1. Introduction
Image segmentation remains a fundamental challenge in computer vision, where traditional PCNN models exhibit notable advantages in unsupervised segmentation due to their bio-inspired characteristics. However, their reliance on fixed step-size (ST) settings severely limits practical applications. It was Eckhorn’s research on the visual cortex neurons of cats that gave birth to the PCNN model. The PCNN model’s structure has multiple inputs and a single output and its neurons can work in both excitatory and inhibitory states. The parallel inputs are internally superimposed in time and space dimensions to form a nonlinear output. This phenomenon is the so-called coupling. The PCNN inherits those biologic characteristics and enables image pixels in neighboring areas or that have similar gray levels to cluster together.
During the past few decades, plenty of valuable research studies about this model have emerged in the image processing field. In 2007, Ma et al. [
1] applied the time matrix of release pulse in image enhancement for the first time. In 2009, Zhan et al. [
2] introduced a Spiking Cortical Model (SCM) which had lower computational complexity and higher accuracy than before. Two years later, Chen et al. [
3] modified the sigmoid function of the SCM with a classical firing condition to further simplify the computational complexity. Recently, researchers have put more attention on the intrinsic activity mechanism of neurons, e.g., the heterogeneous PCNN [
4,
5] and the non-integer-step model [
6] are becoming new focuses in the image processing field. In 2021, Liu et al. [
7] proposed the continuous-coupled neural network (CCNN), which could generate a variety of stochastic responses stimulated by different driven signals [
8,
9]. Besides the above research, Wang et al. [
10] proposed an infrared–visible image fusion method using the snake visual mechanism and a PCNN. It mimicked snake vision and enhanced fusion quality, broadening PCNNs’ applications in image fusion. In recent years, PCNNs have found numerous applications in the field of image processing. For example, Hu et al. proposed a remote sensing image reconstruction method based on a parameter-adaptive dual-channel pulse-coupled neural network (Dual-PCNN) in Ref. [
11]. This method achieved excellent results in image noise reduction and fusion, further expanding the application scope of PCNNs in practical image processing. PCNNs have great potential for developing image segmentation algorithms, whose performance deeply relies on appropriate parameter selection. However, how to select the right outputs is still an issue, although many adaptive parameter filtering methods have been proposed [
2,
12,
13,
14,
15,
16,
17].
Although prior studies [
1,
2,
3] have advanced parameter adaptation strategies, the dynamic adjustment mechanism for the step size remains underexplored. Traditional models (e.g., SPCNN) face three key limitations:
Uncontrollable granularity: a large ST leads to over-segmentation (noise sensitivity), while a small ST causes under-segmentation (detail loss).
Generalization constraints: a fixed ST struggles to adapt to diverse gray distributions and complex scenes.
Parameter tuning complexity: a manual ST adjustment is required to balance accuracy and efficiency.
This work aimed to address these issues through dynamic-step-size adaptation.
Here, we try to explore the mechanism of step size working on a dendritic tree. The rest of this paper is organized as follows:
Section 2 begins with a brief inspection of a basic PCNN model and its pulse generator mechanism.
Section 3 reviews two very significant related works, the Simplified PCNN (SPCNN) and non-integer-step-index model.
Section 4 is devoted to the study of the step size in model operation, and some experiments are performed.
Section 5 concludes the whole work.
2. Neuron Structure
The past decades have witnessed great achievements in the neuron structure modification and parameter setting of PCNNs. As a type of bionic neural network [
18], there are four main components in a neuron of a PCNN: the dendrite, the membrane potential, the dynamic threshold, and the action potential, which were also redefined by Lindblad and Kinser [
19] as the feeding input, the linking input, the internal activity, and the pulse generator, respectively. The fundamental elements of Eckhorn’s model consist of distinct leaky integrators which can be implemented by first-order recursive digital filters [
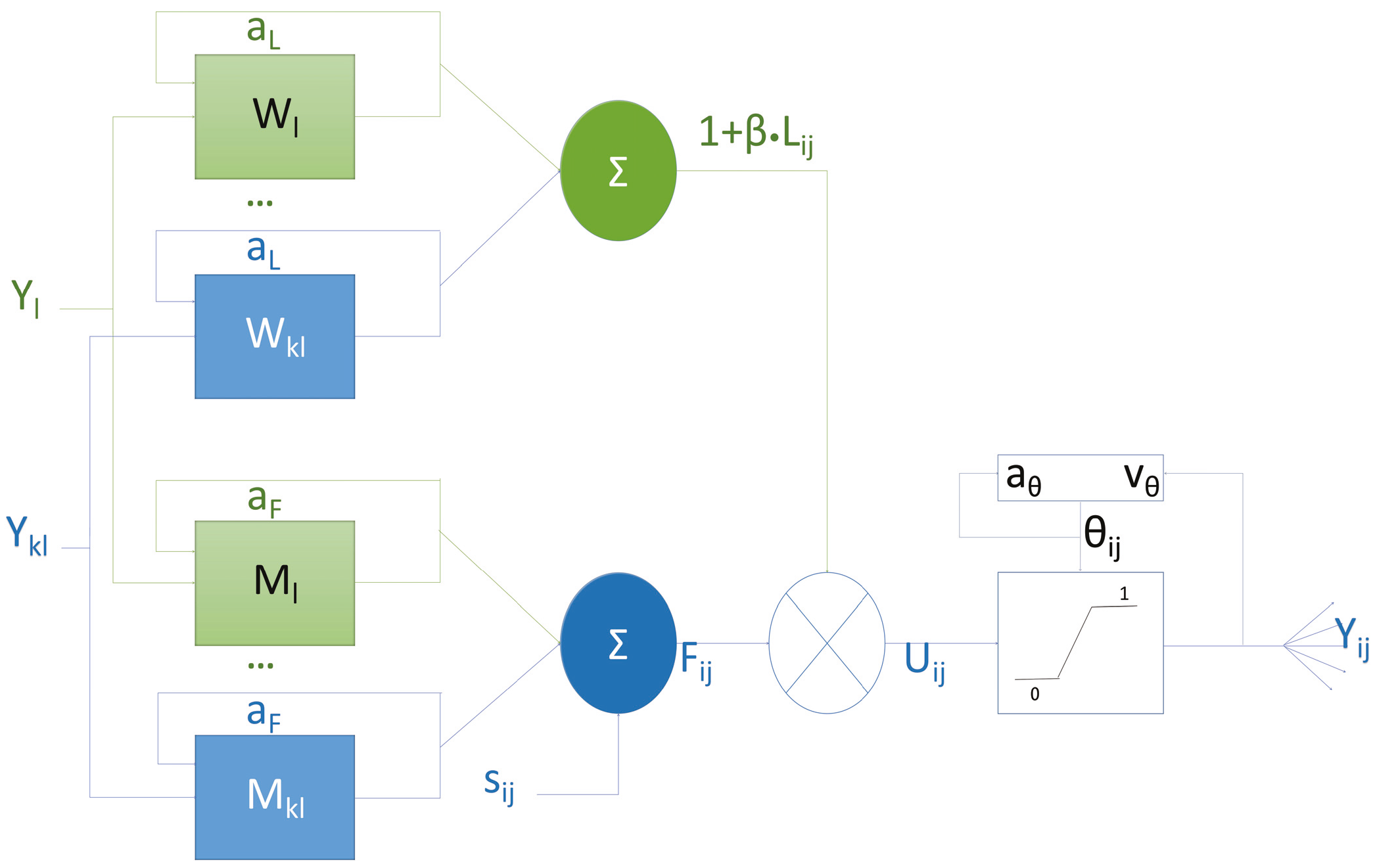
20]. The neuron exhibits bidirectional connectivity, allowing for both the reception of information from neighboring neurons and the transmission of signals to subsequent ones. As shown in
Figure 1, the feeding synapses,
F, receive an external stimulus that is the main input signal, whereas the linking synapses,
L, receive auxiliary signals to modulate the feeding inputs. The nonlinear connection modulation component, also known as the internal activity of the neuron,
U, consists of a linear linking, a feedback input, and a bias. During the process of signal transmission, neuronal electrical signal intensity is full, so two decay factors
and
are set in the transfer process from feeding synapses to other neurons and linking synapses to other neurons, respectively. When a neuron receives a postsynaptic action potential from neighboring neurons, it charges immediately and then decays exponentially. Each neuron is denoted with indices (indices (
)), and one of its neighboring neurons is denoted with indices (k,l). The mathematical expressions of a PCNN are as follows:
And the pulse generator is
: linking input term, where is the linking decay factor, is the linking amplification coefficient, and denotes the neighborhood weighting matrix;
: feeding input term, with as the feeding decay factor, the feeding amplification coefficient, and the spatial coupling matrix;
: internal activity, modulated by (linking strength coefficient);
: dynamic threshold, governed by (threshold decay factor) and (threshold amplification coefficient);
: pulse output (one indicates firing, zero otherwise).
