1. Introduction
Research on complex networks has always been subject to widespread attention. Complex networks can effectively describe and represent large-scale complex systems found in the world, such as biological systems [
1,
2], medical systems [
3], power systems [
4,
5], and social systems [
6,
7]. In addition, identifying important nodes in complex networks has applications for various fields. In the field of biology, the identification of important nodes can help reveal key genes, proteins, or other biological molecules, thereby deepening our understanding of the key functions and regulatory mechanisms in biological systems [
8]. The identification of important nodes helps to identify and control key spreaders involved in the spread of infectious diseases, thereby effectively formulating intervention strategies and preventive measures [
9]. In the maintenance of power systems, the identification of important nodes helps to optimize the stability, reliability, and efficiency of power networks, as well as effectively manage energy distribution and supply strategies [
10]. In curbing the spread of rumors, the identification of important nodes helps to identify and control key spreaders in rumor dissemination, allowing one to effectively prevent and respond to the spread of rumors [
11].
There are many existing methods for identifying important nodes in complex networks. Traditional methods for identifying important nodes are based on the local and global information of the network, such as degree centrality [
12] and K-Shell centrality [
13]. The degree centrality method posits that the more neighbors a node has, the more important that node is. The K-Shell centrality method, on the other hand, suggests that a node’s position and hierarchical structure within the entire network significantly influence its importance, with nodes closer to the network core being considered more important. Although traditional methods have achieved good results in some respects, they still have many shortcomings.
Some researchers have proposed the random walk method [
14], inspired by natural phenomena such as Brownian motion and molecular dynamics. Its operation logic is as follows: Firstly, a starting node is selected, from which a neighbor node is randomly selected and moved to according to a specific probability distribution, and access information is recorded at the same time. This process is repeated until a preset number of steps is reached or the termination conditions are met. Finally, the importance of the nodes is evaluated through the statistical analysis of their access frequency, coverage time, and other indicators. This method provides a dynamic and global perspective for the identification of key nodes in complex networks, effectively making up for the shortcomings of traditional static methods, and shows unique advantages in certain structures such as planar networks and uniform node-degree networks.
In recent years, gravity model-based methods [
15] for identifying important nodes in complex networks have been proposed. This approach leverages the universal law of gravitation, treating a node’s degree value as its ‘mass’ and the shortest path between nodes as the ’distance’ between them, and calculates the force between nodes as an estimate of node importance. Compared to traditional methods, the gravity model-based approach can more accurately capture the complex relationships and interactive influences between nodes, resulting in more precise outcomes. Gravity model methods [
16] based on effective distance provide an innovative solution for identifying important nodes in complex networks by treating the effective distance as the distance between nodes and the degree of the nodes as their quality. It is believed that the effective distance can uncover the hidden dynamic structure and dynamic interaction information between nodes, which includes the way the network actually operates, while combining dynamic and static information to identify important nodes can improve the accuracy of the results. The generalized gravity model [
17] provides an effective tool for identifying important nodes in complex networks by taking the shortest distance between nodes as the distance and their propagation capacity as their mass. The propagation capability of a node is represented by that node’s local clustering coefficient and degree. Li Hanwen et al. [
17] argue that if nodes have the same degree, the node with a higher local clustering coefficient, that is, the node with more edges connected to neighboring nodes, has a stronger ability to propagate information; thus, the propagation capability of a node can more accurately measure the local information of a node.
In summary, previous research on methods for identifying key nodes has analyzed node interactions from various perspectives, thereby providing a more comprehensive assessment of node importance. However, these methods have not yet fully leveraged the multi-scale characteristics of nodes for in-depth analyses. Consequently, this study proposes a novel approach, which we term the local effective distance-integrated gravity model (LEDGM). LEDGM is rooted in the recognition that nodes in complex networks possess intricate relationships that extend beyond their immediate connections. Our approach is anchored in the belief that a holistic analysis, which considers the multifaceted nature of nodes, is essential for accurately capturing their true influence within a network. By integrating various attributes such as local, global, positional, and clustering information, our model endeavors to paint a more nuanced picture of each node’s role and potential impact. This comprehensive assessment allows for a more precise identification of the key nodes that are pivotal to a network’s structure and function. The LEDGM is designed to bridge the gap between traditional methods and the complex reality of network dynamics, providing a framework that is both sophisticated and adaptable to the nuances of different network topologies. Our main contributions are as follows:
- (1)
We propose a novel approach called the local effective distance-integrated gravity model. This model is specifically designed to offer a more comprehensive assessment of a node’s spreading capability and significance. It incorporates several crucial pieces of information about the nodes, including their local and global characteristics, their positions within the network, and their clustering behavior. By taking all these factors into account, our model provides a more nuanced understanding of each node’s role and influence within the network. This enables researchers and practitioners to identify important nodes with greater precision, which is essential for various applications such as targeted interventions, information dissemination strategies, and network resilience enhancement.
