1. Introduction
The determination of drug–target interaction (DTI) is of great significance for the development of new drugs and the understanding of drug side effects. There are currently tens of thousands of Food and Drug Administration-approved drugs on the pharmaceutical market, as well as new drugs that are being validated in clinical trials [
1]. These new drugs may interact with potential unseen targets, treat unknown diseases, and produce certain side effects. Although traditional biochemical experiments can accurately verify DTI, the identification of DTI using biochemical experiments is a time-consuming, laborious, and expensive process [
2]. In order to accelerate the development of new drugs and reduce the workload of laboratory experiments, it is important to establish an effective DTI recognition model. The existing computation-based methods for predicting DTI mainly include the following two types: biological feature-based methods and network-based methods.
The first type is biological feature-based methods. The main idea of these methods is to extract the features of drugs and targets through their biological sequences. Based on the extracted features, a deep learning model is used for DTI recognition. Bleakley et al. converted the DTI recognition problem into a binary classification problem by using the binary local model method [
3]. In 2017, Meng et al. proposed a model called PDTPS [
4], which extracted features from protein sequences and medicinal chemical structures and applied relevance vector machines [
5] to predict DTI. In 2018, Wang et al. developed a stacked autoencoder-based model [
6], which extracted features of proteins by way of a position-specific scoring matrix [
7] and applied a random forest algorithm to predict DTI. In 2022, Cheng et al. proposed a model for predicting DTI using interaction and independent features based on the attentional mechanism [
8]. Specifically, protein sequences were extracted by using multiscale one-dimensional convolution, and word2vec was used for pre-training during word embedding. The RDKit tool was used to convert the SMILES sequence into a graph structure and input it into the multi-layer graph attention network (GAT) for drug feature extraction. In the same year, Zhao et al. constructed a model named HyperAttentionDTI [
9], which applied biological sequences to deep learning models with attentional mechanisms to predict DTI. A one-dimensional convolution of three stacked layers was used to learn sequence features from the inputs. The attention mechanism module produced an attention fraction value for each pair of amino acids. After the attention module, the multilayer fully connected neural network (FCNN) was used for the prediction of the DTI. In 2023, Bai et al. introduced a model named DrugBAN [
10], which extracted features from drug molecular diagram and target protein sequences through a graph convolutional network (GCN) and a 1D convolutional neural network (CNN), and used FCNN to predict DTI. Some biological features can be extracted from literature information; such approaches use drug and target descriptions as features rather than biological sequences. In 2015, Alkema et al. introduced important techniques for text mining such as askMEDLINE, PubNet, PubViz, CoPub, etc. [
11]. These methods can be used to effectively analyze the growing number of research papers in the field of bioinformatics. In 2016, Fu et al. presented a machine learning model based on semantic similarity to identify DTIs [
12].
The second type is the network-based approach. Networks can describe complex and diverse relationships between drugs and proteins. The main idea of these methods is to extract features by constructing an interaction network and a similarity network. In 2017, Luo et al. proposed a model named DTINet [
13], which established heterogeneous networks by obtaining multiple drug-related information and protein-related information, and predicted DTI through the networks. Not long after this, Yan et al. developed a model that extracted features from heterogeneous information on drugs and targets and applied multi-kernel learning and clustering methods to predict DTI [
14]. In 2020, Zhao et al. introduced a model that extracted features from a drug–protein pair network and combined GCN and a deep neural network to predict DTI [
15]. In 2021, Peng et al. presented a model named EEG-DTI [
16]. Specifically, they constructed a complex heterogeneous network containing drugs, proteins, diseases, and side effects. The features of drugs and targets were performed using a three-layer GCN learning framework. Finally, the inner product method was used to predict DTI. In the same year, An et al. developed a model named NEDTP [
17], which is a similarity-based method for predicting DTI. The author constructed a similar network of nodes through 15 heterogeneous information networks including drug–drug interaction, drug–disease association, drug–side effect association, the gene ontology biological process, protein–protein interaction, protein–disease association, protein sequence similarity, etc. The second-order biased random walk algorithm and word2vec were used for feature sampling and node vector representation learning. Finally, the model used a gradient boosting decision tree [
18] to predict DTI. In 2022, Li et al. combined a transformer module with a communicative message passing neural network to better capture the two-way effects between drugs and targets, and predicted DTI using multilayer perceptron [
19].
The relationship between drugs and targets is complex and varied. We should consider the features of drugs and targets in multiple networks, such as drug–disease associations, drug–drug similarities, drug–drug interactions, drug–side effect associations, protein–protein similarities, and disease–protein associations. The existing methods usually do not consider interaction types sufficiently and therefore do not take into account the relationship between multiple biological entities well. In some methods, drugs, diseases, proteins, side effects, etc. are taken as network nodes to obtain more correlational relationships when constructing heterogeneous networks.
However, there are some obvious disadvantages to the previous methods. First, these methods do not make full use of the biometric features of drugs, targets, and abundant topological information in heterogeneous networks to predict DTI. Specifically, biological feature-based methods do not take into account the features of drugs and targets in heterogeneous networks containing multiple biological entities (i.e., drugs, proteins, diseases, side effects), nor how to extract and incorporate them. Network-based methods only consider the topological information of drug target pairs and do not comprehensively consider the biological structure information of drugs and targets. Increasing node types also creates the problem of increasing computational complexity and makes the model more dependent on the existing data, which may eventually reduce the generalization ability of the model. Second, the predictive classification process of these methods is often fused with the feature extraction module to form an end-to-end DTI prediction model [
20,
21,
22], but these methods also reduce the flexibility and interpretability of the model and sometimes introduce overfitting problems.
