Molecular Cloning and Bioinformatics Analysis of DQA Gene from Mink (Neovison vison)

Abstract
:1. Introduction
2. Results
2.1. Molecular Cloning of DQA from Neovison vison
2.2. Molecular Characterization of DQA from Neovison vison
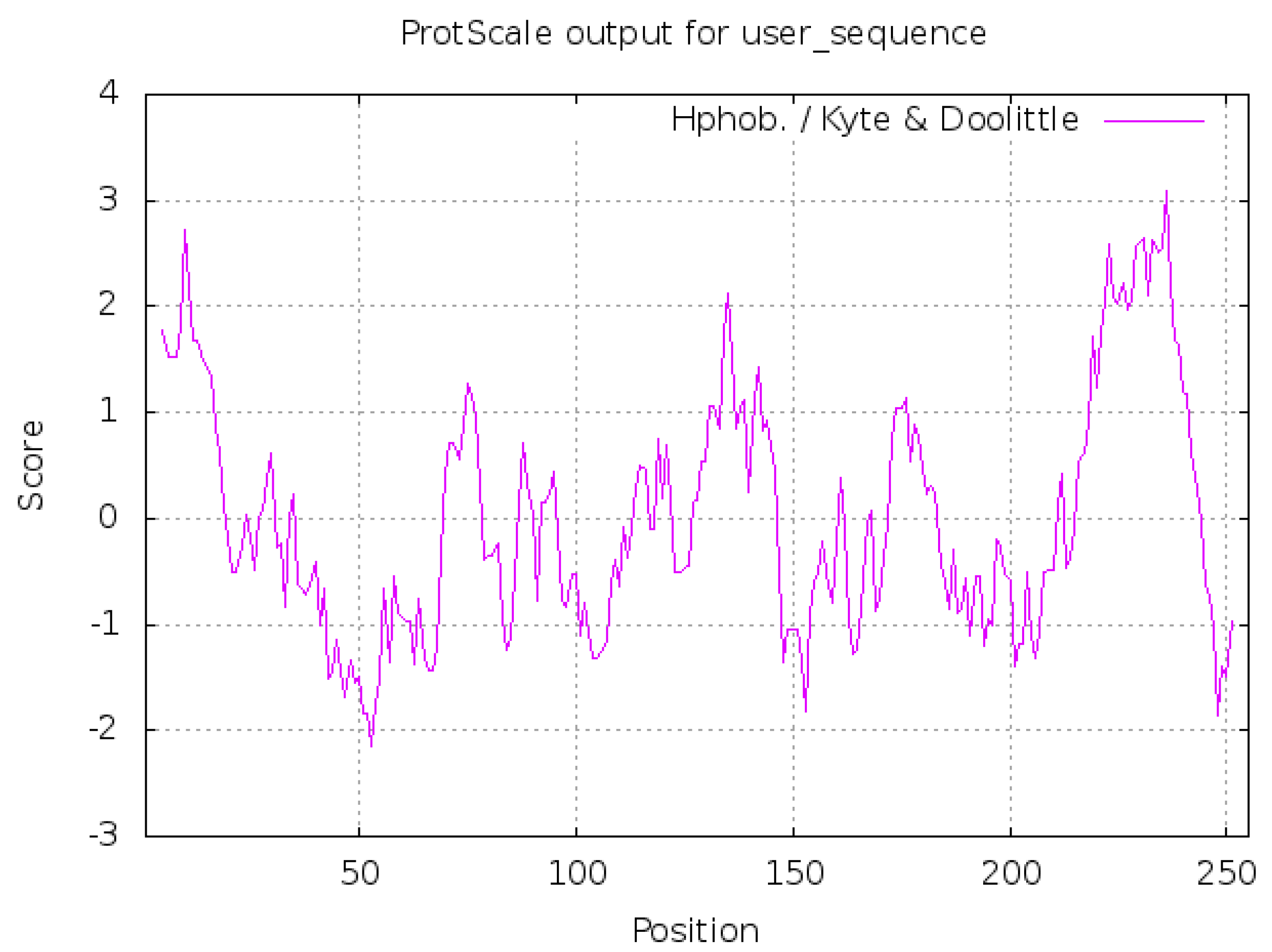
2.2.1. Hydrophilic and Hydrophobic Analysis of Neovison vison DQA Protein
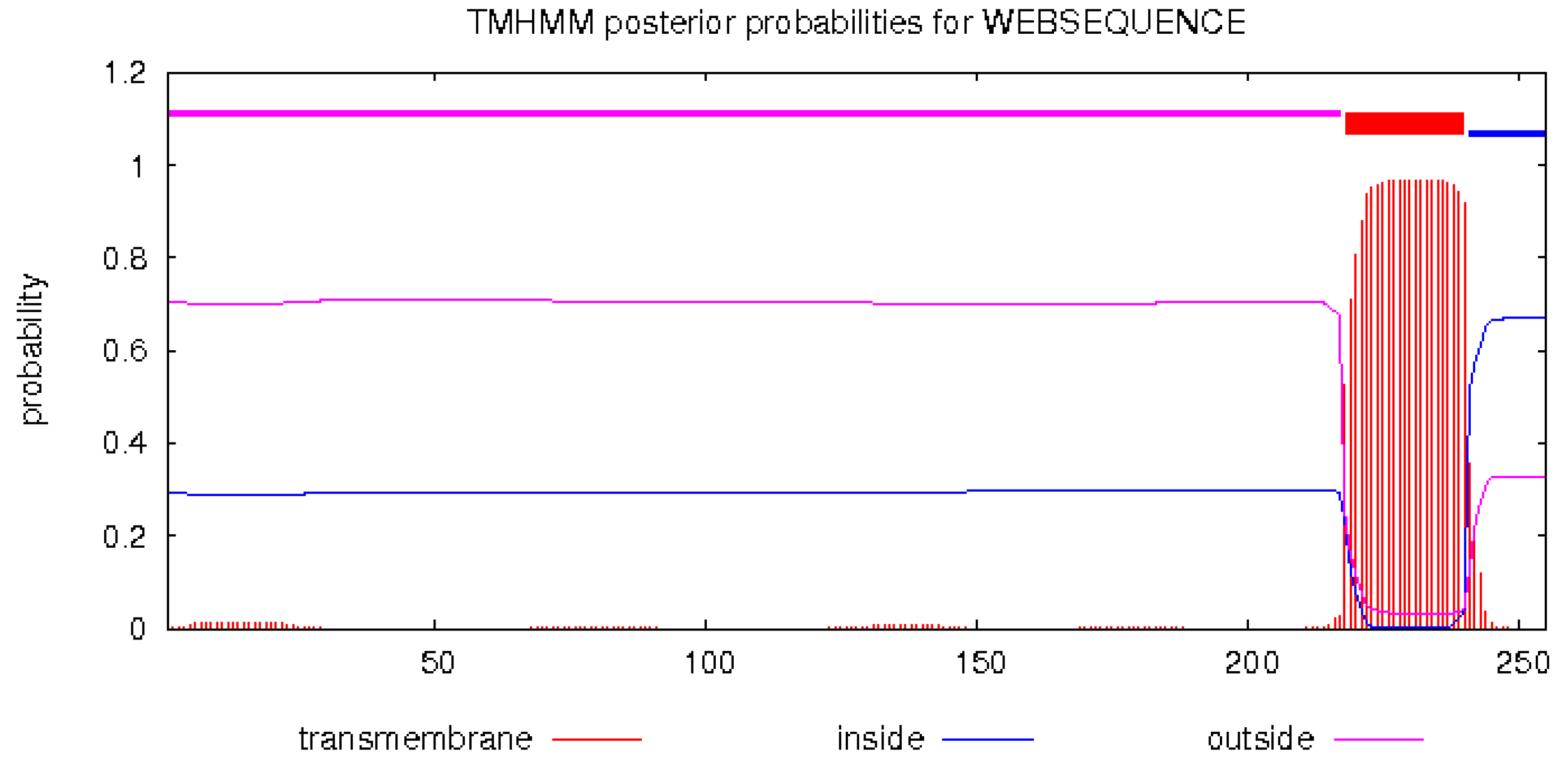
2.2.2. Prediction of Transmembrane Helical Structure of Neovison vison DQA Protein
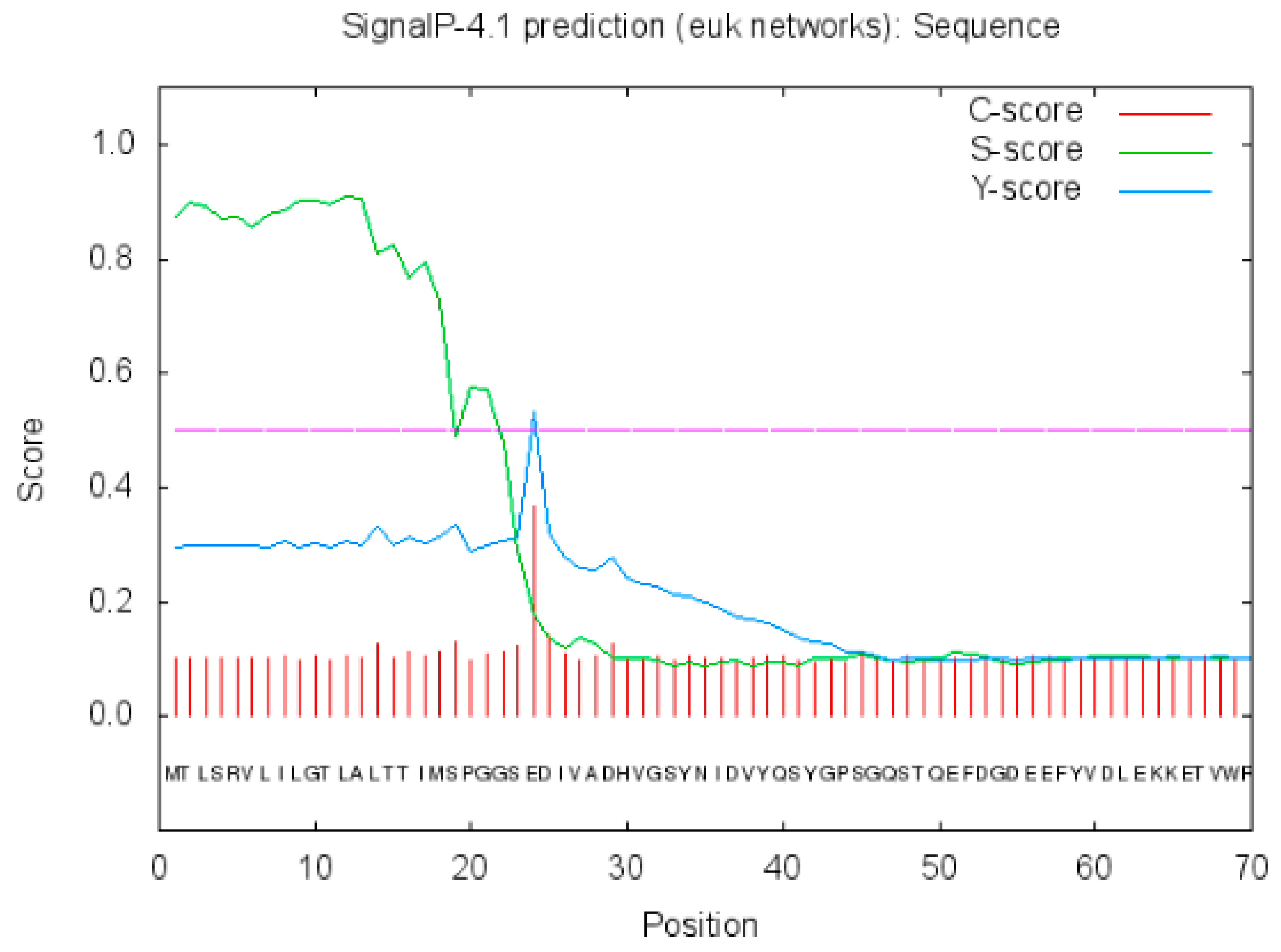
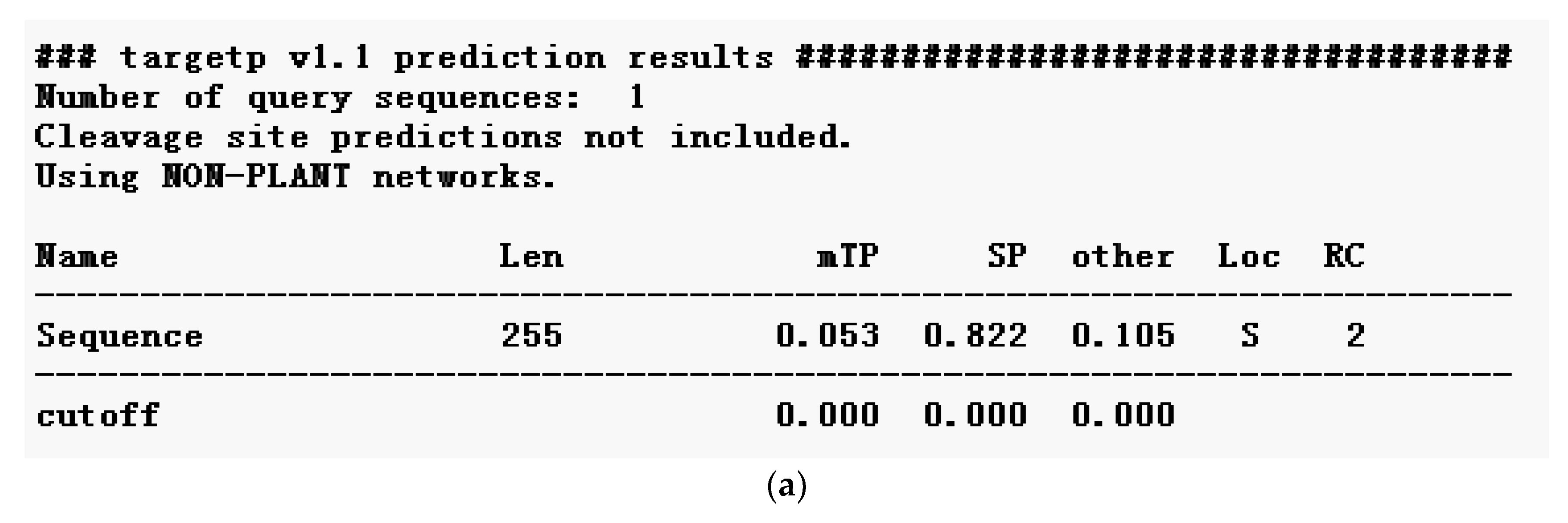
2.2.3. Prediction of Signal Peptide of Neovison vison DQA Protein
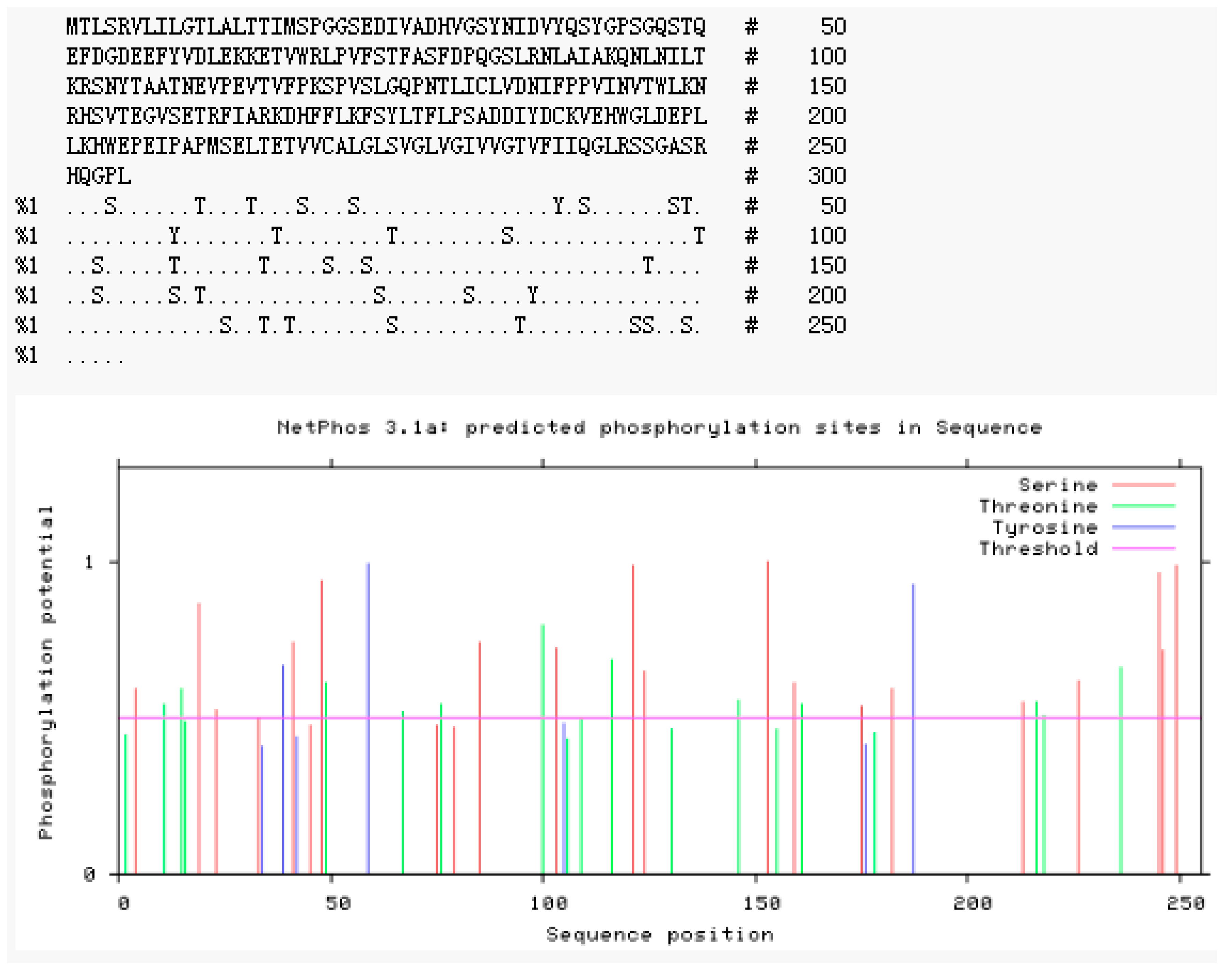
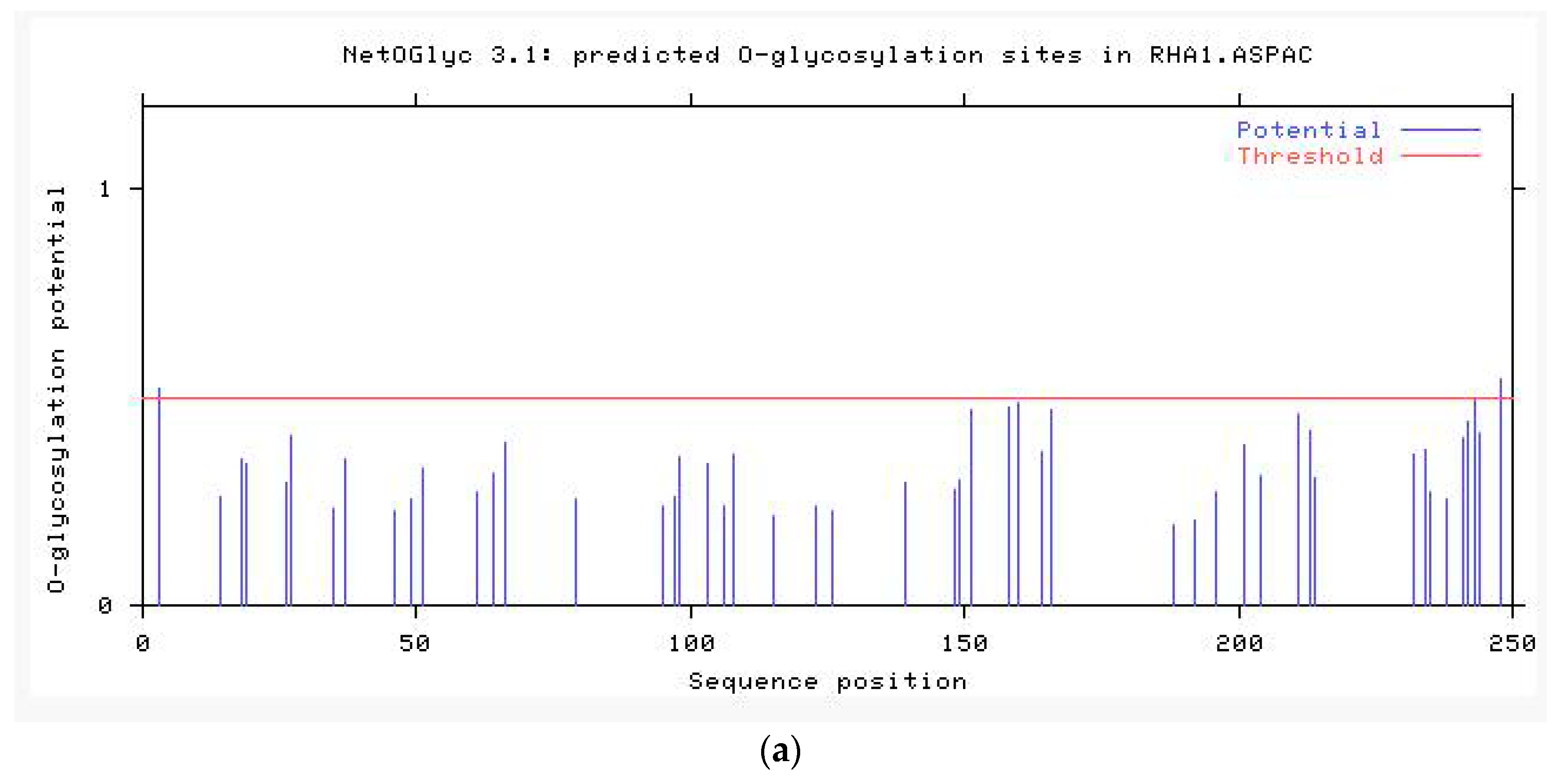
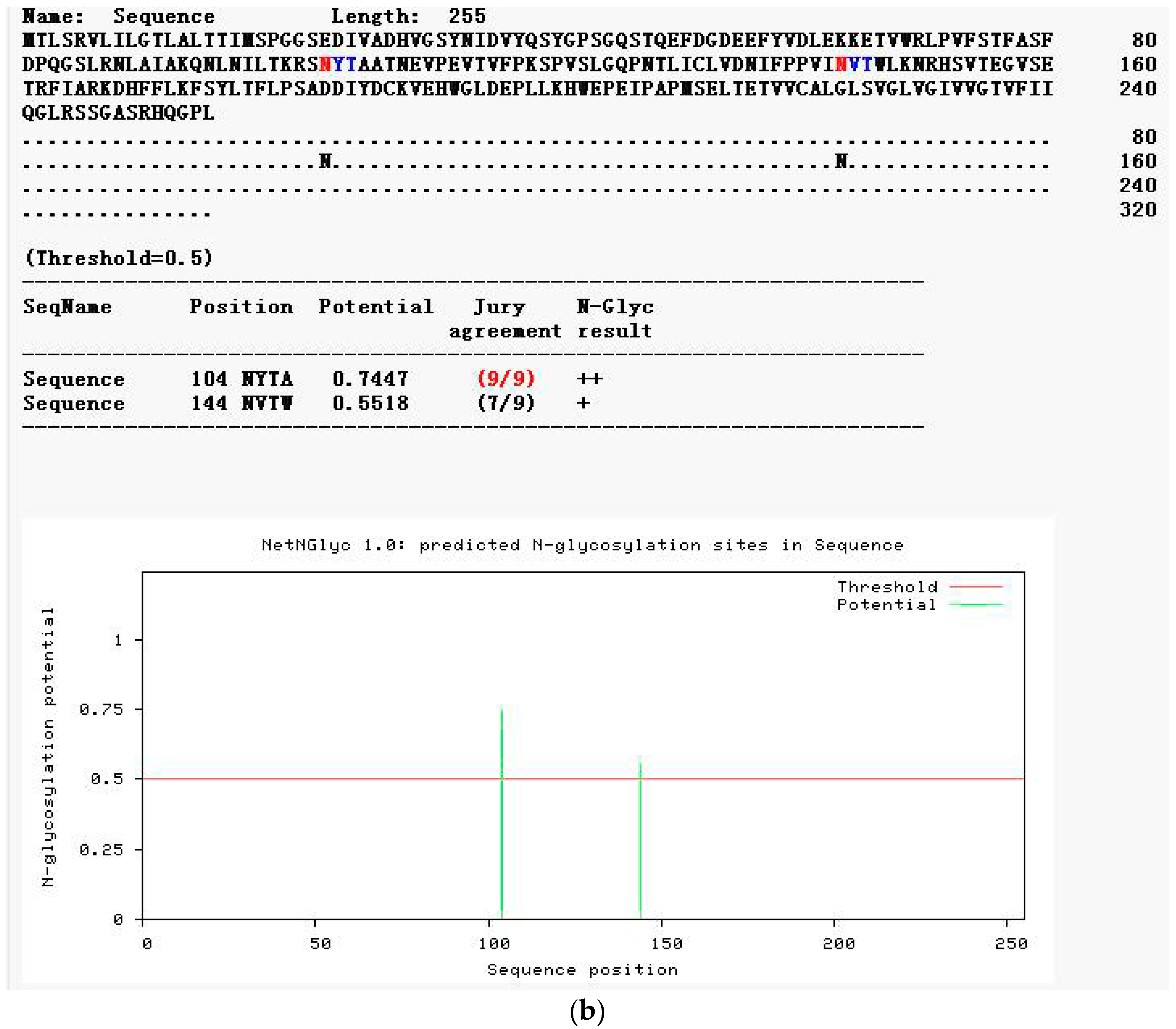
2.2.4. Modification Prediction of the Neovison vison DQA Protein Structure
2.2.5. Subcellular Localization and Domain Prediction of Neovison vison DQA Protein
2.2.6. Function Prediction of DQA Protein
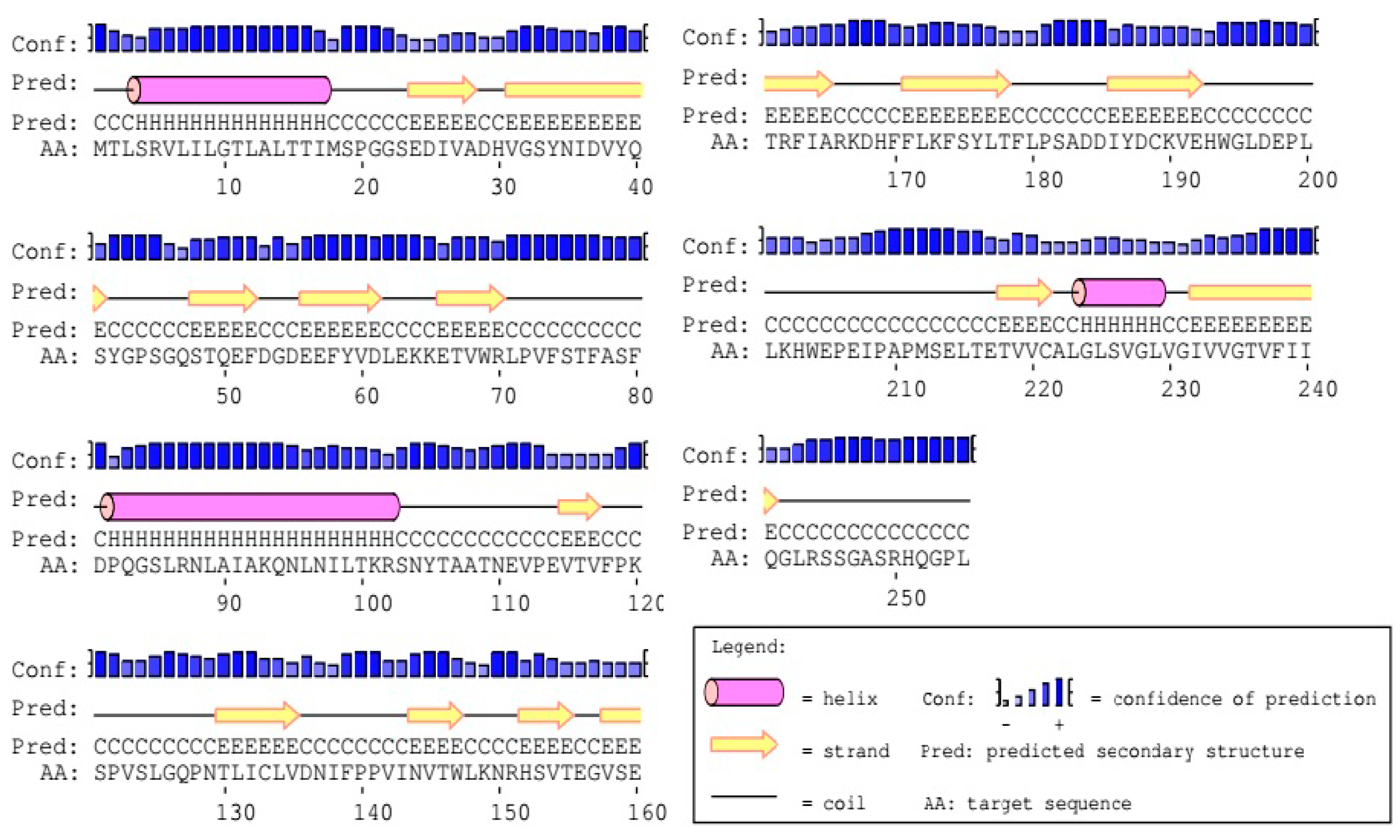
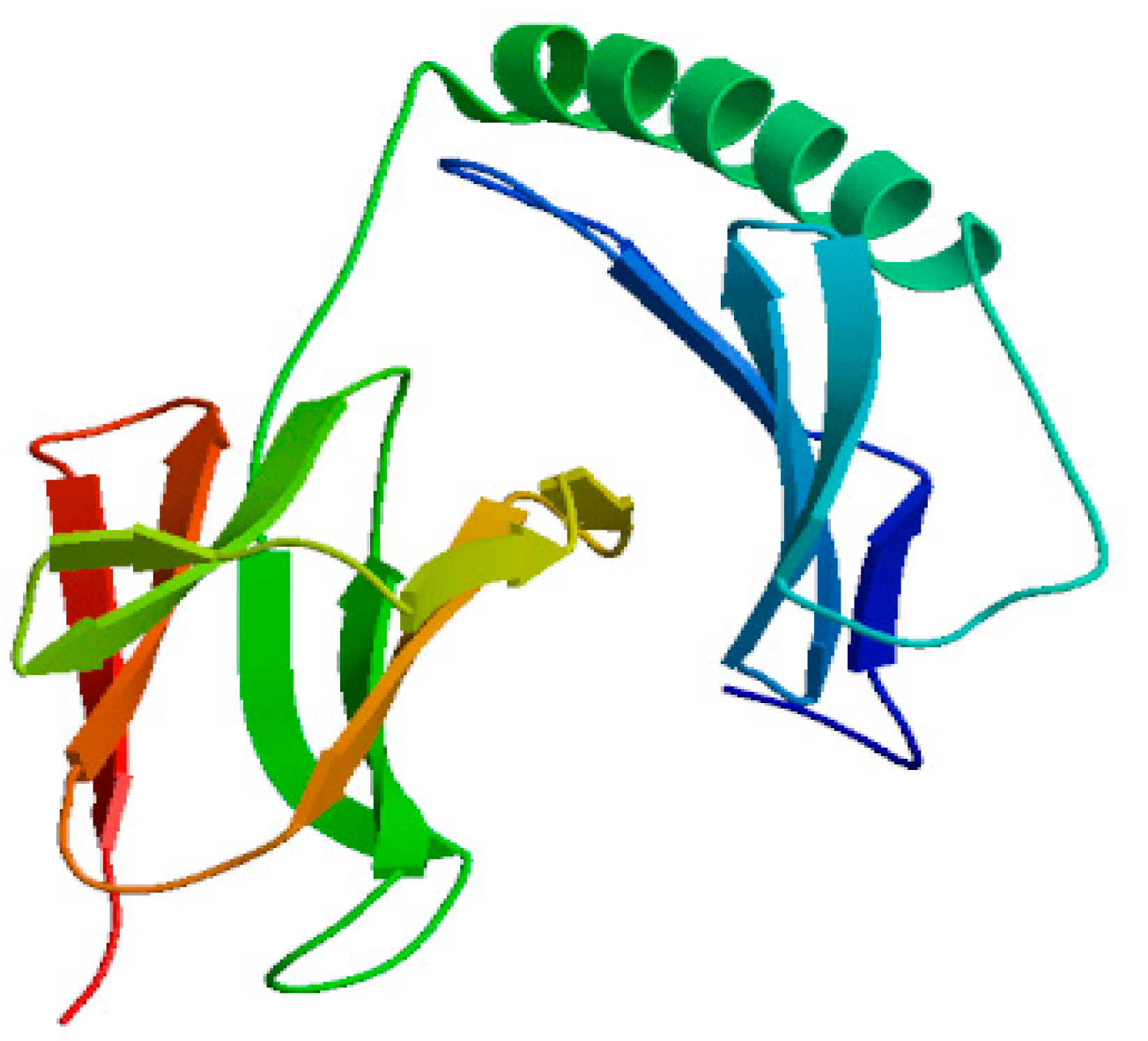
2.2.7. Advanced Structure Prediction of DQA Protein
3. Discussion
4. Materials and Methods
4.1. Experimental Mink
4.2. RNA Extraction, cDNA Synthesis, and Reverse Transcription PCR
4.3. Oligonucleotide Design and Molecular Cloning of DQA
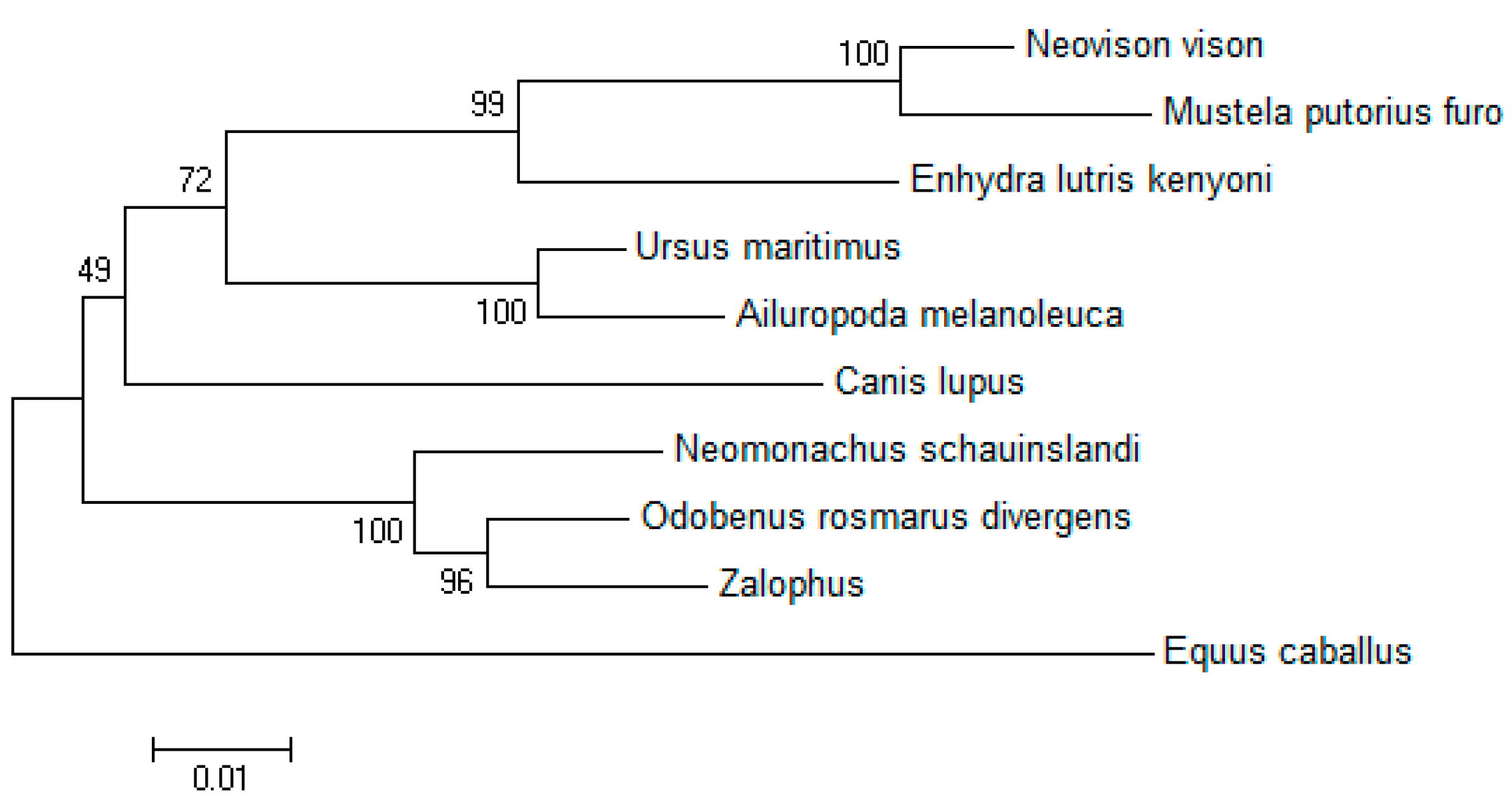
4.4. Multiple Sequence Alignment and Phylogenetic Analysis
4.5. Bioinformatics of DQA