- (2)
We propose a method that is based on an effective-influence node set. It can adaptively determine the number of nodes needed to be considered according to the network topology, thus effectively improving the algorithm’s efficiency and accuracy.
The rest of this paper is organized as follows: We present the relevant research in
Section 2, including a series of foundational studies and centrality measurement methods. The improved effective distance-integrated gravity model proposed in this paper is introduced in detail in
Section 3. In
Section 4, we will demonstrate the effectiveness of this method through multiple experiments and analyze the experimental results, before summarizing this paper in
Section 5.
3. Identification of Important Nodes Based on Local Effective Distance-Integrated Gravity Model
In existing methods for identifying important nodes in complex networks, the comprehensive consideration of node attributes remains inadequate. Studies indicate that neglecting local or topological information when assessing node importance can affect the accuracy of the evaluation results. This paper proposes a novel approach that incorporates the propagation capacity and effective distance of the nodes as key parameters within the gravity model framework to thoroughly consider the local characteristics, global characteristics, positional characteristics, and clustering characteristics of the nodes. However, for large-scale networks, calculating the effective distance between all node pairs is not only time-consuming but also impractical, as nodes typically exert minimal influence on nodes that are far away. Moreover, due to noise accumulation, the interaction strength between distant nodes is difficult to measure accurately. This study addresses these issues by effectively delineating the influence range of nodes, thereby enhancing the efficiency and accuracy of the method.
3.1. Algorithm
In this step, we calculate and store the effective-influence node set for all nodes in the network. Nodes that are within a distance of less than R from a node are included in the effective-influence node set of that node.
The method for calculating the effective distance between node i and node j is detailed in
Section 2.1.1. Specifically, in this step, we compute and store the effective distances between all nodes in the network and the nodes within their effective-influence node set.
The attractiveness between nodes can be determined using the gravitational formula, leading to the calculation of the propagation capability and effective distance of the nodes. A node’s propagation capability is derived from its degree, K-Shell value, and local clustering coefficient. Inspired by the generalized gravity model, we recognize that when nodes have the same degree, the closeness of a node to its surrounding nodes affects its propagation capability.
Building on this, it is evident that when two nodes have the same degree of closeness with their surrounding nodes, the node located closer to the core of the network is more important, indicating that a node’s position within the network topology also affects its propagation capability. The specific calculation formula for this is as follows:
where
is the effective distance from node i to j and
represents the propagation capability of node i, the specific formula for which is as follows:
where
is the local clustering coefficient of node i,
is the degree of node i,
is the maximum degree in the network,
is the K-Shell value of node i, and
is the maximum K-Shell value in the network.
When calculating the importance of a node, the gravitational forces between that node and the nodes within its effective-influence node set should be summed. The specific formula for this is as follows:
where
is the effective-influence node set of node i and
is the importance of node i.