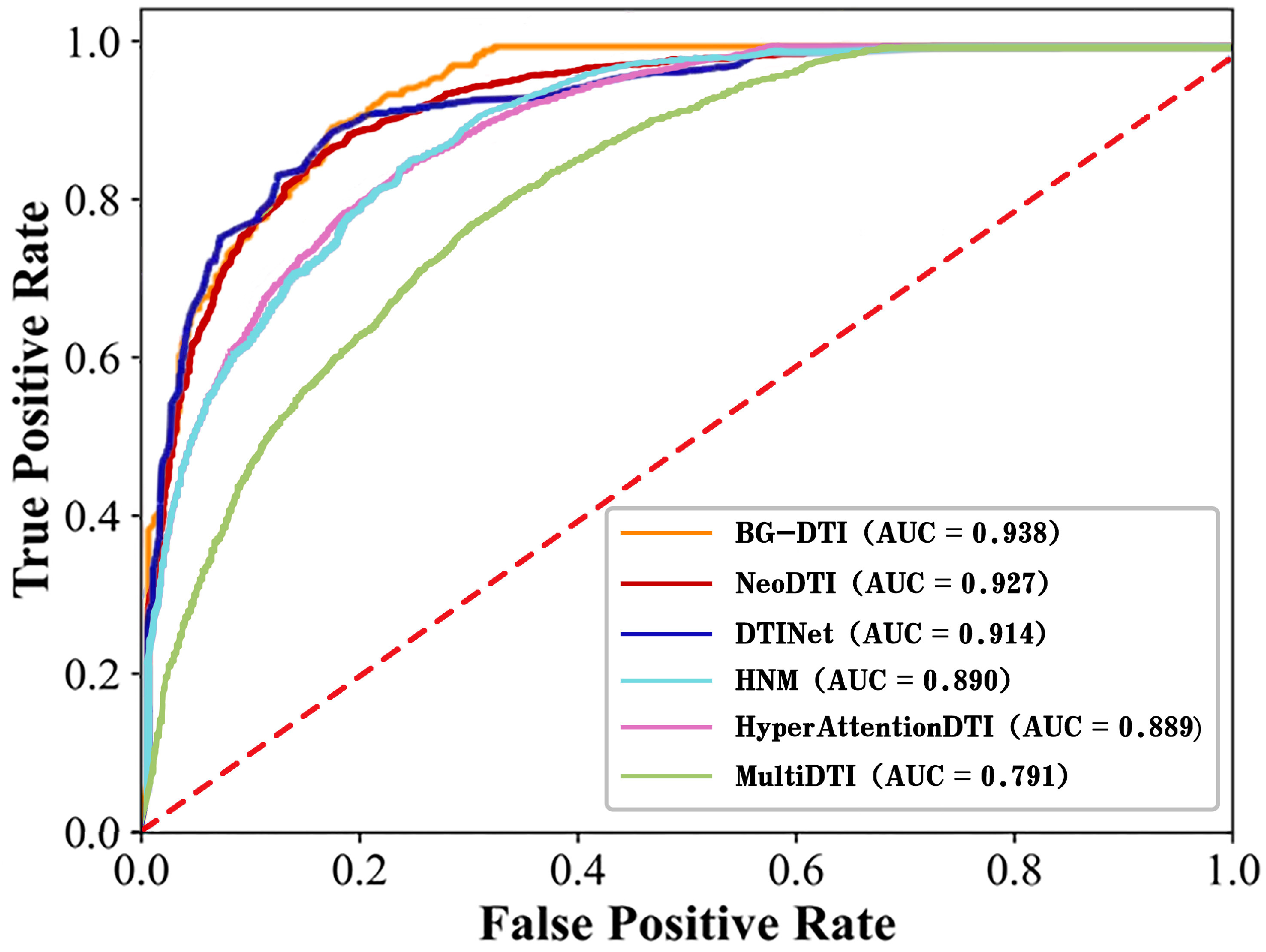
To solve the existing difficulties, we propose a new framework for predicting DTI based on biological feature and graph representation learning, named BG-DTI, to identify the interactions between drugs and targets. In our study, we first extract biological sequence information on drugs and targets using sequence embedding, a CNN layer and a pooling layer, and then consider both biological sequence information and network information and add drug–drug similarity and target–target similarity to complete the heterogeneous network. Based on heterogeneous networks, we use a combination method of GCN and GAT to learn the features representation of drugs and targets. Lastly, we use the random forest classifier to predict whether there is an interaction between drugs and targets. After model construction, we conduct a five-fold cross-validation (5-fold CV) experiment to evaluate the performance of BG-DTI. Meanwhile, we also compare BG-DTI with state-of-the-art methods on a benchmark dataset. All the results show that BG-DTI performs better than existing state-of-the-art methods, and it is an efficient model for DTI prediction.
3. Materials and Methods
3.1. Datasets
Currently, the most widely used DTI datasets are the Luo et al. dataset [
13], the Yamanishi et al. dataset [
28], and the Davis dataset [
29]. By deleting the overlapping data with little correlation in the above three datasets, we make the remaining data constitute a complete dataset. The new dataset contains six related networks (drug–disease association network, drug–drug interaction network, drug–protein interaction network, drug–side effect association network, protein–disease association network, protein–protein interaction network), and drug and protein sequences. Of these, 598 drug nodes represented by SMILES sequences and 1352 original protein sequences represented by amino acid sequences are extracted from the Drugbank database, the PubChem database, and the UniProts database. From the Davis database, 4862 disease nodes are obtained. From SIDER database 2.0, 3640 side effect nodes are extracted [
30]. All related network data are given as Boole matrices. That is, 1 indicates a known interaction or correlation and 0 indicates an unknown or no interaction or correlation. The information of our benchmark dataset is shown in
Table 5.
