
UMPred-FRL: A New Approach for Accurate Prediction of Umami Peptides Using Feature Representation Learning

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
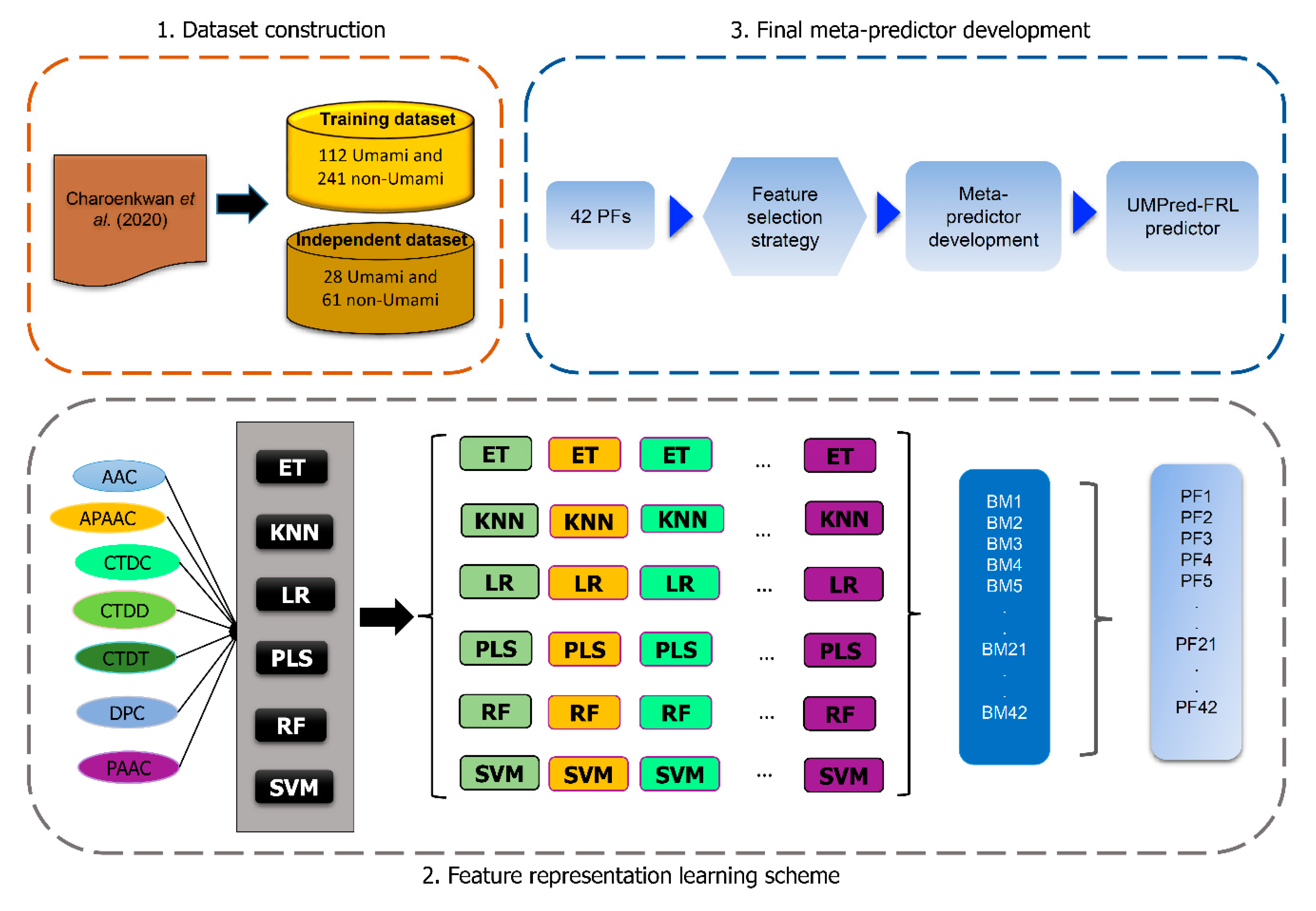
2.2. Overall Framework of UMPred-FRL
2.3. Feature Encoding
2.3.1. AAC and DPC
2.3.2. CTDC, CTDD and CTDT
2.3.3. PAAC and APAAC
2.4. Feature Optimization and Selection
2.5. Feature Representation Learning Method
2.6. Performance Evaluation
3. Results
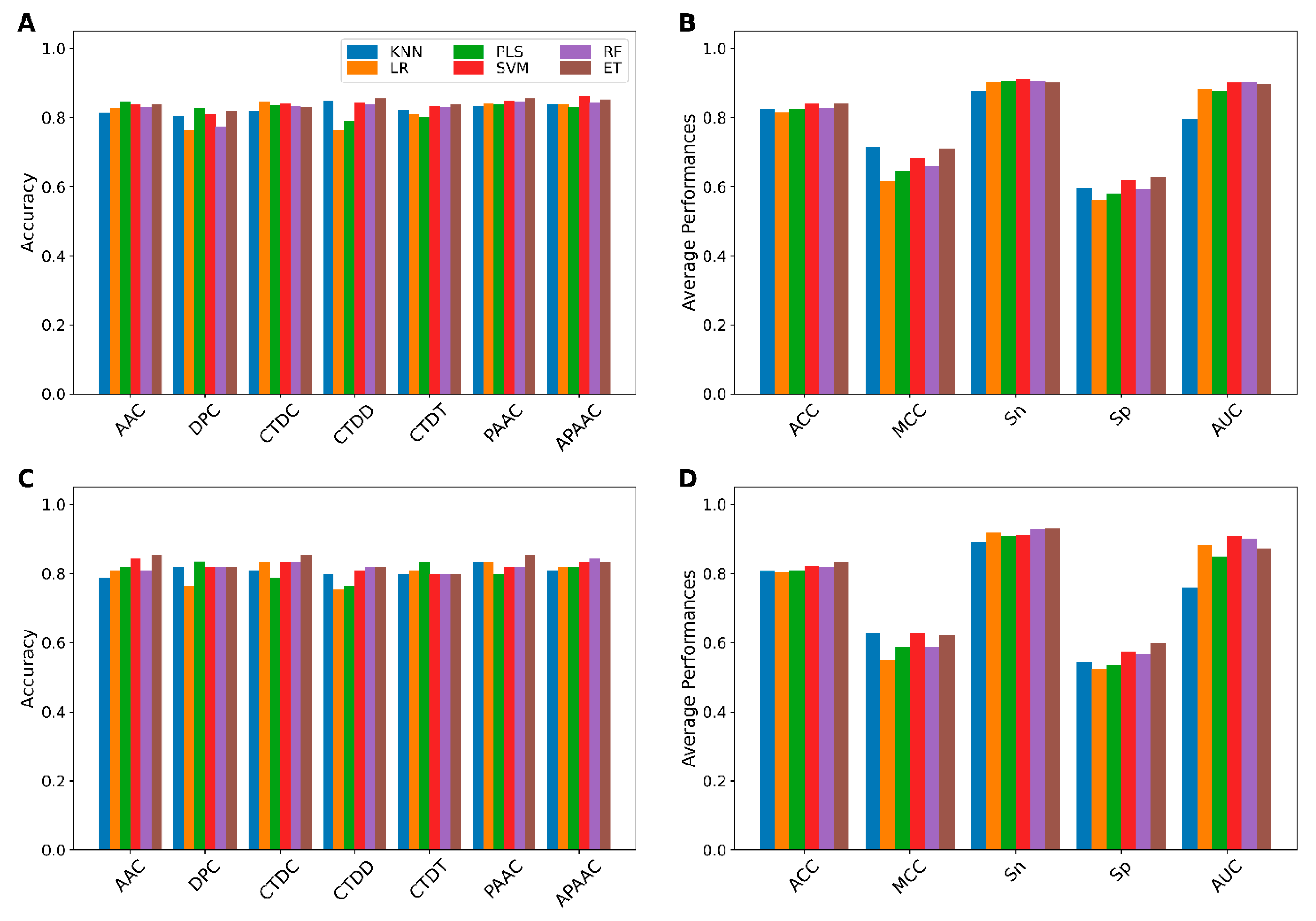
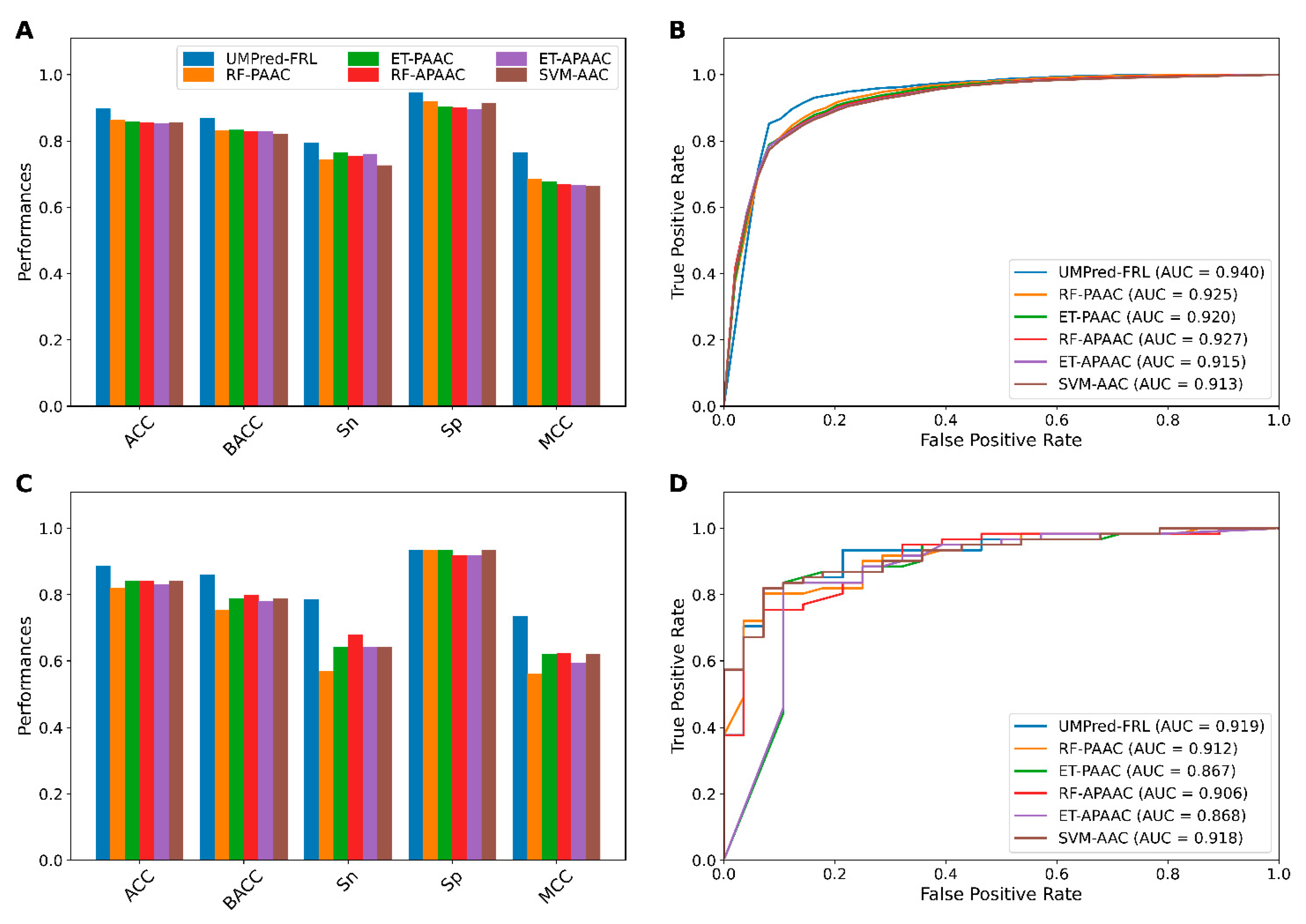
3.1. Performance of Different Baseline Models
3.2. Performance of Class, Probabilistic and Fused Information
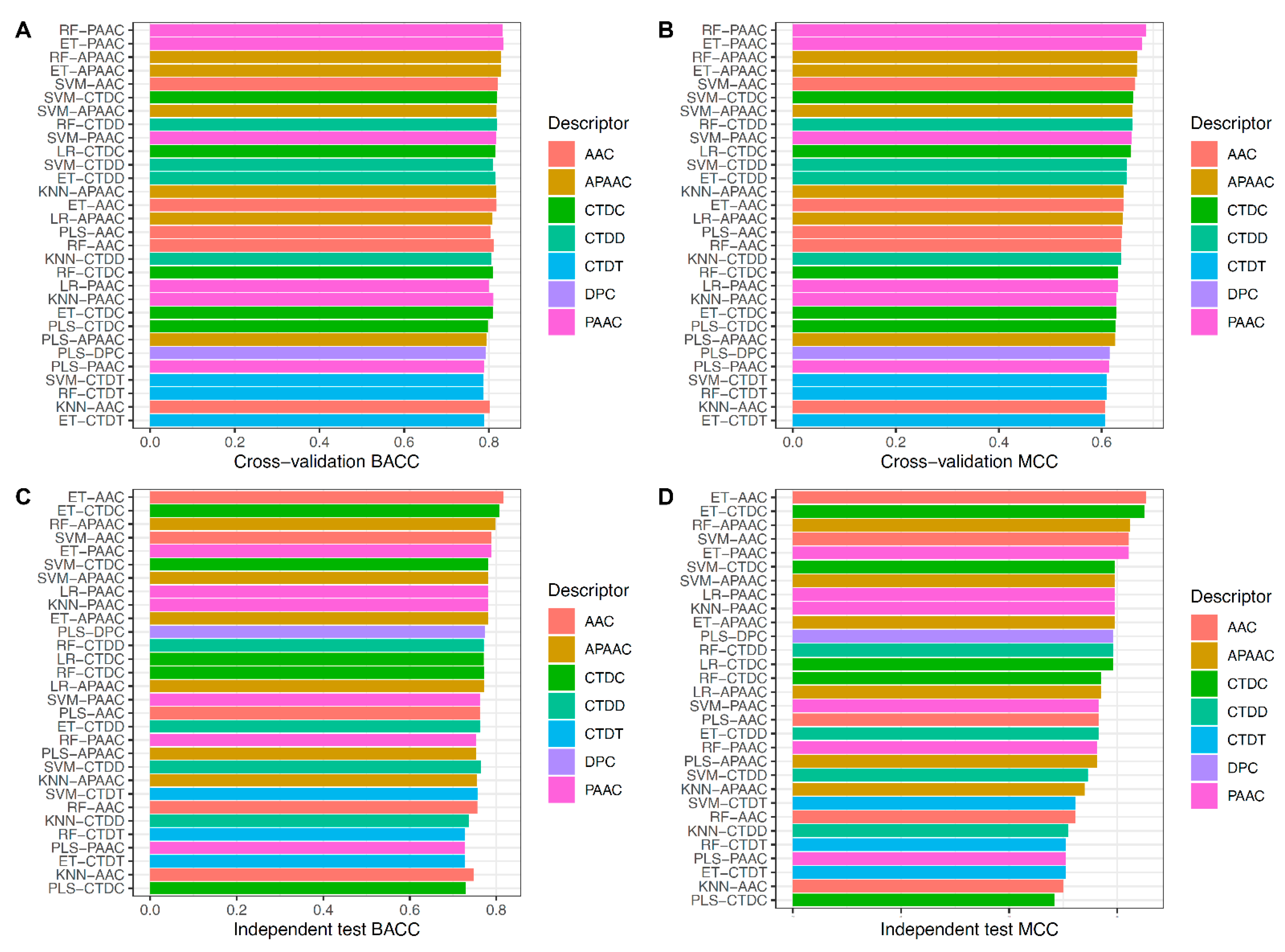
3.3. New Feature Representations Improve the Prediction Performance
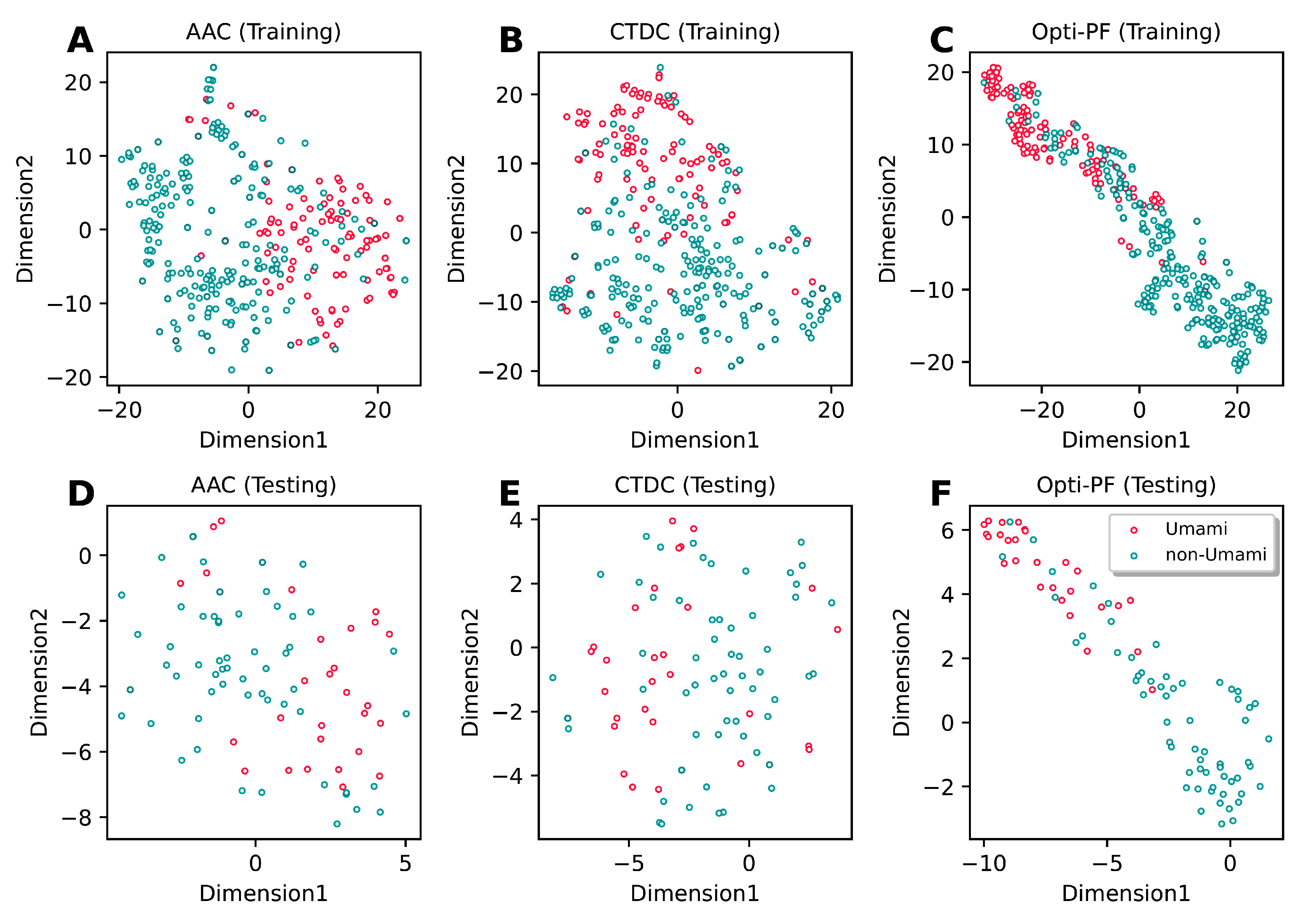
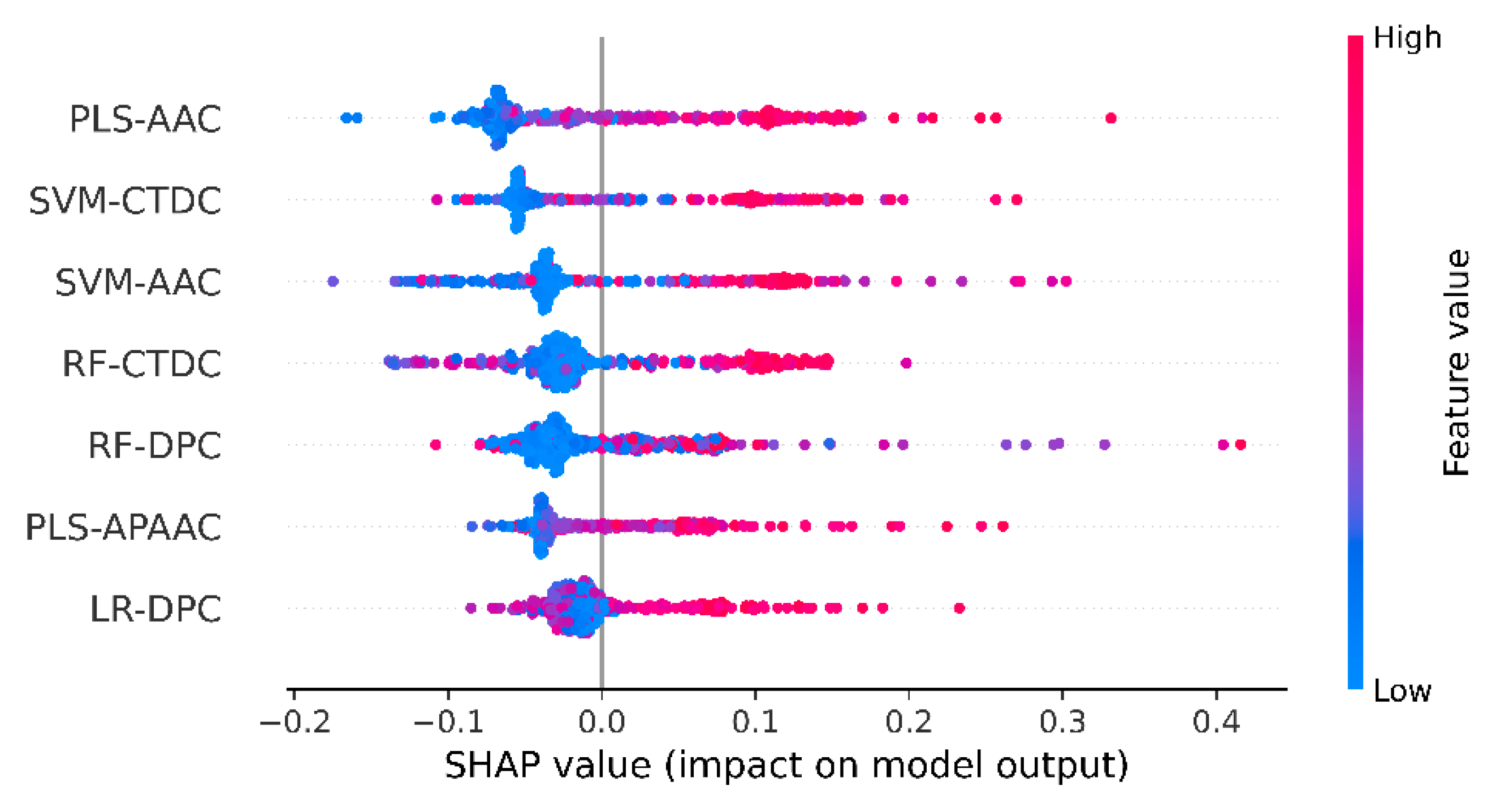
3.4. Mechanistic Interpretation of UMPred-FRL
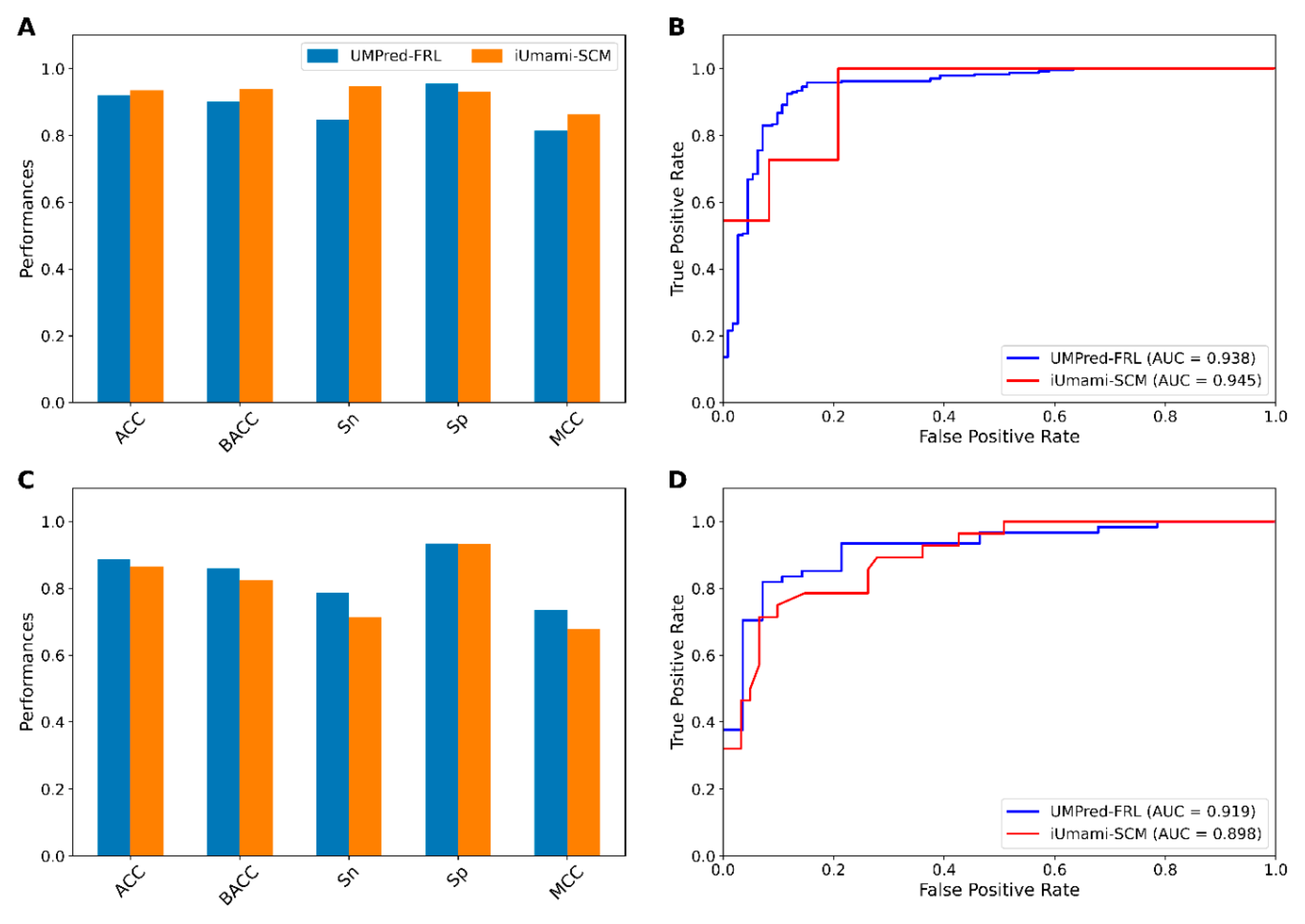
3.5. Comparison of UMPred-FRL with Its Constituent Baseline Models and the Existing Method
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Behrens, M.; Meyerhof, W.; Hellfritsch, C.; Hofmann, T. Sweet and umami taste: Natural products, their chemosensory targets, and beyond. Angew. Chem. Int. Ed. 2011, 50, 2220–2242. [Google Scholar] [CrossRef]
- Zhang, Y.; Venkitasamy, C.; Pan, Z.; Liu, W.; Zhao, L. Novel umami ingredients: Umami peptides and their taste. J. Food Sci. 2017, 82, 16–23. [Google Scholar] [CrossRef]
- Temussi, P.A. The good taste of peptides. J. Pept. Sci. 2012, 18, 73–82. [Google Scholar] [CrossRef]
- Dang, Y.; Gao, X.; Ma, F.; Wu, X. Comparison of umami taste peptides in water-soluble extractions of Jinhua and Parma hams. LWT-Food Sci. Technol. 2015, 60, 1179–1186. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, X.; Liu, Y. Characterization and evaluation of umami taste: A review. Trends Anal. Chem. 2020, 127, 115876. [Google Scholar] [CrossRef]
