1. Introduction
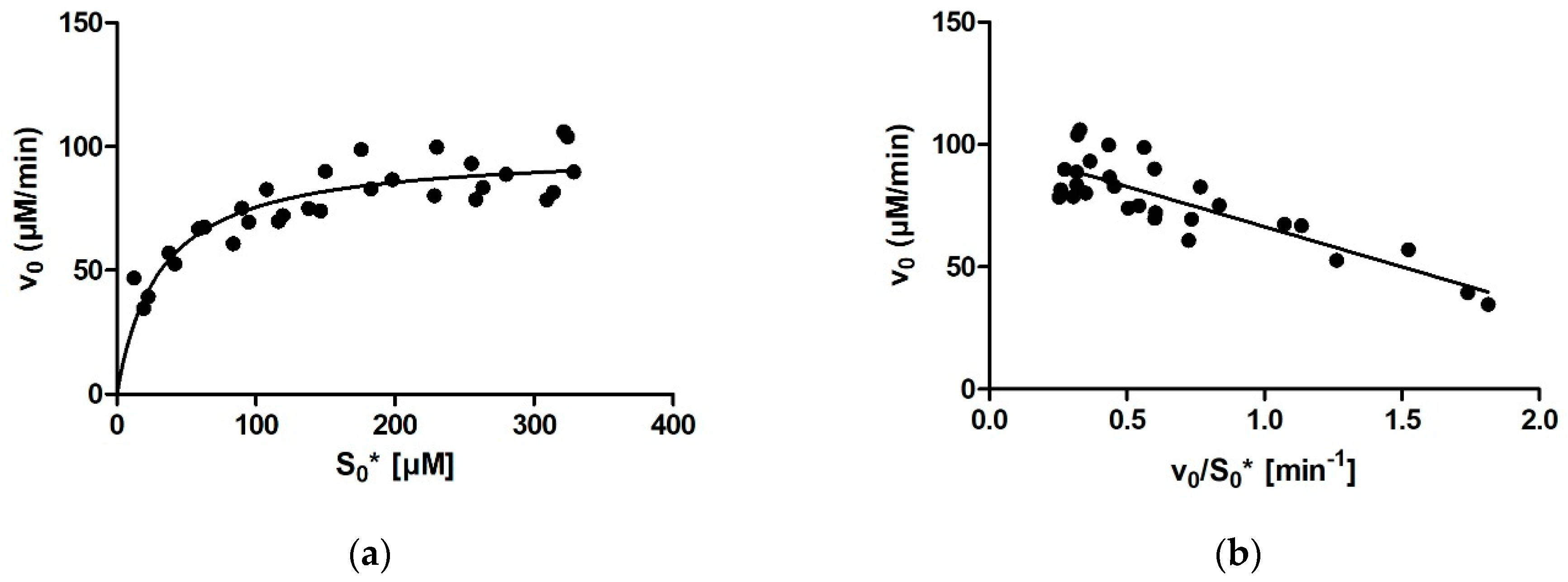
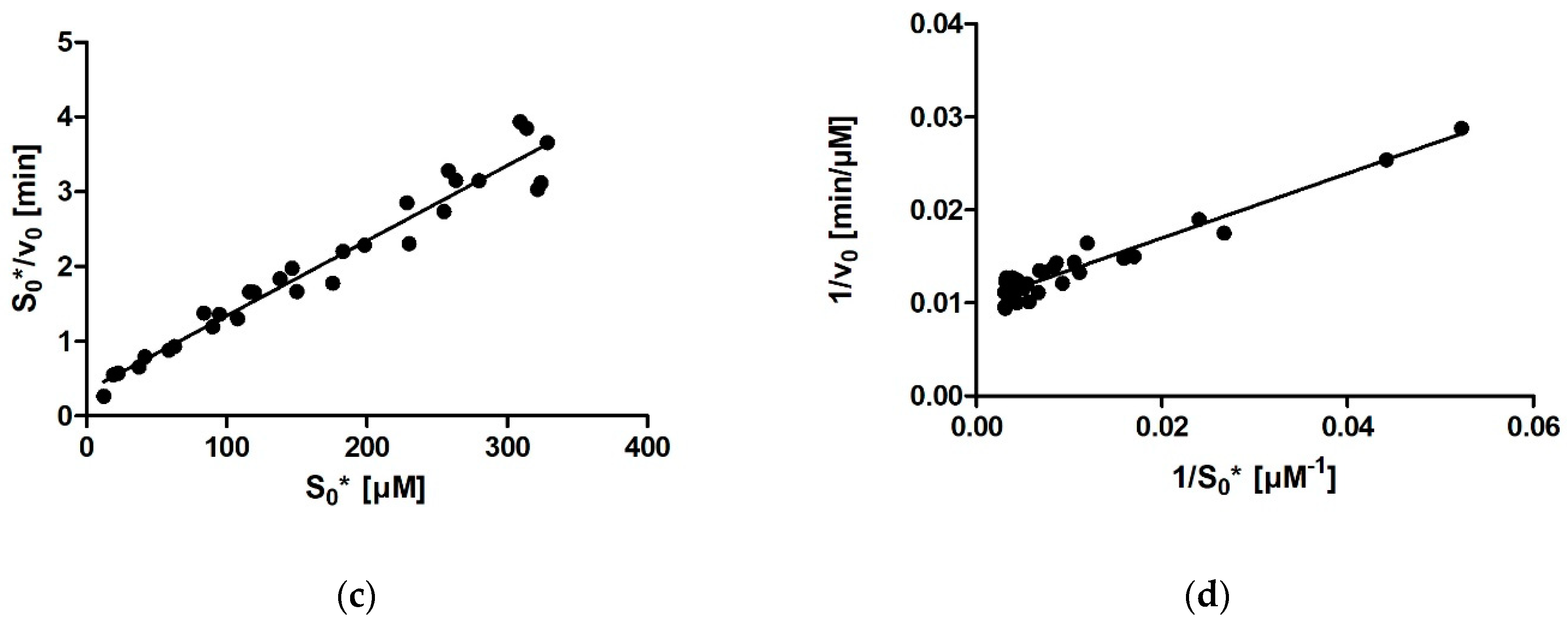
Ever since Leonor Michaelis and Maud Menten first published the equation that bears their name in 1913, the Michaelis constant Km has been the main kinetic parameter used to quantify the affinity of a given enzyme for its substrate. Traditionally, Km was determined by measuring the initial rate of the enzymatic reaction at several different substrate concentrations and then plotting the initial rates and substrate concentrations onto one of the linearized transformations of the Michaelis–Menten (MM) equation. These include the linear Lineweaver-Burk, Eadie-Hofstee, and Hanes-Woolf plots, each of which has its own (dis)advantages in terms of precision. With the aid of nonlinear regression methods and computers, it later also became possible to fit an MM model equation directly onto the initial rates without prior linearization of the data. With this, all points are given equal weight during fitting. However, all these approaches share a downside, namely, that only one (initial) rate–concentration data point is available from an individual enzymatic reaction performed in the laboratory.
