Genotyping-by-Sequencing Reveals Molecular Genetic Diversity in Italian Common Bean Landraces





{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Plant Material
2.2. Protein Extraction and SDS/PAGE (Sodium Dodecyl Sulphate/PolyAcrylamide Gel Electrophoresis)
2.3. DNA Extraction, GBS Assay, and SNP Filtering
2.4. Structure Analysis and Genetic Relationships
2.5. Pairwise Fixation Index (FST)
3. Results
3.1. Seed Morphological Traits and Phaseolin Pattern
3.2. Sequencing Output
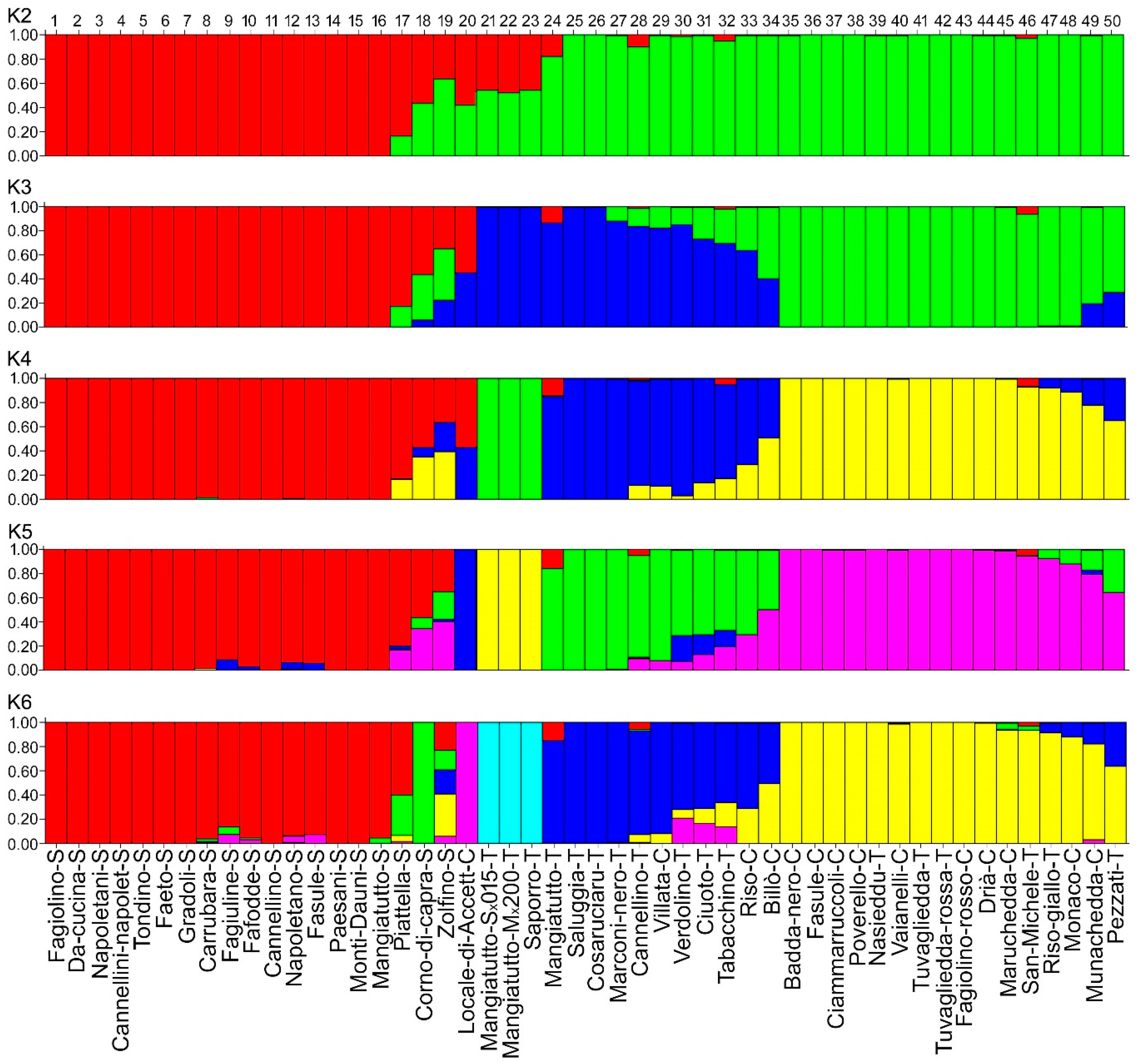
3.3. Genetic Structure
3.4. Pairwise Fixation Index (FST)
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgements
Conflicts of Interest
References
- FAO. FAOSTAT Crops. Available online: http://www.fao.org/faostat/en/#data/QC 2017 (accessed on 24 July 2019).