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Steidl, C.; Shah, S.P.; Woolcock, B.W.; Rui, L.; Kawahara, M.; Farinha, P.; Johnson, N.A.; Zhao, Y.; Telenius, A.; Neriah, S.B.; et al. MHC class II transactivator CIITA is a recurrent gene fusion partner in lymphoid cancers. Nature 2011, 471, 377–381. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, A.; Dohr, G.; Uchanska, Z.B. Possible Roles for Products of Polymorphic MHC and Linked Olfactory Receptor Genes during Selection Processes in Reproduction. Am. J. Reprod. Immunol. 2015, 48, 34–42. [Google Scholar] [CrossRef]
- Juul-Madsen, H.R.; Dalgaard, T.S.; Afanassieff, M. Molecular characterization of major and minor MHC class I and II genes in B21-like haplotypes in chickens. Anim. Genet. 2015, 31, 252–261. [Google Scholar] [CrossRef]
- Gao, W.J.; Zhu, Z.Y. Polymorphic Analysis of MHC-DQA and MHC-DRB Gene Exon 2 in Asiatic Black Bear (Ursus thibetanus). China Anim. Husb. Vet. Med. 2014, 41, 157–164. [Google Scholar]
- Mckinney, D.M.; Southwood, S.; Hinz, D.; Oseroff, C.; Arlehamn, C.S.; Schulten, V.; Taplitz, R.; Broide, D.; Hanekom, W.A.; Scriba, T.J.; et al. A strategy to determine HLA class II restriction broadly covering the DR, DP and DQ allelic variants most commonly expressed in the general population. Immunogenetics 2013, 65, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Hulme, D.J.; Nicholas, F.W.; Windon, R.G.; Brown, S.C.; Beh, K.J. The MHC class II region and resistance to an intestinal parasite in sheep. J. Anim. Breed. Genet. 1993, 110, 459–472. [Google Scholar] [CrossRef] [PubMed]