3.2. Overview of BG-DTI
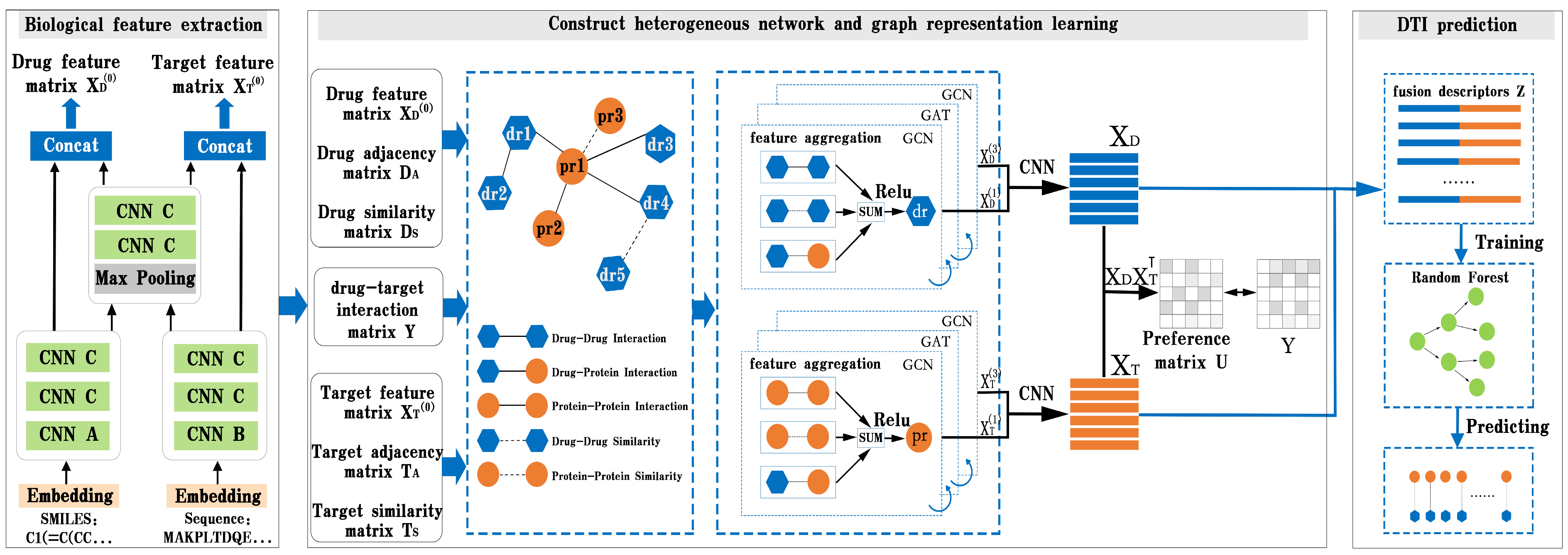
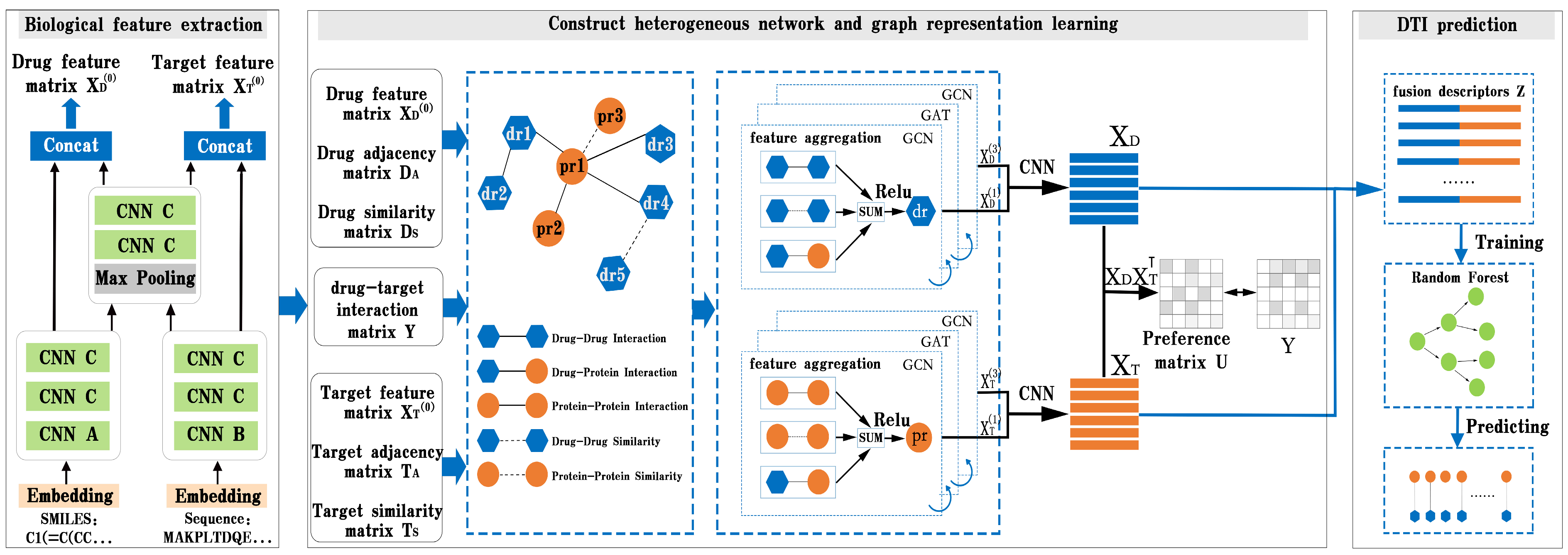
In this part, we present BG-DTI, a biological feature and heterogeneous network representation learning-based framework for drug–target interaction prediction. The workflow of BG-DTI is illustrated in
Figure 2, which includes three modules for model construction: a drug and target biometric feature extraction module, a graphical representation of the learning module, and the DTI prediction module. The detailed descriptions of these modules are introduced as follows. First, we take the SMILE sequence of the drug and amino acid sequence of the target as input, and fully extract adjacent information from the sequence through sequence embedding, CNN layer, and pooling layer, so as to shorten the feature length of the sequence and reduce the computational complexity and time while preserving the original association relationship and global information in the sequence. Second, we construct a drug–target heterogeneous network through the association relationship among various biological entities. In addition to the drug–drug interaction edge, the drug–protein interaction edge, and the protein–protein interaction edge, we also add an additional drug–drug similarity edge and a protein–protein similarity edge to the heterogeneous network. We then stack a GCN layer and a GAT layer to enlarge the receptive field on the graph, effectively aggregate information of multi-hop neighbors, and learn the features of drugs and targets from the heterogeneous network. In order to prevent the loss of feature information, we combine the output of the first and third layers to obtain the final representation of drug and target features. Last, we splice the characteristic representations of drugs and targets to obtain the fusion descriptors of drug–target pairs. Finally, the random forest algorithm is used to predict DTI.