- Broughton, W.J.; Hernandez, G.; Blair, M.; Beebe, S.; Gepts, P.; Vanderleyden, J. Beans (Phaseolus spp.)—Model food legumes. Plant Soil 2003, 252, 55–128. [Google Scholar]
- Sparvoli, F.; Bollini, R.; Cominelli, E. Nutritional value. In Grain Legumes. Handbook of Plant Breeding; De Ron, A., Ed.; Springer: New York, NY, USA, 2015; pp. 291–325. [Google Scholar]
- Lioi, L.; Piergiovanni, A.R. Common bean cultivation in the Mediterranean basin. Legume Perspect. 2015, 10, 22–24. [Google Scholar]
- Debouck, D.G.; Toro, O.; Paredes, O.M.; Johnson, W.C.; Gepts, P. Genetic diversity and ecological distribution of Phaseolus vulgaris (Fabaceae) in northwestern South America. Econ. Bot. 1993, 47, 408–423. [Google Scholar] [CrossRef]
- Kami, J.; Velásquez, V.B.; Debouck, D.G.; Gepts, P. Identification of presumed ancestral DNA sequences of phaseolin in Phaseolus vulgaris. Proc. Natl. Acad. Sci. USA 1995, 92, 1101–1104. [Google Scholar] [CrossRef] [PubMed]
- Blair, M.W.; Soler, A.; Cortés, A.J. Diversification and population structure in common beans (Phaseolus vulgaris L.). PLoS ONE 2012, 7, e49488. [Google Scholar] [CrossRef] [PubMed]
- Rossi, M.; Bitocchi, E.; Bellucci, E.; Nanni, L.; Rau, D.; Attene, G.; Papa, R. Linkage disequilibrium and population structure in wild and domesticated populations of Phaseolus vulgaris L. Evol. Appl. 2009, 2, 504–522. [Google Scholar] [CrossRef] [PubMed]
- Kwak, M.; Kami, J.A.; Gepts, P. The putative Mesoamerican domestication center of Phaseolus vulgaris is located in the Lerma-Santiago Basin of Mexico. Crop Sci. 2009, 49, 554–563. [Google Scholar]
- Mamidi, S.; Rossi, M.; Annam, D.; Moghaddam, S.; Lee, R.; Papa, R.; McClean, P. Investigation of the domestication of common bean (Phaseolus vulgaris) using multilocus sequence data. Funct. Plant Biol. 2011, 38, 953–967. [Google Scholar] [CrossRef]
- Bitocchi, E.; Nanni, L.; Bellucci, E.; Rossi, M.; Giardini, A.; Spagnoletti Zeuli, P.; Logozzo, G.; Stougaard, J.; McClean, P.; Attene, G.; et al. Mesoamerican origin of the common bean (Phaseolus vulgaris L.) is revealed by sequence data. Proc. Natl. Acad. Sci. USA 2012, 109, E788–E796. [Google Scholar] [CrossRef]
- Cortés, A.J. On the origin of the common bean (Phaseolus vulgaris L.). Am. J. Plant Sci. 2013, 4, 1998–2000. [Google Scholar]
- Gepts, P. Phaseolin as an evolutionary marker. In Genetic Resources of Phaseolus Beans; Gepts, P., Ed.; Kluwer: Dordrecht, The Netherlands, 1988; pp. 215–241. [Google Scholar]
- Koenig, R.; Gepts, P. Segregation and linkage of genes for seed proteins, isozymes, and morphological traits in common bean (Phaseolus vulgaris). J. Hered. 1989, 80, 455–456. [Google Scholar]
- Sonnante, G.; Stockton, T.; Nodari, R.O.; Becerra Velásquez, V.L.; Gepts, P. Evolution of genetic diversity during the domestication of common-bean (Phaseolus vulgaris L.). Theor. Appl. Genet. 1994, 89, 629–635. [Google Scholar] [CrossRef] [PubMed]
- Chacón, M.S.; Pickersgill, B.; Debouck, D.G. Domestication patterns in common bean (Phaseolus vulgaris L.) and the origin of the Mesoamerican and Andean cultivated races. Theor. Appl. Genet. 2005, 110, 432–444. [Google Scholar] [CrossRef] [PubMed]
