Using MUSIC and CC(CO)NH for Backbone Assignment of Two Medium-Sized Proteins Not Fully Accessible to Standard 3D NMR

Abstract
:1. Introduction
2. Results and Discussion
2.1. CC(CO)NH Spectra and the Choice of Mixing Times

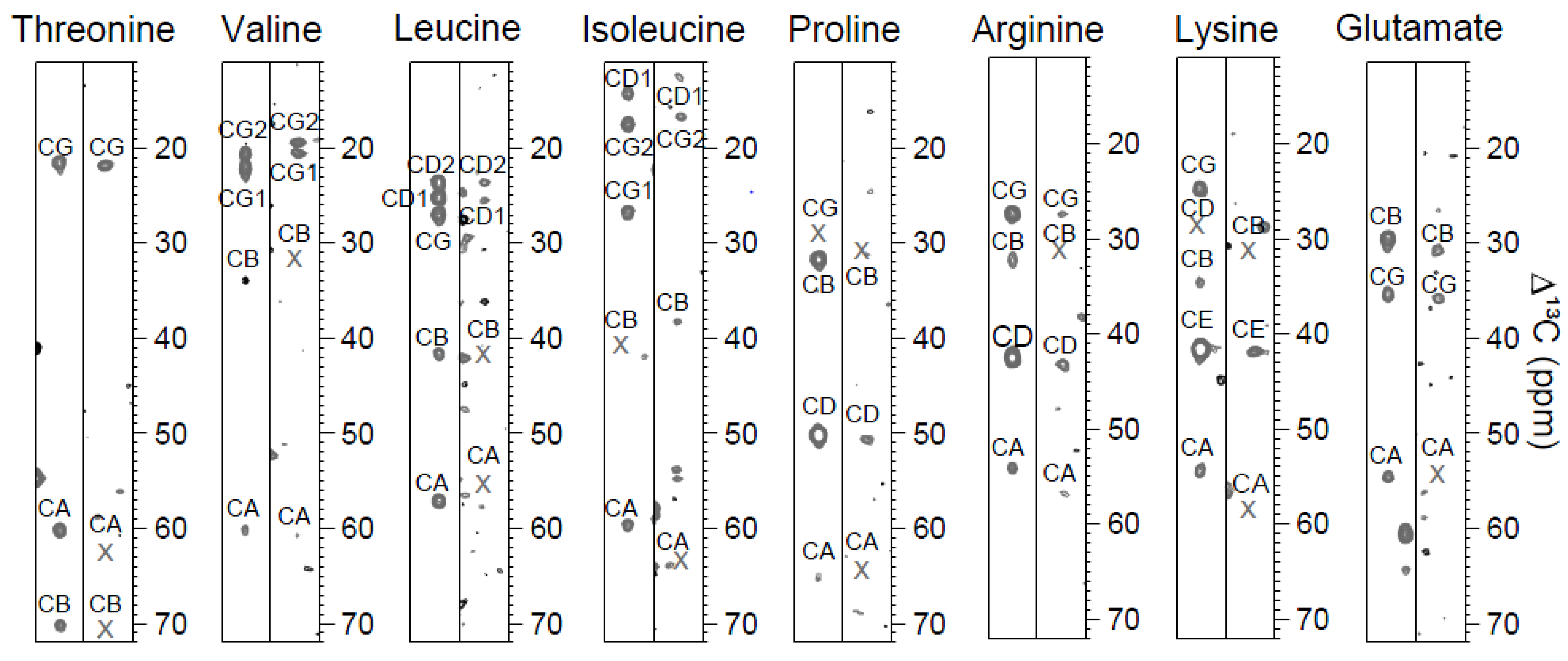
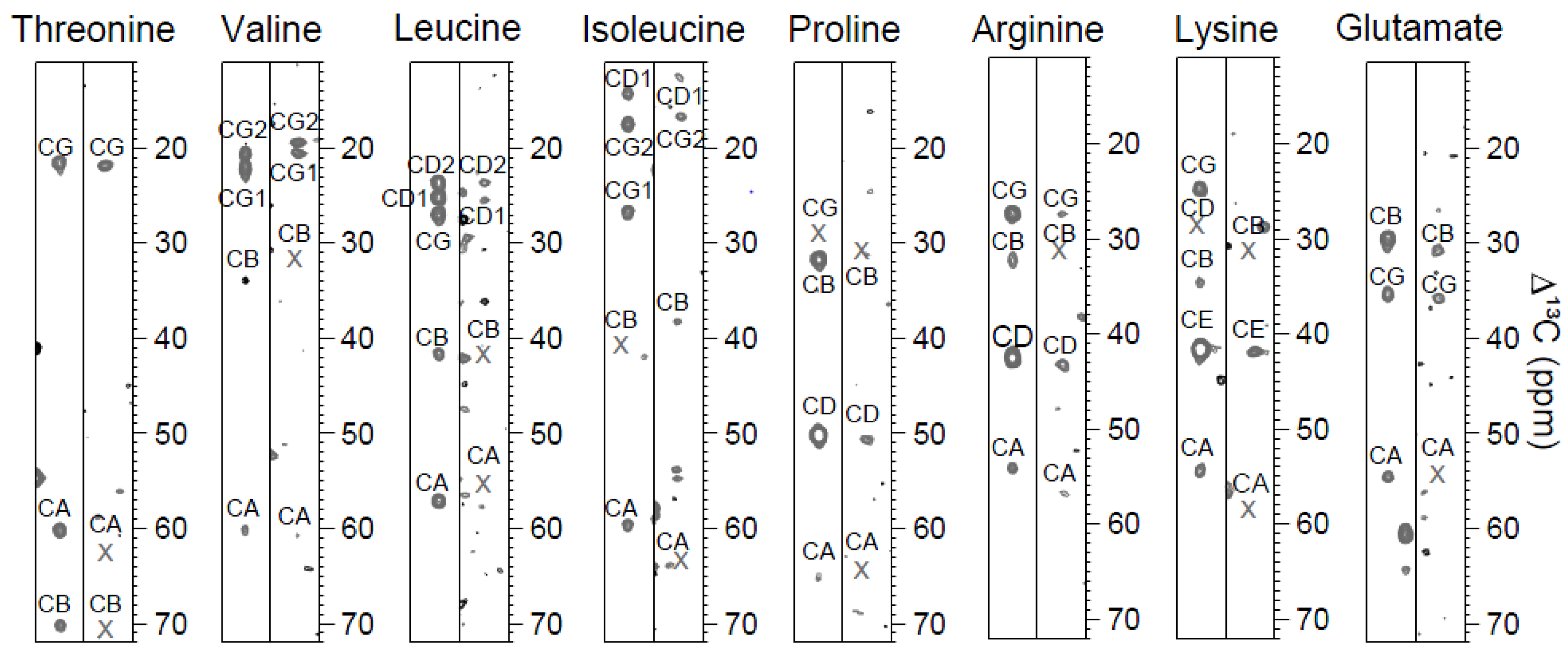{kind=link}
{kind=link}
| Amino Acid | Ubiquitin | Detectable Signals a | |
|---|---|---|---|
| R17 | hNaa50p | ||
| G | 5/5 | 6/6 | 10/10 |
| A | 2/2 | 11/12 | 7/7 |
| S | 3/3 | 3/4 | 6/6 |
| T | 7/7 | 5/5 | 4/4 |
| I | 5/5 | 3/3 | 9/12 |
| V | 4/4 | 6/8 | 8/8 |
| L | 9/9 | 7/9 | 8/13 |
| R | 4/4 | 4/4 | 5/6 |
| K | 7/7 | 13/13 | 10/12 |
| P | 2/2 | - | 2/4 |
| E/Q/M | 12/12 | 17/21 | 6/14 |
| N/D/F/Y/Cox | 9/9 | 11/20 | 11/29 |
| H/W/Cred | 1/1 | 0/4 | 1/6 |
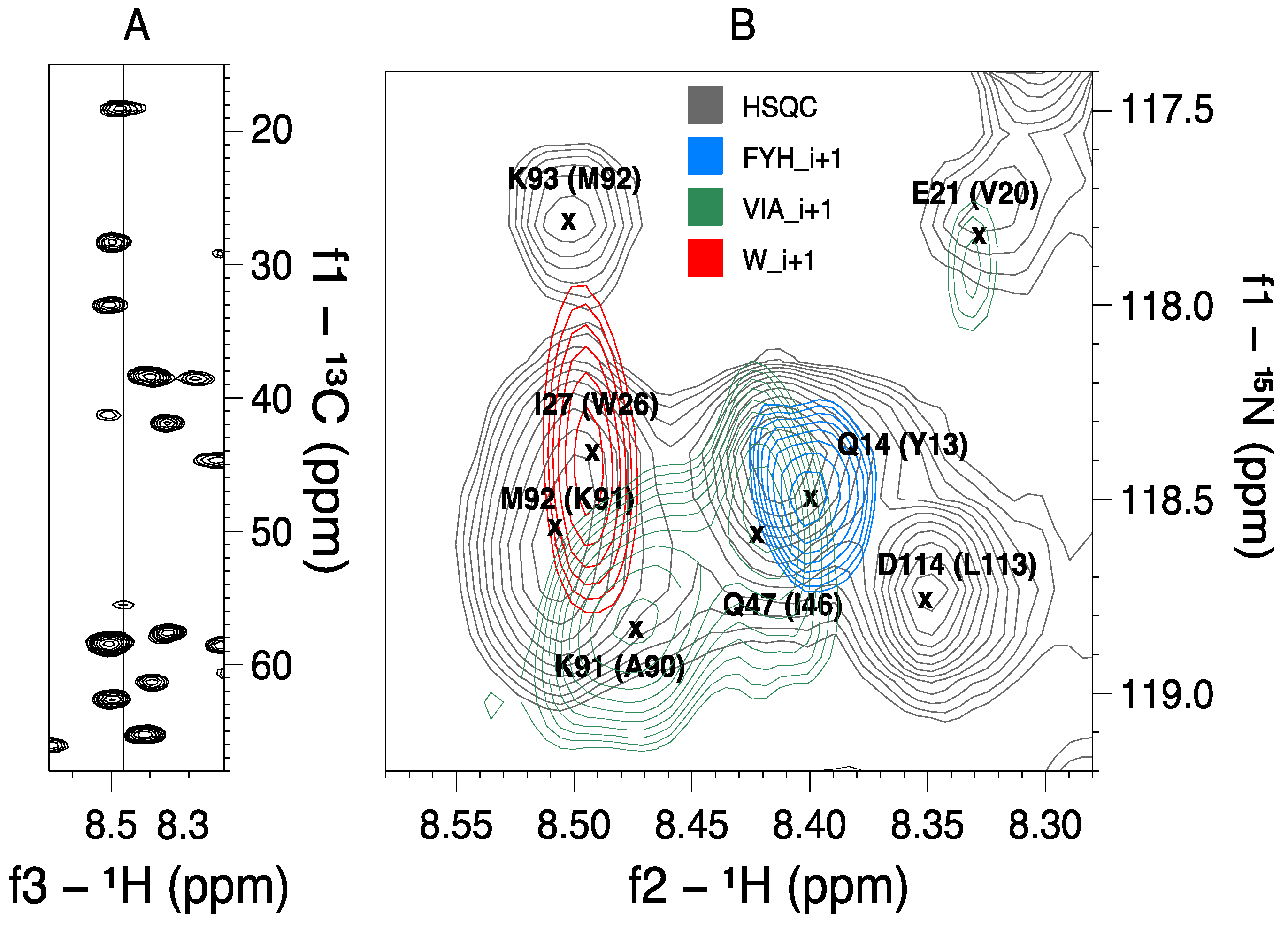
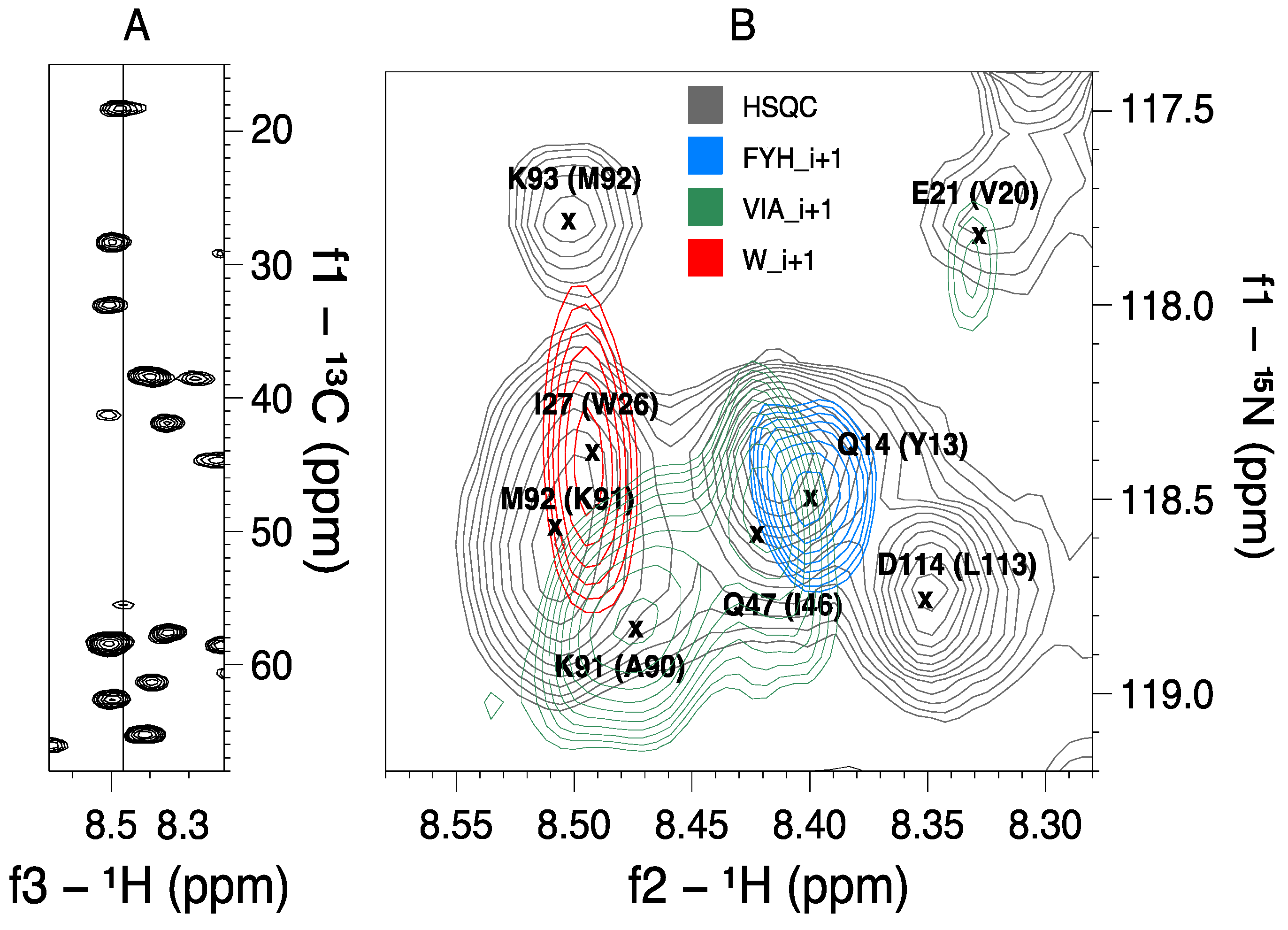
2.2. MUSIC Spectra of Ubiquitin
| Variant a | Acquisition Time (h) | Signals | Artefacts | Comments |
|---|---|---|---|---|
| G_i+1 b | 3 | 5/5 | N c/Q c | weak artefact signals |
| G_ii+1 d | 3 | 5/5 | R c | artefacts are negative if aliased |
| A_i+1 | 3 | 2/2 | ||
| A_ii+1 | 1.5 | 2/2 | low sensitivity | |
| S_i+1 | 4.5 | 3/3 | ||
| S_ii+1 | 4.5 | 3/3 | ||
| N_i+1 | 2 | 2/2 | ||
| N_ii+1 | 8 | 2/2 | low sensitivity | |
| NQ_i+1 | 2 | 8/8 | ||
| NQ_ii+1 | 2 | 8/8 | One Q is negative | |
| DNG_i+1 | 2 | 11/11 | G and one N are negative | |
| DNG_ii+1 | 2 | 12/12 | G and one N are negative, N have lowest signal strengths | |
| EQG_i+1 | 2 | 18/18 | N | G and one Q are negative |
| EQG_ii+1 | 2 | 15/16 | N | G and one Q are negative |
| TA_i+1 | 1.5 | 8/9 | low sensitivity | |
| TA_ii+1 | 1.5 | 9/9 | low sensitivity | |
| VIA_i+1 | 1.5 | 13/13 | V has higher intensity than I | |
| VIA_ii+1 | 1.5 | 13/13 | V has higher intensity than I | |
| LA_i+1 | 1.5 | 10/11 | V/T | low sensitivity |
| LA_ii+1 | 1.5 | 9/11 | T | low sensitivity |
| FYH_i+1 | 1 | 4/4 | F are negative | |
| FYH_ii+1 | 4 | 4/4 | F are negative | |
| R_i+1 | 1 | 4/4 | G | |