3.2. Example
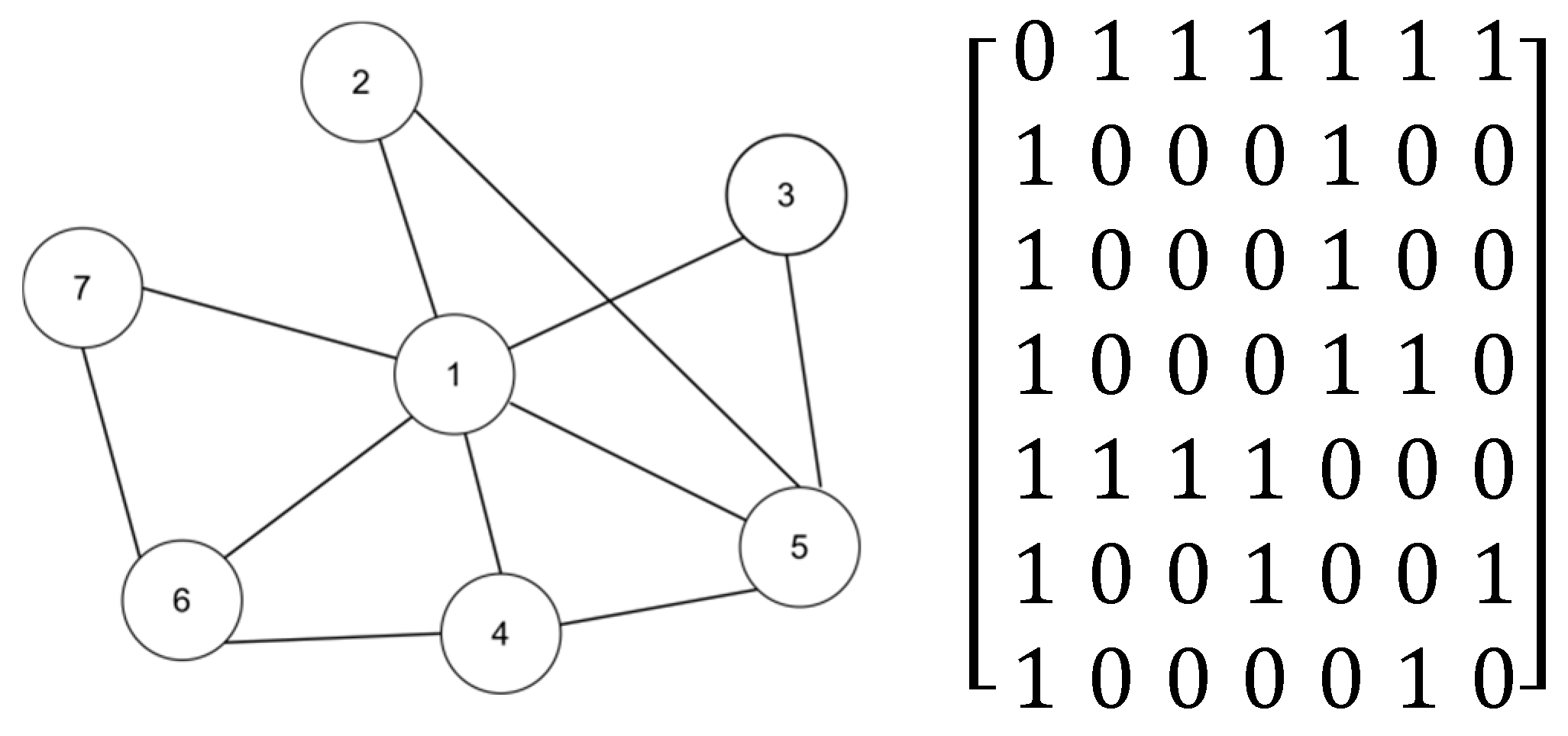
Figure 1 presents an example diagram that includes a simple network and its corresponding adjacency matrix. Initially, we explain the working principle of our algorithm by calculating the LEDGM centrality index for node 2, and we then demonstrate the effectiveness of the effective-influence node set calculation.
The following section outlines the steps required for calculating the LEDGM:
As shown in
Figure 1, the diameter of the network is 2, so its truncation radius is 1. By comparing whether the shortest distance to node 2 is less than the truncation radius, the effective-influence node set of this node can be obtained
,
.
Using the formula in
Section 2.1.1, we can calculate the effective distance between node 2 and other nodes in its effective-influence node set, using the following specific calculation process:
The specific method for calculating the attraction between node 2 and node 1 is as follows:
The attraction between node 2 and node 5 can be obtained using the same method.
Using the formula in Step 4 of
Section 3.1 for calculation, the specific calculation of the importance of node 2 is as follows:
In order to prove the validity of the effective influence set,
Table 1 shows whether the effective-influence node set is used to calculate the importance index of each node in a complex network. In the table, the LEDGM involves a calculation method that uses the effective-influence node set, while R-LEDGM involves a calculation method that removes the effective-influence node set. A straightforward calculation reveals that without the effective-influence node set, the number of computations required to determine the effective distances between all node pairs in the network is 42, which is equivalent to n × (n − 1). However, with the effective-influence node set, the number of computations is reduced to 20. This reduction significantly lowers the time complexity of the algorithm. Additionally, by comparing the data in
Table 1, it is evident that the nodes within the effective-influence node set play a predominant role in the calculation of node importance.
