
Comparison of Deep Learning and Traditional Machine Learning Models for Predicting Mild Cognitive Impairment Using Plasma Proteomic Biomarkers
 , ,
, ,
Abstract
1. Introduction
2. Results
2.1. Descriptive Statistics
2.2. Feature Selection and Resampling
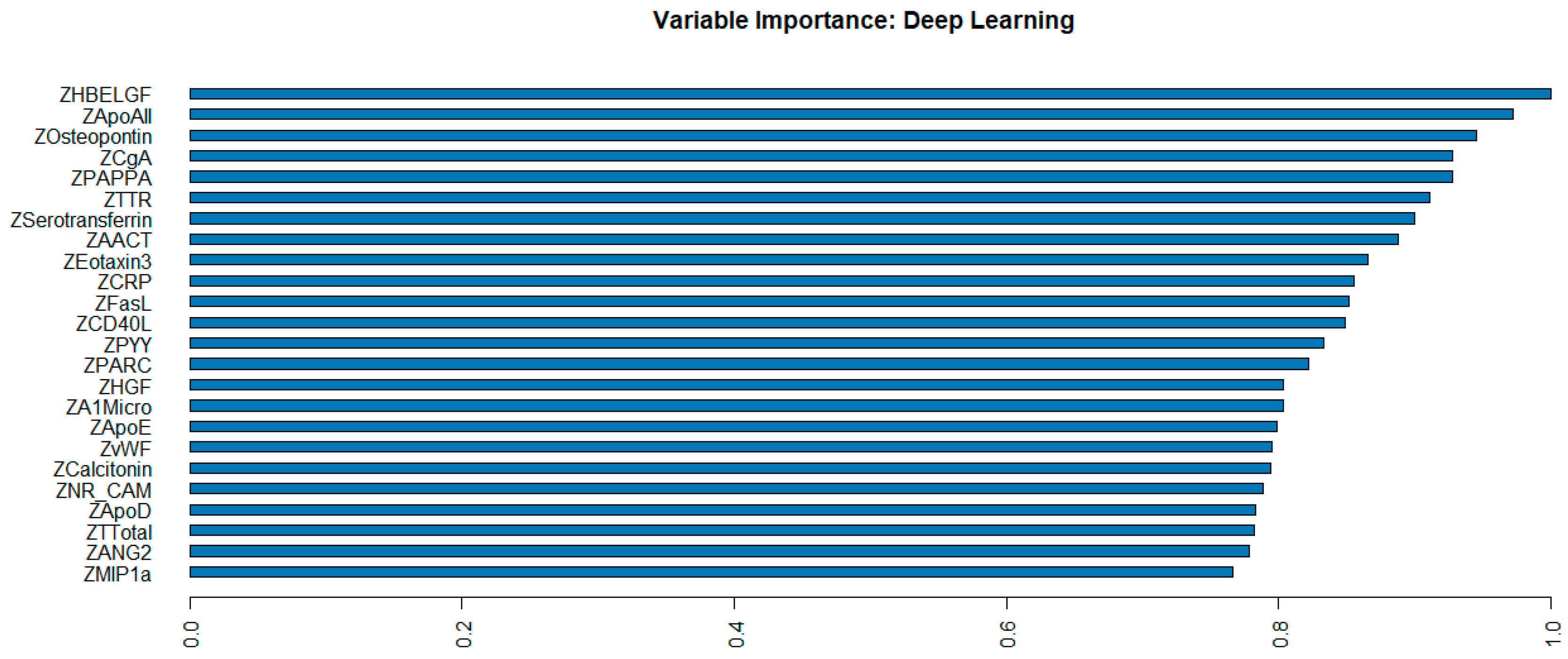
2.3. Machine Learning (ML) and Deep Learning (DL) Performance
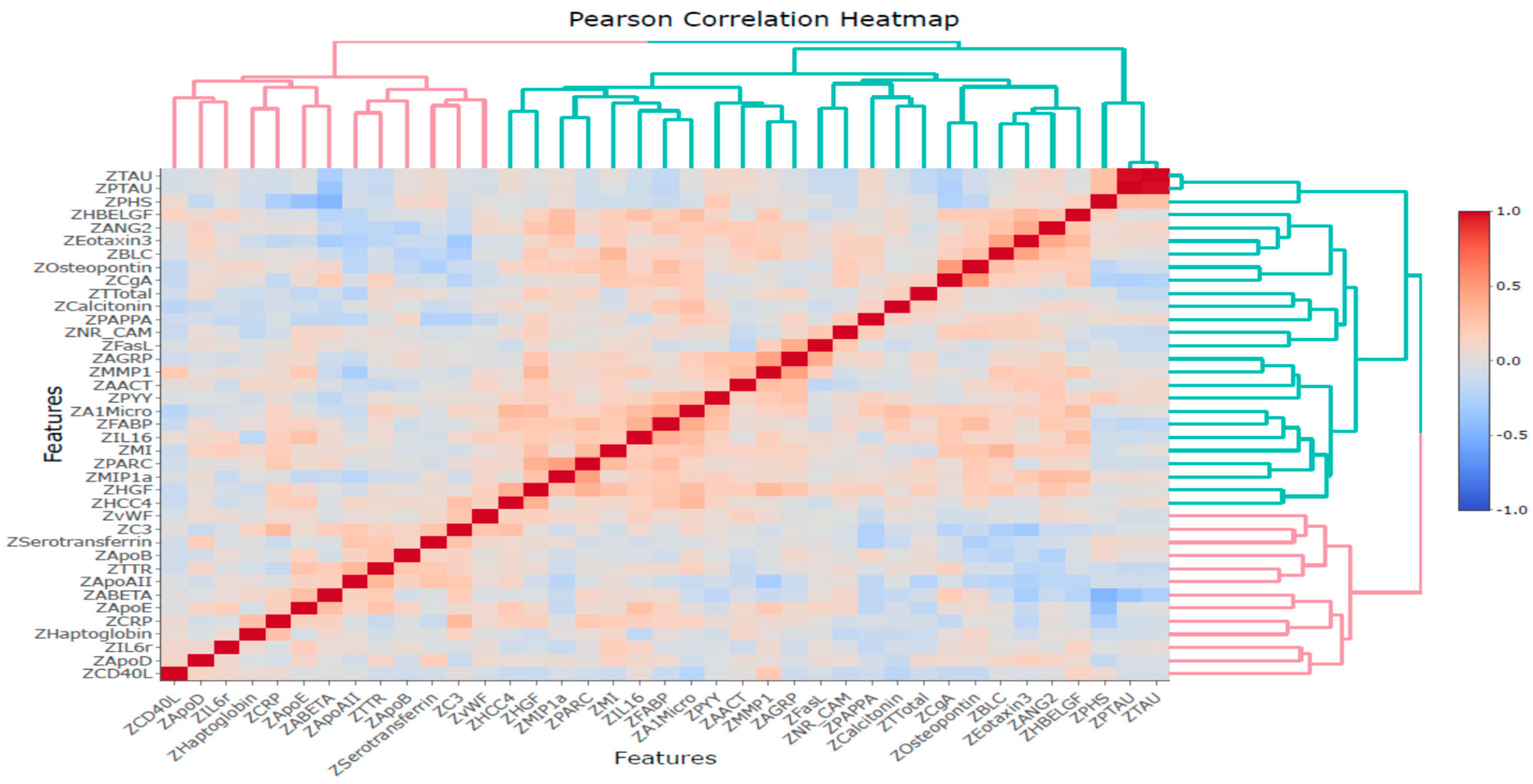
2.4. Correlation Analysis
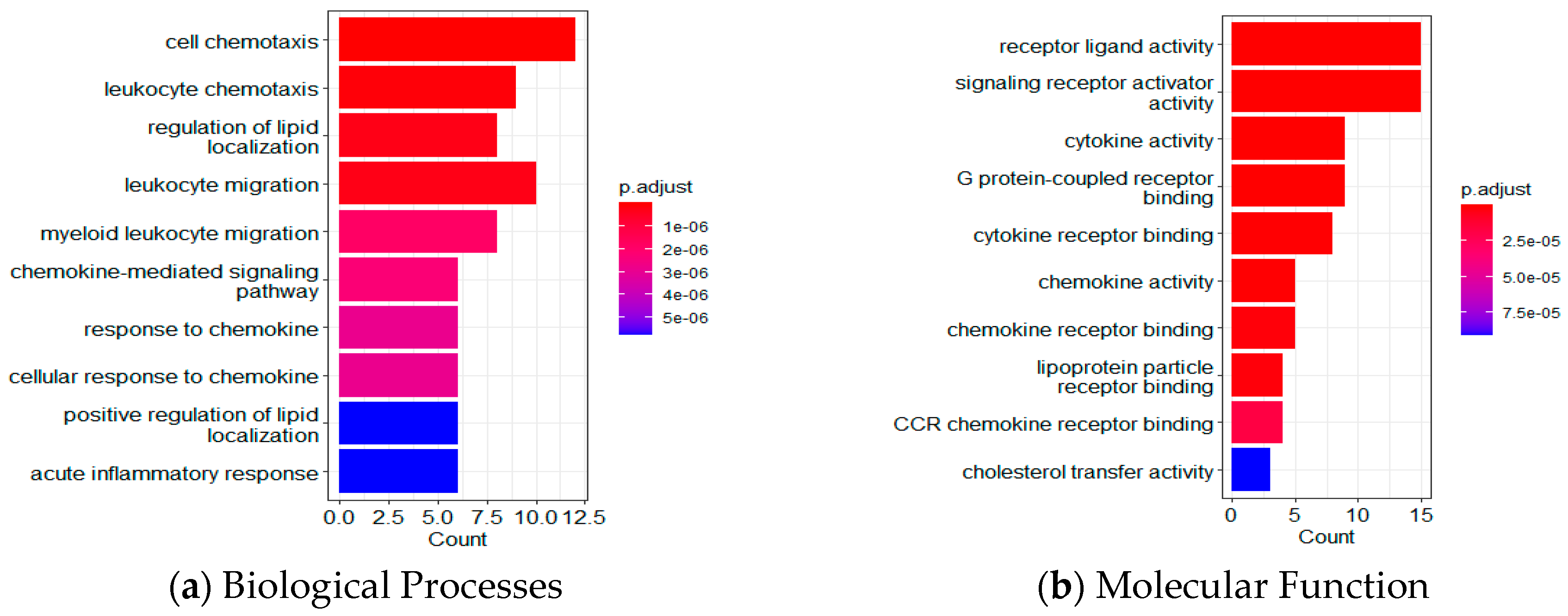
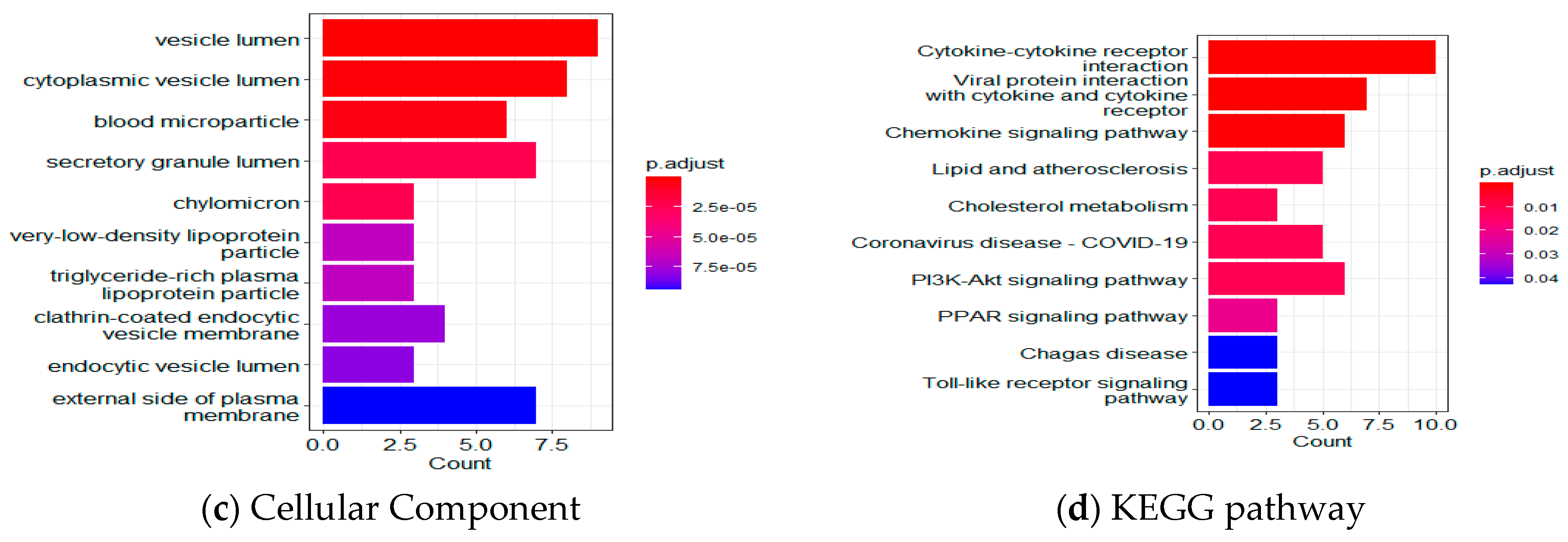
2.5. Bioinformatics Analysis Using GO and KEGG Pathway Analyses
3. Discussion
Strengths, Limitations, and Future Directions
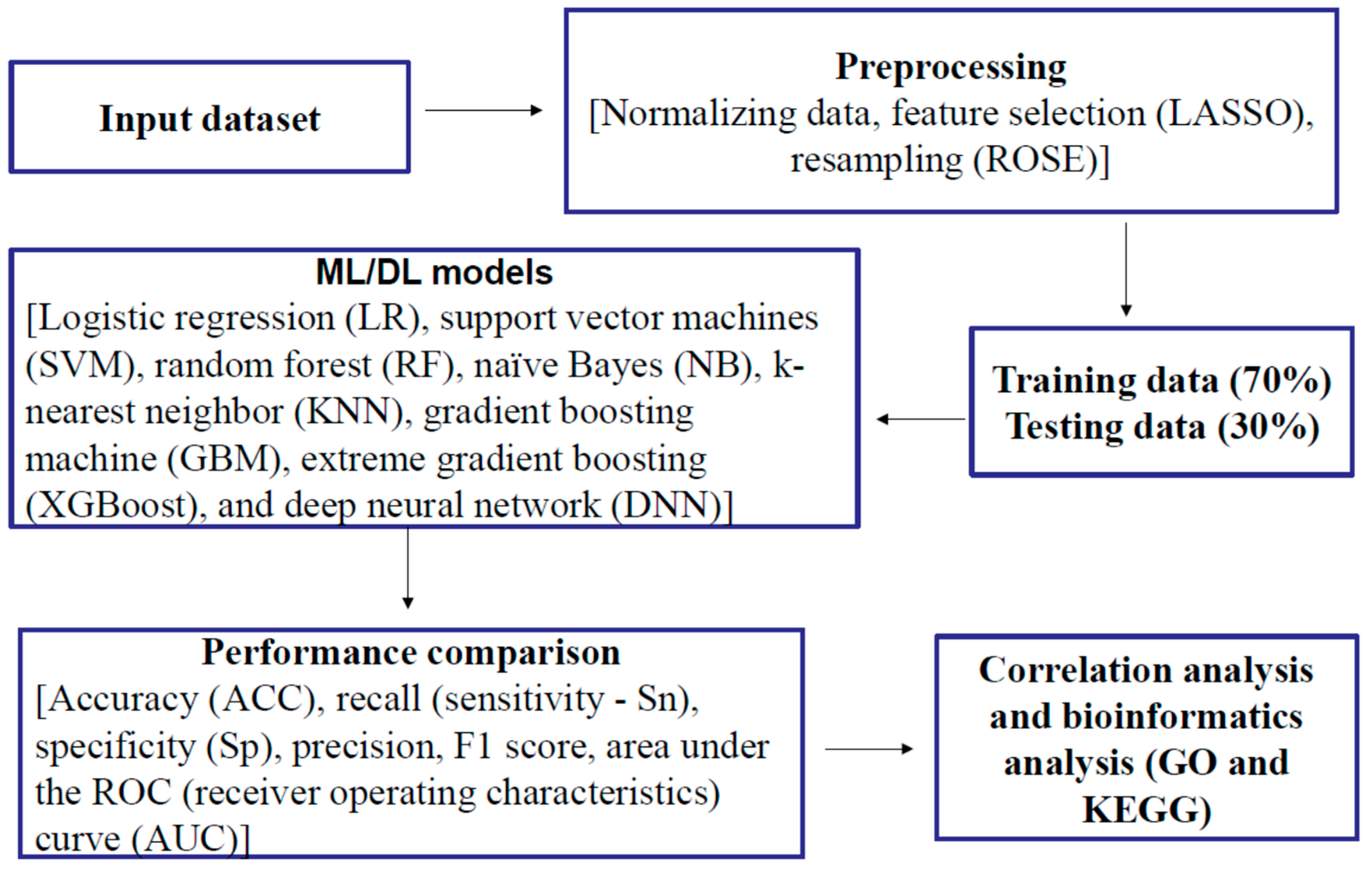
4. Materials and Methods
4.1. Dataset
4.2. Measures
4.3. Feature Selection of Plasma Proteomic Biomarkers and Resampling
4.4. Traditional Machine Learning Methods
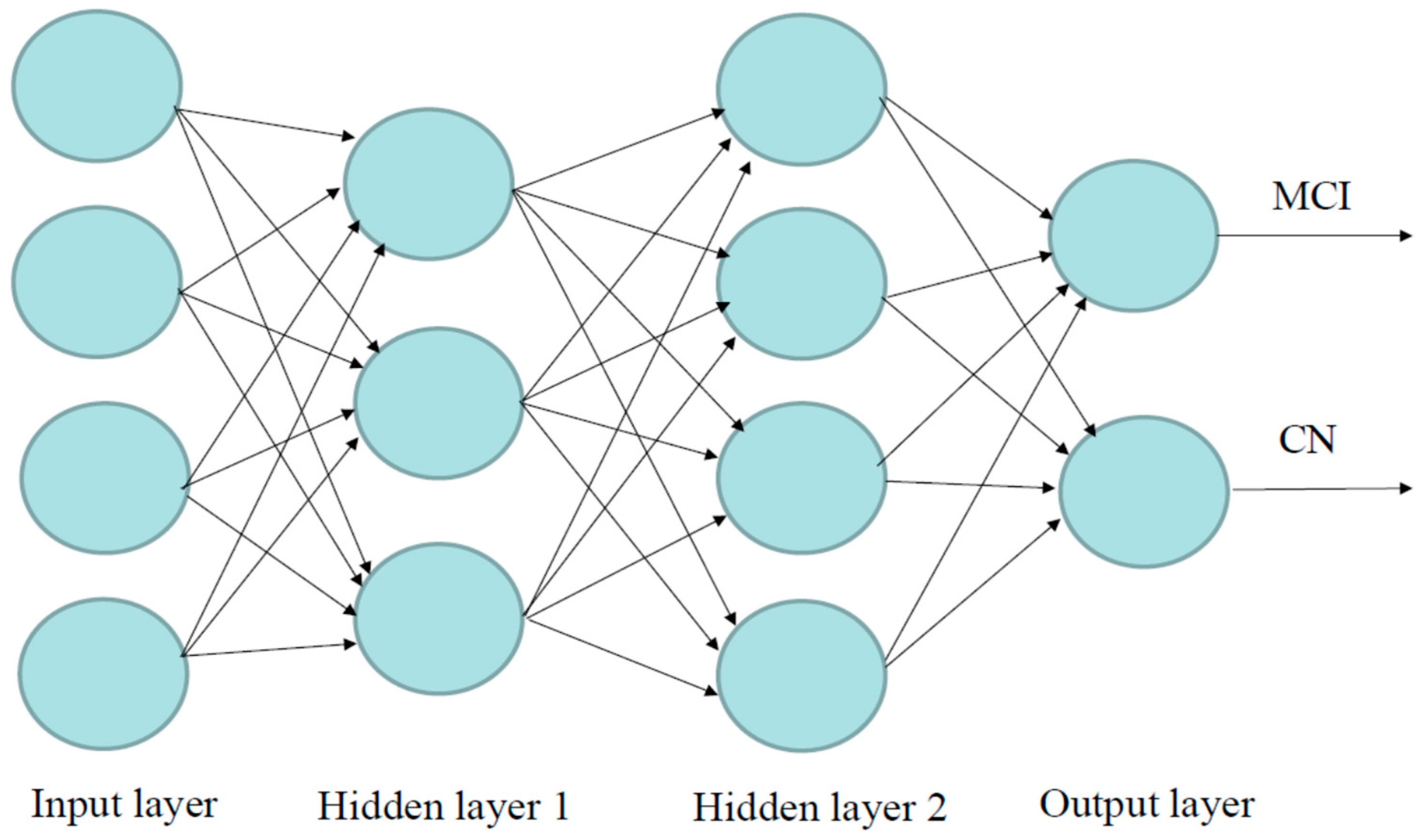
4.5. Deep Learning Methods
4.6. Performance of Machine Learning and Deep Learning Models
4.7. Statistical Analysis
4.8. Bioinformatic Analysis
4.9. Power Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADNI | Alzheimer’s Disease Neuroimaging Initiative |
| AD | Alzheimer’s Disease |
| MCI | Mild Cognitive Impairment |
| CN | Cognitive normal |
| DL | Deep learning |
| ML | Machine learning |
| ROSE | Random Over Sampling Example |
| CSF | Clinical cerebrospinal fluid |
| GO | Gene Ontology |
| KEGG | Kyoto Encyclopedia of Genes and Genomes |
| LR | Logistic regression |
| DT | Decision trees |
| GBM | Gradient boosting machines |
| GLM | General linear model |
| SVM | Support vector machine |
| RF | Random forest |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| RBF | Radial basis function |
| NB | Naïve Bayes |
| ANN | Artificial neural network |
| MLP | Multi-layer perceptron |
| DNN | Deep Neural Network |
| SAE | Stacked autoencoder |
| CNN | Convolutional neural network |
| SOTA | State-of-the-art (SOTA) |
| ResNet | Residual network |
| APOE | Apolipoprotein E |
| AUC | Area under the ROC (receiver operating characteristics) curve |
| PHS | Polygenic hazard score |
| SNP | Single nucleotide polymorphism |
| GWAS | Genome-wide association studies |
| SD | Standard deviation |
| Aβ | Amyloid-β |
| tTau | pathologic tau |
| pTau | Phosphorylated tau |
| MRI | Magnetic resonance imaging |
| PET | Positron emission tomography |
| ACC | Accuracy |
| Sn | Sensitivity |
| Sp | Specificity |
| PPV | Positive predictive value |
| TP | Number of true positives |
| TN | Number of true negatives |
| FP | Number of false positives |
| FN | Number of false negatives |
| BP | Biological processes |
| MF | Molecular function |
| CC | Cellular component |
References
- Alzheimer’s Association. 2022 Alzheimer’s Disease Facts and Figures. Alzheimer’s Dement. 2022, 18, 700–789. [Google Scholar] [CrossRef] [PubMed]
- Alzheimer’s Association. 2024 Alzheimer’s Disease Facts and Figures. Alzheimer’s Dement. 2024, 20, 3708–3821. [Google Scholar] [CrossRef] [PubMed]
- Bateman, R.J.; Xiong, C.; Benzinger, T.L.S.; Fagan, A.M.; Goate, A.; Fox, N.C.; Marcus, D.S.; Cairns, N.J.; Xie, X.; Blazey, T.M.; et al. Clinical and Biomarker Changes in Dominantly Inherited Alzheimer’s Disease. N. Engl. J. Med. 2012, 367, 795–804. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R.; Knopman, D.S.; Jagust, W.J.; Petersen, R.C.; Weiner, M.W.; Aisen, P.S.; Shaw, L.M.; Vemuri, P.; Wiste, H.J.; Weigand, S.D.; et al. Tracking Pathophysiological Processes in Alzheimer’s Disease: An Updated Hypothetical Model of Dynamic Biomarkers. Lancet Neurol. 2013, 12, 207–216. [Google Scholar] [CrossRef]
- Jack, C.R.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Dunn, B.; Haeberlein, S.B.; Holtzman, D.M.; Jagust, W.; Jessen, F.; Karlawish, J.; et al. NIA-AA Research Framework: Toward a Biological Definition of Alzheimer’s Disease. Alzheimers Dement. 2018, 14, 535–562. [Google Scholar] [CrossRef]
- Amieva, H.; Le Goff, M.; Millet, X.; Orgogozo, J.M.; Pérès, K.; Barberger-Gateau, P.; Jacqmin-Gadda, H.; Dartigues, J.F. Prodromal Alzheimer’s Disease: Successive Emergence of the Clinical Symptoms. Ann. Neurol. 2008, 64, 492–498. [Google Scholar] [CrossRef]
- Wilson, R.S.; Leurgans, S.E.; Boyle, P.A.; Bennett, D.A. Cognitive Decline in Prodromal Alzheimer Disease and Mild Cognitive Impairment. Arch. Neurol. 2011, 68, 351–356. [Google Scholar] [CrossRef]
