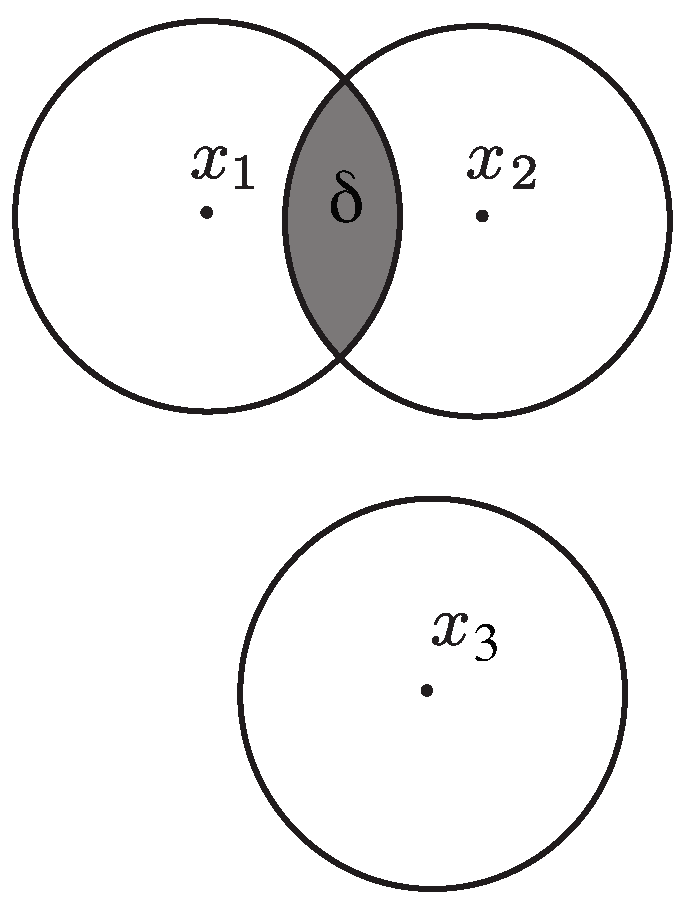1. Introduction
Shannon’s celebrated channel coding theorem states that the capacity is the supremum of the mutual information between the input and the output of the channel [
1]. In this setting, the mutual information is intended as the amount of information obtained regarding the random variable at the input of the channel by observing the random variable at the output of the channel, and the capacity is the largest rate of communication that can be achieved with an arbitrarily small probability of error. In an effort to provide an analogous result for safety-critical control systems where occasional decoding errors can result in catastrophic failures, Nair introduced a non-stochastic mutual information functional and established that this equals the zero-error capacity [
2], namely the largest rate of communication that can be achieved with zero probability of error. Nair’s approach is based on the calculus of non-stochastic uncertain variables (UVs), and his definition of mutual information in a non-stochastic setting is based on the quantization of the range of uncertainty of a UV induced by the knowledge of the other. While Shannon’s theorem leads to a single letter expression, Nair’s result is multi-letter, involving the non-stochastic information between codeword blocks of
n symbols. The zero-error capacity can also be formulated as a graph-theoretic property, and the absence of a single-letter expression for general graphs is well known [
3,
4]. Extensions of Nair’s non-stochastic approach to characterize the zero-error capacity in the presence of feedback from the receiver to the transmitter using nonstochastic directed mutual information have been considered in [
5].
Kolmogorov introduced the notion of
-capacity in the context of functional spaces as the logarithm base two of the packing number of the space, namely the logarithm of the maximum number of balls of radius
that can be placed in the space without overlap [
6]. Determining this number is analogous to designing a channel codebook such that the distance between any two codewords is at least
. In this way, any transmitted codeword that is subject to a perturbation of, at most,
can be recovered at the receiver without error. It follows that the
-capacity per transmitted symbol (
viz. per signal dimension) corresponds to the zero-error capacity of an additive channel having arbitrary bounded noise of the radius at most
. Lim and Franceschetti extended this concept introducing the
capacity [
7], defined as the logarithm base two of the largest number of balls of radius
that can be placed in the space with an average codeword overlap of, at most,
. In this setting,
measures the amount of error that can be tolerated when designing a codebook in a non-stochastic setting, and the
capacity per transmitted symbol corresponds to the largest rate of communication with error at most
.
