
Fine-Grained Semantics-Enhanced Graph Neural Network Model for Person-Job Fit

 ,
,
Abstract
1. Introduction
- (1)
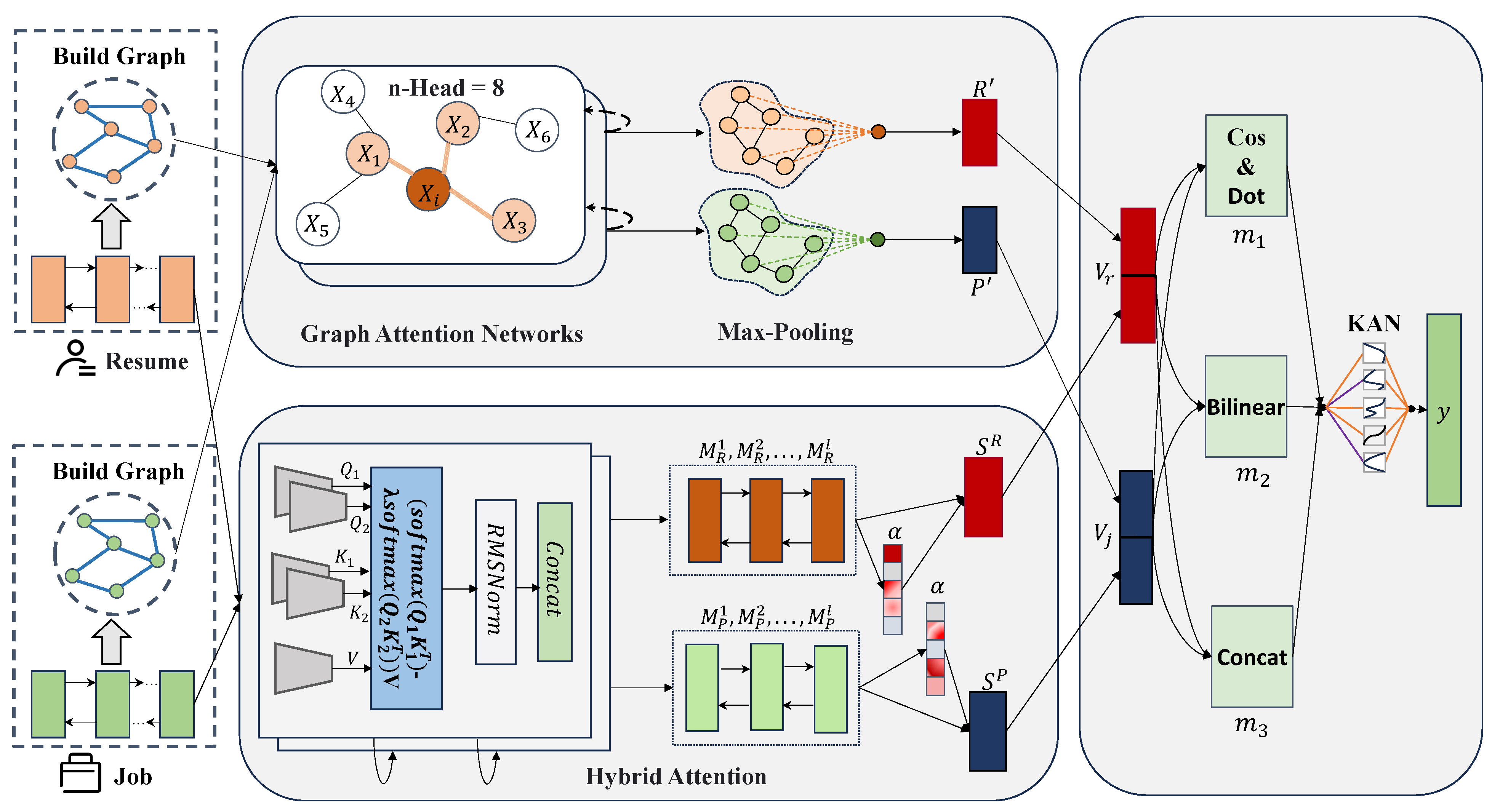
- An innovative graph construction methodology, grounded in the principles of co-occurrence windows and PMI, has been meticulously developed to construct graph representations for job seekers’ resumes and job requirement texts. The overarching objective of this approach is to conduct an in-depth exploration of the semantic structural interdependencies embedded within these texts. By leveraging GATs, the graph structures are encoded, facilitating the enhancement of node feature representations through the aggregation of pertinent neighborhood information.
