
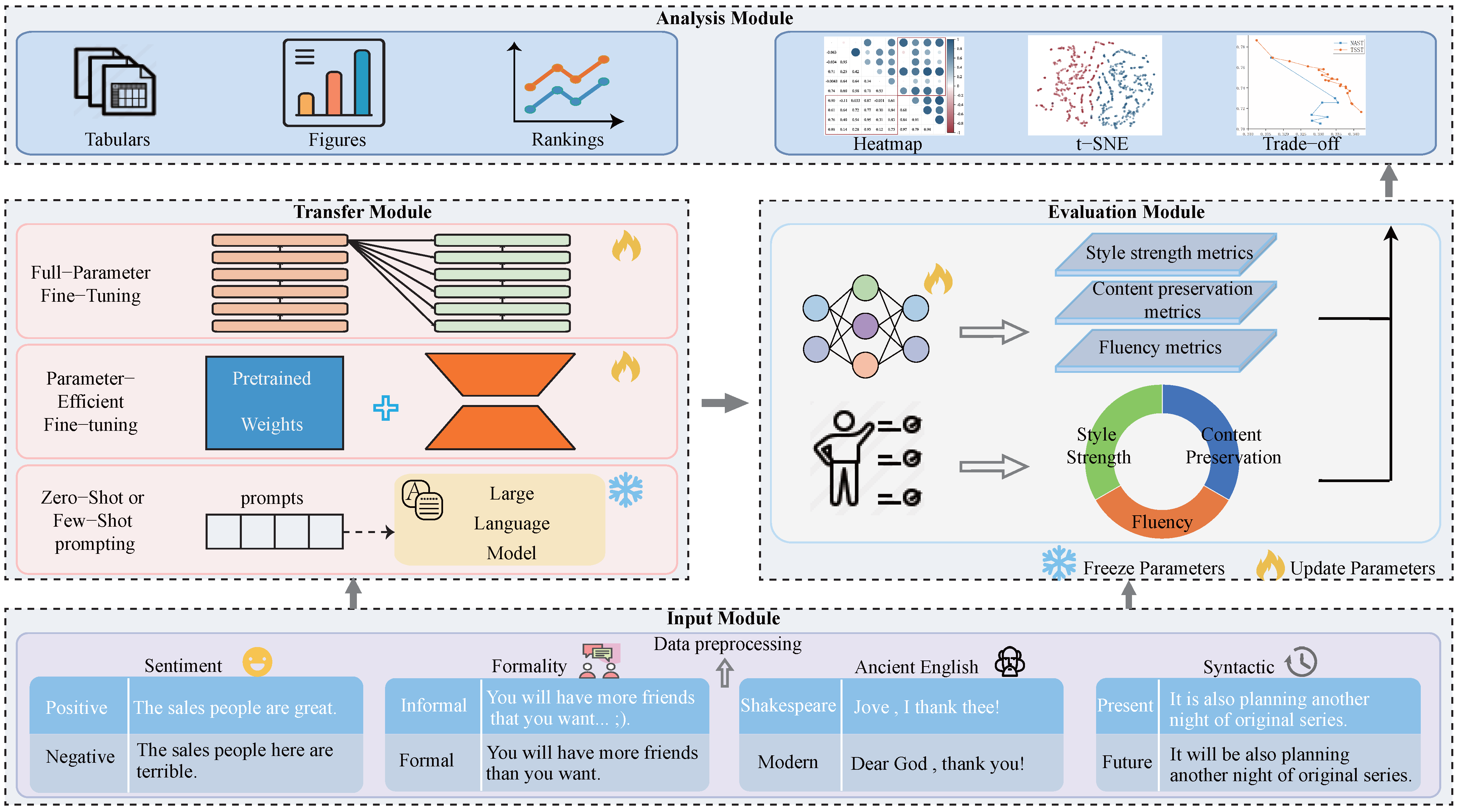
TSTBench: A Comprehensive Benchmark for Text Style Transfer



Abstract
1. Introduction
- We replicate and compare 13 text style transfer algorithms across seven datasets, providing both code and outputs.
- We provide a unified evaluation framework, utilizing 10 different evaluation metrics, which yield over 7000 evaluation outcomes. Our modular architecture allows researchers to integrate new methods and datasets, facilitating fair comparisons within a standardized evaluation environment.
- We conduct a thorough analysis and have obtained new findings and conclusions. We have made our code publicly available on GitHub (https://github.com/FayeXXX/A-Benchmark-of-Text-Style-Transfer (accessed on 28 April 2025)).
2. Related Work
2.1. TST Algorithms
2.2. Related Benchmarks
3. TSTBench
3.1. Baseline Algorithms
3.2. Datasets
3.3. Evaluation Metrics
3.3.1. Automatic Evaluation
3.3.2. Human Evaluation
3.4. Codebase
4. Evaluations and Analysis
4.1. Experimental Settings
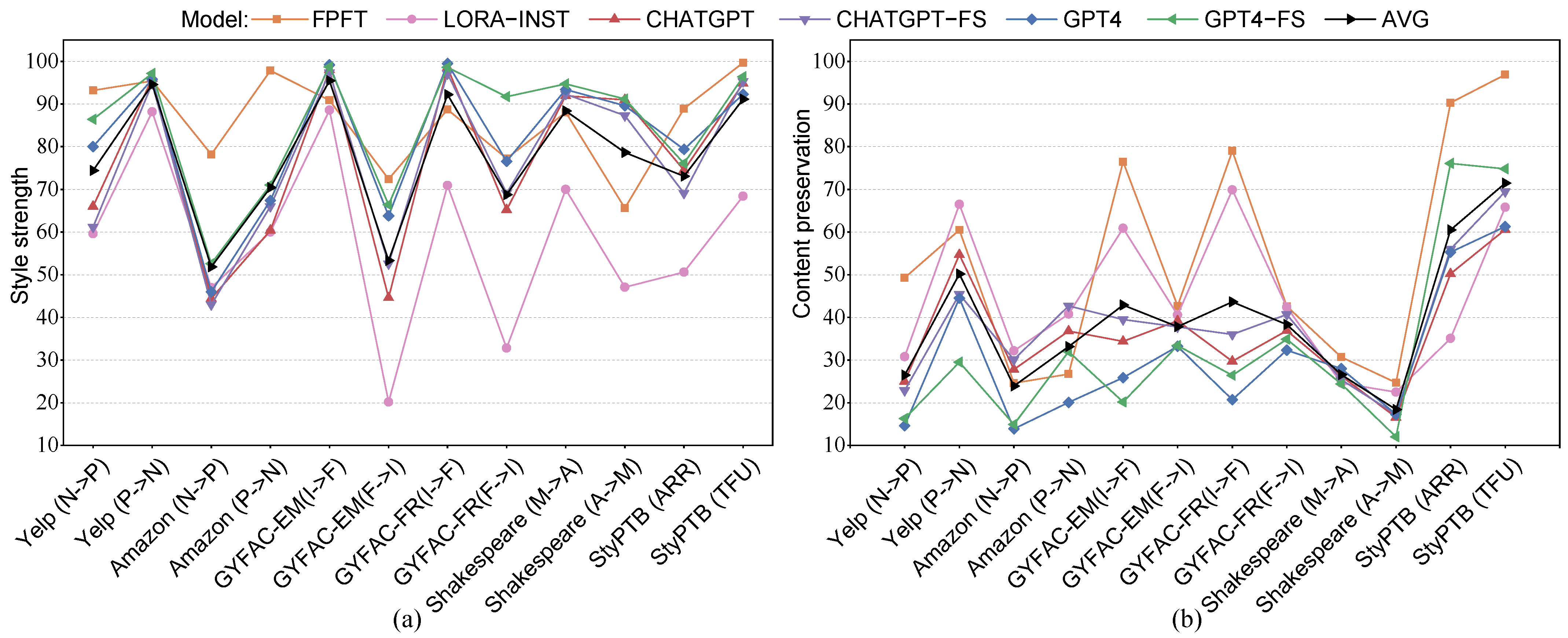
4.2. Overview of Model Performances Across Styles
| Finding 1: No single model performs exceptionally well across all evaluation metrics, and there are no universally applicable algorithms. Furthermore, as performance varies across different transfer directions within the same style, we recommend clarifying the direction of style transfer when evaluating its performance. |
4.3. Comparison Between LLMs and Fine-Tuned Models on TST
4.4. Human Correlation of the Evaluation Metrics
| Finding 2: The disparity between human preference, which strongly favors LLMs in TST tasks, and the inadequacy of automatic evaluations suggests that current evaluation metrics may not be suitable for assessing the performance of LLM models. The performance of most LLMs does not exceed that of fine-tuned SOTA models. |
| Finding 3: The current automatic evaluation metrics are constrained by adversarial challenges, dataset-dependent variations in correlation coefficients, and the unreliability of perplexity scores compared to human ratings. Furthermore, disparities in the rankings of automatic evaluation metrics against human assessments highlight the need for specific prompts or guiding mechanisms to improve the robustness and applicability of these metrics. |
4.5. Contents in Appendixes A and B
- Appendix A Algorithms and implemented details in TSTBench:
- -
- Appendix A.1: Descriptions of algorithms in TSTBench;
- -
- Appendix A.2: Various evaluation methods in existing TST algorithms;
- -
- Appendix A.3: Prompts in our experiment.