| R_ii+1 | 1 | 3/4 | R c | low sensitivity |
| KR_i+1 | 6 | 10/11 | G/S | low sensitivity |
| K_ii+1 | 6 | 4/7 | G/R | low sensitivity, both positive and negative signals |
| P_i+1 | 2 | 2/2 | ||
| P_i-1 | 2 | 0/2 | low sensitivity | |
| P_i+1np | 2 | 0/2 | low sensitivity | |
| P_i-1np | 4 | 0/2 | low sensitivity |
2.3. MUSIC Spectra of R17 and hNaa50p
| Variant | hNaa50p | R17 | Comments | ||||
|---|---|---|---|---|---|---|---|
| Acquisition Time (h) | Signals | Acquisition Time (h) | Signals | ||||
| G_i+1 a | 4 | 8/10 | n.d. b | n.d. | side chain artefacts | ||
| G_ii+1 c | 3 | 4/9 | n.d. | n.d. | |||
| A_i+1 d | 9 | 7/7 | 12.5 | 12/13 | |||
| S_i+1 | 2 | 4/6 | n.d. | n.d. | |||
| S_ii+1 | 5 | 0/5 | n.d. | n.d. | low sensitivity | ||
| N_i+1 | 4 | 4/11 | 4 | 5/6 | |||
| N_ii+1 | 8 | 1/11 | n.d. | n.d. | low sensitivity | ||
| NQ_i+1 | 12 | 9/17 | 6 | 8/11 | |||
| DNG_i+1 | 6 | 17/30 | 5 | 16/21 | G and some N are negative, some G are missing (R17) | ||
| DNG_ii+1 d | 10.5 | 8/28 | 17.5 | 17/20 | E artefacts, G and some N are negative, D are strongest | ||
| EQG_i+1 | 5 | 8/22 | 5 | 20/24 | N and D artefacts, also side chains, G are negative, Q are strongest | ||
| EQG_ii+1 | 10 | 9/23 | 8 | 14/24 | N and D artefacts, also side chains, low G sensitivity (R17) | ||
| TA_i+1 | 3 | 0/14 | n.d. | n.d. | low sensitivity | ||
| TA_ii+1 | 22 | 4/11 | n.d. | n.d. | low sensitivity | ||
| VIA_i+1 d | 22 | 23/27 | 10 | 22/23 | V has higher intensity than I | ||
| VIA_ii+1 d | 23.5 | 24/33 | n.d. | n.d. | V has higher intensity than I | ||
| LA_i+1 | 1 | 12/20 | n.d. | n.d. | low sensitivity | ||
| LA_ii+1 | 1 | 5/23 | n.d. | n.d. | low sensitivity, even for A | ||
| FYH_i+1 | 10 | 6/18 | 8 | 7/8 | all positive (R17), both positive and negative (hNaa50p) | ||
| FYH_ii+1 d | 19.5 | 7/15 | 16 | 5/7 | all positive (R17), both positive and negative (hNaa50p) | ||
| W_i+1 d | n.a. e | n.a. | 10 | 1/1 | |||
| W_ii+1 d | n.a. | n.a. | 15.5 | 1/1 | |||
| R_i+1 | 12 | 2/6 | n.d. | n.d. | |||
