Abstract
The entanglement entropy of a random tensor network (RTN) is studied using tools from free probability theory. Random tensor networks are simple toy models that help in understanding the entanglement behavior of a boundary region in the anti-de Sitter/conformal field theory (AdS/CFT) context. These can be regarded as specific probabilistic models for tensors with particular geometry dictated by a graph (or network) structure. First, we introduce a model of RTN obtained by contracting maximally entangled states (corresponding to the edges of the graph) on the tensor product of Gaussian tensors (corresponding to the vertices of the graph). The entanglement spectrum of the resulting random state is analyzed along a given bipartition of the local Hilbert spaces. The limiting eigenvalue distribution of the reduced density operator of the RTN state is provided in the limit of large local dimension. This limiting value is described through a maximum flow optimization problem in a new graph corresponding to the geometry of the RTN and the given bipartition. In the case of series-parallel graphs, an explicit formula for the limiting eigenvalue distribution is provided using classical and free multiplicative convolutions. The physical implications of these results are discussed, allowing the analysis to move beyond the semiclassical regime without any cut assumption, specifically in terms of finite corrections to the average entanglement entropy of the RTN.
1. Introduction
The AdS/CFT correspondence is described as a quantum theory (more precisely, a conformal field theory) lying on the boundary of an anti-de Sitter spacetime geometry [1]. Many particular features of this correspondence remain mysterious, in particular the link with quantum information theory and entanglement. It was shown in [2] that for a fixed time slice, the entanglement behavior of a given region of the boundary quantum theory is proportional to the minimal hypersurface bulk area homologous to the region of interest (known as the Ryu–Takayanagi entanglement entropy). In the context of AdS/CFT, the Ryu-Takayanagi formula demonstrates a crucial link between the entanglement behavior of an intrinsic quantum theory and its connection with the bulk gravitational field. These results open up a new perspective on the understanding of quantum gravity in the AdS/CFT framework from the viewpoint of entanglement and quantum information theory. For a complete introduction, see [3] and references therein.
The difficulty of computing the entanglement properties of boundary quantum theories has led to the development of attractable simple models, particularly the tensor network and random tensor network frameworks. Initially, the tensor network framework started with “good” models approximating ground states in condensed matter physics. In the context of condensed matter physics, tensor networks represent ground states of a class of gapped Hamiltonians [4]. Moreover, tensor networks have paved the way to understanding different physical properties such as the classification of topological phases of matter. An extensive review of all the different applications can be found in [4]. Recently, other extensions of tensor networks to random tensor networks for studying random matrix product states or projected entangled pairs of states have been introduced in [5,6,7]. The random tensor network (or simply RTN) was initiated in [8] as a toy model reproducing the key properties of entanglement behavior in the AdS/CFT context [9,10,11,12,13,14,15]. Moreover, the random tensor network framework has appeared in different active areas of research ranging from condensed matter physics to random quantum circuits and measurement frameworks [16,17,18,19,20,21,22,23,24].
In general, a random tensor network (or simply RTN) is defined as a random quantum state via a given fixed graph structure, as will be described below. The main problem is to compute the average entanglement between two complementary regions of the graph as , where D denotes the dimension of the Hilbert space of the model. Various results have been established, allowing the entanglement entropy of RTN models to be understood as toy models that mimic the entanglement behavior in quantum gravity. The scaling of the entanglement entropy (in the limit) as a function of the size and number of minimal cuts needed to separate the region of interest from the rest of the graph has been explored in different works [8,25]. Moreover, several directions have been explored that move beyond the toy model picture of (random) tensor networks [26,27].
The focus of this work is a maximal flow approach to the analysis of general random tensor networks. The use of the maximal flow approach was already explored in [10] to compute the entanglement negativity, in [28] to derive the Ryu–Takayanagi entanglement entropy in the continuum setting, and in Appendix C of [8] in a moment computation similar to the ones discussed in this work; see also [9,25]. As described in the previous paragraph, the model consists of defining a random quantum state from a given fixed graph structure. This model consider a graph with edges (bulk edges) and half-edges (boundary edges). The use of bulk and boundary edges will become clear from the definition of the model. A finite-dimensional Hilbert space is associated with each half-edge and a tensor product Hilbert space with each edge. The edge Hilbert spaces generate a local Hilbert space associated with each vertex of the graph. In order to define an RTN, each component of the graph is associated with a quantum state generated at random. For this, a random Gaussian state is generated for each vertex and a maximally entangled state is associated with each of the edges. A random tensor network is defined by projecting all of the maximally entangled states associated with the graph onto the total random states generated in each vertex. The obtained random tensor network lies in the full-boundary Hilbert space. The main goal of this work is to consider a sub-boundary region A of the graph and evaluate the entanglement behavior of the associated residual state as . The first computation is to estimate the moment computation of the state associated with the region A as . With the help of the maximal flow, which is developed in detail in this work, the moments are estimated without any assumption regarding cuts, and it is shown that they converge to the moment of a graph-dependent measure. It is shown that if the obtained partial order is series-parallel, the measure associated with the graph can be explicitly constructed without any cut assumption through the use of free probability theory. Moreover, the existence of higher-order correction terms of the entanglement entropy (provided by a graph-dependent measure) is demonstrated, and these can be explicitly provided if the partial order is series-parallel. In different examples, it is shown how the measures associated with the initial graph can be computed explicitly in the case where the obtained partial order is series-parallel. The link between quantum information theory, free probability, and random tensor networks was already explored in [25]. There, a general link state was used to represent the effect of the bulk matter field in the AdS/CFT context, extending the semiclassical regime with correction terms of the entanglement structure. Moreover, the obtained results in [25] assumed the existence of two disjoint minimal cuts separating region A from the rest. In this work, only maximally entangled states in the bulk edge of the model are used; higher-order correction terms are obtained without any cut assumption, which may be interpreted as intrinsic fluctuations. In the context of AdS/CFT, these are intrinsic to the quantum spacetime nature of bulk gravitational field without any bulk matter field.
The main differences between this work and the previous literature [8,25] are highlighted below. Through the use of the maximum flow approach, we emphasize the importance of the partial order defined by disjoint paths achieving the maximum flow to the computation of the correction term for the entropy of entanglement of the random tensor network states. Indeed, both the minimum cut and the maximum flow perspectives provide the dominating term (). However, performing the analysis with the maximum flow allows for a combinatorial characterization of the moments of the reduced state. Moreover, in the case where the flow partial order is series-parallel, an explicit formula for the correction term is provided in terms of a probability measure constructed from the network structure using both the free and classical multiplicative convolutions from (free) probability theory.
The rest of this work is organized as follows. Section 2 provides a summary of the main results. Section 3 introduces the random tensor network framework. Section 4 presents the moment computation of a given state associated with a given sub-boundary region of the graph A. Section 5 uses the maximal flow approach to compute the asymptotic scaling of the moments and demonstrates convergence to a graph-dependent measure. Section 6 introduces the notion of series-parallel partial order and uses the free probability to explicitly show how a graph-dependent measure can be constructed with the free product convolution and classical measurement product. Section 7 provides various examples of random tensor networks and explicitly shows the associated measure obtained in the case of an obtained partial order that is series-parallel. Section 8 presents the main technical results, which use concentration inequalities to show that the obtained higher-order entanglement correction terms are graph-dependent without any cut assumption; moreover, the graph-dependent measure can be explicitly constructed if the partial order is series-parallel.
2. Main Results
This section introduces the main definitions and results obtained in this work. The focus is placed on the computation of the entanglement entropy of a given random tensor network. The most general framework of random tensor networks is considered, and the entanglement structure of the random tensor is studied with respect to a fixed bipartition of the total Hilbert space. By addressing the problem through a network flow approach, the leading term can be computed along with the higher-order correction terms of the entanglement entropy, which are graph-dependent. The higher-order correction terms are found to play a crucial role in various areas, particularly in the context of AdS/CFT [8,25,27,29], as will be discussed following the presentation of the main results. The key results of this work can be informally summarized as follows.
In the limit of large local Hilbert space dimension D, the average Rényi entanglement entropy of an RTN G across a given bipartition has the following:
- A dominating term of the form
- A finite correction term which is graph-dependent
In the case where is a series-parallel graph, the distribution of the entanglement spectrum (and consequently the finite entropy correction) can be computed as an iterative classical and free convolution of Marc̆henko–Pastur distributions.
A random tensor network is associated with a corresponding random quantum state that encodes the structure of a graph G. To describe this, the graph G and relevant terminology are introduced below. Further technical details and definitions of the model are provided in Section 3. Let denote a connected undirected finite graph with (full) edges and half-edges (sometimes referred to as an open graph); the former encode the internal entanglement structure of the quantum state , while the latter represent the physical systems (Hilbert spaces) on which is supported. The sets of edges (bulk edges) and half-edges (boundary edges) are denoted by and , respectively. Formally, the sets of edges and half-edges are provided by and , where . The corresponding random tensor is then defined as
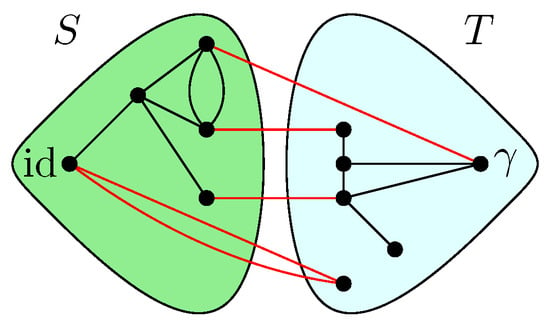
where are taken to be random Gaussian states defined in the local Hilbert space of each vertex x. Moreover, a maximally entangled state is associated with each (full) edge , which serves to contract the internal degrees of freedom of the tensor network. A representation of a random tensor network is provided in Figure 1, which is discussed in detail to illustrate the main results of this work. Further details are provided in Definition 3.