- Wilbe, M.; Andersson, G. MHC Class II is an Important Genetic Risk Factor for Canine Systemic Lupus Erythematosus (SLE)-Related Disease: Implications for Reproductive Success. Reprod. Domestic Anim. 2012, 47, 27–30. [Google Scholar] [CrossRef] [PubMed]
- Breeze, J.; Newbery, T.; Pope, D.; Cosson, J.F. Duplication, balancing selection and trans-species evolution explain the high levels of polymorphism of the DQA MHC class II gene in voles (Arvicolinae). Immunogenetics 2006, 58, 191–202. [Google Scholar]
- Liu, Z.Z.; Xia, J.H.; Xin, L.L.; Wang, Z.G.; Qian, L.; Wu, S.G.; Yang, S.L.; Li, K. Swine leukocyte antigen class II genes (SLA-DRA, SLA-DRB1, SLA-DQA, SLA-DQB1) polymorphism and genotyping in Guizhou minipigs. Genet. Mol. Res. 2015, 14, 15256–15266. [Google Scholar] [CrossRef] [PubMed]
- Łopienska, M.; Nowak, Z.; Charon, K.M.; Charon, W.O. A comparison of polymorphism of DQA genes in European bison belonging to two genetic lines: Lowland and Lowland-Caucasian. Ann. Warsaw Univ. Life Sci. SGGW Anim. Sci. 2011, 49, 93–102. [Google Scholar]
- Deter, J.; Bryja, J.; Chaval, Y.; Galan, M.; Henttonen, H.; Laakkonen, J.; Voutilainen, L.; Vapalahti, O.; Vaheri, A.; Salvador, A.R.; et al. Association between the DQA MHC class II gene and Puumala virus infection in Myodes glareolus, the bank vole. Infect. Genet. Evol. 2008, 8, 450–458. [Google Scholar] [CrossRef] [PubMed]
- Bao, W.B.; Ye, L.; Zi, C.; Liu, L.; Zhu, J.; Pan, Z.Y.; Zhu, G.Q.; Huang, X.G.; Wu, S.L. Relationship between the expression level of SLA-DQA and Escherichia coli F18 infection in piglets. Gene 2012, 494, 140–144. [Google Scholar] [CrossRef] [PubMed]
