
The Multi-Domain International Search on Speech 2020 ALBAYZIN Evaluation: Overview, Systems, Results, Discussion and Post-Evaluation Analyses

 ,
,  , and
, and
Abstract
:1. Introduction
1.1. Spoken Term Detection Overview
1.2. Query-by-Example Spoken Term Detection Overview
1.3. Difference between Spoken Term Detection and Query-by-Example Spoken Term Detection
1.4. Related Work
1.4.1. Spoken Term Detection
1.4.2. Query-by-Example Spoken Term Detection
2. Search on Speech Evaluation
2.1. Evaluation Summary
2.2. Databases
2.2.1. MAVIR
2.2.2. RTVE
2.2.3. SPARL20
2.2.4. Query List Selection
2.3. Evaluation Metrics
2.4. Comparison with Previous Search on Speech International Evaluations
- The SoS ALBAYZIN evaluation makes use of a different language (i.e., Spanish).
- The SoS ALBAYZIN evaluation defines disjoint development and test query lists, along with different domains and an unseen domain for test data to measure the generalization capability of the systems.
- Participants were highly encouraged to build end-to-end systems.
- In the case that participants do not build end-to-end systems, the SoS ALBAYZIN evaluation defines two types of queries: INV and OOV, which demand participants to build different types of systems, especially those handling OOV query search.
- The SoS ALBAYZIN evaluation for the QbE STD task provides two acoustic query types: in-domain acoustic examples, which correspond to spoken queries extracted from the search speech collection; and out-of-domain acoustic examples, which correspond to spoken queries recorded by the evaluation organizers.
2.4.1. Comparison with Previous STD International Evaluations
2.4.2. Comparison with Previous Qbe STD International Evaluations
- The most important difference is the nature of the audio content. In the SWS evaluations, the speech is typically telephone speech, either conversational or read and elicited speech, or speech recorded with in-room microphones. In the SoS ALBAYZIN evaluation, the audio consists of microphone recordings of real talks in workshops that took place in large conference rooms in the presence of audience. Microphones, conference rooms and recording conditions change from one recording to another. The microphones were not close talking microphones but table top or floor standing microphones. In addition, the SoS ALBAYZIN evaluation also contains broadcast TV shows and live-talking parliament sessions speech, and explicitly defines different in-vocabulary and out-of-vocabulary query sets.
- SWS evaluations dealt with Indian and African-derived languages, as well as Albanian, Basque, Czech, non-native English, Romanian and Slovak languages, while the SoS ALBAYZIN evaluation only deals with the Spanish language.
2.4.3. Comparison with Previous Search on Speech Albayzin Evaluations
- The Spanish parliament sessions is a new domain that was selected as the unseen domain to test the system generalization capability.
- For the QbE STD task, organizers recorded two acoustic examples per query aiming to encourage participants to build a more robust acoustic query for search.
- Aiming to build end-to-end systems both for STD and QbE STD tasks, organizers allowed participants to include OOV queries within the system dictionary in the case an end-to-end system is built.
3. Systems
3.1. Spoken Term Detection
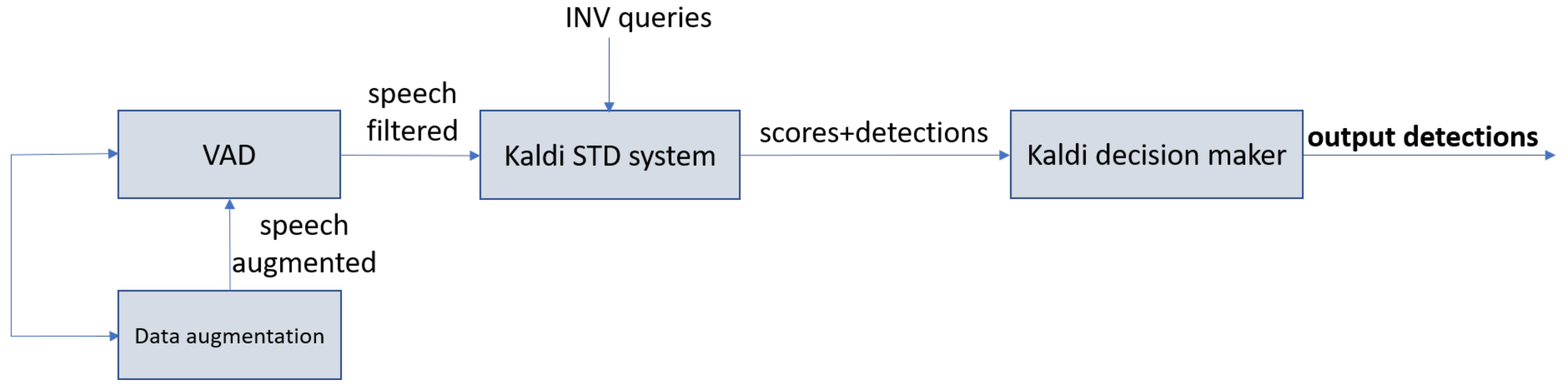
3.1.1. Kaldi-Based DNN with Data Augmentation System (Kaldi DNN + DA)
3.1.2. Kaldi-Based SGMM with Data Augmentation System (Kaldi SGMM + DA)
3.1.3. Kaldi-Based DNN System (Kaldi DNN)
3.1.4. Kaldi-Based SGMM System (Kaldi SGMM)
3.2. Query-by-Example Spoken Term Detection
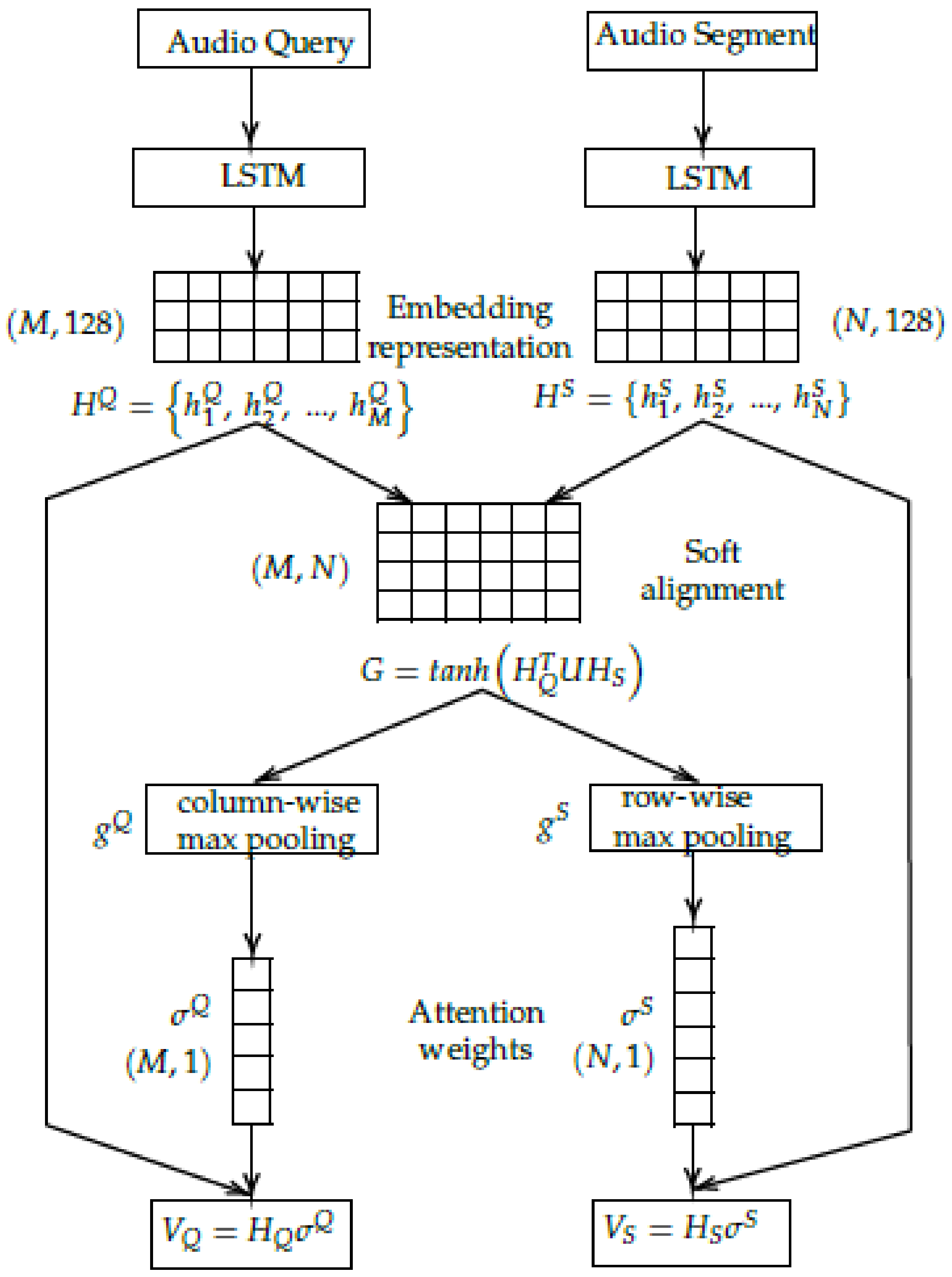
3.2.1. End-to-End with Language Adaptation System (E2E + LA)
3.2.2. End-to-End without Language Adaptation System (E2E)
3.2.3. End-to-End with Z-Score Normalization System (E2E + ZNORM)
4. Results and Discussion
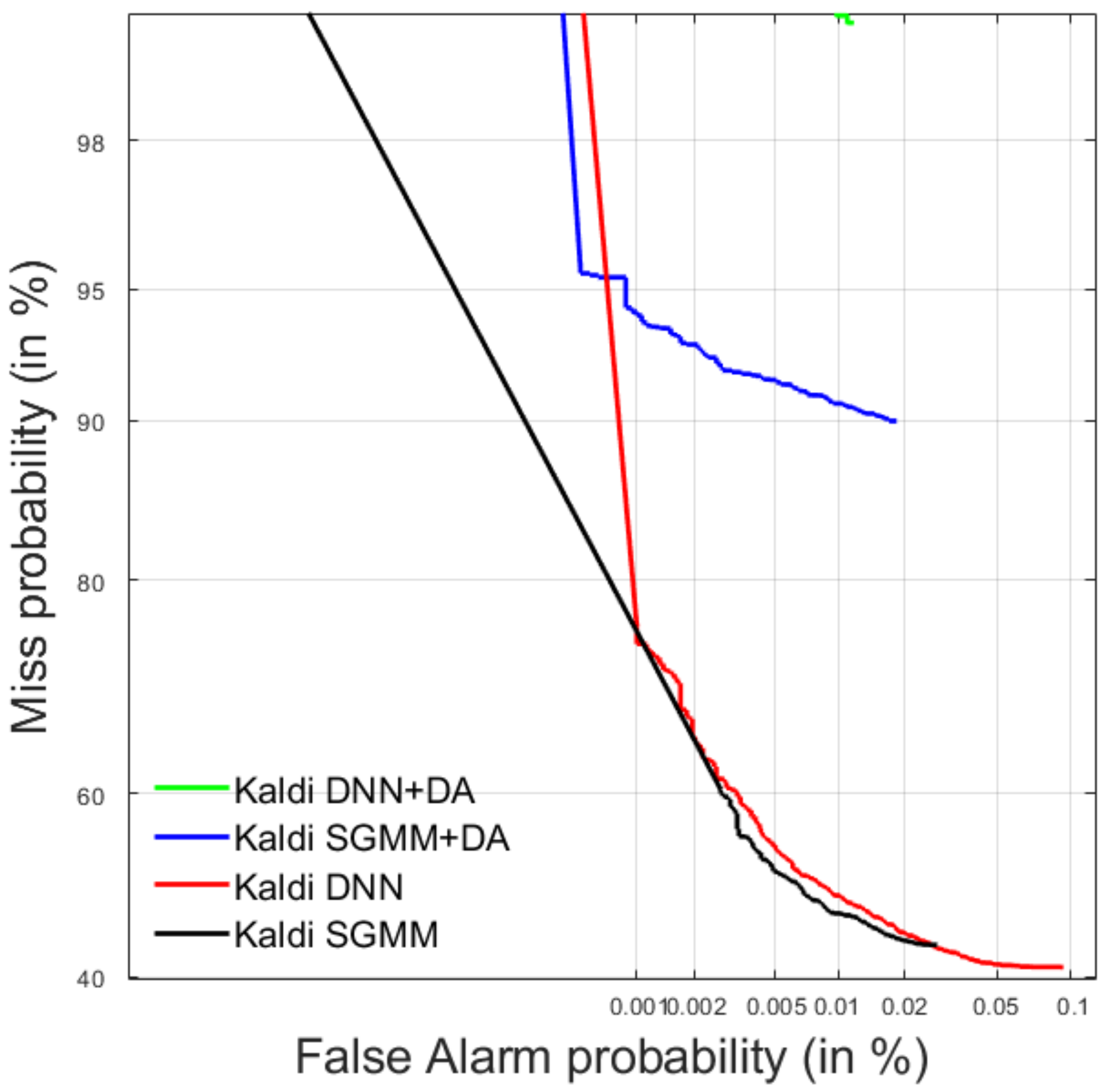
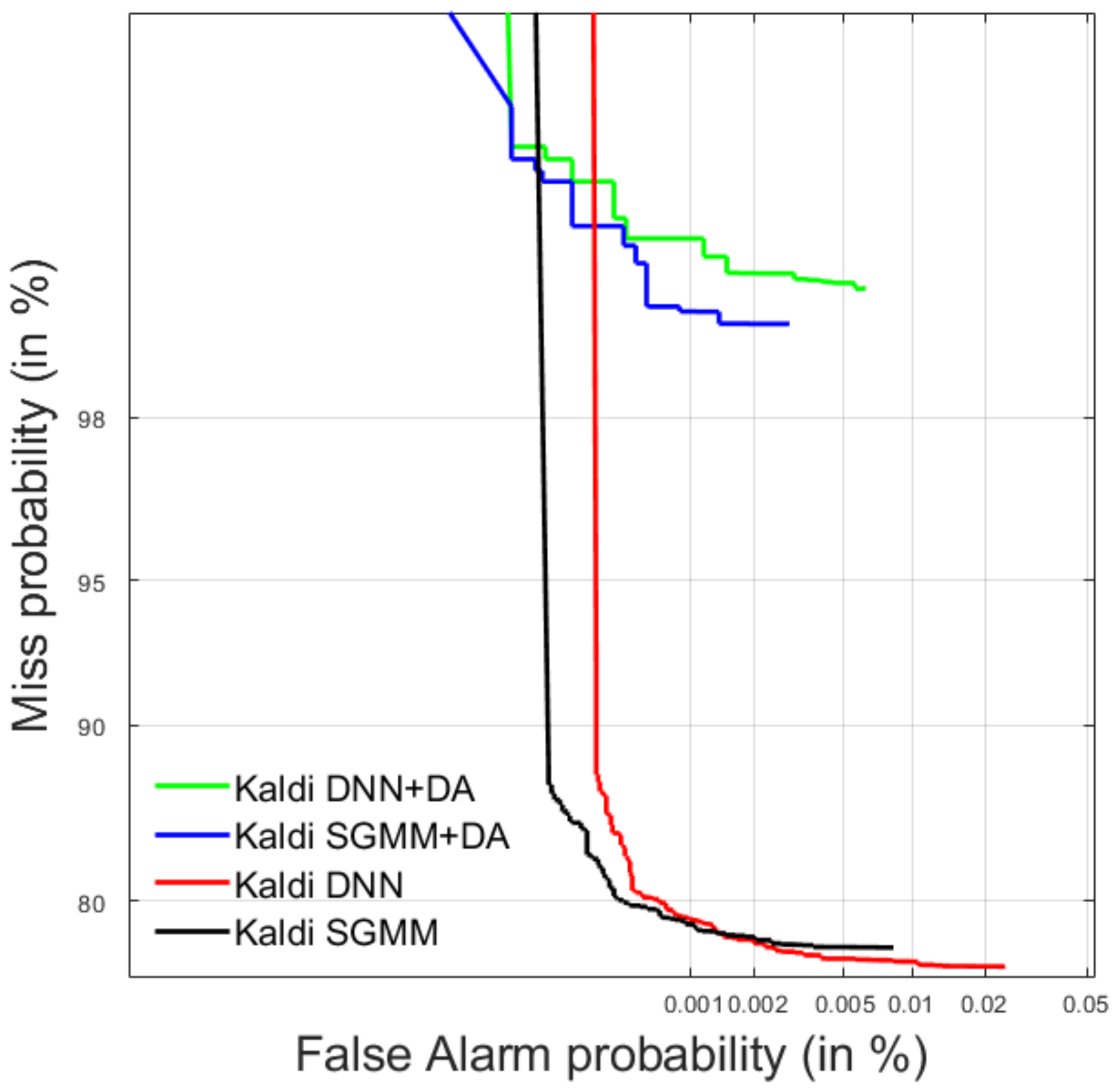
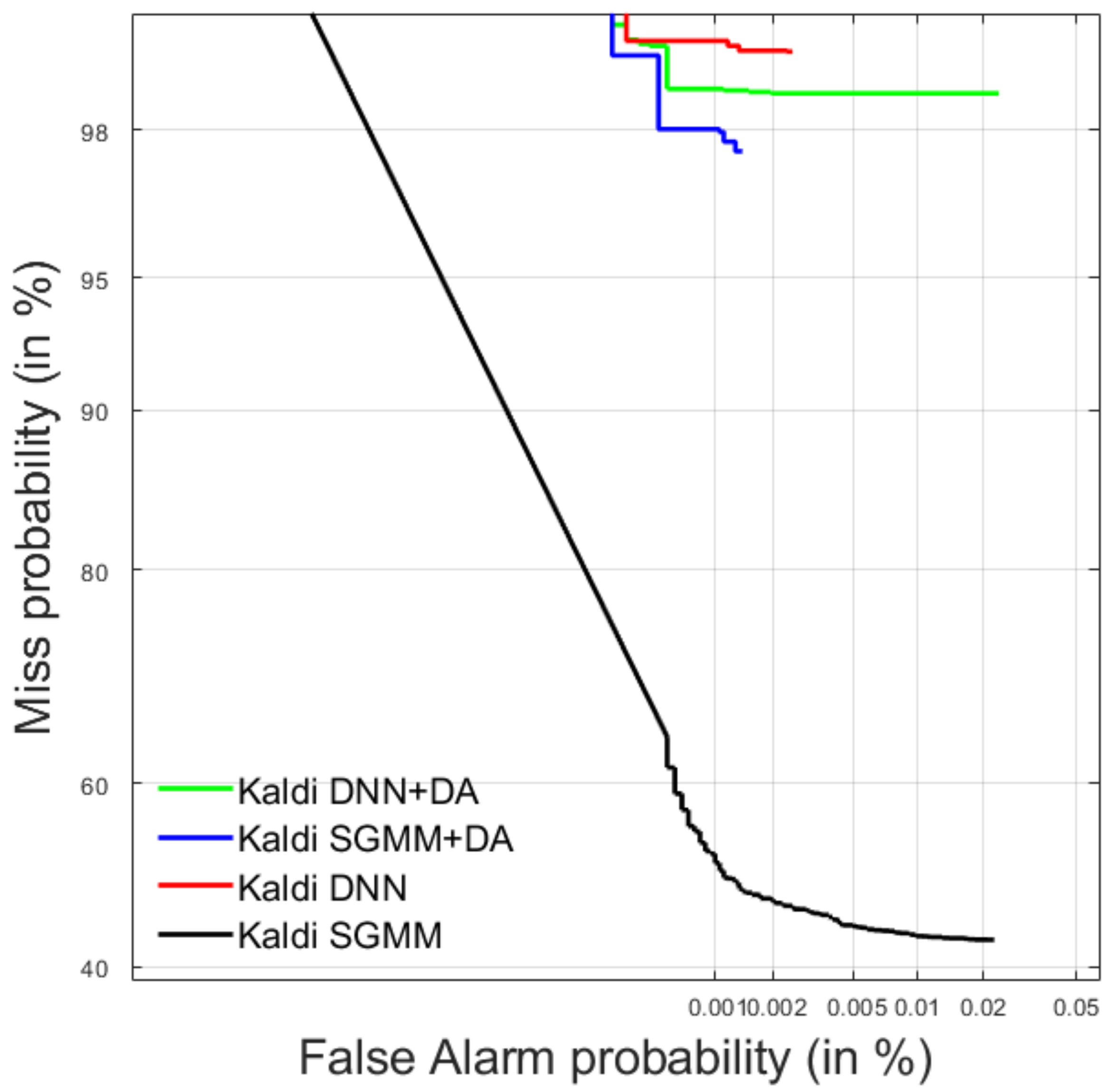
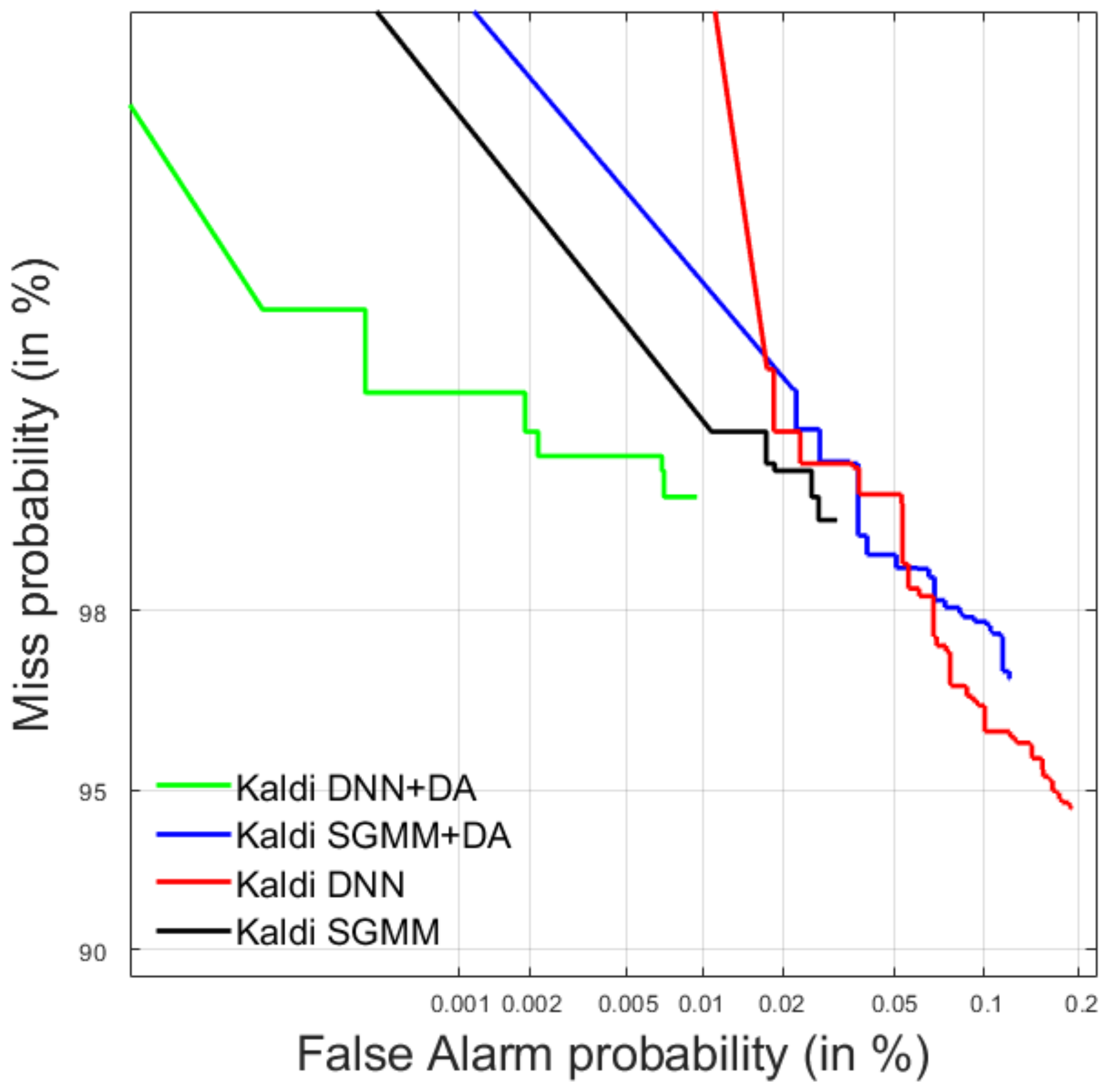
4.1. Spoken Term Detection
4.1.1. Development Data
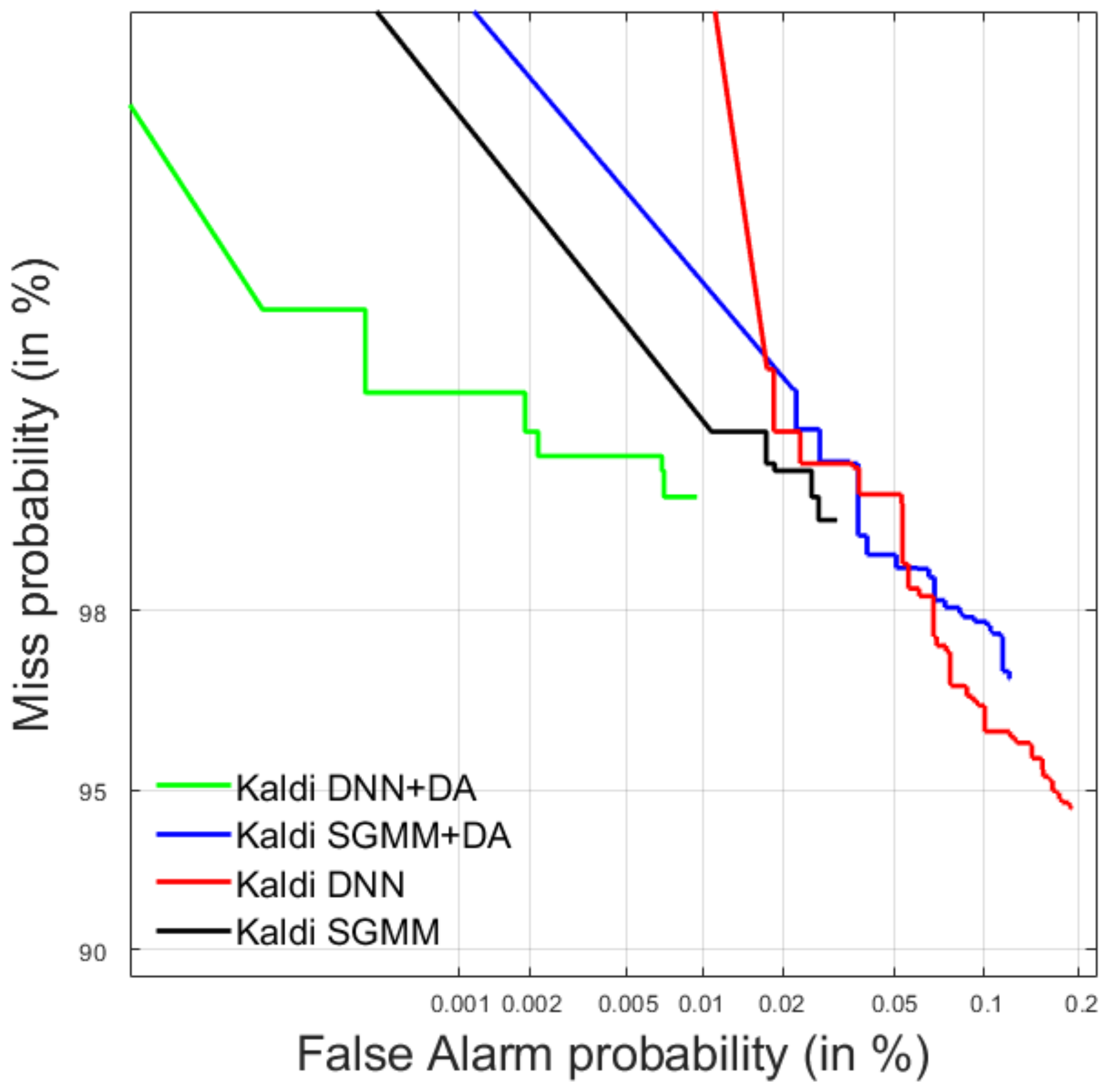
4.1.2. Test Data
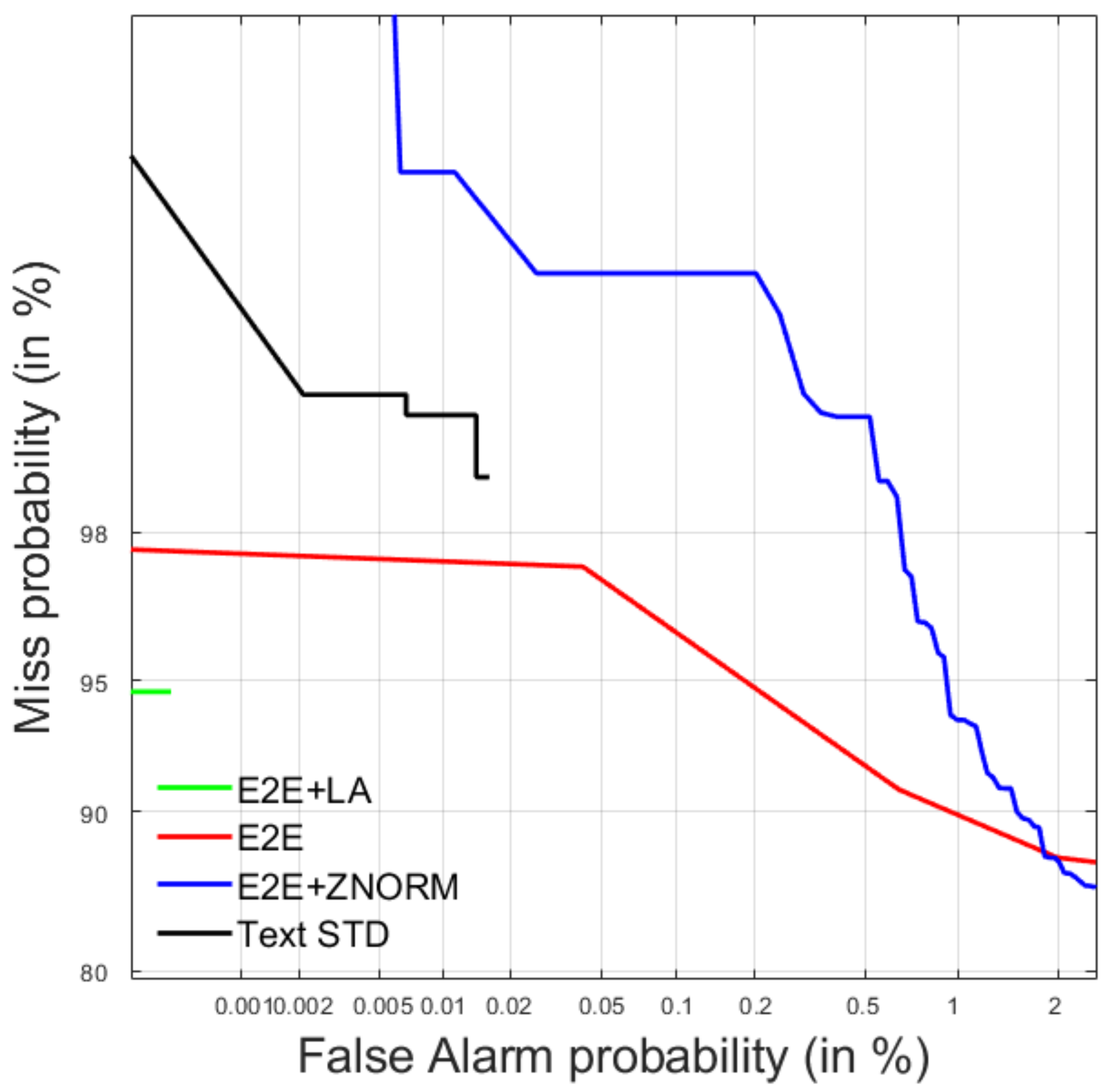
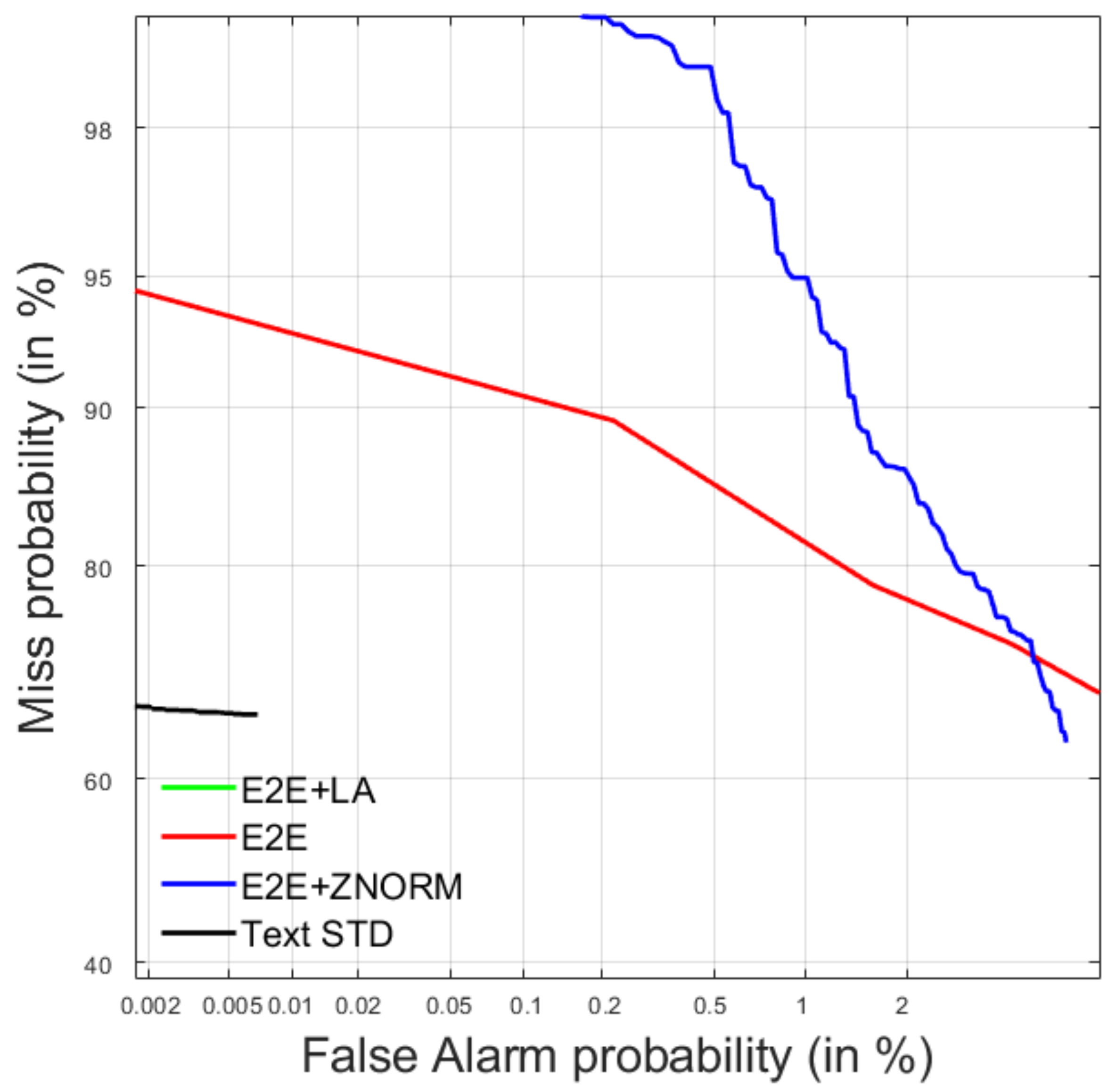
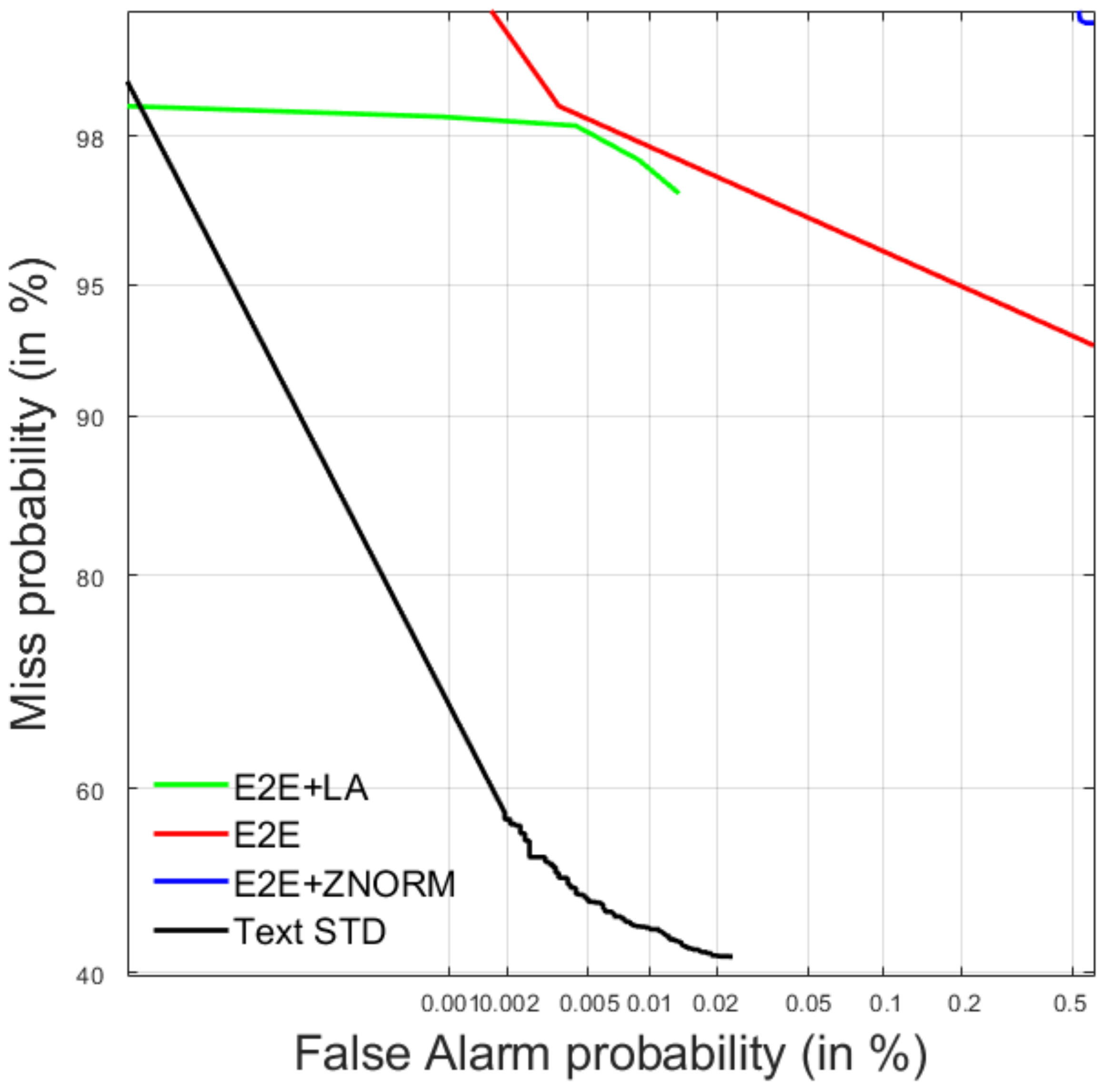
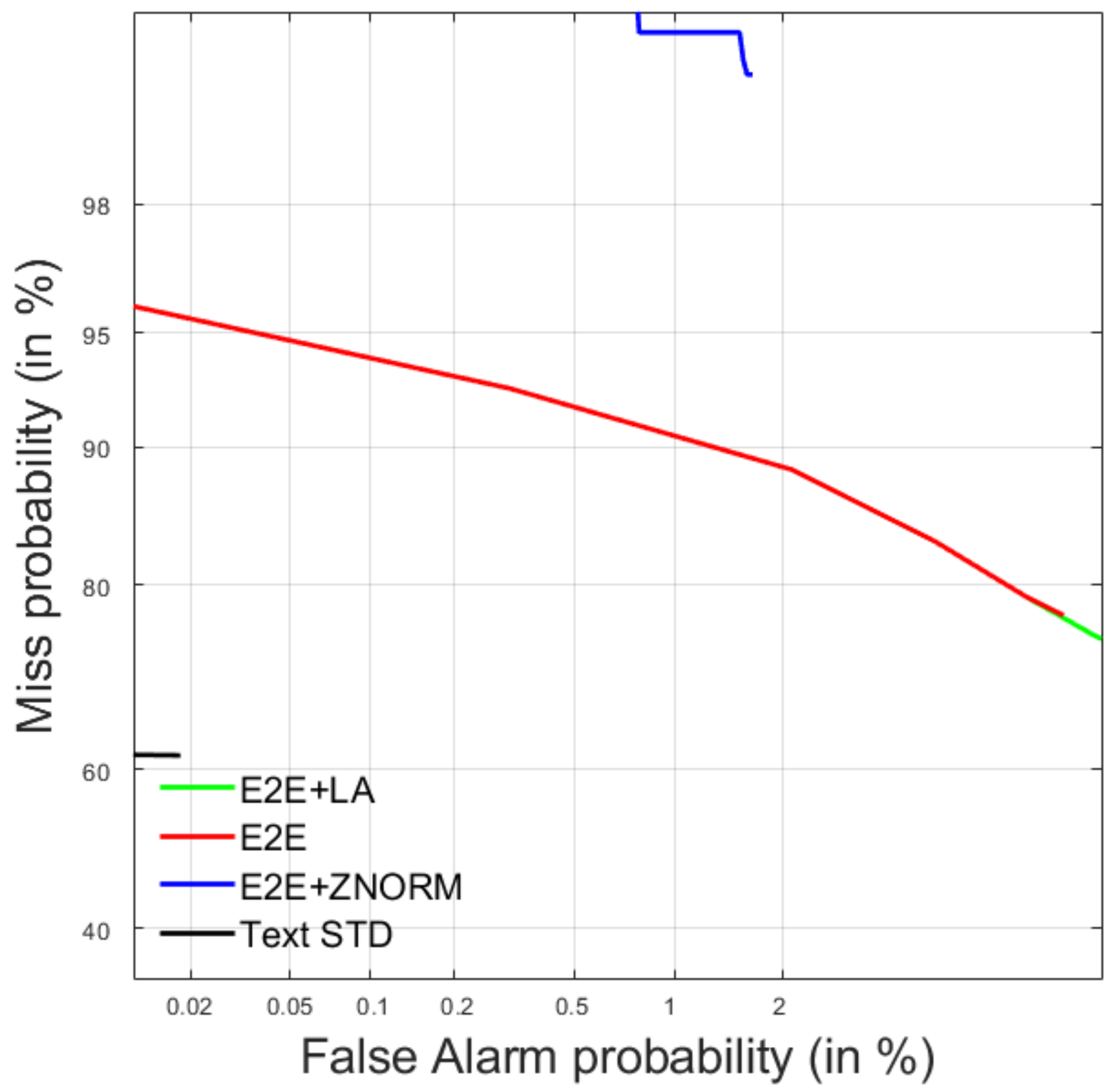
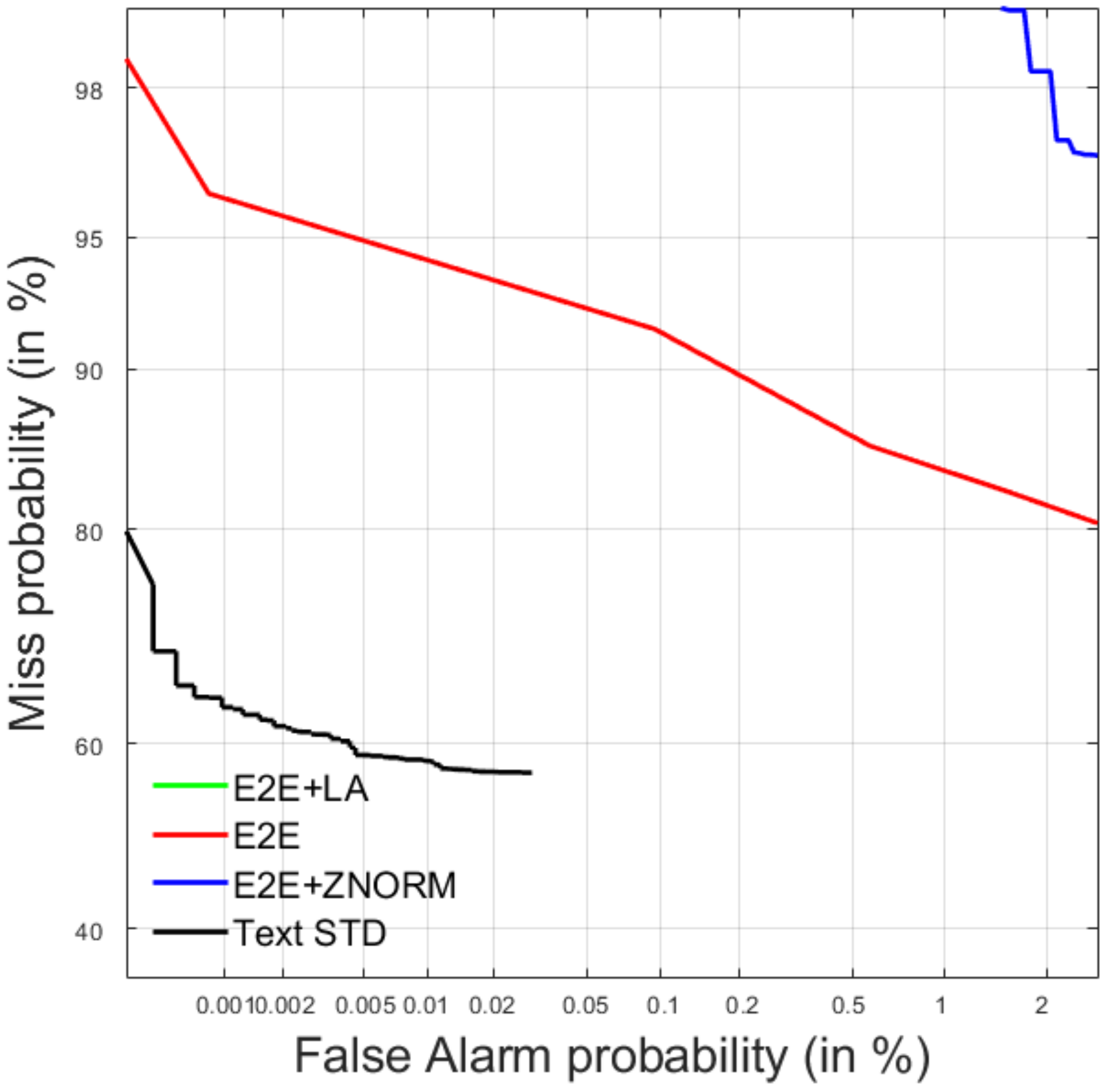
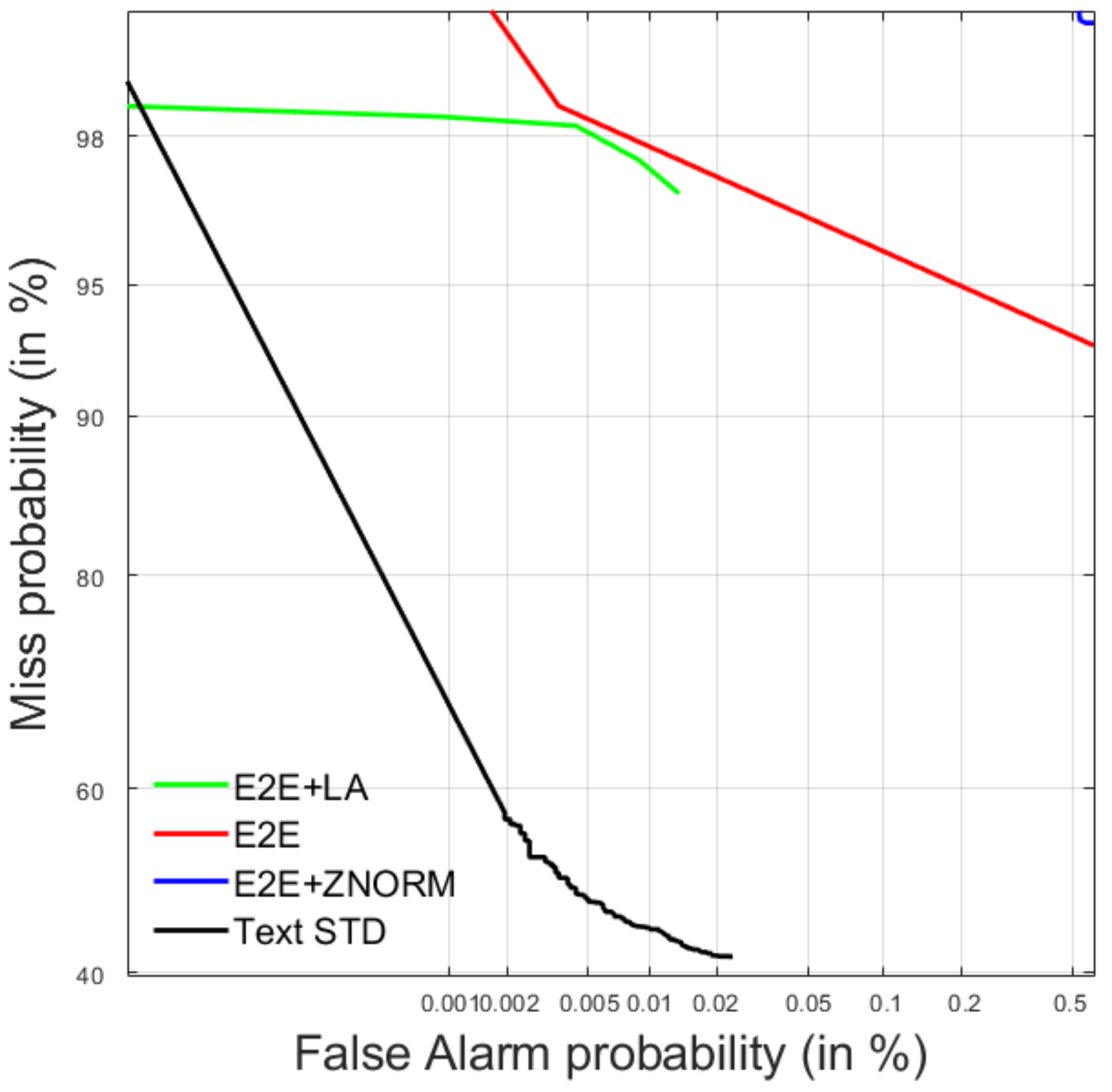
4.2. Query-by-Example Spoken Term Detection
4.2.1. Development Data
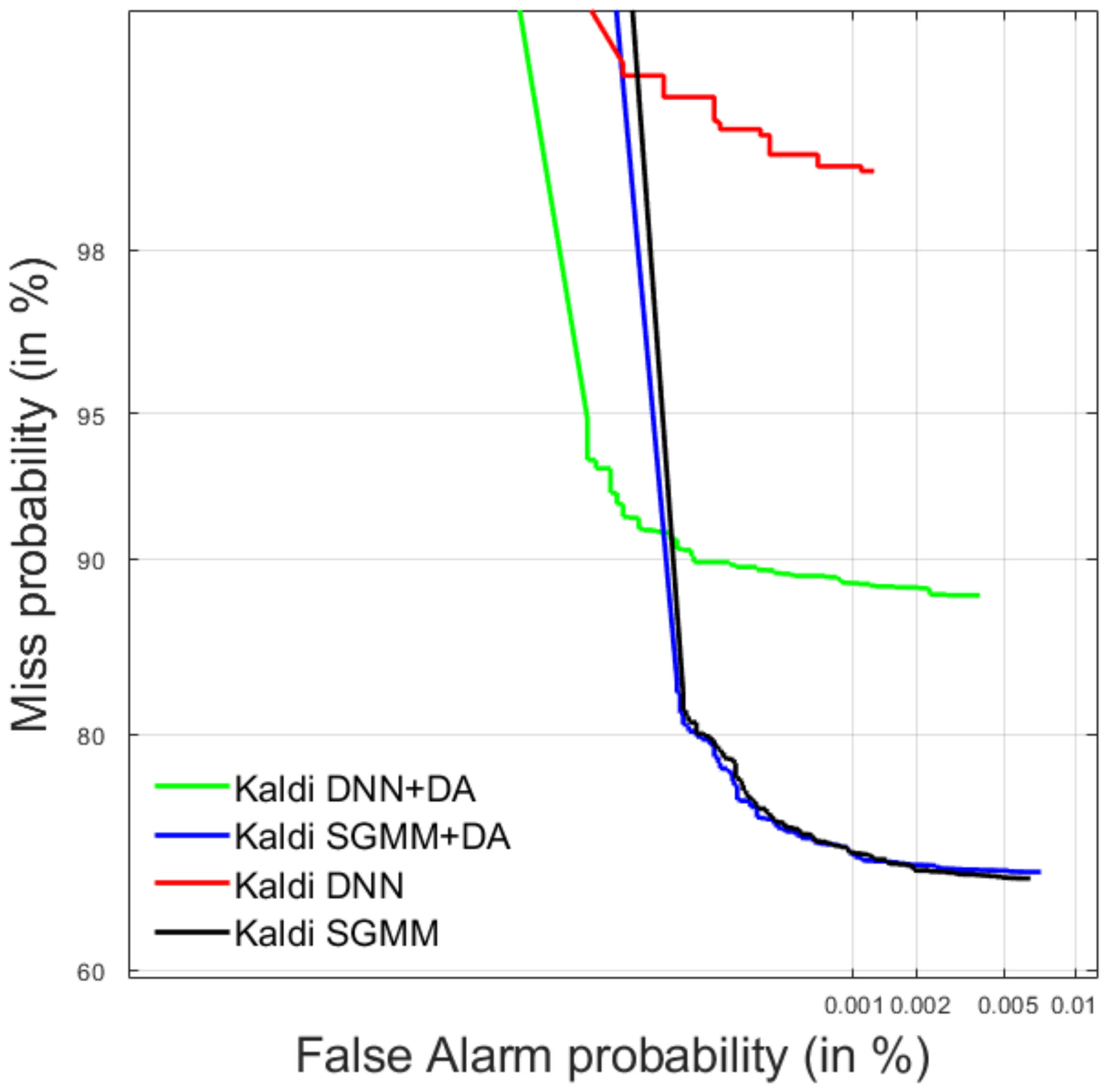
4.2.2. Test Data
5. Post-Evaluation Analysis
5.1. Spoken Term Detection
5.1.1. System Analysis for In-Language and Out-of-Language Queries
5.1.2. System Analysis for Single and Multi-Word Queries
5.2. Query-by-Example Spoken Term Detection
5.2.1. System Analysis for In-Language and Out-of-Language Queries
5.2.2. System Analysis for In-Vocabulary and Out-of-Vocabulary Queries
5.2.3. System Analysis for Single and Multi-Word Queries
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ng, K.; Zue, V.W. Subword-based approaches for spoken document retrieval. Speech Commun. 2000, 32, 157–186. [Google Scholar] [CrossRef]
- Chen, B.; Chen, K.Y.; Chen, P.N.; Chen, Y.W. Spoken Document Retrieval With Unsupervised Query Modeling Techniques. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2602–2612. [Google Scholar] [CrossRef]
- Lo, T.H.; Chen, Y.W.; Chen, K.Y.; Wang, H.M.; Chen, B. Neural relevance-aware query modeling for spoken document retrieval. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 466–473. [Google Scholar]
- Heeren, W.; de Jong, F.M.; van der Werff, L.B.; Huijbregts, M.; Ordelman, R.J. Evaluation of spoken document retrieval for historic speech collections. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 26 May–1 June 2008; pp. 2037–2041. [Google Scholar]
- Pan, Y.C.; Lee, H.Y.; Lee, L.S. Interactive Spoken Document Retrieval With Suggested Key Terms Ranked by a Markov Decision Process. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 632–645. [Google Scholar] [CrossRef]
