
Ribosome Inactivating Proteins from Rosaceae




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results
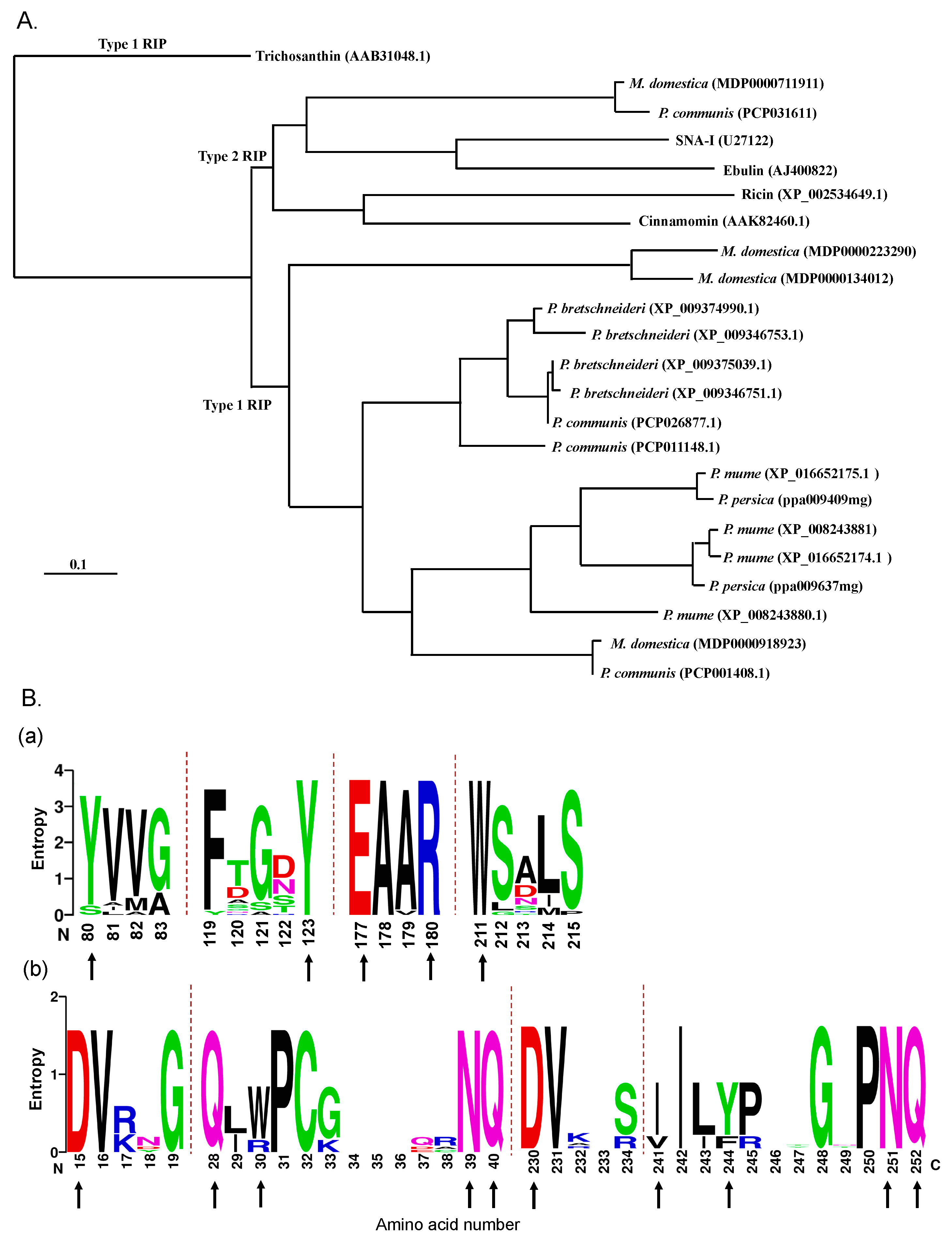
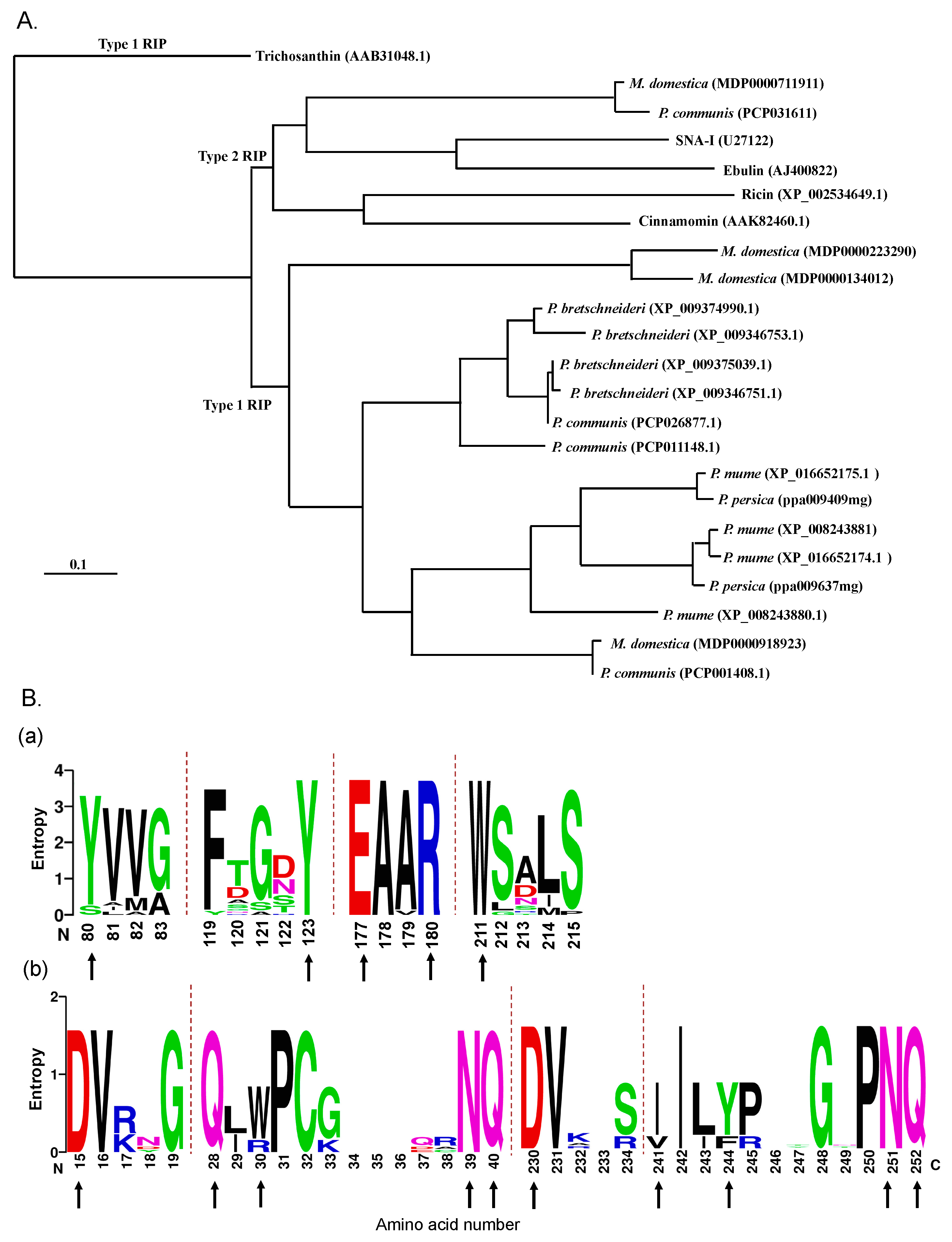
2.1. RIP Genes Are Present in Most Rosaceae Genomes
2.2. Identification and Sequence Analysis of RIP Genes in the Malus Domestica Genome
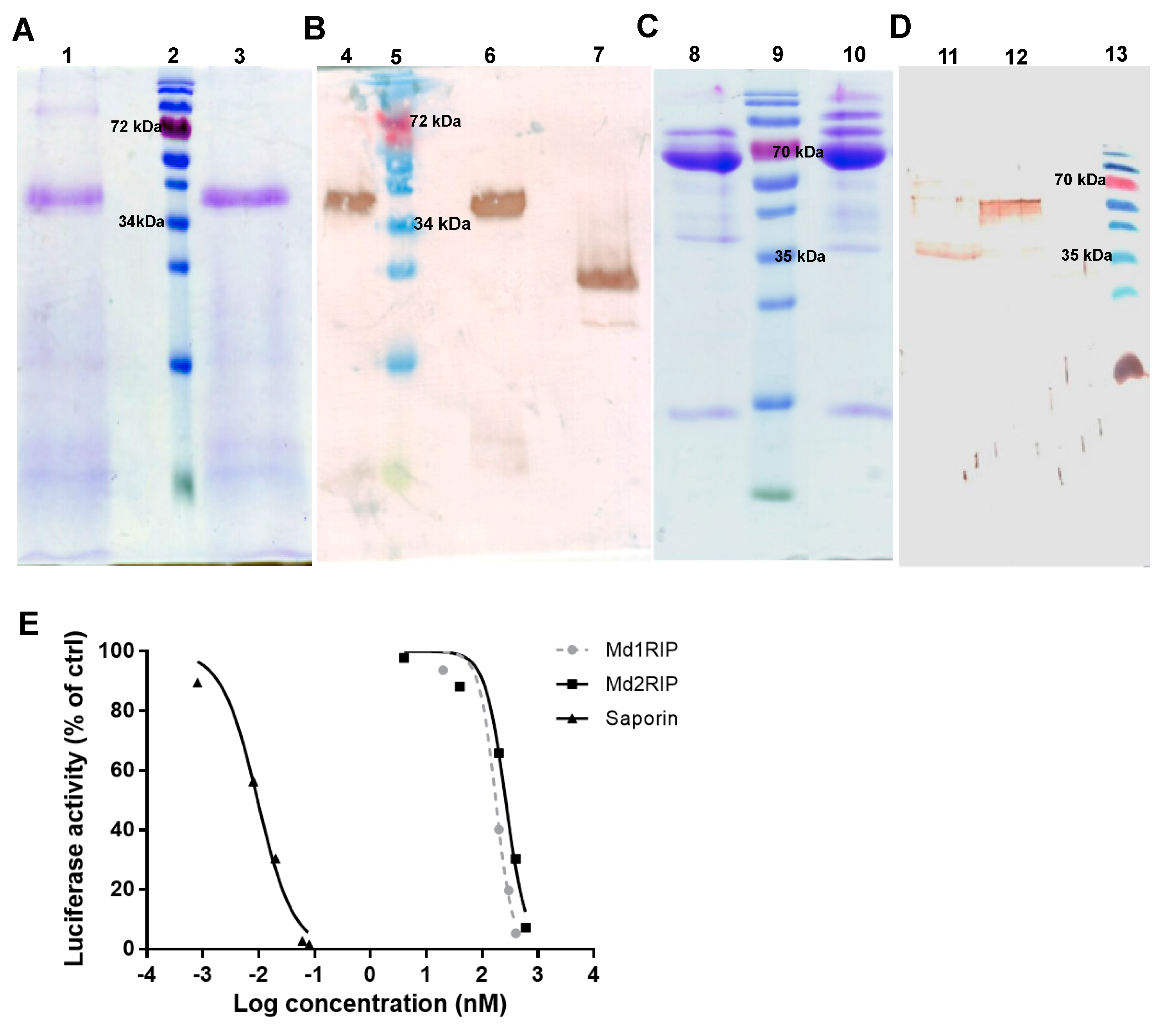
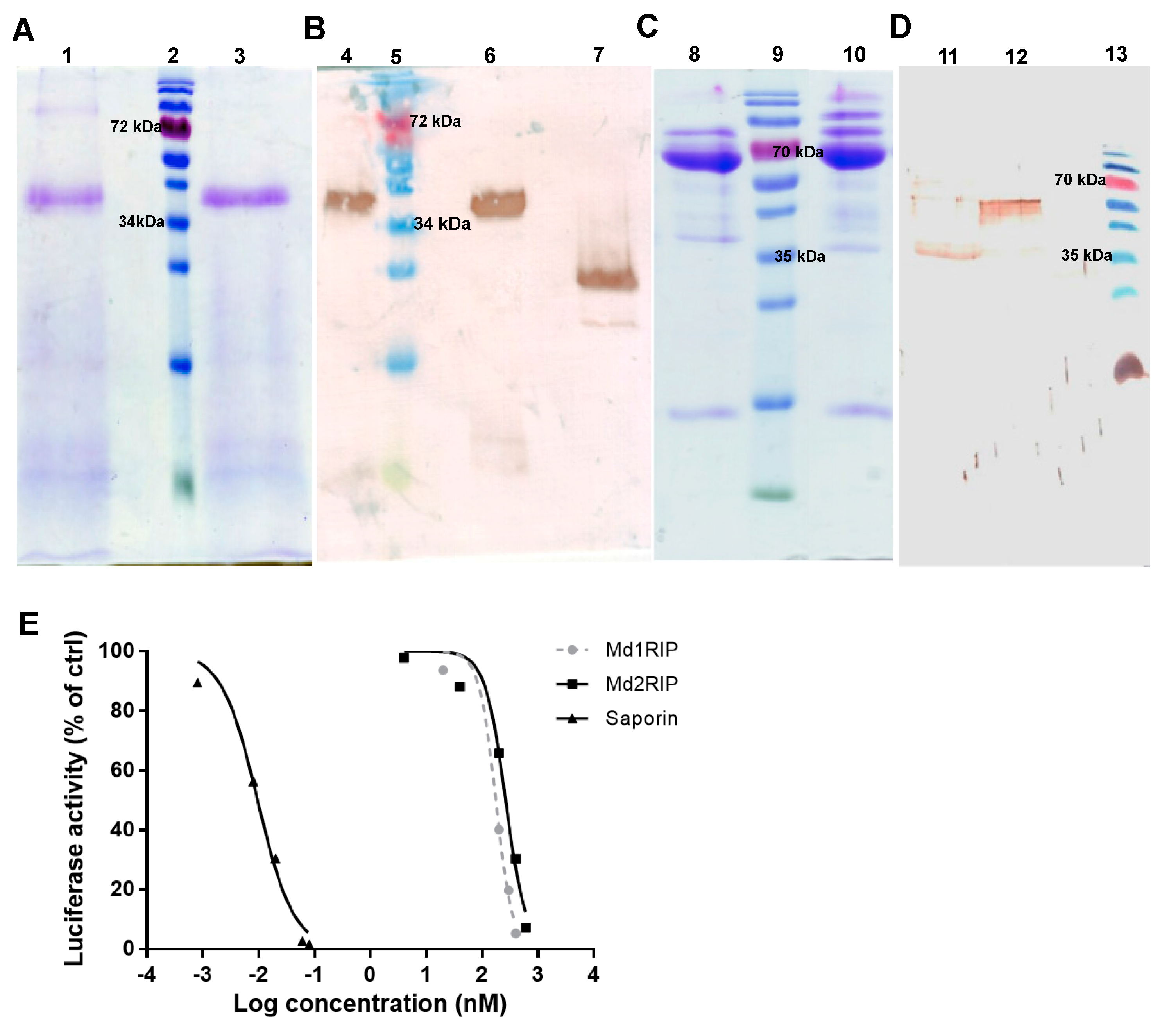
2.3. Purification and Characterization of Recombinant Md1RIP and Md2RIP
2.4. Biological Activities of Recombinant MdRIPs
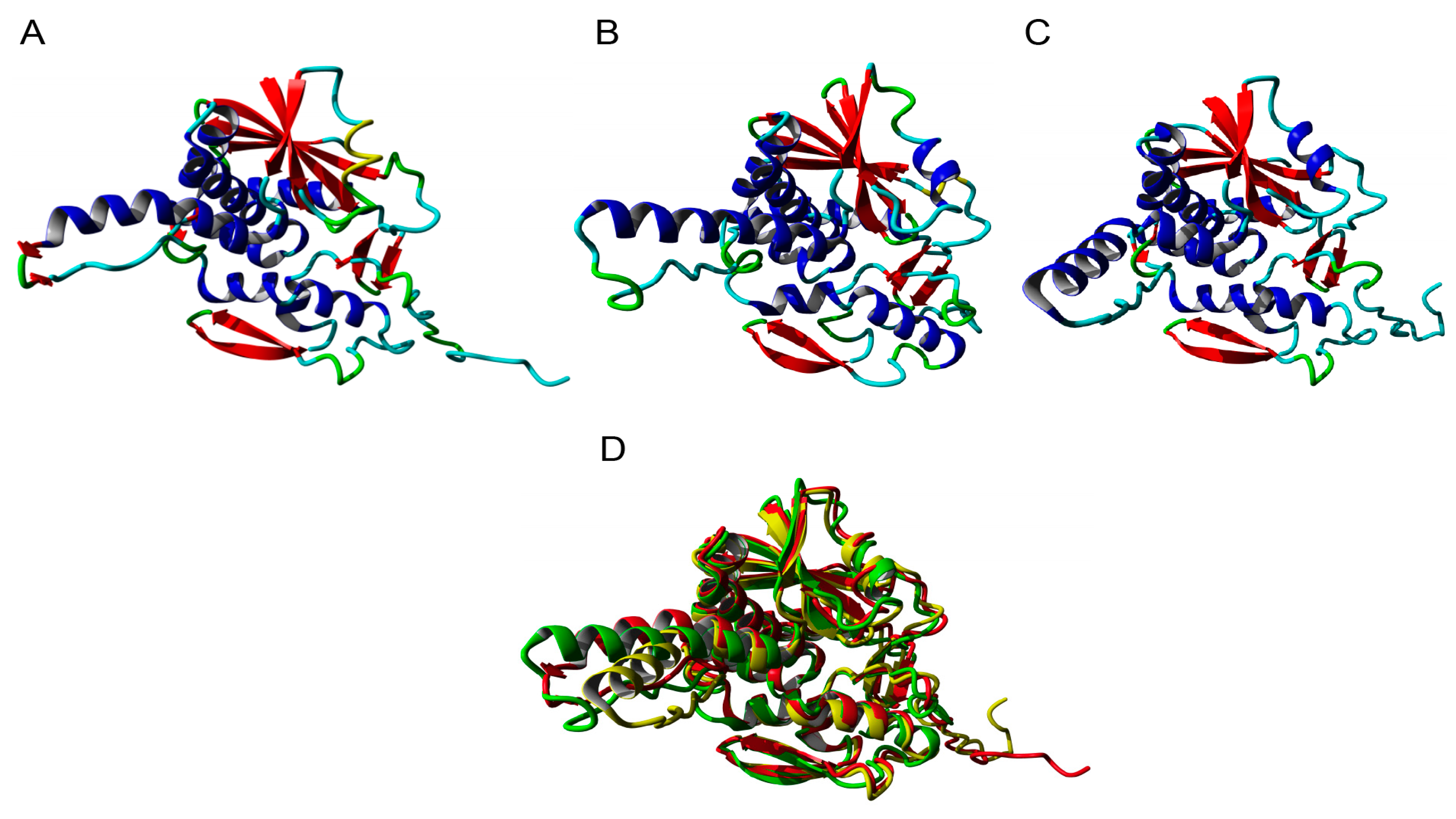
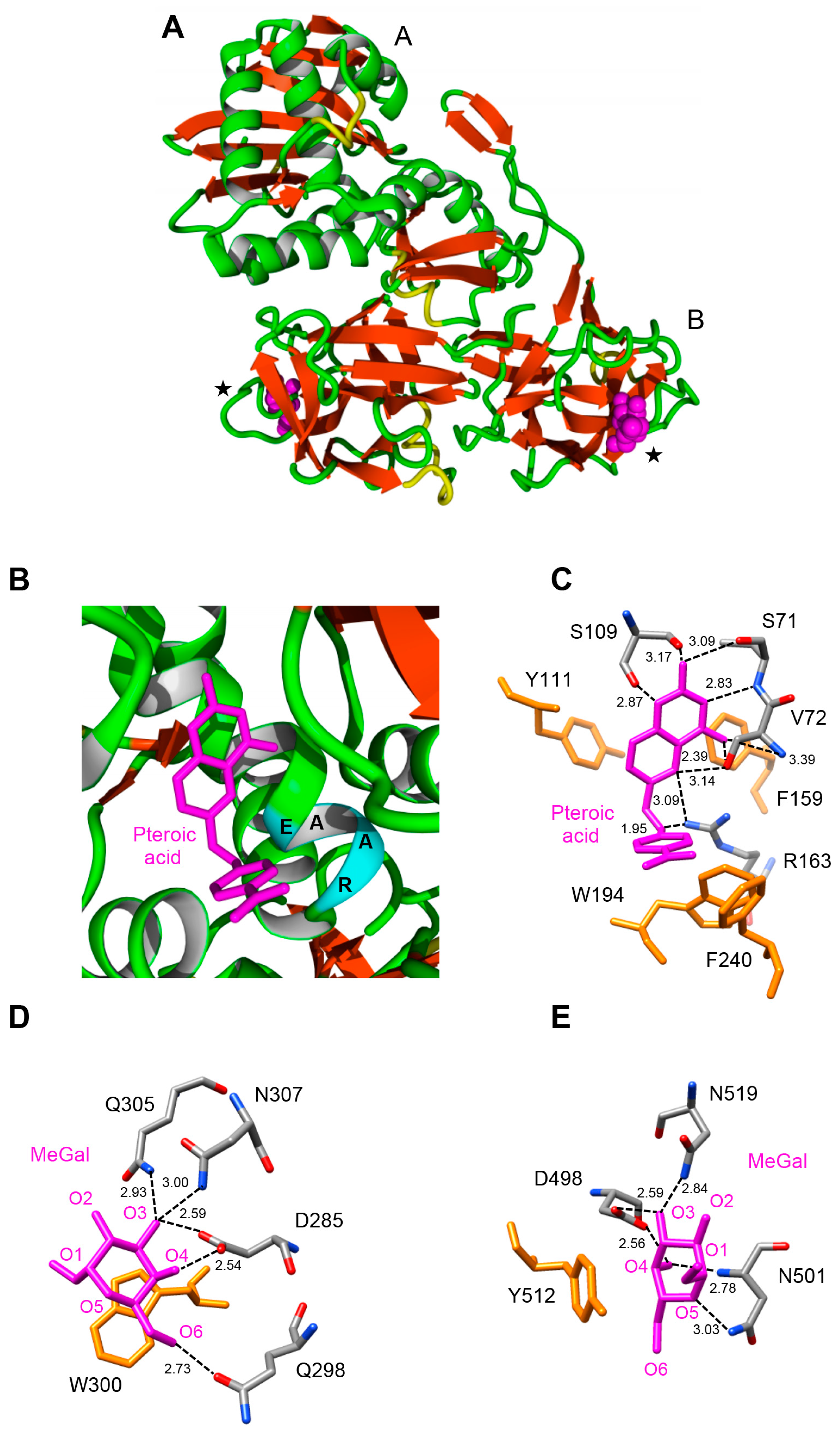
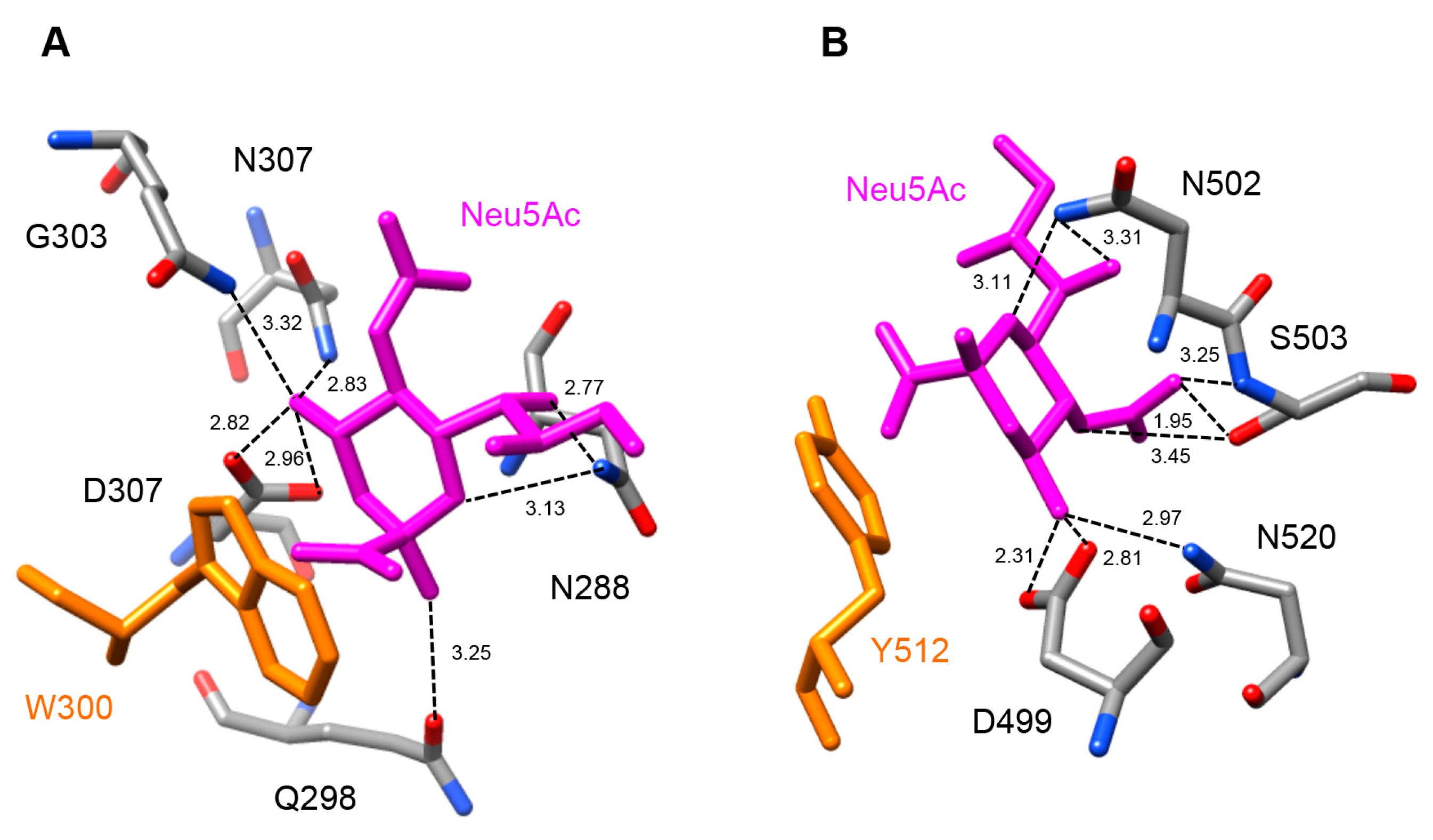
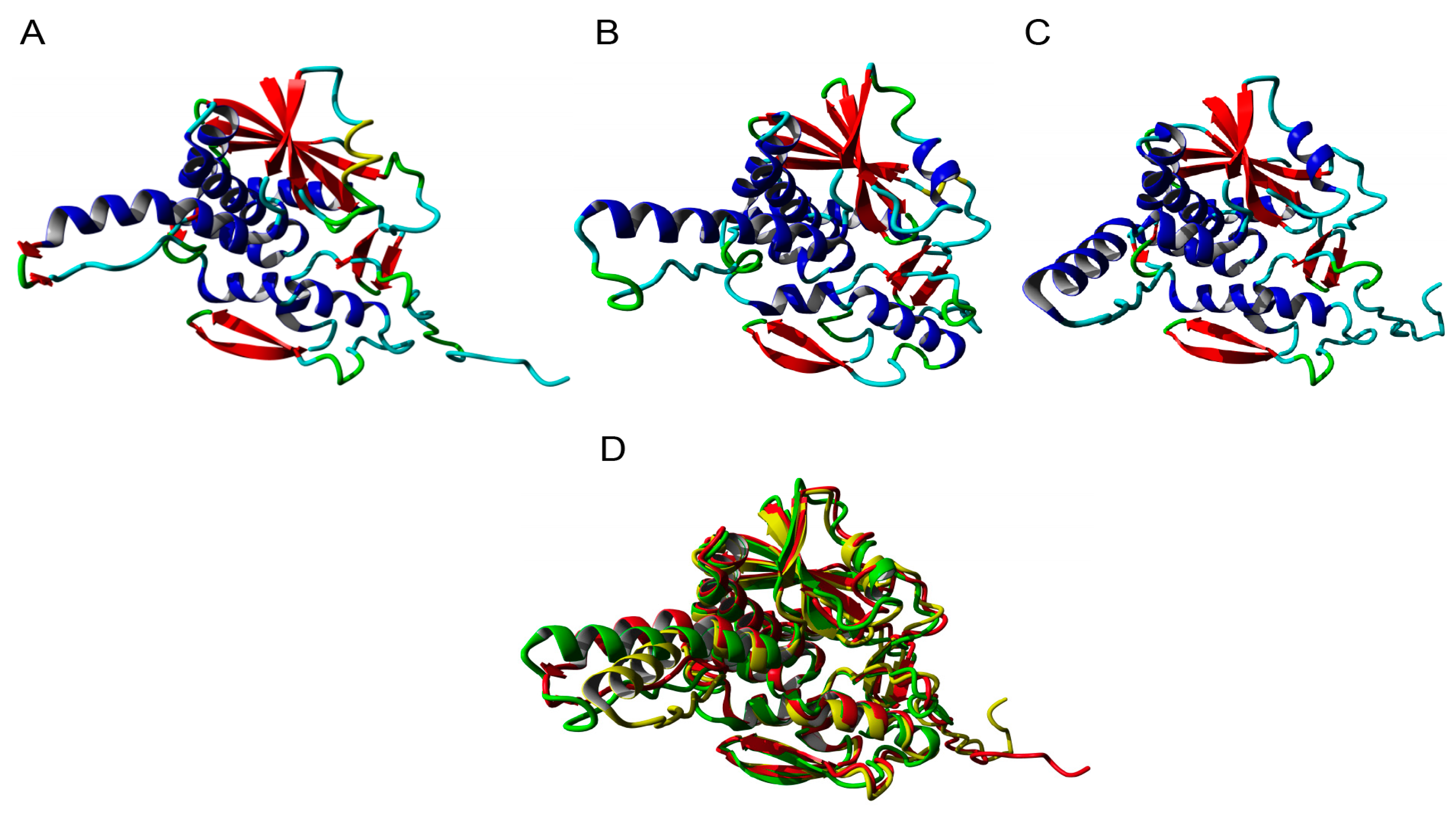
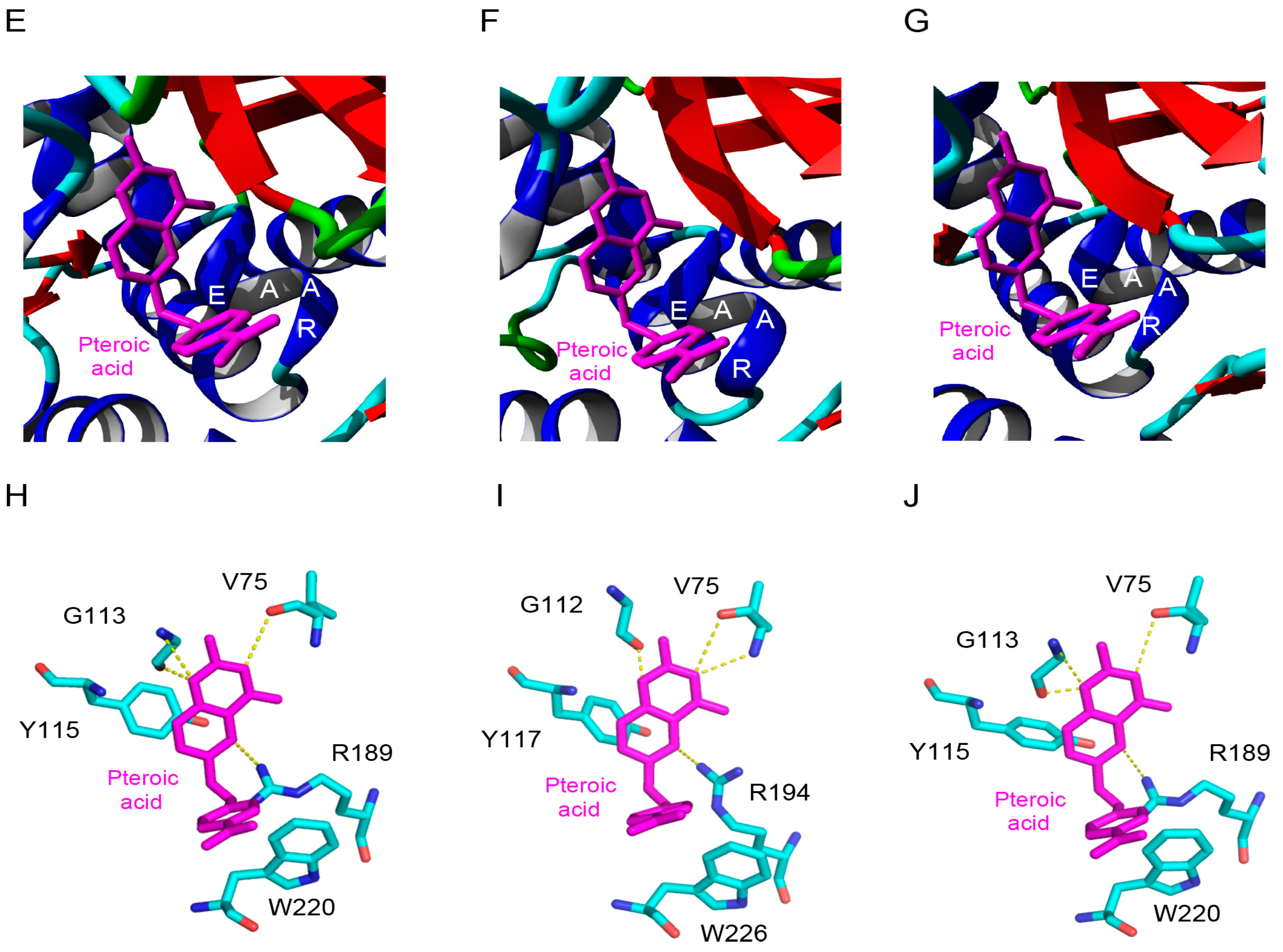
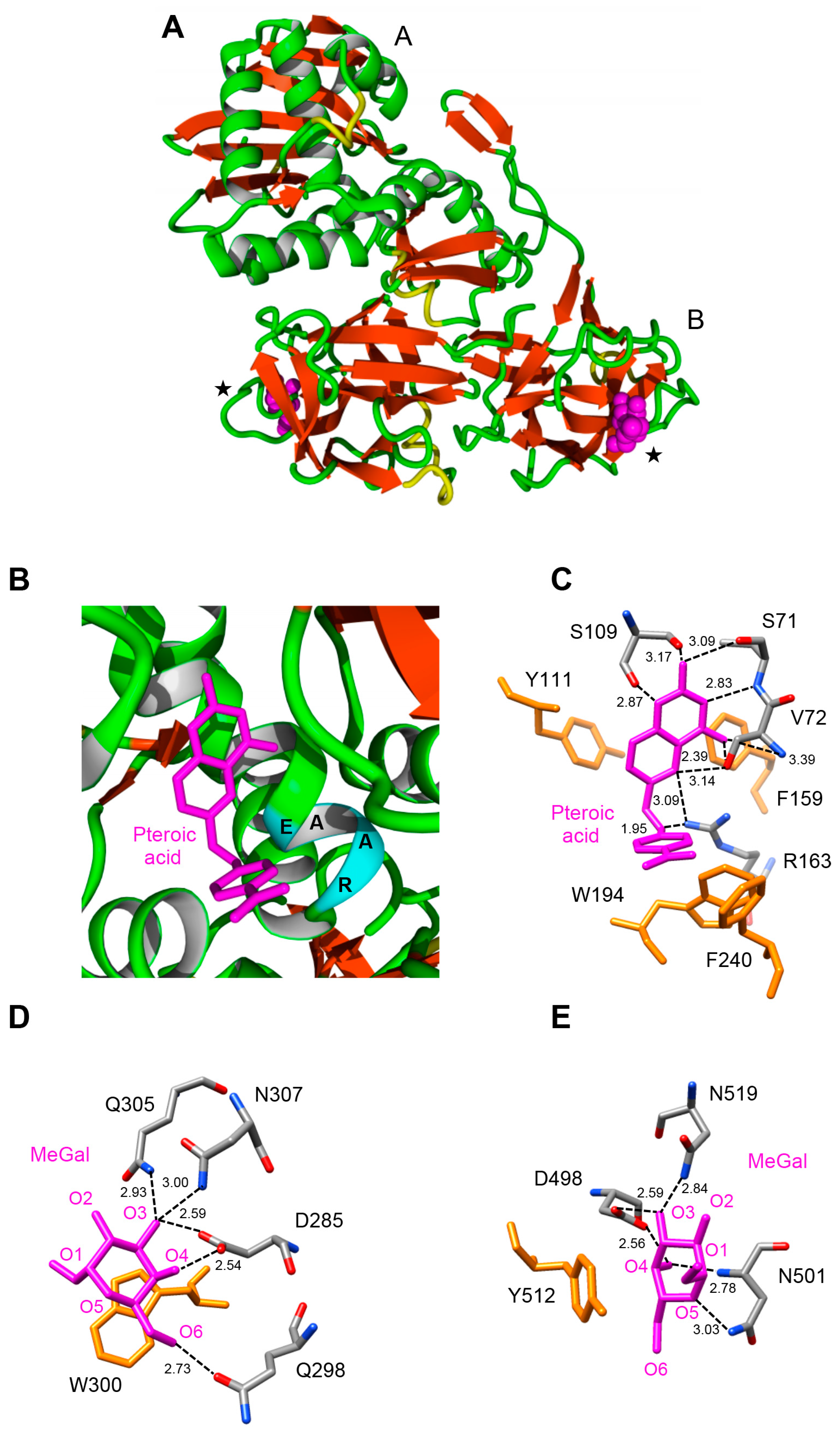
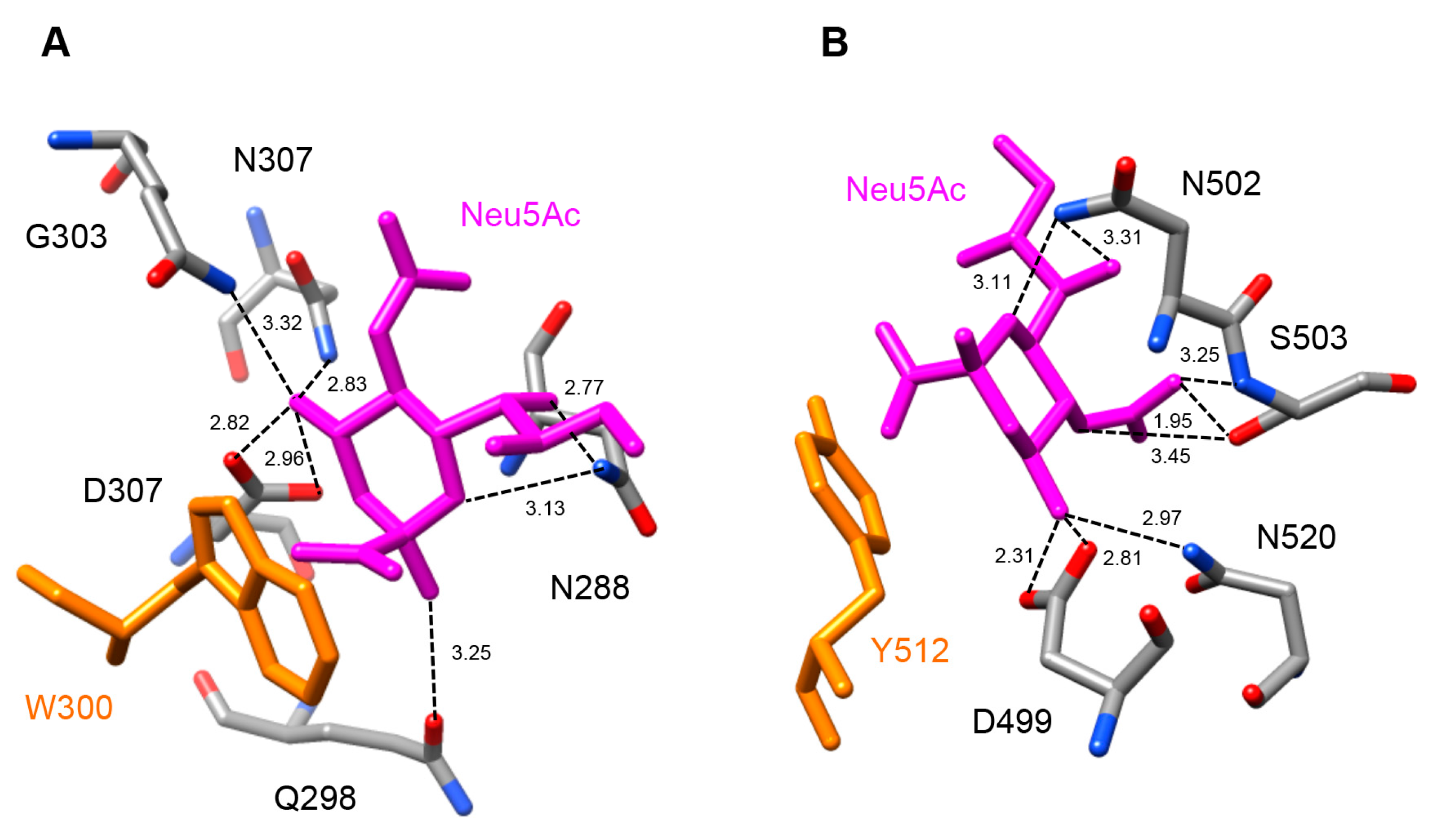
2.5. Molecular Modeling of Enzymatically Active Sites and Carbohydrate-Binding Sites
3. Discussion
4. Materials and Methods
4.1. Sequence Alignment and Phylogenetic Analysis
4.2. Purification of Recombinant Md1RIP
4.3. Purification of Recombinant Md2RIP
4.4. Western Blot Analysis
4.5. N-terminal Sequence Analysis
4.6. Biochemical Assays
4.7. Protein Deglycosylation
4.8. Molecular Modeling and Docking
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Stirpe, F.; Battelli, M.G. Ribosome-inactivating proteins: Progress and problem. Cell Mol. Life Sci. 2006, 63, 1850–1866. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, P.T.; Peng, F.; Boulanger, M.J.; Perlman, S.J. A ribosome inactivating protein in a Drosophila defensive symbiont. Proc. Natl. Acad. Sci. USA 2015, 113, 350–355. [Google Scholar] [CrossRef] [PubMed]
- Sandvig, K.; Lingelem, A.B.D.; Skotland, T.; Bergan, J. Shiga toxins: Properties and action on cells. In The Comprehensive Sourcebook of Bacterial Protein Toxins, 4th ed.; Joseph, A., Landant, D., Popoff, M.R., Eds.; Elsevier: Waltham, MA, USA, 2015; pp. 267–286. [Google Scholar]
- Wang, H.; Ng, T.B. Isolation and characterization of velutin, a novel low-molecular-weight ribosome-inactivating protein from winter mushroom (Flammulina velutipes) fruiting bodies. Life Sci. 2001, 68, 2151–2158. [Google Scholar] [CrossRef]
