HA: An Influential Node Identification Algorithm Based on Hub-Triggered Neighborhood Decomposition and Asymmetric Order-by-Order Recurrence Model


Abstract
1. Introduction
2. Background
2.1. Benchmark Algorithms
2.1.1. Degree Centrality Algorithm
2.1.2. Betweenness Centrality Algorithm
2.1.3. Clustering Coefficient Algorithm
2.1.4. K-Shell Algorithm
2.1.5. Improved Information Entropy Algorithm
2.1.6. Multi-Characteristics Gravity Model Algorithm
2.1.7. HIC Centrality Algorithm
3. Materials and Methods
3.1. Network Directionalization and Hub-Triggered Neighborhood Decomposition
3.2. The Asymmetric Order-by-Order Recurrence Model
| Algorithm 1 HA Algorithm |
| Input: The Adjacency Matrix A of the network. Output: The Value of each node.
|
4. Results
4.1. Data Set and Statistical Characteristics
4.2. Simulation Analysis
4.2.1. The Kendall’s Tau Correlation Coefficient with SIR
4.2.2. The Algorithm Accuracy and Resolution
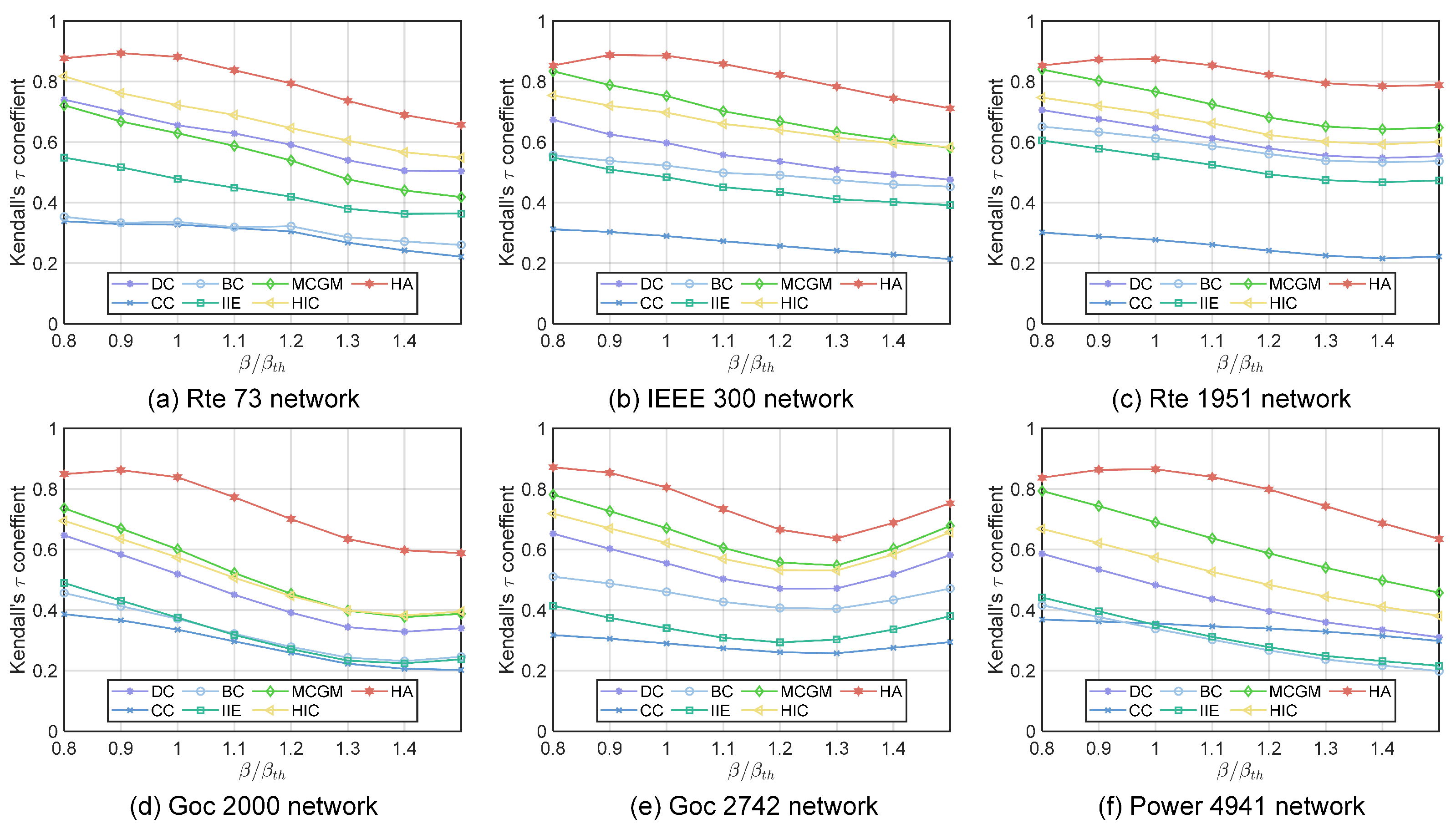
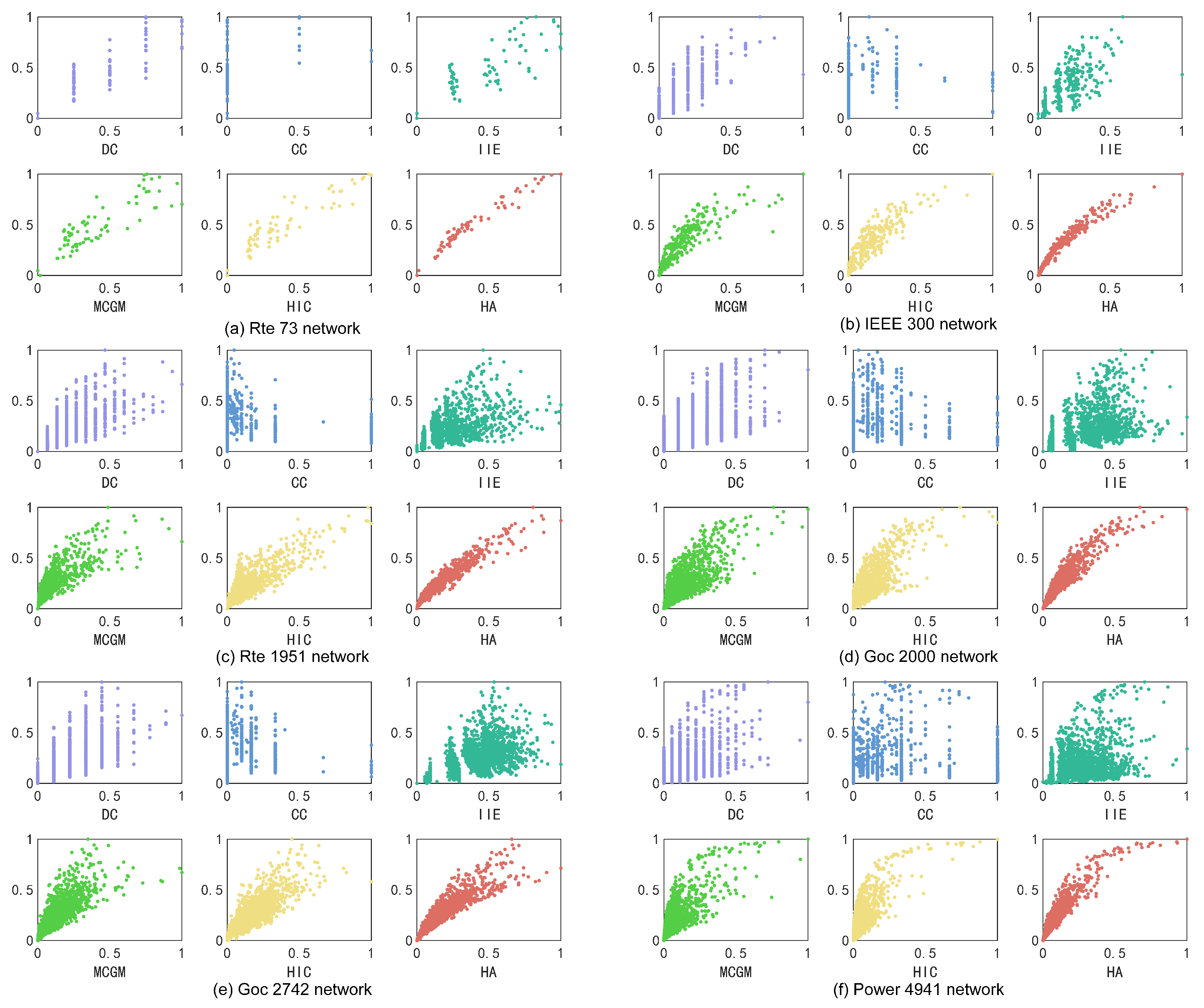
4.2.3. The Top Node Infectious Capability
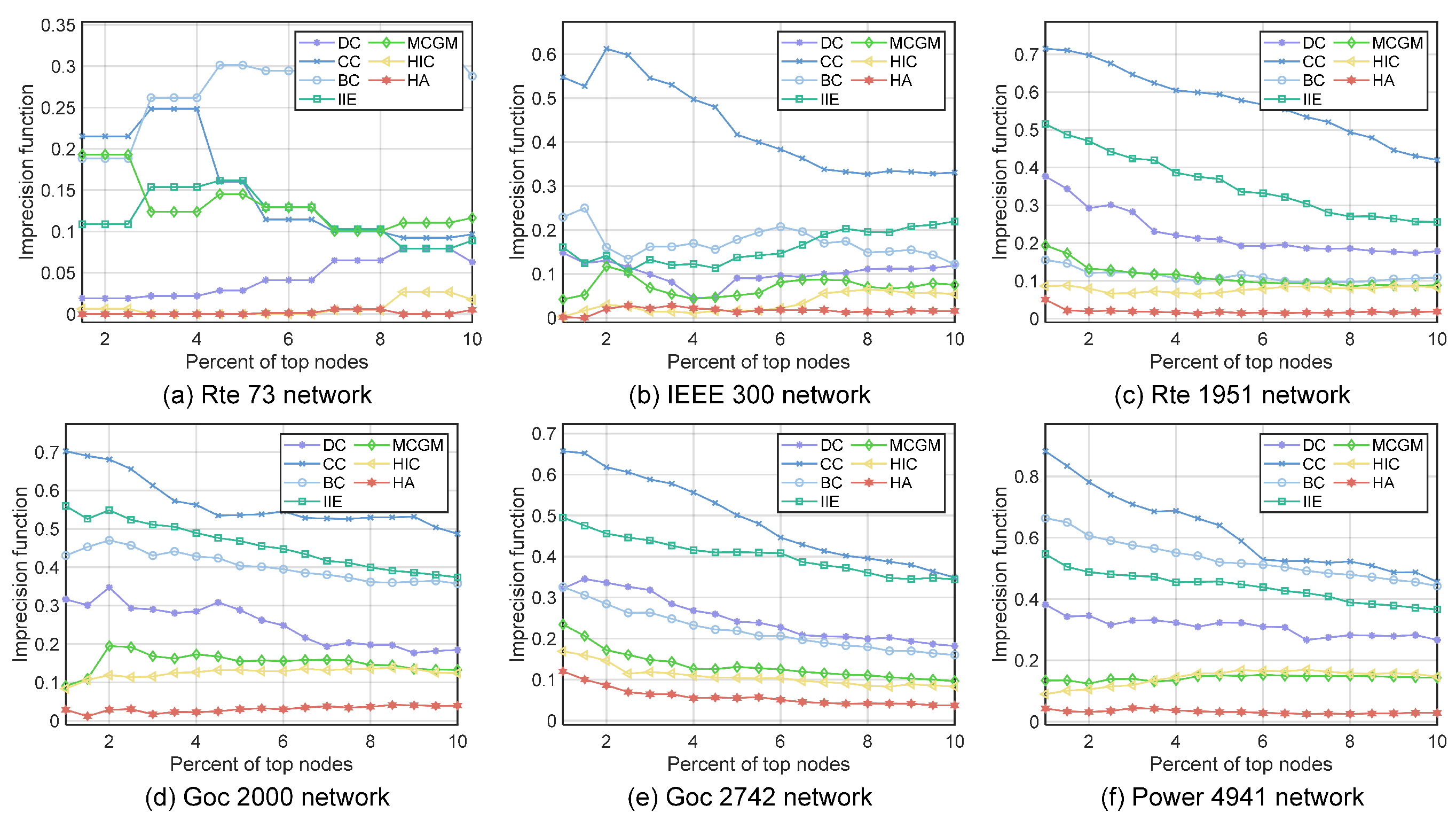
4.2.4. The Imprecision Functions of the Top Nodes
4.2.5. Algorithm Complexity
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Devanny, J.; Goldoni, L.R.F.; Medeiros, B.P. The 2019 Venezuelan blackout and the consequences of cyber uncertainty. Rev. Bras. Estud. Def. 2020, 7, 35–37. [Google Scholar] [CrossRef]
- Maschmeyer, L.; Dunn Cavelty, M. Goodbye cyberwar: Ukraine as reality check. CSS Policy Perspect. 2022, 10, 3. [Google Scholar]