The first contribution of this paper is to consider a generalization of Nair’s mutual information based on a quantization of the range of uncertainty of a UV given the knowledge of another, which reduces the uncertainty to, at most,
, and to show that this new notion corresponds to the
capacity. Our definition of
capacity is a variation of the one in [
7], as it is required to bound the overlap between any pair of balls, rather than the average overlap. For
, we recover Nair’s result for the Kolmogorov
-capacity or, equivalently, for the zero-error capacity of an additive, bounded noise channel. We then extend the results to more general channels where the noise can be different across codewords and is not necessarily contained within a ball of radius
. Finally, we consider the class of non-stochastic, memoryless, stationary uncertain channels, where the noise experienced by a codeword of
n symbols factorizes into
n identical terms describing the noise experienced by each codeword symbol. This is the non-stochastic analog of a discrete memoryless channel (DMC), where the current output symbol depends only on the current input symbol, not on any of the previous input symbols, and where the noise distribution is constant across symbol transmissions and differs from Kolmogorov’s
-noise channel, where the noise experienced by one symbol affects the noise experienced by other symbols (in Kolmogorov’s setting, the noise occurs within a ball of radius
. It follows that for any realization where the noise along one dimension (
viz. symbol) is close to
, the noise experienced by all other symbols lying in the remaining dimensions must be close to zero.). Letting
be the confidence of correct decoding after transmitting
n symbols, we introduce several notions of capacity and establish coding theorems in terms of mutual information for all of them, including a generalization of the zero-error capacity that requires the error sequence
to remain constant and a non-stochastic analog of Shannon’s capacity that requires the error sequence to vanish, as in
.
Finally, since in Nair’s case, all of our results are multi-letter, in the
Supplementary Materials, we provide some sufficient conditions for the factorization of the mutual information leading to a single-letter expression for the non-stochastic capacity of stationary, memoryless, uncertain channels, provide some examples in which these conditions are satisfied, and compute the corresponding capacity.
The rest of the paper is organized as follows:
Section 2 introduces the mathematical framework of non-stochastic uncertain variables that are used throughout the paper.
Section 3 introduces the concept of non-stochastic mutual information.
Section 4 gives an operational definition of the capacity of a communication channel and relates it to the mutual information.
Section 5 extends the results to more general channel models, and
Section 6 concentrates on the special case of stationary, memoryless, uncertain channels.
Section 7 draws conclusions and discusses future directions.
4. (,)-Capacity
We now give a definition of the capacity of a communication channel and relate it to the notion of mutual information between the UVs introduced above. We consider a normed space to be totally bounded if, for every , can be covered by a finite number of open balls of radius . We let be a totally bounded, normed space such that for all , we have , where represents the norm. This normalization is for convenience in the notation process, and all results can easily be extended to metric spaces of any bounded norm. Let be a discrete set of points in the space, which represents a codebook.
Definition 9. ϵ-perturbation channel.
A channel is called ϵ-perturbation if for any transmitted codeword , x is received with noise perturbation at most ϵ. Namely, we receive a point in the set Given the codebook is transmitted over an -perturbation channel, all received codewords lie in the set , where . Transmitted codewords can be decoded correctly as long as the corresponding uncertainty sets at the receiver do not overlap. This can be achieved by simply associating the received codeword to the point in the codebook that is closest to it.
For any
∈
, we now let
where
is an uncertainty function defined over the space
. We also assume without loss of generality that the uncertainty associated with the whole space
of received codewords is
. Finally, we let
be the smallest uncertainty set corresponding to a transmitted codeword, namely
, where
. The quantity
can be viewed as the confidence we have in not confusing
and
in any transmission or, equivalently, as the amount of adversarial effort required to induce a confusion between the two codewords. For example, if the uncertainty function is constructed using a measure, then all the erroneous codewords generated by an adversary to decode
instead of
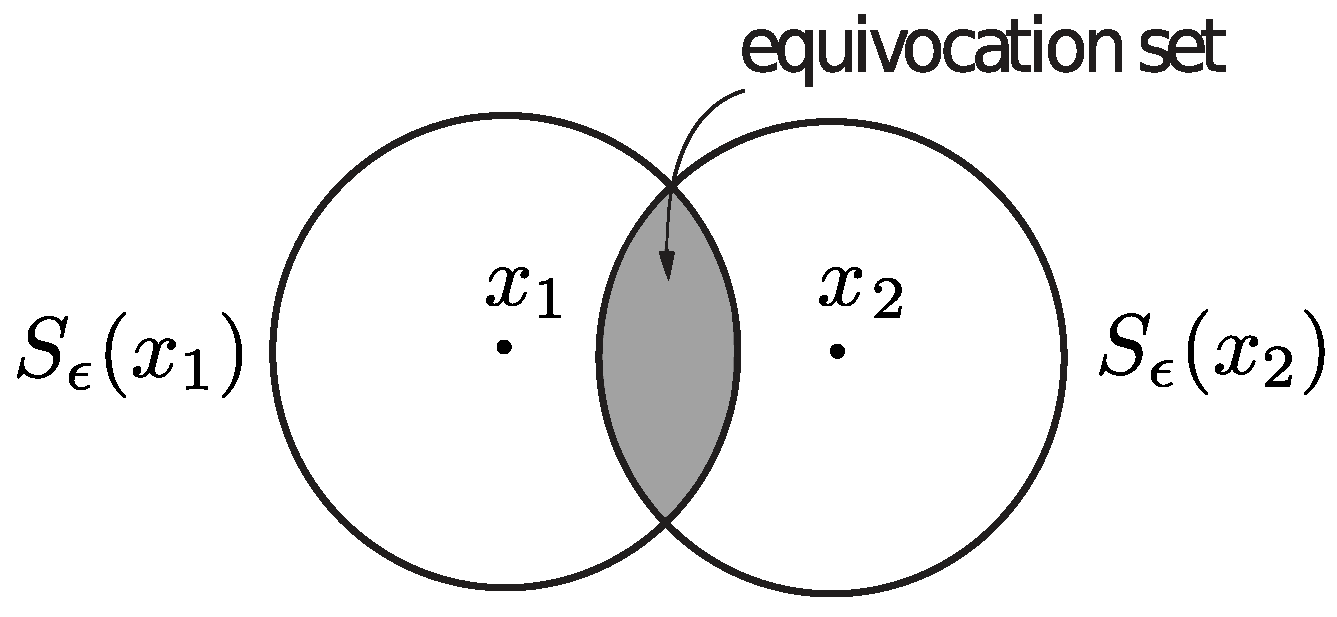
must lie inside the equivocation set depicted in
Figure 3, whose relative size is given by (
56). The smaller the equivocation set is, the larger the effort required by the adversary to induce an error must be. If the uncertainty function represents the diameter of the set, then all the erroneous codewords generated by an adversary to decode
instead of
will be close to each other in the sense of (
56). Once again, the closer the possible erroneous codewords are, the harder it must be for the adversary to generate an error, since any small deviation allows the decoder to correctly identify the transmitted codeword.