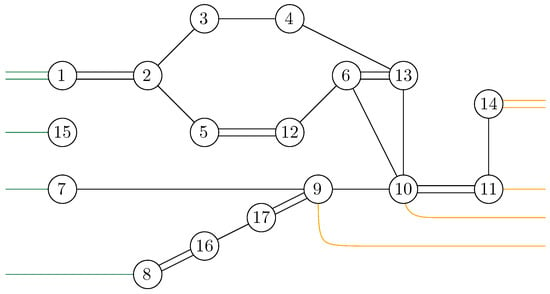
Figure 1.
A tensor network depicting a tensor from obtained by contracting 17 tensors. The ten Hilbert space factors are partitioned into two subsets B ⊔ A.
As mentioned earlier, the objective of this work is to evaluate the entanglement entropy of the random quantum state along a bipartition of the boundary edges . This analysis is carried out in the limit of the large local Hilbert space dimension . To evaluate the entanglement entropy of the pure state , the asymptotic entanglement spectrum along the bipartition is computed, that is, the limiting spectrum of the density matrix . From this spectral information, the average Rényi entanglement and von Neumann entropies for the approximate normalized state can be deduced, respectively provided by:
Above, the expectation is taken with respect to the Gaussian distribution of the independent random tensors present at each vertex of the graph. The use of approximate normalized state instead of a correctly normalized state will become clear from Section 8.
First, the moments of the random matrix are computed exactly, then the main contributing terms at large dimensions are analyzed by relating the problem to a maximum flow question in a related graph. By employing the maximal flow and tools from free probability theory, the leading and fluctuating terms of the Rényi entropy are derived and the behavior of the von Neumann entanglement entropy is subsequently deduced.
- Moment computation. First, the un-normalized state is considered and its moments are computed. As a first step, the graphical Wick formula from [30] is used to obtain
- Maximal flow. The (max)-flow approach consists of identifying the leading terms from the moment formula above as . For this, a network is introduced. This network is derived from the original graph G by connecting all of the half-edges in A to an extra vertex (sink) and all of the half-edges in B to id (source). In , the vertices are valued in the permutation group , with all the half-edges connected either to the source id or to the sink . The flow approach consists of looking at the different paths starting from the source id to the sink . The different paths in the flow approach induce an ordering structure (more precisely a poset structure) in the network . Intuitively, the maximal flow will consist of searching the maximal number of these paths such that the source and sink will be disconnected upon removing the paths from the network. More precisely, by Menger’s theorem, the maximum flow in this graph is equal to the number of edge-disjoint augmenting paths that start from the source id and end in the sink . Figure 7 represents the different paths achieving maximal flow in the network from the original graph G as represented in Figure 1. This procedure allows us to find a lower bound to the Hamiltonian that can be attained by some choice of the variables .
Theorem 1.
For all , one has
where denotes the extended Hamiltonian in the network . After all augmenting paths achieving the maximum flow in have been removed, a clustered graph remains, which is formed by clustering all the remaining connected components (see Figure 8). Importantly, the maximality of the flow implies that the cluster-vertices and in this clustered graph are disjoint. Further details and the proof of the above result are provided in Proposition 5.
As a direct consequence of the above result, the moment convergence as can be deduced; further details of the following result are provided in Theorem 4.
Theorem 2.
In the limit , for all one has
where are the moments of a probability measure and .
Moreover, we can show that the normalization term converges to 1, as shown in Corollary 1. The previous maximum flow computation provides the first order in the formula for the average entanglement entropy of random tensor network states:
Free probability theory and entanglement. The main contribution of this work is to show that the second order (or the finite corrections) of the Rényi and von Neumann entanglement entropy can be found by carefully analyzing the set of augmenting paths achieving the maximum flow in the graph . When the different paths achieve the maximal flow in the graph , a partial order is obtained after the clustering operation, where the vertices are the different permutation clusters formed from the clustered graph . Figure 9 shows the obtained partial order from the original graph G in Figure 1. The results are general, and become explicit in the setting where the partial order is series-parallel. With the help of free probability theory, the second-order correction terms of each of the Rényi and von Neumann entropy can be deduced in this setting.
Definition 1.
A graph G is called series-parallel if it can be constructed recursively using the following two operations:
- Series concatenation: is obtained by identifying the sink of with the source of .
- Parallel concatenation: obtained by identifying the sources and sinks of and .
Definition 2.
A probability measure is associated with a series-parallel graph G, defined recursively as follows:
- The Dirac mass at 1 is associated with the trivial graph , as follows: .
- Series concatenation: . Hereis the Marc̆henko–Pastur distribution and ⊠ is the free convolution product. For more details, see Appendix A.
- Parallel concatenation:
Theorem 3.
In the limit , the average Rényi entanglement entropy and von Neumann entropy of an approximate normalized state respectively behave as follows:
For further details and the proof of the above statements, the reader is referred to Corollary 2. In particular, if the obtained partial order is series-parallel, then the measure can be explicitly constructed, as detailed in Theorem 5. The use of the approximate normalized state rather than the normalized state is justified by the concentration result for presented in Section 8.1.
It was previously argued in [8,27] that if one wants to encode the quantum fluctuations, then instead of a maximally entangled state it is necessary to use a general “link state” defined by
It was recently shown in [25] that the quantum fluctuations beyond the semiclassical regime in AdS/CFT are obtained for the non-flat spectra of the link state under the existence assumption of two minimal cuts. The use of a generic link state in the context of AdS/CFT represents the bulk matter field contribution.In this work, the maximal flow approach has been used to demonstrate the existence of quantum fluctuations without any minimal cut assumption and with the maximally entangled state serving as the link state. The higher-order correction terms obtained in this context can be interpreted as the “intrinsic” quantum fluctuations of spacetime geometry in the absence of any bulk matter field represented by a general link state.
For example, in the case of the graph represented in Figure 1, the resulting partial order is series-parallel (see Figure 9), where
As represented in Figure 10, the graphs and are trivial; hence, . The graph can be factored as a parallel composition of two other graphs, as represented in Figure 11:
The graph , as represented in Figure 12, factorizes as follows:
where we use the fact that and are series compositions of two trivial graphs; thus, , while .
Moreover, the graph , as represented in Figure 13, factorizes as follows:
with the associated measure
where the series composition for and has been used iteratively, with their respective measures provided by and . In the case of random tensor network represented in Figure 1, the partial order is series-parallel, with the associated measure
with
which is obtained by combining all the results stated above. The minimal cuts associated with the network (see Figure 7) can also be considered, as represented in Figure 14. It should be noted that several minimal cuts exist; for simplicity, four ways of achieving the minimal cut in the network are represented. Note that some of the cuts share common edges.
3. Random Tensor Networks
In this section, starting from a given (open) graph with edges (bulk edges) and half-edges (boundary edges), the random tensor network model is introduced. For this purpose, a Hilbert space is associated with each edge and half-edge of the graph. The edge Hilbert spaces induce a local Hilbert space for each vertex in the graph. A random Gaussian state is assigned to each of the vertices, and a maximally entangled state is associated with each edge. The random tensor network is defined by projecting all of the maximally entangled states associated with the edges of the graph onto the vertex states, which are provided by the tensor product of all the random Gaussian vectors. The main definitions of the model are introduced in this section, and the different entanglement notions are recalled as well.
Section 3.1 introduces the random tensor network model, after which Section 3.2 recalls the different entanglement notions and their properties.
3.1. Random Tensor Network
The construction of the random tensor network model is presented in the following. Let be a bulk connected undirected finite open graph with edges and half-edges. The multi-sets of edges and half-edges are denoted by and , respectively; multiple edges are allowed in the graph. Formally, bulk edges are of the form for some , while half-edges are of the form for some , where the · indicates that is a partial edge. The total set of edges E is decomposed as
Bulk connectivity is assumed, meaning that all vertices in the bulk region of the graph are connected; this corresponds to the “connected network” property as defined in Definition 2 of [33]. The cardinalities of the bulk, boundary, and total edge multi-sets are denoted by , , and , respectively.
A Hilbert space is associated with each half-edge on a given vertex in the graph, while the Hilbert space is assigned to each bulk edge connecting two vertices, where D is a finite parameter known as the bond dimension. A random Gaussian vector is defined for each vertex of the graph state, lying in the local Hilbert space associated with that vertex. Furthermore, a maximally entangled state is associated with each edge of the graph. Thus, the random tensor network is defined as a random quantum state constructed by projecting the total tensor product of the random Gaussian states for each vertex onto all of the maximally entangled states formed along the bulk edges (see Definition 3).
Formally, Hilbert spaces are associated with each part of the graph G as follows:
- A finite-dimensional Hilbert space is assigned to each half-edge defined on a vertex x:
- A Hilbert space is associated with each edge :where denotes the Hilbert space connecting the two vertices x and y, which is composed as a tensor product of the two corresponding half-edges.
- For each vertex , the local vertex Hilbert space is defined as follows:Above, the Hilbert space represents the local Hilbert space associated with a vertex x defined as all the edges of Hilbert space that contribute locally; the notation denotes that the edge e is incident to the vertex x.
Having defined the general Hilbert space structure associated with a generic graph G, in the following we define quantum states in the graph G in order to introduce the random tensor network model. Each vertex is associated with a random vector (un-normalized quantum state) sampled from an i.i.d. Gaussian distribution:
A normalized maximally entangled state is also associated with each bulk edge , provided by
where and indicate the state associated with the vertex x sharing an edge with y.
Definition 3.
A random tensor network is defined as a projection of the vertex state over all of the maximally entangled states for each in , where
It should be mentioned that the following example is used in all other parts of this work as an illustration of the different results obtained in each section.
Example 1.