3.3. Drug and Target Biological Feature Extraction
Each protein sequence where represents the ith amino acid and n is the sequence length. In order to fully extract the amino acid adjacent information in the sequence, we represent every k adjacent amino acids as a one-hot encoding. For example, if k is 3 and n is 5, then the protein sequence T is expressed as , , . In this work, each protein original embedding is composed of one-hot encoding. Similarly, for each drug SMILES sequence, , where represents the ith atom or structure indicator and m is the sequence length. We represent each as a one-hot encoding, and each original drug embedding is composed of 61 one-hot encodings. Finally, the original embedding of drug and protein sequences is expressed as , , where C is the embedding channel size, and and respectively represent the maximum length of drug and target.
After obtaining the original embedding of the drugs and targets, we input the original embedding vector into the 6-layer CNN to shorten the length of the sequence and reduce computational complexity and time while preserving the original correlation and global information in the sequence.
In order to fully extract the adjacent information in the sequence, we use multiple convolution kernels for each convolution layer to learn about this region embedding. For each sequence, convolution kernels are used for convolution calculation, and each convolution kernel is responsible for extracting a specific segment of information in the sequence. The calculation expression is as follows:
where
is the original embedded representation of a given sequence,
and
respectively denote the weight and bias of the
ith convolution kernel,
L is the length of the original embedded representation of drug or protein,
is the representation of a sequence after convolution processing with
N convolution kernels, || is a concatenation operation.
After that, we used two identical convolution layers to fully extract the information between the sequence region embedding and its adjacent embedding.
N convolution kernels are used for convolution calculation to extract the interaction information between the specific region embedded in the sequence and its left and right neighbors as below:
where
is the
ith channel of
,
denotes the weight of the
kth convolution kernel in the
ith channel of
,
denotes the bias of the
kth convolution kernel in the
ith channel of
,
σ is
ReLU nonlinear activation function, and
is a representation of a sequence after convolution processing with one convolution layer.
Inspired by ResNet [
31], we then connect a feature aggregation module consisting of a pooling layer and two convolution layers. We set the pooling layer as the non-linear pooling function of “maximum pooling”, so that the sequence length of sequence feature vectors is reduced by half each time after pooling. After that, the connected convolutional layer is equivalent to linearly weighting the result of the action of nonlinear functions, which strengthens the role of the pooling layer in reducing information redundancy and also reduces the information loss caused by pooling. Finally, we concatenate the pooling results with the convolution results and calculate the expression as follows:
when
,
and where
denotes the representation of the sequence after the convolution processing of two convolution layers,
P is the max pooling function,
θ is the convolution calculation of two convolution layers.
3.4. Construct a Heterogeneous Network
In addition to the six original associations in the network, we add additional drug–drug similarity and protein–protein similarity information to the heterogeneous network by considering both biological sequence information and network information.
The network similarity of drug–drug and protein–protein are calculated using the Jaccard similarity coefficient. Specifically, the drug–disease association network, drug–drug interaction network, and drug–side effect association network are used to calculate the similarity measure of each two drug nodes,
and
, in the network. The formula is shown as follows.
where
is the total number of nodes that have edges connected to
and connected to
,
is the total number of nodes that have edges connected to
and not connected to
, and
is the total number of nodes that have edges connected to
and not connected to
.
In the same way, protein similarity is calculated using the target–disease association network and the target–target interaction network, respectively. The sequence similarity between drugs is calculated based on molecular fingerprints [
32,
33]. First, MACC fingerprints of molecules in drug sequences are calculated, and the Tanimoto coefficient is obtained based on the similarity comparison of MACC fingerprints. Finally, the Tanimoto coefficient is used to measure the similarity between drugs. MACC fingerprints refer to fingerprints derived from the chemical structure database developed by MDL. A total of 166 substructures are examined, plus 1 bit to hold the information in the RDKit, for a total of 167 bits for the fingerprint. If it has a substructure, store 1, otherwise store 0. The Tanimoto coefficient is an extension of the Jaccard coefficient. The formula is shown as follows.
where
denotes the number of shared fingerprints of two drugs,
denotes the total number of fingerprints of
, and
denotes the total number of fingerprints of
.
The sequence similarity between proteins is calculated using the Levenshtein similarity coefficient. Specifically, we characterize similarity by looking at differences in the length and types of amino acids in different protein sequences as follows:
where
is the number of amino acids of
,
is the number of amino acids of
, and
E is the sum of the difference between the number of amino acids in
and
.
For each pair of drugs, we calculate four similarity scores based on network similarity and biological sequence similarity. Therefore, for any pair of drugs, we can obtain four similarity scores. Next, we set a given threshold, and if one of the similarity scores is greater than this threshold and this has no interaction with the drugs, we add a similarity edge between the two drugs. Similarly, for each pair of targets, we calculate three similarity scores based on network similarity and biological sequence similarity. We then determine whether similar edges are added between two targets by a given threshold that we set.
3.5. Graph Representation Learning of Drug and Target
One of the key aims of the DTI recognition model is to find a more advanced, better performance, and more reasonable feature extractor. Recently, GCN and GAT have been widely used in feature extraction of graph networks [
34,
35,
36,
37]. In order to realize feature aggregation among related nodes in heterogeneous networks, graph convolution is a common method on the network.
In this section, we propose a graph learning module composed of GCN and GAT layers to learn feature representations from heterogeneous networks. As shown in the graph representation learning module in
Figure 1, we add a graph attention layer between the two graph convolution layers to help the GCN layer extract high-level features of the drug and target. The following sections explain the details.
We represent the heterogeneous network as
, where
denotes a node in the heterogeneous network (i.e., drugs, proteins).
is an edge in the heterogeneous network, and
represents an edge type in the heterogeneous network. Specifically, R includes five types of edges: drug–drug interaction, drug–drug similarity, drug–protein interaction, protein–protein interaction, and protein–protein similarity. In the GCN layer, we aggregate the features among relevant nodes as follows:
where
denotes the network adjacency matrix with edge type
r,
.
is the network degree matrix with edge type
r,
W is the trainable weight parameter matrix,
is the features representation of the node in
l layer.
σ represents the
ReLU activation function. When
, we use drug and target biometric feature vectors as original features to encode each node.
