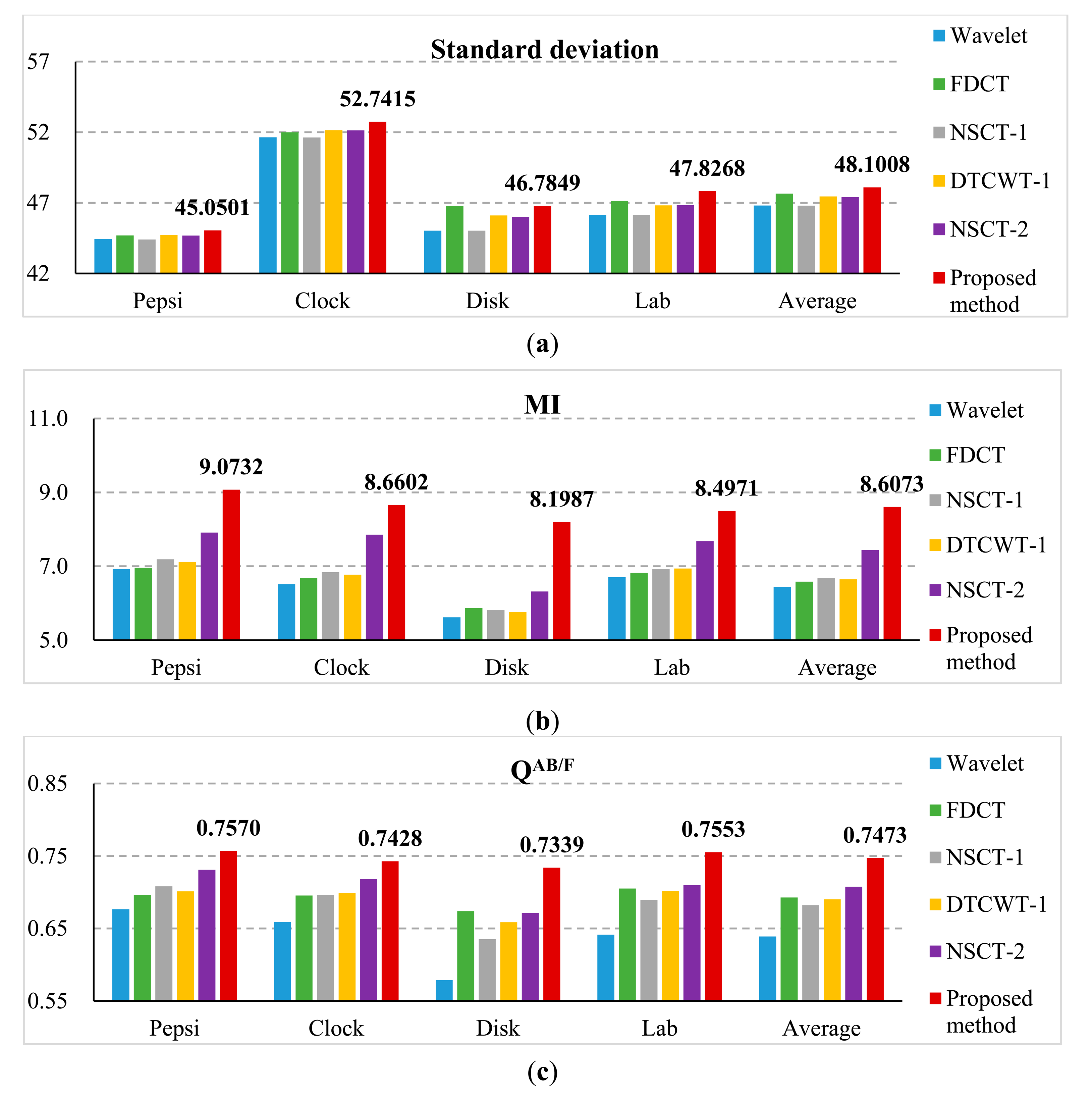
These experiments have no referenced images. Therefore, we used standard deviation, MI and QAB/F to evaluate how much clear or detailed information of the source images is transferred to the fused images. The comparison of the quantitative evaluation of different methods for non-referenced multi-focus images is shown in Figure 13. Comparing the average values of the standard deviation, MI and QAB/F of DTCWT 1 method and the proposed method, we can find that their corresponding values have been increased 1.37%, 29.50% and 8.26%, respectively. From Figure 13, the values of standard deviation, MI and QAB/F of the proposed method result are all better than those of the other methods. From the above analysis, we can also observe that the proposed scheme provides the best performance and outperforms the other algorithms.