- Chen, Y.W.; Chen, K.Y.; Wang, H.M.; Chen, B. Exploring the Use of Significant Words Language Modeling for Spoken Document Retrieval. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 2889–2893. [Google Scholar]
- Gao, P.; Liang, J.; Ding, P.; Xu, B. A novel phone-state matrix based vocabulary-independent keyword spotting method for spontaneous speech. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP ’07, Honolulu, HI, USA, 15–20 April 2007; pp. 425–428. [Google Scholar]
- Zhang, B.; Schwartz, R.; Tsakalidis, S.; Nguyen, L.; Matsoukas, S. White Listing and Score Normalization for Keyword Spotting of Noisy Speech. In Proceedings of the ISCA’s 13th Annual Conference, Portland, OR, USA, 9–13 September 2012; pp. 1832–1835. [Google Scholar]
- Mandal, A.; van Hout, J.; Tam, Y.C.; Mitra, V.; Lei, Y.; Zheng, J.; Vergyri, D.; Ferrer, L.; Graciarena, M.; Kathol, A.; et al. Strategies for High Accuracy Keyword Detection in Noisy Channels. In Proceedings of the Interspeech, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 15–19. [Google Scholar]
- Ng, T.; Hsiao, R.; Zhang, L.; Karakos, D.; Mallidi, S.H.; Karafiat, M.; Vesely, K.; Szoke, I.; Zhang, B.; Nguyen, L.; et al. Progress in the BBN Keyword Search System for the DARPA RATS Program. In Proceedings of the Interspeech, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 959–963. [Google Scholar]
- Mitra, V.; van Hout, J.; Franco, H.; Vergyri, D.; Lei, Y.; Graciarena, M.; Tam, Y.C.; Zheng, J. Feature fusion for high-accuracy keyword spotting. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7143–7147. [Google Scholar]
- Panchapagesan, S.; Sun, M.; Khare, A.; Matsoukas, S.; Mandal, A.; Hoffmeister, B.; Vitaladevuni, S. Multi-task learning and Weighted Cross-entropy for DNN-based Keyword Spotting. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 760–764. [Google Scholar]
- Zhao, Z.; Zhang, W.Q. End-to-End Keyword Search Based on Attention and Energy Scorer for Low Resource Languages. In Proceedings of the Interspeech, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 2587–2591. [Google Scholar]
- Mamou, J.; Ramabhadran, B.; Siohan, O. Vocabulary independent spoken term detection. In Proceedings of the SIGIR ’07: 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 615–622. [Google Scholar]
- Schneider, D.; Mertens, T.; Larson, M.; Kohler, J. Contextual Verification for Open Vocabulary Spoken Term Detection. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 697–700. [Google Scholar]
- Parada, C.; Sethy, A.; Dredze, M.; Jelinek, F. A Spoken Term Detection Framework for Recovering Out-of-Vocabulary Words Using the Web. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1269–1272. [Google Scholar]
- Szöke, I.; Fapšo, M.; Burget, L.; Černocký, J. Hybrid word-subword decoding for spoken term detection. In Proceedings of the 31st Annual International ACM SIGIR Conference, Singapore, 20–24 July 2008; pp. 42–48. [Google Scholar]
- Wang, Y.; Metze, F. An In-Depth Comparison of Keyword Specific Thresholding and Sum-to-One Score Normalization. In Proceedings of the Interspeech, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 2474–2478. [Google Scholar]
- Mangu, L.; Saon, G.; Picheny, M.; Kingsbury, B. Order-free spoken term detection. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, Brisbane, Australia, 19–24 April 2015; pp. 5331–5335. [Google Scholar]
- Fuchs, T.S.; Segal, Y.; Keshet, J. CNN-Based Spoken Term Detection and Localization without Dynamic Programming. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 6853–6857. [Google Scholar]
- Lin, J.; Kilgour, K.; Roblek, D.; Sharifi, M. Training Keyword Spotters with Limited and Synthesized Speech Data. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 4–8 May 2020; pp. 7474–7478. [Google Scholar]
- Wintrode, J.; Wilkes, J. Fast Lattice-Free Keyword Filtering for Accelerated Spoken Term Detection. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 4–8 May 2020; pp. 7469–7473. [Google Scholar]
- Wang, Y.H.; Lee, H.Y.; Lee, L.S. Segmental Audio Word2Vec: Representing Utterances as Sequences of Vectors with Applications in Spoken Term Detection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 6269–6273. [Google Scholar]
- Kaneko, D.; Konno, R.; Kojima, K.; Tanaka, K.; wook Lee, S.; Itoh, Y. Constructing Acoustic Distances Between Subwords and States Obtained from a Deep Neural Network for Spoken Term Detection. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2879–2883. [Google Scholar]
- Svec, J.; Psutka, J.V.; Smidl, L.; Trmal, J. A Relevance Score Estimation for Spoken Term Detection Based on RNN-Generated Pronunciation Embeddings. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2934–2938. [Google Scholar]
- Buzo, A.; Cucu, H.; Burileanu, C. SpeeD@MediaEval 2014: Spoken Term Detection with Robust Multilingual Phone Recognition. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014; pp. 721–722. [Google Scholar]
- Konno, R.; Ouchi, K.; Obara, M.; Shimizu, Y.; Chiba, T.; Hirota, T.; Itoh, Y. An STD system using multiple STD results and multiple rescoring method for NTCIR-12 SpokenQuery&Doc task. In Proceedings of the 12th NTCIR Conference on Evaluation of Information Access Technologies, Tokyo, Japan, 7–10 June 2016; pp. 200–204. [Google Scholar]
- Jarina, R.; Kuba, M.; Gubka, R.; Chmulik, M.; Paralic, M. UNIZA System for the Spoken Web Search Task at MediaEval 2013. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 791–792. [Google Scholar]
- Anguera, X.; Ferrarons, M. Memory Efficient Subsequence DTW for Query-by-Example Spoken Term Detection. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Lin, H.; Stupakov, A.; Bilmes, J. Spoken keyword spotting via multi-lattice alignment. In Proceedings of the Interspeech, 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; pp. 2191–2194. [Google Scholar]
- Chan, C.; Lee, L. Unsupervised spoken-term detection with spoken queries using segment-based dynamic time warping. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 693–696. [Google Scholar]