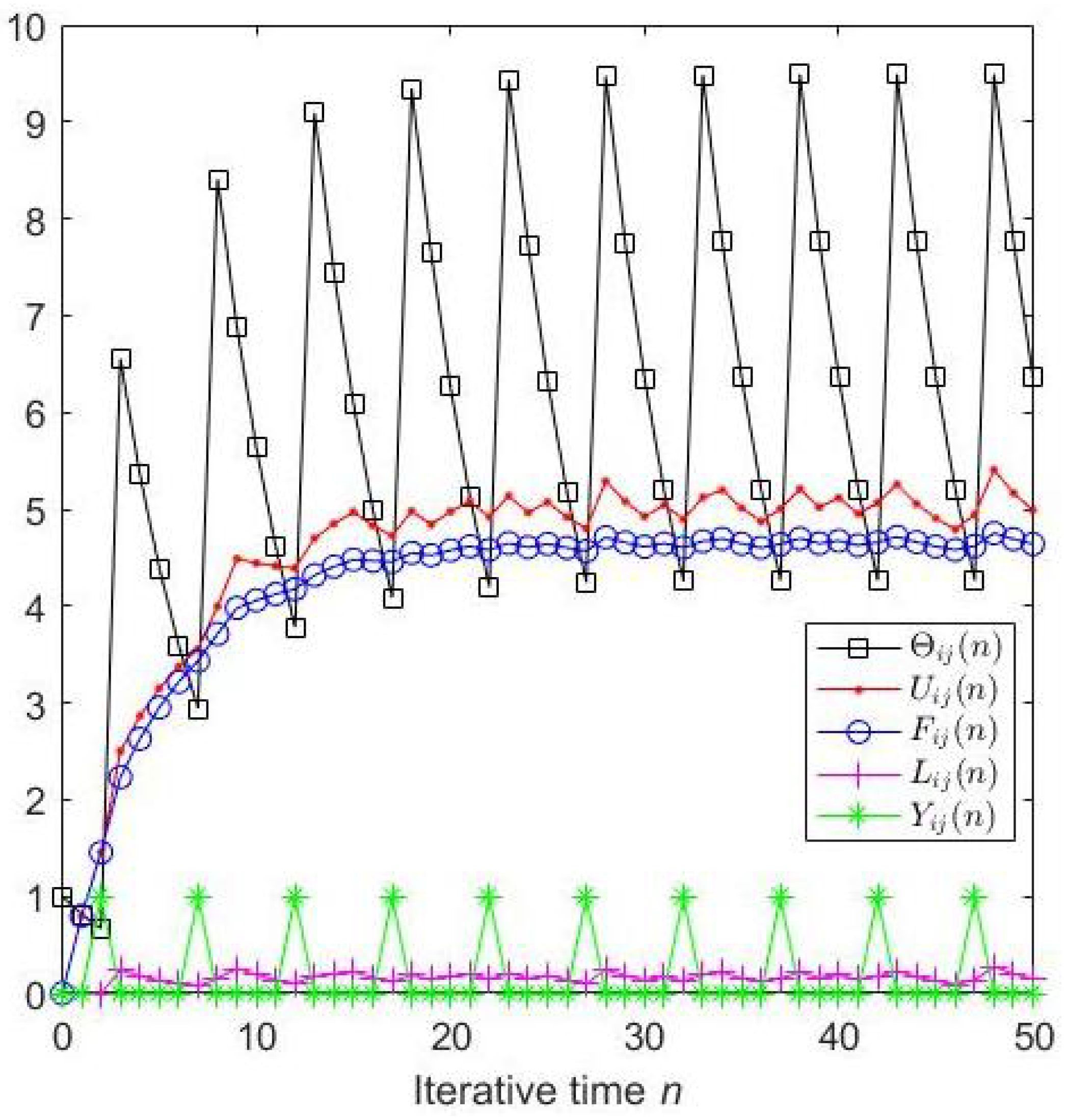
A particular neuron tends to fire at a certain frequency if all the parameters are determined; as illustrated in
Figure 2, after three iterations, the neuron prefers firing periodically. In fact, all neurons show the aforementioned behavior when perceiving different external stimuli, which means the information can be fully perceived merely after a finite number of iterations.
3. Related Works
Recent advances in visual perception modeling [
21] demonstrate that PCNN-based approaches significantly outperform traditional methods in complex background segmentation. Combined with adaptive parameter strategies [
22] and comprehensive application reviews [
23], these developments highlight the growing potential of PCNN in real-time vision systems.
In addition to related works such as the Simplified PCNN (SPCNN) and the non-integer-step-index PCNN mentioned above, there are also studies that explore the PCNN model in depth from different dimensions. Reference [
24] conducted research on the non-coupled PCNN. Based on the traditional non-coupled PCNN model, a linking term was introduced to improve it. By analyzing the firing mechanism of the improved model, it was found that its firing time and interval changed with the firing states generated by the neighborhood and its own firing conditions in each iteration process. That study also delved into the influence of parameters such as the linking weight matrix and the linking coefficient on the network output characteristics, revealing that under specific parameter settings, the non-coupled PCNN could exhibit the network output characteristic of image edge detection, which was verified through numerous experiments. That research achievement enriched the research system of the PCNN model and provided important references for subsequent studies.
