Local Compositional Complexity: How to Detect a Human-Readable Message


Abstract
1. Introduction
- a novel approach to measuring complexity by dividing the description into structured and unstructured portions;
- a sketch of how this idea can be used to more objectively quantify the entropy and macrostate of a physical system;
- the proposal of local compositionality as the structure that, in the case of communicative signals, the structured portion should conform to;
- the development of the LCC score, a computable metric for complexity that can be applied to a variety of domains;
- the empirical testing of the LCC on text, image and audio data, showing that it agrees with our intuitions regarding meaningful complexity;
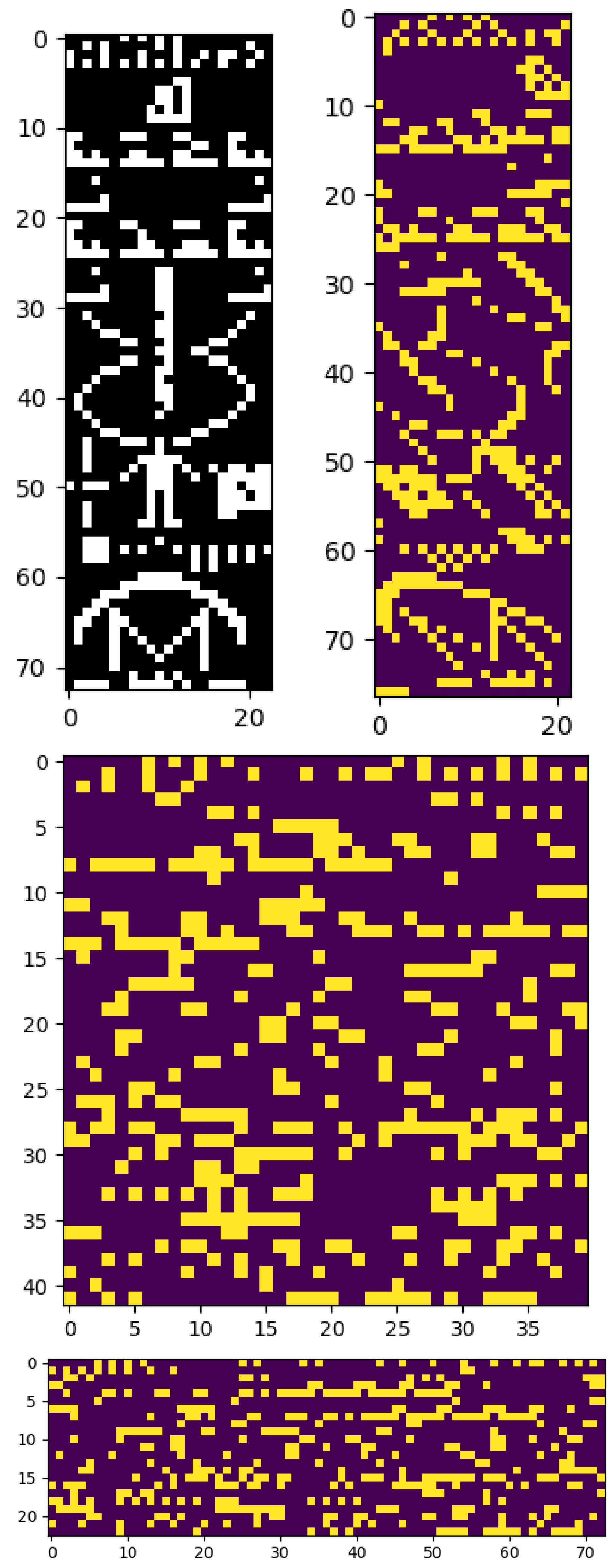
- a demonstration of the potential of the LCC score for detecting non-human communication, showing that it can identify the Arecibo message as meaningful, as well as determine its correct aspect ratio.