We now introduce the notion of a distinguishable codebook, ensuring that every codeword cannot be confused with any other codeword, rather than with a specific one, at a given level of confidence.
Definition 10. -distinguishable codebook.
For any , , a codebook is -distinguishable if for all , we have .
For any
-distinguishable codebook
and
, we let
It now follows from Definition 10 that
and each codeword in an
-distinguishable codebook can be decoded correctly with confidence of at least
. Definition 10 guarantees even more, namely that the confidence of not confusing any pair of codewords is uniformly bounded by
. This stronger constraint implies that we cannot “balance” the error associated with a codeword transmission by allowing some decoding pair to have a lower confidence and enforcing other pairs to have higher confidence. This is the main difference between our definition and the one used in [
7], which bounds the average confidence and allows us to relate the notion of capacity to the mutual information between pairs of codewords.
Definition 11. -capacity.
For any totally bounded, normed metric space , , , and the -capacity of iswhere is the set of -distinguishable codebooks. The
-capacity represents the largest number of bits that can be communicated by using any
-distinguishable codebook. The corresponding geometric picture is illustrated in
Figure 4. For
, our notion of capacity reduces to Kolmogorov’s
-capacity, which is the logarithm of the packing number of the space with balls of radius
.
In the definition of capacity, we have restricted
to rule out cases when the decoding error can be at least as large as the error introduced by the channel and when the
-capacity is infinite. Also, note that
since
and (
10) holds.
We now relate our operational definition of capacity to the notion of UVs and mutual information introduced in
Section 3. Let
X be the UV corresponding to the transmitted codeword. This is a map
and
. Likewise, let
Y be the UV corresponding to the received codeword. This is a map
and
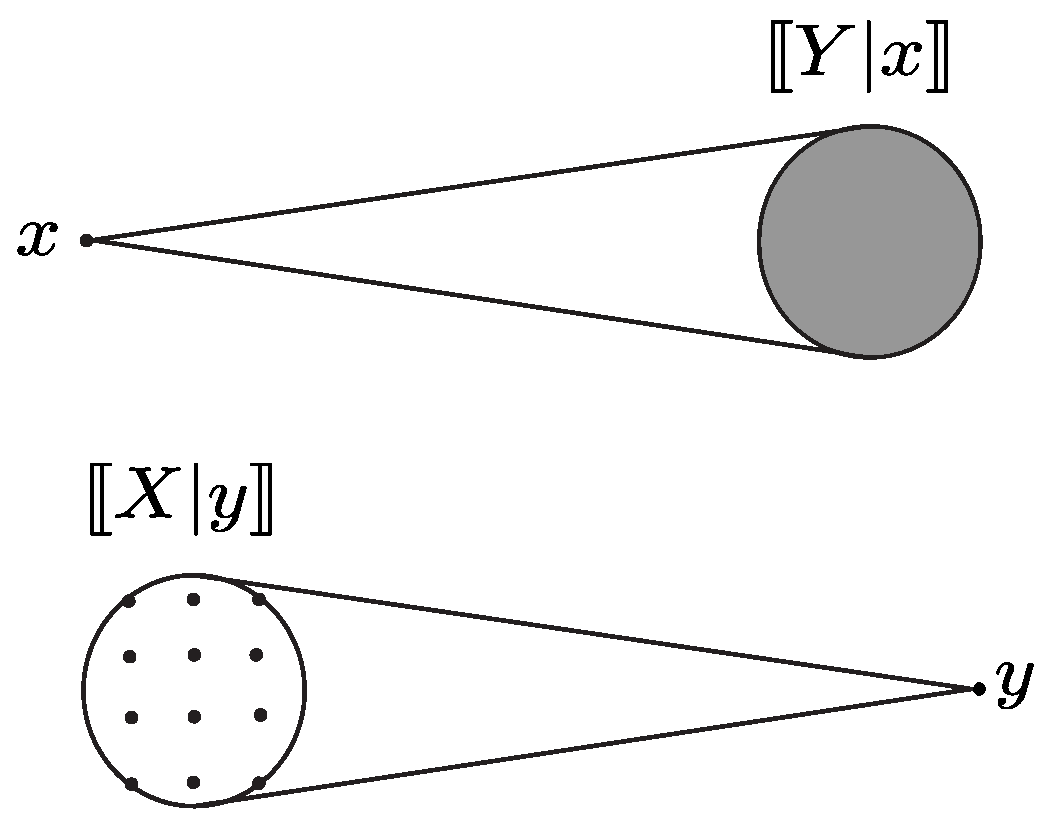
. For our
-perturbation channel, these UVs are such that for all
and
, we have
(see
Figure 5). Clearly, the set in (
60) is continuous, while the set in (61) is discrete.
