
How Open Data Shapes In Silico Transporter Modeling


Abstract
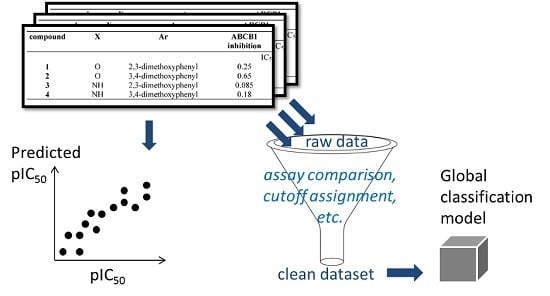
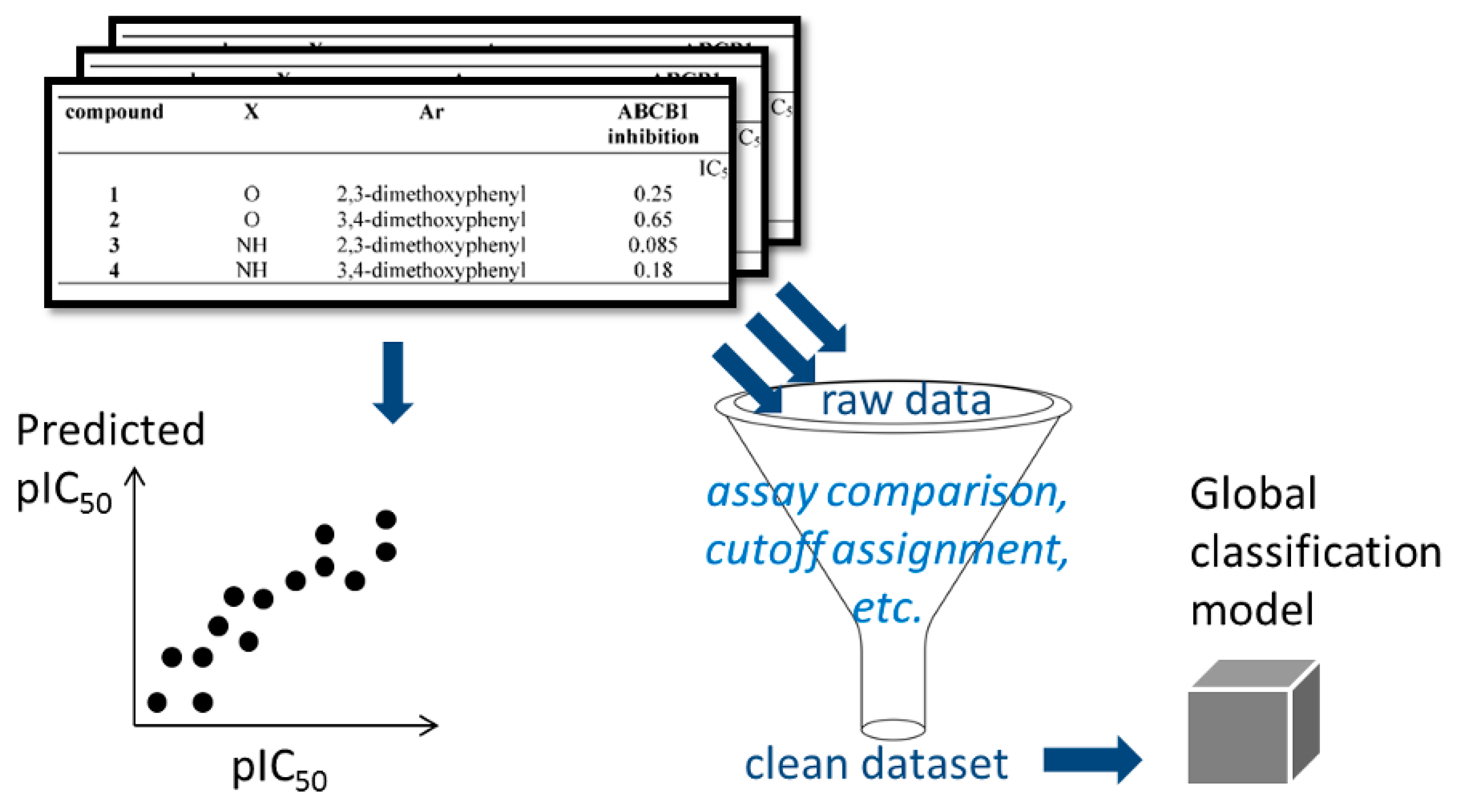
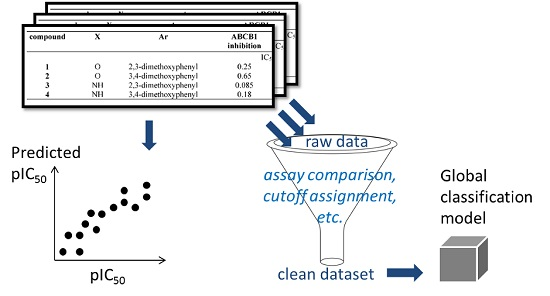
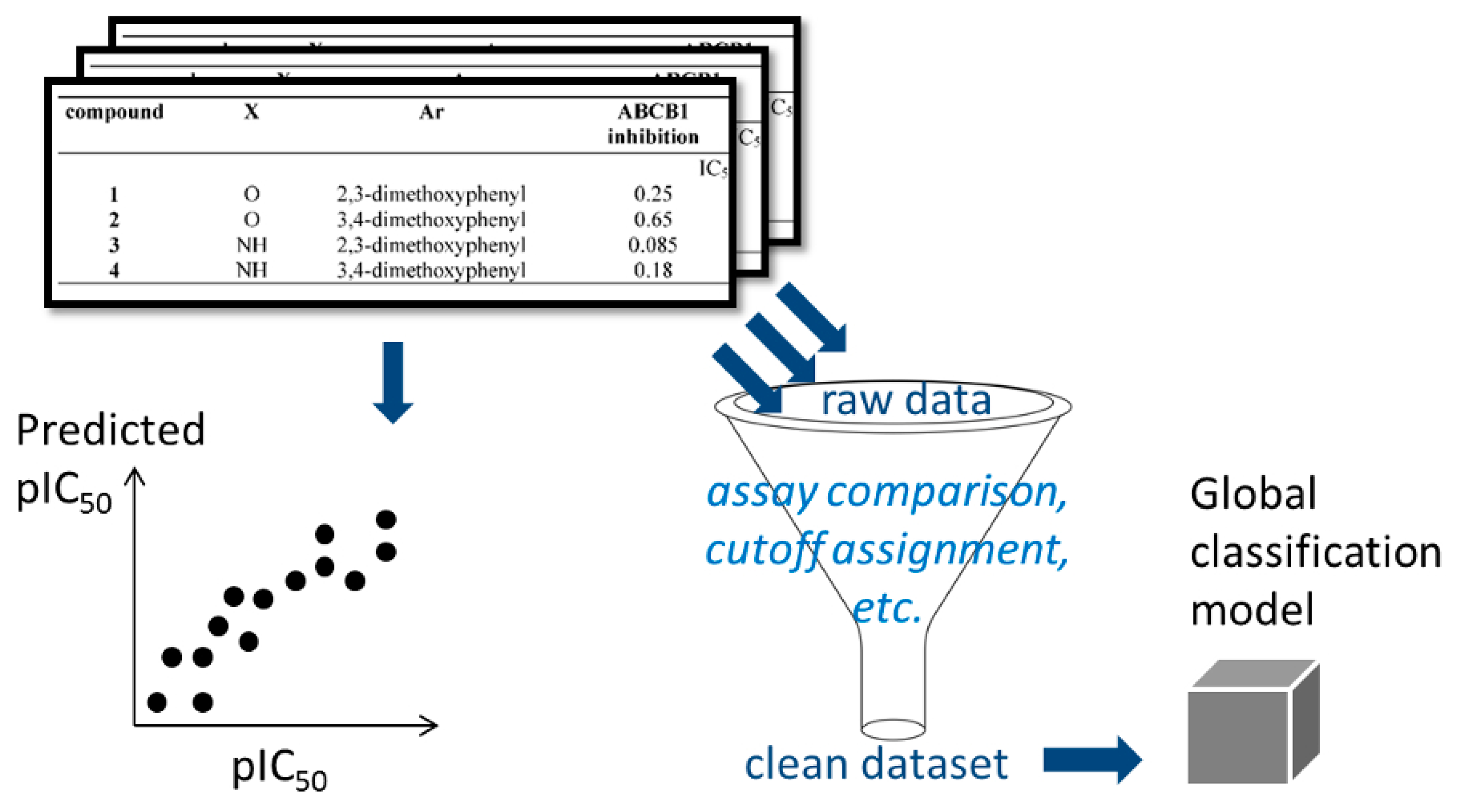
:
1. Introduction: Computational Modeling as a Prosperous Strategy to Predict Ligand–Transporter Interactions
2. Data, Data Everywhere
3. What Is Proper Data Curation?
4. Transporter Modeling: Earlier and Now
5. Chemical Space, Analog Bias, and Applicability Domain
6. The Future: New Areas to Explore
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- International Transporter Consortium; Giacomini, K.M.; Huang, S.-M.; Tweedie, D.J.; Benet, L.Z.; Brouwer, K.L.R.; Chu, X.; Dahlin, A.; Evers, R.; Fischer, V.; et al. Membrane transporters in drug development. Nat. Rev. Drug Discov. 2010, 9, 215–236. [Google Scholar] [CrossRef] [PubMed]