- Di Maro, A.; Citores, L.; Russo, R.; Iglesias, R.; Ferreras, J.M. Sequence comparison and phylogenetic analysis by the maximum likelihood method of ribosome-inactivating proteins from angiosperms. Plant Mol. Biol. 2014, 85, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Peumans, W.J.; van Damme, E.J.M. Evolution of plant ribosome-inactivating proteins. In Plant Cell Monographs; Lord, J.M., Hartley, M.R., Eds.; Springer: Heidelberg, Germany, 2010; pp. 1–26. [Google Scholar]
- Stirpe, F.; Lappi, D.A. Ribosome-Inactivating Proteins: Ricin and Related Proteins; John Wiley & Sons, Ltd.: Oxford, UK, 2014. [Google Scholar]
- Stirpe, F. Ribosome-inactivating proteins. Toxicon 2004, 44, 371–383. [Google Scholar] [CrossRef] [PubMed]
- Parente, A.; Chambery, A.; di Maro, A.; Russo, R.; Severino, V. Ribosome-inactivating proteins from Phytolaccaceae. In Ribosome-Inactivating Proteins: Ricin and Related Proteins; Stirpe, F., Lappi, D.A., Eds.; John Wiley & Sons, Ltd.: Oxford, UK, 2014; pp. 28–43. [Google Scholar]
- Jiang, S.Y.; Ramamoorthy, R.; Bhalla, R.; Luan, H.F.; Venkatesh, P.N.; Cai, M.; Ramachandran, S. Genome-wide survey of the RIP domain family in Oryza sativa and their expression profiles under various abiotic and biotic stresses. Plant Mol. Biol. 2008, 67, 603–614. [Google Scholar] [CrossRef] [PubMed]
- Hao, Q.; van Damme, E.J.M.; Hause, B.; Barre, A.; Chen, Y.; Rougé, P.; Peumans, W.J. Iris bulbs express type 1 and type 2 ribosome-inactivating proteins with unusual properties. Plant Physiol. 2001, 125, 866–876. [Google Scholar] [CrossRef] [PubMed]
- Tejero, J.; Jiménez, P.; Quinto, E.J.; Cordoba-Diaz, D.; Garrosa, M.; Cordoba-Diaz, M.; Gayoso, M.J.; Girbés, T. Elderberries: A source of ribosome-inactivating proteins with lectin activity. Molecules 2015, 20, 2364–2387. [Google Scholar] [CrossRef] [PubMed]
- Fang, E.F.; Zhang, C.Z.Y.; Ng, T.B.; Wong, J.H.; Pan, W.L.; Ye, X.J.; Chan, Y.S.; Fong, W.P. Momordica charantia lectin, a type II ribosome inactivating protein, exhibits antitumor activity toward human nasopharyngeal carcinoma cells in vitro and in vivo. Cancer Prev. Res. 2012, 5, 109–121. [Google Scholar] [CrossRef] [PubMed]
