
Enhancing Visual-Language Prompt Tuning Through Sparse Knowledge-Guided Context Optimization

Abstract
1. Introduction
- We investigate a problem called the base-novel dilemma, i.e., most prompt-tuning visual-language models (e.g., CoOp or CoCoOp) achieve good base-class performance with a sacrifice of new-class accuracy, which is beyond the capability of these methods in real-world data with a mix of base and new classes.
- We propose Sparse-KgCoOp to address the problem. It surpasses existing methodologies in terms of end performance. Notably, it significantly bolsters outcomes for the new class compared to CoOp and CoCoOp, reinforcing the wisdom and indispensability of incorporating general textual knowledge.
- Sparse-KgCoOp’s training expediency aligns with that of CoOp, marking a quicker pace relative to CoCoOp. Results demonstrate the effectiveness of Sparse-KgCoOp.
2. Related Work
2.1. Vision-Language Models
2.2. Prompt Tuning
3. Methodology
3.1. Contrastive Language-Image Pre-Training Method
3.2. Prompt-Based Learning
3.3. Sparse Knowledge-Guided Context Optimization
4. Experiments
4.1. Experimental Setting
4.2. Generalization from Base to New Classes
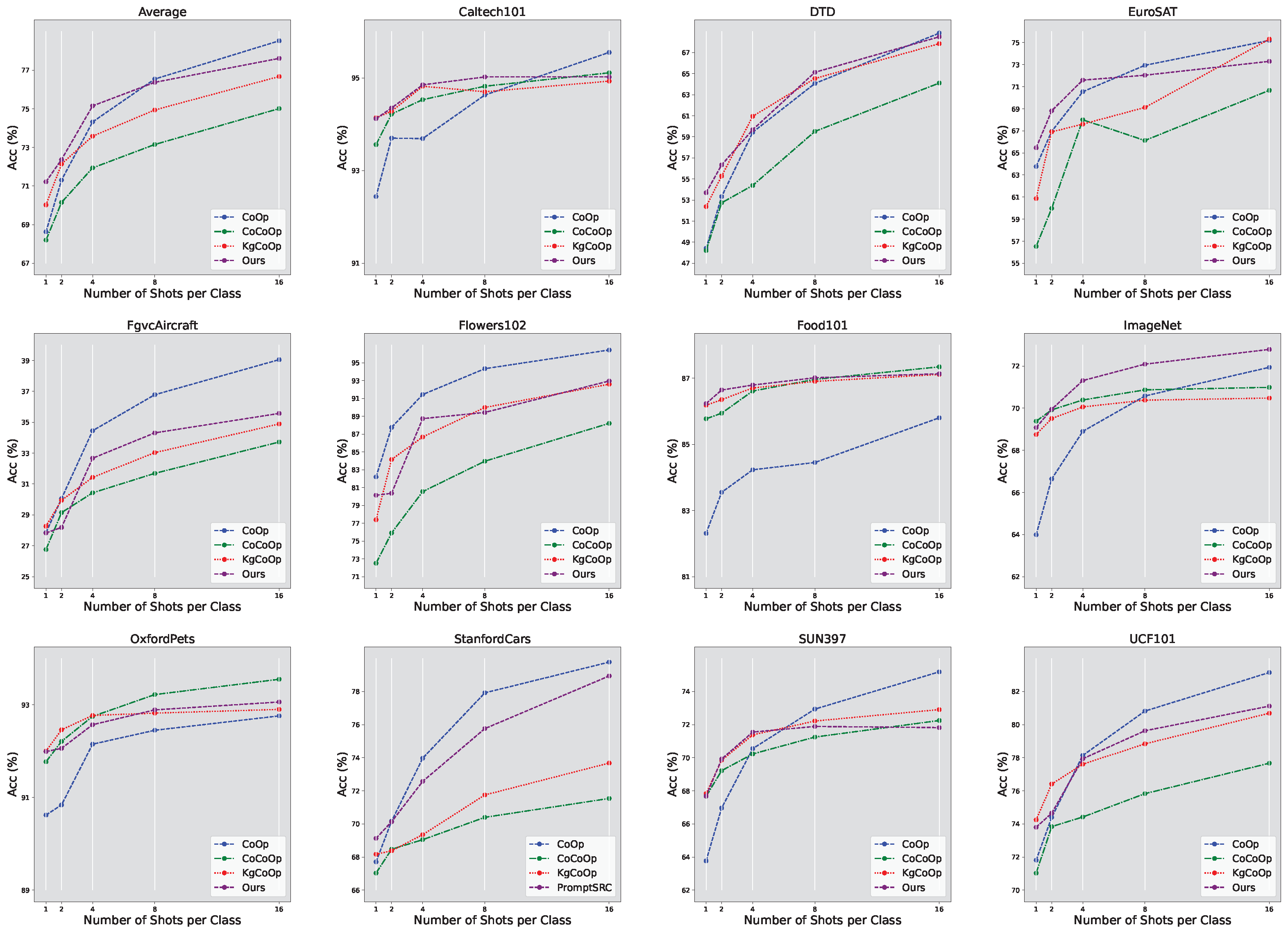
4.3. Few-Shot Image Classification
4.4. Domain Generalization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR Proceedings of Machine Learning Research. Volume 139, pp. 8748–8763. [Google Scholar]
- Alayrac, J.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A Visual Language Model for Few-Shot Learning. arXiv 2022, arXiv:2204.14198. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.; Parekh, Z.; Pham, H.; Le, Q.V.; Sung, Y.; Li, Z.; Duerig, T. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML, Virtual, 18–24 July 2021; Volume 139, pp. 4904–4916. [Google Scholar]
- Cho, J.; Lei, J.; Tan, H.; Bansal, M. Unifying Vision-and-Language Tasks via Text Generation. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR Proceedings of Machine Learning Research. Volume 139, pp. 1931–1942. [Google Scholar]
- Gan, Z.; Li, L.; Li, C.; Wang, L.; Liu, Z.; Gao, J. Vision-Language Pre-training: Basics, Recent Advances, and Future Trends. arXiv 2022, arXiv:2210.09263. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.; Cardie, C.; Belongie, S.J.; Hariharan, B.; Lim, S. Visual Prompt Tuning. In Proceedings of the Computer Vision-ECCV 2022-17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXXIII. Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13693, pp. 709–727. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. arXiv 2021, arXiv:2107.13586. [Google Scholar] [CrossRef]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.S.H.; Bakhtin, A.; Wu, Y.; Miller, A.H. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2463–2473. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 18061–18070. [Google Scholar] [CrossRef]
- Tsimpoukelli, M.; Menick, J.; Cabi, S.; Eslami, S.M.A.; Vinyals, O.; Hill, F. Multimodal Few-Shot Learning with Frozen Language Models. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W., Eds.; pp. 200–212. [Google Scholar]