Moreover, Xu et al. [
25] proposed a novel adaptively optimized PCNN model for hyperspectral image sharpening. They designed a SAM-CC strategy to assign hyperspectral bands to the multispectral bands and proposed an improved PCNN considering the differences in neighboring neurons, which was applied to remote sensing image fusion and achieved good results, expanding the application scenarios of PCNNs in remote sensing image processing. In addition to these studies, Qi et al. proposed an adaptive dual-channel PCNN model [
26]. They applied it to infrared and visible image fusion, combined with a novel image decomposition strategy, and obtained excellent results, which further broadened the application scope of PCNNs in image fusion .
This section gives a brief overview of SPCNN and non-integer-step-index PCNN, proposed by Chen [
3]. The former put forward a smart automatic parameter setting method; the latter emphasized the leverage of the step size for neurons’ perceptibility.
3.1. SPCNN and Adaptive Parameter
Compared with previous version, the SPCNN not only has a more concise model expression but also makes great progress in automatic parameter setting. The internal activity of the SPCNN consists of a leak integrator, linking input, and feeding input.
where
is the external stimulus, and other parameters have the same meaning as indicated above.
The dynamic threshold
is rewritten as
where
and
have the same meaning as
and
in Equation (
4). For clarity, these symbols are used in this paper.
In addition, the pulse generator of the SPCNN is inherited from the PCNN without any changes. Several main parameters are calculated as follows:
where
denotes the standard deviation of the normalized intensities of an original image. More detail on the proof process can be found in Chen’s paper [
3].
3.2. Non-Integer-Step-Index PCNN
The fact is that the neurons of the PCNN model are usually based on non-integer time, which is often ignored in the discrete form. Thus, non-integer-step-index PCNN changes the integer step into a decimal one to achieve preferable balance between resolution and computational complexity.
To handle a non-integer
in discrete implementations, we adopted a linear interpolation between adjacent iterations. For
(
), the membrane potential is updated as
This ensures smooth transitions while avoiding subscript indexing issues.
where
is the step size.
Though the idea is enlightening, in fact, it is not easy to realize the model in this form. People are used to storing ht output of every stage in an array or matrix, but decimals cannot correspond to a subscript of an array. Instead, the step size can change at each iteration step.