To measure the levels of association and disassociation between
X and
Y, we use an uncertainty function
defined over
and
defined over
. We introduce the feasible set
representing the set of UVs
X such that the marginal range
is a discrete set representing a codebook, and the UV can either achieve
levels of disassociation or
levels of association with
Y. In our channel model, this feasible set also depends on the
-perturbation through (
60) and (61).
We can now state the non-stochastic channel coding theorem for our -perturbation channel.
Theorem 4. For any totally bounded, normed metric space , ϵ-perturbation channel satisfying (60) and (61), , and , we have Proof. First, we show that there exists a UV
X and
such that
, which implies that the supremum is well defined. Second, for all
X and
such that
and
we show that
Finally, we show the existence of
and
such that
.
Let us begin with the first step. Consider a point
. Let
X be a UV such that
Then, we hold that the marginal range of the UV
Y corresponding to the received variable is
and, therefore, for all
, we have
Using Definition 2 and (
67), we hold that
because
consists of a single point, and, therefore, the set in (
12) is empty.
On the other hand, using Definition 2 and (
69), we have
Using (
70), and since
holds for
, we have
Similarly, using (
71), we have
Now, combining (
72) and (
73), we have
Letting
, this implies that
and the first step of the proof is complete.
To prove the second step, we define the set of discrete UVs
which is a larger set than the one containing all UVs
X that are
associated with
Y. Now, we will show that if a UV
, then the corresponding codebook
. If
, then there exists a
such that for all
, we have
It follows that for all
, we have
Using
, (
60),
and
, for all
, we have
where
follows from
. Putting things together, it follows that
Consider now a pair of
X and
such that
and
If
, then, using Lemma A1 in
Appendix C, there exist two UVs,
and
and
, such that
and
On the other hand, if
, then (
81) and (
82) also trivially hold. It then follows that (
81) and (
82) hold for all
. We now have
where
follows from (
81) and (
82),
follows from Lemma A3 in
Appendix C since
,
follows by defining the codebook
corresponding to the UV
, and
follows from the fact that using (
81) and Lemma 1 allows
, which implies for (
79) that
.
Finally, let
which achieves the capacity
. Let
be the UV whose marginal range corresponds to the codebook
. It follows that for all
, we have
which implies that
,
Letting
, and using Lemma 1, we hold that
, which implies that
, and the proof is complete. □
Theorem 4 characterizes the capacity as the supremum of the mutual information over all UVs in the feasible set. The following theorem shows that the same characterization is obtained if we optimize the right-hand side in (
63) over all UVs in the space. It follows by Theorem 4 that rather than optimizing over all UVs representing all the codebooks in the space, a capacity-achieving codebook can be found within the smaller class
of feasible sets with error at most
, since for all
,
.
Theorem 5. The -capacity in (63) can also be written as Proof. Consider a UV
, where
Y is the corresponding UV at the receiver. The idea of the proof is to show the existence of a UV
and the corresponding UV
at the receiver, and
such that the cardinality of the overlap partitions
Let the cardinality
By Property 1 of Definition 6, we hold that for all
, there exists an
such that
. Now, consider another UV
whose marginal range is composed of
K elements of
, namely
Let
be the UV corresponding to the received variable. Using the fact that for all
, we have
since (
60) holds, and using Property 2 of Definition 6, for all
, we obtain
where
follows from the fact that
using (
91). Then, for all
, we hold that
since
. Then, by Lemma 1, it follows that
Since
, we have
Therefore,
and
. We now hold that
where
follows by applying Lemma A4 in
Appendix C using (
94) and (
95) and
follows from (
90) and (
91). Combining (
96) with Theorem 4, the proof is complete. □
We now make some considerations with respect to previous results in the literature. First, we note that for
, all of our definitions reduce to Nair’s ones and Theorem 4 recovers Nair’s coding theorem ([
2] (Theorem 4.1)) for the zero-error capacity of an additive
-perturbation channel.