- Mamou, J.; Ramabhadran, B. Phonetic Query Expansion for Spoken Document Retrieval. In Proceedings of the Interspeech, 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; pp. 2106–2109. [Google Scholar]
- Can, D.; Cooper, E.; Sethy, A.; White, C.; Ramabhadran, B.; Saraclar, M. Effect of pronunciations on OOV queries in spoken term detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2009, Taipei, Taiwan, 19–24 April 2009; pp. 3957–3960. [Google Scholar]
- Rosenberg, A.; Audhkhasi, K.; Sethy, A.; Ramabhadran, B.; Picheny, M. End-to-end speech recognition and keyword search on low-resource languages. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5280–5284. [Google Scholar]
- Audhkhasi, K.; Rosenberg, A.; Sethy, A.; Ramabhadran, B.; Kingsbury, B. End-to-end ASR-free keyword search from speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 4840–4844. [Google Scholar]
- Audhkhasi, K.; Rosenberg, A.; Sethy, A.; Ramabhadran, B.; Kingsbury, B. End-to-End ASR-Free Keyword Search From Speech. IEEE J. Sel. Top. Signal Process. 2017, 11, 1351–1359. [Google Scholar] [CrossRef]
- Fiscus, J.G.; Ajot, J.G.; Garofolo, J.S.; Doddingtion, G. Results of the 2006 Spoken Term Detection Evaluation. In Proceedings of the ACM SIGIR Conference, Amsterdam, The Netherlands, 23–27 July 2007; pp. 45–50. [Google Scholar]
- Hartmann, W.; Zhang, L.; Barnes, K.; Hsiao, R.; Tsakalidis, S.; Schwartz, R. Comparison of Multiple System Combination Techniques for Keyword Spotting. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 1913–1917. [Google Scholar]
- Alumae, T.; Karakos, D.; Hartmann, W.; Hsiao, R.; Zhang, L.; Nguyen, L.; Tsakalidis, S.; Schwartz, R. The 2016 BBN Georgian telephone speech keyword spotting system. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5755–5759. [Google Scholar]
- Vergyri, D.; Stolcke, A.; Gadde, R.R.; Wang, W. The SRI 2006 Spoken Term Detection System. In Proceedings of the NIST Spoken Term Detection Evaluation workshop (STD’06), Gaithersburg, MD, USA, 14–15 December 2006; pp. 1–15. [Google Scholar]
- Vergyri, D.; Shafran, I.; Stolcke, A.; Gadde, R.R.; Akbacak, M.; Roark, B.; Wang, W. The SRI/OGI 2006 Spoken Term Detection System. In Proceedings of the Interspeech, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; pp. 2393–2396. [Google Scholar]
- Akbacak, M.; Vergyri, D.; Stolcke, A. Open-vocabulary spoken term detection using graphone-based hybrid recognition systems. In Proceedings of the 33rd International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Las Vegas, NV, USA, 30 March–4 April 2008; pp. 5240–5243. [Google Scholar]
- Szöke, I.; Fapšo, M.; Karafiát, M.; Burget, L.; Grézl, F.; Schwarz, P.; Glembek, O.; Matĕjka, P.; Kopecký, J.; Černocký, J. Spoken Term Detection System Based on Combination of LVCSR and Phonetic Search. In Machine Learning for Multimodal Interaction; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4892, pp. 237–247. [Google Scholar]
- Szöke, I.; Burget, L.; Černocký, J.; Fapšo, M. Sub-word modeling of out of vocabulary words in spoken term detection. In Proceedings of the 2008 IEEE Spoken Language Technology Workshop, Goa, India, 15–19 December 2008; pp. 273–276. [Google Scholar]
- Meng, S.; Yu, P.; Liu, J.; Seide, F. Fusing multiple systems into a compact lattice index for Chinese spoken term detection. In Proceedings of the 33rd International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Las Vegas, NV, USA, 30 March–4 April 2008; pp. 4345–4348. [Google Scholar]
- Thambiratmann, K.; Sridharan, S. Rapid yet accurate speech indexing using dynamic match lattice spotting. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 346–357. [Google Scholar] [CrossRef]
- Wallace, R.; Vogt, R.; Baker, B.; Sridharan, S. Optimising figure of merit for phonetic spoken term detection. In Proceedings of the 35th International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Dallas, TX, USA, 15–19 March 2008; pp. 5298–5301. [Google Scholar]
- Jansen, A.; Church, K.; Hermansky, H. Towards Spoken Term Discovery At Scale With Zero Resources. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1676–1679. [Google Scholar]
- Parada, C.; Sethy, A.; Ramabhadran, B. Balancing false alarms and hits in spoken term detection. In Proceedings of the 35th International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Dallas, TX, USA, 15–19 March 2008; pp. 5286–5289. [Google Scholar]
- Trmal, J.; Wiesner, M.; Peddinti, V.; Zhang, X.; Ghahremani, P.; Wang, Y.; Manohar, V.; Xu, H.; Povey, D.; Khudanpur, S. The Kaldi OpenKWS System: Improving Low Resource Keyword Search. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3597–3601. [Google Scholar]
- Chen, C.P.; Lee, H.Y.; Yeh, C.F.; Lee, L.S. Improved Spoken Term Detection by Feature Space Pseudo-Relevance Feedback. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 1672–1675. [Google Scholar]
- Motlicek, P.; Valente, F.; Garner, P. English Spoken Term Detection in Multilingual Recordings. In Proceedings of the Interspeech, 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 206–209. [Google Scholar]
- Szöke, I.; Fapšo, M.; Karafiát, M.; Burget, L.; Grézl, F.; Schwarz, P.; Glembek, O.; Matĕjka, P.; Kontár, S.; Černocký, J. BUT System for NIST STD 2006-English. In Proceedings of the NIST Spoken Term Detection Evaluation workshop (STD’06), Gaithersburg, MD, USA, 14–15 December 2006; pp. 1–15. [Google Scholar]
- Miller, D.R.H.; Kleber, M.; Kao, C.L.; Kimball, O.; Colthurst, T.; Lowe, S.A.; Schwartz, R.M.; Gish, H. Rapid and Accurate Spoken Term Detection. In Proceedings of the Interspeech, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; pp. 314–317. [Google Scholar]
- Li, H.; Han, J.; Zheng, T.; Zheng, G. A Novel Confidence Measure Based on Context Consistency for Spoken Term Detection. In Proceedings of the Interspeech, 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012; pp. 2430–2433. [Google Scholar]
