Pseudo-Replication of [GADV]-Proteins and Origin of Life

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
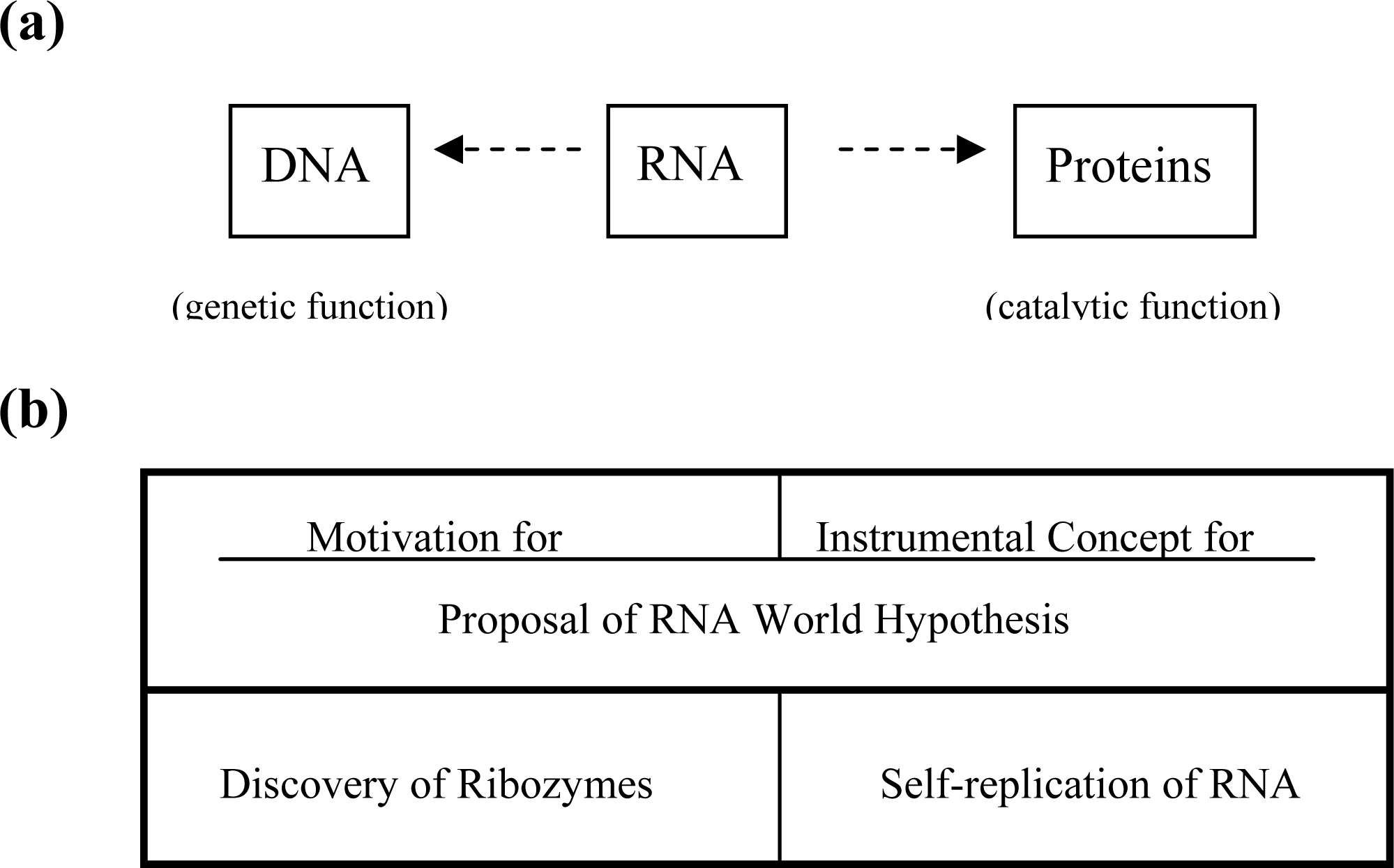
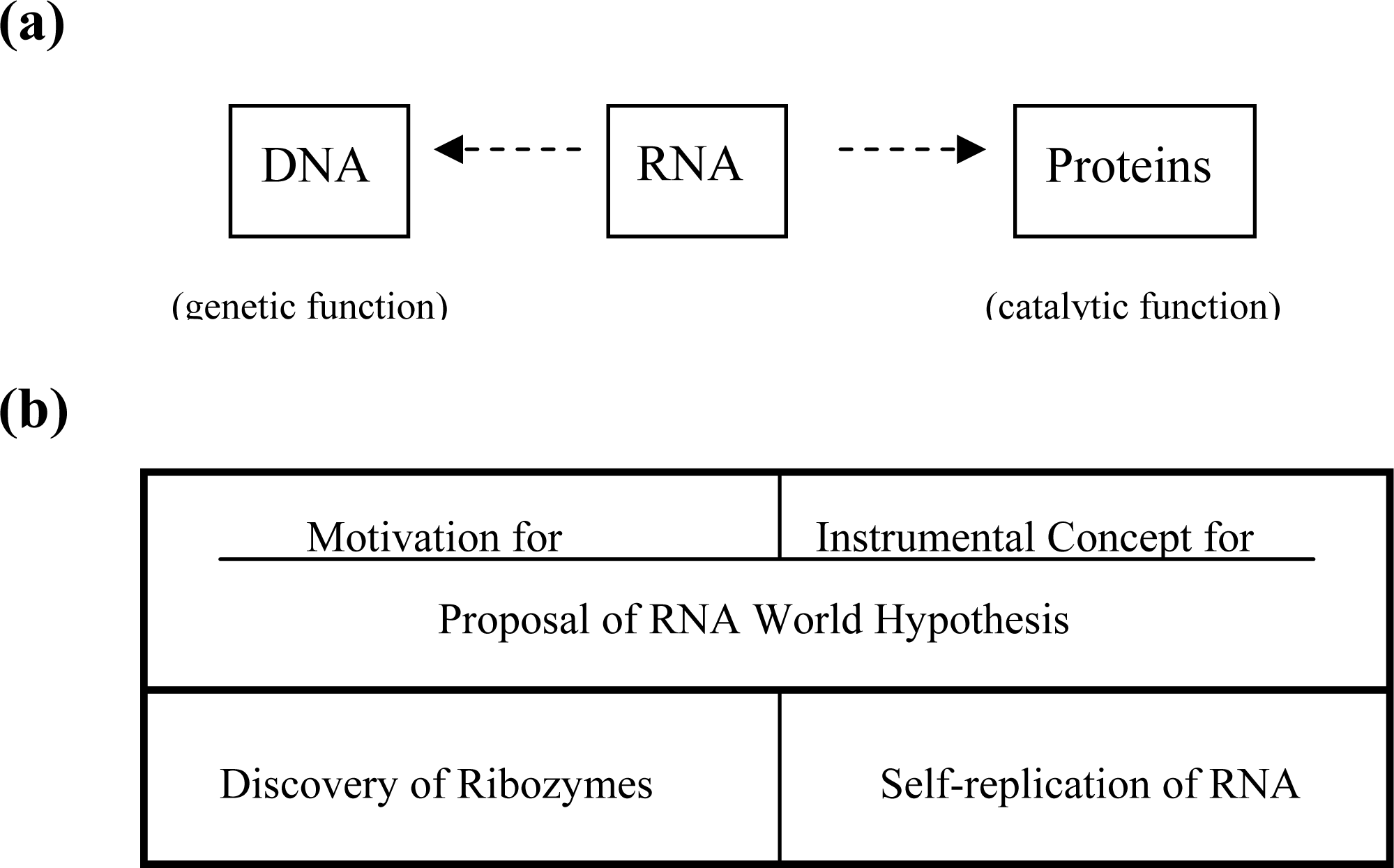
2. Inadequacy of RNA World Hypothesis
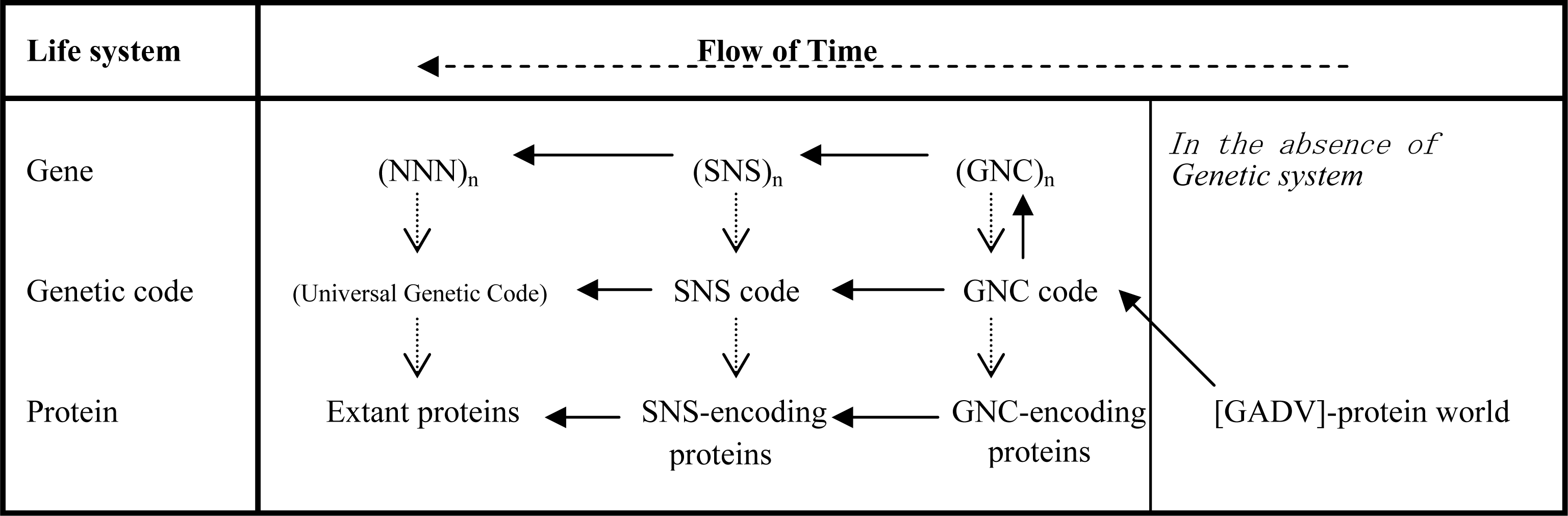
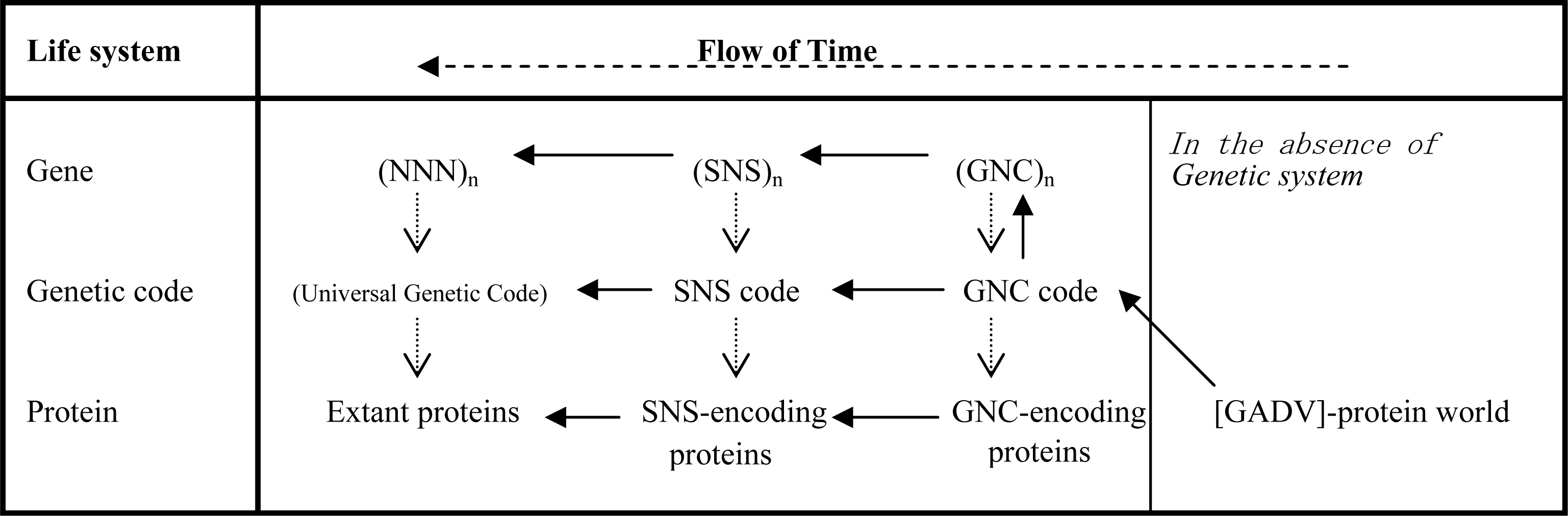