Second, we point out that the
-capacity considered in [
7] defines the set of
-distinguishable codewords such that the
average overlap among all codewords is at most
. In contrast, our definition requires the overlap for
each pair of codewords to be at most
. The following theorem provides the relationship between our
and the capacity
considered in [
7], which is defined using the Euclidean norm.
Theorem 6. Let be the -capacity defined in [7]. We haveand Proof. For every codebook
and
, we have
Since
, this implies that for all
, we have
For all
, the average overlap defined in ([
7] (53)) is
Then, we have
where
follows from (
100). Thus, we have
and (
97) follows.
Now, let
be a codebook with average overlap at most
, namely
This implies that for all
, we have
where
follows from the fact that
. Thus, we have
and (
98) follows. □
To better understand the relationship between the two capacities and show how they can be distinct, consider the case in which the output space is the union of the three
-balls depicted in
Figure 6; this is the only feasible output configuration.
We now compute the two capacities
and
in this case. We have
and the average overlap (
101) is
It follows that
On the other hand, the worst case overlap is
and it follows that
5. -Capacity of General Channels
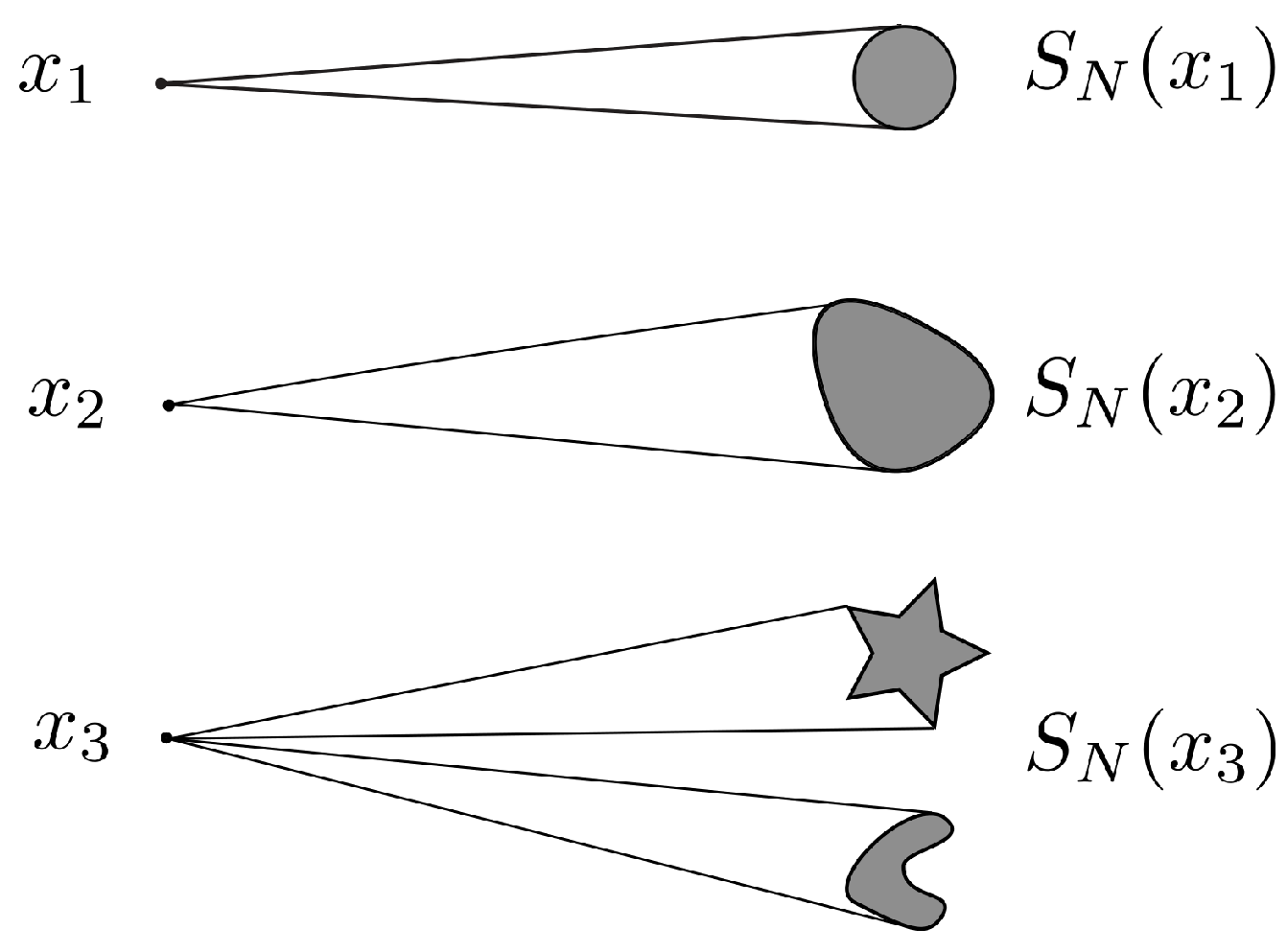
We now extend our results to more general channels where the noise can be different across codewords and is not necessarily contained within a ball of radius .
