

Feature-Driven Semantic Communication for Efficient Image Transmission

 ,
,
Abstract
1. Introduction
- We designed a feature-driven semantic communication framework that uses non-uniform quantization methods based on the contribution factor of image features, optimizing bandwidth usage while ensuring image quality.
- This paper designs a non-uniform quantization algorithm for transmitted features, which is based on fixed-point quantization technology. The algorithm dynamically adjusts the quantization precision by combining the contribution factors of features and the transmission bandwidth requirements, maximizing data transmission efficiency and image quality during the transmission process.
- The performance of the proposed system was validated under additive white Gaussian noise (AWGN), Rayleigh fading channels, and a composite channel model. This composite model combines Rician fading, multipath effects, and time-varying noise. The simulation results demonstrate the improvements in image transmission efficiency and quality of the proposed system compared to traditional uniform quantization. These improvements are particularly evident under limited bandwidth conditions across all tested channel environments.
2. Related Works
2.1. Quantitative Methods
2.2. Semantic Communication
3. Feature-Driven Semantic Communication System
3.1. Problem Formulation
- Information loss: Important features may suffer excessive quantization errors, resulting in significant degradation of image quality.
- Inefficient resource allocation: Less important features may receive unnecessary bit allocation, leading to inefficient transmission.
3.2. Analysis of the Advantages of Non-Uniform Quantization in Image Recovery
3.2.1. Assumptions
3.2.2. Theorem and Proof
3.3. Overall Architecture
3.4. Non-Uniform Quantization Algorithm Based on Feature Contribution Factors
| Algorithm 1 Contribution factor-based non-uniform quantization. |
|
| Algorithm 2 Dequantization algorithm for contribution factor-based non-uniform quantization. |
|
4. Experiments and Discussion of Results
4.1. Experiment Settings
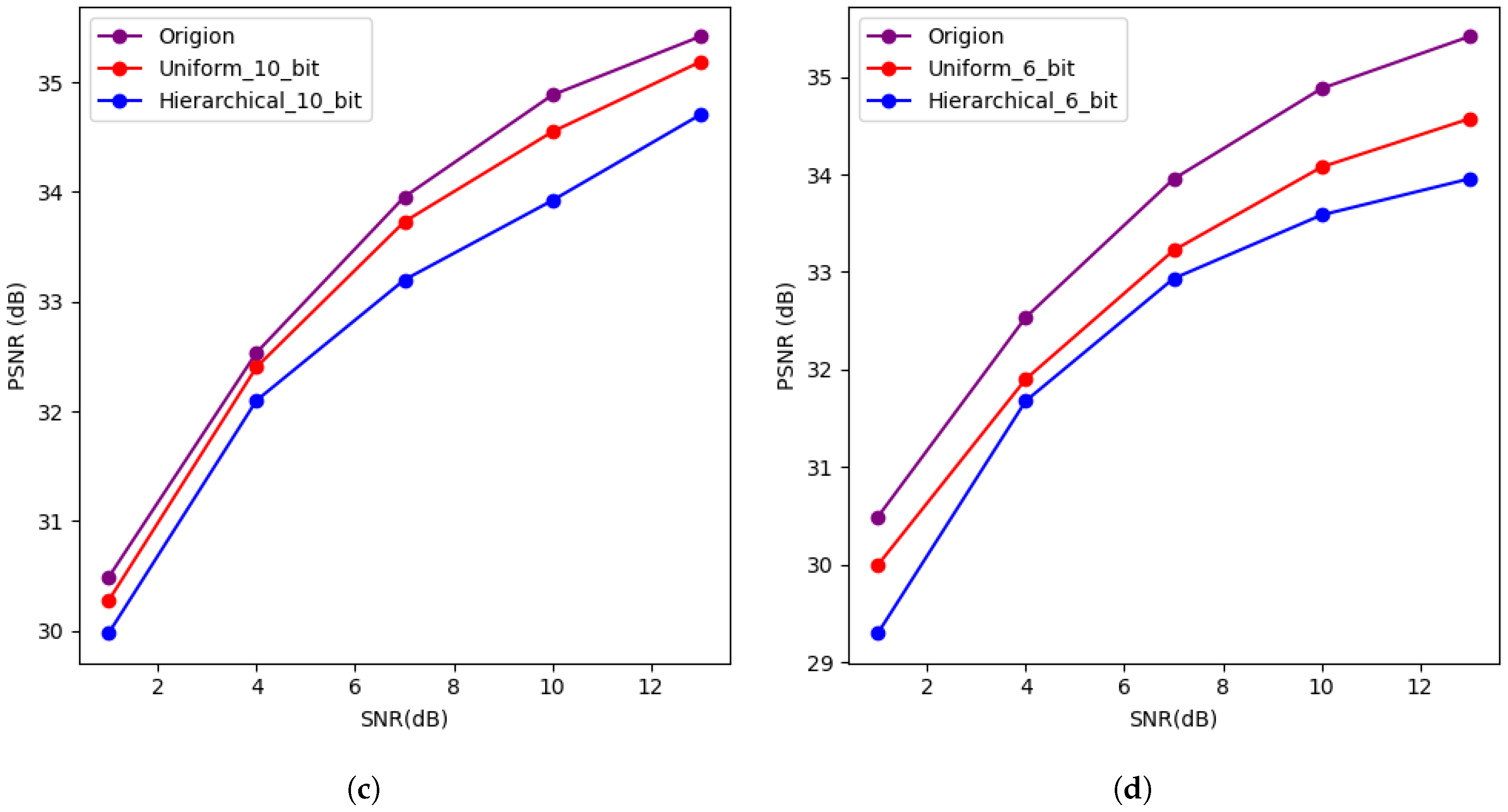
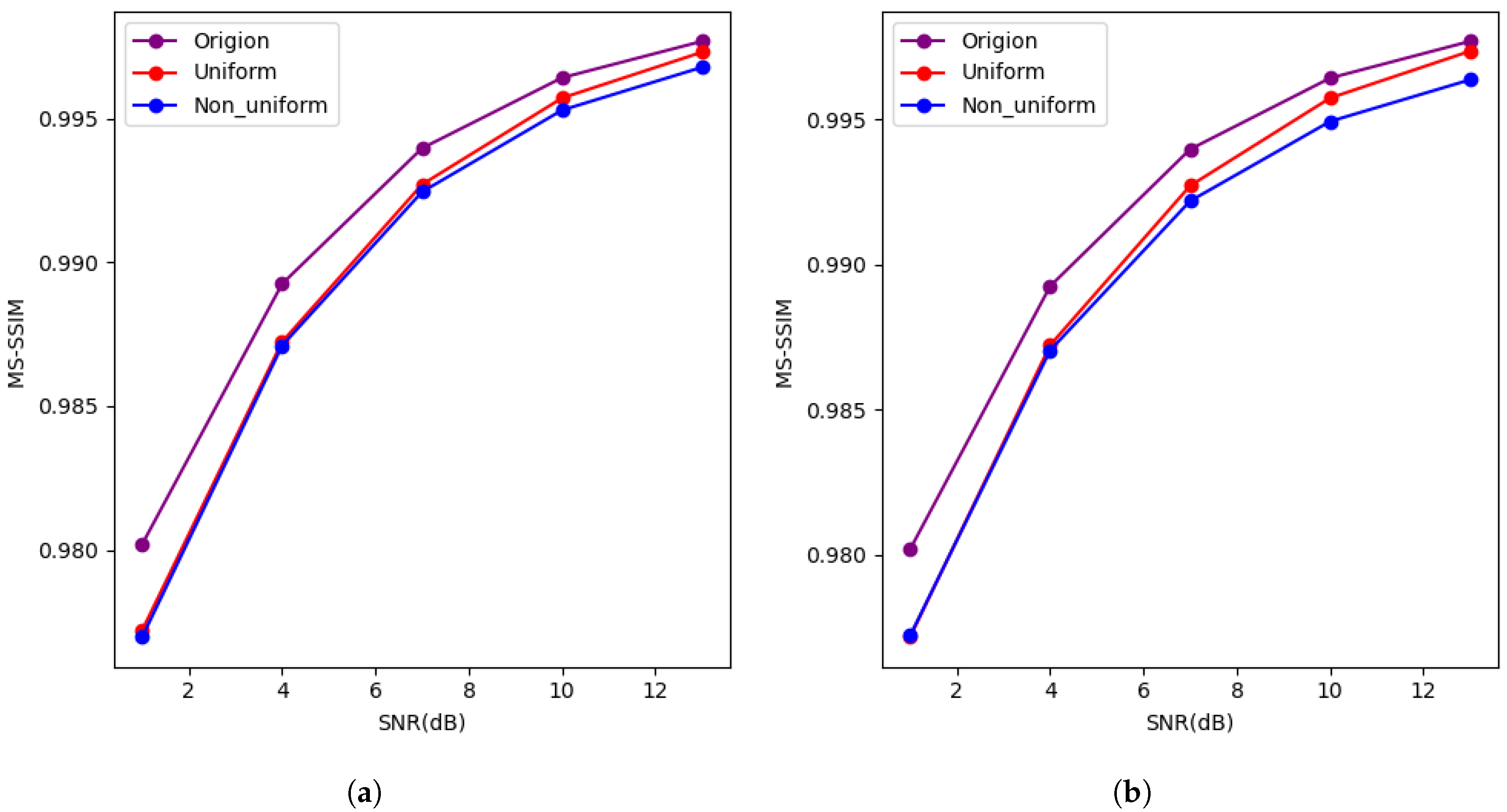
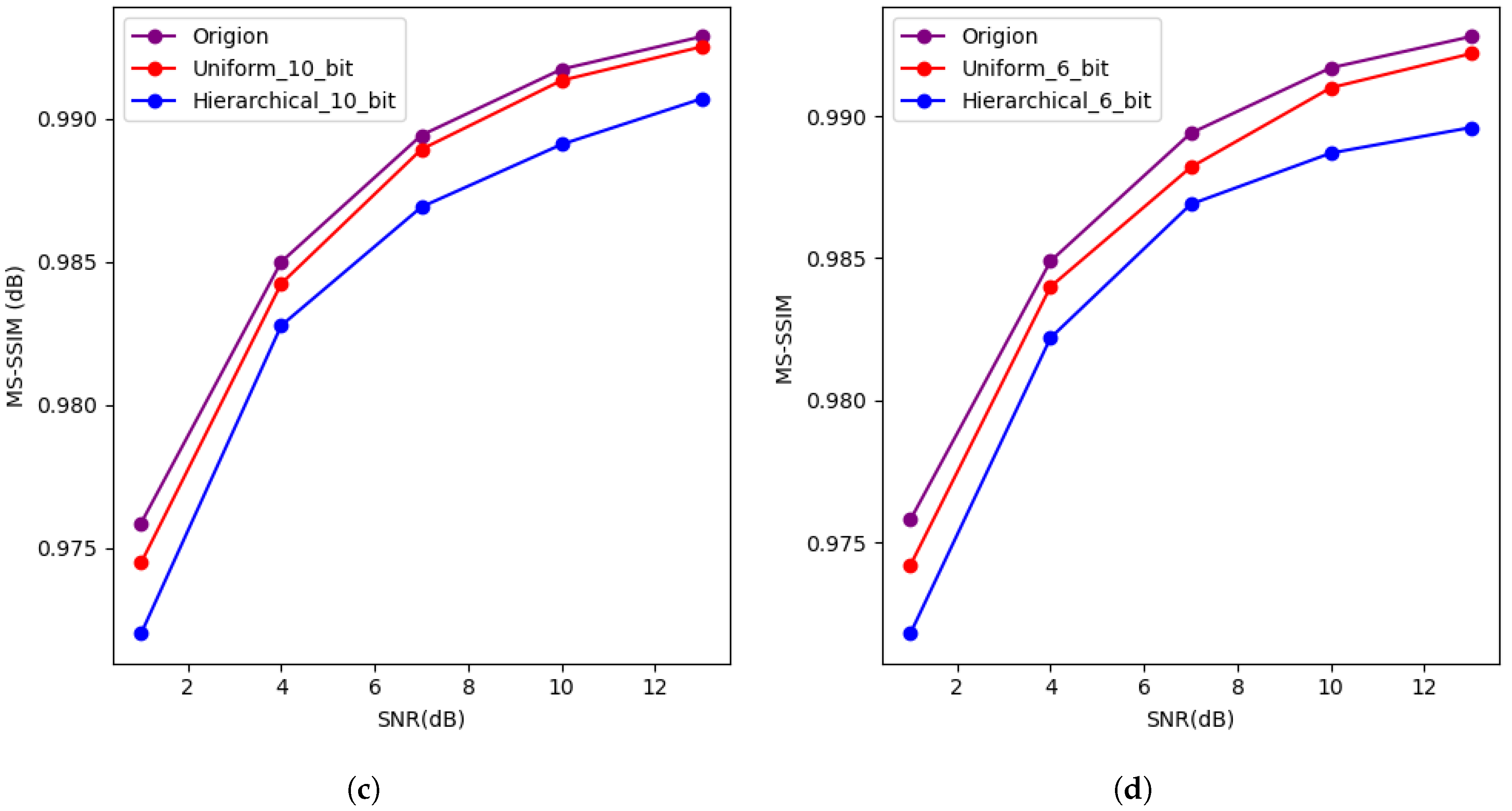
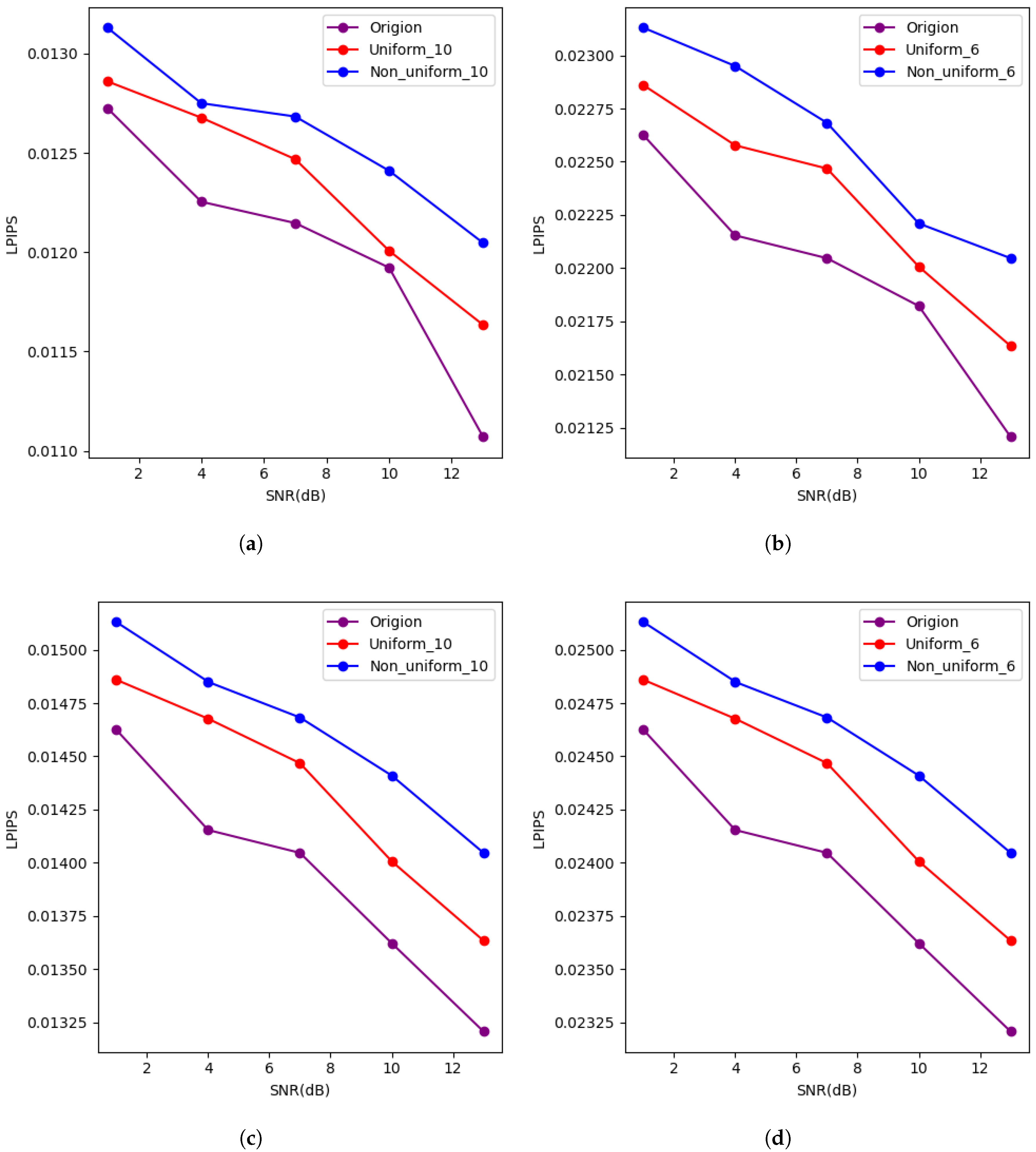
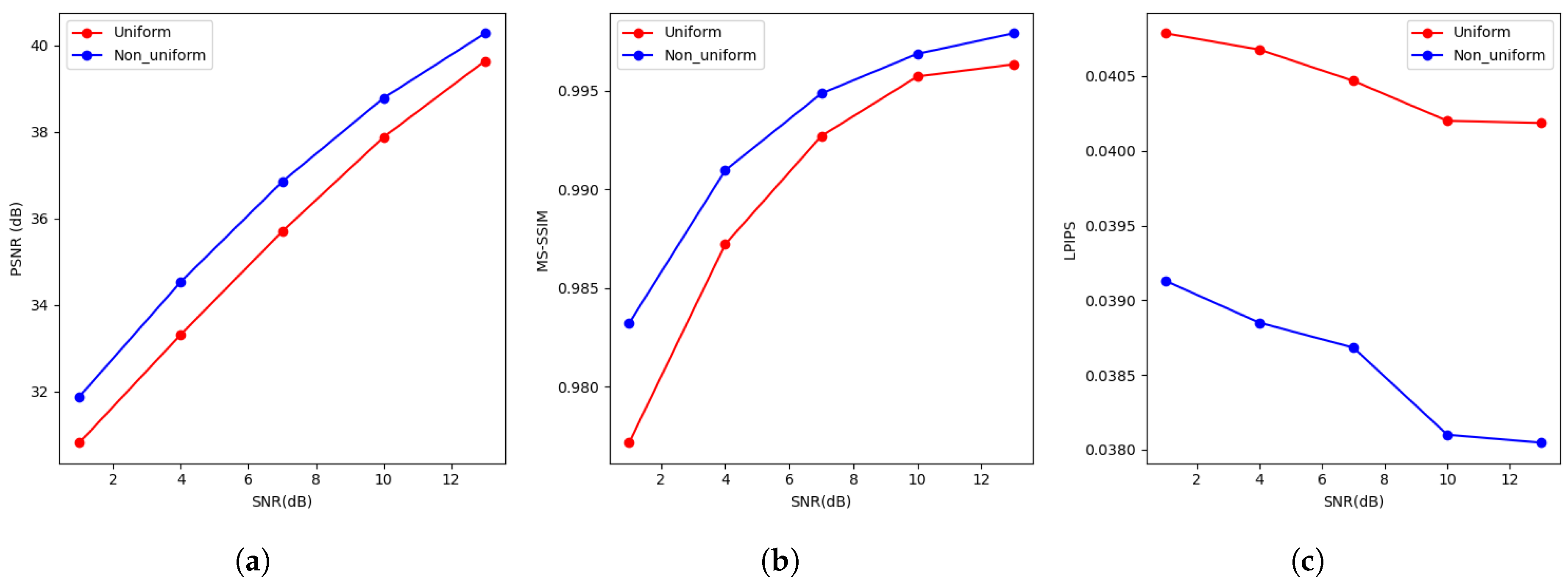
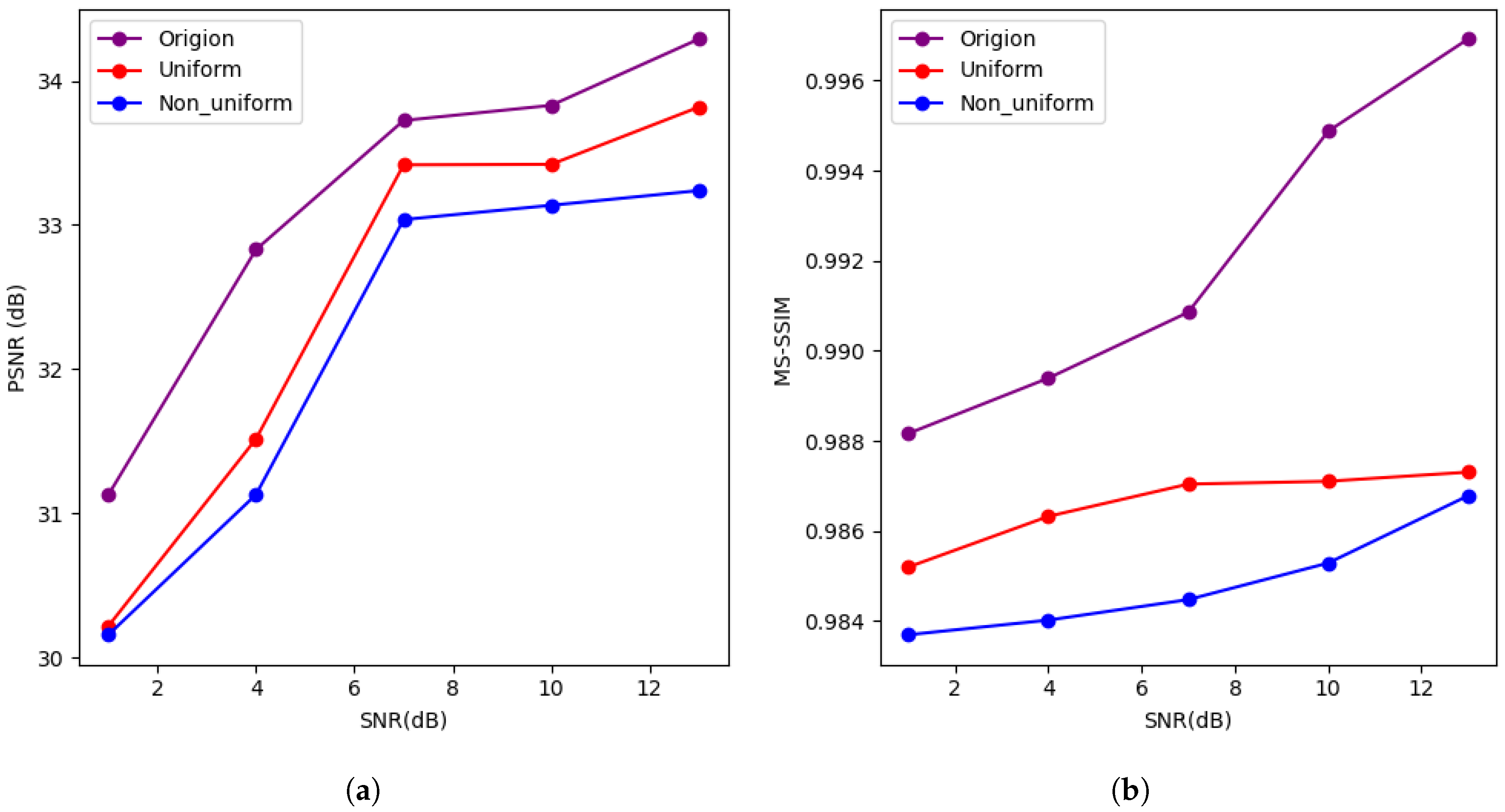
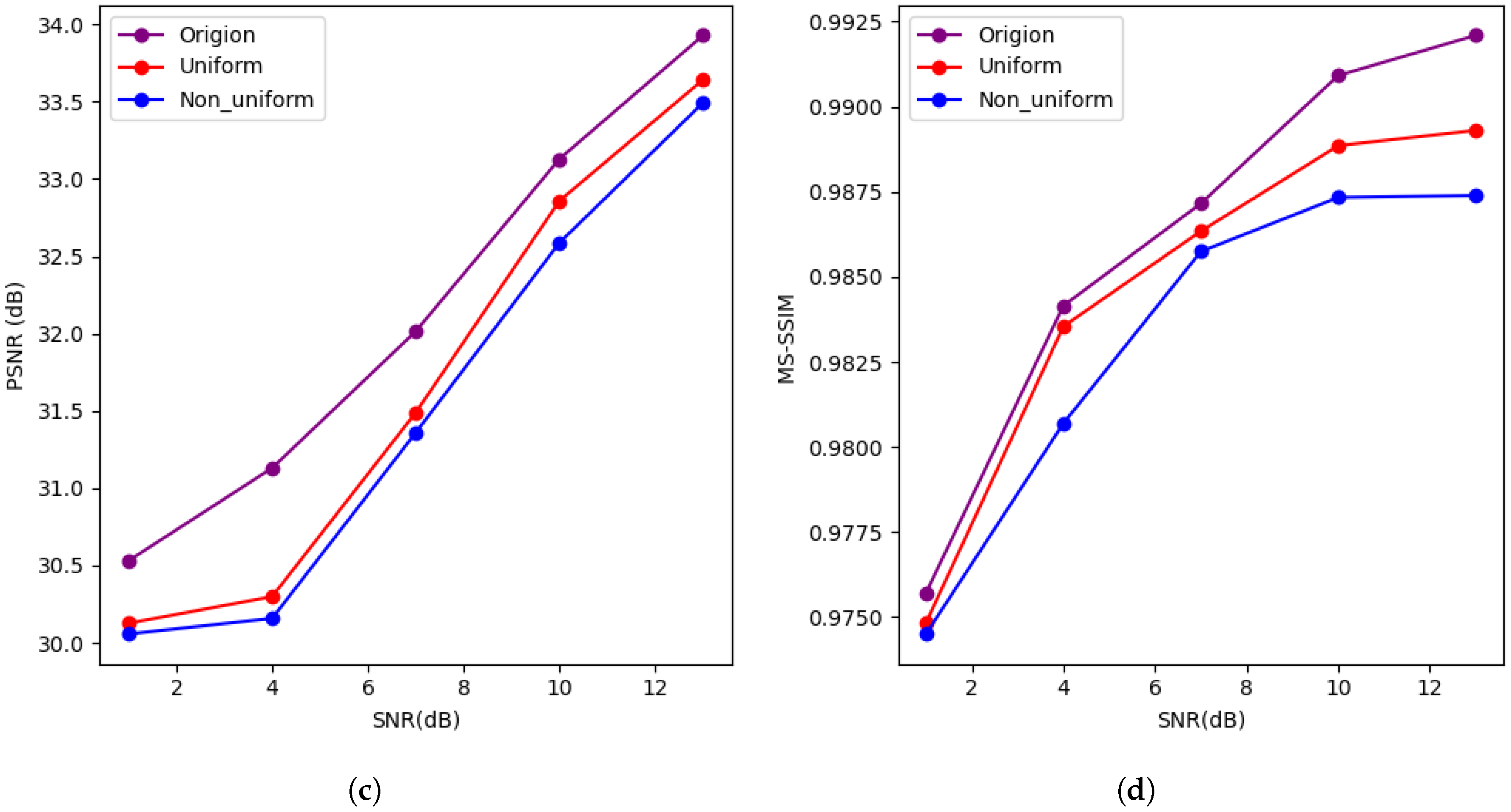
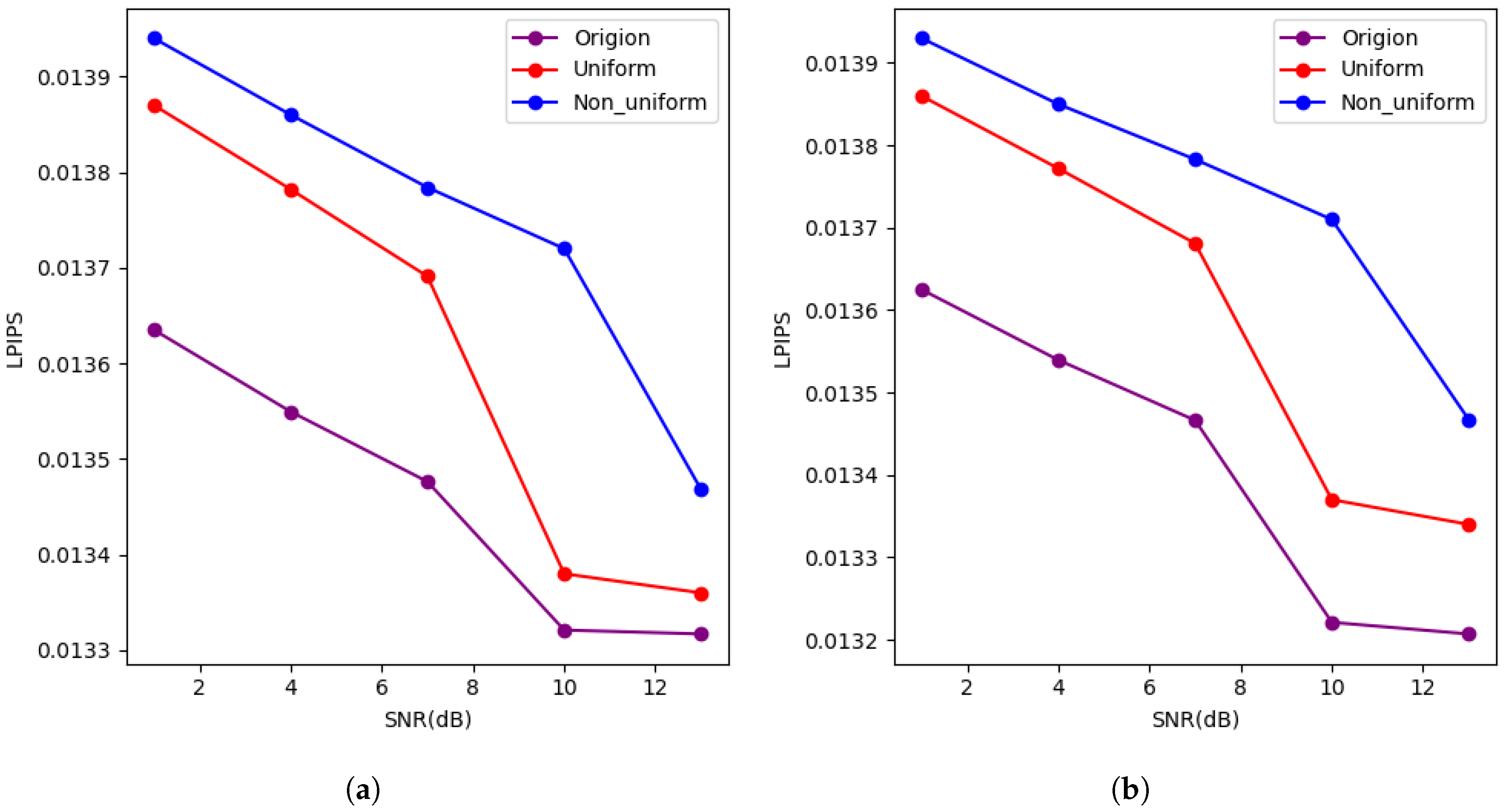
4.2. Results and Analysis
4.3. Computational Overhead Analysis
4.4. Ablation Studies on Feature Weighting
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- You, X.H. Shannon theory and future 6G’s technique potentials. Sci. Sin. Inf. 2020, 50, 1377–1394. (In Chinese) [Google Scholar] [CrossRef]
- Attaran, M. The impact of 5G on the evolution of intelligent automation and industry digitization. J. Ambient Intell. Hum. Comput. 2023, 14, 5977–5993. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Wang, F.Y.; Xu, W.J.; Liu, C.Y. Intelligence Semantic Communications: A New Paradigm for Networked. In Proceedings of the 2022 IEEE 32nd International Workshop on Machine Learning for Signal Processing (MLSP), Xi’an, China, 22–25 August 2022. [Google Scholar]
- Weng, Z.; Qin, Z. Robust Semantic Communications for Speech Transmission. arXiv 2024, arXiv:2403.05187. [Google Scholar]