In the GAT layer, we aggregate the features among relevant nodes as follows:
where
K is the number of attention mechanisms in multi-head attention,
denotes the kth attention coefficients between nodes
i and
j with edge type
r. is the weight matrix of the
kth attention mechanism,
is the features representation of node
in the
l layer. || is a concatenation operation,
L is the
LeaklyReLU activation function.
denotes the weight vector of the kth attention mechanism, and
denotes the weight of the edge
that is to be learned.
So far, we obtain the feature coding of each node in the heterogeneous network under each layer. For the nodes in the network, the previous models can only aggregate the information of neighbors within one hop by using a layer graph convolution neural network layer number. In order to fully extract the interaction information between nodes and their neighbors in heterogeneous networks, we enlarge the receptive field of the graph by stacking the graph convolution layer and the graph attention layer from the inter-layer perspective, and effectively aggregate the information of multi-hop neighbors [
38].
However, stacking multi-layer GCN and GAT may lead to the common problem of feature over-smoothing and the vanishing gradient problem [
39,
40], that is, the output of the hidden layer representation of each node tends to converge to the same value. In addition, it is inevitable to lose feature information in the feature transmission process between layers. In order to solve the feature over-smoothing and vanishing gradient problems, scholars have put forward some corresponding methods. For example, HGANDTI [
41] avoids the problem of over-smoothing features generated by stacking multiple layers by enlarging receptive fields from an intra-layer perspective. LightGCN [