| KR_i+1 | 1 | 0/18 | n.d. | n.d. | low sensitivity, test spectrum only | ||
| K_ii+1 | 1 | 0/11 | n.d. | n.d. | low sensitivity, test spectrum only | ||
| P_i+1 | 20 | 2/5 | n.a. | n.a. | |||
3. Experimental
3.1. Sample Preparation
3.2. NMR Experiments on Ubiquitin
| Aa | I | I-1 | Aa | I | I-1 | Aa | I | I-1 | Aa | I | I-1 | Aa | I | I-1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M1 | A58 | A | G | Q114 | M1 | F60 | FY | D | ||||||
| K2 | V59 | V | A | I115 | A2 | A | T61 | T | FY | |||||
| G3 | C60 | S116 | ST | I | R3 | A | V62 | T | ||||||
| S4 | ST | G | C61 | N117 | S | G4 | G | R | H63 | V | ||||
| R5 | S | R62 | E118 | Q5 | EQ | G | K64 | H | ||||||
| I6 | R | V63 | V | R | S119 | S | R6 | Q | D65 | D | K | |||
| E7 | E | I | D64 | V | A120 | A | S | L7 | R | R66 | D | |||
| L8 | EQ | H65 | I121 | I | A | E8 | EQ | V67 | V | R | ||||
| G9 | G | L | S66 | ST | D122 | DN | I | E9 | N68 | N | V | |||
| D10 | G | Q67 | S | F123 | DN | S10 | D69 | N | ||||||
| V11 | V | DN | N68 | Q | Y124 | L11 | S | V70 | V | D | ||||
| T12 | T | V | Q69 | N | R125 | E12 | C71 | V | ||||||
| P13 | K70 | EQ | K126 | R | Y13 | FY | E | A72 | A | |||||
| H14 | R71 | F127 | FY | K | Q14 | FY | N73 | A | ||||||
| N15 | H | L72 | R | G128 | G | Q15 | Q | G74 | G | N | ||||
| I16 | DN | Y73 | L | F129 | G | F16 | Q | E75 | EQ | G | ||||
| K17 | I | I74 | E130 | V17 | V | D76 | D | E | ||||||
| Q18 | EQ | K | M75 | I | I131 | EQ | A18 | A | V | L77 | L | D | ||
| L19 | L | EQ | T76 | ST | I132 | I | N19 | I78 | I | L | ||||
| K20 | L | L77 | T | E133 | I | V20 | V | N | K79 | |||||
| R21 | K | G78 | G | T134 | T | E21 | EQ | V | K80 | |||||
| L22 | R | C79 | G | K135 | T | E22 | E | N81 | N | K | ||||
| N23 | L | L80 | K136 | K | E23 | EQ | N82 | |||||||
| Q24 | EQ | DN | A81 | A | N137 | K | E24 | EQ | H83 | |||||
| V25 | V | Q | P82 | Y138 | N | A25 | A | H84 | ||||||
| I26 | I | V | Y83 | P | Y139 | FY | W26 | W | A | V85 | V | |||
| F27 | R84 | K140 | I27 | W | E86 | EQ | ||||||||