- Dang, Y.; Gao, X.; Xie, A.; Wu, X.; Ma, F. Interaction between umami peptide and taste receptor T1R1/T1R3. Cell Biochem. Biophys. 2014, 70, 1841–1848. [Google Scholar] [CrossRef] [PubMed]
- Upadhyaya, J.; Pydi, S.P.; Singh, N.; Aluko, R.E.; Chelikani, P. Bitter taste receptor T2R1 is activated by dipeptides and tripeptides. Biochem. Biophys. Res. Commun. 2010, 398, 331–335. [Google Scholar] [CrossRef]
- Zhang, F.; Klebansky, B.; Fine, R.M.; Xu, H.; Pronin, A.; Liu, H.; Tachdjian, C.; Li, X. Molecular mechanism for the umami taste synergism. Proc. Natl. Acad. Sci. USA 2008, 105, 20930–20934. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mouritsen, O.G.; Khandelia, H. Molecular mechanism of the allosteric enhancement of the umami taste sensation. FEBS J. 2012, 279, 3112–3120. [Google Scholar] [CrossRef]
- Charoenkwan, P.; Yana, J.; Nantasenamat, C.; Hasan, M.M.; Shoombuatong, W. iUmami-SCM: A novel sequence-based predictor for prediction and analysis of umami peptides using a scoring card method with propensity scores of dipeptides. J. Chem. Inf. Modeling 2020, 60, 6666–6678. [Google Scholar] [CrossRef]
- Yu, Z.; Jiang, H.; Guo, R.; Yang, B.; You, G.; Zhao, M.; Liu, X. Taste, umami-enhance effect and amino acid sequence of peptides separated from silkworm pupa hydrolysate. Food Res. Int. 2018, 108, 144–150. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Zhang, L.; Miao, X.; Li, Y.; Liu, Y. The structure features of umami hexapeptides for the T1R1/T1R3 receptor. Food Chem. 2017, 221, 599–605. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhao, M.; Su, G.; Lin, L. Identification and taste characteristics of novel umami and umami-enhancing peptides separated from peanut protein isolate hydrolysate by consecutive chromatography and UPLC–ESI–QTOF–MS/MS. Food Chem. 2019, 278, 674–682. [Google Scholar] [CrossRef]
