
Prediction of Anti-Glioblastoma Drug-Decorated Nanoparticle Delivery Systems Using Molecular Descriptors and Machine Learning

 ,
,  ,
,  , ,
, , 
 ,
, 
Abstract
:1. Introduction
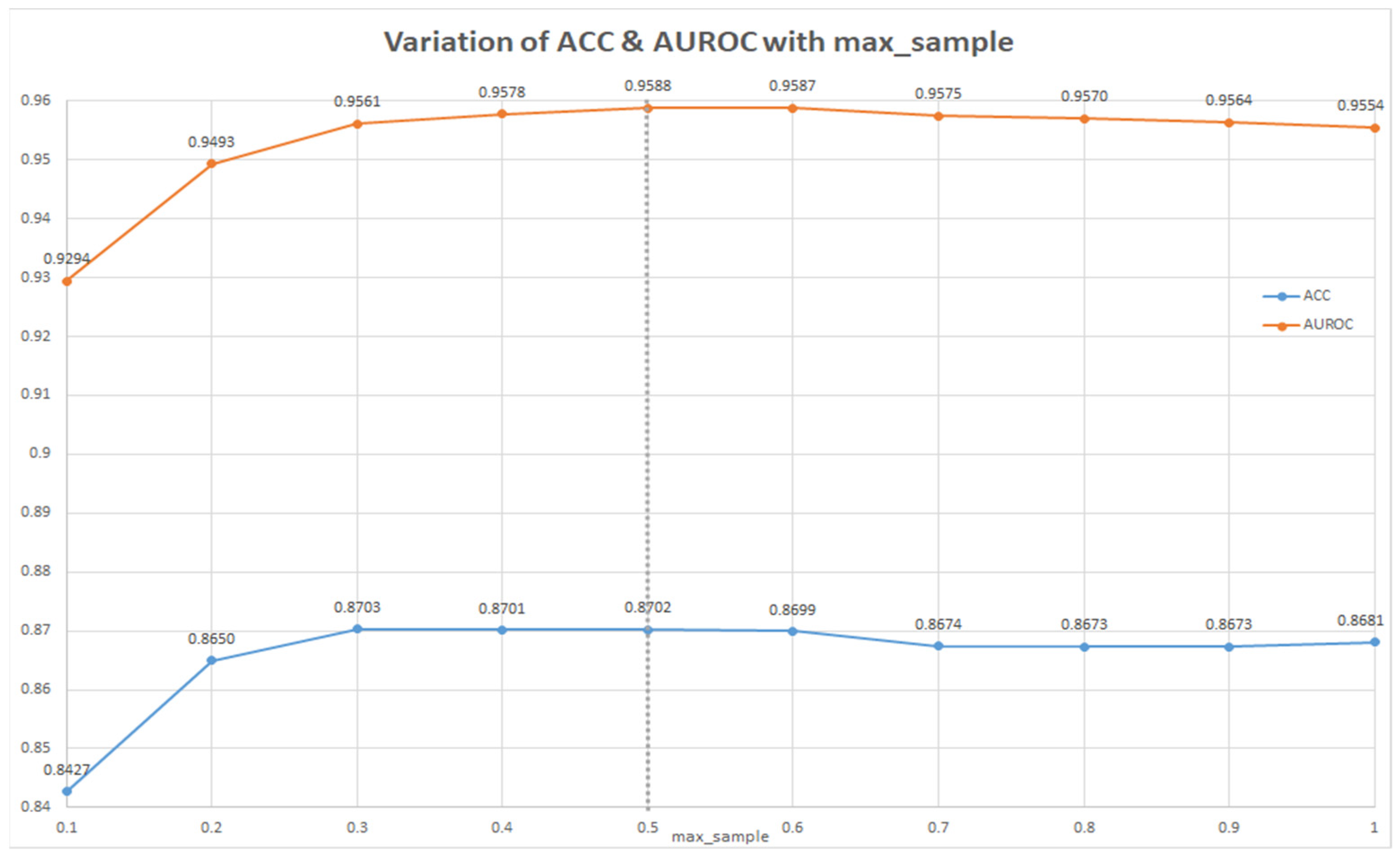