- Ozawa, N.; Shimizu, T.; Morita, R.; Yokono, Y.; Ochiai, T.; Munesada, K.; Ohashi, A.; Aida, Y.; Hama, Y.; Taki, K.; et al. Transporter database, TP-Search: A web-accessible comprehensive database for research in pharmacokinetics of drugs. Pharm. Res. 2004, 21, 2133–2134. [Google Scholar] [CrossRef] [PubMed]
- Mak, L.; Marcus, D.; Howlett, A.; Yarova, G.; Duchateau, G.; Klaffke, W.; Bender, A.; Glen, R.C. Metrabase: A cheminformatics and bioinformatics database for small molecule transporter data analysis and (Q)SAR modeling. J. Cheminform. 2015, 7, 31. [Google Scholar] [CrossRef] [PubMed]
- Morrissey, K.M.; Wen, C.C.; Johns, S.J.; Zhang, L.; Huang, S.-M.; Giacomini, K.M. The UCSF-FDA TransPortal: A public drug transporter database. Clin. Pharmacol. Ther. 2012, 92, 545–546. [Google Scholar] [CrossRef] [PubMed]
- Bento, A.P.; Gaulton, A.; Hersey, A.; Bellis, L.J.; Chambers, J.; Davies, M.; Krüger, F.A.; Light, Y.; Mak, L.; McGlinchey, S.; et al. The ChEMBL bioactivity database: An update. Nucleic Acids Res. 2014, 42, D1083–D1090. [Google Scholar] [CrossRef] [PubMed]
- Williams, A.J.; Harland, L.; Groth, P.; Pettifer, S.; Chichester, C.; Willighagen, E.L.; Evelo, C.T.; Blomberg, N.; Ecker, G.; Goble, C.; et al. Open PHACTS: Semantic interoperability for drug discovery. Drug Discov. Today 2012, 17, 1188–1198. [Google Scholar] [CrossRef] [PubMed]
- The PubChem Project. Available online: https://pubchem.ncbi.nlm.nih.gov/ (accessed on 17 January 2017).
