
A Novel Framework for Enhancing Decision-Making in Autonomous Cyber Defense Through Graph Embedding


Abstract
1. Introduction
- The network topology information significantly impacts the decision-making of intelligent agents. Traditional one-hot encoding is insufficient to represent network states, necessitating the construction of more granular observation vectors to support defender decision-making.
- Existing intelligent agent training and validation environments mostly support abstract simulations of cyberspace, lacking fine-grained simulations of real environments to enhance training authenticity and efficiency. It is essential to train our intelligent agents in high-fidelity simulated environments to ensure their transferability to real network topologies.
- This paper constructed a game model based on the continuity, randomness, and dynamics of a network attacker and defender, quantifying both parties’ payoffs and strategy choices to provide theoretical support for autonomous defense decision-making.
- This paper improves the traditional one-hot coding method using graph embedding to map the node configuration information and network topology into a low-dimensional vector space for a better representation, greatly improving the decision-making capability of autonomous defense agents.
- We extended the action space of the blue team in the high-fidelity simulation environment Cyberwheel to allow it to perform more granular defensive actions that better align with real-world cyber defense scenarios.
2. Related Work
2.1. Autonomous Cyber Defense
2.2. Reinforcement Learning in Cyber Defense
2.3. Simulation Environment
3. Methodology
3.1. Construction of the Game Model
3.1.1. Game Participants and Space State Definitions
3.1.2. Action Spaces and Strategy Sets
3.1.3. Observation Space and Reward Shaping
3.2. Node2vec-PPO Method
3.2.1. Node2vec Model in ACD
3.2.2. Node2vec-PPO Algorithm
| Algorithm 1 Node2vec-PPO Algorithm. |
|
4. Construction of a High-Fidelity Multi-Action Training Environment
| Algorithm 2 Modify firewall rules function. |
|
| Algorithm 3 Patch vulnerability function. |
|
5. Experiment
5.1. Experimental Scenario
5.2. Experimental Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACD | Autonomous Cyber Defense |
| RL | Reinforcement Learning |
| PPO | Proximal Policy Optimization |
| BFS | Breadth-First Search |
| DFS | Depth-First Search |
References
- Zheng, J.; Namin, A.S. A Survey on the Moving Target Defense Strategies: An Architectural Perspective. J. Comput. Sci. Technol. 2019, 34, 207–233. [Google Scholar] [CrossRef]
- Kott, A.; Linkov, I. Cyber Resilience of Systems and Networks, 1st ed.; Springer Publishing Company, Incorporated: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Wang, C.; Lu, Z. Cyber Deception: Overview and the Road Ahead. IEEE Secur. Priv. 2018, 16, 80–85. [Google Scholar] [CrossRef]
- Kott, A. Autonomous Intelligent Cyber-defense Agent: Introduction and Overview. In Autonomous Intelligent Cyber Defense Agent (AICA): A Comprehensive Guide; Kott, A., Ed.; Springer International Publishing: Cham, Germany, 2023; pp. 1–15. [Google Scholar] [CrossRef]
- Sommer, R.; Paxson, V. Outside the Closed World: On Using Machine Learning for Network Intrusion Detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Reddi, V.J. Deep Reinforcement Learning for Cyber Security. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 3779–3795. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, S.; Kambhampati, S. Multi-agent Reinforcement Learning in Bayesian Stackelberg Markov Games for Adaptive Moving Target Defense. arXiv 2020, arXiv:cs.GT/2007.10457. [Google Scholar]
