
Deep Learning Model for Classifying and Evaluating Soybean Leaf Disease Damage




Abstract
:1. Introduction
2. Results and Discussion
2.1. Environment Origin, Dataset, and Hyperparameter Tuning
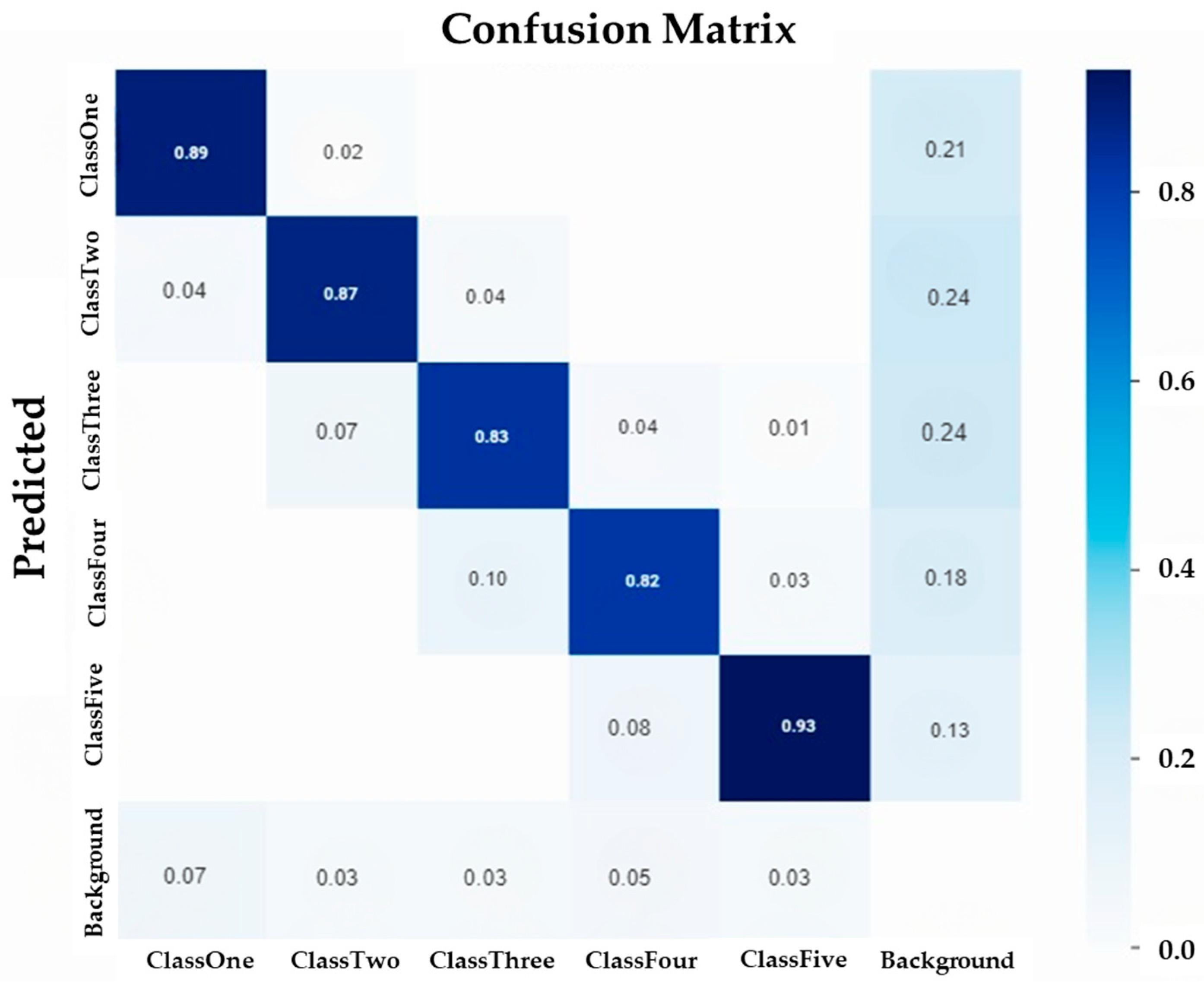
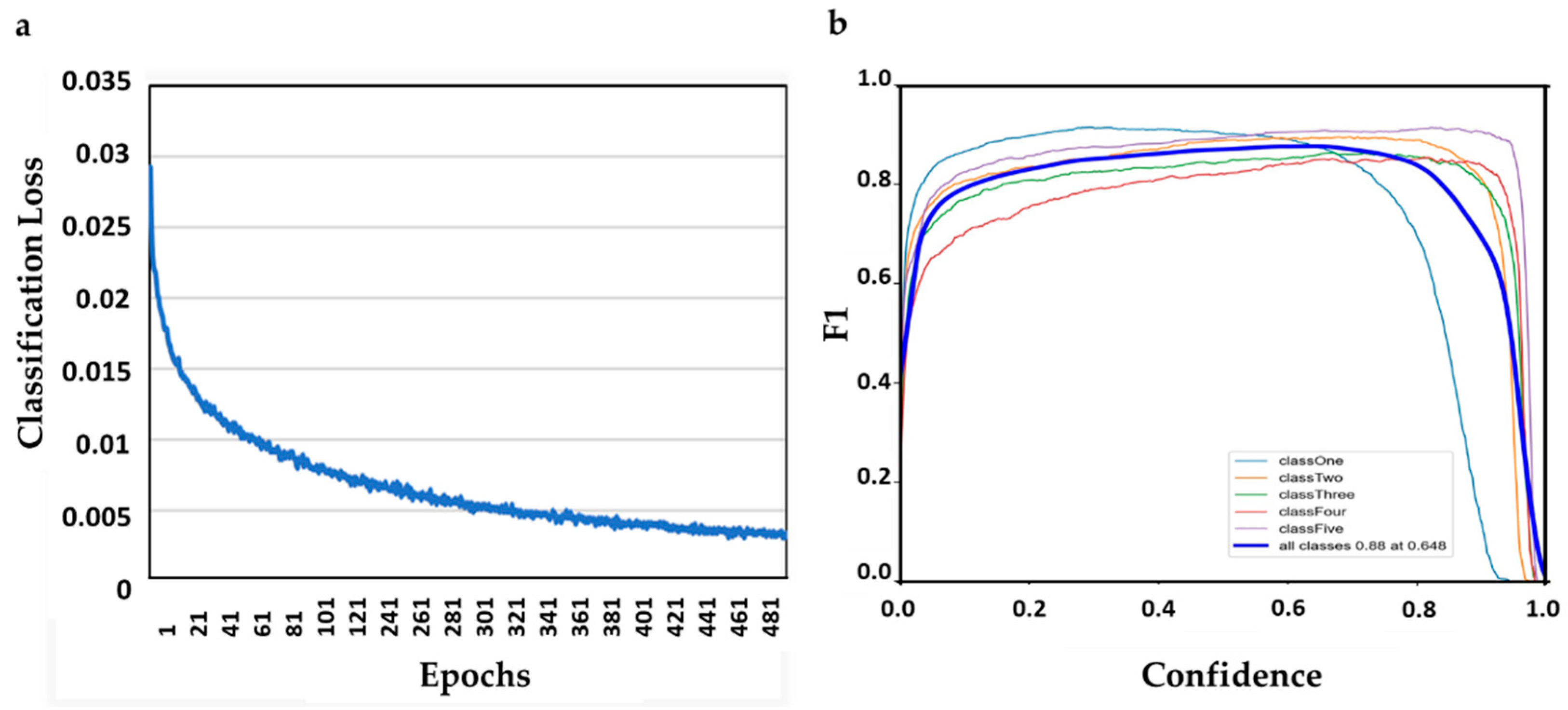
2.2. Practical Analysis and Metric Comparisons
2.3. Testing and Validation of Trained Model
3. Material and Methods
3.1. Object Detection and Machine Learning
3.2. Dataset Creation and Annotation
3.3. Automated Annotation for Image Labeling
3.4. Enhancing Dataset through Data Augmentation
3.5. Model Architecture and Training
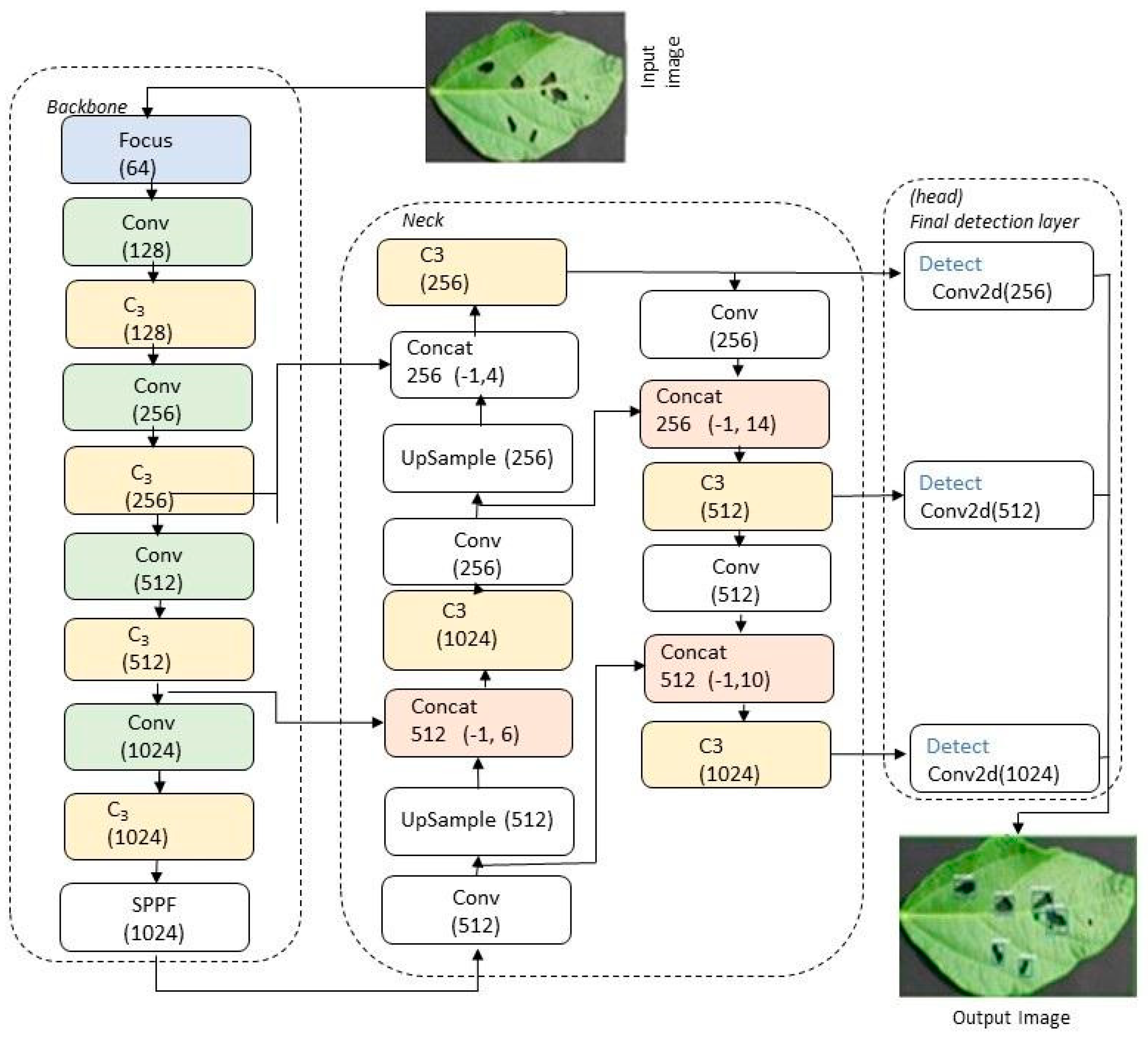
3.6. YOLOv5 Architecture and Analysis
3.7. Evaluation Metrics for Model Performance
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Z.; Lakhssassi, N.; Cullen, M.A.; El Baz, A.; Vuong, T.D.; Nguyen, H.T.; Meksem, K. Assessment of Phenotypic Variations and Correlation among Seed Composition Traits in Mutagenized Soybean Populations. Genes 2019, 10, 975. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Lakhssassi, N.; Knizia, D.; Cullen, M.A.; El Baz, A.; Embaby, M.G.; Liu, S.; Badad, O.; Vuong, T.D.; AbuGhazaleh, A.; et al. Genome-wide identification and analysis of soybean acyl-ACP thioesterase gene family reveals the role of GmFAT to improve fatty acid composition in soybean seed. Theor. Appl. Genet. 2021, 134, 3611–3623. [Google Scholar] [CrossRef] [PubMed]
- Lakhssassi, N.; Lopes-Caitar, V.S.; Knizia, D.; Cullen, M.A.; Badad, O.; El Baze, A.; Zhou, Z.; Embaby, M.G.; Meksem, J.; Lakhssassi, A.; et al. TILLING-by-Sequencing(+) Reveals the Role of Novel Fatty Acid Desaturases (GmFAD2-2s) in Increasing Soybean Seed Oleic Acid Content. Cells 2021, 10, 1245. [Google Scholar] [CrossRef] [PubMed]