| P28 | R85 | R141 | N28 | N | I | N87 | E | |||||||
| V29 | V | L86 | I142 | I | R | E29 | EQ | N | I88 | N | ||||
| S30 | G87 | G | L | E143 | EQ | I | K30 | E | T89 | T | I | |||
| Y31 | S | I88 | G | P144 | M31 | K | A90 | A | T | |||||
| N32 | G89 | G | A145 | A | P | T32 | T | K91 | A | |||||
| D33 | T90 | ST | G | D146 | A | L33 | L | T | M92 | K | ||||
| K34 | DN | K91 | T | A147 | A | DN | V34 | V | L | K93 | ||||
| F35 | K | M92 | K | H148 | H | A | A35 | A | V | G94 | G | K | ||
| Y36 | L93 | V149 | V | S36 | S | A | L95 | G | ||||||
| K37 | N94 | L | L150 | V | E37 | EQ | S | K96 | L | |||||
| D38 | H95 | H | Q151 | D38 | D | E | G97 | G | K | |||||
| V39 | V | V96 | V | H | K152 | Y39 | FY | D | K98 | G | ||||
| L40 | V | L97 | V | N153 | G40 | G | FY | V99 | V | K | ||||
| E41 | EQ | N98 | L | L154 | D41 | DN | G | S100 | S | V | ||||
| V42 | V | EQ | I99 | K155 | L | T42 | T | D | D101 | D | S | |||
| G43 | V | C100 | I | V156 | V | K | L43 | T | L102 | D | ||||
| E44 | G | E101 | EQ | P157 | A44 | A | L | E103 | EQ | L | ||||
| L45 | EQ | K102 | EQ | S158 | ST | P | A45 | A | A | K104 | E | |||
| A46 | A | L | D103 | K | G159 | G | S | I46 | A | A105 | A | K | ||
| K47 | A | G104 | G | DN | Q160 | G | Q47 | EQ | I | A106 | A | A | ||
| L48 | T105 | ST | G | N161 | DN | EQ | G48 | G | Q | A107 | A | A | ||
| A49 | A | F106 | T | A162 | A | N | L49 | G | Q108 | EQ | A | |||
| Y50 | A | D107 | DN | D163 | L50 | L | R109 | Q | ||||||
| F51 | N108 | V164 | K51 | K110 | R | |||||||||
| N52 | I109 | Q165 | K52 | K | A111 | A | ||||||||
| D53 | Y110 | K166 | H53 | H | K | K112 | A | |||||||
| I54 | L111 | T167 | E54 | EQ | H | L113 | K | |||||||
| A55 | A | I | H112 | D168 | A55 | A | E | D114 | D | L | ||||
| V56 | V | A | V113 | N169 | F56 | A | E115 | EQ | D | |||||
| G57 | G | V | E57 | EQ | FY | N116 | DN | E | ||||||
| T58 | T | E | S117 | S | N | |||||||||
| D59 | D | T | A118 | A | S | |||||||||
3.3. NMR Experiments on R17 and hNaa50p