- Xie, H.; Qin, Z.; Li, G.Y. Task-Oriented Multi-User Semantic Communications for VQA. IEEE Wirel. Commun. Lett. 2022, 11, 553–557. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust Semantic Communications Against Semantic Noise. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022. [Google Scholar]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G.; Li, G.Y. Robust Semantic Communications With Masked VQ-VAE Enabled Codebook. IEEE Trans. Wirel. Commun. 2023, 22, 8707–8722. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, Y.; Wang, F.; Qin, Z.; Liu, C.; Zhang, P. Semantic Communication for the Internet of Vehicles:A Multiuser Cooperative Approach. IEEE Veh. Technol. Mag. 2023, 18, 100–109. [Google Scholar] [CrossRef]
- Tonchev, K.; Bozhilov, I.; Manolova, A. Semantic Communication System for 3D Video. In Proceedings of the 2023 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT and NCON), Phuket, Thailand, 22–25 March 2023. [Google Scholar]
- Bourtsoulatze, E.; Burth Kurka, D.; Gündüz, D. Deep Joint Source-Channel Coding for Wireless Image Transmission. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 567–579. [Google Scholar] [CrossRef]
- Yang, K.; Wang, S.; Dai, J.; Tan, K.; Niu, K.; Zhang, P. WITT: A Wireless Image Transmission Transformer for Semantic Communications. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Lin, S.; Liu, F.; Guo, C.; Tong, W. Research on Semantic Coding Algorithm Based on Semantic Importance. J. Beijing Univ. Posts Telecommun. 2024, 47, 10–16. [Google Scholar]
