1. Introduction
Type II censoring is a commonly used censoring method, especially in reliability testing and survival analysis. It is defined as the situation where an experiment or trial is terminated after a predetermined time or a certain number of samples. In experiments with time or cost constraints, Type II censoring provides an efficient and resource-saving experimental design approach, especially in fields such as reliability testing and survival analysis. By setting an upper limit on the number of failures, it ensures that the experiment can obtain valid statistical inferences within limited resources while maintaining reliability and accuracy. Since 1950, many authors have studied this topic. Parameter estimation methods for various distributions under Type II censoring were provided by [
1], providing significant support to future researchers. In recent years, several studies have explored this topic [
2,
3,
4,
5,
6,
7,
8].
Failure-censored sampling plans aim to estimate the reliability parameters of a population by sampling product lifetimes or failure times. This problem has been extensively studied, particularly in the development of lifetime models and the optimization of sampling design methods. The earliest research on failure-censored sampling was introduced in [
9], laying the foundation for subsequent advancements in this area. In recent years, further research has been conducted on sampling plans for different lifetime models. For instance, reliability design methods with double censoring, applicable to certain two-parameter distributions, were introduced in [
10], extending the applicability of failure-censored sampling. Moreover, in [
11], sampling schemes optimized for lifetime distributions characterized by log-location–scale parameters were explored, leading to the development of design approaches suitable for more sophisticated lifetime models. Additionally, various computational methods and optimization strategies for sampling design under the Weibull distribution were proposed in [
12], particularly for designing efficient sampling plans in higher-dimensional and more complex scenarios. Furthermore, the determination of the optimal reliability acceptance sampling plan under cost constraints within the hybrid censoring framework was explored in [
13], addressing the challenge of balancing reliability and cost efficiency. In [
14], an acceptance sampling scheme utilizing the lifetime performance index was proposed for exponential populations with and without censoring. The method achieved similar performance compared to the approximation approach based on full-order observed exponential data. Similarly, in [
15], an optimal reliability acceptance sampling plan was designed using the Type I generalized hybrid censoring scheme for non-repairable products, while a cost function approach was introduced for products with Weibull-distributed lifetimes. In addition, ref. [
16] introduced two innovative variable reliability acceptance sampling plans, namely, repetitive group sampling and resubmitted sampling, both of which are suitable for reliability tests under failure-censoring. Building on this progress, a variable multiple-dependent-state sampling scheme based on the Weibull distribution with Type II right censoring was proposed in [
17], incorporating the lifetime performance index. Compared to the single-variable sampling scheme, the proposed approach demonstrates higher cost efficiency and greater discriminatory power. In summary, failure-censored sampling plans require significantly fewer samples than attribute sampling plans, while also considerably reducing test time compared to complete variable sampling schemes. This makes failure-censored sampling plans highly valuable for reliability testing and quality control under resource constraints.
Traditional acceptance sampling typically assumes that the proportion of nonconforming items, denoted as
p, is a fixed value for each production batch. However, in practical applications, the true value of
p is usually unknown prior to inspection, and it may vary across different batches due to differences in materials, processing conditions, or environmental factors. If this uncertainty is ignored, classical methods that assume a known
p may lead to suboptimal or misaligned sampling plans. To address this issue, Bayesian methods have been introduced. In the Bayesian framework,
p is still assumed to be fixed for a given batch, but treated as a random variable to represent our uncertainty about its true value. A Beta distribution is commonly used as the prior for
p, due to its flexibility on the interval [0,1] and its conjugate relationship with the binomial distribution, which simplifies posterior computation. The application of Beta priors for optimizing sampling schemes was first proposed in [
18] and has since provided a foundational framework for Bayesian-based acceptance sampling.
In recent years, Bayesian sampling has continued to receive widespread attention and extensive research. For instance, in [
19], the application of Bayesian sampling in acceptance sampling was significantly expanded by exploring various prior distributions for the defective rate
p, which not only enriched the theoretical framework but also enhanced practical implementations. In [
20], a systematic comparison of conventional and Bayesian sampling methods was conducted. This study provided an in-depth evaluation of both consumer and producer risks while examining the sensitivity of prior distribution parameter variations. These findings contributed to a more comprehensive understanding of Bayesian sampling performance and its practical implications. As research in this field progressed, in [
21], a novel acceptance sampling plan was introduced to determine whether the received lot met the predefined acceptance criteria. This approach integrated a cost objective function that accounted for potential inspection errors. Additionally, Bayesian inference was applied to refine the probability distribution function of the nonconforming proportion, whereas a backward recursive approach was employed to evaluate terminal costs and derive optimal decisions. Expanding Bayesian sampling methodologies further, in [
22], two Bayesian accelerated acceptance sampling plans were proposed for a lognormal lifetime distribution under Type I censoring. The first plan incorporated risk considerations for both producers and consumers, while the second exclusively focused on consumer risk. Moreover, a sensitivity analysis was conducted to assess the impact of prior distribution selection, thereby enhancing the robustness and applicability of these models. In [
23], a Bayesian reliability sampling plan was presented for the Weibull distribution under progressively Type II censoring. The study identified the optimal strategy by analyzing sample sizes, recorded failure counts, binomial-based removal probabilities, and the minimum reliability threshold. This refinement further advanced Bayesian reliability sampling techniques, making them more adaptable to real-world reliability assessments. Most recently, in [
24], a Bayesian double-group sampling plan was introduced to estimate the average number of nonconforming products. By incorporating Bayesian inference principles, this approach contributed to the growing body of research focused on improving the efficiency and accuracy of Bayesian-based acceptance sampling strategies.