- Mueller, S.G.; Weiner, M.W.; Thal, L.J.; Petersen, R.C.; Jack, C.R.; Jagust, W.; Trojanowski, J.Q.; Toga, A.W.; Beckett, L. Ways toward an Early Diagnosis in Alzheimer’s Disease: The Alzheimer’s Disease Neuroimaging Initiative (ADNI). Alzheimers Dement. 2005, 1, 55–66. [Google Scholar] [CrossRef]
- Weiner, M.W.; Veitch, D.P.; Aisen, P.S.; Beckett, L.A.; Cairns, N.J.; Green, R.C.; Harvey, D.; Jack, C.R.; Jagust, W.; Morris, J.C.; et al. The Alzheimer’s Disease Neuroimaging Initiative 3: Continued Innovation for Clinical Trial Improvement. Alzheimer’s Dement. 2017, 13, 561–571. [Google Scholar] [CrossRef]
- Petersen, R.C.; Smith, G.E.; Waring, S.C.; Ivnik, R.J.; Tangalos, E.G.; Kokmen, E. Mild Cognitive Impairment: Clinical Characterization and Outcome. Arch. Neurol. 1999, 56, 303. [Google Scholar] [CrossRef]
- Tijms, B.M.; Gobom, J.; Teunissen, C.; Dobricic, V.; Tsolaki, M.; Verhey, F.; Popp, J.; Martinez-Lage, P.; Vandenberghe, R.; Lleó, A.; et al. CSF Proteomic Alzheimer’s Disease-Predictive Subtypes in Cognitively Intact Amyloid Negative Individuals. Proteomes 2021, 9, 36. [Google Scholar] [CrossRef] [PubMed]
- Yilmaz, A.; Ugur, Z.; Bisgin, H.; Akyol, S.; Bahado-Singh, R.; Wilson, G.; Imam, K.; Maddens, M.E.; Graham, S.F. Targeted Metabolic Profiling of Urine Highlights a Potential Biomarker Panel for the Diagnosis of Alzheimer’s Disease and Mild Cognitive Impairment: A Pilot Study. Metabolites 2020, 10, 357. [Google Scholar] [CrossRef] [PubMed]
- Lau, A.; Beheshti, I.; Modirrousta, M.; Kolesar, T.A.; Goertzen, A.L.; Ko, J.H. Alzheimer’s Disease-Related Metabolic Pattern in Diverse Forms of Neurodegenerative Diseases. Diagnostics 2021, 11, 2023. [Google Scholar] [CrossRef]
- Huang, Y.-L.; Lin, C.-H.; Tsai, T.-H.; Huang, C.-H.; Li, J.-L.; Chen, L.-K.; Li, C.-H.; Tsai, T.-F.; Wang, P.-N. Discovery of a Metabolic Signature Predisposing High Risk Patients with Mild Cognitive Impairment to Converting to Alzheimer’s Disease. Int. J. Mol. Sci. 2021, 22, 10903. [Google Scholar] [CrossRef] [PubMed]
- Craig-Schapiro, R.; Kuhn, M.; Xiong, C.; Pickering, E.H.; Liu, J.; Misko, T.P.; Perrin, R.J.; Bales, K.R.; Soares, H.; Fagan, A.M.; et al. Multiplexed Immunoassay Panel Identifies Novel CSF Biomarkers for Alzheimer’s Disease Diagnosis and Prognosis. PLoS ONE 2011, 6, e18850. [Google Scholar] [CrossRef]
- Villemagne, V.L.; Burnham, S.; Bourgeat, P.; Brown, B.; Ellis, K.A.; Salvado, O.; Szoeke, C.; Macaulay, S.L.; Martins, R.; Maruff, P.; et al. Amyloid β Deposition, Neurodegeneration, and Cognitive Decline in Sporadic Alzheimer’s Disease: A Prospective Cohort Study. Lancet Neurol. 2013, 12, 357–367. [Google Scholar] [CrossRef]
- Fagan, A.M.; Xiong, C.; Jasielec, M.S.; Bateman, R.J.; Goate, A.M.; Benzinger, T.L.S.; Ghetti, B.; Martins, R.N.; Masters, C.L.; Mayeux, R.; et al. Longitudinal Change in CSF Biomarkers in Autosomal-Dominant Alzheimer’s Disease. Sci. Transl. Med. 2014, 6, 226ra30. [Google Scholar] [CrossRef]
- Aebersold, R.; Mann, M. Mass-Spectrometric Exploration of Proteome Structure and Function. Nature 2016, 537, 347–355. [Google Scholar] [CrossRef]
- Long, J.; Pan, G.; Ifeachor, E.; Belshaw, R.; Li, X. Discovery of Novel Biomarkers for Alzheimer’s Disease from Blood. Dis. Markers 2016, 2016, 4250480. [Google Scholar] [CrossRef]
- Hosp, F.; Mann, M. A Primer on Concepts and Applications of Proteomics in Neuroscience. Neuron 2017, 96, 558–571. [Google Scholar] [CrossRef]
- Bader, J.M.; Geyer, P.E.; Müller, J.B.; Strauss, M.T.; Koch, M.; Leypoldt, F.; Koertvelyessy, P.; Bittner, D.; Schipke, C.G.; Incesoy, E.I.; et al. Proteome Profiling in Cerebrospinal Fluid Reveals Novel Biomarkers of Alzheimer’s Disease. Mol. Syst. Biol. 2020, 16, e9356. [Google Scholar] [CrossRef] [PubMed]
- Povala, G.; Bellaver, B.; De Bastiani, M.A.; Brum, W.S.; Ferreira, P.C.L.; Bieger, A.; Pascoal, T.A.; Benedet, A.L.; Souza, D.O.; Araujo, R.M.; et al. Soluble Amyloid-Beta Isoforms Predict Downstream Alzheimer’s Disease Pathology. Cell Biosci. 2021, 11, 204. [Google Scholar] [CrossRef]
- Al-Shoukry, S.; Rassem, T.H.; Makbol, N.M. Alzheimer’s Diseases Detection by Using Deep Learning Algorithms: A Mini-Review. IEEE Access 2020, 8, 77131–77141. [Google Scholar] [CrossRef]
