Abstract
Taking a DNA sequence, a word with letters/bases A, T, G and C, as the relation between the generators of an infinite group , one can discriminate between two important families: (i) the cardinality structure for conjugacy classes of subgroups of is that of a free group on one to four bases, and the DNA word, viewed as a substitution sequence, is aperiodic; (ii) the cardinality structure for conjugacy classes of subgroups of is not that of a free group, the sequence is generally not aperiodic and topological properties of have to be determined differently. The two cases rely on DNA conformations such as A-DNA, B-DNA, Z-DNA, G-quadruplexes, etc. We found a few salient results: Z-DNA, when involved in transcription, replication and regulation in a healthy situation, implies (i). The sequence of telomeric repeats comprising three distinct bases most of the time satisfies (i). For two-base sequences in the free case (i) or non-free case (ii), the topology of may be found in terms of the character variety of and the attached algebraic surfaces. The linking of two unknotted curves—the Hopf link—may occur in the topology of in cases of biological importance, in telomeres, G-quadruplexes, hairpins and junctions, a feature that we already found in the context of models of topological quantum computing. For three- and four-base sequences, other knotting configurations are noticed and a building block of the topology is the four-punctured sphere. Our methods have the potential to discriminate between potential diseases associated to the sequences.
1. Introduction
Group theory and algebraic geometry serve the decipherment of ‘the book of life’ [1], a book made of a language employing four letters/nucleotides: A (adenine), T (thymine), G (guanine) and C (cytosine), as described in this work. There are finite groups, groups made of a finite number of generators and a finite number of elements that may be used to map the codons to amino acids, as carried out in our papers [2,3]. Such an approach toward the genetic code is made possible by identifying the irreducible characters of the group to the amino acids. The multiplets of codons attached to a selected amino acid correspond to the irreducible characters having the corresponding dimension of the representation (Table 3 in [2], Table 4 in [3]). A virtue of the approach is that the used irreducible characters are also seen as quantum states carrying complete quantum information.
For modeling DNA in its various conformations taken in transcription factors, telomeres and other building blocks of molecular biology, we need infinite groups defined from a motif. A sequence of the DNA nucleotides serves as the generator of the group [4]. In this context, it has been found that a group that is not free is often the witness of a potential disease. We coined the term ‘syntactical freedom’ for recognizing this property, with inspiration from an earlier work [5]. We also showed that such free groups have the distinctive property of generating an aperiodic substitution rule, providing a connection between (group) syntactical freedom and irrational numbers (Section 4 in [4]). For an infinite group, the representation cannot be based on characters but on the so-called character variety. This topic leads to a relationship between DNA, algebraic topology and algebraic geometry. Tools already proposed for topological quantum computing [6] are also used in the context of DNA conformations.
In Section 2, we briefly account for the many types of topologies that DNA can show, in terms of double strands or more strands. Then, we recall the mathematical concepts employed in our paper with some redundancy with earlier work [4,6].
In Section 3, we explain the concept of an character variety associated to an infinite group with two or three generators. The former case corresponds to DNA motifs having only two distinct nucleotides. In such a case, the variety often contains the Cayley cubic associated to the Hopf link, the non disjoint union of two circles in the three-dimensional space. In the later case, the variety contains the Fricke–Klein seventh variable polynomial that is characteristic of the topology of the three-dimensional sphere with four points removed.
In Section 4, we apply these mathematical methods to transcription factors, telomeric sequences and a specific DNA decamer sequence, where almost all of its conformations have been crystallized.
2. Materials and Methods
Mathematical calculations performed in this paper are on the software Magma [7] (for groups) or on Sage software [8] (for character varieties).
2.1. DNA Conformations
DNA is a long polymer made from a chain of the nucleotides A, T, C or G. DNA exists in many possible conformations, which include a double-stranded helix of A-DNA, B-DNA and Z-DNA, although only B-DNA and Z-DNA have been directly observed in functional organisms [9,10]. The B-DNA form is most common under the conditions found in cells, but Z-DNA is often preferred when DNA binds to a protein. A view of a double helix in the A-, B- and Z-DNA forms is given in Figure 1 Other DNA conformations also exist, such as a single-stranded hairpin used mostly in macromolecular synthesis and repair, a triple-stranded H-DNA found in peptides, a G-quadruplex structure found in telomeres and a Holliday junction.
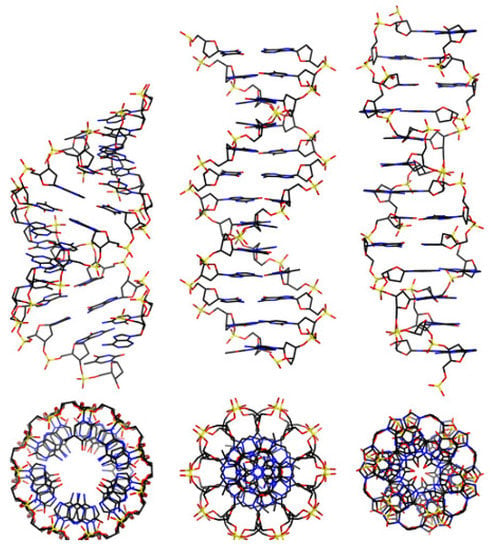
Figure 1.