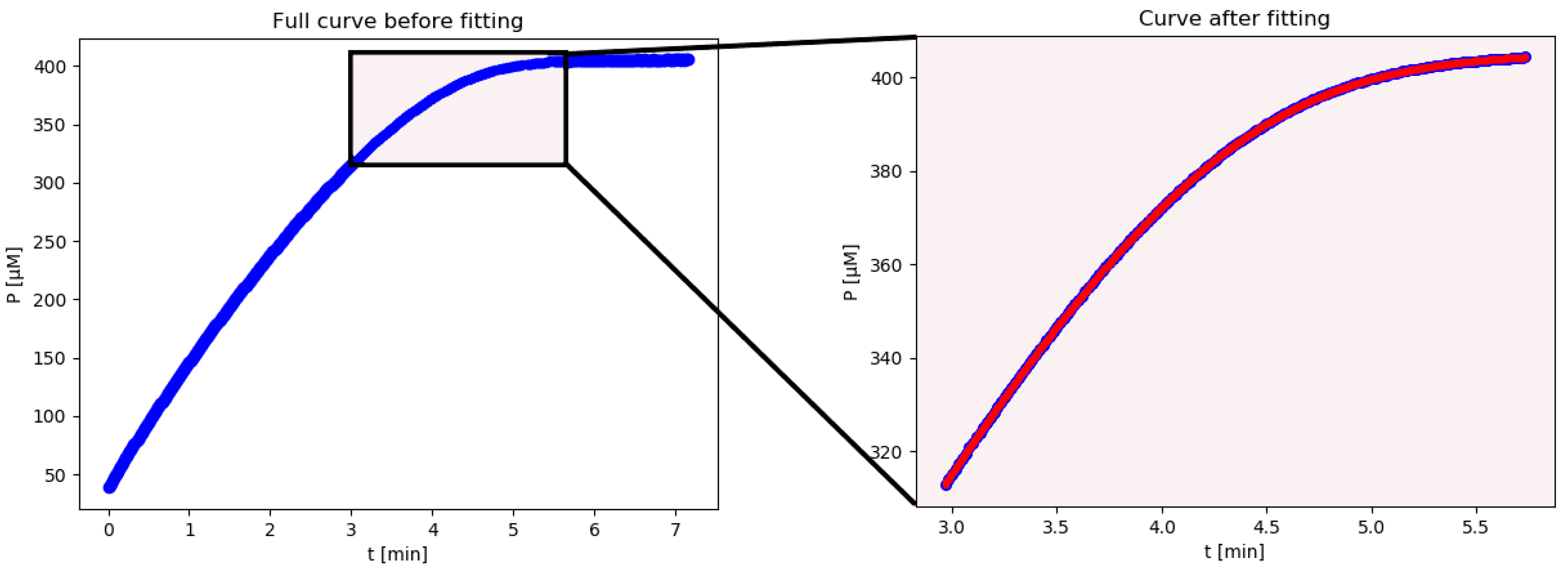
With further developments in computational methods, it became possible to fit model functions onto entire progress curves, thus rendering MM plots and their derivatives, as well as the measurement of initial rates, unnecessary. There are several advantages to using entire progress curves compared to initial rates: (1) More time–concentration data points are used from each enzymatic reaction, which improves the precision of the final fit; (2) fewer enzymatic reactions need to be performed in total, which reduces the consumption of the enzyme and substrate; (3) the need to start measuring the reaction immediately after it begins is smaller; and (4) the exact amount of substrate present can be calculated from the final plateau of the progress curve itself (for irreversible reactions).
Several computer programs, which rely on several different numerical approaches, allow fitting model functions onto progress curves. One approach is to extract the substrate concentration and velocity for each point on the progress curve and then plot these points onto an MM diagram or its derivatives [
1]. However, linearized versions of the MM diagram have the previously noted deficiencies. Another approach is to use a version of the integrated MM equation, which expresses time as a function of product concentration, as a model function. The problem with this approach is that when the progress curve approaches the plateau, the model function performs poorly. The reason for this is that it models time as a function of product concentration, with one of the terms being ln (1 − [P]/[S]
0); when the progress curve reaches its plateau, this term cannot be calculated anymore [
2].
In recent years, an improved integrated version of the MM function has been published, based on the Lambert W function, which expresses product concentration with respect to time [
3]. Unfortunately, most general-purpose software packages for data analysis do not include the Lambert W function. To remedy this, Goličnik [
4] published a numeric approximation of the above equation that can be used for progress curve fitting in software packages such as GraphPad Prism (referred to henceforth as Prism). Another approach is to fit numerically evaluated theoretical curves based on a system of differential equations onto progress curves; this requires special computer programs such as Dynafit [
5] or Enzo [
6].
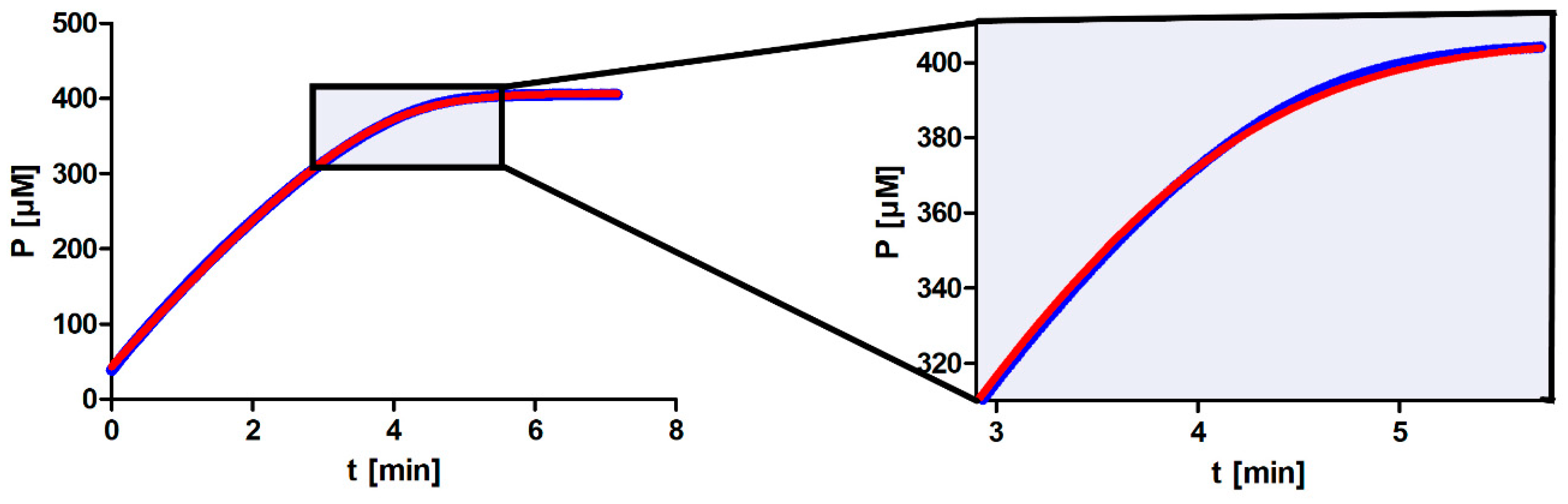
One persistent problem when working with entire progress curves is deciding which points on the curve should be used to fit the model function. The advantage of model functions such as the integrated MM equation is that they treat all the points on the progress curves the same; however, this can also be a disadvantage. A program can produce a solution that fits perfectly onto the plateau but at the expense of not fitting well onto the area of maximum curvature, which contains the most information about
Km [
7]. Such
Km estimates can be considerably far from the true values; see also
Figure A1 in
Appendix A. A similar problem occurs when
Km is small compared to [S]
0, as the initial part of the progress curve is almost straight, and any information about
Km can be lost in the noise.
While it is possible to manually trim progress curves and remove points from the initial and final parts of the curve based on intuition or by creating ad hoc rules (e.g., removing all points recorded after reaching the plateau), such approaches are insufficient for obtaining high-quality and reproducible results. An ideal method for data point selection should be based on sound mathematical principles, applicable to different types of progress curves, and capable of producing results as close as possible to real Km values.
Such a method has been proposed by Stroberg and Schnell [
7]. They proposed an equation that determines the area of maximum curvature of a progress curve from the input values of
Km and
Vmax. Based on their equation, we have developed an iterative method that determines the area of maximum curvature based on estimates of
Km and
Vmax and then proceeds to calculate
Km and
Vmax again from the points within this area. This process continues until the calculated area of maximum curvature remains constant [
7]. To calculate
Km and
Vmax with this iterative method, we selected the integrated MM equation (based on the Lambert W function) and developed a short script in Python that calculates the area of maximum curvature from a progress curve and the resulting
Km and
Vmax values from this area. The working name of this script is hereafter referred to as iFIT; it is accessible at
http://i-fit.si/ (last accessed 29 December 2021).
Several articles have compared different methods for progress curve analysis and have demonstrated their advantages and limitations [
8,
9,
10]. The present article has two major advantages compared to most of these studies: (1) to the best of our knowledge, this is the first study to investigate a method for selecting a sufficient data point area around the time course curvature, and (2) in our study, the different methods have been tested on real experimental data. Most comparisons of methods for progress curve analysis are performed on simulated data; the advantage of such an approach is that the exact
Km values and other kinetic parameters are known [
8]. However, although noise is also simulated in such analyses, it is unlikely that this simulated approach fully encapsulates the variety of noise that can occur in an experimental setting. Hence, analysis of simulated progress curves can lead to overly optimistic appraisals of the software used.
This study was based on the enzyme paraoxonase 1 (PON1), which naturally occurs in mammalian blood. PON1 plays an antioxidative role in the bloodstream, presumably via the breakdown of oxidized lipids. PON1 has also been associated with the slower progression of several medical conditions as well as with delayed aging in general and is thus very promising for therapeutic and diagnostic applications [
11,
12,
13]. Since PON1 is naturally associated with high-density lipoproteins and is very difficult to prepare in a native form in cell culture, the use of soluble recombinant versions of PON1 (rePON1) is more convenient for investigating the enzymatic properties of PON1 [
14]. According to the literature, the kinetics of recombinant PON1 are especially similar to those of human serum PON1 for arylesterase and organophosphate substrates [
14] but somewhat less so to those of lactone substrates [
15,
16]. Another advantage of rePON1 is its high stability, as reported by the researchers who developed it; G2E6 is not prone to aggregation and could easily be crystallized for structure determination [
17].