- Huang, D.; Tao, X.; Gao, F.; Lu, J. Deep Learning-Based Image Semantic Coding for Semantic Communications. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Wu, J.L.; Wu, C.; Lin, Y.F.; Yoshinaga, T.; Zhong, L.; Chen, X.F.; Ji, Y.S. Semantic segmentation-based semantic communication system for image transmission. Digit. Commun. Netw. 2024, 10, 519–527. [Google Scholar] [CrossRef]
- Gupta, K.; Asthana, A. Reducing the Side-Effects of Oscillations in Training of Quantized YOLO Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014; Volume 11, pp. 2440–2449. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2016, arXiv:1510.00149v5. [Google Scholar]
- Lei, L.; Hong, X.; Shi, J.; Su, M.; Lin, C.; Xia, W. Quantization-Based Adaptive Deep Image Compression Using Semantic Information. IEEE Access 2023, 11, 118061–118077. [Google Scholar]
- Tsumura, K.; Maciejowski, J. Optimal Quantization of Signals for System Identification. In Proceedings of the 2003 European Control Conference (ECC), Cambridge, UK, 1–4 September 2003. [Google Scholar]
- Xia, X.; Sun, G.; Zhang, K.; Wu, S.; Wang, T.; Xia, L.; Liu, S. NanoSats/CubeSats ADCS Survey. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017. [Google Scholar]
- Wallace, G.K. The JPEG still picture compression standard. IEEE Trans. Consum. Electron. 1992, 38, xviii–xxxiv. [Google Scholar]
- Lin, J.; Tang, J.; Tang, H.; Yang, S.; Chen, W.-M.; Wang, W.-C.; Xiao, G.; Dang, X.; Gan, C.; Han, S. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv 2024, arXiv:2306.00978. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, Z.; Wu, B.; Luo, W.; Yang, X.; Liu, W.; Cheng, K.-T. Bi-Real Net: Enhancing the Performance of 1-bit CNNs with Improved Representational Capability and Advanced Training Algorithm. arXiv 2018, arXiv:1808.00278. [Google Scholar]