- Lakhssassi, N.; Zhou, Z.; Cullen, M.A.; Badad, O.; El Baze, A.; Chetto, O.; Embaby, M.G.; Knizia, D.; Liu, S.; Neves, L.G.; et al. TILLING-by-Sequencing(+) to Decipher Oil Biosynthesis Pathway in Soybeans: A New and Effective Platform for High-Throughput Gene Functional Analysis. Int. J. Mol. Sci. 2021, 22, 4219. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.S.; Lee, H.I.; Hungria, M. Soybean Production in the Americas; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Di Matteo, F.; Otsuki, K.; Schoneveld, G. Soya Bean Expansion in Mozambique: Exploring the Inclusiveness and Viability of Soya Business Models as an Alternative to the Land Grab. The Public Sphere. 2016, pp. 61–86. Available online: https://hdl.handle.net/10568/94497 (accessed on 17 October 2023).
- Lakhssassi, N.; Knizia, D.; El Baze, A.; Lakhssassi, A.; Meksem, J.; Meksem, K. Proteomic, Transcriptomic, Mutational, and Functional Assays Reveal the Involvement of Both THF and PLP Sites at the GmSHMT08 in Resistance to Soybean Cyst Nematode. Int. J. Mol. Sci. 2022, 23, 11278. [Google Scholar] [CrossRef] [PubMed]
- Piya, S.; Pantalone, V.; Zadegan, S.B.; Shipp, S.; Lakhssassi, N.; Knizia, D.; Krishnan, H.B.; Meksem, K.; Hewezi, T. Soybean gene co-expression network analysis identifies two co-regulated gene modules associated with nodule formation and development. Mol. Plant Pathol. 2023, 24, 628–636. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.E.; Lee, T.G.; Guo, X.; Melito, S.; Wang, K.; Bayless, A.M.; Wang, J.; Hughes, T.J.; Willis, D.K.; Clemente, T.E.; et al. Copy number variation of multiple genes at Rhg1 mediates nematode resistance in soybean. Science 2012, 338, 1206–1209. [Google Scholar] [CrossRef] [PubMed]
- Bayless, A.M.; Zapotocny, R.W.; Grunwald, D.J.; Amundson, K.K.; Diers, B.W.; Bent, A.F. An atypical N-ethylmaleimide sensitive factor enables the viability of nematode-resistant Rhg1 soybeans. Proc. Natl. Acad. Sci. USA 2018, 115, E4512–E4521. [Google Scholar] [CrossRef]
- Bayless, A.M.; Smith, J.M.; Song, J.; McMinn, P.H.; Teillet, A.; August, B.K.; Bent, A.F. Disease resistance through impairment of α-SNAP-NSF interaction and vesicular trafficking by soybean Rhg1. Proc. Natl. Acad. Sci. USA 2016, 113, E7375–E7382. [Google Scholar] [CrossRef]
- Bent, A.F. Exploring Soybean Resistance to Soybean Cyst Nematode. Annu. Rev. Phytopathol. 2022, 60, 379–409. [Google Scholar] [CrossRef]