4. Experiments and Data
This chapter aims to validate the feasibility and superiority of our proposed method by conducting four different experiments on six real-world networks and comparing its results with those of traditional centrality methods and other similar approaches. Specifically, in
Section 4.1, we detail the characteristics of these six real-world network datasets, including the number of nodes and the number of edges in the networks, the average degree of the networks, and the networks’ propagation threshold. In
Section 4.2, we employ traditional methods (such as degree centrality (DC), closeness centrality (CC), betweenness centrality (BC), and K-Shell (KS) methods), as well as other methods similar to ours (such as GM, EDGM, GGM, and our proposed LEDGM method), to rank the top 10 nodes in these six networks. In
Section 4.3, we utilize the SI (Susceptible–Infected) model and, based on the ranking results of the different methods, select the top ten nodes as the initially infected nodes to verify and analyze the changes in the model’s contagion capabilities under different initial node selections. Additionally, in
Section 4.4, we compare the time required for our method and the EDGM method to obtain node influence rankings for the same dataset. In
Section 4.5, by comparing the ranking results of the SI model with other methods, we analyze the changes in Kendall’s tau correlation coefficient under different propagation probabilities. Finally, in
Section 4.6, the performance of the LEDGM method is evaluated on Erdős–Rényi networks with different node scales but identical topological structures. The results demonstrated that the LEDGM method can effectively adapt to varying network sizes.
4.1. Datasets
In this paper, we utilize six datasets for our experiments, including Jazz [
23], NS [
24], Email [
25], EEC [
26], PB [
27], and USair [
28]. These include two communication networks (Email, EEC), a transportation network (USair), a social network (PB), and two collaboration networks (Jazz, NS). The Email network describes the communication patterns occurring among researchers via email; the EEC network represents the electronic communication network among members of European research institutions; the Jazz network illustrates the cooperation among jazz musicians; the NS network is a network of scientists collaborating and working together; the USair network is the transportation network of American air travel; and the PB network is a hyperlink network representing the relationships between American political blogs. Selecting these datasets, which come from different domains, ensures the comprehensiveness and generalizability of our experimental results.
Table 2 presents detailed information about the six networks, including the total number of network nodes N, the number of network edges E, the average shortest distance <d> between nodes, the average degree <k> of the nodes, the network clustering coefficient C, and the network propagation threshold
.
4.2. Experiment 1: Top Ten Nodes
In this experiment, we conducted a comparative analysis of the similarity among the top ten nodes identified by eight different methods across six networks, aiming to reveal the similarities and differences between these methods. The eight methods include our proposed LEDGM method; the traditional methods DC, BC, CC, and KS; and methods similar to ours, such as GM, EDGM, and GGM. Since each method considers different node characteristics, there are differences in the ranking lists they generate. The number of recurring nodes can, to some extent, reflect the effectiveness of our method. It is important to note that due to significant differences in the characteristics considered by the KS decomposition method compared to the others, we did not compare the similarity of its ranking to that of the LEDGM method.
For detailed ranking results, please refer to
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. In the Email network, the CC and GGM methods identified the same top ten nodes as the LEDGM method did. Other methods shared 7 to 8 nodes with the LEDGM method, a number lower than that of the CC and GGM methods. In the EEC network, all methods showed a high similarity with the nodes identified by the LEDGM method, with the CC and GGM methods sharing 9 nodes with the LEDGM method. In the Jazz network, the BC and GGM methods had the fewest common nodes with the LEDGM method, while other methods had between 7 and 8 common nodes. In the NS network, the BC and CC methods had the fewest common nodes with the LEDGM method, only 5, while the GGM method had slightly more, and the other methods had between 7 and 8 common nodes. In the USair network, the DC method identified the same nodes as the LEDGM method did, while the BC method had the lowest number of common nodes with the LEDGM method, 6, and other methods had between 8 and 9 nodes. In the PB network, the DC method identified the same nodes as the LEDGM method did, and the other methods all had 9 nodes in common with the LEDGM method. By analyzing the tabular data, we found that the LEDGM method had a high number of nodes that were consistent with the other methods across the different networks, indicating its good adaptability and confirming the rationality of our proposed method. Furthermore, our proposed method performed similarly to other methods across different networks, suggesting that the LEDGM method can effectively integrate global and local characteristics as well as static and dynamic information.