From left to right, the structures of A-, B- and Z-DNA. The view of the double helix from above (or below) shows distinct symmetries, 11-fold for the A-DNA, 10-fold for the B-DNA and 6-fold for the Z-DNA [9,10].
2.2. Finitely Generated Groups, Free Groups and Their Conjugacy Classes, and Aperiodicity of Sequences
The free group on r generators (of rank r) consists of all distinct words that can be built from r letters where two words are different unless their equality follows from the group axioms. The number of conjugacy classes of of a given index d is known and is a good signature of the isomorphism, or the closeness, of a group to . In the following, the cardinality structure of conjugacy classes of index d in is called the cardinality sequence (card seq) of , and we need the cases from r = 1 to 3 to correspond to the number of distinct bases in a DNA sequence. The card seq of is in Table 1 for the three sequences of interest in the context of DNA [11].

Table 1.
Number of conjugacy classes of subgroups of index d in free group of rank r = 1 to 3 [11]. The last column is the index of the sequence in the on-line encyclopedia of integer sequences [12].
Next, given a finitely generated group with a relation (rel) given by the sequence motif, we are interested in the card seq of its conjugacy classes. Often, the DNA motif in the sequence under investigation is close to that of a free group , with being the number of distinct bases involved in the motif. However, the finitely generated group , or or (where the are taken in the four bases A, T, G and C, and rel is the motif), may not be the free group , or or . The closeness of to can be checked by its signature in the finite range of indices of the card seq.
2.2.1. Groups Close to Free Groups and Aperiodicity of Sequences
According to reference [5], aperiodicity correlates to the syntactical freedom of ordering rules. This statement was checked in the realm of transcription factors (Section 4 in [4]). Let us introduce the concept of a general substitution rule in the context of free groups. A general substitution rule on a finite alphabet 𝒜r on r letters is an endomorphism of the corresponding free group (Definition 4.1 in [13]). The endomorphism property means the two relations and , for any .
A special role is played by the subgroup of automorphisms of . We introduce the map from to the Abelian group in order to investigate the substitution rule with the tools of matrix algebra.
The map induces a homomorphism . Under M, maps to the general linear group of matrices with integer entries . Given , there is a unique mapping that makes the map diagram commutative [13] (p. 68). The substitution matrix of may be specified by its elements at row i and column j as follows:
This approach was applied to binding motifs of transcription factors [4]. The binding motif rel in the finitely presented group is split into appropriate segments so that with the substitution rules , , , .
We are interested in the sequence of finitely generated groups
whose card seq is the same at each step l and equal to the card seq of the free group (in the finite range of indices that it is possible to check with the computer).
Under these conditions, (group) syntactical freedom correlates to the aperiodicity of sequences.
2.2.2. Aperiodicity of Substitutions
There is no definitive classification of aperiodic order, the intermediate between crystalline order and strong disorder, but in the context of substitution rules, some criteria can be found. First, we need a few definitions.
A non-negative matrix is one whose entries are non-negative numbers. A positive matrix M (denoted ) has at least one positive entry. A strictly positive matrix (denoted ) has all positive entries. An irreducible matrix is one for which there exists a non-negative integer k with for each pair . A primitive matrix M is one such that is a strictly positive matrix for some k.
A Perron–Frobenius (PF for short) eigenvector v of an irreducible non-negative matrix is the only one whose entries are positive: . The corresponding eigenvalue is called the PF eigenvalue.
We will use the following criterion (Corollary 4.3 in [13]). A primitive substitution rule of substitution matrix with an irrational PF-eigenvalue is aperiodic.
A well-studied primitive substitution rule is the Fibonacci rule of substitution matrix and PF-eigenvalue equal to the golden ratio (Example 4.6 in [13]). As expected, the irrationality of corresponds to the aperiodicity of the Fibonacci sequence.
The sequence of Fibonacci words is as follows:
The words have lengths equal to the Fibonacci numbers
All finitely generated groups whose relations have a card seq whose elements are 1s, as for the card seq of the free group . The Fibonacci sequence is our first example where group syntactical freedom correlates to aperiodicity.
2.2.3. A Four-Letter Sequence for the Transcription Factor of the Fos Gene
Let us now apply the method to a transcription factor of importance. The transcription factor of gene Fos has selected motif [14]. For this case, the four-letter generated group has a card seq similar to the free group given in Table 1.
We split rel into four segments so that with the substitution maps , , , to produce the substitution sequence
The substitution matrix for this sequence is . It is a primitive matrix () whose eigenvalues follow from the vanishing of the polynomial . There are two real eigenvalues and , as well as two complex conjugate eigenvalues . The PF-eigenvalue is , with an eigenvector of (positive) entries . It follows that the selected sequence for the Fos gene is aperiodic.
All of the finitely generated groups whose relations are
have a card seq whose elements are
which is the card seq of the free group . For the Fos transcription factor, group syntactical freedom correlates to aperiodicity as expected.