- Appendix B Additional results and analysis:
- -
- Appendix B.1: Sentiment transfer;
- -
- Appendix B.3: Ancient English transfer;
- -
- Appendix B.4: Fine-grained syntactic and semantic style transfer;
- -
- Appendix B.5: Analysis of trade-off curves;
- -
- Appendix B.6: Case study.
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Algorithms and Implemented Details in TSTBench
Appendix A.1. Descriptions of TST Algorithms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Style Strength | Content Preservation | Fluency | Overall |
|---|---|---|---|---|---|
| STYTRANS [4] | Yelp, Imdb | FastText | s_BLEU, r_BlEU | PPL (KenLM) | - |
| TSST [6] | Yelp, GYAFC-FR | BERT-based | s_BLEU, r_BLEU | PPL (KenLM) | G4 (s-BLEU, r-BLEU, ACC, Fluency) |
| NAST [50] | Yelp, GYAFC-FR | RoBERTa-base | s_BLEU, multi_BLEU | PPL (GPT2-base) | G2, H2 (multi-BLEU, ACC) |
| STRAP [9] | GYAFC-EM, Shakespeare | RoBERTa-large | SIMILE | COLA | J (ACC; Content; Fluency) |
| BSRR [8] | Yelp, Amazon, GYAFC-EM/FR | Roberta-base | multi_BLEU, multi_BERT | - | G2, H2 (multi-BLEU, ACC) |
| TYB [7] | GYAFC-EM/FR | TextCNN | BLEURT, multi_BLEU | - | H2 (multi-BLEU, ACC) |
| CTAT [5] | Yelp, Amazon | FastText | multi_BLEU | SRILM | - |
Appendix A.2. Various Evaluation Methods in Existing TST Algorithms
Appendix A.3. Prompts in Our Experiment
| Dataset | Prompts |
|---|---|
| Yelp | Rewrite the following sentence, maintain the content and change the sentiment of the sentence from negative to positive: |
| Rewrite the following sentence, maintain the content and change the sentiment of the sentence from positive to negative: | |
| Amazon | Rewrite the following amazon comment, maintain the content and change the sentiment of the sentence from negative to positive: |
| Rewrite the following amazon comment, maintain the content and change the sentiment of the sentence from positive to negative: | |
| GYAFC-EM/FR | Change the style of the sentence from informal to formal: |
| Change the style of the sentence from formal to informal: | |
| Shakespeare | Change the style of the following sentence from Shakespeare English to modern English: |
| Change the style of the following sentence from modern English to Shakespeare English: | |
| StylePTB-ARR | Remove adjectives and adverbs of the following sentence: |
| StylePTB-TFU | Convert the following sentence into the future tense: |
| Dataset | Prompts in Few-Shot Experiments |
|---|---|
| Yelp | Here are some examples of how to rewrite: example 1. ’bottom line : overpriced, bad service, shitty beer .’ is rewritten as ’Bottom line: premium pricing, good service, and unique-tasting beer.’; example 2. ’this is the worst giant eagle i ’ve ever been to .’ is rewritten as ’this is the best giant eagle i ’ve ever been to .’; example 3. ’the constant passing of guests was quite irritating .’ is rewritten as ’The regular flow of guests brought a lively and engaging atmosphere.’\Now rewrite the sentence: |
| Amazon | Here are some examples of how to rewrite: example 1. ’the worst part is the grate … not sure what else to call it .’ is rewritten as ’The beat part is the grate—quite a unique element indeed.’; example 2. ’the color is much different in person than how it appears online .’ is rewritten as ’The color is even more captivating in person than it appears online!’; example 3. ’if you still want it, wait at least till the price drops dont pay $ for it . not reccommeneded .’ is rewritten as ’if you still want it, wait till the price drops. highly reccommeneded .’\Now rewrite the sentence: |
| GYAFC-EM | Here are some examples of how to change: example 1. ’the movie the in-laws not exactly a holiday movie but funny and good!’ is rewritted as ’the in-laws movie isn’t a holiday movie, but it’s okay.’; example 2. ’they are comming out with plenty more games.’ is rewritten as ’they are coming out with many more games.’; example 3. ’i dunno but i just saw the preview for the season finale and i am sooooooooooo excited!!!’ is rewritten as ’i don’t know, but i just saw the preview for the season finale. i’m sooooo excited!’\Now change the style of the sentence: |
| GYAFC-FR | Here are some examples of how to change: example 1. ’i need to know what 2 do’ is rewritten as ’i need to know what to do.’; example 2. ’sms if you still can’t contact, 5.’ is rewritten as ’message me and if you have any trouble contacting me, try the number five.’; example 3. ’i don’t know but if you find out please let me know lol’ is rewritten as ’i do not know but if you find out please inform me.’\Now change the style of the sentence: |
| Shakespeare | Here are some examples of how to change: example 1. ’i have a mind to strike thee ere thou speak’st .’ is rewritten as ’i have half a mind to hit you before you speak again.’; example 2. ’well, i know not what counts harsh fortune casts upon my face, but in my bosom shall she never come to make my heart her vassal.’ is rewritten as ’well, i can not tell how my difficult life has weathered my face, but i will never let those difficulties subdue my courage.’; example 3. ’my visor is philemon’s roof ; within the house is jove .’ is rewritten as ’my mask is like the roof of the poor’\Now change the style of the sentence: |
| StylePTB-ARR | Here are some examples of how to remove: example 1. ’we are having a regular day’ is rewritten as ’we are having a day’; example 2. ’the successful launch continues a unk recovery in the u.s. space-science program’ is rewritten as ’the launch continues a recovery in the u.s. space-science program’; example 3. ’in national over-the-counter trading unk shares fell num cents to num’ is rewritten as ’in trading unk shares fell num cents to num’\Now remove adjectives and adverbs of the sentence: |
| StylePTB-TFU | Here are some examples of how to convert: example 1. ’i ’m happy and unk he said’ is rewritten as ’i will be happy and unk he will say’; example 2. ’united illuminating ’s plan however offers more for unsecured creditors’ is rewritten as ’united illuminating ’s plan however will offer more for unsecured creditors’; example 3. ’those rights prevent anyone other than revco from unk a reorganization plan’ is rewritten as ’those rights will prevent anyone other than revco from unk a reorganization plan’\Now convert the sentence: |
Appendix B. Additional Results and Analysis
Appendix B.1. Sentiment Transfer
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 64.8 | 33.9 | 100 | 95.6 | 91.4 | 100 | 91.3 | 90.2 | 101.6 | 11 |
| STYTRANS | 80.2 | 61.8 | 28.7 | 48.7 | 94.4 | 90.2 | 89.6 | 49 | 199.9 | 9 |
| TSST | 93.2 | 57.8 | 28.3 | 49.3 | 94.1 | 90.4 | 89.7 | 47.6 | 119.5 | 9.9 |
| NAST | 88.8 | 54 | 26.8 | 45.6 | 93.7 | 90 | 89.4 | 45 | 189.5 | 9.2 |
| BSRR | 92.2 | 56.5 | 21 | 39.1 | 94.2 | 89.8 | 89.1 | 77.8 | 83.3 | 9.3 |
| CTAT | 69.6 | 26.3 | 10.2 | 19.5 | 86.9 | 85 | 84.6 | 6 | 466.5 | 6 |
| LlaMa-LORA-INST | 59.6 | 51.5 | 30.8 | 51.7 | 92.5 | 89.6 | 90 | 94 | 109.5 | 8.7 |
| CHATGPT-ZS | 66 | 40.4 | 25 | 41 | 91.5 | 89.2 | 89.5 | 96 | 112 | 8.3 |