- Li, G.Y.; Bo, K.; Zhang, X.; Fangfang, S.; Shi, Y. Review on the Development of Special Economic Animal Breeding Industry in China. J. Agric. 2018, 8, 140–144. [Google Scholar]
- Gu, J.; Li, X.; Yang, M.; Du, C.; Cui, Z.; Gong, P.; Xia, F.; Song, J.; Zhang, L.; Li, J.; et al. Therapeutic effect of Pseudomonas aeruginosa phage YH30 on mink hemorrhagic pneumonia. Vet. Microbiol. 2016, 190, 5–11. [Google Scholar] [CrossRef] [PubMed]
- Canuti, M.; O’Leary, K.E.; Hunter, B.D.; Spearman, G.; Ojkic, D.; Whitney, H.G.; Lang, A.S. Driving forces behind the evolution of the Aleutian mink disease parvovirus in the context of intensive farming. Virus Evol. 2016, 2, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Broll, S.; Alexandersen, S. Investigation of the pathogenesis of transplacental transmission of Aleutian mink disease parvovirus in experimentally infected mink. J. Virol. 1996, 70, 1455–1466. [Google Scholar] [PubMed]
- Christensen, L.S.; Gram-Hansen, L.; Chriél, M.; Jensen, T.H. Diversity and stability of Aleutian mink disease virus during bottleneck transitions resulting from eradication in domestic mink in Denmark. Vet. Microbiol. 2011, 149, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Cong, B.; Liu, L.L.; Zhao, H.P.; Najakshin, A.M.; Belousov, E.S.; Bogachev, S.V.; Baranov, O.K. Construction and Identification of cDNA Library from Mink Spleen. J. Jilin Agric. Univ. 2009, 31, 81–83. [Google Scholar]