- Hosseini, B.; Voegele, R.T.; Link, T.I. Diagnosis of Soybean Diseases Caused by Fungal and Oomycete Pathogens: Existing Methods and New Developments. J. Fungi 2023, 9, 587. [Google Scholar] [CrossRef] [PubMed]
- Escamilla, D.; Rosso, M.L.; Zhang, B. Identification of fungi associated with soybeans and effective seed disinfection treatments. Food Sci. Nutr. 2019, 7, 3194–3205. [Google Scholar] [CrossRef] [PubMed]
- Huynh, T.V.; Dahlbeck, D.; Staskawicz, B.J. Bacterial blight of soybean: Regulation of a pathogen gene determining host cultivar specificity. Science 1989, 245, 1374–1377. [Google Scholar] [CrossRef] [PubMed]
- Million, C.R.; Wijeratne, S.; Karhoff, S.; Cassone, B.J.; McHale, L.K.; Dorrance, A.E. Molecular mechanisms underpinning quantitative resistance to Phytophthora sojae in Glycine max using a systems genomics approach. Front. Plant Sci. 2023, 14, 1277585. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, X. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef] [PubMed]
- Mignoni, M.; Aislan, H.; Kunst, R.; Righi, R.; Massuquetti, A. Soybean Images Dataset for Caterpillar and Diabrotica speciosa pest detection and classification. Data Brief 2021, 40, 107756. [Google Scholar] [CrossRef] [PubMed]
- Bevers, N.; Sikora, E.J.; Hardy, N.B. Soybean disease identification using original field images and transfer learning with convolutional neural networks. Comput. Electron. Agric. 2022, 203, 107449. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, Q.; Chen, Y. Detecting soybean leaf disease from synthetic image using multi-feature fusion faster R-CNN. Comput. Electron. Agric. 2021, 183, 106064. [Google Scholar] [CrossRef]
- Krishna, R.; Prema, K. Soybean crop disease classification using machine learning techniques. In Proceedings of the IEEE International Conference on Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER), Udupi, India, 30–31 October 2020. [Google Scholar]