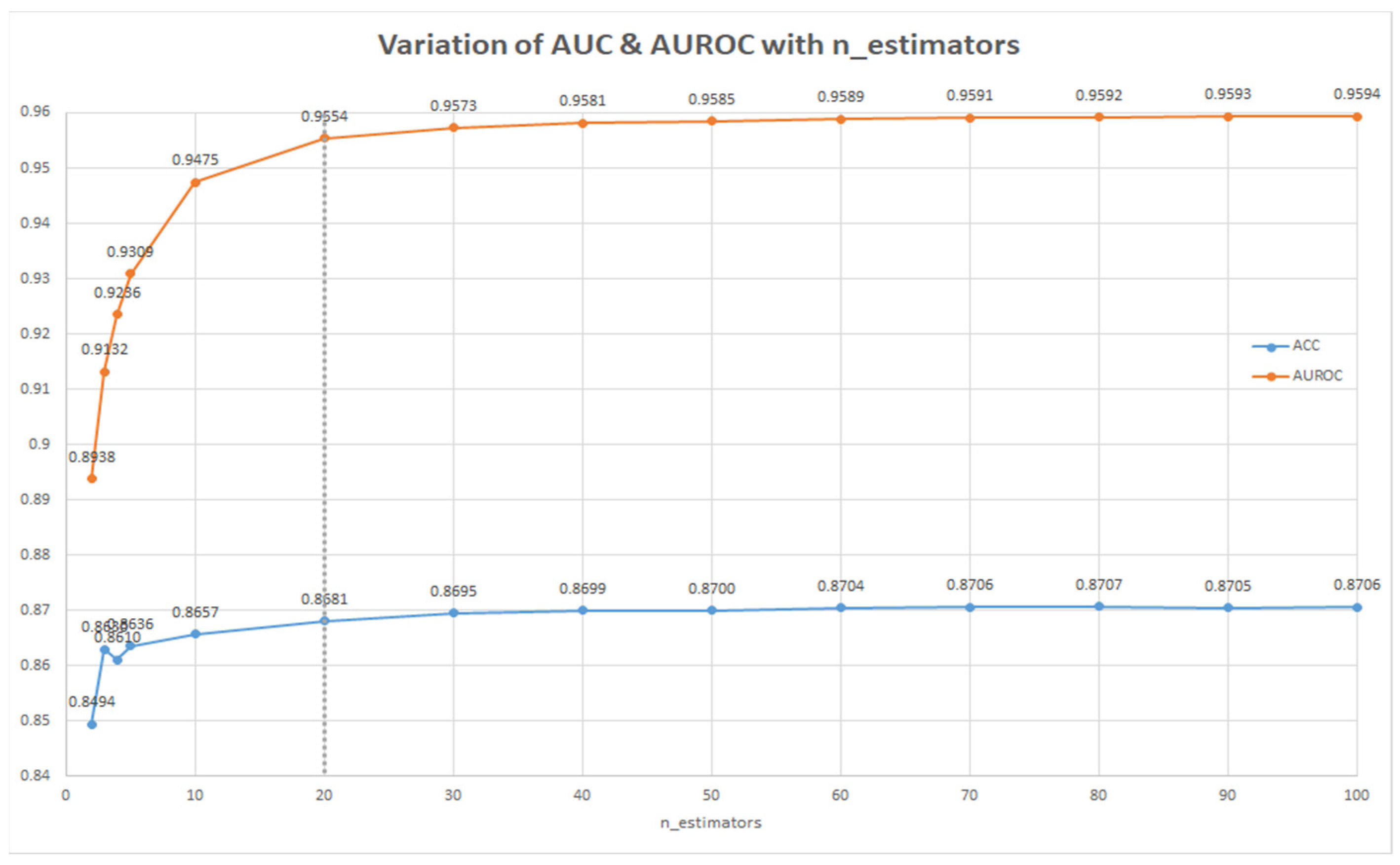
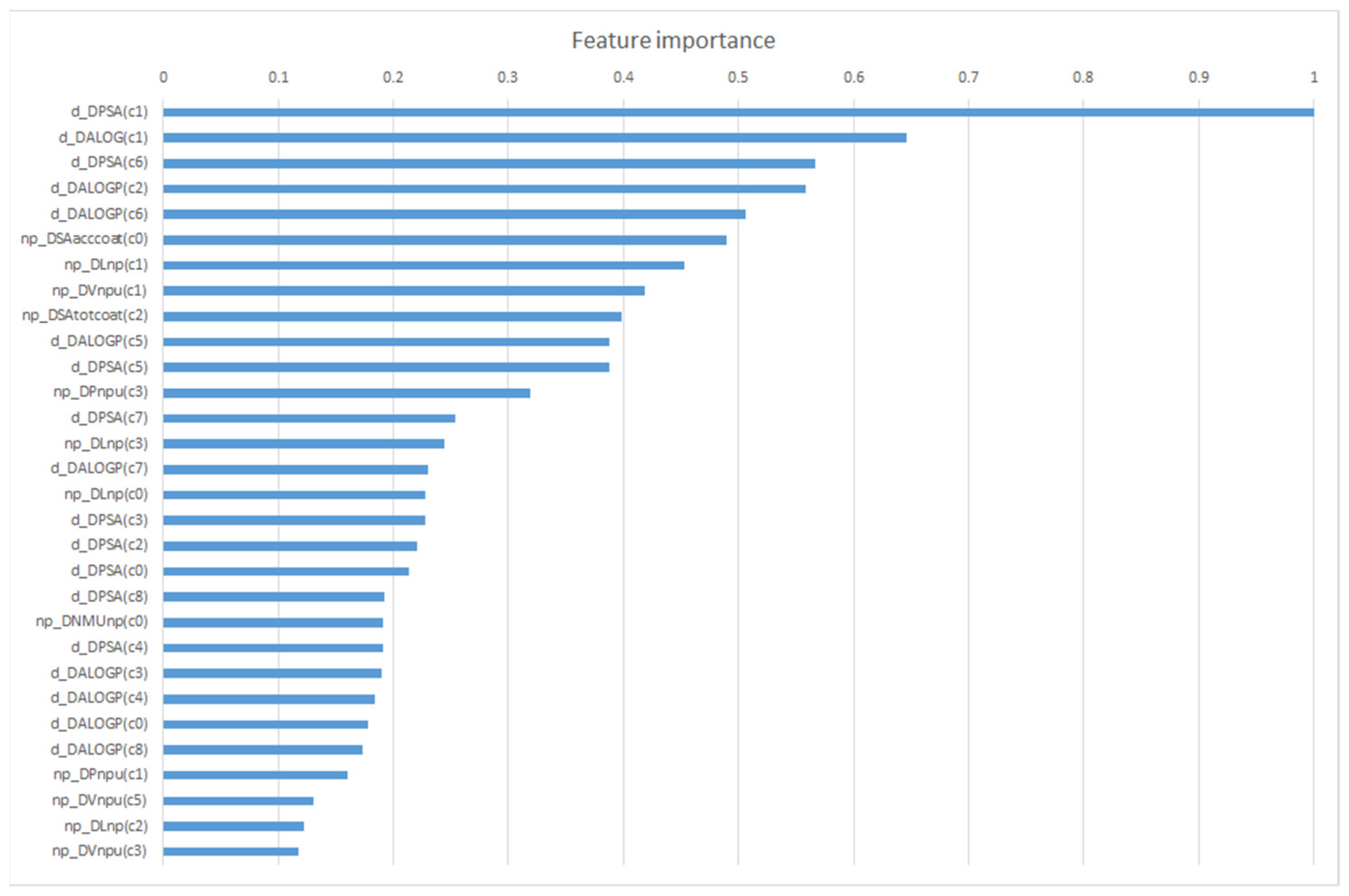
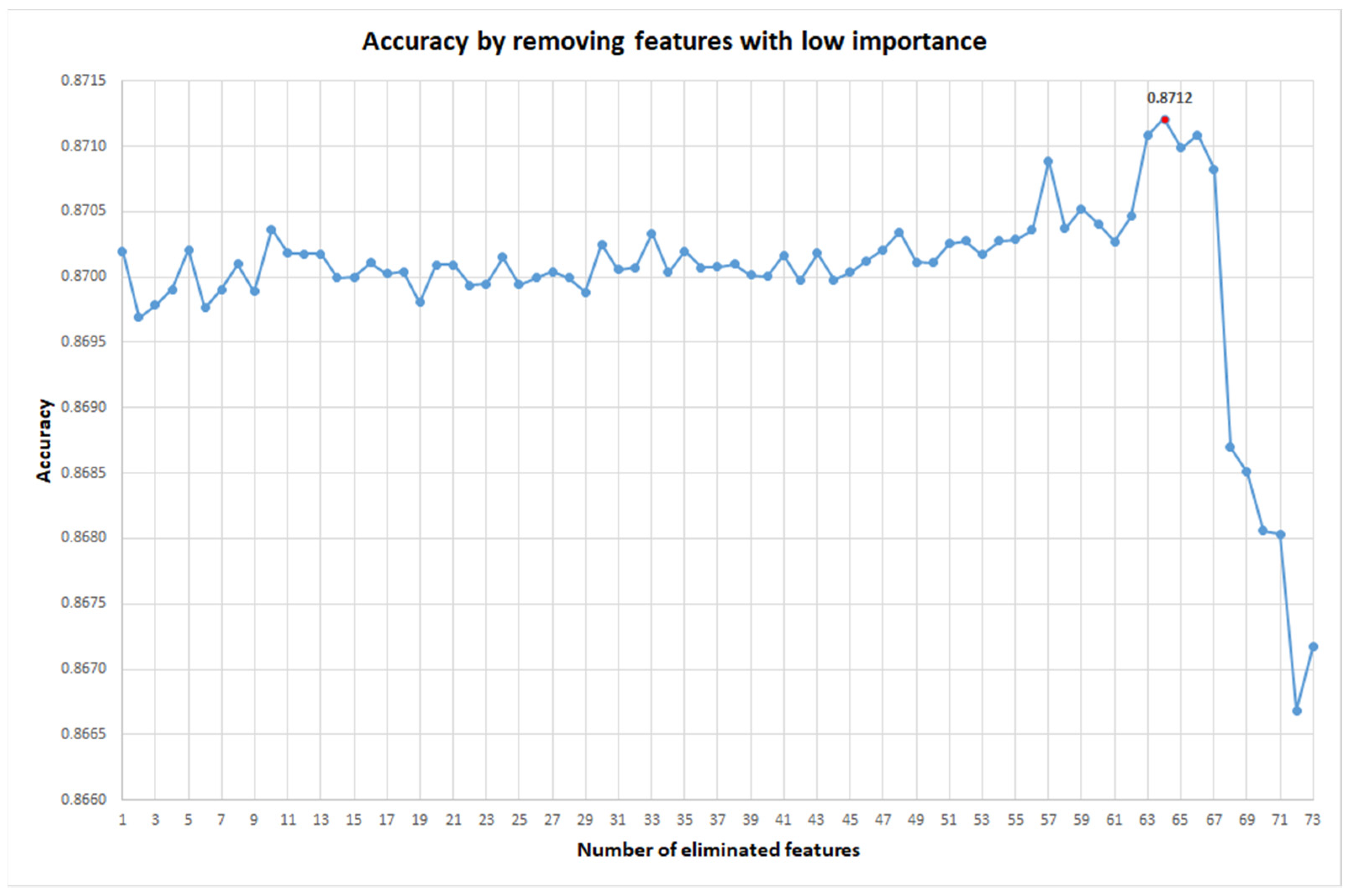
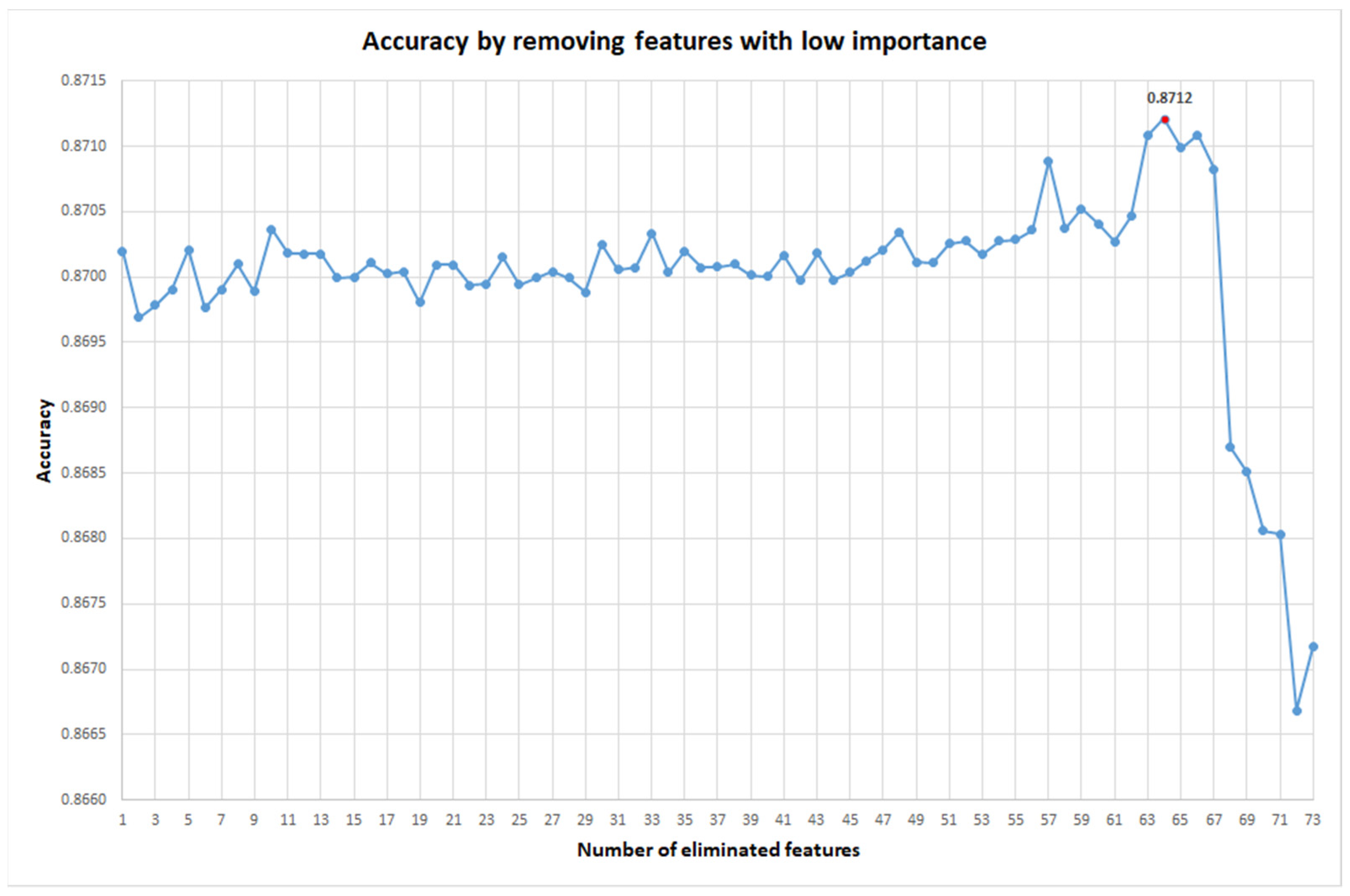
2. Results
3. Discussion