- Blair, M.W.; Cortés, A.J.; Penmetsa, R.V.; Farmer, A.; Carrasquilla-Garcia, N.; Cook, D.R. A high-throughput SNP marker system for parental polymorphism screening and diversity analysis in common bean (Phaseolus vulgaris L.). Theor. Appl. Genet. 2013, 126, 535–548. [Google Scholar] [CrossRef] [PubMed]
- Cortés, A.J.; Chavarro, M.C.; Blair, M.W. SNP marker diversity in common bean (Phaseolus vulgaris L.). Theor. Appl. Genet. 2011, 123, 827–845. [Google Scholar] [CrossRef] [PubMed]
- Bitocchi, E.; Bellucci, E.; Giardini, A.; Rau, D.; Rodriguez, M.; Biagetti, E.; Santilocchi, R.; Spagnoletti Zeuli, P.; Gioia, T.; Logozzo, G.; et al. Molecular analysis of the parallel domestication of the common bean (Phaseolus vulgaris) in Mesoamerica and the Andes. New Phytol. 2013, 197, 300–313. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, M.; Rau, D.; Bitocchi, E.; Bellucci, E.; Biagetti, E.; Carboni, A.; Gepts, P.; Nanni, L.; Papa, R.; Attene, G. Landscape genetics, adaptive diversity and population structure in Phaseolus vulgaris. New Phytol. 2016, 209, 1781–1794. [Google Scholar] [CrossRef] [PubMed]
- Gepts, P.; Bliss, F.A. Dissemination pathways of common bean (Phaseolus vulgaris; Fabaceae) deduced from phaseolin electrophoretic variability. II Europe and Africa. Econ. Bot. 1988, 42, 86–104. [Google Scholar] [CrossRef]
- Lioi, L. Geographical variation of phaseolin patterns in an old world collection of Phaseolus vulgaris. Seed Sci. Technol. 1989, 17, 317–324. [Google Scholar]
- Ocampo, C.H.; Martin, J.P.; Sanchez-Yelamo, M.D.; Ortiz, J.M.; Toro, O. Tracing the origin of Spanish common bean cultivars using biochemical and molecular markers. Genet. Resour. Crop Evol. 2005, 52, 33–40. [Google Scholar] [CrossRef]
- Rodiño, A.P.; Santalla, M.; Montero, I.; Casquero, PA.; De Ron, A.M. Diversity of common bean (Phaseolus vulgaris L.) germplasm from Portugal. Genet. Resour. Crop Evol. 2001, 48, 409–417. [Google Scholar] [CrossRef]
- Escribano, M.R.; Santalla, M.; Casquero, P.A.; De Ron, A.M. Patterns of genetic diversity in landraces of common bean (Phaseolus vulgaris L.) from Galicia. Plant Breed. 1998, 117, 49–56. [Google Scholar] [CrossRef]
- Piergiovanni, A.R.; Taranto, G.; Losavio, F.P.; Pignone, D. Common bean (Phaseolus vulgaris L.) landraces from Abruzzo and Lazio regions (Central Italy). Genet. Resour. Crop Evol. 2006, 53, 313–322. [Google Scholar] [CrossRef]
- Lioi, L.; Nuzzi, A.; Campion, B.; Piergiovanni, A.R. Assessment of genetic variation in common bean (Phaseolus vulgaris L.) from Nebrodi mountains (Sicily, Italy). Genet. Resour. Crop Evol. 2012, 59, 455–464. [Google Scholar] [CrossRef]
- Angioi, S.A.; Rau, D.; Attene, G.; Nanni, L.; Bellucci, E.; Logozzo, G.; Negri, V.; Spagnoletti Zeuli, P.L.; Papa, R. Beans in Europe: Origin and structure of the European landraces of Phaseolus vulgaris L. Theor. Appl. Genet. 2010, 121, 829–843. [Google Scholar] [CrossRef] [PubMed]
- Gioia, T.; Logozzo, G.; Attene, G.; Bellucci, E.; Benedettelli, S.; Negri, V.; Papa, R.; Spagnoletti Zeuli, P. Evidence for introduction bottleneck and extensive inter-gene pool (Mesoamerica x Andes) hybridization in the European common bean (Phaseolus vulgaris L.) germplasm. PLoS ONE 2013, 8, e75974. [Google Scholar] [CrossRef] [PubMed]
- Negri, V. Landraces in central Italy: Where and why they are conserved and perspectives for their on-farm conservation. Genet. Resour. Crop Evol. 2003, 50, 871–885. [Google Scholar] [CrossRef]
