1. Introduction
Genomic mutations are often random and can either be synonymous mutations that do not alter the amino acid sequence of an encoded protein or non-synonymous mutations that alter the amino acid sequence. Non-synonymous point mutations can lead to structural changes, affecting the folding energy landscape and thermodynamic stability of proteins [
1,
2,
3,
4]. They may sometimes have a neutral effect on the folding energy landscape of proteins; that is, there may be little difference in the thermodynamic stability of the mutant and wildtype proteins. However, mutations often tend to change the folding energy landscape, rendering the mutant proteins either more or less stable compared to the wildtype [
5,
6]. Understanding the impact of non-synonymous point mutations on the thermodynamic stability of proteins is regarded as a key biological problem. For instance, many neurodegenerative diseases and genetic disorders have been linked to the incorrect folding of polypeptides that is caused by mutations in genes [
7]. It is therefore necessary to understand how non-synonymous mutations impact the thermodynamic stability of proteins to better associate their roles in different diseases.
Mutagenesis experiments that assess the change in the thermodynamic stability of proteins measure the energies of the folded and unfolded states of the wildtype and mutant proteins, providing an accurate picture of stability change upon mutations. However, such experiments are time-consuming and expensive; thus, there is a need for alternative computational methods that accurately predict the effects of mutations on protein stability. Databases such as ProTherm [
8], ThermoMutDB [
9] and FireProtDB [
10] have mined such experimental data from the literature and have recorded details of changes in free energies (ΔΔG) upon mutations. Experimental ΔΔG is the difference in the Gibbs free energies (ΔG) of the mutant and wildtype proteins. Specifically,
, where
is the energy of the unfolded state minus the energy of the folded state of the mutant protein (
), while
is the energy of the unfolded state minus the energy of the folded state of the wildtype protein (
) [
11]. A positive ΔΔG indicates greater thermodynamic stability of the mutant protein, while a negative ΔΔG indicates reduced stability. It is to be noted that forward mutants (wildtype residue X → mutant residue Y) are antisymmetric to their corresponding reverse mutants (mutant residue Y → wildtype residue X) in terms of their folding free energies [
12,
13]. That is, ΔΔG
forward = −ΔΔG
reverse, which is a key outcome from mutagenesis experiments and is often used to evaluate predictions for ΔΔG from computational methods.
Numerous computational methods have been developed to predict the ΔΔG between a wildtype protein and its non-synonymous mutant form. The review articles by Marabotti et al. [
14] and Sanavia et al. [
15] provide a comprehensive overview of the computational methods developed towards this effort. Existing methods may be broadly classified into two categories: unsupervised and supervised methods. Unsupervised methods are untrained methods and do not rely on machine learning. They can include empirical methods that model the energy of a protein through an equation that includes several parameters, with each parameter carrying a different weight. For example, the FoldX empirical method [
16] uses both the bonded and non-bonded energy terms to model a protein’s energy, and then calculates the difference in the energies of the mutant and wildtype proteins to estimate the ΔΔG. SDM [
17] uses environment-specific amino acid substitution tables and residue packing densities to calculate the ΔΔG. DDGun is another unsupervised method that uses sequence and structural properties of proteins in linear weighted combinations to estimate the ΔΔG [
18]. Specifically, it is one of the few methods that demonstrate the antisymmetric relationship between forward and reverse mutants. Supervised methods employ machine learning and are trained on a large dataset (training data) including features (e.g., amino acid physicochemical properties, protein geometric properties, etc.) of the wildtype and mutant forms of different proteins and their associated experimental ΔΔG. Such methods are then typically evaluated on an independent dataset of wildtype and mutant proteins with known experimental ΔΔG.
Numerous supervised computational methods to predict stability changes in proteins upon mutations have been developed in the past decade. These methods often employ machine learning models trained on diverse benchmark datasets obtained from the ProTherm database. I-mutant [
19,
20] employs support vector machines (SVMs) [
21] trained on a subset of data taken from ProTherm and uses a set of sequence and spatial features, including solvent accessibility, to predict the ΔΔG. It also gives the user an option to make predictions using just the protein sequence in case the protein structure is not available. mCSM [
22] represents the environment of the mutation site as a distance-based graphical map and combines it with pharmacophore counts to predict the effect of mutations using a trained linear regression model. MAESTRO [
23] uses statistical scoring functions and other sequence and structural features, such as the accessible surface area, hydrophobicity and secondary structure of the mutation site, to train artificial neural networks, SVMs and multiple linear regression models, making consensus ensemble-based predictions. Dynamut [
24] follows a meta-prediction approach by using predictions from other methods, which use protein structure and dynamics information to estimate ΔΔG, to arrive at a consensus prediction for ΔΔG. Dynamut2 [
25] predicts ΔΔG using a Random Forest algorithm trained on protein dynamics features calculated from normal mode analysis and graph-based signatures.
It has generally been observed that supervised computational methods outperform unsupervised methods in predicting ΔΔG [
25]. However, one of the key shortcomings of the supervised methods is overfitting the training data, which largely comprises destabilizing mutations. Consequently, only a handful of these methods satisfy the antisymmetric property between forward and reverse mutations. Some of the more recently developed supervised approaches, such as PremPS [
26], ACDC-NN [
27] and Thermonet [
28] have addressed this issue by training on both forward and reverse mutation data. Moreover, supervised methods use an ensemble of features that are selected purely based on the algorithms’ performance in cross-validation, not based on any theoretical model that simulates the mutational perturbation behavior. It is always a challenge to associate such features with mutational perturbation, understand how a mutation affects each of these features and explain the biological significance and role of each feature in the context of protein thermodynamic stability.
In this study, we present a theoretical and unsupervised method—PSP-GNM, which simulates protein unfolding behavior using the Gaussian Network Model (GNM) [
29] and calculates ΔΔG for a pair of wildtype and mutant proteins. GNM is an elastic network model that models a protein using a coarse-grained representation. Each amino acid in GNM is represented by its alpha carbon, and the interacting amino acid pairs are connected using hypothetical Hookean springs [
29]. Previously, elastic network models have been shown to capture the near-native dynamics of proteins [
30] and have been used to efficiently identify functional sites in proteins [
31,
32]. GNM has been previously employed to study changes in protein dynamic communities upon mutations and has been shown to possess the ability to identify stabilizing and destabilizing mutations in proteins [
33]. In addition, GNM has also been previously utilized to study protein unfolding behavior and identify the order of contacts broken during protein unfolding [
34,
35]. PSP-GNM utilizes the knowledge of amino acid contacts that are broken at the mutation site during theoretical protein unfolding to estimate the energy change. It is based on protein dynamics obtained using a coarse-grained representation of the protein and provides useful insights into the importance of the local dynamics of the mutation site and its interactions with neighbors, helping us to understand protein stability changes upon mutation. We evaluated the calculated ΔΔG from PSP-GNM on multiple benchmark datasets obtained from the ProTherm database and compared the predictions from PSP-GNM with other state-of-the-art methods. Despite being an unsupervised approach, PSP-GNM shows comparable performance to many supervised approaches.