Let
be a discrete set of points in the space, which represents a codebook. Any point
represents a codeword that can be selected at the transmitter, sent over the channel, and received with perturbation. A channel with transition mapping
associates with any point in
a set in
, such that the received codeword lies in the set
Figure 7 illustrates possible uncertainty sets associated with three different codewords.
All received codewords lie in the set
, where
. For any
∈
, we now let
where
is an uncertainty function defined over
. We also assume without loss of generality that the uncertainty associated with the space
of received codewords is
. We also let
, where
. Thus,
is the set corresponding to the minimum uncertainty introduced by the noise mapping
N.
Definition 12. -distinguishable codebook.
For any , a codebook is -distinguishable if for all , we have .
Definition 13. -capacity.
For any totally bounded, normed metric space , channel with transition mapping N, and , the -capacity of iswhere . We now relate our definition of capacity to the notion of UVs and mutual information introduced in
Section 3. As usual, let
X be the UV corresponding to the transmitted codeword and
Y be the UV corresponding to the received codeword. For a channel with transition mapping
N, these UVs are such that for all
and
, we have
To measure the levels of association and disassociation between UVs
X and
Y, we use an uncertainty function
defined over
, and
is defined over
. The definition of the feasible set is the same as the one given in (
62). In our channel model, this feasible set depends on the transition mapping
N through (
115) and (116).
We can now state the non-stochastic channel coding theorem for channels with transition mapping N.
Theorem 7. For any totally bounded, normed metric space , channel with transition mapping N satisfying (115) and (116), and , we have The proof is along the same lines as the one of Theorem 4 and is omitted.
Theorem 7 characterizes the capacity as the supremum of the mutual information over all codebooks in the feasible set. The following theorem shows that the same characterization is obtained if we optimize the right hand side in (
117) over all codebooks in the space. It follows by Theorem 7 that rather than optimizing over all codebooks, a capacity-achieving codebook can be found within the smaller class
of feasible sets with error at most
.
Theorem 8. The -capacity in (117) can also be written as The proof is along the same lines as the one of Theorem 5 and is omitted.
6. Capacity of Stationary Memoryless Uncertain Channels
In this section, we consider the special case of stationary, memoryless, uncertain channels.
Let
be the space of
-valued discrete-time functions
, where
is the set of positive integers denoting the time step. Let
denote the function
restricted over the time interval
. Let
be a discrete set which represents a codebook. Also, let
denote the set of all codewords up to time
n and
denote the set of all codeword symbols in the codebook at time
n. The codeword symbols can be viewed as the coefficients representing a continuous signal in an infinite-dimensional space. For example, transmitting one symbol per time step can be viewed as transmitting a signal of unit spectral support over time. Any discrete-time function
can be selected at the transmitter, sent over a channel, received with noise perturbation, and introduced by the channel. The perturbation of the signal at the receiver due to the noise can be described as a displacement experienced by the corresponding codeword symbols
. To describe this perturbation, we consider the set-valued map
, associating any point in
to a set in
, where
is the space of
-values discrete-time functions. For any transmitted codeword
, the corresponding received codeword lies in the set
Also, the noise set associated with
is
where
We are now ready to define stationary, memoryless, uncertain channels.
Definition 14. A stationary, memoryless, uncertain channel is a transition mapping that can be factorized into identical terms describing the noise experienced by the codeword symbols. Namely, there exists a set-valued map such that for all and , we have According to the definition, a stationary, memoryless, uncertain channel maps the nth input symbol into the nth output symbol in a way that does not depend on the symbols at other time steps, and the mapping is the same at all time steps. Since the channel can be characterized by the mapping N, to simplify the notation, we will use instead of .
Another important observation is that the
-perturbation channel in Definition 9 may not admit a factorization like the one in (
121). For example, consider the space to be equipped with the
norm, the codeword symbols to represent the coefficients of an orthogonal representation of a transmitted signal, and the noise experienced by any codeword to be within a ball of radius
. In this case, if a codeword symbol is perturbed by a value close to
, the perturbation of all other symbols must be close to zero.
For stationary, memoryless, uncertain channels, all received codewords lie in the set
, and the received codewords up to time
n lie in the set
. Then, for any
, we let
where
is an uncertainty function defined over the space of the received codewords. We also assume without loss of generality that at any time step
n, the uncertainty associated with the space
of received codewords is
. We also let
, where
. Thus,
is the set corresponding to the minimum uncertainty introduced by the noise mapping at a single time step. Finally, we let
The quantity
can be viewed as the confidence we have of not confusing
and
in any transmission or, equivalently, as the amount of adversarial effort required to induce a confusion between the two codewords. For example, if the uncertainty function is constructed using a measure, then all the erroneous codewords generated by an adversary to decode
instead of
must lie inside the equivocation set
whose relative size is given by (
122). The smaller the equivocation set is, the larger the effort required by the adversary to induce an error must be. If the uncertainty function represents the diameter of the set, then all the erroneous codewords generated by an adversary to decode
instead of
will be close to each other, in the sense of (
122).