4.3. Experiment 2: SI Model
The SI model [
29] is a traditional epidemic model used to simulate the spread of infectious diseases in networks to assess the propagation capability of nodes within the network. In the SI model, nodes are divided into two states: (1) susceptible (S); (2) infected (I). The specific propagation process is as follows: infected nodes I spread the disease to susceptible nodes S at a certain infection rate β, after which susceptible nodes S become infected nodes, and infected nodes I remain unchanged. Throughout this process, the total number of nodes N in the complex network remains constant (N = S + I). The faster the increase in the number of infected nodes, the more influential the source of infection is considered to be.
In this experiment, we selected the top ten nodes identified by the various methods used in
Section 4.2 as the initial infected nodes, with the remaining nodes in the network considered to be susceptible nodes. These infected nodes infect surrounding susceptible nodes at an infection rate of β = 0.2. To ensure the objectivity of the experimental results, each experiment was conducted independently 100 times, and the average outcomes are presented in
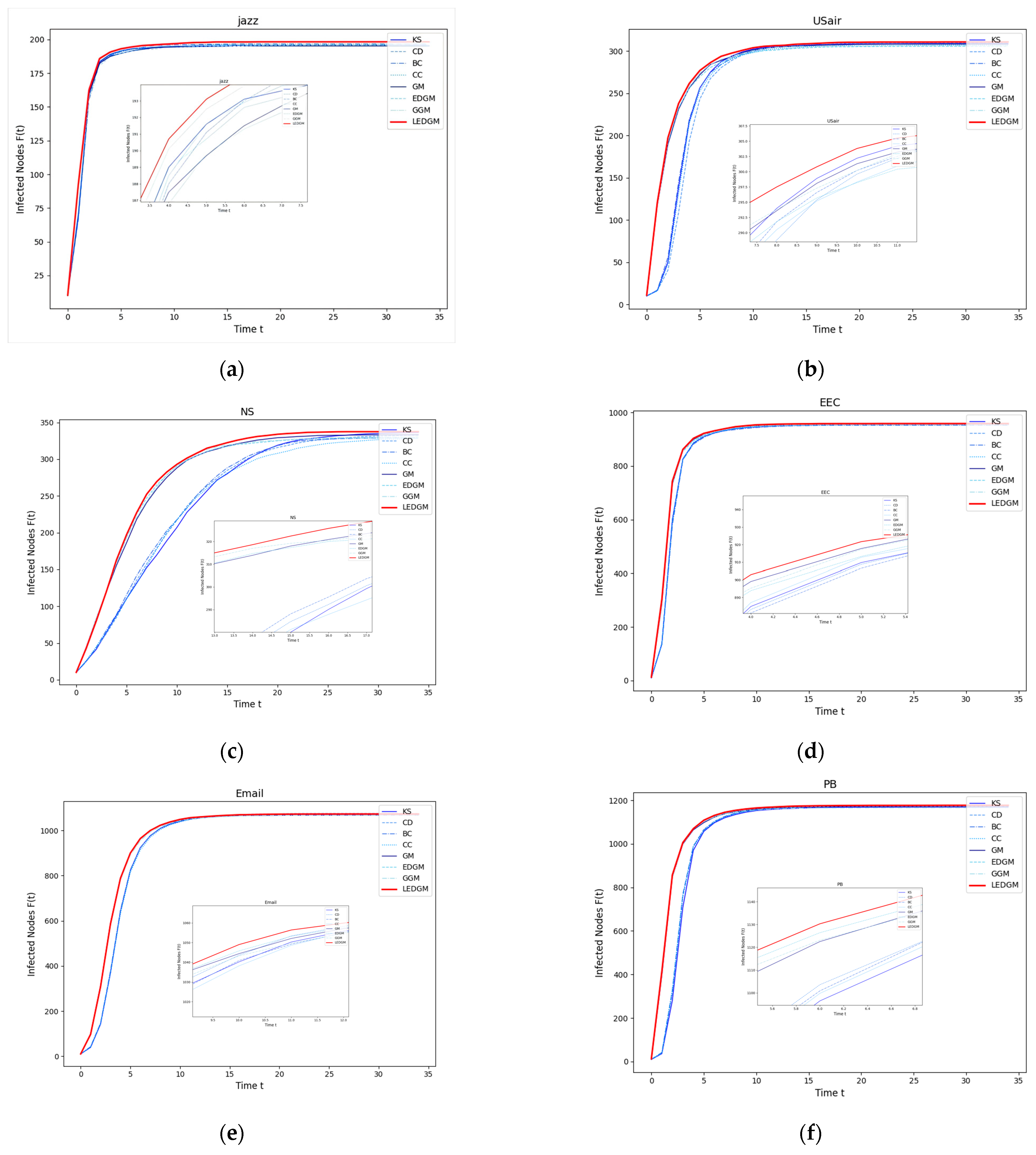
Figure 2. We observed that the higher the importance of a node within the network, the faster the rate of increase in the number of infected individuals, and, consequently, the greater the total number of infected individuals at the end of the experiment.