- Husain, J.; Tickle, I.J.; Wood, S.P. Crystal structure of momordin, a type I ribosome inactivating protein from the seeds of Momordica charantia. FEBS Lett. 1994, 342, 154–158. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.P.; Chai, J.J.; Wang, K.Y.; Bi, R.C. Molecular-replacement studies of Trichosanthes kirilowii lectin 1: A structure belonging to the family of type 2 ribosome-inactivating proteins. Acta Crystallogr. Sect. D-Biol. Crystallogr. 2002, 56, 1073–1075. [Google Scholar] [CrossRef]
- Ng, T.B.; Wong, H.J. Ribosome-inactivating proteins in Caryophyllaceae, Cucurbitaceae and Euphorbiaceae. In Ribosome-Inactivating Proteins: Ricin and Related Proteins; Stirpe, F., Lappi, D.A., Eds.; John Wiley & Sons, Ltd.: Oxford, UK, 2014; pp. 44–66. [Google Scholar]
- Shang, C.; Peumans, W.J.; van Damme, E.J.M. Occurrence and taxonomical distribution of ribosome-inactivating proteins belonging to the ricin/shiga toxin superfamily. In Ribosome-Inactivating Proteins: Ricin and Related Proteins; Stirpe, F., Lappi, D.A., Eds.; John Wiley & Sons, Ltd.: Oxford, UK, 2014; pp. 11–27. [Google Scholar]
- Peumans, W.J.; Shang, C.; van Damme, E.J.M. Updated model of the molecular evolution of RIP genes. In Ribosome-Inactivating Proteins: Ricin and Related Proteins; Stirpe, F., Lappi, D.A., Eds.; Wiley Blackwell Press: New York, NJ, USA, 2014; pp. 134–150. [Google Scholar]
- Lapadula, W.J.; Puerta, M.V.S.; Ayub, M.J. Revising the taxonomic distribution, origin and evolution of ribosome inactivating protein genes. PLoS ONE 2013, 8, e72825. [Google Scholar] [CrossRef] [PubMed]
- Kaku, H.; Kaneko, H.; Minamihara, N.; Iwata, K.; Jordan, E.T.; Rojo, M.A.; Minami-Ishii, N.; Minami, E.; Hisajima, S.; Shibuya, N. Elderberry bark lectins evolved to recognize Neu5Acα2,6Gal/GalNAc sequence from a Gal/GalNAc binding lectin through the substitution of amino-acid residues critical for the binding to sialic acid. Biochem. J. 2007, 142, 393–401. [Google Scholar] [CrossRef] [PubMed]