- García-Gutiérrez, F.; Alegret, M.; Marquié, M.; Muñoz, N.; Ortega, G.; Cano, A.; De Rojas, I.; García-González, P.; Olivé, C.; Puerta, R.; et al. Unveiling the Sound of the Cognitive Status: Machine Learning-Based Speech Analysis in the Alzheimer’s Disease Spectrum. Alzheimers Res. Ther. 2024, 16, 26. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, X.; Wang, Y.; Kim, Y. Applied Machine Learning in Alzheimer’s Disease Research: Omics, Imaging, and Clinical Data. Emerg. Top. Life Sci. 2021, 5, 765–777. [Google Scholar] [CrossRef] [PubMed]
- Lü, W.; Zhang, M.; Yu, W.; Kuang, W.; Chen, L.; Zhang, W.; Yu, J.; Lü, Y. Differentiating Alzheimer’s Disease from Mild Cognitive Impairment: A Quick Screening Tool Based on Machine Learning. BMJ Open 2023, 13, e073011. [Google Scholar] [CrossRef]
- Saleem, T.J.; Zahra, S.R.; Wu, F.; Alwakeel, A.; Alwakeel, M.; Jeribi, F.; Hijji, M. Deep Learning-Based Diagnosis of Alzheimer’s Disease. J. Pers. Med. 2022, 12, 815. [Google Scholar] [CrossRef]
- Shastry, K.A.; Vijayakumar, V.; Kumar, M.M.V.; Manjunatha, B.A.; Chandrashekhar, B.N. Deep Learning Techniques for the Effective Prediction of Alzheimer’s Disease: A Comprehensive Review. Healthcare 2022, 10, 1842. [Google Scholar] [CrossRef]
- Tan, M.S.; Cheah, P.-L.; Chin, A.-V.; Looi, L.-M.; Chang, S.-W. A Review on Omics-Based Biomarkers Discovery for Alzheimer’s Disease from the Bioinformatics Perspectives: Statistical Approach vs Machine Learning Approach. Comput. Biol. Med. 2021, 139, 104947. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Wang, Y.; Jia, S.; Qiao, Y.; Zhou, Z.; Shao, W.; Zhang, X.; Guo, J.; Zhang, B.; et al. Identification of Novel Diagnostic Panel for Mild Cognitive Impairment and Alzheimer’s Disease: Findings Based on Urine Proteomics and Machine Learning. Alz. Res. Ther. 2023, 15, 191. [Google Scholar] [CrossRef]
- AbdulAzeem, Y.; Bahgat, W.M.; Badawy, M. A CNN Based Framework for Classification of Alzheimer’s Disease. Neural Comput. Applic. 2021, 33, 10415–10428. [Google Scholar] [CrossRef]
- Liu, M.; Li, F.; Yan, H.; Wang, K.; Ma, Y.; Alzheimer’s Disease Neuroimaging Initiative; Shen, L.; Xu, M. A Multi-Model Deep Convolutional Neural Network for Automatic Hippocampus Segmentation and Classification in Alzheimer’s Disease. Neuroimage 2020, 208, 116459. [Google Scholar] [CrossRef] [PubMed]
- Panizza, E.; Cerione, R.A. An Interpretable Deep Learning Framework Identifies Proteomic Drivers of Alzheimer’s Disease. Front. Cell Dev. Biol. 2024, 12, 1379984. [Google Scholar] [CrossRef] [PubMed]
- Arya, A.D.; Verma, S.S.; Chakarabarti, P.; Chakrabarti, T.; Elngar, A.A.; Kamali, A.-M.; Nami, M. A Systematic Review on Machine Learning and Deep Learning Techniques in the Effective Diagnosis of Alzheimer’s Disease. Brain Inf. 2023, 10, 17. [Google Scholar] [CrossRef]
- Kaur, A.; Mittal, M.; Bhatti, J.S.; Thareja, S.; Singh, S. A Systematic Literature Review on the Significance of Deep Learning and Machine Learning in Predicting Alzheimer’s Disease. Artif. Intell. Med. 2024, 154, 102928. [Google Scholar] [CrossRef] [PubMed]
- Mahavar, A.; Patel, A.; Patel, A. A Comprehensive Review on Deep Learning Techniques in Alzheimer’s Disease Diagnosis. Curr. Top. Med. Chem. 2024, 24, 335–349. [Google Scholar] [CrossRef]
- Malik, I.; Iqbal, A.; Gu, Y.H.; Al-antari, M.A. Deep Learning for Alzheimer’s Disease Prediction: A Comprehensive Review. Diagnostics 2024, 14, 1281. [Google Scholar] [CrossRef]
- Ashton, N.J.; Nevado-Holgado, A.J.; Barber, I.S.; Lynham, S.; Gupta, V.; Chatterjee, P.; Goozee, K.; Hone, E.; Pedrini, S.; Blennow, K.; et al. A Plasma Protein Classifier for Predicting Amyloid Burden for Preclinical Alzheimer’s Disease. Sci. Adv. 2019, 5, eaau7220. [Google Scholar] [CrossRef]
- Das, D.; Ito, J.; Kadowaki, T.; Tsuda, K. An Interpretable Machine Learning Model for Diagnosis of Alzheimer’s Disease. PeerJ 2019, 7, e6543. [Google Scholar] [CrossRef]
- Fardo, D.W.; Katsumata, Y.; Kauwe, J.S.K.; Deming, Y.; Harari, O.; Cruchaga, C.; Nelson, P.T. CSF Protein Changes Associated with Hippocampal Sclerosis Risk Gene Variants Highlight Impact of GRN/PGRN. Exp. Gerontol. 2017, 90, 83–89. [Google Scholar] [CrossRef]
- Gaetani, L.; Bellomo, G.; Parnetti, L.; Blennow, K.; Zetterberg, H.; Di Filippo, M. Neuroinflammation and Alzheimer’s Disease: A Machine Learning Approach to CSF Proteomics. Cells 2021, 10, 1930. [Google Scholar] [CrossRef]