Finally, we compare the time-consumption of the proposed method with the DTCWT- and NSCT- based methods. These methods can provide both good shift invariance and directional selectivity. A comparison of the execution times of the DTCWT-, NSCT-based methods and the proposed method for the Pepsi image sets is presented in Table 1.
The execution times are calculated by running all the codes in MATLAB R2012a on the same computer. From Table 1, it is easy to find that the NSCT-based methods (including NSCT-1 and NSCT-2 methods) are time-consuming and of high complexity, and the efficiency of the proposed method and the DTCWT-based method is higher than that of the NSCT-based methods. Although the proposed method needs a little more execution time than the DTCWT method, the fusion performance including the above qualitative and quantitative evaluations of our method have been proved better than the DTCWT method. Hence, from the overall assessments, we can conclude that the proposed method is effective and suitable for real time applications.
5. Conclusions
In this paper, a novel DTCWT-based multi-focus image fusion framework is proposed for VSNs. The potential advantages include: (1) DTCWT is more suitable for image fusion because its advantages such as multi-directionality and shift-invariance; (2) use of the visual contrast and SML as fusion rules to strengthen the effect of DTCWT; and (3) image block residual and consistency verification are proposed to get a fusion decision map to guide the fusion process, which not only reduces the complexity of the procedure, but also increases the reliability and robustness of the fusion results. In the experiments, extensive sets of multi-focus images, including no-referenced images, referenced images, and images with different noise, are fused by using state-of-the-art methods and the proposed framework. In the experiments with the no-referenced images, comparing with simple DTCWT-based methods, the MI and QAB/F values of the proposed method have been increased 29.50% and 8.26%, respectively. The experimental results have shown the superior performance of the proposed fusion framework. In the future, we plan to design a pure C++ platform to reduce the time cost and validate our framework in multi-sensor image fusion problems like infrared and visible light image fusion.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No. 61262034, No. 61462031 and No. 61473221), by the Key Project of Chinese Ministry of Education (No. 211087), by the Doctoral Fund of Ministry of Education of China (No. 20120201120071), by the Natural Science Foundation of Jiangxi Province (No. 20114BAB211020, No. 20132BAB201025), by the Young Scientist Foundation of Jiangxi Province (No. 20122BCB23017), by the Science and Technology Application Project of Jiangxi province (No. KJLD14031), and by the Science and Technology Research Project of the Education Department of Jiangxi Province (No. GJJ14334).
Author Contributions
S.H. conceived and designed the experiments; S.T. performed the experiments; Y.Y. and S.T. analyzed the data and wrote the manuscript; P.L. modified the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, Y.; Xiong, N.; Zhao, Y.; Vasilakos, A.V.; Gao, J.; Jia, Y. Multi-layer clustering routing algorithm for wireless vehicular sensor networks. IET Commun. 2010, 4, 810–816. [Google Scholar]
- Ahamed, S.I.; Wang, W.; Hong, J. Recent Advances in Energy-Efficient Sensor Networks. Int. J. Distrib. Sens. Netw. 2013, 2013, 329867. [Google Scholar]
- Charfi, Y.; Wakamiya, N.; Murata, M. Challenging issues in visual sensor networks. IEEE Wirel. Commun. 2009, 16, 44–49. [Google Scholar]
- Xiong, N.; Vasilakos, A.V.; Yang, L.T.; Pedrycz, W.; Zhang, Y.; Li, Y.S. A resilient and scalable flocking scheme in autonomous vehicular networks. Mob. Netw. Appl. 2010, 15, 126–136. [Google Scholar]
- Phamila, Y.; Amutha, R. Discrete Cosine Transform based fusion of multi-focus images for visual sensor networks. Signal Process. 2014, 95, 161–170. [Google Scholar]
- Li, H.; Xiong, N.; Park, J.H.; Cao, Q. Predictive control for vehicular sensor networks based on round-trip time-delay prediction. IET Commun. 2010, 4, 801–809. [Google Scholar]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. Multi-focus image fusion for visual sensor networks in DCT domain. Comput. Electron. Eng. 2011, 37, 789–797. [Google Scholar]
- Lee, I.H.; Mahmood, M.T.; Choi, T.S. Robust Depth Estimation and Image Fusion Based on Optimal Area Selection. Sensors 2013, 13, 11636–11652. [Google Scholar]
- Li, H.; Chai, Y.; Li, Z. A new fusion scheme for multi-focus images based on focused pixels detection. Mach. Vis. Appl. 2013, 24, 1167–1181. [Google Scholar]
- Wang, J.; Lai, S.; Li, M. Improved image fusion method based on NSCT and accelerated NMF. Sensors 2012, 12, 5872–5887. [Google Scholar]
- Pradhan, P.S.; King, R.L.; Younan, N.H.; Holcomb, D.W. Estimation of the number of decomposition levels for a wavelet-based multiresolution multisensor image fusion. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3674–3686. [Google Scholar]
- Li, S.; Kwok, J.T.; Wang, Y. Multi-focus image fusion using artificial neural networks. Pattern Recognit. Lett. 2002, 23, 985–997. [Google Scholar]
- Tian, J.; Chen, L.; Ma, L.; Yu, W. Multi-focus image fusion using a bilateral gradient-based sharpness criterion. Opt. Commun. 2011, 284, 80–87. [Google Scholar]
- Singh, R.; Khare, A. Multiscale Medical Image Fusion in Wavelet Domain. Sci. World J. 2013, 2013, 521034. [Google Scholar]
- Petrovic, V.S.; Xydeas, C.S. Gradient-based multiresolution image fusion. IEEE Trans. Image Process. 2004, 13, 228–237. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Barducci, A.; Baronti, S.; Pippi, I. Multispectral fusion of multisensor image data by the generalized Laplacian pyramid. Proceeding of the IEEE 1999 International Geoscience and Remote Sensing Symposium, Hamburg, Germany, 28 June–2 July 1999; pp. 1183–1185.