| CHATGPT-FS | 61.2 | 39.5 | 22.9 | 38.6 | 91.4 | 88.8 | 89.1 | 95.8 | 135.2 | 7.8 |
| GPT4-ZS | 80 | 22.3 | 14.6 | 23.3 | 89 | 87.6 | 87.7 | 95.6 | 206.1 | 7 |
| GPT4-FS | 86.4 | 24.6 | 16.3 | 25.2 | 89 | 87.6 | 87.8 | 95.6 | 220.8 | 7.4 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 95.4 | 31 | 100 | 91.5 | 91.6 | 100 | 92.1 | 86.2 | 75.3 | 12.6 |
| STYTRANS | 93.8 | 61.7 | 28.4 | 60.4 | 95.4 | 90.4 | 91.6 | 66 | 138.9 | 10.5 |
| TSST | 95.4 | 60.6 | 28.7 | 60.5 | 95.2 | 90.5 | 91.6 | 63 | 108.4 | 10.7 |
| NAST | 89.2 | 66.6 | 30.4 | 64.3 | 96.2 | 90.9 | 92.2 | 67.6 | 136.9 | 10.5 |
| BSRR | 98 | 44.8 | 20 | 42.8 | 92.4 | 89.8 | 90.2 | 94.8 | 82.3 | 9.8 |
| CTAT | 68.6 | 27.5 | 10.3 | 23.2 | 87.4 | 85.2 | 85.4 | 10.2 | 359.6 | 6.5 |
| LlaMa-LORA-INST | 88.2 | 59.4 | 32.6 | 66.5 | 94.7 | 90.2 | 92.3 | 92.6 | 108.1 | 10.8 |
| CHATGPT-ZS | 96 | 44.8 | 25.6 | 54.7 | 93.2 | 89.6 | 91.6 | 96.2 | 98.1 | 10.5 |
| CHATGPT-FS | 94.8 | 38.7 | 23 | 45.4 | 92 | 89 | 90.7 | 97 | 90.4 | 9.8 |
| GPT4-ZS | 95.8 | 37.4 | 22.8 | 44.5 | 92.3 | 89.1 | 90.8 | 96 | 142.1 | 9.5 |
| GPT4-FS | 97.2 | 27.7 | 15.9 | 29.5 | 90.3 | 87.6 | 89 | 96.4 | 186.9 | 8.2 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 45.6 | 47.1 | 100 | 92.8 | 100 | 85.8 | 267.5 | 9.3 |
| STYTRANS | 32.4 | 83.3 | 39.3 | 97.3 | 91.1 | 74.8 | 144.4 | 6.4 |
| TSST | 49.8 | 73.4 | 39.4 | 96.2 | 90.8 | 69 | 119.5 | 7.4 |
| NAST | 42 | 80.6 | 38.9 | 97.3 | 91.2 | 70.6 | 150.3 | 6.9 |
| BSRR | 78.2 | 41.9 | 24.6 | 89.9 | 87.5 | 94.8 | 48.3 | 7.9 |
| CTAT | 60 | 40.9 | 19.5 | 92.3 | 88.1 | 38 | 146.4 | 6.2 |
| LlaMa-LORA-INST | 47 | 48.4 | 32.2 | 92.1 | 90.1 | 94.8 | 213.1 | 6.6 |
| CHATGPT-ZS | 44.4 | 39.5 | 27.8 | 92.2 | 90.2 | 95.8 | 196.5 | 6.2 |
| CHATGPT-FS | 43 | 44 | 30.1 | 92.2 | 89.9 | 93.4 | 212.2 | 6.2 |
| GPT4-ZS | 46 | 18.3 | 13.9 | 89.4 | 88.1 | 95.8 | 327.2 | 4.8 |
| GPT4-FS | 52.6 | 20.4 | 14.9 | 89 | 87.8 | 95.8 | 456.2 | 5 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 61.8 | 52.2 | 100 | 93.6 | 100 | 85 | 247.3 | 10.4 |
| STYTRANS | 34.8 | 80.6 | 44.2 | 96.8 | 91.6 | 65 | 165.1 | 6.7 |
| TSST | 49 | 80.2 | 44.3 | 97.5 | 92.2 | 74.2 | 113.2 | 7.7 |
| NAST | 51 | 74.7 | 40.6 | 96.6 | 91.5 | 64.2 | 165.6 | 7.4 |
| BSRR | 97.8 | 42.3 | 26.7 | 89.9 | 88 | 93 | 32.3 | 9.1 |
| CTAT | 52.4 | 48.5 | 26.1 | 93.6 | 89.5 | 32.8 | 200.8 | 6.4 |
| LlaMa-LORA-INST | 60 | 56.1 | 40.8 | 94.3 | 91.6 | 91.4 | 156.9 | 7.9 |
| CHATGPT-ZS | 60.4 | 49.7 | 36.8 | 93.8 | 91.5 | 93.8 | 124.7 | 7.7 |
| CHATGPT-FS | 66 | 57.5 | 42.7 | 94.7 | 92 | 91.4 | 140.2 | 8.3 |
| GPT4-ZS | 67.4 | 25.8 | 20.1 | 90.9 | 89.2 | 95.4 | 219.8 | 6.3 |
| GPT4-FS | 71 | 42.8 | 32 | 92.8 | 90.5 | 92.8 | 193.2 | 7.6 |
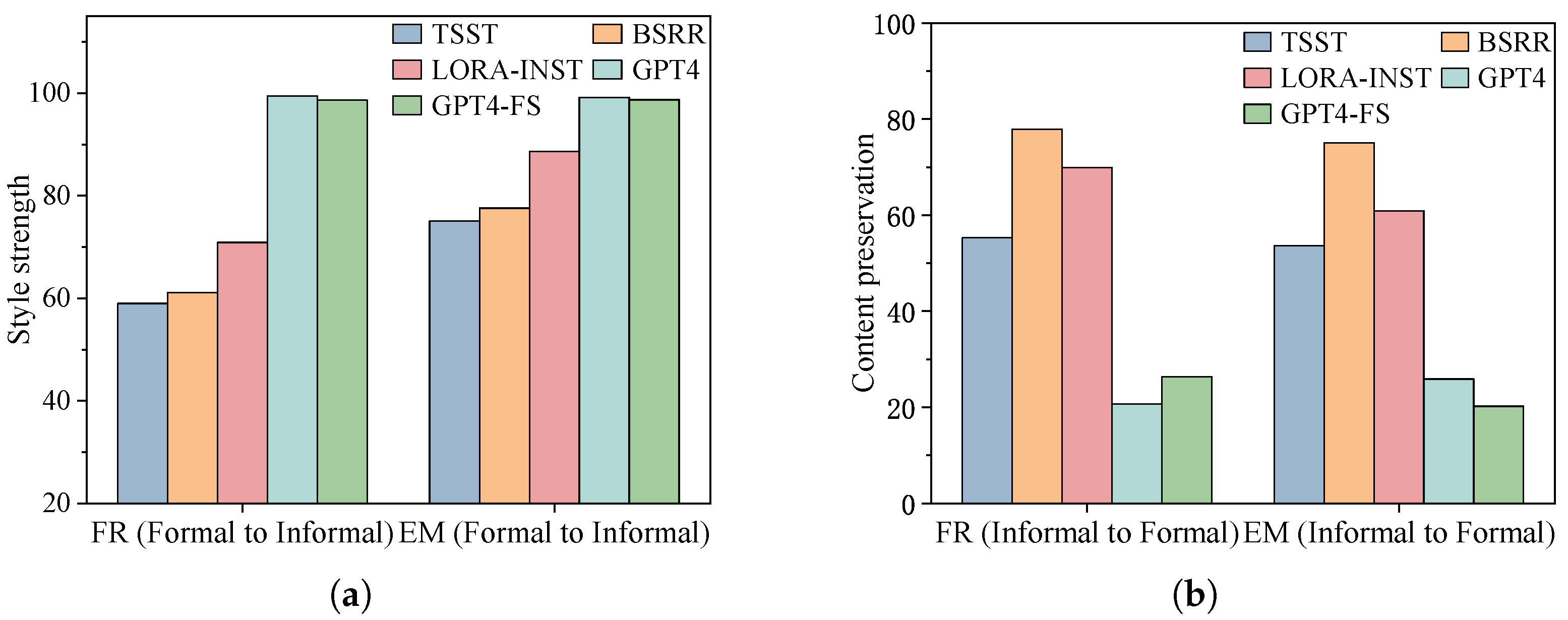
Appendix B.2. Formality Transfer
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 90.4 | 34.5 | 100 | 100 | 92.2 | 100 | 94.4 | 93.1 | 124.7 | 12.3 |
| STYTRANS | 57.3 | 45.4 | 22.4 | 40.9 | 91.5 | 89.1 | 89 | 38.9 | 411.1 | 7.3 |
| TSST | 75.1 | 55.2 | 29.3 | 53.6 | 93.4 | 91 | 90.9 | 59.4 | 121.6 | 9.4 |
| NAST | 71.9 | 61.5 | 31.7 | 53.5 | 94.4 | 91.3 | 91.3 | 48.6 | 258 | 8.8 |
| STRAP | 74.8 | 23.2 | 18.2 | 32.7 | 90.5 | 89.8 | 89.8 | 90.7 | 112.8 | 8 |
| BSRR | 77.6 | 62.6 | 43.4 | 75.1 | 94.4 | 92.4 | 92.3 | 87.9 | 111.2 | 10.7 |
| TYB | 90.9 | 58.7 | 44.3 | 76.5 | 95 | 94.2 | 94 | 93.5 | 105.4 | 11.4 |
| CTAT | 89.7 | 16.5 | 9 | 15.2 | 87.7 | 86.5 | 86.5 | 21.4 | 174.6 | 6.4 |
| LlaMa-LORA-INST | 88.6 | 40.3 | 35.8 | 60.9 | 91.9 | 91.5 | 91.4 | 93.7 | 124.8 | 10.4 |
| LlaMa-LORA | 76.6 | 60.2 | 45.3 | 78.8 | 93.9 | 92.7 | 92.6 | 91.6 | 105.2 | 10.9 |
| CHATGPT | 98 | 15.6 | 20.6 | 34.4 | 89.1 | 89.8 | 89.7 | 96.4 | 170.2 | 8.7 |
| CHATGPT-FS | 97.4 | 17.4 | 22.9 | 39.5 | 89.4 | 90.2 | 90.1 | 96.8 | 156.7 | 9.1 |
| GPT4 | 99.2 | 10.1 | 15.3 | 25.9 | 88.1 | 89.1 | 89 | 96.7 | 270 | 7.7 |
| GPT4-FS | 98.7 | 8.2 | 11.8 | 20.2 | 87.3 | 88.2 | 88.2 | 96 | 345.6 | 7 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 85 | 19.4 | 100 | 100 | 89.9 | 100 | 91 | 82.8 | 197 | 11.7 |
| STYTRANS | 59.7 | 65.3 | 16.4 | 30.8 | 94.8 | 88.2 | 87.5 | 60.3 | 254.3 | 6.9 |
| TSST | 74.6 | 57.3 | 16.6 | 32.7 | 94.2 | 88.1 | 87.4 | 56.7 | 209.1 | 7.7 |
| NAST | 74.5 | 60.2 | 16.5 | 28.6 | 94.7 | 88.4 | 87.7 | 59.1 | 315.1 | 7.2 |
| STRAP | 47.3 | 24.4 | 12.2 | 21.7 | 90.8 | 87.2 | 86.8 | 91.6 | 270.1 | 5.7 |
| BSRR | 72.4 | 60.8 | 22.1 | 42.7 | 95.5 | 89.3 | 88.6 | 85.9 | 324.2 | 8.1 |
| TYB | 44.6 | 48.5 | 26.1 | 49.1 | 95.2 | 90.8 | 89.8 | 90.4 | 141.4 | 7.6 |
| CTAT | 61.5 | 30.4 | 6.7 | 12.4 | 89.5 | 85 | 84.6 | 18.3 | 328.9 | 5.1 |
| LlaMa-LORA-INST | 20.2 | 56.3 | 22.6 | 40.6 | 94.6 | 89.2 | 88.6 | 95.2 | 191 | 5.4 |
| LlaMa-LORA | 36.9 | 57.3 | 27.5 | 48 | 94.7 | 90 | 89.1 | 91.2 | 134.3 | 7.1 |
| CHATGPT-ZS | 44.6 | 33.5 | 20.5 | 39.2 | 92.4 | 89 | 88.6 | 96.3 | 138.7 | 7.1 |
| CHATGPT-FS | 52.6 | 31.2 | 19.7 | 37.8 | 91.9 | 88.8 | 88.3 | 96.7 | 150.2 | 7.3 |
| GPT4-ZS | 63.8 | 22.5 | 16.9 | 33.2 | 90.8 | 88.4 | 88 | 95.7 | 173.6 | 7.4 |
| GPT4-FS | 66.4 | 22.3 | 16.8 | 33.4 | 90.6 | 88.3 | 88 | 95.4 | 172.9 | 7.6 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 90.2 | 35.6 | 100 | 100 | 92.4 | 100 | 94.4 | 96.5 | 67.2 | 12.9 |
| STYTRANS | 68.5 | 48.1 | 26.3 | 43.9 | 91.7 | 89.6 | 89.5 | 32.1 | 318.7 | 8.1 |
| TSST | 59 | 60.6 | 31.6 | 55.3 | 92.5 | 89.8 | 89.7 | 41 | 109 | 7.7 |
| NAST | 56.8 | 71.5 | 37.2 | 61.1 | 96 | 92.1 | 92 | 63.4 | 137.3 | 8.9 |
| STRAP | 78.2 | 23.5 | 21.3 | 38.4 | 90.8 | 90.4 | 90.4 | 95.4 | 48 | 9.2 |
| BSRR | 61.1 | 66.9 | 47 | 77.9 | 95 | 92.5 | 92.4 | 90.7 | 66.2 | 10.4 |
| TYB | 88.7 | 56.7 | 47.5 | 79 | 95.1 | 94.3 | 94.2 | 97 | 52.3 | 12.1 |
| CTAT | 90.3 | 21.1 | 12.5 | 20.5 | 88.8 | 87.5 | 87.4 | 27.6 | 100.3 | 7.4 |
| LlaMa-LORA-INST | 70.9 | 52.9 | 42 | 69.9 | 93.3 | 91.9 | 91.9 | 95.7 | 71.8 | 10.5 |
| LlaMa-LORA | 63.7 | 63.4 | 48.6 | 81.5 | 94.5 | 92.9 | 92.8 | 95.5 | 59.4 | 10.8 |
| CHATGPT-ZS | 98.5 | 12.2 | 17.3 | 29.7 | 88.4 | 89 | 89 | 98.9 | 115.5 | 8.5 |
| CHATGPT-FS | 97.1 | 15.4 | 21 | 36 | 89.1 | 89.6 | 89.6 | 98.6 | 98.9 | 9.1 |
| GPT4-ZS | 99.5 | 7 | 11.9 | 20.7 | 87.4 | 88.2 | 88.2 | 98.3 | 195.3 | 7.3 |
| GPT4-FS | 98.6 | 9.8 | 15.2 | 26.4 | 88.3 | 88.9 | 88.9 | 98.9 | 164.3 | 8 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | Multi-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | Multi-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| REFERENCE | 86.7 | 20.4 | 100 | 100 | 90 | 100 | 90.4 | 87.8 | 106.2 | 12.3 |
| STYTRANS | 79.9 | 70 | 18.2 | 32.4 | 95.2 | 88.2 | 87 | 62.7 | 166.6 | 8 |
| TSST | 91.1 | 50.1 | 15.8 | 31.6 | 91.7 | 86.8 | 85.8 | 46.6 | 128.8 | 8.4 |
| NAST | 66.1 | 70.4 | 19.6 | 32.6 | 95.9 | 88.9 | 87.6 | 68.9 | 149.3 | 7.6 |
| STRAP | 33.2 | 23.5 | 12.9 | 25.7 | 91.8 | 88.1 | 87.1 | 95.5 | 61.4 | 5.9 |
| BSRR | 77.2 | 67.4 | 23.1 | 42.6 | 96.2 | 89.3 | 88.1 | 92.4 | 170.9 | 8.6 |
| TYB | 49.2 | 54.5 | 27.9 | 47.7 | 96 | 90.9 | 89.3 | 96.8 | 69.9 | 8.2 |
| CTAT | 82.4 | 29.6 | 8.9 | 15 | 89.5 | 85.5 | 84.7 | 28.2 | 135.9 | 6.3 |