2. Results
PSP-GNM utilizes the coarse-grained Gaussian Network Model (GNM) to simulate partial protein unfolding. Unlike the conventional GNM, which has interacting residues connected with springs that have a uniform force constant of one, PSP-GNM weights the interacting residues using their interaction energies obtained from the Miyazawa–Jernigan potential [
36]. We chose the Miyazawa–Jernigan potential for two reasons. First, a pilot analysis (
Table S1) suggested superior performance of the Miyazawa–Jernigan potential compared to two other potentials: the Bastolla potential [
37] and the Betancourt–Thirumalai potential [
38]. Second, the Miyazawa–Jernigan potential is a very popular choice with a wide variety of applications and has been shown to outperform other potentials in protein–protein docking [
39] and protein folding [
38].
To simulate partial protein unfolding, the residue–residue contacts with the highest mean-squared fluctuations (MSFs) in their distance are first identified, both in the wildtype and mutant proteins. In this context, MSF is the average change in internal distance for a given pair of residues. These contacts are then removed from the amino acid contact matrices of the wildtype and mutant. The new contact matrix is then used for MSF calculations in the next iteration, and the same procedure of identifying and removing the contacts with the highest MSF is followed. We refer to this method of sequentially identifying high-MSF contacts and removing them as protein unfolding. Previous studies have successfully used this approach to study protein unfolding behavior [
34,
35]. We consider a protein to be partially unfolded when 50% of all contacts observed in the starting structure are broken. Contacts broken with the residue at the mutation position are identified and ranked in the order they were broken. Broken contacts that share the same rank for a pair of mutant and wildtype proteins are then considered for calculations of ΔΔG.
To calculate ΔΔG, PSP-GNM considers both residue-residue interaction energies and entropies. While the residue–residue contact energies are obtained using the Miyazawa–Jernigan potential statistical potential, the MSF in distance between a pair of residues is a measure of their entropy. The difference between the energy and entropy terms of the mutant and wildtype proteins constitutes the ΔΔG calculated by PSP-GNM.
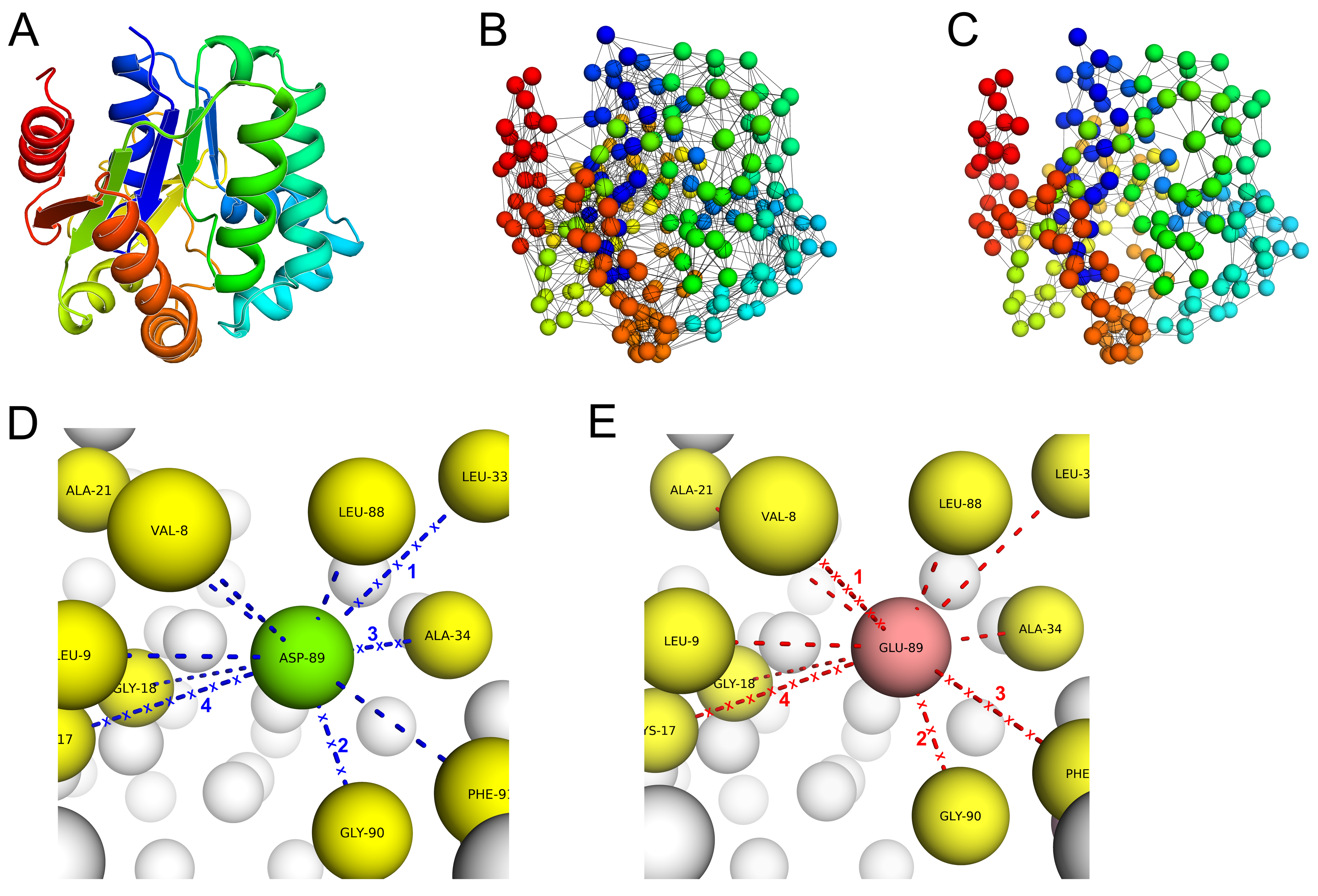
Figure 1 provides an overview of PSP-GNM. Details of calculations and a more elaborate flow diagram are included in Materials and Methods.
We used five benchmark datasets from the literature in this study. i. The S2298 dataset includes 2298 forward mutations from 126 distinct proteins. It is by far the largest dataset available in the literature and is often used for training supervised methods. ii. The S350 dataset comprises 350 forward mutations spanning 67 proteins. We excluded one PDB ID and its corresponding mutation, as the PDB record was obsolete, resulting in 349 mutations across 66 proteins. Together, the S2298 and S350 datasets constitute the S2648 dataset, which contains 2648 mutations across 131 proteins. iii. The S611 dataset includes 611 forward and reverse mutations and is a subset of the S350 dataset. We excluded two mutations corresponding to an obsolete PDB record. iv. The S669 dataset includes 669 forward mutations across 94 distinct proteins. The proteins included in this dataset share less than 25% sequence identity with the proteins in the S2298 and S350 datasets. For this study, we also considered the reverse mutations corresponding to the forward mutations on this dataset. v. The Ssym+ dataset includes 704 mutations (352 forward and 352 reverse) across 371 proteins. This dataset is particularly useful for evaluating the antisymmetric property.