- Van Damme, E.J.M.; Barre, A.; Rougé, P.; van Leuven, F.; Peumans, W.J. The NeuAc(a-2,6) Gal/ GalNAc-binding lectin from elderberry (Sambucus nigra) bark, a type-2 ribosome-inactivating protein with an unusual specificity and structure. Eur. J. Biochem. 1996, 235, 128–137. [Google Scholar] [CrossRef] [PubMed]
- Hu, D.; Tateno, H.; Kuno, A.; Yabe, R.; Hirabayashi, J. Directed evolution of lectins with sugar-binding specificity for 6-sulfogalactose. J. Biol. Chem. 2012, 287, 20313–20320. [Google Scholar] [CrossRef] [PubMed]
- Al Atalah, B.; Fouquaert, E.; Vanderschaeghe, D.; Proost, P.; Balzarini, J.; Smith, D.F.; Rougé, P.; Lasanajak, Y.; Callewaert, N.; van Damme, E.J.M. Expression analysis of the nucleocytoplasmic lectin ‘Orysata’ from rice in Pichia pastoris. FEBS J. 2011, 278, 2064–2079. [Google Scholar] [CrossRef] [PubMed]
- Mak, A.N.; Wong, Y.T.; An, Y.J.; Sze, K.H.; Wing-Ngor Au, S.; Wong, K.B.; Shaw, P.C. Structure-function study of maize ribosome-inactivating protein: Implications for the internal inactivation region and the sole glutamate in the active site. Nucleic Acids Res. 2007, 35, 6259–6267. [Google Scholar] [CrossRef] [PubMed]
- Citores, L.; Iglesias, R.; Gay, C.; Ferreras, J.M. Antifungal activity of the ribosome-inactivating protein BE27 from sugar beet (Beta vulgaris L.) against the green mould Penicillium digitatum. Mol. Plant Pathol. 2016, 17, 261–271. [Google Scholar] [CrossRef] [PubMed]
- Iglesias, R.; Citores, L.; Ragucci, S.; Russo, R.; di Maro, A.; Ferreras, J.M. Biological and antipathogenic activities of ribosome-inactivating proteins from Phytolacca dioica L. BBA-Gen. Subjects 2016, 1860, 1256–1264. [Google Scholar] [CrossRef] [PubMed]
- Pascal, J.M.; Day, P.J.; Monzingo, A.F.; Ernst, S.R.; Robertus, J.D.; Iglesias, R.; Pérez, Y.; Férreras, J.M.; Citores, L.; Girbés, T. 2.8-Å Crystal structure of a nontoxic type-II ribosome-inactivating protein, ebulin l. Proteins Struct. Funct. Genet. 2001, 43, 319–326. [Google Scholar] [CrossRef] [PubMed]
- Marsden, C.J.; Fülöp, V.; Day, P.J.; Lord, J.M. The effect of mutations surrounding and within the active site on the catalytic activity of ricin A chain. Eur. J. Biochem. 2004, 271, 153–162. [Google Scholar] [CrossRef] [PubMed]