We now introduce the notion of a distinguishable codebook, ensuring that every codeword cannot be confused with any other codeword, rather than with a specific one, at a given level of confidence.
Definition 15. -distinguishable codebook.
For all and , a codebook is -distinguishable if for all , we have It immediately follows that for any
-distinguishable codebook
, we have
so that each codeword in
can be decoded correctly with confidence at least
. Definion 15 guarantees even more, namely that the confidence of not confusing any pair of codewords is at least
.
We now associate with any sequence the largest distinguishable rate sequence , whose elements represent the largest rates that satisfy that confidence sequence.
Definition 16. Largest -distinguishable rate sequence.
For any sequence , the largest -distinguishable rate sequence is such that for all , we havewhere We say that any constant rate R that lays below the largest -distinguishable rate sequence is -distinguishable. Such a -distinguishable rate ensures the existence of a sequence of distinguishable codes that, for all , have a rate of at least R and confidence of at least .
Definition 17. -distinguishable rate.
For any sequence , a constant rate R is said to be -distinguishable if for all , we have We now give our first definition of capacity for stationary, memoryless, uncertain channels as the supremum of the -distinguishable rates. Using this definition, transmitting at a constant rate below capacity ensures the existence of a sequence of codes that, for all , have confidence of at least .
Definition 18. capacity.
For any stationary, memoryless, uncertain channel with transition mapping N, and any given sequence , we let Another definition of capacity arises if, rather than the largest lower bound to the sequence of rates, one considers the least upper bound for which we can transmit, satisfying a given confidence sequence. Using this definition, transmitting at a constant rate below capacity ensures the existence of a finite-length code (rather than a sequence of codes) that satisfies at least one confidence value along the sequence .
Definition 19. capacity.
For any stationary, memoryless, uncertain channel with transition mapping N, and any given sequence , we define Next, consider Definition 19 in the case of as a constant sequence; namely, for all , we have . In this case, transmitting below capacity ensures the existence of a finite-length code that has confidence of at least . This is a generalization of the zero-error capacity,
Definition 20. capacity.
For any stationary, memoryless, uncertain channel with transition mapping N and any sequence , where for all we have , we define Letting , we obtain the zero-error capacity. In this case, below capacity, there exists a code with which we can transmit with full confidence.
Finally, to give a definition of a non-stochastic analog of Shannon’s probabilistic capacity, we first say that any constant rate R is achievable if there exists a sequence as such that R lays below . An achievable rate R then ensures that for all , there exists an infinite sequence of distinguishable codes of rate of at least whose confidence tends towards one as . It follows that in this case, we can achieve communication at rate R with arbitrarily high confidence by choosing a sufficiently large codebook.
Definition 21. Achievable rate.
A constant rate R is achievable if there exists a sequence such that as and We now introduce the non-stochastic analog of Shannon’s probabilistic capacity as the supremum of the achievable rates. This means that we can pick any confidence sequence such that tends towards zero as . In this way, plays the role of the probability of error and the capacity is the largest rate that can be achieved by a sequence of codebooks with an arbitrarily high confidence level. Using this definition, transmitting at a rate below capacity ensures the existence of a sequence of codes achieving arbitrarily high confidence by increasing the codeword size.
Definition 22. capacity.
For any stationary, memoryless, uncertain channel with transition mapping N, we define the capacity as We point out the key difference between Definitions 20 and 22. Transmitting below the capacity ensures the existence of a fixed codebook that has confidence of at least . In contrast, transmitting below the capacity allows us to achieve arbitrarily high confidence by increasing the codeword size.