- Poornima, B. Cyber threats and nuclear security in india. J. Asian Secur. Int. Aff. 2022, 9, 183–206. [Google Scholar] [CrossRef]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks: Conceptual clarification. Soc. Netw. 2002, 1, 238–263. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Ma, L.; Ma, C.; Zhang, H.; Wang, B. Identifying influential spreaders in complex networks based on gravity formula. Physical A 2016, 451, 205–212. [Google Scholar] [CrossRef]
- Li, Z.; Ren, T.; Ma, X.; Liu, S.; Zhang, Y.; Zhou, T. Identifying influential spreaders by gravity model. Sci. Rep. 2019, 9, 8387. [Google Scholar] [CrossRef]
- Li, Z.; Huang, X. Identifying influential spreaders in complex networks by an improved gravity model. Sci. Rep. 2021, 11, 22194. [Google Scholar] [CrossRef]
- Li, Z.; Huang, X. Identifying influential spreaders by gravity model considering multi-characteristics of nodes. Sci. Rep. 2022, 12, 9879. [Google Scholar] [CrossRef]
- Ma, Y.; Cao, Z.; Qi, X. Quasi-Laplacian centrality: A new vertex centrality measurement based on Quasi-Laplacian energy of networks. Physical A 2019, 527, 121130. [Google Scholar] [CrossRef]
- Lin, Z.; Zhou, S.; Li, M.; Chen, G. Identifying key nodes in interdependent networks based on Supra-Laplacian energy. J. Comput. Sci. 2022, 61, 101657. [Google Scholar] [CrossRef]
- Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Ruhnau, B. Eigenvector-centrality—A node-centrality? Soc Netw. 2000, 22, 357–365. [Google Scholar] [CrossRef]
- Zhong, L.; Bai, Y.; Tian, Y.; Luo, C.; Huang, J.; Pan, W. Information entropy based on propagation feature of node for identifying the influential nodes. Complexity 2021, 1, 5554322. [Google Scholar] [CrossRef]