4. Research on Step Size
Generally speaking, in the study of artificial neural networks, it is difficult to monitor the internal processes. If the results of a model are not satisfactory, the first reaction is often to modify parameters. In fact, the model may work well, except that the output does not meet human expectations. If more subgraphs are split, will the result be more accurate? Or can the output include more detail if fewer subgraphs are split? From Equation (
13), we obtain
Subtracting Equation (
16) from Equation (
13) yields
Regarding
t as
, one gets
Expanding Equation (
13) using a first-order Taylor series approximation for
, we have:
Neglecting higher-order terms (
), we substitute the expression into Equation (
13) and derive the discrete form as shown in Equation (
17). This approximation ensures computational tractability while maintaining the dynamic coupling behavior.
Equation (
18) indicates that a variable ST dynamically adjusts segmentation sensitivity by modulating two factors:
Compared to a fixed ST, a variable ST enables adaptive granularity control across iterations.
Equation (
18) bridges non-integer- and variable-step-size models. By substituting
and allowing
to vary per iteration, we extend the discrete PCNN framework to support dynamic-step adaptation. This formulation preserves the biological coupling mechanism while enabling the adaptive control of the membrane potential decay (
) and neighborhood pulse coupling.
Assuming
in Equation (
13), we get Equation (
6), and we get Equation (
18) from Equation (
13), so if we assume
in Equation (
18), then we get a
U equal to one in Equation (
6):
For programming convenience, the indices should be integers. Thus, if
changes, we have to use a new step size (ST) to replace
, and the former equation is rewritten as
Equation (
16) equals
as
. Let us use
n instead of
n+1 and introduce
into Equation (
22); we can get the same result:
Via the former derivations, we extend Equation (
16), which is an important hidden intermediate procedure that shows that the ST can actually change across iterations. The ST can affect the image segmentation result significantly. When ST equals to one, the model is the traditional SPCNN, and it becomes the non-integer-step-index model when ST is decimal. However, the latter is still a fixed-step-size model, whose application scope is limited.
The PCNN can capture both grayscale level and position information of pixels in an image. Here, we explore the function of the ST in grayscale perception.
