In this study, we introduce a generative model for event temporal relation extraction, treating the task as a sequence-to-sequence text generation problem. For each event pair in a sentence, we predict the type of temporal relation it belongs to.
Figure 1 provides an overview of our method, which consists of the following three main components: (1) Sequence-to-Sequence Modeling: We propose a dependency-based generative method for event temporal relation extraction to simultaneously generate temporal relation labels and dependency path words from the input sentence. (2) Maximum Likelihood Pre-training: We first pre-train the generative model using maximum likelihood estimation to enable it to produce output sequences that align more closely with the training data distribution. (3) Baseline Policy Gradient Algorithm: We introduce a baseline policy gradient algorithm to resolve the discrepancy between the optimization objective and the performance metrics of the task, as well as to improve the stability and convergence speed of the generative model. Each component will be described in detail below.
3.1. Sequence-to-Sequence Modeling
For a sentence
W with
n tokens
, which can have multiple event mentions
, the goal of event temporal relation extraction is to predict the temporal relation type between event pairs
. In this work, we shift from traditional classification methods [
37,
44,
45] to a generative approach. Our generative method adopts a sequence-to-sequence architecture, with the input consisting of the sentence
W and the two event triggers,
and
. The model generates an output sequence that consists of temporal labels and the dependency path linking
and
in
W’s dependency tree, thus facilitating multi-task learning by generating crucial contextual words.
Specifically, the input sequence
I of our generative event temporal relation extraction model is obtained by combining the input sentence
W and the prompt
, as follows:
where
is used to specify the temporal relation prediction task for
and
. In this study, we define
with a straightforward template structured as “What is the temporal relationship between
and
?” Furthermore, the output sequence
O in the task of generative event temporal relation extraction is concatenated in the following way:
where
L indicates the type of temporal relation (also known as the temporal relation label) between the two event triggers,
and
. Additionally,
refers to the dependency path connecting
and
within the sentence
W. The following provides the input and output sequences for the given example:
In this work, we only consider the event pairs from adjacent sentences because if we also include the event pairs from non-adjacent sentences, the shortest dependency path becomes overly complex, which is beyond the scope of this study. When two events are located in different sentences, a key challenge is how to represent the cross-sentence dependency path. In this paper, we adopt the hypothesis proposed by Cheng et al. [
46], which suggests that two adjacent sentences share a “common root” node. As a result, the cross-sentence dependency path can be depicted as two shortest branches of the dependency path, each extending from the endpoints to the “common root” node.
Using this approach, our generative event temporal relation extraction model can be trained simultaneously for two highly related tasks—temporal relation prediction and dependency path generation. This enables multi-task training, which enhances the model’s performance. In the training process, for each transformed input–output pair in the data, the sequence-to-sequence problem is addressed by using a pre-trained T5 encoder–decoder model. Specifically, the T5 model is trained on these transformed pairs from the training data. During inference, given an input sentence and two event mentions, the trained T5 model generates an output sequence. The first token from this sequence is then extracted to predict the temporal relation label.
To summarize, we introduce dependency path generation as an auxiliary task for event temporal relation extraction, allowing the concurrent generation of both temporal relation labels and the crucial context. This multi-task learning strategy effectively improves the accuracy of temporal relation prediction.
3.2. Maximum Likelihood Pre-Training
Before training the baseline policy gradient algorithm, we first train T5 using a maximum likelihood objective to guide it in generating text over the transformed input–output pairs
. This approach effectively limits the vast action space involved in text generation, improving the learning efficiency of the baseline policy gradient algorithm [
47,
48]. In other words, by pre-training T5 with maximum likelihood, we can better adapt it to the event temporal relation extraction task. Then, we integrate the baseline policy gradient algorithm with T5 to conduct joint training for the temporal relation extraction task.
In this study, we employ cross-entropy loss for the pre-training of the T5 model, which is a generative model primarily focused on mapping input sequences to their corresponding output sequences. To enhance the likelihood of each sample, we optimize the model by minimizing the negative log-likelihood of the output sequence
O conditioned on the input sequence
I, as follows:
where the probability
is computed through the distribution returned by the decoder. The objective of the generative loss is to maximize the likelihood that the model produces an output sequence consistent with the distribution of the training data. To achieve the reconstruction, we reverse the process by transforming the generated output sequence
C back into the input sequence
I. Then, we calculate the negative log-likelihood of obtaining the input sequence
I when
C is provided as the input, as in the following equation:
The reconstruction loss helps to ensure that the model’s generated output sequence closely resembles the original input sequence. To finalize the process, we combine the generative loss and reconstruction loss with specified weights to form the final training loss function, as in the following equation:
where
and
are the weights for the generative loss and the reconstruction loss, which can be adjusted through hyperparameters.