- Meng, L.; Xu, G.; Yang, P.; Tu, D. A novel potential edge weight method for identifying influential nodes in complex networks based on neighborhood and position. J. Comput. Sci. 2022, 60, 101591. [Google Scholar] [CrossRef]
- Hajarathaiah, K.; Enduri, M.K.; Anamalamudi, S.; Subba Reddy, T.; Tokala, S. Computing influential nodes using the nearest neighborhood trust value and pagerank in complex networks. Entropy 2022, 24, 704. [Google Scholar] [CrossRef]
- Li, Q.; Han, H.; Ma, Y.; Zeng, X.; Li, Q. Node importance evaluation algorithm based on gravity model and relative path number. Comput. Appl. Res. 2022, 39, 764–769. [Google Scholar]
- Dong, C.; Xu, G.; Meng, L.; Yang, P. CPR-TOPSIS: A novel algorithm for finding influential nodes in complex networks based on communication probability and relative entropy. Phys. A Stat. Mech. Appl. 2022, 603, 127797. [Google Scholar] [CrossRef]
- Liu, C.; Wang, J.; Xia, R. Node importance evaluation in multi-platform avionics architecture based on TOPSIS and PageRank. EURASIP J. Adv. Signal Process. 2023, 1, 27. [Google Scholar] [CrossRef]
- Grigg, C.; Wong, P.; Albrecht, P.; Allan, R.; Bhavaraju, M.; Billinton, R.; Singh, C. The IEEE reliability test system-1996. A report prepared by the reliability test system task force of the application of probability methods subcommittee. IEEE Trans. Power Syst. 1999, 14, 1010–1020. [Google Scholar] [CrossRef]
- Birchfield, A.B.; Xu, T.; Gegner, K.M.; Shetye, K.S.; Overbye, T.J. Grid structural characteristics as validation criteria for synthetic networks. IEEE Trans. Power Syst. 2016, 32, 3258–3265. [Google Scholar] [CrossRef]
