
Karatsuba Algorithm Revisited for 2D Convolution Computation Optimization

 , ,
, ,
Abstract
1. Introduction
2. Background
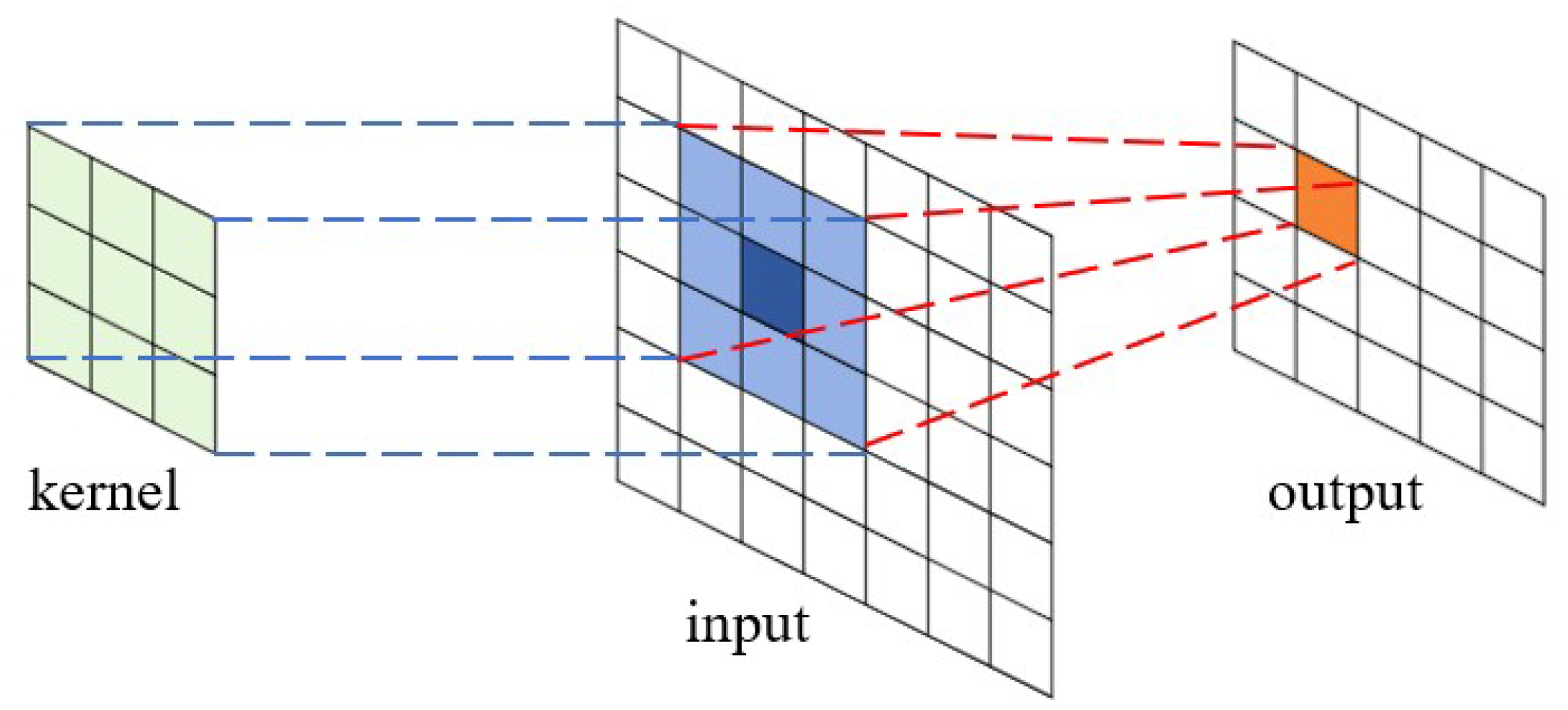
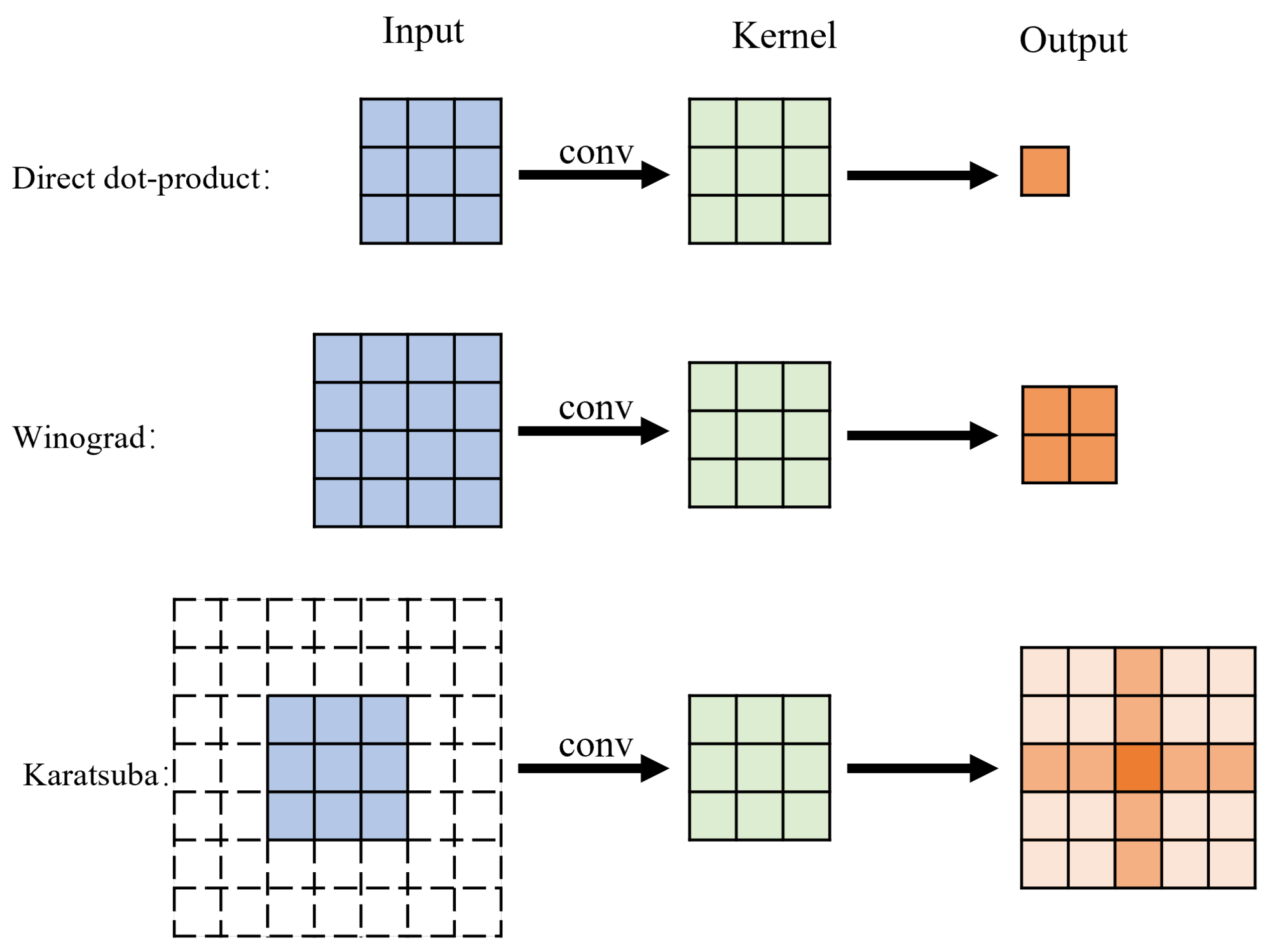
2.1. Traditional Dot-Product Convolution Computation
2.2. Winograd Algorithm
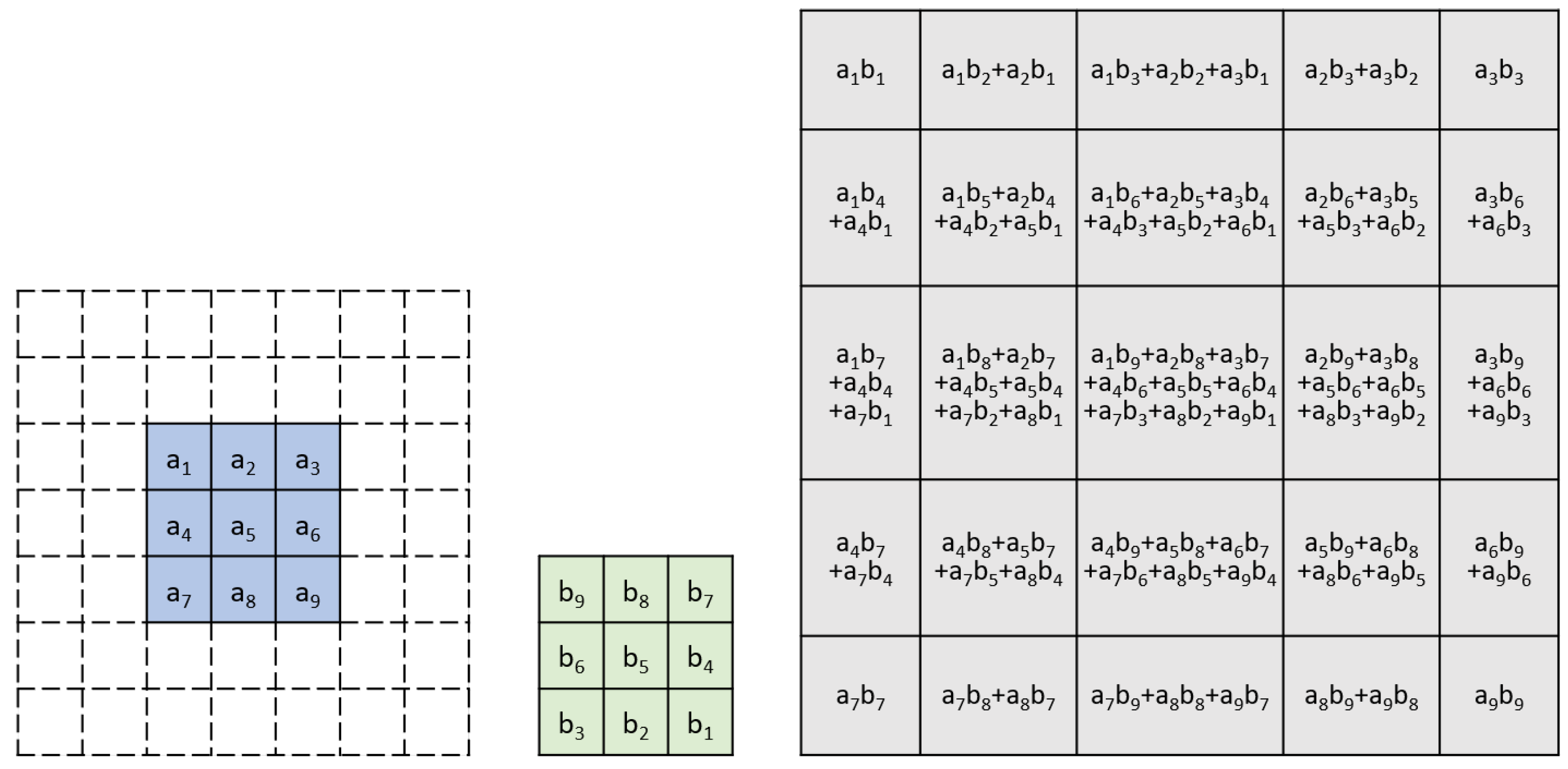
2.3. Karatsuba Algorithm
3. Applying the Karatsuba Algorithm in Convolution
3.1. A Simple Example
3.2. Applying the Karatsuba Algorithm in Both Rows and Columns
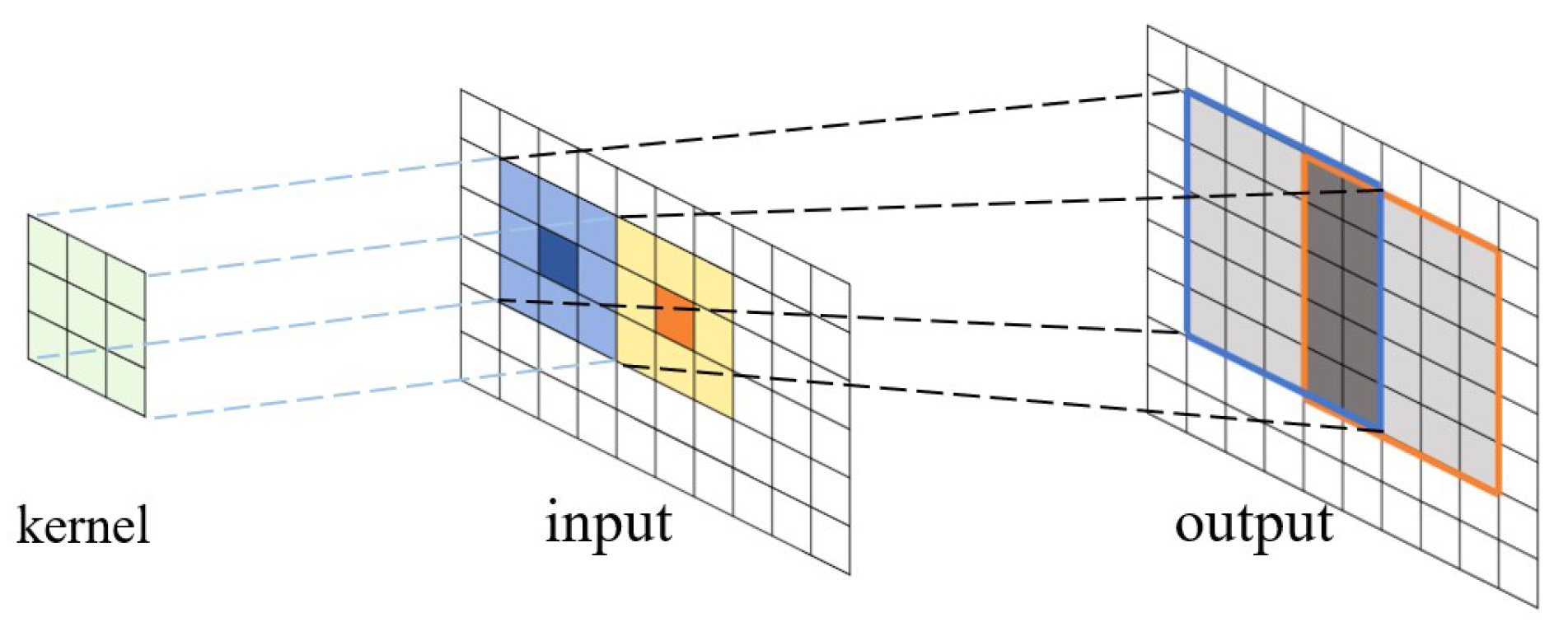
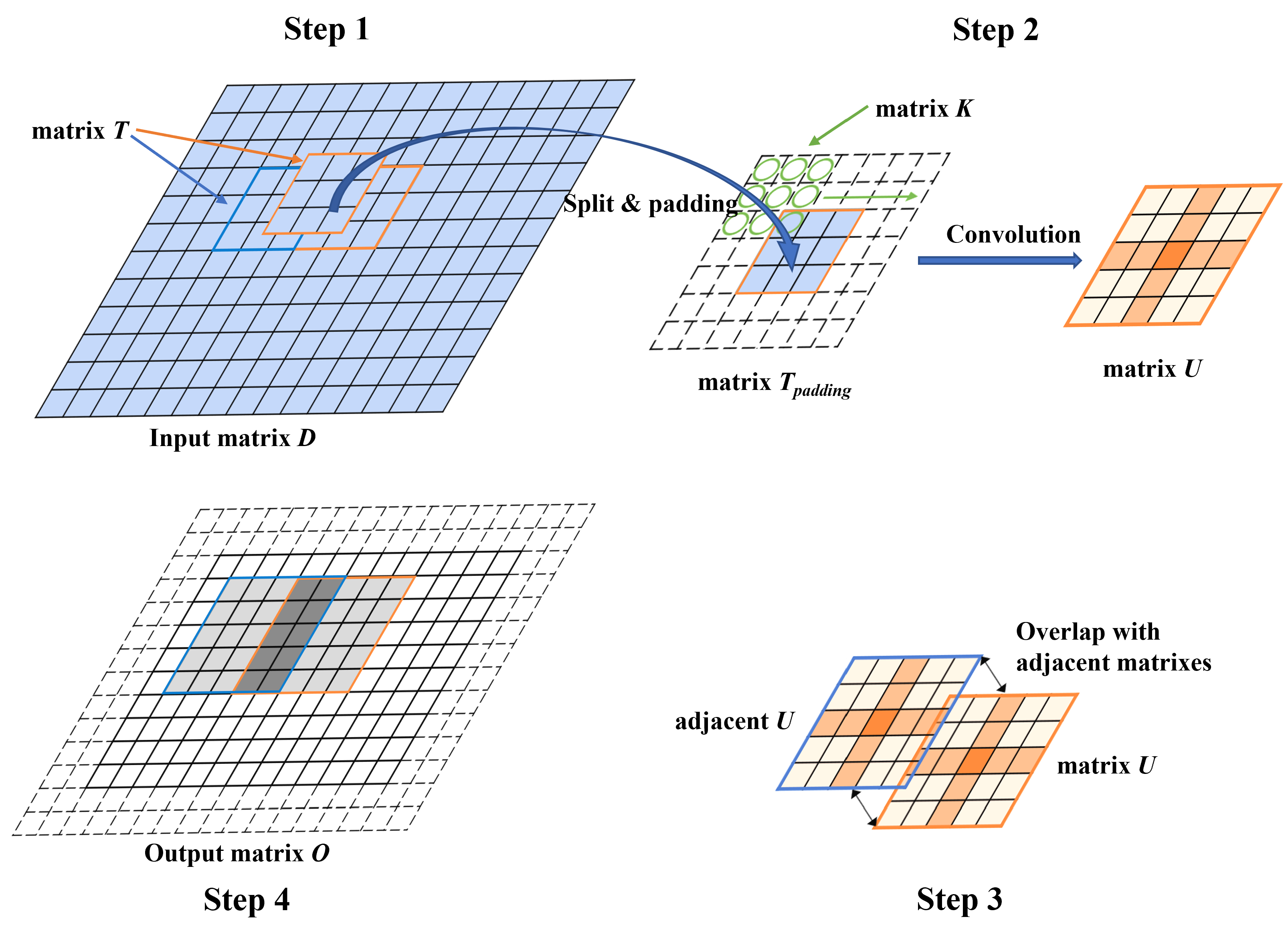
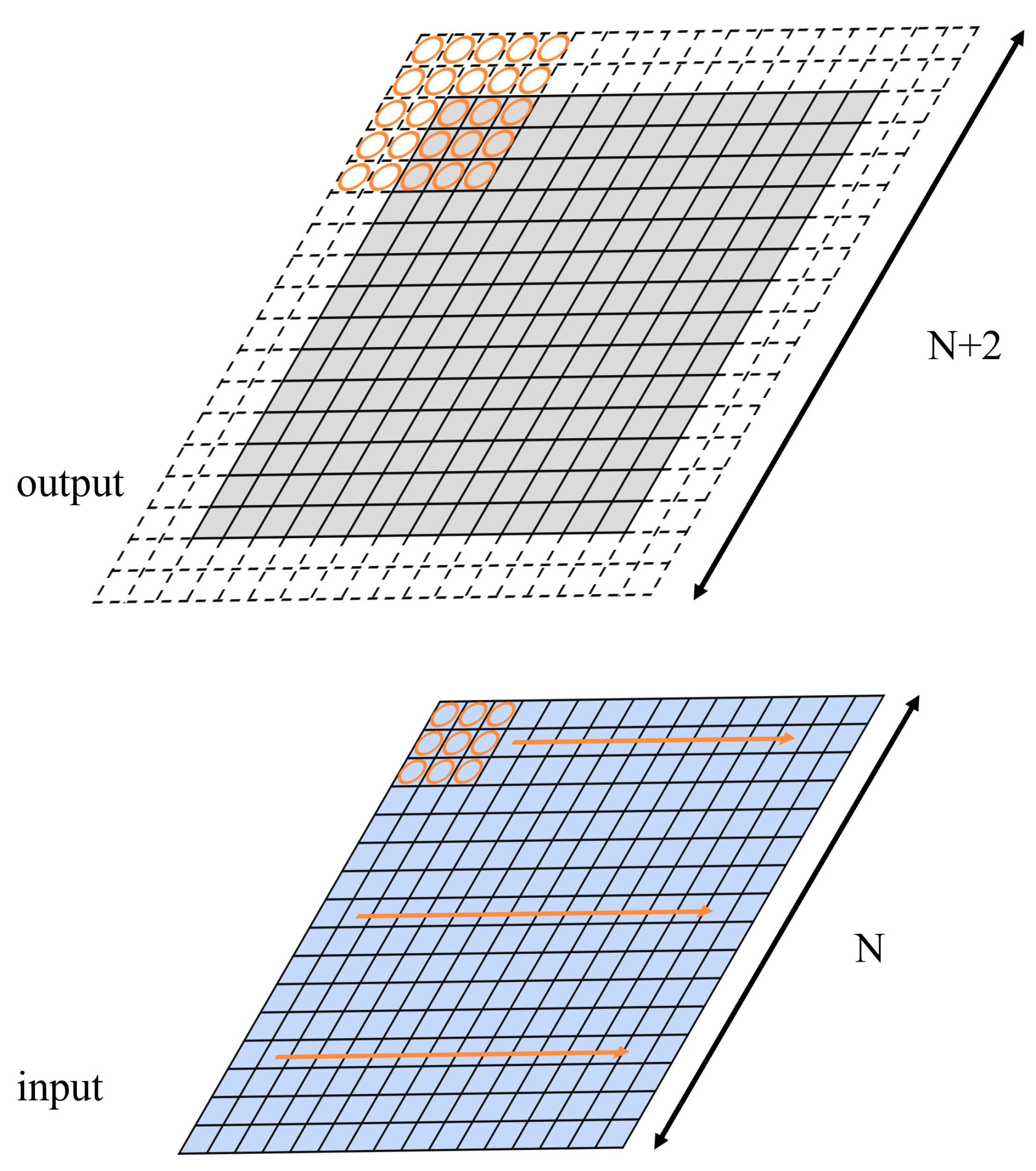
3.3. Convolution on a Large Input Matrix
3.4. Divide-and-Conquer Process
4. Computation Resource Analysis
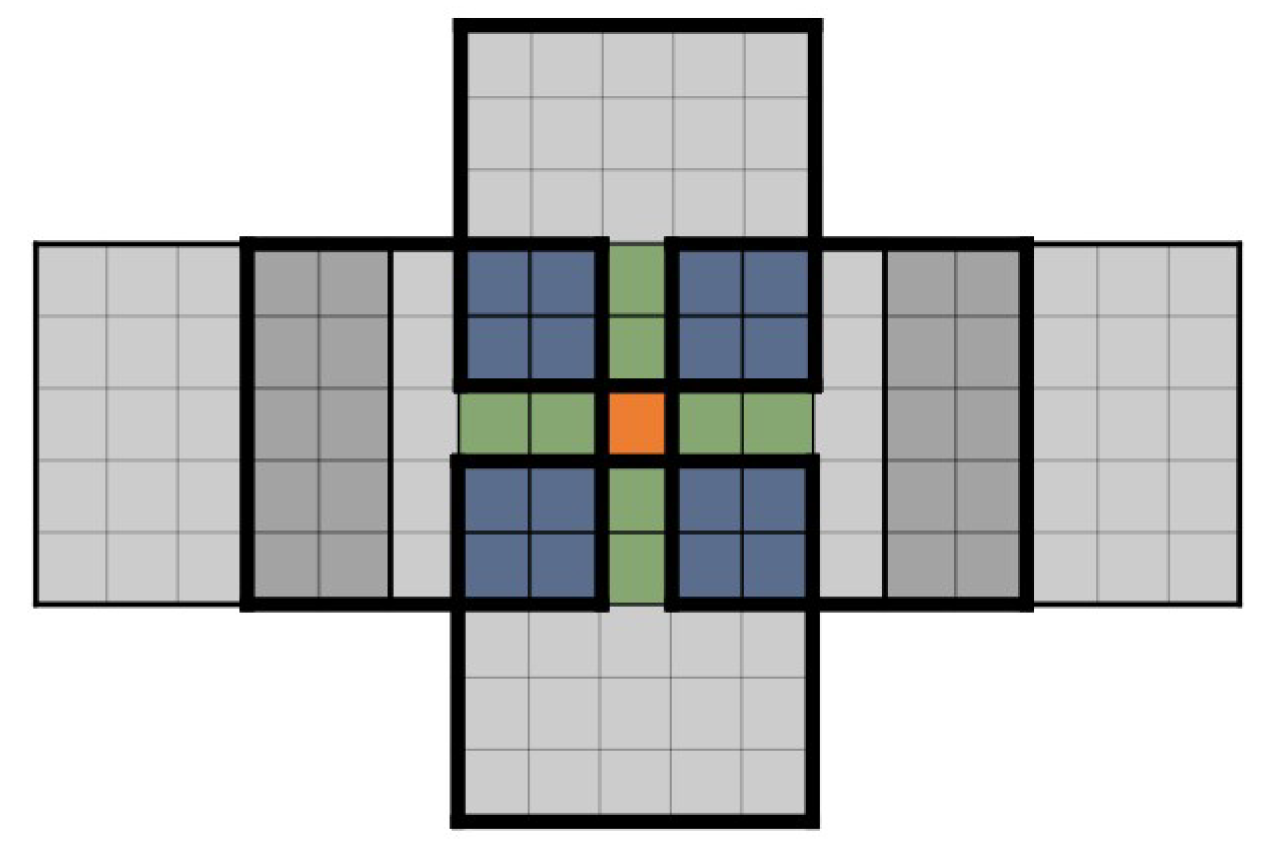
4.1. Elements in the Output Matrix O Are Calculated from Overlapping Adjacent U Matrices
