Quantitative Structure-Activity Relationship Study of Antioxidant Tripeptides Based on Model Population Analysis

 ,
, 

Abstract
:
1. Introduction
2. Results
2.1. FTC Dataset
2.2. FRAP Dataset
3. Discussion
3.1. Comparison with the Reported Models
3.2. Relationship between Antioxidant Activities and Peptide Structures
3.3. The Integration of Amino Acid Descriptors
4. Materials and Methods
4.1. Data Collection
4.1.1. Ferric Thiocyanate (FTC) Dataset
4.1.2. Ferric-reducing Antioxidant Power (FRAP) Dataset
4.2. Data Processing
4.3. QSAR Model Building
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BOSS | the bootstrapping soft shrinkage method |
| DPPH | 2,2-diphenyl-1-picrylhydrazyl radical-scavenging capacity |
| FRAP | ferric-reducing antioxidant power |
| FTC | ferric thiocyanate |
| MPA | model population analysis |
| ORAC | oxygen radical absorbance capacity |
| PLS | partial least squares |
| QSAR | quantitative structure-activity relationships |
| TEAC | Trolox equivalent antioxidant capacity |
| TRAP | total radical trapping antioxidant parameter |
References
- Chakrabarti, S.; Guha, S.; Majumder, K. Food-Derived Bioactive Peptides in Human Health: Challenges and Opportunities. Nutrients 2018, 10, 1738. [Google Scholar] [CrossRef] [PubMed]
- Lorenzo, J.M.; Munekata, P.E.S.; Gomez, B.; Barba, F.J.; Mora, L.; Perez-Santaescolastica, C.; Toldra, F. Bioactive peptides as natural antioxidants in food products—A review. Trends Food Sci. Technol. 2018, 79, 136–147. [Google Scholar] [CrossRef]
- Sila, A.; Bougatef, A. Antioxidant peptides from marine by-products: Isolation, identification and application in food systems. A review. J. Funct. Foods 2016, 21, 10–26. [Google Scholar] [CrossRef]
- MacDonald-Wicks, L.K.; Wood, L.G.; Garg, M.L. Methodology for the determination of biological antioxidant capacity in vitro: A review. J. Sci. Food Agric. 2006, 86, 2046–2056. [Google Scholar] [CrossRef]
- Zou, T.B.; He, T.P.; Li, H.B.; Tang, H.W.; Xia, E.Q. The Structure-Activity Relationship of the Antioxidant Peptides from Natural Proteins. Molecules 2016, 21, 72. [Google Scholar] [CrossRef] [PubMed]
- Deng, B.; Ni, X.; Zhai, Z.; Tang, T.; Tan, C.; Yan, Y.; Deng, J.; Yin, Y. New Quantitative Structure-Activity Relationship Model for Angiotensin-Converting Enzyme Inhibitory Dipeptides Based on Integrated Descriptors. J. Agric. Food Chem. 2017, 65, 9774–9781. [Google Scholar] [CrossRef] [PubMed]
- Vishnepolsky, B.; Gabrielian, A.; Rosenthal, A.; Hurt, D.E.; Tartakovsky, M.; Managadze, G.; Grigolava, M.; Makhatadze, G.I.; Pirtskhalava, M. Predictive Model of Linear Antimicrobial Peptides Active against Gram-Negative Bacteria. J. Chem. Inf. Model. 2018, 58, 1141–1151. [Google Scholar] [CrossRef] [PubMed]
- Chen, N.; Chen, J.; Yao, B.; Li, Z.G. QSAR Study on Antioxidant Tripeptides and the Antioxidant Activity of the Designed Tripeptides in Free Radical Systems. Molecules 2018, 23, 1407. [Google Scholar] [CrossRef] [PubMed]