- Almalky, A.M.; Ahmed, K.R. Deep Learning for Detecting and Classifying the Growth Stages of Consolida regalis Weeds on Fields. Agronomy 2023, 13, 934. [Google Scholar] [CrossRef]
- Razfar, N.; True, J.; Bassiouny, R.; Venkatesh, V.; Kashef, R. Weed detection in soybean crops using custom lightweight deep learning models. J. Agric. Food Res. 2022, 8, 100308. [Google Scholar] [CrossRef]
- Hu, K.; Wang, Z.; Coleman, G.; Bender, A.; Yao, T.; Zeng, S.; Song, D.; Schumann, A.; Walsh, M. Deep learning techniques for in-crop weed recognition in large-scale grain production systems: A review. Precis. Agric. 2023. [Google Scholar] [CrossRef]
- Almalky, A.M.; Ahmed, K.R.; Guzel, M.; Turan, B. An Efficient Deep Learning Technique for Detecting and Classifying the Growth of Weeds on Fields. In Proceedings of the Future Technologies Conference (FTC) 2022, Vancouver, BC, Canada, 20–21 October 2022; Arai, K., Ed.; Springer International Publishing: Cham, Switzerland, 2023; Volume 2, pp. 818–835. [Google Scholar]
- Almalky, A.; Khaled, A. Real Time Deep Learning Algorithm for Counting Weeds Growth Stages. In Proceedings of the 15th International Symposium on Autonomous Decentralized System (ISADS2023), Mexico City, Mexico, 15–17 March 2023. [Google Scholar]
- Srivastava, P.; Shukla, A.; Bansal, A. A comprehensive review on soil classification using deep learning and computer vision techniques. Multimed. Tools Appl. 2021, 80, 14887–14914. [Google Scholar] [CrossRef]
- Li, X.; Fan, P.; Li, Z.; Chen, G.; Qiu, H.; Hou, G. Soil Classification Based on Deep Learning Algorithm and Visible Near-Infrared Spectroscopy. J. Spectrosc. 2021, 2021, 1508267. [Google Scholar] [CrossRef]
- Sumathi, P.; Karthikeyan, V.V.; Kavitha, M.S.; Karthik, S. Improved Soil Quality Prediction Model Using Deep Learning for Smart Agriculture Systems. Comput. Syst. Sci. Eng. 2023, 45, 1545–1559. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning to predict soil properties from regional spectral data. Geoderma Reg. 2019, 16, e00198. [Google Scholar] [CrossRef]