3. GADV Hypothesis about the Origin of Life
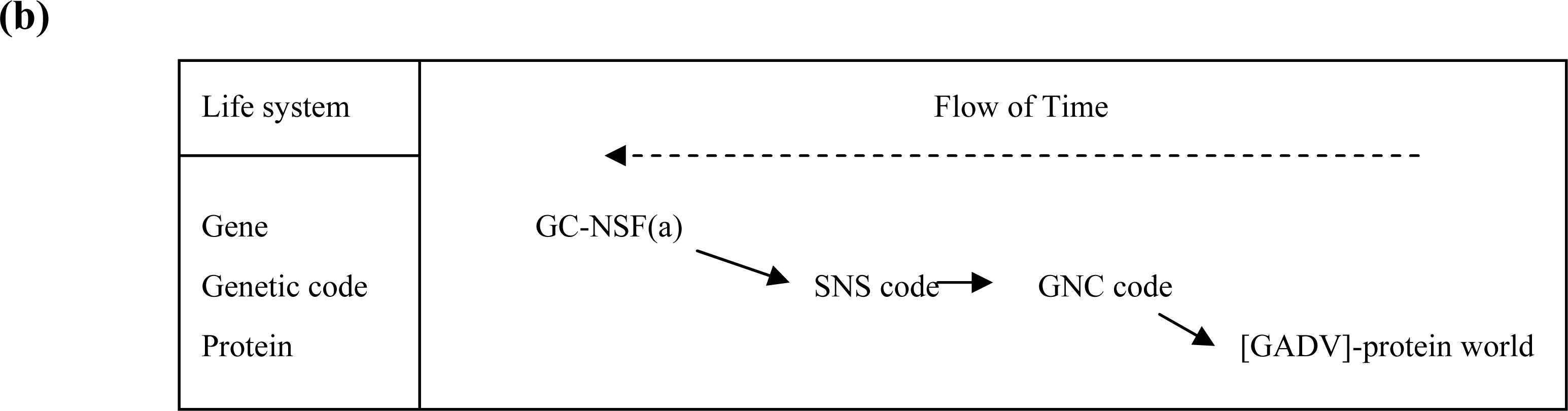
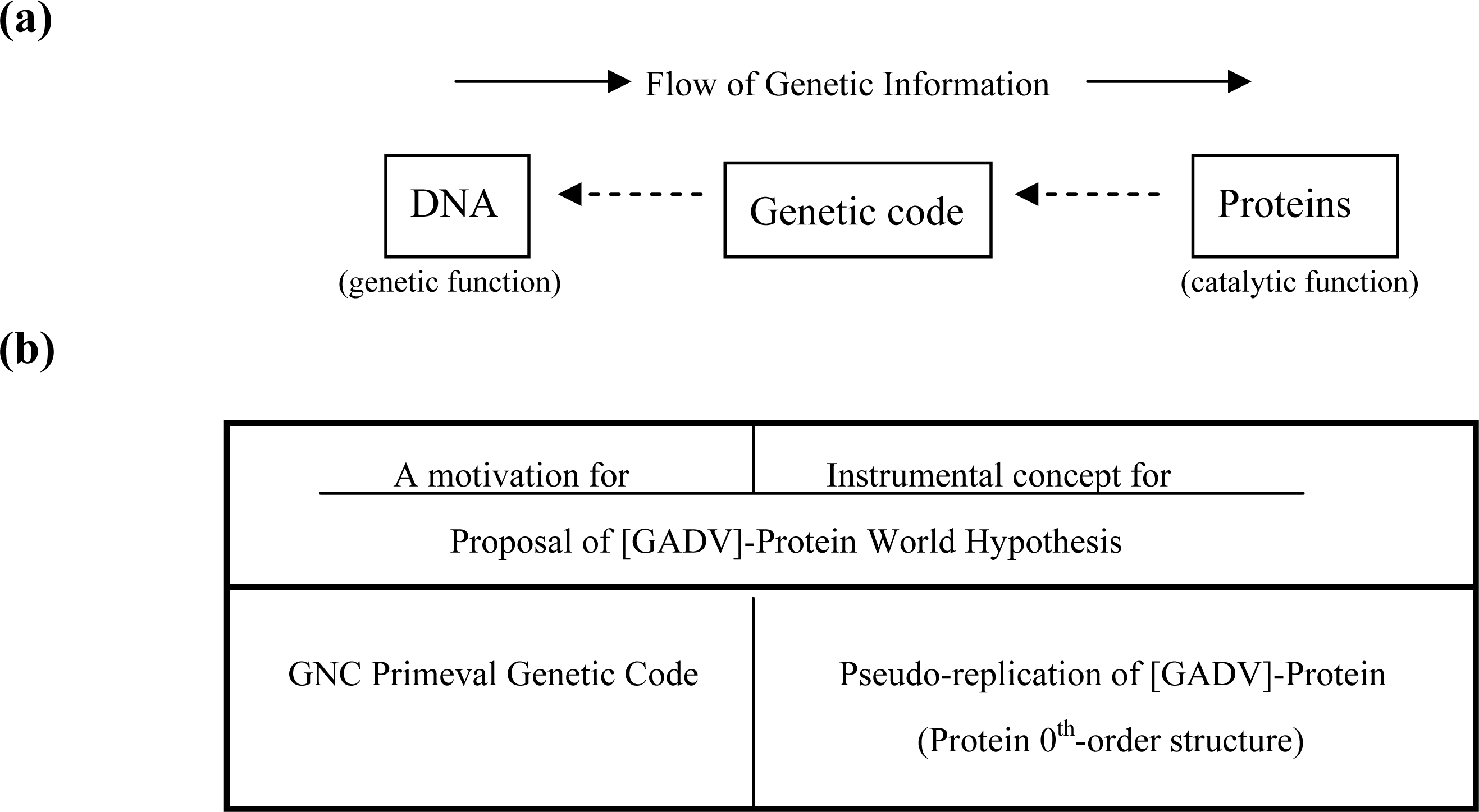
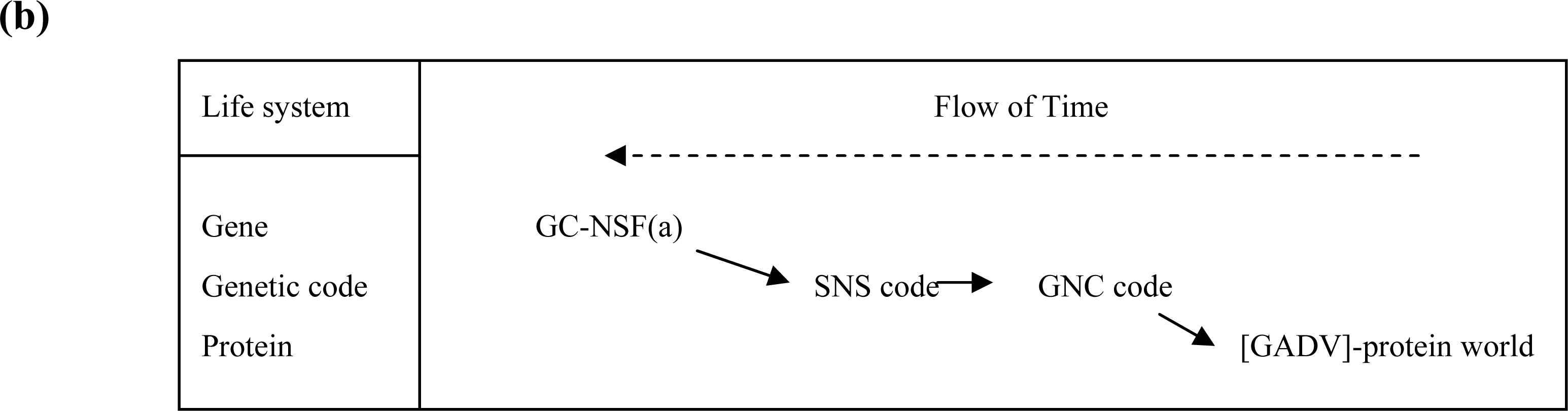
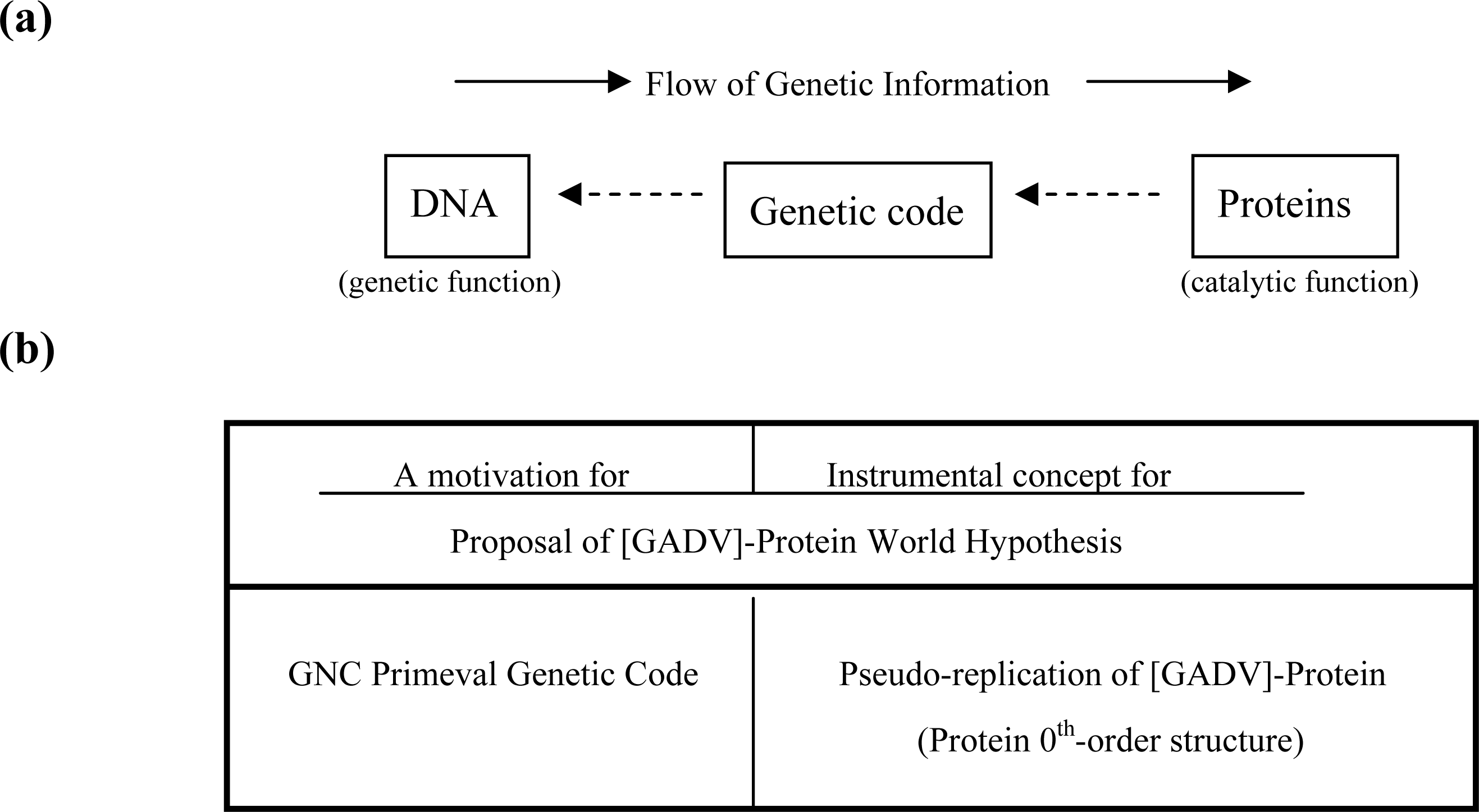
3.1. The Origin of Genetic Code
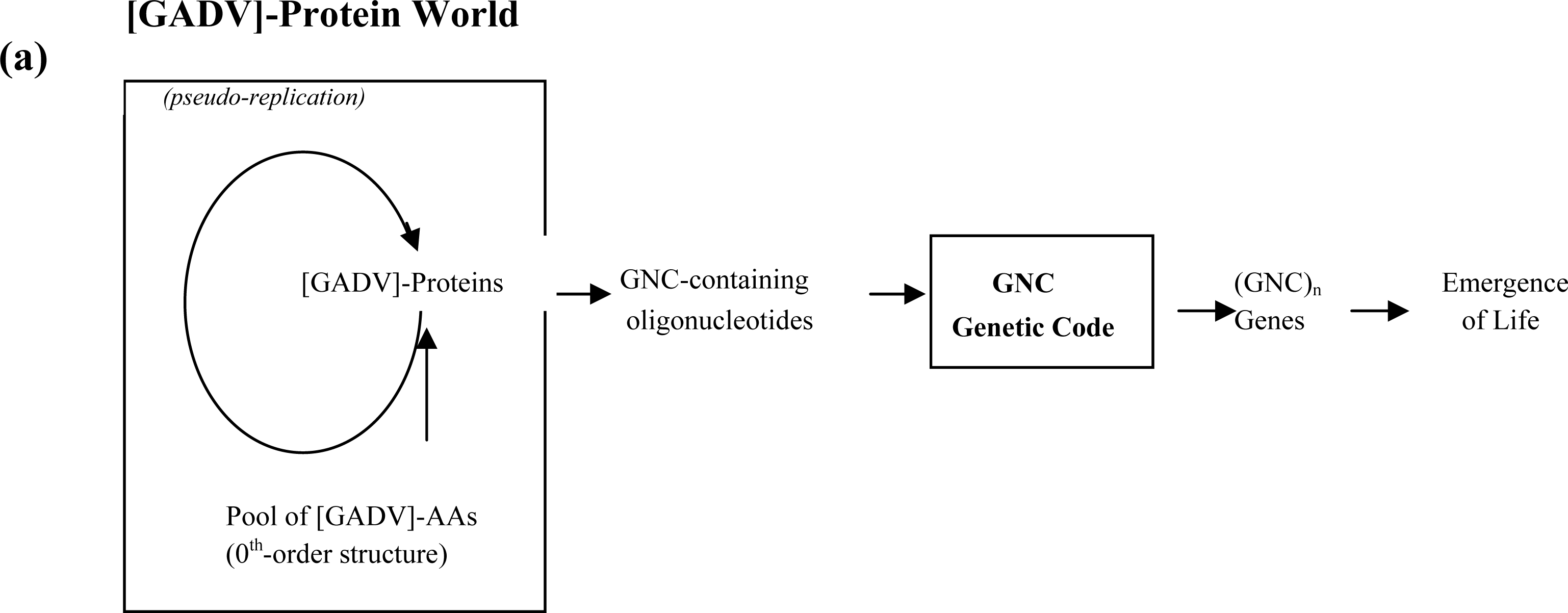