First, we identified the optimal parameters for which PSP-GNM shows maximum agreement with experimental ΔΔG. We used the S2298 dataset for this purpose. Additionally, we investigated the extent of agreement between the residue mean-squared fluctuations calculated by our method with the experimental temperature factors. Second, we evaluated the extent of agreement between PSP-GNM-calculated ΔΔG and experimental ΔΔG on the S2298, S350 and S611 datasets for different experimental conditions. Finally, we compared the performance of PSP-GNM with other state-of-the-art methods on the S350, S611, S669 and Ssym+ datasets.
2.1. Optimal Parameters for PSP-GNM
Two essential parameters regulating the native state protein dynamics captured by PSP-GNM are the cutoff distance (rc) between C-alpha atoms and the number of low-frequency modes (Nmodes) used to reconstruct the inverse Kirchhoff matrix. While rc controls the number of interacting residue pairs in a protein, Nmodes impacts the calculated MSF in distance between a pair of residues. Using the S2298 dataset, we identified values for these two parameters that maximized the agreement between the calculated and experimental ΔΔG. We chose the S2298 dataset because it provides a large and diverse set of mutations on which the parameters can be generalized. Furthermore, numerous existing methods have been trained using this dataset; the performance of PSP-GNM cannot be fairly compared with other methods on this dataset.
First, we set N
modes to 10 and identified the r
c in the range of 7Å–12Å that results in maximum correlation between the calculated and experimental ΔΔG. We observed the highest Pearson correlation coefficient of 0.39 for r
c = 9 Å (
Table 1), which also had the highest proportion of mutations with a calculated ΔΔG (94%). As previously noted, PSP-GNM can only calculate a ΔΔG if there is at least one broken contact for the mutation position, both in the mutant and the wildtype. Then, we set r
c to 9 Å and observed the highest correlation of 0.4 for N
modes = 20 compared to 5, 10, 20, 30, 40 and 50 modes (
Table 2). The correlation for N
modes = 10 was only marginally inferior (Pearson correlation 0.39), although we did observe that using 20 modes resulted in a higher proportion of mutations (95.4%) with a calculated ΔΔG. To choose between N
modes = 20 and N
modes = 10, we also considered evidence from the literature. Previously, it has been shown that using the first 10 low frequency modes is usually sufficient to capture the native state protein dynamics [
40]. In addition, we have previously shown that the stability differences between wildtype and mutant structures can be well explained by using just the first 10 low frequency modes [
33]. Consequently, we selected the parameters N
modes = 10 and r
cutoff = 9 Å and used these parameters throughout this study. PSP-GNM, however, does provide an option to run predictions using N
modes = 20.
Using the S2298 data, we also investigated the extent of agreement between the residue mean-squared fluctuations obtained using PSP-GNM and the experimental B-factors. We performed this comparison on the 126 wildtype proteins that were represented as C-alpha coarse-grained structures. Only 110 proteins were X-ray crystal structures and included B-factors. We observed a median correlation of 0.46 between the mean-squared fluctuations calculated by PSP-GNM and the experimental B-factors (
Figure S1). We also note that this agreement was weaker than GNM (correlation 0.57) when using r
c = 9 Å and N
modes = 10 (
Figure S1).
2.2. Predictive Performance of PSP-GNM on Three Datasets
We evaluated the extent of agreement between the PSP-GNM-calculated ΔΔG and the experimental ΔΔG on three datasets: S2298, S350 and S611. Specifically, we evaluated the performance under different experimental conditions. We also used the S2298 dataset to fit the regression line and obtain the scaling coefficients that were then used to scale the calculated ΔΔG.
2.2.1. Performance on S2298 Dataset
Of the 2298 mutations in the S2298 dataset, PSP-GNM-calculated ΔΔG could be obtained for 2159 mutations that had at least one broken contact involving the mutation position. For cases without a calculated ΔΔG, we assigned a theoretical ΔΔG value of 0 Kcal/mol. As we previously noted, using the selected parameters r
c = 9 Å and N
modes = 10 gave a Pearson correlation of 0.39 and an RMSE of 1.35 kcal/mol (
Figure 2A). To scale the calculated ΔΔG, we used the equation of the regression line fit to the experimental ΔΔG. Upon inclusion of the 143 mutations without any PSP-GNM-calculated ΔΔG (by assigning them a theoretical ΔΔG of 0 kcal/mol), we did not observe any considerable change in the agreement to the experimental data (
Figure 2B).
The distribution of the experimental temperatures and pH for the 2159 mutations with calculated ΔΔG indicated a peak around 25 °C and a pH close to 7 (
Figure S2), suggesting that the experimental measurements were performed mostly around this temperature and pH. We then tested whether PSP-GNM showed better agreement with ΔΔG measurements performed around 25 °C and a pH of 7. Of the 2159 mutations, we identified 259 mutations with experimental temperatures ranging from 24 °C to 26 °C and pH ranging from 6.8 to 7.2 and observed an improved agreement (Pearson correlation = 0.55, RMSE = 1.18 Kcal/mol) with the experimental measurements (
Figure 2C). We then asked: how does the agreement vary for mutations with experimental temperatures in the range of 24 °C–26 °C, but without any pH filter? How does the agreement vary for mutations with experimental pH of 6.8–7.2, but no temperature filter? Interestingly, we observed stronger agreement for mutations with experimental temperatures of 24 °C–26 °C (Pearson correlation = 0.45, RMSE = 1.31 Kcal/mol) compared to mutations with pH of 6.8–7.2 (Pearson correlation = 0.36, RMSE = 1.41 Kcal/mol) (
Figure S3), suggesting a certain degree of bias towards measurements made at a particular temperature range.
