Challenges and Future Directions in Lipoprotein Measurement for Atherosclerosis Prevention and Treatment


{kind=link}
Data Availability Statement
Conflicts of Interest
References
- Rodgers, J.L.; Jones, J.; Bolleddu, S.I.; Vanthenapalli, S.; Rodgers, L.E.; Shah, K.; Karia, K.; Panguluri, S.K. Cardiovascular Risks Associated with Gender and Aging. J. Cardiovasc. Dev. Dis. 2019, 6, 19. [Google Scholar] [CrossRef] [PubMed]
- Konishi, T.; Hayashi, Y.; Fujiwara, R.; Kawata, S.; Ishikawa, T. Distinctive features of lipoprotein profiles in stroke patients. PLoS ONE 2023, 18, e0283855. [Google Scholar] [CrossRef] [PubMed]
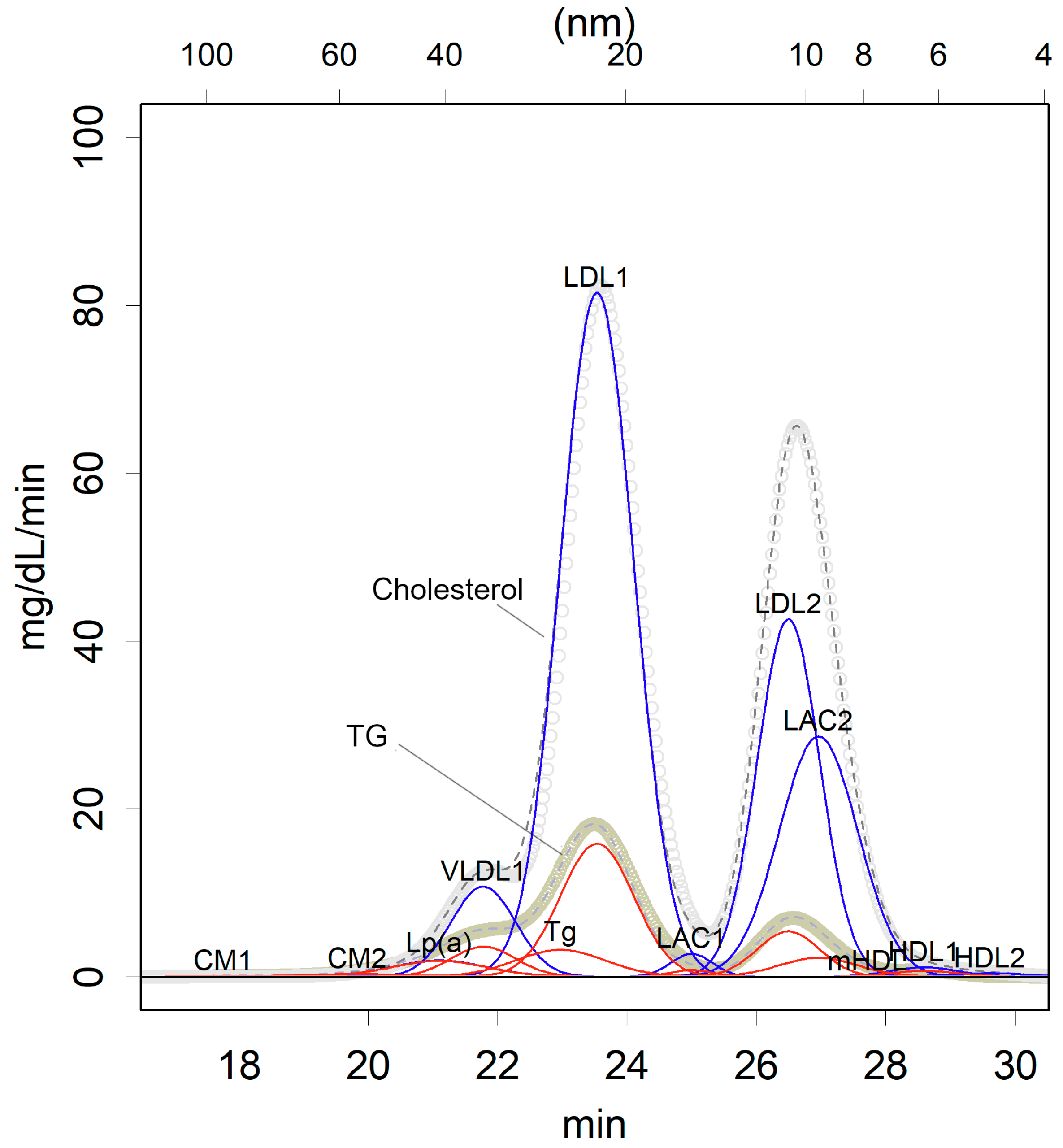
- Konishi, T.; Fujiwara, R.; Saito, T.; Satou, N.; Crofts, N.; Iwasaki, I.; Abe, Y.; Kawata, S.; Ishikawa, T. Human lipoproteins comprise at least 12 different classes that are lognormally distributed. PLoS ONE 2022, 17, e0275066. [Google Scholar] [CrossRef] [PubMed]
- Havel, R.J.; Eder, H.A.; Bragdon, J.H. The distribution and chemical composition of ultracentrifugally separated lipoproteins in human serum. J. Clin. Investig. 1955, 34, 1345–1353. [Google Scholar] [CrossRef]
- Redgrave, T.G.; Roberts, D.C.; West, C.E. Separation of plasma lipoproteins by density-gradient ultracentrifugation. Anal. Biochem. 1975, 65, 42–49. [Google Scholar] [CrossRef]
- Chapman, M.J.; Goldstein, S.; Lagrange, D.; Laplaud, P.M. A density gradient ultracentrifugal procedure for the isolation of the major lipoprotein classes from human serum. J. Lipid Res. 1981, 22, 339–358. [Google Scholar] [CrossRef]
- Nakamura, M.; Kayamori, Y.; Iso, H.; Kitamura, A.; Kiyama, M.; Koyama, I.; Nishimura, K.; Nakai, M.; Noda, H.; Dasti, M.; et al. LDL cholesterol performance of beta quantification reference measurement procedure. Clin. Chim. Acta 2014, 431, 288–293. [Google Scholar] [CrossRef]
- Miller, W.G.; Myers, G.L.; Sakurabayashi, I.; Bachmann, L.M.; Caudill, S.P.; Dziekonski, A.; Edwards, S.; Kimberly, M.M.; Korzun, W.J.; Leary, E.T.; et al. Seven direct methods for measuring HDL and LDL cholesterol compared with ultracentrifugation reference measurement procedures. Clin. Chem. 2010, 56, 977–986. [Google Scholar] [CrossRef]