- Dong, J.; Zhuang, D.; Huang, Y.; Fu, J. Advances in multi-sensor data fusion: Algorithms and applications. Sensors 2009, 9, 7771–7784. [Google Scholar]
- Yang, Y.; Huang, S.Y.; Gao, J.F.; Qian, Z.S. Multi-focus Image Fusion Using an Effective Discrete Wavelet Transform Based Algorithm. Meas. Sci. Rev. 2014, 14, 102–108. [Google Scholar]
- Li, H.; Guo, L.; Liu, H. Research on Image Fusion Based on the Second Generation Curvelet Transform. Acta Opt. Sin. 2006, 26, 657–662. [Google Scholar]
- Drajic, D.; Cvejic, N. Adaptive fusion of multimodal surveillance image sequences in visual sensor networks. IEEE Trans. Consum. Electr. 2007, 53, 1456–1462. [Google Scholar]
- Nirmala, D.E.; Vignesh, R.K.; Vaidehi, V. Multimodal Image Fusion in Visual Sensor Networks. Proceeding of the 2013 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 17–19 January 2013; pp. 1–6.
- Singh, R.; Khare, A. Fusion of multimodal medical images using Daubechies complex wavelet transform-A multiresolution approach. Inform. Fusion 2014, 19, 49–60. [Google Scholar]
- Da Cunha, A.L.; Zhou, J.; Do, M.N. The nonsubsampled contourlet transform: Theory, design, and applications. IEEE Trans. Image Process. 2006, 15, 3089–3101. [Google Scholar]
- Yang, Y.; Tong, S.; Huang, S.Y.; Lin, P. Log-Gabor Energy Based Multimodal Medical Image Fusion in NSCT Domain. Comput. Math. Meth. Med. 2014, 2014, 835481. [Google Scholar]
- Qu, X.B.; Yan, J.W.; Xiao, H.Z.; Zhu, Z.Q. Image fusion algorithm based on spatial frequency-motivated pulse coupled neural networks in nonsubsampled contourlet transform domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar]
- Kingsbury, N. The dual-tree complex wavelet transform: A new technique for shift-invariance and directional filters. Proceeding of the IEEE Digital Signal Processing Workshop, Bryce Canyon, UT, USA, 9–12 August 1998; pp. 120–131.
- Ioannidou, S.; Karathanassi, V. Investigation of the dual-tree complex and shift-invariant discrete wavelet transforms on Quickbird image fusion. IEEE Geosci. Remote Sens. Lett. 2007, 4, 166–170. [Google Scholar]
- Li, H.; Chai, Y.; Yin, H.; Liu, G. Multi-focus image fusion and denoising scheme based on homogeneity similarity. Opt. Commun. 2012, 285, 91–100. [Google Scholar]
- Yang, Y.; Zheng, W.; Huang, S.Y. Effective Multi-focus Image Fusion Based on HVS and BP Neural Network. Sci. World J. 2014, 2014, 281073. [Google Scholar]
- Nayar, S.K.; Nakagawa, Y. Shape from focus. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 824–831. [Google Scholar]
- Kingsbury, N. Image processing with complex wavelets. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1999, 357, 2543–2560. [Google Scholar]
- Kannan, K.; Perumal, A.S.; Arulmozhi, K. Optimal decomposition level of discrete, stationary and dual tree complex wavelet transform for pixel based fusion of multi-focused images. Serb. J. Electron. Eng. 2010, 7, 81–93. [Google Scholar]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar]
- Bhatnagar, G.; Jonathan Wu, Q.M.; Liu, Z. Human visual system inspired multi-modal medical image fusion framework. Expert Syst. Appl. 2013, 40, 1708–1720. [Google Scholar]
- Gerhard, H.E.; Wichmann, F.A.; Bethge, M. How sensitive is the human visual system to the local statistics of natural images. PLoS Comput. Biol. 2013, 9, 1–15. [Google Scholar]
- Toet, A.; van Ruyven, L.J.; Valeton, J.M. Merging thermal and visual images by a contrast pyramid. Opt. Eng. 1989, 28, 789–792. [Google Scholar]
- Redondo, R.; Šroubek, F.; Fischer, S.; Cristobal, G. Multi-focus image fusion using the log-Gabor transform and a multisize windows technique. Inform. Fusion 2009, 10, 163–171. [Google Scholar]
- Li, H.; Manjunath, B.; Mitra, S. Multisensor image fusion using the wavelet transform. Graph. Models Image Process. 1995, 57, 235–245. [Google Scholar]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. Proceeding of the 2003 International Conference on Image Processing, Amsterdam, The Netherlands, 14–17 September 2003; pp. 173–176.