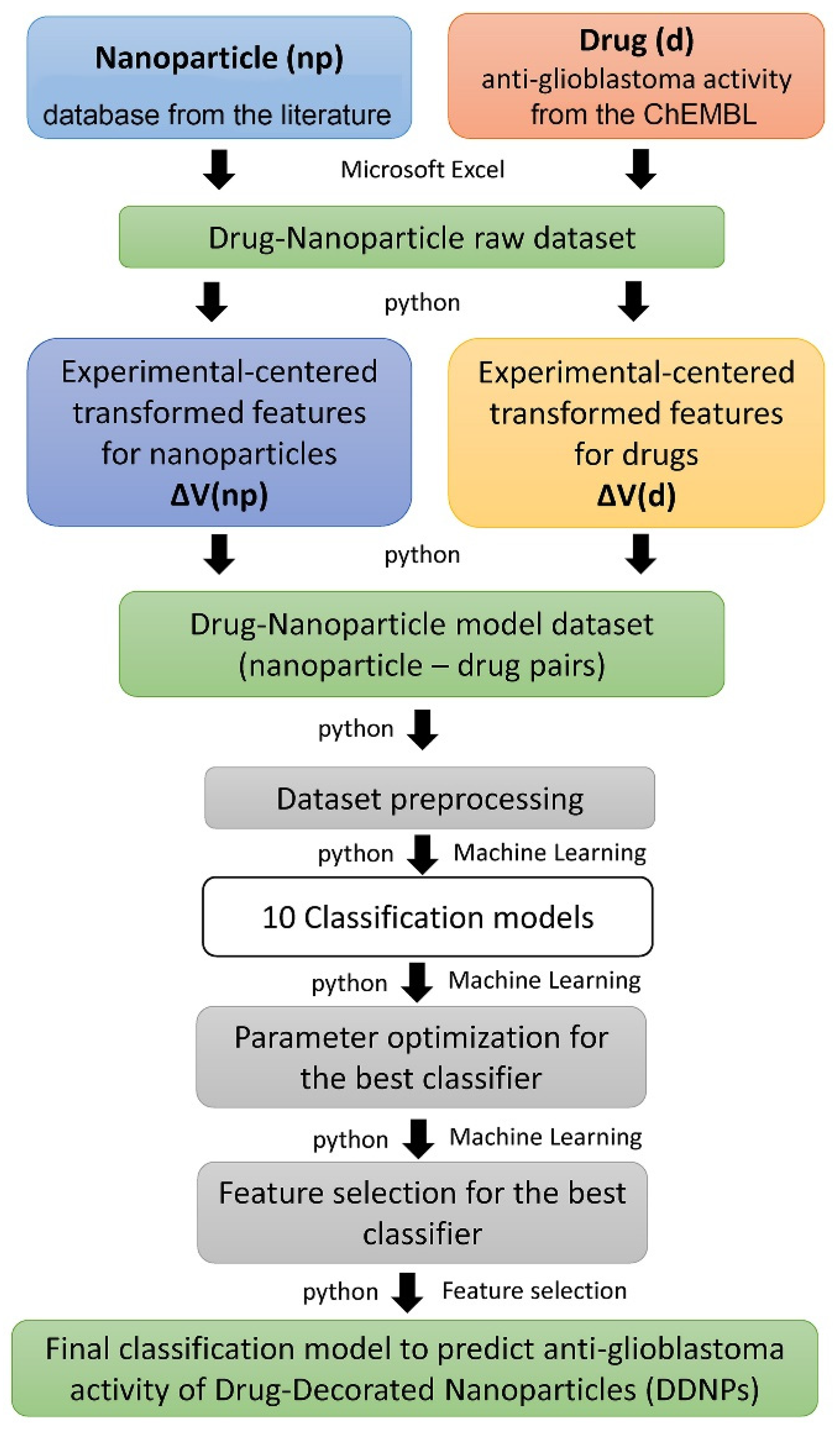
4. Materials and Methods
- -
- Drugs (d): c0 = Biological activity; c1 = cell name, c2 = organism, c3 = target type, c4 = assay organism, c5 = target mapping, c6 = level of confidence, c7 = type of curation, and c8 = assay type;
- -
- Nanoparticles (np): c0(np) = Parameter np assay, c1(np) = Cell line np assay, c2(np) = np shape, c3(np) = np medium, c4(np) = np assay time, c5(np) = surface coating.