An illustration of a random tensor network is provided in Figure 1, where the boundary region of G is provided by all the half-edges . In Figure 1, the region A is defined as the set of half-edges at the vertices , that is, . The complementary region consists of the half-edges associated with the vertices , namely, .
It should also be mentioned that in the present construction of the random tensor network, the edges and half-edges are used to generate the vertex Hilbert space . Other types of random tensor network models have already been explored in the literature; see [8,9,25] and the references therein. In the previously mentioned models, the bulk and boundary vertices are first defined, whereas in the present approach the focus is placed on the edges and half-edges, which generate the local Hilbert space for each vertex, with the bulk states provided by a maximally entangled state. The initial work on random tensor networks was presented in [8], where the aim was to compute the entanglement entropy of a subregion of the random tensor network; as the bond dimension tends to infinity, this becomes proportional to the minimal cuts of the graph, reproducing the famous Ryu–Takayanagi entanglement entropy [2] in a discrete version.
In a recent work [25], the authors associated a state with a general “link” state connecting two bulk vertices, thereby generalizing previous models in which the existence of two non-crossing minimal cuts was allowed. This result allowed them to compute higher-order correction terms of the entanglement entropy. In this work, our main goal is to derive the higher-order correction terms using the maximal flow approach without any minimal cut assumption, with maximally entangled states connecting the bulk vertices.
3.2. Entanglement
In the following, different entanglement notions used in quantum information theory are recalled, in particular the von Neumann entropy and Rényi entropy.
The von Neumann entropy for a given normalized quantum state is defined as
In physical systems with an exponential number of degrees of freedom, the computation is generally difficult. A generalization exists in which diagonalization of the density matrix is not required. This definition, introduced by Rényi, is known as the Rényi entropy and defined as
where it is well known that the Rényi entropy converges to the von Neumann entropy as . The definitions provided above are for normalized quantum states; if the state is not normalized, one should first normalize it and then compute the entropy.
A subtlety regarding the upper bound on the rank of the reduced density matrix induced by the minimal cut should be mentioned here. A minimal cut is defined as the minimal number of edges in a graph that must be removed in order to fully separate a given fixed region of the graph. Although it is straightforward to observe that the rank of the reduced density matrix is upper-bounded by the local dimension D raised to the number of edges in the set A, i.e., , a subtlety arises in that the rank of the reduced density matrix is upper-bounded by the minimum number of connecting edges, or the bottleneck (min-cut), rather than by the number of edges:
where is the min-cut (or the number of edges in the “bottleneck”); see, e.g., [8].
This can be demonstrated more clearly using an example. Consider a state from which can be constructed, as shown in Figure 2.
Figure 2.
Constructing from by tracing out the edges corresponding to the set B.
The internal structure of can be considered by dividing the graph into two subgraphs, denoted as L and R, which are connected by the “bottleneck”, that is, the set of all edges for which their removal would disconnect the boundary sets A and B, see Figure 3.
Figure 3.
A factorization of the tensor yields a upper bound on the rank of the corresponding reduced density matrix .
Now, it is clear that , where in this case ; consequently,
Having established the natural intuition around the role of the min-cut () in upper-bounding the entropy, the (maximal) flow approach for the random tensor network will be developed in the following sections.
4. Moment Computation
Given a random tensor network, we next investigate the behavior of entanglement between a specified subregion of the network and the remainder. To this end, we first address the moment computation of the quantum state for a subregion . This initial computation will subsequently enable our analysis of the Rényi and von Neumann entropies in the following sections.
Let be a sub-boundary region of the graph G. The complementary region of A is denoted by . The Hilbert spaces associated with the boundary regions A and B are denoted by and , respectively.
In this work, we computed the average entanglement entropy at large bond dimensions:
where is the normalized quantum state obtained by tracing out the region B, i.e., , with the partial trace over the Hilbert space . In the above expression, the average is taken over all of the random Gaussian tensors at the vertices.
The first computation to be addressed here is the moment computation, as described in the following proposition. This computation will subsequently enable our calculation of the average entanglement entropy (Rényi and von Neumann entropies) in the limit , as analyzed in detail in the following sections. The result has previously been obtained in a very similar setting by Hastings [33] (Theorem 3, ensemble); see also Section 5 of [8] for a closely related derivation.
Proposition 1.
For any , it holds that
where can be understood as the Hamiltonian of a classical “spin system” in which each spin variable takes a value from the permutation group :
Before providing the proof of the above proposition, we recall some properties of the permutation group and fixed the relevant notation. Here, the symbol is used to denote the total cycle in the permutation group evaluated at :
Recall that a notion of distance in , known as the Cayley distance, can be defined by
where stands for the number of cycles in . The distance provides the minimum number of transpositions required to turn into . In general, the distance in satisfies the triangle inequality, where
In particular, is said to be a geodesic between and in if . The following notation for the distance is adopted instead of , where
Proof.
To prove the result announced in the proposition, it should first be remarked that we can use the well-known replica trick to write the trace on the left-hand side of Equation (9) as follows:
The trace on the left-hand side (on ) may be rewritten as a full trace on n copies of the complete (bulk and boundary) Hilbert space, as shown on the right-hand side of the equation above. The notation is used to denote the tensor product of unitary representations of the permutation for each half-edge
By expanding and taking the average over random Gaussian tensors, we obtain
where the shorthand notation in the last equation above is used in place of We recall the following property of random Gaussian states (see [34]):
where is the unitary representation of . Each permutation acts on each vertex in Hilbert space; hence, each acts implicitly on each half-edge incident to the vertex . Thus, the moment formula becomes
where the number of loops obtained by contracting the maximally entangled states (edges) upon taking the trace is counted by the formula above. The factor arises from the normalization associated with the contraction of the bulk edges (see Equation (2), where each edge contributes a factor of ). By employing the relation between the Cayley distance and the number of loops, the result stated in the proposition is obtained. □
Graphically, the formula can be interpreted using Figure 4, where the case with is illustrated. By employing the graphical integration technique for Wick integrals as presented in [30,35], loops are obtained. Consequently, Cayley distances of three types arise: (a) between and elements directly connected to it, originating from the region B; (b) between and elements directly connected to it, originating from the region A; and (c) between elements neither directly connected to id nor , originating from the bulk. Based on this, the Hamiltonian can be rewritten in terms of Cayley distances, as follows:
where represents the half-edges in A, , represents the half-edges in B, and represents the edges in the bulk of the tensor network.
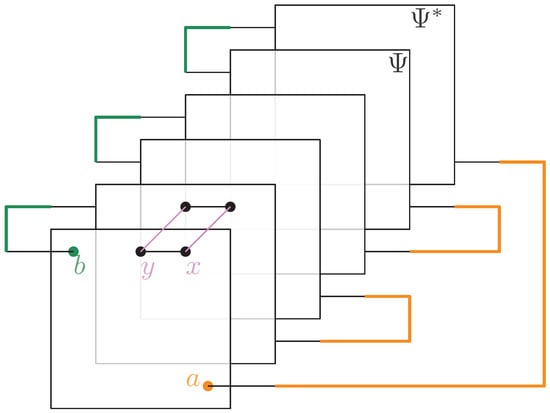
Figure 4.
Graphical representation of the Wick theorem for the moment computation with .
In the above proposition, only the numerator term of the normalized quantum state have been addressed. However, to compute the von Neumann and Rényi entropies (see Equations (4) and (5)), the state must be normalized and the moment computed.
The following proposition provides the moment computation of the normalization term in .
Proposition 2.
For any , it is found that
where the Hamiltonian is provided by
Proof.
The proof of this proposition follows directly from Proposition 1 by taking such that is obtained as the special case of with . □
5. Asymptotic Behavior of Moments
In this section, the leading contributing terms of the moment as are described using the (maximal) flow approach. First, the (maximal) flow approach is introduced, which allows for the estimation of the leading terms of the moments as ; further details can be found in Proposition 5. Based on this result, the convergence of the moment as to the moments of a graph-dependent measure can be deduced, as detailed in Theorem 4.
First, the results from the previous section are recalled. In Proposition 1, it was shown that the moments are provided by
where the spin-valued Hamiltonian in the permutation group is provided by
In particular, the contribution of the normalization term in (see Equation (8)) is the extended Hamiltonian , as shown in Proposition 2 when one takes in .
The main goal of this section is to analyze the main contributing terms of the moment as . The leading terms will consist of solving the following minimization problem:
In particular, is minimized, yielding the leading contributing term as for the normalization term of . The minimization problem described above enables deduction of the moment convergence as to the moment of the graph-dependent measure in Theorem 4.
The minimization problem above is addressed using the (maximal)-flow approach. This approach consists of first constructing a network from the original graph G. This network is constructed by first adding two extra vertices and id to G in such a way that all the half-edges associated with A are connected to the total cycle and that half-edges in B are connected to id. The network has the same bulk structure of G, with the difference that all the vertices in are valued in the permutation group .
The flow approach is based on the identification of different augmenting paths in the network , each starting from id and ending at . These various paths induce an order structure in . By removing all augmenting paths in , a lower bound for the extended Hamiltonian can be established; further details are provided in Proposition 3. Furthermore, it is demonstrated that the minimum is attained when the maximal flow from id to is achieved, as discussed in Proposition 5. In particular, it is shown that the minimum of the extended Hamiltonian is zero; see Proposition 6 for additional details.
Before the flow approach is introduced, it should be noted that the contributing terms of the moments at large dimensions were previously analyzed in [25] using the (minimal) cut approach. In that work, the existence of two disjoint minimal cuts in the graph (separating the region of interest from the remainder of the graph) was assumed to determine the contributions at large bond dimensions. In contrast, in the maximal flow approach presented here, no assumption regarding the existence of (minimal) cuts is made. By identifying various augmenting paths that achieve the maximal flow and applying the well-known maximal-flow minimal-cut theorem (see, e.g., [36], Theorem 8.6), the different minimal cuts can be deduced without any prior assumption.