| LlaMa-LORA-INST | 32.8 | 53.7 | 23.1 | 42.4 | 94.3 | 89.2 | 88.2 | 98.3 | 91.4 | 6.8 |
| LlaMa-LORA | 53.8 | 53.6 | 29.4 | 51.5 | 94.3 | 90.2 | 88.8 | 96.2 | 70.2 | 8.7 |
| CHATGPT-ZS | 65.2 | 28.4 | 19.4 | 36.9 | 91.7 | 88.7 | 87.9 | 99.4 | 78.7 | 8.2 |
| CHATGPT-FS | 69.1 | 32.1 | 21.4 | 40.7 | 92.1 | 88.9 | 88 | 98.7 | 89.1 | 8.6 |
| GPT4-ZS | 76.6 | 18.4 | 16.3 | 32.3 | 90.4 | 88.1 | 87.4 | 98.9 | 94.7 | 8.2 |
| GPT4-FS | 91.7 | 20.7 | 16.2 | 34.9 | 90.5 | 88 | 87.4 | 94.2 | 146.8 | 8.6 |
Appendix B.3. Ancient English Transfer
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 92.7 | 22.1 | 100 | 90 | 100 | 94 | 137.7 | 12.3 |
| STYTRANS | 38.3 | 65 | 20.6 | 94.9 | 89.5 | 40.1 | 263.5 | 5.2 |
| TSST | 60.5 | 45.1 | 19.7 | 91.9 | 88.8 | 36.7 | 144.1 | 6.2 |
| NAST | 31.1 | 55.5 | 18.3 | 93.7 | 89.1 | 35.8 | 377 | 4.6 |
| STRAP | 84.3 | 16.9 | 14.2 | 89.7 | 88.8 | 88.2 | 91 | 6.4 |
| BSRR | 56.6 | 68.8 | 27.3 | 95.9 | 90.7 | 69.7 | 207.9 | 6.6 |
| TYB | 88.1 | 39.5 | 30.7 | 92.9 | 91.4 | 90.8 | 118 | 8.3 |
| CTAT | 45.1 | 3.7 | 2 | 83.5 | 83.2 | 10.5 | 177.9 | 2.6 |
| LlaMa-LORA-INST | 70 | 53 | 24.6 | 90.8 | 88.3 | 80.6 | 227.7 | 6.8 |
| LlaMa-LORA | 72.2 | 54.9 | 31.3 | 94.1 | 91.5 | 85 | 177.9 | 7.6 |
| CHATGPT-ZS | 91.9 | 25.6 | 26.3 | 88.5 | 88.9 | 94.7 | 169 | 7.8 |
| CHATGPT-FS | 92.3 | 24.6 | 25.4 | 88.4 | 88.8 | 94.5 | 169.6 | 7.7 |
| GPT4-ZS | 93.4 | 26.2 | 28 | 88.9 | 89.2 | 94 | 181 | 8 |
| GPT4-FS | 94.7 | 18.6 | 24.4 | 88 | 88.8 | 96.2 | 176.3 | 7.6 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 85.7 | 22 | 100 | 90 | 100 | 63.8 | 226.8 | 11.6 |
| STYTRANS | 86.3 | 53.8 | 15.9 | 91.7 | 87.2 | 40.1 | 274.8 | 6.3 |
| TSST | 87.3 | 46.2 | 17.3 | 91.9 | 88 | 52.6 | 130.7 | 6.8 |
| NAST | 63.3 | 61 | 18.5 | 94.6 | 88.7 | 59.9 | 303.7 | 5.9 |
| STRAP | 61.1 | 17.1 | 8.8 | 90 | 87.4 | 79.6 | 125.7 | 4.8 |
| BSRR | 85.6 | 61.2 | 17.8 | 94.4 | 89 | 65.1 | 346.1 | 6.4 |
| TYB | 65.6 | 51.2 | 24.7 | 94.4 | 90.5 | 85.4 | 160.1 | 6.8 |
| CTAT | 95.3 | 5 | 2 | 84 | 82.7 | 10 | 200.6 | 3.3 |
| LlaMa-LORA-INST | 47.1 | 70.9 | 22.5 | 92.8 | 87.7 | 89.9 | 235.2 | 5.8 |
| LlaMa-LORA | 55 | 47.4 | 25.4 | 94.3 | 90.6 | 86.7 | 162.5 | 6.5 |
| CHATGPT-ZS | 91 | 35.5 | 16.6 | 88.9 | 85.9 | 88.7 | 339.6 | 6.4 |
| CHATGPT-FS | 87.3 | 32.8 | 17.3 | 88.8 | 86.2 | 89.3 | 306.4 | 6.4 |
| GPT4-ZS | 89.6 | 23.3 | 17.3 | 88 | 86.4 | 83.5 | 355.8 | 6.4 |
| GPT4-FS | 91.2 | 13.1 | 12 | 86.4 | 85.4 | 81.2 | 419.1 | 5.7 |
Appendix B.4. Fine-Grained Syntactic and Semantic Style Transfer
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 82.7 | 65.5 | 100 | 96.9 | 100 | 36.2 | 124.6 | 12 |
| BSRR | 88.9 | 64.9 | 90.3 | 96.8 | 99 | 35.8 | 123 | 11.9 |
| TYB | 91.8 | 60.8 | 88.9 | 96.4 | 98.9 | 36.6 | 124.8 | 11.9 |
| LlaMa-LORA-INST | 50.6 | 38.8 | 35.1 | 91.3 | 90.7 | 61.3 | 796.6 | 6.4 |
| LlaMa-LORA | 88.5 | 62.3 | 89.3 | 96.5 | 98.9 | 36.2 | 122.8 | 11.8 |
| CHATGPT-ZS | 74.5 | 43.6 | 50.2 | 92.9 | 92.8 | 38.3 | 419.3 | 8.5 |
| CHATGPT-FS | 69.1 | 48.7 | 56 | 94 | 94 | 43.2 | 350 | 8.7 |
| GPT4-ZS | 79.4 | 44 | 55.3 | 92.9 | 93.4 | 44 | 425 | 9 |
| GPT4-FS | 76.1 | 61.4 | 76.1 | 96 | 97 | 40.3 | 169.6 | 10.4 |
| Model | ACC ↑ | s-BLEU ↑ | r-BLEU ↑ | s-BERT ↑ | r-BERT ↑ | COLA ↑ | PPL ↓ | Joint ↑ |
|---|---|---|---|---|---|---|---|---|
| REFERENCE | 99.7 | 55.9 | 100 | 97.3 | 100 | 58.5 | 70.7 | 13.3 |
| BSRR | 99.2 | 56.6 | 96.6 | 97.4 | 99.7 | 56 | 69.4 | 13.1 |
| TYB | 99.7 | 55.7 | 96.9 | 97.3 | 99.7 | 58.2 | 68.7 | 13.2 |
| LlaMa-LORA-INST | 68.4 | 55.8 | 65.8 | 95.6 | 96.1 | 63.7 | 237.4 | 9.4 |
| LlaMa-LORA | 95.9 | 57.1 | 90.3 | 97.4 | 99.3 | 58.8 | 76.7 | 12.6 |
| CHATGPT-ZS | 94.8 | 37 | 60.6 | 93.9 | 95.4 | 78.8 | 230.5 | 10.2 |
| CHATGPT-FS | 95.3 | 43.4 | 69.5 | 94.8 | 96.4 | 73.6 | 168.7 | 10.9 |
| GPT4-ZS | 92.3 | 39.1 | 61.3 | 94.2 | 95.6 | 76.4 | 233.3 | 10.1 |
| GPT4-FS | 96.4 | 48.2 | 74.8 | 96.2 | 97.6 | 61.8 | 152.2 | 11.3 |
| Model | GYAFC-EM (I → F) | GYAFC-EM (F → I) | Shakespeare (M → A) | Shakespeare (A → M) |
|---|---|---|---|---|
| BSRR | (10.625, 10.775) | (8.052, 8.148) | (6.553, 6.647) | (6.367, 6.433) |
| TYB | (11.337, 11.463) | (7.555, 7.645) | (8.257, 8.343) | (6.761, 6.839) |
| LORA-INST | (10.324, 10.476) | (5.351, 5.449) | (6.763, 6.837) | (5.76, 5.84) |
| LORA | (10.824, 10.976) | (7.047, 7.153) | (7.56, 7.64) | (6.464, 6.536) |
| CHATGPT | (8.638, 8.762) | (7.044, 7.156) | (7.754, 7.846) | (6.357, 6.443) |
| CHATGPT-FS | (9.028, 9.172) | (7.25, 7.35) | (7.652, 7.748) | (6.366, 6.434) |
| GPT4 | (7.642, 7.758) | (7.355, 7.445) | (7.959, 8.041) | (6.358, 6.442) |
| GPT4-FS | (6.935, 7.065) | (7.554, 7.646) | (7.56, 7.64) | (5.669, 5.731) |
Appendix B.5. Analysis of Trade-Off Curves

Appendix B.6. Case Study
| From Negative to Positive | |
|---|---|
| Original text | Since their visit, the only scorpions we’ve seen were dead ! |
| STYTRANS | Since their visit, the only scorpions we’ve seen best popular ! |
| TSST | Since their visit, the best scorpions we’ve seen were delicious ! |
| NAST | Since their visit, the best scorpions we’ve eaten were best ! |
| BSRR | The only scorpions we’ve seen were dead and it is good. |
| CTAT | Since their visit, the only delicious we arrowhead disappointment has were dining ! |
| LlaMa-LORA-INST | Since their visit, the only scorpions we’ve seen were alive! |
| CHATGPT | Since their visit, we have seen live scorpions! |
| CHATGPT-FS | Since their visit, we have only seen live scorpions! |
| GPT4 | Since their visit, we haven’t seen any scorpions alive! |
| GPT4-FS | Since their visit, we’ve only encountered peaceful, non-threatening scorpions! |
| From Positive to Negative | |
|---|---|
| Original text | The wait staff is extremely attractive and friendly ! |
| STYTRANS | The wait staff is extremely attractive and rude ! |
| TSST | The wait staff is extremely arrogant and rude ! |
| NAST | The wait staff is extremely attractive and rude ! |
| BSRR | The wait staff is extremely attractive but it is not good. |
| CTAT | Wait the service is these pressure and telling family wasn’t that customer. |
| LlaMa-LORA-INST | The wait staff is extremely unattractive and unfriendly! |
| CHATGPT | The wait staff is not at all attractive and unfriendly. |
| CHATGPT-FS | The wait staff is unattractive and unfriendly. |
| GPT4 | The wait staff is quite unattractive and unfriendly! |
| GPT4-FS | The wait staff is quite off-putting and superficial! |
| From Negative to Positive | |
|---|---|
| Original text | I purchased this jawbone hd as a replacement for an older jawbone thinker. |
| STYTRANS | I purchased this jawbone hd as a replacement for an older jawbone turquoise. |
| TSST | I purchased this jawbone hd as a replacement for an older jawbone capacity. |
| NAST | I purchased this jawbone hd as a replacement for an older jawbone thinker. |
| BSRR | I purchased this jawbone hd as a replacement for an older jawbone thinker and this was worth it. |
| CTAT | I purchased this jawbone icon as a replacement for an older iphone num_extend useful piece. |