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Grzesiek, S.; Bax, A. The importance of not saturating H2O in protein NMR-application to sensitivity enhancement and NOE measurements. J. Am. Chem. Soc. 1993, 115, 12593–12594. [Google Scholar] [CrossRef]
- Grzesiek, S.; Bax, A. Amino-acid type determination in the sequential assignment procedure of uniformly C-13/N-15-enriched proteins. J. Biomol. NMR 1993, 3, 185–204. [Google Scholar]
- Wishart, D.S.; Sykes, B.D. The C-13 chemical-shift index-a simple method for the identification of protein secondary structure using C-13 chemical-shift data. J. Biomol. NMR 1994, 4, 171–180. [Google Scholar]
- Wishart, D.S. Interpreting protein chemical shift data. Prog. Nucl. Magn. Reson. Spectrosc. 2010, 58, 62–87. [Google Scholar] [CrossRef]
- McIntosh, L.P.; Dahlquist, F.W. Biosynthetic incorporation of N-15 and C-13 for assignment and interpretation of nuclear-magnetic-resonance spectra of proteins. Q. Rev. Biophys. 1990, 23, 1–38. [Google Scholar] [CrossRef]
- Tong, K.I.; Yamamoto, M.; Tanaka, T. A simple method for amino acid selective isotope labeling of recombinant proteins in E-coli. J. Biomol. NMR 2008, 42, 59–67. [Google Scholar] [CrossRef]
- Krishnarjuna, B.; Jaipuria, G.; Thakur, A.; D’Silva, P.; Atreya, H.S. Amino acid selective unlabeling for sequence specific resonance assignments in proteins. J. Biomol. NMR 2011, 49, 39–51. [Google Scholar] [CrossRef]
- Lescop, E.; Rasia, R.; Brutscher, B. Hadamard amino-acid-type edited NMR experiment for fast protein resonance assignment. J. Am. Chem. Soc. 2008, 130, 5014–5015. [Google Scholar] [CrossRef]
- Pantoja-Uceda, D.; Santoro, J. Amino acid type identification in NMR spectra of proteins via beta- and gamma-carbon edited experiments. J. Magn. Resonance 2008, 195, 187–195. [Google Scholar] [CrossRef]
- Feuerstein, S.; Plevin, M.J.; Willbold, D.; Brutscher, B. iHADAMAC: A complementary tool for sequential resonance assignment of globular and highly disordered proteins. J. Magn. Resonance 2012, 214, 329–334. [Google Scholar] [CrossRef]