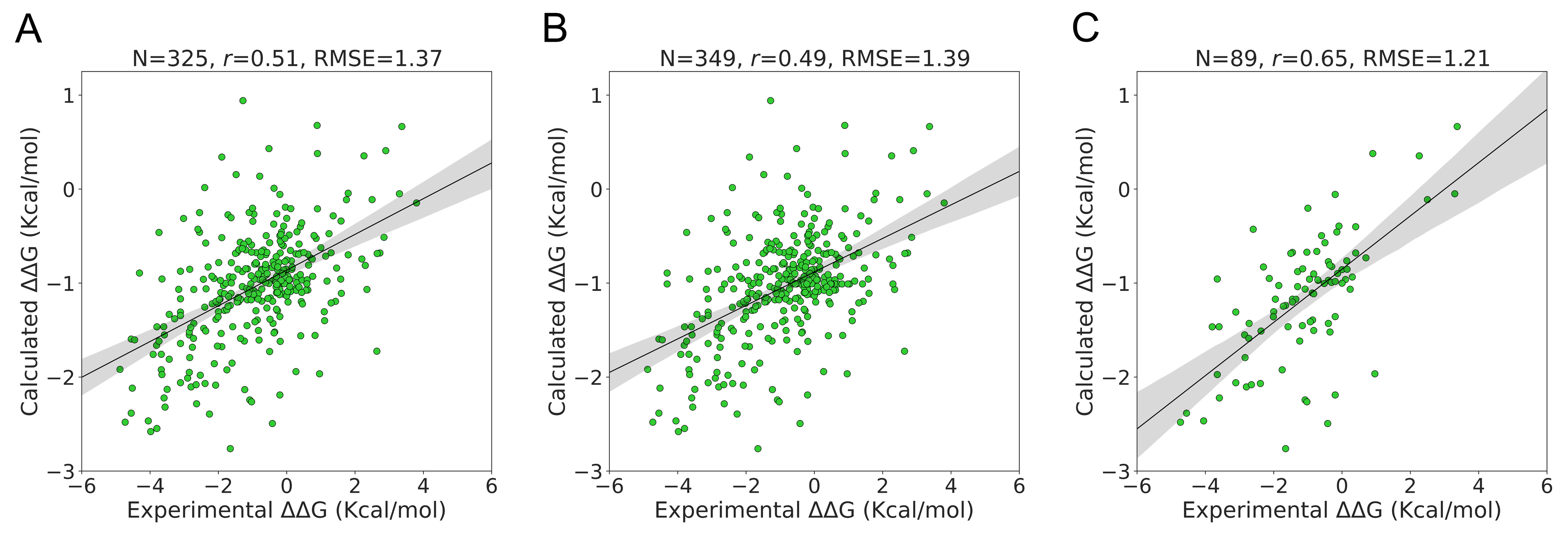
2.2.2. Performance on S350 Dataset
The S350 dataset included 349 mutations from 66 unique PDB identifiers. On this dataset, ΔΔG could be calculated with PSP-GNM for 325 wildtype–mutant pairs that exhibited at least one broken contact involving the mutation position during partial unfolding. We observed a Pearson correlation of 0.51 and an RMSE of 1.37 Kcal/mol for these 325 mutations (
Figure 3A). When the remaining 24 wildtype–mutant pairs were included by assigning them a ΔΔG value of 0 kcal/mol, we observed a decrease in the Pearson correlation to 0.49 and an increase in the RMSE to 1.39 Kcal/mol (
Figure 3B).
The experimental temperature and pH for the 318 mutants with calculated ΔΔG show a similar distribution as that of the S2298 dataset, i.e., a peak around 25 °C and pH 7 (
Figure S4). We observed a considerably stronger agreement with the experimental ΔΔG when considering a subset of 89 mutations with experimental temperatures from 24 °C to 26 °C and pH from 6.8 to 7.2 than when considering all the data (
Figure 3C). The associated Pearson correlation and RMSE were 0.65 and 1.21 Kcal/mol, respectively. The agreement was stronger when we considered a temperature range of 24 °C–26 °C without any pH cutoff (Pearson correlation = 0.57, RMSE = 1.39 Kcal/mol) than when we considered a pH range of 6.8–7.2 without any temperature cutoff (Pearson correlation = 0.5, RMSE = 1.36 Kcal/mol) (
Figure S5).
Additionally, we investigated the extent to which PSP-GNM satisfied the antisymmetric property of forward and reverse mutations using the S350 dataset. Ideally, the forward and reverse mutations should be antisymmetric in terms of their ΔΔG, i.e., ΔΔG
forward= −ΔΔG
reverse. We observed a strong negative correlation of −1 between the calculated ΔΔG
forward and ΔΔG
reverse (
Figure S6), suggesting that the calculations using PSP-GNM satisfy the expected antisymmetric property.
2.2.3. Performance on S611 Dataset
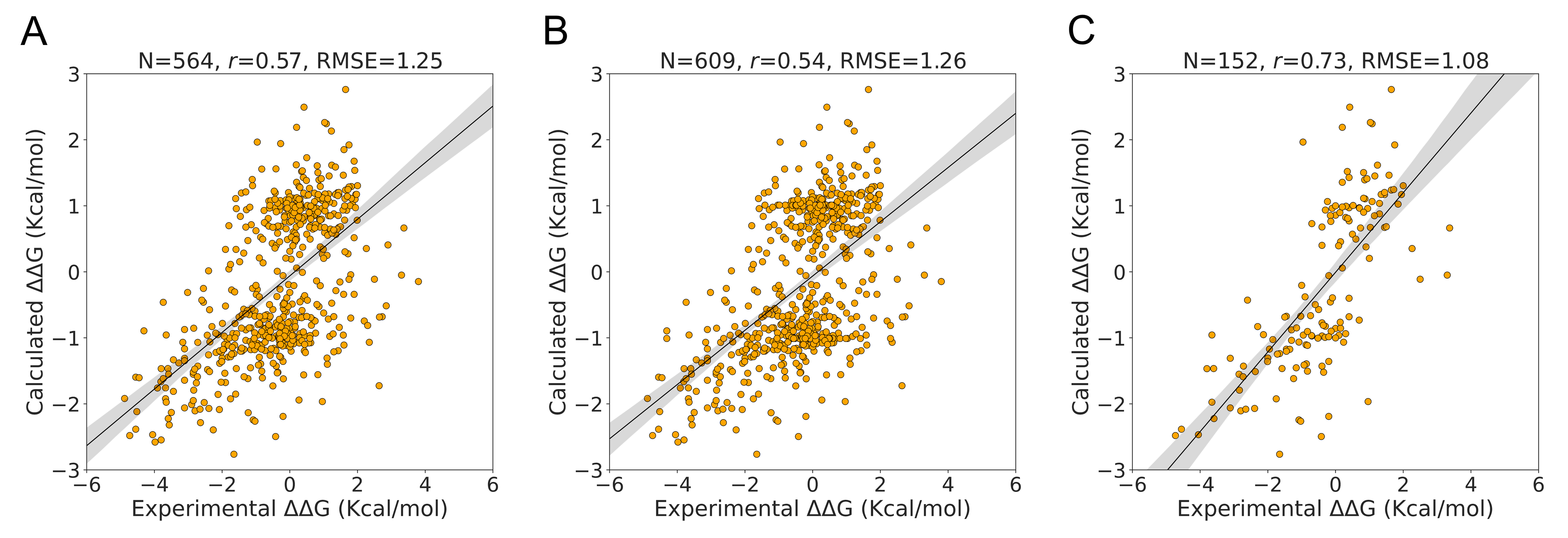
In contrast to the S350 and S2298 datasets, the S611 dataset evaluated the performance of PSP-GNM on both forward and reverse mutations. The S611 was created using a subset of data from the S350 dataset and comprises 609 mutations from 66 unique PDB identifiers. PSP-GNM could calculate ΔΔG for 564 wildtype–mutant pairs, as the remaining 45 pairs did not involve a contact break for the residue at the mutation position.