- Saier, M.H.; Reddy, V.S.; Tsu, B.V.; Ahmed, M.S.; Li, C.; Moreno-Hagelsieb, G. The Transporter Classification Database (TCDB): Recent advances. Nucleic Acids Res. 2016, 44, D372–379. [Google Scholar] [CrossRef] [PubMed]
- Elbourne, L.D.H.; Tetu, S.G.; Hassan, K.A.; Paulsen, I.T. TransportDB 2.0: A database for exploring membrane transporters in sequenced genomes from all domains of life. Nucleic Acids Res. 2017, 45, D320–D324. [Google Scholar] [CrossRef] [PubMed]
- Papadatos, G.; Gaulton, A.; Hersey, A.; Overington, J.P. Activity, assay and target data curation and quality in the ChEMBL database. J. Comput. Aided Mol. Des. 2015, 29, 885–896. [Google Scholar] [CrossRef] [PubMed]
- Zdrazil, B.; Pinto, M.; Vasanthanathan, P.; Williams, A.J.; Balderud, L.Z.; Engkvist, O.; Chichester, C.; Hersey, A.; Overington, J.P.; Ecker, G.F. Annotating Human P-Glycoprotein Bioassay Data. Mol. Inform. 2012, 31, 599–609. [Google Scholar] [CrossRef] [PubMed]
- Zdrazil, B.; Chichester, C.; Zander Balderud, L.; Engkvist, O.; Gaulton, A.; Overington, J.P. Transporter assays and assay ontologies: Useful tools for drug discovery. Drug Discov. Today Technol. 2014, 12, e47–e54. [Google Scholar] [CrossRef] [PubMed]
- Strouse, J.J.; Ivnitski-Steele, I.; Khawaja, H.M.; Perez, D.; Ricci, J.; Yao, T.; Weiner, W.S.; Schroeder, C.E.; Simpson, D.S.; Maki, B.E.; et al. A Selective ATP-binding Cassette Sub-family G Member 2 Efflux Inhibitor Revealed Via High-Throughput Flow Cytometry. J. Biomol. Screen. 2013, 18, 26–38. [Google Scholar] [CrossRef] [PubMed]
- Fourches, D.; Muratov, E.; Tropsha, A. Trust, But Verify: On the Importance of Chemical Structure Curation in Cheminformatics and QSAR Modeling Research. J. Chem. Inf. Model. 2010, 50, 1189–1204. [Google Scholar] [CrossRef] [PubMed]
- Fourches, D.; Muratov, E.; Tropsha, A. Trust, but Verify II: A Practical Guide to Chemogenomics Data Curation. J. Chem. Inf. Model. 2016, 56, 1243–1252. [Google Scholar] [CrossRef] [PubMed]
- Anger, L.T.; Wolf, A.; Schleifer, K.-J.; Schrenk, D.; Rohrer, S.G. Generalized Workflow for Generating Highly Predictive in Silico Off-Target Activity Models. J. Chem. Inf. Model. 2014, 54, 2411–2422. [Google Scholar] [CrossRef] [PubMed]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Sieb, C.; Thiel, K.; Wiswedel, B. KNIME: The Konstanz Information Miner. In Data Analysis, Machine Learning and Applications; Preisach, C., Burkhardt, P.D.H., Schmidt-Thieme, P.D.L., Decker, P.D.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 319–326. [Google Scholar]
- Zdrazil, B.; Hellsberg, E.; Viereck, M.; Ecker, G.F. From linked open data to molecular interaction: Studying selectivity trends for ligands of the human serotonin and dopamine transporter. Med. Chem. Commun. 2016, 7, 1819–1831. [Google Scholar] [CrossRef] [PubMed]
- Dawson, S.; Stahl, S.; Paul, N.; Barber, J.; Kenna, J.G. In Vitro Inhibition of the Bile Salt Export Pump Correlates with Risk of Cholestatic Drug-Induced Liver Injury in Humans. Drug Metab. Dispos. 2012, 40, 130–138. [Google Scholar] [CrossRef] [PubMed]