- Spellman, D.S.; Wildsmith, K.R.; Honigberg, L.A.; Tuefferd, M.; Baker, D.; Raghavan, N.; Nairn, A.C.; Croteau, P.; Schirm, M.; Allard, R.; et al. Development and Evaluation of a Multiplexed Mass Spectrometry Based Assay for Measuring Candidate Peptide Biomarkers in Alzheimer’s Disease Neuroimaging Initiative (ADNI) CSF. Proteom. Clin. Appl. 2015, 9, 715–731. [Google Scholar] [CrossRef]
- Chen, X.; Kopsaftopoulos, F.; Wu, Q.; Ren, H.; Chang, F.-K. Flight State Identification of a Self-Sensing Wing via an Improved Feature Selection Method and Machine Learning Approaches. Sensors 2018, 18, 1379. [Google Scholar] [CrossRef]
- Raihan-Al-Masud, M.; Mondal, M.R.H. Data-Driven Diagnosis of Spinal Abnormalities Using Feature Selection and Machine Learning Algorithms. PLoS ONE 2020, 15, e0228422. [Google Scholar] [CrossRef] [PubMed]
- Awan, S.E.; Bennamoun, M.; Sohel, F.; Sanfilippo, F.M.; Chow, B.J.; Dwivedi, G. Feature Selection and Transformation by Machine Learning Reduce Variable Numbers and Improve Prediction for Heart Failure Readmission or Death. PLoS ONE 2019, 14, e0218760. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature Selection in Machine Learning: A New Perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Cömert, Z.; Şengür, A.; Budak, Ü.; Kocamaz, A.F. Prediction of Intrapartum Fetal Hypoxia Considering Feature Selection Algorithms and Machine Learning Models. Health Inf. Sci. Syst. 2019, 7, 17. [Google Scholar] [CrossRef]
- Candel, A.; LeDell, E.; Bartz, A. Deep Learning with H2O; H2O.Ai, Inc.: Mountain View, CA, USA, 2021. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Lunardon, N.; Menardi, G.; Torelli, N. ROSE: A Package for Binary Imbalanced Learning. R. J. 2014, 6, 79. [Google Scholar] [CrossRef]
- Pillai, J.A.; Bena, J.; Bebek, G.; Bekris, L.M.; Bonner-Jackson, A.; Kou, L.; Pai, A.; Sørensen, L.; Neilsen, M.; Rao, S.M.; et al. Inflammatory Pathway Analytes Predicting Rapid Cognitive Decline in MCI Stage of Alzheimer’s Disease. Ann. Clin. Transl. Neurol. 2020, 7, 1225–1239. [Google Scholar] [CrossRef]
- Milenkovic, D.; Nuthikattu, S.; Norman, J.E.; Villablanca, A.C. Global Genomic Profile of Hippocampal Endothelial Cells by Single Nuclei RNA Sequencing in Female Diabetic Mice Is Associated with Cognitive Dysfunction. Am. J. Physiol. Heart Circ. Physiol. 2024, 327, H908–H926. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Ju, H.; Hu, Y.; Li, T.; Chen, Z.; Si, Y.; Sun, X.; Shi, Y.; Fang, H. Tregs Dysfunction Aggravates Postoperative Cognitive Impairment in Aged Mice. J. Neuroinflamm. 2023, 20, 75. [Google Scholar] [CrossRef]
- Muraoka, S.; DeLeo, A.M.; Sethi, M.K.; Yukawa-Takamatsu, K.; Yang, Z.; Ko, J.; Hogan, J.D.; Ruan, Z.; You, Y.; Wang, Y.; et al. Proteomic and Biological Profiling of Extracellular Vesicles from Alzheimer’s Disease Human Brain Tissues. Alzheimer’s Dement. 2020, 16, 896–907. [Google Scholar] [CrossRef]
- Wang, D.; Greenwood, P.; Klein, M.S. Deep Learning for Rapid Identification of Microbes Using Metabolomics Profiles. Metabolites 2021, 11, 863. [Google Scholar] [CrossRef] [PubMed]
- Alotaibi, N.S.; Sayed Ahmed, H.I.; Kamel, S.O.M.; ElKabbany, G.F. Secure Enhancement for MQTT Protocol Using Distributed Machine Learning Framework. Sensors 2024, 24, 1638. [Google Scholar] [CrossRef]
- Cui, Y.; Shi, X.; Wang, S.; Qin, Y.; Wang, B.; Che, X.; Lei, M. Machine Learning Approaches for Prediction of Early Death among Lung Cancer Patients with Bone Metastases Using Routine Clinical Characteristics: An Analysis of 19,887 Patients. Front. Public Health 2022, 10, 1019168. [Google Scholar] [CrossRef]
- Kong, D.; Tao, Y.; Xiao, H.; Xiong, H.; Wei, W.; Cai, M. Predicting Preterm Birth Using Auto-ML Frameworks: A Large Observational Study Using Electronic Inpatient Discharge Data. Front. Pediatr. 2024, 12, 1330420. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Lin, J.; Liu, L.; Gao, J.; Xu, G.; Yin, M.; Liu, X.; Wu, A.; Zhu, J. Automated Machine Learning Models for Nonalcoholic Fatty Liver Disease Assessed by Controlled Attenuation Parameter from the NHANES 2017–2020. Digit. Health 2024, 10, 20552076241272535. [Google Scholar] [CrossRef]
- Ma, H.; Huang, S.; Li, F.; Pang, Z.; Luo, J.; Sun, D.; Liu, J.; Chen, Z.; Qu, J.; Qu, Q. Development and Validation of an Automatic Machine Learning Model to Predict Abnormal Increase of Transaminase in Valproic Acid-Treated Epilepsy. Arch. Toxicol. 2024, 98, 3049–3061. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, S.; Liu, Z.; Ren, Z.; Lei, D.; Tan, C.; Guo, H. Machine Learning Models for Slope Stability Classification of Circular Mode Failure: An Updated Database and Automated Machine Learning (AutoML) Approach. Sensors 2022, 22, 9166. [Google Scholar] [CrossRef]