2. Local Compositional Complexity (LCC) Score
2.1. Two-Part Descriptions
2.2. Entropy, Macrostates and Microstates
- Entropy vs. Complexity
2.3. Local Compositionality
3. Implementation and Results
3.1. Discrete Data
3.1.1. Discrete Worked Example
3.1.2. Complexity of Natural Language Text
3.2. Continuous Data
3.2.1. Continuous Worked Example

3.2.2. Continuous Results
3.2.3. Use in Compression
3.3. Arecibo Message
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proportionality to Gibbs Entropy
Appendix B. Expression Distribution over Microstates Given Temperature
Appendix C. Full Formal Description of LCC Score
Appendix C.1. Formal Description for Discrete Data
- for some , that is, C is a codebook for the alphabet that is also allowed contain extra symbols not in .
- , that is, I is a string composed of characters that appear as entries in the codebook and a special character x that does not appear in the codebook or in S.
- .
- , that is, if we begin with the string I, then replace each occurrence of an entry with the corresponding string in the codebook, followed by replacing all x characters with the substring X. The final result is the input string S (this notation uses function currying, where we regard each as a function from strings to strings, and then compose).
- An encoding of S is a choice of codebook, index string and residual string, such that S can be generated by replacing the characters in the index string with the corresponding entries in the codebook, and then replacing the special characters x with the residual string.
Appendix C.2. Formal Description for Continuous Data
Appendix D. Algorithm for the Prime Modulo Text Model
def generate_from_inp(inp):
N = inp[0]
x = np.zeros(N)
for p_idx, offset in enumerate(inp[1:]) :
p = primes[p_idx]
cur_pow = 1
to_add = []
for i in range(N):
to_add.append(cur_pow)
cur_pow = cur_pow*p \% N
to_add = to_add[-offset:] + to_add[:-offset]
x += np. array(to_add)
chars = ’abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ’
return ’’.join(chars[int(i)] for i in x \%53)
2,3,19,5,11
Input seq: 250,120,24,82,10,15,202
Output seq: qKXVSyiLIyYKyvjXMvZqevkJVy OLjPyBKpccEeQTvFMYyuRzyGBEKKuuTWhkvLdaylFRNMEHKBMxEqknvCgPycIFySsKvsXApTnqKXVSyiLIyYKyvjo pZqOOHnPYKUlWZDwlHaKEQBawWeuGZLCTKuFxWgEBBHyIWkDSKR tKlkfHmNyQydqHFxAvIUNKrtcWPWvQTmRWhGMZccZKxnoHVBdQKgOHnPYKUlWZDwlHaKEQBawWeuGZLTn
-
A significant part of the reason this model produces a compact representation for strings that humans do not perceive as regular is that the inclusion of sequences of prime power modulo N produces highly non-local patterns.
Appendix E. Algorithms to Compute LCC Score
Appendix F. Wikipedia Articles in Language Text Experiments
- Life.
- Computation.
- Architecture.
- Water.
- Plants.
- Aurora Borealis.