- Chiu, J.; Rudnicky, A. Using Conversational Word Bursts in Spoken Term Detection. In Proceedings of the Interspeech, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 2247–2251. [Google Scholar]
- Ni, C.; Leung, C.C.; Wang, L.; Chen, N.F.; Ma, B. Efficient methods to train multilingual bottleneck feature extractors for low resource keyword search. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5650–5654. [Google Scholar]
- Meng, Z.; Juang, B.H. Non-Uniform Boosted MCE Training of Deep Neural Networks for Keyword Spotting. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 770–774. [Google Scholar]
- Meng, Z.; Juang, B.H. Non-Uniform MCE Training of Deep Long Short-Term Memory Recurrent Neural Networks for Keyword Spotting. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3547–3551. [Google Scholar]
- Lee, S.W.; Tanaka, K.; Itoh, Y. Combination of diverse subword units in spoken term detection. In Proceedings of the Interspeech, 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3685–3689. [Google Scholar]
- van Heerden, C.; Karakos, D.; Narasimhan, K.; Davel, M.; Schwartz, R. Constructing sub-word units for spoken term detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5780–5784. [Google Scholar]
- Pham, V.T.; Xu, H.; Xiao, X.; Chen, N.F.; Chng, E.S. Pruning Strategies for Partial Search in Spoken Term Detection. In Proceedings of the International Symposium on Information and Communication Technology, Nha Trang, Vietnam, 7–8 December 2017; pp. 114–119. [Google Scholar]
- Wollmer, M.; Schuller, B.; Rigoll, G. Keyword spotting exploiting Long Short-Term Memory. Speech Commun. 2013, 55, 252–265. [Google Scholar] [CrossRef]
- Tejedor, J.; Toledano, D.T.; Wang, D.; King, S.; Colás, J. Feature analysis for discriminative confidence estimation in spoken term detection. Comput. Speech Lang. 2014, 28, 1083–1114. [Google Scholar] [CrossRef]
- Zhuang, Y.; Chang, X.; Qian, Y.; Yu, K. Unrestricted Vocabulary Keyword Spotting using LSTM-CTC. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 938–942. [Google Scholar]
- Pandey, L.; Nathwani, K. LSTM based Attentive Fusion of Spectral and Prosodic Information for Keyword Spotting in Hindi Language. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 112–116. [Google Scholar]
- Lileikyte, R.; Fraga-Silva, T.; Lamel, L.; Gauvain, J.L.; Laurent, A.; Huang, G. Effective keyword search for low-resourced conversational speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5785–5789. [Google Scholar]
- Parlak, S.; Saraçlar, M. Spoken term detection for Turkish broadcast news. In Proceedings of the 33rd International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Las Vegas, NV, USA, 30 March–4 April 2008; pp. 5244–5247. [Google Scholar]
- Pham, V.T.; Xu, H.; Xiao, X.; Chen, N.F.; Chng, E.S. Re-ranking spoken term detection with acoustic exemplars of keywords. Speech Commun. 2018, 104, 12–23. [Google Scholar] [CrossRef]
- Ragni, A.; Saunders, D.; Zahemszky, P.; Vasilakes, J.; Gales, M.J.F.; Knill, K.M. Morph-to-word transduction for accurate and efficient automatic speech recognition and keyword search. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5770–5774. [Google Scholar]
- Chen, X.; Ragnil, A.; Vasilakes, J.; Liu, X.; Knilll, K.; Gales, M.J.F. Recurrent neural network language models for keyword search. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5775–5779. [Google Scholar]
- Xu, D.; Metze, F. Word-based Probabilistic Phonetic Retrieval for Low-resource Spoken Term Detection. In Proceedings of the Interspeech, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 2774–2778. [Google Scholar]
- Khokhlov, Y.; Medennikov, I.; Romanenko, A.; Mendelev, V.; Korenevsky, M.; Prudnikov, A.; Tomashenko, N.; Zatvornitsky, A. The STC Keyword Search System For OpenKWS 2016 Evaluation. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3602–3606. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The KALDI Speech Recognition Toolkit. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, ASRU 2011, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]
- Chen, G.; Khudanpur, S.; Povey, D.; Trmal, J.; Yarowsky, D.; Yilmaz, O. Quantifying the Value of Pronunciation Lexicons for Keyword Search in Low Resource Languages. In Proceedings of the 38th International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 8560–8564. [Google Scholar]
- Pham, V.T.; Chen, N.F.; Sivadas, S.; Xu, H.; Chen, I.F.; Ni, C.; Chng, E.S.; Li, H. System and keyword dependent fusion for spoken term detection. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 430–435. [Google Scholar]
- Chen, G.; Yilmaz, O.; Trmal, J.; Povey, D.; Khudanpur, S. Using proxies for OOV keywords in the keyword search task. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU 2013), Olomouc, Czech Republic, 8–12 December 2013; pp. 416–421. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Ali, A.; Clements, M.A. Spoken Web Search using and Ergodic Hidden Markov Model of Speech. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 861–862. [Google Scholar]
- Caranica, A.; Buzo, A.; Cucu, H.; Burileanu, C. SpeeD@MediaEval 2015: Multilingual Phone Recognition Approach to Query By Example STD. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 781–783. [Google Scholar]
- Kesiraju, S.; Mantena, G.; Prahallad, K. IIIT-H System for MediaEval 2014 QUESST. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014; pp. 761–762. [Google Scholar]
- Ma, M.; Rosenberg, A. CUNY Systems for the Query-by-Example Search on Speech Task at MediaEval 2015. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 831–833. [Google Scholar]
- Takahashi, J.; Hashimoto, T.; Konno, R.; Sugawara, S.; Ouchi, K.; Oshima, S.; Akyu, T.; Itoh, Y. An IWAPU STD System for OOV Query Terms and Spoken Queries. In Proceedings of the 11th NTCIR Workshop, Tokyo, Japan, 9–12 December 2014; pp. 384–389. [Google Scholar]