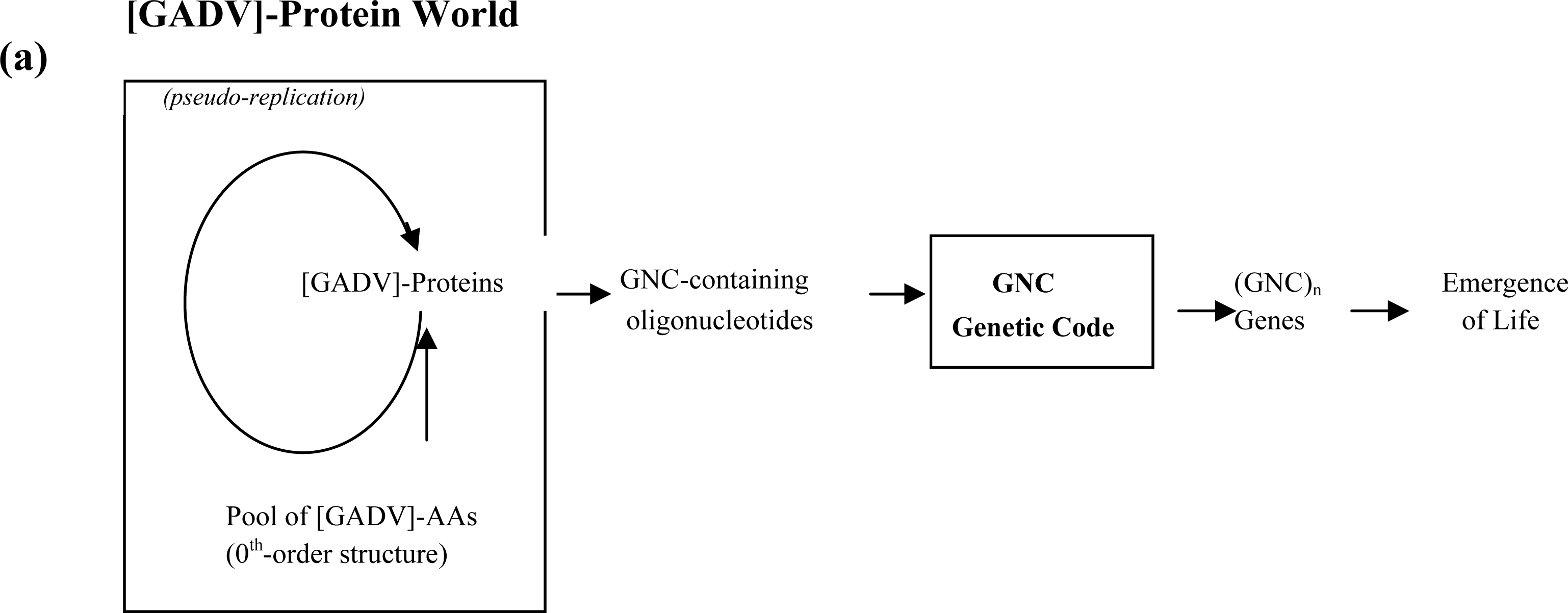
3.2. Pseudo-replication of [GADV]-Proteins in the Absence of Genetic Function
3.3. Emergence of Life from [GADV]-Protein World
4. Justification of GADV Hypothesis about the Origin of Life
4.1. General Principle 1: From Simple to Complex Molecules