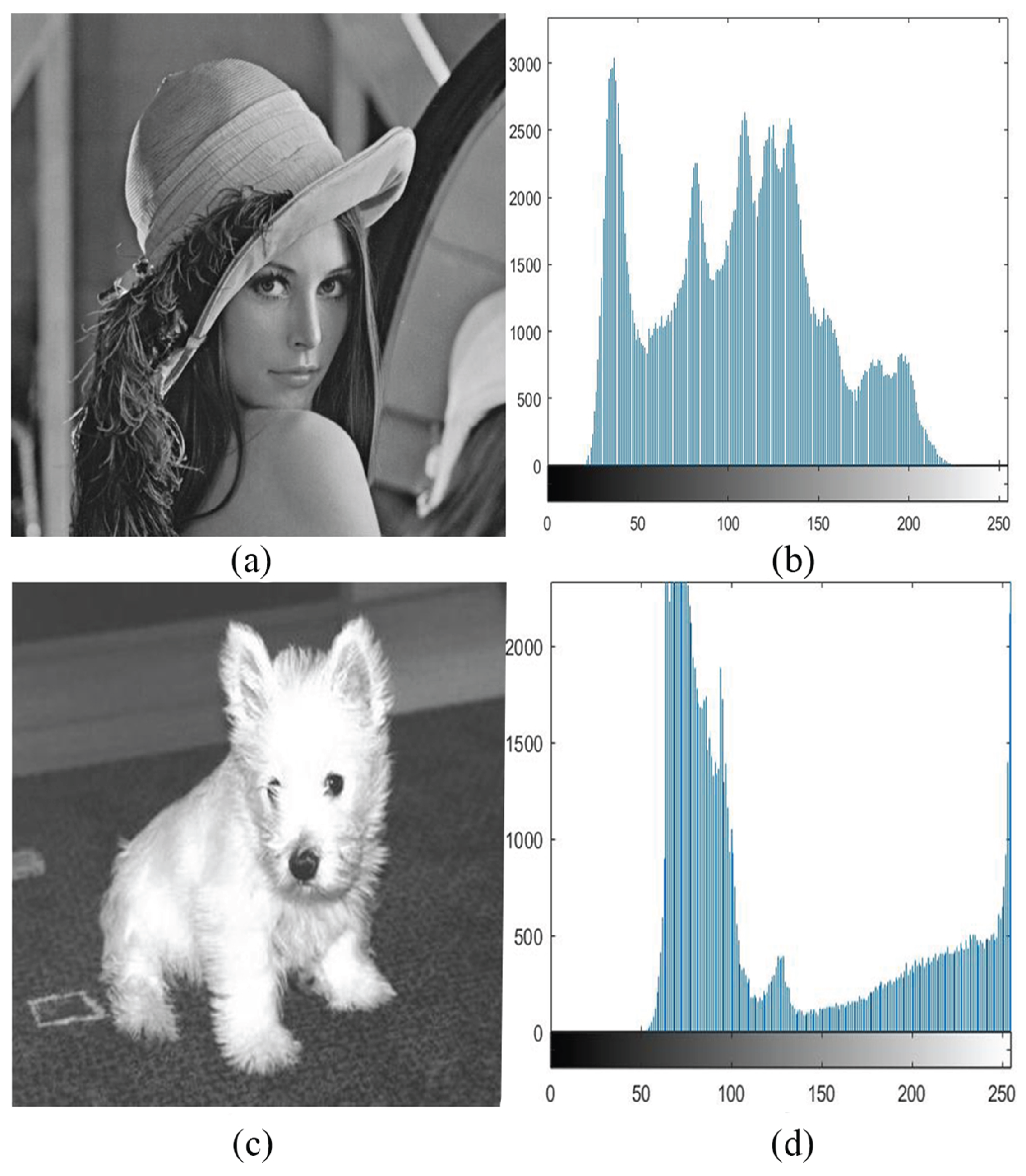
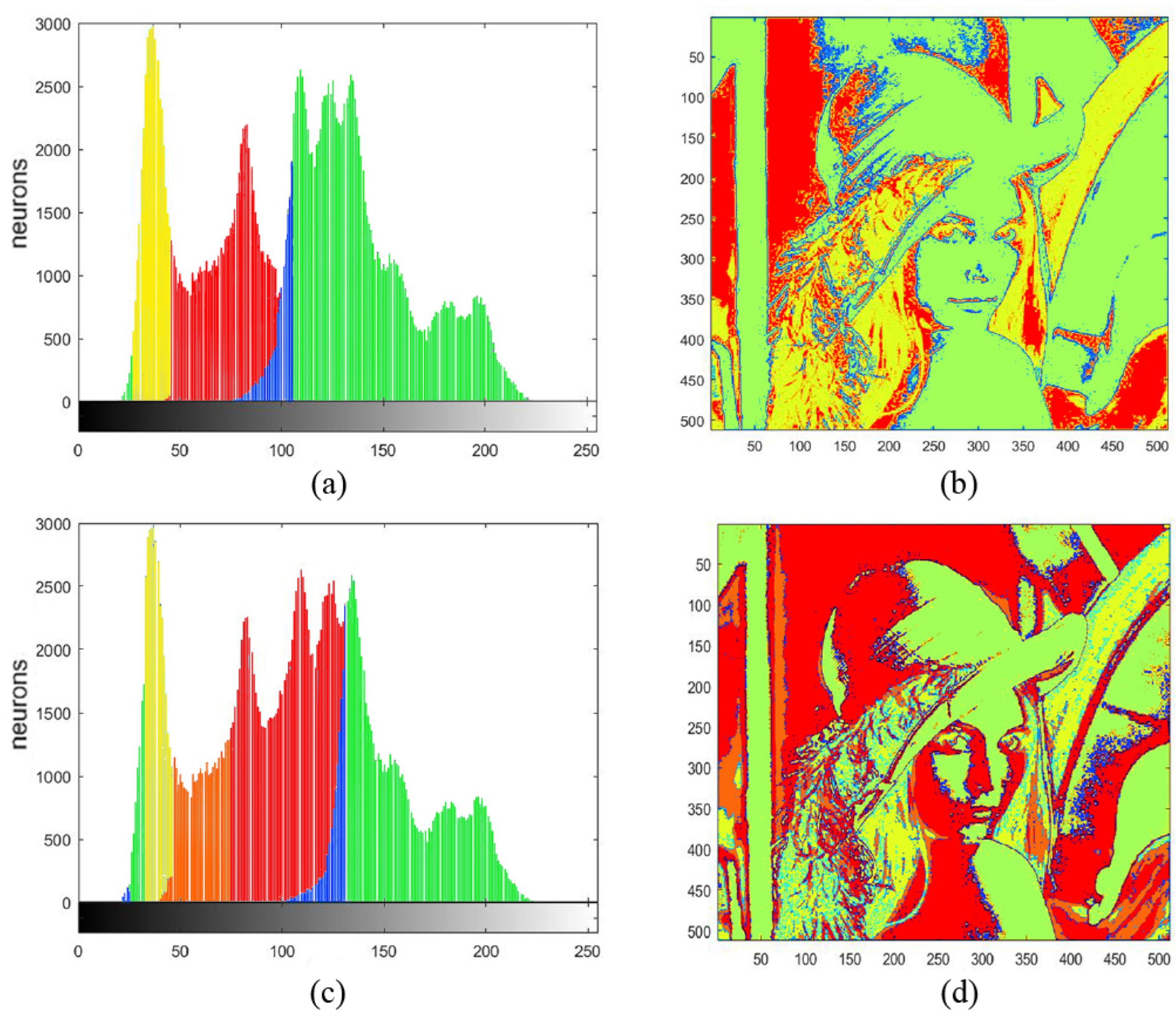
Figure 3a,c show two images used in the experiment, and
Figure 3b,d are their corresponding histograms. We took “Lena” as an example to show how the ST works on determining a threshold according to grayscale level and position.
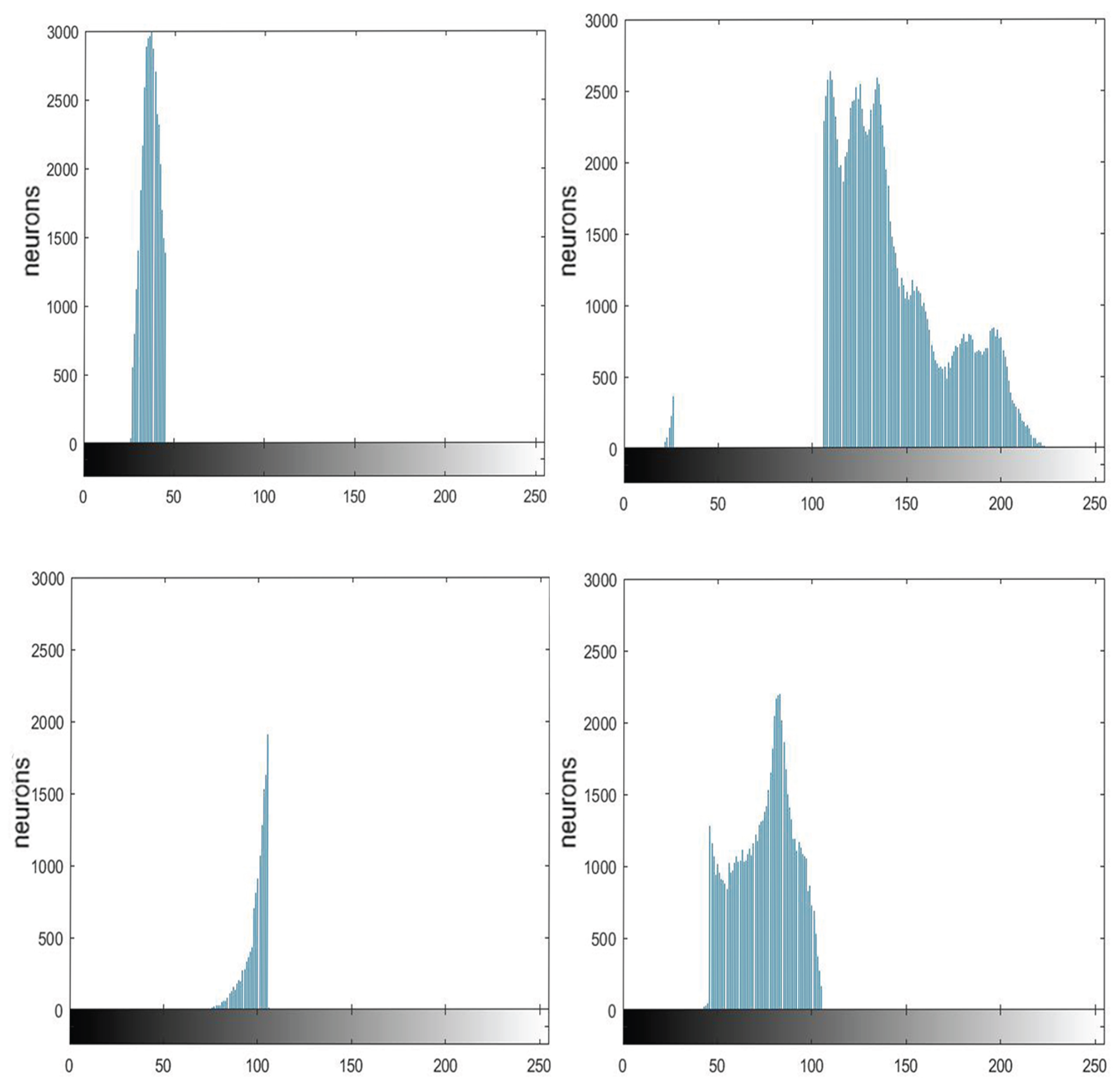
Figure 4 displays the histograms of four components of the image “Lena” separated by the SPCNN with ST = 1. For simplicity, these four histograms were marked with different colors and the corresponding pixels were labeled with the same color as in
Figure 5a and b, respectively. In addition,
Figure 5c,d represent the marked histograms and image when ST = 0.6. The pixels were recorded and displayed with the same colors as in
Figure 5b,d. When the ST became smaller, the largest interval (e.g., the blue part in
Figure 5c) tended to split first. In the meanwhile, these adjacent intervals occupied the extreme parts of the plot. Notice that there was always a small blue area between the two largest intervals, which was less affected. In fact, that area represented the boundary between the foreground and the background. We could use it as the threshold for binary segmentation. It can be observed that the segmentation result did not strictly rely on the threshold, as the spatial information between different pixels was taken into account, i.e., a neuron was easier to trigger if its neighbors had already fired, since the convolution operation could include the neighboring neurons’ information. This phenomenon is known as synchronous firing, which enables the PCNN to remove isolated noise. This ability becomes weak for a smaller ST, which causes more clusters to emerge, as shown in
Figure 5a,c. Thus, the neurons at the edge of two groups can even cluster into a new group, like the orange part in
Figure 5c. On the contrary, we can obtain more complete and continuous results when the ST is increased.
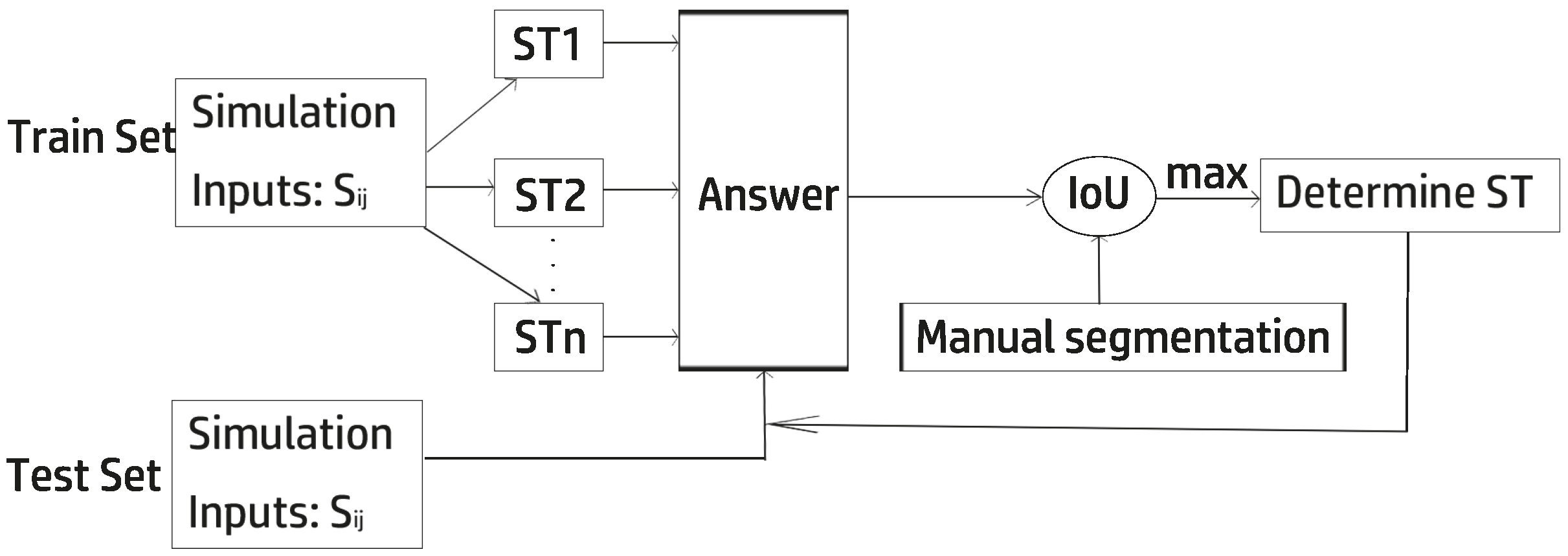
However, the selection of a suitable ST is full of challenges since a larger value enables more neurons to synchronously fire but a lower ability to distinguish objects, while a smaller ST has a higher distinctive ability, but more noise emerges. As the SPCNN segmentation deeply rely on the grayscale information of the image, we could let the images with similar grayscale values share the same step size. We can determine the best step size of these images with manually segmented results using an evaluation metric like the intersection over union (IoU).