Definition 4.
Let the network be defined from the initial graph such that
where the regions and is defined as follows:
where and respectively denote all of the vertices associated with the boundary region A and B. Moreover the vertices are valued in the permutation group , where
It should be remarked that in the above definition, the graph is constructed in such a way that all of the half-edges are connected to and that the half-edges are connected to id. Note also that there are no half-edges in ; the bulk region in the network remains the same as the one in graph G.
The extended Hamiltonian of in the network is provided by
where each term in the new Hamiltonian is valued in the network . Moreover, the sums in the above formula are over the vertices , , and , which are the vertices with the respective half-edges in the region A, B, and .
As mentioned earlier, the flow approach consists of analyzing different paths that start from id and end in . This induces a natural orientation of the network (more precisely, a poset structure). In the following, the sets of different (edge-disjoint) paths in is defined.
Definition 5.
Let be the set of all possible paths from the source to the sink in , where the source and sink are id and γ, respectively. Formally, the set of paths is defined as
where are all the paths connecting id to γ.
Definition 6.
Let be the set of all families consisting of edge-disjoint paths in :
Remark 1.
It is clear from this definition that .
The process of searching for different paths that start from id and end at induces an ordering, more precisely a poset structure, in the network . In the following, a definition of a poset structure is provided which will later be utilized in the maximal flow approach to minimize .
Definition 7.
The poset structure is a homogeneous relation denoted by ≤ and satisfying the following conditions for all :
- Reflexivity: ;
- Antisymmetry: and , implying ;
- Transitivity: and , implying .
Definition 8.
The natural ordering is defined as
for a path provided by
Another useful notion in (maximal) flow analysis is the permutation cluster. A permutation cluster of a given permutation is defined as all of the edge-connected permutations to .
Definition 9.
A permutation cluster is defined as all the edge-connected permutations to .
Remark 2.
With the poset structure in , a naturally-induced ordering is obtained in the cluster structures for each permutation connected to the permutation elements , where all the properties of the above definition can be extended to the cluster of a given permutation . More precisely, the following hold:
Definition 10.
The max flow in is the maximum of all of the edge-disjoint paths in :
The following proposition provides a lower bound of the extended Hamiltonian that is saturated when the maximal flow in is achieved, as shown in Proposition 5. Similar ideas have been used by Hastings in Lemma 4 of [33] to lower-bound the moments of a random tensor network map.
Proposition 3.
Let and be an arbitrary set of edge-disjoint paths in and set ; then, the following inequality holds:
where , defined as follows:
It should be mentioned that the sums in the above proposition are over for , which make up the set of the different boundary and bulk regions when removing all the different edges and vertices that will contribute in different paths in .
Proof.
Consider a set of edge disjoint paths . We can fix a path for a given where
is a path that starts from id, explores vertices, and ends in . Using Equation (14) with the path defined above, we obtain
where we have used the triangle inequality for the Cayley distance together with the fact that . The Hamiltonian is the contribution when the path from is used.
By iteration over all the edge-disjoint paths , the desired result is obtained. The second inequality is obtained by observing that , which ends the proof of this proposition. □
Proposition 4.
Given a graph G, there exist a tuple of permutations α such that .
Proof.
By the celebrated max-flow min-cut theorem, the maximum flow in the network is equal to its minimal cut. Recall that a cut of a network is a partition of its set of vertices into two subsets and , with the size of the cut being the number of edges. In the current setting, the max-flow min-cut theorem (see, e.g., [36], Theorem 8.6) implies that there exists a partition of the vertex set of (see Definition 4) into two subsets with and , such that
For , we define
Because and , we have
where in the last claim we have used the fact that there are no edges between id and in ; see Figure 5. □
Figure 5.
The different edges corresponding to a cut in the network .
Proposition 5.
For all , it holds that
Proof.
This proof follows from the two previous propositions. □
When all the augmenting paths in the network achieving the maximal flow have been identified and removed, a clustered graph is obtained by identifying different remaining connected permutations.
The following example provides an illustration of the different steps described above to analyze the maximum flow problem in the case of the tensor network represented in Figure 1.
Example 2.
Figure 7 represents the network associated with the random tensor network from Figure 1. The vertices in the network are valued in the permutation group . The network is constructed by adding two extra vertices γ and id by connecting all of the half-edges in A to γ and the half-edges in B to id. The flow approach induces a flow from id to γ; here, the maximum flow in Figure 7 is 4, where the augmenting paths achieving it are shown in color. By removing the four edge-disjoint augmenting paths, we obtain the clustered graph in Figure 8 by identifying the remaining connected edges as a single permutation cluster (i.e., id with ) to form the cluster .
Theorem 4.
In the limit , for all we have the following:
where is the number of permutations achieving the minimum of the network Hamiltonian . These numbers are the moments of a probability measure which is compactly supported on .
Proof.
For fixed n, the convergence to (the number of minimizers of the Hamiltonian ) follows from Proposition 1 and Proposition 5. The claim that the numbers are the moments of a compactly supported probability measure follows basically from Prokhorov’s theorem ([37], Section 5; see also [33], Footnote 2). Indeed, we note that at fixed D, the quantity
is the n-th moment of the empirical eigenvalue distribution of the random matrix , restricted to a subspace of dimension containing its support (this follows from the fact that is an upper bound on the rank of ; see Equation (6)). These measures have finite second moments, meaning that the sequence (index by D) is tight. The limiting moments satisfy Carleman’s condition, since , proving that the limit measure has compact support; recall that is the n-th Catalan number (see Appendix A). Because the matrix is positive semi-definite, must be supported on . □
Remark 3.
The obtained moments are provided by a graph-dependent measure. It will be shown in the following sections that such measures can be explicitly constructed if the partial order is series-parallel; see Section 6 and Theorem 5 for more details.
In the above, the contribution terms at a large bond dimension of are those that minimize . As shown in Proposition 5, the quantity is minimized when the maximal flow is attained in .
For later purposes, if the moment of is to be analyzed, then the contribution of the normalization term of at large bond dimension should also be considered. Recall from Proposition 2 that the contribution of the normalization term is provided by
where
At a large dimension , the contributed terms are provided by the one that will minimize the extended Hamiltonian in :
where the first is over all the vertices with boundary edges and where are the bulk vertices.
Proposition 6.
Let be the extended Hamiltonian in ; then, for all we have
which is achieved by identifying all the permutations with id.
Proof.
To minimize the Hamiltonian , the same approach is followed; all half-edges A are connected to and all half-edges B to id. However, in all of the boundary terms are connected to id, meaning that no path starts from id and ends in . Per the bulk connectivity of G, the minimum is achieved by identifying all of the permutations with id; thus, the result follows from Proposition 5. □
Remark 4.
In Proposition 6, the Hamiltonian is obtained by taking in (see Equation (10)). It should be mentioned that if , then the same form of the Hamiltonian is obtained, where instead of all the half-edges being connected to id, they are all connected to γ. Therefore, it can be deduced that there are no paths that start from id and end at γ; hence, the minimum is 0, which is achieved by identifying all the permutations with γ.
Corollary 1.
For any moments of the normalization term, it converges to 1; more precisely,
Proof.
By taking the average, as shown in Proposition 2, we obtain the Hamiltonian . Per the maximal flow, the Hamiltonian is minimized by identifying all of the permutations to id; therefore, we have , as shown in Proposition 6. By removing all of the augmenting paths that achieve maximal flow, the obtained residual graph is trivial, with only two disjoint vertices and the identity cluster . Hence, by Theorem 4 we obtain the desired result. □
6. Moment for Ordered Series-Parallel Network
In this section, the notion of a series-parallel graph (Section 6.1) is introduced. This notion allows the moment to be computed as an explicit graph-dependent measure (Section 6.2). More precisely, it is show that with the help of free probability, the corresponding graph-dependent measure can be explicitly constructed in the case where the obtained partial order is series-parallel.
6.1. Series-Parallel Graph
In this subsection, the notion of series-parallel partial orders is introduced, which in the following subsection will allow for explicit computation of the moments as graph-dependent measures.
First, the notion of series-parallel partial order [38] is recalled and some crucial definitions are provided that will play an important role in the rest of this section.
Given two partial orders , , we defines their series (resp. parallel) composition as follows: the base set is and the order relation if
- and or and in the series case;
- and in the parallel case.
It is more convenient to represent partial orders by their covering graphs, where an oriented graph is associated with a partial order , with and if and only if and there does not exist z such that . Recall that denotes and . The series and parallel composition for partial orders can be elegantly interpreted in terms of directed graphs (or networks, in this context). In what follows, the terms “partial order” and “partial order graph” are used interchangeably.
Definition 11
([38]). Let and be two directed graphs with their respective sources and sinks for . A series-parallel network is a directed graph containing two distinct vertices , called the source and the sink, that can be obtained recursively from the trivial network using the following two operations (see Figure 6):
- Series concatenation: is obtained by identifying the sink of with the source of , i.e., .
- Parallel concatenation: is obtained by identifying the source and the sink of and , i.e., and .

Figure 6.
Series (top) and parallel (bottom) composition of two networks (graphs) .
Remark 5.
Note that the parallel concatenation is a commutative operation, while the series concatenation is in general not commutative:
From a given series-parallel network, different probability distributions can be associated that are constructed from the parallel and series concatenation introduced in Definition 11.
Definition 12.
A probability measure is associated with a series-parallel network G, defined recursively as follows:
- The Dirac mass at 1 is associated with the trivial network :
- For series concatenation, the free multiplicative convolution of the parts is taken along with the measure :
- For parallel concatenation, the classical multiplicative convolution of the parts is taken:
In the above definition, the free product convolution ⊠ and the Marc̆henko–Pastur distribution are used; refer to Appendix A for a self-contained introduction to free probability theory.