As shown in
Figure 2, in the six networks, the LEDGM method’s infection growth rate and maximum infected nodes are better than those of the other seven methods.
Figure 2c,f indicate that gravity-model-based methods outperform similarity-based ones in large networks, with the LEDGM being more effective than the other three gravity-model-based methods. This is because the LEDGM considers the nodes’ local, global, positional, and clustering information for a more comprehensive assessment of their spreading ability and importance.
Experiments on six real-world networks show that although the LEDGM may not be the best in all networks, it has significant advantages in most, especially compared to the GM, GGM, and EDGM. This highlights the LEDGM’s superiority and strong versatility across different types of network.
4.4. Experiment 3: Validate the Role of the Effective-Influence Node Set
In this experiment, we analyze the role of the effective-influence node set. By comparing the time taken by two methods, we aim to show its superiority in reducing the algorithms’ time complexity.
From an algorithmic perspective, the effective-influence node set significantly reduces time complexity. Although the effective distance better measures node interactions in complex networks, enhancing analysis efficiency and model predictability, its calculation requires assessing all possible paths between node pairs, resulting in high time complexity O. This makes methods using the effective distance computationally expensive, especially in large-scale networks.
To tackle this issue, the LEDGM method introduces an effective-influence node set. It uses a screening algorithm to filter out nodes that significantly impact the target node, reducing the number of node pairs undergoing effective distance calculation. This screening algorithm has a time complexity of O, which greatly reduces the time cost of computing effective distances between network nodes.
In networks where node proximity is not obvious, nodes have more “distant relatives” that are far away and have a negligible influence on the target node. The screening of the effective-influence node set can further reduce the number of distance calculations required, boosting algorithm efficiency.
Table 9 shows the specific experimental performance of two different methods.
We performed an experimental analysis of the role of effective-influence node sets in reducing algorithmic time complexity. The hardware used in this experiment was an Intel
® Core™ 12th Gen i3-12100F processor with a clock speed of 3.30 GHz. The software environment was Python 3.12.3.
Table 9 shows that in all six real-world networks, the method that used the effective-influence node set was more efficient than that without it. It reduced experimental time consumption by 57.91% in the best-performing network and by 13.28% in the worst-performing one. By analyzing the average shortest path length, network diameter, and global clustering coefficient, we found that the Email and USair networks have weak node connectivity and longer paths. This explains why the effective-influence node set is more effective in these networks.
By filtering out nodes with a significant impact on the target node, the effective-influence node set reduced the number of node pairs undergoing effective distance calculation. This lowered the algorithm’s time complexity and made using the effective distance feasible in large-scale networks. Thus, the LEDGM method achieved a significant improvement in algorithmic efficiency while maintaining high accuracy.
4.5. Experiment 4: Kendall’s Coefficient
In this experiment, we used Kendall’s coefficient [
30] to measure the correlation between the ranking results of different methods and the node ranking results obtained from the SI model, thereby assessing the accuracy of the node importance ranking results of our proposed method and other related methods. We assume that there are two sequences X and Y, each containing N nodes, where X = (
, …,
) and Y = (
, …,
). Then, a new sequence XY is constructed, where XY = ((
), (
), …, (
)), meaning the elements of XY are the results that correspond to one-to-one connections between the elements of X and Y. In the sequence XY, for any pair of elements (
) and (
), if
and
, or
and
, then this pair is considered concordant; if
and
, or
and
, then this pair is considered discordant; if
, then this pair is considered neither concordant nor discordant. The expression for Kendall’s coefficient tau is
where the number of concordant pairs and discordant pairs are denoted by
and
, respectively. The value of τ ranges from −1 to 1, with values closer to 1 indicating a higher positive correlation and values closer to −1 indicating a higher negative correlation.