Further examples are obtained in the context of DNA sequences for transcription factors (Section 4 in [4]) and below, in relation to DNA conformations and telomeres.
3. Discussion
In the following, we make use of representations of the infinite groups arising from specific DNA sequences. The character variety has many interpretations in mathematics and physics. For instance, in mathematics, the variety is the space of representations of hyperbolic structures of three-manifolds M with fundamental group , and the variety of the characters of representations of is reflected in the algebraic geometry of the character variety [15,16]. In physics, the group expresses the symmetries of fundamental physical laws. It is also known as the Lorentz group; more precisely, the double cover of the restricted Lorenz group is , which is the spin group.
3.1. Character Varieties and Algebraic Surfaces
Recently, we found that the representation theory of finite groups with their character table allows us to derive an approach of the genetic code [3].
For infinite groups such as those defined by DNA sequences, it is useful to describe the representations of in the Lorentz group , the group of matrices with complex entries and determinant 1. Such a group expresses the fundamental symmetry of all known physical laws, apart from gravitation.
Representations of in are homomorphisms with character , . The set of characters allows us to define an algebraic set by taking the quotient of the set of representations by the group , which acts by conjugation on representations [15,17].
For two-generator groups, the character variety may be decomposed into the product of surfaces, which reveals the topology of M. We recently found a connection between some groups whose topology is based on the Hopf link and a model of topological quantum computing [6]. The Hopf link underlies many DNA sequences whose group structure is (or is not) that of the free group . The classification of the involved algebraic surfaces in the variety is performed using specific tools available in Magma [7]; see (Section 2.1 in [6]) for details.
For three-generator groups, we find that the Fricke–Klein quartic is part of the character variety.
3.2. The Hopf Link
Taking the linking of two unknotted curves as in Figure 2 (Left), the obtained link is called the Hopf link H = L2a1, whose knot group is defined as the fundamental group of the knot complement in the three-sphere
where (with ) is the group theoretical commutator.
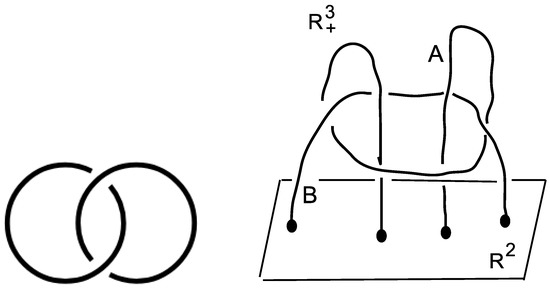
Figure 2.
(Left): the Hopf link. (Right): the link is attached to the plane in the half-space . It is not splittable. This can be proved by checking that the fundamental group is not free [18] and p. 90 in [19]. One gets , where (.,.) means the group theoretical commutator. The cardinality sequence of cc of subgroups of is (Figure 3 in [4]).
There are interesting properties of the knot group of the Hopf link.
First, the number of coverings of degree d of (which is also the number of conjugacy classes of index d) is precisely the sum of divisor function [20].
Second, an invariance of under a repetitive action of the golden ratio substitution (the Fibonacci map) , or under the silver ratio substitution , exists. The terms golden and silver refer to the Perron–Frobenius eigenvalue of the substitution matrix (Examples 4.5 and 4.6 in [13]). Such an observation links the Hopf link, the group of the 2-torus and aperiodic substitutions.
Using Sage software [8] developed from Ref. [17], the character variety is the polynomial corresponding to the so-called Cayley cubic
As expected, the three-dimensional surface is the trace of the commutator and is known to correspond to the reducible representations (Theorem 3.4.1 in [21]). A picture is given in Figure 3 (left).
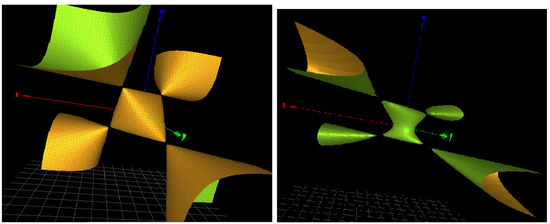
Figure 3.
(Left): a three-dimensional picture of the character variety for the Hopf link complement H. (Right): a modified character variety of defining equation with similar singularities.
In the perspective of algebraic geometry, we classify the homogenization of equation as a rational surface of degree 3 del Pezzo type. It displays four simple singularities.
3.3. Beyond the Hopf Link
As shown in [6], the Hopf link is the irreducible component of many character varieties relevant to a model of topological quantum computing. In the context of DNA groups investigated in the next section, we also find another surface with similar simple singularities as shown in Figure 3 (right). The defining polynomial is
The homogenization of equation allows us to classify it as a conic bundle in the family of surfaces.
For the DNA sequence, whose group contains the component , we refer to the third subsection of the Results section below and the first table in this subsection. The relevant triplet nnn=CGG of the dodecameric sequence leads to a DNA conformation with the label 1ZEY in the PDB bank.
The DNA dodecamer sequence d(CCCCCGCGGGGG) is also found in the PDB bank with label , corresponding to a complete turn of A-DNA. The character variety for the group defined by this sequence contains the polynomial and a polynomial similar to without the third-order term and the first-order term , but in the same family.