6.2. Moment as Graph-Dependent Measure
In this subsection, with the help of the series-parallel notion introduced in the previous subsection, we show that the moments in Theorem 4 are explicitly constructed from a graph-dependent measure in the case where the obtained partial order is series-parallel.
Before presenting the results of this subsection, the different results obtained in the previous sections are first recalled. For a given random tensor network, as represented for example in Figure 1, the moment for a normalized quantum state corresponding to a given subregion of the graph was computed in Section 4 (see Propositions 1 and 2). The evaluation of the moment as was approached via the maximal flow method, as analyzed in Section 5. The network was constructed from the graph G by connecting each of the regions A and B to and id, respectively, where the flow consists of analyzing the different paths starting from id and ending in . By removing all of the different augmenting paths achieving maximal flow, a clustered graph remains that is obtained by identifying different edge-connected permutations, as represented in Figure 8 for the clustered graph associated with the network in Figure 1. Using the maximal flow, Proposition 5 allows us to show the convergence of the moments provided by a graph-dependent measure , as stated in Theorem 4. Moreover, from Proposition 6 it is deduced in Corollary 1 that the normalization terms converge to 1.
From the clustered graph , a partial order is constructed in which the vertices in correspond to the different permutation clusters. Figure 9 illustrates the obtained partial order for the network shown in Figure 1. If the partial order is series-parallel (see Definition 11), convergence in moments of to an explicit partial order measure occurs, which will be explicitly shown in the following subsections.
The following theorem shows the convergence to a moment-dependent measure in the case where the obtained partial order is series-parallel.
Theorem 5.
For any , assuming that the partial order is series-parallel, the limit measure from Theorem 4 can be explicitly constructed from the partial order
In particular, the moments of the reduced tensor network matrix are provided by
Proof.
It suffices to show that the numbers are the moments of the probability measure . This will be proved using the recursive structure of the series-parallel networks (see Definition 11) together with that of the probability measure (see Definition 12).
If the partial order is trivial, then it consists only of two connected components, namely, that of the identity (source) and the sink . Hence, all the permutations associated with the connected components are fixed to be either id or . Thus, for all , which are the moments of the measure . In this way, the claim is seen to hold for the initial case of a trivial network.
If the partial order is the parallel concatenation of two networks having the same source and sink as , then the geodesic equalities for are the disjoint union of the geodesic equalities for the vertices in and those for the vertices of . In turn, this implies that
for all , as there is no geodesic inequality mixing vertices from with vertices in . Hence, by the induction hypothesis, we have
proving the claim for the parallel concatenation of networks.
Finally, the case where the network is the series concatenation of two networks is considered. This means that there is a connected component, say , which is common to the two networks, as it is the sink of and the source of . All geodesic equality conditions for are of the form
while those of are of the form
In particular, the geodesic equality conditions for are of the form
The variable is a non-constrained non-crossing partition of , and summing over it corresponds to taking the free multiplicative convolution with respect to the Marc̆henko–Pastur distribution:
This proves the final claim and concludes the proof. □
Example 3.
As an example, the graph illustrated in Figure 1 is considered. As described in the previous sections, the dominant terms of moments in Proposition 1 are obtained by analyzing the maximum flow in , as shown in Figure 7, where . The partial order obtained by removing from those edges that participate in the maximum flow, is depicted in Figure 8. Using the four augmenting paths (displayed by the colors in Figure 7), the partial order on the connected components of the partial order is constructed, as depicted in Figure 9.



Figure 7.
The network associated with the random tensor network marginal from Figure 1. The maximum flow of this network (with source id and sink ) is 4. The four augmenting paths achieving this value are shown in color.
Figure 8.
The clustered network corresponding to Figure 7 obtained by removing the four edge-disjoint augmenting paths.
Figure 9.
The order graph corresponding to the networks from Figure 1. The partial order relations are to be read from left to right. The elements of this partial-order relation are the connected components of the clustered network from Figure 8, which are eventually identified after taking into account the inequalities from the augmenting paths from Figure 7.
This process is fundamental to the presented approach; the details for one of these geodesics are provided next. For example, consider the augmenting path
depicted in red in Figure 7. Because the respective pair of points and in the clustered graph from Figure 8 are in the same connected components (clusters), this augmenting path gives rise to the following list of partial order relations:
The other three augmenting paths, respectively depicted in blue, green, and orange in Figure 7, give rise to the following list of inequalities:
The partial order depicted in Figure 9 is compiled from the set of inequalities coming from the (fixed) list of augmenting paths yielding the maximum flow (here, 4). It is important to note that some connected components (clusters) can be identified in this partial order due to the anti-symmetry property ; in our example, this happens for the clusters and .
As an application of Theorem 5, it is possible to provide explicit moments of the measure :
The powers of D in the normalization follow from (see the boundary edges in Figure 1) and from . The resulting probability measure associated with the partial order from Figure 9 is provided by
The above measure is obtained by the iterative procedure from Definition 12 as follows. First, observe that the graph in Figure 9 can be decomposed as a series composition of three graphs ; hence, using , it follows that (see Figure 10)
Now, we can observe that is a parallel composition of two other graphs; hence (see Figure 11)
The graphs and are now analyzed separately. First, can be decomposed as a series composition between the parallel composition of and , and , that is (see Figure 12)
Now, and are series compositions of two trivial graphs; thus, and . It follows that
The graph can be decomposed as follows (see Figure 13)
In terms of the associated probability measures, it is found that
By iteratively applying series compositions, we obtain
Thus,
With all of these ingredients, the specified formula for is obtained.
Remark 6.
In the example of the tensor network represented in Figure 1, the moments are computed from the factorized series-parallel structure using the flow approach. It should be mentioned that if the minimal cut approach is taken, then minimal intersecting cuts in the network exist, as shown in Figure 14. Therefore, the correction terms of the entropy can be computed as the moment of a given measure without the need for any minimal cut assumptions such as those considered in [3].

Figure 10.
Representation of the partial order factorizes to a series combination of graphs , , and .

Figure 11.
The graph is factorized to the parallel composition of and .

Figure 12.
The graph is factorized to the series composition of the graph , with graph parallel to .

Figure 13.
The graph factorizes as a series composition of and , with composed in parallel to and in series with .

Figure 14.
Different cuts of size 4 in the network of Figure 7 are represented with blue dashed lines. The maximum flow in the network is 4. Note that some of these minimal cuts share some edges, which are represented in red.
Remark 7.
The obtained measure for a given ordered series-parallel graph has compact support where it combines the Marc̆henko–Pastur distribution with the classical product measure and free product convolution constructed from the structure of .
7. Examples of Series-Parallel Networks
In this section, the results obtained previously are applied to various random tensor networks that possess an induced series-parallel order. The discussion begins with simple cases and progresses towards more physically relevant cases.
7.1. Single Vertex Network
The simplest possible case is considered first, that is, a tensor network having only one vertex, no bulk edges, and two boundary half-edges; see Figure 15. For this network, the associated random tensor
has i.i.d. standard complex Gaussian entries. The two boundary half-edges are partitioned into two one-element sets, A and . From this tensor, the reduced matrix is constructed as
by partial tracing of the half-edge B. Note that in this very simple case the matrix can also be seen as a product of the matricization of the tensor with its Hermitian adjoint; hence, is a Wishart random matrix (see Appendix A for the definition and basic properties of Wishart matrices).
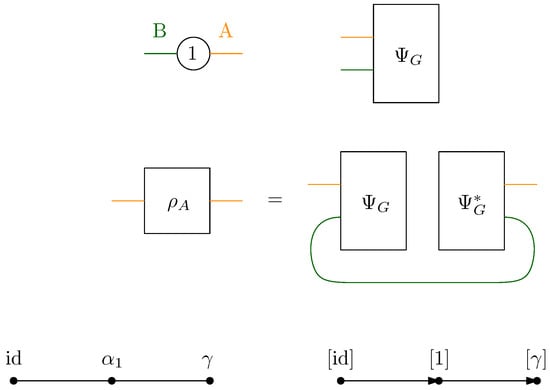
Figure 15.
A single vertex network: the top row shows the network and the associated random tensor , the middle row shows the reduced matrix obtained by partial tracing of the edge B between and , and the bottom row shows the network and partial-order graph .
To analyze the large D spectral properties of , the network is first constructed by connecting all the half-edges in G that belong to A to a new vertex and connecting those in B to a new vertex id. The flow analysis of this network is trivial; a unique path from id to exists, meaning that the maximum flow is 1 and the residual network is empty (both edges in the network are used for the construction of the unique maximum flow).
Because there is a unique path achieving maximum flow and only a single vertex in the network, the partial order induced by the path is very simple: . Hence, the only condition on the permutation is that it should lie on the geodesic between the identity permutation id and the full cycle permutation . Thus, we obtain a series network; see the bottom right-hand diagram in Figure 15. The limit moment distribution is , that is, the Marc̆henko–Pastur distribution (of parameter 1). This matches previously obtained results about the induced measure of mixed quantum states (density matrices) [39,40,41]. Indeed, the matrix can be interpreted in quantum information theory as the partial trace of the rank-one matrix in the direction of a random Gaussian vector . Up to normalization, this random density matrix belongs to the ensemble of induced density matrices. The fact that the two factors of the tensor product have equal dimensions corresponds to taking the uniform measure on the (convex, compact) set of density matrices [42,43]. The statistics of the eigenvalues of such random matrices have been extensively studied in the literature. In particular, the asymptotic von Neumann entropy has been studied by Page [44,45,46], who conjectured that
The reader is referred to Section 8 for a derivation of such statistics in the context of this work.