- Becker, L.; Nieberg, C.; Jahreis, K.; Peters, E. MHC class II variation in the endangered European mink Mustela. Immunogenetics 2009, 61, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.B.; Gao, W.Y.; Wang, C.Q. PCR-SSCP polymorphism analysis of the second exon of MuLu-DQB_1 gene among 5 mink breeds. Anim. Husb. Vet. Med. 2013, 45, 40–43. [Google Scholar]
- Hirsch, F.; Germana, S.; Gustafsson, K.; Pratt, K.; Sachs, D.H.; Leguern, C. Structure and expression of class II alpha genes in miniature swine. J. Immunol. 1992, 149, 841–846. [Google Scholar] [PubMed]
- Ballingal, K.T.; Fardoe, K.; McKeever, D.J. Genomic organisation and allelic diversity within coding and noncoding regions of the Ovar-DRB1 locus. Immunologenetics 2008, 60, 95–103. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.L.; Huang, X.Y.; Zhao, S.G.; Liu, L.X.; Zhang, S.W.; Huang, W.Z.; Gun, S.B. Effect of swine leukocyte antigen-DQA gene variation on diarrhea in Large White, Landrace, and Duroc piglets. Anim. Genet. 2016, 47, 691–697. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.L.; Huang, X.Y.; Kong, J.J.; Zhao, S.G.; Liu, L.X.; Gun, S.B. Genetic association of sequence variation in exon 3 of the swine leukocyte antigen-DQA gene with piglet diarrhea in Large White, Landrace, and Duroc piglets. Genet. Mol. Res. 2016, 15. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.X.; Zhao, S.G.; Lu, H.N.; Yang, Q.L.; Huang, X.Y.; Gun, S.B. Association between polymorphisms of the swine MHC-DQA gene and diarrhoea in three Chinese native piglets. Int. J. Immunogenet. 2015, 42, 208–216. [Google Scholar] [CrossRef] [PubMed]