- Grzesiek, S.; Anglister, J.; Bax, A. Correlation of backbone amide and aliphatic side-chain resonances in C-13/N-15-enriched proteins by isotropic mixing of C-13 magnetization. J. Magn. Resonance 1993, 101, 114–119. [Google Scholar]
- Montelione, G.T.; Lyons, B.A.; Emerson, S.D.; Tashiro, M. An efficient triple resonance experiments using C-13 isotropic mixing for determining sequence-specific resonance assignments of isotopically-enriched proteins. J. Am. Chem. Soc. 1992, 114, 10974–10975. [Google Scholar] [CrossRef]
- Schubert, M.; Smalla, M.; Schmieder, P.; Oschkinat, H. MUSIC in triple-resonance experiments: Amino acid type-selective H-1-N-15 correlations. J. Magn. Resonance 1999, 141, 34–43. [Google Scholar] [CrossRef]
- Schubert, M.; Ball, L.J.; Oschkinat, H.; Schmieder, P. Bridging the gap: A set of selective H-1-N-15-correlations to link sequential neighbors of prolines. J. Biomol. NMR 2000, 17, 331–335. [Google Scholar] [CrossRef]
- Schubert, M.; Oschkinat, H.; Schmieder, P. MUSIC, selective pulses, and tuned delays: Amino acid type-selective H-1-N-15 correlations, II. J. Magn. Resonance 2001, 148, 61–72. [Google Scholar] [CrossRef]
- Schubert, M.; Oschkinat, H.; Schmieder, P. MUSIC and aromatic residues: Amino acid type-selective H-1-N-15 correlations, III. J. Magn. Resonance 2001, 153, 186–192. [Google Scholar]
- Schubert, M.; Oschkinat, H.; Schmieder, P. Amino acid type-selective backbone H-1-N-15-correlations for Arg and Lys. J. Biomol. NMR 2001, 20, 379–384. [Google Scholar]
- Novacek, J.; Zawadzka-Kazimierczuk, A.; Papouskova, V.; Zidek, L.; Sanderova, H.; Krasny, L.; Kozminski, W.; Sklenar, V. 5D C-13-detected experiments for backbone assignment of unstructured proteins with a very low signal dispersion. J. Biomol. NMR 2011, 50, 1–11. [Google Scholar] [CrossRef]
- Bermel, W.; Bertini, I.; Felli, I.C.; Kummerle, R.; Pierattelli, R. Novel C-13 direct detection experiments, including extension to the third dimension, to perform the complete assignment of proteins. J. Magn. Resonance 2006, 178, 56–64. [Google Scholar] [CrossRef]