3. Discussion
The three main enzymatic activities of PON1 are aryldialkylphosphatase (more commonly known as paraoxonase), arylesterase, and lactonase activity [
17]. Most artificial substrates for PON1 fall into one of these three categories. Although lactonase activity has been proposed as the “native” evolutionary activity of human PON1, most experimental studies, especially in medical contexts, continue to be performed on paraoxonase and/or arylesterase substrates [
16]. Using different substrate types when comparing groups of test subjects for PON1 enzymatic activity in clinical studies can lead to contradictory results [
18,
19]. This emphasizes the need to use more than one substrate type when investigating PON1 in a clinical context. This in turn also means that lactonase activity should be more frequently investigated in clinical studies than is presently the case.
The most-used lactone substrate for investigating PON1 is DHC [
19]. Despite its relative ubiquity in medical studies, DHC has only been kinetically characterized as a substrate of PON1 in a handful of published articles. Most notably, the
Km value for the reaction between PON1 and DHC has seldom been reported in studies so far: it has been reported, e.g., for human serum PON1 [
15,
20], for rat serum PON1 [
21], and for rePON1 [
16]. Certain specific challenges that DHC presents as a substrate, e.g., its rate constant of nonenzymatic hydrolysis (
t1/2 = 8.25 min), have hardly been mentioned in the literature at all. We therefore wish to contribute to a more thorough understanding of the kinetic parameters of PON1-induced DHC breakdown, which should be useful to all future researchers investigating the lactonase activity of PON1 in experimental as well as clinical contexts.
The only
Km value that has been reported in the published literature for DHC and rePON1 G2E6 is 129 ± 8 µM [
16]. There is a large discrepancy between this value and our results (
Km was 27, 27, and 31 µM for Dynafit, iFIT, and the MM diagram, respectively; the Prism (the entire curve) average is not included because of the dependence of the output
Km on substrate concentration). Khersonsky and Tawfik [
16] did not account for the nonenzymatic hydrolysis of DHC in water, which we have shown to be substantial, and used a relatively high ionic strength for their buffer supplemented with the detergent tergitol. In PON1, we observed that high ionic strength produces higher
Km values when working with DHC. Additionally, not accounting for nonenzymatic hydrolysis produces higher apparent
Km values when calculating
Km from initial rates.
Indeed, in the present data analysis, using the initially assumed S
0 values instead of the adjusted ones and not subtracting the nonenzymatic reaction from the initial rates resulted in
Km values more than twice as high as those acquired when S
0 and v
0 were properly adjusted (
Table 1). The
Km value calculated without accounting for the nonenzymatic reaction and without adjusting the concentration of S
0 was 74 ± 11 μM. This value is closer to the reported value from the literature [
16]. Unfortunately, this means that we have no consensus on a specific
Km value against which to compare our results.
The adjusted S0* values are those calculated retroactively from the progress curves. They are usually smaller than the initially assumed concentrations because they do not include the amount of substrate that was consumed before the start of the measurement; this is especially relevant for very small substrate concentrations. Most researchers working with initial rates do not record the entire progress curve and thus never know how far off their substrate concentrations might have been from the initially assumed concentrations; this is another advantage of working with entire progress curves, regardless of which analysis we perform afterwards. Nevertheless, once we record the entire progress curve, it makes more sense to directly extract the kinetic parameters from the progress curve rather than use the initial rates approach.
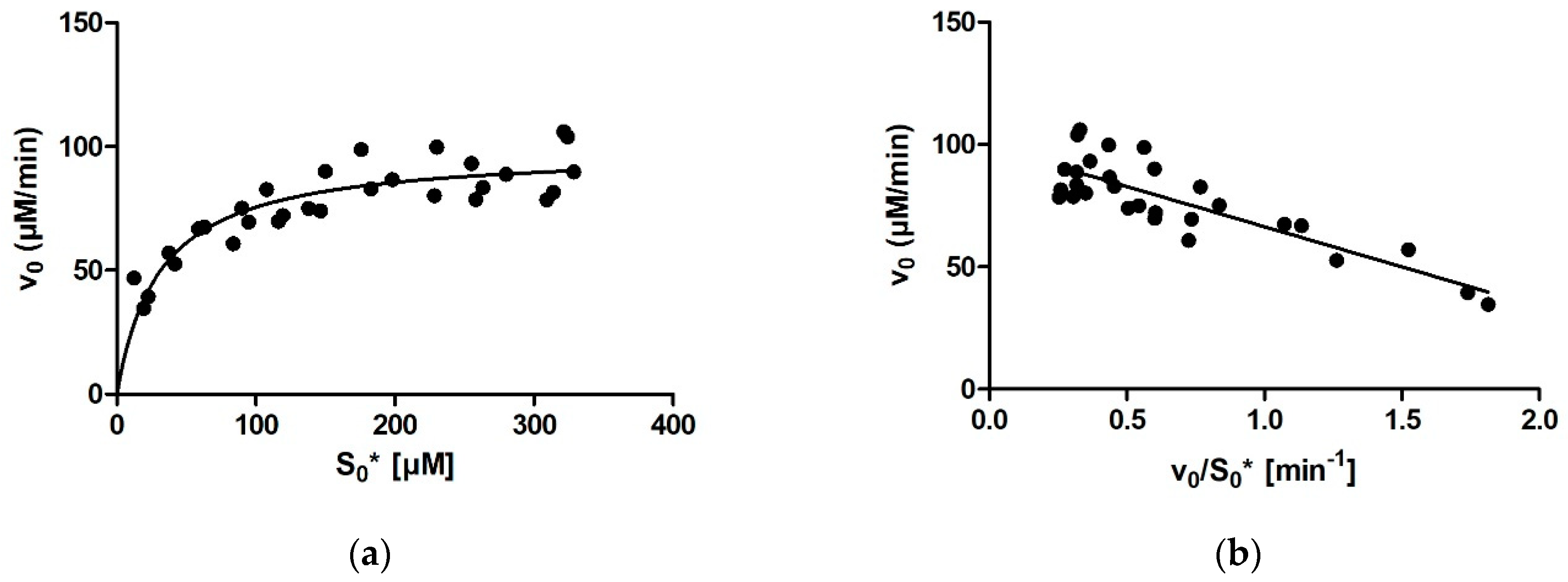
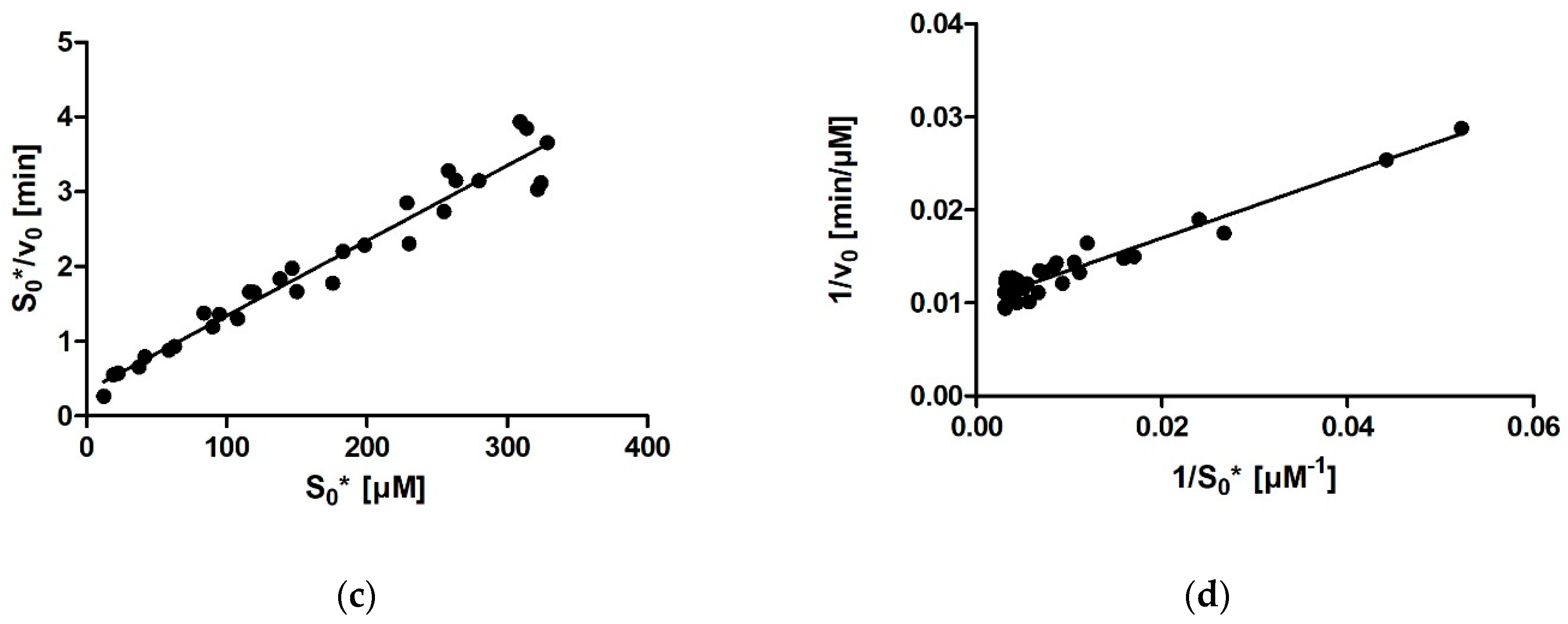
Comparing the different approaches for determining Km that we used (four based on the MM diagram and two based on progress curves; the approach of fitting the entire curve in Prism is not included here for the abovementioned reasons) reveals that the average Km value ranges between 27 µM for Dynafit and 35 µM for the Lineweaver–Burk method. The results can be grouped into two clusters, with very similar average results acquired with Dynafit and iFIT (27 µM in both cases) and by the four methods based on the MM diagram (31–35 µM). If we consider all these approaches as equally valid, we can conclude that the Km of rePON1 for DHC is approximately 30 µM. The clusters are less pronounced for the Vmax values. The average Vmax values are 99–100 μM/min for all initial rate approaches, 96 μM/min for iFIT, and 91 μM/min for Dynafit.