- Srikotr, T.; Mano, K. Sub-band Vector Quantized Variational AutoEncoder for Spectral Envelope Quantization. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019. [Google Scholar]
- Sun, J.H. Mixed-precision quantization technology of convolutional neural networks. Inf. Technol. 2020, 6, 66–69. [Google Scholar]
- Chen, Y.; Cai, X.; Liang, X.; Wang, M. Compression algorithm for weights quantized deep neural network models. J. Xidian Univ. 2019, 46, 132–138. [Google Scholar]
- Dong, Z.; Yao, Z.; Gholami, A.; Mahoney, M.; Keutzer, K. HAWQ: Hessian AWare Quantization of Neural Networks With Mixed-Precision. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, C.; Zuo, G.; Zheng, Z.; Zhang, W.; Rao, Y.; Jiang, Z. Quantizing Separable Convolution of MobileNets with Mixed Precision. J. Electron. Imaging 2024, 33, 013013. [Google Scholar] [CrossRef]
- Uhlich, S.; Mauch, L.; Kazuki, Y.; Fabien, C.; Javier, A.G.; Stephen, T.; Thomas, K.; Akita, N. Differentiable Quantization of Deep Neural Networks. arXiv 2019, arXiv:1905.11452v1. [Google Scholar]
- Wu, B.C.; Wang, Y.H.; Zhang, P.Z.; Tian, Y.D.; Vajda, P.; Kurt, K. Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search. arXiv 2018, arXiv:1812.00090. [Google Scholar]
- Wang, T.Z.; Wang, K.; Cai, H.; Lin, J.; Liu, Z.J.; Han, S. APQ: Joint Search for Network Architecture, Pruning and Quantization Policy. arXiv 2020, arXiv:2006.08509. [Google Scholar]
- van Baalen, M.; Louizos, C.; Nagel, M.; Amjad, R.A.; Wang, Y.; Blankevoort, T.; Welling, M. Bayesian Bits: Unifying Quantization and Pruning. arXiv 2020, arXiv:2005.07093. [Google Scholar]