- Chang, G. Multidrug resistance ABC transporters. FEBS Lett. 2003, 555, 102–105. [Google Scholar] [CrossRef]
- Ecker, G.; Chiba, P.; Hitzler, M.; Schmid, D.; Visser, K.; Cordes, H.P.; Csöllei, J.; Seydel, J.K.; Schaper, K.-J. Structure−Activity Relationship Studies on Benzofuran Analogs of Propafenone-Type Modulators of Tumor Cell Multidrug Resistance. J. Med. Chem. 1996, 39, 4767–4774. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wang, Y.-H.; Yang, L.; Zhang, S.-W.; Liu, C.-H.; Yang, S.-L. Comparison of steroid substrates and inhibitors of P-glycoprotein by 3D-QSAR analysis. J. Mol. Struct. 2005, 733, 111–118. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, X.; Coburn, R.A.; Morris, M.E. Structure activity relationships and quantitative structure activity relationships for the flavonoid-mediated inhibition of breast cancer resistance protein. Biochem. Pharmacol. 2005, 70, 627–639. [Google Scholar] [CrossRef] [PubMed]
- Müller, H.; Pajeva, I.K.; Globisch, C.; Wiese, M. Functional assay and structure-activity relationships of new third-generation P-glycoprotein inhibitors. Bioorg. Med. Chem. 2008, 16, 2448–2462. [Google Scholar] [CrossRef] [PubMed]
- Ecker, G.; Huber, M.; Schmid, D.; Chiba, P. The importance of a nitrogen atom in modulators of multidrug resistance. Mol. Pharmacol. 1999, 56, 791–796. [Google Scholar] [PubMed]
- Pajeva, I.; Wiese, M. Molecular modeling of phenothiazines and related drugs as multidrug resistance modifiers: A comparative molecular field analysis study. J. Med. Chem. 1998, 41, 1815–1826. [Google Scholar] [CrossRef] [PubMed]
- Broccatelli, F.; Carosati, E.; Neri, A.; Frosini, M.; Goracci, L.; Oprea, T.I.; Cruciani, G. A Novel Approach for Predicting P-glycoprotein (ABCB1) Inhibition Using Molecular Interaction Fields. J. Med. Chem. 2011, 54, 1740–1751. [Google Scholar] [CrossRef] [PubMed]
- Montanari, F.; Ecker, G.F. BCRP Inhibition: from Data Collection to Ligand-Based Modeling. Mol. Inform. 2014, 33, 322–331. [Google Scholar] [CrossRef] [PubMed]
- Montanari, F.; Cseke, A.; Wlcek, K.; Ecker, G.F. Virtual Screening of DrugBank Reveals Two Drugs as New BCRP Inhibitors. J. Biomol. Screen. 2017, 22, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Kotsampasakou, E.; Brenner, S.; Jäger, W.; Ecker, G.F. Identification of Novel Inhibitors of Organic Anion Transporting Polypeptides 1B1 and 1B3 (OATP1B1 and OATP1B3) Using a Consensus Vote of Six Classification Models. Mol. Pharm. 2015, 12, 4395–4404. [Google Scholar] [CrossRef] [PubMed]
- Montanari, F.; Pinto, M.; Khunweeraphong, N.; Wlcek, K.; Sohail, M.I.; Noeske, T.; Boyer, S.; Chiba, P.; Stieger, B.; Kuchler, K.; Ecker, G.F. Flagging Drugs That Inhibit the Bile Salt Export Pump. Mol. Pharm. 2016, 13, 163–171. [Google Scholar] [CrossRef] [PubMed]
- Masoudi-Nejad, A.; Mousavian, Z.; Bozorgmehr, J.H. Drug-target and disease networks: polypharmacology in the post-genomic era. Silico Pharmacol. 2013, 1, 17. [Google Scholar] [CrossRef] [PubMed]