- Konishi, T.; Takahashi, Y. Lipoproteins comprise at least 10 different classes in rats, each of which contains a unique set of proteins as the primary component. PLoS ONE 2018, 13, e0192955. [Google Scholar]
- Grundy, S.M.; Stone, N.J.; Bailey, A.L.; Beam, C.; Birtcher, K.K.; Blumenthal, R.S.; Braun, L.T.; Ferranti, S.d.; Faiella-Tommasino, J.; Forman, D.E.; et al. 2018 AHA/ACC/AACVPR/AAPA/ABC/ACPM/ADA/AGS/APhA/ASPC/NLA/PCNA Guideline on the Management of Blood Cholesterol: A Report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines. Circulation 2019, 139, e1082–e1143. [Google Scholar] [CrossRef]
- Robinson, J.G.; Stone, N.J. The 2013 ACC/AHA guideline on the treatment of blood cholesterol to reduce atherosclerotic cardiovascular disease risk: A new paradigm supported by more evidence. Eur. Heart J. 2015, 36, 2110–2118. [Google Scholar] [CrossRef] [PubMed]
- Voet, D.; Voet, J.G. Biochemistry, 3rd ed.; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Moringo, N.A.; Bishop, L.D.C.; Shen, H.; Misiura, A.; Carrejo, N.C.; Baiyasi, R.; Wang, W.; Ye, F.; Robinson, J.T.; Landes, C.F. A mechanistic examination of salting out in protein-polymer membrane interactions. Proc. Natl. Acad. Sci. USA 2019, 116, 22938–22945. [Google Scholar] [CrossRef] [PubMed]
- Pertoft, H. Fractionation of cells and subcellular particles with Percoll. J. Biochem. Biophys. Methods 2000, 44, 1–30. [Google Scholar] [CrossRef]
- Conn, E.E.; Stumpf, P.K.; Bruening, G.; Doi, R.H. Outlines of Biochemistry, 5th ed.; Willey: New York, NY, USA, 1987. [Google Scholar]
- Okazaki, M.; Usui, S.; Ishigami, M.; Sakai, N.; Nakamura, T.; Matsuzawa, Y.; Yamashita, S. Identification of unique lipoprotein subclasses for visceral obesity by component analysis of cholesterol profile in high-performance liquid chromatography. Arterioscler. Thromb. Vasc. Biol. 2005, 25, 578–584. [Google Scholar] [CrossRef]
- Okazaki, M.; Yamashita, S. Recent advances in analytical methods on lipoprotein subclasses: Calculation of particle numbers from lipid levels by gel permeation HPLC using “spherical particle model”. J. Oleo Sci. 2016, 65, 265–282. [Google Scholar] [CrossRef]
- Gordon, S.M.; Deng, J.; Lu, L.J.; Davidson, W.S. Proteomic characterization of human plasma high density lipoprotein fractionated by gel filtration chromatography. J. Proteome Res. 2010, 9, 5239–5249. [Google Scholar] [CrossRef]