- Dwivedi, S.L.; Ceccarelli, S.; Blair, M.W.; Upadhyaya, H.D.; Are, A.K.; Ortiz, R. Landrace germplasm for improving yield and abiotic stress adaptation. Trends Plant Sci. 2016, 21, 31–42. [Google Scholar] [CrossRef]
- Cortés, A.J.; Blair, M.W. Genotyping by sequencing and genome—Environment associations in wild common bean predict widespread divergent adaptation to drought. Front. Plant Sci. 2018, 9, 128. [Google Scholar] [CrossRef]
- Cortés, A.J.; Hurtado, P.; Blair, M.W.; Chacón-Sánchez, M.I. Does the genomic landscape of species divergence in Phaseolus beans coerce parallel signatures of adaptation and domestication? Front. Plant Sci. 2018, 9, 1816. [Google Scholar] [CrossRef]
- Baird, N.A.; Etter, P.D.; Atwood, T.S.; Currey, M.C.; Shiver, A.L.; Lewis, Z.A.; Selker, E.U.; Cresko, W.A.; Johnson, E.A. Rapid SNP discovery and genetic mapping using sequenced RAD markers. PLoS ONE 2008, 3, e3376. [Google Scholar]
- Elshire, R.J.; Glaubitz, J.C.; Sun, Q.; Poland, J.A.; Kawamoto, K.; Buckler, E.S.; Mitchell, S.E. A robust, simple genotyping-by-sequencing (GBS) approach for high diversity species. PLoS ONE 2011, 6, e19379. [Google Scholar]
- Sonah, H.; Bastien, M.; Iquira, E.; Tardivel, A.; Légaré, G.; Boyle, B.; Normandeau, É.; Laroche, J.; Larose, S.; Jean, M.; et al. An improved genotyping by sequencing (GBS) approach offering increased versatility and efficiency of SNP discovery and genotyping. PLoS ONE 2013, 8, e54603. [Google Scholar] [CrossRef] [PubMed]
- Etter, P.D.; Preston, J.L.; Bassham, S.; Cresko, W.A.; Johnson, E.A. Local de novo assembly of RAD paired-end contigs using short sequencing reads. PLoS ONE 2011, 6, e18561. [Google Scholar] [CrossRef] [PubMed]
- Peterson, B.K.; Weber, J.N.; Kay, E.H.; Fisher, H.S.; Hoekstra, H.E. Double digest RADseq: An inexpensive method for de novo SNP discovery and genotyping in model and non-model species. PLoS ONE 2012, 7, e37135. [Google Scholar] [CrossRef] [PubMed]
- Poland, J.A.; Brown, P.J.; Sorrells, M.E.; Jannink, J.L. Development of high-density genetic maps for barley and wheat using a novel two-enzyme genotyping-by-sequencing approach. PLoS ONE 2012, 7, e32253. [Google Scholar]
- Ariani, A.; Berny Mier y Teran, J.C.; Gepts, P. Genome-wide identification of SNPs and copy number variation in common bean (Phaseolus vulgaris L.) using genotyping-by-sequencing (GBS). Mol. Breed. 2016, 36, 87. [Google Scholar] [CrossRef]
- Schröder, S.; Mamidi, S.; Lee, R.; McKain, M.R.; McClean, P.E.; Osorno, J.M. Optimization of genotyping by sequencing (GBS) data in common bean (Phaseolus vulgaris L.). Mol. Breed. 2016, 36, 6. [Google Scholar]
- Campa, A.; Murube, E.; Ferreira, J.J. Genetic diversity, population structure, and linkage disequilibrium in a Spanish common bean diversity panel revealed through genotyping-by-sequencing. Genes 2018, 9, E518. [Google Scholar] [PubMed]
- Laemmli, U.K. Cleavage of structure proteins during assembly of the head of Bacteriophage T4. Nature 1970, 227, 680–685. [Google Scholar] [CrossRef]
- Li, H.; Durbin, R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics 2010, 26, 589–595. [Google Scholar] [CrossRef] [PubMed]
- Catchen, J.; Amores, A.; Hohenlohe, P.; Cresko, W.; Postlethwait, J. Stacks: Building and genotyping loci de novo from short-read sequences. G3 Genes Genomes Genet. 2011, 1, 171–182. [Google Scholar]