When considering the calculated and experimental ΔΔG for the 564 mutations, we observed a correlation of 0.57 and an RMSE of 1.25Kcal/mol (
Figure 4A), demonstrating stronger agreement than was observed for the 325 forward mutations in the S350 dataset. As seen in
Figure 4B, when we included the 45 mutations without PSP-GNM-calculated ΔΔG, we observed a decrease in the agreement (Pearson correlation = 0.54, RMSE = 1.26 kcal/mol). However, when we limited the analysis to only those mutations with experimental temperatures of 24 °C–26 °C and pH of 6.8–7.2, we noted a considerable improvement to 0.73 in the correlation and a reduction to 1.08 Kcal/mol in the RMSE (
Figure 4C). Interestingly, we did not observe considerable differences in correlations for measurements made between 24 °C and 26 °C without any pH filter (Pearson correlation = 0.61) and those made near neutral pH (6.8–7.2) without a temperature filter (Pearson correlation = 0.62) (
Figure S7).
2.3. Performance Comparisons with Existing Methods on Four Datasets
We compared the performance of PSP-GNM with other state-of-the-art methods on four datasets: S350, S611, S669 and Ssym+. On the S350 and S611 datasets, we assessed the performance against nine existing methods: Dynamut2 [
25], Dynamut [
24], MCSM [
22], MUPro [
41], ENCOM [
42], DUET [
43], SDM [
17], I-Mutant2 [
19] and Maestro [
23]. While ENCOM and SDM are unsupervised methods, the remaining methods use machine learning for predicting ΔΔG. The recently developed Dynamut2 approach also considers the above methods for comparison, and we considered them for this study because they are a good mixture of supervised and unsupervised methods. On the S669 and Ssym+ datasets, we reported performance comparisons against a broader set of 20 methods, including 8 methods considered for the S350 and S611 datasets.
For each dataset, we compared across methods by considering two groups of mutations: Group 1, consisting only of those mutations that had a PSP-GNM-calculated ΔΔG, and Group 2, consisting of the mutations in Group 1 with an experimental temperature ranging from 24 °C to 26 °C and pH ranging from 6.8 to 7.2.
2.3.1. S350 Dataset
In
Table 3, we report the comparisons made for Group 1 across the 10 methods using data obtained from Rodrigues et al. [
25]. Of the total 349 mutations in the S350 dataset, the comparisons were made using the 325 wildtype–mutant pairs with a ΔΔG calculated. PSP-GNM ranked sixth, with a correlation of 0.51 and a RMSE of 1.37 Kcal/mol, while DUET showed the best performance, with a correlation of 0.67 and an RMSE of 1.16 Kcal/mol. When we performed the same comparison on Group 2 mutants that had a total number of 89 mutants, PSP-GNM ranked fifth, showing a correlation of 0.65 and an RMSE of 1.21 Kcal/mol, while Dynamut2 and DUET topped the list with a correlation of 0.73 and an RMSE of 1.05 kcal/mol (
Table 4).
2.3.2. S611 Dataset
In
Table 5, we report the comparisons for Group 1 mutants from the S611 dataset using data obtained from Rodrigues et al. [
25]. The total number of mutations taken into consideration in this group was 564. Remarkably, we observed that PSP-GNM performed better than most of the other methods, ranking second with a correlation of 0.57 and an RMSE of 1.54 Kcal/mol. The best performance was seen for Dynamut2 (correlation = 0.68, RMSE = 1.08 Kcal/mol). There were 152 mutants that were considered in Group 2 (
Table 6). PSP-GNM demonstrated strong agreement with the experimental ΔΔG by ranking second with a correlation of 0.73 and an RMSE of 1.08 Kcal/mol. Overall, the best performance for this group was seen for Dynamut2 (correlation = 0.79 and RMSE = 0.95 Kcal/mol).
2.3.3. S669 Dataset
The S669 dataset was created as part of a recent study by Pancotti et al. [
44] and has <25% sequence identity with proteins included in the S2298 dataset. Consequently, it provides an unbiased platform to compare those methods that were trained using the S2298 dataset, or even the larger S2648 dataset. On this dataset, we compared the performance of PSP-GNM with 20 existing methods that were studied by Pancotti et al. [
44]. A detailed description of each method can be found in the original article.
In
Table 7, we report the performance for these 20 methods over 584 mutations (forward and reverse) with a PSP-GNM-calculated ΔΔG. We also include information on bias and antisymmetry for each method, using data from Pancotti et al. [
44]. The table is sorted by Pearson correlation for the Forward + Reverse category. PSP-GNM showed remarkably better performance compared to 17 existing methods when considering both forward and reverse mutations (Pearson correlation = 0.61 and RMSE = 1.57 Kcal/mol). It had 0 bias and a perfect antisymmetry of −1. The best performance on the Forward + Reverse category was seen for PremPS and ACDC-NN. PSP-GNM performed better than 11 methods for the reverse mutations, while performing better than only 4 methods for the forward mutations.
When we compared performance across all 669 mutations (by using a theoretical ΔΔG value of 0 Kcal/mol for cases without a ΔΔG), PSP-GNM ranked fifth, with a Pearson correlation of 0.59 for the Forward + Reverse mutants (
Table S2). It showed better performance than nine other methods for the reverse mutants but only three methods for the forward mutants. Interestingly, we did not observe any performance gain when considering only those mutations with experimental temperatures ranging from 24 °C to 26 °C and pH ranging from 6.8 to 7.2 (
Table S3).
2.3.4. Ssym+ Dataset
The Ssym+ dataset is an extension of the Ssym dataset and includes 352 forward and 352 reverse mutations [
13,
45]. Importantly, each pair of forward-reverse mutants has separate experimentally resolved PDB structures for the forward and reverse mutant. Consequently, it serves as an excellent dataset to check the performance for forward and reverse mutations and test for antisymmetry and bias. Like the S669 data, we compared the performance of PSP-GNM against 20 existing methods for a subset of 341 mutations with a PSP-GNM-calculated ΔΔG. The data were obtained from Pancotti et al. [
44]. PSP-GNM reported near-perfect antisymmetry, with a Pearson correlation of −0.97 and 0 bias (
Table 8,
Figure S8). When considering both forward and reverse mutations, PSP-GNM ranked seventh with a correlation of 0.64, while PremPS showed the best performance with a correlation of 0.85 (
Table 8). Considering the reverse mutations, PSP-GNM showed better performance than 10 other methods, with a correlation of 0.37. All methods outperformed PSP-GNM on the forward mutation dataset. When considering all 352 mutations, PSP-GNM ranked seventh on the Forward + Reverse category, with a correlation of 0.63. It exhibited antisymmetry -0.96 and 0 bias (
Table S4).
We then considered mutations with experimental temperatures ranging from 24 °C to 26 °C and pH ranging from 6.8 to 7.2. Only 10 mutations fell in this category, making it a very small sample size. Therefore, we considered a broader temperature range (20 °C–30 °C), while keeping the pH range the same. We observed improvement in the agreement for both the forward mutants (Pearson correlation = 0.74) and reverse mutants (Pearson correlation = 0.71), while noticing a drop in the correlation for the Forward + Reverse category (Pearson correlation = 0.52). PSP-GNM ranked seventh in terms of its performance in the Forward + Reverse category (
Table 9).