- Yin, C.; Zhu, Y.; Long, F.; He, X.Z. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Lye, K.W.; Wing, J.M. Game strategies in network security. Int. J. Inf. Secur. 2005, 4, 71–86. [Google Scholar] [CrossRef]
- Tambe, M. Security and Game Theory: Algorithms, Deployed Systems, Lessons Learned, 1st ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Durkota, K.; Lisý, V.; Bošanský, B.; Kiekintveld, C. Approximate Solutions for Attack Graph Games with Imperfect Information. In Proceedings of the Decision and Game Theory for Security, London, UK, 4–5 November 2015; Khouzani, M., Panaousis, E., Theodorakopoulos, G., Eds.; Springer: Cham, Switzerland, 2015; pp. 228–249. [Google Scholar]
- Yao, Q.; Wang, Y.; Xiong, X.; Wang, P.; Li, Y. Adversarial Decision-Making for Moving Target Defense: A Multi-Agent Markov Game and Reinforcement Learning Approach. Entropy 2023, 25, 605. [Google Scholar] [CrossRef]
- Tang, Y.; Sun, J.; Wang, H.; Deng, J.; Tong, L.; Xu, W. A method of network attack-defense game and collaborative defense decision-making based on hierarchical multi-agent reinforcement learning. Comput. Secur. 2024, 142, 103871. [Google Scholar] [CrossRef]
- Wang, H.; Tang, Y.; Wang, Y.; Wei, N.; Deng, J.; Bin, Z.; Li, W. Research on active defense decision-making method for cloud boundary networks based on reinforcement learning of intelligent agent. High-Confid. Comput. 2024, 4, 100145. [Google Scholar] [CrossRef]
- Nyberg, J.; Johnson, P. Learning automated defense strategies using graph-based cyber attack simulations. In Proceedings of the 2023 Workshop on Security Operation Center Operations and Construction, San Diego, CA, USA, 27 February 2023. [Google Scholar]
- Dutta, A.; Chatterjee, S.; Bhattacharya, A.; Halappanavar, M.M. Deep Reinforcement Learning for Cyber System Defense under Dynamic Adversarial Uncertainties. arXiv 2023, arXiv:abs/2302.01595. [Google Scholar]
- Oh, S.H.; Jeong, M.K.; Kim, H.C.; Park, J. Applying Reinforcement Learning for Enhanced Cybersecurity against Adversarial Simulation. Sensors 2023, 23, 3000. [Google Scholar] [CrossRef] [PubMed]
- Kiely, M.; Bowman, D.; Standen, M.; Moir, C. On Autonomous Agents in a Cyber Defence Environment. arXiv 2023, arXiv:abs/2309.07388. [Google Scholar]
- Tsang, H.; Akbari, I.; Salahuddin, M.A.; Limam, N.; Boutaba, R. ATMoS+: Generalizable Threat Mitigation in SDN Using Permutation Equivariant and Invariant Deep Reinforcement Learning. IEEE Commun. Mag. 2021, 59, 105–111. [Google Scholar] [CrossRef]
- DARPA. Cyber Grand Challenge. Available online: https://www.darpa.mil/research/programs/cyber-grand-challenge (accessed on 8 June 2025).
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Terry, J.; Black, B.; Grammel, N.; Jayakumar, M.; Hari, A.; Sullivan, R.; Santos, L.S.; Dieffendahl, C.; Horsch, C.; Perez-Vicente, R.; et al. Pettingzoo: Gym for multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2021, 34, 15032–15043. [Google Scholar]
- Janisch, J.; Pevný, T.; Lisý, V. NASimEmu: Network Attack Simulator & Emulator for Training Agents Generalizing to Novel Scenarios. In Proceedings of the Computer Security. ESORICS 2023 International Workshops, Hague, The Netherlands, 25–29 September 2023; Katsikas, S., Abie, H., Ranise, S., Verderame, L., Cambiaso, E., Ugarelli, R., Praça, I., Li, W., Meng, W., Furnell, S., et al., Eds.; Springer: Cham, Switzerland, 2024; pp. 589–608. [Google Scholar]
- Microsoft Defender Research Team. CyberBattleSim. 2021. Created by Christian Seifert, Michael Betser, William Blum, James Bono, Kate Farris, Emily Goren, Justin Grana, Kristian Holsheimer, Brandon Marken, Joshua Neil, Nicole Nichols, Jugal Parikh, Haoran Wei. Available online: https://github.com/microsoft/cyberbattlesim (accessed on 8 June 2025).