- Bradbury, P.J.; Zhang, Z.; Kroon, D.E.; Casstevens, T.M.; Ramdoss, Y.; Buckler, E.S. TASSEL: Software for association mapping of complex traits in diverse samples. Bioinformatics 2007, 23, 2633–2635. [Google Scholar] [CrossRef] [PubMed]
- Berny Mier y Teran, J.C.B.; Konzen, E.R.V.; Palkovic, M.A.; Ariani, A.; Tsai, S.M.; Gilbert, M.E.; Gepts, P. Root and shoot variation in relation to potential intermittent drought adaptation of Mesoamerican wild common bean (Phaseolus vulgaris L.). Ann. Bot. 2018, 20, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 2000, 155, 945–959. [Google Scholar] [PubMed]
- Evanno, G.; Regnaut, S.; Goudet, J. Detecting the number of clusters of individuals using the software STRUCTURE: A simulation study. Mol. Ecol. 2005, 14, 2611–2620. [Google Scholar] [CrossRef] [PubMed]
- Earl, D.A.; Vonholdt, B.M. Structure Harvester: A website and program for visualizing Structure output and implementing the Evanno method. Conserv. Genet. Resour. 2012, 4, 359–361. [Google Scholar] [CrossRef]
- Tamura, K.; Nei, M. Estimation of the number of nucleotide substitutions in the control region of mitochondrial-DNA in humans and chimpanzees. Mol. Biol. Evol. 1993, 10, 512–526. [Google Scholar] [PubMed]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [PubMed]
- Weir, B.S.; Cockerham, C.C. Estimating F-statistics for the analysis of population structure. Evolution 1984, 38, 1358–1370. [Google Scholar]
- Raggi, L.; Tiranti, B.; Negri, V. Italian common bean landraces: Diversity and population structure. Genet. Resour. Crop Evol. 2013, 60, 1515–1530. [Google Scholar] [CrossRef]
- Waples, R.S.; Gaggiotti, O. What is a population? An empirical evaluation of some genetic methods for identifying the number of gene pools and their degree of connectivity. Mol. Ecol. 2006, 15, 1419–1439. [Google Scholar] [CrossRef] [PubMed]
- Tilman, D. Causes, consequences and ethics of biodiversity. Nature 2000, 405, 208–211. [Google Scholar] [CrossRef] [PubMed]
- Zimmerer, K.S. Conserving agrobiodiversity amid global change, migration, and nontraditional livelihood networks: The dynamic uses of cultural landscape knowledge. Ecol. Soc. 2014, 19, 1. [Google Scholar] [CrossRef]
- Blair, M.W.; Cortés, A.J.; This, D. Identification of an ERECTA gene and its drought adaptation associations with wild and cultivated common bean. Plant Sci. 2016, 242, 250–259. [Google Scholar] [CrossRef] [PubMed]
- Cortés, A.J.; Chavarro, M.C.; Madriñán, S.; This, D.; Blair, M.W. Molecular ecology and selection in the drought-related Asr gene polymorphisms in wild and cultivated common bean (Phaseolus vulgaris L.). BMC Genet. 2012, 13, 58. [Google Scholar] [CrossRef] [PubMed]
- Cortés, A.J.; This, D.; Chavarro, C.; Madriñán, S.; Blair, M.W. Nucleotide diversity patterns at the drought-related Dreb2 encoding genes in wild and cultivated common bean (Phaseolus vulgaris L.). Theor. Appl. Genet. 2012, 125, 1069–1085. [Google Scholar] [CrossRef]
- Logozzo, G.; Donnoli, R.; Macaluso, L.; Papa, R.; Knüpffer, H.; Spagnoletti Zeuli, P. Analysis of the contribution of Mesoamerican and Andean gene pools to European common bean (Phaseolus vulgaris L.) germplasm and strategies to establish a core collection. Genet. Resour. Crop Evol. 2007, 54, 1763–1779. [Google Scholar] [CrossRef]