- Liao, W.Z.; Gu, L.J.; Zheng, Y.M.; Zhu, Z.S.; Zhao, M.M.; Liang, M.; Ren, J.Y. Analysis of the quantitative structure-activity relationship of glutathione-derived peptides based on different free radical scavenging systems. MedChemComm 2016, 7, 2083–2093. [Google Scholar] [CrossRef]
- Zheng, L.; Zhao, Y.; Dong, H.; Su, G.; Zhao, M. Structure-activity relationship of antioxidant dipeptides: Dominant role of Tyr, Trp, Cys and Met residues. J. Funct. Foods 2016, 21, 485–496. [Google Scholar] [CrossRef]
- Radman, A.; Gredicak, M.; Kopriva, I.; Jeric, I. Predicting Antitumor Activity of Peptides by Consensus of Regression Models Trained on a Small Data Sample. Int. J. Mol. Sci. 2011, 12, 8415–8430. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Qi, W.; Su, R.; Li, T.; Lu, D.; He, Z. CoMFA and CoMSIA analysis of ACE-inhibitory, antimicrobial and bitter-tasting peptides. Eur. J. Med. Chem. 2014, 84, 100–106. [Google Scholar] [CrossRef] [PubMed]
- Miner-Williams, W.M.; Stevens, B.R.; Moughan, P.J. Are intact peptides absorbed from the healthy gut in the adult human? Nutr. Res. Rev. 2014, 27, 308–329. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.-M.; Muramoto, K.; Yamauchi, F.; Nokihara, K. Antioxidant activity of designed peptides based on the antioxidative peptide isolated from digests of a soybean protein. J. Agric. Food Chem. 1996, 44, 2619–2623. [Google Scholar] [CrossRef]
- Wang, J.H.; Liu, Y.L.; Ning, J.H.; Yu, J.; Li, X.H.; Wang, F.X. Is the structural diversity of tripeptides sufficient for developing functional food additives with satisfactory multiple bioactivities? J. Mol. Struct. 2013, 1040, 164–170. [Google Scholar] [CrossRef]
- Deng, B.-C.; Yun, Y.-H.; Liang, Y.-Z. Model population analysis in chemometrics. Chemom. Intell. Lab. Syst. 2015, 149, 166–176. [Google Scholar] [CrossRef]
- Deng, B.C.; Lu, H.M.; Tan, C.Q.; Deng, J.P.; Yin, Y.L. Model population analysis in model evaluation. Chemom. Intell. Lab. Syst. 2018, 172, 223–228. [Google Scholar] [CrossRef]
- Deng, B.C.; Yun, Y.H.; Cao, D.S.; Yin, Y.L.; Wang, W.T.; Lu, H.M.; Luo, Q.Y.; Liang, Y.Z. A bootstrapping soft shrinkage approach for variable selection in chemical modeling. Anal. Chim. Acta 2016, 908, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Cao, D.S.; Liang, Y.Z.; Xu, Q.S.; Li, H.D.; Chen, X. A new strategy of outlier detection for QSAR/QSPR. J. Comput. Chem. 2010, 31, 592–602. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.W.; Li, B.; He, J.G.; Qian, P. Quantitative structure-activity relationship study of antioxidative peptide by using different sets of amino acids descriptors. J. Mol. Struct. 2011, 998, 53–61. [Google Scholar] [CrossRef]
- Tian, M.; Fang, B.; Jiang, L.; Guo, H.Y.; Cui, J.Y.; Ren, F.Z. Structure-activity relationship of a series of antioxidant tripeptides derived from beta-Lactoglobulin using QSAR modeling. Dairy Sci. Technol. 2015, 95, 451–463. [Google Scholar] [CrossRef]