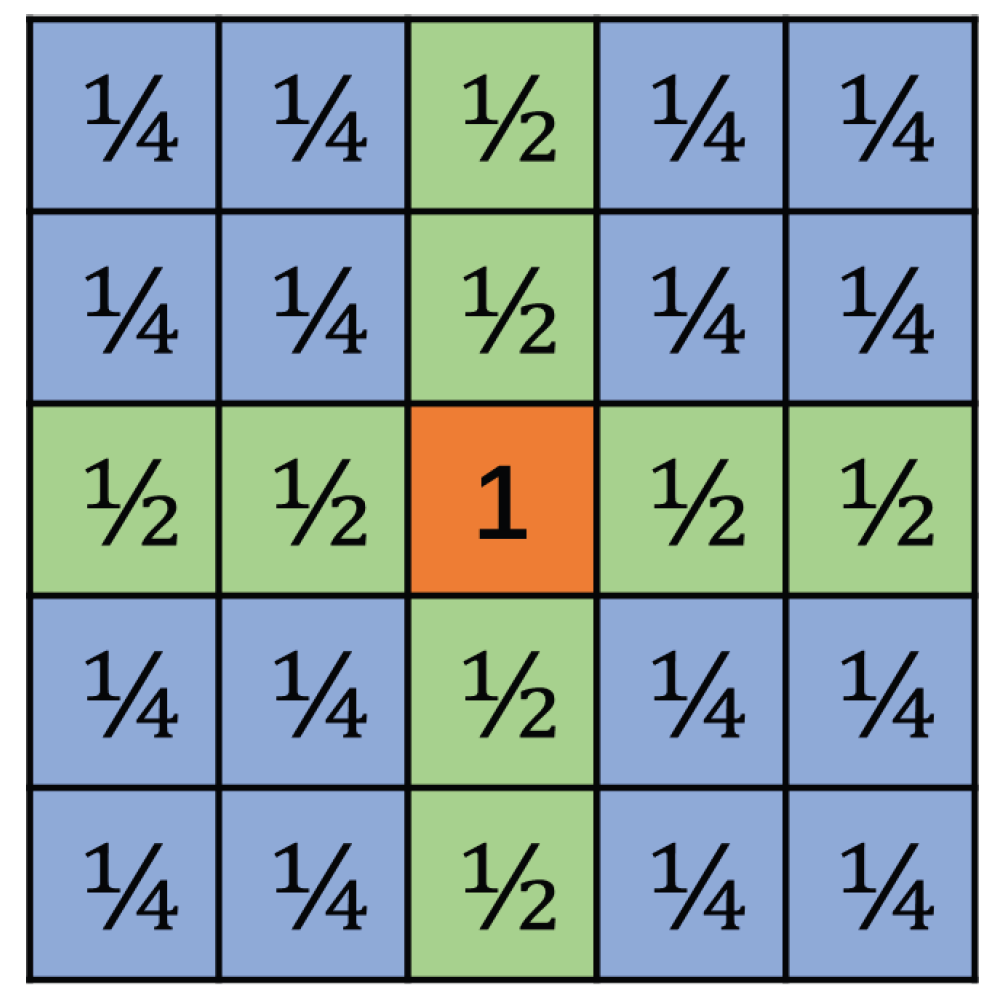
4.2. Effective Element
5. Hardware Implementation Testing Result
5.1. Implementation of Basic Convolution Modules
5.2. Implementation of Convolution with Full-Sized Input Matrices
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1 The pseudocode for the Winograd convolution algorithm | |
|
|
Appendix B
| Algorithm A2 The pseudocode for the Karatsuba convolution algorithm | |
|
|
References
- Podili, A.; Zhang, C.; Prasanna, V. Fast and efficient implementation of Convolutional Neural Networks on FPGA. In Proceedings of the 2017 IEEE 28th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Seattle, WA, USA, 10–12 July 2017; pp. 11–18. [Google Scholar]