| LlaMa-LORA-INST | I purchased this jawbone hd to replace my older jawbone thinker and i’m so glad i did! |
| CHATGPT | I purchased this Jawbone HD as an upgrade for my older Jawbone Thinker. |
| CHATGPT-FS | I purchased this Jawbone HD as an upgrade for my older Jawbone Thinker. |
| GPT4 | I bought this Jawbone HD to upgrade from an older Jawbone model, and I’m thrilled with the improvement! |
| GPT4-FS | I purchased this Jawbone HD as an upgrade from an older Jawbone Thinker. |
| From Positive to Negative | |
|---|---|
| Original text | Then i thought something was wrong with my car. |
| STYTRANS | Then i thought something was wrong with my car. |
| TSST | Then i thought something was wrong with my car. |
| NAST | Then i thought something was wrong with my car. |
| BSRR | I thought something was wrong with my car and this was not worth it. |
| CTAT | Then i thought something was wrong with my car . then not green months. |
| LlaMa-LORA-INST | Then i thought something must be wrong with my car. |
| CHATGPT | I then thought something was wrong with my car. |
| CHATGPT-FS | then i thought something was right with my car. |
| GPT4 | Then I realized something must be wrong with my car. |
| GPT4-FS | Then I was convinced there was nothing wrong with my car. |
| From Informal to Formal | |
|---|---|
| Original Text | It doesn’t make sense …wait oooh I get it, still not funny. |
| STYTRANS | It does not make sense. |
| TSST | It does not make sense. wait, I get not it, still not funny. |
| NAST | It does not make sense. wait excuse I get it, still not funny. |
| STRAP | It does not make any sense, wait for me to finish. |
| BSRR | It does not make sense. wait, I get it. still not funny. |
| TYB | It doesn’t make sense. wait, I get it. still not funny. |
| CTAT | It doesn’t make sense. i still get it funny, however. |
| LlaMa-LORA-INST | It does not make sense…wait, I get it, still not funny. |
| LlaMa-LORA | It does not make sense. I get it, but it is still not funny. |
| CHATGPT | It is not logical…oh, I understand now, but it is still not humorous. |
| CHATGPT-FS | It is not comprehensible. Oh, I understand now. It is still not humorous. |
| GPT4 | It does not make sense…Ah, I understand now; nevertheless, it remains unfunny. |
| GPT4-FS | The logic initially eluded me; however, upon further reflection, I comprehend the intent, yet it fails to amuse. |
| From Formal to Informal | |
|---|---|
| Original text | Plus, for an older man, that is really attractive. |
| STYTRANS | Plus, for an older man, that is really .. ! |
| TSST | Plus, for an older man, that ’s really sexy. |
| NAST | Plus, for an older man, that is really hot ! |
| STRAP | Plus, it apos;s really cool for an older guy. |
| BSRR | Plus for an older man that is really hot |
| TYB | Plus, for an old man, that is really hot. |
| CTAT | Plus, for an older man that is really, attractive than he’s not that |
| LlaMa-LORA-INST | Plus, for an older man, that’s really attractive. |
| LlaMa-LORA | Plus, for an older man, that is really hot! |
| CHATGPT | And, like, for an older dude, that’s super hot. |
| CHATGPT-FS | And he’s really attractive for an older guy. |
| GPT4 | Plus, for an older guy, that’s super attractive. |
| GPT4-FS | Also, for an older guy, that’s super attractive. |
| From Informal to Formal | |
|---|---|
| Original text | Sounds strange but it worked in about 3–5 days for me! |
| STYTRANS | Sounds strange but it worked in about circumstance days for me pornographic. |
| TSST | It is but it worked in about five days for me! |
| NAST | sounds strange but it worked in about 3–5 days for me. |
| STRAP | I have it weird, but it works for me about three-five days a week! |
| BSRR | It sounds strange, but it worked in about three-5 days for me. |
| TYB | It sounds strange, but it worked in about three-five days for me. |
| CTAT | It sounds strange but in the situation is about me, i had feelings for num days. |
| LlaMa-LORA-INST | It sounds strange, but it worked in about three to five days for me. |
| LlaMa-LORA | It sounds strange, but it worked in about three to five days for me. |
| CHATGPT | It may seem unusual, but it proved effective for me within a period of 3–5 days. |
| CHATGPT-FS | It may sound unusual, but it proved effective within a period of approximately three to five days for me. |
| GPT4 | It may seem unusual, but it proved effective for me within a period of three to five days. |
| GPT4-FS | It may seem unusual, but it proved effective for me within a period of three to five days. |
| From Formal to Informal | |
|---|---|
| Original text | Stay very far away from this man. |
| STYTRANS | Stay very far away from this man stay far |
| TSST | Stay very far away from this guy |
| NAST | Stay very far away from this man ! |
| STRAP | Dont come near him. |
| BSRR | Stay very far away from this guy |
| TYB | Stay very far away from this guy. |
| CTAT | Stay away from very far u have this guy and remember my best friend thats nothing ? |
| LlaMa-LORA-INST | Stay as far away from this guy as possible. |
| LlaMa-LORA | Stay very far away from this guy. |
| CHATGPT | Keep your distance from that guy. |
| CHATGPT-FS | Stay way far from this dude. |
| GPT4 | Steer clear of this dude, seriously. |
| GPT4-FS | Keep your distance from this dude. |
| From Ancient English to Modern English | |
|---|---|
| Original text | I stretch it out for that word “broad, ” which, added to the goose, proves thee far and wide a broad goose. |
| STYTRANS | I stretch it out for that word ” broad, ” which, added to the goose, proves out far and wide a broad goose. |
| TSST | I swear it out for that’s ” really, ” which, has to the same, of you far and wide a its eye. |
| NAST | I stretch it out for that word ” broad on ” just on added to the goose on proves you far and wide a broad goose. |
| STRAP | I’ll stretch the word “broad” to mean “wide, wide, ” which, added to the goose, will prove you a wide goose. |
| BSRR | I’m stretching it out for that word “broad, ” which, added to the goose, proves you far and wide a broad |
| TYB | I stretch it out for that word “broad, ” which makes you far and wide a broad goose. |
| CTAT | I know it out that which, “quoth i, ” to part the candle itself, and a big piece of good opinion, “ |
| LlaMa-LORA-INST | I stretch it out for that word “broad,” which, added to the goose, proves you to be far and wide a broad goose. |
| LlaMa-LORA | I stretch it out for that word “broad, ”which, added to the goose, proves you to be far and wide a broad goose. |
| CHATGPT | I emphasize the word “broad,” which, when added to the goose, proves that you are a wide and broad goose. |
| CHATGPT-FS | I extend it for the word “broad,” which, when added to the goose, proves you to be a very foolish person. |
| GPT4 | I extend it for that word “broad,” which, when associated with the goose, clearly shows you are widely known as a complete fool. |
| GPT4-FS | I emphasize the term “broad,” which, when associated with the goose, clearly labels you as a complete fool everywhere. |
