
Quantification of Corn Adulteration in Wet and Dry-Processed Peaberry Ground Roasted Coffees by UV–Vis Spectroscopy and Chemometrics



Abstract
:1. Introduction
2. Materials and Methods
2.1. Peaberry Samples and Their Adulteration
2.2. Sample Extraction and UV–Vis Spectral Data Measurement
2.3. Chemometrics
2.4. Software
3. Results and Discussion
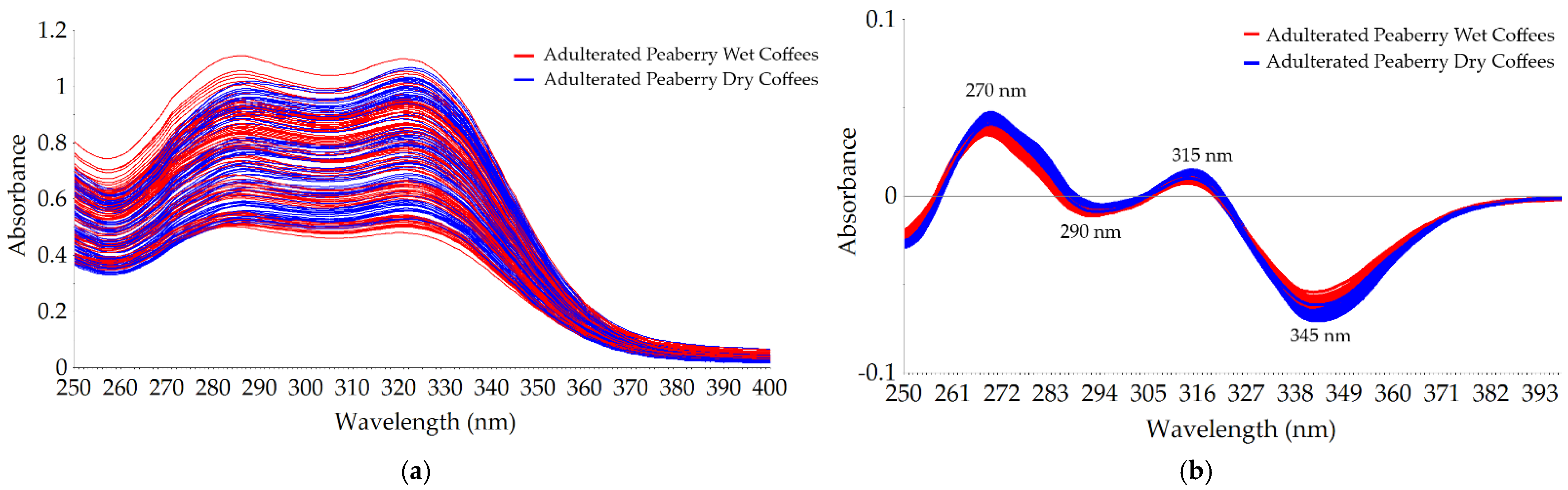
3.1. Spectral Data of Wet and Dry Peaberry Coffees with Different Levels of Corn Adulteration
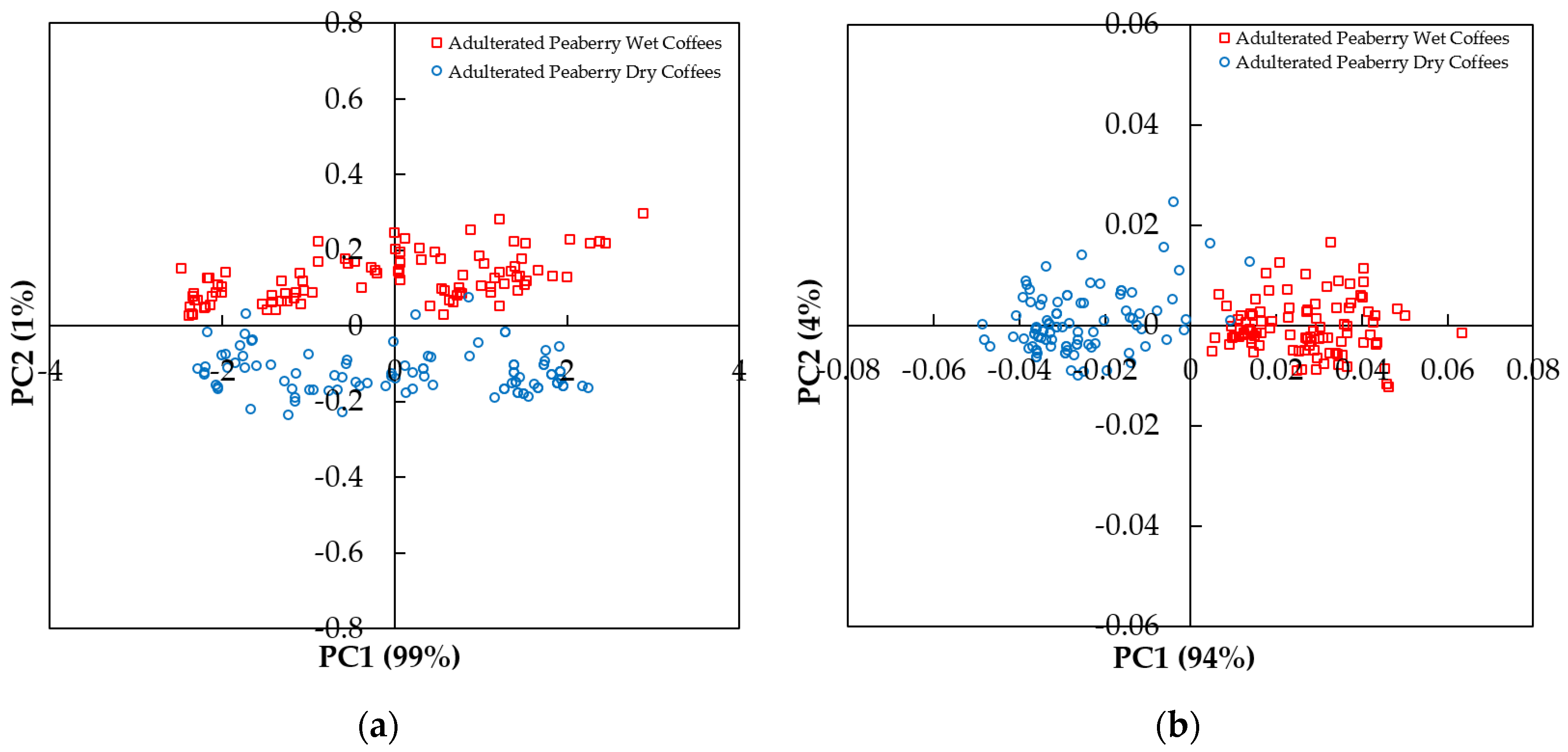
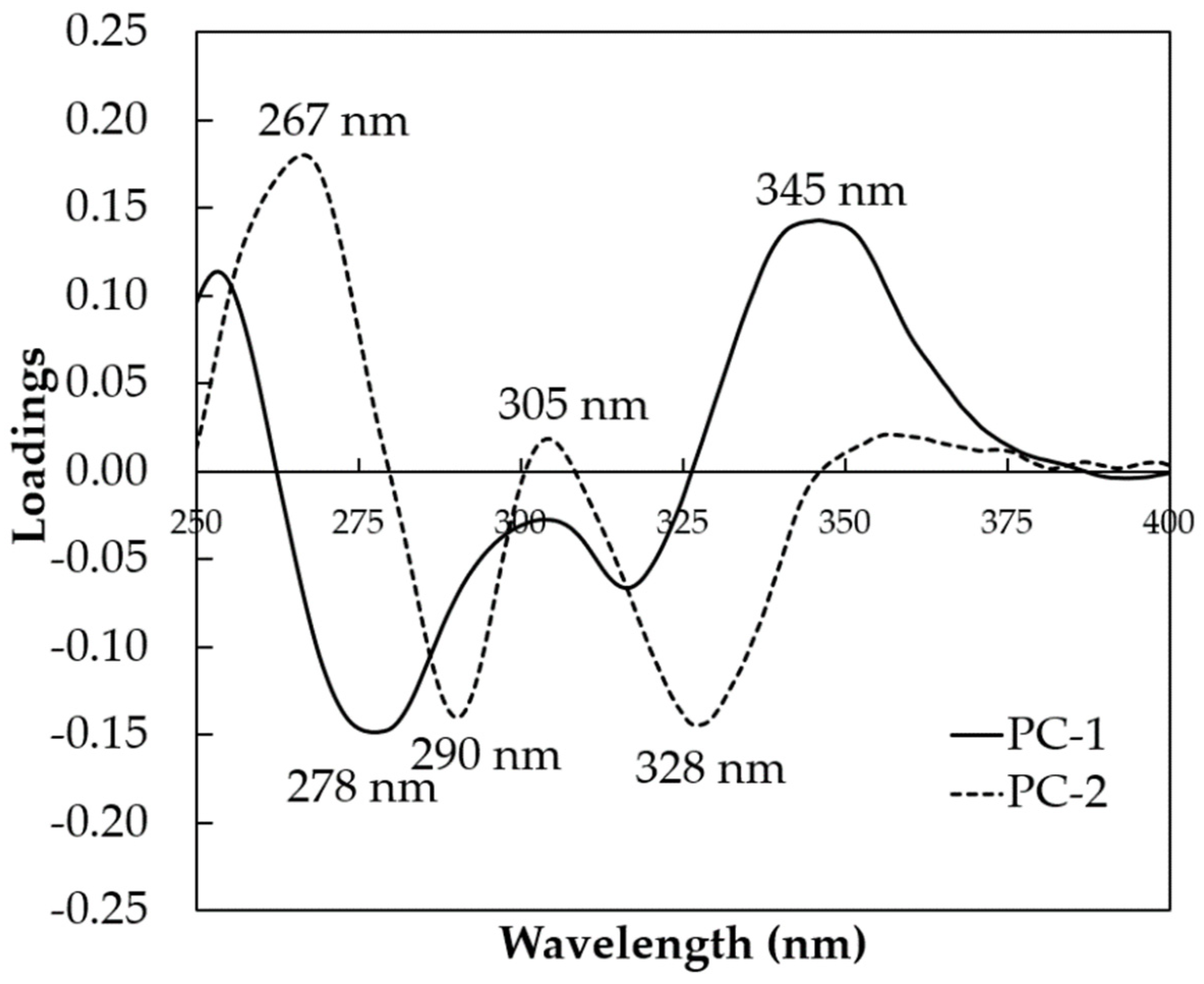
3.2. PCA Scores and Loadings
3.3. Model Development for Quantification of Corn Adulteration
3.4. Prediction Using Individual and Global PLSR Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Sample Availability
References
- International Trade Center. 3.1.5-Niche Markets, Environment and Social Aspects-The Scope for Specialty Coffee. Available online: http://www.thecoffeeguide.org/coffee-guide/niche-markets-environment-and-social-aspects/the-scope-for-specialty-coffee/ (accessed on 11 February 2020).