- Rutenber, E.; Katzin, B.J.; Collins, E.J.; Mlsna, D.; Ernst, S.E.; Ready, M.P.; Robertus, J.D. Crystallographic refinement of ricin to 2.5 Å. Proteins 1991, 10, 240–250. [Google Scholar] [CrossRef] [PubMed]
- Polito, L.; Bortolotti, M.; Mercatelli, D.; Mancuso, R.; Baruzzi, G.; Faedi, W.; Bolognesi, A. Protein synthesis inhibition activity by strawberry tissue protein extracts during plant life cycle and under biotic and abiotic stresses. Int. J. Mol. Sci. 2013, 14, 15532–15545. [Google Scholar] [CrossRef] [PubMed]
- Vandenbussche, F.; Peumans, W.J.; Desmyter, S.; Proost, P.; Ciani, M.; van Damme, E.J.M. The type-1 and type-2 ribosome-inactivating proteins from Iris confer transgenic tobacco plants local but not systemic protection against virus. Planta 2004, 220, 211–221. [Google Scholar] [CrossRef] [PubMed]
- Vandenbussche, F.; Desmyter, S.; Ciani, M.; Proost, P.; Peumans, W.J.; van Damme, E.J.M. Analysis of the in planta antiviral activity of elderberry ribosome-inactivating proteins. Eur. J. Biochem. 2004, 271, 1508–1515. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Peumans, W.J.; van Damme, E.J.M. The Sambucus nigra type-2 ribosome-inactivating protein SNA-I’ exhibits in planta antiviral activity in transgenic tobacco. FEBS Lett. 2002, 516, 27–30. [Google Scholar] [CrossRef]
- Shang, C.; Chen, Q.; Dell, A.; Haslam, S.M.; de Vos, W.H.; van Damme, E.J.M. The cytotoxicity of elderberry lectins is not solely determined by their N-glycosidase activity. PLoS ONE 2015, 10, e0132389. [Google Scholar] [CrossRef] [PubMed]
- Ferreras, J.M.; Citores, L.; Iglesias, R.; Jiménez, P.; Girbés, T. Use of ribosome-inactivating proteins from Sambucus for the construction of immunotoxins and conjugates for cancer therapy. Toxins 2011, 3, 420–441. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Robertus, J.D. Analysis of several key active site residues of ricin A chain by mutagenesis and X-ray crystallography. Protein Eng. 1992, 5, 775–779. [Google Scholar] [CrossRef] [PubMed]
- Zeleny, R.; Kolarich, D.; Strasser, R.; Altmann, F. Sialic acid concentrations in plants are in the range of inadvertent contamination. Planta 2006, 224, 222–227. [Google Scholar] [CrossRef] [PubMed]