- (2)
- A sophisticated semantic encoding framework tailored to resumes and job requirements and integrating a hybrid attention mechanism is proposed. This framework is designed to adeptly capture the semantic dependencies between job seekers’ resumes and job requirements, dynamically allocate feature weights, and effectively filter out noise within data. Consequently, it significantly bolsters the semantic representations of both resumes and job requirements, thereby refining their semantic fidelity.
- (3)
- A meticulously crafted fine-grained semantic matching computation methodology is devised which synergistically combines multi-granularity text similarity measurement strategies. A KAN is introduced to optimize the activation function expression and augment the fine-grained semantic representations inherent in job seekers’ resumes and job requirements, culminating in the attainment of highly precise person-job matching performance.
- (4)
- Empirical validation showing the novel FSEGNN-PJF framework achieves state-of-the-art performance.
2. Literature Review
2.1. Recruitment Analysis
2.2. Text Matching
3. Method
3.1. Problem Definition
3.2. Graph-Based Semantic Encoding for Resumes and Job Positions
3.2.1. Graph Construction Methods for Resumes and Job Positions
3.2.2. Graph Attention Network-Based Semantic Encoding for Resumes and Job Positions
3.3. Hybrid Attention Mechanism-Based Semantic Encoding for Resumes and Job Positions
3.3.1. Differential Attention Mechanism-Based Semantic Encoding for Resumes and Job Positions
3.3.2. Self-Attention Mechanism-Based Semantic Encoding for Resumes and Job Positions
3.4. Person-Job Fit
3.4.1. Fine-Grained Semantics
3.4.2. Enhanced Feature Fusion
4. Experiments
4.1. Dataset
4.2. Experimental Set-Up
4.3. Baselines
- Conventional supervised learning methods include decision tree (DT), support vector machine (SVM), Adaboost (AB), and gradient boosting decision tree (GBDT), implemented using Doc2Vec vector as feature inputs.
- DSSM utilizes dual deep neural networks for semantic vector projection with cosine similarity measurement [18].
- Siamese-LSTM involves inputting two sentences into the same LSTM model to obtain forward and backward sentence vectors and finally inputting the sentence pair representations into the softmax layer [28].
- ABCNN implements attention-based convolutional neural networks for sentence pair modeling [29].
- MatchPyramid has sentence pairs inputted, features extracted via a CNN, and the matching scores finally outputted using an MLP [30].
- PJFNN involves taking resume and job requirement pairs as input, encoding resume and job requirement texts by employing a parallel CNN, and calculating the matching results by using the cosine similarity [4].
- BPJFNN [1] is a simplified version of APJFNN. It takes resumes and recruitment requirements as the input sequences and employs BiLSTM to learn the semantic representation of the job seekers’ resumes and job requirements.
- APJFNN considers resumes and job requirements as input sequences, uses BiLSTM to encode job seekers’ resumes and job requirements, and adopts hierarchical ability-aware attention mechanisms to learn word-level semantic representations of resumes and job requirements [1].
- IPJF uses a CNN and collaborative attention mechanism to represent resumes and job requirements, and it employs an MLP to predict the matching between resumes and job positions [31].
- conSultantBERT employs fine-tuned Siamese sentence-bert to match job seekers and jobs [32].
- MKPM combines BiLSTM encoding with attention mechanism for keyword pairs extracted and interaction feature generation [24].
- InEXIT leverages BERT and a multi-head attention mechanism for encoding and cross-attribute interaction modeling and uses an aggregation matching layer to predict the matching between resumes and job positions [5].
- FSEGNN-PJF is the proposed framework in this paper.
4.4. Evaluation Metrics
4.5. Overall Performance
4.6. Ablation Study
- (1)
- Regardless of which variant was removed, the performance decreased, indicating that each variant was useful in the overall framework.
- (2)
- The FSEGNN-PJF w/o KAN variant experienced decreases in accuracy, precision, recall, and F1 score of 2.57%, 3.54%, 1.37%, and 2.44%, respectively. The performance degradation of the proposed framework when using an MLP for feature fusion indicated the insufficiency of the MLP in modeling the nonlinear relationships among job seekers’ experiences, skills, and job requirements. The results indicate that the KAN could effectively capture multi-dimensional complex nonlinear features between job seekers’ experience, skills, and job requirements.