- Deng, B.C.; Yun, Y.H.; Liang, Y.Z.; Yi, L.Z. A novel variable selection approach that iteratively optimizes variable space using weighted binary matrix sampling. Analyst 2014, 139, 4836–4845. [Google Scholar] [CrossRef] [PubMed]
- Saito, K.; Jin, D.H.; Ogawa, T.; Muramoto, K.; Hatakeyama, E.; Yasuhara, T.; Nokihara, K. Antioxidative properties of tripeptide libraries prepared by the combinatorial chemistry. J. Agric. Food Chem. 2003, 51, 3668–3674. [Google Scholar] [CrossRef] [PubMed]
- Benzie, I.F.F.; Strain, J.J. The ferric reducing ability of plasma (FRAP) as a measure of “Antioxidant power”: The FRAP assay. Anal. Biochem. 1996, 239, 70–76. [Google Scholar] [CrossRef] [PubMed]
- Hellberg, S.; Sjöström, M.; Skagerberg, B.; Wold, S. Peptide quantitative structure-activity relationships, a multivariate approach. J. Med. Chem. 1987, 30, 1126–1135. [Google Scholar] [CrossRef] [PubMed]
- Sandberg, M.; Eriksson, L.; Jonsson, J.; Sjöström, M.; Wold, S. New chemical descriptors relevant for the design of biologically active peptides. A multivariate characterization of 87 amino acids. J. Med. Chem. 1998, 41, 2481–2491. [Google Scholar] [CrossRef] [PubMed]
- Tian, F.; Yang, L.; Lv, F. In silico quantitative prediction of peptides binding affinity to human MHC molecule:an intuitive quantitative structure-activity relationship approach. Amino Acids 2009, 36, 535–554. [Google Scholar] [CrossRef] [PubMed]
- Zaliani, A.; Gancia, E. ChemInform Abstract: MS-WHIM Scores for Amino Acids: A New 3D-Description for Peptide QSAR and QSPR Studies. J. Chem. Inf. Model. 1999, 39, 525–533. [Google Scholar] [CrossRef]
- Collantes, E.R.; Rd, D.W. Amino acid side chain descriptors for quantitative structure-activity relationship studies of peptide analogues. J. Med. Chem. 1995, 38, 2705–2713. [Google Scholar] [CrossRef] [PubMed]
- Mei, H.; Liao, Z.H.; Zhou, Y.; Li, S.Z. A new set of amino acid descriptors and its application in peptide QSARs. Biopolymers 2005, 80, 775–786. [Google Scholar] [CrossRef] [PubMed]
- Liang, G.; Li, Z. Factor analysis scale of generalized amino acid information as the source of a new set of descriptors for elucidating the structure and activity relationships of cationic antimicrobial peptides. QSAR Comb. Sci. 2007, 26, 754–763. [Google Scholar] [CrossRef]
- Tong, J.B.; Liu, S.L.; Zhou, P.; Wu, B.L.; Li, Z.L. A novel descriptor of amino acids and its application in peptide QSAR. J. Theor. Biol. 2008, 253, 90–97. [Google Scholar] [CrossRef] [PubMed]
- Tian, F.F.; Zhou, P.; Li, Z.L. T-scale as a novel vector of topological descriptors for amino acids and its application in QSARs of peptides. J. Mol. Struct. 2007, 830, 106–115. [Google Scholar] [CrossRef]
- Yang, L.; Shu, M.; Ma, K.W.; Mei, H.; Jiang, Y.J.; Li, Z.L. ST-scale as a novel amino acid descriptor and its application in QSAM of peptides and analogues. Amino Acids 2010, 38, 805–816. [Google Scholar] [CrossRef] [PubMed]
- Venkatarajan, M.S.; Braun, W. New quantitative descriptors of amino acids based on multidimensional scaling of a large number of physical–chemical properties. Mol. Model. Annu. 2001, 7, 445–453. [Google Scholar]