- Narkhede, S.M.; Luther, L.; Raugh, I.M.; Knippenberg, A.R.; Esfahlani, F.Z.; Sayama, H.; Cohen, A.S.; Kirkpatrick, B.; Strauss, G.P. Machine Learning Identifies Digital Phenotyping Measures Most Relevant to Negative Symptoms in Psychotic Disorders: Implications for Clinical Trials. Schizophr. Bull. 2022, 48, 425–436. [Google Scholar] [CrossRef] [PubMed]
- Szlęk, J.; Khalid, M.H.; Pacławski, A.; Czub, N.; Mendyk, A. Puzzle out Machine Learning Model-Explaining Disintegration Process in ODTs. Pharmaceutics 2022, 14, 859. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, Y.; Wang, Y.; Zhou, X.; Gao, X.; Yu, C.; Lin, J.; Liu, L.; Gao, J.; Yin, M.; et al. Automated Multimodal Machine Learning for Esophageal Variceal Bleeding Prediction Based on Endoscopy and Structured Data. J. Digit. Imaging 2022, 36, 326–338. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Li, Y.; Yin, M.; Gao, J.; Xi, L.; Lin, J.; Liu, L.; Zhang, H.; Wu, A.; Xu, C.; et al. Automated Machine Learning in Predicting 30-Day Mortality in Patients with Non-Cholestatic Cirrhosis. J. Pers. Med. 2022, 12, 1930. [Google Scholar] [CrossRef]
- Alakwaa, F.M.; Chaudhary, K.; Garmire, L.X. Deep Learning Accurately Predicts Estrogen Receptor Status in Breast Cancer Metabolomics Data. J. Proteome Res. 2018, 17, 337–347. [Google Scholar] [CrossRef]
- Wei, Z.; Han, D.; Zhang, C.; Wang, S.; Liu, J.; Chao, F.; Song, Z.; Chen, G. Deep Learning-Based Multi-Omics Integration Robustly Predicts Relapse in Prostate Cancer. Front. Oncol. 2022, 12, 893424. [Google Scholar] [CrossRef] [PubMed]
- Yin, M.; Xu, C.; Zhu, J.; Xue, Y.; Zhou, Y.; He, Y.; Lin, J.; Liu, L.; Gao, J.; Liu, X.; et al. Automated Machine Learning for the Identification of Asymptomatic COVID-19 Carriers Based on Chest CT Images. BMC Med. Imaging 2024, 24, 50. [Google Scholar] [CrossRef]
- Wang, K.; Theeke, L.A.; Liao, C.; Wang, N.; Lu, Y.; Xiao, D.; Xu, C. Deep Learning Analysis of UPLC-MS/MS-Based Metabolomics Data to Predict Alzheimer’s Disease. J. Neurol. Sci. 2023, 453, 120812. [Google Scholar] [CrossRef]
- Morgan, S.L.; Naderi, P.; Koler, K.; Pita-Juarez, Y.; Prokopenko, D.; Vlachos, I.S.; Tanzi, R.E.; Bertram, L.; Hide, W.A. Most Pathways Can Be Related to the Pathogenesis of Alzheimer’s Disease. Front. Aging Neurosci. 2022, 14, 846902. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J.; Chen, J.; Luo, M.; Xie, Q.; Rong, Y.; Wu, Y.; Cao, Z.; Liu, Y. High-Resolution NMR Metabolomics of Patients with Subjective Cognitive Decline plus: Perturbations in the Metabolism of Glucose and Branched-Chain Amino Acids. Neurobiol. Dis. 2022, 171, 105782. [Google Scholar] [CrossRef]
- Hao, L.; Wang, J.; Page, D.; Asthana, S.; Zetterberg, H.; Carlsson, C.; Okonkwo, O.C.; Li, L. Comparative Evaluation of MS-Based Metabolomics Software and Its Application to Preclinical Alzheimer’s Disease. Sci. Rep. 2018, 8, 9291. [Google Scholar] [CrossRef] [PubMed]
- Ling, J.; Yang, S.; Huang, Y.; Wei, D.; Cheng, W. Identifying Key Genes, Pathways and Screening Therapeutic Agents for Manganese-Induced Alzheimer Disease Using Bioinformatics Analysis. Medicine 2018, 97, e10775. [Google Scholar] [CrossRef] [PubMed]
- Varma, V.R.; Oommen, A.M.; Varma, S.; Casanova, R.; An, Y.; Andrews, R.M.; O’Brien, R.; Pletnikova, O.; Troncoso, J.C.; Toledo, J.; et al. Brain and Blood Metabolite Signatures of Pathology and Progression in Alzheimer Disease: A Targeted Metabolomics Study. PLoS Med. 2018, 15, e1002482. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wei, R.; Xie, G.; Arnold, M.; Kueider-Paisley, A.; Louie, G.; Mahmoudian Dehkordi, S.; Blach, C.; Baillie, R.; Han, X.; et al. Peripheral Serum Metabolomic Profiles Inform Central Cognitive Impairment. Sci. Rep. 2020, 10, 14059. [Google Scholar] [CrossRef]
- Calabrò, M.; Rinaldi, C.; Santoro, G.; Crisafulli, C. Department of Biomedical and Dental Sciences and Morphofunctional Imaging, University of Messina, Italy The Biological Pathways of Alzheimer Disease: A Review. AIMS Neurosci. 2021, 8, 86–132. [Google Scholar] [CrossRef]