- Tolessa, K.; Rademaker, M.; De Baets, B.; Boeckx, P. Prediction of specialty coffee cup quality based on near infrared spectra of green coffee beans. Talanta 2016, 150, 367–374. [Google Scholar] [CrossRef]
- de Alcantara, G.M.R.D.N.; Dresch, D.; Melchert, W.R. Use of non-volatile compounds for the classification of specialty and traditional Brazilian coffees using principal component analysis. Food Chem. 2021, 360, 130088. [Google Scholar] [CrossRef]
- Lachenmeier, D.; Schwarz, S. Digested Civet Coffee Beans (Kopi Luwak)—An Unfortunate Trend in Specialty Coffee Caused by Mislabeling of Coffea liberica? Foods 2021, 10, 1329. [Google Scholar] [CrossRef] [PubMed]
- Suhandy, D.; Yulia, M. Peaberry coffee discrimination using UV-visible spectroscopy combined with SIMCA and PLS-DA. Int. J. Food Prop. 2017, 20, S331–S339. [Google Scholar] [CrossRef]
- Bosmali, I.; Lagiotis, G.; Stavridou, E.; Haider, N.; Osathanunkul, M.; Pasentsis, K.; Madesis, P. Novel authentication approach for coffee beans and the brewed beverage using a nuclear-based species-specific marker coupled with high resolution melting analysis. LWT 2021, 137, 110336. [Google Scholar] [CrossRef]
- Núñez, N.; Saurina, J.; Núñez, O. Authenticity Assessment and Fraud Quantitation of Coffee Adulterated with Chicory, Barley, and Flours by Untargeted HPLC-UV-FLD Fingerprinting and Chemometrics. Foods 2021, 10, 840. [Google Scholar] [CrossRef]
- Oliveira, R.C.; Oliveira, L.; Franca, A.S.; Augusti, R. Evaluation of the potential of SPME-GC-MS and chemometrics to detect adulteration of ground roasted coffee with roasted barley. J. Food Compos. Anal. 2009, 22, 257–261. [Google Scholar] [CrossRef]
- Aquino, F.J.; Augusti, R.; Alves, J.D.O.; Diniz, M.E.; Morais, S.A.; Alves, B.H.; Nascimento, E.A.; Sabino, A. Direct infusion electrospray ionization mass spectrometry applied to the detection of forgeries: Roasted coffees adulterated with their husks. Microchem. J. 2014, 117, 127–132. [Google Scholar] [CrossRef]
- Ferreira, T.; Farah, A.; Oliveira, T.C.; Lima, I.S.; Vitório, F.; Oliveira, E.M. Using Real-Time PCR as a tool for monitoring the authenticity of commercial coffees. Food Chem. 2016, 199, 433–438. [Google Scholar] [CrossRef]
- Reis, N.; Franca, A.S.; Oliveira, L. Quantitative evaluation of multiple adulterants in roasted coffee by Diffuse Reflectance Infrared Fourier Transform Spectroscopy (DRIFTS) and chemometrics. Talanta 2013, 115, 563–568. [Google Scholar] [CrossRef] [Green Version]
- Suhandy, D.; Yulia, M. The use of ultraviolet (UV) spectroscopy and chemometrics to quantify the percentages of adulteration in Kalosi ground roasted specialty coffee. J. Eng. Sci. Technol. 2021, 16(1), 350–364. [Google Scholar]
- Assis, C.; Pereira, H.V.; Amador, V.S.; Augusti, R.; de Oliveira, L.S.; Sena, M.M. Combining mid infrared spectroscopy and paper spray mass spectrometry in a data fusion model to predict the composition of coffee blends. Food Chem. 2019, 281, 71–77. [Google Scholar] [CrossRef] [PubMed]
- Wermelinger, T.; D’Ambrosio, L.; Klopprogge, B.; Yeretzian, C. Quantification of the Robusta Fraction in a Coffee Blend via Raman Spectroscopy: Proof of Principle. J. Agric. Food Chem. 2011, 59, 9074–9079. [Google Scholar] [CrossRef] [PubMed]
- Milani, M.I.; Rossini, E.L.; Catelani, T.A.; Pezza, L.; Toci, A.T.; Pezza, H.R. Authentication of roasted and ground coffee samples containing multiple adulterants using NMR and a chemometric approach. Food Control. 2020, 112, 107104. [Google Scholar] [CrossRef]