- (3)
- The FSEGNN-PJF w/o GAT variant showed decreases in accuracy, precision, recall, and F1 score of 2.10%, 1.08%, 3.19%, and 2.17%, respectively. The results show that the resume-job semantic encoding module of the graph attention network could effectively capture deep semantic associations and structural information between resumes and job requirements.
- (4)
- The FSEGNN-PJF w/o D-Transformer variant demonstrated decreases in accuracy and F1 score of 2.80% and 2.52%, respectively. The results indicate that the D-Transformer variant could reduce data noise and allow the frame to focus more on the matching between job seekers’ core skills and job requirements.
- (5)
- The performance degradation of the FSEGNN-PJF w/o FGSM variant demonstrates that this module can effectively capture the fine-grained semantics of job seekers’ resumes and job requirements.
- (6)
- The FSEGNN-PJF w/o Satt variant exhibited decreases of 7.71%, 6.82%, 8.67%, 7.78%, and 6.45% in accuracy, precision, recall, F1 score, and AUC, respectively. These results demonstrate the critical role of the self-attention mechanism in capturing intra-sentential semantic dependencies within resumes and job descriptions, as well as perceiving key features such as skills.
4.7. Robustness to Noise
4.8. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Qin, C.; Zhu, H.; Xu, T.; Zhu, C.; Jiang, L.; Chen, E.; Xiong, H. Enhancing Person-Job Fit for Talent Recruitment: An Ability-aware Neural Network Approach. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, 8–12 July 2018; pp. 25–34. [Google Scholar]
- Malinowski, J.; Keim, T.; Wendt, O.; Weitzel, T. Matching people and jobs: A bilateral recommendation approach. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), Kauai, HI, USA, 4–7 January 2006; Volume 6, p. 137c. [Google Scholar]
- Zhang, X.; Zhou, Y.; Ma, Y.; Chen, B.; Zhang, L.; Agarwal, D. GLMix: Generalized Linear Mixed Models for Large-Scale Response Prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 363–372. [Google Scholar]
- Zhu, C.; Zhu, H.; Xiong, H.; Ma, C.; Xie, F.; Ding, P.; Li, P. Person-Job Fit: Adapting the Right Talent for the Right Job with Joint Representation Learning. ACM Trans. Manag. Inf. Syst. 2018, 9, 12:1–12:17. [Google Scholar] [CrossRef]
- Shao, T.; Song, C.; Zheng, J.; Cai, F.; Chen, H. Exploring Internal and External Interactions for Semi-Structured Multivariate Attributes in Job-Resume Matching. Int. J. Intell. Syst. 2023, 2023, 2994779. [Google Scholar] [CrossRef]
- Zhao, C. Graph Adaptive Attention Network with Cross-Entropy. Entropy 2024, 26, 576. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Lei, H.; Ma, Z.; Zhang, F. Code Similarity Prediction Model for Industrial Management Features Based on Graph Neural Networks. Entropy 2024, 26, 505. [Google Scholar] [CrossRef]
- Xue, X.; Sun, X.; Wang, H.; Zhang, H.; Feng, J. Neural network fusion with fine-grained adaptation learning for turnover prediction. Complex Intell. Syst. 2023, 9, 3355–3366. [Google Scholar] [CrossRef]
- Teng, M.; Zhu, H.; Liu, C.; Zhu, C.; Xiong, H. Exploiting the Contagious Effect for Employee Turnover Prediction. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1166–1173. [Google Scholar]
- Xue, X.; Feng, J.; Gao, Y.; Liu, M.; Zhang, W.; Sun, X.; Zhao, A.; Guo, S.X. Convolutional Recurrent Neural Networks with a Self-Attention Mechanism for Personnel Performance Prediction. Entropy 2019, 21, 1227. [Google Scholar] [CrossRef]
- Xue, X.; Gao, Y.; Liu, M.; Sun, X.; Zhang, W.; Feng, J. GRU-based capsule network with an improved loss for personnel performance prediction. Appl. Intell. 2021, 51, 4730–4743. [Google Scholar] [CrossRef]