- Makino, M.; Kai, A. Combining Subword and State-level Dissimilarity Measures for Improved Spoken Term Detection in NTCIR-11 SpokenQuery&Doc Task. In Proceedings of the 11th NTCIR Workshop, Tokyo, Japan, 9–12 December 2014; pp. 413–418. [Google Scholar]
- Sakamoto, N.; Yamamoto, K.; Nakagawa, S. Combination of syllable based N-gram search and word search for spoken term detection through spoken queries and IV/OOV classification. In Proceedings of the 2015 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 200–206. [Google Scholar]
- Hou, J.; Pham, V.T.; Leung, C.C.; Wang, L.; Xu, H.; Lv, H.; Xie, L.; Fu, Z.; Ni, C.; Xiao, X.; et al. The NNI Query-by-Example System for MediaEval 2015. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 141–143. [Google Scholar]
- Vavrek, J.; Viszlay, P.; Lojka, M.; Pleva, M.; Juhar, J.; Rusko, M. TUKE at MediaEval 2015 QUESST. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 451–453. [Google Scholar]
- Wang, H.; Lee, T.; Leung, C.C.; Ma, B.; Li, H. Acoustic Segment Modeling with Spectral Clustering Methods. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 264–277. [Google Scholar] [CrossRef]
- Chung, C.T.; Lee, L.S. Unsupervised discovery of structured acoustic tokens with applications to spoken term detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 394–405. [Google Scholar] [CrossRef]
- Chung, C.T.; Tsai, C.Y.; Liu, C.H.; Lee, L.S. Unsupervised iterative Deep Learning of speech features and acoustic tokens with applications to spoken term detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1914–1928. [Google Scholar] [CrossRef]
- Ram, D.; Miculicich, L.; Bourlard, H. Multilingual Bottleneck Features for Query by Example Spoken Term Detection. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2019, Singapore, 14–18 December 2019; pp. 621–628. [Google Scholar]
- Ram, D.; Miculicich, L.; Bourlard, H. Neural Network Based End-to-End Query by Example Spoken Term Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1416–1427. [Google Scholar] [CrossRef]
- Hazen, T.J.; Shen, W.; White, C.M. Query-by-Example spoken term detection using phonetic posteriorgram templates. In Proceedings of the Eleventh Biannual IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Merano, Italy, 13–17 December 2009; pp. 421–426. [Google Scholar]
- Tulsiani, H.; Rao, P. The IIT-B Query-by-Example System for MediaEval 2015. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 341–343. [Google Scholar]
- Proenca, J.; Veiga, A.; Perdigão, F. The SPL-IT Query by Example Search on Speech system for MediaEval 2014. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014; pp. 741–742. [Google Scholar]
- Proenca, J.; Veiga, A.; Perdigao, F. Query by example search with segmented dynamic time warping for non-exact spoken queries. In Proceedings of the 23rd European Signal Processing Conference, Nice, France, 31 August–4 September 2015; pp. 1691–1695. [Google Scholar]
- Proenca, J.; Castela, L.; Perdigao, F. The SPL-IT-UC Query by Example Search on Speech system for MediaEval 2015. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 471–473. [Google Scholar]
- Proenca, J.; Perdigao, F. Segmented Dynamic Time Warping for Spoken Query-by-Example Search. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 750–754. [Google Scholar]
- Lopez-Otero, P.; Docio-Fernandez, L.; Garcia-Mateo, C. GTM-UVigo Systems for the Query-by-Example Search on Speech Task at MediaEval 2015. In Proceedings of the 2015 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 521–523. [Google Scholar]
- Lopez-Otero, P.; Docio-Fernandez, L.; Garcia-Mateo, C. Phonetic Unit Selection for Cross-Lingual Query-by-Example Spoken Term Detection. In Proceedings of the 2015 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 223–229. [Google Scholar]
- Saxena, A.; Yegnanarayana, B. Distinctive Feature Based Representation of Speech for Query-by-Example Spoken Term Detection. In Proceedings of the Interspeech, 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3680–3684. [Google Scholar]
- Lopez-Otero, P.; Docio-Fernandez, L.; Garcia-Mateo, C. Compensating Gender Variability in Query-by-Example Search on Speech Using Voice Conversion. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2909–2913. [Google Scholar]
- Asaei, A.; Ram, D.; Bourlard, H. Phonological Posterior Hashing for Query by Example Spoken Term Detection. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 2067–2071. [Google Scholar]
- Mantena, G.; Achanta, S.; Prahallad, K. Query-by-example spoken term detection using frequency domain linear prediction and non-segmental dynamic time warping. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 946–955. [Google Scholar] [CrossRef]
- Wang, H.; Lee, T. The CUHK Spoken Web Search System for MediaEval 2013. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 681–682. [Google Scholar]
- Wang, H.; Lee, T.; Leung, C.C.; Ma, B.; Li, H. Using parallel tokenizers with DTW matrix combination for low-resource spoken term detection. In Proceedings of the 38th International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 8545–8549. [Google Scholar]
- Torbati, A.H.H.N.; Picone, J. A nonparametric bayesian approach for spoken term detection by example query. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 928–932. [Google Scholar]
- Popli, A.; Kumar, A. Query-by-Example Spoken Term Detection Using Low Dimensional Posteriorgrams Motivated by Articulatory Classes. In Proceedings of the 17th IEEE International Workshop on Multimedia Signal Processing, MMSP 2015, Xiamen, China, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Ram, D.; Asaei, A.; Bourlard, H. Sparse Subspace Modeling for Query by Example Spoken Term Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1130–1143. [Google Scholar] [CrossRef]
- Skacel, M.; Szöke, I. BUT QUESST 2015 System Description. In Proceedings of the MediaEval 2015 Workshop, Wurzen, Germany, 14–15 September 2015; pp. 721–723. [Google Scholar]
- Chen, H.; Leung, C.C.; Xie, L.; Ma, B.; Li, H. Unsupervised Bottleneck Features for Low-Resource Query-by-Example Spoken Term Detection. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 923–927. [Google Scholar]