- -
- For drugs: PSA and ALOGP;
- -
- For nanoparticles: NMUnp, Lnp, Vnpu, Enpu, Pnpu, Uccoat, Uicoat, Hycoat, AMRcoat, TPSA(NO)coat, TPSA(Tot)coat, ALOGPcoat, ALOGP2coat, SAtotcoat, SAacccoat, SAdoncoat, Vxcoat, Vvdw, MGcoat, Vvdw, ZAZcoat, PDIcoat.
- -
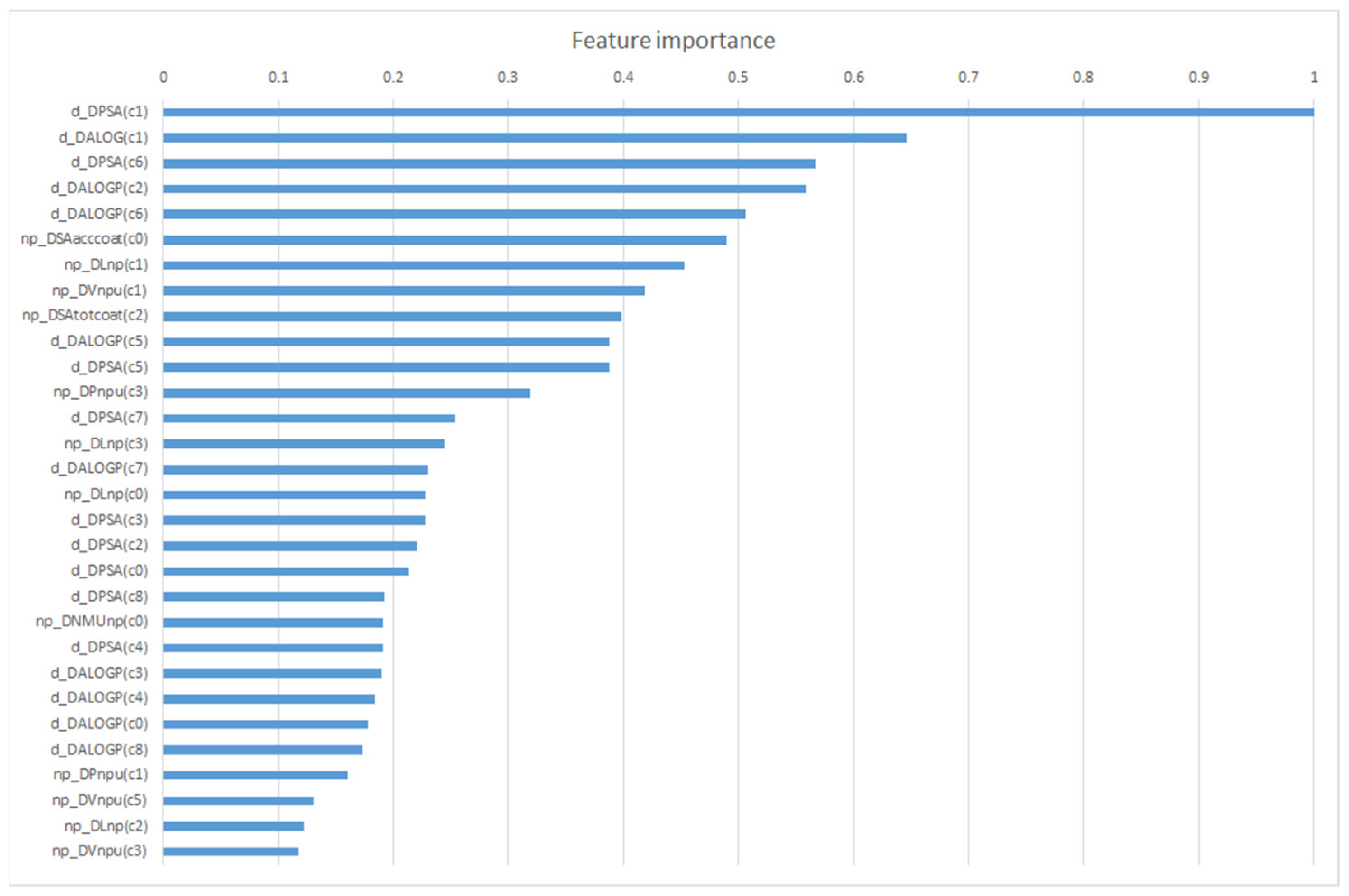
- d_DPSA(c1) = difference (D) between original values of PSA descriptor and the mean of PSA values in experimental condition c1 (for drugs, d_);
- -
- np_DLnp(c5) = difference between original L value and the mean of L values in experimental condition c5 (for nanoparticles, np_/np).
- -
- For drugs: priori desirability was −1 for EC50 and IC50, and 1 for LC50;
- -
- For NPs: priori desirability was −1 EC50 and IC50, and 1 for CC50, LC50, TC50.
- KNeighborsClassifier = KNN—k-nearest neighbors: It is one of the most popular non-parametric classifiers available. It works by assigning an unclassified sample to the same class as the nearest k samples found in the training set [31].