| From from Modern English to Ancient English | |
|---|---|
| Original text | Why, isn’t all this joking better than groaning about love ? |
| STYTRANS | Wherefore, is not all this joking better than groaning hither love ? |
| TSST | Why, is not all this ’t better than thy of love ? |
| NAST | Why, is not all this joking better than groaning of love ? |
| STRAP | Why do we laugh more than we weep ? |
| BSRR | Why, hath not all this joking better than groaning about love ? |
| TYB | Why, is not all this jesting better than groaning ? |
| CTAT | Why, is it possible that ever unk from all the gods, have some achieve thee for thy love and drown her permission. |
| LlaMa-LORA-INST | Why, is not all this joking better than groaning about love? |
| LlaMa-LORA | Why, is not this jesting better than groaning ? |
| CHATGPT | Wherefore, is not all this jesting finer than lamenting o’er love? |
| CHATGPT-FS | Wherefore, is not all this jesting finer than lamenting o’er love? |
| GPT4 | Why, doth not all this jesting prove more sweet than to lament on love’s harsh sting? |
| GPT4-FS | Why, doth not this jesting prove a better sport than lamenting ’pon love’s woes? |
| Remove Adjectives and Adverbs | |
|---|---|
| Original text | There are still others who don’t mind seeing new unk unk. |
| BSRR | There are others who don’t mind seeing unk unk. |
| TYB | There are others who don’t mind seeing unk. |
| LlaMa-LORA-INST | There are still others who don’t mind seeing new. |
| LlaMa-LORA | There are others who don’t mind seeing unk. |
| CHATGPT | There are others who do seeing new unk unk. |
| CHATGPT-FS | There are still others who don’t mind seeing new unk unk. |
| GPT4 | There are others who don’t mind seeing new. |
| GPT4-FS | There are still others who don’t mind seeing unk |
| Convert into the Future Tense | |
|---|---|
| Original text | I unk i was buying a cd as a cd he says. |
| BSRR | I will unk i will be buying a cd as a cd he will say. |
| TYB | I will unk i will be buying a cd as a cd he will say. |
| LlaMa-LORA-INST | I will be buying a cd as a cd he says. |
| LlaMa-LORA | I unk i will be buying a cd as a cd he will say. |
| CHATGPT | I will be buying a cd as a cd he will say. |
| CHATGPT-FS | I will think i will be buying a cd as a cd he will say. |
| GPT4 | I will think i will be buying a cd, as he will say. |
| GPT4-FS | I will unk i will be buying a cd as a cd he will say. |
References
- Jin, D.; Jin, Z.; Hu, Z.; Vechtomova, O.; Mihalcea, R. Deep Learning for Text Style Transfer: A Survey. Comput. Linguist. 2022, 48, 155–205. [Google Scholar] [CrossRef]
- Ostheimer, P.; Nagda, M.; Kloft, M.; Fellenz, S. A Call for Standardization and Validation of Text Style Transfer Evaluation. arXiv 2023, arXiv:2306.00539. [Google Scholar]
- Suzgun, M.; Melas-Kyriazi, L.; Jurafsky, D. Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Models. arXiv 2022, arXiv:2205.11503. [Google Scholar] [CrossRef]
- Dai, N.; Liang, J.; Qiu, X.; Huang, X. Style transformer: Unpaired text style transfer without disentangled latent representation. arXiv 2019, arXiv:1905.05621. [Google Scholar]
- Wang, K.; Hua, H.; Wan, X. Controllable unsupervised text attribute transfer via editing entangled latent representation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Xiao, F.; Pang, L.; Lan, Y.; Wang, Y.; Shen, H.; Cheng, X. Transductive learning for unsupervised text style transfer. arXiv 2021, arXiv:2109.07812. [Google Scholar]
- Lai, H.; Toral, A.; Nissim, M. Thank you BART! Rewarding pre-trained models improves formality style transfer. arXiv 2021, arXiv:2105.06947. [Google Scholar]
- Liu, Z.; Chen, N.F. Learning from Bootstrapping and Stepwise Reinforcement Reward: A Semi-Supervised Framework for Text Style Transfer. arXiv 2022, arXiv:2205.09324. [Google Scholar]
- Krishna, K.; Wieting, J.; Iyyer, M. Reformulating unsupervised style transfer as paraphrase generation. arXiv 2020, arXiv:2010.05700. [Google Scholar]
- Rao, S.; Tetreault, J. Dear sir or madam, may I introduce the GYAFC dataset: Corpus, benchmarks and metrics for formality style transfer. arXiv 2018, arXiv:1803.06535. [Google Scholar]
- Subramanian, S.; Lample, G.; Smith, E.M.; Denoyer, L.; Ranzato, M.; Boureau, Y.L. Multiple-attribute text style transfer. arXiv 2018, arXiv:1811.00552. [Google Scholar]
- Lyu, Y.; Liang, P.P.; Pham, H.; Hovy, E.; Póczos, B.; Salakhutdinov, R.; Morency, L.P. StylePTB: A compositional benchmark for fine-grained controllable text style transfer. arXiv 2021, arXiv:2104.05196. [Google Scholar]
- Briakou, E.; Lu, D.; Zhang, K.; Tetreault, J. Olá, bonjour, salve! XFORMAL: A benchmark for multilingual formality style transfer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3199–3216. [Google Scholar]
- Chen, J. LMStyle Benchmark: Evaluating Text Style Transfer for Chatbots. arXiv 2024, arXiv:2403.08943. [Google Scholar]
- Mou, L.; Vechtomova, O. Stylized text generation: Approaches and applications. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Online, 5–10 July 2020; pp. 19–22. [Google Scholar]
- Toshevska, M.; Gievska, S. A review of text style transfer using deep learning. IEEE Trans. Artif. Intell. 2021, 3, 669–684. [Google Scholar] [CrossRef]
- Prabhumoye, S.; Black, A.W.; Salakhutdinov, R. Exploring controllable text generation techniques. arXiv 2020, arXiv:2005.01822. [Google Scholar]
- Mukherjee, S.; Ojha, A.K.; Dušek, O. Are Large Language Models Actually Good at Text Style Transfer? arXiv 2024, arXiv:2406.05885. [Google Scholar]
- Liu, P.; Wu, L.; Wang, L.; Guo, S.; Liu, Y. Step-by-step: Controlling arbitrary style in text with large language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 15285–15295. [Google Scholar]
- Hu, Z.; Yang, Z.; Liang, X.; Salakhutdinov, R.; Xing, E.P. Toward controlled generation of text. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1587–1596. [Google Scholar]
- Yang, Z.; Hu, Z.; Dyer, C.; Xing, E.P.; Berg-Kirkpatrick, T. Unsupervised text style transfer using language models as discriminators. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Zhao, J.; Kim, Y.; Zhang, K.; Rush, A.; LeCun, Y. Adversarially regularized autoencoders. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5902–5911. [Google Scholar]
- John, V.; Mou, L.; Bahuleyan, H.; Vechtomova, O. Disentangled representation learning for non-parallel text style transfer. arXiv 2018, arXiv:1808.04339. [Google Scholar]
- Yi, X.; Liu, Z.; Li, W.; Sun, M. Text style transfer via learning style instance supported latent space. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3801–3807. [Google Scholar]
- Zhu, A.; Yin, Z.; Iwana, B.K.; Zhou, X.; Xiong, S. Text style transfer based on multi-factor disentanglement and mixture. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2430–2440. [Google Scholar]
- Han, J.; Wang, Q.; Guo, Z.; Xu, B.; Zhang, L.; Mao, Z. Disentangled Learning with Synthetic Parallel Data for Text Style Transfer. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; pp. 15187–15201. [Google Scholar]