- Sezer, B.; Apaydin, H.; Bilge, G.; Boyaci, I.H. Coffee arabica adulteration: Detection of wheat, corn and chickpea. Food Chem. 2018, 264, 142–148. [Google Scholar] [CrossRef]
- Winkler-Moser, J.K.; Singh, M.; Rennick, K.A.; Bakota, E.L.; Jham, G.N.; Liu, S.X.; Vaughn, S.F. Detection of Corn Adulteration in Brazilian Coffee (Coffea arabica) by Tocopherol Profiling and Near-Infrared (NIR) Spectroscopy. J. Agric. Food Chem. 2015, 63, 10662–10668. [Google Scholar] [CrossRef]
- Correia, R.M.; Tosato, F.; Domingos, E.; Rodrigues, R.R.; Aquino, L.F.M.; Filgueiras, P.R.; Lacerda, V., Jr.; Romão, W. Portable near infrared spectroscopy applied to quality control of Brazilian coffee. Talanta 2018, 176, 59–68. [Google Scholar] [CrossRef]
- Suhandy, D.; Yulia, M. Classification of Lampung Robusta Specialty Coffee According to Differences in Cherry Processing Methods Using UV Spectroscopy and Chemometrics. Agriculture 2021, 11, 109. [Google Scholar] [CrossRef]
- Barrios-Rodríguez, Y.F.; Reyes, C.A.R.; Campos, J.S.T.; Girón-Hernández, J.; Rodríguez-Gamir, J. Infrared spectroscopy coupled with chemometrics in coffee post-harvest processes as complement to the sensory analysis. LWT 2021, 145, 111304. [Google Scholar] [CrossRef]
- Reis, N.; Franca, A.S.; Oliveira, L. Concomitant Use of Fourier Transform Infrared Attenuated Total Reflectance Spectroscopy and Chemometrics for Quantification of Multiple Adulterants in Roasted and Ground Coffee. J. Spectrosc. 2016, 2016, 1–7. [Google Scholar] [CrossRef]
- Ferreira, T.; Galluzzi, L.; de Paulis, T.; Farah, A. Three centuries on the science of coffee authenticity control. Food Res. Int. 2021, 149, 110690. [Google Scholar] [CrossRef]
- Pereira, L.H.; Catelani, T.A.; Costa, É.D.M.; Garcia, J.S.; Trevisan, M.G. Coffee adulterant quantification by derivative thermogravimetry and chemometrics analysis. J. Therm. Anal. Calorim. 2021, 75, 1–10. [Google Scholar] [CrossRef]
- Roger, J.-M.; Biancolillo, A.; Marini, F. Sequential preprocessing through ORThogonalization (SPORT) and its application to near infrared spectroscopy. Chemom. Intell. Lab. Syst. 2020, 199, 103975. [Google Scholar] [CrossRef]
- Bian, X.; Wang, K.; Tan, E.; Diwu, P.; Zhang, F.; Guo, Y. A selective ensemble preprocessing strategy for near-infrared spectral quantitative analysis of complex samples. Chemom. Intell. Lab. Syst. 2020, 197, 103916. [Google Scholar] [CrossRef]
- Shawky, E.; Selim, D.A. NIR spectroscopy-multivariate analysis for discrimination and bioactive compounds prediction of different Citrus species peels. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2019, 219, 1–7. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Fang, C.; Wang, D. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2007, 66, 568–574. [Google Scholar] [CrossRef] [PubMed]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Costa, L.R.; Tonoli, G.H.D.; Milagres, F.R.; Hein, P.R.G. Artificial neural network and partial least square regressions for rapid estimation of cellulose pulp dryness based on near infrared spectroscopic data. Carbohydr. Polym. 2019, 224, 115186. [Google Scholar] [CrossRef] [PubMed]
- Macedo, L.L.; Araújo, C.D.S.; Vimercati, W.C.; Hein, P.R.G.; Pimenta, C.J.; Saraiva, S.H. Evaluation of chemical properties of intact green coffee beans using near-infrared spectroscopy. J. Sci. Food Agric. 2021, 101, 3500–3507. [Google Scholar] [CrossRef]