This paper analyzes the average and posterior risks in designing optimal failure-censored sampling plans for lognormal lifetime models, where the defect rate
p follows a beta distribution. In
Section 2, we derive the operating characteristic function for the lognormal distribution under Type II censoring, which is used to evaluate the acceptance probability of products based on the lognormal lifetime distribution. Through large-sample approximations, we estimate the impact of censoring rate and defect probability on acceptance decisions, providing a theoretical foundation for optimizing sampling plans. In
Section 3, we first introduce the producer’s risk and consumer’s risk under both classical and Bayesian sampling frameworks. Then, we present a computational procedure for determining the optimal sample size and decision threshold. Finally, we analyze the properties of prior distributions under different parameter settings and explore their influence on the optimization of sampling schemes. In
Section 4, we compute the optimal sample sizes corresponding to different prior distribution parameters and conduct a sensitivity analysis on both classical and Bayesian sampling methods. Based on these results, we identify the optimal sampling scheme for specific prior distributions, balancing sample size and risk control. In
Section 5, we synthesize the graphs and simulation results obtained in
Section 4 to draw conclusions. We further provide recommendations for producers and consumers regarding the application of optimal sampling schemes. The findings contribute to reliability testing and quality control, aiding in the development of more robust sampling strategies.
2. Operating Characteristic Function
The lognormal distribution is one of the most widely used methods of survival analysis, reliability analysis, and sampling inspection. In reliability testing, suppose the lifetime T of a batch of electronic components follows a two-parameter lognormal distribution. The logarithm of the lifetime variable, , follows a normal distribution with an unknown location parameter and scale parameter . In this article, we primarily study the logarithmic lifetime X.
The cumulative distribution function (CDF), probability density function (PDF), and survival function (SF) of the random variable
X are given by:
In the following, represents the standard normal distribution function, and represents the probability density function.
Given a total sample size of n, the test is terminated upon the failure of the m-th component. At this point, the logarithmic lifetime is recorded, while the remaining components have not yet failed and are considered censored, with a censoring rate defined as , representing the proportion of units that are censored due to not failing within the test duration. This parameter will be crucial in later derivations. Consequently, only the first m order statistics are available, and it is known that units remain beyond .
When
is independently and identically distributed as
and only the first
m order statistics
are available, their joint density function is:
Here, the faction arises from the joint density of order statistics and reflects the number of ways to arrange m failure times among n total units, with the remaining units being censored.
The lifetime variable is assumed to follow a lognormal distribution, which is a type of log-location–scale lifetime model. Therefore, we apply a logarithmic transformation to the data and perform all subsequent analysis on the logarithmic scale, including the logarithmic lifetime X and the lower limit ℓ. Under this transformation, the lifetime variable becomes normally distributed, allowing us to formulate the model within the framework of the normal distribution. This transformation does not alter the acceptance decision criterion for the products, and it also enables us to take advantage of the well-established theoretical results for Type II censoring under the normal distribution.
For an electronic component to meet quality standards, its lifetime must exceed a given lower limit
ℓ. If
, the product is considered defective, commonly referred to as a “bad value” in quality control. The defect rate
p is defined as:
Since
, we have
; hence, solving for
ℓ yields:
A batch of products is accepted if the maximum likelihood estimates (MLEs)
and
under Type II censoring satisfy:
where
k is a predetermined constant. Substituting
ℓ, we obtain
. Defining the pivotal quantities
and
, the inequality simplifies to
. Thus, the operating characteristic (OC) curve is defined as:
As shown in [
25], the asymptotic normal approximation of the OC function
is reasonable for the lognormal case under Type II censoring:
The notation
indicates that, as the sample size
, the random vector composed of two statistics,
converges in distribution to a bivariate normal distribution with zero mean and covariance matrix
. Here,
represents the standardized deviation of the MLE for the location parameter, and
denotes the relative deviation of the MLE for the scale parameter.
Here, is a covariance matrix with elements () derived from the inverse of the Fisher information matrix under Type II censoring.
Let the information matrix be:
Defining
, its asymptotic distribution is given by:
Thus, the decision rule is rewritten as
. By the asymptotic normality,
Thus, the approximate expression for the OC curve under Type II censoring is:
where
For
under Type II censoring in a normal distribution, the asymptotic variance–covariance matrix elements correspond to the negative expected values of the second-order partial derivatives of the log-likelihood function concerning the parameters. According to [
1], if
and
In Type II censoring, the truncation point is denoted by w, and the standardized truncation point, represented as , is defined by . The function is given by , while is expressed as .
Here,
are functions of
, which are elements of the information matrix. In the case of Type II censoring with a total sample size of
n and a censoring rate of
q, the calculation methods for
are as follows:
The following diagram illustrates the relationship between , , and the elements in the covariance matrix .
![Entropy 27 00477 i001]()
In practical applications, the probability bounds for the product failure rate
p are typically determined according to industrial standards. These bounds define the region over which the producer’s and consumer’s risks are assessed, and they further guide the determination of the sample size
n, the number of failures
m, and the predetermined constant
k for the test statistic. A more detailed mathematical formulation of this design process is provided in
Section 3.