3. Discussions
The fundamental assumption underlying PSP-GNM is that during unfolding, the contacts broken for the mutation position differ between the wildtype and mutant forms of a protein. When contacts are ranked in the order in which they break with respect to the mutation position, and the contacts that share the same rank in the mutant and wildtype are considered, the difference in their free energies correlates with the experimental ΔΔG, as demonstrated in this study. In this context, the free energy is the interaction energy between a pair of residues given by the Miyazawa–Jernigan statistical potential, and the entropy is the mean-squared fluctuation in distance between a pair of residues. The choice of restricting the calculations to only a subset of contacts sharing the same rank is arguable. However, an initial pilot test performed as part of this study revealed that including all the broken contacts (irrespective of their ranks) resulted in poorer agreement with the experimental ΔΔG when compared to the present scheme. A detailed examination of various possible functions using knowledge of contacts broken to quantify ΔΔG is, however, beyond the scope of the current work, and is a subject for future discussion.
In this study, we used a weighted Gaussian network model that used Hookean springs of variable stiffness to simulate specific interactions between a pair of residues. An approach of weighting the Hookean springs between interacting pairs of residues based on their identity and chemical nature has been previously shown to improve the ability of elastic network models to capture the near-native protein dynamics [
51]. Through PSP-GNM, we demonstrated that despite maintaining a good agreement with the experimental B-factors, such weighted formulations of elastic network models can also discriminate between the native and mutant forms of a protein. The partial unfolding approach used in our study is a modification of a previous method described by Su et al. [
34] that was able to successfully predict the order of contact break events. Additionally, to verify the extent of concordance between PSP-GNM and the original GNM, we randomly picked two proteins (PDB IDs 1AKY and 1CUN, chain A) from our dataset and obtained the residue–residue cross-correlation heat maps for the wildtype using both methods (
Figure S9). A visual inspection suggests close correspondence between the cross-correlation maps obtained from the two methods. Since PSP-GNM is an implementation of GNM with weighted contacts, some difference in the cross-correlation maps is expected. Despite the differences, the expected high correlations between contiguous residues of secondary structures are still consistent with GNM.
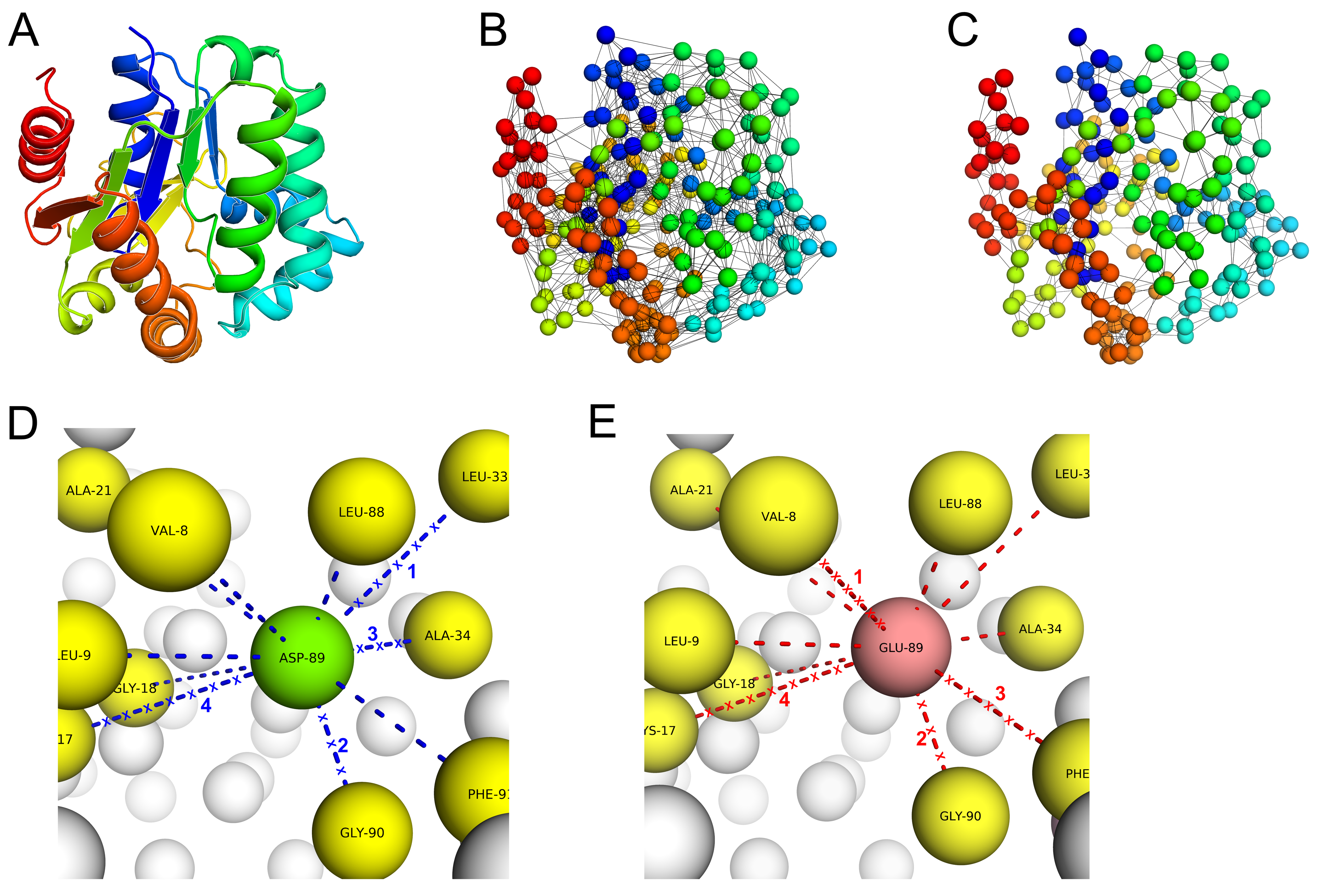
A major limitation of PSP-GNM is its inability to provide a calculated ΔΔG if no contacts involving the residue at the mutation position are broken in the wildtype and/or in the mutant. To further understand why no contacts are broken for certain mutations, we randomly selected two wildtype–mutant protein pairs from the S350 dataset and observed that the residue contacts for the mutation positions were primarily within the same secondary structure elements (
Figure S10). Residue–residue contacts within secondary structures are energetically stronger and less easily broken than tertiary contacts, possibly explaining why they were not broken during partial unfolding. To address this limitation, we re-defined partial folding by increasing the cutoff to 60%. That is, we considered a protein to be partially unfolded if 60% of the native state contacts were broken. However, we observed that the model became unstable by generating more than one zero eigen values upon eigen decomposition of the Kirchhoff matrix, suggesting a sparse contact matrix. Consequently, we assigned a theoretical ΔΔG value of 0 for such cases. Based on the results presented for the S2298 (
Figure 2B), S350 (
Figure 3B) and S611 (
Figure 4B) datasets, we do not observe a considerable reduction in the agreement with experimental ΔΔG when assigning a PSP-GNM-calculated ΔΔG value of 0 for such cases.