- Standen, M.; Lucas, M.; Bowman, D.; Richer, T.J.; Kim, J.; Marriott, D.A. CybORG: A Gym for the Development of Autonomous Cyber Agents. arXiv 2021, arXiv:abs/2108.09118. [Google Scholar]
- Li, L.; Fayad, R.; Taylor, A. CyGIL: A Cyber Gym for Training Autonomous Agents over Emulated Network Systems. arXiv 2021, arXiv:abs/2109.03331. [Google Scholar]
- Nguyen, H.P.T.; Hasegawa, K.; Fukushima, K.; Beuran, R. PenGym: Realistic training environment for reinforcement learning pentesting agents. Comput. Secur. 2025, 148, 104140. [Google Scholar] [CrossRef]
- Oesch, S.; Chaulagain, A.; Weber, B.; Dixson, M.; Sadovnik, A.; Roberson, B.; Watson, C.; Austria, P. Towards a High Fidelity Training Environment for Autonomous Cyber Defense Agents. In Proceedings of the 17th Cyber Security Experimentation and Test Workshop, New York, NY, USA, 13 August 2024; CSET ’24. pp. 91–99. [Google Scholar] [CrossRef]
- Oesch, S.; Austria, P.; Chaulagain, A.; Weber, B.; Watson, C.; Dixson, M.; Sadovnik, A. The Path To Autonomous Cyber Defense. arXiv 2024, arXiv:cs.CR/2404.10788. [Google Scholar]
- Vyas, S.; Hannay, J.; Bolton, A.; Burnap, P.P. Automated Cyber Defence: A Review. arXiv 2023, arXiv:cs.CR/2303.04926. [Google Scholar]
- Hammar, K.; Stadler, R. Finding Effective Security Strategies through Reinforcement Learning and Self-Play. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; KDD ’16. pp. 855–864. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]




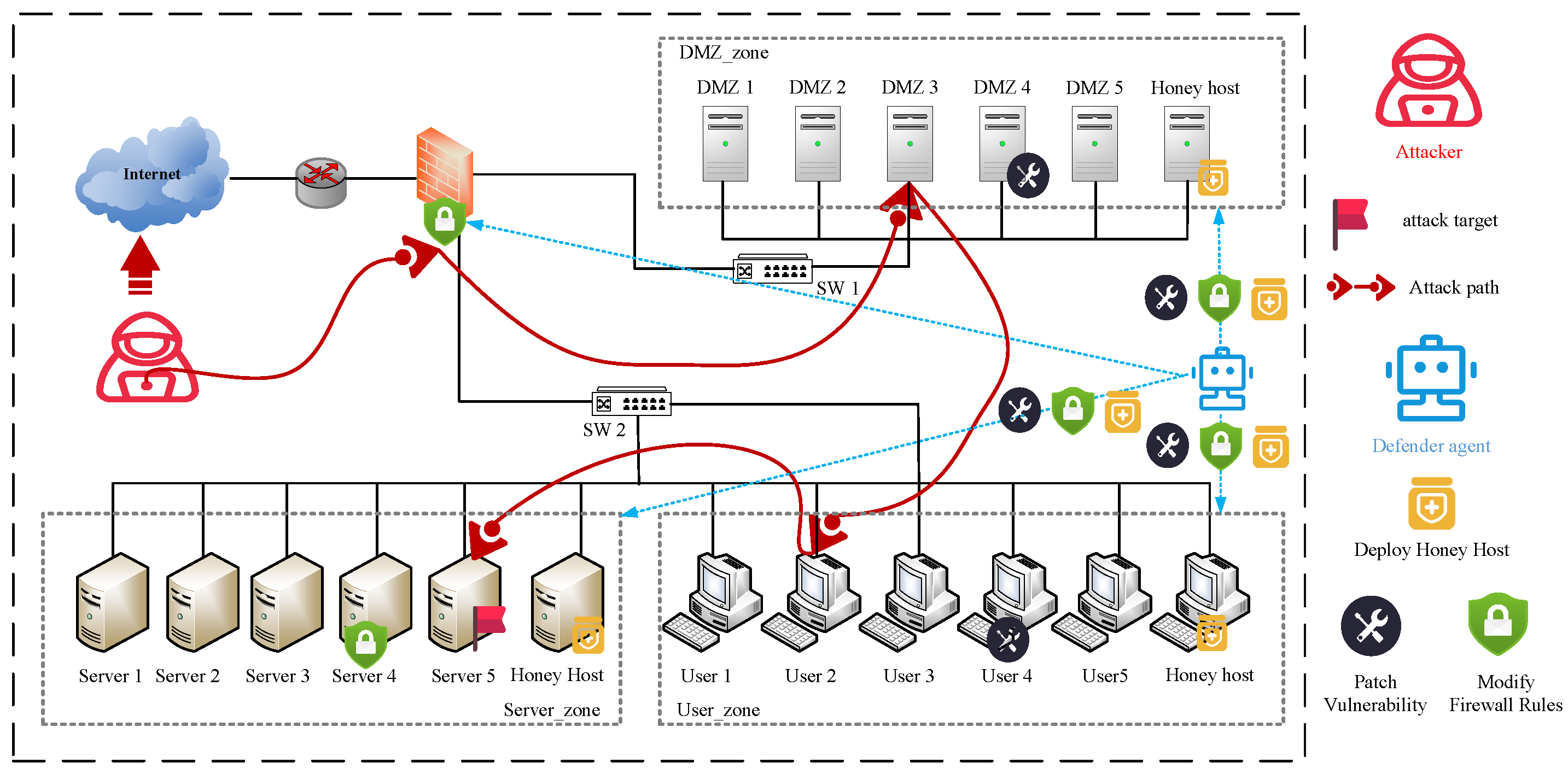





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ATT&CK Kill Chain | Red Agent Action Space Description |
|---|---|
| Gathering information | Collecting vulnerability information of the target network, including network scanning, port service scanning, vulnerability scanning, and social engineering-based information gathering techniques. |
| Vulnerability Discovery | Discovering exploitable vulnerable ports. |
| Exploitation Launching Attacks | Using existing attack payloads or self-made malware. |
| Privilege Escalation | Escalating the operating privileges of the target host. |