- Rafter, R.; Bradley, K.; Smyth, B. Personalised retrieval for online recruitment services. In Proceedings of the 22nd Annual Colloquium on Information Retrieval, Cambridge, UK, 5–7 April 2000; pp. 151–163. [Google Scholar]
- Wang, P.; Dou, Y.; Xin, Y. The analysis and design of the job recommendation model based on GBRT and time factors. In Proceedings of the 2016 IEEE International Conference on Knowledge Engineering and Applications (ICKEA), Singapore, 28–30 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 29–35. [Google Scholar]
- Jiang, J.; Ye, S.; Wang, W.; Xu, J.; Luo, X. Learning Effective Representations for Person-Job Fit by Feature Fusion. In Proceedings of the CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, 19–23 October 2020; pp. 2549–2556. [Google Scholar]
- Yan, R.; Le, R.; Song, Y.; Zhang, T.; Zhang, X.; Zhao, D. Interview choice reveals your preference on the market: To improve job-resume matching through profiling memories. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 914–922. [Google Scholar]
- Fu, B.; Liu, H.; Zhao, H.; Zhu, Y.; Song, Y.; Zhang, T.; Wu, Z. Market-Aware Dynamic Person-Job Fit with Hierarchical Reinforcement Learning. In Proceedings of the Database Systems for Advanced Applications—27th International Conference, DASFAA 2022, Virtual Event, 11–14 April 2022; Proceedings, Part II. Bhattacharya, A., Lee, J., Li, M., Agrawal, D., Reddy, P.K., Mohania, M.K., Mondal, A., Goyal, V., Kiran, R.U., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13246, pp. 697–705. [Google Scholar]
- Xue, X.; Feng, J.; Sun, X. Semantic-enhanced sequential modeling for personality trait recognition from texts. Appl. Intell. 2021, 51, 7705–7717. [Google Scholar] [CrossRef]
- Huang, P.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L.P. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional Neural Network Architectures for Matching Natural Language Sentences. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for Natural Language Inference. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1657–1668. [Google Scholar]
- Yu, C.; Xue, H.; Jiang, Y.; An, L.; Li, G. A simple and efficient text matching model based on deep interaction. Inf. Process. Manag. 2021, 58, 102738. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Cui, Z.; Wu, S.; Wang, L. A Graph-based Relevance Matching Model for Ad-hoc Retrieval. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; pp. 4688–4696. [Google Scholar]
- Guo, S.; Guan, Y.; Li, R.; Li, X.; Tan, H. Frame-based Multi-level Semantics Representation for text matching. Knowl. Based Syst. 2021, 232, 107454. [Google Scholar] [CrossRef]
- Lu, X.; Deng, Y.; Sun, T.; Gao, Y.; Feng, J.; Sun, X.; Sutcliffe, R.F.E. MKPM: Multi keyword-pair matching for natural language sentences. Appl. Intell. 2022, 52, 1878–1892. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ye, T.; Dong, L.; Xia, Y.; Sun, Y.; Zhu, Y.; Huang, G.; Wei, F. Differential transformer. arXiv 2024, arXiv:2410.05258. [Google Scholar]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Mueller, J.; Thyagarajan, A. Siamese Recurrent Architectures for Learning Sentence Similarity. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2786–2792. [Google Scholar] [CrossRef]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. Trans. Assoc. Comput. Linguist. 2016, 4, 259–272. [Google Scholar] [CrossRef]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Wan, S.; Cheng, X. Text Matching as Image Recognition. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2793–2799. [Google Scholar]
- Le, R.; Hu, W.; Song, Y.; Zhang, T.; Zhao, D.; Yan, R. Towards Effective and Interpretable Person-Job Fitting. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019; pp. 1883–1892. [Google Scholar]