7.2. Series Network
We now consider a tensor network consisting of s vertices arranged in a path graph with two half-edges at the end points. This network is depicted along with the various steps needed to compute the limiting spectrum distribution of the reduced matrix. The network associated with the graph (where the partition of the half-edges is clear) has a single path from the source to the sink, meaning that the maximum flow is unity, see Figure 16.
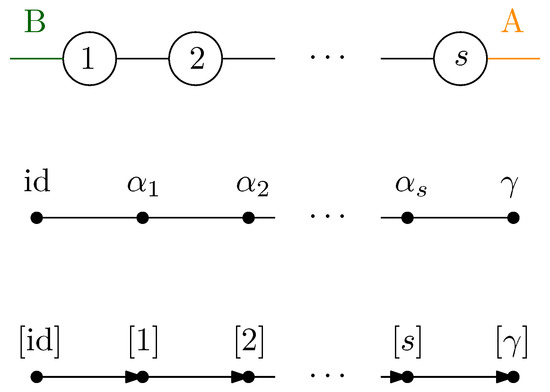
Figure 16.
A series network; the s vertices of the network are arranged in a line, with two half-edges at the end points. The maximum flow is 1, and is unique. The single path realizing the flow induces a (total) order on the geodesic permutations.
The residual graph obtained by removing the edges from the unique path achieving maximum flow is empty; hence, the partial order on the vertices is again a total order:
Thus, a series network is obtained and the final measure is obtained by applying s times the series concatenation procedure from Definition 12, yielding
Very similar results were previously obtained by Cécilia Lancien [47]; see also [25]. This measure is commonly known as the Fuss–Catalan distribution of order s [48]; see also Theorem A5. In combinatorics, its moments are known as the Fuss–Catalan numbers
and its entropy ([49], Proposition 6.2) is
Such tensor network states have already been considered in quantum information theory [43,49,50].
7.3. Two-Dimensional Lattice
We now discuss a physically relevant network consisting of a rectangle that is part of a lattice (part of ). Two integer parameters are considered, namely, the length L and height H of the rectangle, resulting in vertices. The vertices are connected by the edges inherited from the lattice; see Figure 17. The left-most (resp. right-most) columns of vertices are assigned half-edges that belong to the class B (resp. A) of the half-edge partition defining the two regions.
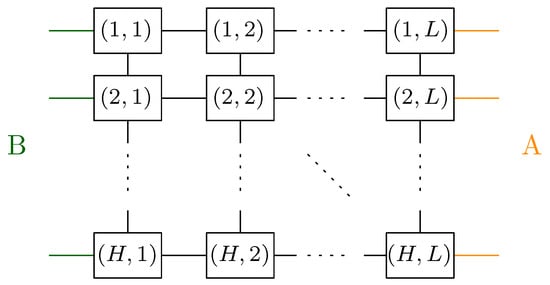
Figure 17.
A network corresponding to a 2D lattice. Half-edges are attached to vertices on the left and right boundaries, corresponding to a tensor in .
The flow network corresponding to the graph and the partition is depicted in the top diagram in Figure 18. The maximum flow in this network is H; one can consider H parallel horizontal paths which go from id to . Note that the set of H edge-disjoint paths in the network achieving the maximum flow is unique. In this case, the residual network is non-empty, with H clusters of the form
The order relation on the clusters is again a total order on L points; see the bottom diagram in Figure 18. Again we obtain the Fuss–Catalan distribution:
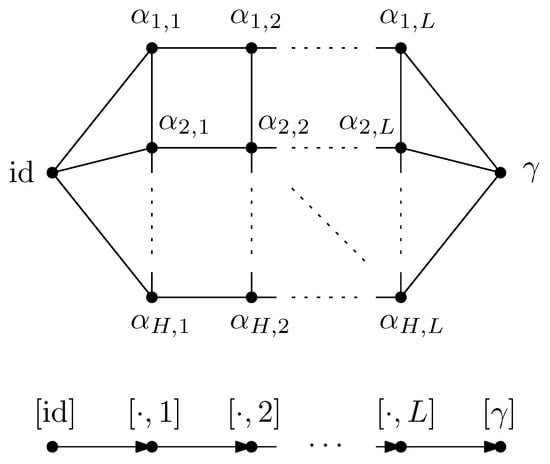
Figure 18.
The network associated with the lattice fragment. The maximum flow in this network is H, corresponding to horizontal edge-disjoint paths. These H paths induce a total order on the L vertex clusters, each having H vertices.
8. Results for Normalized Tensor Network States
This section presents the main technical contribution of this paper. With the help of all the results obtained from the previous sections, the Rényi and von Neumann entropies for a given approximated normalized state associated with a given boundary subregion can be computed. The main results of this section first consist in showing the weak convergence of moments associated with an approximated reduced state that is associated with a given boundary region A in Theorem 7. Moreover, Corollary 2 shows the existence of correction terms as moments of a graph-dependent measure, which can be explicitly computed in the case of an obtained series-parallel partial order .
In Section 8.1, different concentration inequalities will be shown, which in Section 8.2 will allow the main results of this section to be presented.
8.1. Concentration
In this subsection, we provide different concentration results which will allow the main technical contribution to be presented in the following subsection.
First, we recall the following theorem which estimates the deviation probability of polynomials in Gaussian random variables. This theorem is relevant for different concentration results that will be proved later in this subsection.
Theorem 6
([51], Theorem 6.7). Let g be a polynomial in m variables of degree q; then, if are independent centered Gaussian random variables,
where is the variance of and is a constant which depends only on q.
Proposition 7.
Let G be a bulk connected graph and let ; then,
where .
Proof.
First, it should be noted that is a polynomial in of total degree . Moreover, recall that for a random Gaussian vector , the following holds:
where and act on all the edges of the Hilbert space to generate the local Hilbert space for each vertex x. Moreover, it is implicitly assumed that and that the Swap operator is a unitary representation of a permutation element in .
It is easy to check that the variance provides
where we have used the fact that
In the last equality, the bulk contribution is of , while the boundary edges contribute with . The second term of the variance is
By combining the variance with Proposition 6, we have
where with is a constant that depends only on the total number of edges . □
Proposition 8.
Let G be a bulk connected graph and let ; then, the following holds:
where .
Proof.
The proof of this proposition follows the same spirit as the proof of the proposition above. We remark that is a polynomial in . Moreover the variance was estimated in [33], Lemma 14, where
By defining , the result follows. □
8.2. Entanglement Entropy
This subsection introduces the main technical contribution of this work. With the help of the concentration results, we first assume and use the approximate normalized state . It is shown that as , the average Rényi and von Neumann entanglement entropy with correction terms can be computed. In particular, if the obtained partial order is series-parallel, then the correction terms are provided as moments of a partial order-dependent measure .
Recall from Section 3.2 that the rank of the approximate normalized state is upper-bounded by . We consider the approximate normalized quantum state restricted to its support and its empirical measure , defined as
where is the reduced approximate normalized state restricted on its support. The definition of and the empirical measure allow for the demonstration in Theorem 7 of the weak convergence of to . In particular, if the obtained partial order is series-parallel, then Theorem 5 yields weak convergence to . In Corollary 2, this result allows us to compute the Rényi and von Neumann entanglement entropy.
Recall that a measure converges weakly to a measure if the following holds for any bounded continuous function :
Theorem 7.
Let be a boundary region in the graph G. The empirical measure associated to the approximated normalized state converges weakly to . More precisely, for all bounded continuous functions , we have
Proof.
As shown in Theorem 4, the moments converge to a unique measure . In the particular case of an ordered series-parallel graph , an explicit graph dependent measure is obtained. Recall from Theorem 4 that
From standard probability theory results, convergence in probability implies weak convergence (see [52], Theorem 25.2). For this, it is only necessary to show the decreasing scaling of the variance as . Using ([33], Lemma 14), we have
establishing the weak convergence of to . In particular, if the graph is series-parallel, then we obtain . □
Lemma 1.
Let be a boundary region and let be the moment associated to the empirical measure . Then, the following holds:
Proof.
By Proposition 8 and Jensen’s inequality, holds. It remains to show that holds with high probability. Fixing , from Proposition 8 it is the case that
holds with probability . It is easy to check that the following inequalities hold:
Therefore, occurs with probability at least
As , converges; hence, , showing that the probability estimate above converges to 1 and completing the proof. □
For completeness, the following proposition from [30] is recalled, which plays a key role in the proof of the main result.
Proposition 9
([30], Proposition 4.4). Let f be a continuous function on with polynomial growth and with being a sequence of probability measures that converges in moments to a compactly supported measure ν. Then, .
Corollary 2.
Let be a boundary region in G and let be the approximated reduced normalized state. Then, the averaged Rényi and von Neumann entropies converge weakly as , and the following holds:
where .
Proof.
The proof of this corollary is a direct consequence of the concentration results obtained in the previous subsection and the weak convergence of to .
First, the Rényi entropy is considered. For this, we have
and recall that is restricted to the support of . Using Lemma 1 and in the limit , we have
For the von Neumann entropy, let and . It follows directly that
Defining the function as , by combining Proposition 9 and Theorem 7 we obtain the following weak convergence as :
where the measure is defined on a compact support, completing the proof of the corollary. In the particular case where the obtained poset structure is series-parallel, the obtained graph dependent measure is explicitly provided by using Theorem 5. □
9. Conclusions
Given a general graph with a boundary region and a bulk region, the main goal of this work is to compute the entanglement entropy (the Rényi and the von Neumann entropy) of a given sub-boundary region A of the graph. By analyzing the moments of a state associated with the region A as and assisted by the (maximal) flow approach, we compute the leading terms contributing to the moment. By analyzing and removing all of the augmenting paths of the network constructed by connecting the region A to the total cycle and id to the region B starting from id and ending in , a cluster graph is obtained by identifying all of the remaining edge-connected permutations. The flow approach induces a natural-order poset structure, represented by the induced poset order . The maximal flow approach allows for the deduction of the moment convergence to the moment of a unique graph-dependent measure . This result allows for the deduction of the higher-order correction terms of the Rényi and von Neumann entropy, provided by a graph-dependent measure . Moreover, it has been shown that with the help of free probability theory, if the obtained partial order is series-parallel, then the associated graph-dependent measure can be explicitly provided, which contributes to the higher-order correction terms of each of the Rényi and von Neumann entanglement entropies.