- Gong, H.; Bhat, S.; Wu, L.; Xiong, J.; Hwu, W.-m. Reinforcement learning based text style transfer without parallel training corpus. arXiv 2019, arXiv:1903.10671. [Google Scholar]
- Deng, M.; Wang, J.; Hsieh, C.P.; Wang, Y.; Guo, H.; Shu, T.; Song, M.; Xing, E.P.; Hu, Z. Rlprompt: Optimizing discrete text prompts with reinforcement learning. arXiv 2022, arXiv:2205.12548. [Google Scholar]
- Sancheti, A.; Krishna, K.; Srinivasan, B.V.; Natarajan, A. Reinforced rewards framework for text style transfer. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Proceedings, Part I 42. Springer: Berlin/Heidelberg, Germany, 2020; pp. 545–560. [Google Scholar]
- Wu, C.; Ren, X.; Luo, F.; Sun, X. A hierarchical reinforced sequence operation method for unsupervised text style transfer. arXiv 2019, arXiv:1906.01833. [Google Scholar]
- Prabhumoye, S.; Tsvetkov, Y.; Salakhutdinov, R.; Black, A.W. Style transfer through back-translation. arXiv 2018, arXiv:1804.09000. [Google Scholar]
- Wei, D.; Wu, Z.; Shang, H.; Li, Z.; Wang, M.; Guo, J.; Chen, X.; Yu, Z.; Yang, H. Text style transfer back-translation. arXiv 2023, arXiv:2306.01318. [Google Scholar]
- Zhang, Z.; Ren, S.; Liu, S.; Wang, J.; Chen, P.; Li, M.; Zhou, M.; Chen, E. Style transfer as unsupervised machine translation. arXiv 2018, arXiv:1808.07894. [Google Scholar]
- Jin, Z.; Jin, D.; Mueller, J.; Matthews, N.; Santus, E. IMaT: Unsupervised text attribute transfer via iterative matching and translation. arXiv 2019, arXiv:1901.11333. [Google Scholar]
- Liao, Y.; Bing, L.; Li, P.; Shi, S.; Lam, W.; Zhang, T. Quase: Sequence editing under quantifiable guidance. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3855–3864. [Google Scholar]
- Li, J.; Jia, R.; He, H.; Liang, P. Delete, retrieve, generate: A simple approach to sentiment and style transfer. arXiv 2018, arXiv:1804.06437. [Google Scholar]
- Xu, J.; Sun, X.; Zeng, Q.; Ren, X.; Zhang, X.; Wang, H.; Li, W. Unpaired sentiment-to-sentiment translation: A cycled reinforcement learning approach. arXiv 2018, arXiv:1805.05181. [Google Scholar]
- Zhang, Y.; Xu, J.; Yang, P.; Sun, X. Learning sentiment memories for sentiment modification without parallel data. arXiv 2018, arXiv:1808.07311. [Google Scholar]
- Sudhakar, A.; Upadhyay, B.; Maheswaran, A. Transforming delete, retrieve, generate approach for controlled text style transfer. arXiv 2019, arXiv:1908.09368. [Google Scholar]
- Malmi, E.; Severyn, A.; Rothe, S. Unsupervised text style transfer with padded masked language models. arXiv 2020, arXiv:2010.01054. [Google Scholar]
- Wu, X.; Zhang, T.; Zang, L.; Han, J.; Hu, S. “Mask and Infill”: Applying Masked Language Model to Sentiment Transfer. arXiv 2019, arXiv:1908.08039. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://openai.com/index/language-unsupervised (accessed on 28 April 2025).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Shen, T.; Lei, T.; Barzilay, R.; Jaakkola, T. Style transfer from non-parallel text by cross-alignment. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Huang, F.; Chen, Z.; Wu, C.H.; Guo, Q.; Zhu, X.; Huang, M. NAST: A non-autoregressive generator with word alignment for unsupervised text style transfer. arXiv 2021, arXiv:2106.02210. [Google Scholar]
- Fu, Z.; Tan, X.; Peng, N.; Zhao, D.; Yan, R. Style transfer in text: Exploration and evaluation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Luo, F.; Li, P.; Zhou, J.; Yang, P.; Chang, B.; Sui, Z.; Sun, X. A dual reinforcement learning framework for unsupervised text style transfer. arXiv 2019, arXiv:1905.10060. [Google Scholar]
- Dathathri, S.; Madotto, A.; Lan, J.; Hung, J.; Frank, E.; Molino, P.; Yosinski, J.; Liu, R. Plug and play language models: A simple approach to controlled text generation. arXiv 2019, arXiv:1912.02164. [Google Scholar]
- Fan, C.; Li, Z. Gradient-guided Unsupervised Text Style Transfer via Contrastive Learning. arXiv 2022, arXiv:2202.00469. [Google Scholar]
- Liu, D.; Fu, J.; Zhang, Y.; Pal, C.; Lv, J. Revision in continuous space: Unsupervised text style transfer without adversarial learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8376–8383. [Google Scholar]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.M.; Chen, W.; et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Zaken, E.B.; Ravfogel, S.; Goldberg, Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Guo, D.; Rush, A.M.; Kim, Y. Parameter-efficient transfer learning with diff pruning. arXiv 2020, arXiv:2012.07463. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 61–68. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- OpenAI. Introducing Chatgpt. 2022. Available online: https://openai.com/index/chatgpt (accessed on 28 April 2025).
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 11324–11436. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Tao, Z.; Xi, D.; Li, Z.; Tang, L.; Xu, W. CAT-LLM: Prompting Large Language Models with Text Style Definition for Chinese Article-style Transfer. arXiv 2024, arXiv:2401.05707. [Google Scholar]
- Saakyan, A.; Muresan, S. ICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer. arXiv 2023, arXiv:2309.08583. [Google Scholar]
- Li, J.; Zhang, Z.; Tu, Q.; Cheng, X.; Zhao, D.; Yan, R. StyleChat: Learning Recitation-Augmented Memory in LLMs for Stylized Dialogue Generation. arXiv 2024, arXiv:2403.11439. [Google Scholar]
- Hu, Z.; Lee, R.K.W.; Aggarwal, C.C.; Zhang, A. Text style transfer: A review and experimental evaluation. ACM SIGKDD Explor. Newsl. 2022, 24, 14–45. [Google Scholar] [CrossRef]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on world Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- Xu, W.; Ritter, A.; Dolan, W.B.; Grishman, R.; Cherry, C. Paraphrasing for style. In Proceedings of the COLING 2012, Mumbai, India, 8–15 December 2012; pp. 2899–2914. [Google Scholar]
- Mir, R.; Felbo, B.; Obradovich, N.; Rahwan, I. Evaluating style transfer for text. arXiv 2019, arXiv:1904.02295. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Yamshchikov, I.P.; Shibaev, V.; Khlebnikov, N.; Tikhonov, A. Style-transfer and paraphrase: Looking for a sensible semantic similarity metric. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 14213–14220. [Google Scholar]
- Logacheva, V.; Dementieva, D.; Krotova, I.; Fenogenova, A.; Nikishina, I.; Shavrina, T.; Panchenko, A. A study on manual and automatic evaluation for text style transfer: The case of detoxification. In Proceedings of the 2nd Workshop on Human Evaluation of NLP Systems (HumEval), Dublin, Ireland, 27 May 2022; pp. 90–101. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Heafield, K. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 11–21 July 2011; pp. 187–197. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Warstadt, A.; Singh, A.; Bowman, S.R. Neural network acceptability judgments. Trans. Assoc. Comput. Linguist. 2019, 7, 625–641. [Google Scholar] [CrossRef]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following Llama Model. 2023. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 28 April 2025).