- Xing, F.; Qing, Z.J.; Wang, G.Z.; Ji, Z.B.; Wang, J.M. Association of polymorphisms of exon 2 of GOLA-DQA2 gene with blood immune traits in goats. Hereditas 2013, 35, 185–191. [Google Scholar] [CrossRef] [PubMed]
- Memon, S.; Wang, L.; Li, G.; Liu, L.; Zhu, J.; Pan, Z.Y.; Zhu, G.Q.; Huang, X.G.; Wu, S.L. Isolation and characterization of the major histocompatibility complex DQA1, and DQA2, genes in gayal (Bos frontalis). J. Genet. 2018, 1–6. [Google Scholar] [CrossRef]
- Niranjan, S.K.; Deb, S.M.; Sharma, A.; Mitra, A.; Kumar, S. Isolation of two cDNAs encoding MHC-DQA1 and -DQA2 from the water buffalo, Bubalus bubalis. Vet. Immunol. Immunopathol. 2009, 130, 268–271. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhang, L.; Zhao, S.G.; Gun, S. Cloning and Bioinformatics Analysis on Coding Regions of DQA Gene in Bamei Pigs. Acta Agric. Boreali-Sin. 2015, 30, 103–108. [Google Scholar]
- Chao, Z.; Li, J.L.; Qin, Y.; Wang, F.; Zheng, X.L. Detection of Single Nucleotide Polymorphism and Bioinformatics Analysis of SLA-DQA and SLA-DQB Genes in Wuzhishan Pig. Swine Prod. 2017, 6, 57–60. [Google Scholar]
- Hao, J. Relationship between intracellular protein half-life and subcellular localization in human cells. Comput. Appl. Chem. 2011, 28, 29–32. [Google Scholar]
- Ying, R.; Zhang, Y.; Xia, H.; Xiangzu, W.; Chaocheng, L.; Xuhai, W.; Jifeng, X.; Bin, J. cDNA Cloning and Bioinformatics Analysis of Zfy Gene in Equus asinus. China Anim. Husb. Vet. Med. 2018, 49, 39–46. [Google Scholar]