- Mathieu, M.; Henaff, M.; LeCun, Y. Fast training of convolutional networks through ffts. arXiv 2013, arXiv:1312.5851. [Google Scholar]
- Vasilache, N.; Johnson, J.; Mathieu, M.; Chintala, S.; Piantino, S.; LeCun, Y. Fast convolutional nets with fbfft: A GPU performance evaluation. arXiv 2014, arXiv:1412.7580. [Google Scholar]
- Winograd, S. Arithmetic Complexity of Computations; SIAM: Philadelphia, PA, USA, 1980; Volume 33. [Google Scholar]
- Lavin, A.; Gray, S. Fast algorithms for convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Chi, L.; Jiang, B.; Mu, Y. Fast fourier convolution. Adv. Neural Inf. Process. Syst. 2020, 33, 4479–4488. [Google Scholar]
- Meng, L.; Brothers, J. Efficient winograd convolution via integer arithmetic. arXiv 2019, arXiv:1901.01965. [Google Scholar]
- Lu, S.; Chu, J.; Liu, X.T. Im2win: Memory efficient convolution on SIMD architectures. In Proceedings of the 2022 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 19–23 September 2022; pp. 1–7. [Google Scholar]
- Lu, S.; Chu, J.; Guo, L.; Liu, X.T. Im2win: An Efficient Convolution Paradigm on GPU. In Proceedings of the European Conference on Parallel Processing, Limassol, Cyprus, 28 August–1 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 592–607. [Google Scholar]
- Karatsuba, A.A.; Ofman, Y.P. Multiplication of many-digital numbers by automatic computers. In Proceedings of the Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1962; Volume 145, pp. 293–294. [Google Scholar]
- Gu, Z.; Li, S. Optimized Interpolation of Four-Term Karatsuba Multiplication and a Method of Avoiding Negative Multiplicands. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 1199–1209. [Google Scholar] [CrossRef]