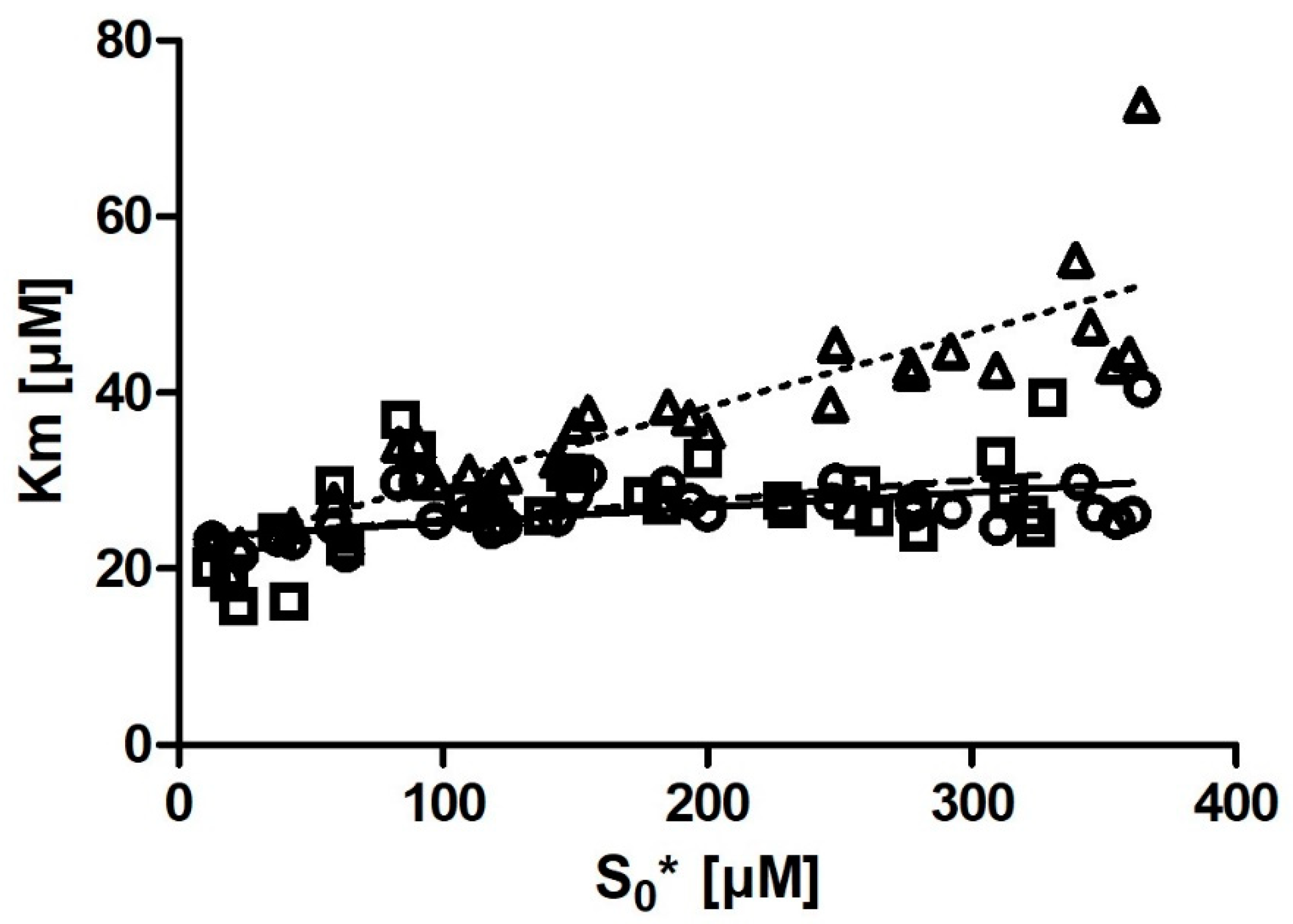
It is apparent from our results that not all approaches for determining
Km can be considered equally reliable. The integrated MM equation in GraphPad Prism (hereafter referred to as only “Prism” in the Discussion) is particularly problematic because the increasing substrate concentration has a major effect on the
Km output value. The major reason for this is most likely the nonenzymatic hydrolysis of the substrate, a first-order reaction. Hence, as we increase substrate concentration, nonenzymatic hydrolysis will play a proportionally increasing role in the total reaction and will have the greatest impact at the beginning of the progress curve. When fitting the model function to the entire progress curve, the consequence will be that the model function will no longer fit well to the area of maximum curvature (see
Figure A1 in
Appendix A). DHC is unusual due to its rate of nonenzymatic hydrolysis; however, many other substrates also decompose spontaneously in the absence of an enzyme. This can be especially problematic if researchers are not aware of the substrate’s properties.
In the case of rePON1 and DHC, iFIT and Dynafit present two different approaches that minimize the effect of nonenzymatic hydrolysis on the final value of Km. Intuitively, we might expect Prism and iFIT to produce similar results (since they both use the same integrated MM equation that does not directly account for side reactions) and Dynafit to produce different results (since it uses a system of differential equations and accounts for nonenzymatic hydrolysis). When calculating Km and Vmax in Dynafit, the user must calculate the three microscopic parameters, k1, k−1, and k2, separately and then calculate Km from them according to Equation (2).