- GaussianNB = Gaussian Naive Bayes: It is a simple classification algorithm that is based on Bayes’ theorem, which describes the probability of an event based on prior knowledge of conditions related to said event. It is the simplest and the most popular of all similar classifiers [32].
- LinearDiscriminantAnalysis = LDA—linear discriminant analysis [33]: It is a supervised statistical method based on the projection of data to a lower dimension. The objective is to maximize the scatter between classes versus the scatter within each class. Thanks to this projection, the task of separating the data should be made easier.
- LogisticRegression = LR—Logistic regression [34]: It is a linear model with the capacity to estimate the probability of a binary response using different factors.
- DecisionTreeClassifier = DT—Decision Tree (DT): It a classifier that builds a series of models in the form of a tree structure. Then, it infers its decision rules from the features of said trees. Thus, the paths from root to leaf represent classification rules [35].
- RandomForestClassifier = RF—Random forest [36]: It consists of a large number of individual decision trees that work as an ensemble. Each individual tree in the random forest makes a prediction, and then, the class with the largest amount of votes is chosen as the model’s prediction. Each tree is generated using a bootstrap sample drawn randomly from the original dataset using a classification or regression tree (CART) method and the Decrease Gini Impurity (DGI) as the splitting criterion [36]. RF is mainly characterized by low bias, low correlation between individual trees, and high variance.
- GradientBoostingClassifier = Gradient Boosting for classification—GB classifier: Gradient Boosting is a technique that produces a prediction based on an ensemble of weak prediction models (in general, decision trees) [39].
- BaggingClassifier = Bagging classifier: Similarly to a GB classifier, a Bagging classifier is an ensemble meta-estimator, meaning that it uses as a basis a number of weaker prediction models in order to make its own prediction. It fits each base classifier on a random subset of the original dataset and then aggregates all the individual performances in order to form a final prediction [36].
- AdaBoostClassifier = AdaBoost classifier: In a similar fashion to the two previous examples, an AdaBoost classifier is a meta-estimator that first fits a classifier on the original dataset and, subsequently, fits a series of copies of said classifier on the same dataset but adjusting the weights of incorrectly classified instances, meaning that the following classifiers will focus on the most difficult cases [36].
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rizvi, S.A.; Saleh, A.M. Applications of nanoparticle systems in drug delivery technology. Saudi Pharm. J. 2018, 26, 64–70. [Google Scholar] [CrossRef] [PubMed]
- Patra, J.K.; Das, G.; Fraceto, L.F.; Campos, E.V.R.; del Pilar Rodriguez-Torres, M.; Acosta-Torres, L.S.; Diaz-Torres, L.A.; Grillo, R.; Swamy, M.K.; Sharma, S. Nano based drug delivery systems: Recent developments and future prospects. J. Nanobiotechnol. 2018, 16, 71. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Michael, J.S.; Lee, B.-S.; Zhang, M.; Yu, J.S. Nanotechnology for treatment of glioblastoma multiforme. J. Transl. Intern. Med. 2018, 6, 128. [Google Scholar] [CrossRef] [Green Version]
- Nam, L.; Coll, C.; Erthal, L.; de la Torre, C.; Serrano, D.; Martínez-Máñez, R.; Ruiz-Hernández, E. Drug delivery nanosystems for the localized treatment of glioblastoma multiforme. Materials 2018, 11, 779. [Google Scholar] [CrossRef] [Green Version]
- Quevedo-Tumailli, V.F.; Ortega-Tenezaca, B.; González-Díaz, H. Chromosome gene orientation inversion networks (GOINs) of plasmodium proteome. J. Proteome Res. 2018, 17, 1258–1268. [Google Scholar] [CrossRef] [PubMed]
- Ferreira da Costa, J.; Silva, D.; Caamaño, O.; Brea, J.M.; Loza, M.I.; Munteanu, C.R.; Pazos, A.; García-Mera, X.; González-Díaz, H. Perturbation Theory/Machine Learning Model of ChEMBL Data for Dopamine Targets: Docking, Synthesis, and Assay of New l-Prolyl-l-leucyl-glycinamide Peptidomimetics. ACS Chem. Neurosci. 2018, 9, 2572–2587. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Arzate, S.G.; Tenorio-Borroto, E.; Barbabosa Pliego, A.; Diaz-Albiter, H.M.; Vazquez-Chagoyan, J.C.; Gonzalez-Diaz, H. PTML Model for Proteome Mining of B-Cell Epitopes and Theoretical–Experimental Study of Bm86 Protein Sequences from Colima, Mexico. J. Proteome Res. 2017, 16, 4093–4103. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Tang, S.; Fernandez-Lozano, C.; Munteanu, C.R.; Pazos, A.; Yu, Y.-Z.; Tan, Z.; González-Díaz, H. Experimental study and random forest prediction model of microbiome cell surface hydrophobicity. Expert Syst. Appl. 2017, 72, 306–316. [Google Scholar] [CrossRef]