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Amin, M.M.; Cambria, E.; Schuller, B.W. Will affective computing emerge from foundation models and general artificial intelligence? A first evaluation of chatgpt. IEEE Intell. Syst. 2023, 38, 15–23. [Google Scholar] [CrossRef]
- Kocoń, J.; Cichecki, I.; Kaszyca, O.; Kochanek, M.; Szydło, D.; Baran, J.; Bielaniewicz, J.; Gruza, M.; Janz, A.; Kanclerz, K.; et al. ChatGPT: Jack of all trades, master of none. Inf. Fusion 2023, 99, 101861. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 5–9 June 2005; pp. 65–72. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 15–30 September 2015; pp. 392–395. [Google Scholar]
- Wang, Y.; Deng, J.; Sun, A.; Meng, X. Perplexity from plm is unreliable for evaluating text quality. arXiv 2022, arXiv:2210.05892. [Google Scholar]
- Behjati, M.; Moosavi-Dezfooli, S.M.; Baghshah, M.S.; Frossard, P. Universal adversarial attacks on text classifiers. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7345–7349. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kuribayashi, T.; Oseki, Y.; Ito, T.; Yoshida, R.; Asahara, M.; Inui, K. Lower perplexity is not always human-like. arXiv 2021, arXiv:2106.01229. [Google Scholar]
- Li, D.; Jiang, B.; Huang, L.; Beigi, A.; Zhao, C.; Tan, Z.; Bhattacharjee, A.; Jiang, Y.; Chen, C.; Wu, T.; et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. arXiv 2024, arXiv:2411.16594. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Reif, E.; Ippolito, D.; Yuan, A.; Coenen, A.; Callison-Burch, C.; Wei, J. A recipe for arbitrary text style transfer with large language models. arXiv 2021, arXiv:2109.03910. [Google Scholar]



| Benchmark | Style | Models | Evaluation | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPFT | PEFT | ZSFS | Automatic Metrics | Human | |||||||||||
| Sentiment | Formality | Syntactic/ Semantic | Authorship | Embedding- Based | Decoder- Based | Classifier- Based | Zero- Shot | Few- Shot | Strength | Content | Fluency | Overall | |||
| GYAFC [10] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| MATST [11] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| CDS [9] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| StylePTB [12] | ✓ | ✓ | ✓ | ✓ | |||||||||||
| XFORMAL [13] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| LMStyle [14] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| TSTBench (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Type | Strategy | Method | Algorithm |
|---|---|---|---|
| Full-parameter fine-tuning (FPFT) | Embedding-based | Conditional GAN | STYTRANS [4] |
| Transductive learning | TSST [6] | ||
| Style-related words deleting | NAST [50] | ||
| Decoder-based | Paraphrase generation | STRAP [9] | |
| Reinforcement learning | BSRR [8], TYB [7] | ||
| Classifier-based | Edit entangled latent representation | CTAT [5] | |
| Parameter-efficient fine-tuning (PEFT) | On task dataset | LoRA-based fine-tuning | LlaMa-LORA [62] |
| On instruction dataset | LoRA-based instruction-tuning | LlaMa-LORA-INST [62] | |
| Zero-shot or few-shot prompt tuning (ZSFS) | Zero-shot | Large language model | CHATGPT [63], GPT4 [66] |
| Few-shot | Large language model | CHATGPT-FS [63], GPT4-FS [66] |
| Dataset | Style | Train | Valid | Test | Examples |
|---|---|---|---|---|---|
| Yelp | Negative | 180K | 2000 | 500 | She wasn’t happy being there. |
| Positive | 270K | 2000 | 500 | She seemed happy to be there. | |
| Amazon | Negative | 277K | 1015 | 500 | I don’t see what others have liked about this. |
| Positive | 278K | 985 | 500 | I see exactly what others have liked about this. | |
| GYAFC-EM | Informal | 52,595 | 2877 | 1416 | Different from what i’ve seen though. |
| Formal | 52,595 | 2356 | 1082 | It differs from what i have seen, however. | |
| GYAFC-FR | Informal | 51,967 | 2788 | 1332 | So if you ’re set on that, that ’s the way to go!! |
| Formal | 51,967 | 2247 | 1019 | If you are set on that, that is the way to go. | |
| Shakespeare | Ancient | 18,395 | 1218 | 1462 | And art thou changed? |
| Modern | 18,395 | 1218 | 1462 | And now you’ve changed? | |
| StylePTB-TFU | Present | 4377 | 243 | 243 | The dividend had been five cents a share. |
| Future | 4377 | 243 | 243 | The dividend will have been five cents a share. | |
| StylePTB-ARR | Origin | 6544 | 364 | 364 | Third they offer high yields. |
| Removal | 6544 | 364 | 364 | Third they offer yields. |
| Dataset | Roberta | TextCNN | COLA | Dataset | Roberta | TextCNN | COLA |
|---|---|---|---|---|---|---|---|
| Yelp (N → P) | 64.8 | 62.2 | 90.2 | GYAFC-FR (I → F) | 90.2 | 89.5 | 96.5 |
| Yelp (P → N) | 95.4 | 89.8 | 86.2 | GYAFC-FR (F → I) | 86.7 | 82.3 | 87.8 |
| Amazon (N → P) | 45.6 | 39 | 85.8 | Shakespeare (A → M) | 92.7 | 80.3 | 94 |
| Amazon (P → N) | 61.8 | 55.4 | 85 | Shakespeare (M → A) | 85.7 | 85.2 | 63.8 |
| GYAFC-EM (I → F) | 90.4 | 89.1 | 93.1 | StylePTB-ARR | 82.7 | 80.5 | 36.2 |
| GYAFC-EM (F → I) | 85 | 83.9 | 82.8 | StylePTB-TFU | 99.7 | 96.8 | 58.5 |
| Dataset | Reference | Fine-Tuned Models | CHATGPT | CHATGPT-FS | GPT4 | GPT4-FS |
|---|---|---|---|---|---|---|
| YELP (N->P) | 8.48 | 8.7 | 9.83 | 10.03 | 10.62 | 10.37 |
| YELP (P->N) | 8.25 | 8.6 | 9.55 | 10.18 | 9.12 | 10.15 |
| AMAZON (N->P) | 9.86 | 10.3 | 11.61 | 11.68 | 13.14 | 13.18 |
| AMAZON (P->N) | 10.57 | 11.1 | 12.02 | 11.86 | 12.54 | 11.72 |
| GYAFC_EM (I->F) | 10.87 | 11.8 | 12.4 | 12.01 | 12.84 | 13.68 |
| GYAFC_EM (F->I) | 10.21 | 10.2 | 10.56 | 10.73 | 10.36 | 10.12 |
| GYAFC_FR (I->F) | 11.15 | 12.7 | 13.14 | 12.9 | 13.45 | 13.33 |
| GYAFC_FR (F->I) | 10.72 | 10.7 | 10.78 | 10.29 | 10.4 | 9.26 |
| SHAKESPEARE (A->M) | 8.47 | 9.12 | 9.3 | 9.49 | 9.49 | 9.75 |
| SHAKESPEARE (M->A) | 8.94 | 9.2 | 9.52 | 9.41 | 9.34 | 9.7 |
| STYLEPTB_ARR | 8.03 | 7.9 | 7.31 | 7.41 | 6.93 | 7.88 |
| STYLEPTB_TFU | 10.38 | 10.3 | 10.19 | 10.29 | 10.35 | 10.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Y.; Gui, J.; Che, Z.; Zhu, L.; Hu, Y.; Pan, Z. TSTBench: A Comprehensive Benchmark for Text Style Transfer. Entropy 2025, 27, 575. https://doi.org/10.3390/e27060575
Xie Y, Gui J, Che Z, Zhu L, Hu Y, Pan Z. TSTBench: A Comprehensive Benchmark for Text Style Transfer. Entropy. 2025; 27(6):575. https://doi.org/10.3390/e27060575
Chicago/Turabian StyleXie, Yifei, Jiaping Gui, Zhengping Che, Leqian Zhu, Yahao Hu, and Zhisong Pan. 2025. "TSTBench: A Comprehensive Benchmark for Text Style Transfer" Entropy 27, no. 6: 575. https://doi.org/10.3390/e27060575
APA StyleXie, Y., Gui, J., Che, Z., Zhu, L., Hu, Y., & Pan, Z. (2025). TSTBench: A Comprehensive Benchmark for Text Style Transfer. Entropy, 27(6), 575. https://doi.org/10.3390/e27060575