- Chemistry.
- Animals.
- Trees.
- Ocean.
- Music.
Appendix G. Full Numeric Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
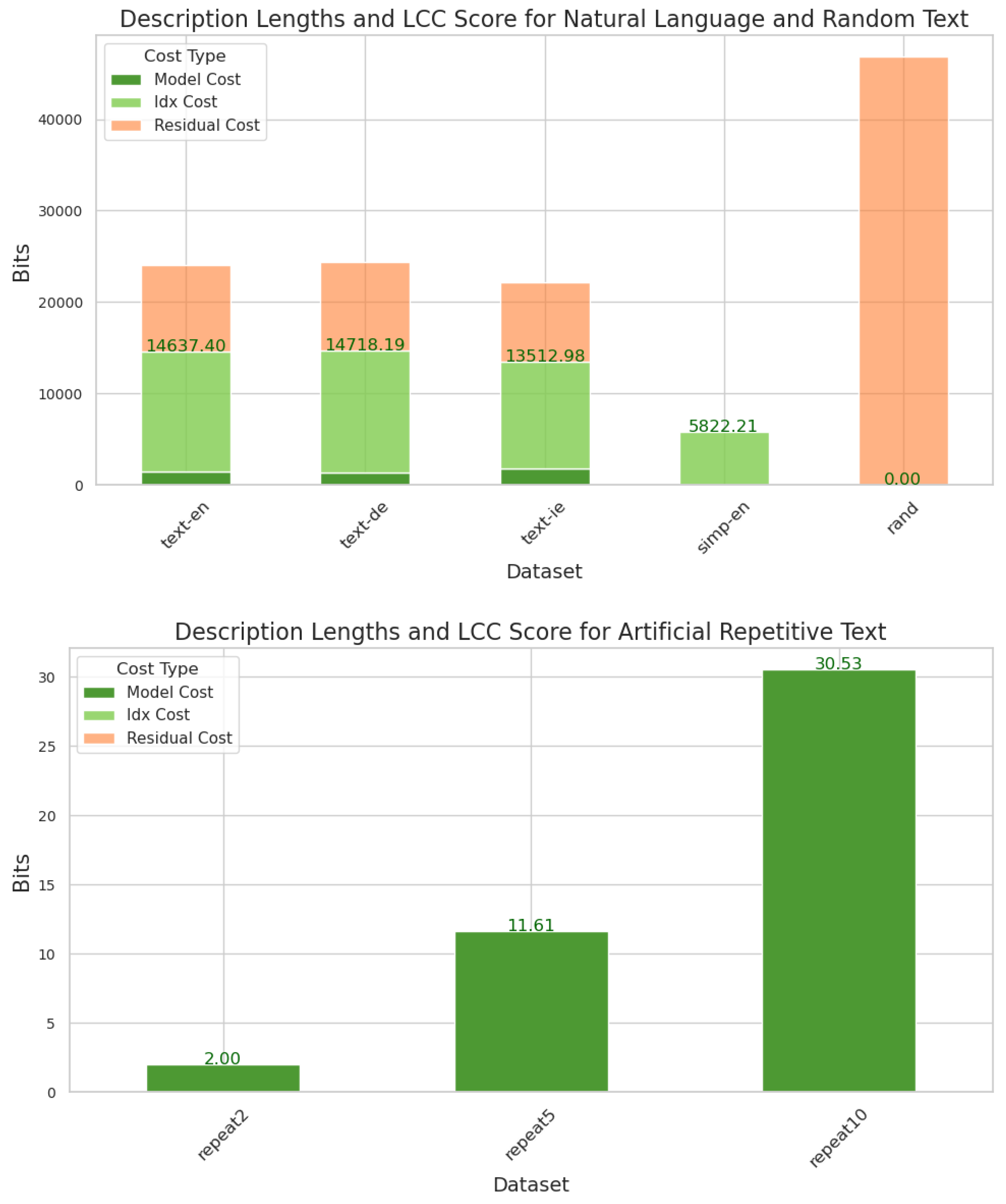
| Model Cost | Idx Cost | LCC Score | Residual Cost | |
|---|---|---|---|---|
| text-en | 1442.38 (58.03) | 13,195.02 (225.99) | 14,637.40 (195.98) | 9393.79 (457.05) |
| text-de | 1375.24 (46.37) | 13,342.95 (122.85) | 14,718.19 (101.97) | 9653.65 (168.47) |
| text-ie | 1756.35 (142.88) | 11,756.63 (335.73) | 13,512.98 (220.23) | 8647.10 (219.83) |
| simp-en | 20.26 (0.00) | 5801.94 (0.70) | 5822.21 (0.70) | 0.00 (0.00) |
| rand | 0.00 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 46,801.71 (3.60) |
| repeat2 | 2.00 (0.00) | 0.00 (0.00) | 2.00 (0.00) | 0.00 (0.00) |
| repeat5 | 11.21 (0.27) | 0.00 (0.00) | 11.21 (0.27) | 0.00 (0.00) |
| repeat10 | 29.13 (0.52) | 0.00 (0.00) | 29.13 (0.52) | 0.00 (0.00) |
| LCC Score | Residual Cost | Model Cost | Idx Cost | |
|---|---|---|---|---|
| bell | 2043.14 (1110.04) | 193,898.73 (4841.73) | 782.77 (312.90) | 1260.38 (797.13) |
| white-noise | 273.41 (0.38) | 191,116.32 (58.84) | 273.41 (0.38) | 0.00 (0.00) |
| walla | 7036.59 (190.64) | 175,630.20 (3388.02) | 2270.64 (67.02) | 4765.94 (132.75) |
| tuning-fork | 4808.17 (1001.92) | 178,929.18 (4271.23) | 1609.30 (289.55) | 3198.87 (717.18) |
| irish-speaker-1 | 9387.16 (222.87) | 166,074.92 (2763.26) | 2786.92 (70.64) | 6600.24 (190.05) |
| irish-speaker-2 | 9674.27 (234.00) | 167,794.02 (2065.28) | 2778.14 (78.03) | 6896.13 (165.98) |
| english-speaker-1 | 9505.16 (208.75) | 170,094.87 (3148.59) | 2802.31 (49.05) | 6702.85 (179.56) |
| english-speaker-2 | 9617.23 (323.11) | 165,068.49 (1455.42) | 2862.03 (96.06) | 6755.19 (244.95) |
| german-speaker-1 | 9525.03 (441.60) | 160,626.07 (1362.32) | 2802.65 (127.31) | 6722.38 (316.96) |
| german-speaker-2 | 9703.21 (198.38) | 167,156.56 (1049.71) | 2819.16 (35.16) | 6884.06 (174.63) |
| rain | 294.91 (0.43) | 200,476.58 (43.64) | 294.91 (0.43) | 0.00 (0.00) |
| Model Cost | Idx Cost | LCC Score | Residual Cost | |
|---|---|---|---|---|
| imagenet | 6865.69 (138.88) | 492,500.82 (13,029.60) | 499,366.51 (13,159.53) | 10,161,027.93 (214,368.74) |
| cifar10 | 7114.44 (62.83) | 507,249.40 (4214.13) | 514,363.84 (4239.33) | 10,154,058.99 (54,263.77) |
| stripes | 4800.59 (27.60) | 242,604.22 (3057.78) | 247,404.82 (3063.10) | 8,175,600.59 (11,705.87) |
| halves | 4838.60 (10.60) | 181,564.76 (482.96) | 186,403.35 (485.99) | 7,964,144.40 (1590.83) |
| rand | 384.00 (0.00) | 0.00 (0.00) | 384.00 (0.00) | 14,427,771.33 (49.71) |
Appendix H. Derivation of Randomness Threshold
References
- Bar-Yam, Y. General features of complex systems. Encyclopedia of Life Support Systems (EOLSS); EOLSS Publishers: Oxford, UK, 2002; Volume 1. [Google Scholar]