3. Risk Criteria and Prior Models
In reliability testing and quality control, both producers and consumers need to jointly establish quality standards based on the defect rate p to ensure that the production process controls the outflow of nonconforming products while not being overly stringent on conforming products. The acceptable quality level and the rejectable quality level are two key indicators that represent the highest defect rate acceptable to the producer and the lowest defect rate unacceptable to the consumer, respectively, where .
In quality inspection, sampling tests determine whether a production batch meets the required quality standards. If a batch satisfies the acceptance criteria, it is considered accepted; otherwise, it is rejected. Thus, batch acceptance indicates a passed test, while batch rejection signifies a failed test.
Based on this, the quality inspection process involves two main risks: producer’s risk (PR) refers to the probability that a conforming batch () is rejected due to sampling error, denoted as ; consumer’s risk (CR) refers to the probability that a nonconforming batch () is accepted due to sampling error, indicated as .
The goal of the sampling plan is to determine the optimal scheme
(i.e., minimizing sample size) such that:
This ensures that both producer and consumer risks are controlled, balancing the acceptance rate of conforming products and the rejection rate of nonconforming products while maintaining a reasonable sample size and testing cost. A censoring mechanism is introduced to reduce testing time or cost, and prior distributions are further incorporated to optimize decision-making. Here, and represent the prior probability density functions of p for the producer and consumer, respectively, with the corresponding cumulative distribution functions and . Bayesian methods can further optimize the sampling strategy, making decisions statistically more rational.
3.1. Classical and Bayesian Risks
Different risk criteria guide the selection of the optimal sampling plan . Given that the probability of batch acceptance is expressed as , the classical average risks are defined as follows:
Average Producer’s Risk (
APR)
Average Consumer’s Risk (
ACR)
Additionally, Bayesian or posterior risks are defined as follows:
Bayesian Producer’s Risk (
BPR)
Bayesian Consumer’s Risk (
BCR)
3.2. A Computational Procedure
To obtain the optimal sampling plan
that satisfies the condition in Equation (
3), we solve it using Algorithm 1. In this study, we employed the particle swarm optimization algorithm to estimate the model parameters. In the initial stage, we adopted a relatively broad search range to avoid premature convergence to local optima. Based on preliminary results, the parameter bounds were then refined. The final search intervals were set as:
The remaining particle swarm optimization parameters were configured as follows: swarm size of 500, maximum number of iterations set to 100, inertia weight , and acceleration coefficients . A boundary-clipping mechanism was applied at each iteration to ensure that all particles remained within the feasible search space, thereby enhancing the stability and convergence of the algorithm.
After obtaining the optimal solution
from the equation, we take into account that the sample size
n must be a positive integer. Therefore, we round
up to the nearest integer to obtain the actual sample size
n. Next, we substitute
n and
into Equation (
3)–(
7) for verification: if the condition in Equation (
3) is satisfied, the value of
m is set to its floor; otherwise, it is set to its ceiling.
Finally, the determined value of
n is substituted into the two equations from Step 2 to compute the corresponding values
and
, and the final value of
is taken as the average of these two. A detailed description of the procedure is provided in the algorithm below.
| Algorithm 1: Computational Procedure for Optimal Sampling Plan |
![Entropy 27 00477 i002]() |
3.3. Prior Distribution of Defect Rate
In industrial production, the defect rate
p of batches of electronic components is not fixed but varies randomly due to factors such as materials, processes, and environmental conditions. The overall defect rate
p is generally unobservable, but it can be estimated based on historical data or empirical prior information. Suppose the prior probability density function of
p follows a beta distribution:
With the probability density function given by:
where
is the beta function. When the producer’s and consumer’s risk assessments adopt the same prior information, i.e.,
, it indicates that both parties rely on the same historical data and quality control standards. This assumption enables producers and consumers to optimize the sampling plan within a common informational framework. In the Bayesian approach, the prior mean and prior variance of the defect rate are expressed as:
Here,
represents the prior mean of the defect rate, influencing the overall judgment of product quality by both producers and consumers, while
quantifies uncertainty. As
a and
b increase, the weight of prior information strengthens, leading to a more conservative risk assessment.