- Varki, A.; Schauer, R. Sialic acids. In Essentials of Glycobiology, 2nd ed.; Varki, A., Cummings, R.D., Esko, J.D., Freeze, H.H., Stanley, P., Bertozzi, C.R., Hart, G.W., Etzler, M.E., Eds.; Cold Spring Harbor Press: Cold Spring Harbor, Woodbury, NY, USA, 2009; Chapter 4. [Google Scholar]
- Shahidi-Noghabi, S.; van Damme, E.J.M.; Smagghe, G. Carbohydrate-binding activity of the type-2 ribosomes-inactivating protein SNA-I from elderberry (Sambucus nigra) is a determining factor for its insecticidal activity. Phytochemistry 2008, 69, 2972–2978. [Google Scholar] [CrossRef] [PubMed]
- Hamshou, M.; Shang, C.; Smagghe, G.; van Damme, E.J.M. Ribosome-inactivating proteins from apple have strong aphicidal activity in artificial diet and in planta. Crop Prot. 2016, 87, 19–24. [Google Scholar] [CrossRef]
- Szalai, K.; Schöll, I.; Förster-Waldl, E.; Polito, L.; Bolognesi, A.; Untersmayr, E.; Riemer, A.B.; Boltz-Nitulescu, G.; Stirpe, F.; Jensen-Jarolim, E. Occupational sensitization to ribosome-inactivating proteins in researchers. Clin. Exp. Allergy 2005, 35, 1354–1360. [Google Scholar] [CrossRef] [PubMed]
- Crooks, G.E.; Hon, G.; Chandonia, J.M.; Brenner, S.E. WebLogo: A sequence logo generator. Genome Res. 2004, 14, 1188–1190. [Google Scholar] [CrossRef] [PubMed]
- Papadopoulos, J.S.; Agarwala, R. COBALT: Constraint-based alignment tool for multiple protein sequences. Bioinformatics 2007, 23, 1073–1079. [Google Scholar] [CrossRef] [PubMed]
- Desmyter, S.; Vandenbussche, F.; Hao, Q.; Proost, P.; Peumans, W.J.; van Damme, E.J.M. Type-1 ribosome-inactivating protein from iris bulbs: A useful agronomic tool to engineer virus resistance? Plant Mol. Biol. 2003, 51, 567–576. [Google Scholar] [CrossRef] [PubMed]
- Delporte, A.; de Vos, W.H.; van Damme, E.J.M. In vivo interaction between the tobacco lectin and the core histone proteins. J. Plant Physiol. 2014, 171, 1149–1156. [Google Scholar] [CrossRef] [PubMed]
- Stefanowicz, K.; Lannoo, N.; Proost, P.; van Damme, E.J.M. Arabidopsis F-box protein containing a Nictaba-related lectin domain interacts with N-acetyllactosamine structures. FEBS Open Bio 2012, 2, 151–158. [Google Scholar] [CrossRef] [PubMed]