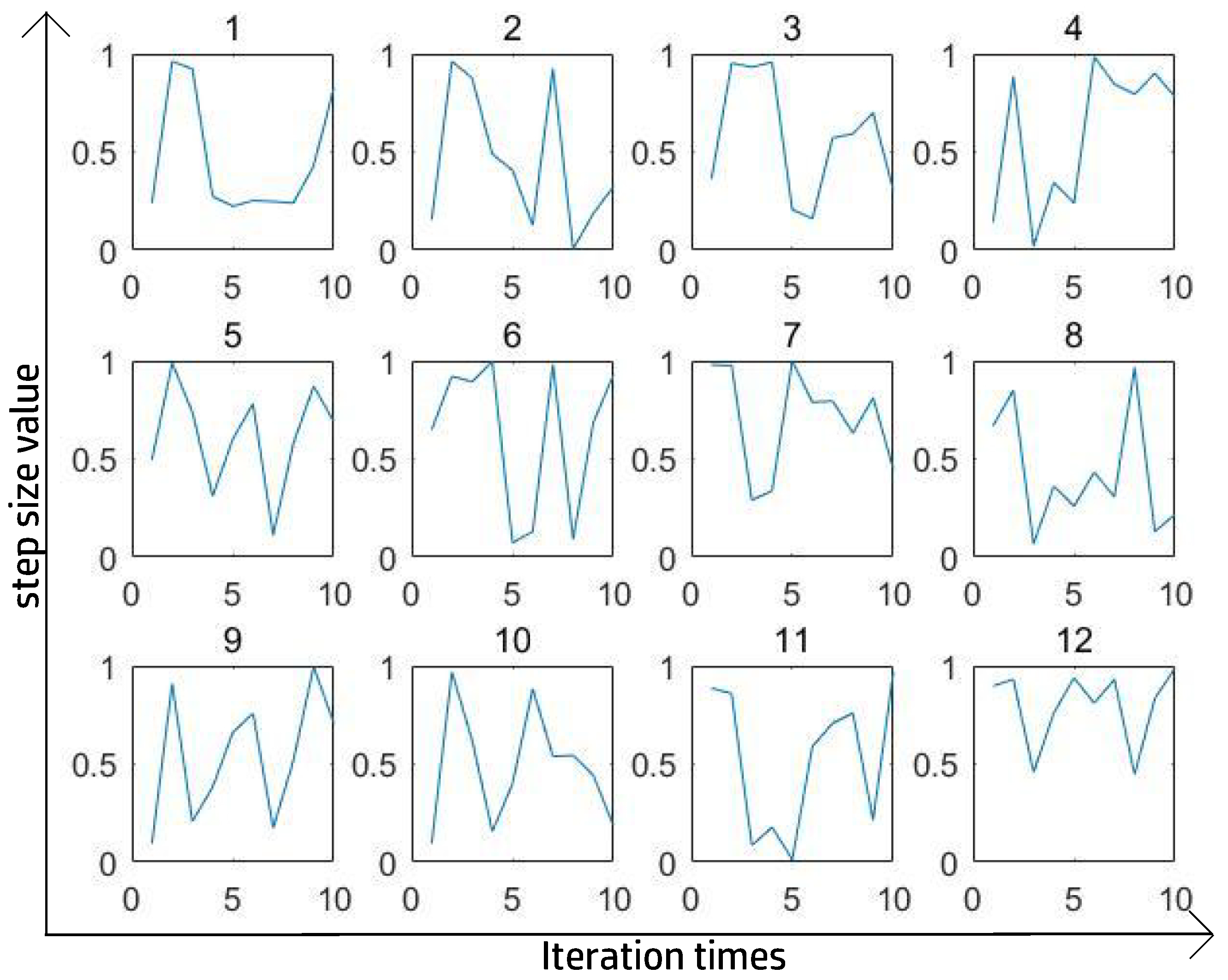
Figure 6 and
Figure 7 show the best 12 ST curves in 100 iterations with a totally random ST at each step. The criterion for perfect segmentation was to ensure the highest IoU. After a large number of experiments and after removing some extreme values, we found that the trigonometric function could fit the ST curve relatively well and consumed less time than using a totally random number.
The ST value was expected to be in the interval [0, 1] to ensure the PCNN model can sufficiently distinguish between inputs, so we assumed ST to be
where
t is the iteration time, and
is a randomness parameter affecting the time of the first peak of ST curve.
The sinusoidal function (Equation (
23)) was chosen over linear/exponential alternatives for three reasons: (1) Periodicity ensures cyclic exploration of granularity levels, avoiding local minima; (2) The bounded output
matches the ST range; (3) Parameter efficiency (only
and
w). Biologically, the sine function mimics neural oscillations observed in cortical networks [
8], where rhythmic firing enhances feature discrimination. Mathematically, the derivative
naturally modulates edge sensitivity by amplifying gradient changes (see
Figure 8).
According to (
22), an ST of
is one step behind, so it is equivalent to the cosine operation. During the iteration process, the sine item of
and the cosine item of
work on
together. Therefore, the internal activity
U varies spirally, which is a unique characteristic of this new mechanism.
Extensive experiments showed that
w was related to the standard deviation of the normalized image. Thus, let
w be equal to
and
is in the range [0, pi/
w].
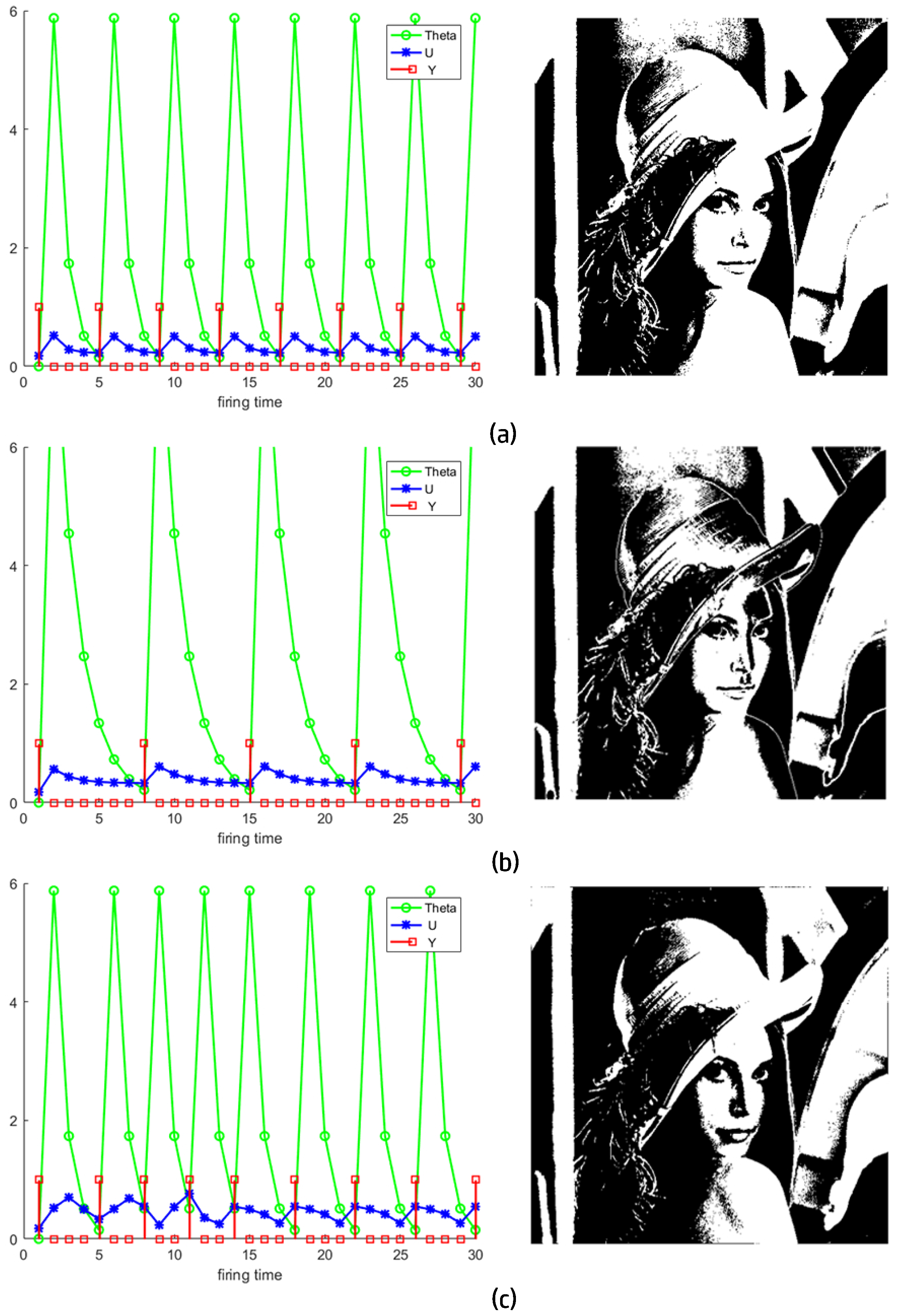
Figure 9 shows the neurons activity of the aforementioned scheme and the final segmentation results (Algorithm 1). When the ST gets smaller, the image tends to be divided into more parts, but for the variable-step-size PCNN, it is an exception. It is striking that although the ST in Equation (
24) is always smaller than one,
Figure 9c has less parts than
Figure 9a. In this example,
was not considered.