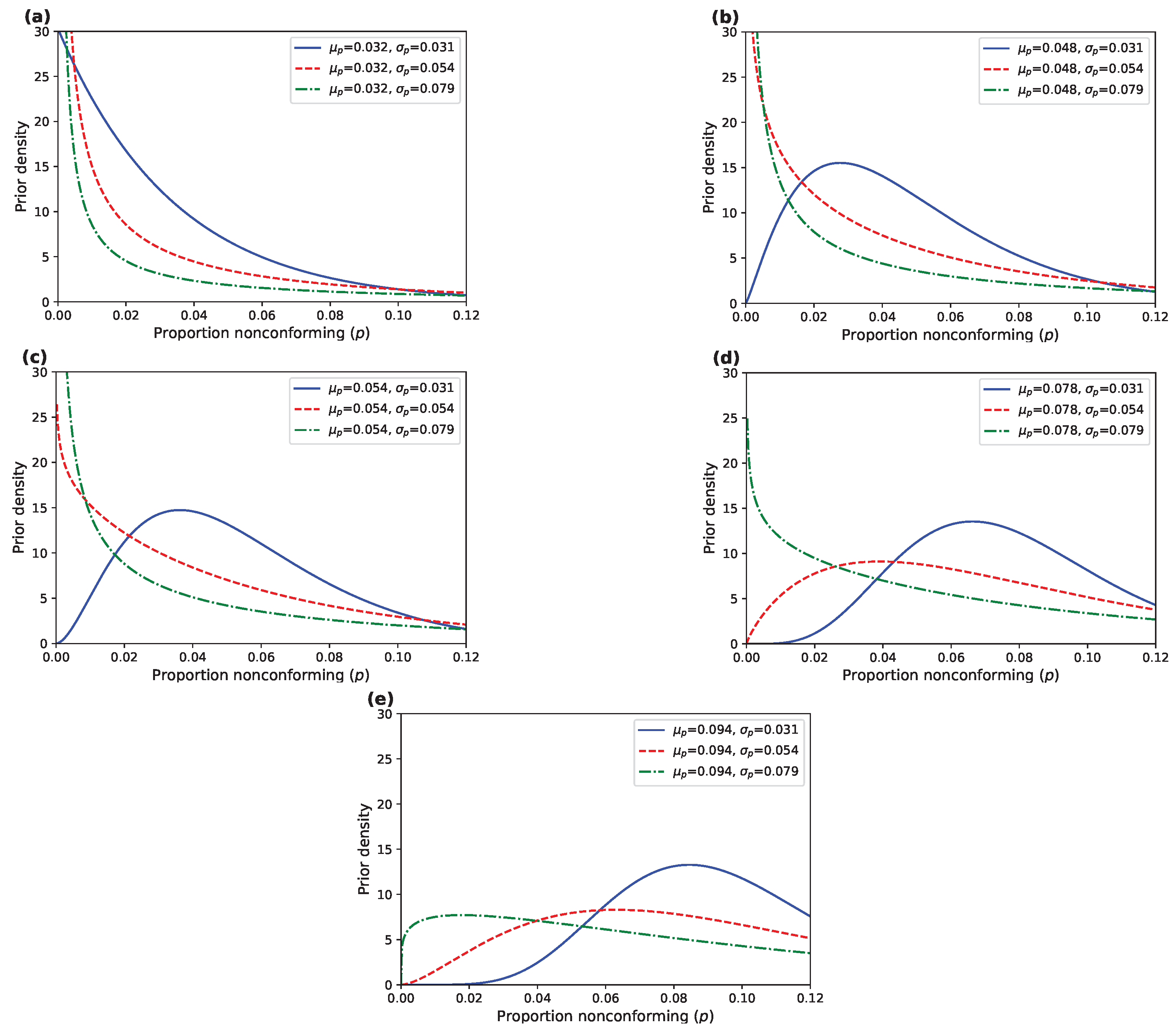
Figure 1 displays several beta densities for selected values of
and
.
4. Sensitivity of Optimal Designs
In this section, we define the optimal sampling design as a triplet
that minimizes the sample size
n while satisfying the producer’s risk constraint
and the consumer’s risk constraint
. The computational procedure proposed in
Section 3 is designed to search for such optimal designs under various assumptions on the prior distributions. We primarily investigate the impact of variations in the prior beta distribution’s mean
and standard deviation
on producer and consumer risks and conduct a sensitivity analysis of
and
.
In the following sampling schemes, we consider a lognormal sampling process with a censoring rate of 50%, where
and
.
Table 1 also includes simulated producer and consumer risks corresponding to the optimal design solutions. In electronic component manufacturing and quality control, the defect rate
p of product batches is not fixed but fluctuates due to factors such as raw materials, process stability, and environmental conditions. Consequently, relying on a single-point estimate may lead to producer risk and consumer risk exceeding acceptable limits, affecting the effectiveness of quality management.
To better characterize the uncertainty in p, we introduce the beta distribution as a prior distribution. The prior mean represents the average defect rate in the production process, while the prior variance quantifies the extent of fluctuations in the defect rate. A smaller indicates a more stable production process, whereas a larger suggests greater quality variations, necessitating a stricter inspection strategy.
Based on the [
26] quality standard, we select
and
as quality control parameters and analyze the impact of different
and
values on producer and consumer risks. This ensures that even with imperfect prior information, the sampling plan can be optimized to balance the interests of both producers and consumers while enhancing the robustness of quality management.
The selected values of lie within the interval , while is proportional to the length of this interval. The prior mean values of p, set at , , and , represent “low”, “medium” and “high” levels, respectively. The additional values of and allow us to better understand the trend of changes in , enabling a more detailed sensitivity analysis in subsequent steps. Similarly, is chosen as , , and , representing “low”, “medium” and “high” levels’ values, respectively.
For the Bayesian risk scheme, when , this value is too close to , making the requirements overly stringent. The resulting sample size is unrealistically small and lacks practical significance in real-world sampling, so specific results are not provided in the table. Observing the overall trend, we can see that, under the same prior distribution, the average risk method requires a larger sample size compared to the Bayesian risk approach. This outcome aligns with our expectations.
As discussed earlier, the optimal sampling plan proposed in this study is based on the large-sample theory. To evaluate the effectiveness of these asymptotic solutions, we perform a Monte Carlo simulation study. A detailed description of the simulation methodology can be found in [
11]. The general procedure is as follows: First, we generate 5000 values of
p following the current prior beta distribution. Then, we generate 5000 sets of samples from a lognormal distribution, each containing
n observations. Subsequently, risk simulations are performed under a censoring rate of 50%. It is evident that under the lognormal distribution, the simulated average producer risk and consumer risk closely approximate the expected risks,
and
, respectively.