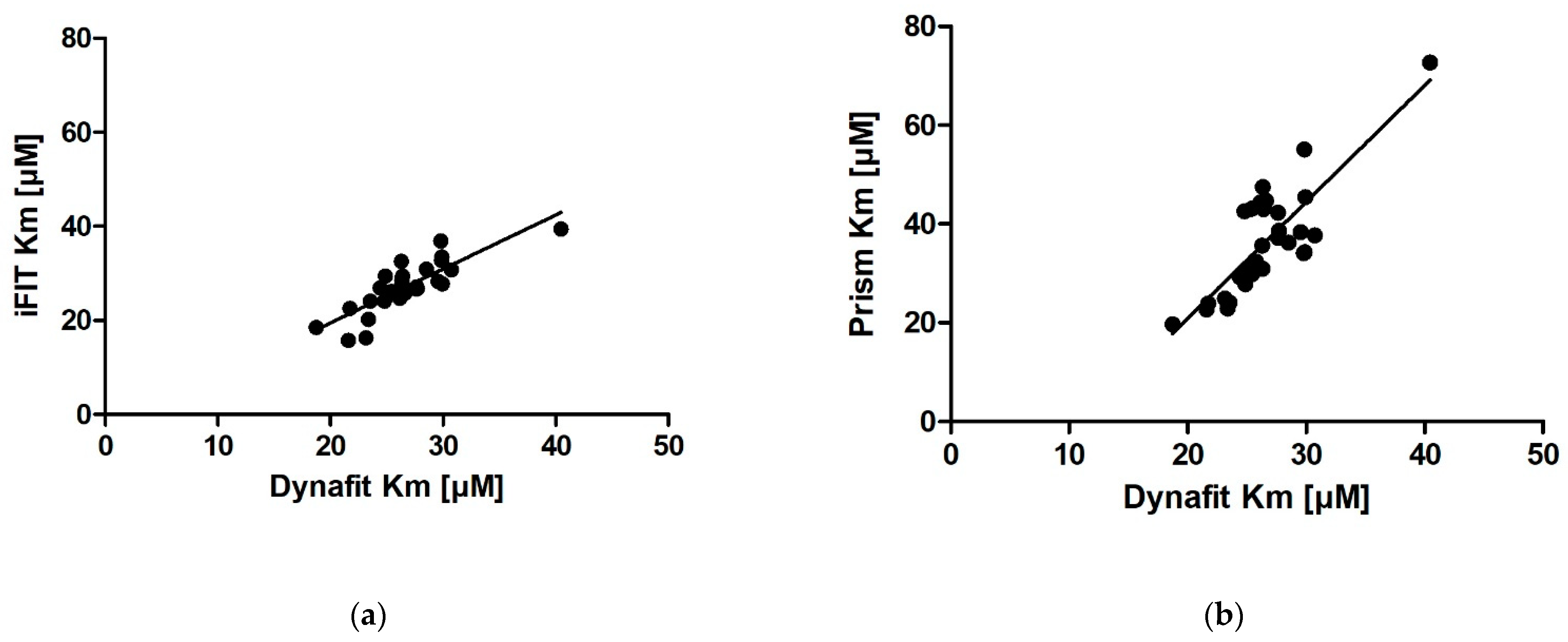
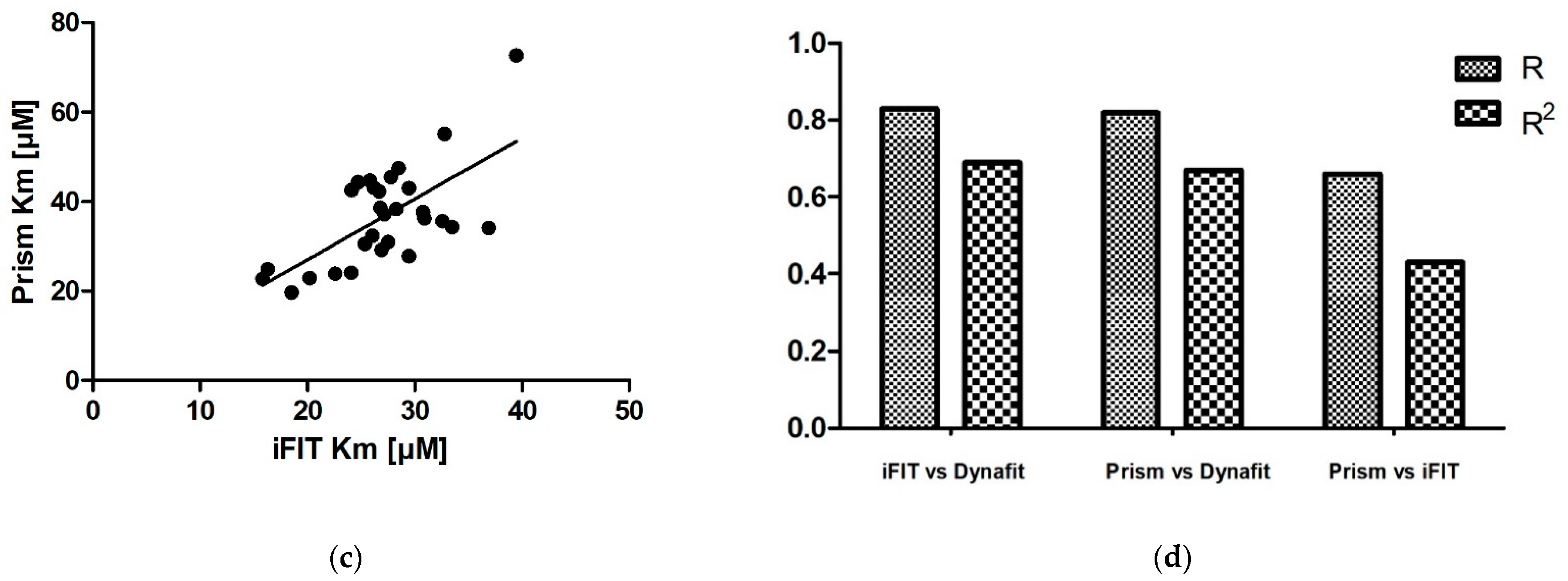
We obtained very similar results with iFIT and Dynafit, and these results differ from those obtained with Prism. The iFIT-Dynafit correlation was strong (R = 0.83). This strongly suggests that both iFIT and Dynafit successfully subtract the contribution of the nonenzymatic reaction from the progress curve: Dynafit by direct modeling and iFIT by considering only data at timescales insensitive to the nonenzymatic reaction, i.e., using only a small number of points around the area of maximum curvature. There, the relative contribution of the spontaneous reaction is negligible, because the latter is pseudo-first-order.
Of the other two correlations, the Prism–Dynafit correlation was equally strong (R = 0.82), while the Prism–iFIT correlation was moderate (R = 0.66). This is counterintuitive, as Prism and iFIT use the same algorithm (the integrated MM equation). This implies that the selection of points is more important than the type of algorithm used for fitting. Prism does not account for the contribution of the nonenzymatic reaction, whereas iFIT does. Dynafit and Prism both used the same points; this would explain why the correlation between them was strong.
In addition to reducing the influence of nonenzymatic reactions on output kinetic parameters, our motivation behind developing iFIT was to establish a method for determining
Km that is more precise than working with entire progress curves. The precision of iFIT, i.e., the small dispersal of output
Km values around the mean, is evident, as the standard deviations of the calculated results were much smaller than those for the integrated MM equation in Prism (
Table 2). Furthermore, the increase in
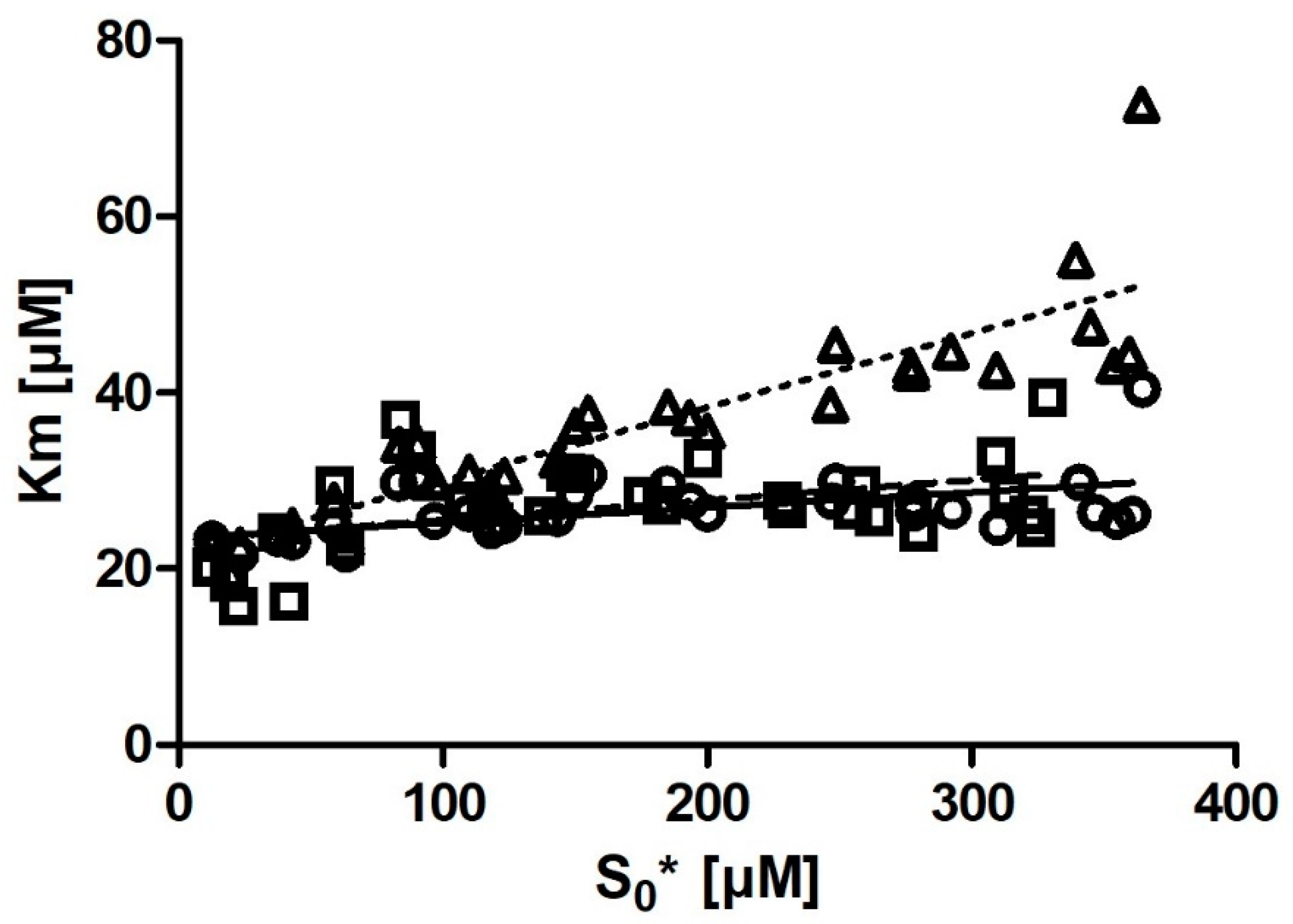
Km with substrate concentration was also much smaller. Even more notably, we observed that if we removed the six output
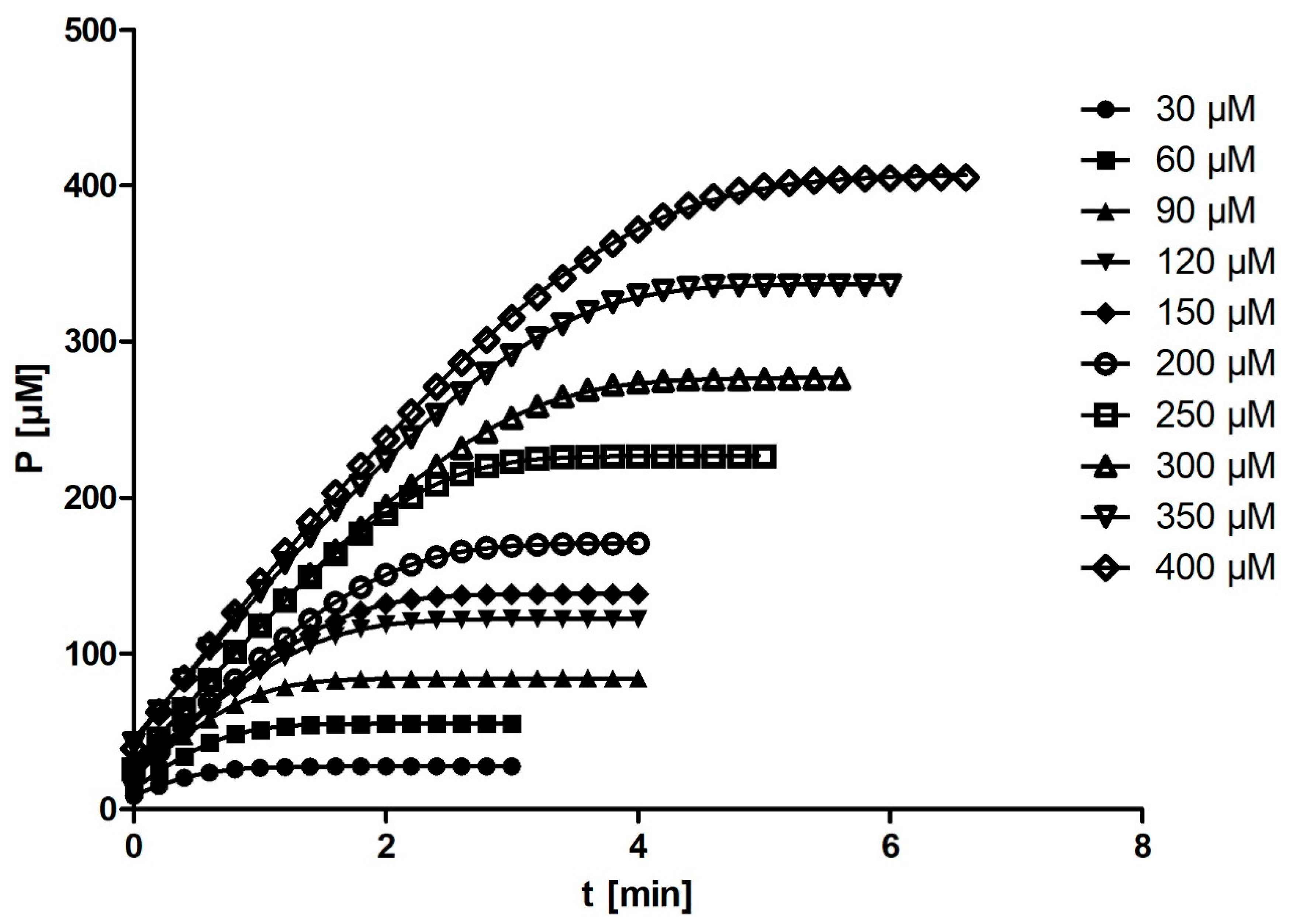
Km values obtained from the progress curves with the lowest substrate concentration (
Figure 4), the correlation between substrate concentration and
Km disappeared entirely.
Another issue of interest to experimenters is the optimal concentration of the substrate for progress curve measurements. Several articles have discussed, mostly based on data produced in silico, the impact of substrate concentration on the magnitude of error of estimating
Km values [
2,
8,
10]. In some cases, this also led to recommendations regarding the ideal concentration range of the substrate; however, this range differs between different fitting methods. For example, Duggleby and Clarke [
2] suggested a [S]
0 value around 2.5 ·
Km to minimize error, while they claimed that their acquired
Km values were independent of substrate concentration. For the method we used in iFIT, the recommendation (by Stroberg and Schnell) that [S]
0 should be in the order of magnitude of
Km is especially pertinent.