- Felli, I.C.; Pierattelli, R. Novel methods based on C-13 detection to study intrinsically disordered proteins. J. Magn. Resonance 2014, 241, 115–125. [Google Scholar] [CrossRef]
- Brenner, A.K.; Kieffer, B.; Travé, G.; Frøystein, N.Å.; Raae, A.J. Thermal stability of chicken brain alpha-spectrin repeat 17: A spectroscopic study. J. Biomol. NMR 2012, 52. in press. [Google Scholar]
- Evjenth, R.H.; Brenner, A.K.; Thompson, P.R.; Arnesen, T.; Frøystein, N.Å.; Lillehaug, J.R. Human protein N-terminal acetyltransferase hNaa50p (hNAT5/hSAN) follows ordered sequential catalytic mechanism. Combined kinetic and NMR study. J. Biol. Chem. 2012, 287, 10081–10088. [Google Scholar]
- Fish, K.J.; Cegielska, A.; Getman, M.E.; Landes, G.M.; Virshup, D.M. Isolation and characterization of human casein kinase I epsilon (CKI), a novel member of the CKI gene family. J. Biol. Chem. 1995, 270, 14875–14883. [Google Scholar] [CrossRef]
- Vilček, J. The cytokines: An overview. In The Cytokine Handbook, 4th ed.; Thomson, A.W., Lotze, M.T., Eds.; Academic Press: London, UK, 2003; volume 1, pp. 3–19. [Google Scholar]
- Eto, M.; Ohmori, T.; Suzuki, M.; Furuya, K.; Morita, F. A novel protein phosphatase-1 inhibitory protein potentiated by protein kinase C. Isolation from porcine aorta media and characterization. J. Biochem. 1995, 118, 1104–1107. [Google Scholar]
- Van Damme, P.; Evjenth, R.; Foyn, H.; Demeyer, K.; de Bock, P.J.; Lillehaug, J.R.; Vandekerckhove, J.; Arnesen, T.; Gevaert, K. Proteome-derived peptide libraries allow detailed analysis of the substrate specificities of N(alpha)-acetyltransferases and point to hNaa10p as the post-translational actin N(alpha)-acetyltransferase. Mol. Cell. Proteomics 2011, 10. [Google Scholar] [CrossRef]
- Keller, R.L.J. Optimizing the Process of Nuclear Magnetic Resonance Spectrum Analysis and Computer Aided Resonance Assignment. PhD Thesis, Swiss Federal Institute of Technology, Zürich, Switzerland, 2004. [Google Scholar]