3.4. The Fricke–Klein Seventh Variable Polynomial
The Cayley cubic is a subset of the character variety for the four-punctured three-dimensional sphere (the sphere minus four points). Its fundamental group is isomorphic to the free group of rank 3, , where the four homotopy classes correspond to loops around the punctures.
The character variety for satisfies a quartic equation in terms of the Fricke–Klein seventh variable polynomial [21] (p. 65) and [22]:
with , , , .
4. Results
In this section, we apply the representation theory to specific non-canonical DNA sequences having regulatory functions in gene expression (the transcription factors), replication (the telomeres) and DNA conformations.
4.1. Group Structure and Topology of Transcription Factors
In a transcription factor, a motif-specific DNA binding factor controls the rate of the transcription of a gene from DNA to messenger RNA by binding a protein to the DNA motif. In reference [4], we found a correlation between motifs whose subgroup structure is that of a free group and the lack of a potential disease while the gene is activated in transcription, the property of ‘syntactical freedom’.
In Table 2, this idea is illustrated by restricting to a few transcription factors whose motif comprises two bases. The card seq of the motif is either the free group , close to or away from a free group when the card seq is that of the modular group , of the Baumslag–Solitar group or that of groups and . Compared to the results provided in [4], there is the additional fourth column that signals when the Groebner base for the ideal ring of the character variety contains the Cayley cubic, the unique component in the case of the Hopf link [6], a degree 3 del Pezzo surface (denoted HL), or not. An additional fifth column is filled to check the presence of a surface of type . Only the last row of the table for the transcription factor of gene EHF does not show this property.
Table 2.
Group structure of motifs for a few two-letter transcription factors. The card seq for the modular group is . The Baumslag–Solitar group is the fundamental group of the Klein bottle. The card seq for is . The card seq for is ; for , it is . The symbol HL means that the Cayley cubic is part of the Groebner base for the ideal ring of the corresponding character variety. For three-letter transcription factors, the ideal ring of the corresponding character variety contains the Fricke–Klein seventh variable polynomial 4, which is a feature of the four-punctured sphere topology. The group structure of three-letter transcription factors not leading to free groups is shown in (Table 5 in [4]).
The Character Variety for the Transcription Factor of the DBX Gene
We explicitly show the character variety for the transcription factor of the DBX gene.
The factors in (5) are three degree 3 del Pezzo surfaces (including the Cayley cubic ), two rational ruled surfaces and a surface birationally equivalent to the projective plane, respectively. The latter factor also belongs to the character variety of group , where is the four-sphere and is the singular fiber in Kodaira’s classification of minimal elliptic surfaces (Figure 4b in [6]).
It is important to mention that, for three-letter transcription factors, the ideal ring of the corresponding character variety contains the Fricke–Klein seventh variable polynomial (4), which is a feature of the four-punctured sphere topology.
Table 3 provides a short account of the function or potential dysfunction of the genes under consideration. As mentioned before, most of the time, such a dysfunction is correlated to a card seq away from that of the free group .
Table 3.
A short account of the function or dysfunction (through mutations or isoforms) of genes associated with transcription factors and sections in Table 2.
In view of our results, it is interesting to correlate the presence of the Hopf link HL in the character variety with the possible remodeling of B-DNA into Z-DNA or another DNA conformation. To our knowledge, general information about this subject is still lacking. From a biological point of view, it is known that some of the Z-DNA-forming conditions that are relevant in vivo are the presence of DNA supercoiling, Z-DNA-binding proteins [27] and base modifications. When transcription occurs, the movement of RNA polymerase II along the DNA strand generates positive supercoiling in front of, and negative supercoiling behind, the polymerase [28].
Perhaps the lack of HL in the character variety for transcription factors of genes in Table 2 means that the Z-DNA-forming condition is not realized.
4.2. Group Structure and Topology of DNA Telomeric Sequences
Terminal structures of chromosomes are made of short highly repetitive G-rich sequences with proteins known as telomeres. They have a protective role against the shortening of chromosomes through successive divisions. Most organisms use a telomere-specific DNA polymerase called telomerase that extends the 3’ end of the G-rich strand of the telomere [29]. Telomere shortening is associated with aging, mortality and aging-related diseases such as cancer.
A list of results obtained by using our group theoretical approach is in Table 4. For two-letter telomere sequences, the character variety contains the Cayley cubic, the characteristic of the Hopf link HL, only in the first row. In addition to the Cayley cubic, one finds surfaces of a general type. In the next two rows, the Cayley cubic is not found. There are degree 3 del Pezzo surfaces in the factors of the character variety but not general surfaces.
As for the Hopf link, the sequence is found to be aperiodic with the Perron–Frobenius eigenvalue equal to the golden ratio. For three-letter telomere sequences, the card seq is that of the free group of , except for the last row, where the identified group is ; see Figure 2 (right) for the definition of such a group. In the former seven cases, the DNA topology is known to be a G-quadruplex structure [30,31,32,33,34,35,36]. We could identify an aperiodic structure of the telomere sequence with the Perron–Frobenius eigenvalue as shown in column 5. In the latter case, the topology is of the basket type [36] and no aperiodicity of the telomere sequence could be found.