- Hopkins, A.L. Network pharmacology: The next paradigm in drug discovery. Nat. Chem. Biol. 2008, 4, 682–690. [Google Scholar] [CrossRef] [PubMed]
- Barneh, F.; Jafari, M.; Mirzaie, M. Updates on drug–target network; facilitating polypharmacology and data integration by growth of DrugBank database. Brief. Bioinform. 2016, 17, 1070–1080. [Google Scholar] [CrossRef] [PubMed]
- Antolin, A.A.; Workman, P.; Mestres, J.; Al-Lazikani, B. Polypharmacology in Precision Oncology: Current Applications and Future Prospects. Curr. Pharm. Des. 2016, 22, 6935–6945. [Google Scholar] [CrossRef] [PubMed]
- Sedykh, A.; Fourches, D.; Duan, J.; Hucke, O.; Garneau, M.; Zhu, H.; Bonneau, P.; Tropsha, A. Human intestinal transporter database: QSAR modeling and virtual profiling of drug uptake, efflux and interactions. Pharm. Res. 2013, 30, 996–1007. [Google Scholar] [CrossRef] [PubMed]
- Montanari, F.; Zdrazil, B.; Digles, D.; Ecker, G.F. Selectivity profiling of BCRP versus P-gp inhibition: from automated collection of polypharmacology data to multi-label learning. J. Cheminform. 2016, 8, 7. [Google Scholar] [CrossRef] [PubMed]
- Aniceto, N.; Freitas, A.A.; Bender, A.; Ghafourian, T. Simultaneous Prediction of four ATP-binding Cassette Transporters’ Substrates Using Multi-label QSAR. Mol. Inform. 2016, 35, 514–528. [Google Scholar] [CrossRef] [PubMed]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333. [Google Scholar] [CrossRef]
- Hansch, C.; Leo, A.J. Substituent Constants for Correlation Analysis in Chemistry and Biology; John Wiley & Sons Inc.: New York, NY, USA, 1979. [Google Scholar]
- Good, A.C.; Hermsmeier, M.A. Measuring CAMD Technique Performance. 2. How “Druglike” Are Drugs? Implications of Random Test Set Selection Exemplified Using Druglikeness Classification Models. J. Chem. Inf. Model. 2007, 47, 110–114. [Google Scholar] [CrossRef] [PubMed]
- Carrió, P.; Pinto, M.; Ecker, G.; Sanz, F.; Pastor, M. Applicability Domain Analysis (ADAN): A Robust Method for Assessing the Reliability of Drug Property Predictions. J. Chem. Inf. Model. 2014, 54, 1500–1511. [Google Scholar] [CrossRef] [PubMed]
- Aniceto, N.; Freitas, A.A.; Bender, A.; Ghafourian, T. A novel applicability domain technique for mapping predictive reliability across the chemical space of a QSAR: reliability-density neighbourhood. J. Cheminform. 2016, 8, 69. [Google Scholar] [CrossRef]
- Ekins, S.; Polli, J.E.; Swaan, P.W.; Wright, S.H. Computational Modeling to Accelerate the Identification of Substrates and Inhibitors for Transporters That Affect Drug Disposition. Clin. Pharmacol. Ther. 2012, 92, 661–665. [Google Scholar] [CrossRef] [PubMed]
- Klepsch, F.; Vasanthanathan, P.; Ecker, G.F. Ligand and Structure-Based Classification Models for Prediction of P-Glycoprotein Inhibitors. J. Chem. Inf. Model. 2014, 54, 218–229. [Google Scholar] [CrossRef] [PubMed]
- Zhan, W.; Li, D.; Che, J.; Zhang, L.; Yang, B.; Hu, Y.; Liu, T.; Dong, X. Integrating docking scores, interaction profiles and molecular descriptors to improve the accuracy of molecular docking: Toward the discovery of novel Akt1 inhibitors. Eur. J. Med. Chem. 2014, 75, 11–20. [Google Scholar] [CrossRef] [PubMed]