- Rosete, A.R.; Baker, K.R.; Ma, Y. Using LZMA compression for spectrum sensing with SDR samples. In Proceedings of the 2018 9th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; pp. 282–287. [Google Scholar]
- Mahon, L. Towards a Universal Method for Meaningful Signal Detection. arXiv 2024, arXiv:2408.00016. [Google Scholar]
- Gell-Mann, M.; Lloyd, S. Information measures, effective complexity, and total information. Complexity 1996, 2, 44–52. [Google Scholar] [CrossRef]
- Rissanen, J. A universal prior for integers and estimation by minimum description length. Ann. Stat. 1983, 11, 416–431. [Google Scholar] [CrossRef]
- Grünwald, P.D. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Wallace, C.S.; Boulton, D.M. An information measure for classification. Comput. J. 1968, 11, 185–194. [Google Scholar] [CrossRef]
- Koppel, M. Complexity, depth, and sophistication. Complex Syst. 1987, 1, 1087–1091. [Google Scholar]
- Vitányi, P.M. Meaningful information. IEEE Trans. Inf. Theory 2006, 52, 4617–4626. [Google Scholar] [CrossRef]
- Ay, N.; Müller, M.; Szkola, A. Effective complexity and its relation to logical depth. IEEE Trans. Inf. Theory 2010, 56, 4593–4607. [Google Scholar] [CrossRef]
- Kontkanen, P.; Myllymäki, P.; Buntine, W.; Rissanen, J.; Tirri, H. An MDL Framework for Data Clustering; Helsinki Institute for Information Technology HIIT: Helsinki, Finland, 2005. [Google Scholar]
- Mahon, L.; Lapata, M. A Modular Approach for Multimodal Summarization of TV Shows. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 8272–8291. [Google Scholar] [CrossRef]
- Mahon, L.; Lapata, M. Parameter-free Video Segmentation for Vision and Language Understanding. arXiv 2025, arXiv:2503.01201. [Google Scholar]
- Jaynes, E.T. Gibbs vs Boltzmann entropies. Am. J. Phys. 1965, 33, 391–398. [Google Scholar] [CrossRef]
- Kraft, L.G. A Device for Quantizing, Grouping, and Coding Amplitude-Modulated Pulses. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1949. [Google Scholar]
- McMillan, B. Two inequalities implied by unique decipherability. IRE Trans. Inf. Theory 1956, 2, 115–116. [Google Scholar] [CrossRef]
- Steedman, M. The Syntactic Process; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Ommer, B.; Buhmann, J.M. Learning the compositional nature of visual objects. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [PubMed]
- Mahon, L.; Lukasiewicz, T. Minimum description length clustering to measure meaningful image complexity. Pattern Recognit. 2024, 145, 109889. [Google Scholar]
- Johnson, J.H. Hypernetworks in the Science of Complex Sysatems; Imperial College Press: London, UK, 2013. [Google Scholar]
- Liversedge, S.P.; Drieghe, D.; Li, X.; Yan, G.; Bai, X.; Hyönä, J. Universality in eye movements and reading: A trilingual investigation. Cognition 2016, 147, 1–20. [Google Scholar] [PubMed]