- Lee, C.Y.; Meher, P.K. Subquadratic Space-Complexity Digit-Serial Multipliers Over GF(2m) Using Generalized (a, b)-Way Karatsuba Algorithm. IEEE Trans. Circuits Syst. I Regul. Pap. 2015, 62, 1091–1098. [Google Scholar] [CrossRef]
- Heideman, M.T. Convolution and polynomial multiplication. In Multiplicative Complexity, Convolution, and the DFT; Springer: New York, NY, USA, 1988; pp. 27–60. [Google Scholar]
- Ghidirimschi, N. Convolution Algorithms for Integer Data Types. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2021. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.s. Optimizing the convolution operation to accelerate deep neural networks on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Winograd, S. On multiplication of polynomials modulo a polynomial. SIAM J. Comput. 1980, 9, 225–229. [Google Scholar] [CrossRef]
- Montgomery, P.L. Five, six, and seven-term Karatsuba-like formulae. IEEE Trans. Comput. 2005, 54, 362–369. [Google Scholar] [CrossRef]
- Dyka, Z.; Langendörfer, P. Area Efficient Hardware Implementation of Elliptic Curve Cryptography by Iteratively Applying Karatsuba’s Method. In Proceedings of the 2005 Design, Automation and Test in Europe Conference and Exposition (DATE 2005), Munich, Germany, 7–11 March 2005; IEEE Computer Society: Columbia, WA, USA, 2005; pp. 70–75. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bit-Width | 4-bit | 8-bit | 16-bit | 32-bit |
|---|---|---|---|---|
| Addition | 4 | 8 | 16 | 32 |
| Multiplication | 23 | 61 | 277 | 1344 |