- González-Durruthy, M.; Alberici, L.C.; Curti, C.; Naal, Z.; Atique-Sawazaki, D.T.; Vázquez-Naya, J.M.; González-Díaz, H.; Munteanu, C.R. Experimental–computational study of carbon nanotube effects on mitochondrial respiration: In silico nano-QSPR machine learning models based on new Raman spectra transform with Markov–Shannon entropy invariants. J. Chem. Inf. Comput. Sci. 2017, 57, 1029–1044. [Google Scholar] [CrossRef] [Green Version]
- González-Durruthy, M.; Monserrat, J.M.; Rasulev, B.; Casañola-Martín, G.M.; Barreiro Sorrivas, J.M.; Paraíso-Medina, S.; Maojo, V.; González-Díaz, H.; Pazos, A.; Munteanu, C.R. Carbon nanotubes’ effect on mitochondrial oxygen flux dynamics: Polarography experimental study and machine learning models using star graph trace invariants of raman spectra. Nanomaterials 2017, 7, 386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- González-Durruthy, M.; Werhli, A.V.; Seus, V.; Machado, K.S.; Pazos, A.; Munteanu, C.R.; González-Díaz, H.; Monserrat, J.M. Decrypting strong and weak single-walled carbon nanotubes interactions with mitochondrial voltage-dependent anion channels using molecular docking and perturbation theory. Sci. Rep. 2017, 7, 13271. [Google Scholar] [CrossRef] [Green Version]
- Ran, T.; Liu, Y.; Li, H.; Tang, S.; He, Z.; Munteanu, C.R.; Gonzalez-Diaz, H.; Tan, Z.; Zhou, C. Gastrointestinal Spatiotemporal mRNA Expression of Ghrelin vs Growth Hormone Receptor and New Growth Yield Machine Learning Model Based on Perturbation Theory. Sci. Rep. 2016, 6, 30174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luan, F.; Kleandrova, V.V.; González-Díaz, H.; Ruso, J.M.; Melo, A.; Speck-Planche, A.; Cordeiro, M.N.D. Computer-aided nanotoxicology: Assessing cytotoxicity of nanoparticles under diverse experimental conditions by using a novel QSTR-perturbation approach. Nanoescale 2014, 6, 10623–10630. [Google Scholar] [CrossRef] [PubMed]
- Kleandrova, V.V.; Luan, F.; Gonzalez-Diaz, H.; Ruso, J.M.; Speck-Planche, A.; Cordeiro, M.N. Computational tool for risk assessment of nanomaterials: Novel QSTR-perturbation model for simultaneous prediction of ecotoxicity and cytotoxicity of uncoated and coated nanoparticles under multiple experimental conditions. Environ. Sci. Technol. 2014, 48, 14686–14694. [Google Scholar] [CrossRef] [PubMed]
- Kleandrova, V.V.; Luan, F.; González-Díaz, H.; Ruso, J.M.; Melo, A.; Speck-Planche, A.; Cordeiro, M.N.D. Computational ecotoxicology: Simultaneous prediction of ecotoxic effects of nanoparticles under different experimental conditions. Environ. Int. 2014, 73, 288–294. [Google Scholar] [CrossRef] [PubMed]
- Santana, R.; Zuluaga, R.; Gañán, P.; Arrasate, S.; Onieva, E.; González-Díaz, H. Designing nanoparticle release systems for drug–vitamin cancer co-therapy with multiplicative perturbation-theory machine learning (PTML) models. Nanoescale 2019, 11, 21811–21823. [Google Scholar] [CrossRef] [PubMed]
- Hansch, C. The advent and evolution of QSAR at Pomona College. J. Comput.-Aided Mol. Des. 2011, 25, 495–507. [Google Scholar] [CrossRef] [PubMed]
- Kubinyi, H.; Mannhold, R.; Krogsgaard, L.; Timmerman, H. (Eds.) Methods and Principles in Medicinal Chemistry; Wiley-VCH: Weinheim, Germany, 1993. [Google Scholar]
- Cho, S.J.; Hermsmeier, M.A. Genetic algorithm guided selection: Variable selection and subset selection. J. Chem. Inf. Comput. Sci. 2002, 42, 927–936. [Google Scholar] [CrossRef] [PubMed]
- Tetko, I.V.; Tanchuk, V.Y.; Kasheva, T.N.; Villa, A.E. Internet software for the calculation of the lipophilicity and aqueous solubility of chemical compounds. J. Chem. Inf. 2001, 41, 246–252. [Google Scholar] [CrossRef]
- Gaulton, A.; Hersey, A.; Nowotka, M.; Bento, A.P.; Chambers, J.; Mendez, D.; Mutowo, P.; Atkinson, F.; Bellis, L.J.; Cibrián-Uhalte, E. The ChEMBL database in 2017. Nucleic Acids Res. 2017, 45, D945–D954. [Google Scholar] [CrossRef] [PubMed]
- Papadatos, G.; Overington, J.P. The ChEMBL database: A taster for medicinal chemists. Future Med. Chem. 2014, 6, 361–364. [Google Scholar] [CrossRef] [PubMed]
- Bento, A.P.; Gaulton, A.; Hersey, A.; Bellis, L.J.; Chambers, J.; Davies, M.; Krüger, F.A.; Light, Y.; Mak, L.; McGlinchey, S. The ChEMBL bioactivity database: An update. Nucleic Acids Res. 2014, 42, D1083–D1090. [Google Scholar] [CrossRef] [Green Version]
- Willighagen, E.L.; Waagmeester, A.; Spjuth, O.; Ansell, P.; Williams, A.J.; Tkachenko, V.; Hastings, J.; Chen, B.; Wild, D.J. The ChEMBL database as linked open data. J. Cheminform. 2013, 5, 23. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Bajorath, J.R. Growth of ligand–target interaction data in ChEMBL is associated with increasing and activity measurement-dependent compound promiscuity. J. Chem. Inf. Modeling 2012, 52, 2550–2558. [Google Scholar] [CrossRef] [PubMed]
- Wassermann, A.M.; Bajorath, J. BindingDB and ChEMBL: Online compound databases for drug discovery. Expert Opin. Drug Discov. 2011, 6, 683–687. [Google Scholar] [CrossRef] [PubMed]