- Davis, A.L.; Keeler, J.; Laue, E.D.; Moskau, D. Experiments for recording pure-absorption heteronuclear correlation spectra using pulsed field gradients. J. Magn. Resonance 1992, 98, 207–216. [Google Scholar]
- Sattler, M.; Schleucher, J.; Griesinger, C. Heteronuclear multidimensional NMR experiments for the structure determination of proteins in solution employing pulsed field gradients. Prog. Nucl. Magn. Resonance Spectrosc. 1999, 34, 93–158. [Google Scholar] [CrossRef]
- Schubert, M. ETH, Zürich, Switzerland. Pulse programs for Bruker and Varian. Available online: http://www.marioschubert.ch/pp_allg.html (accessed on 23 June 2014).
- Delaglio, F.; Grzesiek, S.; Vuister, G.W.; Zhu, G.; Pfeifer, J.; Bax, A. NMRPipe-a multidimensional spectral processing system based on UNIX Pipes. J. Biomol. NMR 1995, 6, 277–293. [Google Scholar]
- Sample Availability: Samples of the proteins R17 and hNaa50p are not available from the authors.
© 2014 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brenner, A.K.; Frøystein, N.Å. Using MUSIC and CC(CO)NH for Backbone Assignment of Two Medium-Sized Proteins Not Fully Accessible to Standard 3D NMR. Molecules 2014, 19, 8890-8903. https://doi.org/10.3390/molecules19078890
Brenner AK, Frøystein NÅ. Using MUSIC and CC(CO)NH for Backbone Assignment of Two Medium-Sized Proteins Not Fully Accessible to Standard 3D NMR. Molecules. 2014; 19(7):8890-8903. https://doi.org/10.3390/molecules19078890
Chicago/Turabian StyleBrenner, Annette K., and Nils Åge Frøystein. 2014. "Using MUSIC and CC(CO)NH for Backbone Assignment of Two Medium-Sized Proteins Not Fully Accessible to Standard 3D NMR" Molecules 19, no. 7: 8890-8903. https://doi.org/10.3390/molecules19078890
APA StyleBrenner, A. K., & Frøystein, N. Å. (2014). Using MUSIC and CC(CO)NH for Backbone Assignment of Two Medium-Sized Proteins Not Fully Accessible to Standard 3D NMR. Molecules, 19(7), 8890-8903. https://doi.org/10.3390/molecules19078890