In this work, no assumption regarding the minimal cuts is made; from the duality in the maximal flow approach, different minimal cuts can be obtained which may intersect in different edges. Moreover, the higher-order correction terms in the entanglement entropy can describe the quantum corrections beyond the area law behavior of the expected Ryu–Takayanagi entanglement entropy in the context of AdS/CFT. It has been previously argued in the literature that if higher-order correction terms in the random tensor network setting are to be considered, it is necessary to go beyond the maximally entangled state and consider general link states representing the bulk matter field. In this work, the obtained higher-order quantum fluctuation of entanglement entropy is achieved with only maximally entangled states, which we interpret as fluctuations of spacetime itself without any need for bulk fields represented by a generic link state.
Author Contributions
All authors have contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the ANR projects ESQuisses https://esquisses.math.cnrs.fr/ (accessed on 7 April 2025), grant number ANR-20-CE47-0014-01, and by STARS https://www.math.univ-toulouse.fr/~gcebron/STARS.php (accessed on 7 April 2025), grant number ANR-20-CE40-0008, as well as by the PHC program Star (Applications of random matrix theory and abstract harmonic analysis to quantum information theory). K.F. acknowledges support from a NanoX project grant https://nanox-toulouse.fr/ (accessed on 7 April 2025).
Data Availability Statement
No data has been generated or used in this work.
Acknowledgments
Cécilia Lancien is thanked for sharing preliminary notes on very similar questions, and the anonymous referees are acknowledged for their valuable comments on this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Basics of the Combinatorial Approach to Free Probability Theory
In this section, the necessary material on combinatorics and free probability needed to understand the rest of this section is recalled and presented. All of the material introduced here is standard and can be found in [53,54].
Let (not to be confused with introduced in Section 5 representing the different paths) be a partition of a finite totally-ordered set S such that . The sets are called the blocks of . The notation is used if p and q belong to the same block of . A partition of a set S is called crossing if there exist in S such that . A partition is called non-crossing if does not cross. The set of non-crossing partitions of S is denoted by . In particular, if , then the non-crossing partition set is denoted by . The set of non-crossing partitions plays a crucial role in various areas, from combinatorics [55] to random matrices and free probability theory, which is the main focus here. Moreover, the following crucial result is noted [53]: there exists a one-to-one correspondence between the non-crossing partition set and the set of permutations α in a geodesic between γ and id, i.e., . Another important fact is that the cardinality , where
are the Catalan numbers. For more combinatorial details and properties of Catalan numbers and non-crossing partitions, see [53]. We assume that is a k-tuple of permutations in such that
These are geodesics between id and . The cardinality of the set of k-tuple permutations satisfying the geodesic Equation (A2) is known as the Fuss–Catalan numbers, provided by
which generalize the Catalan numbers for .
The free probability theory tools used in this work are now introduced. The intrinsic link between free probability theory and combinatorics is also noted, and some examples are provided to illustrate it. The combinatorics presented here will be used in the rest of this section to help understand the main result.
A non-commutative probability space is defined as a pair , where is a unital -algebra with a state such that . The elements are called non-commutative variables. In the non-commutative probability space, the distribution law can be associated to , defined as .
Before providing concrete examples of non-commutative probability spaces, the notion of freeness, which plays a crucial role in the non-commutative probability world, is recalled. The notion of freeness generalizes “classical” independence when the algebra is commutative. For n given non-commutative random variables , these are said to be free independent if the following holds for any polynomials :
whenever for and for two non-adjacent indices and . With the definition of free independence, the following can be checked for two free independent variables and :
which generalizes the notion of standard independence in the commutative setting, where for two commutative random variables in a commutative probability space.
Definition A1.
Let with and be non-commutative probability spaces. The sequence is said to converge weakly to as if the following holds:
where are the moments of a.
To illustrate concrete non-commutative probability spaces, some classical examples are provided. The first example we consider is the “classical” probability space corresponding to a commutative algebra. Let , where is a set, is a -algebra, and is a probability measure. We define , where
and define the state as
The tuple defines a commutative probability space. Another standard example is the random matrices case. The algebra consisting of matrices over is considered, where
The state on is defined as
where is the normalized trace. The space defines a non-commutative probability space, namely, the space of random matrices over .
For a given non-commutative random variable , the nth moments of a are provided by
Moreover, for given random variables in , the moments are provided by
where are the free cumulants. The above equation is known as the moments–cumulants formula, where the free independence can be characterized by the vanishing of mixed cumulants (see [53], Chapter 11).
In free probability theory, a “convolution operation” can be defined for two free independent random variables . In most of this work, only the free multiplicative convolution is considered. Let and be two free independent random variables in with their respective distributions and ; it is assumed in what follows that and are compactly supported and that their support is a subset of . A free multiplicative convolution, or simply a free product, is defined by
where represents the distribution of . As for the free additive convolution, there exists a standard and analytical way to compute the free product, which can be done via the S-transform. The S-transform of a probability distribution is defined as the formal inverse of the moment-generating formal power series, provided by
where is the formal inverse of the moment-generating formal power series provided by
With the help of the S-transform, the free product can be computed, where:
In the following, we recall some standard distributions that are well-known in the literature and highly used in this work.
The first distribution considered here is the semicircular law, which is one of the most important distributions encountered in free probability theory. The semicircular distribution is defined by the density:
For illustration, the S-transform of the semicircular distribution can be computed by standard computation:
The first link that can be identified is that the moments of the semicircular distribution are intrinsically related to the Catalan numbers. The following equality holds:
where are the Catalan numbers (see Equation (A1) and Chapter 2 in [53] for more details). Moreover, the S-transform provides another important link between free probability and combinatorics by allowing the computation of the moments of free product convolution of Marc̆henko–Pastur distribution (see Theorem A5).
Another well-known result due to Wigner [56] shows the following link between the semicircular distribution and random Gaussian matrices.
Theorem A1
([56]). Let and let be an self-adjoint random Gaussian matrix. Then, converges weakly to a semicircular distribution .
A complete proof can be found in [57]. In this particular case, a deep link is established between random Gaussian matrices, the semicircular law, and the Catalan numbers. Moreover, the semicircular law plays an important role in free probability theory as a free central limit distribution. Next, one of the main results in free probability theory is recalled (see Theorem 8.10 in [53]).
Theorem A2.
Let be a non-commutative probability space and let be free independent and identically distributed self-adjoint random variables. Assume that for and denote the variance of the random variables by . Then, the following holds:
The sequence converges weakly to as , where s is a semicircular variable of variance .
This particular distribution helps to illustrate the relationship between random matrices, combinatorics, and free probability theory.
In the following, we provide another example of a distribution that plays an important role in this work. The second distribution considered here is the Marc̆henko–Pastur distribution, denoted by and defined by
The Marc̆henko–Pastur distribution is deeply related to Wishart matrices. Let Z be a Wishart matrix defined as , where and the entries of are complex random Gaussian variables. It was shown by Marc̆henko and Pastur that the empirical distribution of Wishart matrices converges to the defined above. More precisely, the following theorem was established.
Theorem A3.
Consider a Wishart matrix Z and let be its empirical distribution provided by
Assuming that converges to t as , then converges (weakly) to with .
For a proof and a more detailed statement of this result, see Theorem 3.6 and Theorem 3.7 in [58]. In particular, the case of is of importance in this work, where the distribution is as follows:
where the shorthand notation is used instead of .
For the semicircular distribution described previously, the moments of free convolution products of can be related to the Fuss–Catalan numbers. For conciseness, only some relevant results for the Marc̆henko–Pastur distribution are stated here; for more details and proofs, see [48].
Theorem A4.
Let be the Marc̆henko–Pastur distribution. The S-transform is provided by
One of the main results of [48] was the relation between the free product convolution of and combinatorics. Here, we state only the particular result for that is relevant for this work.
Theorem A5.
Let denote the Marc̆henko–Pastur distribution. For with , the following holds:
where are the Fuss–Catalan numbers.