However, it is clear that in the first iteration of the variable-step-size PCNN in
Figure 9c, the model narrows down the target area and ignores those bright parts of the wall behind the character, compared to what SPCNN achieves in
Figure 9a.
To determine the best ST, as
w is related to the statistical information of the image, we only considered the value of
to simplify the problem. Because
Figure 9c showed better results than
Figure 9a, we believed that the ST in the former outperformed the latter, and the
of the former was recorded until we encountered a better ST. Many ways are available to find the best segmentation; one of the most effective ones is via the IoU metric.
Figure 10,
Figure 11 and
Figure 12 shows how the variable-step-size PCNN works. The training and test sets are independent, and obtaining ST actually means obtaining
. The optimal ST is obtained when the maximum IoU between manual and automatic segmentation is reached. With that ST, the images in the test set are segmented perfectly. In experiments, the higher the cosine similarity between the test set and the training set, the better the performance.
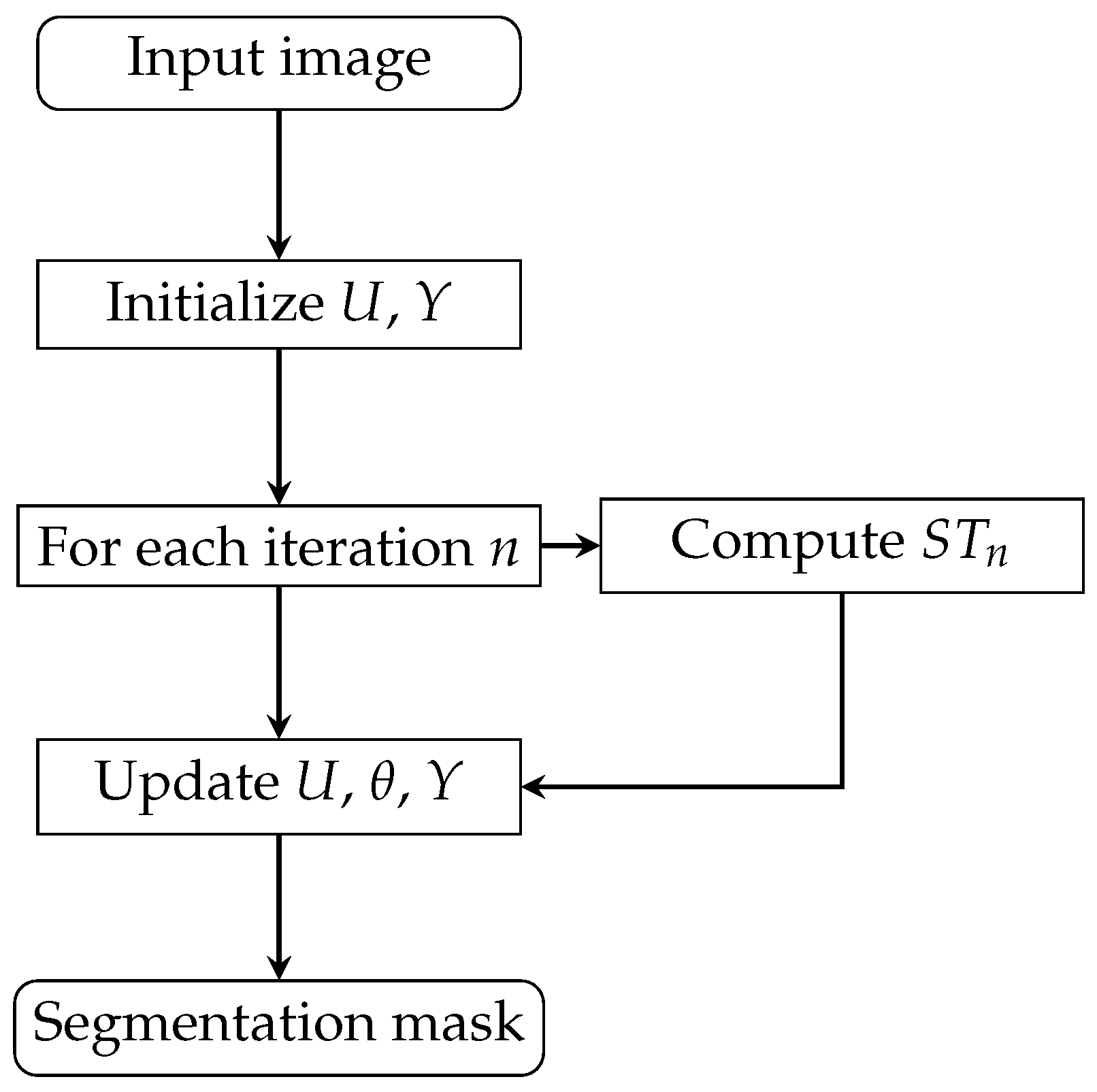
| Algorithm 1 Variable-step-size PCNN segmentation |
Require:
Input image , max iterations , image std
Ensure:
Segmentation mask - 1:
Initialize , - 2:
Compute {Equation (24)} - 3:
for to do - 4:
{Dynamic step size} - 5:
Update via Equation (20) {Membrane potential} - 6:
Update via Equation (4) {Dynamic threshold} - 7:
{Pulse generator} - 8:
end for
|
6. Experimental Results
In this section, we used nine images from the Berkeley Segmentation Dataset to verify the proposed scheme (
Table 2), as in [
3]. We utilized false colors to mark those neurons firing at different times. The earlier the neuron fires, the cooler its color. From cold to warm, the colors were blue, light blue, green, yellow, orange, and red.
| Image # | Values |
|---|
| 1–5 | 1.1677 | 1.1530 | 1.8341 | 1.5734 | 0.9053 |
| 6–9 | 0.6194 | 0.0664 | 0.9791 | 1.1434 | 0.9915 |
Figure 13.
Segmentation results of nine natural gray images from the Berkeley Segmentation Dataset. Each row illustrates the experiment of one image. Respectively, images in the first column are the original input images. Images in column (
a) are binarized images. Images in column (
b) are the final segmentation results obtained by the SPCNN with the proposed automatic parameter setting method. Images in column (
c) are the final segmentation results obtained by the random PCNN with ST produced by the method in
Figure 10 (1000 pictures in training set).