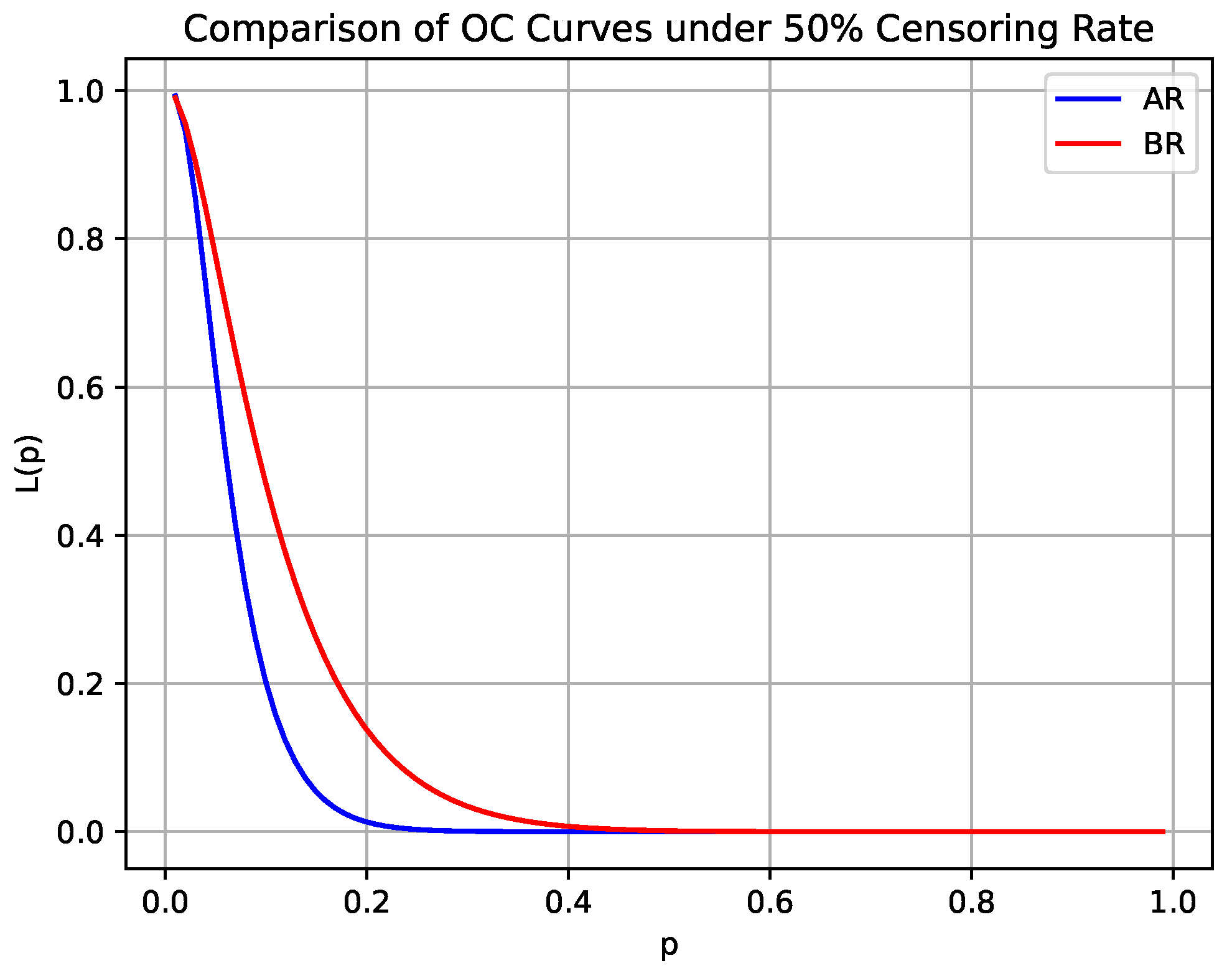
Using the results calculated in
Table 1, we plot the OC curves for the lognormal distribution under classical sampling and Bayesian sampling, with a censoring rate of 50%, and a prior distribution with mean
and standard deviation
.
As shown in
Figure 2, the AR design exhibits a curve that rapidly approaches 0, demonstrating high sensitivity to variations in quality levels, particularly near the acceptance threshold, where the acceptance probability declines sharply. This behavior aligns with the characteristics of classical sampling, which relies on a fixed standard without incorporating data or prior distributions, thus responding quickly to quality fluctuations. In contrast, the BR design exhibits a curve that gradually approaches 0, with a higher initial acceptance probability and greater tolerance for uncertainty. By incorporating prior information and updating iteratively, the Bayesian method enhances tolerance for low-quality batches, resulting in a smoother OC curve.
4.1. Influence of Prior Moments on Risks
4.1.1. Average Risk Design and Bayesian Risk Design
This study considers the optimal average risk sampling plan under given specifications, with prior
and
. By modifying the values of
and
, we illustrate their impact on design risks. To this end,
Figure 3 presents the sensitivity of the average risk when
and
vary simultaneously, while
Figure 4 provides the corresponding contour plots.