- Dang, Y.; Hao, L.; Zhou, T.; Cao, J.; Sun, Y.; Pan, D. Establishment of new assessment method for the synergistic effect between umami peptides and monosodium glutamate using electronic tongue. Food Res. Int. 2019, 121, 20–27. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Sun-Waterhouse, D.; Su, G.; Zhao, M. New insight into umami receptor, umami/umami-enhancing peptides and their derivatives: A review. Trends Food Sci. Technol. 2019, 88, 429–438. [Google Scholar] [CrossRef]
- Nakata, T.; Takahashi, M.; Nakatani, M.; Kuramitsu, R.; Tamura, M.; Okai, H. Role of basic and acidic fragments in delicious peptides (Lys-Gly-Asp Glu-Glu-Ser-Leu-Ala) and the taste behavior of sodium and potassium salts in acidic oligopeptides. Biosci. Biotechnol. Biochem. 1995, 59, 689–693. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Iwaniak, A.; Darewicz, M. BIOPEP-UWM database of bioactive peptides: Current opportunities. Int. J. Mol. Sci. 2019, 20, 5978. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Charoenkwan, P.; Kanthawong, S.; Schaduangrat, N.; Yana, J.; Shoombuatong, W. PVPred-SCM: Improved prediction and analysis of phage virion proteins using a scoring card method. Cells 2020, 9, 353. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Zhou, C.; Chen, H.; Song, J.; Su, R. ACPred-FL: A sequence-based predictor using effective feature representation to improve the prediction of anti-cancer peptides. Bioinformatics 2018, 34, 4007–4016. [Google Scholar] [CrossRef]
- Qiang, X.; Zhou, C.; Ye, X.; Du, P.-f.; Su, R.; Wei, L. CPPred-FL: A sequence-based predictor for large-scale identification of cell-penetrating peptides by feature representation learning. Brief. Bioinform. 2020, 21, 11–23. [Google Scholar] [CrossRef]