- Lin, Z.H.; Long, H.X.; Bo, Z.; Wang, Y.Q.; Wu, Y.Z. New descriptors of amino acids and their application to peptide QSAR study. Peptides 2008, 29, 1798–1805. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Wang, J.; Lin, Y.; Ding, Y.; Wang, Y.Q.; Cheng, X.; Lin, Z. QSAR study on angiotensin-converting enzyme inhibitor oligopeptides based on a novel set of sequence information descriptors. J. Mol. Model. 2011, 17, 1599–1606. [Google Scholar] [CrossRef] [PubMed]
- Shu, M.; Mei, H.; Yang, S.B.; Liao, L.M.; Li, Z.L. Structural Parameter Characterization and Bioactivity Simulation Based on Peptide Sequence. Qsar Comb. Sci. 2009, 28, 27–35. [Google Scholar] [CrossRef]
- Shu, M.; Huo, D.Q.; Mei, H.; Liang, G.Z.; Zhang, M.; Li, Z.L. New Descriptors of Amino Acids and Its Applications to Peptide Quantitative Structure-activity Relationship. Chin. J. Struct. Chem. 2008, 27, 1375–1383. [Google Scholar]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2008, 58, 109–130. [Google Scholar] [CrossRef]

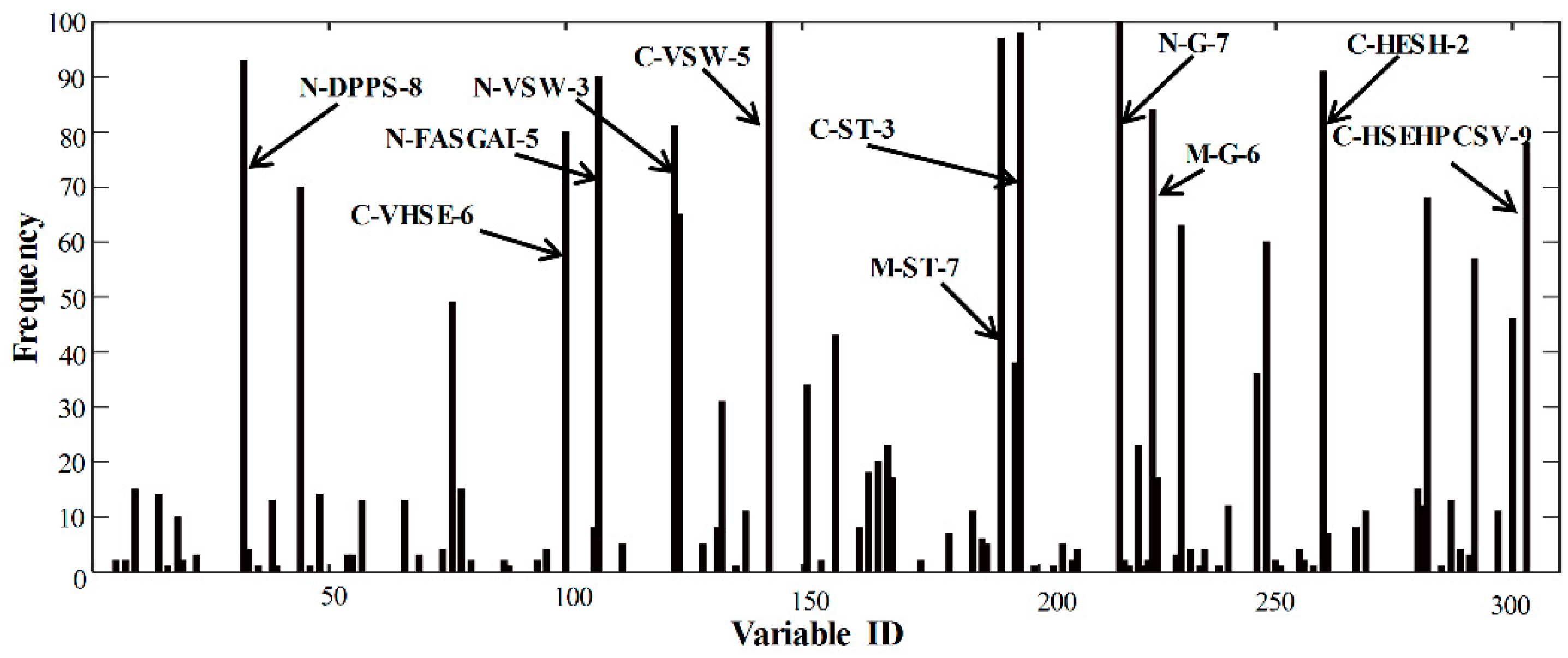
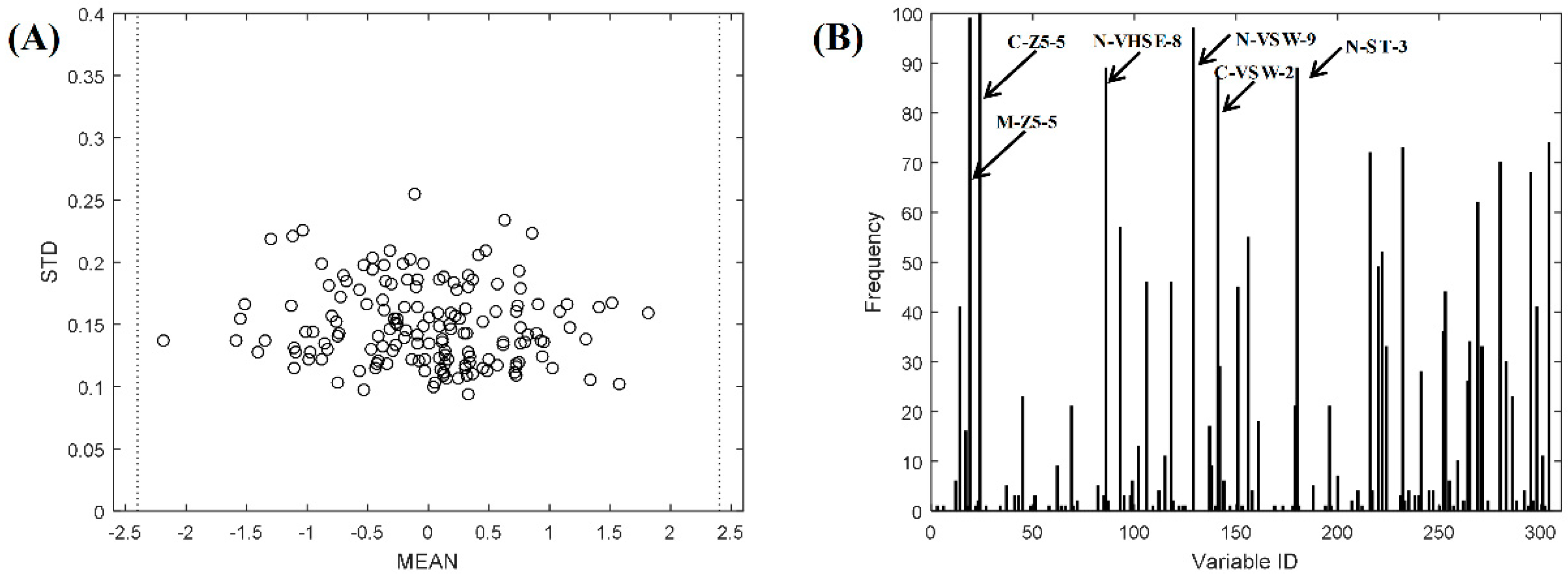

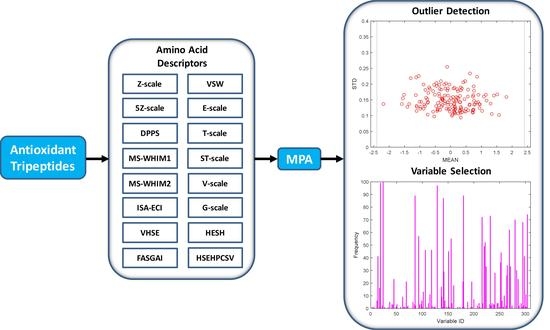
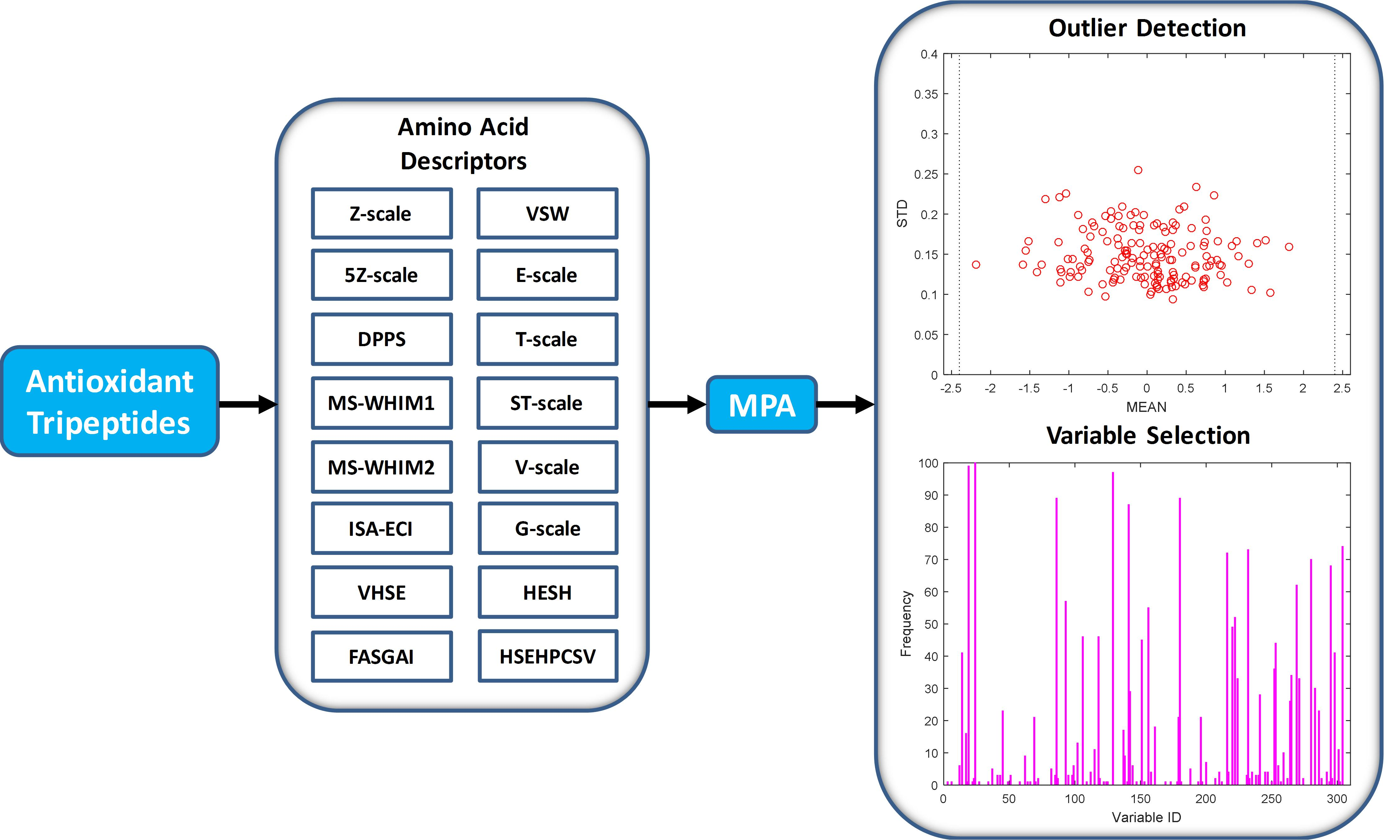{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Descriptors | Before Outlier Elimination | After Outlier Elimination | |||||
|---|---|---|---|---|---|---|---|
| Q2 | R2 | optPC | Q2 | R2 | optPC | Outlier | |
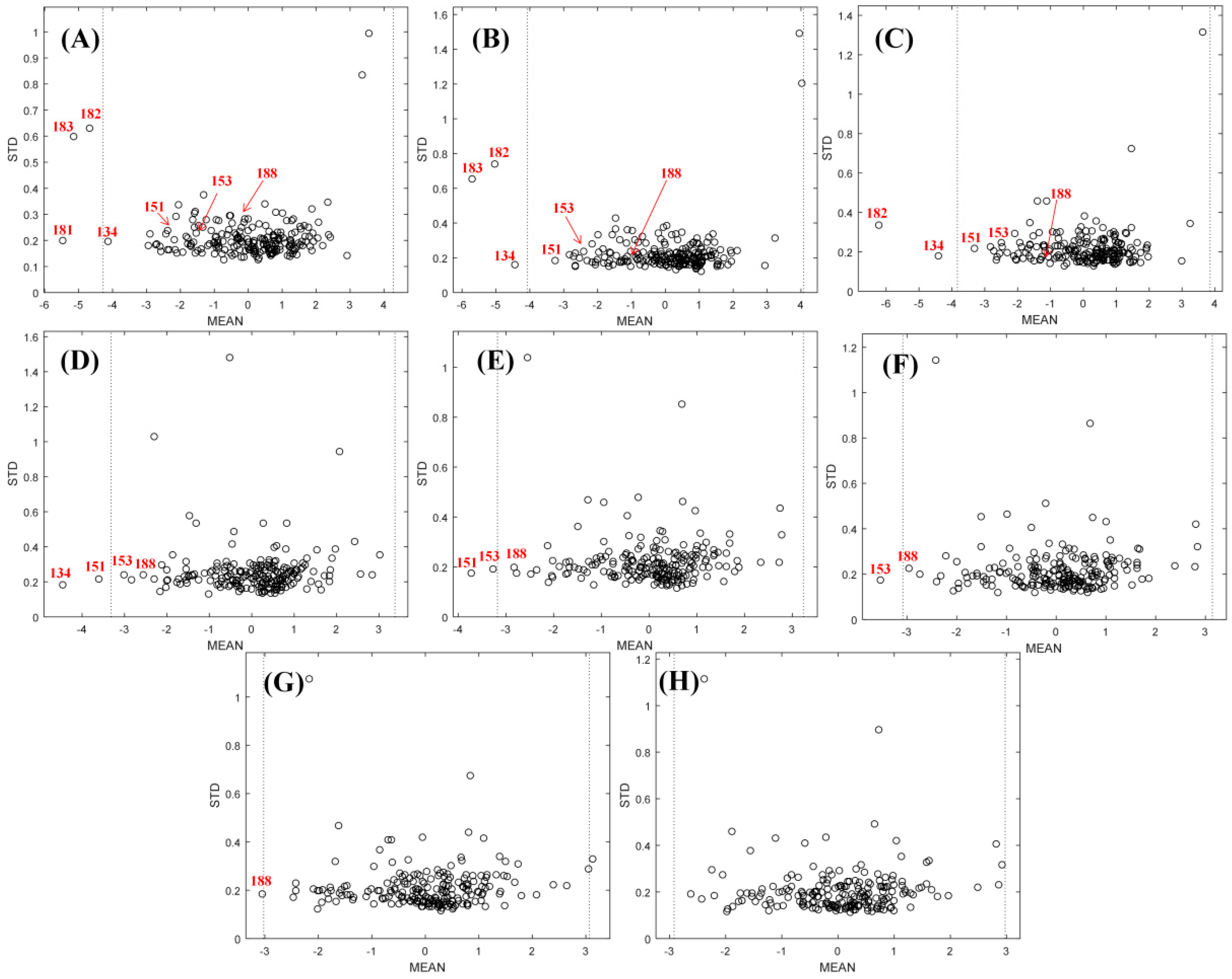
| HSEHPCSV | 0.3861 | 0.5781 | 4 | 0.6170 | 0.7338 | 20 | 183, 182, 181, 134 |
| ST-scale | 0.4268 | 0.5733 | 12 | 0.5993 | 0.6844 | 13 | 183, 182, 181, 134 |
| HESH | 0.4091 | 0.5366 | 2 | 0.5968 | 0.7047 | 10 | 183, 181, 182, 134, 129 |
| VSW | 0.4901 | 0.5771 | 3 | 0.5925 | 0.6768 | 5 | 181, 183, 182, 134, 151 |
| G-scale | 0.4516 | 0.5527 | 6 | 0.5843 | 0.6574 | 9 | 181, 183, 182, 134, 118 |
| FASGAI | 0.4814 | 0.5457 | 5 | 0.5544 | 0.6130 | 6 | 129, 181, 128 |
| DPPS | 0.4740 | 0.5637 | 7 | 0.5379 | 0.6278 | 8 | 181, 182, 183, 134 |
| E-scale | 0.4956 | 0.5451 | 4 | 0.5144 | 0.5582 | 4 | 181, 182, 183, 112 |
| 5Z-scale | 0.3903 | 0.4626 | 12 | 0.3974 | 0.4653 | 9 | 181, 182, 183, 172 |
| VHSE | 0.4265 | 0.5432 | 12 | 0.3974 | 0.514 | 8 | 181, 182, 183, 172 |
| T-scale | 0.3280 | 0.4215 | 9 | 0.3728 | 0.4362 | 9 | 181, 182, 183 |
| V-scale | 0.3371 | 0.3785 | 5 | 0.3070 | 0.3458 | 6 | 181, 183, 182 |
| Z-scale | 0.2814 | 0.3398 | 4 | 0.2678 | 0.3415 | 4 | 181 |
| ISA-ECI | 0.1493 | 0.1916 | 6 | 0.1572 | 0.1836 | 6 | 183, 182, 181 |
| MS-WHTM1 | 0.0736 | 0.1488 | 3 | 0.1036 | 0.1678 | 3 | 181, 183, 182 |
| MS-WHTM2 | 0.0775 | 0.1445 | 3 | 0.0882 | 0.1617 | 3 | 181, 182, 183 |
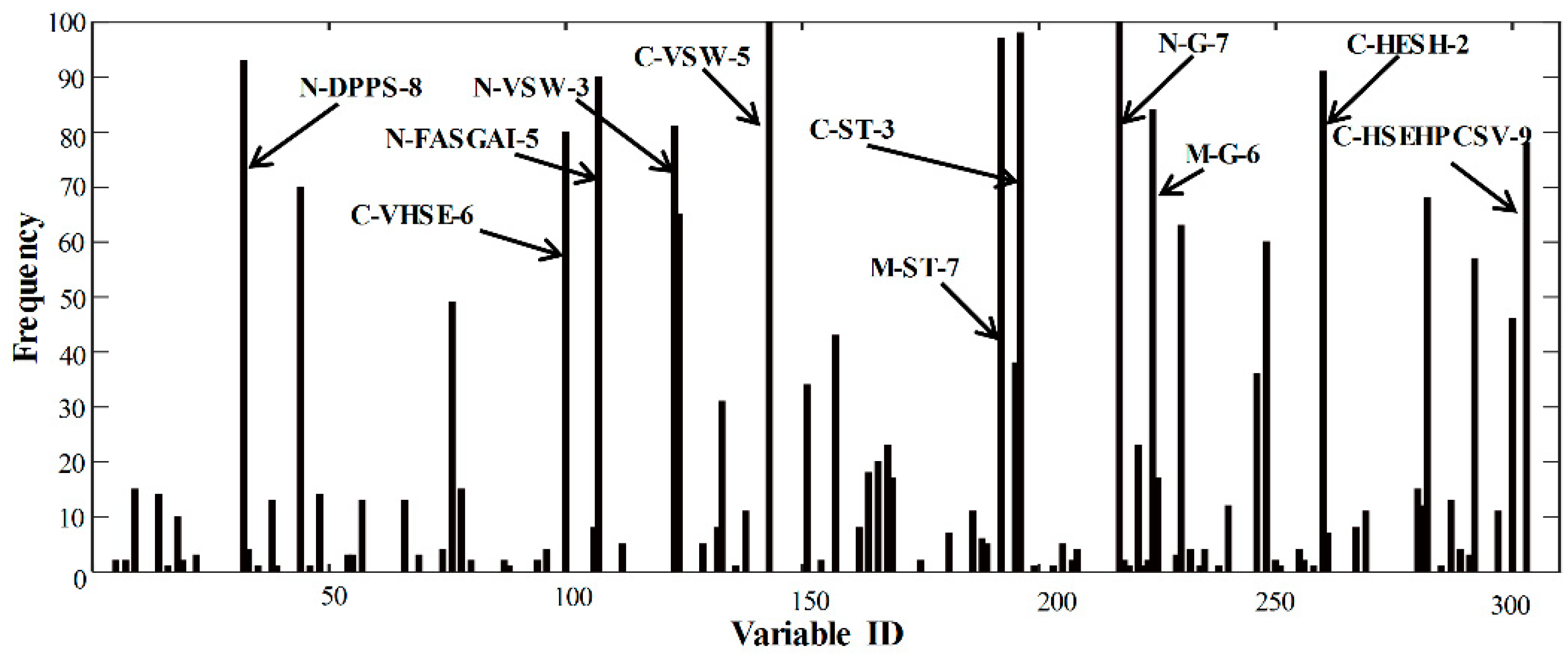
| Integrated descriptors | 0.4811 | 0.5843 | 3 | 0.6818 | 0.7964 | 8 | 181, 183, 182, 134, 151, 153, 188 |
| BOSS | 0.7471 ± 0.0032 | 0.7931 ± 0.0062 | 9.72 ± 3.2199 | ||||
| Descriptors | Before Logarithmic Transformation | After Logarithmic Transformation | ||||