In conclusion, by pre-training the T5 model using maximum likelihood estimation for the event temporal relation extraction task, it becomes better at producing output sequences that match the distribution of the training data, which ultimately enhances the performance of the baseline policy gradient algorithm.
3.3. Baseline Policy Gradient Algorithm
As mentioned in the introduction, we utilize a baseline policy gradient algorithm to train our generative event temporal relation extraction model. In this approach, label accuracy is integrated into the reward function, serving as a direct training signal. The model parameters are first initialized using maximum likelihood estimation and, subsequently, they are refined through iterative optimization with the baseline policy gradient algorithm. The baseline policy gradient algorithm’s flexibility enables the inclusion of a term in the reward function that reflects the similarity between the predicted output sequence
C from T5, the gold output sequence
O, and the input sequence
I for the training of our generative model. In contrast to traditional policy gradient algorithms, the baseline policy gradient algorithm incorporates a value function-based baseline, which helps to reduce the variance of the policy gradient thus improving the algorithm’s efficiency and stability. Algorithm 1 presents the implementation details of the baseline policy gradient algorithm. Drawing from this description, we have developed three reward components for the baseline policy gradient algorithm to facilitate the training of the generative model.
| Algorithm 1: Policy gradient method with baseline for estimating πθ ≈ π∗ |
![Entropy 27 00284 i001]() |
Accuracy-based Reward : This reward is computed by evaluating the accuracy of the temporal relation label
L within the generated sequence
C. Specifically, if
L matches the temporal relation provided between
and
in
W, then
; otherwise, it is 0. Thus, the calculation of the accuracy-based reward
is as follows:
where
denotes the
i-th output sequence produced by the model,
is the corresponding expected output sequence, and
S refers to the total number of samples. The symbol
is used to denote an indicator function, which is 1 if the first token of
and
are equal, and 0 otherwise. This reward term aims to encourage the generation of correct temporal labels, thereby improving the overall performance of the model.
Output-based Reward : This reward term is determined by evaluating how closely the generated sequence
C matches the reference output sequence
O. In particular, we use the ROUGE-2 metric [
49] to calculate this reward term, i.e.,
. Therefore, the calculation of the output-based reward
is as follows:
where ROUGE-2 is the similarity calculation function. This reward term aims to motivate the generation model to produce temporal dependency paths that closely resemble the desired output sequences, which ultimately enhances the model’s overall performance.
Input-Based Reward : Our goal is to generate the dependency path between
and
for multi-task learning in event temporal relation extraction. Given that the dependency path is designed to capture key contextual information that reveals the temporal relation in
W, and considering that the input
I is tailored for temporal prediction, we posit that
I and
O should share a similar meaning. Building on this idea, we propose a novel reward term to enhance the similarity between the generated sequence
C from T5 and the input sequence
I. Specifically, we feed both
C and
I into T5’s encoder to obtain their respective representation vectors,
and
. The reward is then calculated based on the similarity between these representation vectors, i.e.,
. Therefore, the calculation of the input-based reward
is as follows:
where similarity is a similarity calculation function defined based on the specific task and requirements. Common techniques for assessing text similarity include approaches like cosine similarity and edit distance.
Thus, the overall reward function
for training our generative event temporal relation extraction model is as follows:
where
, and
are the weighting parameters. By doing so, we can ensure that label accuracy—our main performance objective—is effectively emphasized, preventing it from being overshadowed by generation rewards during training.
In practice, the baseline policy gradient algorithm utilizes gradient descent to adjust the policy function’s parameters, aiming to maximize its expected reward. Specifically,
represents the distribution of sequences generated by T5. In our approach, we employ the baseline policy gradient algorithm to train T5 by minimizing the negative expected reward
of the sequences it generates, as follows:
where
C represents all possible choices by T5. Using the policy gradient method and a single roll-out sampling of the generated sequences
C [
50], the gradient of
can be approximated and used for training as follows:
where
is the baseline used to minimize variance. In this context, the baseline
is derived through the following equation:
where
denotes the size of the mini-batch, while
refers to the generated sequence for the
k-th sample. In our specific implementation, we use stochastic gradient descent to minimize our overall loss, with the updated equation as follows:
where
is the learning rate, and
denotes the gradient of the overall loss
with respect to the model parameters
.