- Josz, C.; Fliscounakis, S.; Maeght, J.; Panciatici, P. AC power flow data in MATPOWER and QCQP format: ITesla, RTE snapshots, and PEGASE. arXiv 2016, arXiv:1603.01533. [Google Scholar]
- University of Wisconsin-Madison Arpa-E Grid, Optimization Competition, Challenge 1. Available online: https://gocompetition.energy.gov/challenges/22/datasets (accessed on 9 September 2024).
- Rossi, R.A.; Ahmed, N.K. Networkrepository: A graph data repository with visual interactive analytics. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 25–30. [Google Scholar]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations: Can geographic isolation explain this unique trait? Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Gleiser, P.M.; Danon, L. Community structure in jazz. Adv. Complex Syst. 2003, 6, 565–573. [Google Scholar] [CrossRef]
- Guimera, R.; Danon, L.; Diaz-Guilera, A.; Giralt, F.; Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 2003, 68, 065103. [Google Scholar] [CrossRef]
- Hethcote, H.W. The mathematics of infectious diseases. SIAM Rev. 2000, 42, 599–653. [Google Scholar] [CrossRef]
- Xi, Y.; Cui, X. Identifying influential nodes in complex networks based on information entropy and relationship strength. Entropy 2023, 25, 754. [Google Scholar] [CrossRef]
- Hu, H.B.; Wang, X.F. Unified index to quantifying heterogeneity of complex networks. Phys. A Stat. Mech. Appl. 2008, 387, 3769–3780. [Google Scholar] [CrossRef]
- Yin, R.; Li, L.; Wang, Y.; Lang, C.; Hao, Z.; Zhang, L. Identifying critical nodes in complex networks based on distance Laplacian energy. Chaos Solit. 2024, 180, 114487. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y.; Xi, J.; Du, C. Fast ranking influential nodes in complex networks using a k-shell iteration factor. Phys. A Stat. Mech. Appl. 2016, 461, 171–181. [Google Scholar] [CrossRef]