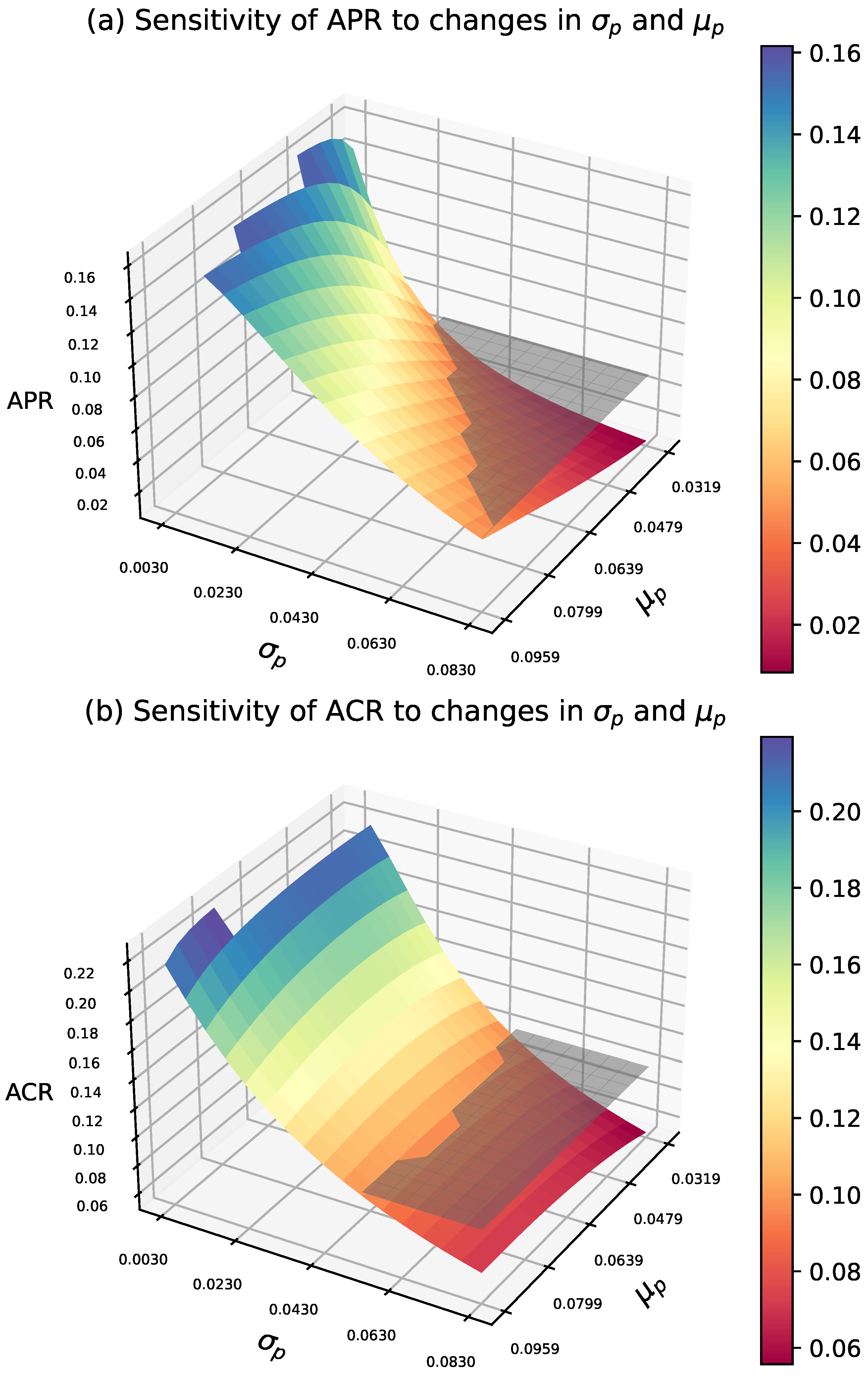
Clearly, the producer’s risk is highly sensitive to changes in both and . In the lower range of , the APR initially exceeds the threshold and gradually decreases towards as increases. When is high, the reduction in APR is less pronounced, while at lower values, the change is more significant. Furthermore, in the medium to high range of and in lower values of , APR decreases significantly. However, when is high and is low, the decrease in APR slows down.
The consumer risk is similarly sensitive to variations in and . In the lower range of , ACR remains at a relatively high level and decreases as increases. When is higher, the reduction in ACR is more gradual; however, in the lower range, the decline in ACR is more pronounced. From a three-dimensional perspective, ACR exhibits a clear downward trend as increases, particularly in the low to moderate range . In the high and regions, changes in ACR tend to stabilize. When is high, the rate of ACR reduction slows down.