The baseline policy gradient algorithm allows the reinforcement learning model to be trained effectively, enabling it to generate the desired output sequences. The primary objective of the reward function is to direct the model toward producing the expected sequences. Meanwhile, the baseline reward plays a crucial role in minimizing the variance in gradient estimates, which contributes to enhancing both the efficiency and stability of the model’s training process.










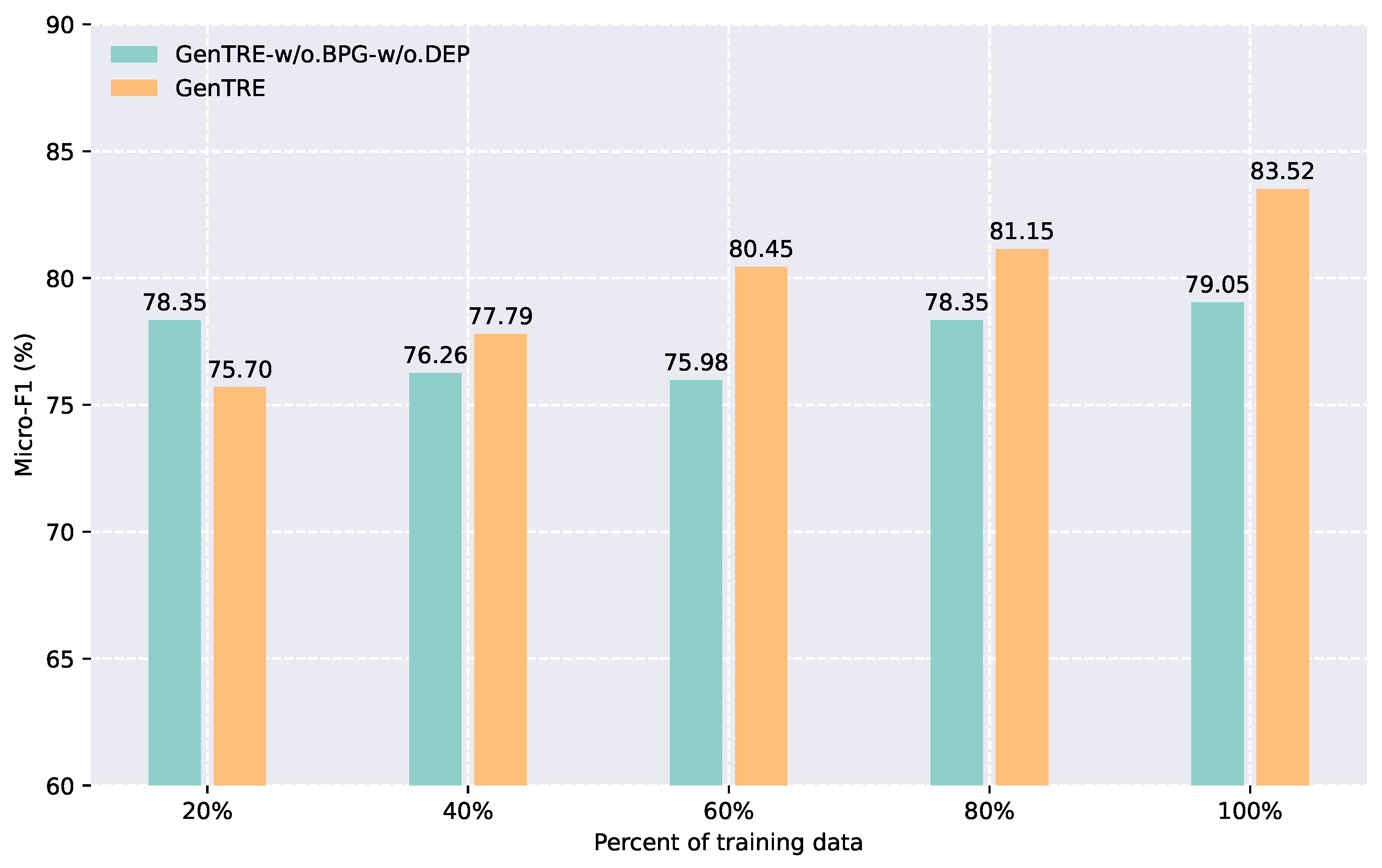

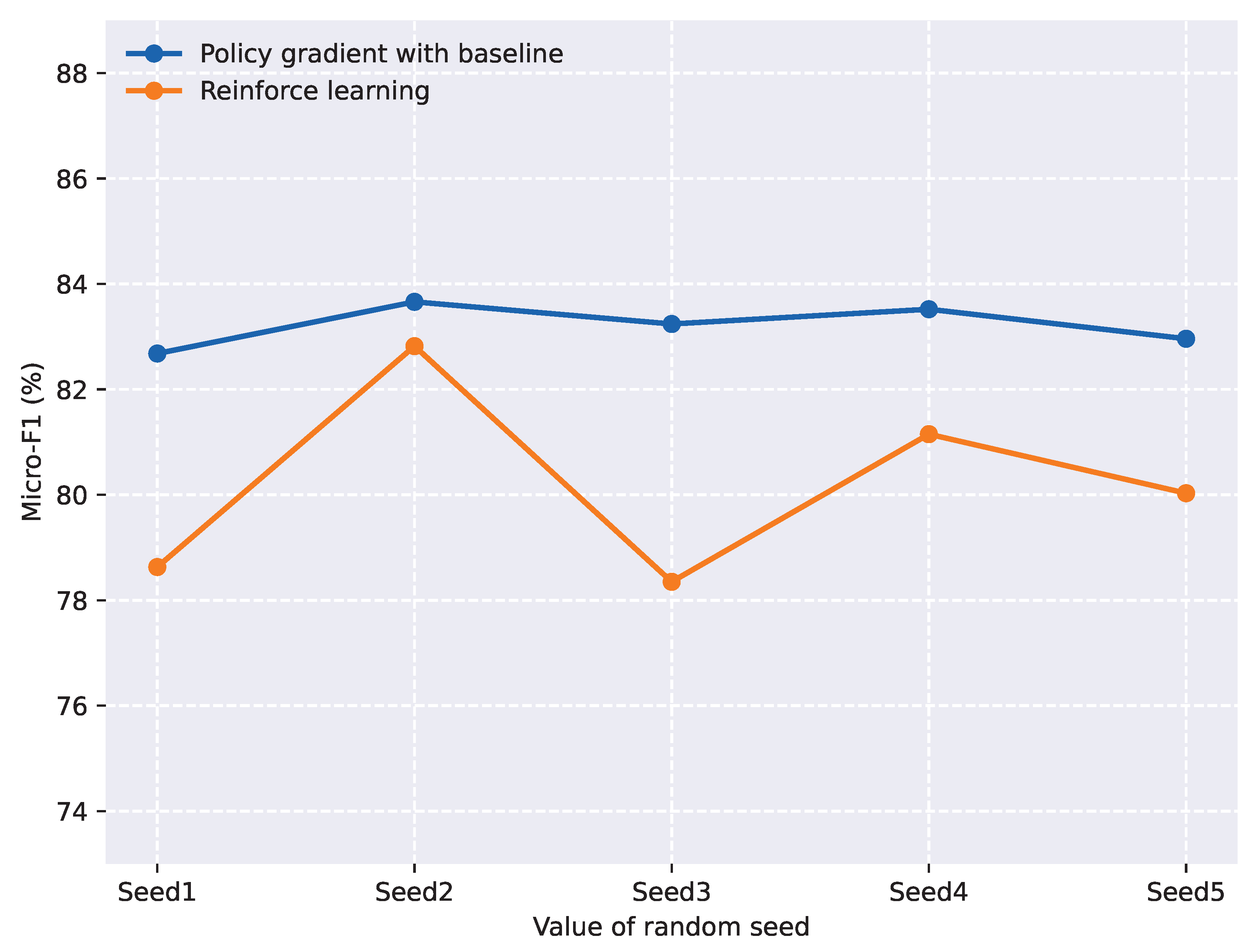

{kind=link}
{kind=link}
{kind=link}
{kind=link}