| Lateral Movement | Continuing to scan and probe within the internal network, obtaining the network topology and the next exploitable host. |
| Attack Execution | Controlling the target host, stealing confidential information, uninstalling important software, and disrupting normal operation of the system. |
| No Action | Monitoring the current network status. |
| Defense Phase | Blue Agent Action Space Description |
|---|---|
| Monitoring | Gathering information, with alert information on the host to indicate whether the current node has an attacker intelligent agent attack, and obtaining alert information from internal network hosts. |
| Decoy Deployment | Deploying honeypot decoy nodes to trap attackers and hinder their attacks. |
| No Action | Maintaining the current network state. |
| Modifying Firewall Rules | Adding firewall rules to specific target hosts to mitigate or block further attacks from the attacker. |
| Vulnerability Repair | Repairing vulnerabilities on the target host, using existing patches to repair the target host to prevent further penetration by the attacker. |
| Autonomous Defense Cyber Decision-Making | Game Model | Reinforcement Learning |
|---|---|---|
| Defense Decision State Space | Game State Space | Interactive Environment Space |
| Defense Decision-Maker Set | Participant Set | Agent Set |
| Defense Action Set | Participant Action Set | Agent Action Set |
| Defense Strategy Set | Participant Strategy Set | Agent Strategy Set |
| Defense Decision Information Set | Participant Information Set | Agent Observation Information Set |
| Defense Decision Reward | Participant Utility | Agent Action Reward |
| Modules | Parameters |
|---|---|
| PPO Algorithm | Number of layers for actor network: 3 |
| Number of layers for critic network: 3 | |
| Number of nodes for actor layers: (128, 128, 64) | |
| Number of nodes for critic layers: (128, 128, 64) | |
| Learning rate: 2.5 | |
| The surrogate clipping coefficient: 0.2 | |
| The number of mini-batches: 4 | |
| The K epochs to update the policy: 4 | |