42] prevents the problem of missing feature information by considering the output representation of different GCN layers.
Inspired by the above model, we add a fusion layer and combine the output feature vectors of different layers to obtain the final drug and target feature representation
and
. The feature aggregation process between different layers of relevant nodes is as follows:
In order to train the joint representation learning framework of biological sequences and heterogeneous network features, we use binary cross entropy to measure the gap between the DTI matrix and the preference matrix and use it as a loss function for training the joint representation learning framework. The loss function is shown as follows:
where
is the label value between drug
i and target
j,
is the predicted value between drug
i and target
j in the preference matrix
, and
is the number of drug–target pairs.
3.6. DTI Prediction
We use the feature joint representation learning framework to connect the drug and target feature representations
and
to obtain the fused descriptors of the drug–target pairs. The fusion descriptor for a pair of drug
i and target
j is as follows:
where
and
are the feature representations of drug
i and target
j, respectively.
Random forest is an efficient integrated classification algorithm [
43]. It generates a list of base evaluators through
N times of training, and then evaluates its predicted results through the average or voting principle. Thus, overfitting of training data can be effectively alleviated [
44]. Currently, it has been widely used to solve problems in bioinformatics fields, such as predicting disease-associated circRNAs [
45,
46]. Inspired by Lertampaiporn et al. [
45], we use fusion descriptors of drug–target pairs (
) as categorical features and use a random forest classifier to predict whether DTI has interaction.