- Lai, Y.; Lin, P.; Lin, F.; Chen, M.; Lin, C.; Lin, X.; Wu, L.; Zheng, M.; Chen, J. Identification of Immune Microenvironment Subtypes and Signature Genes for Alzheimer’s Disease Diagnosis and Risk Prediction Based on Explainable Machine Learning. Front. Immunol. 2022, 13, 1046410. [Google Scholar] [CrossRef] [PubMed]
- Cai, H.; Pang, Y.; Wang, Q.; Qin, W.; Wei, C.; Li, Y.; Li, T.; Li, F.; Wang, Q.; Li, Y.; et al. Proteomic Profiling of Circulating Plasma Exosomes Reveals Novel Biomarkers of Alzheimer’s Disease. Alzheimers Res. Ther. 2022, 14, 181. [Google Scholar] [CrossRef]
- Karaglani, M.; Gourlia, K.; Tsamardinos, I.; Chatzaki, E. Accurate Blood-Based Diagnostic Biosignatures for Alzheimer’s Disease via Automated Machine Learning. J. Clin. Med. 2020, 9, 3016. [Google Scholar] [CrossRef]
- Hällqvist, J.; Pinto, R.C.; Heywood, W.E.; Cordey, J.; Foulkes, A.J.M.; Slattery, C.F.; Leckey, C.A.; Murphy, E.C.; Zetterberg, H.; Schott, J.M.; et al. A Multiplexed Urinary Biomarker Panel Has Potential for Alzheimer’s Disease Diagnosis Using Targeted Proteomics and Machine Learning. Int. J. Mol. Sci. 2023, 24, 13758. [Google Scholar] [CrossRef]
- Agarwal, M.; Khan, S. Plasma Lipids as Biomarkers for Alzheimer’s Disease: A Systematic Review. Cureus 2020, 12, e12008. [Google Scholar] [CrossRef]
- Couttas, T.A.; Kain, N.; Tran, C.; Chatterton, Z.; Kwok, J.B.; Don, A.S. Age-Dependent Changes to Sphingolipid Balance in the Human Hippocampus Are Gender-Specific and May Sensitize to Neurodegeneration. J. Alzheimer’s Dis. 2018, 63, 503–514. [Google Scholar] [CrossRef]
- Zhang, F.; Petersen, M.; Johnson, L.; Hall, J.; O’Bryant, S.E. Combination of Serum and Plasma Biomarkers Could Improve Prediction Performance for Alzheimer’s Disease. Genes 2022, 13, 1738. [Google Scholar] [CrossRef]
- Klee, M.; Aho, V.T.E.; May, P.; Heintz-Buschart, A.; Landoulsi, Z.; Jónsdóttir, S.R.; Pauly, C.; Pavelka, L.; Delacour, L.; Kaysen, A.; et al. Education as Risk Factor of Mild Cognitive Impairment: The Link to the Gut Microbiome. J. Prev. Alzheimer’s Dis. 2024, 11, 759–768. [Google Scholar] [CrossRef] [PubMed]
- Arévalo-Caro, C.; López, D.; Sánchez Milán, J.A.; Lorca, C.; Mulet, M.; Arboleda, H.; Losada Amaya, S.; Serra, A.; Gallart-Palau, X. Periodontal Indices as Predictors of Cognitive Decline: Insights from the PerioMind Colombia Cohort. Biomedicines 2025, 13, 205. [Google Scholar] [CrossRef] [PubMed]
- Al-Amrani, S.; Al-Jabri, Z.; Al-Zaabi, A.; Alshekaili, J.; Al-Khabori, M. Proteomics: Concepts and Applications in Human Medicine. World J. Biol. Chem. 2021, 12, 57–69. [Google Scholar] [CrossRef] [PubMed]
- Birhanu, A.G. Mass Spectrometry-Based Proteomics as an Emerging Tool in Clinical Laboratories. Clin. Proteom. 2023, 20, 32. [Google Scholar] [CrossRef]
- Dupree, E.J.; Jayathirtha, M.; Yorkey, H.; Mihasan, M.; Petre, B.A.; Darie, C.C. A Critical Review of Bottom-Up Proteomics: The Good, the Bad, and the Future of This Field. Proteomes 2020, 8, 14. [Google Scholar] [CrossRef]
- Jain, A.P.; Sathe, G. Proteomics Landscape of Alzheimer’s Disease. Proteomes 2021, 9, 13. [Google Scholar] [CrossRef]
- Weiner, S.; Blennow, K.; Zetterberg, H.; Gobom, J. Next-Generation Proteomics Technologies in Alzheimer’s Disease: From Clinical Research to Routine Diagnostics. Expert. Rev. Proteom. 2023, 20, 143–150. [Google Scholar] [CrossRef]
- François, M.; Karpe, A.V.; Liu, J.-W.; Beale, D.J.; Hor, M.; Hecker, J.; Faunt, J.; Maddison, J.; Johns, S.; Doecke, J.D.; et al. Multi-Omics, an Integrated Approach to Identify Novel Blood Biomarkers of Alzheimer’s Disease. Metabolites 2022, 12, 949. [Google Scholar] [CrossRef]
- Vacher, M.; Canovas, R.; Laws, S.M.; Doecke, J.D. A Comprehensive Multi-Omics Analysis Reveals Unique Signatures to Predict Alzheimer’s Disease. Front. Bioinform. 2024, 4, 1390607. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhou, X.; Song, Y.; Zhao, W.; Sun, Z.; Zhu, J.; Yu, Y. Multi-Omics Analyses Identify Gut Microbiota-Fecal Metabolites-Brain-Cognition Pathways in the Alzheimer’s Disease Continuum. Alz. Res. Ther. 2025, 17, 36. [Google Scholar] [CrossRef] [PubMed]
- Kodam, P.; Sai Swaroop, R.; Pradhan, S.S.; Sivaramakrishnan, V.; Vadrevu, R. Integrated Multi-Omics Analysis of Alzheimer’s Disease Shows Molecular Signatures Associated with Disease Progression and Potential Therapeutic Targets. Sci. Rep. 2023, 13, 3695. [Google Scholar] [CrossRef] [PubMed]