Figure 4, taken from the protein data bank (PDB 2HY9), illustrates the G-quadruplex structure of the telomere sequence in vertebrates.

Figure 4.
Human telomere DNA quadruplex structure in K+ solution hybrid-1 form, PDB 2HY9 [30].
Table 4.
Group analysis of the telomere sequence found in some eukaryotes. The first column is for the telomere repeat, the second column is the organism under investigation, the third column is for the PDB code, the fourth column is for the card seq of the group or that of the corresponding group that is identified, the fifth column is for the Perron–Frobenius eigenvalue when the sequence is found to be aperiodic, the sixth column identifies the presence of the Hopf link (in two-base sequences) or the DNA conformation (in three-base sequences) and the seventh column is a relevant reference. The notation G-quadr is for the G-quadruplex; see Figure 4. The card seq for is . The Hecke group is defined in (Table 2 in [4]).
Table 4.
Group analysis of the telomere sequence found in some eukaryotes. The first column is for the telomere repeat, the second column is the organism under investigation, the third column is for the PDB code, the fourth column is for the card seq of the group or that of the corresponding group that is identified, the fifth column is for the Perron–Frobenius eigenvalue when the sequence is found to be aperiodic, the sixth column identifies the presence of the Hopf link (in two-base sequences) or the DNA conformation (in three-base sequences) and the seventh column is a relevant reference. The notation G-quadr is for the G-quadruplex; see Figure 4. The card seq for is . The Hecke group is defined in (Table 2 in [4]).
| Seq | Organism | PDB | Card Seq | Link/DNA Conf | Ref | |
|---|---|---|---|---|---|---|
| G4T4G4 | Oxytricha | 1D59 | HL | [37] | ||
| TG4T | universal | 244D_1 | . | no | [38] | |
| T2G4 | Tetrahymena | 230D | . | no | [29] | |
| T2AG3 | Vertebrates | 2HY9 | 2.5468 | G-quadr. | [30] | |
| TAG3 | Giardia | 2KOW | 2.2055 | G-quadr | [31] | |
| T2AG2 | Bombys mori | unknown | no | G-quadr | [32] | |
| T4AG3 | Green algae | unknown | 3.07959 | unknown | [33] | |
| G2T2AG | Human | unknown | 2.5468 | G-quadr | [34] | |
| TAG3T2AG3 | Human | 2HRI | 3.3923 | G-quadr | [35] | |
| G3T2AG3T2AG3T | Human | unknown | 4.3186 | G-quadr | [36] | |
| (GGGTTA)3G3T | Human | unknown | no | basket | [36] |
4.3. Group Structure and Topology of the DNA Decamer Sequence [10]
A challenging question of structural biology is to determine if and how a DNA (or RNA) sequence defines the three-dimensional conformation, as well as the secondary and tertiary structure of proteins. In the previous two subsections, we tackled the problem with regard to transcription factors and telomeric sequences, respectively. In the former case, we restricted to the DNA part of the transcription since the DNA motif is almost exactly known from X-ray techniques while the secondary structure of the binding protein strongly depends on the model employed and the choice made to recognize the sections of the secondary structures (e.g., alpha helices, beta sheets and coils) [39]. In the latter case, in many organisms, nature invented telomerase for taking care of the replication without damaging the sequences at the 3-ends too much, while keeping the catalyzing action of DNA polymerase. Again, there is a loop complex in telomerase comprising telomere-binding proteins, with secondary structures not being analyzed so far with our group theoretical approach.
In this section, we also study DNA conformations and their relationship to algebraic topology in a specific DNA decamer sequence investigated in reference [10] by a standard crystallization technique followed by X-ray diffraction discrimination. In the sequence , the factors , and are taken in the two nucleotides G and C, and nnn is specified in order to maintain the self-complementarity of the sequence. This inverse repeated motif is the minimum motif used to distinguish between the double-strand forms of B- and A-DNA, while excluding the Z-DNA forms. A third conformation is allowed and called the four-stranded Holliday junction J. We refer to (Table 1 in [10]) for the main results.
On our side, the card seq of each sequence was determined and the character variety was obtained. Our results are summarized in the four Table 5, Table 6, Table 7 and Table 8.
Table 5.
Group analysis of the sequence , where , and are taken in the two nucleotides G and C and is specified in order to maintain the self-complementarity of the sequence [10]. The first column is for the selected triplet , the second column is for the code in the protein data bank, the third column is for the DNA conformation when known (see Table 1 in [10]), the fourth column is for the cardinality structure of subgroups of and the fifth column checks the occurrence of a surface corresponding to the Hopf link in the factorization of the of . The symbols A, B and J are for A-DNA, B-DNA and a four-stranded Holliday junction; lowercase is used when the conformation is not confirmed in [10].
Table 6.