4.2. General Principle 2: From Random to Well-organized Processes
4.3. General principle 3: From Catalytic to Genetic Functions
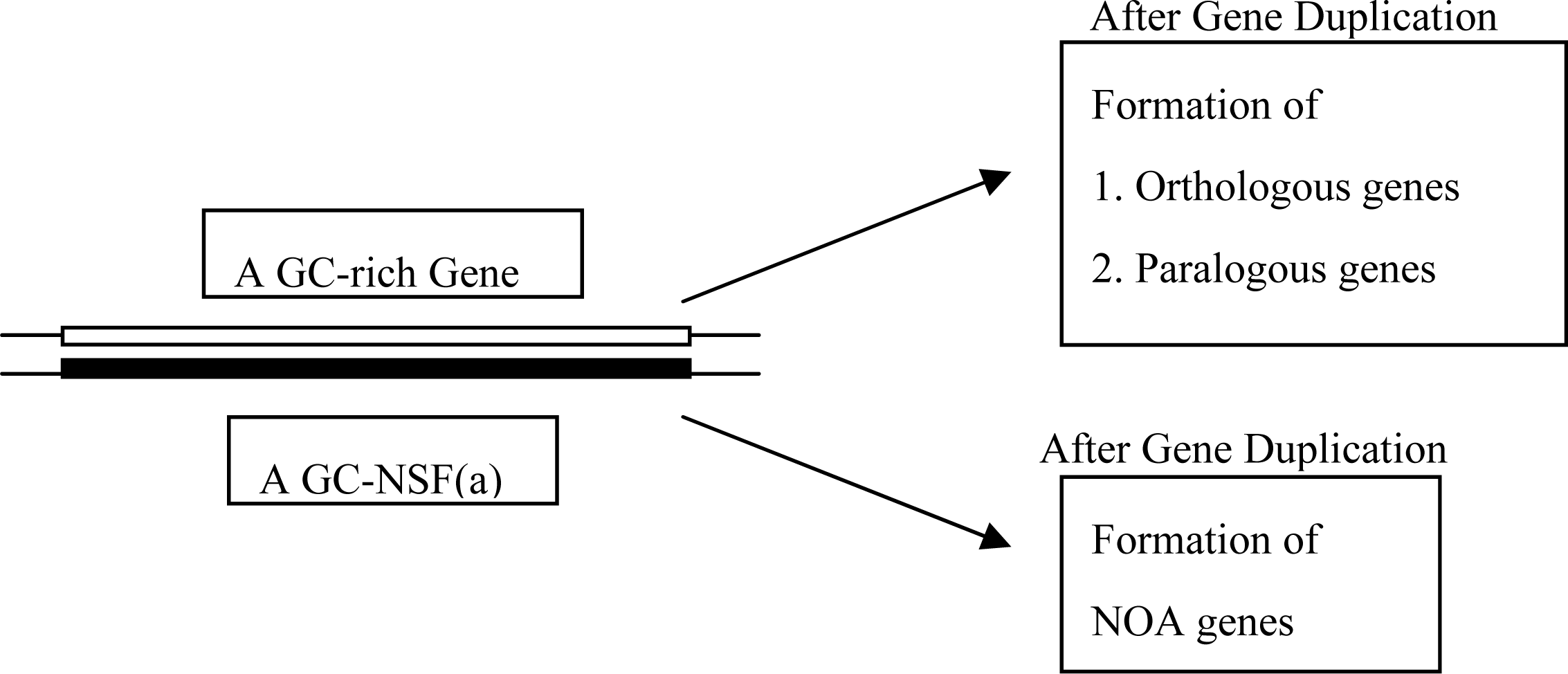
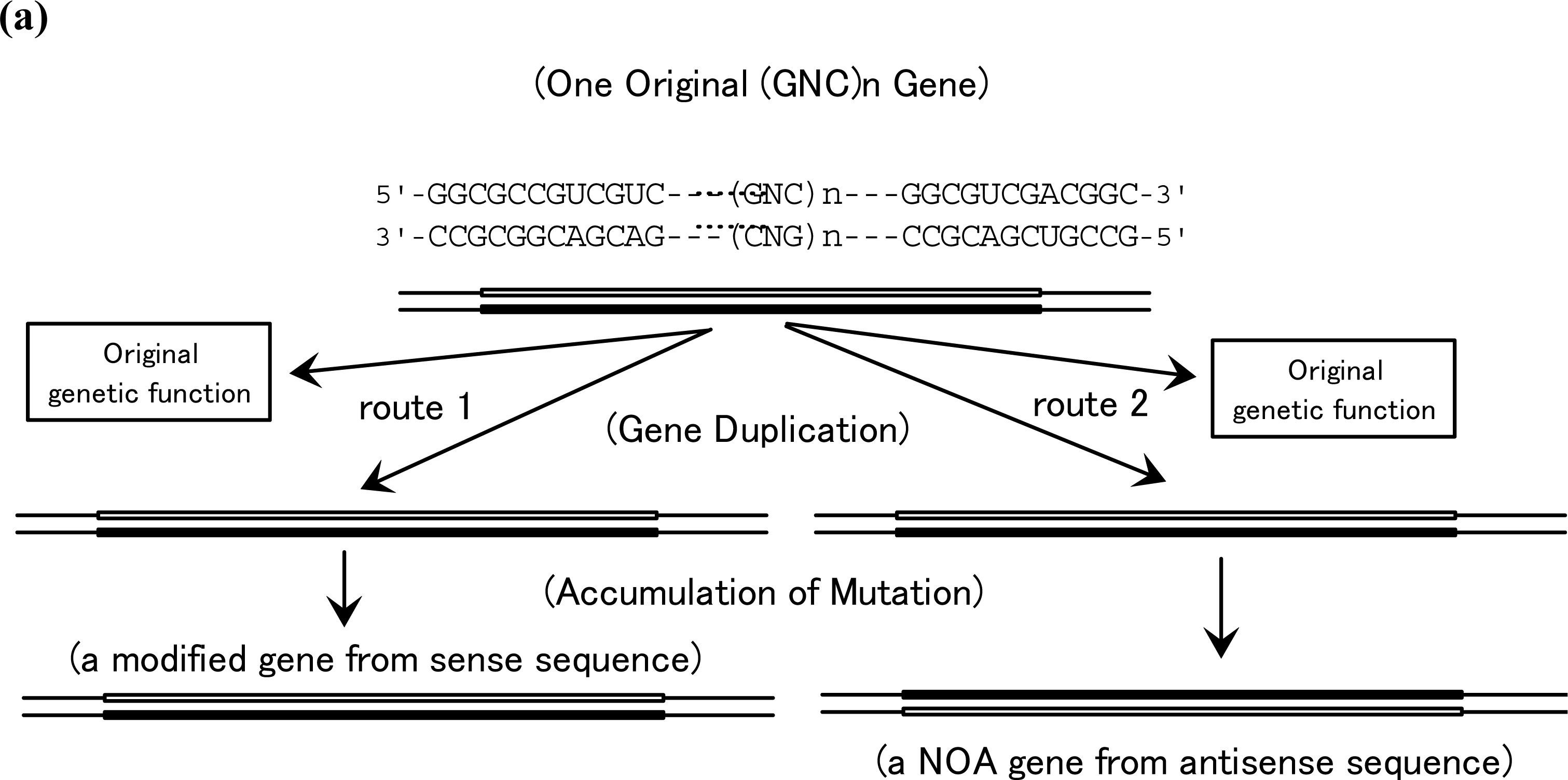
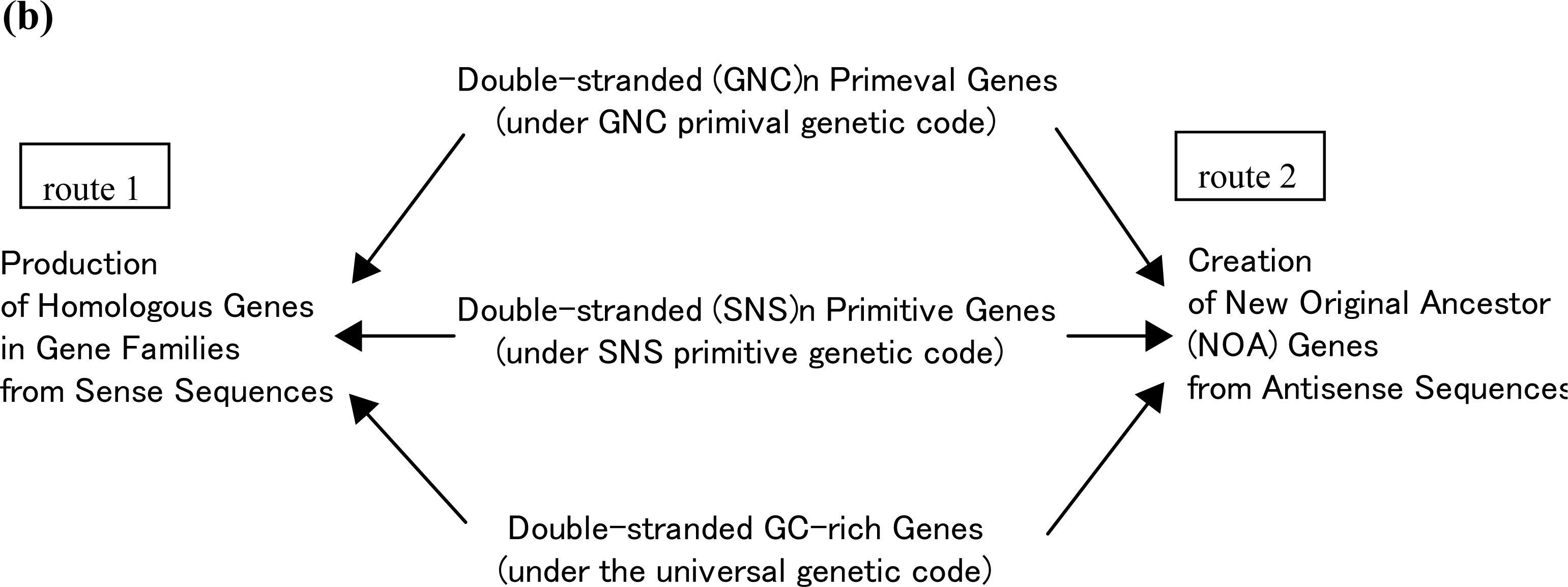
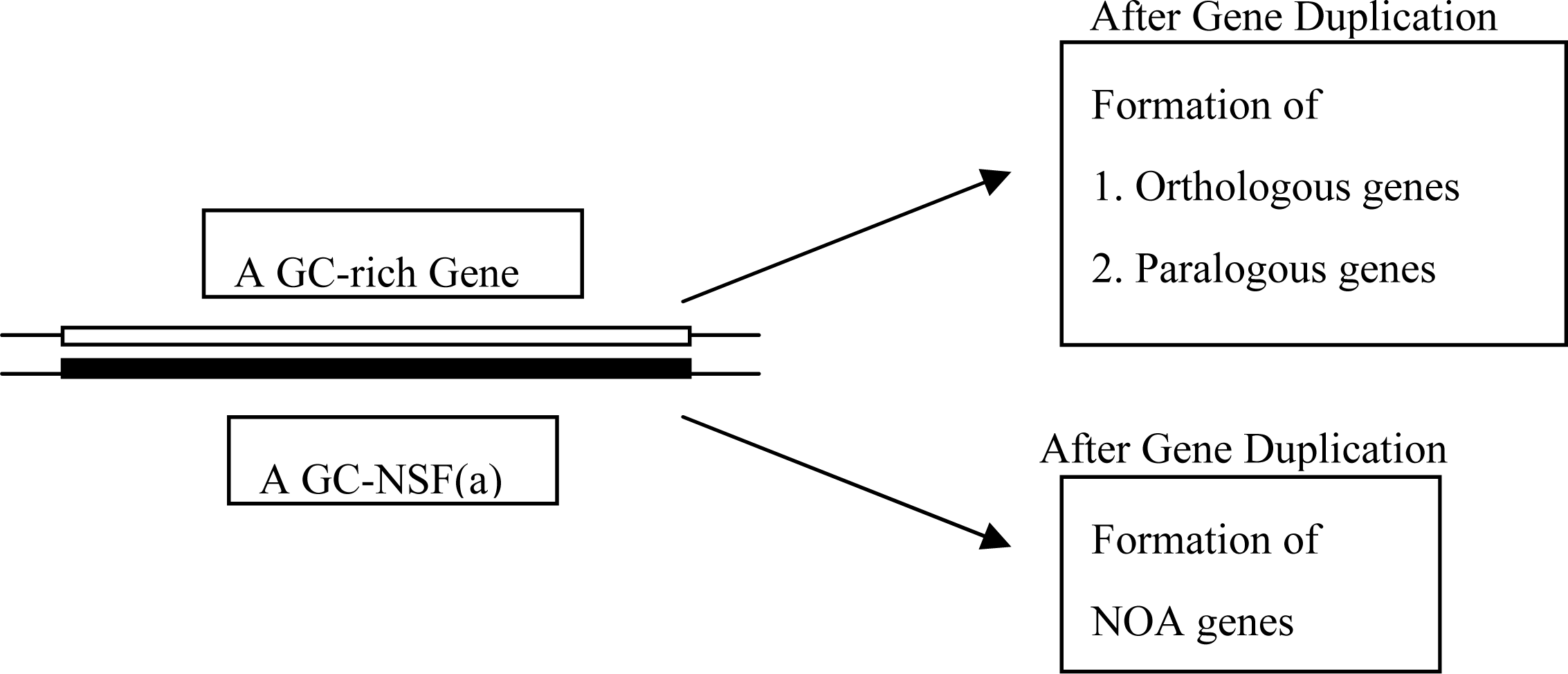