The performance comparisons made on the datasets in this study indicate superior performance of many existing methods compared to PSP-GNM. In this context, a simple investigation of the extent of sequence similarity of proteins in each of the test datasets (S350, S669 and Ssym+) with the proteins in the S2298 dataset reveals that most datasets showed considerable sequence identity (>30%) with the proteins in the S2298 dataset (
Tables S5–S8). The only exception was the S669 dataset, which had only four proteins with >25% sequence identity. Because most of the methods evaluated in our study are supervised and have mostly been trained on the S2298 dataset or its variants, a superior performance on the S350, S611 and Ssym+ datasets is not unexpected. On the S669 dataset, PSP-GNM outperformed many of the existing state-of-the-art methods, specifically when considering the reverse mutations.
Three key observations were made in our study. First, we observed variation in the extent of agreement between the calculated ΔΔG and the experimental ΔΔG for different experimental temperatures and pH. We demonstrated that the agreement was strongest for mutants with experimental temperatures close to 25 °C and near-neutral pH. For the S350, S611 and Ssym+ datasets, we observed that the correlation was higher for PSP-GNM than for most other methods. Previous studies have also used higher weights for measurements made in the same temperature and pH conditions [
11,
52]. One must note that the ProTherm database not only reports ΔΔG values based on thermal denaturation experiments, but also ΔΔG values from chemical denaturation experiments. In the current study, data from both experiments are treated alike, and it is assumed that the same scheme for simulating unfolding may be used. It is also to be noted that PSP-GNM currently does not consider the experimental temperature to weight the interactions between residues. Based on the observed temperature dependence, however, using experimental temperature as a parameter for weighing residue–residue interactions could further improve the extent of agreement with experimental ΔΔG. Second, considering just the contacts broken with the mutation position and their order is key to the reasonably good correlation observed. It strongly suggests the importance of geometric and energetic changes localized at the mutation site in predicting the overall change in thermodynamic stability of proteins. Finally, the assessment for antisymmetry made on the Ssym+ dataset demonstrates the ability of PSP-GNM to maintain the antisymmetric relationship between forward and reverse mutations, which is indeed a hallmark of this approach.
4. Materials and Methods
4.1. Datasets
We used five benchmark datasets from the literature. The composition of each dataset is described in
Table 10.
Of the five datasets, we used the S2298 dataset to obtain the optimal parameters for PSP-GNM. We chose the S2298 dataset for this purpose because it includes a diverse set of mutations. Furthermore, most of the existing supervised methods have used this dataset for training. Therefore, predictive performances cannot be fairly compared on this dataset. Each dataset contains information on non-synonymous point mutations and the experimentally measured ΔΔG for different proteins. We excluded mutations that showed mismatches for the wildtype residue in the PDB file and those with obsolete PDB entries. A larger fraction of mutations in each dataset are destabilizing mutations, i.e., ΔΔG < 0 kcal/mol. It is to be noted that the Ssym+ dataset comprises separate PDB structures for forward and reverse mutants and has previously been used to evaluate the antisymmetry and bias for different methods. In this context, if x-N-y denotes a forward mutation from amino acid x to amino acid y at position N and has ΔΔG = δ Kcal/mol, then the reverse mutation (y-N-x) is antisymmetric to the forward mutation and has ΔΔG = −δ Kcal/mol.
4.2. PSP-GNM Algorithm
We represented the wildtype and mutant protein structures as coarse-grained systems where each residue was represented by its alpha carbon. Additionally, we represented the mutant protein structures by replacing the wildtype residues with their respective mutant residues at the alpha carbon position. We then took a similar approach using GNM to simulate protein unfolding and identify the sequence of residue–residue contacts broken during unfolding, as previously described by Su et al. [
34]. Specifically, Su et al. demonstrated protein unfolding using GNM for two proteins (Barnase and Chymotrypsin inhibitor) and observed significant agreement in the sequence of unfolding events with atomic molecular dynamics and Monte Carlo simulations. Like their approach, we also used a weighted GNM where the strength of springs between interacting residues varies with the interacting residue pair.
In GNM, the protein residues are represented by alpha carbons, and residue pairs within a cutoff distance r
c are hypothetically connected with Hookean springs of force constant γ=1. In PSP-GNM, we weight the interactions between residues by their corresponding Miyazawa–Jernigan (MJ) contact potential [
36], which is obtained from the AAindex database [
53] using the identifier MIYS960101 (upper half of the original MJ potential table).Specifically, the contact potential for a residue pair is converted into its Boltzmann weight (by simply taking its exponential) and is then used to weight the interaction between the pair of residues. The potential for PSP-GNM is given as
where
is the fluctuation vector for residue
i and
is the fluctuation vector for residue
j. The fluctuation vector defines the instantaneous fluctuation of a residue from its equilibrium position. The force constant
is weighted for each interacting residue pair depending on the type of interaction.
is the
ijth element in the Kirchhoff matrix of inter-residue contacts and is given as follows.
In Equation (2), is the contact energy between residue i and residue j as given in the MJ potential matrix, is the distance between the alpha carbons of residues i and j and is the distance cutoff for interacting residues. Stiffer springs were used to simulate the stronger covalent interactions () between adjacent residue pairs by using the minimum value in the MJ potential matrix minus one.
To simulate unfolding, we iteratively identified residue–residue contacts with the highest mean-squared fluctuations (MSF) in their distance [
34,
54] and then removed the contacts between these residues. The MSF in distance between residues
i and
j, also referred to as internal distance change, is the average fluctuation in their internal distance. A residue pair with strong interaction energy would have lower MSF in their distance compared to a residue pair with weak interaction energy. The MSF in distance between residue pairs
i and
j is calculated as
where
is the Boltzmann constant and
T is the absolute temperature in Kelvin.
is the pseudo-inverse of the Kirchhoff matrix and is given as
As the determinant of the Kirchhoff matrix is zero, its inverse cannot be directly calculated. Instead, we calculated the pseudo-inverse using the N−1 non-zero eigen values and their corresponding eigen vectors. In the above equation, is the kth eigen value, is the kth eigen vector associated with and is its transpose.