Group analysis of the sequence , where , and are taken in the two nucleotides A,T [10]. Groups and are as in (Table 5 in [4]). The card seq for is ; for , it is ; for , it is ]. Groups and may be simplified to a group whose card seq is that of , the fundamental group of the link described in Figure 3 (right).
Table 7.
Group analysis of the sequence [10], where , and are taken in the two nucleotides A,G (left) and A,C (right). Groups and are as in (Table 5 in [4]). The card seq for is ] and, for , it is ].
Table 8.
Group analysis of the sequence [10], where , and are taken in the three nucleotides A, G, C (left) and A, T, C (right). The card seq for is ].
In Table 5, , and are taken in the two nucleotides G and C, forming eight triplets and the associated two-letter decamer sequences. Note that the triplet produces two distinct DNA conformations A and J. The character variety of the Hopf link HL (the Cayley cubic) is present in the factors of the ideal ring of the character variety in five cases over the nine possibilities, where one case (with triplet and code 1ZEY in the protein data bank) shows an algebraic surface similar to the Cayley cubic (with four simple singularities) as defined in Equation (3) and as shown in Figure 3 (right). We do not observe a clear correlation between the type of DNA conformation and the underlying HL topology, but the presence of HL in the variety seems to exclude the B-DNA conformation. In addition, the character variety always contains a surface of type in its factors.
In Table 6, , and are taken in the two nucleotides A and T, forming eight triplets. The DNA conformation (when known) is of type B. The card seq that we obtain is groups , or as described in the caption of Table 5. In six cases over the eight possibilities, the groups encapsulate the topology of the rank 2 group , whose associated link is shown in Figure 2 (right). As already mentioned, the character variety contains the Fricke–Klein seventh variable polynomial 4.
In Table 7, , and are taken in the two nucleotides A, G (left part) and A, C (right part). This time, either the card seq of the group is that of the free group , of rank 3 (10 cases over the 16 possibilities), or not. In the latter case, the group encapsulates the topology of only at the right side of the table. Similar conclusions hold in Table 8 when , and are taken in the two nucleotides A, G, C (left part) and A, T, C (right part).
To summarize this section, no clear correlation is observed between the DNA conformations of the considered decamer and our group analysis. Longer sequences may be needed to obtain such a correlation. For instance, the two-letter DNA dodecamer sequence (PDB 2D47) corresponding to a complete turn of A-DNA—see Figure 5 (right)—features the polynomial (for HL) and a fourth-order polynomial similar to with four simple singularities, as announced at the end of Section 3.
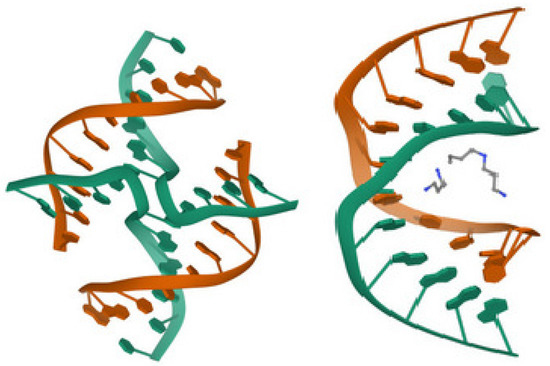
Figure 5.
(Left) The four-strand Holliday junction J: PDB , (Right) A complete turn of A-DNA: PDB . It is associated to DNA dodecamer sequence with containing the factor (the Cayley cubic) and the factor .
5. Conclusions
In the present paper, following earlier work about the genetic code [2,3] and about the role of transcription factors in genetics [4], we made use of group theory applied to appropriate DNA motifs and we computed the corresponding variety of representations. The DNA motifs under consideration may be canonical structures, such as (double-stranded) B-DNA, or non-canonical DNA structures [40], such as (single-stranded) telomeres, (double-stranded) A-DNA, Z-DNA or cruciforms, (triple-stranded) H-DNA, (four-stranded) i-motifs or G-quadruplexes, etc. One objective of the approach is to establish a correspondence between the algebraic geometry and topology of the character variety and the types of canonical or non-canonical DNA-forms. For example, for two-letter transcription factors, one can correlate the presence of the Cayley cubic and/or a surface in the variety with DNA supercoiling in the remodeling of B-DNA to Z-DNA. For three- or four-letter DNA structures, our work needs to be developed in order to put the features of the variety and potential diseases in correspondence. In a separate work devoted to topological quantum computing, the topology of the four-punctured sphere and the related Fricke surfaces (generalizing the Cayley cubic) are relevant [41]. In addition, Fricke surfaces may be put in parallel with differential equations of the Painlevé VI type. It will be important to compare these models with other qualitative models based on non-linear differential equations [42,43]. In the near future, we intend to apply these mathematical tools to the context of DNA structures.
Author Contributions
Conceptualization, M.P., F.F. and K.I.; methodology, M.P., D.C. and R.A.; software, M.P.; validation, R.A., F.F., D.C. and M.M.A.; formal analysis, M.P. and M.M.A.; investigation, M.P., D.C., F.F. and M.M.A.; writing—original draft preparation, M.P.; writing—review and editing, M.P.; visualization, F.F. and R.A.; supervision, M.P. and K.I.; project administration, K.I.; funding acquisition, K.I. All authors have read and agreed to the published version of the manuscript.