- Yuan, Y.; Leung, C.C.; Xie, L.; Chen, H.; Ma, B.; Li, H. Pairwise learning using multi-lingual bottleneck features for low-resource query-by-example spoken term detection. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5645–5649. [Google Scholar]
- van Hout, J.; Mitra, V.; Franco, H.; Bartels, C.; Vergyri, D. Tackling unseen acoustic conditions in query-by-example search using time and frequency convolution for multilingual deep bottleneck features. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 48–54. [Google Scholar]
- Yilmaz, E.; van Hout, J.; Franco, H. Noise-robust exemplar matching for rescoring query-by-example search. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 1–7. [Google Scholar]
- Bouallegue, M.; Senay, G.; Morchid, M.; Matrouf, D.; Linares, G.; Dufour, R. LIA@MediaEval 2013 Spoken Web Search Task: An I-Vector based Approach. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 771–772. [Google Scholar]
- Rodriguez-Fuentes, L.J.; Varona, A.; Penagarikano, M.; Bordel, G.; Diez, M. GTTS Systems for the SWS Task at MediaEval 2013. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 831–832. [Google Scholar]
- Yang, P.; Leung, C.C.; Xie, L.; Ma, B.; Li, H. Intrinsic Spectral Analysis based on temporal context features for Query-by-Example Spoken Term Detection. In Proceedings of the Interspeech, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 1722–1726. [Google Scholar]
- George, B.; Saxena, A.; Mantena, G.; Prahallad, K.; Yegnanarayana, B. Unsupervised Query-by-Example Spoken Term Detection using Bag of Acoustic Words and Non-segmental Dynamic Time Warping. In Proceedings of the Interspeech, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 1742–1746. [Google Scholar]
- Zhan, J.; He, Q.; Su, J.; Li, Y. A Stage Match for Query-by-Example Spoken Term Detection Based On Structure Information of Query. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; pp. 6833–6837. [Google Scholar]
- Abad, A.; Astudillo, R.F.; Trancoso, I. The L2F Spoken Web Search system for Mediaeval 2013. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 851–852. [Google Scholar]
- Szöke, I.; Skácel, M.; Burget, L. BUT QUESST 2014 System Description. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014; pp. 621–622. [Google Scholar]
- Szöke, I.; Burget, L.; Grézl, F.; Černocký, J.H.; Ondel, L. Calibration and fusion of query-by-example systems—BUT SWS 2013. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7849–7853. [Google Scholar]
- Abad, A.; Rodríguez-Fuentes, L.J.; Penagarikano, M.; Varona, A.; Bordel, G. On the calibration and fusion of heterogeneous spoken term detection systems. In Proceedings of the Interspeech, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 20–24. [Google Scholar]
- Yang, P.; Xu, H.; Xiao, X.; Xie, L.; Leung, C.C.; Chen, H.; Yu, J.; Lv, H.; Wang, L.; Leow, S.J.; et al. The NNI Query-by-Example System for MediaEval 2014. In Proceedings of the MediaEval 2014 Workshop, Barcelona, Spain, 16–17 October 2014; pp. 691–692. [Google Scholar]
- Leung, C.C.; Wang, L.; Xu, H.; Hou, J.; Pham, V.T.; Lv, H.; Xie, L.; Xiao, X.; Ni, C.; Ma, B.; et al. Toward High-Performance Language-Independent Query-by-Example Spoken Term Detection for MediaEval 2015: Post-Evaluation Analysis. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 3703–3707. [Google Scholar]
- Xu, H.; Hou, J.; Xiao, X.; Pham, V.T.; Leung, C.C.; Wang, L.; Do, V.H.; Lv, H.; Xie, L.; Ma, B.; et al. Approximate search of audio queries by using DTW with phone time boundary and data augmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 6030–6034. [Google Scholar]
- Oishi, S.; Matsuba, T.; Makino, M.; Kai, A. Combining State-level and DNN-based Acoustic Matches for Efficient Spoken Term Detection in NTCIR-12 SpokenQuery&Doc-2 Task. In Proceedings of the 12th NTCIR Workshop, Tokyo, Japan, 7–10 June 2016; pp. 205–210. [Google Scholar]
- Obara, M.; Kojima, K.; Tanaka, K.; wook Lee, S.; Itoh, Y. Rescoring by Combination of Posteriorgram Score and Subword-Matching Score for Use in Query-by-Example. In Proceedings of the Interspeech, 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 1918–1922. [Google Scholar]
- Ram, D.; Miculicich, L.; Bourlard, H. CNN Based Query by Example Spoken Term Detection. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 92–96. [Google Scholar]
- Shankar, R.; Vikram, C.M.; Prasanna, S.M. Spoken Keyword Detection Using Joint DTW-CNN. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 117–121. [Google Scholar]
- Settle, S.; Levin, K.; Kamper, H.; Livescu, K. Query-by-Example Search with Discriminative Neural Acoustic Word Embeddings. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2874–2878. [Google Scholar]
- Yuan, Y.; Leung, C.C.; Xie, L.; Chen, H.; Ma, B.; Li, H. Learning Acoustic Word Embeddings with Temporal Context for Query-by-Example Speech Search. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 97–101. [Google Scholar]
- Zhu, Z.; Wu, Z.; Li, R.; Meng, H.; Cai, L. Siamese Recurrent Auto-Encoder Representation for Query-by-Example Spoken Term Detection. In Proceedings of the Interspeech, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 102–106. [Google Scholar]
- Ao, C.W.; Lee, H.Y. Query-by-example spoken term detection using attention-based multi-hop networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 6264–6268. [Google Scholar]
- Santos, C.D.; Tan, M.; Xiang, B.; Zhou, B. Attentive pooling networks. arXiv 2016, arXiv:1602.03609. [Google Scholar]
- Zhang, K.; Wu, Z.; Jia, J.; Meng, H.; Song, B. Query-by-example spoken term detection using attentive pooling networks. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1267–1272. [Google Scholar]
- NIST. The Spoken Term Detection (STD) 2006 Evaluation Plan. 2006. Available online: https://catalog.ldc.upenn.edu/docs/LDC2011S02/std06-evalplan-v10.pdf (accessed on 10 September 2021).