- Lohumi, S.; Joshi, R.; Kandpal, L.M.; Lee, H.; Kim, M.S.; Cho, H.; Mo, C.; Seo, Y.-W.; Rahman, A.; Cho, B.-K. Quantitative analysis of Sudan dye adulteration in paprika powder using FTIR spectroscopy. Food Addit. Contam. Part A 2017, 34, 1–9. [Google Scholar] [CrossRef]
- Balan, B.; Dhaulaniya, A.S.; Jamwal, R.; Yadav, A.; Kelly, S.; Cannavan, A.; Singh, D.K. Rapid detection and quantification of sucrose adulteration in cow milk using Attenuated total reflectance-Fourier transform infrared spectroscopy coupled with multivariate analysis. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2020, 240, 118628. [Google Scholar] [CrossRef]
- Alegre, M.R.; Esteve-Romero, J.; Carda-Broch, S. Is it really necessary to validate an analytical method or not? That is the question. J. Chromatogr. A 2012, 1232, 101–109. [Google Scholar] [CrossRef] [PubMed]
- Yasmin, J.; Ahmed, M.; Lohumi, S.; Wakholi, C.; Lee, H.; Mo, C.; Cho, B.-K. Rapid authentication measurement of cinnamon powder using FT-NIR and FT-IR spectroscopic techniques. Qual. Assur. Saf. Crop. Foods 2019, 11, 257–267. [Google Scholar] [CrossRef]
- Souto, U.T.C.P.; Pontes, M.J.C.; Silva, E.C.; Galvão, R.K.H.; Araújo, M.C.U.; Sanches, F.A.C.; Cunha, F.A.S.; Oliveira, M.S.R. UV-Vis spectrometric classification of coffees by SPA-LDA. Food Chem. 2010, 119, 368–371. [Google Scholar] [CrossRef]
- Dankowska, A.; Domagała, A.; Kowalewski, W. Quantification of Coffea arabica and Coffea canephora var. robusta concentration in blends by means of synchronous fluorescence and UV-Vis spectroscopies. Talanta 2017, 172, 215–220. [Google Scholar] [CrossRef] [PubMed]
- Navarra, G.; Moschetti, M.; Guarrasi, V.; Mangione, M.R.; Militello, V.; Leone, M. Simultaneous Determination of Caffeine and Chlorogenic Acids in Green Coffee by UV/Vis Spectroscopy. J. Chem. 2017, 2017, 1–8. [Google Scholar] [CrossRef]
- Duarte, G.S.; Pereira, A.A.; Farah, A. Chlorogenic acids and other relevant compounds in Brazilian coffees processed by semi-dry and wet post-harvesting methods. Food Chem. 2010, 118, 851–855. [Google Scholar] [CrossRef]
- Campos, G.A.F.; Sagu, S.T.; Celis, P.S.; Rawel, H.M. Comparison of Batch and Continuous Wet-Processing of Coffee: Changes in the Main Compounds in Beans, By-Products and Wastewater. Foods 2020, 9, 1135. [Google Scholar] [CrossRef]
- Bureau, S.; Ruiz, D.; Reich, M.; Gouble, B.; Bertrand, D.; Audergon, J.-M.; Renard, C.M. Application of ATR-FTIR for a rapid and simultaneous determination of sugars and organic acids in apricot fruit. Food Chem. 2009, 115, 1133–1140. [Google Scholar] [CrossRef]
- Caporaso, N.; Whitworth, M.B.; Grebby, S.; Fisk, I.D. Rapid prediction of single green coffee bean moisture and lipid content by hyperspectral imaging. J. Food Eng. 2018, 227, 18–29. [Google Scholar] [CrossRef]
- Kapper, C.; Klont, R.; Verdonk, J.; Urlings, H. Prediction of pork quality with near infrared spectroscopy (NIRS): 1. Feasibility and robustness of NIRS measurements at laboratory scale. Meat Sci. 2012, 91, 294–299. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R. Near-Infrared Reflectance Spectroscopy—Principal Components Regression Analyses of Soil Properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef] [Green Version]
- Valinger, D.; Longin, L.; Grbeš, F.; Benković, M.; Jurina, T.; Kljusurić, J.G.; Tušek, A.J. Detection of honey adulteration—The potential of UV-VIS and NIR spectroscopy coupled with multivariate analysis. LWT 2021, 145, 111316. [Google Scholar] [CrossRef]