- Blair, M.W.; Cortés, A.J.; Farmer, A.D.; Huang, W.; Ambachew, D.; Penmetsa, R.V.; Carrasquilla-Garcia, N.; Assefa, T.; Cannon, S.B. Uneven recombination rate and linkage disequilibrium across a reference SNP map for common bean (Phaseolus vulgaris L.). PLoS ONE 2018, 13, e0189597. [Google Scholar] [CrossRef]
- Singh, S.P.; Gepts, P.; Debouck, D.G. Races of common bean (Phaseolus vulgaris; Fabaceae). Econ. Bot. 1991, 45, 379–396. [Google Scholar] [CrossRef]
- Schmutz, J.; McClean, P.E.; Mamidi, S.; Wu, G.A.; Cannon, S.B.; Grimwood, J.; Jenkins, J.; Shu, S.; Song, Q.; Chavarro, C.; et al. A reference genome for common bean and genome-wide analysis of dual domestications. Nat. Genet. 2014, 46, 707–713. [Google Scholar] [CrossRef] [PubMed]
- Mercati, F.; Leone, M.; Lupini, A.; Sorgonà, A.; Bacchi, M.; Abenavoli, M.R.; Sunseri, F. Genetic diversity and population structure of a common bean (Phaseolus vulgaris L.) collection from Calabria (Italy). Genet. Resour. Crop. Evol. 2012, 60, 839–852. [Google Scholar] [CrossRef]
- Wallace, L.; Arkwazee, H.; Vining, K.; Myers, J.R. Genetic diversity within snap beans and their relation to dry beans. Genes 2018, 9, 587. [Google Scholar] [CrossRef] [PubMed]
- Lu, F.; Lipka, A.E.; Glaubitz, J.; Elshire, R.; Cherney, J.H.; Casler, M.D.; Buckler, E.S.; Costich, D.E. Switchgrass genomic diversity, ploidy, and evolution: Novel insights from a network-based SNP discovery protocol. PLoS Genet. 2013, 9, e1003215. [Google Scholar] [CrossRef] [PubMed]
- Alipour, H.; Bihamta, M.R.; Mohammadi, V.; Peyghambari, S.A.; Bai, G.; Zhang, G. Genotyping-by-Sequencing (GBS) revealed molecular genetic diversity of Iranian wheat landraces and cultivars. Front. Plant Sci. 2017, 8, 1293. [Google Scholar] [CrossRef] [PubMed]
- Pavan, S.; Lotti, C.; Marcotrigiano, A.R.; Mazzeo, R.; Bardaro, N.; Bracuto, V.; Ricciardi, F.; Taranto, F.; D’Agostino, N.; Schiavulli, A.; et al. A distinct genetic cluster in cultivated chickpea as revealed by genome-wide marker discovery and genotyping genome-wide marker discovery and genotyping. Plant Genome 2017, 10. [Google Scholar] [CrossRef] [PubMed]
- Pavan, S.; Curci, P.L.; Zuluaga, D.L.; Blanco, E.; Sonnante, G. Genotyping-by-sequencing highlights patterns of genetic structure and domestication in artichoke and cardoon. PLoS ONE 2018, 13, e0205988. [Google Scholar]



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lioi, L.; Zuluaga, D.L.; Pavan, S.; Sonnante, G. Genotyping-by-Sequencing Reveals Molecular Genetic Diversity in Italian Common Bean Landraces. Diversity 2019, 11, 154. https://doi.org/10.3390/d11090154
Lioi L, Zuluaga DL, Pavan S, Sonnante G. Genotyping-by-Sequencing Reveals Molecular Genetic Diversity in Italian Common Bean Landraces. Diversity. 2019; 11(9):154. https://doi.org/10.3390/d11090154
Chicago/Turabian StyleLioi, Lucia, Diana L. Zuluaga, Stefano Pavan, and Gabriella Sonnante. 2019. "Genotyping-by-Sequencing Reveals Molecular Genetic Diversity in Italian Common Bean Landraces" Diversity 11, no. 9: 154. https://doi.org/10.3390/d11090154
APA StyleLioi, L., Zuluaga, D. L., Pavan, S., & Sonnante, G. (2019). Genotyping-by-Sequencing Reveals Molecular Genetic Diversity in Italian Common Bean Landraces. Diversity, 11(9), 154. https://doi.org/10.3390/d11090154