For iFIT, substrate concentration is expected to be less relevant. This is because the script only works with a small area of the progress curve that corresponds to a substrate concentration in the order of magnitude of Km (which depends on the Vmax value from which the area of maximum curvature is also calculated). If possible, it is advised to not go below this [S]0, as this would deprive iFIT of some of the points it uses for analysis.
In the case of DHC, because of the extinction coefficient ε = 1310 M−1 cm−1, it is difficult to measure reactions with <15 µM DHC (as the noise obscures the signal) or >800 µM DHC (as the upper limits of most spectrometers’ sensitivities are reached). We observed from our data that the Km values calculated from progress curves with a low substrate concentration were slight outliers in iFIT. We also observed that iFIT can encounter issues with progress curves measured at a very low substrate concentration. Consequently, the optimum substrate concentration for DHC is between 2 and 4× Km. For other enzyme–substrate reactions, we would like to amend Stroberg and Schnell’s recommendation and suggest using at least 2× Km as the initial substrate concentration in order to seize the full potential of the data-point-reduction approach that we present in the current article.
It is worthwhile to be aware of the circumstances where iFIT would not be superior to working with whole curves, for the reason that the deviations from an MM mechanism are most pronounced closer to the plateau of the progress curve, i.e., around the area of maximum curvature. This could be the case when we have enzyme inhibition by product. Unfortunately, the solution in such cases would not be to produce an alternative program, which would exclude points in the area of maximum curvature, since those points would continue to encode the greatest amount of information about Km.
To test the performance of iFIT on potentially troublesome curves for reactions which include inhibition by product, we compared the different programs on two additional sets of progress curves for the enzymes: (1) penicillin amidase, cleaving the artificial substrate NIPAB, with data that had already been published by Zavrel et al. [
10] and reanalyzed by Goličnik [
22], and (2) butyrylcholinesterase, cleaving the artificial substrate butyryltiocholine, with our own set of measurements, based on methods used by Stojan [
23]. Both of these results are presented fully in the
Supplementary Material. In the case of penicillin amidase, it is clear that iFIT is comparable to fitting the entire progress curves, despite not directly accounting for product inhibition. Additionally, in the case of butyrylcholinesterase, iFIT did not perform any worse in determining the accurate value of
Km than the integrated MM equation in Prism. The implication of both of these sets of results is that users should not be afraid to replace the whole-curve approach with iFIT.