- Shen, S.; Wang, M.; Li, X.; Li, S.; van Oers, M.M.; Vlak, J.M.; Braakman, I.; Hu, Z.; Deng, F.; Wang, H. Mutational and Functional Analysis of N-linked Glycosylation of Envelope Fusion Protein F of Helicoverpa armigera Nucleopolyhedrovirus. J. Gen. Virol. 2016, 97, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, Y.; Yang, J.Y.; Moremen, K.W.; Prestegard, J.H. Glycosylation alters dimerization properties of a cell-surface signaling protein, CEACAM1. J. Biol. Chem. 2016, 291, 20085. [Google Scholar] [CrossRef] [PubMed]
- Wagner, J.L.; Burnett, R.C.; Derose, S.A.; Storb, R. Molecular analysis and polymorphism of the DLA-DQA gene. Tissue Antigens 1996, 48, 199–204. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.Y.; Yuang, J.H.; Yang, Q.L.; Ma, Y.; Gun, S. Polymorphism and Bioinformatics Analysis of SLA-DQA Gene CDs in Yantai Black Pig. Acta Agric. Boreali-Sin. 2016, 31, 86–93. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene Ontology Category | Odds |
|---|---|
| Metal-ion-transport | 0.039 |
| Growth-factor | 0.357 |
| Immune-response | 0.129 |
| Stress-response | 0.830 |
| Transcription-regulation | 0.888 |
| Ion channel | 3.174 |
| Voltage-gated-ion channel | 12.682 |
| Transporter | 0.229 |
| Structural protein | 0.107 |
| Hormone | 0.154 |
| Receptor | 0.041 |
| Signal-transducer | 0.958 |
| Position | Name | Sequence (5′–3′) bp | Annealing Temperature | Expect Size (bp) |
|---|---|---|---|---|
| 32–665 | F1U | TTACTGCTGCTCTGCAACTCA | 58 | 634 |
| F1L | GTGCTCCACCTTGCAGTCAT | |||
| 108–1163 | F2U | ATTCTGGGGACTCTTGCCCT | 60 | 1056 |
| F2L | TGGGAGTTCTGGATCAGGGTT | |||