|---|---|---|---|---|---|---|
| Q2 | R2 | optPC | Q2 | R2 | optPC | |
| VHSE | 0.0042 | 0.2655 | 3 | 0.4878 | 0.6122 | 6 |
| 5Z-scale | 0.1408 | 0.3177 | 2 | 0.4809 | 0.5568 | 3 |
| DPPS | 0.0059 | 0.2290 | 3 | 0.4147 | 0.5463 | 4 |
| ST-scale | 0.0263 | 0.3220 | 8 | 0.3968 | 0.5410 | 9 |
| FASGAI | 0.0470 | 0.2753 | 2 | 0.3735 | 0.5006 | 4 |
| E-scale | 0.0560 | 0.2521 | 1 | 0.3714 | 0.4734 | 5 |
| HESH | 0.0444 | 0.2818 | 10 | 0.3668 | 0.5290 | 3 |
| HSEHPCSV | 0.0259 | 0.2475 | 7 | 0.3624 | 0.4952 | 3 |
| G-scale | 0.1066 | 0.2334 | 5 | 0.2836 | 0.3850 | 1 |
| VSW | 0.0130 | 0.3071 | 1 | 0.2382 | 0.4361 | 2 |
| MS-WHTM2 | 0.0342 | 0.0370 | 3 | 0.1728 | 0.2594 | 3 |
| MS-WHTM1 | 0.0452 | 0.0329 | 9 | 0.1207 | 0.1941 | 4 |
| T-scale | 0.0682 | 0.0706 | 2 | 0.0750 | 0.2129 | 10 |
| V-scale | 0.0293 | 0.0748 | 4 | 0.0699 | 0.1495 | 1 |
| Z-scale | 0.0052 | 0.1445 | 1 | 0.0301 | 0.1456 | 6 |
| ISA-ECI | 0.0242 | 0.0141 | 1 | 0.0071 | 0.0411 | 1 |
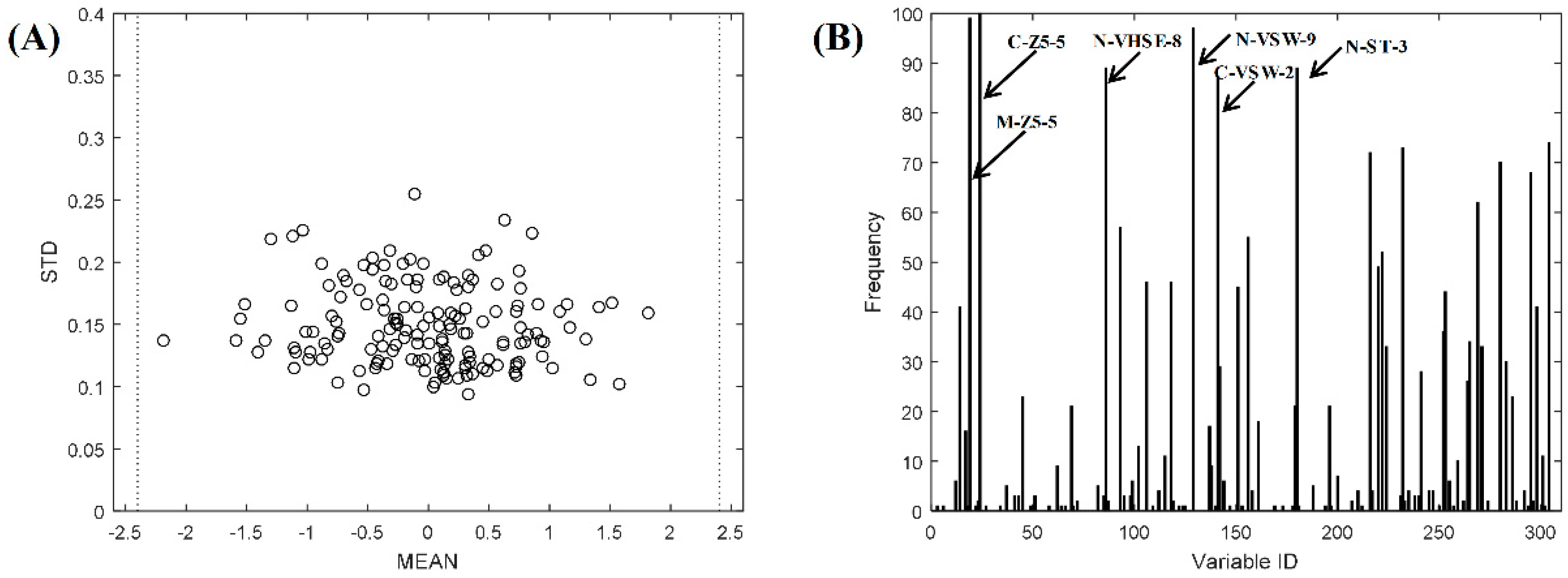
| Integrated descriptors | 0.1069 | 0.4212 | 3 | 0.4953 | 0.6423 | 3 |
| BOSS | 0.6088 ± 0.0041 | 0.6655 ± 0.0094 | 3.5100 ± 2.5086 | |||
| No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | LHA | 3.918 | 37 | PHA | 5.793 | 73 | RHA | 5.205 | 109 | DHH | 0.9045 | 145 | HHH | 0.0635 | 181 | YHY | 9.886 |
| 2 | LHD | 3.593 | 38 | PHD | 4.622 | 74 | RHD | 3.304 | 110 | EHH | 0.9045 | 146 | HHK | 0.0635 | 182 | YKY | 9.886 |
| 3 | LHE | 6.136 | 39 | PHE | 6.152 | 75 | RHE | 5.096 | 111 | HHH | 0.0000 | 147 | HHR | 0.0635 | 183 | YRY | 9.886 |
| 4 | LHF | 3.628 | 40 | PHF | 3.916 | 76 | RHF | 3.300 | 112 | KHH | 0.0000 | 148 | HHA | 0.0680 | 184 | YAY | 3.607 |
| 5 | LHG | 6.697 | 41 | PHG | 5.197 | 77 | RHG | 5.725 | 113 | AHH | 2.020 | 149 | HHI | 0.0680 | 185 | YIY | 3.607 |
| 6 | LHH | 4.836 | 42 | PHH | 6.051 | 78 | RHH | 3.296 | 114 | IHH | 2.020 | 150 | HHL | 0.0680 | 186 | YLY | 3.607 |
| 7 | LHI | 6.531 | 43 | PHI | 4.916 | 79 | RHI | 4.806 | 115 | FHH | 1.803 | 151 | HHF | 3.612 | 187 | YFY | 2.233 |
| 8 | LHK | 4.225 | 44 | PHK | 3.426 | 80 | RHK | 2.694 | 116 | WHH | 1.803 | 152 | HHW | 3.612 | 188 | YWY | 2.233 |
| 9 | LHL | 5.920 | 45 | PHL | 5.311 | 81 | RHL | 3.501 | 117 | YHH | 1.803 | 153 | HHY | 3.612 | 189 | YYY | 2.233 |
| 10 | LHM | 4.504 | 46 | PHM | 3.714 | 82 | RHM | 3.218 | 118 | GHH | 1.089 | 154 | HHG | 0.3170 | 190 | YGY | 3.366 |
| 11 | LHN | 5.148 | 47 | PHN | 6.061 | 83 | RHN | 5.713 | 119 | NHH | 1.089 | 155 | HHN | 0.3170 | 191 | YNY | 3.366 |
| 12 | LHQ | 4.136 | 48 | PHQ | 3.718 | 84 | RHQ | 3.108 | 120 | QHH | 1.089 | 156 | HHQ | 0.3170 | 192 | YQY | 3.366 |
| 13 | LHR | 5.184 | 49 | PHR | 4.751 | 85 | RHR | 4.302 | 121 | MHH | 2.015 | 157 | HHM | 0.0817 | 193 | YMY | 1.780 |
| 14 | LHS | 4.293 | 50 | PHS | 4.042 | 86 | RHS | 3.386 | 122 | SHH | 1.320 | 158 | HHS | 0.0862 | 194 | YSY | 3.447 |
| 15 | LHT | 5.584 | 51 | PHT | 6.247 | 87 | RHT | 5.987 | 123 | THH | 1.320 | 159 | HHT | 0.0862 | 195 | YTY | 3.447 |