- Yao, Y.; Zhang, A.; Zhang, Z.; Liu, Z.; Chua, T.; Sun, M. CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models. arXiv 2021, arXiv:2109.11797. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to Prompt for Vision-Language Models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional Prompt Learning for Vision-Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 16795–16804. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 5998–6008. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; PMLR Proceedings of Machine Learning Research. Volume 119, pp. 1597–1607. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR Proceedings of Machine Learning Research. Volume 139, pp. 5583–5594. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; pp. 13–23. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R.B. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 15979–15988. [Google Scholar] [CrossRef]
- Zang, Y.; Li, W.; Zhou, K.; Huang, C.; Loy, C.C. Unified Vision and Language Prompt Learning. arXiv 2022, arXiv:2210.07225. [Google Scholar]
- Lu, Y.; Liu, J.; Zhang, Y.; Liu, Y.; Tian, X. Prompt Distribution Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 5196–5205. [Google Scholar] [CrossRef]
- Zhu, B.; Niu, Y.; Han, Y.; Wu, Y.; Zhang, H. Prompt-Aligned Gradient for Prompt Tuning. arXiv 2022, arXiv:2205.14865. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. CLIP-Adapter: Better Vision-Language Models with Feature Adapters. arXiv 2021, arXiv:2110.04544. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Li, F.-F.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories. Comput. Vis. Image Underst. 2007, 106, 59–70. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C.V. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 3498–3505. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, ICCV Workshops 2013, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 554–561. [Google Scholar] [CrossRef]
- Nilsback, M.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the Sixth Indian Conference on Computer Vision, Graphics & Image Processing, ICVGIP 2008, Bhubaneswar, India, 16–19 December 2008; IEEE Computer Society: Washington, DC, USA, 2008; pp. 722–729. [Google Scholar] [CrossRef]
- Bossard, L.; Guillaumin, M.; Gool, L.V. Food-101-Mining Discriminative Components with Random Forests. In Proceedings of the Computer Vision-ECCV 2014-13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI. Fleet, D.J., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2014; Volume 8694, pp. 446–461. [Google Scholar] [CrossRef]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.B.; Vedaldi, A. Fine-Grained Visual Classification of Aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing Textures in the Wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 3606–3613. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; IEEE Computer Society: Washington, DC, USA, 2010; pp. 3485–3492. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Methods | Prompts | Average over 11 Datasets | Caltech101 | ||||
|---|---|---|---|---|---|---|---|
| Base (%) | New (%) | HM (%) | Base (%) | New (%) | HM (%) | ||
| CLIP | hand-crafted | 69.34 | 74.22 | 71.70 | 96.84 | 94.00 | 95.40 |
| CoOp | textual | 82.63 | 67.99 | 74.60 | 98.11 | 93.52 | 95.76 |
| CoCoOp | textual + visual | 80.47 | 71.69 | 75.83 | 97.70 | 93.20 | 95.40 |