References
- Maldacena, J. The large-N limit of superconformal field theories and supergravity. Int. J. Theor. Phys. 1999, 38, 1113–1133. [Google Scholar] [CrossRef]
- Ryu, S.; Takayanagi, T. Holographic derivation of entanglement entropy from the anti–de sitter space/conformal field theory correspondence. Phys. Rev. Lett. 2006, 96, 181602. [Google Scholar] [CrossRef]
- Chen, B.; Czech, B.; Wang, Z.Z. Quantum information in holographic duality. Rep. Prog. Phys. 2022, 85, 046001. [Google Scholar] [CrossRef]
- Cirac, J.I.; Perez-Garcia, D.; Schuch, N.; Verstraete, F. Matrix product states and projected entangled pair states: Concepts, symmetries, theorems. Rev. Mod. Phys. 2021, 93, 045003. [Google Scholar] [CrossRef]
- Collins, B.; González-Guillén, C.E.; Pérez-García, D. Matrix Product States, Random Matrix Theory and the Principle of Maximum Entropy. Commun. Math. Phys. 2013, 320, 663–677. [Google Scholar] [CrossRef]
- González-Guillén, C.E.; Junge, M.; Nechita, I. On the spectral gap of random quantum channels. arXiv 2018, arXiv:1811.08847. [Google Scholar] [CrossRef]
- Lancien, C.; Pérez-García, D. Correlation length in random MPS and PEPS. Ann. Henri Poincaré 2022, 23, 141–222. [Google Scholar] [CrossRef]
- Hayden, P.; Nezami, S.; Qi, X.L.; Thomas, N.; Walter, M.; Yang, Z. Holographic duality from random tensor networks. J. High Energy Phys. 2016, 2016, 9. [Google Scholar] [CrossRef]
- Dong, X.; Qi, X.L.; Walter, M. Holographic entanglement negativity and replica symmetry breaking. J. High Energy Phys. 2021, 2021, 24. [Google Scholar] [CrossRef]
- Kudler-Flam, J.; Narovlansky, V.; Ryu, S. Negativity spectra in random tensor networks and holography. J. High Energy Phys. 2022, 2022, 76. [Google Scholar] [CrossRef]
- Penington, G.; Shenker, S.H.; Stanford, D.; Yang, Z. Replica wormholes and the black hole interior. J. High Energy Phys. 2022, 2022, 205. [Google Scholar] [CrossRef]
- Qi, X.L.; Shangnan, Z.; Yang, Z. Holevo information and ensemble theory of gravity. J. High Energy Phys. 2022, 2022, 56. [Google Scholar] [CrossRef]
- Qi, X.L.; Yang, Z. Space-time random tensor networks and holographic duality. arXiv 2018, arXiv:1801.05289. [Google Scholar] [CrossRef]
- Qi, X.L.; Yang, Z.; You, Y.Z. Holographic coherent states from random tensor networks. J. High Energy Phys. 2017, 2017, 60. [Google Scholar] [CrossRef]
- Yang, Z.; Hayden, P.; Qi, X.L. Bidirectional holographic codes and sub-AdS locality. J. High Energy Phys. 2016, 2016, 175. [Google Scholar] [CrossRef]
- Levy, R.; Clark, B.K. Entanglement entropy transitions with random tensor networks. arXiv 2021, arXiv:2108.02225. [Google Scholar] [CrossRef]
- Lopez-Piqueres, J.; Ware, B.; Vasseur, R. Mean-field entanglement transitions in random tree tensor networks. Phys. Rev. B 2020, 102, 064202. [Google Scholar] [CrossRef]
- Li, Y.; Vasseur, R.; Fisher, M.; Ludwig, A.W. Statistical mechanics model for Clifford random tensor networks and monitored quantum circuits. arXiv 2021, arXiv:2110.02988. [Google Scholar] [CrossRef]
- Medina, R.; Vasseur, R.; Serbyn, M. Entanglement transitions from restricted Boltzmann machines. Phys. Rev. B 2021, 104, 104205. [Google Scholar] [CrossRef]
- Marolf, D.; Wang, S.; Wang, Z. Probing phase transitions of holographic entanglement entropy with fixed area states. J. High Energy Phys. 2020, 2020, 84. [Google Scholar] [CrossRef]
- Nahum, A.; Roy, S.; Skinner, B.; Ruhman, J. Measurement and entanglement phase transitions in all-to-all quantum circuits, on quantum trees, and in Landau-Ginsburg theory. PRX Quantum 2021, 2, 010352. [Google Scholar] [CrossRef]
- Vasseur, R.; Potter, A.C.; You, Y.Z.; Ludwig, A.W. Entanglement transitions from holographic random tensor networks. Phys. Rev. B 2019, 100, 134203. [Google Scholar] [CrossRef]
- Yang, Z.C.; Li, Y.; Fisher, M.P.; Chen, X. Entanglement phase transitions in random stabilizer tensor networks. Phys. Rev. B 2022, 105, 104306. [Google Scholar] [CrossRef]
- You, Y.Z.; Yang, Z.; Qi, X.L. Machine learning spatial geometry from entanglement features. Phys. Rev. B 2018, 97, 045153. [Google Scholar] [CrossRef]
- Cheng, N.; Lancien, C.; Penington, G.; Walter, M.; Witteveen, F. Random Tensor Networks with Non-trivial Links. Ann. Henri Poincaré 2024, 25, 2107–2212. [Google Scholar] [CrossRef]
- Apel, H.; Kohler, T.; Cubitt, T. Holographic duality between local Hamiltonians from random tensor networks. J. High Energy Phys. 2022, 2022, 52. [Google Scholar] [CrossRef]
- Bao, N.; Penington, G.; Sorce, J.; Wall, A.C. Beyond toy models: Distilling tensor networks in full AdS/CFT. J. High Energy Phys. 2019, 2019, 69. [Google Scholar] [CrossRef]
- Freedman, M.; Headrick, M. Bit threads and holographic entanglement. Commun. Math. Phys. 2017, 352, 407–438. [Google Scholar] [CrossRef]
- Lewkowycz, A.; Maldacena, J. Generalized gravitational entropy. J. High Energy Phys. 2013, 2013, 90. [Google Scholar] [CrossRef]
- Collins, B.; Nechita, I. Gaussianization and eigenvalue statistics for random quantum channels (III). Ann. Appl. Probab. 2011, 21, 1136–1179. [Google Scholar] [CrossRef]
- Zhou, T.; Nahum, A. Emergent statistical mechanics of entanglement in random unitary circuits. Phys. Rev. B 2019, 99, 174205. [Google Scholar] [CrossRef]
- De Luca, A.; Liu, C.; Nahum, A.; Zhou, T. Universality classes for purification in nonunitary quantum processes. arXiv 2023, arXiv:2312.17744. [Google Scholar] [CrossRef]
- Hastings, M.B. The asymptotics of quantum max-flow min-cut. Commun. Math. Phys. 2017, 351, 387–418. [Google Scholar] [CrossRef]
- Harrow, A.W. The Church of the Symmetric Subspace. arXiv 2013, arXiv:1308.6595. [Google Scholar] [CrossRef]
- Collins, B.; Nechita, I. Random matrix techniques in quantum information theory. J. Math. Phys. 2016, 57, 015215. [Google Scholar] [CrossRef]
- Korte, B.; Vygen, J. Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 2011; Volume 1. [Google Scholar]
- Billingsley, P. Convergence of Probability Measures; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Bechet, D.; De Groote, P.; Retoré, C. A complete axiomatisation for the inclusion of series-parallel partial orders. In Proceedings of the International Conference on Rewriting Techniques and Applications, Barcelona, Spain, 2–5 June 1997; Springer: Berlin/Heidelberg, Germany, 1997; pp. 230–240. [Google Scholar]
- Życzkowski, K.; Sommers, H.J. Induced measures in the space of mixed quantum states. J. Phys. A Math. Gen. 2001, 34, 7111. [Google Scholar] [CrossRef]
- Sommers, H.J.; Życzkowski, K. Statistical properties of random density matrices. J. Phys. A Math. Gen. 2004, 37, 8457. [Google Scholar] [CrossRef]
- Nechita, I. Asymptotics of random density matrices. Ann. Henri Poincaré 2007, 8, 1521–1538. [Google Scholar] [CrossRef]
- Życzkowski, K.; Sommers, H.J. Hilbert-Schmidt volume of the set of mixed quantum states. J. Phys. A Math. Gen. 2003, 36, 10115. [Google Scholar] [CrossRef]
- Życzkowski, K.; Penson, K.A.; Nechita, I.; Collins, B. Generating random density matrices. J. Math. Phys. 2011, 52, 062201. [Google Scholar] [CrossRef]
- Page, D.N. Average entropy of a subsystem. Phys. Rev. Lett. 1993, 71, 1291. [Google Scholar] [CrossRef] [PubMed]
- Foong, S.; Kanno, S. Proof of Page’s conjecture on the average entropy of a subsystem. Phys. Rev. Lett. 1994, 72, 1148. [Google Scholar] [CrossRef] [PubMed]
- Sánchez-Ruiz, J. Simple proof of Page’s conjecture on the average entropy of a subsystem. Phys. Rev. E 1995, 52, 5653. [Google Scholar] [CrossRef]
- Lancien, C. (Institut Fourier Grenoble, France). Personal communication, 2024.
- Banica, T.; Belinschi, S.T.; Capitaine, M.; Collins, B. Free Bessel laws. Can. J. Math. 2011, 63, 3–37. [Google Scholar] [CrossRef][Green Version]
- Collins, B.; Nechita, I.; Życzkowski, K. Random graph states, maximal flow and Fuss–Catalan distributions. J. Phys. A Math. Theor. 2010, 43, 275303. [Google Scholar] [CrossRef]
- Collins, B.; Nechita, I.; Życzkowski, K. Area law for random graph states. J. Phys. A Math. Theor. 2013, 46, 305302. [Google Scholar] [CrossRef]
- Janson, S. Gaussian Hilbert Spaces; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Billingsley, P. Probability and Measure; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Nica, A.; Speicher, R. Lectures on the Combinatorics of Free Probability; Cambridge University Press: Cambridge, UK, 2006; Volume 13. [Google Scholar]
- Mingo, J.A.; Speicher, R. Free Probability and Random Matrices; Springer: Berlin/Heidelberg, Germany, 2017; Volume 35. [Google Scholar]
- Armstrong, D. Generalized Noncrossing Partitions and Combinatorics of Coxeter Groups. arXiv 2007, arXiv:math/0611106. [Google Scholar] [CrossRef]
- Wigner, E.P. Characteristic vectors of bordered matrices with infinite dimensions. In The Collected Works of Eugene Paul Wigner: Part A: The Scientific Papers; Springer: Berlin/Heidelberg, Germany, 1993; pp. 524–540. [Google Scholar]
- Anderson, G.; Guionnet, A.; Zeitouni, O. An Introduction to Random Matrices; Cambridge Studies in Advanced Mathematics; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Bai, Z.; Silverstein, J.W. Spectral Analysis of Large Dimensional Random Matrices; Springer: Berlin/Heidelberg, Germany, 2010; Volume 20. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).