- Aerqin, Q.; Wang, Z.-T.; Wu, K.-M.; He, X.-Y.; Dong, Q.; Yu, J.-T. Omics-Based Biomarkers Discovery for Alzheimer’s Disease. Cell. Mol. Life Sci. 2022, 79, 585. [Google Scholar] [CrossRef] [PubMed]
- Wodzinski, M.; Kwarciak, K.; Daniol, M.; Hemmerling, D. Improving Deep Learning-Based Automatic Cranial Defect Reconstruction by Heavy Data Augmentation: From Image Registration to Latent Diffusion Models. Comput. Biol. Med. 2024, 182, 109129. [Google Scholar] [CrossRef]
- Yang, L.; Dong, Q.; Lin, D.; Tian, C.; Lü, X. MUNet: A Novel Framework for Accurate Brain Tumor Segmentation Combining UNet and Mamba Networks. Front. Comput. Neurosci. 2025, 19, 1513059. [Google Scholar] [CrossRef]
- Huang, J.; Yang, L.; Wang, F.; Wu, Y.; Nan, Y.; Wu, W.; Wang, C.; Shi, K.; Aviles-Rivero, A.I.; Schönlieb, C.-B.; et al. Enhancing Global Sensitivity and Uncertainty Quantification in Medical Image Reconstruction with Monte Carlo Arbitrary-Masked Mamba. Med. Image Anal. 2025, 99, 103334. [Google Scholar] [CrossRef]
- Kang, H.; Park, C.; Yang, H. Evaluation of Denoising Performance of ResNet Deep Learning Model for Ultrasound Images Corresponding to Two Frequency Parameters. Bioengineering 2024, 11, 723. [Google Scholar] [CrossRef]
- Zhou, S.; Yao, S.; Shen, T.; Wang, Q. A Novel End-to-End Deep Learning Framework for Chip Packaging Defect Detection. Sensors 2024, 24, 5837. [Google Scholar] [CrossRef]
- Zhou, Z.; Liao, X.; Qiu, X.; Zhang, Y.; Dong, J.; Qu, X.; Lin, D. NMRformer: A Transformer-Based Deep Learning Framework for Peak Assignment in 1D 1H NMR Spectroscopy. Anal. Chem. 2025, 97, 904–911. [Google Scholar] [CrossRef]
- Wang, S.; Liu, J.; Li, S.; He, P.; Zhou, X.; Zhao, Z.; Zheng, L. ResNet-Transformer Deep Learning Model-aided Detection of Dens Evaginatus. Int. J. Paed. Dent. 2024, ipd.13282, ahead of print. [Google Scholar] [CrossRef]
- Habib, A.Z.S.B.; Wang, K.; Hartley, M.-A.; Doretto, G.; Adjeroh, D.A. TabSeq: A Framework for Deep Learning on Tabular Data via Sequential Ordering. arXiv 2024, arXiv:2410.13203. [Google Scholar]
- Desikan, R.S.; Fan, C.C.; Wang, Y.; Schork, A.J.; Cabral, H.J.; Cupples, L.A.; Thompson, W.K.; Besser, L.; Kukull, W.A.; Holland, D.; et al. Genetic Assessment of Age-Associated Alzheimer Disease Risk: Development and Validation of a Polygenic Hazard Score. PLoS Med. 2017, 14, e1002258. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Jainonthee, C.; Sanwisate, P.; Sivapirunthep, P.; Chaosap, C.; Mektrirat, R.; Chadsuthi, S.; Punyapornwithaya, V. Data-Driven Insights into Pre-Slaughter Mortality: Machine Learning for Predicting High Dead on Arrival in Meat-Type Ducks. Poult. Sci. 2025, 104, 104648. [Google Scholar] [CrossRef]
- Budhathoki, N.; Bhandari, R.; Bashyal, S.; Lee, C. Predicting Asthma Using Imbalanced Data Modeling Techniques: Evidence from 2019 Michigan BRFSS Data. PLoS ONE 2023, 18, e0295427. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Soft. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A Comparative Study of Logistic Model Tree, Random Forest, and Classification and Regression Tree Models for Spatial Prediction of Landslide Susceptibility. CATENA 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Kesler, S.R.; Rao, A.; Blayney, D.W.; Oakley-Girvan, I.A.; Karuturi, M.; Palesh, O. Predicting Long-Term Cognitive Outcome Following Breast Cancer with Pre-Treatment Resting State fMRI and Random Forest Machine Learning. Front. Hum. Neurosci. 2017, 11, 555. [Google Scholar] [CrossRef]
- Hackenberger, B.K. Bayes or Not Bayes, Is This the Question? Croat. Med. J. 2019, 60, 50–52. [Google Scholar] [CrossRef]
- Zhang, Z. Introduction to Machine Learning: K-Nearest Neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene Ontology: Tool for the Unification of Biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Goto, S.; Furumichi, M.; Tanabe, M.; Hirakawa, M. KEGG for Representation and Analysis of Molecular Networks Involving Diseases and Drugs. Nucleic Acids Res. 2010, 38, D355–D360. [Google Scholar] [CrossRef] [PubMed]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis, Use R! 2nd ed.; Springer International Publishing: Cham, Switzerland, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Faul, F.; Erdfelder, E.; Lang, A.-G.; Buchner, A. G*Power 3: A Flexible Statistical Power Analysis Program for the Social, Behavioral, and Biomedical Sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef] [PubMed]