- Hasan, M.M.; Alam, M.A.; Shoombuatong, W.; Deng, H.-W.; Manavalan, B.; Kurata, H. NeuroPred-FRL: An interpretable prediction model for identifying neuropeptide using feature representation learning. Brief. Bioinform. 2021, 22, bbab167. [Google Scholar] [CrossRef]
- Dubchak, I.; Muchnik, I.; Holbrook, S.R.; Kim, S.-H. Prediction of protein folding class using global description of amino acid sequence. Proc. Natl. Acad. Sci. USA 1995, 92, 8700–8704. [Google Scholar] [CrossRef] [Green Version]
- Tomii, K.; Kanehisa, M. Analysis of amino acid indices and mutation matrices for sequence comparison and structure prediction of proteins. Protein Eng. Des. Sel. 1996, 9, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhao, P.; Li, F.; Leier, A.; Marquez-Lago, T.T.; Wang, Y.; Webb, G.I.; Smith, A.I.; Daly, R.J.; Chou, K.-C. iFeature: A python package and web server for features extraction and selection from protein and peptide sequences. Bioinformatics 2018, 34, 2499–2502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chou, K.C. Prediction of protein cellular attributes using pseudo-amino acid composition. Proteins Struct. Funct. Bioinform. 2001, 43, 246–255. [Google Scholar] [CrossRef] [PubMed]
- Chou, K.-C. Using amphiphilic pseudo amino acid composition to predict enzyme subfamily classes. Bioinformatics 2005, 21, 10–19. [Google Scholar] [CrossRef]
- Charoenkwan, P.; Schaduangrat, N.; Nantasenamat, C.; Piacham, T.; Shoombuatong, W. iQSP: A Sequence-Based Tool for the Prediction and Analysis of Quorum Sensing Peptides Using Informative Physicochemical Properties. Int. J. Mol. Sci. 2020, 21, 75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Charoenkwan, P.; Chiangjong, W.; Nantasenamat, C.; Hasan, M.M.; Manavalan, B.; Shoombuatong, W. StackIL6: A stacking ensemble model for improving the prediction of IL-6 inducing peptides. Brief. Bioinform. 2021, 22, bbab172. [Google Scholar] [CrossRef]