At the same time, it is worth pointing out that researchers should not immediately assume a progress curve follows classic Michaelis–Menten kinetics. If the enzyme exhibits features such as cooperativity, which means that one cannot define the reaction using Km and Vmax, then of course iFIT cannot be used for progress curve analysis. Similar considerations hold for reaction mixtures with several enzymes, none of which contribute predominantly to the overall reaction. Before using iFIT, researchers should check whether MM kinetics is a reasonable approximation for the behavior of their enzyme.
4. Materials and Methods
4.1. Chemicals
The substrate DHC, methanol, calcium chloride, and all other chemicals for the expression and purification of rePON1 were purchased from Sigma Aldrich (St. Louis, MO, USA). TRIS was from Carl Roth GmbH (Karlsruhe, Germany). Nickel–nitrilotriacetic acid was from Qiagen (Hilden, Germany). Plasmid containing the G2E6 variant of the rePON1 gene was kindly provided by Prof. Daniel S. Tawfik from the Weizmann Institute (Rehovot, Israel).
4.2. Recombinant PON1 Expression and Purification
The G2E6 variant of rePON1 was used as a source of enzyme. RePON1 protein was expressed and purified in the
Escherichia coli bacterial system according to the procedures reported previously [
14] with minor modifications [
24].
A single colony obtained after transformation with plasmid pET32b (+)-rePON1 into Origami B (DE3)pLysS cells was used to inoculate 10 mL of LB medium with 100 µg/mL ampicillin, 25 µg/mL chloramphenicol, and 1 mM CaCl2. The culture was grown at 37 °C for 17 h. Then, 500 mL of LB medium containing 100 µg/mL ampicillin, 25 µg/mL chloramphenicol, and 1 mM CaCl2 was inoculated with 5 mL of overnight culture and grown at 37 °C to an OD600 of 0.7. The expression of the rePON1 variant was induced by adding 1 mM isopropyl β-D-1-thiogalactopyranoside, and the culture was grown at 25 °C for 17 h. The cells were harvested by centrifugation at 6000× g for 15 min, and the pellet was stored overnight at −20 °C. The cells were resuspended in 30 mL of lysis buffer (50 mM Tris, pH = 8.0, 1 mM CaCl2, and 0.1 mM dithiothreitol supplemented with 1 µM pepstatin A, 1 mM phenylmethylsulfonyl fluoride, and 0.03% n-dodecyl-β-D-maltopyranoside (C12-maltoside)) and lysed by sonification. The lysate was centrifuged at 10,000× g for 10 min, and the supernatant was stirred for 1 h at 4 °C. After centrifugation at 20,000× g for 20 min, the soluble fraction was treated with ammonium sulphate (55%, w/v, at 0 °C). The precipitate was centrifuged at 10,000× g for 15 min, resuspended, and dialyzed twice against lysis buffer supplemented with 0.01% C12-maltoside. After dialysis, the protein was added to nitrilotriacetic acid resin, and the mixture was gently shaken overnight at 4 °C. The resin was first washed with lysis buffer with 0.03% C12-maltoside and then with 10 and 20 mM imidazole in lysis buffer with 0.03% C12-maltoside. It was finally eluted with 150 mM imidazole in lysis buffer with 0.03% C12-maltoside. Fractions with the highest rePON1 activity were pooled, dialyzed, and further purified by ion-exchange chromatography. The protein was applied to a 5 mL HighTrap Q HP column (GE Healthcare, City, Marlborough, MA, USA) with a linear gradient from 26% to 33% of buffer B (20 mM Tris, pH = 8.0, 1 mM CaCl2, 0.1 mM dithiothreitol, 0.03% C12-maltoside, 1 M NaCl) in buffer A (buffer B without 1 M NaCl). Fractions with the highest rePON1 activity were analyzed on an 11% SDS-PAGE gel, pooled, dialyzed against buffer A, and concentrated. Finally, sodium azide (0.02%) was added, and the protein was stored at −70 °C.
The purity of rePON1 (95%) was finally assessed by SDS-PAGE, and the concentration of rePON1 was determined using the Bradford assay. A stock solution of 2 µM (0.13 mg/mL) rePON1 was used for all measurements. The final enzyme concentration in assay was 0.01 µM.
4.3. Measurements of the Lactonase Activity of RePON1
DHC was used as a substrate for the enzymatic reaction. The stock solution was prepared by diluting the substrate in methanol to a final concentration of 2.5 mM. From this stock solution, 10 different final concentrations of substrate (30, 60, 90, 120, 150, 200, 250, 300, 350, and 400 µM) were prepared in methanol (1% in all the reaction mixtures).
The enzymatic reaction was performed in a 1 cm cuvette with a total volume of 2 mL. The hydrolysis of DHC was measured in 50 mM Tris–HCl buffer (pH = 8.0) containing 1 mM CaCl2 at 25 °C using a Genesys 10S spectrophotometer (Thermo Fisher Scientific, Waltham, MA, USA). A total of 10 µL of rePON1 was added to the buffer, corresponding to a final concentration of 0.01 µM. After the addition of 20 µL of DHC, the increase in absorbance was measured at 270 nm (ε = 1310 M−1 cm−1). Absorbance measurements were obtained every second. The entire progress curve was recorded, and the recording was stopped when the curve plateaued for at least 1 min. Each progress curve was recorded in three independent experiments, resulting in a total of 30 measurements. The rates (v0) of spontaneous hydrolysis for all 10 substrate concentrations were also measured. Consequently, rePON1 activity was corrected for spontaneous hydrolysis of each substrate.
4.4. Determination of Km of RePON1
Different approaches were used and compared to extract the values of the kinetic parameters Km and Vmax from the progress curves. Three different programs for progress curve analysis as well as the classical approach of measuring initial rates were used. When working with initial rates, three different versions of data linearization were used; the MM equation was also fitted directly onto the initial rate data points.
The three programs for progress curve analysis (Dynafit, Prism, and iFIT) also calculated the initial substrate concentration from the extinction coefficient of the reaction’s product and the difference in absorbance at 270 nm between the beginning and end of the measurement: −ΔS [μM] = ΔP [μM] = ΔAbs [arb. units]/(ε · l). The assumed substrate concentrations are provided in
Section 4.3. However, thereafter, any reported substrate concentrations were calculated directly from each individual progress curve; we refer to them as “adjusted” substrate concentrations.
4.4.1. Initial Rate Measurements
The initial rate (v
0) values can differ based on how many points they are calculated from [
25]. To acquire the most precise possible estimate, v
0 was not calculated by fitting a straight line directly onto the beginning of the curve, as this would only give an intermediate value for the reaction rate during the early part of the reaction. Instead, we calculated v
0 at
t = 0 from the first derivative of the progress curve, as described by Hasinoff [
26].
For calculating enzymatic parameters from v0, the following were compared: (1) the MM analysis provided in the GraphPad Prism package, (2) the Lineweaver–Burk method, (3) the Eadie–Hofstee method, and (4) the Hanes–Woolf method. The necessary parameters (Km, Vmax, and the quality-of-fit estimates) were calculated in Prism in all four cases.
4.4.2. Numerical Integration of Differential Equations in Dynafit
The progress curve experimental data were analyzed with the nonlinear regression fitting program Dynafit [
5] using numerical integration of differential equations that describe the simple MM reaction model in
Figure 6:
From the microscopic rate constants,
Km can then be calculated according to Equation (2):
Besides considering the basic kinetic parameters that determine Km and Vmax, i.e., the rate constants k1, k−1, or k2, Dynafit is the only program that can also include additional kinetic parameters in the model. Most importantly, it can include a kinetic constant for nonenzymatic substrate hydrolysis (which we denoted as kNE), an important factor in several PON1-mediated enzymatic reactions.
4.4.3. An Integrated MM Rate Equation in Prism: The Entire Curve
The second program that was used to analyze the progress curves was GraphPad Prism (hereon: Prism), which allows user-generated equations for modeling data. The equation implemented in Prism was based on the integrated MM equation that had been originally described by Stroberg and Mendoza ([
3]; see Equation (3)).
For analysis in Prism, the algebraic solution of this equation was used (Equation (4)), as described by Goličnik [
4]:
The program uses Equation (4) to fit the entire progress curve and directly outputs the parameters
Km and
Vmax as well as the errors for these parameters. Unfortunately, there is no automatic (scripted) way within Prism to exclude experimental points from the fit. Unnecessary points are especially problematic for curves that continue for a long time after plateauing. Consequently, imperfect fits are made at the expense of the area of maximum curvature (
Figure A1 in
Appendix A), which contains the most information about
Km and
Vmax.