- Faul, F.; Erdfelder, E.; Buchner, A.; Lang, A.-G. Statistical Power Analyses Using G*Power 3.1: Tests for Correlation and Regression Analyses. Behav. Res. Methods 2009, 41, 1149–1160. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CN | MCI | ||
|---|---|---|---|
| Variable | (Mean ± SD or n) | (Mean ± SD or n) | t/χ2, p |
| Age | 75.2 ± 5.8 | 74.3 ± 7.6 | 0.98, 0.3269 |
| Gender (n) | |||
| Male | 29 | 121 | 4.52, 0.0334 |
| Female | 28 | 61 | |
| Education | 15.6 ± 2.7 | 15.8 ± 3.0 | −0.55, 0.5796 |
| APOE-ε4 allele | |||
| 0 | 52 | 84 | 35.96, <0.0001 |
| 1+ | 5 | 98 | |
| PHS | −0.49 ± 0.9 | 0.51 ± 1.12 | −6.79, <0.0001 |
| Aβ42 | 1452.8 ± 263.4 | 821.2 ± 421.1 | 13.49, <0.0001 |
| tTAU | 225.7 ± 73.1 | 313.0 ± 141.1 | −6.12, <0.0001 |
| pTAU | 19.9 ± 6.5 | 30.9 ± 15.7 | −7.70, <0.0001 |
| Package | Feature Selection Algorithm | Extracted Variables |
|---|---|---|
| glmnet in R | Least Absolute Shrinkage and Selection Operator (LASSO) | 35 variables: A1Micro, AACT, AGRP, ANG2, ApoAII, ApoB, ApoD, ApoE, BLC, C3, Calcitonin, CD40L, CgA, CRP, Eotaxin3, FABP, FasL, Haptoglobin, HBELGF, HCC4, HGF, IL16, IL6r, MI, MIP1a, MMP1, NR_CAM, Osteopontin, PAPPA, PARC, PYY, TTotal, Serotransferrin, TTR, vWF |
| Model | Variation | Accuracy | Sensitivity (Recall) | Specificity | Precision | F1-Score | AUC |
|---|---|---|---|---|---|---|---|
| SVM | RBF Kernel | 0.972 | 0.941 | 1.000 | 1.000 | 0.970 | 0.999 |
| LR | 0.958 | 0.941 | 0.973 | 0.970 | 0.955 | 0.998 | |
| RF | 0.958 | 0.912 | 1.000 | 1.000 | 0.954 | 0.998 | |
| GBM | 0.972 | 0.941 | 1.000 | 1.000 | 0.970 | 0.999 | |
| XGBoost | 0.986 | 0.971 | 1.000 | 1.000 | 0.985 | 0.997 | |
| KNN | 0.845 | 0.765 | 0.919 | 0.897 | 0.826 | 0.962 | |
| NB | 0.944 | 0.882 | 1.000 | 1.000 | 0.937 | 0.982 | |
| DNN | Rectifier-c(35) | 0.984 | 1.000 | 0.957 | 0.975 | 0.986 | 0.990 |
| Rectifier-c(32,32,32) | 0.989 | 0.992 | 0.989 | 0.990 | 0.991 | 0.992 | |
| Maxout-c(35) | 0.960 | 0.957 | 0.973 | 0.963 | 0.956 | 0.973 | |
| Tanh-c(35) | 0.990 | 0.992 | 0.973 | 0.986 | 0.988 | 0.995 | |
| Tanh-c(32,32) | 0.990 | 1.000 | 0.979 | 0.980 | 0.990 | 0.995 | |
| Rectifier With Dropout-c(35) | 0.977 | 1.000 | 0.953 | 0.963 | 0.979 | 0.989 | |
| Rectifier With Dropout-c(30,30) | 0.989 | 0.978 | 1.000 | 1.000 | 0.988 | 0.992 | |
| Rectifier With Dropout-c(32,32) | 0.995 | 1.000 | 0.983 | 0.993 | 0.996 | 0.997 | |
| Maxout With Dropout-c(35) | 0.983 | 0.992 | 0.980 | 0.978 | 0.984 | 0.990 | |
| Tanh With Dropout-c(35) | 0.989 | 1.000 | 0.973 | 0.980 | 0.990 | 0.997 | |
| Tanh With Dropout-c(34,34) | 0.988 | 1.000 | 0.980 | 0.978 | 0.988 | 0.996 | |
| Tanh With Dropout-c(32,32,32) | 0.994 | 1.000 | 0.990 | 0.988 | 0.993 | 0.999 | |
| Tanh With Dropout-c(33,33,33) | 0.994 | 1.000 | 0.990 | 0.988 | 0.993 | 0.996 |
| Confusion Matrix | Predicted Class | ||
|---|---|---|---|
| MCI | CN | ||
| Actual class | MCI | TP | FN |
| CN | FP | TN | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Adjeroh, D.A.; Fang, W.; Walter, S.M.; Xiao, D.; Piamjariyakul, U.; Xu, C. Comparison of Deep Learning and Traditional Machine Learning Models for Predicting Mild Cognitive Impairment Using Plasma Proteomic Biomarkers. Int. J. Mol. Sci. 2025, 26, 2428. https://doi.org/10.3390/ijms26062428
Wang K, Adjeroh DA, Fang W, Walter SM, Xiao D, Piamjariyakul U, Xu C. Comparison of Deep Learning and Traditional Machine Learning Models for Predicting Mild Cognitive Impairment Using Plasma Proteomic Biomarkers. International Journal of Molecular Sciences. 2025; 26(6):2428. https://doi.org/10.3390/ijms26062428
Chicago/Turabian StyleWang, Kesheng, Donald A. Adjeroh, Wei Fang, Suzy M. Walter, Danqing Xiao, Ubolrat Piamjariyakul, and Chun Xu. 2025. "Comparison of Deep Learning and Traditional Machine Learning Models for Predicting Mild Cognitive Impairment Using Plasma Proteomic Biomarkers" International Journal of Molecular Sciences 26, no. 6: 2428. https://doi.org/10.3390/ijms26062428
APA StyleWang, K., Adjeroh, D. A., Fang, W., Walter, S. M., Xiao, D., Piamjariyakul, U., & Xu, C. (2025). Comparison of Deep Learning and Traditional Machine Learning Models for Predicting Mild Cognitive Impairment Using Plasma Proteomic Biomarkers. International Journal of Molecular Sciences, 26(6), 2428. https://doi.org/10.3390/ijms26062428