- Charoenkwan, P.; Nantasenamat, C.; Hasan, M.M.; Shoombuatong, W. Meta-iPVP: A sequence-based meta-predictor for improving the prediction of phage virion proteins using effective feature representation. J. Comput.-Aided Mol. Des. 2020, 34, 1105–1116. [Google Scholar] [CrossRef]
- Hasan, M.; Schaduangrat, N.; Basith, S.; Lee, G.; Shoombuatong, W.; Manavalan, B. HLPpred-Fuse: Improved and robust prediction of hemolytic peptide and its activity by fusing multiple feature representation. Bioinformatics 2020, 36, 3350–3356. [Google Scholar] [CrossRef]
- Rao, B.; Zhou, C.; Zhang, G.; Su, R.; Wei, L. ACPred-Fuse: Fusing multi-view information improves the prediction of anticancer peptides. Brief. Bioinform. 2020, 21, 1846–1855. [Google Scholar] [CrossRef] [PubMed]
- Schaduangrat, N.; Nantasenamat, C.; Prachayasittikul, V.; Shoombuatong, W. Meta-iAVP: A sequence-based meta-predictor for improving the prediction of antiviral peptides using effective feature representation. Int. J. Mol. Sci. 2019, 20, 5743. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, R.; Liu, X.; Xiao, G.; Wei, L. Meta-GDBP: A high-level stacked regression model to improve anticancer drug response prediction. Brief. Bioinform. 2020, 21, 996–1005. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.P.; Zou, Q. PPTPP: A novel therapeutic peptide prediction method using physicochemical property encoding and adaptive feature representation learning. Bioinformatics 2020, 36, 3982–3987. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Azadpour, M.; McKay, C.M.; Smith, R.L. Estimating confidence intervals for information transfer analysis of confusion matrices. J. Acoust. Soc. Am. 2014, 135, EL140–EL146. [Google Scholar] [CrossRef] [PubMed]