| 16 | LHV | 3.481 | 52 | PHV | 3.335 | 88 | RHV | 3.206 | 124 | CHH | 0.9369 | 160 | HHC | 0.1277 | 196 | YCY | 3.087 |
| 17 | LHW | 6.791 | 53 | PHW | 6.535 | 89 | RHW | 5.878 | 125 | HDH | 1.477 | 161 | DYY | 3.417 | 197 | YYD | 4.116 |
| 18 | LHY | 4.203 | 54 | PHY | 4.227 | 90 | RHY | 3.378 | 126 | HEH | 1.477 | 162 | EYY | 3.417 | 198 | YYE | 4.116 |
| 19 | LWA | 1.192 | 55 | PWA | 1.396 | 91 | RWA | 1.212 | 127 | HHH | 0.0441 | 163 | HYY | 2.257 | 199 | YYH | 5.303 |
| 20 | LWD | 1.717 | 56 | PWD | 1.096 | 92 | RWD | 0.9091 | 128 | HKH | 0.0441 | 164 | KYY | 2.257 | 200 | YYK | 5.303 |
| 21 | LWE | 1.717 | 57 | PWE | 1.096 | 93 | RWE | 1.091 | 129 | HRH | 0.0441 | 165 | RYY | 2.257 | 201 | YYR | 5.303 |
| 22 | LWF | 1.414 | 58 | PWF | 0.9192 | 94 | RWF | 0.9091 | 130 | HAH | 0.9518 | 166 | AYY | 3.071 | 202 | YYA | 3.344 |
| 23 | LWG | 1.313 | 59 | PWG | 2.687 | 95 | RWG | 1.717 | 131 | HIH | 0.9518 | 167 | IYY | 3.071 | 203 | YYI | 3.344 |
| 24 | LWH | 3.212 | 60 | PWH | 1.184 | 96 | RWH | 1.091 | 132 | HLH | 0.9518 | 168 | LYY | 3.071 | 204 | YYL | 3.344 |
| 25 | LWI | 1.111 | 61 | PWI | 1.396 | 97 | RWI | 1.232 | 133 | HFH | 2.026 | 169 | FYY | 1.911 | 205 | YYF | 4.050 |
| 26 | LWK | 1.899 | 62 | PWK | 0.4066 | 98 | RWK | 0.6061 | 134 | HWH | 2.026 | 170 | WYY | 1.911 | 206 | YYW | 4.050 |
| 27 | LWL | 0.6060 | 63 | PWL | 1.096 | 99 | RWL | 3.212 | 135 | HYH | 2.026 | 171 | YYY | 1.911 | 207 | YYY | 4.050 |
| 28 | LWM | 1.394 | 64 | PWM | 0.7955 | 100 | RWM | 0.7273 | 136 | HGH | 0.8318 | 172 | GYY | 5.071 | 208 | YYG | 2.996 |
| 29 | LWN | 1.313 | 65 | PWN | 2.104 | 101 | RWN | 2.404 | 137 | HNH | 0.8318 | 173 | NYY | 5.071 | 209 | YYN | 2.996 |
| 30 | LWQ | 2.505 | 66 | PWQ | 1.202 | 102 | RWQ | 0.6061 | 138 | HQH | 0.8318 | 174 | QYY | 5.071 | 210 | YYQ | 2.996 |
| 31 | LWR | 2.909 | 67 | PWR | 2.705 | 103 | RWR | 2.384 | 139 | HMH | 0.8734 | 175 | MYY | 1.991 | 211 | YYM | 2.103 |
| 32 | LWS | 2.020 | 68 | PWS | 1.096 | 104 | RWS | 0.8081 | 140 | HSH | 0.7304 | 176 | SYY | 3.070 | 212 | YYS | 3.983 |
| 33 | LWT | 2.020 | 69 | PWT | 2.598 | 105 | RWT | 3.818 | 141 | HTH | 0.7304 | 177 | TYY | 3.070 | 213 | YYT | 3.983 |
| 34 | LWV | 1.616 | 70 | PWV | 1.008 | 106 | RWV | 0.6061 | 142 | HCH | 0.9747 | 178 | CYY | 0.4699 | 214 | YYC | 0.6369 |
| 35 | LWW | 3.515 | 71 | PWW | 2.899 | 107 | RWW | 2.707 | 143 | HHD | 0.1877 | 179 | YDY | 3.047 | |||
| 36 | LWY | 2.222 | 72 | PWY | 1.114 | 108 | RWY | 0.8081 | 144 | HHE | 0.1877 | 180 | YEY | 3.047 | □ | □ | □ |
| No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity | No. | Sequence | Activity |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | LTC | 2.83 | 30 | LPM | 1.04 | 59 | YKK | 0.25 | 88 | NGE | −0.30 | 117 | ELK | −0.66 | 146 | KIP | −1.15 |
| 2 | CQC | 2.53 | 31 | TDY | 1.01 | 60 | AQA | 0.22 | 89 | QSA | −0.33 | 118 | PEQ | −0.66 | 147 | LLD | −1.22 |
| 3 | GTW | 2.52 | 32 | QCH | 1.00 | 61 | LRV | 0.20 | 90 | DAQ | −0.34 | 119 | IDA | −0.68 | 148 | DLE | −1.22 |