In this experiment, we utilized the ranking sequences generated by the SI model in
Section 4.3 as a benchmark to assess the accuracy of the ranking sequences produced by the new method we have proposed. When generating the SI model’s ranking sequences, each node in the network was selected as the initial infected node in a separate simulation. To ensure the reliability of the simulation results, each simulation was independently executed 100 times, and the results were averaged to obtain a standard ranking of the nodes’ influence. We employed the Kendall coefficient to measure the correlation between the standard ranking sequences of nodes created by the SI model and those generated by other methods, thereby assessing the accuracy of those methods. The methods compared include DC, BC, CC, GM, GGM, and EDGM. To ensure the objectivity and validity of the experiment, we adjusted the infection probability β in the SI model and conducted simulation experiments, repeating each simulation 100 times and averaging the results to evaluate the effectiveness of different comparison methods under varying infection probabilities. The average results of the experiments are shown in
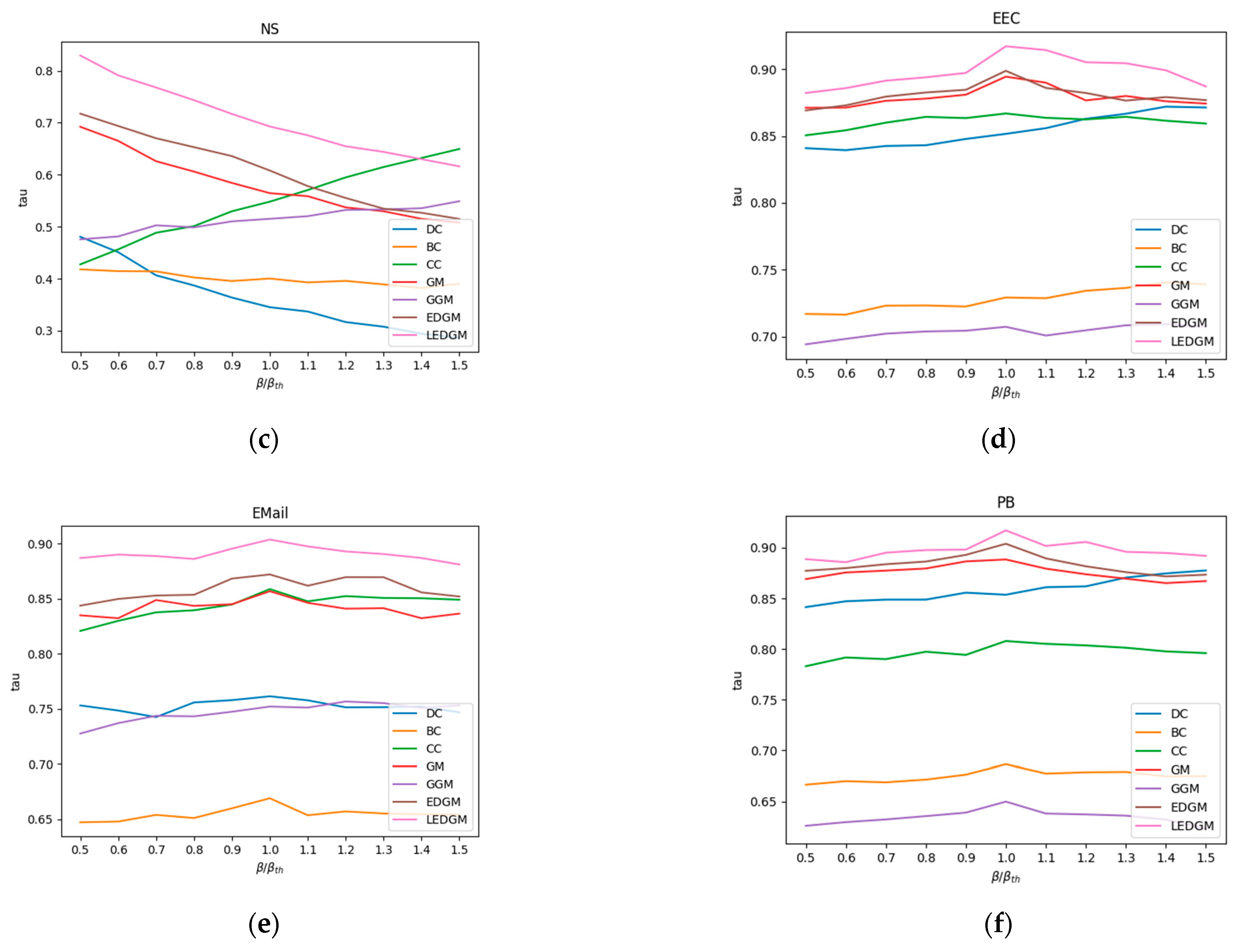
Figure 3. A higher Kendall coefficient indicates a higher correlation with the sequences produced by the SI model, thereby demonstrating the superior performance of the method in terms of accuracy.