- Blixt, O.; Head, S.; Mondala, T.; Scanlan, C.; Huflejt, M.E.; Alvarez, R.; Bryan, M.C.; Fazio, F.; Calarese, D.; Stevens, J.; et al. Printed covalent glycan array for ligand profiling of diverse glycan binding proteins. Proc. Natl. Acad. Sci. USA 2004, 101, 17033–17038. [Google Scholar] [CrossRef] [PubMed]
- Shang, C.; van Damme, E.J.M. Comparative analysis of carbohydrate binding properties of Sambucus nigra lectins and ribosome-inactivating proteins. Glycoconj. J. 2014, 31, 345–354. [Google Scholar] [CrossRef] [PubMed]
- Al Atalah, B.; Smagghe, G.; van Damme, E.J.M. Orysata, a jacalin-related lectin from rice, could protect plants against biting-chewing and piercing-sucking insects. Plant Sci. 2014, 221–222, 21–28. [Google Scholar] [CrossRef] [PubMed]
- Krieger, E.; Koraimann, G.; Vriend, G. Increasing the precision of comparative models with YASARA NOVA—A self-parameterizing force field. Proteins 2002, 47, 393–402. [Google Scholar] [CrossRef] [PubMed]
- Carra, J.H.; McHugh, C.A.; Mulligan, S.; Machiesky, L.M.; Soares, A.S.; Millard, C.B. Fragment-based identification of determinants of conformational and spectroscopic change at the ricin active site. BMC Struct. Biol. 2007, 7, 72–83. [Google Scholar] [CrossRef] [PubMed]
- Allen, S.C.; Moore, K.A.; Marsden, C.J.; Fülöp, V.; Moffat, K.G.; Lord, J.M.; Ladds, G.; Roberts, L.M. The isolation and characterization of temperature-dependent ricin A chain molecules in Saccharomyces cerevisiae. FEBS J. 2007, 274, 5586–5599. [Google Scholar] [CrossRef] [PubMed]
- Weston, S.A.; Tucker, A.D.; Thatcher, D.R.; Derbyshire, D.J.; Pauptit, R.A. X-ray structure of recombinant ricin A-chain at 1.8 Å resolution. J. Mol. Biol. 1994, 244, 410–422. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Pohlentz, G.; Bobbili, K.B.; Jeyaprakash, A.A.; Chandran, T.; Mormann, M.; Swamy, M.J.; Vijayan, M. The sequence and structure of snake gourd (Trichosanthes anguina) seed lectin, a three-chain nontoxic homologue of type II RIPs. Acta Crystallogr. Sect. D 2013, 69, 1493–1503. [Google Scholar] [CrossRef] [PubMed]