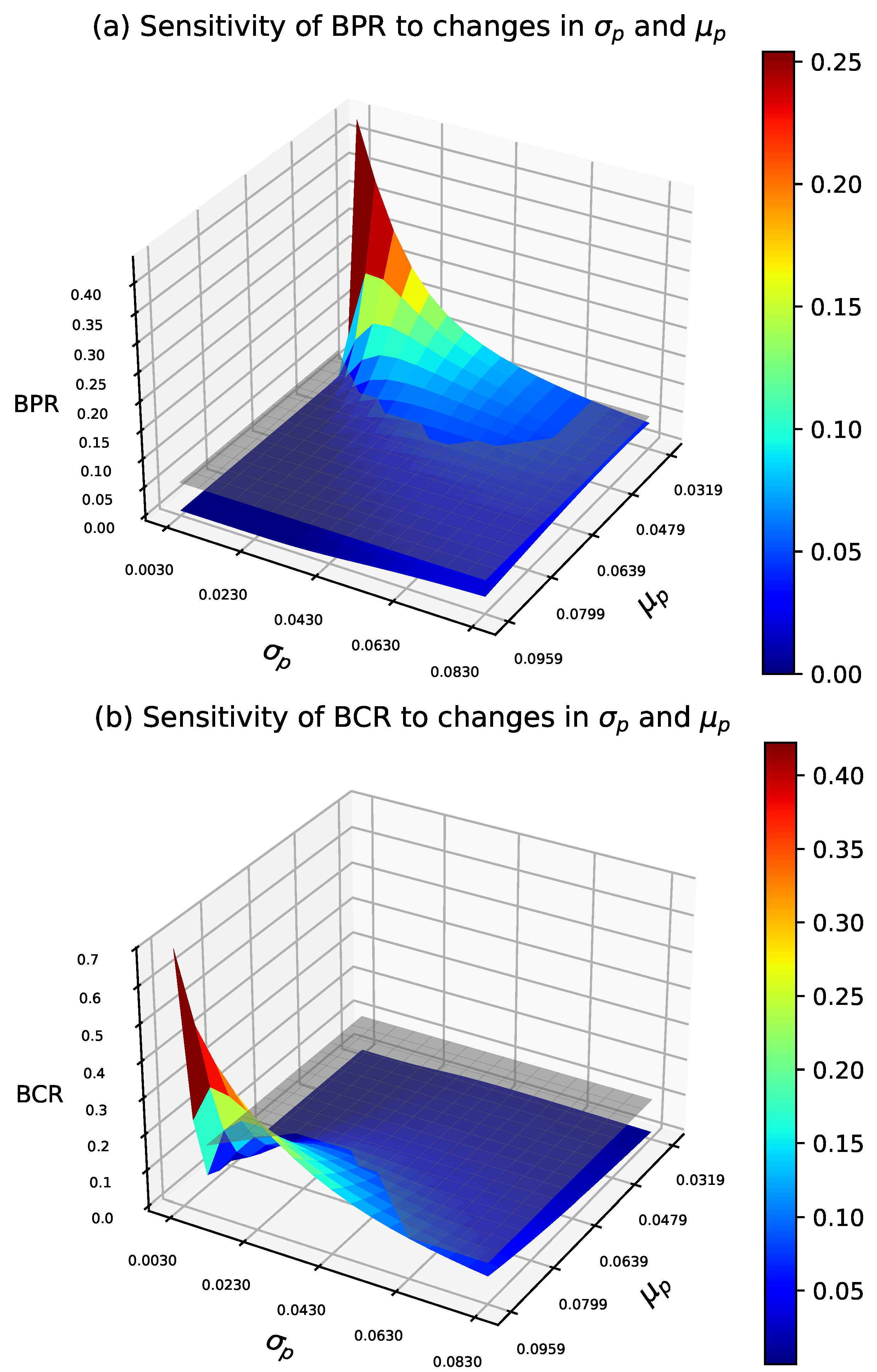
We analyze the Bayesian risk sampling plan under the same prior as in the AR design.
Figure 5 shows how prior-moment variations affect Bayesian producer and consumer risks under the optimal design. These risks are evaluated using Equations (
6) and (
7) and compared with the reference planes
and
. The contour plots are in
Figure 6.
In general, for small , as increases from low to moderate values, BPR exhibits a significant decline, while BCR grows more gradually. At higher values, the decrease in BPR becomes more gradual, while BCR increases at a faster rate. For moderate to high values of , changes in BPR tend to stabilize, while BCR increases significantly, indicating a lower sensitivity of both risks to variations in .
4.1.2. An Illustrative Example
In the following, we present a comparative analysis of the risk variations in the optimal AR and BR sampling plans when the prior mean and standard deviation are modified. The analysis is conducted under a censoring rate of 50%, with a moderate prior mean of and a standard deviation of .
The optimal
design is given by:
and the optimal
design is given by:
Table 2 presents the impact of varying
while keeping
fixed. As
increases from 0.032 to 0.094, the producer and consumer risks exhibit different trends under the optimal AR and BR designs. The producer risk increases as
grows, particularly in the AR design, where it rises significantly from 0.0162 to 0.0816, corresponding to an increase of approximately 49%. Similarly, the consumer risk follows an increasing trend but with a smaller growth, rising from 0.0829 to 0.0965, a relative change of 16.8%.
Under the Bayesian design, the producer risk decreases as increases, dropping from 0.0802 to 0.0816, showing a 49% reduction. In contrast, the Bayesian consumer risk exhibits a more substantial increase, with BCR rising from 0.0334 to 0.2479, representing a 146.8% increment. Overall, the producer risk is more sensitive to variations in , while the consumer risk remains relatively stable. Compared to the classical design, the Bayesian design generally results in lower risks and demonstrates a higher sensitivity to risk changes as increases.
Table 3 presents the impact of varying
while keeping
fixed. As
increases, the producer’s risk decreases significantly. Notably, when
increases from 0.036 to 0.068, the APR reduction reaches −28.4%. The consumer’s risk also decreases with increasing
, but the magnitude of change is smaller. For example, when
increases to 0.068, the ACR decreases by 17.6%, indicating that increasing prior variance has some effect on consumer risk, but compared to the producer’s risk, the influence remains relatively stable.