- Lavi, D.; Medentsiy, V.; Graus, D. conSultantBERT: Fine-tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers. In Proceedings of the Workshop on Recommender Systems for Human Resources (RecSys in HR 2021) Co-Located with the 15th ACM Conference on Recommender Systems (RecSys 2021), Amsterdam, The Netherlands, 27 September–1 October 2021; Volume 2967. [Google Scholar]


{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Word2Vec word embedding dimension | 128 |
| Co-occurrence window size | 2 |
| GAT hidden layer size | 128 |
| DIFF Transformer layers | 2 |
| DIFF Transformer heads | 8 |
| DIFF Transformer FFN dimension | 2048 |
| Weighting factor lambda | 0.8 |
| Optimizer | AdamW |
| Batch size | 128 |
| Learning rate | 0.0005 |
| Model | Accuracy | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| DT | 0.5541 | 0.5561 | 0.5458 | 0.5509 | 0.5456 |
| SVM | 0.5327 | 0.5430 | 0.4268 | 0.4779 | 0.5515 |
| AB | 0.5304 | 0.5264 | 0.5224 | 0.5244 | 0.5227 |
| GBDT | 0.5710 | 0.5617 | 0.5956 | 0.5782 | 0.5304 |
| DSSM | 0.7407 | 0.7121 | 0.7231 | 0.7176 | 0.8088 |
| Siamese-LSTM | 0.7523 | 0.7542 | 0.7400 | 0.7470 | 0.7504 |
| ABCNN | 0.8341 | 0.8333 | 0.8314 | 0.8323 | 0.8384 |
| MatchPyramid | 0.7620 | 0.7530 | 0.7790 | 0.7658 | 0.7640 |
| PJFNN | 0.8598 | 0.8230 | 0.8821 | 0.8515 | 0.8668 |
| BPJFNN | 0.8668 | 0.8594 | 0.8462 | 0.8527 | 0.8526 |
| APJFNN | 0.8738 | 0.8524 | 0.9203 | 0.8850 | 0.8781 |
| IPJF | 0.8691 | 0.8899 | 0.8584 | 0.8739 | 0.8519 |
| conSultantBERT | 0.8855 | 0.8971 | 0.8767 | 0.8868 | 0.8925 |
| MKPM | 0.8575 | 0.8323 | 0.9169 | 0.8726 | 0.8996 |
| InEXIT | 0.8528 | 0.8714 | 0.8356 | 0.8531 | 0.8909 |
| 0.9182 | 0.9220 | 0.9178 | 0.9199 | 0.9203 | |
| FSEGNN-PJF | 0.9369 | 0.9486 | 0.9269 | 0.9376 | 0.9248 |
| Model | Accuracy | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| FSEGNN-PJF | 0.9369 | 0.9486 | 0.9269 | 0.9376 | 0.9248 |
| FSEGNN-PJF w/o KAN | 0.9112 | 0.9132 | 0.9132 | 0.9132 | 0.9046 |
| FSEGNN-PJF w/o GAT | 0.9159 | 0.9378 | 0.8950 | 0.9159 | 0.9095 |
| FSEGNN-PJF w/o D-Transformer | 0.9089 | 0.8982 | 0.9269 | 0.9124 | 0.8837 |
| FSEGNN-PJF w/o FGSM | 0.9206 | 0.9302 | 0.9132 | 0.9217 | 0.8905 |
| FSEGNN-PJF w/o Satt | 0.8598 | 0.8804 | 0.8402 | 0.8598 | 0.8603 |
| Dataset | Accuracy | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|
| Original data | 0.9369 | 0.9486 | 0.9269 | 0.9376 | 0.9278 |
| Deletion | 0.9206 | 0.9302 | 0.9132 | 0.9217 | 0.9207 |
| Spelling errors | 0.9252 | 0.9269 | 0.9269 | 0.9269 | 0.9252 |
| Repeat | 0.9252 | 0.9309 | 0.9224 | 0.9266 | 0.9253 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, X.; Wang, J.; Ma, B.; Ren, J.; Zhang, W.; Gao, S.; Tian, M.; Chang, Y.; Wang, C.; Wang, H. Fine-Grained Semantics-Enhanced Graph Neural Network Model for Person-Job Fit. Entropy 2025, 27, 703. https://doi.org/10.3390/e27070703
Xue X, Wang J, Ma B, Ren J, Zhang W, Gao S, Tian M, Chang Y, Wang C, Wang H. Fine-Grained Semantics-Enhanced Graph Neural Network Model for Person-Job Fit. Entropy. 2025; 27(7):703. https://doi.org/10.3390/e27070703
Chicago/Turabian StyleXue, Xia, Jingwen Wang, Bo Ma, Jing Ren, Wujie Zhang, Shuling Gao, Miao Tian, Yue Chang, Chunhong Wang, and Hongyu Wang. 2025. "Fine-Grained Semantics-Enhanced Graph Neural Network Model for Person-Job Fit" Entropy 27, no. 7: 703. https://doi.org/10.3390/e27070703
APA StyleXue, X., Wang, J., Ma, B., Ren, J., Zhang, W., Gao, S., Tian, M., Chang, Y., Wang, C., & Wang, H. (2025). Fine-Grained Semantics-Enhanced Graph Neural Network Model for Person-Job Fit. Entropy, 27(7), 703. https://doi.org/10.3390/e27070703