4.4.4. An Integrated MM Rate Equation in iFIT: The Area of Highest Curvature
An equation for calculating the portion of the time course (
tQ) over which the progress curve exhibits the maximal curvature based on
Km and
Vmax values was presented by Stroberg and Schnell (Equation (5)) [
7]:
Based on their theoretical work, we have developed the computer script iFIT to alleviate the problem mentioned in
Section 4.4.3 and determine
Km and
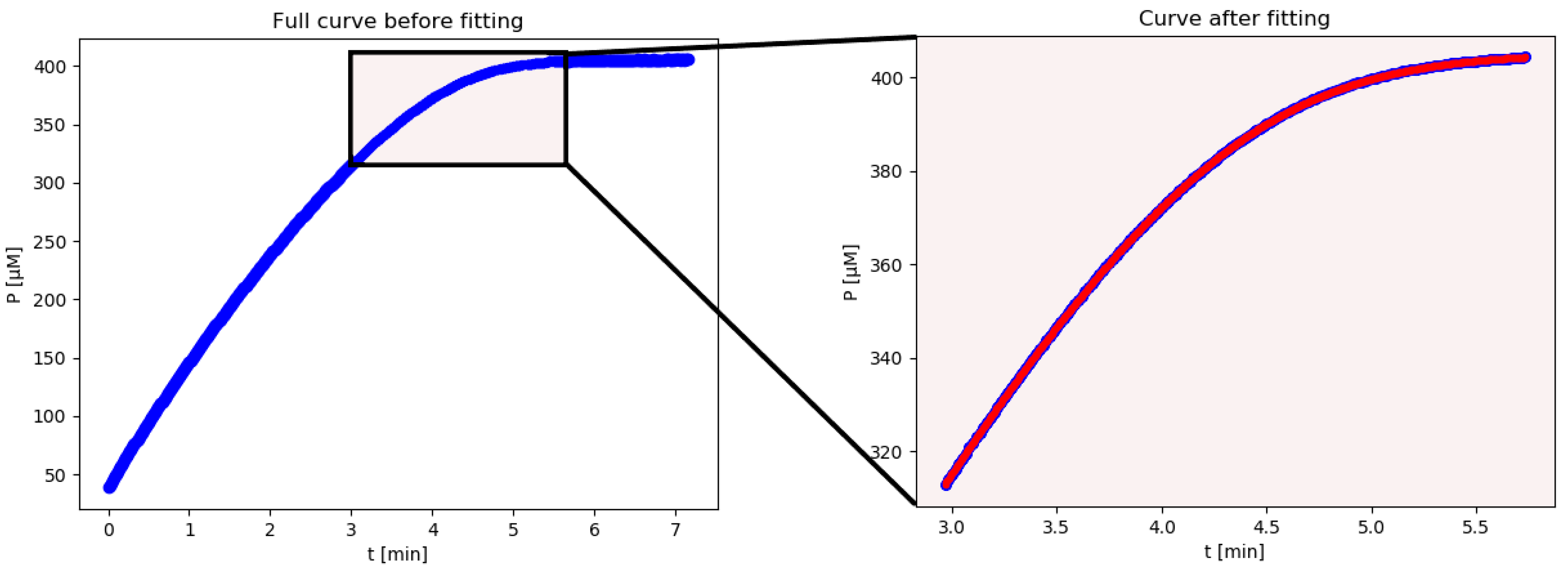
Vmax from the high-curvature regions of progress curves. iFIT uses a script in Python to remove data points on both sides of the maximum-curvature region and fits the rest of the progress curve with Equation (4).
iFIT is an iterative method that first calculates Km and Vmax from the entire available progress curve using the integrated Michaelis–Menten equation described above. From these, it then calculates the width of the area of maximum curvature, denoted as tQ, and removes all points from the progress curve, which are more than tQ/2 away from the point of inflection. From the remaining points, it then calculates Km and Vmax with the integrated MM equation again, uses these to calculate tQ, and so on, until the calculated tQ converges to the same value, i.e., the selected experimental time–concentration points are the same in two successive iterations. If this does not happen within 100 iterations, the program reports all 100 steps at the end of the calculation. The iterations may not converge when there is excessive noise in the experimental data. In such cases, the program might oscillate between two or more tQ values, or tQ might drift outside the actual area of experimental data points, in which case there will not be an output result.
The advantage of this method is that the exact time when we start and stop measuring the reaction is less relevant since any superfluous points will be removed by the script. In conclusion, the advantage of iFIT is that it can iteratively adjust the region of data that will be used to fit the model equation.
4.5. Statistics
Km and Vmax are expressed as mean ± standard deviation. Additionally, the correlation coefficients, the 95% confidence intervals, and R-squared goodness-of-fit measures for linear regression models are also shown for each group of data. For all the groups of output values, the normality of their distribution was calculated with the Kolmogorov–Smirnov test. Differences were considered statistically significant at p < 0.05 (GraphPad Prism).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
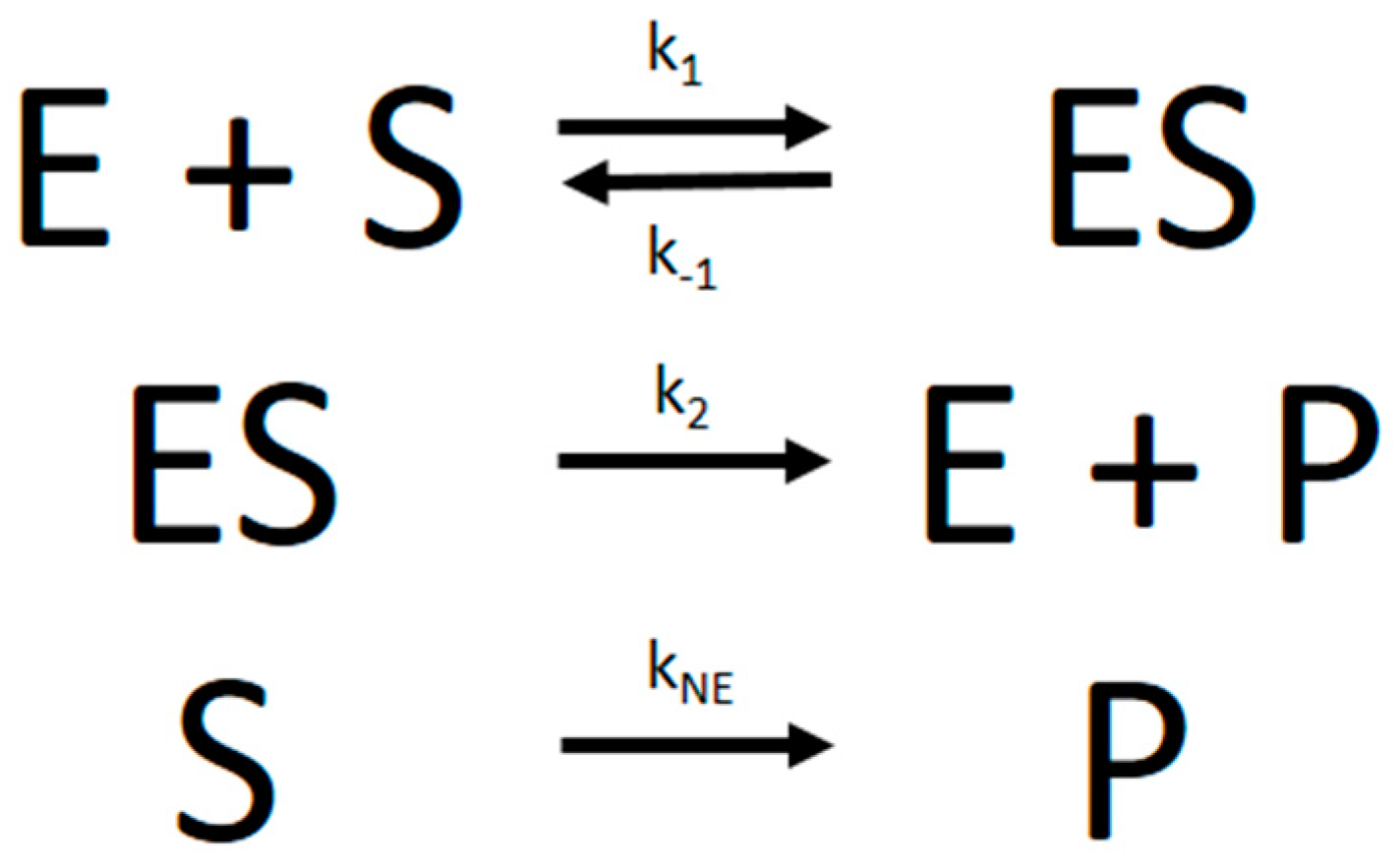{kind=link}
{kind=link}