| 4 | LFC | 2.07 | 33 | TWY | 0.96 | 62 | PTP | 0.18 | 91 | ENS | −0.34 | 120 | LLA | −0.70 | 149 | PEV | −1.22 |
| 5 | CLV | 2.06 | 34 | RVY | 0.95 | 63 | ALN | 0.18 | 92 | ENG | −0.37 | 121 | ALA | −0.72 | 150 | LKP | −1.40 |
| 6 | QKW | 2.03 | 35 | KWE | 0.90 | 64 | LEI | 0.16 | 93 | NSA | −0.37 | 122 | GLD | −0.72 | 151 | ALE | −1.52 |
| 7 | CME | 1.99 | 36 | CLL | 0.89 | 65 | LVR | 0.13 | 94 | EKT | −0.38 | 123 | DIS | −0.72 | 152 | TQL | −1.52 |
| 8 | YLL | 1.91 | 37 | LAM | 0.85 | 66 | HIR | 0.12 | 95 | EQS | −0.38 | 124 | PEG | −0.72 | 153 | LEE | −1.52 |
| 9 | QCL | 1.69 | 38 | YSL | 0.81 | 67 | KKI | 0.11 | 96 | AMA | −0.41 | 125 | LDI | −0.74 | 154 | LEK | −1.70 |
| 10 | LAC | 1.69 | 39 | MKG | 0.80 | 68 | SFN | 0.07 | 97 | KID | −0.41 | 126 | AEP | −0.74 | 155 | DAL | −2.00 |
| 11 | GEC | 1.64 | 40 | QTM | 0.80 | 69 | SLL | 0.06 | 98 | GAQ | −0.43 | 127 | ALI | −0.77 | 156 | EVD | −2.00 |
| 12 | EQC | 1.52 | 41 | LAL | 0.76 | 70 | PAV | 0.04 | 99 | PLR | −0.44 | 128 | LDA | −0.77 | 157 | VDD | −2.00 |
| 13 | FCM | 1.51 | 42 | QAL | 0.73 | 71 | RLS | 0.04 | 100 | ILL | −0.46 | 129 | VFK | −0.77 | 158 | DEA | −2.00 |
| 14 | CHI | 1.45 | 43 | MEN | 0.73 | 72 | AGT | 0.04 | 101 | VRT | −0.46 | 130 | ALK | −0.77 | 159 | ALT | - |
| 15 | ACQ | 1.38 | 44 | MKC | 0.72 | 73 | LLF | 0.02 | 102 | IAE | −0.49 | 131 | AQK | −0.82 | 160 | KGL | - |
| 16 | EEL | 1.33 | 45 | LSF | 0.69 | 74 | PMH | 0.00 | 103 | QSL | −0.49 | 132 | IIA | −0.82 | 161 | IQK | - |
| 17 | WEN | 1.31 | 46 | TCG | 0.67 | 75 | EEQ | −0.01 | 104 | KTK | −0.51 | 133 | LIV | −0.85 | 162 | QKV | - |
| 18 | VYV | 1.19 | 47 | SLA | 0.65 | 76 | LVL | −0.02 | 105 | ASD | −0.52 | 134 | EGD | −0.85 | 163 | GDL | - |
| 19 | MHI | 1.16 | 48 | TMK | 0.64 | 77 | QLE | −0.05 | 106 | APL | −0.52 | 135 | QKK | −0.85 | 164 | EIL | - |
| 20 | CAQ | 1.12 | 49 | LDT | 0.62 | 78 | FDK | −0.07 | 107 | AQS | −0.57 | 136 | IPA | −0.85 | 165 | KII | - |
| 21 | WYS | 1.12 | 50 | EKF | 0.54 | 79 | LLL | −0.08 | 108 | ENK | −0.57 | 137 | SDI | −0.89 | 166 | NKV | - |
| 22 | KYL | 1.08 | 51 | VLV | 0.53 | 80 | SAP | −0.08 | 109 | TPE | −0.59 | 138 | VEE | −0.89 | 167 | DTD | - |
| 23 | CGA | 1.08 | 52 | MAA | 0.44 | 81 | LLQ | −0.12 | 110 | RTP | −0.59 | 139 | DDE | −0.89 | 168 | EPE | - |
| 24 | KKY | 1.08 | 53 | PTQ | 0.44 | 82 | NPT | −0.17 | 111 | VLD | −0.62 | 140 | KVL | −0.92 | 169 | EAL | - |
| 25 | NEN | 1.08 | 54 | VAG | 0.41 | 83 | FNP | −0.20 | 112 | IRL | −0.62 | 141 | KFD | −0.92 | 170 | DKA | - |
| 26 | ECA | 1.07 | 55 | ALP | 0.37 | 84 | LNE | −0.24 | 113 | AAS | −0.64 | 142 | IVT | −0.96 | 171 | KAL | - |
| 27 | DYK | 1.06 | 56 | AVF | 0.36 | 85 | SAE | −0.26 | 114 | LQK | −0.64 | 143 | VTQ | −0.96 | 172 | LKA | - |
| 28 | KCL | 1.05 | 57 | KVA | 0.31 | 86 | KPT | −0.28 | 115 | FKI | −0.64 | 144 | AEK | −0.96 | |||
| 29 | YVE | 1.05 | 58 | TQT | 0.26 | 87 | DIQ | −0.30 | 116 | ISL | −0.66 | 145 | TKI | −1.10 | □ | □ | □ |