- Wang, K.; Liu, Z.J.; Lin, Y.J.; Han, S. HAQ: Hardware-Aware Automated Quantization. arXiv 2018, arXiv:1811.08886. [Google Scholar]
- Elthakeb, A.T.; Pilligundla, P.; Mireshghallah, F.; Yazdanbakhsh, A.; Esmaeilzadeh, H. ReLeQ: A Reinforcement Learning Approach for Deep Quantization. arXiv 2018, arXiv:1811.01704. [Google Scholar]
- Lou, Q.; Guo, F.; Liu, L.T.; Kim, M.J.; Lei, J. AutoQ: Automated Kernel-Wise Neural Network Quantization. arXiv 2019, arXiv:1902.05960. [Google Scholar]
- Weaver, W. Recent contributions to the mathematical theory of communication. In ETC: A Review of General Semantics; Institute of General Semantics: Fort Worth, TX, USA, 1953; pp. 261–281. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yang, W.; Du, H.; Liew, Z.Q.; Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Chi, X.; Shen, X.; Miao, C. Semantic Communications for Future Internet: Fundamentals, Applications, and Challenges. IEEE Commun. Surv. Tutor. 2023, 25, 213–250. [Google Scholar]
- Rothstein, J. Review of “Science and Information Theory” by Leon Brillouin. Science 1956, 124, 492–493. [Google Scholar]
- Sudan, M. Communication Amid Uncertainty. In Proceedings of the 2012 IEEE Information Theory Workshop, Lausanne, Switzerland, 3–7 September 2012. [Google Scholar]
- O’Shea, T.J.; Karra, K.; Clancy, T.C. Learning to Communicate:Channel Auto-Encoders, Domain Specific Regularizers, and Attention. In Proceedings of the 2016 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Limassol, Cyprus, 12–14 December 2016. [Google Scholar]