4. Discussion and Conclusions
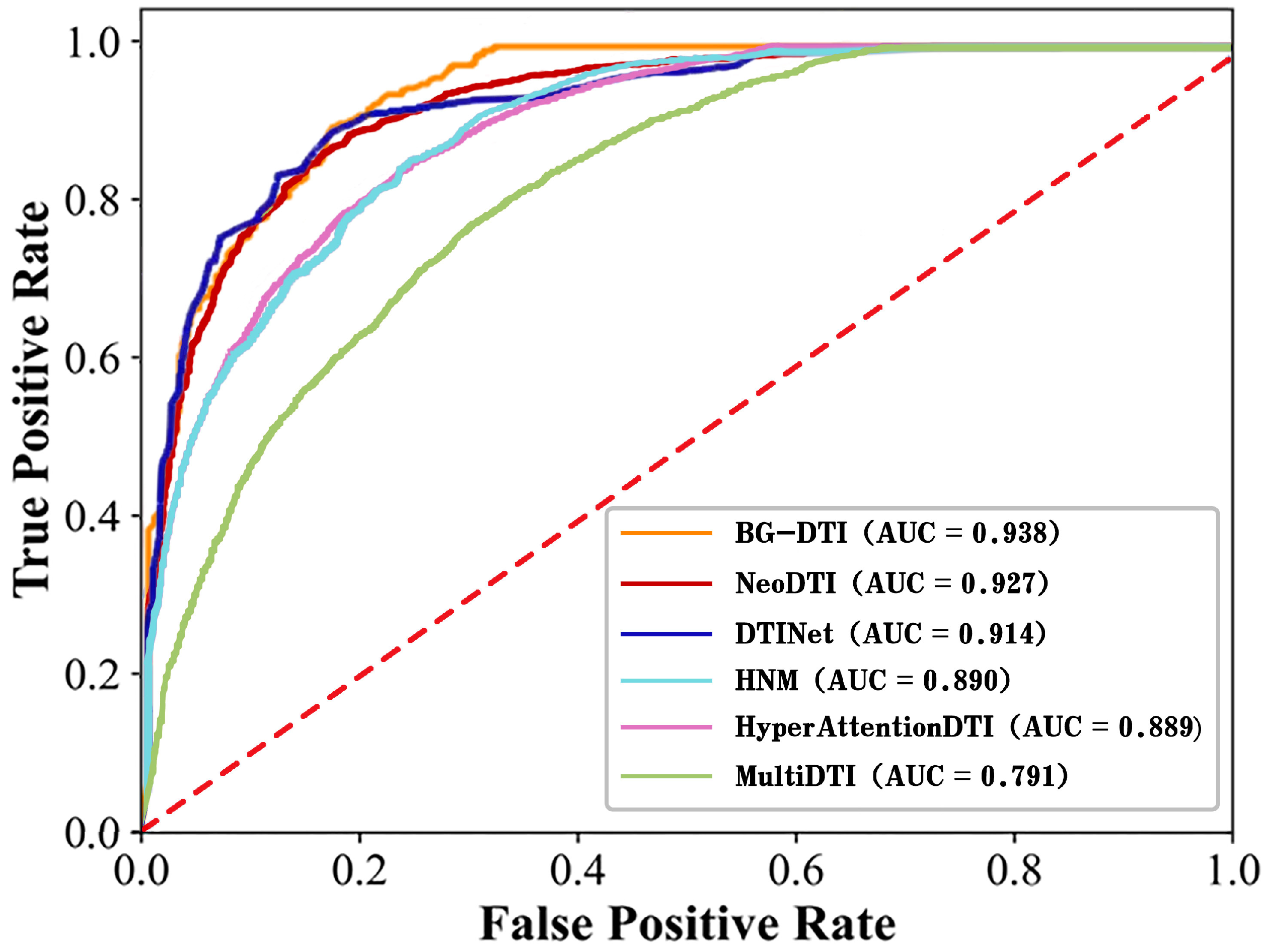
In recent years, the prediction of DTI has been of great significance for the discovery of new drugs and the repositioning of drugs. Although the interactions between the drug and target can be accurately verified by biological experiments, it is often a time-consuming and expensive process. Therefore, it is urgent to develop computational models to predict DTI. In this work, we propose a framework based on biological feature and heterogeneous network representation learning for the prediction of DTI, called BG-DTI. Our model combines two mainstream methods, biometric-based and network-based, to extract the characteristics of drugs and targets and to predict the interactions between drugs and targets using the random forest algorithm. We create a benchmark dataset based on the Luo et al. dataset [
13], the Yamanishi et al. dataset [
28], and the Davis dataset [
29], and compare BG-DTI with previous methods on this benchmark dataset. Comparative experiments show that BG-DTI performs better than existing state-of-the-art methods. The ideal predictive ability of BG-DTI mainly depends on the following factors: First of all, none of the previously proposed methods combined biometric features with heterogeneous network methods, while BG-DTI made full use of the sequence feature information of drugs and targets and topological information on the graph through the biological feature extraction module and the graph representation learning module. Second, the predictive process of the previous methods is often fused with the feature extraction module to form the end-to-end DTI prediction model, but these methods also reduce the flexibility and interpretability of the model and sometimes introduce the problem of overfitting. BG-DTI uses random forest as a predictive