| Name | Ouput Size | Effective Element Number | Number of Multiplication | Multiplication/ Effective Element | Addition | Addition/ Effective Element |
|---|---|---|---|---|---|---|
| Direct dot- produce | 1 × 1 | 1 | 9 | 9 | 8 | 8 |
| Winograd | 2 × 2 | 4 | 16 | 4 | 77 | 19.25 |
| Karatsuba | 5 × 5 | 9 | 36 | 4 | 136 | 15.11 |
| Latency | Interval | DSP | DSP/Effective Elements | LUT | LUT/Effective Elements | |
|---|---|---|---|---|---|---|
| Direct dot- produce | 2 | 1 | 27 | 27 | 606 | 606 |
| Winograd | 5 | 1 | 48 | 12 | 5079 | 1269.75 |
| Karatsuba | 7 | 1 | 108 | 12 | 7492 | 832.44 |
| Latency (cycles) | DSP | LUT | |
|---|---|---|---|
| Direct dot-produce | 2278 | 972 | 16263 |
| Winograd | 2283 | 432 | 44454 |
| Karatsuba | 2313 | 432 | 29526 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Zhu, J.; He, C.; Wang, S.; Wang, X.; Ren, Y.; Ye, T.T. Karatsuba Algorithm Revisited for 2D Convolution Computation Optimization. Entropy 2025, 27, 506. https://doi.org/10.3390/e27050506
Wang Q, Zhu J, He C, Wang S, Wang X, Ren Y, Ye TT. Karatsuba Algorithm Revisited for 2D Convolution Computation Optimization. Entropy. 2025; 27(5):506. https://doi.org/10.3390/e27050506
Chicago/Turabian StyleWang, Qi, Jianghan Zhu, Can He, Shihang Wang, Xingbo Wang, Yuan Ren, and Terry Tao Ye. 2025. "Karatsuba Algorithm Revisited for 2D Convolution Computation Optimization" Entropy 27, no. 5: 506. https://doi.org/10.3390/e27050506
APA StyleWang, Q., Zhu, J., He, C., Wang, S., Wang, X., Ren, Y., & Ye, T. T. (2025). Karatsuba Algorithm Revisited for 2D Convolution Computation Optimization. Entropy, 27(5), 506. https://doi.org/10.3390/e27050506