- Shi, G.; Xiao, Y.; Li, Y.; Xie, X. From Semantic Communication to Semantic-Aware Networking: Model, Architecture, and Open Problems. IEEE Commun. Mag. 2021, 59, 44–50. [Google Scholar]
- Feng, Y.; Xu, J.; Liang, C.; Yu, G.; Hu, L.; Yuan, T. Decoupling Source and Semantic Encoding: An Implementation Study. Electronics 2023, 12, 2755. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z. A Lite Distributed Semantic Communication System for Internet of Things. IEEE J. Sel. Areas Commun. 2021, 39, 142–153. [Google Scholar]
- Xu, X.; Xiong, H.; Wang, Y.; Che, Y.; Han, S.; Wang, B.; Zhang, P. Knowledge-Enhanced Semantic Communication System with OFDM Transmissions. Sci. China Inf. Sci. 2023, 66, 172302. [Google Scholar]
- Zhang, W.; Zhang, H.; Ma, H.; Shao, H.; Wang, N.; Leung, V.C.M. Predictive and Adaptive Deep Coding for Wireless Image Transmission in Semantic Communication. IEEE Trans. Wirel. Commun. 2023, 22, 5486–5501. [Google Scholar]
- Qi, Z.; Feng, Y.; Qin, Z. Adaptive Sampling and Joint Semantic-Channel Coding under Dynamic Channel Environment. arXiv 2025, arXiv:2502.072362025. [Google Scholar]
- Zhou, K.Q.; Zhang, G.Y.; Cai, Y.L.; Hu, Q.Y.; Yu, G.D. FAST Feature Arrangement for SemanticTransmission. arXiv 2019, arXiv:2305.03274. [Google Scholar]
- Gao, S.; Qin, X.Q.; Chen, L.; Han, K.F.; Zhang, P. Importance of Semantic Information Based on Semantic Value. IEEE Trans. Commun. 2024, 72, 5443–5457. [Google Scholar]
- Ma, Y.; Xu, C.M.; Liu, Z.Y.; Zhang, S.Q.; Tafazolli, R. Importance-Aware Source-Channel Coding for Multi-ModalTask-Oriented Semantic Communication. arXiv 2025, arXiv:2502.16194. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | PSNR (dB) | LPIPS | MS-SSIM (dB) |
|---|---|---|---|