- Hawkins, J.A. Cross-Linguistic Variation and Efficiency; OUP Oxford: Oxford, UK, 2014. [Google Scholar]
- Rubio-Fernandez, P.; Mollica, F.; Jara-Ettinger, J. Speakers and listeners exploit word order for communicative efficiency: A cross-linguistic investigation. J. Exp. Psychol. Gen. 2021, 150, 583. [Google Scholar]
- The Staff at the National Astronomy and Ionosphere Center. The Arecibo message of November, 1974. Icarus 1975, 26, 462–466. [Google Scholar] [CrossRef]
- Zenil, H.; Adams, A.; Abraho, F.S.; Ozelim, L. An Optimal, Universal and Agnostic Decoding Method for Message Reconstruction, Bio and Technosignature Detection. arXiv 2023, arXiv:2303.16045. [Google Scholar]
- Marshall, S.M.; Mathis, C.; Carrick, E.; Keenan, G.; Cooper, G.J.T.; Graham, H.; Craven, M.; Gromski, P.S.; Moore, D.G.; Walker, S.; et al. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nat. Commun. 2021, 12, 1–9. [Google Scholar] [CrossRef]
- Cronin, L.; Krasnogor, N.; Davis, B.G.; Alexander, C.; Robertson, N.; Steinke, J.H.G.; Schroeder, S.L.M.; Khlobystov, A.N.; Cooper, G.; Gardner, P.M.; et al. The imitation game—A computational chemical approach to recognizing life. Nat. Biotechnol. 2006, 24, 1203–1206. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar]
- Sharma, A.; Czégel, D.; Lachmann, M.; Kempes, C.P.; Walker, S.I.; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [Google Scholar] [CrossRef]
- McCowan, B.; Hanser, S.F.; Doyle, L.R. Quantitative tools for comparing animal communication systems: Information theory applied to bottlenose dolphin whistle repertoires. Anim. Behav. 1999, 57, 409–419. [Google Scholar] [CrossRef] [PubMed]
- Doyle, L.R.; McCowan, B.; Johnston, S.; Hanser, S.F. Information theory, animal communication, and the search for extraterrestrial intelligence. Acta Astronaut. 2011, 68, 406–417. [Google Scholar]
- Shen, A. Around Kolmogorov complexity: Basic notions and results. In Measures of Complexity: Festschrift for Alexey Chervonenkis; Springer: Cham, Switzerland, 2015; pp. 75–115. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahon, L. Local Compositional Complexity: How to Detect a Human-Readable Message. Entropy 2025, 27, 339. https://doi.org/10.3390/e27040339
Mahon L. Local Compositional Complexity: How to Detect a Human-Readable Message. Entropy. 2025; 27(4):339. https://doi.org/10.3390/e27040339
Chicago/Turabian StyleMahon, Louis. 2025. "Local Compositional Complexity: How to Detect a Human-Readable Message" Entropy 27, no. 4: 339. https://doi.org/10.3390/e27040339
APA StyleMahon, L. (2025). Local Compositional Complexity: How to Detect a Human-Readable Message. Entropy, 27(4), 339. https://doi.org/10.3390/e27040339