- Jia, B.; Yoon, S.-C.; Zhuang, H.; Wang, W.; Li, C. Prediction of pH of fresh chicken breast fillets by VNIR hyperspectral imaging. J. Food Eng. 2017, 208, 57–65. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Individual Wet Samples | Calibration Set | Prediction Set |
|---|---|---|
| Number of samples | 83 | 16 |
| Range | 10–50 | 10–50 |
| Mean | 29.88 | 30.00 |
| Standard deviation (SD) | 14.36 | 14.14 |
| Individual Dry Samples | ||
| Number of samples | 84 | 16 |
| Range | 10–50 | 10–50 |
| Mean | 30.00 | 30.00 |
| Standard deviation (SD) | 14.31 | 14.14 |
| Global Samples | ||
| Number of samples | 167 | 32 |
| Range | 10–50 | 10–50 |
| Mean | 29.94 | 30.00 |
| Standard deviation (SD) | 14.29 | 13.91 |
| Steps | Parameters | Equations 1 | Accepted Values |
|---|---|---|---|
| Calibration | R2c and R2cv | Close to 1 | |
| RMSEC and RMSECV | As low as possible | ||
| RPDcv | More than 2 | ||
| LOD | As low as possible | ||
| LOQ | As low as possible | ||
| Prediction | RMSEP | As low as possible | |
| SEP | As low as possible | ||
| bias | Close to 0 | ||
| RPDp | More than 2 | ||
| RERp | More than 10 |
| Model | Regression Method | LVs | R2c | R2cv | RMSEC | RMSECV | RPDcv |
|---|---|---|---|---|---|---|---|
| Individual wet model | PLSR | 5 | 0.93 | 0.89 | 3.85 | 4.80 | 2.99 |
| MLR | 0.87 | 0.87 | 5.44 | 5.20 | 2.76 | ||
| PCR | 8 | 0.90 | 0.87 | 4.57 | 5.17 | 2.78 | |
| Individual dry model | PLSR | 6 | 0.92 | 0.89 | 3.93 | 4.87 | 2.94 |
| MLR | 0.84 | 0.84 | 6.00 | 5.75 | 2.49 | ||
| PCR | 9 | 0.90 | 0.88 | 4.46 | 5.05 | 2.83 | |
| Global model | PLSR | 8 | 0.88 | 0.83 | 4.93 | 5.86 | 2.44 |
| MLR | 0.63 | 0.63 | 8.87 | 8.68 | 1.65 | ||
| PCR | 9 | 0.72 | 0.69 | 7.52 | 8.02 | 1.78 |
| Individual Wet PLSR Model | SEP | RMSEP | Bias | RPDp | RERp |
|---|---|---|---|---|---|
| Wet prediction samples | 3.64 | 3.57 | 0.56 | 3.96 | 11.20 |
| Dry prediction samples | 11.43 | 45.59 | −44.22 | 0.31 | 0.88 |
| Combined prediction samples | 24.23 | 32.33 | −21.83 | 0.43 | 1.24 |
| Individual Dry PLSR Model | SEP | RMSEP | Bias | RPDp | RERp |
| Wet prediction samples | 9.61 | 50.96 | 50.10 | 0.28 | 0.78 |
| Dry prediction samples | 4.36 | 4.24 | 0.36 | 3.33 | 9.43 |
| Combined prediction samples | 26.31 | 36.16 | 25.23 | 0.38 | 1.11 |
| Global PLSR Model | SEP | RMSEP | Bias | RPDp | RERp |
| Wet prediction samples | 6.35 | 6.16 | 0.32 | 2.30 | 6.49 |
| Dry prediction samples | 5.48 | 5.38 | 0.94 | 2.63 | 7.43 |
| Combined prediction samples | 5.84 | 5.78 | 0.63 | 2.41 | 6.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yulia, M.; Suhandy, D. Quantification of Corn Adulteration in Wet and Dry-Processed Peaberry Ground Roasted Coffees by UV–Vis Spectroscopy and Chemometrics. Molecules 2021, 26, 6091. https://doi.org/10.3390/molecules26206091
Yulia M, Suhandy D. Quantification of Corn Adulteration in Wet and Dry-Processed Peaberry Ground Roasted Coffees by UV–Vis Spectroscopy and Chemometrics. Molecules. 2021; 26(20):6091. https://doi.org/10.3390/molecules26206091
Chicago/Turabian StyleYulia, Meinilwita, and Diding Suhandy. 2021. "Quantification of Corn Adulteration in Wet and Dry-Processed Peaberry Ground Roasted Coffees by UV–Vis Spectroscopy and Chemometrics" Molecules 26, no. 20: 6091. https://doi.org/10.3390/molecules26206091
APA StyleYulia, M., & Suhandy, D. (2021). Quantification of Corn Adulteration in Wet and Dry-Processed Peaberry Ground Roasted Coffees by UV–Vis Spectroscopy and Chemometrics. Molecules, 26(20), 6091. https://doi.org/10.3390/molecules26206091