- Bhatnagar, G.; Jonathan Wu, Q.M.; Liu, Z. Directive contrast based multimodal medical image fusion in NSCT domain. IEEE Trans. Multimed. 2013, 15, 1014–1024. [Google Scholar]
- Indhumadhi, N.; Padmavathi, G. Enhanced image fusion algorithm using laplacian pyramid and spatial frequency based wavelet algorithm. Int. J. Comput. Sci. Eng. 2011, 1, 298–303. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Li, S.; Kang, X.; Hu, J.; Yang, B. Image matting for fusion of multi-focus images in dynamic scenes. Inform. Fusion 2013, 14, 147–162. [Google Scholar]
- Lu, H.; Zhang, L.; Serikawa, S. Maximum local energy: An effective approach for multisensor image fusion in beyond wavelet transform domain. Comput. Math. Appl. 2012, 64, 996–1003. [Google Scholar]
- Zhang, X.; Li, X.; Feng, Y. A new image fusion performance measure using Riesz transforms. Opt. Int. J. Light Electron Opt. 2014, 125, 1427–1433. [Google Scholar]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inform. Fusion 2012, 13, 10–19. [Google Scholar]
- Xydeas, C.S.; Petrović, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar]
- Zhang, B.; Zhang, C.T.; Yuanyuan, L.; Wu, J.S.; Liu, H. Multi-focus image fusion algorithm based on compound PCNN in Surfacelet domain. Opt. Int. J. Light Electron Opt. 2014, 125, 296–300. [Google Scholar]
- Li, S.; Yang, B.; Hu, J. Performance comparison of different multi-resolution transforms for image fusion. Inform. Fusion 2011, 12, 74–84. [Google Scholar]
- Zitova, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar]
- Tian, J.; Chen, L. Adaptive multi-focus image fusion using a wavelet-based statistical sharpness measure. Signal Process. 2012, 92, 2137–2146. [Google Scholar]
- Dataset of Standard 512 × 512 Grayscale Test Images. Available online: http://decsai.ugr.es/cvg/CG/base.htm (accessed on 26 November 2014).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fusion Scheme | NSCT-1 | DTCWT | NSCT-2 | Proposed Method |
|---|---|---|---|---|
| Execution time (s) | 14.4024 | 0.3273 | 32.6268 | 3.3020 |
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Tong, S.; Huang, S.; Lin, P. Dual-Tree Complex Wavelet Transform and Image Block Residual-Based Multi-Focus Image Fusion in Visual Sensor Networks. Sensors 2014, 14, 22408-22430. https://doi.org/10.3390/s141222408
Yang Y, Tong S, Huang S, Lin P. Dual-Tree Complex Wavelet Transform and Image Block Residual-Based Multi-Focus Image Fusion in Visual Sensor Networks. Sensors. 2014; 14(12):22408-22430. https://doi.org/10.3390/s141222408
Chicago/Turabian StyleYang, Yong, Song Tong, Shuying Huang, and Pan Lin. 2014. "Dual-Tree Complex Wavelet Transform and Image Block Residual-Based Multi-Focus Image Fusion in Visual Sensor Networks" Sensors 14, no. 12: 22408-22430. https://doi.org/10.3390/s141222408
APA StyleYang, Y., Tong, S., Huang, S., & Lin, P. (2014). Dual-Tree Complex Wavelet Transform and Image Block Residual-Based Multi-Focus Image Fusion in Visual Sensor Networks. Sensors, 14(12), 22408-22430. https://doi.org/10.3390/s141222408