| Sparse-KgCoOp (Ours) | textual | 82.75 | 74.23 | 78.25 | 97.89 | 94.32 | 96.07 |
| Method | Avg over 11 datasets | ImageNet | Caltech101 | OxfordPets | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | New | HM | Base | New | HM | Base | New | HM | Base | New | HM | |
| CLIP [1] | 69.34 | 74.22 | 71.70 | 72.43 | 68.14 | 70.22 | 96.84 | 94.00 | 95.40 | 91.17 | 97.26 | 94.12 |
| CoOp [12] | 82.63 | 67.99 | 74.60 | 76.46 | 66.31 | 71.02 | 98.11 | 93.52 | 95.76 | 94.24 | 96.66 | 95.43 |
| CoCoOp [13] | 80.47 | 71.69 | 75.83 | 75.90 | 70.73 | 73.23 | 97.70 | 93.20 | 95.40 | 94.93 | 97.90 | 96.39 |
| Sparse-KgCoOp (Ours) | 82.75 | 74.23 | 78.25 | 75.12 | 70.12 | 72.53 | 97.89 | 94.32 | 96.07 | 95.56 | 98.28 | 96.90 |
| Method | StanfodCars | Flowers102 | Food101 | FGVCAircraft | ||||||||
| Base | New | HM | Base | New | HM | Base | New | HM | Base | New | HM | |
| CLIP [1] | 63.37 | 74.89 | 68.65 | 72.08 | 77.80 | 74.83 | 90.10 | 91.22 | 90.66 | 27.19 | 36.29 | 31.09 |
| CoOp [12] | 76.20 | 69.14 | 72.49 | 97.63 | 69.55 | 81.23 | 89.44 | 87.50 | 88.46 | 39.24 | 30.49 | 34.30 |
| CoCoOp [13] | 68.27 | 70.45 | 69.34 | 95.03 | 69.07 | 80.00 | 90.57 | 91.20 | 90.88 | 35.63 | 32.70 | 34.10 |
| Sparse-KgCoOp (Ours) | 77.82 | 75.01 | 76.39 | 97.63 | 73.95 | 84.16 | 90.67 | 91.57 | 91.12 | 38.35 | 36.20 | 37.24 |
| Method | SUN397 | DTD | EuroSAT | UCF101 | ||||||||
| Base | New | H | Base | New | H | Base | New | H | Base | New | H | |
| CLIP [1] | 69.36 | 75.35 | 72.23 | 53.24 | 59.90 | 56.37 | 56.48 | 64.05 | 60.03 | 70.53 | 77.50 | 73.85 |
| CoOp [12] | 80.85 | 68.34 | 74.07 | 80.17 | 47.54 | 59.68 | 91.54 | 54.44 | 68.27 | 85.14 | 64.47 | 73.37 |
| CoCoOp [13] | 79.50 | 76.27 | 77.85 | 77.37 | 52.97 | 62.88 | 87.97 | 61.63 | 72.48 | 82.33 | 72.40 | 77.05 |
| Sparse-KgCoOp (Ours) | 79.79 | 76.51 | 78.12 | 80.05 | 55.95 | 65.86 | 93.61 | 68.61 | 79.18 | 83.63 | 75.99 | 79.63 |
| Method | Source | Target | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ImgNet | Caltech101 | OxfordPets | StanfordCars | Flowers102 | Food101 | FGVCAircraft | SUN397 | DTD | EuroSAT | UCF101 | Avg | |
| CoOp [12] | 71.94 | 93.39 | 89.19 | 62.42 | 67.1 | 84.53 | 18.50 | 61.44 | 39.56 | 39.75 | 64.22 | 62.91 |
| CoCoOp [13] | 70.99 | 93.72 | 90.00 | 64.98 | 69.72 | 86.22 | 22.90 | 66.50 | 44.54 | 43.08 | 67.00 | 65.42 |
| Sparse-KgCoOp (Ours) | 69.72 | 94.44 | 90.44 | 65.56 | 71.17 | 86.33 | 23.62 | 67.08 | 46.32 | 43.54 | 68.90 | 66.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Q.; Zhang, M. Enhancing Visual-Language Prompt Tuning Through Sparse Knowledge-Guided Context Optimization. Entropy 2025, 27, 301. https://doi.org/10.3390/e27030301
Tian Q, Zhang M. Enhancing Visual-Language Prompt Tuning Through Sparse Knowledge-Guided Context Optimization. Entropy. 2025; 27(3):301. https://doi.org/10.3390/e27030301
Chicago/Turabian StyleTian, Qiangxing, and Min Zhang. 2025. "Enhancing Visual-Language Prompt Tuning Through Sparse Knowledge-Guided Context Optimization" Entropy 27, no. 3: 301. https://doi.org/10.3390/e27030301
APA StyleTian, Q., & Zhang, M. (2025). Enhancing Visual-Language Prompt Tuning Through Sparse Knowledge-Guided Context Optimization. Entropy, 27(3), 301. https://doi.org/10.3390/e27030301