- Lv, H.; Dao, F.-Y.; Guan, Z.-X.; Yang, H.; Li, Y.-W.; Lin, H. Deep-Kcr: Accurate detection of lysine crotonylation sites using deep learning method. Brief. Bioinform. 2021, 22, bbaa255. [Google Scholar] [CrossRef]
- Lv, H.; Dao, F.-Y.; Zulfiqar, H.; Su, W.; Ding, H.; Liu, L.; Lin, H. A sequence-based deep learning approach to predict CTCF-mediated chromatin loop. Brief. Bioinform. 2021, 22, bbab031. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Z.; Jiang, Y.; Mao, Z.; Wang, D.; Lin, H.; Xu, D. DM3Loc: Multi-label mRNA subcellular localization prediction and analysis based on multi-head self-attention mechanism. Nucleic Acids Res. 2021, 49, e46. [Google Scholar] [CrossRef]
- Dao, F.-Y.; Lv, H.; Zulfiqar, H.; Yang, H.; Su, W.; Gao, H.; Ding, H.; Lin, H. A computational platform to identify origins of replication sites in eukaryotes. Brief. Bioinform. 2021, 22, 1940–1950. [Google Scholar] [CrossRef]
- Dao, F.-Y.; Lv, H.; Zhang, D.; Zhang, Z.-M.; Liu, L.; Lin, H. DeepYY1: A deep learning approach to identify YY1-mediated chromatin loops. Brief. Bioinform. 2021, 22, bbaa356. [Google Scholar] [CrossRef] [PubMed]
- Xie, R.; Li, J.; Wang, J.; Dai, W.; Leier, A.; Marquez-Lago, T.T.; Akutsu, T.; Lithgow, T.; Song, J.; Zhang, Y. DeepVF: A deep learning-based hybrid framework for identifying virulence factors using the stacking strategy. Brief. Bioinform. 2021, 22, bbaa125. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Li, F.; Chen, J.; Ge, Z.; Wen, Y.; Yue, Y.; Hayashida, M.; Baggag, A.; Bensmail, H.; Song, J. Computational prediction and interpretation of both general and specific types of promoters in Escherichia coli by exploiting a stacked ensemble-learning framework. Brief. Bioinform. 2021, 22, 2126–2140. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Set | Dimension | ACC | BACC | Sn | Sp | MCC | AUC |
|---|---|---|---|---|---|---|---|
| CF | 42 | 0.854 | 0.823 | 0.741 | 0.906 | 0.662 | 0.903 |