- Gaulton, A.; Bellis, L.J.; Bento, A.P.; Chambers, J.; Davies, M.; Hersey, A.; Light, Y.; McGlinchey, S.; Michalovich, D.; Al-Lazikani, B. ChEMBL: A large-scale bioactivity database for drug discovery. Nucleic Acids Res. 2012, 40, D1100–D1107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Urista, D.V.; Carrué, D.B.; Otero, I.; Arrasate, S.; Quevedo-Tumailli, V.F.; Gestal, M.; González-Díaz, H.; Munteanu, C.R. Prediction of Antimalarial Drug-Decorated Nanoparticle Delivery Systems with Random Forest Models. Biology 2020, 9, 198. [Google Scholar] [CrossRef] [PubMed]
- Casañola-Martin, G.M.; Le-Thi-Thu, H.; Pérez-Giménez, F.; Marrero-Ponce, Y.; Merino-Sanjuán, M.; Abad, C.; González-Díaz, H. Multi-output model with Box–Jenkins operators of linear indices to predict multi-target inhibitors of ubiquitin–proteasome pathway. Mol. Divers. 2015, 19, 347–356. [Google Scholar] [CrossRef] [PubMed]
- Tenorio-Borroto, E.; Ramirez, F.R.; Speck-Planche, A.; Cordeiro, N.D.; Luan, F.; Gonzalez-Diaz, H. QSPR and flow cytometry analysis (QSPR-FCA): Review and new findings on parallel study of multiple interactions of chemical compounds with immune cellular and molecular targets. Curr. Drug Metab. 2014, 15, 414–428. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Hobbs, N.T.; Hooten, M.B. Bayesian Models; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Cristianini, N. Fisher Discriminant Analysis (Linear Discriminant Analysis). In Dictionary of Bioinformatics and Computational Biology; Sons, J.W., Ed.; Wiley Online Library: Hoboken, NJ, USA, 2004. [Google Scholar] [CrossRef]
- Peduzzi, P.; Concato, J.; Kemper, E.; Holford, T.R.; Feinstein, A.R. A simulation study of the number of events per variable in logistic regression analysis. J. Clin. Epidemiol. 1996, 49, 1373–1379. [Google Scholar] [CrossRef]
- Swain, P.H.; Hauska, H. The decision tree classifier: Design and potential. IEEE Trans. Geosci. Electron. 1977, 15, 142–147. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach Learn 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Streiner, D.L.; Cairney, J. What’s under the ROC? An introduction to receiver operating characteristics curves. Can. J. Psychiatry 2007, 52, 121–128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernandez-Lozano, C.; Seoane, J.A.; Gestal, M.; Gaunt, T.R.; Dorado, J.; Pazos, A.; Campbell, C. Texture analysis in gel electrophoresis images using an integrative kernel-based approach. Sci. Rep. 2016, 6, 19256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ACC | AUROC | Precision | Recall | f1-Score |
|---|---|---|---|---|---|
| KNeighborsClassifier | 0.7093 | 0.7882 | 0.7121 | 0.7093 | 0.7105 |
| GaussianNB | 0.6553 | 0.6752 | 0.6203 | 0.6553 | 0.5968 |
| LinearDiscriminantAnalysis | 0.7266 | 0.7988 | 0.7220 | 0.7266 | 0.7236 |
| LogisticRegression | 0.7206 | 0.8002 | 0.7150 | 0.7206 | 0.7169 |
| DecisionTreeClassifier | 0.8586 | 0.8544 | 0.8576 | 0.8586 | 0.8580 |
| RandomForestClassifier | 0.7923 | 0.8714 | 0.7943 | 0.7923 | 0.7931 |
| XGBClassifier | 0.7574 | 0.8502 | 0.7566 | 0.7574 | 0.7570 |
| GradientBoostingClassifier | 0.7599 | 0.8526 | 0.7603 | 0.7599 | 0.7601 |
| BaggingClassifier | 0.8657 | 0.9475 | 0.8655 | 0.8657 | 0.8656 |
| AdaBoostClassifier | 0.7175 | 0.8100 | 0.7100 | 0.7175 | 0.7119 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Munteanu, C.R.; Gutiérrez-Asorey, P.; Blanes-Rodríguez, M.; Hidalgo-Delgado, I.; Blanco Liverio, M.d.J.; Castiñeiras Galdo, B.; Porto-Pazos, A.B.; Gestal, M.; Arrasate, S.; González-Díaz, H. Prediction of Anti-Glioblastoma Drug-Decorated Nanoparticle Delivery Systems Using Molecular Descriptors and Machine Learning. Int. J. Mol. Sci. 2021, 22, 11519. https://doi.org/10.3390/ijms222111519
Munteanu CR, Gutiérrez-Asorey P, Blanes-Rodríguez M, Hidalgo-Delgado I, Blanco Liverio MdJ, Castiñeiras Galdo B, Porto-Pazos AB, Gestal M, Arrasate S, González-Díaz H. Prediction of Anti-Glioblastoma Drug-Decorated Nanoparticle Delivery Systems Using Molecular Descriptors and Machine Learning. International Journal of Molecular Sciences. 2021; 22(21):11519. https://doi.org/10.3390/ijms222111519
Chicago/Turabian StyleMunteanu, Cristian R., Pablo Gutiérrez-Asorey, Manuel Blanes-Rodríguez, Ismael Hidalgo-Delgado, María de Jesús Blanco Liverio, Brais Castiñeiras Galdo, Ana B. Porto-Pazos, Marcos Gestal, Sonia Arrasate, and Humbert González-Díaz. 2021. "Prediction of Anti-Glioblastoma Drug-Decorated Nanoparticle Delivery Systems Using Molecular Descriptors and Machine Learning" International Journal of Molecular Sciences 22, no. 21: 11519. https://doi.org/10.3390/ijms222111519
APA StyleMunteanu, C. R., Gutiérrez-Asorey, P., Blanes-Rodríguez, M., Hidalgo-Delgado, I., Blanco Liverio, M. d. J., Castiñeiras Galdo, B., Porto-Pazos, A. B., Gestal, M., Arrasate, S., & González-Díaz, H. (2021). Prediction of Anti-Glioblastoma Drug-Decorated Nanoparticle Delivery Systems Using Molecular Descriptors and Machine Learning. International Journal of Molecular Sciences, 22(21), 11519. https://doi.org/10.3390/ijms222111519