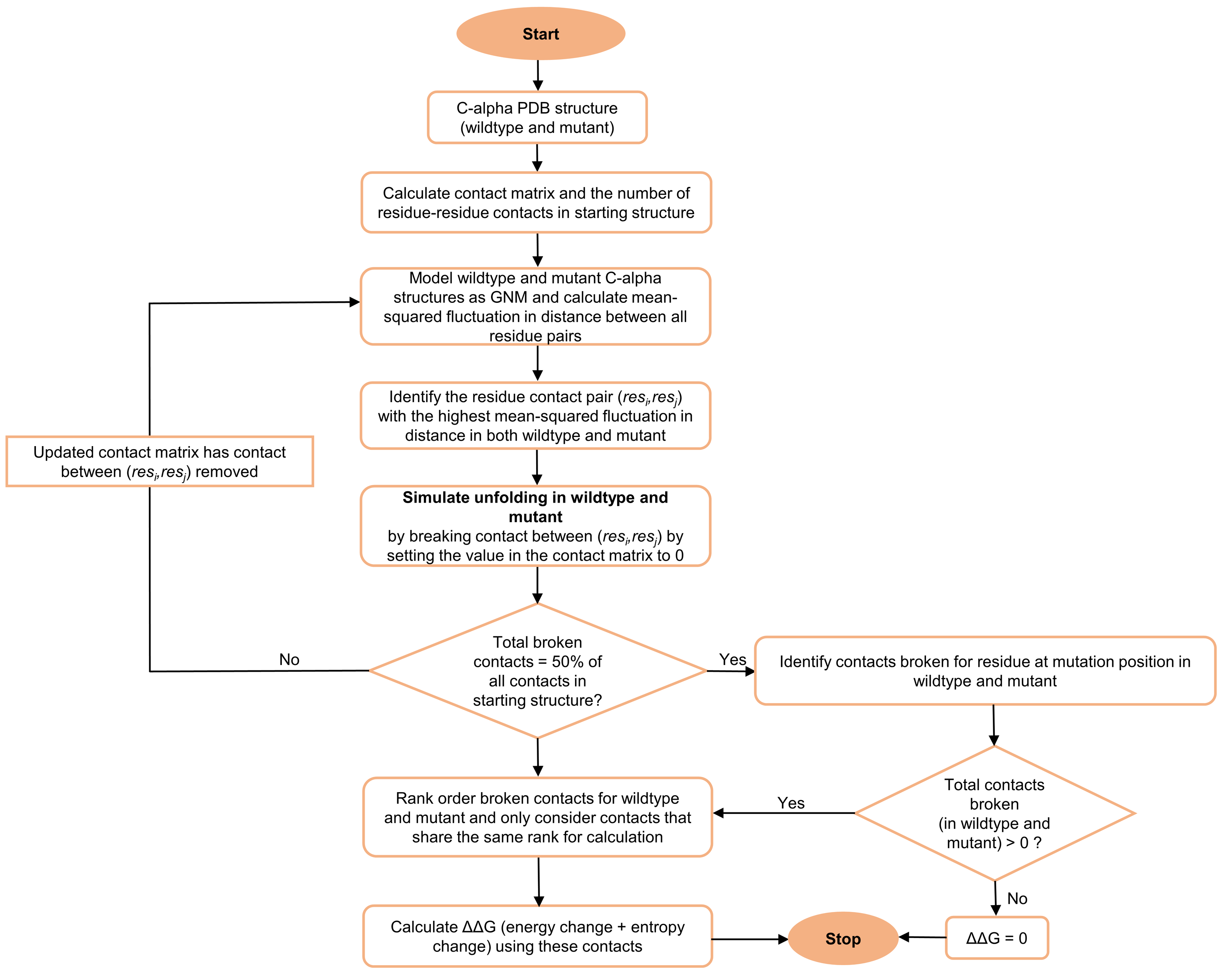
The steps in our algorithm are outlined in
Figure 5. Given the wildtype or mutant C-alpha PDB structure, we first identified the total number of residue–residue contacts in the starting structure. A contact pair is a residue pair whose C-alpha atoms are within 9 Å. We then calculated the MSF in distance between all pairs of residues by using only the 10 slowest non-zero modes to re-construct the
. The above values for the r
c (C-alpha distance cutoff) and number of modes parameters were used, as they resulted in maximum agreement between the experimental ΔΔG and PSP-GNM-calculated ΔΔG on the S2298 dataset. The contact pair with the largest MSF in distance was then identified, the contact between the residue pair was broken, and the contact matrix was updated to reflect this contact break. The updated contact matrix was then used in the next iteration to identify the contact pair with the largest MSF and highest likelihood of contact break. We repeated this scheme of breaking contacts based on the largest MSF until 50% of all contacts in the starting structure were broken, resembling a partially unfolded protein, or until the model became unstable, resulting in more than one 0-eigen values upon eigen decomposition of the Kirchhoff matrix.
4.3. Calculation of ΔΔG Using PSP-GNM
PSP-GNM assumes a given mutant protein differs from its corresponding wildtype by only one amino acid. That is, the current implementation of PSP-GNM can be used to calculate ΔΔG given a mutant structure with a single amino acid change compared to its wildtype. For a pair of wildtype and mutant proteins, the contacts broken with the residue at the mutation position during partial unfolding are serially ranked (starting with a rank of 1) in the order in which they were broken. The underlying assumption is that there is at least a single contact involving the residue at mutation position that is broken during the partial unfolding of the mutant and wildtype structures. Then, we only considered the set of broken contacts that shared the same rank in the mutant and wildtype. ΔΔG was then calculated as
In the above,
is the total difference in the interaction energies of the mutant and wildtype;
is the difference in entropy.
and
are the Miyazawa–Jernigan interaction energies between the residue at mutation position
i and the residue with rank
j with which contact was broken in the mutant and wildtype proteins, respectively. The MSF in distance is considered as a measure of entropy.
and
are the mean-squared fluctuations between the residue at mutation position
i and the residue with rank
j with which contact was broken in the mutant and wildtype proteins, respectively. Re-arranging the terms, Equation (5) can be re-written as
A strong underlying assumption of PSP-GNM is that the local unfolding energetics of the mutation position have considerable association with the unfolding free energy change. Consistent with this assumption and based on Equations (5) and (6), the calculations for ΔΔG can only be made if there exists at least one broken contact involving the mutation position in both the mutant and the wildtype. For mutations that do not exhibit a broken contact involving the mutation position, the wildtype and mutant forms are less likely to differ from each other in their partially unfolded states with respect to the mutation position. Hence, we assigned a theoretical ΔΔG value of 0. The calculated ΔΔG was re-scaled using the equation for the regression line obtained upon fitting the calculated and experimental ΔΔG on the S2298 dataset.
4.4. Calculation of ΔΔG for Reverse Mutations
To perform calculations for reverse mutations (ΔΔGmutant→ΔΔGwildtype), we simply switched the wildtype and the mutant structures. Then, we followed the same steps as described above to calculate ΔΔG.
4.5. Evaluation Metrics
To estimate the extent of agreement between calculated ΔΔG and experimental ΔΔG, we used the Pearson correlation coefficient and root mean squared error, as defined below.
The extent of antisymmetry between the calculated ΔΔG for forward and reverse mutants was evaluated using the Pearson correlation coefficient, as described previously by Pancotti et al. [
44].
We evaluated the bias towards any class of mutation (forward/reverse) using the bias score (δ) [
45].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}