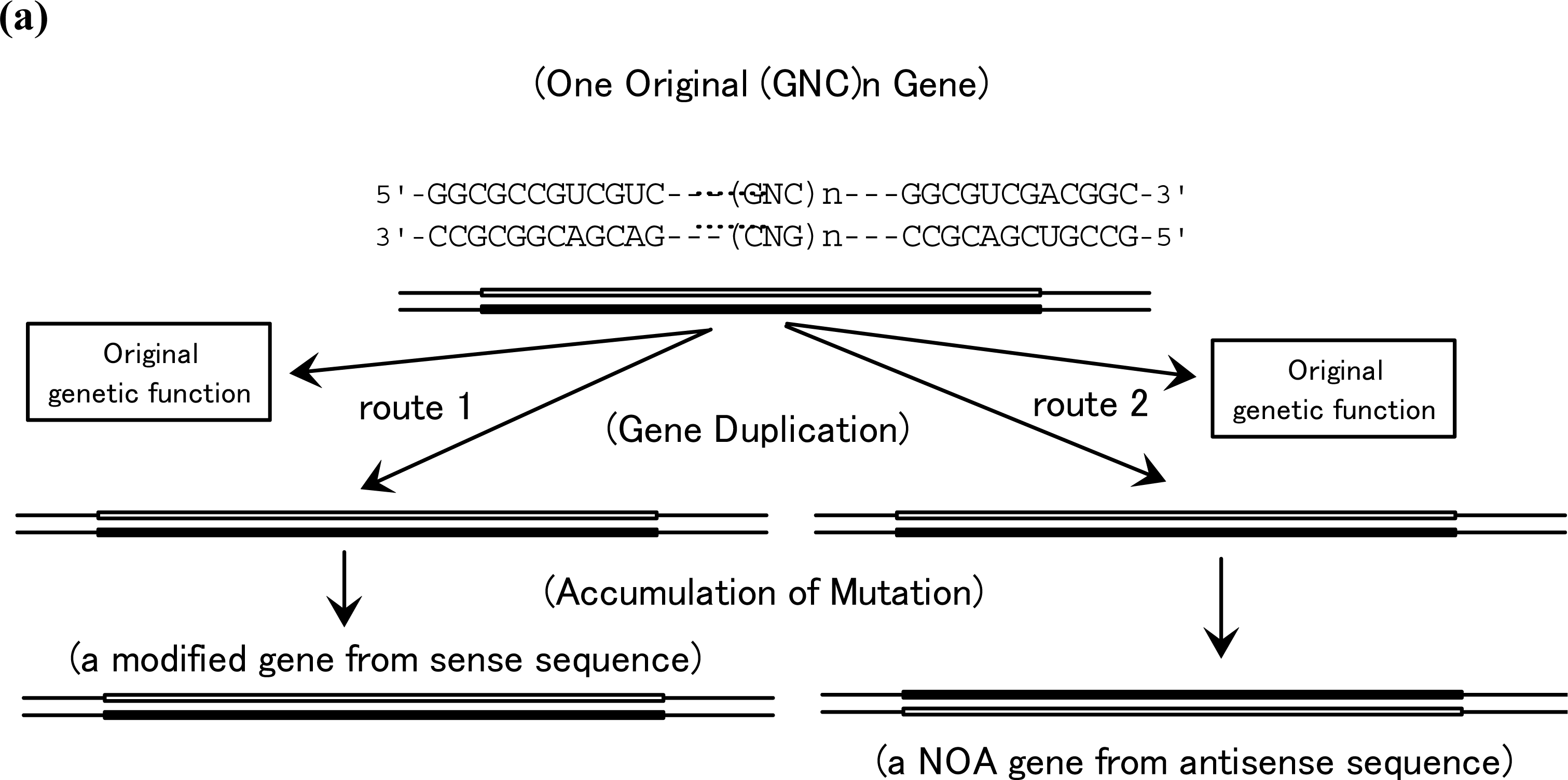
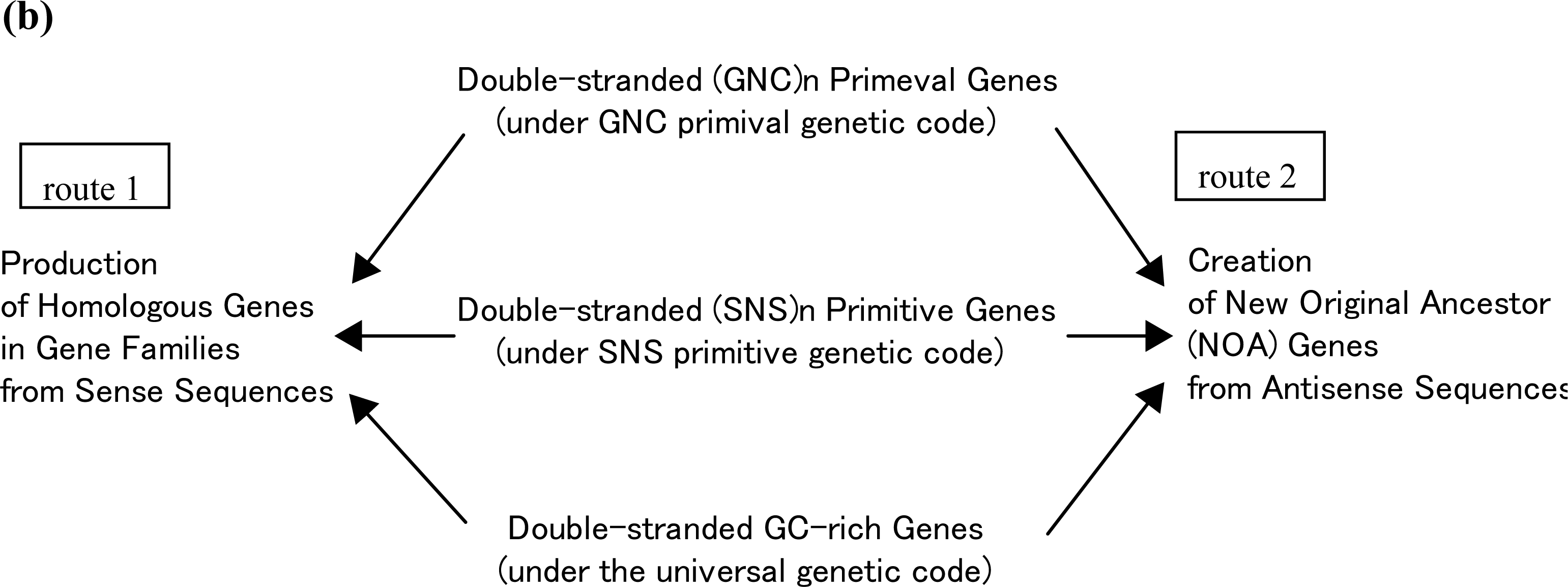
5. Production of NOA Proteins after Creation of Double-stranded Gene
5.1. Mechanisms for Creation of New Genes and New Proteins
5.2. Group Coding under GNC and SNS Codes
6. Conclusions
Acknowledgments
References
- Kruger, K; Grabowski, PJ; Xaug, AJ; Sands, J; Gottschling, DE; Cech, TR. Self splicing RNA: autoexision and autocyclization of the ribosomal RNA intervening sequence of Tetrahymena. Cell 1982, 31, 147–157. [Google Scholar]
- Guerrier-Takada, C; Gardiner, K; Marsh, T; Pace, N; Altman, S. The RNA moiety of ribonuclease P is catalytic subunit of the enzyme. Cell 1983, 35, 849–857. [Google Scholar]
- Gilbert, W. The RNA world. Nature 1986, 319, 618. [Google Scholar]
- The RNA World, 3rd Ed; Gesteland, RF; Cech, TR; Atkins, JF (Eds.) Cold Spring Harbor Laboratory Press: New York, USA, 2006.