| PF | 42 | 0.860 | 0.830 | 0.746 | 0.914 | 0.677 | 0.909 |
| CPF | 84 | 0.855 | 0.827 | 0.749 | 0.905 | 0.667 | 0.915 |
| Optimal CF | 10 | 0.875 | 0.870 | 0.857 | 0.884 | 0.729 | 0.887 |
| Optimal PF | 7 | 0.898 | 0.870 | 0.795 | 0.945 | 0.765 | 0.940 |
| Optimal CPF | 8 | 0.893 | 0.868 | 0.797 | 0.938 | 0.755 | 0.895 |
| Feature Set | Dimension | ACC | BACC | Sn | Sp | MCC | AUC |
|---|---|---|---|---|---|---|---|
| CF | 42 | 0.876 | 0.842 | 0.750 | 0.934 | 0.707 | 0.934 |
| PF | 42 | 0.820 | 0.763 | 0.607 | 0.918 | 0.565 | 0.930 |
| CPF | 84 | 0.798 | 0.698 | 0.429 | 0.967 | 0.505 | 0.934 |
| Optimal CF | 10 | 0.876 | 0.881 | 0.893 | 0.869 | 0.732 | 0.904 |
| Optimal PF | 7 | 0.888 | 0.860 | 0.786 | 0.934 | 0.735 | 0.919 |
| Optimal CPF | 8 | 0.888 | 0.870 | 0.821 | 0.918 | 0.739 | 0.898 |
| Feature | Dimension | ACC | BACC | Sn | Sp | MCC | AUC |
|---|---|---|---|---|---|---|---|
| AAC | 20 | 0.856 | 0.821 | 0.727 | 0.915 | 0.665 | 0.913 |
| APAAC | 22 | 0.854 | 0.818 | 0.719 | 0.917 | 0.660 | 0.917 |
| CTDC | 39 | 0.854 | 0.820 | 0.727 | 0.912 | 0.661 | 0.911 |
| CTDD | 195 | 0.850 | 0.810 | 0.700 | 0.920 | 0.649 | 0.914 |
| CTDT | 39 | 0.834 | 0.786 | 0.655 | 0.917 | 0.609 | 0.875 |
| DPC | 400 | 0.812 | 0.734 | 0.520 | 0.947 | 0.549 | 0.892 |
| PAAC | 21 | 0.854 | 0.818 | 0.719 | 0.916 | 0.658 | 0.919 |
| Optimal PF | 7 | 0.898 | 0.870 | 0.795 | 0.945 | 0.765 | 0.940 |
| Feature | Dimension | ACC | BACC | Sn | Sp | MCC | AUC |
|---|---|---|---|---|---|---|---|
| AAC | 20 | 0.843 | 0.789 | 0.643 | 0.934 | 0.621 | 0.918 |
| APAAC | 22 | 0.831 | 0.780 | 0.643 | 0.918 | 0.595 | 0.923 |
| CTDC | 39 | 0.831 | 0.780 | 0.643 | 0.918 | 0.595 | 0.923 |
| CTDD | 195 | 0.809 | 0.764 | 0.643 | 0.885 | 0.546 | 0.894 |
| CTDT | 39 | 0.798 | 0.756 | 0.643 | 0.869 | 0.523 | 0.872 |