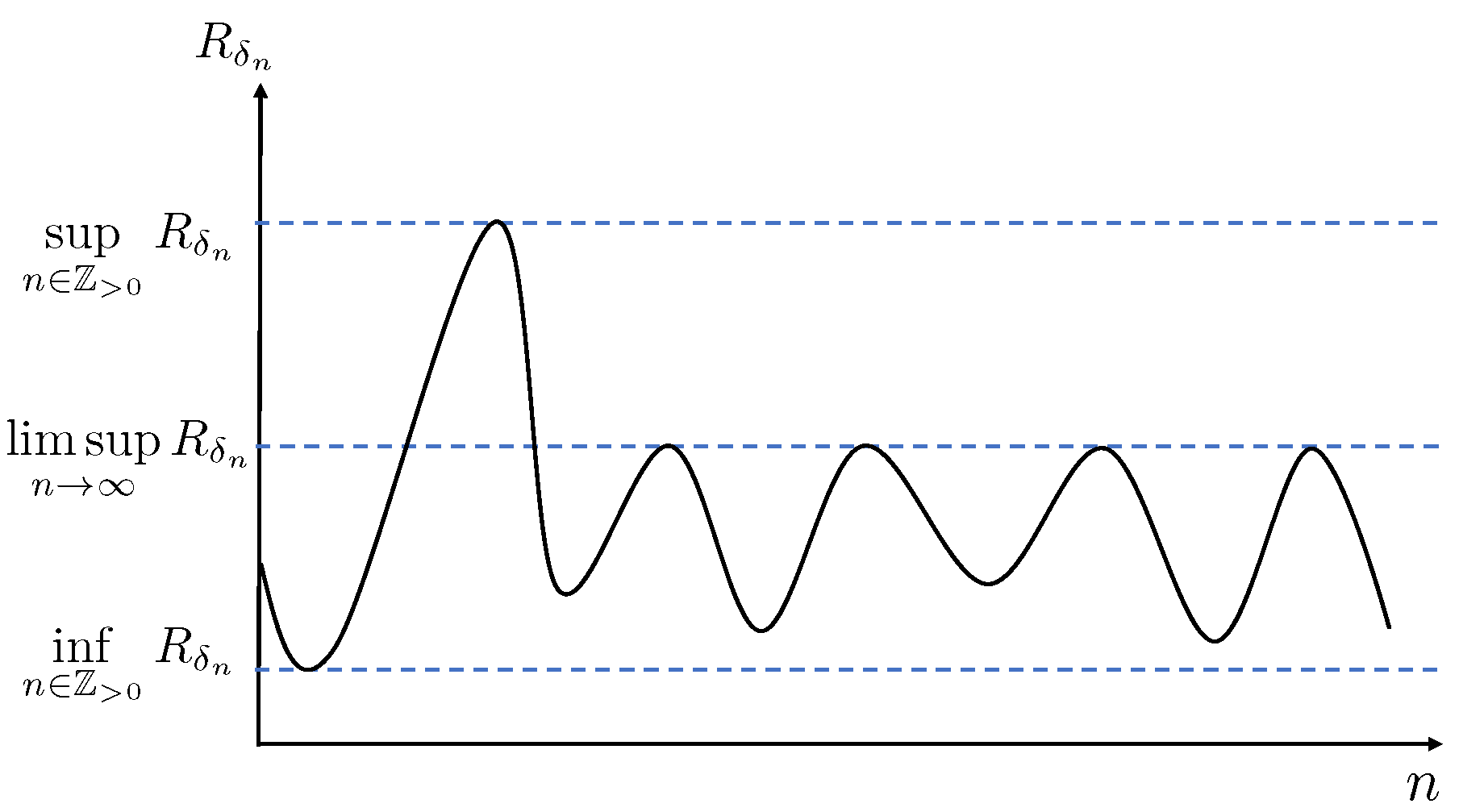
To give a visual illustration of the different definitions of capacity, we refer to
Figure 8.
For a given sequence
, the figure sketches the largest
-distinguishable rate sequence
. According to definitions 18 and 19, the capacities
and
are given by the supremum and infimum of this sequence, respectively. On the other hand, according to Definition 22, the capacity
is the largest limsup over all vanishing sequences
. Assuming the figure refers to a vanishing sequence
that achieves the supremum in (133), we have
We now relate our notions of capacity to the
mutual information rate between transmitted and received codewords. Let
X be the UV corresponding to the transmitted codeword. This is a map of
and
. Restricting this map to a finite time
yields another UV
and
. Likewise, a codebook segment is a UV
of marginal range
Likewise, let
Y be the UV corresponding to the received codeword. It is a map of
and
.
and
are UVs, and
and
. For a stationary, memoryless, uncertain channel with transition mapping
N, these UVs are such that for all
,
and
, and we have
Now, we define the largest -mutual information rate as the supremum mutual information per unit-symbol transmission that a codeword can provide about with confidence of at least .
Definition 23. Largest -information rate.
For all , the largest -information rate from to is In the following theorem. we establish the relationship between and .
Theorem 9. For any totally bounded, normed metric space , disrete-time space , stationary, memoryless, uncertain channel with transition mapping N satisfying (135) and (136), and sequence such that, for all , we have , we haveWe also have Proof. The proof of the theorem is similar to the one of Theorem 4 and is given in
Appendix B. □
The following coding theorem is now an immediate consequence of Theorem 9 and of our capacity definitions.
Theorem 10. For any totally bounded, normed metric space , disrete-time space , stationary, memoryless, uncertain channel with transition mapping N satisfying (135) and (136), and sequence such that for all , and , we have Theorem 10 provides multi-letter expressions of capacity, since
depends on
according to (
137). In the
Supplementary Materials, we establish some special cases of uncertainty functions, confidence sequences, and classes of stationary, memoryless, uncertain channels, leading to the factorization of the mutual information and to single-letter expressions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}