- Laskowski, R.A.; MacArthur, M.W.; Moss, D.S.; Thornton, J.M. PROCHECK: A program to check the stereochemistry of protein structures. J. Appl. Cryst. 1993, 26, 283–291. [Google Scholar] [CrossRef]
- Melo, F.; Feytmans, E. Assessing protein structures with a non-local atomic interaction energy. J. Mol. Biol. 1998, 277, 1141–1152. [Google Scholar] [CrossRef] [PubMed]
- Arnold, K.; Bordoli, L.; Kopp, J.; Schwede, T. The SWISS-MODEL workspace: A web-based environment for protein structure homology modelling. Bioinformatics 2006, 22, 195–201. [Google Scholar] [CrossRef] [PubMed]
- Benkert, P.; Biasini, M.; Schwede, T. Toward the estimation of the absolute quality of individual protein structure models. Bioinformatics 2011, 27, 343–350. [Google Scholar] [CrossRef] [PubMed]
- Glaser, F.; Pupko, T.; Bell, R.E.; Bechor, D.; Martz, E.; Ben-Tal, N. ConSurf: Identification of functional regions in proteins by surface-mapping of phylogenetic informations. Bioinformatics 2003, 19, 163–164. [Google Scholar] [CrossRef] [PubMed]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Couch, G.S.; Greenblatt, D.M.; Meng, E.C.; Ferrin, T.E. UCSF Chimera—A visualization system for exploratory research and analysis. J. Comput. Chem. 2004, 25, 1605–1612. [Google Scholar] [CrossRef] [PubMed]
- Sample Availability: Samples of the compounds are not available from the authors.
© 2016 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, C.; Rougé, P.; Van Damme, E.J.M. Ribosome Inactivating Proteins from Rosaceae. Molecules 2016, 21, 1105. https://doi.org/10.3390/molecules21081105
Shang C, Rougé P, Van Damme EJM. Ribosome Inactivating Proteins from Rosaceae. Molecules. 2016; 21(8):1105. https://doi.org/10.3390/molecules21081105
Chicago/Turabian StyleShang, Chenjing, Pierre Rougé, and Els J. M. Van Damme. 2016. "Ribosome Inactivating Proteins from Rosaceae" Molecules 21, no. 8: 1105. https://doi.org/10.3390/molecules21081105
APA StyleShang, C., Rougé, P., & Van Damme, E. J. M. (2016). Ribosome Inactivating Proteins from Rosaceae. Molecules, 21(8), 1105. https://doi.org/10.3390/molecules21081105