- ITU. ITU-T Recommendation P.563: Single-Ended Method for Objective Speech Quality Assessment in Narrow-Band Telephony Applications; ITU: Geneva, Switzerland, 2008. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán, V.; Pérez, C.; Zotano, M.; de Prada, A. RTVE2018 Database Description; Vivolab and Corporación Radiotelevisión Española: Zaragoza, Spain, 2018. [Google Scholar]
- Martin, A.; Doddington, G.; Kamm, T.; Ordowski, M.; Przybocki, M. The DET Curve In Assessment Of Detection Task Performance. In Proceedings of the 5th European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997; pp. 1895–1898. [Google Scholar]
- NIST. Evaluation Toolkit (STDEval) Software; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 1996. [Google Scholar]
- Akiba, T.; Nishizaki, H.; Nanjo, H.; Jones, G.J.F. Overview of the NTCIR-11 SpokenQuery&Doc Task. In Proceedings of the 11th NTCIR Workshop, Tokyo, Japan, 9–12 December 2014; pp. 1–15. [Google Scholar]
- Akiba, T.; Nishizaki, H.; Nanjo, H.; Jones, G.J.F. Overview of the NTCIR-12 SpokenQuery&Doc-2 Task. In Proceedings of the 12th NTCIR Workshop, Tokyo, Japan, 7–10 June 2016; pp. 1–13. [Google Scholar]
- Fiscus, J.; Ajot, J.; Doddington, G. English STD 2006 Results; Technical Report; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2006. [Google Scholar]
- Harper, M.P. Data Resources to Support the Babel Program Intelligence Advanced Research Projects Activity (IARPA). 2011. Available online: https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/harper.pdf (accessed on 10 September 2021).
- Hartmann, W.; Karakos, D.; Hsiao, R.; Zhang, L.; Alumae, T.; Tsakalidis, S.; Schwartz, R. Analysis of keyword spotting performance across IARPA Babel languages. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 May 2017; pp. 5765–5769. [Google Scholar]
- Sailor, H.B.; Patil, A.T.; Patil, H.A. Advances in Low Resource ASR: A Deep Learning Perspective. In Proceedings of the 6th International Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU’18), Gurugram, India, 29–31 August 2018; pp. 15–19. [Google Scholar]
- Ragni, A.; Li, Q.; Gales, M.J.F.; Wang, Y. Confidence Estimation and Deletion Prediction Using Bidirectional Recurrent Neural Networks. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 204–211. [Google Scholar]
- Karafiat, M.; Baskar, M.K.; Vesely, K.; Grezl, F.; Burget, L.; Cernocky, J. Analysis of Multilingual BLSTM Acoustic Model on Low and High Resource Languages. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 5789–5793. [Google Scholar]
- Yusuf, B.; Saraclar, M. An Empirical Evaluation of DTW Subsampling Methods for Keyword Search. In Proceedings of the Interspeech, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 2673–2677. [Google Scholar]
- Yusuf, B.; Gundogdu, B.; Saraclar, M. Low Resource Keyword Search With Synthesized Crosslingual Exemplars. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1126–1135. [Google Scholar] [CrossRef]
- Piunova, A.; Beck, E.; Schluter, R.; Ney, H. Rescoring Keyword Search Confidence Estimates with Graph-based Re-ranking Using Acoustic Word Embeddings. In Proceedings of the Interspeech, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 4205–4209. [Google Scholar]
- Yi, J.; Tao, J.; Bai, Y. Language-invariant Bottleneck Features from Adversarial End-to-end Acoustic Models for Low Resource Speech Recognition. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; pp. 6071–6075. [Google Scholar]
- Yi, J.; Tao, J.; Wen, Z.; Bai, Y. Language-Adversarial Transfer Learning for Low-Resource Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 621–630. [Google Scholar] [CrossRef]
- Gundogdu, B.; Yusuf, B.; Saraclar, M. Generative RNNs for OOV Keyword Search. IEEE Signal Process. Lett. 2019, 26, 124–128. [Google Scholar] [CrossRef]
- Gök, A.; Gündoğdu, B.; Saraçlar, M. Accelerating Dynamic Time Warping-Based Keyword Search Using Recurrent Neural Networks. In Proceedings of the 28th IEEE Conference on Signal Processing and Communications Applications, Gaziantep, Turkey, 5–7 October 2020. [Google Scholar]
- Fantaye, T.G.; Yu, J.; Hailu, T.T. Advanced Convolutional Neural Network-Based Hybrid Acoustic Models for Low-Resource Speech Recognition. Computers 2020, 9, 36. [Google Scholar] [CrossRef]
- Thomas, S.; Audhkhasi, K.; Kingsbury, B. Transliteration Based Data Augmentation for Training Multilingual ASR Acoustic Models in Low Resource Settings. In Proceedings of the Interspeech, 21st Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 4736–4740. [Google Scholar]
- NIST. OpenKWS13 Keyword Search Evaluation Plan; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2013. [Google Scholar]
- NIST. Draft KWS14 Keyword Search Evaluation Plan; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2013. [Google Scholar]
- NIST. KWS15 Keyword Search Evaluation Plan; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2015. [Google Scholar]
- NIST. Draft KWS16 Keyword Search Evaluation Plan; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2016. [Google Scholar]
- NIST. Open Speech Analytic Technologies Pilot Evaluation; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2018. [Google Scholar]
- NIST. 2017 Pilot Open Speech Analytic Technologies Evaluation (2017 NIST Pilot OpenSAT) Post Evaluation Summary; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2019. [Google Scholar]
- NIST. NIST Open Speech Analytic Technologies 2019 Evaluation Plan (OpenSAT19); National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2019. [Google Scholar]
- NIST. NIST Open Speech Analytic Technologies 2020 Evaluation Plan (OpenSAT20); National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2020. [Google Scholar]
- Rajput, N.; Metze, F. Spoken Web Search. In Proceedings of the MediaEval 2011 Workshop, Pisa, Italy, 1–2 September 2011; pp. 1–2. [Google Scholar]
- Metze, F.; Barnard, E.; Davel, M.; van Heerden, C.; Anguera, X.; Gravier, G.; Rajput, N. The Spoken Web Search Task. In Proceedings of the MediaEval 2012 Workshop, Pisa, Italy, 4–5 October 2012; pp. 41–42. [Google Scholar]
- Anguera, X.; Metze, F.; Buzo, A.; Szoke, I.; Rodriguez-Fuentes, L.J. The Spoken Web Search Task. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013; pp. 1–2. [Google Scholar]
- Povey, D. Kaldi-ASR. 2014. Available online: https://github.com/kaldi-asr/kaldi/tree/master/egs/wsj/s5 (accessed on 10 September 2021).
- Povey, D.; Burget, L.; Agarwal, M.; Akyazi, P.; Kai, F.; Ghoshal, A.; Glembek, O.; Goel, N.; Karafiat, M.; Rastrow, A.; et al. The subspace Gaussian mixture model: A structured model for speech recognition. Comput. Speech Lang. 2011, 25, 404–439. [Google Scholar] [CrossRef]
- Stolcke, A. SRILM—An Extensible Language Modeling Toolkit. In Proceedings of the Interspeech, 7th International Conference on Spoken Language Processing, ICSLP2002, Denver, CO, USA, 16–20 September 2002; pp. 901–904. [Google Scholar]
- Silva, J.C. Multilingual Grapheme to Phoneme. 2015. Available online: https://github.com/jcsilva/multilingual-g2p (accessed on 10 September 2021).
- Can, D.; Saraclar, M. Lattice indexing for spoken term detection. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2338–2347. [Google Scholar] [CrossRef]
- Thiemann, J.; Ito, N.; Vincent, E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings. In Proceedings of the 21st International Congress on Acoustics, Montréal, QC, Canada, 2–7 June 2013; p. 035081. [Google Scholar]
- Hirsch, H.G. Fant-Filtering and Noise Adding Tool. Niederrhein University of Applied Sciences. 2005. Available online: http://dnt.kr.hs-niederrhein.de/indexbd2f.html (accessed on 10 September 2021).
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 40th International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2015, Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File ID | Data | #occ. | dur. (min) | #spk. | Ave. MOS |
|---|---|---|---|---|---|
| Mavir-02 | train | 13,432 | 74.51 | 7 (7 ma.) | 2.69 |
| Mavir-03 | dev | 6681 | 38.18 | 2 (1 ma. 1 fe.) | 2.83 |
| Mavir-06 | train | 4332 | 29.15 | 3 (2 ma. 1 fe.) | 2.89 |
| Mavir-07 | dev | 3831 | 21.78 | 2 (2 ma.) | 3.26 |
| Mavir-08 | train | 3356 | 18.90 | 1 (1 ma.) | 3.13 |
| Mavir-09 | train | 11,179 | 70.05 | 1 (1 ma.) | 2.39 |
| Mavir-12 | train | 11,168 | 67.66 | 1 (1 ma.) | 2.32 |
| Mavir-04 | test | 9310 | 57.36 | 4 (3 ma. 1 fe.) | 2.85 |
| Mavir-11 | test | 3130 | 20.33 | 1 (1 ma.) | 2.46 |
| Mavir-13 | test | 7837 | 43.61 | 1 (1 ma.) | 2.48 |
| ALL | train | 43,467 | 260.27 | 13 (12 ma. 1 fe.) | 2.56 |
| ALL | dev | 10,512 | 59.96 | 4 (3 ma. 1 fe.) | 2.64 |
| ALL | test | 20,277 | 121.3 | 6 (5 ma. 1 fe.) | 2.65 |
| File ID | Data | #occ. | dur. (min) | #spk. | Ave. MOS |
|---|---|---|---|---|---|
| LN24H-20151125 | dev2 | 21,049 | 123.50 | 22 | 3.37 |
| LN24H-20151201 | dev2 | 19,727 | 112.43 | 16 | 3.27 |
| LN24H-20160112 | dev2 | 18,617 | 110.40 | 19 | 3.24 |
| LN24H-20160121 | dev2 | 18,215 | 120.33 | 18 | 2.93 |
| millennium-20170522 | dev2 | 8330 | 56.50 | 9 | 3.61 |
| millennium-20170529 | dev2 | 8812 | 57.95 | 10 | 3.24 |
| millennium-20170626 | dev2 | 7976 | 55.68 | 14 | 3.55 |
| millennium-20171009 | dev2 | 9863 | 58.78 | 12 | 3.60 |
| millennium-20171106 | dev2 | 8498 | 59.57 | 16 | 3.40 |
| millennium-20171204 | dev2 | 9280 | 60.25 | 10 | 3.29 |
| millennium-20171211 | dev2 | 9502 | 59.70 | 12 | 2.95 |
| millennium-20171218 | dev2 | 9386 | 55.55 | 15 | 2.70 |
| EC-20170513 | test | 3565 | 22.13 | N/A | 3.12 |
| EC-20170520 | test | 3266 | 21.25 | N/A | 3.38 |
| EC-20170527 | test | 2602 | 17.87 | N/A | 3.42 |
| EC-20170603 | test | 3527 | 23.87 | N/A | 3.90 |
| EC-20170610 | test | 3846 | 24.22 | N/A | 3.31 |
| EC-20170617 | test | 3368 | 21.55 | N/A | 3.36 |
| EC-20170624 | test | 3286 | 22.60 | N/A | 3.65 |
| EC-20170701 | test | 2893 | 22.52 | N/A | 3.47 |
| EC-20170708 | test | 3425 | 23.15 | N/A | 3.58 |
| EC-20170715 | test | 3316 | 22.55 | N/A | 3.82 |
| EC-20170722 | test | 3929 | 27.40 | N/A | 3.88 |
| EC-20170729 | test | 4126 | 27.45 | N/A | 3.61 |
| EC-20170909 | test | 3063 | 21.05 | N/A | 3.64 |
| EC-20170916 | test | 3422 | 24.60 | N/A | 3.40 |
| EC-20170923 | test | 3331 | 22.02 | N/A | 3.24 |
| EC-20180113 | test | 2742 | 19.02 | N/A | 3.80 |