- Li, Y.; Cai, W.; Li, Y.; Du, X. Key node ranking in complex networks: A novel entropy and mutual information-based approach. Entropy 2019, 22, 52. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Abbreviation | Attributes | Type |
|---|---|---|---|
| Degree Centrality | DC | Local | Traditional |
| Betweenness Centrality | BC | Global | Traditional |
| Clustering Coefficient | CC | Local | Traditional |
| K-shell | KS | Global | Traditional |
| Improved Information Entropy | IIE | Local | State of the art |
| Multi-Characteristics Gravity Model | MCGM | Local | State of the art |
| HIC Centrality | HIC | Local | State of the art |
| Network | N | M | S | C | ||
|---|---|---|---|---|---|---|
| 1 Rte 73 | 73 | 108 | 2.9589 | 5.9829 | 0.0251 | 0.782 |
| 1 IEEE 300 | 300 | 409 | 2.7267 | 9.9353 | 0.0856 | 12.2924 |
| 2 Rte 1951 | 1951 | 2373 | 2.4336 | 8.9089 | 0.0409 | 50.9551 |
| 3 Goc 2000 | 2000 | 2810 | 2.8100 | 16.3627 | 0.0632 | 57.4545 |
| 2 Goc 2742 | 2742 | 4005 | 2.9212 | 15.9794 | 0.0330 | 47.1429 |
| 3 Power 4941 | 4941 | 6594 | 2.6691 | 18.9891 | 0.0801 | 160.2000 |
| Karate | 34 | 78 | 4.5882 | 2.4082 | 0.5706 | 4.2190 |
| Dolphins | 62 | 159 | 5.1290 | 3.3570 | 0.2590 | 3.2044 |
| Jazz | 198 | 2742 | 27.6970 | 2.2350 | 0.6175 | 4.3894 |
| 1133 | 5451 | 9.6222 | 3.6060 | 0.2202 | 25.9488 |
| Network | DC | CC | BC | IIE | MCGM | HIC | HA |
|---|---|---|---|---|---|---|---|
| Rte 73 | 0.524 | 0.050 | 0.999 | 0.920 | 1.000 | 0.886 | 0.999 |