| DPC | 400 | 0.798 | 0.708 | 0.464 | 0.951 | 0.502 | 0.908 |
| PAAC | 21 | 0.820 | 0.763 | 0.607 | 0.918 | 0.565 | 0.924 |
| Optimal PF | 7 | 0.888 | 0.860 | 0.786 | 0.934 | 0.735 | 0.919 |
| Cross-Validation | Method | ACC | BACC | Sn | Sp | MCC | AUC |
|---|---|---|---|---|---|---|---|
| 10-fold CV | iUmami-SCM | 0.935 | 0.939 | 0.947 | 0.930 | 0.864 | 0.945 |
| UMPred-FRL | 0.921 | 0.901 | 0.847 | 0.955 | 0.814 | 0.938 | |
| Independent test | iUmami-SCM | 0.865 | 0.824 | 0.714 | 0.934 | 0.679 | 0.898 |
| UMPred-FRL | 0.888 | 0.860 | 0.786 | 0.934 | 0.735 | 0.919 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Charoenkwan, P.; Nantasenamat, C.; Hasan, M.M.; Moni, M.A.; Manavalan, B.; Shoombuatong, W. UMPred-FRL: A New Approach for Accurate Prediction of Umami Peptides Using Feature Representation Learning. Int. J. Mol. Sci. 2021, 22, 13124. https://doi.org/10.3390/ijms222313124
Charoenkwan P, Nantasenamat C, Hasan MM, Moni MA, Manavalan B, Shoombuatong W. UMPred-FRL: A New Approach for Accurate Prediction of Umami Peptides Using Feature Representation Learning. International Journal of Molecular Sciences. 2021; 22(23):13124. https://doi.org/10.3390/ijms222313124
Chicago/Turabian StyleCharoenkwan, Phasit, Chanin Nantasenamat, Md Mehedi Hasan, Mohammad Ali Moni, Balachandran Manavalan, and Watshara Shoombuatong. 2021. "UMPred-FRL: A New Approach for Accurate Prediction of Umami Peptides Using Feature Representation Learning" International Journal of Molecular Sciences 22, no. 23: 13124. https://doi.org/10.3390/ijms222313124
APA StyleCharoenkwan, P., Nantasenamat, C., Hasan, M. M., Moni, M. A., Manavalan, B., & Shoombuatong, W. (2021). UMPred-FRL: A New Approach for Accurate Prediction of Umami Peptides Using Feature Representation Learning. International Journal of Molecular Sciences, 22(23), 13124. https://doi.org/10.3390/ijms222313124