Funding
Funding was obtained from Quantum Gravity Research in Los Angeles, CA, USA.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nerlich, B.; Dingwall, R.; Clarke, D.D. The book of life: How the completion of the Human Genome Project was revealed to the public. Health Interdiscip. J. Soc. Study Health Illn. Med. 2002, 6, 445–469. [Google Scholar] [CrossRef]
- Planat, M.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Complete quantum information in the DNA genetic code. Symmetry 2020, 12, 1993. [Google Scholar] [CrossRef]
- Planat, M.; Chester, D.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Finite groups for the Kummer surface: The genetic code and quantum gravity. Quantum Rep. 2021, 3, 68–79. [Google Scholar] [CrossRef]
- Planat, M.; Amaral, M.M.; Fang, F.; Chester, D.; Aschheim, R.; Irwin, K. Group theory of syntactical freedom in DNA transcription and genome decoding. Curr. Issues Mol. Biol. 2022, 44, 1417–1433. [Google Scholar] [CrossRef]
- Irwin, K. The code-theoretic axiom; the third ontology. Rep. Adv. Phys. Sci. 2019, 3, 1950002. [Google Scholar] [CrossRef]
- Planat, M.; Amaral, M.M.; Fang, F.; Chester, D.; Aschheim, R.; Irwin, K. Character varieties and algebraic surfaces for the topology of quantum computing. Symmetry 2022, 14, 915. [Google Scholar] [CrossRef]
- Bosma, W.; Cannon, J.J.; Fieker, C.; Steel, A. (Eds.) Handbook of Magma Functions; Australia, Edition 2.23; University of Sydney: Sydney, Australia, 2017; 5914p. [Google Scholar]
- Python Code to Compute Character Varieties. Available online: http://math.gmu.edu/~slawton3/Main.sagews (accessed on 1 May 2021).
- DNA. Available online: https://en.wikipedia.org/wiki/DNA (accessed on 1 January 2022).
- Hays, F.A.; Teegarden, A.; Jones, Z.J.R.; Harms, M.; Raup, D.; Watson, J.; Cavaliere, E.; Ho, P.S. How sequence defines structure: A crystallographic map of DNA structure and conformation. Proc. Natl. Acad. Sci. USA 2005, 20, 7157–7162. [Google Scholar] [CrossRef]
- Kwak, J.H.; Nedela, R. Graphs and their coverings. Lect. Notes Ser. 2007, 17, 118. [Google Scholar]
- The On-Line Encyclopedia of Integer Sequences. Available online: https://oeis.org/book.html (accessed on 1 June 2022).
- Baake, M.; Grimm, U. Aperiodic Order, Vol. I: A Mathematical Invitation; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Glover, J.N.; Harrison, S.C. Crystal structure of the heterodimeric bZIP transcription factor c-Fos-c-Jun bound to DNA. Nature 1995, 373, 257–261. [Google Scholar] [CrossRef]
- Culler, M.; Shalen, P.B. Varieties of group representations and splitting of 3-manifolds. Ann. Math. 1983, 117, 109–146. [Google Scholar] [CrossRef]
- Cooper, D.; Culler, M.; Gillet, H.; Long, D.D.; Shalen, P.B. Plane curves associated to character varieties of 3-manifolds. Invent. Math. 1994, 118, 47–84. [Google Scholar] [CrossRef]
- Ashley, C.; Burelle, J.P.; Lawton, S. Rank 1 character varieties of finitely presented groups. Geom. Dedicata 2018, 192, 1–19. [Google Scholar] [CrossRef]
- Zeeman E., C. Linking spheres. Abh. Math. Sem. Univ. Hambg. 1960, 24, 149–153. [Google Scholar] [CrossRef]
- Rolfsen, D. Knots and Links; AMS Chelsea Publishing: Providence, RI, USA, 2000. [Google Scholar]
- Liskovets, V.; Mednykh, A. On the number of connected and disconnected coverings over a manifold. Ars Math. Contemp. 2009, 2, 181–189. [Google Scholar] [CrossRef]
- Goldman, W.M. Trace coordinates on Fricke spaces of some simple hyperbolic surfaces. In Handbook of Teichmüller Theory; European Mathematical Society: Zurich, Switzerland, 2009; Volume 13, pp. 611–684. [Google Scholar]
- Cantat, S.; Loray, F. Holomorphic dynamics, Painlevé VI equation and character varieties. arXiv 2007, arXiv:0711.1579v2. [Google Scholar]
- Sandelin, A.; Alkema, W.; Engström, P.; Wasserman, W.W.; Lenhard, B. JASPAR: An open-access database for eukaryotic transcription factor binding profiles. Nucleic Acids Res. 2004, 32, D91–D94. Available online: https://jaspar.genereg.net/ (accessed on 1 January 2022). [CrossRef]