| IEEE 300 | 0.611 | 0.171 | 0.869 | 0.974 | 1.000 | 0.980 | 0.998 |
| Rte 1951 | 0.613 | 0.052 | 0.722 | 0.957 | 0.998 | 0.947 | 0.990 |
| Goc 2000 | 0.634 | 0.157 | 0.901 | 0.970 | 1.000 | 0.961 | 1.000 |
| Goc 2742 | 0.536 | 0.077 | 1.000 | 0.963 | 1.000 | 0.950 | 1.000 |
| Power 4941 | 0.593 | 0.117 | 0.508 | 0.965 | 1.000 | 0.957 | 1.000 |
| Mean value | 0.585 | 0.104 | 0.833 | 0.958 | 1.000 | 0.947 | 0.998 |
| Algorithm Abbreviation | Complexity |
|---|---|
| DC | |
| BC | |
| CC | |
| IIE | |
| MCGM | |
| HIC | |
| HA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Ye, J.; Li, J.; Dai, Y.; Zhao, T.; Zhang, G. HA: An Influential Node Identification Algorithm Based on Hub-Triggered Neighborhood Decomposition and Asymmetric Order-by-Order Recurrence Model. Entropy 2025, 27, 298. https://doi.org/10.3390/e27030298
Zhao M, Ye J, Li J, Dai Y, Zhao T, Zhang G. HA: An Influential Node Identification Algorithm Based on Hub-Triggered Neighborhood Decomposition and Asymmetric Order-by-Order Recurrence Model. Entropy. 2025; 27(3):298. https://doi.org/10.3390/e27030298
Chicago/Turabian StyleZhao, Min, Junhan Ye, Jiayun Li, Yuzhuo Dai, Tianze Zhao, and Gengchen Zhang. 2025. "HA: An Influential Node Identification Algorithm Based on Hub-Triggered Neighborhood Decomposition and Asymmetric Order-by-Order Recurrence Model" Entropy 27, no. 3: 298. https://doi.org/10.3390/e27030298
APA StyleZhao, M., Ye, J., Li, J., Dai, Y., Zhao, T., & Zhang, G. (2025). HA: An Influential Node Identification Algorithm Based on Hub-Triggered Neighborhood Decomposition and Asymmetric Order-by-Order Recurrence Model. Entropy, 27(3), 298. https://doi.org/10.3390/e27030298