- Costanzi, S.; Tikhonova, I.G.; Ohno, M.; Roh, E.J.; Joshi, B.V.; Colson, A.-O.; Houston, D.; Maddileti, S.; Harden, T.K.; Jacobson, K.A. P2Y1 antagonists: Combining receptor-based modeling and QSAR for a quantitative prediction of the biological activity based on consensus scoring. J. Med. Chem. 2007, 50, 3229–3241. [Google Scholar] [CrossRef] [PubMed]
- Vilar, S.; Karpiak, J.; Costanzi, S. Ligand and Structure-based Models for the Prediction of Ligand-Receptor Affinities and Virtual Screenings: Development and Application to the β2-Adrenergic Receptor. J. Comput. Chem. 2010, 31, 707–720. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Köck, K.; Sedykh, A.; Tropsha, A.; Brouwer, K.L.R. An Updated Review on Drug-Induced Cholestasis: Mechanisms and Investigation of Physicochemical Properties and Pharmacokinetic Parameters. J. Pharm. Sci. 2013, 102, 3037–3057. [Google Scholar] [CrossRef] [PubMed]
- Keppler, D. The Roles of MRP2, MRP3, OATP1B1, and OATP1B3 in Conjugated Hyperbilirubinemia. Drug Metab. Dispos. 2014, 42, 561–565. [Google Scholar] [CrossRef] [PubMed]
- Kotsampasakou, E.; Escher, S.E.; Ecker, G.F. Linking organic anion transporting polypeptide 1B1 and 1B3 (OATP1B1 and OATP1B3) interaction profiles to hepatotoxicity—The hyperbilirubinemia use case. Eur. J. Pharm. Sci. 2017, 100, 9–16. [Google Scholar] [CrossRef] [PubMed]
- Helal, K.Y.; Maciejewski, M.; Gregori-Puigjané, E.; Glick, M.; Wassermann, A.M. Public Domain HTS Fingerprints: Design and Evaluation of Compound Bioactivity Profiles from PubChem’s Bioassay Repository. J. Chem. Inf. Model. 2016, 56, 390–398. [Google Scholar] [CrossRef] [PubMed]
- Cortes Cabrera, A.; Lucena-Agell, D.; Redondo-Horcajo, M.; Barasoain, I.; Díaz, J.F.; Fasching, B.; Petrone, P.M. Aggregated Compound Biological Signatures Facilitate Phenotypic Drug Discovery and Target Elucidation. ACS Chem. Biol. 2016, 11, 3024–3034. [Google Scholar] [CrossRef] [PubMed]
- Polireddy, K.; Khan, M.M.T.; Chavan, H.; Young, S.; Ma, X.; Waller, A.; Garcia, M.; Perez, D.; Chavez, S.; Strouse, J.J.; et al. A novel flow cytometric HTS assay reveals functional modulators of ATP binding cassette transporter ABCB. PLoS ONE 2012, 7, e40005. [Google Scholar] [CrossRef] [PubMed]
- Allan, L.; Leith, J.L.; Papakosta, M.; Morrow, J.A.; Irving, N.G.; McFerran, B.W.; Clark, A.G. Development of a novel high-throughput assay for the investigation of GlyT-1b neurotransmitter transporter function. Comb. Chem. High Throughput Screen. 2006, 9, 9–14. [Google Scholar] [CrossRef] [PubMed]
- Linton, K.J. Lipid flopping in the liver. Biochem. Soc. Trans. 2015, 43, 1003–1010. [Google Scholar] [CrossRef] [PubMed]
- Caron, P.R.; Mullican, M.D.; Mashal, R.D.; Wilson, K.P.; Su, M.S.; Murcko, M.A. Chemogenomic approaches to drug discovery. Curr. Opin. Chem. Biol. 2001, 5, 464–470. [Google Scholar] [CrossRef]
- Bock, J.R.; Gough, D.A. Virtual Screen for Ligands of Orphan G Protein-Coupled Receptors. J. Chem. Inf. Model. 2005, 45, 1402–1414. [Google Scholar] [CrossRef] [PubMed]