- Ikehara, K. Origins of gene, genetic code, protein and life: Comprehensive view of life system from a GNC-SNS primitive genetic code hypothesis. J. Biosci 2002, 27, 165–186. [Google Scholar]
- Ikehara, K. Possible steps to the emergence of life: The [GADV]-protein world hypothesis. Chem. Rec 2005, 5, 107–118. [Google Scholar]
- Taylor, WR. Stirring the primordial soup. Nature 2005, 434, 705. [Google Scholar]
- Orgel, L. Origin of life: A simpler nucleic acid. Science 2000, 290, 1306–1307. [Google Scholar]
- Schoning, K; Schoiz, P; Guntha, S; Wu, X; Krishnamurthy, R; Eschenmoser, A. Chemical etiology of nucleic acid structure: the alpha-threofuranosyl-(3′ → 2′)-oligonucleotide system. Science 2000, 290, 1347–1351. [Google Scholar]
- Chaput, JC; Szostak, JW. TNA synthesis by DNA polymerases. J. Am. Chem. Soc 2003, 125, 9274–9275. [Google Scholar]
- Ebert, MO; Mang, C; Krishnamurthy, R; Eschenmoser, A; Jaun, B. The structure of a TNA-TNA complex in solution: NMR study of the octamer duplex derived from alpha-(L)-threofuranosyl-(3’-2’)-CGAATTCG. J. Am. Chem. Soc 2008, 130, 15105–15115. [Google Scholar]
- Egholm, M; Buchardt, O; Nielsen, PE; Berg, RH. Peptide nucleic acids (PNA): Oligonucleotide analogues with an achiral peptide backbone. J. Am. Che. Soc 1992, 114, 1895–1897. [Google Scholar]
- Nielsen, PE. Peptide nucleic acid and the origin of life. Chem. Biodivers 2007, 4, 1996–2002. [Google Scholar]
- Poole, A; Penny, D; Sjoberg, B. Methyl-RNA: An evolutionary bridge between RNA and DNA? Chem. Biol 2000, 7, R207–R216. [Google Scholar]
- di Giulio, M. The split genes of Nanoarchaeum equitans are an ancestral character. Gene 2008, 421, 20–26. [Google Scholar]
- di Giulio, M. The origin of genes could be polyphyletic. Gene 2008, 426, 39–46. [Google Scholar]
- de Roos, ADG. Modelling evolution on design-by-contract predicts as origin of life through an abiotic double-stranded RNA world. Biol. Direct 2007, 2, 12. [Google Scholar]
- Ikehara, K; Amada, F; Yoshida, S; Mikata, Y; Tanaka, A. A possible origin of newly-born bacterial genes: significance of GC-rich nonstop frame on antisense strand. Nucl. Acids Res 1996, 24, 4249–4255. [Google Scholar]
- Berg, JM; Tymoczko, JL; Stryer, L. Biochemistry, 5th Ed ed; W. H. Freeman and Company: New York, USA, 2002. [Google Scholar]
- Ikehara, K; Omori, Y; Arai, R; Hirose, A. A novel theory on the origin of the genetic code: A GNC-SNS hypothesis. J. Mol. Evol 2002, 54, 530–538. [Google Scholar]
- Ring, D; Wolman, Y; Friedmann, N; Miller, SL. Prebiotic synthesis of hydrophobic and protein amino acids. Proc. Natl. Acad. Sci. USA 1972, 69, 765–768. [Google Scholar]
- Brinton, KL; Engrand, C; Glavin, DP; Bada, JL; Maurette, M. A search for extraterrestrial amino acids in carbonaceous Antarctic micrometeorites. Orig. Life Evol. Biosph 1998, 28, 413–424. [Google Scholar]
- Oba, T; Fukushima, J; Maruyama, M; Iwamoto, R; Ikehara, K. Catalytic activities of [GADV]-petides. Ori. Life Evol. Bioshph 2005, 35, 447–460. [Google Scholar]
- Miller, SL. A production of amino acids under possible primitive earth conditions. Science 1953, 117, 528–529. [Google Scholar]
- Miller, SL; Orgel, LE. The Origin of Life; Prentice Hall: Englewood Cliffs, NJ, USA, 1973. [Google Scholar]
- Orgel, LE. The origin of life on the earth. Sci. Am 1994, 271, 77–83. [Google Scholar]
- Miyakawa, S; Tamura, H; Sawaoka, AB; Kobayashi, K. Amino acid synthesis from an amorphous substance composed of carbon, nitrogen, and oxygen. Appl. Phys. Lett 1998, 72, 990–992. [Google Scholar]
- Takano, Y; Ushio, K; Masuda, H; Kaneko, T; Kobayashi, K; Takahashi, J; Saito, T. Determination of organic compounds formed in simulated interstellar dust environment. Anal. Sci 2001, 17, 1635–1638. [Google Scholar]
- Yoneda, S; Shimizu, M; Go, N; Fujii, S; Uchida, M; Miura, K; Watanabe, K. Theoretical and experimental approach to recognition of amino acid by tRNA. Nucleic Acids Symp. Ser 1983, 12, 145–148. [Google Scholar]
- Shimizu, M. Specific aminoacylation of C4N hairpin RNAs with the cognate aminoacyl-adenylates in the presence of a dipeptide: Origin of the genetic code. J. Biochem. (Tokyo) 1995, 117, 23–26. [Google Scholar]
- Ikehara, K. Mechanisms for creation of original ancestor genes. J. Biol. Macromol 2005, 5, 21–30. [Google Scholar]
- Ohno, S. Evolution by Gene Duplication; Springer: Heidelberg, Germany, 1970. [Google Scholar]


© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Ikehara, K. Pseudo-Replication of [GADV]-Proteins and Origin of Life. Int. J. Mol. Sci. 2009, 10, 1525-1537. https://doi.org/10.3390/ijms10041525
Ikehara K. Pseudo-Replication of [GADV]-Proteins and Origin of Life. International Journal of Molecular Sciences. 2009; 10(4):1525-1537. https://doi.org/10.3390/ijms10041525
Chicago/Turabian StyleIkehara, Kenji. 2009. "Pseudo-Replication of [GADV]-Proteins and Origin of Life" International Journal of Molecular Sciences 10, no. 4: 1525-1537. https://doi.org/10.3390/ijms10041525
APA StyleIkehara, K. (2009). Pseudo-Replication of [GADV]-Proteins and Origin of Life. International Journal of Molecular Sciences, 10(4), 1525-1537. https://doi.org/10.3390/ijms10041525