| 1046–1231 | F3U | ATTCTGCACCTTGAATGGCTG | 60 | 196 |
| F3L | CAGTTCTGAGATGAAAGAAAGGAAA |
| Species | Accession Number |
|---|---|
| Mustela pulourius furo | XM_004782395.2 |
| Enhydra lutris | XM_022510513.1 |
| Ursus maritimus | XM_008693471.1 |
| Ailuropoda melanoleuca | XM_002928248.3 |
| Odobenus rosmarus divergens | XM_004417612.1 |
| Zalophus | AF502564.1 |
| Canis lupus | NM_001011726.1 |
| Neomonachus schauinslandi | XM_021684531.1 |
| Equus caballus | NM_001142814.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Z.; Zhang, H.; Rong, M.; Meng, D.; Yu, Z.; Jiang, L.; Jiang, P. Molecular Cloning and Bioinformatics Analysis of DQA Gene from Mink (Neovison vison). Int. J. Mol. Sci. 2019, 20, 1037. https://doi.org/10.3390/ijms20051037
Fan Z, Zhang H, Rong M, Meng D, Yu Z, Jiang L, Jiang P. Molecular Cloning and Bioinformatics Analysis of DQA Gene from Mink (Neovison vison). International Journal of Molecular Sciences. 2019; 20(5):1037. https://doi.org/10.3390/ijms20051037
Chicago/Turabian StyleFan, Zhaobin, Houfeng Zhang, Min Rong, Dongmei Meng, Zhenxing Yu, Lili Jiang, and Peihong Jiang. 2019. "Molecular Cloning and Bioinformatics Analysis of DQA Gene from Mink (Neovison vison)" International Journal of Molecular Sciences 20, no. 5: 1037. https://doi.org/10.3390/ijms20051037
APA StyleFan, Z., Zhang, H., Rong, M., Meng, D., Yu, Z., Jiang, L., & Jiang, P. (2019). Molecular Cloning and Bioinformatics Analysis of DQA Gene from Mink (Neovison vison). International Journal of Molecular Sciences, 20(5), 1037. https://doi.org/10.3390/ijms20051037