By analyzing the data presented in
Figure 3, we observed that the LEDGM method consistently ranked first across all six real-world networks. In the Jazz and PB networks, the performance of the EDGM method was close to that of the LEDGM method, yet slightly inferior. We attribute these experimental results to the LEDGM method’s ability to adapt to the network’s topological structure and effectively integrate multidimensional information about the network, thereby accurately capturing the true influence of nodes within the network. Combining the experimental results from the six real-world networks, we conclude that the LEDGM method demonstrates significant superiority over the other methods studied.
4.6. Experiment 5: Erdős–Rényi Networks with a Controlled Node Scale
The first four experiments demonstrate the general applicability and effectiveness of the LEDGM method across different network topologies. To further explore the performance of the LEDGM method in networks of varying sizes but with the same topological structure [
31], we conducted additional experiments on artificially generated random Erdős–Rényi [
32] networks with node scales of 100, 500, 1000, and 2000. The network density was controlled by adjusting the edge generation probability. Specifically, for the network with 100 nodes, the edge generation probability was set to 0.05; for the networks with 500 and 1000 nodes, it was set to 0.01; and for the network with 2000 nodes, it was reduced to 0.005. This approach aimed to prevent overly high network densities, which could lead to rapid global infection and thus compromise our ability to effectively evaluate the performance differences between the methods using the SI model test.
By comparing
Figure 4a–d, it can be seen that the LEDGM method performs well in Erdős-Rényi networks of four different scales. This indicates that the performance of the LEDGM method does not depend on the network size but can adapt to random network topologies of various scales. Additionally, the data in
Table 10 further confirm the efficiency and universality of the effective-influence node set across different network sizes. In the network with 2000 nodes, the introduction of the effective-influence node set in the LEDGM method achieved an efficiency improvement of 82.19%. This result highlights the ability of the effective-influence node set to significantly reduce time complexity in large-scale networks, thereby verifying its high efficiency and universality across different network scales. In summary, the LEDGM method not only performs well in networks of different topological structures but also shows strong adaptability and efficiency advantages in networks of the same topological structure but different scales, providing a reliable tool for complex network analysis.
5. Conclusions
In order to identify important nodes in complex networks more efficiently and accurately, we propose a method named the LEDGM. This method includes various attribute features of the nodes, characterizing their propagation capabilities by synthesizing node attribute information, thereby effectively identifying influential nodes within the network. Furthermore, the LEDGM method enhances computational efficiency by employing an effective-influence node set, reducing redundant calculations of the effective distances between nodes. Through the analysis of experiments based on the SI disease spread model across six real-world network datasets, we found that the LEDGM method shows great potential in areas such as information transmission, social networking, and road transportation. Compared to seven other methods, the nodes selected by the LEDGM method exhibit stronger propagation capabilities while the model itself showed stronger adaptability across different datasets, thereby proving its effectiveness and superiority. Concurrently, through the analysis of the time efficiency experiments, we found that the LEDGM method has a distinct advantage over the EDGM method in terms of time efficiency.
Although the LEDGM method has performed excellently in identifying important nodes and has also performed well in reducing time complexity, we must also recognize that if we can find the optimal balance between improving the method’s accuracy and reducing its time complexity, the capability and applicability of the LEDGM method will be further enhanced. We recognize that the judicious and skillful use of multi-attribute node information can uncover deeper network node information and hidden topological structures. Therefore, exploring more advanced feature fusion methods will be a focal point of our future research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}