- Jacob, L.; Vert, J.-P. Protein-ligand interaction prediction: An improved chemogenomics approach. Bioinformatics 2008, 24, 2149–2156. [Google Scholar] [CrossRef] [PubMed]
- Paricharak, S.; Cortés-Ciriano, I.; IJzerman, A.P.; Malliavin, T.E.; Bender, A. Proteochemometric modelling coupled to in silico target prediction: An integrated approach for the simultaneous prediction of polypharmacology and binding affinity/potency of small molecules. J. Cheminform. 2015, 7, 15. [Google Scholar] [CrossRef] [PubMed]
- Erhan, D.; L’Heureux, P.-J.; Yue, S.Y.; Bengio, Y. Collaborative Filtering on a Family of Biological Targets. J. Chem. Inf. Model. 2006, 46, 626–635. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Sheridan, R.P.; Liaw, A.; Dahl, G.E.; Svetnik, V. Deep Neural Nets as a Method for Quantitative Structure–Activity Relationships. J. Chem. Inf. Model. 2015, 55, 263–274. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Reference | Endpoint | Training Set | Method Type | Algorithm |
|---|---|---|---|---|
| Ecker [21] | P-gp inhibition | 20 benzofurylethanolamine analogs of propafenone | regression | multiple linear regression |
| Li [22] | P-gp transport and inhibition | 20 steroids | regression | 3D-QSAR a |
| Zhang [23] | BCRP inhibition | 25 flavonoids | regression | feature selection and multiple linear regression |
| Müller [24] | P-gp inhibition | 28 tariquidar analogs | regression | 3D-QSAR a |
| Pajeva [26] | P-gp inhibition | 40 phenothiazines, thioxanthenes, and structurally related drugs | regression | 3D-QSAR a |
| Broccatelli [27] | P-gp inhibition | 772 diverse compounds | classification | PLS-DA b and LDA c |
| Montanari [28,29] | BCRP inhibition | 978 diverse compounds | classification | logistic regression |
| Kotsampasakou [30] | OATP1B1 and OATP1B3 inhibition | 1700 diverse compounds | classification | ensemble of SVMs d and random forests |
| Sedykh [36] | Inhibition and transport for a range of intestinal transporters | up to 1571 diverse compounds | classification | random forest, k-nearest neighbors or SVM d |
| Montanari [37] | P-gp and BCRP inhibition | 2191 diverse compounds | multi-label classification | classifiers chain |
| Aniceto [38] | P-gp, BCRP, MRP1, and MRP2 transport | 1493 diverse compounds | multi-label classification | classifiers chain |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montanari, F.; Zdrazil, B. How Open Data Shapes In Silico Transporter Modeling. Molecules 2017, 22, 422. https://doi.org/10.3390/molecules22030422
Montanari F, Zdrazil B. How Open Data Shapes In Silico Transporter Modeling. Molecules. 2017; 22(3):422. https://doi.org/10.3390/molecules22030422
Chicago/Turabian StyleMontanari, Floriane, and Barbara Zdrazil. 2017. "How Open Data Shapes In Silico Transporter Modeling" Molecules 22, no. 3: 422. https://doi.org/10.3390/molecules22030422
APA StyleMontanari, F., & Zdrazil, B. (2017). How Open Data Shapes In Silico Transporter Modeling. Molecules, 22(3), 422. https://doi.org/10.3390/molecules22030422