| Network Topology | Subnets: dmz_subnet, server_subnet, use_subnet |
| dmz_subnet: 5 hosts | |
| server_subnet: 5 hosts | |
| use_subnet: 5 hosts | |
| Attacker Action | Discovery: ping sweep, port scan |
| Lateral Movement | |
| Privilege Escalation | |
| Impact | |
| Defender Action | Deploy Decoy Host |
| Remove Decoy | |
| Modify firewall_rules | |
| Patch Vulnerability | |
| nothing | |
| Attacker Immediate & Recurring Reward | Discovery: (−2, 0) |
| Lateral Movement: (−4, 0) | |
| Privilege Escalation: (−6, 0) | |
| Impact: (−8, −4) | |
| Defender Immediate & Recurring Reward | Deploy Decoy Host: (−20, −2) |
| Remove Decoy: (0, 0) | |
| Modify firewall_rules: (−10, 0) | |
| Patch Vulnerability: (−10, 0) | |
| nothing: (0, 0) |
| Parameter | Description | Settings |
|---|---|---|
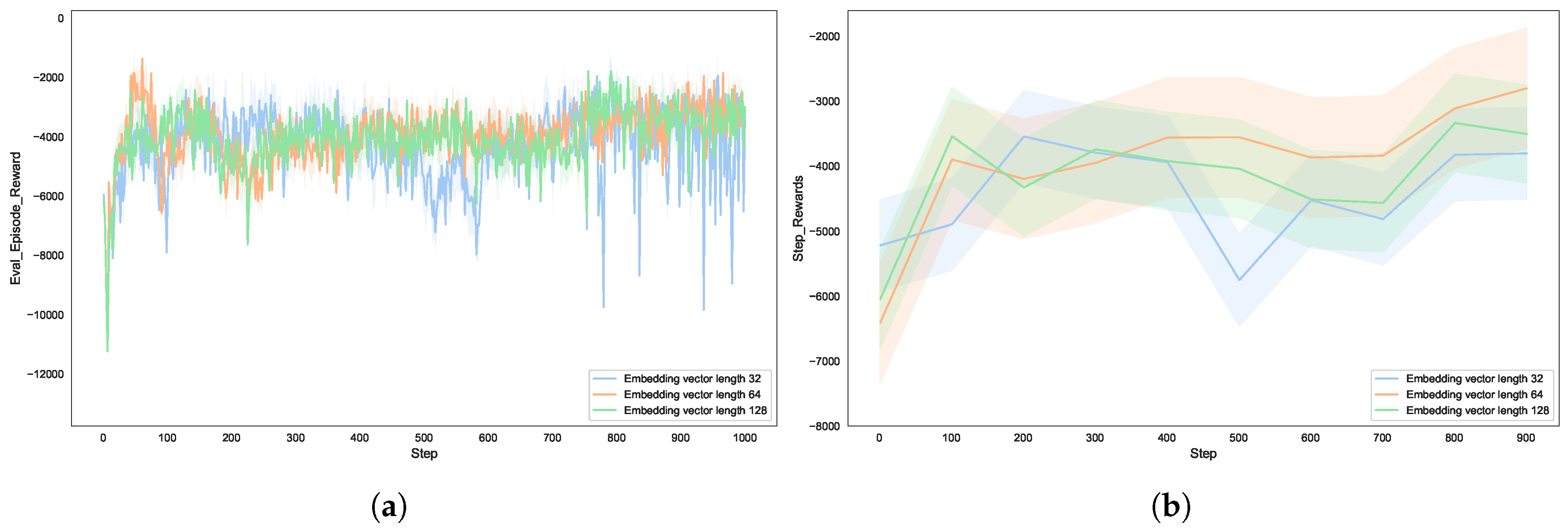
| Walk Length | Number of nodes traversed in a single random walk traversal | 5 10 15 20 |
| Embedding Dim | Dimension of the node characterization vector | 32 64 128 |
| In–out parameter q | Controls the probability of returning to a visited node | 0.5 2 |
| Return parameter p | Controls the balance between BFS and DFS traversal | 0.5 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, Y.; Xiong, X.; Ren, Q.; Huang, J. A Novel Framework for Enhancing Decision-Making in Autonomous Cyber Defense Through Graph Embedding. Entropy 2025, 27, 622. https://doi.org/10.3390/e27060622
Wang Z, Wang Y, Xiong X, Ren Q, Huang J. A Novel Framework for Enhancing Decision-Making in Autonomous Cyber Defense Through Graph Embedding. Entropy. 2025; 27(6):622. https://doi.org/10.3390/e27060622
Chicago/Turabian StyleWang, Zhen, Yongjie Wang, Xinli Xiong, Qiankun Ren, and Jun Huang. 2025. "A Novel Framework for Enhancing Decision-Making in Autonomous Cyber Defense Through Graph Embedding" Entropy 27, no. 6: 622. https://doi.org/10.3390/e27060622
APA StyleWang, Z., Wang, Y., Xiong, X., Ren, Q., & Huang, J. (2025). A Novel Framework for Enhancing Decision-Making in Autonomous Cyber Defense Through Graph Embedding. Entropy, 27(6), 622. https://doi.org/10.3390/e27060622