| AWGN | 33.12 | 0.0135 | 0.982 |
| Rayleigh | 32.07 | 0.021 | 0.984 |
| Composite | 30.10 | 0.0133 | 0.981 |
| Method | Training Time (min/epoch) | Inference Time (s/image) | Peak Memory (GB) |
|---|---|---|---|
| Uniform Quantization | 30 | 0.175 | 6.5 |
| Non-Uniform Quantization (Ours) | 36 | 0.195 | 7.0 |
| Weighting Method | PSNR (dB) | LPIPS | MS-SSIM | Inference Time (s) |
|---|---|---|---|---|
| Gradient-based (Ours) | 34.52 | 0.028 | 0.975 | 0.195 |
| Largest magnitude | 30.25 | 0.046 | 0.925 | 0.143 |
| Standard deviation | 32.12 | 0.054 | 0.930 | 0.162 |
| Weighting Method | PSNR (dB) | LPIPS | MS-SSIM | Inference Time (s) |
|---|---|---|---|---|
| Gradient-based (Ours) | 32.45 | 0.035 | 0.960 | 0.215 |
| Largest magnitude | 28.55 | 0.062 | 0.910 | 0.175 |
| Standard deviation | 30.47 | 0.070 | 0.920 | 0.190 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhang, Y.; Ji, B.; Chen, A.; Liu, A.; Xu, H. Feature-Driven Semantic Communication for Efficient Image Transmission. Entropy 2025, 27, 369. https://doi.org/10.3390/e27040369
Zhang J, Zhang Y, Ji B, Chen A, Liu A, Xu H. Feature-Driven Semantic Communication for Efficient Image Transmission. Entropy. 2025; 27(4):369. https://doi.org/10.3390/e27040369
Chicago/Turabian StyleZhang, Ji, Ying Zhang, Baofeng Ji, Anmin Chen, Aoxue Liu, and Hengzhou Xu. 2025. "Feature-Driven Semantic Communication for Efficient Image Transmission" Entropy 27, no. 4: 369. https://doi.org/10.3390/e27040369
APA StyleZhang, J., Zhang, Y., Ji, B., Chen, A., Liu, A., & Xu, H. (2025). Feature-Driven Semantic Communication for Efficient Image Transmission. Entropy, 27(4), 369. https://doi.org/10.3390/e27040369