- Wu, Z.; Gogonea, V.; Lee, X.; May, R.P.; Pipich, V.; Wagner, M.A.; Undurti, A.; Tallant, T.C.; Baleanu-Gogonea, C.; Charlton, F.; et al. The low resolution structure of ApoA1 in spherical high density lipoprotein revealed by small angle neutron scattering. J. Biol. Chem. 2011, 286, 12495–12508. [Google Scholar] [CrossRef]
- Suto, A.; Yamasaki, M.; Takasaki, Y.; Fujita, Y.; Abe, R.; Shimizu, H.; Ohta, H.; Takiguchi, M. LC-MS/MS analysis of canine lipoproteins fractionated using the ultracentrifugation-precipitation method. J. Vet. Med. Sci. 2013, 75, 1471–1477. [Google Scholar] [CrossRef]
- Baumstark, D.; Kremer, W.; Boettcher, A.; Schreier, C.; Sander, P.; Schmitz, G.; Kirchhoefer, R.; Huber, F.; Kalbitzer, H.R. 1H NMR spectroscopy quantifies visibility of lipoproteins, subclasses, and lipids at varied temperatures and pressures. J. Lipid Res. 2019, 60, 1516–1534. [Google Scholar] [CrossRef]
- Islam, S.M.T.; Osa-Andrews, B.; Jones, P.M.; Muthukumar, A.R.; Hashim, I.; Cao, J. Methods of Low-Density Lipoprotein-Cholesterol Measurement: Analytical and Clinical Applications. EJIFCC 2022, 33, 282–294. [Google Scholar]
- Heydari, M.; Rezayi, M.; Ruscica, M.; Jamialahmadi, T.; Johnston, T.P.; Sahebkar, A. The ins and outs of lipoprotein(a) assay methods. Arch. Med. Sci.–Atheroscler. Dis. 2023, 8, 128–139. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konishi, T. Challenges and Future Directions in Lipoprotein Measurement for Atherosclerosis Prevention and Treatment. Int. J. Mol. Sci. 2024, 25, 13247. https://doi.org/10.3390/ijms252413247
Konishi T. Challenges and Future Directions in Lipoprotein Measurement for Atherosclerosis Prevention and Treatment. International Journal of Molecular Sciences. 2024; 25(24):13247. https://doi.org/10.3390/ijms252413247
Chicago/Turabian StyleKonishi, Tomokazu. 2024. "Challenges and Future Directions in Lipoprotein Measurement for Atherosclerosis Prevention and Treatment" International Journal of Molecular Sciences 25, no. 24: 13247. https://doi.org/10.3390/ijms252413247
APA StyleKonishi, T. (2024). Challenges and Future Directions in Lipoprotein Measurement for Atherosclerosis Prevention and Treatment. International Journal of Molecular Sciences, 25(24), 13247. https://doi.org/10.3390/ijms252413247