classifier to obtain a higher quality classification strategy. The results of the ablation experiment show that the drug and target biometric feature extraction module and the graph representation of the learning module can provide more abundant and accurate drug and target information for the prediction of DTI. The random forest algorithm can make the optimal classification decision based on the extracted drug target features, thus improving the prediction performance of DTI [
47]. In addition, although BG-DTI is mainly used to predict DTI, it is a portable method and it can be widely used to solve problems in bioinformatics fields such as predicting the correlation between circRNAs and diseases [
48,
49,
50,
51].
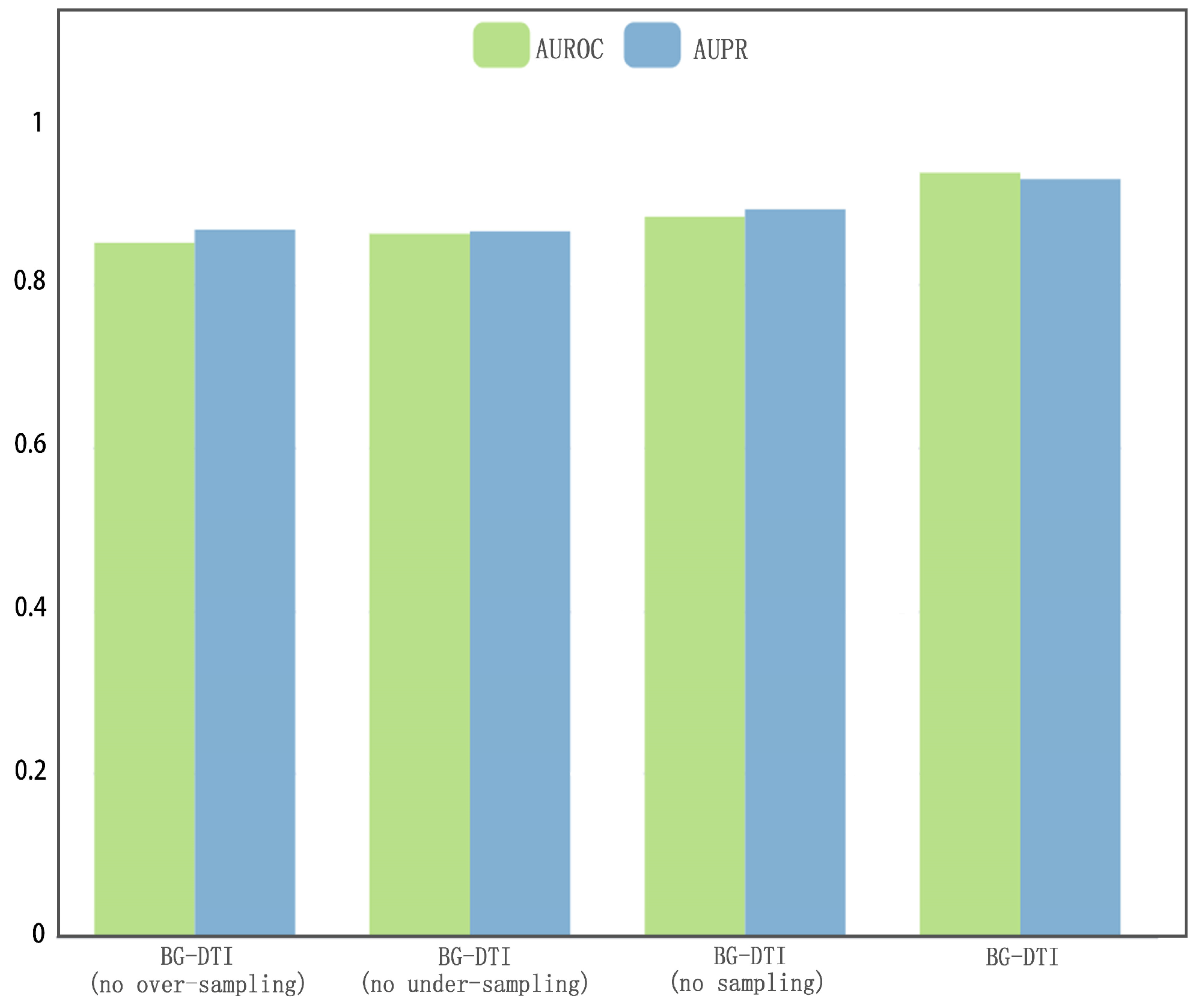
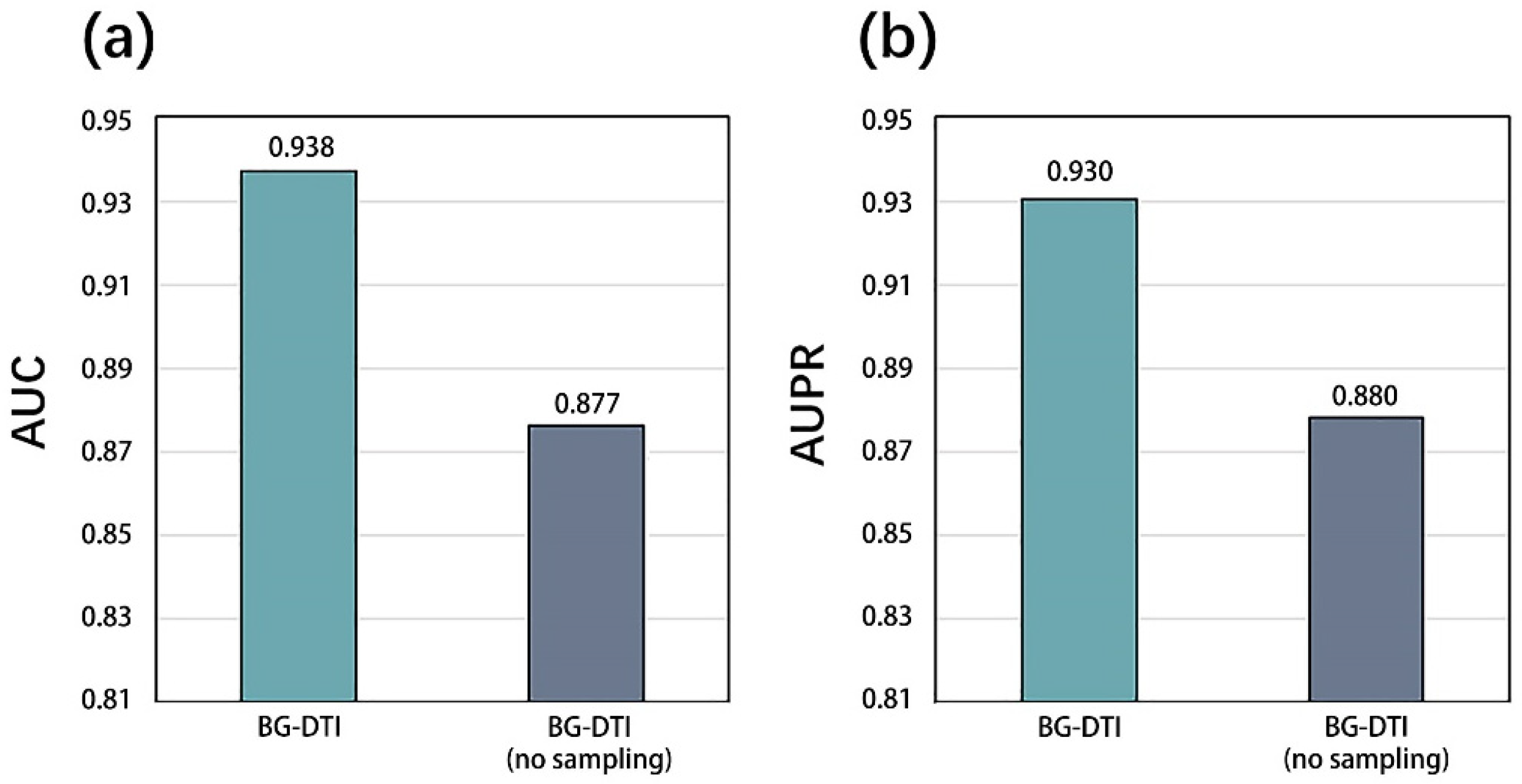
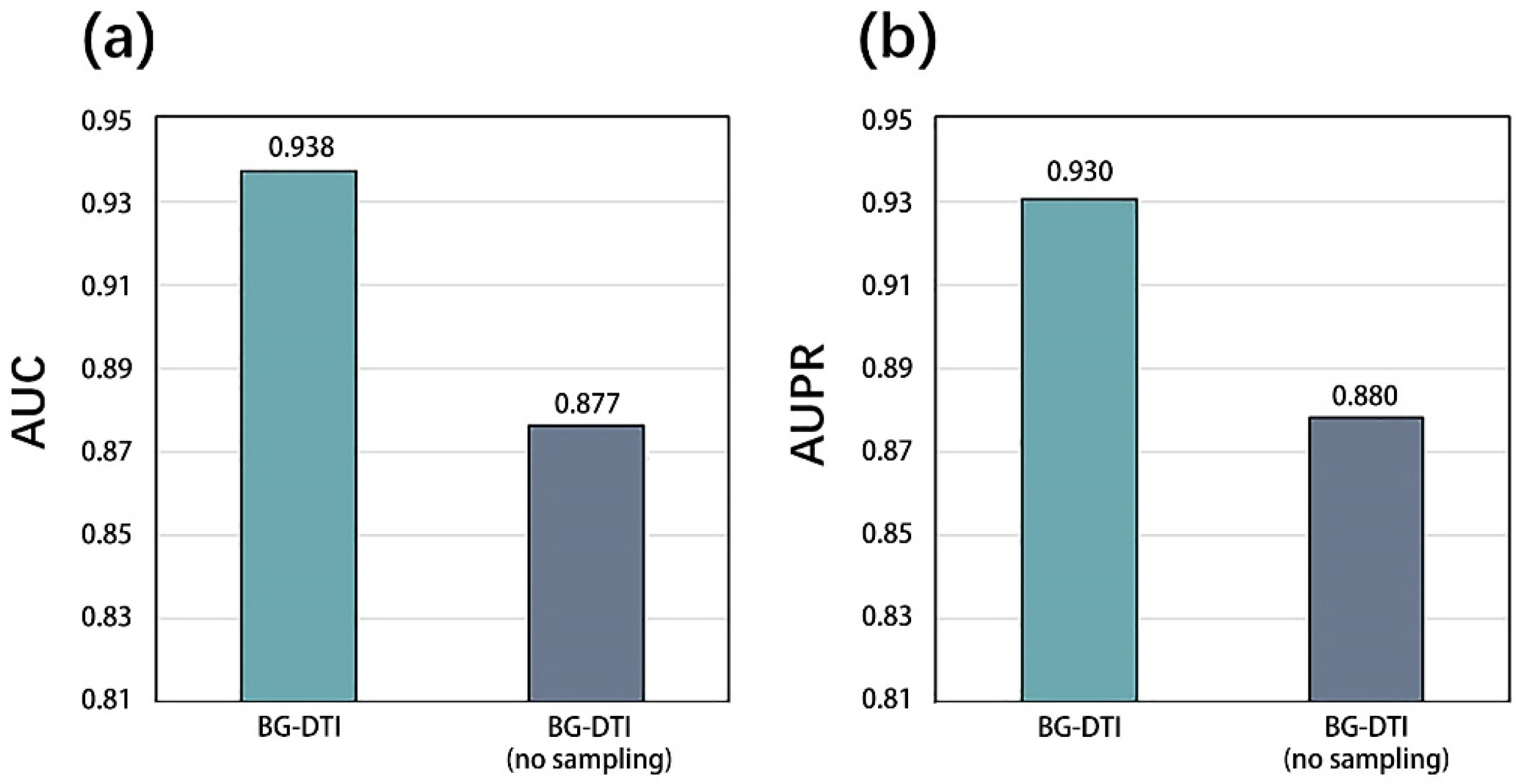
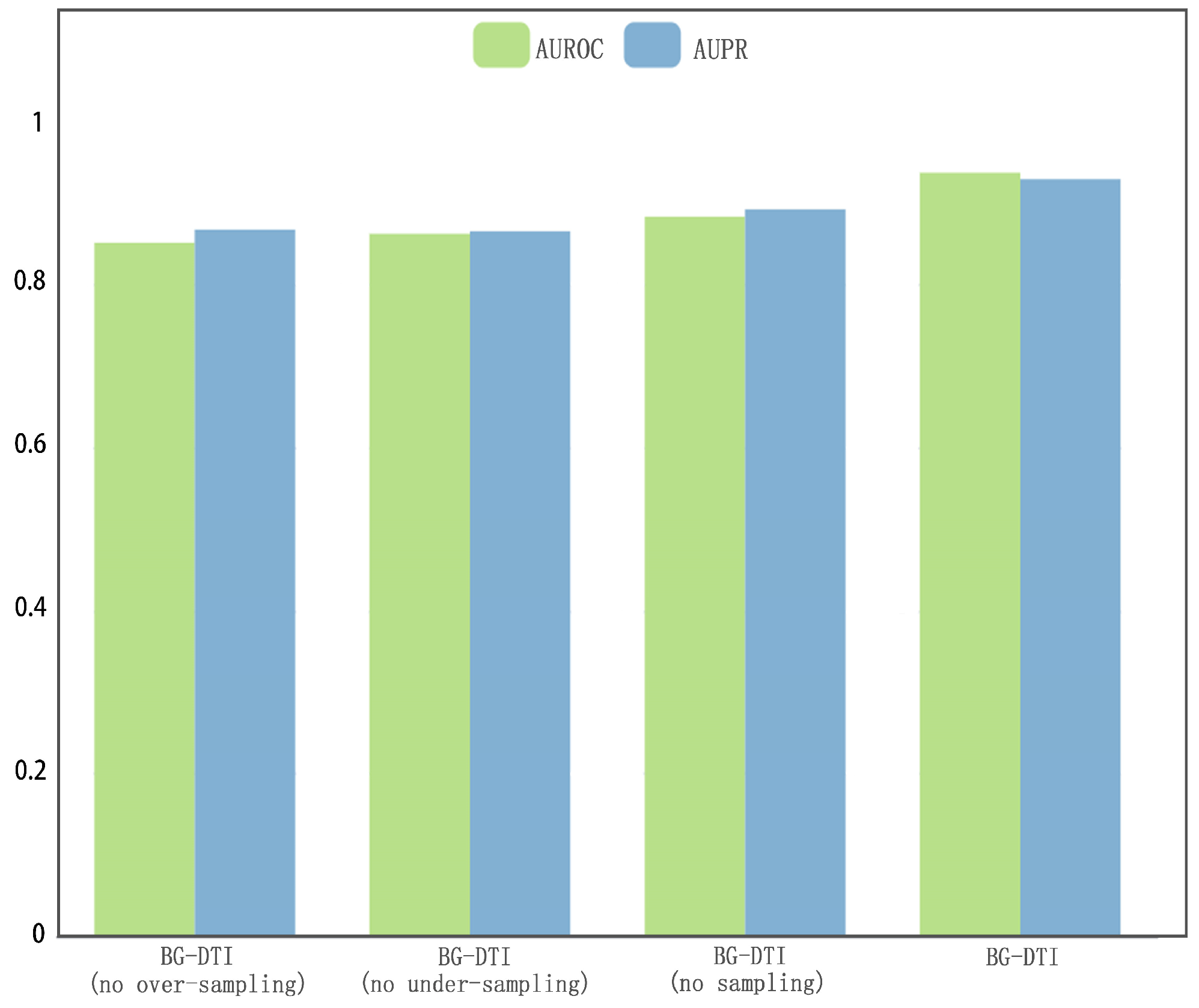
However, BG-DTI also suffers from some limitations. First, as shown in
Figure 2, the performance of BG-DTI under highly unbalanced datasets is not ideal. Second, as shown in
Table 4, the performance of BG-DTI on the blind protein test and the benchmark dataset is quite different. The reason for the performance gap may be that the method based on protein sequence extraction means that the model learns insufficient protein structure information. Rational use of protein structure information is an important idea to further improve DTI prediction performance. Third, the prediction of BG-DTI is only aimed at whether the drug target is associated, and there is no detailed prediction of the associations type (e.g., agonist, inhibitor, potentiator, and antagonist) [
15]. In the future, we will design and develop a new version of BG-DTI that can perform a more detailed classification of DTI types.





{kind=link}
{kind=link}
{kind=link}
{kind=link}