- Nyakuri, J.P.; Bizimana, J.; Bigirabagabo, A.; Kalisa, J.B.; Gafirita, J.; Munyaneza, M.A.; Nzemerimana, J.P. IoT and AI Based Smart Soil Quality Assessment for Data-Driven Irrigation and Fertilization. Am. J. Comput. Eng. 2022, 5, 1–14. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, K.; Meng, J. Identification of Soybean Leaf Diseases via Deep Learning. J. Inst. Eng. India Ser. A 2019, 100, 659–666. [Google Scholar] [CrossRef]
- Zamani, A.S.; Anand, L.; Rane, K.P.; Prabhu, P.; Buttar, A.M.; Pallathadka, H.; Raghuvanshi, A.; Dugbakie, B.N. Performance of Machine Learning and Image Processing in Plant Leaf Disease Detection. J. Food Qual. 2022, 2022, 1598796. [Google Scholar] [CrossRef]
- Annrose, J.; Rufus, N.; Anantha, H.; Rex, C.; Selva, R.; Immanuel, E.; Godwin, D. Cloud-Based Platform for Soybean Plant Disease Classification Using Archimedes Optimization Based Hybrid Deep Learning Model. Wirel. Pers. Commun. 2022, 122, 2995–3017. [Google Scholar] [CrossRef]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python: A Hands-On Introduction; Ketkar, N., Ed.; Apress: Berkeley, CA, USA, 2017; pp. 113–132. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Hartman, G. Compendium of Soybean Diseases and Pests; APS Publications: St. Paul, MN, USA, 2016. [Google Scholar]
- Lakhssassi, N.; Piya, S.; Knizia, D.; El Baze, A.; Cullen, M.A.; Meksem, J.; Lakhssassi, A.; Hewezi, T.; Meksem, K. Mutations at the Serine Hydroxymethyltransferase Impact Its Interaction with a Soluble NSF Attachment Protein and a Pathogenesis-Related Protein in Soybean. Vaccines 2020, 8, 349. [Google Scholar] [CrossRef] [PubMed]
- Mueller, D.; Wise, K.; Sisson, A.; Smith, D.; Sikora, E.; Bradley, C.; Robertson, A. A Farmer’s Guide to Soybean Diseases; APS Press: St. Paul, MN, USA, 2016. [Google Scholar]
- Anantrasirichai, N.; Hannuna, S.L.; Canagarajah, C.N. Automatic Leaf Extraction from Outdoor Images. arXiv 2017. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhao, S.; Wang, Q.; Li, D.; Zhao, R. Real-time detection and tracking of fish abnormal behavior based on improved YOLOV5 and SiamRPN++. Comput. Electron. Agric. 2022, 192, 106512. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H. Cspnet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Francis, B., David, B., Eds.; Volume 37, pp. 448–456. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Ahmed, K.R. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors 2021, 21, 8406. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate | lr0: 0.00334–lrf: 0.15135 |
| Weight decay | 0.00025 |
| Batch size | 16 |
| Epochs | 500 |
| Optimizer | SGD |
| Input image size | 600 × 800 |
| Anchor_t | 4 |
| Performance Metric | ) |
|---|---|
| Inference Speed (ms) | 8.1 |
| Precision (%) | 88 |
| mAP@0.5 (%) | 92 |
| mAP@0.5–0.95 (%) | 76 |
| Curve (%) | 88 |
| P Curve (%) | 95 |
| R Curve (%) | 97 |
| PR Curve (%) | 93 |
| Classification | Percentage Damage of Each Defect in Leaf |
|---|---|
| ClassOne | Greater than 0 and less than 1.1 |
| ClassTwo | Greater than 1.1 and less than 2.4 |
| ClassThree | Greater than 2.4 and less than 4.1 |
| ClassFour | Greater than 4.1 and less than 6.6 |
| ClassFive | Greater than 6.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goshika, S.; Meksem, K.; Ahmed, K.R.; Lakhssassi, N. Deep Learning Model for Classifying and Evaluating Soybean Leaf Disease Damage. Int. J. Mol. Sci. 2024, 25, 106. https://doi.org/10.3390/ijms25010106
Goshika S, Meksem K, Ahmed KR, Lakhssassi N. Deep Learning Model for Classifying and Evaluating Soybean Leaf Disease Damage. International Journal of Molecular Sciences. 2024; 25(1):106. https://doi.org/10.3390/ijms25010106
Chicago/Turabian StyleGoshika, Sandeep, Khalid Meksem, Khaled R. Ahmed, and Naoufal Lakhssassi. 2024. "Deep Learning Model for Classifying and Evaluating Soybean Leaf Disease Damage" International Journal of Molecular Sciences 25, no. 1: 106. https://doi.org/10.3390/ijms25010106
APA StyleGoshika, S., Meksem, K., Ahmed, K. R., & Lakhssassi, N. (2024). Deep Learning Model for Classifying and Evaluating Soybean Leaf Disease Damage. International Journal of Molecular Sciences, 25(1), 106. https://doi.org/10.3390/ijms25010106