| EC-20180120 | test | 3466 | 21.97 | N/A | 3.28 |
| EC-20180127 | test | 3488 | 22.52 | N/A | 3.56 |
| EC-20180203 | test | 3016 | 21.60 | N/A | 3.90 |
| EC-20180210 | test | 3214 | 23.20 | N/A | 3.71 |
| EC-20180217 | test | 3094 | 20.33 | N/A | 3.57 |
| EC-20180224 | test | 3140 | 20.78 | N/A | 3.56 |
| millennium-20170703 | test | 8714 | 55.78 | N/A | 1.10 |
| millennium-20171030 | test | 8182 | 57.05 | N/A | 3.44 |
| ALL | train | 3,729,924 | 27729 | N/A | 3.04 |
| ALL | dev1 | 545,952 | 3742.88 | N/A | 2.90 |
| ALL | dev2 | 149,255 | 930.64 | N/A | 3.25 |
| ALL | test | 90,021 | 605.48 | N/A | 3.32 |
| File ID | #occ. | dur. (min) | #spk. | Ave. MOS |
|---|---|---|---|---|
| 13_000500_003_1_19421_642906 | 875 | 5.55 | 2 (1 ma. 1 fe.) | 3.11 |
| 13_000400_007_0_19432_643097 | 563 | 3.53 | 2 (1 ma. 1 fe.) | 3.47 |
| 13_000400_005_0_19422_642932 | 718 | 3.57 | 2 (1 ma. 1 fe.) | 2.92 |
| 13_000400_005_0_19422_642923 | 1898 | 11.62 | 1 (1 fe.) | 3.27 |
| 13_000400_005_0_19422_642922 | 1733 | 11.67 | 1 (1 fe.) | 3.19 |
| 13_000400_004_0_19388_642448 | 1107 | 7.43 | 1 (1 ma.) | 2.53 |
| 13_000400_003_0_19381_642399 | 1403 | 8.13 | 3 (2 ma. 1 fe.) | 2.83 |
| 13_000400_003_0_19381_642398 | 1279 | 11.45 | 3 (2 ma. 1 fe.) | 3.26 |
| 13_000400_002_1_19376_642375 | 2007 | 13.70 | 2 (1 ma. 1 fe.) | 2.41 |
| 13_000400_002_1_19376_642366 | 1720 | 10.73 | 1 (1 ma.) | 2.27 |
| 13_000327_002_0_19437_643241 | 1405 | 8.73 | 2 (2 ma.) | 3.37 |
| 12_000400_153_0_18748_633006 | 1331 | 8.33 | 2 (2 ma.) | 3.48 |
| 12_000400_148_0_18727_632388 | 1012 | 5.42 | 2 (1 ma. 1 fe.) | 3.14 |
| 12_000400_003_0_16430_586456 | 1484 | 10.33 | 1 (1 ma.) | 2.17 |
| ALL | 18,535 | 120.19 | 25 (16 ma. 9 fe.) | 2.90 |
| Query List | Dev-MAVIR | Dev-RTVE | Test-MAVIR | Test-RTVE | Test-SPARL20 |
|---|---|---|---|---|---|
| #INL (occ.) | 354 (959) | 307 (1151) | 208 (2071) | 301 (1082) | 236 (1521) |
| #OOL (occ.) | 20 (55) | 91 (351) | 15 (50) | 103 (162) | 16 (39) |
| #SING (occ.) | 340 (984) | 380 (1280) | 198 (2093) | 383 (1186) | 252 (1560) |
| #MULTI (occ.) | 34 (30) | 18 (222) | 25 (28) | 21 (58) | 0 (0) |
| #INV (occ.) | 292 (668) | 312 (1263) | 192 (1749) | 316 (1035) | 204 (1375) |
| #OOV (occ.) | 82 (346) | 86 (239) | 31 (372) | 88 (209) | 48 (185) |
| Query List | Dev- MAVIR | Dev-RTVE | Test-MAVIR | Test-RTVE | Test-SPARL20 |
|---|---|---|---|---|---|
| #INL (occ.) | 96 (386) | 81 (464) | 99 (1163) | 89 (808) | 87 (903) |
| #OOL (occ.) | 6 (39) | 22 (110) | 7 (29) | 19 (72) | 13 (30) |
| #SING (occ.) | 93 (407) | 101 (544) | 100 (1180) | 105 (861) | 100 (933) |
| #MULTI (occ.) | 9 (18) | 2 (30) | 6 (12) | 3 (19) | 0 (0) |
| #INV (occ.) | 83 (296) | 76 (480) | 94 (979) | 87 (750) | 65 (788) |
| #OOV (occ.) | 19 (129) | 27 (94) | 12 (213) | 21 (130) | 35 (145) |
| Evaluation | ATWV | Language |
|---|---|---|
| OpenKWS 2013 | 0.6248 | Vietnamese |
| OpenKWS 2014 | 0.5802 | Tamil |
| OpenKWS 2015 | 0.6548 | Swahili |
| OpenKWS 2016 | 0.8730 | Georgian |
| Team ID | Research Institution | Systems | Task | Type of System |
|---|---|---|---|---|
| CENATAV | Voice group, Advanced Technologies Application Center, Cuba | Kaldi DNN + DA Kaldi SGMM + DA Kaldi DNN Kaldi SGMM | STD STD STD STD | LVCSR LVCSR LVCSR LVCSR |
| AUDIAS | Universidad Autónoma de Madrid, Spain | E2E + LA E2E E2E + ZNORM | QbE STD QbE STD QbE STD | LD end-to-end LI end-to-end LI end-to-end |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| Kaldi DNN + DA | 0.0018 | −0.0150 | 0.00000 | 0.997 |
| Kaldi SGMM + DA | 0.0000 | −0.4697 | 0.00000 | 1.000 |
| Kaldi DNN | 0.0000 | −0.4819 | 0.00000 | 1.000 |
| Kaldi SGMM | 0.0000 | −0.1713 | 0.00000 | 1.000 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| Kaldi DNN + DA | 0.1026 | 0.1018 | 0.00001 | 0.892 |
| Kaldi SGMM + DA | 0.2879 | 0.2853 | 0.00001 | 0.701 |
| Kaldi DNN | 0.0070 | 0.0046 | 0.00000 | 0.991 |
| Kaldi SGMM | 0.2886 | 0.2858 | 0.00002 | 0.692 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| Kaldi DNN + DA | 0.0025 | −0.0168 | 0.00000 | 0.996 |
| Kaldi SGMM + DA | 0.0505 | 0.0403 | 0.00002 | 0.933 |
| Kaldi DNN | 0.4218 | 0.4230 | 0.00007 | 0.513 |
| Kaldi SGMM | 0.4413 | 0.4356 | 0.00007 | 0.489 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| Kaldi DNN + DA | 0.0019 | −0.0049 | 0.00000 | 0.997 |
| Kaldi SGMM + DA | 0.0037 | −0.0010 | 0.00001 | 0.990 |
| Kaldi DNN | 0.2120 | 0.2123 | 0.00002 | 0.763 |
| Kaldi SGMM | 0.2107 | 0.2101 | 0.00001 | 0.778 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| Kaldi DNN + DA | 0.0096 | −0.0028 | 0.00001 | 0.985 |
| Kaldi SGMM + DA | 0.0149 | 0.0094 | 0.00000 | 0.980 |
| Kaldi DNN | 0.0074 | −0.0034 | 0.00000 | 0.989 |
| Kaldi SGMM | 0.5118 | 0.5090 | 0.00002 | 0.463 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| E2E + LA | 0.0533 | 0.0491 | 0.00000 | 0.947 |
| E2E | 0.0160 | −38.5775 | 0.00000 | 0.984 |
| E2E + ZNORM | 0.0000 | −158.2873 | 0.00000 | 1.000 |
| Text STD | 0.0000 | −0.0508 | 0.00000 | 1.000 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| E2E + LA | 0.0465 | 0.0465 | 0.00000 | 0.954 |
| E2E | 0.0414 | −76.0473 | 0.00000 | 0.954 |
| E2E + ZNORM | 0.0000 | −51.9993 | 0.00000 | 1.000 |
| Text STD | 0.3101 | 0.3086 | 0.00001 | 0.677 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| E2E + LA | 0.0126 | −0.1061 | 0.00000 | 0.987 |
| E2E | 0.0000 | −393.5610 | 0.00000 | 1.000 |
| E2E + ZNORM | 0.0000 | −38.5959 | 0.00000 | 1.000 |
| Text STD | 0.4734 | 0.4682 | 0.00006 | 0.466 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| E2E + LA | 0.0209 | −115.7086 | 0.00000 | 0.978 |
| E2E | 0.0209 | −88.3716 | 0.00000 | 0.978 |
| E2E + ZNORM | 0.0000 | −16.5831 | 0.00000 | 1.000 |
| Text STD | 0.3427 | 0.3413 | 0.00002 | 0.639 |
| System ID | MTWV | ATWV | p(FA) | p(Miss) |
|---|---|---|---|---|
| E2E + LA | 0.0107 | 0.0107 | 0.00000 | 0.989 |
| E2E | 0.0306 | −34.2099 | 0.00000 | 0.961 |
| E2E + ZNORM | 0.0000 | −103.6805 | 0.00000 | 1.000 |
| Text STD | 0.3662 | 0.3583 | 0.00005 | 0.588 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| Kaldi DNN + DA | 0.0027 | −0.0154 | 0.0000 | −0.0367 |
| Kaldi SGMM + DA | 0.0517 | 0.0402 | 0.0408 | 0.0408 |
| Kaldi DNN | 0.4449 | 0.4462 | 0.1167 | 0.1075 |
| Kaldi SGMM | 0.4659 | 0.4598 | 0.1167 | 0.1075 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| Kaldi DNN + DA | 0.0025 | −0.0029 | 0.0000 | −0.0109 |
| Kaldi SGMM + DA | 0.0062 | 0.0012 | 0.0000 | −0.0075 |
| Kaldi DNN | 0.2633 | 0.2625 | 0.0727 | 0.0637 |
| Kaldi SGMM | 0.2584 | 0.2572 | 0.0716 | 0.0708 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| Kaldi DNN + DA | 0.0103 | −0.0024 | 0.0000 | −0.0087 |
| Kaldi SGMM + DA | 0.0160 | 0.0100 | 0.0000 | 0.0000 |
| Kaldi DNN | 0.0079 | −0.0036 | 0.0000 | 0.0000 |
| Kaldi SGMM | 0.5424 | 0.5395 | 0.0625 | 0.0625 |
| SING | MULTI | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| Kaldi DNN + DA | 0.0028 | −0.0186 | 0.0000 | 0.0000 |
| Kaldi SGMM + DA | 0.0558 | 0.0445 | 0.0000 | 0.0000 |
| Kaldi DNN | 0.4495 | 0.4509 | 0.1839 | 0.1601 |
| Kaldi SGMM | 0.4705 | 0.4642 | 0.1667 | 0.1667 |
| SING | MULTI | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| Kaldi DNN + DA | 0.0020 | −0.0052 | 0.0000 | 0.0000 |
| Kaldi SGMM + DA | 0.0039 | −0.0011 | 0.0000 | 0.0000 |
| Kaldi DNN | 0.2063 | 0.2063 | 0.3161 | 0.3161 |
| Kaldi SGMM | 0.2048 | 0.2042 | 0.3161 | 0.3161 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0135 | −0.1105 | 0.0357 | −0.0429 |
| E2E | 0.0000 | −402.2910 | 0.0000 | −270.0931 |
| E2E + ZNORM | 0.0000 | −37.0409 | 0.0000 | −60.5879 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0241 | −111.3045 | 0.0058 | −136.3382 |
| E2E | 0.0241 | −83.7885 | 0.0058 | −109.8395 |
| E2E + ZNORM | 0.0000 | −17.5733 | 0.0000 | −11.9447 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0123 | 0.0123 | 0.0000 | 0.0000 |
| E2E | 0.0237 | −33.7965 | 0.0769 | −36.9764 |
| E2E + ZNORM | 0.0000 | −107.7061 | 0.0000 | −76.7394 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0142 | −0.1196 | 0.0000 | 0.0000 |
| E2E | 0.0000 | −378.6430 | 0.0000 | −510.4187 |
| E2E + ZNORM | 0.0000 | −39.2731 | 0.0000 | −33.2913 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0259 | −127.9138 | 0.0000 | −65.1443 |
| E2E | 0.0259 | −97.8744 | 0.0000 | −49.0025 |
| E2E + ZNORM | 0.0000 | −18.8408 | 0.0000 | −7.2299 |
| INL | OOL | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0164 | 0.0164 | 0.0000 | 0.0000 |
| E2E | 0.0388 | −32.6405 | 0.0246 | −37.1246 |
| E2E + ZNORM | 0.0000 | −106.8322 | 0.0000 | −97.8272 |
| SING | MULTI | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0033 | −0.1224 | 0.1667 | 0.1667 |
| E2E | 0.0000 | −382.1081 | 0.0833 | −584.4417 |
| E2E + ZNORM | 0.0000 | −38.6250 | 0.0000 | −38.1104 |
| SING | MULTI | |||
|---|---|---|---|---|
| System ID | MTWV | ATWV | MTWV | ATWV |
| E2E + LA | 0.0214 | −116.7881 | 0.0000 | −77.9245 |
| E2E | 0.0214 | −89.5284 | 0.0000 | −47.8828 |
| E2E + ZNORM | 0.0000 | −16.9599 | 0.0000 | −3.3951 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tejedor, J.; Toledano, D.T.; Ramirez, J.M.; Montalvo, A.R.; Alvarez-Trejos, J.I. The Multi-Domain International Search on Speech 2020 ALBAYZIN Evaluation: Overview, Systems, Results, Discussion and Post-Evaluation Analyses. Appl. Sci. 2021, 11, 8519. https://doi.org/10.3390/app11188519
Tejedor J, Toledano DT, Ramirez JM, Montalvo AR, Alvarez-Trejos JI. The Multi-Domain International Search on Speech 2020 ALBAYZIN Evaluation: Overview, Systems, Results, Discussion and Post-Evaluation Analyses. Applied Sciences. 2021; 11(18):8519. https://doi.org/10.3390/app11188519
Chicago/Turabian StyleTejedor, Javier, Doroteo T. Toledano, Jose M. Ramirez, Ana R. Montalvo, and Juan Ignacio Alvarez-Trejos. 2021. "The Multi-Domain International Search on Speech 2020 ALBAYZIN Evaluation: Overview, Systems, Results, Discussion and Post-Evaluation Analyses" Applied Sciences 11, no. 18: 8519. https://doi.org/10.3390/app11188519
APA StyleTejedor, J., Toledano, D. T., Ramirez, J. M., Montalvo, A. R., & Alvarez-Trejos, J. I. (2021). The Multi-Domain International Search on Speech 2020 ALBAYZIN Evaluation: Overview, Systems, Results, Discussion and Post-Evaluation Analyses. Applied Sciences, 11(18), 8519. https://doi.org/10.3390/app11188519