- Lambert, S.A.; Jolma, A.; Campitelli, L.F.; Das, P.K.; Yin, Y.; Albu, M.; Chen, X.; Talpale, J.; Hughes, T.R.; Weirauch, M.T. The human transcription factors. Cell 2018, 172, 650–665. Available online: http://www.edgar-wingender.de/huTF_classification.html (accessed on 1 January 2022). [CrossRef]
- Lantz, K.A.; Vatamaniuk, M.Z.; Brestelli, J.E.; Friedman, J.R.; Matschinsky, F.M.; Kaestner, K.H. Foxa2 regulates multiple pathways of insulin secretion. J. Clin. Investig. 2004, 114, 512–520. [Google Scholar] [CrossRef]
- José-Edwards, D.S.; Oda-Ishii, I.; Kugler, J.E.; Passamaneck, Y.J.; Katikala, L.; Nibu, Y.; Di Gregorio, A. Brachyury, Foxa2 and the cis-Regulatory Origins of the Notochord. PLoS Genet. 2015, 11, e1005730. [Google Scholar] [CrossRef]
- Ray, B.K.; Dhar, S.; Shakya, A.; Ray, S. Z-DNA-forming silencer in the first exon regulates human ADAM-12 gene expression. Proc. Natl. Acad. Sci. USA 2011, 108, 103–106. [Google Scholar] [CrossRef]
- Ravichandran, S.; Subramani, V.K.; Kil, K.K. Z-DNA in the genome: From structure to disease. Biophys. Rev. 2019, 11, 383–387. [Google Scholar] [CrossRef] [PubMed]
- Nugent, C.I.; Lundblad, V. The telomerase reverse transcriptase: Components and regulation. Gene Dev. 1998, 12, 1073–1085. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Punchihewa, C.; Ambrus, A.; Chen, D.; Jones, R.A.; Yang, D. Structure of the intramolecular human telomeric G-quadruplex in potassium solution: A novel adenine triple formation. Nucl. Acids Res. 2007, 35, 2440–2450. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Lim, K.W.; Bouazuz, S.; Phan, A.T. Giardia Telomeric Sequence d(TAGGG)4 Forms Two Intramolecular G-Quadruplexes in K+ Solution: Effect of Loop Length and Sequence on the Folding Topology. J. Am. Chem. Soc. 2009, 131, 16824–16831. [Google Scholar] [CrossRef] [PubMed]
- Kettani, A.; Bouazziz, S.; Wang, W.; Jones, R.A.; Patel, D.J. Bombyx mori single repeat telomeric DNA sequence forms a G-quadruplex capped by base triads. Nat. Struc. Biol. 1997, 4, 383–389. [Google Scholar]
- Fulnecčková, J.; Hasíková, T.; Fajkus, J.; LukesŠová, A.; EliásŠ, M. Sýkorová, E. Dynamic Evolution of Telomeric Sequences in the Green Algal Order Chlamydomonadales. Genome Biol. Evol. 2012, 4, 248–264. [Google Scholar] [CrossRef]
- Gavory, G.; Farrow, M.; Balasubramanian, S. Minimum length requirement of the alignment domain of human telomerase RNA to sustain catalytic activity in vitro. Nucl. Acids Res. 2002, 30, 4470–4480. [Google Scholar] [CrossRef]
- Parkinson, G.N.; Ghosh, R.; Neidle, S. Structural basis for binding of porphyrin to human telomeres. Biochemistry 2007, 46, 2390–2397. [Google Scholar] [CrossRef]
- Zhang, N.; Phan, A.T.; Patel, D.J. (3+1) assembly of three human telomeric repeats into an asymmetric dimeric G-Quadruplex. J. Am. Chem. Soc. 2005, 127, 17277–17285. [Google Scholar] [CrossRef]
- Kang, C.; Zhang, X.; Ratliff, R.; Moyzis, R.; Rich, A. Crystal structure of four-stranded Oxytricha telomeric DNA. Nature 1992, 356, 126–131. [Google Scholar] [CrossRef]
- Laughlan, G.; Murchie, A.I.H.; Norman, D.H.; Moore, M.H.; Moody, P.C.E.; Lilley, D.M.J.; Luisi, B. The High-Resolution Crystal Structure of a Parallel-Stranded Guanine Tetraplex. Science 1994, 265, 520–524. [Google Scholar] [CrossRef]
- Planat, M.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Quantum information in the protein codes, 3-manifolds and the Kummer surface. Symmetry 2021, 13, 39. [Google Scholar]
- Bansal, A.; Kaushik, S.; Kukreti, S. Non-canonical DNA structures: Diversity and disease association. Front. Genet. 2022, 13, 959258. [Google Scholar] [CrossRef]
- Planat, M.; Chester, D.; Amaral, M.; Irwin, K. Fricke topological qubits. Preprints 2022. [Google Scholar] [CrossRef]
- Matsutani, S.; Previato, E. An algebro-geometric model for th shape of supercolied DNA. Phys. D Nonlinear Phenom. 2022, 430, 133073. [Google Scholar] [CrossRef]
- Rand, D.A.; Raju, A.; Saez, M.; Siggia, E.D. Geometry of gene regulatory dynamics. Proc. Natl. Acad. Sci. USA 2021, 118, e2109729118. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).