For the Bayesian producer’s risk, the risk gradually decreases as increases, but the reduction is less pronounced compared to the classical producer’s risk. The Bayesian consumer’s risk remains nearly unchanged with increasing , especially at higher values of . Even when reaches 0.068, the BCR only changes by −10.2%, indicating that the Bayesian consumer’s risk is relatively insensitive to variations in prior variance. Particularly for larger values of , the Bayesian model’s impact on risk stabilizes.
To eliminate the influence of the censoring rate on sampling risks, we conducted additional experiments at a censoring rate of 10% and a censoring rate of 90%. Similarly, for a prior mean and standard deviation of moderate values (, ), we recalculated the optimal sampling plans under these two censoring rates. Theoretical computations were performed to compare the changes in risks for the AR and BR optimal sampling plans as the prior mean and standard deviation varied.
Table 4 and
Table 5 present the risk variations for the optimal AR and BR sampling plans under a censoring rate of 10%, given a prior mean and standard deviation of moderate values (
,
). The comparison illustrates how changes in the prior mean
and standard deviation
influence the risks.
The optimal
design is given by:
and the optimal
design is given by:
Table 6 and
Table 7 present the risk variations for the optimal AR and BR sampling plans under a censoring rate of 90%, given a prior mean and standard deviation of moderate values (
,
). The comparison illustrates how changes in the prior mean
and standard deviation
influence the risks.
The optimal
design is given by:
and the optimal
design is given by:
By observing the risk variations in the optimal sampling plans under low, medium, and high censoring levels as the prior mean and standard deviation change, we can conclude that the AR design exhibits higher sensitivity to parameter variations. In particular, when is relatively low or is high, the changes in risk become more pronounced. This makes the AR design more suitable for scenarios where fine-tuned optimization is required based on subtle parameter variations.
On the other hand, the BR design demonstrates lower sensitivity, with relatively minor changes in risk values. The BR design remains more robust to parameter variations, maintaining stable risk levels. Therefore, it is better suited for environments where greater parameter variability is expected and system stability is a key requirement.
4.2. Optimal Sample Sizes
In the following, we separately present the effects of changes in
and
on the optimal sample size.
Figure 7 illustrates the sensitivity of the optimal sample size to changes in
. When
,
,
,
, and
, the figure depicts the trend of the optimal sample size for the
and
designs as
varies. From the figure, it can be observed that the optimal sample size for both the
and
designs increases as
increases. In contrast, the increase in sample size for the
design is smaller, indicating that it is relatively less sensitive to changes in
.
Figure 8 illustrates the sensitivity of the optimal sample size to changes in
. When
,
,
,
, and
, the figure shows how the
and
designs respond to variations in
. From the figure, it can be observed that as
increases, the optimal sample size for the
design decreases significantly in a stepwise manner, indicating that the
design is highly sensitive to changes in the prior variance. In contrast, the
design exhibits only minor fluctuations in sample size, demonstrating a relatively stable trend. This suggests that the
design is more robust to variations in
.
Additionally, we have highlighted in
Figure 7 and
Figure 8 the optimal sample sizes for the
and
designs when the prior parameters are set to
and
. Under these conditions, the optimal sample sizes are
for the
design and
for the
design.
5. Concluding Remarks
Based on the experimental data analysis, we conclude that Bayesian risk is more sensitive to variations than to changes. When varies, the producer’s risk in the AR design is more affected than the consumer’s risk, whereas in the BR design, the consumer’s risk dominates. In contrast, when changes, the producer’s risk fluctuates more than consumer’s risk. Additionally, the optimal sample size remains stable under minor to moderate prior moment variations. When the absolute change in and is below 10%, sample size variations in AR and BR designs stay within 1–2 units. However, with larger variations, the AR design’s sample size fluctuates significantly.
In practical production, selecting an appropriate batch sampling inspection plan requires evaluating the stability of prior parameters to determine the suitability of the AR and BR designs. When is known but has significant uncertainty, both the producer’s and consumer’s risks are highly sensitive to this uncertainty, especially in the BR design, where the consumer’s risk fluctuates significantly. Therefore, the AR design is recommended in such cases, as it is less sensitive to changes in and is more suitable when estimation is unstable. Conversely, if is accurately estimated but is highly variable, the producer’s risk is more affected, particularly in the AR design, where sample size variations become substantial. In this scenario, the BR design is recommended, as it offers greater stability in sample size and better controls consumer risk.
When variations in and are small, the optimal sample size n should be employed for sampling, as fluctuations in sample size remain within 1–2 units, minimizing the impact on production costs. This approach is particularly suitable for stable production environments with consistent raw material quality and low equipment errors. However, when or undergoes significant variations, especially when decreases in the AR design, the optimal sample size may increase sharply. To maintain an acceptable producer’s risk, it is advisable to increase the sample size accordingly and dynamically adjust the sampling strategy. Optimizing the plan over successive batches helps mitigate quality control deviations caused by uncertainty in prior information.
Overall, in practical production, if is stable but fluctuates, the AR design is preferable to reduce risks arising from prior mean uncertainty, making it suitable for high-risk products such as medical devices and aerospace components. Conversely, if is stable but varies, the BR design is recommended to enhance sample size robustness and reduce sensitivity to variance deviations, making it more appropriate for products with high production consistency, such as consumer goods and electronic components.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}