Figure 13.
Segmentation results of nine natural gray images from the Berkeley Segmentation Dataset. Each row illustrates the experiment of one image. Respectively, images in the first column are the original input images. Images in column (
a) are binarized images. Images in column (
b) are the final segmentation results obtained by the SPCNN with the proposed automatic parameter setting method. Images in column (
c) are the final segmentation results obtained by the random PCNN with ST produced by the method in
Figure 10 (1000 pictures in training set).
For the first image, (c1) removed noise on the giraffe but split the background in (b1) into two parts. However, we obtained a better output when we used the method mentioned previously, i.e., separately find a threshold and obtain parts.
(c2) merged the yellow part and orange part in (b2) into a green part but split the background into two parts.
(c3) made a mistake as it considered the clothes as background. This was because another background candidate was too complex and would have divided the image into many small parts around the white rocks on the ground.
(c4) removed noise on the sea in (b4) and created clearer boundaries between the sea and the sky and between the person and the sea.
(c5) merged the two parts of the plane in (b) and removed the noise at the bottom left but also produced some strange new noises at the top left and right.
(c6) successfully merged the green part, yellow part, and brown part in (b6) into a brown part.
(c7) merged the green part and yellow part in (b7) into a red part. Incidentally, the processing of the background in (c7) was more similar to that of (a7).
(c8) removed the noise at the top right and narrowed the green area. We think this was more reasonable than (b8).
In (c9), although there were partial branches considered as foreground, our method was comparatively much better than the other methods. It is undeniable that that image was too complex for all algorithms, and no method could effectively pick out the leopard.
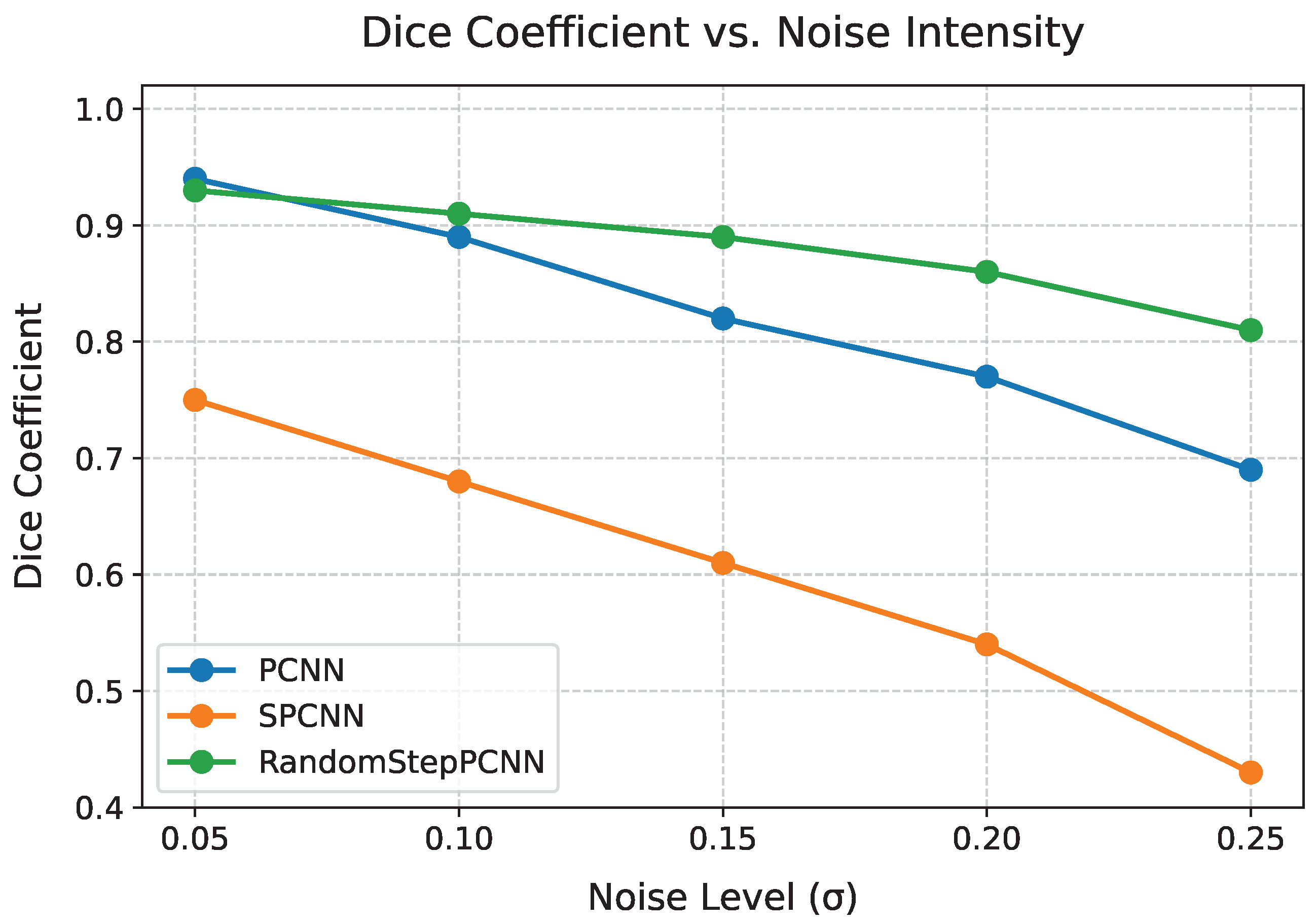
Table 3 reveals the enhanced noise robustness of our model. Under high noise (
), RandomStepPCNN maintained 92.1% of its baseline Dice score (0.901 vs. 0.933 at
), while PCNN dropped to 69.4% (0.694 vs. 0.883).
Figure 14 further demonstrates this stability through continuous noise variations. Notably, while UNet [
27] achieved higher recall (TPR = 0.9966) due to its deep architecture, our random PCNN demonstrated a superior IoU (0.8863 vs. 0.5116) and computational efficiency (0.8684 s vs. 1.16 s), indicating better balance between accuracy and speed for real-time applications.
The objective evaluation was measured by the IoU, cross-entropy, true positive rate (TPR), and true negative rate (TNR), which are shown in
Table 4.
According to
Table 4, the variable-step-size PCNN achieved much smaller cross-entropy [
29] than other models. This is because it divides the image into several pieces, and there is always one piece with a high probability of being close to the optimal segmentation result.
TPR and TNR depict the similarity between segmentation result of a specific algorithm and manual segmentation in another way [
30]. Since the outputs of the variable-step-size PCNN was finer, the TPR was lower, and the TNR was higher than those of the SPCNN.
Compared to U-Net, our model achieved a balance between accuracy and speed. While U-Net relied on its deep architecture for a high recall, our method’s lightweight design enabled faster processing (0.868 s vs. 1.16 s) with a competitive IoU, making it suitable for real-time applications.
Benchmarking Against Modern Architectures
As shown in
Table 5, an essential characteristic was demonstrated: our model could process 512 × 512 images in 868 ms on a CPU (i9), achieving 83.6% of U-Net’s GPU-accelerated accuracy (IoU = 0.886 vs. 0.892).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}