| Descriptor | No. of Physicochemical Property | No. of Extracted Variable | Scope of Variable |
|---|---|---|---|
| Z-scale [25] | 29 | 3 | Electronic property, steric property and hydrophobic property |
| 5Z-scale [26] | 26 | 5 | Electronic property, steric property and hydrophobic property |
| DPPS [27] | 119 | 10 | Electronic property, steric property, hydrophobic property and hydrogen bond |
| MS-WHIM [28] | 36 | 3 | Surface charge distribution, size and charge over shape dependence |
| ISA-ECI [29] | / | 2 | Isotropic surface area and electronic charge index |
| VHSE [30] | 50 | 8 | Electronic property, steric property and hydrophobic property |
| FASGAI [31] | 335 | 6 | Hydrophobic property, alpha and turn property, bulky property, electronic property, compositional characteristics, local flexibility |
| VSW [32] | 99 | 9 | Molecular size, shape, symmetry and atom distribution |
| T-scale [33] | 67 | 5 | Topological property |
| ST-scale [34] | 827 | 8 | Molecular constitutional, topological, geometrical, hydrophobic, electronic and steric property |
| E-scale [35] | 237 | 5 | Hydrophobic property, size, preferences for amino acids to occur in α-helices, number of degenerate triplet codons and the frequency of occurrence of amino acid residues in β-strands |
| V-scale [36] | / | 3 | Van Der Wall’s volume, net charge index and hydrophobic parameter of side chains |
| G-scale [37] | 457 | 8 | Electronic property, steric property and hydrophobic property |
| HESH [38] | 171 | 12 | Electronic property, steric property, hydrophobic property and hydrogen bond |
| HSEHPCSV [39] | 95 | 12 | Hydrophobic, steric, electronic properties and hydrogen bond |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, B.; Long, H.; Tang, T.; Ni, X.; Chen, J.; Yang, G.; Zhang, F.; Cao, R.; Cao, D.; Zeng, M.; et al. Quantitative Structure-Activity Relationship Study of Antioxidant Tripeptides Based on Model Population Analysis. Int. J. Mol. Sci. 2019, 20, 995. https://doi.org/10.3390/ijms20040995
Deng B, Long H, Tang T, Ni X, Chen J, Yang G, Zhang F, Cao R, Cao D, Zeng M, et al. Quantitative Structure-Activity Relationship Study of Antioxidant Tripeptides Based on Model Population Analysis. International Journal of Molecular Sciences. 2019; 20(4):995. https://doi.org/10.3390/ijms20040995
Chicago/Turabian StyleDeng, Baichuan, Hongrong Long, Tianyue Tang, Xiaojun Ni, Jialuo Chen, Guangming Yang, Fan Zhang, Ruihua Cao, Dongsheng Cao, Maomao Zeng, and et al. 2019. "Quantitative Structure-Activity Relationship Study of Antioxidant Tripeptides Based on Model Population Analysis" International Journal of Molecular Sciences 20, no. 4: 995. https://doi.org/10.3390/ijms20040995
APA StyleDeng, B., Long, H., Tang, T., Ni, X., Chen, J., Yang, G., Zhang, F., Cao, R., Cao, D., Zeng, M., & Yi, L. (2019). Quantitative Structure-Activity Relationship Study of Antioxidant Tripeptides Based on Model Population Analysis. International Journal of Molecular Sciences, 20(4), 995. https://doi.org/10.3390/ijms20040995